GitOps for Capture the Flag Platforms
In this paper, we present CTF Pilot, a GitOps-based framework for the deployment and management of Capture The Flag (CTF) competitions. By leveraging Git repositories as the single source of truth for challenge definitions and infrastructure configur…
Authors: Mikkel Bengtson Albrechtsen, Jacopo Mauro, Torben Worm
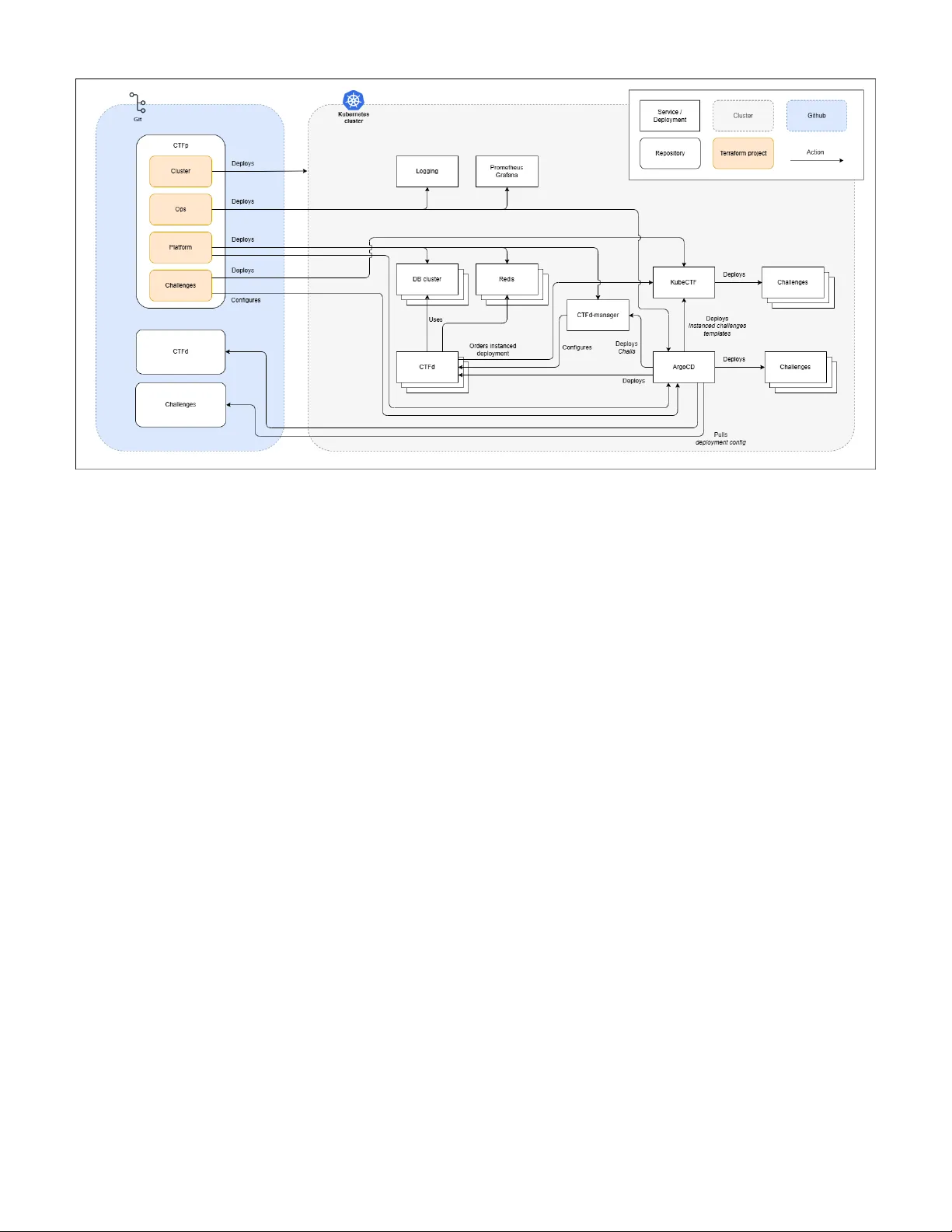
GitOps for Capture the Flag Platforms Mikkel Bengtson Albrechtsen ∗ † , Jacopo Mauro ∗ , T orben W orm ∗ ∗ University of Southern Denmark, Odense, Denmark † Brunnerne, Denmark themikkel@brunnerne.dk, mauro@imada.sdu.dk, tow@mmmi.sdu.dk Abstract —In this paper , we pr esent CTF Pilot , a GitOps- based framework for the deployment and management of Cap- ture The Flag (CTF) competitions. By leveraging Git repositories as the single source of truth f or challenge definitions and infras- tructure configurations, CTF Pilot enables automated, version- controlled deployments that enhance collaboration among chal- lenge authors and organizers. W e detail the design criteria and implementation of CTF Pilot and evaluate our approach through a real-world CTF event, demonstrating its cost efficiency and its effectiveness in handling high participant concurrency while ensuring r obust isolation and ease of challenge develop- ment. Our results indicate that CTF Pilot improves the expe- rience for organizers and participants, and we present the lessons learned, highlighting opportunities for future impro vement. Index T erms —K ubernetes, Containers, CTF , Capture The Flag I . I N T R O D U C T I O N Capture The Flag (CTF) competitions [1] are a popular format for cybersecurity challenges, where participants solve tasks to earn points and capture ”flags”. These ev ents often require complex infrastructure to host challenges, manage participant access, and ensure fair play . The (possible) high number of participants in CTF e vents demands robust infras- tructure and scalable solutions that can handle concurrent ac- cess and peak loads while maintaining isolation between teams to prevent cheating. The consequences of misconfiguration or downtime can be high, as it can lead to a poor experience for participants and organizers alike. CTF environments are generally composed of multiple services and applications in order to serve the challenges and collect and present the results [2]. While the services and challenges are typically containerized, setting up CTF en vironments can be comple x and error-prone, especially when scaling to accommodate a large number of participants. A particularly persistent difficulty lies in the dev elopment and deployment of challenges themselves: authors must manually build, package, and publish challenge artifacts, often relying on ad-hoc scripts or inconsistent deployment practices. These fragmented workflo ws increase the likelihood of configuration drift, and lead to unpredictable runtime beha vior . T o address these issues, we advocate for the usage of Infrastructure-as-Code (IaC) and GitOps. By expressing both infrastructure and challenge definitions declaratively and stor- ing them in version-controlled repositories, or ganizers can ensure reproducibility and automate the provisioning pipeline. GitOps controllers continuously reconcile the live system with the repository state, reducing manual intervention and enabling challenge authors to focus on content creation instead of operational complexity . This shift turns challenge deployment into a structured, revie wable, and reliable process that scales naturally with the size of the e vent. In this paper , we present CTF Pilot , a GitOps-driv en framew ork that unifies challenge dev elopment, deployment, and infrastructure management for large-scale Capture The Flag (CTF) competitions. Central to our contribution is a dev elopment workflo w that integrates IaC and GitOps prin- ciples to simplify challenge creation, standardize deployment, and ensure consistency across the entire system. The solution supports efficient challenge de velopment, high participant con- currency with strict isolation guarantees. W e demonstrate the effecti v eness of our approach through its deployment in a lar ge CTF event, presenting participant feedback and discussing the key lessons learned from the operational experience. The paper is structured as follows: Section II provides background information on CTF competitions and GitOps principles. Section III details the design and implementation of CTF Pilot . Section IV presents the ev aluation and discus- sion of the approach through a real-world CTF e vent. Section V discusses related work in the field. Finally , Section VI concludes the paper and outlines future work. I I . P R E L I M I N A R I E S In this section, we provide background information starting with basic information on Capture The Flag competitions. Next, we introduce the automation paradigms that enable automated, scalable, and reproducible deployment workflows. Finally , we describe the key platforms and tools we used for dev eloping CTF Pilot . A. Captur e The Flag Competitions Capture The Flag (CTF) competitions are cybersecurity ex ercises in which participants solve challenges to obtain “flags”, i.e., secret tokens that prov e successful exploitation or analysis. CTFs serve a dual purpose: they are widely used in educational settings to foster hands-on learning in security topics, and they form the basis of competitiv e events at both national and international le vels [1]. CTF ev ents typically follow one of two major formats: Jeopar dy-style and Attack–Defense . In Jeopardy-style compe- titions, participants solv e standalone challenges across cat- egories such as web exploitation, cryptography , forensics, mobile security , rev erse engineering, and binary exploitation. Each challenge provides a flag upon successful completion and contributes points to the team’ s score. Attack–Defense competitions, on the other hand, in v olve teams defending their own vulnerable services while simultaneously attacking the services of others. Although more complex to organize, Attack–Defense CTFs closely mirror real-world adversarial conditions. In this work, we focus on Jeopardy-style CTFs, which are more prev alent in educational contexts and easier to standardize for automated deployment. B. Automation P aradigms Infrastructur e as Code: Infrastructure as Code (IaC) is a paradigm for pro visioning and managing computing en- vironments through declarativ e, machine-readable configura- tion files rather than manual administrati ve procedures. By treating infrastructure definitions as software artifacts, IaC brings software engineering principle such as version control, automated testing, code re vie w into the domain of system and platform management. This approach helps eliminate configuration drift, making system behavior more predictable and transparent [3]. Modern IaC tools (e.g., OpenT ofu/T erraform, Pulumi) sup- port a broad set of cloud and on-premises platforms. They provide mechanisms for modularization, dependency resolu- tion, dry-run e valuation, and state inspection, enabling teams to manage complex infrastructures at scale. Continuous Inte gration and Delivery: Continuous Integra- tion and Continuous Deliv ery (CI/CD) ha ve become founda- tional practices in modern software engineering. The original concept of continuous integration dates back to the late 1980s with early build management systems [4]. Over time, this ev olv ed into full CI/CD pipelines that automate not only build and test but also deployment [5]. At their core, CI/CD pipelines orchestrate a series of automated stages. Follo wing lightweight pre-commit checks, code is integrated and subjected to developer test suites, static analysis, and integration testing. These validations are crucial for detecting regressions and enforcing secure coding practices [6]. Compilation then produces distributable artif acts, which can be containerized to guarantee consistent ex ecution across heterogeneous environments. The deliv ery stage pro- motes artifacts to staging, where both functional and non- functional requirements are assessed before deployment. The ab undance of av ailable CI/CD tools reflects the maturity of the DevOps ecosystem. Selection often depends on com- patibility , vendor support, cost, and platform constraints [7]. Because org anizational needs e volv e, migrations between tools are frequent. V endor lock-in remains a persistent concern, as pipelines tightly coupled to a single system increase future migration costs. T o mitigate this, open standards such as the Open Container Initiativ e [8] and containerization strategies hav e been proposed. Security considerations further compli- cate pipeline design. The DevSecOps paradigm emphases em- bedding security throughout the software lifecycle, a necessity in light of widespread supply chain attacks [9], [10]. GitOps: GitOps [11] is a software operations paradigm that extends the principles of Continuous Deliv ery into infrastruc- ture management. In a GitOps workflow , the entire system configuration—including application manifests, infrastructure definitions, and security policies—is stored as versioned code in a Git repository . The state of the repository represents the desired state of the system, while automated agents continu- ously reconcile the li ve infrastructure against that repository . In practice, GitOps merges operational automation with software engineering discipline. Changes to manifests trigger automated deployments without manual access to production clusters, reducing configuration drift and operational risk. Rollback mechanisms are simplified since any pre vious system version can be restored by re verting a Git commit. The declarativ e model also facilitates compliance, as ev ery change is revie wable and logged. C. Platforms and T ooling K ubernetes: Kubernetes [12] is an open-source container or- chestration platform originally dev eloped by Google and later donated to the Cloud Nativ e Computing Foundation (CNCF), becoming the de facto standard for container orchestration in cloud-nativ e en vironments. It provides a declarative model for deploying, scaling, and managing containerized applications across clusters of physical or virtual machines. At its core, Kubernetes abstracts computing resources as a cluster of nodes , each hosting one or more pods —the smallest deployable unit in the Kubernetes model. Pods encapsulate one or more containers that share storage volumes and network interfaces. The system’ s declarative configuration is defined through Y AML manifests that specify the desired cluster state. Kubernetes’ control plane continuously reconciles this desired state against the actual state, automatically performing scheduling, restarts, or rescaling as needed. Because of its declarativ e nature and strong automation capabilities, Kuber- netes provides a robust substrate for systems that require scalability , self-healing, and multi-tenant isolation. CTFd: CTFd [13] is an open-source web platform for hosting and managing CTF competitions. It implements a complete competition workflow including user registration, team management, challenge deployment, flag submission, scoring, and liv e leaderboard updates. The system follo ws a modular architecture written in Python and based on the Flask web framew ork. Persistent data are stored in a relational database (commonly PostgreSQL or MySQL), while transient state and caching are handled through a Redis backend. CTFd exposes a RESTful API and a plugin system that allows organizers to extend its functionality—such as custom authentication providers, automated scoring engines, and in- tegrations with orchestration systems. Organizers can create challenges through a graphical interface or by importing structured JSON manifests. Each challenge definition includes metadata (category , points, description, and flag type) and an optional connection string that points to the running in- stance of the challenge. Ho we ver , CTFd by itself does not provide the capability to launch or manage per -team isolated en vironments. Traditionally , competitions relying solely on CTFd must pre-deploy shared challenges or integrate external automation scripts. kube-ctf: kube-ctf [14] is a instancing system by DownUn- derCTF , built to use Kubernetes-nativ e principles to manage CTF challenge instances in an automated and scalable manner . It extends the Kubernetes control plane by introducing custom resources representing challenges, which it uses to generate per-team deployments. When a team deploys and instance, kube-ctf automatically deploys its resources with a team- specific ID to Kubernetes. Kubernetes scheduling is then lev eraged to start and maintain the specified resources. kube-ctf uses Y AML definitions to define the resources to deploy for each team (e.g., deployments, services and ingress) and network policies to isolate each pod in the instancing namespace. T o limit the o verall resource usage, there is a preset limit of instances running per team. Kube-janitor [15] is then used to automatically delete instances after a preset amount of time to free up resources. I I I . S Y S T E M D E S I G N A N D I M P L E M E N TA T I O N In this section, we present the overall design and imple- mentation of CTF Pilot starting with the key design goals, architectural choices, and the core infrastructure components dev eloped. Design Goals and Requir ements CTF Pilot was designed to support a modern, large- scale Capture The Flag (CTF) competition combining high participant concurrency with strict isolation guarantees. Ke y design goals included: • Scalability: enable dynamic provisioning of hundreds of challenge instances on demand, while maintaining consistent performance. • Reliability and fault tolerance: automatically recov er from component failures, maintaining service continuity during competition peaks. • Isolation: ensure that each team interacts only with its own challenge instance, pre venting cross-team interfer- ence or leakage. • Reproducibility: manage all resources through Infrastructure-as-Code, ensuring complete reproducibility for debugging and root cause analysis in case of problems. • Cost efficiency: maintain low operational expenses, al- lowing the quick creation and tearing down of the entire infrastructure. • Ease of operation: provide a lightweight management and deployment pipeline for challenge authors and ev ent organizers. Ar chitectur al Design and Implementation T o meet the design goals without reinv enting existing so- lutions, we adopted a hybrid approach that integrates mature, open-source CTF framew orks with custom-built automation and orchestration components. Specifically , we utilized CTFd for the management of challenges and scoreboards, and kube-ctf for dynamic challenge instancing. These systems were extended with our o wn infrastructure automation layer, enabling seamless interaction between services and allo wing fully automated deployment, configuration, and teardown of the CTF environment through declarati ve configuration files. This architecture combines the reliability of well-tested CTF management systems with the flexibility of Infrastructure- as-Code, making it possible to reproduce and redeploy the entire en vironment in a consistent and transparent manner . Fig- ure Fig. 1 illustrates the overall system architecture, showing the integration of the major components and their deployment flow within the Kubernetes-based platform. Kubernetes was selected as the container orchestration en- gine to host the challenges and all the services due to its ability to ensure fault tolerance and scalability across multiple nodes. The cluster architecture consists of four node pools: • Control Planes: managing the Kubernetes control plane and orchestrating the ov erall cluster . • Agents: ex ecuting general workloads, including monitor- ing, deployment engines, and the main CTF services. • Challs: dedicated to hosting challenge containers, both shared and instanced. • Scale: an autoscaled pool managed by the Cluster Autoscaler to dynamically allocate additional resources when scheduling constraints occur . Cor e Infrastructur e Components T raefik [16] was used as re verse proxy and ingress con- troller . T raefik surpasses traditional alternative solutions like Nginx and HAProxy by providing comprehensiv e support for various configuration methods, sensible defaults, and fea- tures such as TLS certificate management and observability tools [17]. It automatically detects and configures routes to backend services within Kubernetes, supporting dynamic service discov ery , SSL termination, and load balancing. Its seamless integration with Kubernetes ingress resources and support for middle ware mechanisms make it particularly suited for multi-service deployments such as CTF platforms, where flexibility and automation are essential. For metrics and performance monitoring, we deployed the Prometheus – Grafana stack [18], [19]. Prometheus collects metrics via HTTP-based exporters and provides a powerful query language (PromQL) for real-time analysis. Grafana complements Prometheus by offering a rich, inter- activ e visualization layer , supporting customizable dashboards, alerting mechanisms, and correlation of multiple data sources. T ogether , they enable precise observ ability ov er resource uti- lization, application performance, and cluster health. Filebeat [20] is used to collect logs from containerized applications and system components, and forwarding them to centralized logging solutions. In our setup, it aggregates logs from cluster nodes and application pods, ensuring uniform log collection across distributed components. These logs are then processed and indexed by an external Elastic Search - Kibana stack [21], allowing for long-term storage, advanced querying, and visualization of historical logs. Fig. 1. High-level overvie w of the CTF Pilot infrastructure. W e developed sev eral custom visualization dashboards to enhance observability and analysis. Specifically , we designed a fully custom Grafana dashboard inspired by [22], pro- viding tailored insights into challenge activity and system performance. W e also integrated Kibana for log analysis and trend monitoring, creating a dedicated dashboard to track participant behavior and detect the use of automated tools. W e complemented these with of f-the-shelf Grafana dashboards primarily focused on Kubernetes resource utilization, ensuring a comprehensi ve monitoring setup spanning both application- lev el and infrastructure-lev el metrics. The network architecture of CTF Pilot was designed to ensure both security and scalability by segmenting services into distinct domains. The infrastructure is divided into three primary categories: Management, Challenges, and Scoreboard, each hosted on separate DNS entries. This separation facili- tates clearer network policies and reduces the risk of cross- service interference. TLS certificates are managed automat- ically using the free Let’ s Encrypt provider [23], enabling seamless rene wal and minimizing manual intervention. Chal- lenge instances are exposed via wildcard domains to allo w dynamic allocation of per -team endpoints without requiring manual DNS configuration. T o further enhance security and reliability , we used the free tier of Cloudflare as a protecti ve and caching layer in front of both the Management and Scoreboard services. This setup mitigates Distributed Denial- of-Service (DDoS) risks 1 , provides rate limiting and W eb Application Firewall (W AF) features, and improv es content deliv ery performance through its global CDN. Internally , the 1 Previous experience from other CTF organizing teams has experienced them. See, e.g., [24] cluster nodes are connected via a secure VPN overlay , en- suring encrypted communication between components across physical and virtual boundaries. Challenges F rontend and Execution For scoreboard and challenge frontend, CTFd was deployed within the Kubernetes cluster . The deployment relied on a clustered database and caching layer . Specifically , a multi- node MariaDB Galera cluster was provisioned through the mariadb-operator [25], while a clustered Redis cache was managed by the redis-operator [26]. These configu- rations ensured automatic failov er and high av ailability . T o en- sure robustness, the system performed automated backups ev- ery 15 minutes, distributed across multiple physical locations to enhance data resilience. Handout files are served through S3-compatible object storage [27], offloading do wnload traffic from the main infrastructure. For the deployment and execution of the challenges we got inspired by existing open-source initiativ es, particularly DownUnderCTF’ s kube-ctf . The kube-ctf platform utilize Custom Resource Definitions (CRDs) to store templates of challenges. When deploying a challenge, an API request is sent to the kube-ctf challenge manager , which fills out the templating in the challenge templates, and deploys them to Kubernetes. Thereby relying on the native orchestration layer to manage lifecycle and resource allocation. W e utilized specifically the ”challenge-manager”, ”landing” services and their modified CTFd Plugin that we further change to better personalize the display of the challenges and the possibility to hav e multiple endpoints to reach the challenge. Each challenge instance comprised one or more deploy- ments, services, and ingresses, depending on the challenge re- quirements. T o manage states such as “offline” and “loading, ” we le veraged Traefik ’ s routing capabilities. kube-ctf included a fallback page for offline challenges, while custom error middlew are was used to indicate “challenge starting” states, enhancing transparency for participants. Deployment For the deployment of CTF Pilot , we utilized OpenT ofu [28], an open-source Infrastructure-as-Code tool forked from T erraform, that allows for declarativ e management of cloud and on-premises resources. The infrastructure deployment was organized into four OpenT ofu projects— Cluster , Ops , Platform , and Challenges : • Cluster: cluster creation and configuration; • Ops: logging, monitoring, operators, and ArgoCD ; • Platform: CTFd and supporting services; • Challenges: deployment and management of challenge instances. The use of multiple projects was due to the need to isolate Custom Resource Definitions (CRDs) and minimize state complexity . Full deployment could be completed in under 30 minutes, and shutdown in under 10 minutes. In order to facilitate deployment of challenges, we use ArgoCD [29], i.e., a GitOps tool that synchronize deployment files from Git into Kubernetes. The challenges were split into two deployment files: Challenge Information and Challenge Deployment. The Challenge Information is a simple configu- ration file that contains details such as the challenge’ s name, description, and structure. The Challenge Deployment defines how the challenge is launched in the system. Depending on the type of challenge, this could either be a shared setup (using a helm chart) or an indi vidual setup (using a kube-ctf resource to create separate en vironments for each participant). T o import the challenge information into CTFd, a CTFd manager was implemented as a Go-based service that detects changes of Challenge Informations. By using the go-ctfd library [30], it synchronizes the Challenge Information into CTFd and watches for new and updated challenge information continuosly updating CTFd to match the expected state. As far as Challenge Deployments are concerned, these were automatically handled by Ar goCD, with kube-ctf handling per - team instances for instanced deployments. A. F acilitating Challenge Development T o streamline the challenge dev elopment process, a series of tools were introduced to promote standardization, automation, and traceability . The workflo w , depicted in Fig. 2 begins with Discord [31], where a custom bot integrates challenge discussion and management directly within the communication platform. The bot automates project initialization by creat- ing a GitHub issue, a dedicated branch, and an associated pull request (PR), effecti vely linking challenge ideation with version-controlled de velopment. The GitHub issue provides progress tracking through a project board, while the PR enables collaborativ e revie w and integration. Each challenge adheres to a standardized schema describing metadata such as name, type, flags, associated Dockerfiles, and scoring information. This schema ensures consistency and enables automated tooling to interact programmatically with challenge definitions. Based on this structure, challenge builds were fully automated. Docker images were generated and published to the GitHub Container Registry , while handout materials placed in designated directories were automatically packaged into ZIP archi ves for participant distribution. This automated pipeline allowed dev elopers to focus solely on challenge logic and design, abstracting aw ay the complexity of packaging, deployment, and distribution. The resulting system substantially reduced manual overhead and improv ed reproducibility across the challenge lifecycle. All source code dev eloped for this work is av ailable at https://github .com/ctfpilot. In total, the codebase comprises approximately 3.8k lines of Python, 2.8k lines of Go, and 8.2k lines for OpenT ofu. I V . E V A L UA T I O N A N D D I S C U S S I O N The scalability , reliability , and user experience of the de- veloped CTF platform was assessed in a large-scale CTF competition, called BrunnerCTF 2025 [32]. The ev ent had registered a total of 2,860 participants and 1,491 teams. Among these, 1,158 teams obtained at least the minimum score of 10 points, demonstrating a wide le vel of engagement. The CTF featured 83 challenges across 10 categories: Shake & Bake for be ginners (21), Boot2Root (6), Crypto (9), F or ensics (5), Misc (10), Mobile (3), OSINT (4), Pwn (6), Reverse Engineering (9), and W eb (10). All challenges were solved at least once, with the winning team solving 79 out of 83 challenges. The platform supported three types of challenges: Static (54), Shar ed (6), and Instanced (23). Static challenges required only textual descriptions or downloadable files, Shared challenges ran on a common remote host acces- sible to all participants, and Instanced challenges provisioned isolated en vironments per team. At peak load, approximately 600 instances were simultaneously active, consuming around 8 vCPUs and 43 GB of RAM. During the first hour, roughly 750 instances were deployed. The Kubernetes-based infrastructure was hosted on Hetzner [33], chosen for their fav orable cost-performance ratio and the fact that their servers were located in Europe. The cluster comprised 164 vCPUs and 386 GB of RAM distrib uted across 14 nodes: three for the control planes (CPX31 type), three for the agent nodes (CCX33 type), se ven for the challenge nodes (CPX51 type), and one for the scaling node (CPX51 type). Peak resource utilization reached approximately 26 vCPUs and 67 GB RAM, leaving significant unused capacity and demonstrating rob ust headroom for load fluctuations. De- ployment automation was achieved using K ube-Hetzner [34], an open-source T erraform-based frame work for Kubernetes provisioning on Hetzner servers. This setup facilitated rapid deployment, reproducibility , and configuration transparency . Fig. 2. Challenge development workflow . Despite the scale of the infrastructure, costs remained remark- ably low: the total expenditure, including both development and production clusters, amounted to 265.18 C. The pro- duction en vironment alone, acti ve from early August until the e vent’ s conclusion on August 25, cost 127.45 C. The dev elopment cluster , maintained for approximately 1.5 months to enable testing and challenge validation, accounted for the remaining 137.73 C. These figures demonstrate that high- performance CTF infrastructure can be achiev ed at minimal expense through careful resource management and the use of cost-effecti v e bare-metal providers. Network metrics indicated between 1,500 and 2,500 con- current connections at any giv en time. Over the course of the ev ent, the platform processed more than 35 million HTTP requests, with peak throughput around 160,000 requests per minute. Some instances receiv ed over one million requests individually and CTFd accounted for approximately 3 million requests as reported by Cloudflare. Analysis of incoming traffic through user agents provided by HTTP traffic logging rev ealed numerous brute-force attempts, highlighting the need for effecti ve rate limiting and monitoring mechanisms. Operational Issues and Mitigation The e vent experienced a partial outage during the first 22 minutes. Initially suspected to be caused by CTFd, the issue was e ventually traced to the Traefik ingress controller . Due to a misconfiguration in the autoscaling setup, caused by missing resource specifications for a log-forwarding sidecar , the controller failed to scale beyond its minimum of three replicas. The resulting overload led to slow responses and repeated container restarts. T emporary mitigation in volv ed manually allocating additional CPU and memory resources, immediately stabilizing the platform. Once proper resource limits were defined, CPU utilization across the cluster dropped by over 90%, and performance normalized. Although CTFd did not directly cause downtime, the use of a clustered Redis cache introduced stability issues, as CTFd does not nativ ely support this configuration. The system experienced intermittent crashes due to key retriev al errors within the Flask caching library . Redundancy via six con- current replicas mitigated user-facing downtime. For future deployments a non-clustered Redis setup with failover support to improve reliability should be considered. Email verification was enforced for all participants, re- sulting in more than 6,000 outbound messages. Using the Brev o email service [35] ensured high deliverability . Howe ver , Google temporarily deferred emails due to domain-based rate limiting. The issue was mitigated by switching sender domains mid-ev ent. For future events, multiple preconfigured domains should be considered to prev ent throttling. Lessons Learned Post-ev ent feedback from participants was overwhelmingly positiv e, particularly regarding the quality of challenges, sys- tem stability , and the responsiveness of the organizing team. This outcome suggests that the platform successfully balanced scalability , reliability , and user experience, validating its suit- ability for future educational and competitive cybersecurity ev ents. The infrastructure w as also highlighted in revie ws of the CTF , with participating highligting that “The qual- ity of challenges + infra was insanely high, the challenges also had immense v ariation in difficulty , from beginner to advanced” [32]. A participant feedback survey with 39 re- spondant found that participants where satisfied with the CTF and infrastructure (85% gav e it a score of 4 or 5 on a 5 Likert scale). Respondents in particular appreciated small details like the loading screen on instance startup done by exploiting T raefik status middlew are serving “No service a vailable” status in the loading page. Although the challenge development workflow was largely automated, sev eral pain points were identified throughout deployment and ev aluation. One recurring limitation was the inability to test challenges directly on the cluster before full deployment. This restriction occasionally led to late-stage reengineering and adjustments under time pressure. Introduc- ing a dedicated pre-deployment testing en vironment—capable of instantiating challenges in an isolated, production-like set- ting—would significantly streamline validation and reduce the risk of deployment-time failures. Additionally , large challenge assets caused repository management difficulties, underscoring the need for external storage solutions or content deliv ery mechanisms to minimize repository bloat and improve scal- ability for future editions. A surve y run after the CTF challenge with 9 CTF authors highlights that they felt ov erwhelmed in figuring out how to dev elop and revie w challenges. Moreover , they mentioned that it was difficult to ha ve an overvie w o ver what challenges needed revie w , and navigate the challenges when the repos- itory grew to a large challenge count. Sev eral improv ements were suggested for future iterations. Some authors proposed organizing a dedicated workshop to introduce ne w contrib utors to the system, noting that sev eral participants had limited experience with GitHub and had not pre viously used GitHub Projects or Issues to track progress. Others recommended providing a clear overvie w of the files to modify in the base template, to help authors understand which parts to edit and which to leave unchanged. Empirical e vidence from the ev ent further confirmed the operational advantages of instanced environments. During the competition, shared challenge boxes experienced performance degradation due to overloading and CPU throttling, partic- ularly in the case of TCP-based challenges where limited logging capabilities prevented accurate attrib ution of exces- siv e load to specific teams. In contrast, instanced challenges operated in isolated containers, ensuring that each team’ s resource consumption af fected only their own en vironment. This approach not only maintained consistent performance across participants but also improved reliability and facilitated incident tracking. These observations highlight that large- scale instancing is both technically feasible and essential for preserving fairness, stability , and observability in competitiv e cybersecurity en vironments. Monitoring and observability played a critical role in main- taining platform stability . While Prometheus and Grafana offered robust real-time dashboards, the absence of fine- grained alert rules limited proactiv e issue detection. Certain performance anomalies—such as CPU throttling, overloaded remotes, and excessi ve network utilization—were identified only after prolonged observation. Enhancing the monitoring stack with tailored alert policies, and automated anomaly detection would improve operational responsi veness. As far as security is concerned, despite clear rules pro- hibiting scanning and brute-force attacks, participant behavior repeatedly demonstrated that such activities occur regardless of formal restrictions. Consequently , future iterations of the platform must incorporate stronger safeguards, such as rate limiting, sandboxing, and automated intrusion detection. Inte- grating these security controls into the logging and monitoring framew ork would not only protect system integrity but also provide v aluable insights into emerging attack vectors. In our deployment, sandboxing was implemented to the extent possible within the constraints of Kubernetes. W e did not observe significant issues related to participants attempting to abuse the platform, as each containerized challenge instance was constrained by CPU limits, ef fectiv ely providing a natural form of rate limiting. There was a single attempt to escape a container; howe v er , it was unsuccessful. Discussions with others CTF or ganizing groups re vealed that container escape remains their primary concern. As far as security is concerned, we would like to note that due to the adoption of the GitOps approach our entire infrastructure is automatically updated from Git repositories. T o do so we store challenge details inside the Kubernetes cluster and an attacker who gains access to the system could potentially see sensitive information like challenge data (e.g., their source code) or important credentials (e.g., database password and administrator access token for CTFd). One solution to securing the infrastructure, would be to split the infrastructure in two separate clusters, one responsible for the scoreboard and management and one to deploy the challenge instances. This minimizes the possibility for lateral mov ements within the infrastructure. Clearly , in this case, more resources would be needed to operate a second cluster . V endor Lock-In Considerations The current platform relies on a few external non-open source dependencies or providers, most notably Cloudflare, T raefik and GitHub. The use of Cloudflare and T raefik primar- ily serv es as a content deli v ery network and re verse proxy . This dependency is non-critical and could easily be replaced with alternativ e CDN providers without substantial architectural changes, as the integration is limited to standard DNS and caching configurations. In contrast, the reliance on GitHub is more deeply in- tegrated into the platform’ s workflow . Several components, including continuous integration pipelines and project man- agement, are implemented using GitHub Actions and GitHub’ s project boards. These integrations are v endor-specific and would not directly transfer to other Git-based services (e.g., GitLab) without modification. While the codebase itself could be migrated with relati ve ease, reproducing the au- tomation and coordination mechanisms would require reimple- mentation using the respectiv e platform’ s CI/CD and project management tools. Thus, although the GitHub dependency is not fundamental to the design, it remains a practical constraint due to the conv enience and maturity of the GitHub ecosystem. V . R E L A T E D W O R K A number of platforms have been dev eloped to support the deployment and management of Capture the Flag (CTF) com- petitions. These systems vary in their degree of automation, deployment strategies, and integration with scoring platforms. Commercial platforms, such as Parrot CTFs [36], Hack The Box [37], T ryHackMe CTF Builder [38], and CTFd Enterprise [13], of fer comprehensiv e ecosystems that combine challenge deployment, scoring, and user management within managed infrastructures. While these services significantly reduce the operational overhead for organizers, they often come at the expense of transparency and flexibility , depending on vendor - maintained infrastructures and closed-source implementations. Open-source initiati ves such as kCTF [39] and kube-ctf [14] take a dif ferent approach by focusing on scalable de- ployment and isolation within Kubernetes. Google’ s kCTF provides a hardened environment for securely running con- tainerized challenges and has been widely adopted for large- scale competitions. Similarly , kube-ctf introduces Kubernetes- nativ e abstractions to manage per -team challenge instances and automate their lifecycle. Both systems, howe ver , concentrate on the runtime and isolation aspects of CTF deployment, rather than on the full authoring and synchronization pipeline from challenge definition to scoreboard publication. CTFer .io [30] represents another relev ant de velopment. It adopts a GitOps-based approach similar to ours, offering a SaaS platform for managing challenge definitions and syn- chronizing them with CTFd. Its released components include a challenge manager and a CTFd integration for the challenge manager . Ho we ver , CTFer .io currently provides only partial open-source cov erage of its components, limiting its adapt- ability to self-hosted or research-oriented contexts. Another interesting platform is Haaukins [40], which fo- cuses primarily on providing each participant with an iso- lated laboratory en vironment. This lab can be accessed either through a virtual priv ate network or via a web-based Linux interface. Haaukins emphasizes educational settings and indi- vidualized en vironments, but does not specifically address and facilitate challenge creation and testing. Compared to these existing systems, CTF Pilot aims to bridge the gap between infrastructure management and challenge authoring by adopting a fully GitOps-driv en ap- proach. This workflow not only supports auditability and version control b ut also aligns naturally with standard software dev elopment practices (e.g., peer re view , automated testing). V I . C O N C L U S I O N S A N D F U T U R E W O R K This paper presented CTF Pilot , a GitOps-driv en frame- work designed to support the de velopment, deployment, and operation of large-scale Jeopardy-style Capture The Flag (CTF) competitions. W e ev aluated the system through its deployment in a real-world CTF ev ent inv olving thousands of participants and ov er eighty challenges. Overall, the deployment experience confirms that the de- sign choices underlying CTF Pilot provide an ef fecti ve foundation for automating large-scale CTF ev ents, deliv ering both technical robustness and an improved experience for participants and org anizers. The system successfully scaled to handle hundreds of simultaneous challenge instances with stable performance. Isolation guarantees were fulfilled through the use of dedicated instanced deployments, which prev ented cross-team interference and facilitated granular observ ability . Reproducibility was achiev ed through a combination of Infras- tructure as Code and GitOps, enabling full cluster creation and teardown within minutes and ensuring transparent versioning of all infrastructure components. Operational ov erhead was significantly reduced through automation layers such as the challenge manager and CI/CD-dri v en artifact generation, while the hosting strategy kept ov erall costs remarkably low . Finally , the standardized dev elopment workflo w for the challenges improv ed consistency and packaging errors, though the e v al- uation also revealed se veral areas where authoring could be simplified further . A central direction for future work is to further simplify the deployment model. This could be achieved by abstracting away low-le vel deployment details and embedding essential configuration information (e.g., container definitions, exposed services) directly within the challenge description. Such an approach would lower the entry barrier for ne w contrib utors while maintaining the ability to define advanced setups in v olv- ing multiple containers or complex networking requirements. Another promising avenue for improvement concerns the integration between the infrastructure and the communica- tion tools used during the challenge dev elopment process. In particular , the Discord integration could be extended to improv e transparency and coordination among contributors. For example, implementing a command that lists challenges currently under re vie w would allow participants to obtain a real-time o vervie w of pending tasks, thereby facilitating collaboration during the re view phase. The GitOps workflo w itself also presents opportunities for refinement. One potential enhancement would be to separate automatically generated artifacts (i.e., compiled deployment manifests, deri ved configuration files) into a distinct repository . This w ould shield challenge authors from direct exposure to lo w-le vel infrastructure code and reduce the likelihood of accidental misconfigurations during re view . R E F E R E N C E S [1] European Union Agency for Cybersecurity (ENISA), “CTF ev ents – Contemporary practices and state-of-the-art in capture- the-flag competitions, ” https://www .enisa.europa.eu/publications/ ctf- ev ents- contemporary- practices- and- state- of- the- art, ENISA, T ech. Rep., 2021. [2] C. T aylor, P . Arias, J. Klopchic, C. Matarazzo, and E. Dube, “CTF: State-of-the-Art and Building the Next Generation, ” in 2017 USENIX W orkshop on Advances in Security Education (ASE 17) . V ancouver, BC: USENIX Association, 2017. [3] K. Morris, Infrastructur e as Code: Managing Servers in the Cloud , 1st ed. O’Reilly Media, Inc., 2016. [4] G. E. Kaiser, D. E. Perry , and W . M. Schell, “Infuse: fusing integration test management with change management, ” in Pr oceedings of the 13th Annual International Computer Software and Applications Confer ence, COMPSAC . IEEE, 1989, pp. 552–558. [5] J. Humble and D. Farley , Continuous delivery: reliable softwar e releases thr ough build, test, and deployment automation . Pearson Education, 2010. [6] L. Bass, I. W eber, and L. Zhu, DevOps: A Software Architect’ s P er spec- tive . Addison-W esley Professional, 2015. [7] Cloud Native Computing Foundation, “CNCF Cloud Nativ e Landscape, ” https://landscape.cncf.io/, 2025. [8] Open Container Initiativ e, “Open Container Initiative, ” https:// opencontainers.org/, 2025. [9] R. Cox, “Fifty Y ears of Open Source Software Supply Chain Security: For decades, software reuse was only a lofty goal. Now it’s very real.” Queue , vol. 23, no. 1, p. 84–107, 2025. [10] J. Bird, DevSecOps: A leader’ s guide to pr oducing secure software without compromising flow , feedback and continuous impr ovement . Addison-W esley Professional, 2020. [11] GitLab Inc., “What is GitOps?” https://about.gitlab .com/topics/gitops/, 2025. [12] The Kubernetes Authors, “Kubernetes: Production-grade container or- chestration, ” https://kubernetes.io/, 2025. [13] CTFd LLC, “CTFd: The Easiest Capture the Flag Framework, ” https: //ctfd.io, 2025. [14] “DownUnderCTF/kube-ctf, ” Do wnUnderCTF . [Online]. A vailable: https: //github .com/DownUnderCTF/kube- ctf [15] Kube-Janitor Authors, “Kube-Janitor, ” https://codeberg.org/hjacobs/ kube- janitor, 2025. [16] T raefik Labs, “T raefik, ” https://traefik.io, 2025. [17] G. Rathi, S. Amin, S. Jain, M. Y achawad, and K. Digholkar , “Perfor- mance Analysis of Different Ingress Controllers Within the Kubernetes Cluster , ” in 2024 IEEE International Confer ence on Information T ec h- nology , Electr onics and Intelligent Communication Systems (ICITEICS) , 2024, pp. 1–6. [18] Prometheus Authors, “Prometheus, ” https://prometheus.io, 2025. [19] Grafana Labs, “Grafana, ” https://grafana.com, 2025. [20] Elastic, “Filebeat, ” https://www .elastic.co/beats/filebeat, 2025. [21] ——, “The elastic stack, ” https://www .elastic.co/elastic- stack, 2025. [22] Grafana Labs. CTFd Exporter. https://grafana.com/grafana/dashboards/ 23095- ctfd/. [23] Internet Security Research Group. (2025) Let’ s Encrypt. https:// letsencrypt.org. [24] DownUnderCTF T eam, “Infra Writeup 2022: DownUnderCTF, ” https: //downunderctf.com/, 2022. [25] MariaDB Operator T eam, “MariaDB Operator , ” https://github .com/ mariadb- operator/mariadb- operator, 2025. [26] Opstree Solutions, “Redis Operator , ” https://github.com/ O T - CONT AINER- KIT/redis- operator, 2025. [27] Hetzner Online GmbH, “S3 Storage Solution: Object Storage by Het- zner , ” https://www .hetzner .com/storage/object- storage/. [28] OpenT ofu, “OpenT ofu, ” https://opentofu.org/. [29] Argo Project, “Argo CD, ” https://argoproj.github .io/cd/. [30] CTFer .io, “go-ctfd, ” https://github.com/ctfer - io/go- ctfd, 2025. [31] Discord Inc., “Discord, ” https://discord.com. [32] Brunnerne. CTFtime.org / BrunnerCTF 2025. https://ctftime.org/e vent/ 2835. [33] Hetzner Online GmbH, “Af fordable Dedicated Serv ers, Cloud & Hosting from Germany, ” https://www .hetzner .com/. [34] Kube-Hetzner, “T erraform Hcloud Kube-Hetzner, ” https://github.com/ kube- hetzner/terraform- hcloud- kube- hetzner, 2025. [35] Brev o, “Brevo Email Marketing Software, Automation & CRM, ” https: //www .brevo.com/. [36] Parrot CTFs Events: Cybersecurity Competitions & W orkshops. Parrot CTFs. [Online]. A vailable: https://parrot- ctfs.com/events [37] Hack The Box, “Attack Execution, ” https://app.arcade.software/share/ KfeufQyCnKZFmKdMfrsg. [38] Introducing our New CTF Builder Feature! T ryHackMe. [Online]. A vailable: https://tryhackme.com/resources/blog/new-ctf- builder [39] Google, “kCTF, ” https://github.com/google/kctf, 2025. [40] T . K. Panum, K. Hageman, J. M. Pedersen, and R. R. Hansen, “Haaukins: A Highly Accessible and Automated V irtualization Platform for Security Education, ” in 19th IEEE International Conference on Advanced Learning T echnologies, ICALT 2019, Macei ´ o, Brazil, J uly 15-18, 2019 . IEEE, 2019, pp. 236–238. [Online]. A vailable: https://doi.org/10.1109/ICAL T .2019.00073
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment