CAST-TTS: A Simple Cross-Attention Framework for Unified Timbre Control in TTS
Current Text-to-Speech (TTS) systems typically use separate models for speech-prompted and text-prompted timbre control. While unifying both control signals into a single model is desirable, the challenge of cross-modal alignment often results in ove…
Authors: Zihao Zheng, Wen Wu, Chao Zhang
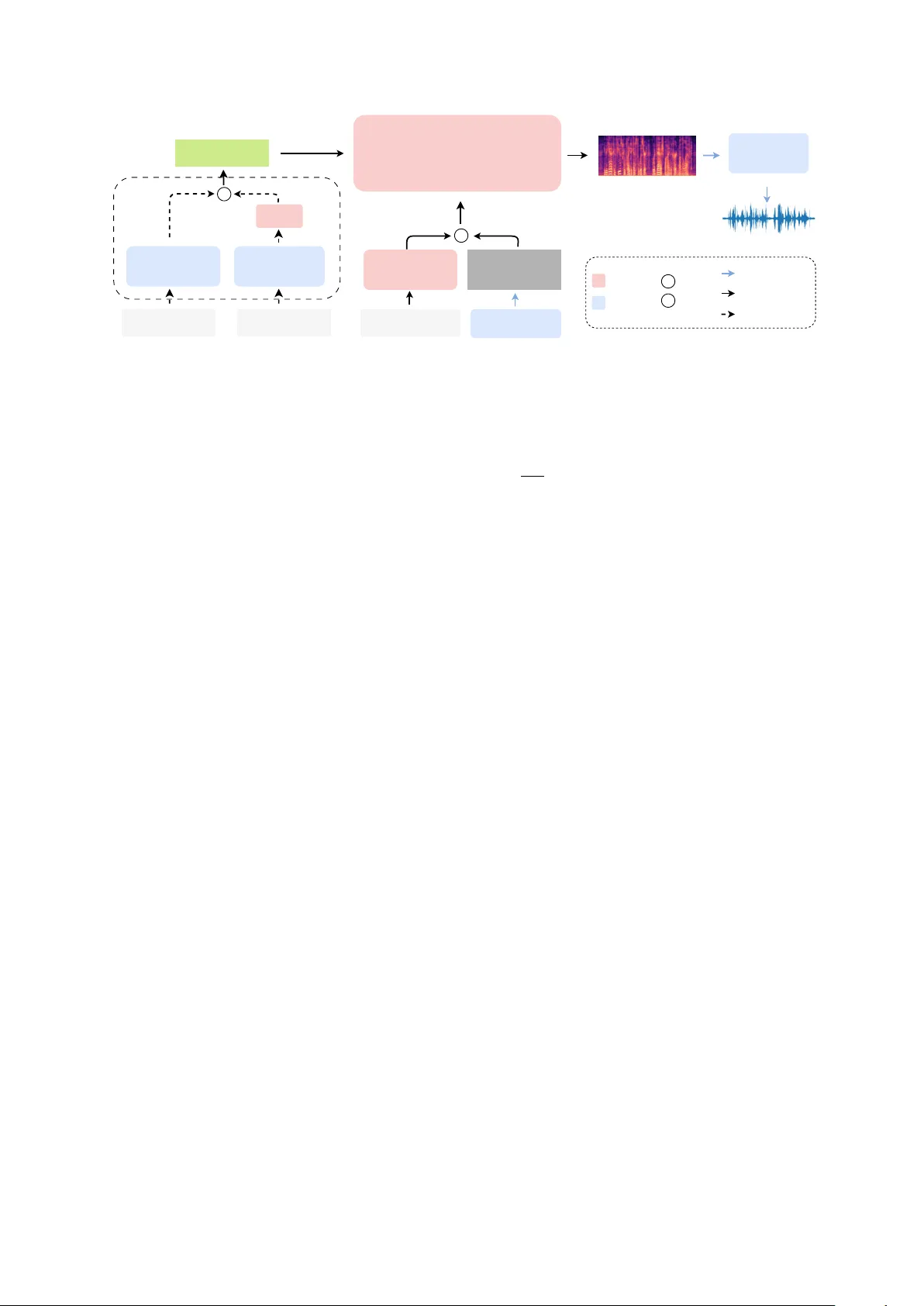
CAST -TTS: A Simple Cr oss-Attention Framework f or Unified T imbr e Contr ol in TTS Zihao Zheng 1 , 2 , W en W u 1 , Chao Zhang 1 , Mengyue W u 2 , Xuenan Xu 1 1 Shanghai AI Lab, China 2 MoE K ey Lab of Artificial Intelligence, X-LANCE Lab, Shanghai Jiao T ong Univ ersity , China rookie9@sjtu.edu.cn, wsntxxn@gmail.com Abstract Current T ext-to-Speech (TTS) systems typically use separate models for speech-prompted and text-prompted timbre control. While unifying both control signals into a single model is de- sirable, the challenge of cross-modal alignment often results in ov erly complex architectures and training objecti ve. T o address this challenge, we propose CAST -TTS, a simple yet effecti ve framew ork for unified timbre control. Features are extracted from speech prompts and text prompts using pre-trained en- coders. The multi-stage training strategy efficiently aligns the speech and projected text representations within a shared em- bedding space. A single cross-attention mechanism then al- lows the model to use either of these representations to con- trol the timbre. Extensive experiments validate that the uni- fied cross-attention mechanism is critical for achieving high- quality synthesis. CAST -TTS achieves performance compara- ble to specialized single-input models while operating within a unified architecture. The demo page can be accessed at https://HiRookie9.github .io/CAST -TTS-P a ge Index T erms : text-to-speech synthesis, Timbre Control, com- putational paralinguistics 1. Introduction In recent years, T ext-to-Speech (TTS) systems have made sig- nificant progress, enabling the generation of speech with high naturalness and fidelity . Recent TTS models often possess zero-shot v oice cloning capabilities, allowing them to mimic a speaker’ s timbre from a short speech prompt [1, 2, 3, 4]. By training on a speech-infilling task, zero-shot TTS models based on flow-matching ha v e shown strong performance [1, 2, 5]. A parallel line of research explores the use of text prompts to control speaker characteristics [6, 7]. In contrast to speech prompts, textual captions provide a more coarse-grained but flexible approach to controlling speaker timbre. Large language models (LLMs) and expert systems are in volv ed in automatic data annotation pipelines, facilitating the construction of large- scale, open-source datasets [8]. In representati ve w orks such as Parler -TTS [6] and CapSpeech [7], textual captions are first en- coded by a pre-trained text encoder . The resulting embeddings then condition the synthesis model through a cross-attention mechanism, which has prov en effecti ve for accurate timbre at- tribute control. The effecti veness of this conditioning mecha- nism has also been demonstrated in T e xt-to-Image (T2I) and T ext-to-Audio (T2A) models [9, 10]. Models that exclusi vely use either a speec h pr ompt or a te xt pr ompt often fail to meet the di verse needs of users across dif- ferent scenarios. Consequently , prior research has begun to ex- Under revie w at Interspeech 2026. plore the combination of these two forms. StyleFusion TTS [11] integrates style descriptions with audio prompts, but it requires both inputs simultaneously during inference. FleSpeech offers a more flexible solution, enabling various combinations of audio, text, and even facial inputs to enhance adaptability [12]. How- ev er , FleSpeech employs a complex architecture comprising an autoregressi ve language model, a flo w-matching backbone, and a diffusion-based prompt encoder . The design necessitates opti- mizing several loss functions simultaneously for semantic pre- diction, feature reconstruction, and prompt alignment, thereby increasing the risk of training instability . In this work, we introduce CAST -TTS , a framework em- polying C ross- A ttention mechanism combining either S peech or T ext prompts. For text prompts, we use Flan-T5 [13] to en- code the descriptiv e text. The resulting features are then pro- jected into the shared timbre embedding space via a lightweight projector . For speech prompts, we follow the procedure of E2- TTS-x1 [2]. An original speech utterance is randomly split into prompt and target. Montreal Forced Aligner (MF A) is used to obtain transcriptions for the target part [14]. For the speaker timbre encoding, we employ a pre-trained speak er encoder [15] to extract embeddings from the prompt part. This design elim- inates the masking strate gy in E2-TTS and results in a consis- tent conditioning paradigm of the timbre under speech and text prompt scenarios. Follo wing established practices, the target text transcription is first encoded by a Con vNeXt V2 module, then concatenated with noisy latent [16]. Separately , speaker information from ei- ther modality is incorporated into the model via cross-attention. W e adopt a multi-stage training strategy to optimize and align the shared timbre embedding space. In summary , our contribu- tions are as follows: • A simple architecture that uses cross-attention to fuse speech prompt conditions. This remov es the requirement for com- plex masking and is aligned with te xt prompts conditioning. • A unified frame work capable of handling both speech and textual modalities by projecting te xt embeddings into speech- based timbre embedding space with a multi-stage training strategy . • Extensive ablation studies and comparative results that vali- date our design choices and demonstrate the effecti veness of the unified model. 2. CAST -TTS CAST -TTS is a non-autoregressi ve (NAR) TTS system de- signed to integrate speech-prompted and text-prompted timbre control within a single framew ork. T o achieve this, a uni- fied timbre encoder is employed to encode the inputs of both modalities into a shared embedding space. W e further design a Flow-Matching T ransformer Speaker Encoder Flan-T5 Projector T ext Prompt ConvNext V2 Blocks T arget T ranscription c V ocoder Timbre Embed G Cross-attention Noise Duration Predictor T rainable Frozen Infer Chosen T rain & Infer c Concat G Gate Speech Prompt Timbre Encoder Figure 1: An overvie w of CAST -TTS. The timbre encoder con verts speec h or text prompts into timbr e embeddings, which condition the synthesis model thr ough a cr oss-attention mechanism. multi-stage training strategy to optimize the cross-modal feature alignment. 2.1. Architectur e As illustrated in Figure 1, CAST -TTS mainly consists of a timbre encoder and a Transformer flow-matching backbone. The timbre encoder processes either a speech prompt or a text prompt, to generate an embedding that controls speak er timbre. The Transformer backbone predicts the target mel-spectrogram, which is subsequently conv erted into an audio wa veform by a BigVGAN v ocoder [17]. The timbre encoder comprises two parts: the speech branch and the text branch. The speech branch is a speaker encoder that transforms the input speech prompt into a timbre embed- ding sequence T ∈ R T × D . Based on a comparison of different models in Section 4.2.1, we select the encoder of a W avLM- based [18] ECAP A-TDNN [15]. In the text branch, the in- put caption is encoded by a Flan-T5 encoder [13]. A linear projector then maps the text embeddings into the timbre em- bedding space, since speech prompts inherently contain richer and more fine-grained speaker information than textual descrip- tions. This directional alignment designates the rich speech em- bedding space as the unified conditioning space, forcing the text features to align with the more expressi ve speech modality . The input text transcription is first con verted into a se- quence of character embeddings, then padded with filler tokens to match the length of the target mel-spectrogram. W e employ Con vNeXt V2 blocks for character encoding, given the proven ability in prior works [1]. The Transformer backbone incorporates sev eral Trans- former blocks with long skip connections between blocks. Zero-initialized adaptiv e Layer Norm (adaLN-zero) is used to stabilize training. The Transformer backbone receives three in- puts: the noisy mel-spectrogram M , character embeddings C , and timbre embeddings T . First, the noisy mel-spectrogram is concatenated with the character embeddings. Within each block of the Transformer , the latent representation is encoded through self-attention. Subsequently , it interacts with the timbre em- bedding via cross-attention, followed by a final feed-forward network (FFN). 2.2. T raining CAST -TTS is trained with flo w-matching loss. This objectiv e trains a neural network v θ to parameterize a velocity field that defines a continuous-time flow between the data distribution x 0 ∼ p data ( x 0 ) and a standard Gaussian prior x 1 ∼ N (0 , I ) : d x τ dτ = v θ ( x τ , τ ) x τ = (1 − τ ) · x 0 + τ · x 1 , τ ∈ [0 , 1] L FM = E τ , x 0 , x 1 ∥ v θ ( x τ , τ , C , T ) − ( x 1 − x 0 ) ∥ 2 where θ denotes model parameters, τ is the flo w step, and L FM is the flow-matching training loss. Throughout the training pro- cess, the pre-trained speak er encoder and the Flan-T5 text en- coder remain frozen. CAST -TTS is trained in three distinct stages. This process utilizes two distinct data formats: speech-prompted pairs and text-prompted pairs, which are detailed further in Section 3.1: • Speech Synthesis Pre-training: W e first train the Con vNeXt V2 blocks and Transformer layers using only the speech- prompted dataset. This stage equips the model with a ba- sic ability to generate coherent speech conditioned on timbre embeddings. • T ext Condition Alignment: Next, we freeze the pre- trained components and train only the pr ojector on the te xt- prompted dataset. This efficiently aligns the text representa- tion space with the established speech-derived timbre embed- ding space. • Joint Fine-tuning: Finally , all trainable components are jointly fine-tuned on the combined dataset. This stage refines the alignment between both modalities and enhances overall synthesis quality and controllability . 2.3. Inference CAST -TTS generates target speech based on a target transcrip- tion T gen and a speech or te xt prompt. Since NAR models can- not inherently predict audio duration, an external duration pre- dictor is required to determine the length of the output speech. For speech prompt, we employ Whisper -large-v3 extracting the reference transcription T ref [19]. Following previous works, we estimate target duration based on the ratio of character counts in T ref and T gen . For text prompt, we leverage the pre- trained duration predictor from CapSpeech, which accepts both the transcription and the prompt to estimate the total duration of the target speech [7]. During inference, classifier -free guidance (CFG) is employed to improv e the generation quality [20]: v CFG θ ( x τ , C , T ) = (1 − w ) v θ ( x τ , ∅ , ∅ ) + w v θ ( x τ , C , T ) T able 1: Objective and subjective evaluation r esults. The arr ows ( ↓↑ ) indicate whether lower or higher scores are better . Objective Ev aluations Subjective Ev aluations Prompt Model WER(%) ↓ SPK-Sim ↑ Style-A CC(%) ↑ UTMOS ↑ N-MOS ↑ Sim-MOS ↑ Speech F5-TTS-v1 2.31 75.4 - 3.87 4.13 4.17 MaskGCT 3.54 74.5 - 3.90 3.73 3.93 ZipV oice-L 1.77 66.7 - 4.26 3.90 4.01 CAST -TTS 2.05 78.4 - 3.91 3.86 4.09 T ext CapSpeech-N AR 5.11 - 88.93 4.06 4.08 4.05 Parler -TTS-Large 5.53 - 82.04 3.80 3.46 3.52 CAST -TTS 3.89 - 91.15 4.01 4.03 4.11 where w is the guidance scale. 3. Experiments 3.1. Datasets Since CAST -TTS synthesizes speech conditioned on speech or text prompts, the training data comprises two corresponding types of data pairs. LibriTTS-R dataset [21] is selected for speech-prompted training. W e obtain word-lev el alignments for each utterance using the MF A model, follo wing the methodology of E2-TTS- x1 [2]. For each sample, we determine a random split times- tamp. The audio segment preceding this timestamp serves as the speech prompt. The remaining audio segment and its corre- sponding transcription become the tar get and input respectively . For natural language conditioning, we mainly use the LibriTTS-R subset of CapTTS dataset [7]. A part of Gi- gaSpeech is included to add child, teen, and elderly speak- ers [22], since LibriTTS-R lacks speakers of these ages. CapTTS emplo ys specialized models to annotate discrete labels for speaker attributes: gender, accent, pitch, tonal expressiv e- ness and speaking rate. Subsequently , LLM is used to generate descriptiv e captions from these labels. In total, the training data is comprised of approximately 1360 hours of audio, including ∼ 282K speech-prompted data pairs and ∼ 434K text-prompted data pairs. 3.2. Experimental Setup The T ransformer backbone follows CapSpeech, with 22 layers, 16 attention heads and a hidden size of 1024. The training de- tails in three stages are: • Stage 1: 400K steps with a peak learning rate of 7.5e-5. • Stage 2: 200K steps with a peak learning rate of 1.5e-5. • Stage 3: 100K steps with a peak learning rate of 2.5e-5. The learning rate takes a linear decay schedule with a weight decay of 0.01. During inference, the CFG scale is set to 3.0. 3.3. Evaluation W e ev aluate the model’ s performance on two distinct test sets, each targeting a different conditioning modality . For speech-prompted ev aluation, we choose LibriSpeech-PC test- clean [23]. For te xt-prompted evaluation, we use the CapTTS test subsets corresponding to the LibriTTS-R and GigaSpeech audio. Objectiv e metrics include W ord Error Rate (WER), Speaker Similarity (SPK-Sim), Style-A CC and UTMOS. WER is com- puted using whisper -lar ge-v3 along with the Whisper text nor- malizer . T itaNet [24] is used for SPK-Sim ev aluation, com- puting the similarity of speaker embeddings between prompt and generated speech. Style-ACC is the average accuracy of age, gender , pitch, expressi veness of tone, and speed. The re- liance on hard thresholds for classifying continuous predictions makes the baseline metrics for pitch, expressi veness, and speed sensitiv e to minor value changes near the boundaries. W e there- fore relax the ev aluation criterion by allowing predictions to fall within adjacent categories, which is more stable and represen- tativ e. UTMOS is used for ev aluating audio quality [25]. Subjectiv e metrics include the Mean Opinion Score (MOS) to ev aluate speech naturalness (N-MOS) and similarity (Sim- MOS). 10 highly educated raters without hearing loss are in- vited to score 10 random samples from each of the test dataset. 4. Results 4.1. Generation Perf ormance For the speech-prompted synthesis task, we benchmark our CAST -TTS against sev eral leading models: F5-TTS-v1 [1], MaskGCT [3], and the LibriTTS-trained version of ZipV oice (denoted as ZipV oice-L) [4]. The results in T able 1 demon- strate that CAST -TTS achie ves the highest SPK-SIM among all models and deliv ers competitive WER and UTMOS scores. F5- TTS-v1 demonstrates a clear advantage in the subjectiv e rat- ings, likely due to its training on the large-scale Emilia dataset. Notably , CAST -TTS achieves performance on par with the other competing TTS systems. This indicates that CAST -TTS possesses strong synthesis performance and e xcellent speaker- cloning capabilities. In the text-prompted synthesis task, CAST -TTS is com- pared against CapSpeech-NAR [7] and Parler-TTS-Lar ge [6]. CAST -TTS achieves the best results in both WER and Style- A CC, while also yielding a strong UTMOS score. For subjec- tiv e metrics, CAST -TTS also exhibits highly competitive per- formance. These results highlight the superior performance of CAST -TTS in generating high-fidelity speech that accurately re- flects the guidance of text-based style captions. 4.2. Ablation Study T o validate our method, we conduct ablation studies in vestigat- ing the effects of the speak er feature, the fusion mechanism, and the training strategy . 4.2.1. Speaker F eatures T o in vestigate the ef fecti veness of feature representation for the speech prompt, we compare three dif ferent features, all inte- T able 2: Ablation study on model arc hitectur es. W e evaluate the impact of differ ent methods under both speech and text pr ompted conditions. Speech Prompt T ext Prompt Model Featur e WER(%) ↓ SPK-Sim ↑ UTMOS ↑ WER(%) ↓ Style-A CC(%) ↑ UTMOS ↑ CAST -SA Melspec 3.74 35.8 3.97 4.17 81.25 3.78 ECAP A-TDNN 5.48 43.0 4.00 6.56 90.00 3.91 CAST -SACA Melspec 2.67 35.5 3.95 4.52 90.10 3.89 ECAP A-TDNN 3.18 41.2 4.06 4.93 90.26 3.90 CAST -CA ECAP A-TDNN 3.13 69.5 3.82 4.47 89.01 3.91 CAST -TTS-BASE ECAP A-TDNN 2.87 75.4 3.87 4.03 87.96 3.85 CAST -TTS-TV 2.85 77.2 3.79 4.08 87.98 3.81 CAST -TTS 2.05 78.4 3.91 3.89 91.15 4.01 grated into the backbone via the cross-attention mechanism. Mel-spectrogram is usually fused with the noisy latent by con- catenation followed by self-attention, rather than cross-attention in prior works. ECAP A-TDNN and TitaNet features are ex- tracted from pre-trained speaker verification models. For a fair comparison of SPK-Sim, we compute scores using TitaNet and ECAP A-TDNN respectively , denoted as Sim-T and Sim-E. T able 3: Ablation results for speech featur es. Featur e WER(%) ↓ Sim-T ↑ Sim-E ↑ Melspec 3.41 47.9 32.8 T itaNet 3.50 80.9 64.4 ECAP A-TDNN 2.51 80.0 72.8 As sho wn in T able 3, the mel-spectrogram yields a sub- stantially lower SPK-SIM score compared to both dedicated speaker features, since mel-spectrogram contains a mixture of acoustic and semantic information. In contrast, speaker fea- tures are explicitly trained to disentangle and represent only the speaker-rele vant acoustic characteristics, which allows the model to learn the target speaker identity more directly and ef- fectiv ely from the speech prompt. Since ECAP A-TDNN fea- tures demonstrate more robust ov erall performance across the metrics than T itaNet features, we select the encoder of ECAP A- TDNN as the speaker encoder for CAST -TTS. 4.2.2. Fusion Mechanism W e conduct an ablation study to in vestigate the optimal mech- anism for fusing the speech and te xt prompt embeddings. W e design and compare three distinct architectures: • CAST -SA: This approach concatenates the timbre embed- ding with the noisy latent, relying on self-attention for fusion. W e test it with both mel-spectrogram and ECAP A-TDNN features, since mel-spectrogram is a common choice for this fusion style in prior works [1, 2]. • CAST -SA CA: This model represents an intuitive hybrid ap- proach. It fuses the speech prompt via concatenation and self- attention, while integrating the text prompt embedding using cross-attention. • CAST -CA: This is our proposed architecture, which uses cross-attention to uniformly fuse both the speech and text prompt representation. All models are trained for 400K steps on the full dataset for a fair comparison. The results are sho wn in T able 2. Over- all, CAST -SA CA models perform better than CAST -SA. Re- garding features, while mel-spectrogram yields a lower WER, ECAP A-TDNN is superior across nearly all other indicators. CAST -CA achiev es highly competitiv e WER, Style-ACC, and UTMOS scores while demonstrating a clear adv antage in SPK- SIM. This validates the effecti veness of using cross-attention as the primary mechanism for integrating timbre features. 4.2.3. T raining Strate gy W e in vestigate three training strategies to v alidate our proposed approach. First, we train CAST -TTS-CA directly in an end- to-end fashion as a baseline (CAST -TTS-BASE). Second, we ev aluate CAST -TTS-TV , which prepends a learnable task vec- tor to the timbre embedding to explicitly differentiate between modality types. The third method is our proposed multi-stage training strategy . T o ensure a fair comparison, all models are trained for a total of 700K steps. As shown in T able 2, CAST -TTS-TV exhibits no impro ved performance o ver the CAST -TTS-B ASE baseline after incorpo- rating a task vector . This result suggests that explicit distinction between the two tasks does not yield better performance. The superior performance of CAST -TTS across all metrics high- lights the adv antages of our training strategy . This approach allows the model to first establish a robust speech synthesis foundation and then ef ficiently align the text modality to the pre-trained space before a final joint refinement. 5. Conclusion A unified model supporting both speech and text prompts of fers significant flexibility for TTS, yet existing solutions are often architecturally comple x due to the inherent difficulty of cross- modal alignment. T o address this issue, we propose CAST - TTS: a simple cross-attention framework for unified timbre con- trol. W e extract features from the input speech or te xt prompt using pre-trained encoders, mapping the text embedding into a unified timbre embedding space with a simple projector . T o fuse these control signals, we employ cross-attention and pro- pose a multi-stage training strate gy for optimized cross-modal alignment. CAST -TTS achie ves strong results on both speech- prompted and te xt-prompted synthesis tasks. Due to limitations in our dataset, it currently lacks control over attributes such as emotion and accent, which we identify as important directions for our future work. 6. Generativ e AI Use Disclosure In this work, generati v e AI was e xclusi vely utilized to fix gram- matical mistakes and adjust terminology , while all core research activities, including study design, data collection, analysis, and scientific reasoning, were conducted independently by the au- thors. 7. References [1] Y . Chen, Z. Niu, Z. Ma, K. Deng, C. W ang, J. JianZhao, K. Y u, and X. Chen, “F5-tts: A fairytaler that fak es fluent and faithful speech with flo w matching, ” in Pr oceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , 2025, pp. 6255–6271. [2] S. E. Eskimez, X. W ang, M. Thakker, C. Li, C.-H. Tsai, Z. Xiao, H. Y ang, Z. Zhu, M. T ang, X. T an et al. , “E2 tts: Embarrassingly easy fully non-autoregressi ve zero-shot tts, ” in 2024 IEEE spoken language technology workshop (SLT) . IEEE, 2024, pp. 682–689. [3] Y . W ang, H. Zhan, L. Liu, R. Zeng, H. Guo, J. Zheng, Q. Zhang, X. Zhang, S. Zhang, and Z. Wu, “Maskgct: Zero-shot text-to- speech with masked generativ e codec transformer , ” arXiv preprint arXiv:2409.00750 , 2024. [4] H. Zhu, W . Kang, Z. Y ao, L. Guo, F . Kuang, Z. Li, W . Zhuang, L. Lin, and D. Pove y , “Zipvoice: Fast and high-quality zero-shot text-to-speech with flow matching, ” arXiv preprint arXiv:2506.13053 , 2025. [5] M. Le, A. Vyas, B. Shi, B. Karrer , L. Sari, R. Moritz, M. W illiamson, V . Manohar, Y . Adi, J. Mahadeokar et al. , “V oicebox: T ext-guided multilingual universal speech generation at scale, ” Advances in neural information processing systems , vol. 36, pp. 14 005–14 034, 2023. [6] Y . Lacombe, V . Sriv astav , and S. Gandhi, “Parler-tts, ” https: //github .com/huggingface/parler - tts, 2024. [7] H. W ang, J. Hai, D. Chong, K. Thakkar, T . Feng, D. Y ang, J. Lee, T . Thebaud, L. M. V elazquez, J. Villalba et al. , “Cap- speech: Enabling downstream applications in style-captioned text-to-speech, ” arXiv pr eprint arXiv:2506.02863 , 2025. [8] D. L yth and S. King, “Natural language guidance of high- fidelity text-to-speech with synthetic annotations, ” arXiv preprint arXiv:2402.01912 , 2024. [9] R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer , “High-resolution image synthesis with latent diffusion models, ” in Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , 2022, pp. 10 684–10 695. [10] J. Hai, Y . Xu, H. Zhang, C. Li, H. W ang, M. Elhilali, and D. Y u, “Ezaudio: Enhancing text-to-audio generation with efficient dif- fusion transformer , ” in Proc. Interspeech 2025 , 2025, pp. 4233– 4237. [11] Z. Chen, X. Li, Z. Ai, and S. Xu, “Stylefusion tts: Multimodal style-control and enhanced feature fusion for zero-shot text-to- speech synthesis, ” in Chinese Confer ence on P attern Recognition and Computer V ision (PRCV) . Springer , 2024, pp. 263–277. [12] H. Li, Y . Li, X. W ang, J. Hu, Q. Xie, S. Y ang, and L. Xie, “Flespeech: Fle xibly controllable speech generation with various prompts, ” arXiv preprint , 2025. [13] H. W . Chung, L. Hou, S. Longpre, B. Zoph, Y . T ay , W . Fe- dus, Y . Li, X. W ang, M. Dehghani, S. Brahma et al. , “Scal- ing instruction-finetuned language models, ” J ournal of Mac hine Learning Resear ch , v ol. 25, no. 70, pp. 1–53, 2024. [14] M. McAulif fe, M. Socolof, S. Mihuc, M. W agner, and M. Son- deregger , “Montreal forced aligner: T rainable text-speech align- ment using kaldi, ” in Pr oc. Interspeech 2017 , 2017, pp. 498–502. [15] B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAP A- TDNN: Emphasized Channel Attention, propagation and aggre- gation in TDNN based speak er verification, ” in Interspeech 2020 , 2020, pp. 3830–3834. [16] S. W oo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “Convne xt v2: Co-designing and scaling con vnets with masked autoencoders, ” in Pr oceedings of the IEEE/CVF con- fer ence on computer vision and pattern r ecognition , 2023, pp. 16 133–16 142. [17] S. G. Lee, W . Ping, B. Ginsburg, B. Catanzaro, and S. Y oon, “Bigvgan: A univ ersal neural vocoder with large-scale training, ” in 11th International Conference on Learning Representations, ICLR 2023 , 2023. [18] S. Chen, C. W ang, Z. Chen, Y . W u, S. Liu, Z. Chen, J. Li, N. Kanda, T . Y oshioka, X. Xiao et al. , “W avlm: Large-scale self- supervised pre-training for full stack speech processing, ” IEEE Journal of Selected T opics in Signal Pr ocessing , vol. 16, no. 6, pp. 1505–1518, 2022. [19] A. Radford, J. W . Kim, T . Xu, G. Brockman, C. McLeav ey , and I. Sutskev er , “Robust speech recognition via large-scale weak supervision, ” in International conference on machine learning . PMLR, 2023, pp. 28 492–28 518. [20] J. Ho and T . Salimans, “Classifier-free diffusion guidance, ” in NeurIPS 2021 W orkshop on Deep Generative Models and Down- str eam Applications . [21] Y . Koizumi, H. Zen, S. Karita, Y . Ding, K. Y atabe, N. Morioka, M. Bacchiani, Y . Zhang, W . Han, and A. Bapna, “Libritts-r: A re- stored multi-speaker text-to-speech corpus, ” in Proc. Interspeech 2023 , 2023, pp. 5496–5500. [22] G. Chen, S. Chai, G.-B. W ang, J. Du, W .-Q. Zhang, C. W eng, D. Su, D. Pove y , J. Trmal, J. Zhang et al. , “Gigaspeech: An ev olv- ing, multi-domain asr corpus with 10,000 hours of transcribed au- dio, ” in Pr oc. Interspeech 2021 , 2021, pp. 3670–3674. [23] A. Meister, M. No viko v , N. Karpov , E. Bakhturina, V . Lavrukhin, and B. Ginsburg, “Librispeech-pc: Benchmark for evaluation of punctuation and capitalization capabilities of end-to-end asr mod- els, ” in 2023 IEEE automatic speech recognition and understand- ing workshop (ASR U) . IEEE, 2023, pp. 1–7. [24] N. R. Koluguri, T . Park, and B. Ginsb urg, “T itanet: Neural model for speaker representation with 1d depth-wise separable con v o- lutions and global context, ” in ICASSP 2022-2022 IEEE inter- national confer ence on acoustics, speech and signal pr ocessing (ICASSP) . IEEE, 2022, pp. 8102–8106. [25] T . Saeki, D. Xin, W . Nakata, T . Koriyama, S. T akamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022, ” Interspeech 2022 , 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment