DyJR: Preserving Diversity in Reinforcement Learning with Verifiable Rewards via Dynamic Jensen-Shannon Replay
While Reinforcement Learning (RL) enhances Large Language Model reasoning, on-policy algorithms like GRPO are sample-inefficient as they discard past rollouts. Existing experience replay methods address this by reusing accurate samples for direct pol…
Authors: Long Li, Zhijian Zhou, Tianyi Wang
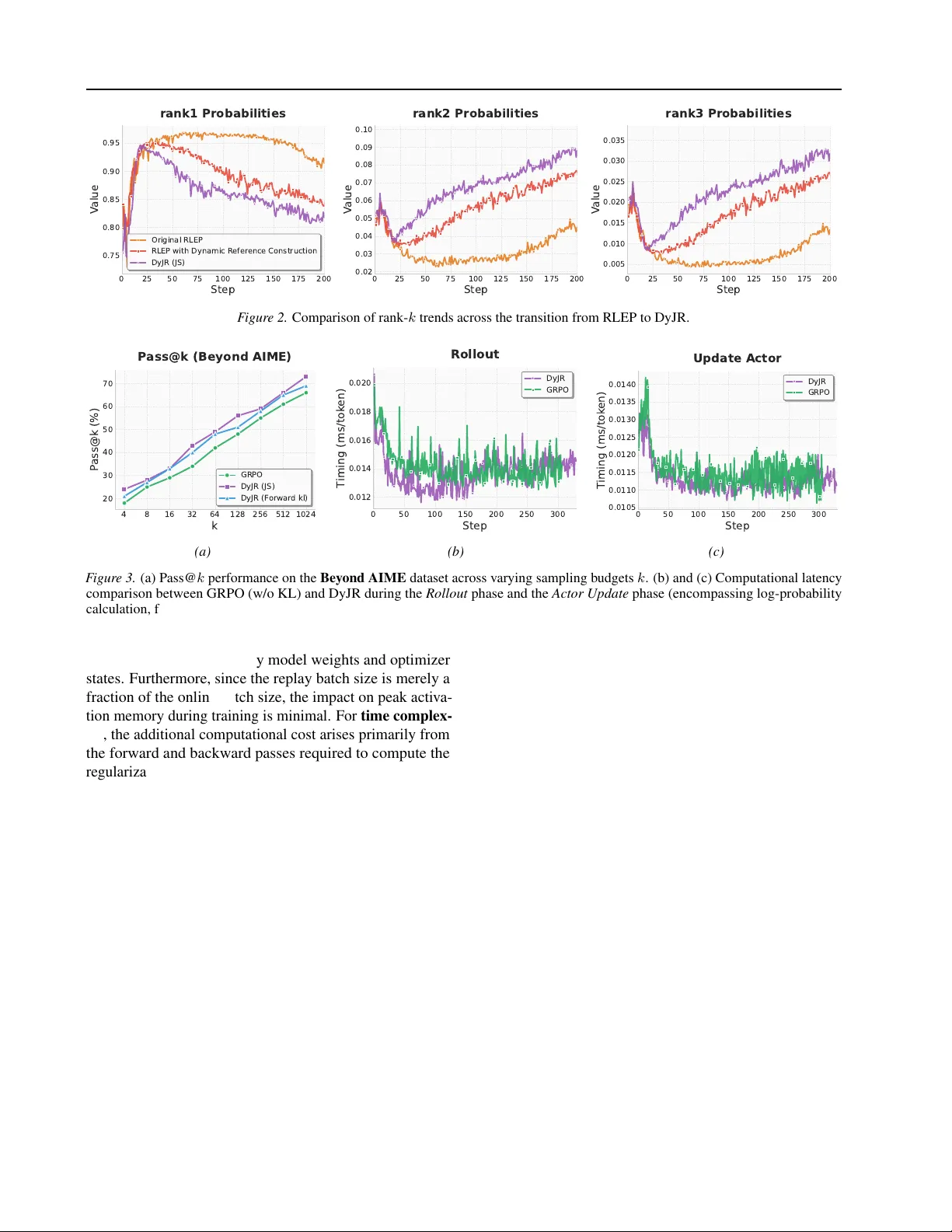
DyJR: Preser ving Div ersity in Reinfor cement Lear ning with V erifiable Rewards via Dynamic Jensen-Shannon Replay Long Li 1 * Zhijian Zhou 2 3 * Tianyi W ang 4 W eidi Xu 5 Zuming Huang 5 W ei Chu 5 Zhe W ang 1 Shirui Pan 1 † Chao Qu 2 6 † Y uan Qi 2 6 Abstract While Reinforcement Learning (RL) enhances Large Language Model reasoning, on-policy algo- rithms like GRPO are sample-inefficient as they discard past rollouts. Existing experience replay methods address this by reusing accurate samples for direct polic y updates, but this often incurs high computational costs and causes mode collapse via ov erfitting. W e argue that historical data should prioritize sustaining diversity rather than simply reinforcing accuracy . T o this end, we propose Dynamic J ensen-Shannon Replay (DyJR) , a sim- ple yet ef fectiv e regularization frame work using a dynamic reference distrib ution from recent tra- jectories. DyJR introduces tw o innov ations: (1) A T ime-Sensitiv e Dynamic Buffer that uses FIFO and adaptiv e sizing to retain only temporally prox- imal samples, synchronizing with model ev olu- tion; and (2) Jensen-Shannon Diver gence Regu- larization, which replaces direct gradient updates with a distributional constraint to prevent div ersity collapse. Experiments on mathematical reasoning and T ext-to-SQL benchmarks demonstrate that DyJR significantly outperforms GRPO as well as baselines such as RLEP and Ex-GRPO, while maintaining training efficienc y comparable to the original GRPO. Furthermore, from the perspec- tiv e of Rank- k token probability ev olution, we show that DyJR enhances di versity and mitigates ov er-reliance on Rank-1 tokens, elucidating how specific sub-modules of DyJR influence the train- ing dynamics. ∗ Equal contribution. † Co-corresponding authors. 1 Griffith Uni- versity , Australia 2 Fudan Univ ersity , China 3 Shanghai Innov ation Institute, China 4 Beijing University of Post and T elecommuni- cations 5 INFL Y TECH, China 6 Shanghai Academy of Artificial Intelligence for Science, China. Correspondence to: Long Li < long.li@griffithuni.edu.au > . Pr eprint. Mar ch 18, 2026. 1. Introduction Reasoning capability is central to Artificial General Intelli- gence in the large language models (LLMs) era ( OpenAI , 2023 ; Y ang et al. , 2025 ; Zhu et al. , 2025a ). Models like OpenAI o1 demonstrate that Reinforcement Learning (RL) transcends preference alignment by enhancing logic through long Chain-of-Thought (CoT) exploration ( OpenAI , 2024 ; Guo et al. , 2025 ). While “long thinking” via V erifiable Re- wards is no w mainstream ( Chen et al. , 2025b ), a key bottle- neck exists: the on-policy nature of current Reinforcement Learning with V erifiable Re ward (RL VR) ( Cai et al. , 2025 ; Cai & Sugiyama , 2026 ) algorithms causes expensi ve rollout data to be discarded after a single update ( Shao et al. , 2024 ; Zhan et al. , 2025 ). This inefficienc y wastes v ast resources and prevents learning from past successes, hindering the scalability of RL in reasoning tasks ( Fu et al. , 2025 ; Zhou et al. , 2026 ). Experience Replay ( Rolnick et al. , 2019 ; Mnih et al. , 2013 ; Lillicrap , 2015 ; Liu et al. , 2026 ) has recently been adapted for LLM training to improv e sample efficienc y . Meth- ods such as ReMix ( Liang et al. , 2025 ), RePO ( Li et al. , 2025b ), Ex-GRPO ( Zhan et al. , 2025 ),and RLEP ( Zhang et al. , 2025 ) reuse historical trajectories by following a data augmentation paradigm. These approaches typically main- tain massiv e buf fers to store historical samples and treat them as additional positiv e instances for direct policy gra- dient updates. Formally , they optimize a joint objecti ve J ( θ ) = J on ( θ ) + α J exp ( θ ) using the same standard clipped surrogate objecti ve for both terms. 1 W e contend that this mainstream approach suffers from two cor e misconceptions . First, indiscriminate forward updates exacerbate mode collapse. By directly maximizing the like- lihood of historical trajectories, the model is coerced into ov er-fitting specific solution paths ( Zhu et al. , 2025b ; Peng et al. , 2025 ), leading to a swift erosion of its exploratory potential ( W ang et al. , 2025 ; Y ue et al. , 2025 ; Cheng et al. , 1 Specifically , J exp ( θ ) takes the exact same form as the on- policy objecti ve: E q ∼B exp [min( r ( θ ) ˆ A, clip ( r ( θ ) , 1 − ϵ, 1 + ϵ ) ˆ A )] , where r ( θ ) = π θ π old . This effecti vely treats replayed trajectories as additional off-polic y samples. 1 DyJR: Preser ving Diversity in RL VR via Dynamic Jensen-Shannon Replay 2025 ). Second, traditional Experience Replay methods ne- cessitate substantial training resources for sample storage and reuse; for instance, approaches like RLEP incur massi ve GPU memory overhead by archiving the entire trajectory history . In contrast, our empirical findings suggest that historical data is not uniformly valuable, as RL training exhibits a rapid transition window where the model’ s en- tropy decreases sharply during the early stages (typically the first 20 steps) before con v erging to a peaked distrib ution. Consequently , by prioritizing large-scale sample storage ex- clusi vely during this volatile initial phase while maintaining a minimal footprint in later stages, one can achiev e perfor- mance comparable to continuous lar ge-scale storage while drastically reducing memory requirements. Based on these observations, we redefine the role of Experi- ence Replay in reasoning tasks: the objectiv e should shift from accuracy optimization via correct samples to a regular- ization mechanism for sustaining di versity . Guided by this philosophy , we propose the Dynamic Jensen-Shannon Re- play Algorithm ( DyJR ). Unlike previous approaches, DyJR introduces two ke y innov ations. Regarding data construc- tion , we replace brute-force storage with a non-uniform dynamic buf fer strategy . Specifically , we implement a dy- namic capacity mechanism that expands the buf fer to re- tain a larger v olume of samples during the rapid transition phase—thereby capturing high-entropy reasoning patterns— and subsequently contracts it. Crucially , we emplo y a First- In-First-Out (FIFO) protocol for buf fer updates, retaining only samples that are most temporally proximal to the cur- rent model. Empirical evidence indicates that while retain- ing excessiv e historical data with large temporal variance impedes learning, utilizing temporally adjacent data mini- mizes training resource consumption while yielding optimal performance. Re garding data utilization , we move away from direct policy gradient updates and introduce Jensen- Shannon div ergence as a re gularization constraint. By treat- ing the mixture of historical policies as a dynamic distrib u- tional anchor , we minimize the Jensen-Shannon diver gence between the current polic y and this mixture. This prev ents the model from drifting away from div erse successful paths without aggressiv ely altering the optimization direction. Our main contributions are summarized as follo ws: (1) Redefining the Replay Paradigm: From Accuracy Optimization to Diversity Regularization. W e demon- strate that the primary value of replayed data lies in sus- taining diversity rather than merely reinforcing accuracy . Consequently , we replace direct gradient updates with a Jensen-Shannon div ergence distrib utional constraint, effec- tiv ely preserving the model’ s e xploration capability and robustness. (2) Proposing a Dynamic Data Construction Strategy Based on T emporal Proximity . W e introduce a non- uniform dynamic buf fer mechanism that expands storage during the rapid transition phase to capture high-entrop y pat- terns and contracts it as the model stabilizes. By employing a FIFO protocol to retain only the most temporally adjacent samples, we achieve optimal performance while minimizing training resource consumption. (3) Extensive Experiments and Fine-Grained Analysis. W e demonstrate rob ust improvements across div erse tasks (e.g., Math and T ext-to-SQL) and architectures (Qwen and Llama families), achie ving substantial g ains in both Pass@1 and Pass@k with negligible GPU memory overhead. Fur- thermore, we provide a detailed ablation analysis from the perspectiv e of Rank- k token probability e volution to eluci- date how DyJR’ s sub-modules influence training dynamics. 2. Preliminaries In this section, we formalize the RL VR setup and intro- duce the foundational algorithms: Group Relativ e Policy Optimization (GRPO) and JS div ergence. 2.1. RL Backbone: GRPO W e formulate the reasoning task as a Markov Decision Pro- cess (MDP). Giv en a query x , a policy π θ generates a rea- soning chain y = ( y 1 , . . . , y L ) . The en vironment returns a binary rew ard r ( x, y ) ∈ { 0 , 1 } . Standard PPO requires a value function critic, which is computationally expensi ve for LLMs. Instead, we utilize GRPO ( Shao et al. , 2024 ), which estimates baselines using group statistics. For each query x , GRPO samples a group of G outputs { y 1 , . . . , y G } from the old policy π θ old . The advantage for the i -th output is computed as: ˆ A i = r ( x, y i ) − µ group σ group (1) where µ group and σ group are the mean and standard deviation of rew ards within the group. The GRPO objective maxi- mizes the surrogate loss: L GRPO ( θ ) = − 1 G G X i =1 min ρ i ˆ A i , clip ( ρ i , 1 − ϵ, 1 + ϵ ) ˆ A i (2) where ρ i = π θ ( y i | x ) π θ old ( y i | x ) is the importance sampling ratio. 2.2. Forward KL Di vergence In contrast to symmetric measures, the Forward K ullback- Leibler (KL) diver gence is a standard asymmetric metric typically minimized in maximum lik elihood estimation. For a target distrib ution P and an approximating distribution Q , it is defined as: D KL ( P ∥ Q ) = E x ∼ P ln P ( x ) Q ( x ) (3) 2 DyJR: Preser ving Diversity in RL VR via Dynamic Jensen-Shannon Replay The Forw ard KL is characterized by its mode-covering behavior . Because the expectation is taken with respect to the reference distribution P , the di vergence penalizes Q sev erely if Q ( x ) is small where P ( x ) is large. Consequently , minimizing D KL ( P ∥ Q ) forces Q to spread its probability mass to cov er all modes of P , ensuring broad support e ven if it results in assigning mass to lo w-probability regions of the target distrib ution. 2.3. Jensen-Shannon Div ergence The Jensen-Shannon di ver gence offers a symmetrized and smoothed alternativ e to the KL diver gence. For two prob- ability distributions P and Q , the JS di ver gence is defined via a mixture distribution M = 1 2 ( P + Q ) as: D JS ( P ∥ Q ) = 1 2 D KL ( P ∥ M ) + 1 2 D KL ( Q ∥ M ) (4) Unlike the standard KL diver gence, which is asymmetric and unbounded (potentially approaching infinity if the sup- port of Q does not fully encompass P ), the JS div ergence is symmetric and bounded within [0 , ln 2] . 3. Method W e now introduce DyJR. While GRPO provides efficient exploration, it is prone to mode collapse in sparse-reward settings. DyJR mitigates this by maintaining a Dynamic Replay Buffer and applying a JS Regularization term deriv ed from the definition in Sec. 2 . Algorithm 1 DyJR 1: Input: Dataset D , Policy π θ , Max Age M , Reg Coef fi- cient α JS . 2: Initialize: Buf fer S ← ∅ . 3: f or step t = 1 , . . . , T do 4: Rollout: Sample queries X , generate group Y ∼ π θ old ( X ) . 5: Eval: Compute re wards R and group confidence C id . 6: Buffer Maintenance: 7: 1. Evict samples where age > M . 8: 2. Select new samples based on C id and schedule η (Eq. 6 ). 9: 3. Store ( x, y , log π θ old ) into S . 10: Optimization: 11: Calculate L GRPO on online batch ( X, Y ) using Eq. (2). 12: Sample batch B replay uniformly from S . 13: Calculate L JS on B replay using Eq. ( 7 )-( 9 ). 14: Update θ minimizing L GRPO + α JS L JS . 15: end f or 3.1. Dynamic Reference Construction T o lev erage historical success, we construct a reference distribution Q B supported by a Replay Buffer S t . Dynamic Replay Buffer T o address the non-stationarity of the policy , we enforce a Max Age ( M ) constraint. The buf fer strictly retains only perfect samples ( r = 1 ) generated within the last M steps. T o enable efficient di ver gence computation without re-forw arding, we store the token-lev el log-probabilities computed at generation time. A b uffer entry is defined as ( x k , y k , log π ( k ) old ) . At step t , any stale sample is evicted: S t = { ( x k , y k , log π ( k ) old ) | r ( y k ) = 1 , t − T id k ≤ M } (5) This ensures the reference distrib ution tightly tracks the shifting capability boundary of the current policy π θ . Bias-A ware Adaptive Data Selection T o mitigate the selection bias inherent in filtering exclusi vely for correct- ness while ensuring robust coverage across varying task difficulties, we propose a confidence-stratified descend- ing admission strategy . For each query in batch B t , we define the empirical confidence C id as the count of correct responses among G sampled paths. W e strictly prioritize high-confidence samples by iterativ ely admitting perfect trajectories where C id = k , sweeping k from G down to 1 : P new t ← P new t ∪{ ( x, y , log π old ) ∈ B t | C id = k , r ( y ) = 1 } (6) This process halts once the ne wly admitted samples reach the target fill rate η (default 5%). This “High-to-Lo w” mech- anism inherently provides a difficulty-adaptive property: (1) For Easy T asks, it preferentially secures high-confidence samples ( C id ≈ G ), ensuring a lo w-variance reference; (2) For Hard T asks, it naturally relaxes admission criteria to capture rare solutions ( C id ≪ G ), thereby prev enting data starvation and the “catastrophic for getting” of difficult capabilities. Mitigating Early Di versity Collapse A critical challenge in RL VR is the rapid collapse of policy entrop y during early training stages, often occurring before the replay buf fer is sufficiently populated. T o counteract this, we implement a T ime-A ware Adaptiv e Schedule. During the initial warm- up phase (e.g., the first 20 steps), we temporarily elev ate the target fill rate η from 5% to 20%. By proactiv ely ad- mitting a broader spectrum of exploratory samples during initialization, this strategy rapidly di v ersifies the reference distribution, ef fecti vely smoothing the optimization trajec- tory and safeguarding against premature mode collapse. 3 DyJR: Preser ving Diversity in RL VR via Dynamic Jensen-Shannon Replay 3.2. JS Regularization Implementation W e apply JS div ergence to re gularize π θ tow ards the buf fer distribution Q B . While Eq. (3) gi ves the theoretical defini- tion, computing standard JS div ergence implies calculating the mixture distribution M , which is intractable for auto- regressi ve models. Instead, we employ a low-v ariance generati ve estima- tor ( W ang et al. , 2023 ). For a sample s drawn from S t , we compute the probability ratio u s using the current policy and the stored log-probabilities: u ( j ) s = exp log π θ ( y ( j ) s | x s , y ( 0.375). Evaluation is performed on highly challenging benchmarks, including AIME25 ( Li et al. , 2024a ), HMMT25 ( Baluno vi ´ c et al. , 2025 ), BR UMO25 ( Baluno vi ´ c et al. , 2025 ), AMC23, Minerv a ( Le wko wycz et al. , 2022 ) and Beyond AIME. This task is designed to observe the significant performance leap from a low baseline to high-lev el proficiency follo wing RL training. (2) A SQL generation task based on Llama-3.1-8B-Instruct ( Meta AI , 2024 ), which focuses on moderate-difficulty reasoning typically within a 1k token limit. The model is trained on the BIRD ( Li et al. , 2024b ) dataset and ev aluated across both BIRD and Spider ( Y u et al. , 2018 ) datasets to test cross-domain performance. In this work, we employ multiple e xperimental setups to v alidate the effecti veness of DyJR in comparison with baseline methods; T able 3 summarizes the detailed configurations for all setups. Specifically , Replay Bsz denotes the batch size of newly added data items during each data fusion step. For DPH-RL , following the experimental protocol in their original work, we incorporate samples that yield 6 correct responses out of 8 sampled paths into the regularization term. Regarding RLEP , we preserve two correct solution trajectories for each query q in the replay b uf fer . These b uffered samples are subsequently treated as data generated by the current policy π θ and integrated into the joint policy update process. 2 https://huggingface.co/datasets/open-r1/OpenR1-Math-220k 12 DyJR: Preser ving Diversity in RL VR via Dynamic Jensen-Shannon Replay T able 4. ExGRPO-specific hyperparameters for experience replay . Parameter V alue Description Replay ratio ( ρ ) 0.5 Fraction of replay samples in each mini-batch Delayed replay threshold 0.35 Minimum batch Pass@1 required to acti vate e xperience replay Difficulty b ucket range [0 , 7] Bounds for difficulty-based buck eting ( k /K ) Replay metric Entropy Criterion for ev aluating trajectory quality T rajectory selection mode Argmin Select the lowest-entrop y successful trajectory per prompt For Pass@1, we employ greedy decoding (i.e., temperature T = 0 ). For Mean@256, we generate 256 samples with a temperature of T = 0 . 7 and calculate the av erage accuracy across all samples. ExGRPO. (Experiential Group Relativ e Policy Optimization) ( Zhan et al. , 2025 ) extends GRPO with an experience replay frame work that integrates e xperience management and mixed optimization . During training, ExGRPO maintains an experience pool that maps each prompt to a set of pre viously successful solution trajectories, and categorizes prompts into difficulty b uckets according to their most recent rollout accuracy . T o prevent ov erfitting to trivial cases, prompts whose rollouts are entirely correct are mov ed into a r etir ed set and excluded from subsequent replay . At each update step, ExGRPO applies a replay ratio ρ to partition each mini-batch into on-policy samples and replayed experiences. Difficulty b uckets are sampled using a Gaussian weighting centered at 0 . 5 , thereby emphasizing prompts of intermediate difficulty . For each selected prompt, ExGRPO further selects the successful trajectory with the lowest entrop y under the current policy , encouraging stable exploitation while mitigating e xcessiv e div ersity collapse. The additional hyperparameters introduced by ExGRPO are summarized in T able 4 , while all other training configurations follow the GRPO baseline in the T able 3 . C. The Irreplaceability of Early Exploration T able 5. Performance of DyJR on v arious mathematical benchmarks. init denotes the percentage of rollout samples retained per step during the initial 20 steps, while η represents the retention rate thereafter . The maximum age of the FIFO buf fer is consistently set to 8 steps. Model AIME25 AMC23 Beyond AIME BRUMO25 HMMT25 Minerva * A vg DyJR ( init = 20% , η = 20% ) 22.9 72.5 12.5 33.8 12.6 51.0 34.2 DyJR ( init = 20% , η = 5% ) 23.1 72.0 12.7 33.4 12.7 50.4 34.1 DyJR ( init = 10% , η = 5% ) 22.5 69.2 11.4 31.5 11.5 48.2 32.4 DyJR ( init = 5% , η = 5% ) 21.8 68.5 10.1 29.2 10.3 47.8 31.3 W e ev aluated whether maintaining a consistently large sample collection rate yields significant differences compared to our current strategy , with results presented in the T able 5 . Our ablation study yields two critical observations re garding data utilization: 1. Diminishing Returns of Late-Stage Data: Maintaining a consistently high global sampling rate ( 0 . 2 ) implies no significant performance gain compared to our dynamic strategy . This suggests that as the model stabilizes in the mid-to-late stages, a minimal set of replay samples suffices to anchor the distribution, v alidating the memory efficienc y of DyJR’ s dynamic contraction. 2. Criticality of Initial Data: Con versely , reducing the sampling rate during the initial phase ( init ) results in a significant deterioration of performance. Reevaluating Replay V alue—Div ersity Over Accuracy . These findings challenge the con ventional understanding of Experience Replay . If the primary value of replayed data lay solely in its correctness (i.e., reinforcing accurate solutions to prev ent forgetting), then late-stage trajectories—generated by a model with higher accuracy—should theoretically be more val uable than early-stage ones. Howe ver , our experiments re veal a paradox: although the early-stage model exhibits lower accuracy , the data it generates is indispensable for final performance. This contradiction strongly suggests that the 13 DyJR: Preser ving Diversity in RL VR via Dynamic Jensen-Shannon Replay efficac y of DyJR stems not from merely cloning correct behaviors, but from preserving the high entropy and r easoning diversity inherent in early training. By lev eraging these early , div erse trajectories as a distributional constraint via JS div ergence, DyJR prev ents the model from prematurely con ver ging to a narro w solution path (mode collapse). Consequently , unlike static replay methods that simply mitigate for getting, DyJR activ ely safeguards the model’ s e xploration capability , leading to substantial gains in Pass@1. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment