Surrogate-Assisted Genetic Programming with Rank-Based Phenotypic Characterisation for Dynamic Multi-Mode Project Scheduling
The dynamic multi-mode resource-constrained project scheduling problem (DMRCPSP) is of practical importance, as it requires making real-time decisions under changing project states and resource availability. Genetic Programming (GP) has been shown to…
Authors: Yuan Tian, Yi Mei, Mengjie Zhang
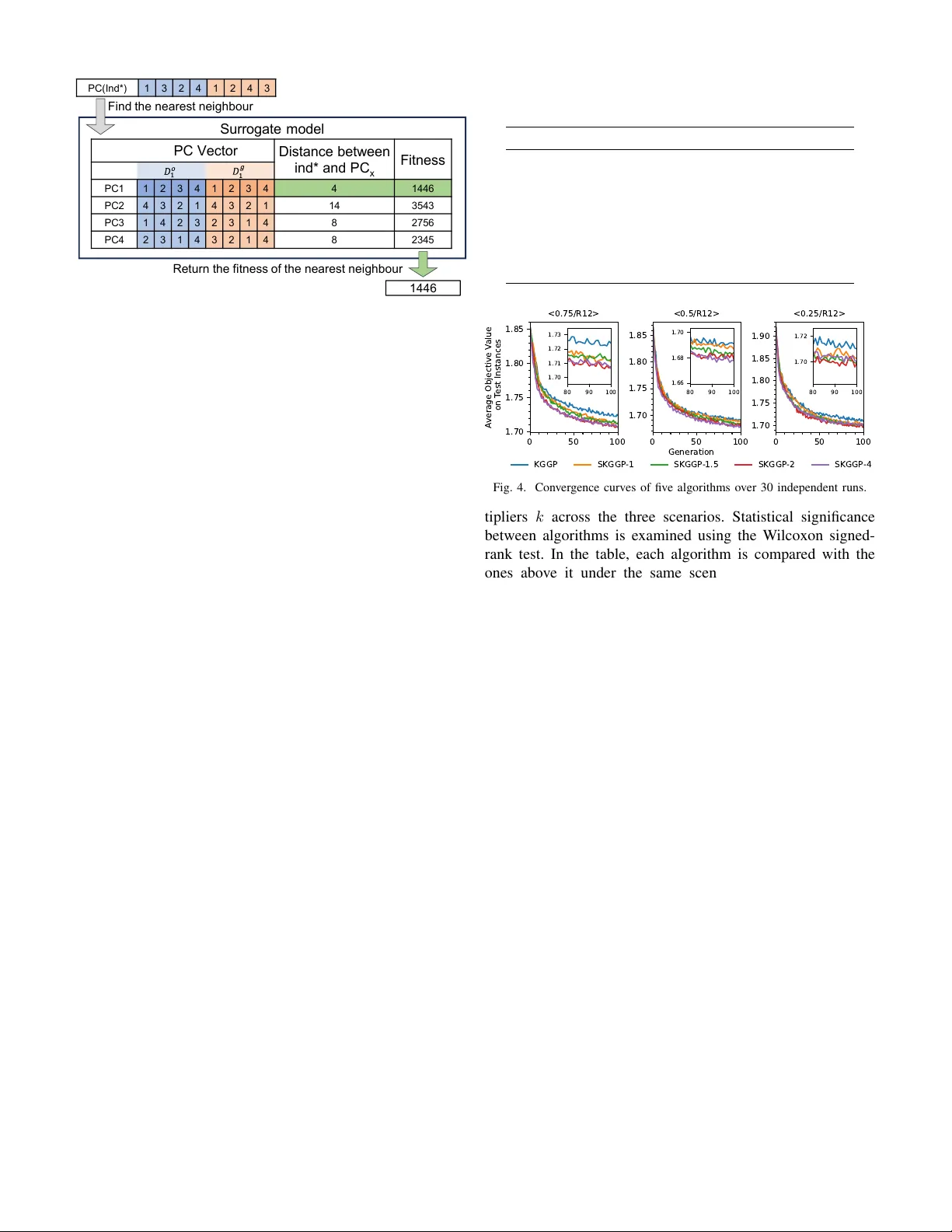
Surrogate-Assisted Genetic Programming with Rank-Based Phenotypic Characterisation for Dynamic Multi-Mode Project Scheduling Y uan T ian B , Y i Mei, Mengjie Zhang Centr e for Data Science and Artificial Intelligence & Sc hool of Engineering and Computer Science V ictoria University of W ellington, PO Box 600, W ellington 6140, Ne w Zealand {yuan.tian, yi.mei, mengjie.zhang}@ecs.vuw .ac.nz Abstract —The dynamic multi-mode resour ce-constrained project scheduling problem (DMRCPSP) is of practical impor- tance, as it r equires making r eal-time decisions under changing project states and resour ce availability . Genetic Programming (GP) has been shown to effectively ev olve heuristic rules for such decision-making tasks; however , the ev olutionary process typically relies on a large number of simulation-based fitness evaluations, resulting in high computational cost. Surrogate models offer a promising solution to reduce evaluation cost, but their application to GP requir es problem-specific pheno- typic characterisation (PC) schemes of heuristic rules. There is currently a lack of suitable PC schemes for GP applied to DMRCPSP . This paper proposes a rank-based PC scheme derived from heuristic-driven ordering of eligible activity–mode pairs and activity groups in decision situations. The resulting PC vectors enable a surrogate model to estimate the fitness of unevaluated GP individuals. Based on this scheme, a surrogate- assisted GP algorithm is developed. Experimental results demon- strate that the proposed surrogate-assisted GP can identify high- quality heuristic rules consistently earlier than the state-of-the- art GP approach f or DMRCPSP , while introducing only marginal computational overhead. Further analyses demonstrate that the surrogate model provides useful guidance for offspring selection, leading to improved evolutionary efficiency . Index T erms —Project Scheduling, Hyper -heuristics, Genetic Programming, Surrogate model, Phenotypic characterisation I . I N T R O D U C T I O N Project scheduling is a fundamental component of project management, as high-quality scheduling decisions are essential for completing projects within budget and time constraints. The multi-mode resource-constrained project scheduling prob- lem (MRCPSP) [1], [2] is a well-formalised problem set- ting, in which the start times and execution modes of ac- tivities must be determined under precedence and resource constraints to minimise the ov erall duration of the project. In the dynamic MRCPSP (DMRCPSP) considered in this study , the actual durations of activities are uncertain and only become known during execution. As a result, scheduling decisions—specifically , which activities should be ex ecuted and in which modes—must be made online as the project state updates. This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible. Heuristic rules are well-suited to such dynamic decision- making scenarios due to their lo w computational cost. Genetic Programming (GP) [3], as a hyper-heuristic approach, has been widely used to automatically ev olve scheduling heuristics based on problem-specific attrib utes and decision contexts. Howe ver , ev olving effecti v e heuristics requires a large num- ber of expensiv e simulation-based fitness e valuations, which sev erely limit scalability and hinder practical applicability in dynamic decision-making environments. Surrogate-assisted GP [4], [5] has shown promise in re- ducing ev aluation costs for scheduling heuristics. Ho we ver , its successful application critically depends on the av ailability of problem-specific phenotypic characterisation (PC) schemes that can meaningfully capture the behavioural differences among heuristics. For DMRCPSP , there does not exist such a scheme, and the existing schemes in related problems are not applicable in this case, which prevents the surrogate-assisted GP frameworks from being directly applied to this problem. Motiv ated by the need to enable computationally efficient GP-based decision-making for DMRCPSP , this paper aims to bridge the abov e gap by de veloping a suitable phenotypic characterisation and integrating it into a surrogate-assisted GP approach. Specifically , the research objectiv es of this work are as follows: • T o design a problem-specific phenotypic characterisation scheme for GP heuristics in DMRCPSP based on the ranking behaviour of heuristics ov er eligible activities. • T o develop a surrogate-assisted GP algorithm that incor- porates the proposed PC scheme. • T o verify the ef fecti veness of the PC scheme and compare the performance of the surrogate-assisted GP with the state-of-the-art GP for DMRCPSP . I I . B AC K G RO U N D A. Pr oblem Description The dynamic multi-mode resource-constrained project scheduling problem considers the scheduling of a set of project activities subject to precedence and resource constraints. Each activity can only start after all of its predecessor activities hav e been completed. For each activity , multiple e xecution modes are av ailable, each with a dif ferent expected duration and resource requirement. In a dynamic en vironment, the exact duration of an acti vity is not known in advance and is only rev ealed during execution. The actual duration varies within a predefined range determined by optimistic and pessimistic estimates around the expected duration. At any point in time, only a limited amount of renew able resources is a vailable, and the total resource consumption of acti vities executed in parallel must not e xceed the corresponding resource capacities. The objecti ve of the DMRCPSP is to construct a feasible project schedule that respects both precedence and resource constraints while minimising the overall project makespan. B. Genetic Pr ogramming for DMRCPSP Genetic Programming (GP) has been widely applied as a hyper-heuristic method for solving complex scheduling prob- lems, including standard RCPSP [6]–[8], job shop scheduling [3], and related domains [9], [10]. In GP-based scheduling, heuristic rules are ev olved to guide decision-making during schedule construction or simulation. For the dynamic multi-mode RCPSP , recent studies [11]– [13] hav e focused on improving decision-making mechanisms to efficiently utilise resources. A representative approach [13] formulates schedules to utilise resources efficiently using heuristic rules. First, an activity ordering rule ranks eligible activity–mode pairs according to their priority values, and a promising subset of candidates is selected. Next, feasible activity groups are enumerated from the selected candidates, and an activity group selection rule determines which group should be executed. GP employs a multi-tree representation to ev olve these two rules simultaneously . This decision-making frame work is ef fectiv e for DMRCPSP , as it allows GP to jointly optimise acti vity ordering and group selection strategies. Howe ver , the computational cost of ev aluating GP indi viduals remains a major bottleneck, since each indi vidual must be embedded into a simulation to assess its scheduling performance. C. Surr ogate Models for Scheduling Heuristics Surrogate models [14] are a class of techniques designed to accelerate ev olutionary algorithms on such problems by approximating expensi ve fitness e valuations using computa- tionally cheaper alternativ es. The basic idea is to replace a portion of full ev aluations with inexpensi ve estimations based on previously ev aluated solutions. In the design of surrogate models for GP-based scheduling heuristics, two main approaches have been explored in the literature: simplified simulation models [15] and phenotypic characterisation-based methods [4]. The first approach relies on replacing the original, computationally expensiv e ev alu- ation with a simplified simulation model, for example, by reducing the number of jobs, machines, or resources con- sidered during ev aluation. While such simplified models can reduce the computational cost to some extent, the time savings are often limited. Moreover , their ef fecti veness depends on carefully selecting which problem parameters can be reduced without significantly compromising ev aluation fidelity , which itself requires additional empirical inv estigation. The second approach adopts a more abstract and compu- tationally efficient strategy . Instead of executing a full (or reduced) simulation, this approach extracts a set of rep- resentativ e decision situations from the original simulation en vironment. GP heuristics are then applied to these situations to make decisions, and their decision-making behaviours are recorded and transformed into numerical feature vectors. As a representativ e example, reference [4] proposed a phenotypic characterisation scheme for the job shop scheduling problem based on a reference rule. In each decision situation, all candidate operations are ranked and inde xed according to a predefined reference rule, and the operation selected by a GP heuristic is represented by its corresponding rank index. Consequently , the phenotypic characterisation (PC) vector of a GP indi vidual consists of the indices of the selected operations across all decision situations. These PC vectors can then be used to measure beha vioural similarity between GP individuals, and, when combined with known fitness values, to estimate the fitness of unev aluated individuals using surrogate models such as nearest-neighbour regression. A ke y challenge in applying PC-based surrogate methods lies in the design of an effecti ve scheme that can faithfully map the behaviour of GP heuristics to a numerical vector representation. The PC scheme introduced in [4] has subsequently been applied to other scheduling domains, including flexible job shop scheduling [5] and multi-project RCPSP [16], but this scheme does not apply to GP for DMRCPSP . The main limitation lies in the fact that the scheme in [4] is designed for single-choice decision scenarios, whereas the heuristic rules in [13] are applied to both ranking-based decision situations and activity group selection, which corresponds to subset selection. While subset selection can be adapted by enumerating and indexing activity groups, enumerating activity orderings is impractical due to the factorial growth of permutations. More- ov er , assigning indices to permutations destroys the semantic relationships between different orderings. In addition, the PC scheme in [4] records only the rank of the highest-priority candidate determined by a reference rule, ignoring the relative ordering of other candidates in the same decision situation. As a result, two heuristic rules that select the same highest- priority candidate b ut differ substantially in the ordering of remaining candidates may be considered identical, leading to inaccurate distance measurements between GP individuals. These limitations moti v ate the de velopment of a new PC scheme that can effecti vely capture ranking-based and subset- selection decision behaviours in DMRCPSP , enabling the application of surrogate-assisted GP to this problem. I I I . P R O P O S E D M E T H O D A. Overall F rame work The proposed algorithm adopts the framew ork from [4], representing a con ventional surrogate-assisted GP workflow . An ov erview of the algorithm is illustrated in Fig. 1, where the differences introduced in this work are highlighted in blue. The algorithm begins with an initial population P . For each individual in the population, a phenotypic characterisation Ran d o m ly initia li se p o p u lat ion F u ll f itn e ss e va lua tio n Co m p u t e PC v e c t o r o f Rem o ve d u p li ca te s fr o m S to p ? B u il d su r r o g a te m o d e l w ith Gener ate o f f sp r ing Co m p u t e PC v e c t o r o f E s t im a t e f it n e s s u s in g s u r r o g a t e m o d e l F o r m w ith b e st ind ivi d u a ls fr o m N Y Ret u r n b e st ind ivi d u a l Rem o ve d u p li ca te s fr o m Fig. 1. Flowchart of the surrogate-assisted GP algorithm. (PC) vector is computed; the scheme of PC is detailed in Sec- tion III-B. Duplicate individuals in terms of PC vector are then remov ed, and the remaining unique individuals are ev aluated using the full fitness function. During the ev olutionary loop, the PC vectors of the current population are used to construct a surrogate model. Subsequently , k × | P | intermediate offspring P imd are generated, where k is referred to as the of fspring multiplier . The PC vectors of the intermediate offspring are computed, the of fspring with the unique vector are kept, and the surrogate model is employed to estimate their fitness values (details of the surrogate estimation are provided in Section III-C). Finally , the top | P | offspring, as ranked by the surrogate, are selected for full fitness ev aluation. The ev olutionary loop repeats until the stopping criterion is met, and the best individual found is returned. Since this work extends the approach in [13] by introducing a surrogate model, GP indi vidual representation, full fitness ev aluation procedure, as well as crossover , mutation, and selection operators, remain the same as in that work; thus, they are omitted in this paper . More details can be found in [13]. B. New Phenotypic Characterisation Scheme A well-designed PC scheme should reflect the behaviour of GP individuals during full fitness ev aluation. In this work, each individual consists of two trees: an activity ordering rule and an activity group selection rule. The activity ordering rule is applied to compute ordering priority values for eligible activity–mode pairs at each decision point. Based on these priority values, a knee point selection strategy is employed to identify a promising subset of acti vity–mode pairs. From this subset, feasible acti vity groups are enumerated, and the activity group selection rule is then used to select the activity group with the highest priority for execution. Motiv ated by the distinct roles of the two heuristic rules, we propose a decision-situation-based PC scheme, as illustrated in Fig. 2. T wo types of decision situations are considered: activity ordering situations and activity group selection situa- tions. In each decision situation, the eligible acti vities and the corresponding project state information are obtained from data sampled during the schedule simulation. For a giv en GP individual, the corresponding heuristic rule n u m b e r o f e l i g i b l e a c t i v i t y - m o d e p a i rs A ct i v i t y o rd e ri n g s i t u a t i o n s Act i v i t y g ro u p s e l e ct i o n s i t u a t i o n s Decision situ a tio n s Act i v i t y o rd e ri n g ru l e G ro u p s e l e ct i o n ru l e GP ind ivi d u a l 2 … 1 0 Decision ve cto r s Ph e n o t y p ic ch a r a ct e r iz a t io n ve ct o r … … … 1 … 7 … … … 2 … 1 0 … … … 1 … 7 … … … n u m b e r o f e l i g i b l e a c t i v i t y - m o d e g ro u p s Si t u a t i o n … Ac t . - m o d e p a i r A1 … E2 … … Pri o ri t y v a l u e 1 5 … 7 8 … … R a n k 2 … 1 0 … … Si t u a t i o n … Ac t . - m o d e g ro u p (A1 , D 2 ) … (B1 , E1 ) … … Pri o ri t y v a l u e 2 3 … 1 0 5 … … R a n k 1 … 7 … … Fig. 2. Phenotypic characterisation scheme of a GP individual. is applied to each decision situation to compute priority values and rankings for all eligible activity–mode pairs or activ- ity–mode groups. A smaller priority value indicates a higher rank. The ranks of all candidates in each decision situation are extracted to form a decision vector . Finally , the decision vectors obtained from all decision situations are concatenated to produce the complete PC vector of a GP individual. This scheme captures the ranking behaviour of heuristic rules across representati ve decision conte xts, providing a phenotypic description of GP individuals. C. Surr ogate-Based F itness Estimation The surrogate model is used to predict the relative quality of candidate offspring for selection purposes, rather than to replace the true fitness ev aluation. In this work, a simple nearest-neighbour surrogate model is employed for fitness estimation. The surrogate takes as input the PC vectors of the current population along with their corresponding fitness values. T o estimate the fitness of a new individual, the Man- hattan distance is computed between its PC vector and the PC vectors of all individuals stored in the surrogate database. The fitness value of the nearest neighbour in the PC space is then assigned as the estimated fitness of the new indi vidual. It is worth noting that the training samples in the surrogate model are not accumulated across generations. Since the full fitness ev aluation inv olves stochastic simulation with different random seeds in each generation, fitness v alues of indi viduals from different generations are not directly comparable. There- fore, the surrogate database contains only individuals from the current population. An illustrativ e example of the fitness estimation process is shown in Fig. 3. In this example, the PC v ector consists of one activity ordering situation and one activity group selection situation. The surrogate database contains the PC vectors and fitness values of four individuals. When predicting the fitness of a new individual, denoted as I nd ∗ , the Manhattan distances between I nd ∗ and the four PC vectors are computed. I nd ∗ is closest to P C 1 with a distance of 4; the fitness v alue associated with P C 1 is returned as the estimated fitness. S u r r o g a t e m o d e l PC Ve ct o r Di sta n ce b e tw e e n ind * a n d P C x F itn e ss PC 1 1 2 3 4 1 2 3 4 4 1 4 4 6 PC 2 4 3 2 1 4 3 2 1 1 4 3 5 4 3 PC 3 1 4 2 3 2 3 1 4 8 2 7 5 6 PC 4 2 3 1 4 3 2 1 4 8 2 3 4 5 PC (I n d * ) 1 3 2 4 1 2 4 3 1 4 4 6 F i n d th e n e a r e st n e i g h b o u r Ret u r n t h e fi tn e ss o f th e n e a r e st n e i g h b o u r Fig. 3. Example of fitness estimation by the surrogate model. I V . E X P E R I M E N TA L S T U DY A. Experiment Deign T o e valuate the ef fectiv eness of the proposed approach, the algorithm in [13], namely KGGP , is adopted as the baseline for comparison. All algorithms use the same simulation en- vironment and GP parameter settings as in [13] to ensure a fair comparison. In the simulation, each project consists of 200 activities, where each activity can be executed in three modes, and a total of 12 renewable resource types are considered. The precedence complexity among activities is characterised using the order strength [1] metric. Three lev els of precedence complexity are e xamined, with order strength values of 0.75, 0.5, and 0.25, corresponding to high, medium, and low precedence density , respectiv ely . The resulting test scenarios are denoted as 0.75/R12, 0.5/R12, and 0.25/R12. T o obtain reliable performance estimates, each GP individual is ev aluated on fiv e project instances, and the a verage makespan relativ e to the corresponding lower bound is used as the fitness value. The proposed algorithm is referred to as SKGGP , i.e., surrogate-assisted KGGP . For the PC scheme, ten decision situations are sampled from the simulation runtime for each type of decision situation. Each sampled situation contains more than ten eligible acti vity–mode pairs or activity–mode groups. T o in vestigate the impact of different offspring multi- pliers k on the ev olutionary process, four values are consid- ered: k = 1 , 1 . 5 , 2 and 4 . The corresponding algorithms are denoted as SKGGP-1, SKGGP-1.5, SKGGP-2, and SKGGP- 4, respecti vely . All GP algorithms are implemented using the Python DEAP 1 framew ork, with a population size of 1000 and 100 generations, resulting in up to 10 5 full fitness ev aluations. Each algorithm is independently executed 30 times for each scenario. All experiments were conducted on identical com- putational nodes within a high-performance computing cluster – New Zealand eScience Infrastructure (NeSI) 2 . B. T est P erformance T able I reports the mean and standard deviation of the test performance achieved by the heuristic rules trained using KGGP (baseline) and SKGGP with different offspring mul- 1 https://github .com/DEAP/deap/ 2 https://www .nesi.org.nz/ T ABLE I T H E M E AN ( STA N DA R D D E VI ATI O N ) O F T HE O BJ E C T IV E V A L UE S O B T A I NE D BY FI VE A LG O R I TH M S F RO M 3 0 I N D E PE N D EN T RU N S . Algorithm <0.75/R12> <0.5/R12> <0.25/R12> KGGP 1.724 ± 0.013 1.691 ± 0.011 1.710 ± 0.016 SKGGP-1 1.711 ± 0.010 1.686 ± 0.014 1.702 ± 0.014 ( ↑ ) ( ≈ ) ( ≈ ) SKGGP-1.5 1.713 ± 0.013 1.684 ± 0.016 1.699 ± 0.014 ( ↑ )( ≈ ) ( ≈ )( ≈ ) ( ↑ )( ≈ ) SKGGP-2 1.708 ± 0.009 1.678 ± 0.014 1.700 ± 0.015 ( ↑ )( ≈ )( ≈ ) ( ↑ )( ↑ )( ≈ ) ( ↑ )( ≈ )( ≈ ) SKGGP-4 1.706±0.010 1.678±0.014 1.700±0.021 ( ↑ )( ↑ )( ↑ )( ≈ ) ( ↑ )( ↑ )( ↑ )( ≈ ) ( ↑ )( ≈ )( ≈ )( ≈ ) 0 50 100 1.70 1.75 1.80 1.85 <0.75/R12> 0 50 100 1.70 1.75 1.80 1.85 <0.5/R12> 0 50 100 1.70 1.75 1.80 1.85 1.90 <0.25/R12> 80 90 100 1.70 1.71 1.72 1.73 80 90 100 1.66 1.68 1.70 80 90 100 1.70 1.72 Generation A verage Objective V alue on T est Instances KGGP SKGGP -1 SKGGP -1.5 SKGGP -2 SKGGP -4 Fig. 4. Conv ergence curves of five algorithms over 30 independent runs. tipliers k across the three scenarios. Statistical significance between algorithms is examined using the Wilcoxon signed- rank test. In the table, each algorithm is compared with the ones above it under the same scenario, and the results are indicated using the symbols “( ↑ )” (significantly better), “( ↓ )” (significantly worse), and “( ≈ )” (no significant difference). Fig. 4 illustrates the performance of the best indi vidual from each generation, e valuated on the test set during the training process. Overall, SKGGP demonstrates superior performance to KGGP when a larger number of intermediate offspring are generated. In particular, SKGGP-2 and SKGGP-4 outperform KGGP across all scenarios. The con vergence curves further show that SKGGP-2 and SKGGP-4 con ver ge substantially faster than KGGP . Although SKGGP-4 generates twice as many intermediate offspring per generation as SKGGP-2, the performance dif ference between the two variants is rel- ativ ely small. The impact of different offspring multipliers on offspring selection is further analysed in Section IV -D. For cases with fewer intermediate offspring, such as SKGGP- 1.5, improved performance over KGGP is observed in two of the three scenarios. The abov e comparisons verify the effecti veness of the proposed PC scheme and the surrogate model design. Notably , SKGGP-1, which does not generate additional intermediate of fspring, con ver ges faster than KGGP in the 0.75/R12-1 scenario. This result indicates that the PC- based duplicate remov al mechanism alone can also contribute to performance improvement to some extent. C. Saved Budget Analysis Figure 5 provides an alternativ e perspectiv e by illustrating the ratio of full fitness ev aluations sav ed while still achieving the same performance as the baseline KGGP . The x-axis repre- 0.2 0.4 <0.75/R12> <0.5/R12> <0.25/R12> 0 50 k 100 k 0.4 0.2 0.0 0 50 k 100 k 0 50 k 100 k KGGP Evaluation Budget Budget Saved R atio SKGGP -1 SKGGP -1.5 SKGGP -2 SKGGP -4 Fig. 5. Budget saved to reach the performance of KGGP . sents the number of full fitness ev aluations already consumed by the baseline KGGP . For a given x value, the y-axis shows the budget saved ratio, which is computed by first identifying the best solution found by KGGP at that ev aluation count, and then locating the earliest ev aluation at which another algorithm discovers a solution of equal or better quality . The difference between these two e v aluation indices, normalised by the number of ev aluations used by KGGP , defines the budget sav ed ratio. This analysis highlights the ability of surrogate-assisted KGGP (SKGGP) to identify heuristic rules of comparable quality using fe wer full ev aluations and at earlier stages of ev olution. In the early phase of evolution, the ratio is negati ve, indicating that the heuristic rules discovered by SKGGP are inferior to those found by KGGP at the same number of ev aluations. Howe ver , as ev olution progresses, SKGGP be- gins to accelerate its con ver gence. Once heuristic rules of equiv alent quality to those of KGGP are reached, SKGGP can sav e approximately 20–40% of full fitness ev aluations. These results demonstrate that the surrogate model effecti vely pre- selects intermediate of fspring, thereby improving the quality of individuals entering the next generation. As a consequence, high-quality heuristic rules can be discovered earlier , leading to a more ev aluation-efficient ev olutionary process. D. Surr ogate P erformance and Impact of Offspring Multiplier on Offspring Quality T o further in vestigate the performance of the surrogate model and the impact of different offspring multipliers k on the ev olutionary process, we conduct an additional analysis based on the population generated by the baseline KGGP at each generation. Specifically , for each generation, four times the population size of intermediate of fspring are generated, and their true fitness values are obtained through full e valuation. These true fitness v alues are then compared with the fitness values estimated by the surrogate model. This analysis aims to address the following two questions: • Whether the surrogate model is capable of distinguishing high-quality individuals from low-quality ones. • T o what extent increasing the number of intermediate offspring improv es offspring quality . T o answer the first question, we measure the precision of the surrogate model at each generation under different v alues of k , and the results are shown in Fig. 6. This metric reflects the extent to which the surrogate model can correctly select individuals that should be retained for the next generation. Here, a true positive is defined as an indi vidual whose true fitness ranks within the top 1000 and whose estimated fitness also ranks within the top 1000. A false positiv e refers to an individual whose estimated fitness ranks within the top 1000, but whose true fitness rank is worse than 1000. The precision is the ratio of true positiv e instances ov er all positiv e instances. The precision of the surrogate model decreases as the offspring multiplier k increases. When k = 1 . 5 , the precision reaches approximately 80–90%. For k=2, the precision drops to belo w 70%, while for k = 4 , it further decreases to around 50–60%. This trend is intuitiv e, as selecting the top 1000 individuals becomes increasingly challenging as the number of intermediate offspring grows. One possible explanation for this phenomenon lies in the limited size of the surrogate database. Since the database only contains PC vectors from the current population, the surrogate model may lack sufficient representativ e samples to make accurate predictions when faced with a large number of candidate offspring. T o answer the second question, the intermediate offspring are further divided into two groups: base of fspring, which consist of the first 1000 generated offspring, and e xtra off- spring, which include the of fspring generated beyond the population size (i.e., the 1001st and subsequent offspring). W e then examine ho w many individuals from the extra offspring are selected into the top 1000 based on estimated fitness. Among these selected extra offspring, individuals whose true fitness and estimated fitness both rank within the top 1000 are classified as correctly added, while those whose estimated fitness ranks within the top 1000 but whose true fitness ranks outside the top 1000 are classified as incorrectly added. The corresponding statistics are reported in Fig. 7. When k = 1 . 5 , approximately 300 individuals per genera- tion are selected from the extra of fspring (1001–1500), most of which are correctly added, with only about 50 individuals being incorrectly added. For k = 2 , around 350 individuals are correctly added, while approximately 100 indi viduals are incorrectly added. This indicates that, for k = 2 , about 35% of the extra offspring successfully replace the original offspring, enter the subsequent e volutionary process and contribute to improving population quality . This observation further demon- strates the ef fecti veness of generating intermediate offspring followed by surrogate-based selection. When k = 4 , although the number of correctly added individuals slightly increases compared to k = 2 , the number of incorrectly added individuals rises substantially to around 300. This result is consistent with the lower precision observed for k = 4 and partially explains why SKGGP-2 and SKGGP- 4 achiev e similar overall performance. Although SKGGP-4 generates twice as many intermediate offspring per generation as SKGGP-2, the surrogate model is less capable of accurately distinguishing high-quality indi viduals from lo w-quality ones, leading to the introduction of both beneficial and detrimental individuals into the population. 0 50 100 0.5 0.6 0.7 0.8 0.9 <0.75/R12> 0 50 100 <0.5/R12> 0 50 100 <0.25/R12> Generation P r ecision k=1.5 k=2 k=4 Fig. 6. Mean precision by various offspring multipliers k across generation. 0 50 100 100 200 300 400 <0.75/R12> 0 50 100 <0.5/R12> 0 50 100 <0.25/R12> Generation Count k=1.5-cor r ectly added k=1.5-incor r ectly added k=2-cor r ectly added k=2-incor r ectly added k=4-cor r ectly added k=4-incor r ectly added Fig. 7. Mean count of true positiv e and false positiv e by various of fspring multipliers k across generations. E. Surr ogate Overhead T o examine whether the introduction of the surrogate model imposes a significant computational overhead, we report the av erage per-generation ev aluation time of SKGGP across different scenarios in T able II. Full e v aluation refers to the time required to ev aluate | P | individuals (i.e., 1000) in the current generation using the simulation model. Surrogate estimation denotes the time needed to compute the PC vectors of k ∗ | P | intermediate of fspring and to estimate their fitness v alues using the surrogate model. Overall, the time spent on surrogate estimation is approximately 1/20 to 1/40 of that required for full ev aluation. This indicates that the surrogate-related ov erhead is relativ ely small, demonstrating that the surrogate model can enhance the conv ergence of the algorithm with only a marginal increase in computational cost. V . C O N C L U S I O N S This paper proposes a phenotypic characterisation scheme for genetic programming applied to the dynamic multi-mode T ABLE II M E AN E V A L UA T I O N T I ME O F F U LL E V A L UA T I O N A N D S U RR O GAT E E S TI M A T I ON I N S E C ON D S . Scenario Algorithm Full Evaluation Surrogate Estimation 0.75/R12 SKGGP-1 266.27 9.65 SKGGP-1.5 275.01 10.94 SKGGP-2 333.73 13.05 SKGGP-4 362.33 20.26 0.5/R12 SKGGP-1 556.13 14.00 SKGGP-1.5 602.91 19.63 SKGGP-2 541.95 22.89 SKGGP-4 593.04 45.40 0.25/R12 SKGGP-1 784.37 10.53 SKGGP-1.5 967.90 13.83 SKGGP-2 948.97 15.27 SKGGP-4 881.96 23.98 resource-constrained project scheduling problem. By analysing the decision situations encountered during GP-based schedul- ing, a rank-based PC vector is designed to transform the behavioural characteristics of GP indi viduals into a numerical vector . This addresses the lack of suitable PC schemes for GP in DMRCPSP and enables behaviour -lev el comparison between indi viduals. The proposed PC scheme is integrated into a surrogate-assisted GP framework, where it is used to measure distances between GP indi viduals and to estimate the fitness of unev aluated intermediate offspring. Experimental results demonstrate that the SKGGP algorithm is able to ev olve higher-quality heuristic rules than the baseline KGGP with significantly fewer expensi ve fitness ev aluations. Further analyses reveal the surrogate model’ s ability to pre-select promising offspring and quantify the contribution of different numbers of intermediate offspring to population quality . Despite these advantages, the precision of the current sur- rogate model decreases when selecting from a large number of intermediate offspring. Future work will therefore focus on improving surrogate accuracy by expanding the surro- gate database, exploring more e xpressiv e PC schemes, and in vestigating alternativ e machine learning models for fitness estimation. R E F E R E N C E S [1] V . V . Peteghem and M. V anhoucke, “ An experimental in vestigation of metaheuristics for the multi-mode resource-constrained project schedul- ing problem on new dataset instances, ” Eur opean Journal of Oper ational Resear ch , vol. 235, no. 1, pp. 62–72, 2014. [2] S. Hartmann and D. Briskorn, “ An updated surve y of variants and extensions of the resource-constrained project scheduling problem, ” Eur opean Journal of Operational Researc h , vol. 297, no. 1, pp. 1–14, 2022. [3] F . Zhang, Y . Mei, S. Nguyen, and M. Zhang, “Surve y on genetic programming and machine learning techniques for heuristic design in job shop scheduling, ” IEEE T ransactions on Evolutionary Computation , vol. 28, no. 1, pp. 147–167, 2024. [4] T . Hildebrandt and J. Branke, “On Using Surrogates with Genetic Programming, ” Evolutionary computation , vol. 23, no. 3, pp. 343–367, 2015. [5] F . Zhang, Y . Mei, S. Nguyen, M. Zhang, and K. C. T an, “Surrogate- Assisted Ev olutionary Multitask Genetic Programming for Dynamic Flexible Job Shop Scheduling, ” IEEE T ransactions on Evolutionary Computation , vol. 25, no. 4, pp. 651–665, 2021. [6] M. Ðumi ´ c and D. Jakobo vi ´ c, “Ensembles of priority rules for re- source constrained project scheduling problem, ” Applied Soft Comput- ing , vol. 110, p. 107606, 2021. [7] J. Luo, M. V anhoucke, J. Coelho, and W . Guo, “ An efficient genetic programming approach to design priority rules for resource-constrained project scheduling problem, ” Expert Systems with Applications , vol. 198, no. 1, p. 116753, 2022. [8] M. Ðumi ´ c and D. Jakobovi ´ c, “Using priority rules for resource- constrained project scheduling problem in static en vironment, ” Com- puters & Industrial Engineering , vol. 169, p. 108239, 2022. [9] S. W ang, Explainable Genetic Pr ogr amming for Evolving Routing P olicies of Uncertain Capacitated Arc Routing Pr oblems . Phd thesis, T e Herenga W aka-V ictoria Univ ersity of W ellington, 2023. [10] T . Guo, Y . Mei, M. Zhang, R. Sun, Y . Zhu, and W . Du, “Genetic pro- gramming with multifidelity surrog ates for large-scale dynamic air traf fic flow management, ” IEEE T ransactions on Evolutionary Computation , vol. 29, no. 6, pp. 2671–2685, 2025. [11] Y . Tian, Y . Mei, and M. Zhang, “Learning Heuristics via Genetic Pro- gramming for Multi-mode Resource-constrained Project Scheduling, ” in 2024 IEEE Congress on Evolutionary Computation (CEC) , pp. 01–08, June 2024. [12] Y . Tian, Y . Mei, and M. Zhang, “Genetic Programming with Activity Group Selection for Dynamic Multi-mode Resource-Constrained Project Scheduling Problems, ” in 2025 IEEE Congress on Evolutionary Com- putation (CEC) , pp. 1–4, IEEE, June 2025. [13] Y . Tian, Y . Mei, and M. Zhang, “Scalable knee-point guided activity group selection in multi-tree genetic programming for dynamic multi- mode project scheduling, ” arXiv: 2601.14485 , 2026. [14] Y . Jin, H. W ang, and C. Sun, “Data-Driven Surrogate-Assisted Evo- lutionary Optimization, ” in Data-Driven Evolutionary Optimization: Inte grating Evolutionary Computation, Machine Learning and Data Science , pp. 147–172, Cham: Springer International Publishing, 2021. [15] S. Nguyen, M. Zhang, and K. C. T an, “Surrogate-Assisted Genetic Pro- gramming W ith Simplified Models for Automated Design of Dispatching Rules, ” IEEE T ransactions on Cybernetics , vol. 47, no. 9, pp. 2951– 2965, 2017. [16] H. Chen, X. Li, and L. Gao, “ A surrogate-assisted dual-tree genetic programming framework for dynamic resource constrained multi-project scheduling problem, ” International Journal of Production Research , vol. 62, no. 16, pp. 5631–5653, 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment