Proactive Rejection and Grounded Execution: A Dual-Stage Intent Analysis Paradigm for Safe and Efficient AIoT Smart Homes
As Large Language Models (LLMs) transition from information providers to embodied agents in the Internet of Things (IoT), they face significant challenges regarding reliability and interaction efficiency. Direct execution of LLM-generated commands of…
Authors: Xinxin Jin, Zhengwei Ni, Zhengguo Sheng
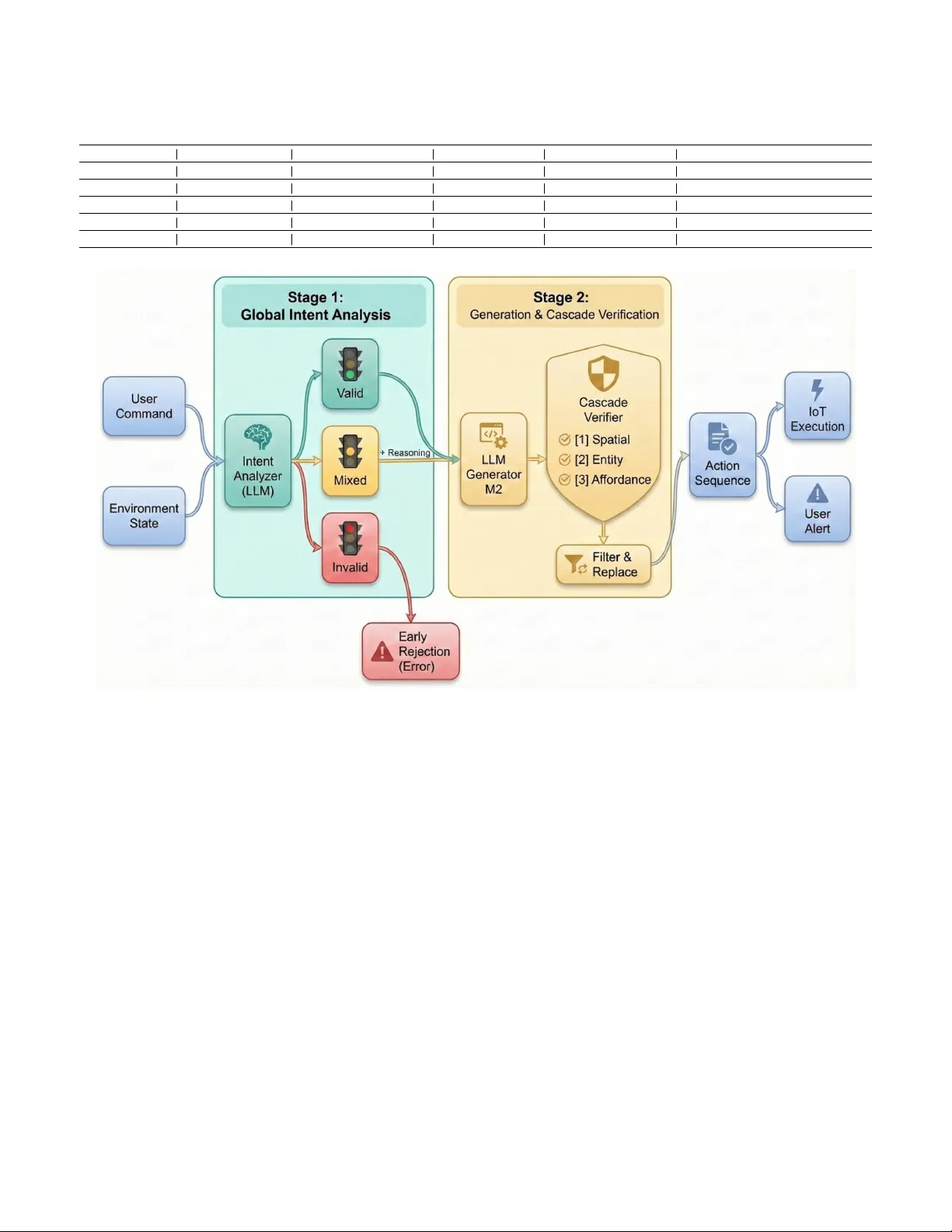
1 Proacti v e Rejection and Grounded Execution: A Dual-Stage Intent Analysis Paradigm for Safe and Ef ficient AIoT Smart Homes Xinxin Jin, Zhengwei Ni, Member , IEEE, Zhengguo Sheng, Senior Member , IEEE, and V ictor C. M. Leung, Life F ellow , IEEE Abstract —As Large Language Models (LLMs) transition fr om information pro viders to embodied agents in the Internet of Things (IoT), they face significant challenges regarding reli- ability and interaction efficiency . Direct execution of LLM- generated commands often leads to entity hallucinations (e.g., trying to contr ol non-existent de vices). Meanwhile, existing it- erative framew orks (e.g., SA GE) suffer fr om the Interaction Frequency Dilemma, oscillating between reckless execution and excessive user questioning. T o address these issues, we propose a Dual-Stage Intent-A ware (DS-IA) Framework. This framework separates high-level user intent understanding from low-lev el physical execution. Specifically , Stage 1 serves as a semantic firewall to filter out inv alid instructions and resolve vague commands by checking the current state of the home. Stage 2 then employs a deterministic cascade verifier—a strict, step-by- step rule checker that verifies the room, device, and capability in sequence—to ensure the action is actually physically possible befor e execution. Extensive experiments on the HomeBench and SA GE benchmarks demonstrate that DS-IA achieves an Exact Match (EM) rate of 58.56% (outperforming baselines by over 28%) and improv es the rejection rate of inv alid instructions to 87.04%. Evaluations on the SA GE benchmark further re veal that DS-IA resolves the Interaction Frequency Dilemma by balancing proacti ve querying with state-based inference. Specifically , it boosts the A utonomous Success Rate (resolving tasks without unnecessary user intervention) from 42.86% to 71.43%, while maintaining high precision in identifying irreducible ambigu- ities that truly necessitate human clarification. These results underscore the framework’ s ability to minimize user disturbance through accurate en vironmental gr ounding. Index T erms —Large Language Models, Smart Home, Embod- ied AI, Hallucination, Intent Analysis The work of Zhengwei Ni was supported in part by Zhejiang Provincial Natural Science Foundation of China under Grant No.LMS26F010017 and in part by the T ongxiang General Artificial Intelligence Research Institute Project T A GI2-B-2024-0017. Xinxin Jin and Zhengwei Ni are with the School of Informa- tion and Electronic Engineering (Sussex Artificial Intelligence Insti- tute), Zhejiang Gongshang Univ ersity , Hangzhou 310018, China. (e-mail: 24020090056@pop.zjgsu.edu.cn, zhengwei.ni@zjgsu.edu.cn) Zhengguo Sheng is with the Sussex Artificial Intelligent Institute, Zhejiang Gongshang Univ ersity , Hangzhou 310018, China, and also with the Depart- ment of Engineering and Design, Univ ersity of Sussex, BN1 9RH, Brighton, U.K. (e-mail: z.sheng@sussex.ac.uk) V ictor C. M. Leung is with the Artificial Intelligence Research Institute, Shenzhen MSU-BIT Univ ersity , Shenzhen 518172, China, also with the College of Computer Science and Software Engineering, Shenzhen Univ ersity , Shenzhen 518060, China, and also with the Department of Electrical and Computer Engineering, The University of British Columbia, V ancouver , BC V6T 1Z4, Canada (e-mail: vleung@ieee.org). Zhengwei Ni is the corresponding author. I . I N T RO D U C T I O N W ith the exponential expansion of the Internet of Things (IoT) ecosystem and the deep integration of Artificial In- telligence (AI), smart home agents are ev olving from rule- based traditional models to AI-driv en autonomous modes. In this ev olution, Large Language Models (LLMs), with their exceptional natural language understanding, commonsense reasoning [1], and generalized kno wledge, hav e become the core driver for the next generation of intelligent IoT [2]. This technological advancement has propelled a paradigm shift in IoT applications: from the traditional “ Ask-Answer” process to an “ Ask-Act” process. In the Ask-Act phase, LLMs are no longer merely information providers but are required to function as Embodied Agents, generating specific action plans based on user instructions and en vironmental states to driv e physical devices [3]. Howe ver , while this shift grants smart homes immense flexibility , it introduces fundamental challenges: due to the inherent stochasticity of LLM-generated content, connecting them directly via APIs to the deterministic physical world creates a natural “Reliability Gap, ” leading to ex ecution errors and e ven physical safety risks. T o bridge this gap and achiev e reliable grounded con- trol, existing research has primarily explored two interaction reasoning modes, both sho wing theoretical limitations when handling complex real-world home instructions. The first is the single-turn interaction mode. Although Ren et al. pro- posed “Uncertainty Alignment” to seek human help when confidence is low [4], our research finds that relying solely on model self-consistency to judge physical ambiguity is infeasible. Lacking environmental state constraints, single-turn generation often exhibits ov er -confidence, resulting in sev ere Entity Hallucinations. The second mode is the iterative pattern represented by SAGE (Iterati ve ReAct) [3], which attempts to solve execution problems through a loop of “Instruction- Plan-T ool Use. ” Ho we ver , SAGE faces a sev ere “Interaction Frequency Dilemma” in deployment: the system struggles to balance “silent execution” and “active questioning. ” Conserva- tiv e strategies tend to frequently question the user , disrupting the con venience of smart homes, while aggressive strategies may ex ecute recklessly to minimize interaction. The root cause of this dilemma lies in the lack of deep cog- nition of instruction ambiguity and global planning in existing iterativ e framew orks. Ivanov a et al., in the AmbiK dataset, classified home instruction ambiguity into “preference-based, ” 2 “common-sense, ” and “safety-critical” types [5]. Framew orks like SA GE, adopting a “think-while-acting” reactive strategy , lack mechanisms to identify these ambiguity types before ex ecution. This leads to “myopic” beha vior , where the model gets trapped in tool inv ocation details. This blind exploration causes models to fail in distinguishing between preference ambiguities (requiring confirmation) and in v alid entity errors (requiring rejection) when facing mixed instructions, leading to two typical failures, as visually demonstrated in Fig. 1: T ask Omission (forgetting subsequent instructions) and Forced Hallucination (forcibly mapping to incorrect de vices). Addressing the contradiction between “unconstrained single-turn generation” and “myopic iterative interaction, ” we draw inspiration from Zhang et al. ’ s use of intent analysis for jailbreak defense [6] and propose establishing a “Global Decision Context. ” W e construct a Dual-Stage Intent-A ware (DS-IA) Frame work designed to combine global perspectiv e with rigorous execution. Unlike SA GE’ s passiv e “error-then- fix” mechanism, our framework adopts a “Proactiv e Analysis” paradigm. Specifically , Stage 1 is Global Intent Analysis, acting as a “semantic router” to assess v alidity and strip core intents; Stage 2 is Grounding V alidation, introducing a “Room- Device-Capability” cascade check and a “Generate-and-Filter” strategy for mixed intents, ensuring ev ery output action is anchored to a real physical entity . Our main contributions are summarized as follows: • Proposing an “Analyze-then-Act” Proacti ve Paradigm: W e rev eal the mechanism behind the “Interaction Frequency Dilemma” in existing iterative framew orks and propose a mechanism that decouples macro-intent analysis from micro-action ex ecution. • Designing a Dual-Stage Framework with Cascade V er- ification: W e construct a system architecture featuring “Pre-ex ecution Intent Routing” and “Hierarchical Entity V erification. ” Specifically for mixed intents, we propose a “Generate-and-Filter” strategy to eliminate task omission and forced hallucinations. • V alidation on HomeBench [7] and SA GE Bench- marks: Experiments on the challenging HomeBench dataset show our method significantly reduces hallu- cination rates. Furthermore, ev aluations on the SA GE benchmark prove that our method minimizes unnecessary human interactions while maintaining high task success rates. T o facilitate future research and foster open collaboration, the complete codebase, en vironment snapshots, and ev aluation scripts used in this study are publicly a v ailable at https: //github .com/xxscy/DS- IA- smart.git. I I . R E L A T E D W O R K This study intersects with three key domains: LLM-based planning for IoT , ambiguity resolution in human-robot inter- action, and ef ficient agent deployment. A. LLM-based Planning for Smart Homes The paradigm of smart home control is shifting from slot- filling to generative planning. Early works like [8] explored utilizing LLMs to infer high-lev el user intents (e.g., "set up for a party") into device states. T o bridge the gap between generation and ex ecution, ProgPrompt [9] introduced a pro- grammatic prompt structure that grounds plans into pythonic code, significantly improving executability . Similarly , IoT - LLM [10] demonstrated that augmenting LLMs with IoT sensor data can enhance physical reasoning capabilities. Howe ver , these methods typically operate in an open-loop manner or rely on heavy prompt engineering. SA GE [3] advanced this by introducing an iterativ e ReAct loop. Y et, as noted in recent studies on IoT -LM [11], purely reactiv e agents struggle with multi-sensory alignment and often incur high latency . Our DS-IA framew ork b uilds upon these foundations but introduces a dual-stage verification mechanism to enforce physical grounding constraints e xplicitly . B. Ambiguity Resolution and Human Interaction Ambiguity is a pervasi ve challenge in domestic en viron- ments. The AmbiK dataset [5] categorizes ambiguity into preference, common-sense, and safety types. Existing ap- proaches to resolve these ambiguities largely rely on human intervention or multimodal cues. For instance, Abugurain et al. [12] proposed a frame work that uses GPT -4 to generate clarifying questions for users, while Calò et al. [13] utilized visual cues to disambiguate commands. While effecti ve, these “ Ask-First” strategies contrib ute to the “Interaction Frequency Dilemma. ” Frequent questioning can degrade user experience. Our work proposes a State- A war e Disambiguation strategy , which aligns with the goal of reducing human cognitiv e load by inferring intent from the current environmental snapshot, calling for help only when necessary . C. Security , Privacy , and Efficiency Deploying LLMs in pri vate homes raises concerns re garding hallucinations and data priv acy . ChatIoT [14] highlights the security risks in IoT management and proposes Retriev al- Augmented Generation (RA G) to mitigate threats. Further- more, to address the computational overhead of large models, Huang et al. [15] explored T ailored Small Language Models (SLMs) for priv acy-preserving on-device processing. These works inspire our future direction of distilling the Intent Anal- ysis module into edge-friendly SLMs to balance performance and pri v acy . I I I . M E T H O D O L O G Y A. Pr oblem F ormulation W e model the smart home instruction ex ecution task as a Physically Constrained Sequence Generation Problem. Definition 1 (En vir onment State S t ): W e formalize the home en vironment state at time t as a hierarchical knowledge graph S t = { R, D , C } . • R = { r 1 , ..., r n } represents the set of physical rooms. • D t = { ( d i , r d i ) | d i ∈ D g l obal , r d i ∈ R } represents the set of av ailable devices bound to specific rooms at time 3 User Input: "T urn on reading lamp, AND lock front door ." (a) T ask Omission (My opic) Agent Processing: Focus on Sub-task 1 Ambiguity Check: Found multiple lamps? T ool Call: ask_user("Which one?") User Answer: "The one in the bedroom." Execute Action: turn_on(bedroom_lamp) Premature End of Execution (Sub-task 2 for gotten!) Gets trapped in tool details; Sub-task 2 is completely dropped! Y es User Input: "T urn on the humidifier in the kitchen." (b) Forced Hallucination Agent Processing: Attempt to locate kitchen.humidifier En vironment: Kitchen: [Oven, Fridge] (No humidifier!) Entity Check: T arget not found? Blind Exploration T ool: search_device("humidifier") Incorrect Mapping: Found living_room.humidifier Forced Execution (on wrong de vice): turn_on(living_room...) F ails to r eject invalid entity; F orcibly maps to a wrong device! Y es, try fixing Fig. 1. Failure mechanisms in existing reactive frameworks. (a) T ask Omission: The agent loses global context when trapped in multi-turn interactions. (b) Forced Hallucination: The agent forcibly maps an unexecutable command to an incorrect entity due to the lack of a proactive rejection mechanism. t , where D g l obal denotes the uni versal vocab ulary of all supported de vice types in the system. • C t ( d i ) = { f i, 1 , ..., f i,k } represents the set of callable capabilities (methods) currently a v ailable for device d i at time t . Definition 2 (Instruction and Action): Giv en a user instruction U , the system generates an action sequence A = { a 1 , a 2 , ..., a m } . Each atomic action a k is represented as a structured tuple: a k = ⟨ r k , d k , f k , p k ⟩ (1) where r k , d k , f k , and p k denote the target room, target device identifier , target capability (function), and function parameters, respectiv ely . T raditional end-to-end models attempt to maximize the conditional probability P ( A | U ; θ ) , where θ represents the frozen parameters of a pre-trained LLM. Howe ver , in open- vocab ulary settings, this unconstrained probabilistic generation often leads to a k pointing to non-existent entities. Thus, we introduce a physical grounding constraint function Φ( A, S t ) and modify the inference-time decoding objectiv e to: A ∗ = argmax A ( P ( A | U, S t ; θ ) · I [Φ( A, S t ) = 1]) (2) where I [ · ] is the indicator function that outputs 1 if the generated sequence is entirely feasible within the current en vironment, and 0 otherwise. B. Stage 1: Global Intent Analysis and Routing The Intent Analysis (IA) module acts as a semantic firewall. It utilizes the LLM’ s semantic understanding to parse the instruction based strictly on the current en vironment snapshot S t . The output of this module is formalized as an analysis object O I A = ⟨ T ype , Reasoning ⟩ , where T ype categorizes the instruction into one of three classes, and Reasoning contains the diagnostic context. The three classes are: • C v al id (V alid): All mentioned entities can be found in S t with high confidence. 4 T ABLE I C O MPA R IS O N O F S M A RT H O ME C O N TR OL F R A ME W O RK S . D S - IA AC H I E VE S T H E B ES T BA L A NC E B E TW E E N P H YS I C A L S AF E T Y A N D I N TE R AC T I ON E FFI CI E N C Y . Framework T ype Representative Methods Reasoning Paradigm Ambiguity Strategy Physical Safety Main Limitation Slot Filling BER T -based Supervised / T emplate None High (T emplate-bound) Poor generalization to unseen commands Direct Generation GPT -3.5/4 End-to-End Model Probability Low (Prone to Hallucination) Severe entity hallucinations; no feedback Reactive Agents SAGE [3], ReAct [16] Iterative (Think-Act Loop) Passiv e (On Error) Medium Interaction Frequency Dilemma ; Disturbing Uncertainty Planning Ren et al. [4] Probabilistic Alignment Confidence Threshold Medium Linguistic confidence = Physical truth DS-IA (Ours) This W ork Analyze-then-Act (Dual-Stage) Activ e State-A wareness V ery High (Cascade Check) Dependent on real-time snapshot freshness Fig. 2. W orkflow of the Dual-Stage Intent-A ware (DS-IA) Framework. This image shows the modular architecture: Stage 1 proactively analyzes intent, and Stage 2 utilizes a cascade verifier shield to ensure physical feasibility . • C inv al id (In valid): The instruction explicitly points to non-existent de vices. The system triggers Early Rejection. • C mixed (Mixed): The instruction contains multiple sub- tasks with a mix of v alid and in valid entities. C. Stage 2: Hierar chical Gr ounding V erification For instructions passed by IA ( C v al id and C mixed ), we use In-Context Learning to generate a raw candidate action sequence A raw . T o eradicate hallucinations, we design a Three-Lev el Cascade V erifier to inspect each atomic action a k = ⟨ r k , d k , f k , p k ⟩ ∈ A raw : Level 1: Spatial T opology V erification ( V R ) Checks if the target room exists in the house: V R ( a k ) = 1 ⇐ ⇒ r k ∈ R (3) Level 2: Entity Alignment V erification ( V D ) Checks if the target device actually exists in the specified room at time t : V D ( a k ) = 1 ⇐ ⇒ ( d k , r k ) ∈ D t (4) Level 3: Aff ordance V erification ( V C ) Checks if the de vice supports the requested capability at time t : V C ( a k ) = 1 ⇐ ⇒ f k ∈ C t ( d k ) (5) The atomic constraint for a single action is Φ( a k , S t ) = V R ( a k ) ∧ V D ( a k ) ∧ V C ( a k ) . T o strictly align with standard em- bodied ev aluation protocols (such as the HomeBench dataset), if an action fails any of these checks ( Φ( a k , S t ) = 0 ), the verifier explicitly outputs a standardized error token ( ϵ err ) to flag the physical violation. Consequently , the sequence-lev el constraint from Eq. 2 is enforced by applying this atomic filtering across all generated steps. D. Mixed Intent Resolution Strate gy For C mixed instructions, where valid and inv alid sub-tasks coexist (e.g., "turn on the TV and the non-existent heater"), traditional reactiv e models typically suf fer from either “all- or-nothing” execution failures or forced hallucinations. T o ov ercome this, we employ a “Generate-and-Filter” strategy (Algorithm 1) designed to maximize task recall while strictly prev enting unexecutable actions. 5 The operational process consists of two main phases: 1) Reasoning-Guided Generation: Instead of generating actions blindly , the Stage 2 LLM generator drafts a raw candidate sequence A raw conditioned on the diagnostic context ( O I A . Reasoning) explicitly passed from Stage 1. This prior kno wledge serv es as a macro-le vel roadmap, pre-warning the generator about missing entities and reducing the search space. 2) Atomic Filtering and Sequential Alignment: Once A raw is generated, the Three-Lev el Cascade V erifier independently ev aluates each atomic action a k . As re- quired by standard benchmark protocols, unex ecutable actions must be flagged with the error token ( ϵ err ). In the context of complex mixed intents, our frame work perfectly masters this requirement: instead of suffering from cascading execution failures or blindly dropping the failed task, the verifier precisely substitutes the localized failure with ϵ err . This precise substitution is structurally crucial, as it preserves the sequential align- ment of the original multi-step instruction, completely prev enting subsequent valid actions from being tempo- rally displaced or entirely omitted (T ask Omission). Finally , the system aggregates the ex ecution results to for - mulate precise textual feedback ( M sg ). Rather than returning a generic error, the agent informs the user exactly which sub-tasks succeeded and which were safely bypassed due to physical constraints, thereby ensuring a transparent human- agent interaction. E. A Running Example of the DS-IA F ramework T o concretely illustrate how the DS-IA framework bridges the reliability gap, consider a complex C mixed instruction and a specific en vironment snapshot S t : • User Instruction ( U ): "T urn on the bedr oom r eading lamp, set the kitchen dehumidifier to 50%, and lock the fr ont door ." • En vironment Snapshot ( S t ): – Living Room : Reading Lamp (ON) – Bedroom : Reading Lamp (OFF) – Kitchen : Oven, Fridge (No Dehumidifier) – Entrance : Smart Lock (UNLOCKED) Step 1: Stage 1 Intent Analysis & Routing. The LLM router analyzes U against S t . For "bedroom reading lamp," it confirms the entity exists and is v alid ( C v al id ). For "kitchen dehumidifier ," the router detects a C inv al id intent because the device is missing from the snapshot. For "lock front door ," it is C v al id . The overall instruction is routed as C mixed and passed to Stage 2 with its diagnostic reasoning O I A . Step 2: Stage 2 Generation & Cascade V erification. The generator drafts a raw action sequence A raw . The Cascade V erifier then strictly checks each action: 1) turn_on(bedroom_lamp) : Passes V R ∧ V D ∧ V C . (Accepted) 2) set_humidity(kitchen_dehum, 50) : Fails Lev el 2 V erification ( V D = 0 ). Replaced with error token ϵ err . 3) lock(entrance_lock) : Passes all checks. (Ac- cepted) Final Output: Unlike reacti ve frame works that might hallucinate a dehumidifier or drop the lock command due to mid-way tool failures, DS- IA safely outputs a filtered sequence A f inal = { turn_on(bedroom_lamp), lock(entrance_lock) } and alerts the user: "Executed lamps and locks. F ailed: Kitchen dehumidifier not found." This demonstrates zero T ask Omission and zero Forced Hallucination. F . Prompt Engineering Strate gy The performance of the DS-IA framew ork relies heavily on structured prompt design. Moving away from standard few-shot prompting, we adopt a “Constraint-A ware Instruction Prompting” strategy . W e introduce two key mechanisms into the prompts: 1) State Injection: W e flatten the hierarchical knowledge graph S t into a compact textual representation. 2) Negative Constraints: W e explicitly instruct the model on what not to do (e.g., "Output error_input when operating non-existent attributes and de vices"). Due to space limitations, the e xact and complete prompt templates utilized for both Stage 1 (Global Intent Analysis) and Stage 2 (Code Generation) are detailed in Appendix . Algorithm 1 Mixed Intent Resolution via Generate-and-Filter Input: User Instruction U , Environment State S t Output: Executable Sequence A f inal , Feedback M sg 1: // Stage 1: Intent Routing 2: O I A ← IntentAnalysis ( U, S t ) 3: if O I A . T ype == C inv al id then 4: retur n ∅ , "Operation rejected: No valid de vice." 5: end if 6: // Stage 2: Generation & Filtering 7: A raw ← LLM_Generate ( U, S t , O I A . Reasoning ) 8: A f inal ← List () , E r ror S et ← Set () 9: for each atomic action a k = ⟨ r k , d k , f k , p k ⟩ in A raw do 10: v 1 ← V R ( a k ) 11: v 2 ← V D ( a k ) 12: v 3 ← V C ( a k ) 13: if v 1 ∧ v 2 ∧ v 3 is T rue then 14: A f inal . append ( a k ) 15: else 16: A f inal . append ( ϵ err ) ▷ Error T oken 17: E r ror S et. add ( d k ) 18: end if 19: end for 20: // Construct Feedback 21: if E r ror S et is not empty then 22: M sg ← "Executed v alid actions. Failed: " + E r ror S et 23: else 24: M sg ← "Success." 25: end if 26: retur n A f inal , M sg 6 I V . E X P E R I M E N TA L S E T U P W e ev aluate the DS-IA frame work on two complementary benchmarks: HomeBench for robustness and SA GE Bench- mark for interaction ef ficiency . A. Datasets 1) HomeBench (Robustness): HomeBench contains 100 simulated home en vironments and 2,500 instructions, ev al- uating the agent’ s ability to ground instructions in physical constraints. The instructions are categorized into three types: V alid (standard ex ecutable commands), In v alid (targeting non- existent entities, comprising 38.6% of the data), and Mixed (containing both v alid and in valid sub-tasks). Input/Output Instance (Mixed T ask): • Input Context ( S t ): Kitchen: [Light (OFF)] • Input Instruction ( U ): "T urn on the kitc hen light and the oven." • Expected Output ( A ): {kitchen.light.turn_on(), ϵ err } (Explanation: The model must e xecute the valid light command while r eplacing the non-existent oven command with an err or token.) 2) SA GE Benchmark (Interaction Efficiency): This bench- mark contains 50 complex tasks focusing on Human-Robot Interaction (HRI), covering scenarios like Device Resolu- tion, Personalization, and Intent Disambiguation. It ev aluates whether the agent can appropriately balance autonomous ex- ecution and proacti ve questioning. Input/Output Instance (Device Resolution): • Input Context ( S t ): Bedroom: [Lamp_A (ON), Lamp_B (OFF)] • Input Instruction ( U ): "T urn on the lamp." • Expected Output (Autonomous): {bedroom.lamp_B.turn_on()} (Explanation: The agent should silently resolve the ambiguity based on the device states without disturbing the user . If both lamps were OFF , the expected output would shift to an interactive tool call like ask_user("Which lamp?") .) B. Baselines and Models W e compare against: 1) Standard Few-Shot: Uses 4-shot prompting with full en vironment context, representing nati ve LLM capabili- ties. 2) SA GE (Iterativ e ReAct): The state-of-the-art indus- trial framew ork using tool calls ( query_devices , human_interaction ) [3]. T o ensure fair comparison and v erify generalization: • For HomeBench: All methods use Qwen-2.5-7B-Instruct on an NVIDIA R TX 5090 (BFloat16, SDP A enabled). DS-IA uses Greedy Decoding ( T = 0 ). • For SA GE Benchmark: W e unify both the baseline and our framework to utilize GPT -4o-mini. This choice is made to ensure strict alignment with the original SA GE paper’ s experimental settings [3] for fair reproduction and ev aluation. C. Evaluation Metrics T o comprehensively assess both the physical safety and the interaction ef ficiency of the smart home agents, we employ distinct metric suites tailored to our two benchmarks: 1. Metrics for HomeBench (Physical Grounding & Safety): • Exact Match (EM): The primary metric for execution accuracy and safety . For valid instructions (V alid Sin- gle/V alid Multi/Mixed Multi), it ev aluates whether the generated action sequence perfectly matches the oracle ground truth without any hallucinations. F or explicitly in valid instructions (IS/IM), a perfect match dictates that the system successfully generated the designated error_input token, which represents the system’ s Rejection Rate. • F1-Score: Provides a granular e v aluation of partial cor - rectness by measuring the precision and recall of the predicted rooms, de vices, and actions/attributes within the generated code. 2. Metrics for SA GE Benchmark (Interaction Effi- ciency): • T ask Success Rate (Succ. Rate): A global ev aluation of whether a multi-turn task was ultimately resolved. Unlike standard EM, Succ. Rate is achie ved through two distinct, context-dependent interaction dimensions: • A utonomous Succ. Rate: Evaluates performance on clear tasks. It measures the agent’ s ability to successfully deduce and execute the required actions without unnec- essarily querying the user (penalizing over -cautiousness and redundant API calls). • Clarification Succ. Rate: Evaluates performance on am- biguous tasks. It measures the agent’ s ability to correctly halt physical execution and proacti vely in voke human- centric tools (e.g., ask_user ) to acquire missing infor- mation (penalizing forced hallucinations). V . R E S U LT S A N D A N A L Y S I S A. Robustness on HomeBench T o systematically ev aluate the frame work’ s robustness against entity hallucinations, we categorize the HomeBench instructions into five distinct types based on their validity and complexity . T able II visualizes these categories with concrete examples and maps them to their corresponding ev aluation metrics. T ABLE II T A X ON O M Y O F H O M E B E N CH T AS K S A N D M E T RI C M A PP I N G . ( A S SU M I N G S t D O ES N OT C O N T A IN A N O V E N ) T ask Category Instruction Example T argeted Metric & Capability VS (V alid Single) "Turn on the lamp." EM & F1: Evaluates normal instruction-following recall. VM (V alid Multi) "T urn on lamp, lock door ." IS (In valid Single) "Turn on the oven." Rejection Rate: Evaluates safety and hallucination suppression. IM (In valid Multi) "T urn on ov en and heater ." MM (Mixed Multi) "T urn on lamp and oven." EM & F1: Evaluates filter ability . Understanding this mapping is crucial because success on V alid tasks measures execution capability , whereas success on 7 T ABLE III P E RF O R M AN C E C O M P A R I S ON O N H O M E B E N C H ( EM : E X AC T M A T C H , F 1 : F 1 - S CO R E ) . B O L D I N DI C A T ES B E S T P ER F O R MA N C E . Method VS (V alid Single) IS (Inv alid Single) VM (V alid Multi) IM (Inv alid Multi) MM (Mixed Multi) Overall EM F1 EM F1 EM F1 EM F1 EM F1 EM F1 Baseline 66.96% 66.89% 14.07% 14.08% 37.55% 69.18% 0.00% 5.82% 0.49% 33.23% 29.98% 35.72% SA GE 48.63% 49.18% 29.84% 29.84% 9.09% 47.42% 0.00% 0.00% 1.77% 29.80% 1.77% 30.84% DS-IA (Ours) 50.40% 50.37% 87.04% 87.16% 50.00% 76.98% 38.46% 73.08% 24.49% 77.42% 58.56% 74.90% In valid tasks strictly measures physical safety (the ability to trigger Early Rejection). T able III presents the comprehensive quantitativ e results across these dimensions. DS-IA achieves a remarkable overall success rate (EM) of 58.56% and an F1-score of 74.90%, significantly outperforming the Baseline (29.98% EM) and SA GE (1.77% EM). 1) Analysis of Baseline P erformance Anomalies: It is worth noting that the SA GE frame work e xhibits an unexpectedly low EM rate (1.77%) on HomeBench compared to its orig- inal paper . W e attribute this performance degradation to the mismatch between Reactiv e Architectures and In valid Instruc- tions. SA GE relies on an iterative “Observ e-Reason-Act” loop. When facing in valid instructions (which constitute 38.6% of HomeBench), SA GE lacks a mechanism to stop early . Instead, it exhausti vely in vok es search tools (e.g., scan_devices ) until it either hallucinates a semantic match (Forced Ground- ing) or exhausts the context windo w . This highlights the necessity of our Stage 1 “Semantic Firewall, ” which filters out these unex ecutable queries before they trigger the costly reactiv e loop. 2) Analysis of Hallucination Suppr ession: In the IS (Inv alid Single) task, which directly tests the capability to reject hallucinations, Baseline only achieves 14.07%, indicating a strong tendency for “Forced Grounding. ” In contrast, DS-IA achiev es 87.04%. This quantum leap prov es that the Stage 1 intent routing mechanism effecti vely serves as a semantic firew all. 3) Analysis of Mixed Intents: For MM (Mixed Multi) tasks, DS-IA achieves an F1 score of 77.42% (Success Rate: 24.49%), compared to Baseline’ s F1 of 33.23%. This validates the “Generate-and-Filter” strategy , which allo ws the agent to ex ecute valid sub-tasks while safely discarding hallucinations, av oiding the “all-or-nothing” failure mode common in single- stage models. 4) Impr ovement on V alid Instructions: Notably , compared to previous iterations, our framework maintains a competitive performance on VS (V alid Single) tasks (50.40%), narro wing the gap with the Baseline while providing significantly higher safety guarantees. For complex VM (V alid Multi) tasks, DS- IA outperforms the Baseline with a 50.00% success rate, demonstrating superior capability in handling long-horizon planning. B. Case Study: Suppr ession of F or ced Hallucination T o intuiti vely demonstrate the safety advantage of DS- IA ov er SA GE on the HomeBench dataset, we analyze a representativ e failure case in volving in v alid entities (Case ID: home45_one_1306 ). Scenario Description: • User Instruction: "Set the intensity of the dehumidifiers to 0 in the stor e r oom." • En vironment Context: The simulated home does not contain a “store room” or does not hav e a dehumidifier in that location. The user’ s request targets a non-existent entity . • Ground T ruth: The system should report an error and ex ecute nothing ( error_input ). Comparison of Framework Beha viors: 1) SA GE (Baseline) F ailure: As shown in the SA GE ex ecution logs, the baseline model output: study_room.dehumidifiers.set_intensity(0) Analysis: Lacking an explicit rejection mechanism, SA GE exhibited “F orced Grounding. ” It semantically mapped the non-existent “store room” to the nearest valid entity “study room” and ex ecuted the command. This illustrates the "Reliability Gap" where the model prioritizes execution over faithfulness, leading to unin- tended physical operations. 2) DS-IA (Ours) Success: Our framew ork output: {error_input} Analysis: • Stage 1 (Intent Analysis): The Intent Router scanned the environment snapshot S t . It de- tected that the target entity (store_room, dehumidifier) was missing from the graph. • Decision: The instruction was classified as C inv al id . • Action: The system triggered the Early Rejection protocol, bypassing the generation stage entirely . This case strongly v alidates that incorporating a pre- ex ecution verification stage is essential for pre venting LLM hallucinations in safety-critical IoT en vironments. C. Ablation Study: Computational Efficiency and Safety T o deeply analyze the contrib ution of the Intent Analysis (IA) module, we conducted an ablation study on a subset of 1,000 tasks, comparing the Full Framework (DS-IA) against a w/o Stage 1 (No IA) baseline. In the baseline, instructions are directly fed to the code generator without prior semantic routing. Rather than merely ev aluating general execution, this ab- lation explicitly focuses on the frame work’ s physical safety capabilities and computational economics. T able IV details the safety metrics (In valid Instruction Rejection Rate) alongside the API call frequency and token consumption for both con- figurations. 8 User: "Set dehumidifier to 0 in store room" SA GE Framework Search similar ... Found: "Study Room" Wrong Action: T urn off Study Room Dehumidifier DS-IA Framework Stage 1 Check: Store Room / ∈ S t -> INV ALID Correct Action: Reject & Report Error Fig. 3. V isual comparison of handling a non-existent device instruction on HomeBench. SAGE hallucinates a target (Forced Grounding), while DS-IA correctly rejects the command (Early Rejection). T ABLE IV A B LAT IO N O N S A FE T Y A N D E FFI CI E N C Y ( 1 ,0 0 0 T A SK S ) . D S - I A B O O S TS P H YS I C A L S AF E T Y ( R EJ E C T IO N R A T E ) W H I LE T R AD I N G C H E AP I N PU T T OK E N S T O M AS S I V ELY R E D UC E E X P E NS I V E AU T OR E G RE S S I VE C O D E G E NE R A T IO N C Y C L ES . Method Safety Stage 1 (Intent Analysis) Stage 2 (Code Generation) IS EM (Rejection) Calls T okens Calls T okens No IA Baseline 83.29% 0 0 1,000 2,982,070 DS-IA (Ours) 88.69% 1,000 3,262,848 819 2,554,231 1) F ortifying Safety thr ough Early Rejection: As observed in T able IV, the IA module serves as a critical semantic fire- wall. W ithout Stage 1, the baseline attempts to ground every user instruction blindly , leading to a higher risk of Forced Hallucinations on in v alid commands. By isolating existence verification in Stage 1, DS-IA correctly intercepts explicitly in valid intents before the y reach the generator . This strict Early Rejection mechanism boosts the system’ s absolute physical safety , increasing the exact match rate on In v alid Single (IS) instructions from 83.29% to 88.69%, firmly establishing a “Do No Harm” protocol for smart home control. 2) Massive Reduction in Gener ation Overhead: Beyond safety , the Early Rejection mechanism fundamentally opti- mizes the computational dynamics of the agent. By bypassing the generation phase for explicitly inv alid intents, DS-IA slashes the number of heavy Code Generation calls by 18.1% (from 1,000 down to 819). Consequently , the framework successfully saves over 427,000 generation tokens in Stage 2. 3) The Economics of Prefill vs. Decoding: While DS-IA introduces 3.26M tokens in Stage 1, this apparent overhead is highly asymmetrical in practice. In modern LLM architectures, Stage 1 (IA) predominantly in v olves prefill (pr ompt) pr ocess- ing to read the en vironment snapshot S t . Prefill is highly parallelizable and computationally cheap. Con versely , Stage 2 (Code Generation) relies heavily on autore gr essive decoding , which is memory-bandwidth-bound, exceptionally slow , and computationally expensi ve. By trading inexpensi ve input (IA) tok ens for a massi ve reduction in expensi ve generation (CodeGen) tokens, DS-IA implements a highly ef ficient Adapti ve Computation strategy . It ensures that the heavy lifting of code generation is reserved strictly for physically v alid tasks, entirely eradicating the wasted compute on hallucinated commands. D. Interaction Ef ficiency on SA GE Benchmark T o rigorously ev aluate interaction efficienc y in complex Human-Robot Interaction (HRI) scenarios, we utilize the SA GE Benchmark (50 tasks). Unlike traditional metrics that only re ward physical execution, we define T ask Success Rate (Succ. Rate) globally: a task is considered successful if the agent either correctly e xecutes an autonomous action when information is suf ficient, or accurately in vokes human-centric tools (e.g., ask_user ) to proacti vely acquire missing in- formation when faced with irreducible ambiguity . T able V illustrates the comprehensiv e performance across different dimensions. T ABLE V T A S K S UC C E S S R A T E ( S U C C . R A T E ) B R E A KD OW N O N S AG E B E NC H M A RK . S U C C ES S I S AC H I EV E D B Y E I T H ER S A FE AU T ON O M O US E X EC U T I ON O R C O R RE C T P RO AC TI V E C L A R IFI C A T I O N . T ask Category SA GE (Baseline) DS-IA (Ours) Global J udgment Metrics Clarification Succ. Rate (Ambiguous) 75.00% 75.00% Autonomous Succ. Rate (Clear) 42.86% 71.43% Detailed T ask Succ. Rate Breakdown Intent Resolution 33.33% 70.83% Device Resolution 46.15% 69.44% Personalization 27.27% 54.55% Persistence 25.00% 100.00% Command Chaining 62.50% 62.50% Simple Commands 57.14% 85.71% 1) Compr ehensive Analysis of Inter action Data: • Balancing A utonomy and Proactive Querying: At the macro level, SA GE suffers from severe “Over - cautiousness” and frequent questioning. When the human interaction module is enabled, the baseline often falls into a repetitiv e querying loop, achieving an Autonomous Succ. Rate of only 42.86%. This means it excessi vely disturbs the user with redundant questions in over half of the tasks that could have been solved independently . By decoupling intent routing from physical generation, DS-IA boosts this autonomy to 71.43%. Concurrently , on ambiguous tasks strictly requiring human intervention, DS-IA perfectly maintains the Clarification Succ. Rate at 75.00%. This proves that our framew ork effecti vely suppresses the LLM’ s tendency to ask frequent, unneces- sary questions, while successfully preserving its critical ability to recognize genuine information deficiency and seek help only when truly needed. • Superior Disambiguation (Intent & Device Resolu- tion): For Intent Resolution (33.33% → 70.83%) and Device Resolution (46.15% → 69.44%), user instructions typically contain v ague nouns requiring state-based de- duction. SA GE’ s reactiv e “think-while-acting” loop often gets trapped in infinite API calls or hallucinates target parameters. In contrast, DS-IA ’ s Stage 1 module acts as a semantic firewall, pre-aligning the v ague instruction with the en vironment snapshot S t before generation, 9 yielding massiv e absolute gains of +37.5% and +23.29% respectiv ely . • Handling Complex Contexts (Personalization & Per - sistence): Personalization tasks in volve subjective user preferences, where DS-IA exactly doubles the baseline success rate (27.27% → 54.55%) through stricter seman- tic routing. More impressiv ely , on Persistence tasks that require long-term state monitoring, SAGE fundamentally struggles (25.00%) due to context forgetfulness over multiple turns. DS-IA achiev es a perfect 100.00% Succ. Rate here, as its cascade verifier mechanically anchors ev ery generated action to the physical truth, eradicating contextual hallucinations. • F oundational Capabilities (Simple & Chained Com- mands): Even on Simple Commands, SA GE often ov er - complicates the ex ecution trace, leading to format col- lapse (57.14%). DS-IA directly maps these to valid actions, increasing robustness to 85.71%. Finally , for Command Chaining (purely sequential logic without deep ambiguity), both framew orks perform equally well (62.50%), confirming that DS-IA introduces sophisti- cated disambiguation capabilities without degrading the baseline’ s foundational multi-step instruction-following competence. V I . C O N C L U S I O N This paper addresses two fundamental bottlenecks in de- ploying LLM-based agents for smart homes: the “Reliabil- ity Gap” (entity hallucinations) and the “Interaction Fre- quency Dilemma” (excessiv e user disturbance). W e propose the Dual-Stage Intent-A ware (DS-IA) framework, which pio- neers an “ Analyze-then-Act” paradigm by decoupling macro- intent routing from micro-grounding v alidation. A. Summary of Contributions Our extensi ve e v aluation on HomeBench and SA GE bench- marks yields three critical insights: • Safety as a Priority: DS-IA acts as an effecti ve semantic firew all. By achieving an 87.04% Exact Match (EM) on inv alid instructions (HomeBench IS) compared to the baseline’ s 14.07%, our framew ork demonstrates a rob ust capability for early rejection. This ef fecti vely eradicates the risk of “Forced Grounding, ” ensuring physical safety ev en at the cost of slight recall loss on simple tasks. • A utonomy with Precision: W e successfully mitigate the interaction dilemma inherent in reacti ve frameworks. The proposed DS-IA framework improves the Autonomous Success Rate (the ability to resolve tasks independently without redundant user queries) from 42.86% (SA GE) to 71.43%. This significant enhancement demonstrates that State-A ware Disambiguation can ef fecti vely resolve most functional ambiguities by grounding intent in the physical environment, thereby minimizing unnecessary user disturbances while maintaining ex ecution precision. • Long-Horizon Robustness: The 100% success rate on Persistence tasks demonstrates that our structured ground- ing mechanism is superior to reactive approaches in maintaining context over time. B. Limitations and Futur e W ork Despite these advancements, we identify three directions for future optimization: 1) Multimodal P er ception: Currently , DS-IA relies on te x- tual metadata. Inspired by [13] and [11], future w ork will integrate V ision-Language Models (VLMs) to resolve visual references (e.g., “T urn on that red lamp” ) and process multi-sensory data. 2) Privacy-Pr eserving SLM Distillation: T o address in- ference latency and priv acy concerns raised in [15], we plan to distill the Intent Analysis module into specialized Small Language Models (SLMs). This will enable on- device ex ecution, eliminating the need to send pri v ate home states to the cloud. 3) Personalized Memory: Follo wing the findings in [8], we aim to incorporate a V ector Database (RAG) to memorize user habits, allo wing the agent to implicitly resolve preference-based ambiguities. In conclusion, DS-IA of fers a robust, safe, and ef ficient blueprint for the next generation of embodied IoT agents, bridging the gap between linguistic reasoning and physical ex ecution. A P P E N D I X T o ensure full reproducibility and to demonstrate how physical grounding constraints are explicitly injected into the Large Language Models, Figure 4 provides the exact system prompts and contextual structures utilized in both stages of our DS-IA frame work. R E F E R E N C E S [1] Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Brian Ichter , Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. 2022. Chain- of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS ’22). Curran Associates Inc., Red Hook, NY , USA, Article 1800, 24824–24837. [2] W ang, L., Ma, C., Feng, X. et al. A survey on lar ge language model based autonomous agents. Front. Comput. Sci. 18, 186345 (2024). https://doi.org/10.1007/s11704-024-40231-1 [3] Dmitriy Rivkin, Francois Hogan, Amal Feriani, Abhisek Konar , Adam Sigal, Xue Liu, and Gre gory Dudek, “ AIoT Smart Home via Au- tonomous LLM Agents, ” IEEE Internet of Things Journal , vol. 12, no. 3, pp. 2458–2472, 2025. DOI: 10.1109/JIOT .2024.3471904. [4] Allen Z. Ren, Anushri Dixit, Alexandra Bodro v a, Sumeet Singh, Stephen T u, Noah Brown, Peng Xu, Leila T akayama, Fei Xia, Jake V arley , Zhen- jia Xu, Dorsa Sadigh, Andy Zeng, and Anirudha Majumdar, “Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners, ” in Pr oceedings of The 7th Confer ence on Robot Learning , vol. 229, PMLR, Nov . 2023, pp. 661–682. [5] Anastasia Iv anov a, Bakaeva Eva, Zoya V olovikov a, Alexey Ko v alev , and Aleksandr Pano v . 2025. AmbiK: Dataset of Ambiguous T asks in Kitchen En vironment. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 33216–33241, V ienna, Austria. Association for Computational Linguistics. [6] Y uqi Zhang, Liang Ding, Lefei Zhang, and Dacheng T ao. 2025. Intention Analysis Makes LLMs A Good Jailbreak Defender. In Proceedings of the 31st International Conference on Computational Linguistics, pages 2947–2968, Abu Dhabi, U AE. Association for Computational Linguistics. 10 (a) Prompt T emplate for Stage 1: Global Intent Analysis S Y S T EM R O LE : Y ou are a smart home intent analyzer . Y our task is to strictly e v aluate if the user’ s command can be executed based on the provided en vironment state. E N V I RO N M E NT C O N T E X T : {Device_Status_Snapshot} E V A L UA T I O N R U L E S : Check these THREE things for each operation: 1) Room existence: Does the mentioned room exist? 2) Device existence: Does the de vice e xist in that room? 3) Action support: Does the de vice support the requested action/attrib ute? O U T P UT F O R M A T : Output a JSON object containing an array of operations (with valid and reason fields) and a global all_valid boolean flag. (b) Prompt T emplate for Stage 2: Code Generation S Y S T EM R O LE & N E G A T I V E C O N S T R A IN T S : Y ou are ’Al’, a helpful AI Assistant that controls the devices in a house. Complete the following task as instructed or answer the following question with the information provided only . The current status of the device and the methods it possesses are provided below , please only use the methods provided. Output "error_input" when operating non-existent attributes and devices. Only output machine instructions and enclose them in {}. E N V I RO N M E NT C O N T E X T & C A PA B I LI T I E S : The following provides the status of all de vices in each room of the current household, the adjustable attributes... {Device_Status_Snapshot} The following provides the methods to control each device in the current household: {Device_Methods_Snapshot} F E W - S H OT D E M O N S T R A T I O N S ( O P T I O NA L ) : {In_Context_Examples} U S E R I N T E RA CT I O N : --------------------- Here are the user instructions you need to reply to. {User_Command} Fig. 4. The complete constraint-aware prompt templates utilized in the DS-IA framework. (a) The Stage 1 prompt acts as a semantic fire wall to extract diagnostic reasoning. (b) The Stage 2 prompt generates the final execution sequence, integrating strict negativ e constraints ( e.g., utilizing error_input for unexecutable actions) to enforce physical grounding. 11 [7] Silin Li, Y uhang Guo, Jiashu Y ao, Zeming Liu, and Haifeng W ang. 2025. HomeBench: Evaluating LLMs in Smart Homes with V alid and In v alid Instructions Across Single and Multiple Devices. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 12230–12250, V ienna, Austria. Association for Computational Linguistics. [8] King, E., Y u, H., Lee, S., and Julien, C., “"Get ready for a party": Exploring smarter smart spaces with help from large lan- guage models”, arXiv e-prints, Art. no. arXiv:2303.14143, 2023. doi:10.48550/arXiv .2303.14143. [9] Singh, I., Blukis, V ., Mousavian, A. et al. ProgPrompt: program genera- tion for situated robot task planning using large language models. Auton Robot 47, 999–1012 (2023). https://doi.org/10.1007/s10514-023-10135- 3 [10] T uo An, Y unjiao Zhou, Han Zou, Jianfei Y ang,IoT -LLM: A frame- work for enhancing large language model reasoning from real- world sensor data,Patterns,V olume 7, Issue 1,2026,101429,ISSN 2666- 3899,https://doi.org/10.1016/j.patter .2025.101429. [11] S. Mo, R. Salakhutdinov , L.-P . Morency , and P . P . Liang, “IoT -LM: Large Multisensory Language Models for the Internet of Things, ” arXiv pr eprint arXiv:2407.09801 , 2024. [12] M. Abugurain and S. Park, “Integrating Disambiguation and User Preferences into Large Language Models for Robot Motion Planning, ” arXiv pr eprint arXiv:2404.14547 , 2024. [13] Calò, T ., De Russis, L. Enhancing smart home interaction through mul- timodal command disambiguation. Pers Ubiquit Comput 28, 985–1000 (2024). https://doi.org/10.1007/s00779-024-01827-3 [14] Y e Dong, Y an Lin Aung, Sudipta Chattopadhyay , and Jianying Zhou, “ChatIoT : Large Language Model-based Security Assistant for Inter- net of Things with Retrieval-Augmented Generation, ” arXiv e-prints , arXiv:2502.09896, February 2025. DOI: 10.48550/arXiv .2502.09896. [15] Xinyu Huang, Leming Shen, Zijing Ma, and Y uanqing Zheng, “T ow ards Priv acy-Preserving and Personalized Smart Homes via T ailored Small Language Models, ” IEEE Tr ansactions on Mobile Computing , pp. 1–16, 2026. DOI: 10.1109/TMC.2026.3654976. [16] Shunyu Y ao, Jef frey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao, “ReAct: Synergizing Reasoning and Acting in Language Models, ” arXiv pr eprint arXiv:2210.03629 , 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment