Adaptive Theory of Mind for LLM-based Multi-Agent Coordination
Theory of Mind (ToM) refers to the ability to reason about others' mental states, and higher-order ToM involves considering that others also possess their own ToM. Equipping large language model (LLM)-driven agents with ToM has long been considered t…
Authors: Chunjiang Mu, Ya Zeng, Qiaosheng Zhang
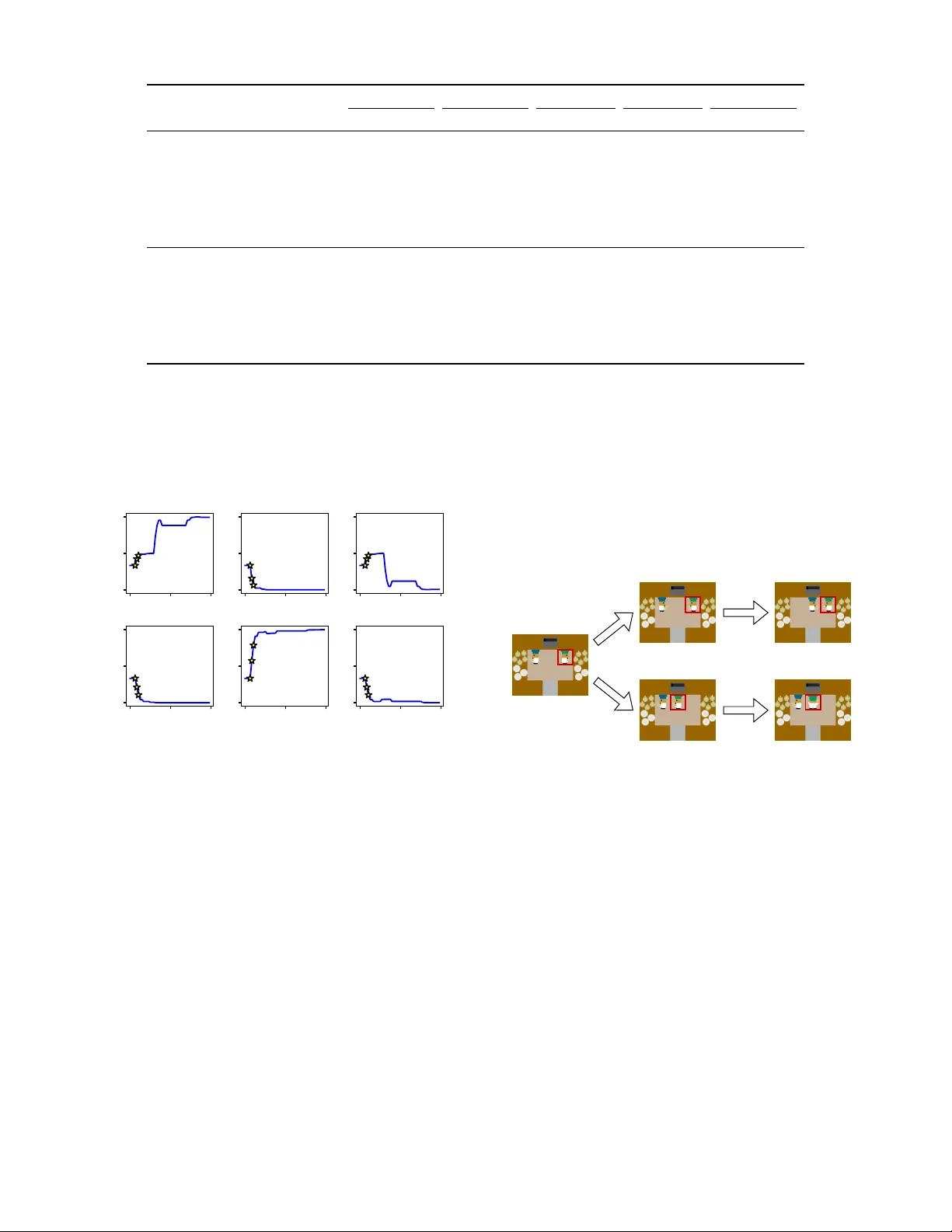
Adaptiv e Theory of Mind f or LLM-based Multi-Agent Coordination Chunjiang Mu 1,2, * , Y a Zeng 1 , Qiaosheng Zhang 2 , Kun Shao 3 , Chen Chu 4 , Hao Guo 5 , Danyang Jia 1 , Zhen W ang 1, † , Shuyue Hu 2,† 1 School of Cybersecurity , Northwestern Polytechnical Univ ersity 2 Shanghai Artificial Intelligence Laboratory 3 Huawei Noah’ s Ark Lab 4 School of Statistics and Mathematics, Y unnan Uni versity of Finance and Economics 5 QiY uan Lab w-zhen@nwpu.edu.cn, hushuyue@pjlab .org.cn Abstract Theory of Mind (T oM) refers to the ability to reason about others’ mental states, and higher-order T oM in volv es con- sidering that others also possess their o wn T oM. Equipping large language model (LLM)-driven agents with T oM has long been considered to improv e their coordination in multi- agent collaborati ve tasks. Howe ver , we find that misaligned T oM orders—mismatches in the depth of T oM reasoning be- tween agents—can lead to insufficient or e xcessi ve reasoning about others, thereby impairing their coordination. T o address this issue, we design an adaptiv e T oM (A-T oM) agent, which can align in T oM orders with its partner . Based on prior in- teractions, the agent estimates the partner’ s likely T oM order and le verages this estimation to predict the partner’ s action, thereby facilitating behavioral coordination. W e conduct em- pirical evaluations on four multi-agent coordination tasks: a repeated matrix g ame, tw o grid navigation tasks and an Over - cooked task. The results validate our findings on T oM align- ment and demonstrate the effecti veness of our A-T oM agent. Furthermore, we discuss the generalizability of our A-T oM to non-LLM-based agents, as well as what would diminish the importance of T oM alignment. Code — https://github .com/ChunjiangMonkey/Adaptiv e- T oM 1. Introduction Multi-agent coordination in volves the precise alignment of actions among multiple agents to enable effecti ve joint be- havior , and is widely applied in areas such as autonomous driving (Zhang et al. 2024b), sw arm robotics (K egeleirs and Birattari 2025), and distributed control (Ge et al. 2025). A key challenge in this area is zero-shot coordination, where agents need to coordinate with previously unseen partners without prior joint training or communication (Hu et al. 2020). Large language models (LLMs) have been widely used to construct zero-shot coordination agents, as they pos- sess strong decision-making and generalization capabilities, * This work was done during his internship at Shanghai Artifi- cial Intelligence Laboratory . † Corresponding author . Copyright © 2026, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserved. and can be deployed without task-specific training (Agashe et al. 2023; Zhang et al. 2024a; Liu et al. 2024). Effecti ve coordination with unseen partners requires the ability to model and anticipate their beha vior . Recent re- search has incorporated explicit Theory of Mind (T oM) into the architecture of LLM-based agents, enabling them to model others by reasoning about others’ beliefs, desires, and intentions (Li et al. 2023a; Agashe et al. 2023). T oM-based workflo w designs and prompting techniques have demon- strated clear ef fecti veness and become an important compo- nent in the design of agents in multi-agent problems. More generally , since other agents may also possess T oM capabil- ities, it is necessary to equip LLM-based agents with higher- order T oM to reason about others’ reasoning (e.g., “I be- liev e that you believe... ”) (de W eerd, V erbrugge, and V er - heij 2014; W ellman 2018). Howe ver , it has been found that higher T oM orders do not necessarily impro ve performance, in either cooperative or competitive multi-agent tasks (Li et al. 2023a; Shao et al. 2024; Zhang et al. 2025). Prior work empirically attributes the performance drop either to the limited ability of LLMs to perform higher-order T oM reasoning, or to ov er-reasoning introduced by higher-order T oM itself. In this paper , we highlight a deeper underlying cause for the performance drop observ ed between agents with T oM— the misalignment of their T oM orders . According to the definition of the T oM order , an agent with k th-order T oM aligns best with agents of ( k − 1) -th or ( k +1) -th order; oth- erwise, the mismatch may lead to either insuf ficient or ex- cessiv e reasoning. For instance, consider two cars dri ving tow ard each other on a narrow road. If both dri vers attempt to av oid a collision by swerving to the same side, an accident can still occur . This is a typical case where the misalignment of T oM (both 1st-order T oMs in this case) leads to serious consequences. W e find that such misalignment has a signifi- cant impact on coordination between LLM-based agents by experiments. T o address this issue, we propose the first adaptive T oM agent (A-T oM) driven by LLMs, which estimates its part- ner’ s T oM order in real time and selects actions that struc- turally align with it. The A-T oM agent consists of multi- ple hypothetical agents, each representing a order of T oM. During real-time interactions, the A-T oM agent selects one of candidate actions—generated by these hypothetical agents—as its prediction of the partner’ s action. This selec- tion is guided by the historical prediction accuracies of the hypothetical agents. W e model this process as an Expert Advice problem (Cesa-Bianchi et al. 1997), and we solve it using online learning algorithms that ha ve theoretical performance guar - antees. Finally , our A-T oM agents selects actions from the av ailable action set that can coordinate with the prediction action to interact with the actual partner . Through experi- ments on a repeated matrix game, two grid world na viga- tion tasks and an Overcooked task, we v alidate our A-T oM agent can rob ustly coordinate with different types of part- ners. Overall, our contrib utions are as follo ws: • W e identify alignment in T oM orders between agents as a critical factor for achie ving successful coordination. • W e de velop an A-T oM agent for zero-shot coordination which can align with the partner’ s T oM order in real time. • W e v alidated the correctness of our findings and the ef- fectiv eness of our A-T oM agent across multiple coordi- nation tasks. Furthermore, we analyze the generalization of our findings and A-T oM agent. 2. Related W ork Large Language Model-Based Agent. Equipped with various modules such as perception, memory , and controller, LLM-based agents hav e proven successful in addressing dif- ficult tasks across multiple domains, such as robotic control (Brohan et al. 2023; W u et al. 2023), industrial automation (Xia et al. 2023), GUI operation (Gur et al. 2024; Y an et al. 2023), and playing open-world games (W ang et al. 2023a,b). Moreov er , multiple LLM-based agents can collaborate to ac- complish large-scale task like software de velopment (Hong et al. 2023; Qian et al. 2024) and social simulation (Park et al. 2023). The above work demonstrates that LLM-based agents can make reliable decisions in both single-agent and multi-agent tasks. Therefore, we lev erage the LLM-based agent as a rational decision-maker to in vestigate the impact of T oM alignment between rational collaborators. In addi- tion, due to their promising generalization ability , using of LLM-based agents eliminates the need to design decision rules or train agents from scratch for each task. Enhancing Multi-Agent Collaboration Thr ough Theory of Mind. T oM is the capacity of human to reason about the beliefs, desires, and intentions of others, which is cru- cial in human social interactions. In multi-agent collabora- tion, explicitly equipping AI agents—including LLM-based agents—with T oM enables them to infer others’ hidden states and predict their behavior , thereby enhancing com- munication ef ficiency between agents (W ang et al. 2022; Zhu, Neubig, and Bisk 2021; Li et al. 2023a), overcoming challenges of partial observability in the en vironment (Fuchs et al. 2021; Cross et al. 2024), and improving coordination among agents (W u et al. 2021; Agashe et al. 2023; Zhang et al. 2024a). Ho wever , some studies ha ve shown that equip- ping agents with higher-order T oM does not always lead to the expected improv ements (Li et al. 2023a; Shao et al. 2024). In this paper, we in vestig ate the critical role of T oM reasoning depth alignment in facilitating collaboration be- tween LLM-based agents. Our work is primarily inspired by prior research on inferring others’ T oM (Y oshida, Dolan, and Friston 2008; De W eerd, V erbrugge, and V erheij 2013) and dynamically matching partners for agents with specific T oM orders (Shao et al. 2024). 3. Method 3.1 Problem F ormulation W e consider a fully cooperative decision-making problem in volving two agents within a given Markovian en viron- ment, where the actions of agents require coordination to achiev e an optimal outcome. The en vironment can be for- malized as a tuple M = ⟨S , A 1 , A 2 , T , R, γ ⟩ . S is the shared state space. A 1 and A 2 are the action spaces of the two agents. T : S × A 1 × A 2 → ∆( S ) is the transition func- tion. R : S × A 1 × A 2 → R is a shared reward function that ensures that both agents receiv e the same reward. γ ∈ [0 , 1) is the discount factor . Denote the policies of two agents by π 1 : S → ∆( A 1 ) and π 2 : S → ∆( A 2 ) . The joint policy of two agents is denoted as π = ( π 1 , π 2 ) . Although LLM-based agents do not require a reward function for training, we still use the discounted expected return (i.e., the value function) to define the r ationality of LLM-based agents. At each step, two rational LLM-based agents aim to select the joint actions a ∗ : = ( a ∗ 1 , a ∗ 2 ) that maximize their joint value function: a ∗ = arg max a ∈A 1 ×A 2 Q π ( s, a ) , (1) where Q π ( s, a ) = E π " ∞ X t =0 γ t R ( s t , a t ) s 0 = s, a 0 = a # . (2) In some states, there are multiple optimal joint actions sat- isfying a ∗ , 1 = a ∗ , 2 = · · · = max Q π ( s, a ) . T wo agents must coordinate to agree on the same optimal joint action. Howe ver , it can be particularly challenging in the absence of communication or prior agreement (Boutilier 1999). 3.2. T oM Modeling The order of T oM is the depth of recursive reasoning an agent uses to model its partner’ s behavior . For con venience, we refer to an agent with k -th order T oM as a T oM- k agent. W e now define the decision-making process of an agent i with dif ferent orders of T oM reasoning as follo ws. without loss of generality , we assume i = 2 . T oM-0 agent. A T oM-0 agent treats its partner as part of the en vironment state. Its decision depends solely on the en- vironment state: π (0) i ( s ) : = arg max a ∈A i Q π ( s, a ) . (3) T oM-1 agent. A T oM-1 agent assumes that its partner j is a T oM-0 agent. Its first-order belief b (1) i is partner j ’ s pre- dicted action a pred j : b (1) i : = a pred j , where a pred j = π (0) j ( s ) . (4) The agent then selects the action that best coordinates with a pred j : π (1) i ( s, b (1) i ) : = arg max a ∈A i Q π ( s, a pred j , a ) . (5) T oM-2 agent. Similar to a T oM-1 agent, a T oM-2 agent first infers the partner’ s action a pred j as its second-order be- lief. Differently , the T oM-2 agent thinks that its partner j is a T oM-1 agent and agent j thinks agent i is a T oM-0 agent: b (2) i : = a pred j , where a pred j = π (1) j ( s, b (1) j ) . (6) Here, b (1) j can be computed in the same manner as in eq. (3), eq. (4) and eq. (5). The subscript j in b (1) j indicates that this belief corresponds to agent i ’ s prediction—made from agent j ’ s perspecti ve—about the action agent i will take. Then, the T oM-2 agent’ s policy is to tak e an action that best responds to b (2) i : π (2) i ( s, b (2) i ) : = arg max a ∈A i Q π ( s, a pred j , a ) . (7) T oM- k agent. More generally , the policy of a T oM- k agent ( k > 0) is defined recursi vely as: b ( k ) i : = a pred j , where a pred j = π ( k − 1) j ( s, b ( k − 1) j ) . (8) π ( k ) i ( s, b ( k ) i ) : = arg max a ∈A i Q π ( s, a pred j , a ) . (9) In this work, we focus to k ≤ 2 , since higher-order T oM imposes significant cognitive burdens and empirical studies suggest that humans typically reason about others only up to the second-order T oM (Camerer, Ho, and Chong 2004; De- vaine, Hollard, and Daunizeau 2014). The recursi ve struc- ture of T oM reasoning implies that a T oM- k agent assumes its partner to be a T oM- ( k − 1) agent. Naturally , such agents ar e mor e likely to coor dinate successfully when interacting with T oM- ( k − 1) or T oM- ( k +1) partners. W e refer to this compatibility as aligned T oM orders . Based on this insight, we argue that agents should focus on understanding how their partner thinks, rather than just reacting to what their partner does. Adapting to the partner’ s T oM order is a more effecti ve way to achie ve coordination. 3.3. T oM Alignning W e now introduce our adaptiv e T oM agent (A-T oM agent) that can dynamically estimate the T oM order of the partner during the interaction. Specifically , we formulate the T oM order alignment problem as an online expert advice prob- lem, where each T oM- k policy π ( k ) j is treated as an expert (Cesa-Bianchi et al. 1997). … T oM-0 Agent T oM-1 Agent T oM-2 Agent … … Figure 1: Illustration of T oM reasoning of different orders. The A-T oM agent maintains a set of hypothetical agents with distinct T oM order [ π ( k ) j ] k ∈{ 0 , 1 , 2 } along with their cor - responding cumulative losses (or weights). The agent con- tinuously updates these weights based on interaction out- comes to better estimate the true T oM order of partner j . The update process is as follo ws: 1) using hypothetical agent to generate a set of candidate actions [ ˆ a ( k ) j ] k ∈{ 0 , 1 , 2 } ; 2) select- ing one candidate action as the predicted partner action ˆ a j , based on corresponding hypothetical agents’ historical pre- diction accuracies; 3) selecting a response action coordinat- ing with the predicted partner action; and (4) observing the actual partner action and updating the prediction accuracy of each hypothetical agent. The online learning mechanisms for Steps 2) and 4) are determined by the specific expert advice algorithm. In this work, we consider two such algorithms: Follo w-the-Leader (FTL) (Kalai and V empala 2005) and Hedge (Freund and Schapire 1997), which are sho wn in detail in algorithm 1 and algorithm 2, respectively . FTL achiev es a re gret bound of O (log T ) in stable settings, making it suitable for coordi- nation with partners of fix ed T oM orders. Hedge, in contrast, maintains a soft expert weight distribution ov er T oM orders, enabling it to handle uncertainty and adapt to non-stationary behavior with a worst-case regret bound of O ( √ T log N ) . Here, T denotes the total number of executions of the algo- rithm and N is the number of e xperts. In this work, N = 3 for we consider three T oM orders. Conceptually , our T oM alignment frame work transforms the original coordination pr oblem in the policy space into a alignment pr oblem in T oM-order space, ther eby r educing the dimensionality and structural complexity of coordina- tion. From a perspectiv e of learning, our method lev erages the reasoning capabilities of LLMs by assigning them learn- ing tasks at an abstraction order that aligns naturally with their strengths, rather than burdening them with low-le vel, fine-grained details. 3.4. LLM-Based Agent Implementation W e use LLMs to construct agents with fixed T oM orders and the A-T oM agent. Each LLM-based agent consists of four modules: a state encoding module, a T oM module, a decision module, and an action controller . The state encod- ing module con verts the structured en vironment state into a natural language description. The T oM module predicts the partner’ s action, where we recursiv ely construct hypotheti- cal agents with dif ferent T oM orders. For a T oM- k agent, the T oM module infers the partner’ s behavior by inv oking a Algorithm 1: T oM Alignment via Follow-the-Leader (FTL) 1: Input: The en vironment M , ego agent π i , candidate T oM orders K = { 0 , 1 , 2 } , hypothetical T oM agents { π ( k ) j } k ∈K 2: Initialize cumulativ e loss L ( k ) ← 0 for all k ∈ K 3: Initialize t ← 1 4: while M is not terminated do 5: Observe current state s 6: for each k ∈ K do 7: ˆ a ( k ) j ← π ( k ) j ( s, b ( k ) j ) 8: end for 9: ˆ k ← arg min k ∈K L ( k ) , a pred j ← ˆ a ( ˆ k ) j 10: Acting: a t i ← π i ( s, a pred j ) 11: t ← t + 1 12: Observing true partner’ s action a t − 1 j 13: for each k ∈ K do 14: if ˆ a ( k ) j = a t − 1 j then 15: Update loss: L ( k ) ← L ( k ) + 1 16: end if 17: end for 18: end while T oM- ( k − 1) hypothetical agent. For our A-T oM agent, the T oM module includes three hypothetical agents: a T oM-0 agent, a T oM-1 agent, and a T oM-2 agent. The decision module takes as input both the state description and the pre- dicted partner action from the T oM module, and outputs the agent’ s action. The action controller con verts natural lan- guage actions produced by the LLM into executable actions in the environments. In summary , we follow the two-stage design of LLM-based agents with T oM: first, the LLM pre- dicts the partner’ s behavior; then, this predicted beha vior is incorporated into the LLM’ s input to inform action selection (Agashe et al. 2023; Zhang et al. 2024a). Given that state- of-the-art LLMs already provide sufficiently reliable output quality for most planning tasks, we do not introduce any additional output verification component in practice, which also helps reduce inference latency and system comple xity . 4. Experimental Setup 4.1. T ask Setup W e conduct empirical ev aluations in three fully coopera- tiv e environments with different structures: a repeated ma- trix game, two grid world navigation tasks, and an Over- cooked scenario. Repeated Matrix Game. In each round, two agents se- lect simultaneously between two options A and B without communication or prior agreement. If both agents select the same option (A-A or B-B), they each receive 0 points; if they select different options (A-B or B-A), they each re- ceiv e 5 points. Therefore, agents must consistently break the symmetry in order to achiev e stable coordination and maxi- mize collective re ward. W e consider two settings: Memory- 1 and Memory-N. In the Memory-1 setting, each agent can observe the partner’ s action in the previous round. In the Algorithm 2: T oM Alignment via Hedge 1: Input: The en vironment M , ego agent π i , candidate T oM orders K = { 0 , 1 , 2 } , hypothetical T oM agents { π ( k ) j } k ∈K , learning rate η = 1 2: Initialize expert weight w ( k ) ← 1 for all k ∈ K 3: Initialize t ← 1 4: while M is not terminated do 5: Observe current state s 6: for each k ∈ K do 7: Normalize e xpert weight: P ( k ) ← w ( k ) P k ′ ∈K w ( k ′ ) 8: ˆ a ( k ) j ← π ( k ) j ( s, b ( k ) j ) 9: end for 10: ˆ k ∼ P ( k ) , a pred j ← ˆ a ˆ k j 11: Acting: a t i ← π i ( s, a pred j ) 12: t ← t + 1 13: Observing true partner’ s action a t − 1 j 14: for each k ∈ K do 15: if ˆ a ( k ) j = a t j then 16: ℓ ( k ) ← 1 17: else 18: ℓ ( k ) ← 0 19: end if 20: Update expert weight: w ( k ) ← w ( k ) · exp( − η · ℓ ( k ) ) 21: end for 22: end while (a) Game 1 (b) Game 2 (c) Overcooked Figure 2: Illustrative diagrams of two grid world navigation tasks and the Overcooked layout. Memory-N setting, each agent has access to the cumulative counts of ho w many times the partner has chosen each op- tion. Grid W orld Na vigation (Kleiman-W einer et al. 2016). T wo agents are each assigned a distinct color and a corre- sponding target location. The goal is for both agents to reach their o wn tar get locations. At each step, both agents simul- taneously mo ve in one of four directions: up, do wn, left, and right. Agents cannot move outside the grid, enter the other agent’ s goal, occupy the same position, or swap positions within a single step. An episode ends once both agents hav e successfully reached their goals. W e employ two grid world navigation tasks: Game 1 (fig. 2a) and Game 2 (fig. 2b). In Game 1, agents must coordinate over their trajectories to av oid blocking each other, while Game 2’ s narrower lay- out requires one agent to temporarily move aw ay from its own goal to mak e room for the partner , making coordination Alignment Agent Profile Memory-1 Memory-N Game 1 Game 2 Over cooked Point ↑ Point ↑ Time ↓ T ime ↓ T ime ↓ Misaligned T oM-0 vs T oM-0 0.00 (0.00) 11.67 (20.69) 30.00 (0.00) 30.00 (0.00) 100.00 (0.00) T oM-0 vs T oM-2 0.00 (0.00) 16.00 (26.47) 28.17 (5.64) 30.00 (0.00) 94.97 (13.59) T oM-1 vs T oM-1 0.00 (0.00) 0.00 (0.00) 23.37 (9.38) 30.00 (0.00) 96.40 (8.89) T oM-2 vs T oM-0 0.00 (0.00) 22.00 (27.72) 30.00 (0.00) 29.93 (0.37) 99.13 (2.94) T oM-2 vs T oM-2 0.00 (0.00) 12.33 (23.59) 29.67 (1.37) 30.00 (0.00) 83.50 (22.03) Aligned T oM-0 vs T oM-1 75.00 (0.00) 75.00 (0.00) 6.00 (0.00) 8.13 (1.63) 44.17 (3.74) T oM-1 vs T oM-0 75.00 (0.00) 75.00 (0.00) 6.03 (0.18) 7.07 (0.37) 43.83 (4.50) T oM-1 vs T oM-2 75.00 (0.00) 75.00 (0.00) 6.10 (0.66) 7.10 (0.40) 48.90 (12.27) T oM-2 vs T oM-1 75.00 (0.00) 75.00 (0.00) 5.93 (0.37) 7.93 (1.36) 51.00 (12.88) T able 1: A verage coordination performance between two agents with fixed T oM orders across fiv e task settings. Dif ferent orderings of the same agent profile (e.g., T oM-0 vs T oM-2 and T oM-2 vs T oM-0 ) indicate the cases where the two agents take the roles of Player 1 and Player 2, respecti vely . F or repeated matrix games (Memory-1 and Memory-N), we employ the P oint obtained by the agent from the game (ranging from 0 to 75) as the metric. A higher point v alue indicates better performance. For grid w orld navig ation tasks (Game 1 and Game 2) and Ov ercooked, we employ the completion T ime (ranging from 0 to 30 for two grid world navigation task, and 0 to 100 for Overcooked) as the metric. F or the failed samples, their completion times are setting to the maximum step limit. A lower completion time value indicates better performance. The values in parentheses indicate the variance. more challenging. Over cooked (Carroll et al. 2019). In this scenario (fig. 2c), tw o agents need to collaborate to cook and deli ver onion soup. Each agent can move up, down, left, and right within the layout and interact with permissible kitchen fa- cilities, icluding one pot, one deli very area, two onion dis- pensers, two plate dispensers, and four kitchen counters. The pot automatically cooks three onions into soup ov er 20 time steps. So agents need to place enough onions into the pot and be ready to plate and deliver the soup once it is cooked. The layout we employ is adapted from the original Cramped Room in Overcooked-AI, with the key difference that all kitchen facilities in our layout are placed in a fully sym- metric configuration. This symmetry imposes a greater chal- lenge on the agents’ coordination. 4.2. Agent Setup In the repeated matrix game, under the memory-1 setting, the state s is the partner’ s action in the pre vious round; un- der the memory-N setting, the state is the counts of the part- ner’ s two choices over the past N rounds. Since agents tend to maintain coordination indefinitely once it is achiev ed in the repeated matrix game, we initialize each episode in an uncoordinated state to eliminate the roughly 50% coordina- tion success rate that would otherwise result from random initial actions. In two grid world navigation task, the state is the positions of both players. In the Overcooked task, the state includes the positions of both players, the items they are holding, as well as the statuses of the pot and kitchen counters. At each timestep, we provide the agent with the av ailable action space from which it selects an action. The repeated matrix game runs for 15 steps. While tw o grid world navigation tasks and Overcooked tasks hav e max- imum step limits of 30 and 100, respectively . T asks not com- pleted within these limits are treated as failures. All e xperi- ments use LLaMA-3.3-70B-Instruct as the underlying LLM with temperature = 0.1. All random seeds are set to 42. Each configuration is repeated independently 30 times, and we re- port the av eraged results. 5. Result 5.1. Effect of T oM Misalignment T able 1 presents the ef fects of T oM misalignment on coor - dination performance across dif ferent tasks and ev aluation metrics. Overall, across all tasks, coordination is most suc- cessful when the agent’ s T oM order is aligned with that of the partner . In repeated matrix games, we observe that un- der the Memory-1 setting, only certain aligned pairs achieve high points. The reason lies in o verthinking caused by mis- aligned T oM orders. For e xample, when two T oM-1 agents play , each assumes that the other will change their choice due to a coordination f ailure in the previous step. As a result, they neither updates their o wn choice, leading to repeated failures. Under the Memory-N setting, the coordination pat- tern becomes more widespread, and misaligned pairs also exhibit some success. Except for T oM-1 agents in self-play , coordination failures often appear as both agents repeatedly alternating between the same two options. Over time, this back-and-forth causes both actions to occur in memory with similar frequency . Eventually , the randomness in the choice of LLM-based agent may result in occasional successful co- ordination. Interestingly , we can observe that the results on the two grid world navig ation tasks (especially Game 2) more closely resemble those under the Memory-1 setting in the repeated matrix game, whereas the results on Overcook ed are more similar to those under the Memory-N setting. This discrepancy may be attributed to Overcook ed’ s larger action space and the reduced decision optimality resulting from its higher difficulty . W e will discuss this point in more detail later . Nev ertheless, all this result supports our core hypothe- sis: in cooperativ e settings, alignment of T oM orders signif- Algorithm Agent Profile Memory-1 Memory-N Game 1 Game 2 Over cooked Point ↑ Point ↑ T ime ↓ Time ↓ Time ↓ FTL A-T oM vs T oM-0 75.00 (0.00) 75.00 (0.00) 6.03 (0.18) 7.00 (0.00) 45.33 (11.62) T oM-0 vs A-T oM 75.00 (0.00) 75.00 (0.00) 5.87 (0.51) 7.63 (1.19) 43.53 (4.51) A-T oM vs T oM-1 70.00 (0.00) 70.00 (0.00) 7.80 (0.81) 10.53 (2.01) 52.17 (10.19) T oM-1 vs A-T oM 70.00 (0.00) 70.00 (0.00) 7.70 (0.88) 9.30 (0.88) 51.83 (10.04) A-T oM vs T oM-2 75.00 (0.00) 75.00 (0.00) 6.03 (0.67) 7.17 (0.53) 45.30 (5.52) T oM-2 vs A-T oM 75.00 (0.00) 75.00 (0.00) 6.00 (0.00) 8.60 (2.18) 47.67 (6.23) A-T oM vs A-T oM 0.00 (0.00) 0.00 (0.00) 20.90 (9.03) 27.23 (5.93) 51.17 (7.36) Hedge A-T oM vs T oM-0 72.83 (3.39) 72.50 (3.88) 6.00 (0.00) 8.07 (0.25) 47.47 (9.13) T oM-0 vs A-T oM 73.33 (3.56) 73.00 (3.37) 6.00 (0.00) 9.40 (2.13) 46.60 (6.69) A-T oM vs T oM-1 70.00 (4.73) 70.17 (4.82) 7.87 (0.51) 10.07 (1.55) 57.60 (10.22) T oM-1 vs A-T oM 70.00 (4.55) 70.33 (4.72) 8.23 (1.98) 10.00 (2.20) 53.17 (7.49) A-T oM vs T oM-2 73.00 (3.11) 72.50 (4.10) 6.27 (0.74) 8.17 (0.46) 46.00 (5.79) T oM-2 vs A-T oM 72.83 (2.84) 72.33 (3.65) 6.03 (0.18) 9.47 (1.74) 47.80 (6.91) A-T oM vs A-T oM 68.17 (10.13) 64.33 (10.81) 7.60 (2.27) 8.57 (2.80) 50.53 (7.65) T able 2: A verage coordination performance of our A-T oM agent across five task settings. The meaning and calculation of the metrics are the same as in T able 1. icantly enhances coordination performance, and this ef fect generalizes across different types of tasks. 1 25 49 0.0 0.5 1.0 prob T oM-0 partner 1 25 49 0.0 0.5 1.0 1 25 49 0.0 0.5 1.0 1 25 49 P (0) 0.0 0.5 1.0 prob T oM-1 partner 1 25 49 P (1) 0.0 0.5 1.0 1 25 49 P (2) 0.0 0.5 1.0 step Figure 3: The ev olution of the normalized expert weights of the A-T oM (Hedge) agents when collaborating with T oM-0 and T oM-1 partners. 5.2. Perf ormance of A-T oM Agent T able 2 shows the coordination performance of adapti ve agents in all tasks different interacting with fixed-T oM-order partners. Overall, for all partners with fixed T oM orders, both FTL and Hedge A-T oM agent show strong perfor- mance, as if the y were the agents with T oM orders aligned to that of the partners. Nev ertheless, in coordination with partners of fixed T oM orders, FTL exhibits a slight per- formance advantage over Hedge, likely due to its ability to more rapidly identify and adapt to the partner’ s T oM characteristics. In self-play between two A-T oM agents, howe ver , Hedge A-T oM agent demonstrates significantly stronger adaptability than FTL, especially in repeated matrix games and tw o grid world navigation tasks. This is because the Hedge algorithm has a greater capacity for exploration, making it easier to align with a changing partner in terms of T oM order . In summary , the results of the two A-T oM agents are consistent with the characteristics of the respecti ve on- line learning algorithms the y employ , and the failure of FTL self-play highlights the importance of achie ving coordina- tion in terms of T oM order . [0.42, 0.16, 0.42] [0.47, 0.06, 0.47] [0.21, 0.58, 0.21] [0.33, 0.33, 0.33] [0.1 1, 0.78, 0.1 1] step 4 step 5 step 6 T oM-0 Partner T oM-1 Partner Figure 4: Snapshots of the game state of Ov ercooked at step 4, 5, and 6 when the A-T oM (Hedge) collaborating with T oM-0 and T oM-1 partners. The values below the snapshot are normalized expert weights of A-T oM agents (Hedge), which are marked with star symbols in fig. 3. 5.3. Case Study How does our A-T oM agent work in detail? W e present two cases from our experiments, where the Hedge A-T oM agent plays with a T oM-0 agent and a T oM-1 agent in Over - cooked. Figure 3 shows how A-T oM agents’ s normalized ex- pert weights ( P (0) , P (1) , P (2) ) ev olves. W e observe that as the game progresses, the A-T oM agent gradually identifies the partner’ s T oM order correctly . T o better understand what driv es the adjustment, we analyze the first update of normal- ized expert weights in both cases—both of which occur at step 5. W e present snapshots of the game state at steps 4, 5, and 6 in Figure 4, and highlight these steps in Figure 3. Up to step 4, two agents’ actions do not require coordination, so the A-T oM agents cannot yet infer the partner’ s T oM order at that stage. Howe ver , at step 5, when both agents attempt to approach the pot, the actions dif fer between the T oM-0 agent and the T oM-1 agent. The T oM-0 agent does not take the A-T oM agent’ s action into account, resulting in a conflict with the A-T oM agent as they both try to occupy the same position. In contrast, the T oM-1 agent infers that the A-T oM agent intends to mov e west and thus select to stay . Based on this observ ation, the A-T oM agents update their expert weights at the end of this step. The updated expert weights then influence its behavior in step 6: the A-T oM agent paired with the T oM-0 agent yields to avoid conflict; the A-T oM agent paired with the T oM-1 agent prepares to place the in- gredient into the pot in order to complete the task as quickly as possible. The two cases above also help illustrate how misaligned T oM orders can lead to coordination failures. 6. Generalization Analysis 6.1. Play with Non-LLM-Based Agents W e no w examine how the A-T oM agent collaborates with non-LLM-based partners. Using Overcook ed as a case study , we consider two baseline agents: (1) Greedy , a planning-based agent implemented in the official Overcooked-ai library (Carroll et al. 2019), and (2) PBT , a widely used standard MARL agent baseline in the Over- cooked en vironment (Jaderberg et al. 2017; Carroll et al. 2019; Li et al. 2023b). As shown in table 3, our A-T oM agent demonstrates the strongest generalization performance. No- tably , the A-T oM agent tends to interpret the greedy agent and the PBT agent as T oM-0 agents in most cases, and as T oM-2 agents in a minority of cases. Specifically , the a ver - age normalized expert weights are as follo ws: FTL on the greedy agent—[0.93, 0.01, 0.05], FTL on the PBT agent— [0.80, 0.05, 0.16], Hedge on the greedy agent—[0.75, 0.08, 0.18], and Hedge on the PBT agent—[0.55, 0.09, 0.36]. Giv en that T oM-0 and T oM-2 agents may sometimes pro- duce identical decisions, and considering the inherent ran- domness in behavior , we find that fr om the perspective of an A-T oM agent , the planning or RL agent does not exhibit genuine T oM capabilities. Agent T ype Over cooked T ime ↓ T oM-0 64.60 (26.62) T oM-1 55.97 (19.80) T oM-2 60.41 (23.70) Greedy 54.06 (22.47) PBT 49.09 (17.63) A-T oM agent (FTL) 48.05 (10.44) A-T oM agent (Hedge) 49.16 (10.83) T able 3: A verage coordination performance of different types of agents under cross-play settings in Overcooked. The values in parentheses indicate the v ariance. 6.2. When T oM Alignment May Not Matter In this paper , we highlight the importance of T oM alignment for effecti ve coordination. Howe ver , several factors may in- fluence this importance. As demonstrated in our earlier e x- periments, potential f actors include the size of the task’ s op- timal action space and the rationality of the agents. T o vali- date these factors, we e v aluate agents with different T oM or- ders in a 3-action repeated matrix game, where each agent’ s action space consists of three actions: A, B, and C. The re- ward rule remains the same: both players receiv e 5 points only when they choose different actions. What dif fers is that for each action taken by the partner , there are no w two ac- tions that can successfully coordinate with it. In addition, we set the LLM’ s temperature to 0.9 to make its decisions less rational and its outputs more div erse. T able 4 presents the results: compared to the results in T a- ble 1, the scores between T oM-misaligned agents is higher, while the scores between T oM-aligned agents is lower . This offers preliminary evidence for our method’ s applicability: the clear er the optimal action space and the more r ational the agents, the greater the T oM misalignment failur es—and the mor e ef fective our appr oach. Alignment Agent Pair Memory-1 Memory-N Point ↑ Point ↑ Misaligned T oM-0 vs T oM-0 40.50 (29.08) 35.33 (33.50) T oM-0 vs T oM-2 64.17 (12.94) 55.33 (29.39) T oM-1 vs T oM-1 54.33 (33.16) 50.50 (29.37) T oM-2 vs T oM-0 66.00 (9.86) 63.33 (25.40) T oM-2 vs T oM-2 58.83 (27.63) 50.33 (32.82) Aligned T oM-0 vs T oM-1 73.50 (2.98) 65.33 (20.59) T oM-1 vs T oM-0 74.00 (2.42) 71.33 (6.56) T oM-1 vs T oM-2 46.50 (32.65) 55.83 (24.36) T oM-2 vs T oM-1 61.00 (26.31) 70.33 (5.40) T able 4: A verage coordination performance between two agents with fixed T oM orders in 3-action repeated matrix game. The v alues in parentheses indicate the v ariance. 7. Conclusion In this paper , we report our key finding: equipping agents with T oM does not necessarily impro ve coordination among them—only aligned T oM reasoning leads to ef fecti ve col- laboration. T o address this, we propose an adaptive T oM agent (A-T oM agent), which frames T oM alignment as an expert advice problem. A-T oM agent dynamically infers the partner’ s T oM order and adjusts its behavior accord- ingly to achieve coordination. Conceptually , A-T oM agent transforms behavioral coordination into alignment at the or - der of T oM. Through experiments across multiple tasks, we demonstrate both the validity of our finding and the effec- tiv eness of the proposed A-T oM agent architecture. Further- more, we analyze the scenarios in which T oM alignment is required the most. W e hope that our work can offer valu- able insights into promoting collaboration among today’ s in- creasingly capable agents. Acknowledgments This research was supported in part by the National Ke y Research and De velopment Project of China (No. 2024YFE0210900), the National Science Fund for Dis- tinguished Y oung Scholarship of China (No. 62025602), the National Natural Science Foundation of China (Nos. U22B2036, 6250076060 and 62506300), the T echnological Innov ation T eam of Shaanxi Province (No. 2025RS-CXTD- 009), the International Cooperation Project of Shaanxi Province (No. 2025GH-YBXM-017), the Shanghai Munic- ipal Science and T echnology Major Project, the T encent Foundation and Xplorer Prize. References Agashe, S.; Fan, Y .; Re yna, A.; and W ang, X. E. 2023. Llm- coordination: ev aluating and analyzing multi-agent coordi- nation abilities in large language models. arXiv preprint arXiv:2310.03903 . Boutilier , C. 1999. Sequential optimality and coordination in multiagent systems. In IJCAI , volume 99, 478–485. Brohan, A.; Chebotar , Y .; Finn, C.; Hausman, K.; Herzog, A.; Ho, D.; Ibarz, J.; Irpan, A.; Jang, E.; Julian, R.; et al. 2023. Do as i can, not as i say: Grounding language in robotic affordances. In Conference on robot learning , 287– 318. PMLR. Camerer , C. F .; Ho, T .-H.; and Chong, J.-K. 2004. A cog- nitiv e hierarchy model of games. The Quarterly Journal of Economics , 119(3): 861–898. Carroll, M.; Shah, R.; Ho, M. K.; Griffiths, T .; Seshia, S.; Abbeel, P .; and Dragan, A. 2019. On the utility of learn- ing about humans for human-ai coordination. Advances in neural information pr ocessing systems , 32. Cesa-Bianchi, N.; Freund, Y .; Haussler, D.; Helmbold, D. P .; Schapire, R. E.; and W armuth, M. K. 1997. How to use expert advice. J ournal of the ACM (JA CM) , 44(3): 427–485. Cross, L.; Xiang, V .; Bhatia, A.; Y amins, D. L.; and Haber, N. 2024. Hypothetical minds: Scaffolding theory of mind for multi-agent tasks with large language models. arXiv pr eprint arXiv:2407.07086 . De W eerd, H.; V erbrugge, R.; and V erheij, B. 2013. Ho w much does it help to kno w what she kno ws you kno w? An agent-based simulation study . Artificial Intelligence , 199: 67–92. de W eerd, H.; V erbrugge, R.; and V erheij, B. 2014. Agent- based models for higher-order theory of mind. In Advances in Social Simulation: Pr oceedings of the 9th Conference of the Eur opean Social Simulation Association , 213–224. Springer . Dev aine, M.; Hollard, G.; and Daunizeau, J. 2014. The social Bayesian brain: does mentalizing make a difference when we learn? PLoS computational biology , 10(12): e1003992. Freund, Y .; and Schapire, R. E. 1997. A decision-theoretic generalization of on-line learning and an application to boosting. J ournal of computer and system sciences , 55(1): 119–139. Fuchs, A.; W alton, M.; Chadwick, T .; and Lange, D. 2021. Theory of mind for deep reinforcement learning in hanabi. arXiv pr eprint arXiv:2101.09328 . Ge, X.; Han, Q.-L.; Zhang, X.-M.; Ding, D.; and Ning, B. 2025. Distrib uted coordination control of multi-agent systems under intermittent sampling and communication: a comprehensiv e surv ey . Science China Information Sciences , 68(5): 151201. Gur , I.; Furuta, H.; Huang, A. V .; Safdari, M.; Matsuo, Y .; Eck, D.; and Faust, A. 2024. A Real-W orld W ebAgent with Planning, Long Context Understanding, and Program Syn- thesis. In The T welfth International Conference on Learning Repr esentations . Hong, S.; Zhuge, M.; Chen, J.; Zheng, X.; Cheng, Y .; W ang, J.; Zhang, C.; W ang, Z.; Y au, S. K. S.; Lin, Z.; et al. 2023. MetaGPT : Meta programming for a multi-agent collabora- tiv e framework. In The T welfth International Confer ence on Learning Repr esentations . Hu, H.; Lerer , A.; Peysakhovich, A.; and Foerster , J. 2020. “other-play” for zero-shot coordination. In International Confer ence on Machine Learning , 4399–4410. PMLR. Jaderberg, M.; Dalibard, V .; Osindero, S.; Czarnecki, W . M.; Donahue, J.; Raza vi, A.; V inyals, O.; Green, T .; Dunning, I.; Simonyan, K.; et al. 2017. Population based training of neural networks. arXiv pr eprint arXiv:1711.09846 . Kalai, A.; and V empala, S. 2005. Efficient algorithms for online decision problems. Journal of Computer and System Sciences , 71(3): 291–307. Ke geleirs, M.; and Birattari, M. 2025. T o wards applied swarm robotics: current limitations and enablers. F rontier s in Robotics and AI , 12: 1607978. Kleiman-W einer, M.; Ho, M. K.; Austerweil, J. L.; Littman, M. L.; and T enenbaum, J. B. 2016. Coordinate to cooper- ate or compete: abstract goals and joint intentions in social interaction. In Pr oceedings of the annual meeting of the cog- nitive science society , volume 38. Li, H.; Chong, Y .; Stepputtis, S.; Campbell, J. P .; Hughes, D.; Le wis, C.; and Sycara, K. 2023a. Theory of Mind for Multi-Agent Collaboration via Large Language Models. In Pr oceedings of the 2023 Conference on Empirical Methods in Natural Languag e Pr ocessing , 180–192. Li, Y .; Zhang, S.; Sun, J.; Du, Y .; W en, Y .; W ang, X.; and Pan, W . 2023b. Cooperativ e Open-Ended Learning Frame- work for Zero-Shot Coordination. In Proceedings of the 40th International Confer ence on Machine Learning , ICML ’23. JMLR.org. Liu, J.; Y u, C.; Gao, J.; Xie, Y .; Liao, Q.; W u, Y .; and W ang, Y . 2024. LLM-Powered Hierarchical Language Agent for Real-time Human-AI Coordination. In Proceedings of the 23r d International Conference on Autonomous Agents and Multiagent Systems , 1219–1228. Park, J. S.; O’Brien, J.; Cai, C. J.; Morris, M. R.; Liang, P .; and Bernstein, M. S. 2023. Generativ e agents: Interactiv e simulacra of human behavior . In Pr oceedings of the 36th annual acm symposium on user interface softwar e and tech- nology , 1–22. Qian, C.; Liu, W .; Liu, H.; Chen, N.; Dang, Y .; Li, J.; Y ang, C.; Chen, W .; Su, Y .; Cong, X.; et al. 2024. ChatDev: Com- municativ e Agents for Software Dev elopment. In Proceed- ings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (V olume 1: Long P apers) , 15174– 15186. Shao, J.; Y uan, T .; Lin, T .; Cao, X.; and Luo, B. 2024. Cogniti ve Insights and Stable Coalition Matching for Fostering Multi-Agent Cooperation. arXiv pr eprint arXiv:2405.18044 . W ang, G.; Xie, Y .; Jiang, Y .; Mandlekar, A.; Xiao, C.; Zhu, Y .; Fan, L.; and Anandkumar , A. 2023a. V oyager: An open- ended embodied agent with large language models. arXiv pr eprint arXiv:2305.16291 . W ang, Y .; Xu, J.; W ang, Y .; et al. 2022. T oM2C: T arget- oriented Multi-agent Communication and Cooperation with Theory of Mind. In International Conference on Learning Repr esentations . W ang, Z.; Cai, S.; Chen, G.; Liu, A.; Ma, X.; Liang, Y .; and CraftJarvis, T . 2023b. Describe, e xplain, plan and select: in- teractiv e planning with lar ge language models enables open- world multi-task agents. In Pr oceedings of the 37th Inter- national Confer ence on Neural Information Pr ocessing Sys- tems , 34153–34189. W ellman, H. M. 2018. Theory of mind: The state of the art. Eur opean Journal of Developmental Psyc hology , 15(6): 728–755. W u, J.; Antono v a, R.; Kan, A.; Lepert, M.; Zeng, A.; Song, S.; Bohg, J.; Rusinkiewicz, S.; and Funkhouser, T . 2023. T idybot: Personalized robot assistance with large language models. Autonomous Robots , 47(8): 1087–1102. W u, S. A.; W ang, R. E.; Evans, J. A.; T enenbaum, J. B.; Parkes, D. C.; and Kleiman-W einer , M. 2021. T oo many cooks: Bayesian inference for coordinating multi-agent col- laboration. T opics in Cognitive Science , 13(2): 414–432. Xia, Y .; Shenoy , M.; Jazdi, N.; and W eyrich, M. 2023. T o- wards autonomous system: flexible modular production sys- tem enhanced with lar ge language model agents. In 2023 IEEE 28th International Confer ence on Emer ging T ec hnolo- gies and F actory A utomation (ETF A) , 1–8. IEEE. Y an, A.; Y ang, Z.; Zhu, W .; Lin, K.; Li, L.; W ang, J.; Y ang, J.; Zhong, Y .; McAuley , J.; Gao, J.; et al. 2023. Gpt-4v in wonderland: Large multimodal models for zero-shot smart- phone gui navigation. arXiv preprint . Y oshida, W .; Dolan, R. J.; and Friston, K. J. 2008. Game the- ory of mind. PLoS computational biology , 4(12): e1000254. Zhang, C.; Y ang, K.; Hu, S.; W ang, Z.; Li, G.; Sun, Y .; Zhang, C.; Zhang, Z.; Liu, A.; Zhu, S.-C.; et al. 2024a. ProAgent: building proacti ve cooperati ve agents with large language models. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , v olume 38, 17591–17599. Zhang, R.; Hou, J.; W alter , F .; Gu, S.; Guan, J.; R ¨ ohrbein, F .; Du, Y .; Cai, P .; Chen, G.; and Knoll, A. 2024b. Multi-agent reinforcement learning for autonomous driving: A surve y . arXiv pr eprint arXiv:2408.09675 . Zhang, Y .; Mao, S.; Ge, T .; W ang, X.; Xia, Y .; Lan, M.; and W ei, F . 2025. K-Lev el Reasoning: Establishing Higher Or- der Beliefs in Lar ge Language Models for Strate gic Reason- ing. In Pr oceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computa- tional Linguistics: Human Language T echnologies (V olume 1: Long P apers) , 7212–7234. Zhu, H.; Neubig, G.; and Bisk, Y . 2021. Few-shot language coordination by modeling theory of mind. In International confer ence on machine learning , 12901–12911. PMLR.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment