NeuronSpark: A Spiking Neural Network Language Model with Selective State Space Dynamics
We ask whether a pure spiking backbone can learn large-scale language modeling from random initialization, without Transformer distillation. We introduce NeuronSpark, a 0.9B-parameter SNN language model trained with next-token prediction and surrogat…
Authors: Zhengzheng Tang
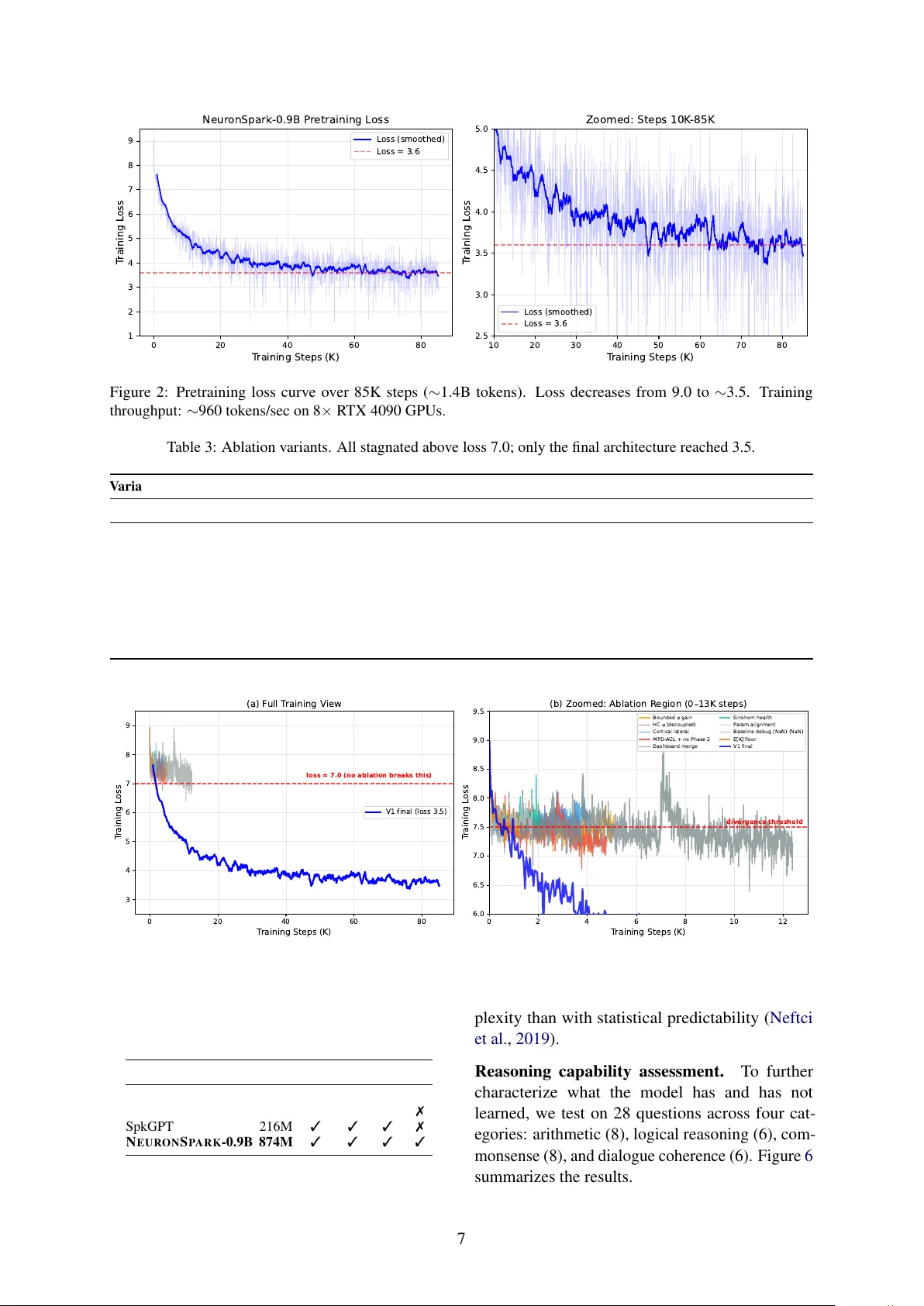
N E U R O N S PA R K : A Spiking Neural Network Language Model with Selectiv e State Space Dynamics Zhengzheng T ang * Boston Uni versity zztangbu@bu.edu Abstract W e ask whether a pure spiking backbone can learn large-scale language modeling from ran- dom initialization, without T ransformer dis- tillation. W e introduce N E U R O N S PA R K , a 0.9B-parameter SNN language model trained with next-token prediction and surrogate gra- dients. The model combines selectiv e state- space spiking dynamics, leakage-current inter - layer communication, PonderNet adaptiv e timesteps, fused Triton PLIF kernels, and stabi- lization techniques (residual centering, lateral- inhibition normalization, and natural-gradient compensation). Under a constrained b udget (about 1.4B pretraining tokens and 6.5K SFT steps), N E U RO N S PA R K -0.9B reaches 3.6 pre- training loss and shows early multi-turn dia- logue beha vior after SFT . These results support the feasibility of end-to-end language modeling with a pure SNN architecture at this scale. 1 Introduction Large language models (LLMs) based on Trans- formers ( V aswani et al. , 2017 ) hav e achiev ed re- markable success across natural language process- ing tasks. Howe ver , their quadratic attention mech- anism and dense floating-point computation raise fundamental questions about computational ef fi- ciency and biological plausibility . Meanwhile, spik- ing neural networks (SNNs) ( Maass , 1997 ) — the “third generation” of neural networks — process information through discrete spik es and temporal dynamics, of fering potential adv antages in energy ef ficiency and neuromorphic hardware deployment. 1 Code: https://github.com/Brain2nd/NeuronSpark- V1 . NeuronSpark-0.9B (HuggingFace): https://huggingface.co/Brain2nd/NeuronSpark- 0.9B . NeuronSpark-0.9B (ModelScope): https://www. modelscope.ai/models/Brain2nd/NeuronSpark- 0.9B . NeuronSpark-0.9B-Chat (HuggingFace): https: //huggingface.co/Brain2nd/NeuronSpark- 0.9B- Chat . NeuronSpark-0.9B-Chat (ModelScope): https://www.modelscope.ai/models/Brain2nd/ NeuronSpark- 0.9B- Chat . Despite significant progress in SNN-based vi- sion models, SNN language modeling remains un- derde veloped. This gap is important because lan- guage is a central benchmark for general sequence modeling; without evidence at language-model scale, claims about SNNs as a practical alternativ e to dense T ransformer computation remain limited. Existing approaches such as SpkGPT ( Zhu et al. , 2024 ), SpkBER T ( Bal and Sengupta , 2024 ), and SpkBER T -110M ( Lv et al. , 2023 ) either rely on distillation from pretrained T ransformers, retain non-spiking components in critical stages, or re- main at relativ ely small model scale. Consequently , the field still lacks a clear answer to the follow- ing question: Can a pure SNN arc hitectur e learn language fr om random initialization at meaningful scale under standar d ne xt-token tr aining? In this work, we address this gap by introduc- ing N E U R O N S P A R K , a 0.9B-parameter SNN lan- guage model trained from random initialization. Gi ven the av ailable compute budget (8 × R TX 4090 GPUs), we train on approximately ∼ 1.4B tokens from a 10B-token corpus; despite this constraint, the model exhibits non-tri vial language generation and dialogue behavior . Our key technical insight is that the membrane potential dynamics of Leaky Integrate-and-Fire (LIF) neurons can be formu- lated as a selectiv e state space model ( Gu and Dao , 2024 ), where the decay rate β , input gain α , and firing threshold V th serve as input-dependent gat- ing mechanisms analogous to Mamba’ s selection mechanism. This perspectiv e enables us to design an end-to-end spiking language architecture that is both trainable at scale and interpretable through the SSM lens. A key modeling choice is to treat layer - to-layer signals as floating-point leakage-current signals, while retaining 0/1 spikes as the internal neuronal e vent process; this distinction avoids the expressi vity bottleneck of purely binary inter-layer communication. 1 Contributions. 1. W e propose the Selecti ve State Space SNN Block with 7 parallel projection paths, com- puting dynamic β ( t ) , α ( t ) , V th ( t ) from input signals through learned modulation networks with structured initialization, establishing a formal SNN–SSM duality (Section 3.4 ). 2. W e introduce leakage-current activation (1 − β ) · V post as the default inter-layer sig- nal for PLIFNode boundaries, which naturally emphasizes fast-responding neurons and pro- vides implicit temporal-scale weighting (Sec- tion 3.3 ). 3. W e design PonderNet adaptive timesteps at each sublayer , enabling per-token dynamic SNN computation depth with geometric- distribution weighting and ponder cost reg- ularization (Section 3.6 ). 4. W e develop T riton-fused PLIF kernels with per-element and row-parameter v ariants, per - forming the entire PLIF forward/backward (in- cluding surrogate gradient) in a single k ernel launch (Section 4.3 ). 5. W e introduce residual centering and lateral inhibition normalization as SNN-nativ e sta- bilization techniques, along with a two-phase natural gradient compensation for modula- tion parameters (Sections 4.1 – 4.4 ). 6. W e train and release N E U R O N S PA R K -0.9B under a constrained data b udget, and pro vide e vidence that a pure SNN can acquire non- tri vial language modeling ability from random initialization (Section 5 ). Collecti vely , these contrib utions tar get a single bottleneck in prior work: the lack of a scalable, end-to-end spiking recipe for language modeling that is both theoretically grounded and practically trainable. 2 Related W ork Spiking Neural Networks f or Language. Prior work can be grouped by the specific gap it leav es unaddressed. Distillation dependence : Sp- kBER T ( Bal and Sengupta , 2024 ) and SpkBER T - 110M ( Lv et al. , 2023 ) transfer representations from pretrained ANN/T ransformer models, which reduces evidence that language competence can emerge from fully spiking training dynamics. Par - tial spiking pipelines : SpkGPT ( Zhu et al. , 2024 ) demonstrates generativ e behavior with spike-based hidden computation, but still retains non-spiking components (e.g., embedding/output stages), lea v- ing end-to-end spiking feasibility unresolved. Scale limitations : existing studies are typically limited to ≤ 216M parameters, well below contem- porary language-model regimes. Our work tar gets these three gaps jointly by training a 0.9B model from random initialization with standard next- token prediction and spiking dynamics throughout the core sequence-processing stack. State Space Models. Structured State Spaces (S4) ( Gu et al. , 2022 ) introduced ef ficient linear recurrence for sequence modeling. Mamba ( Gu and Dao , 2024 ) added input-dependent selection, achie ving T ransformer -competiti ve performance. Mamba-2 ( Dao and Gu , 2024 ) established a for - mal duality between SSMs and attention. W e observe that SNN membrane dynamics V [ t ] = β ( t ) · V [ t − 1] + α ( t ) · I [ t ] are structurally identi- cal to the selecti v e SSM recurrence, with β as the decay coef ficient and α as the input gate. The spike- and-reset mechanism adds a discrete nonlinearity absent in continuous SSMs. Adaptive Computation. Adaptiv e Computation T ime (A CT) ( Grav es , 2016 ) allo ws networks to v ary computation per input. PonderNet ( Banino et al. , 2021 ) improved upon A CT with a geometric distribution prior . W e apply PonderNet at the SNN timestep le vel within each sublayer: the K frames per token are aggregated with learned halt proba- bilities, enabling different tok ens to use 1 to K max ef fecti ve SNN steps. Surrogate Gradient T raining. The non- dif ferentiability of spike generation ( Θ( V − V th ) ) is addressed by surrogate gradient methods ( Neftci et al. , 2019 ; Zenk e and V ogels , 2021 ), which replace the Heaviside deri v ati ve with smooth approximations. N E U R O N S P A R K uses Sigmoid surrogate gradients ( α = 4 . 0 ) throughout, imple- mented in the SpikingJelly framew ork ( Fang et al. , 2023 ), with custom T riton kernels that fuse the surrogate computation into the sequential scan. 3 Architectur e This section is or ganized around one central method question: ho w to make a pure SNN lan- guage model simultaneously expressi v e, trainable, 2 Figure 1: N E U R O N S PA R K architecture o vervie w . The residual stream carries continuous values h ; PLIFLeak denotes PLIF neurons with leakage activ ation (1 − β ) · V post . PonderNet aggregation (applied per sublayer) collapses K frames per token with learned geometric-distribution weights. Inter-layer communication uses floating-point leakage-current signals; binary spikes are internal firing ev ents rather than the default layer -to-layer representation. The decode stage uses uniform K -frame mean. Residual centering (subtract per-tok en mean) is applied before each residual addition. and scalable. Our design follows a four -step logic: (1) define a stable neuron-lev el state update, (2) choose an inter-layer signal that av oids binary- communication bottlenecks, (3) b uild a selective sequence block on top of that signal, and (4) add system-le vel training stabilizers so optimization remains tractable at 0.9B scale. 3.1 Overview N E U R O N S P A R K follo ws a three-stage pipeline (Figure 1 ): (1) Encode : T oken IDs → em- bedding ( D -dim) → repeat K times, producing a ( T · K , B , D ) tensor . Gradients flo w directly through embedding; the output head reuses the embedding matrix (weight tying ( Press and W olf , 2017 )). (2) SNN F orward : L =20 decoder layers with gradient checkpointing, each containing an SNNBlock (attention analogue) and an SNNFFN (MLP analogue), with PonderNet adaptiv e K - frame aggregation. All neuron states reset per sequence. (3) Decode : RMSNorm ( Zhang and Sennrich , 2019 ) → output PLIFNode (leakage) → K -frame uniform mean → projection → lateral in- hibition ( Carandini and Hee ger , 2012 ) → tied head → logits. Each decoder layer follows a Pre-LN residual pattern matching Qwen3/LLaMA ( T ouvron et al. , 2023 ; Y ang et al. , 2025 ): h ← h + center OutProj ( PonderAgg ( SNNBlock ( · · · ))) (1) h ← h + center OutProj ( PonderAgg ( SNNFFN ( · · · ))) (2) where center ( x ) = x − mean ( x ) is residual centering (Section 4.1 ). The residual stream h ∈ R T K × B × D carries continuous values throughout; only the SNN sublayers operate on spike/membrane dynamics. The remainder of this section instantiates this logic in order: PLIF dynamics define the base state transition, leakage-current activ a- tion defines the default inter-layer representation, SNNBlock/SNNFFN define sequence computation, and the final subsections describe optimization- oriented stabilizers. 3.2 PLIF Neuron Dynamics All neurons in N E U RO N S PA R K follow the Paramet- ric Leaky Integrate-and-Fire (PLIF) model ( Fang et al. , 2021 ). This subsection provides the dy- namical foundation on which all later architectural choices are built. W e distinguish two v ariants: PLIFNode (fixed parameters). Used at layer boundaries (input neurons, gate/up neurons, out- 3 put neuron). Each has D -dimensional (or D ff - dimensional) learnable parameters: V pre [ t ] = β · V post [ t − 1] + (1 − β ) · x [ t ] (3) s [ t ] = Θ( V pre [ t ] − V th ) (4) V post [ t ] = V pre [ t ] − V th · s [ t ] (5) where β = σ ( w ) ∈ (0 , 1) with w ∼ N ( logit (1 − 1 /τ 0 ) , 0 . 5) and V th ∼ U (0 . 5 v 0 , 1 . 5 v 0 ) . The ran- dom initialization creates div ersity across dimen- sions: different neurons ha ve dif ferent time con- stants and firing sensitivities. Equation ( 5 ) imple- ments soft r eset : the membrane potential is reduced by V th upon firing, preserving residual charge. SelectivePLIFNode (dynamic parameters). Used inside SNNBlock for D · N hidden neu- rons. Parameters β ( t ) , α ( t ) , V th ( t ) are computed per-step from the input (Section 3.4 ): V [ t ] = β ( t ) · V [ t − 1] + α ( t ) · I [ t ] (6) s [ t ] = Θ( V [ t ] − V th ( t )) (7) V [ t ] − = V th ( t ) · s [ t ] (8) This is structurally identical to Mamba’ s selectiv e SSM recurrence h [ t ] = ¯ A ( t ) · h [ t − 1] + ¯ B ( t ) · x [ t ] , with the addition of the spike-and-reset nonlinear - ity . 3.3 Membrane Potential Leakage Activ ation A critical design choice is the signal transmit- ted between components. This is the key bridge from neuron dynamics to netw ork-lev el informa- tion flow . Standard SNN practice uses binary spikes s [ t ] ∈ { 0 , 1 } , b ut this se verely limits gradi- ent flo w through the surrogate function’ s narrow support. An alternativ e is the raw membrane poten- tial V post , but this treats all neurons equally re gard- less of their temporal dynamics. W e use leakage-current activ ation as the de- fault inter-layer signal. In other words, unless explicitly stated otherwise, downstream layers consume floating-point leakage-current signals (bioelectric-state proxies) rather than binary spikes: leak [ t ] = (1 − β ) · V post [ t ] (9) This quantity is the amount of membrane potential that will dissipate due to exponential decay before the next input arri v es. Biologically , it corresponds to the leak current through the membrane conduc- tance ( Hodgkin and Huxley , 1952 ; Abbott , 1999 ). This leakage-current acti v ation provides natu- ral temporal-scale weighting : neurons with large (1 − β ) (fast dynamics, short memory) produce proportionally larger signals, while neurons with small (1 − β ) (slo w dynamics, long memory) are implicitly attenuated. This reweighting is applied at all PLIFNode outputs: input neurons (2 per layer), gate/up neurons in SNNFFN (2 per layer), and the output neuron. The Selecti vePLIFNode hidden neurons inside SNNBlock output raw V post rather than leakage, be- cause β ( t ) is dynamic (varies per step) and cannot be absorbed into a static downstream weight matrix. This is a deliberate design choice: leakage scaling applies only at fixed- β boundaries. 3.4 Selective State Space SNN Block W ith neuron dynamics and inter -layer signaling fixed, we next define the core sequence module. The SNNBlock is the attention analogue, process- ing input through D · N hidden spiking neurons with input-dependent parameters. It computes sev en parallel pr ojections from the input leak- age signal — six input projections and one output projection: Input projections ( D → D · N or D → D ): I [ t ] = W in · leak [ t ] (10) β ( t ) = σ ( W β · leak [ t ] + b β ) (11) α ( t ) = softplus ( W α · leak [ t ] + b α ) (12) V th ( t ) = V min + | W th · leak [ t ] + b th | (13) g [ t ] = σ ( W gate · leak [ t ]) (14) I skip [ t ] = W skip · leak [ t ] (15) The modulation projections W β , W α , W th are ini- tialized at 0 . 1 × the scale of W in , ensuring that β ( t ) , α ( t ) , V th ( t ) are dominated by their respecti v e biases at the start of training, providing a stable initialization. Hidden neuron dynamics. The D · N hidden neurons follow Selectiv ePLIF (Eqs. 6 – 8 ), com- puted via fused T riton PLIF kernels (Section 4.3 ). Output projection ( D · N → D ): out [ t ] = W out · V post [ t ] ⊙ g [ t ] + I skip [ t ] (16) Note: the output uses V post (not leakage) from the hidden neurons, because β ( t ) is dynamic. The gate g provides multiplicati v e control o ver which dimensions pass through. The skip connection I skip ensures gradient flow e ven when all hidden neurons are silent. 4 Structured initialization. The modulation bi- ases b β , b α , b th recei ve carefully designed initial- ization (details in Appendix A ): b β is logit-spaced across N groups targeting β ∈ [0 . 80 , 0 . 99] (multi- timescale); b α is initialized near softplus − 1 (1 . 0) so initial α ≈ 1 ; b th is calibrated from stationary v ariance σ V = p p/ 3 · p 1 − β 2 K with target fir- ing rates 25%–8% across N groups; W in ro ws are scaled by p 1 − β 2 per group; W out columns are scaled by 1 / √ p fire per group. 3.5 SNN Feed-F orward Network The SNNFFN mirrors the SwiGLU MLP ( T ouvron et al. , 2023 ) with spiking neurons replacing the acti v ation function: gate_leak = (1 − β g ) · V post ( PLIF gate ( W gate · leak )) (17) up_leak = (1 − β u ) · V post ( PLIF up ( W up · leak )) (18) out = W down · ( gate_leak ⊙ up_leak ) (19) + W skip · leak (20) The element-wise product of two leakage signals replaces SiLU ( x ) ⊙ x gating in SwiGLU ( Shazeer , 2020 ). Both PLIF neurons provide implicit nonlin- earity through the inte grate-fire-reset cycle; their leakage outputs carry temporal dynamics that pure acti vation functions cannot express. W down is ini- tialized with 1 / √ L scaling to pre vent gradient e x- plosion through deep residual chains. 3.6 PonderNet Adaptiv e Timesteps Each token is represented as K SNN frames. Rather than uniformly av eraging all K frames, we learn per -frame halt probabilities following Ponder - Net ( Banino et al. , 2021 ): p k = σ ( W halt · frame k + b halt ) ∈ (0 , 1) (21) S k = Q k − 1 j =1 (1 − p j ) (surviv al probability) (22) λ k = p k · S k , ˆ λ k = λ k / P k ′ λ k ′ (23) output = P k ˆ λ k · frame k , E [ K ] = P k k · ˆ λ k (24) E [ K ] serves as a ponder cost regularizer ( λ ponder = 0 . 01 ). PonderNet is applied independently at each sublayer ( 2 L = 40 aggregation points). W halt is initialized with Xa vier uniform × 0 . 01 and b halt = − 3 . 5 ( σ ( − 3 . 5) ≈ 0 . 03 ), so PonderNet starts near - uniform and gradually specializes. After aggre gation, the result is projected through OutProj ( D → D , no bias), then broadcast back to K frames for residual addition. 4 Stabilization and Efficient Implementation 4.1 Residual Centering Each sublayer’ s output projection is mean- subtracted before residual addition: center ( x ) = x − 1 D P D d =1 x d . This eliminates DC drift that would otherwise accumulate across 20 residual lay- ers. 4.2 Lateral Inhibition Normalization The output layer uses lateral inhibition (di- visi ve normalization): LateralInhib ( h ) = γ · h / q 1 D P d h 2 d + ϵ , where γ ∈ R D is a learn- able gain. This is mathematically equiv alent to RMSNorm ( Zhang and Sennrich , 2019 ) but cor- responds to di visi ve normalization ( Carandini and Heeger , 2012 ). W e implement it as a fused T riton kernel. 4.3 T riton Fused PLIF Ker nels The PLIF recurrence in volves a sequential scan that cannot be trivially parallelized due to spike- and-reset. W e implement two variants of fused T riton ( T illet et al. , 2019 ) k ernels: Per -element kernel (Selectiv ePLIFNode, dy- namic β [ k ] , V th [ k ] ): single-pass sequential scan with inline char ge–fire–reset and Sigmoid surro- gate gradient in the backward pass. All arithmetic in fp32 with bf16 storage. Row-parameter kernel (PLIFNode, fixed β , V th ): parameters loaded once into re gisters, re- ducing global memory reads from 3 per step to 1, yielding ∼ 40% speedup. Backward kernel accu- mulates ∇ β , ∇ V th in registers. CPU fallback : 3-phase approach via Hillis- Steele parallel prefix scan ( Blelloch , 1990 ; Martin and Cundy , 2018 ), spike fix ed-point iteration, and surrogate gradient re-computation. 4.4 Natural Gradient Compensation The modulation biases b β , b α , b th suf fer from two gradient pathologies. W e apply compensation after gradient unscaling and before gradient clipping: Phase 1: Activation saturation. ∇ b β ← ∇ b β / max( β (1 − β ) , 1 /C max ) , effecti v ely per- forming gradient descent in β -space. Similarly for α : ∇ b α ← ∇ b α / max( σ ( b α ) , 0 . 1) . Phase 2: Cross-layer equalization. For each modulation parameter type, normalize per-layer gradient norms to the geometric mean: ∇ layer i ← ∇ layer i · GeoMean ( ∥∇ 1 ∥ , . . . , ∥∇ L ∥ ) / ∥∇ i ∥ . 5 5 Experiments 5.1 Setup Model configuration. N E U RO N S PA R K -0.9B: D = 896 , N = 8 , K = 16 , L = 20 , D ff = 2688 , 6144-token BPE ( Sennrich et al. , 2016 ) v ocabulary , 874M parameters. Datasets. Pr etr aining : Seq-Monkey ( Mobv oi , 2023 ) ( ∼ 29M samples, ∼ 10B tokens). SFT : BelleGroup train_3.5M_CN ( BelleGroup , 2023 ) ( ∼ 3.5M con v ersations). Compute constraints. All training was con- ducted on 8 × NVIDIA R TX 4090 GPUs. Due to limited compute, we train on small subsets : T able 1: Dataset utilization. Stage Full Dataset Actual Used Fraction Pretrain ∼ 10B tokens 85K steps ( ∼ 1.4B tokens) ∼ 14% SFT ∼ 3.5M con- versations 6.5K steps ( ∼ 42K samples) ∼ 1.2% T raining details. Pretraining: Adam ( Loshchilo v and Hutter , 2019 ), peak lr = 2 × 10 − 4 , 1000-step warmup, cosine decay , gradient accumulation 8, ef fecti ve batch 64, bfloat16 ( Micikevicius et al. , 2018 ), gradient checkpointing ( Chen et al. , 2016 ). Neuron parameters receiv e 10 × base lr . SFT : AdamW (lr = 5 × 10 − 5 , weight decay 0.01), train- ing only on assistant response tokens. 5.2 Results T able 2: Training results for N E U R O N S PA R K -0.9B. Metric Pretrain SFT T raining loss 3.6 2.1 Parameters 874M T raining steps 85,000 6,500 T okens seen ∼ 1.4B ∼ 0.4B Hardware 8 × NVIDIA R TX 4090 Qualitative evaluation. After SFT , the model demonstrates basic Chinese dialogue (translated; model outputs in Chinese): Q: What is the capital of China? A: The capital of China is Beijing. Q: Hello! A: Ho w can I help you? These observ ations suggest that a pure SNN ar - chitecture can support coherent language genera- tion from random initialization, e ven under limited- data training. 5.3 Architectur e Ablation via T raining Stability During de velopment, we e xplored multiple archi- tectural v ariants (each trained 1K–12K steps). T a- ble 3 summarizes 7 variants; Figure 3 shows loss curves. 5.4 Comparison with Existing SNN Language Models T o complement aggreg ate training metrics, we next analyze how computation is allocated internally and what linguistic structure the model has learned. 5.5 Biological Interpretability Analysis W e analyze the trained N E U R O N S P A R K -0.9B-Chat model to examine whether its learned SNN dynam- ics exhibit linguistically and biologically meaning- ful patterns. All analyses are conducted on 40 Chinese sentences spanning science, daily life, ed- ucation, economics, and complex multi-clause con- structions. Figure 4 presents the four main findings. Computation allocation is structural, not pr e- dictive. A natural hypothesis is that PonderNet allocates more SNN steps to tokens that are harder to predict (high surprisal = − log P ( next token ) ). Figure 5 tests this directly on 541 tokens (40 sen- tences). Naïvely , surprisal and E[K] appear nega- ti vely correlated ( r = − 0 . 50 ); ho we ver , this is en- tirely dri ven by the BOS (beginning-of-sequence) sentinel token, which has extremely lo w E[K] (3.2) and high surprisal (8.9) by construction. Excluding BOS tokens, the correlation drops to r = − 0 . 12 (near zero), and binned analysis confirms that mean E[K] is essentially flat ( ∼ 7.4–7.9) across all sur- prisal ranges. This reveals that PonderNet’ s computation budget is governed by structural/syntactic role rather than predictiv e difficulty : punctuation and function words receiv e fewe r steps not because they are easy to predict, but because they play a structurally simpler role in the sequence. This is consistent with biological findings that neural pro- cessing ef fort correlates more with syntactic com- 6 0 20 40 60 80 T raining Steps (K) 1 2 3 4 5 6 7 8 9 T raining L oss Neur onSpark-0.9B P r etraining L oss L oss (smoothed) L oss = 3.6 10 20 30 40 50 60 70 80 T raining Steps (K) 2.5 3.0 3.5 4.0 4.5 5.0 T raining L oss Zoomed: Steps 10K -85K L oss (smoothed) L oss = 3.6 Figure 2: Pretraining loss curve o ver 85K steps ( ∼ 1.4B tokens). Loss decreases from 9.0 to ∼ 3.5. T raining throughput: ∼ 960 tokens/sec on 8 × R TX 4090 GPUs. T able 3: Ablation variants. All stagnated above loss 7.0; only the final architecture reached 3.5. V ariant Steps Loss What Changed Final V1 85K 3.5 Full architectur e MPD-A GL + no Phase 2 4.8K 7.21 Adaptive surrog ate gradient, remov ed cross-layer equalization E[K] floor 1.2K 7.47 Added minimum E[K] floor Bounded α 5.1K 7.47 Bounded gain multiplier HC α (decoupled) 3.7K 7.44 Separate α parameter Sinkhorn health 2.1K 7.62 † Sinkhorn-projected health score Cortical lateral 4.1K 7.66 † Cross-token causal spike propagation No gradient sync 0.6K NaN Missing gradient synchronization † Div erged (loss > 7.5). 0 20 40 60 80 T raining Steps (K) 3 4 5 6 7 8 9 T raining L oss loss = 7.0 (no ablation breaks this) (a) F ull T raining V iew V1 final (loss 3.5) 0 2 4 6 8 10 12 T raining Steps (K) 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 T raining L oss divergence threshold (b) Zoomed: Ablation R egion (0 13K steps) Bounded gain HC (decoupled) Cortical lateral MPD- A GL + no Phase 2 Dashboar d mer ge Sinkhor n health P aram alignment Baseline debug (NaN) (NaN) E[K] floor V1 final Figure 3: T raining loss: final architecture (blue) vs. 9 ablation variants. None of the ablation variants achie v es a loss below 7.0. T able 4: Comparison with existing SNN language mod- els. Model Par . From Core Gen. Dia. SpkBER T -110M 110M ✗ ✓ ✗ ✗ SpkBER T 110M ✗ ✓ ✗ ✗ SpkGPT 216M ✓ ✓ ✓ ✗ N E U RO N S PA R K -0.9B 874M ✓ ✓ ✓ ✓ plexity than with statistical predictability ( Neftci et al. , 2019 ). Reasoning capability assessment. T o further characterize what the model has and has not learned, we test on 28 questions across four cat- egories: arithmetic (8), logical reasoning (6), com- monsense (8), and dialogue coherence (6). Figure 6 summarizes the results. 7 Figure 4: Biological interpretability of N E U RO N S PA R K -0.9B-Chat. (a) Per-token E[K]: punctuation recei ves fe wer steps than content words. (b) POS-lev el E[K]: function words/punctuation are lo wer by about ∼ 0.7. (c) Per-layer E[K]: SNNBlock increases with depth, SNNFFN stays near 7–8. (d) Learned β distribution: 67.3% fast ( < 0 . 9 ), 32.7% slow ( ≥ 0 . 9 ). Figure 5: Surprisal vs. E[K] (40 Chinese sentences, 541 tokens). (a) The apparent correlation is dominated by BOS tokens: r = − 0 . 50 ov erall, r = − 0 . 12 without BOS. (b) Binned E[K] is nearly flat across surprisal, indicating allocation is largely independent of predicti v e dif ficulty . The model achie ves 0% on arithmetic (unable to perform any calculation), 25% on common- sense (mostly coincidental keyw ord matches), and 83% on logic (though inspection reveals many “correct” answers arise from the expected ke yword appearing in repetiti ve output rather than genuine inference). By contrast, all 6 coherence tests produce fluent, grammatical Chinese r esponses , confirming that the model has acquired surface- le vel language generation ability . Critically , panel (b) shows that E[K] is flat ( ∼ 7.6) across all categories , regardless of task dif ficulty . The model does not allocate additional SNN computation for harder reasoning tasks, fur - 8 ther confirming that PonderNet’ s adaptiv e compu- tation is dri ven by structural token properties (Sec- tion 3.3 ) rather than semantic reasoning demands. These results are consistent with the limited training budget: the model has learned structural language patterns (fluency , POS-dependent compu- tation) b ut has not yet acquired the f actual kno wl- edge or compositional reasoning that w ould require substantially more training data. Adaptive computation aligns with linguistic complexity . Panel (a) shows that PonderNet as- signs systematically fewer SNN timesteps to punc- tuation (E[K] ≈ 5.7) and function words (E[K] ≈ 7.4) than to content words (nouns 8.0, v erbs 8.0, adjec- ti ves 8.2). This pattern — emerging without any explicit linguistic supervision — mirrors the in- tuition that structurally predictable tok ens require less neural computation. The BOS tok en recei ves the fe west steps (E[K]=3.2), consistent with it be- ing a fixed sentinel requiring no contextual process- ing. Depth-dependent computation budget. Panel (c) re v eals a striking asymmetry: SNNBlock E[K] increases monotonically with layer depth (from ∼ 4 at layer 2 to ∼ 12.7 at layer 19), while SNNFFN E[K] remains relati vely flat ( ∼ 7–8). This suggests that deeper layers require more SNN timesteps for the attention-analogue computation (SNNBlock) but not for the feed-forward trans- formation (SNNFFN). A possible interpretation is that deeper layers perform more complex contextual inte gration, requiring longer membrane- potential e volution, while the point-wise nonlinear transformation in SNNFFN saturates at a fixed computation depth. Multi-timescale neuron specialization. Panel (d) shows that the 143,360 hidden neurons self-org anize into fast-responding ( β < 0 . 9 , 67.3%) and slo w-memory ( β ≥ 0 . 9 , 32.7%) populations. This is reminiscent of biological cortical circuits where fast-spiking interneurons coexist with regular -spiking pyramidal cells operating at dif ferent timescales. The distrib ution is unimodal with a long right tail, indicating that the model learns a continuum of timescales rather than a sharp dichotomy , with a preference for faster dynamics. 6 Discussion Our central claim is that large-scale language mod- eling in a pure SNN regime is not only conceptu- ally plausible b ut empirically attainable when the architectural design directly addresses the optimiza- tion and expressivity gaps left by prior SNN lan- guage studies. Beyond feasibility , our interpretabil- ity analyses (Section 5.5 ) re veal that the trained model de v elops computational strate gies with strik- ing parallels to biological neural processing. SNN–SSM duality . The selecti ve PLIF dynam- ics establish a direct correspondence with Mamba’ s selecti ve SSM: β ( t ) ↔ ¯ A ( t ) , α ( t ) ↔ ¯ B ( t ) , V [ t ] ↔ h [ t ] . The spike-and-reset mechanism intro- duces a hard, input-dependent nonlinearity absent in continuous SSMs. Biological interpretability: structure bef ore semantics. Three complementary experiments (Section 5.5 ) paint a coherent picture of what the model learns and how it allocates neural resources: (1) Resour ce allocation mirr or s syntactic r ole, not pr edictive difficulty . PonderNet assigns system- atically fe wer SNN steps to punctuation and func- tion words than to content words (nouns, verbs, adjecti ves), mirroring how biological cortical cir - cuits allocate differential processing effort based on stimulus structural complexity rather than statis- tical surprise ( Carandini and Heeger , 2012 ). Crit- ically , E[K] is uncorrelated with token surprisal ( r = − 0 . 12 after e xcluding the BOS sentinel), con- firming that adapti ve computation is go verned by syntactic role rather than prediction error — a pat- tern consistent with neurolinguistic findings that neural processing load correlates more with syn- tactic complexity than with information-theoretic surprisal. (2) Hierar chical computation depth resembles cortical pr ocessing. Deeper layers allocate pro- gressi vely more SNN timesteps (SNNBlock E[K] increases from ∼ 4 at layer 2 to ∼ 12.7 at layer 19), while SNNFFN E[K] remains stable ( ∼ 7–8). This asymmetry parallels the cortical hierarchy where higher-order areas exhibit longer temporal inte- gration windo ws, and point-wise transformations (analogous to SNNFFN) saturate at a fixed process- ing depth. (3) Multi-timescale neur on specialization. The 143,360 hidden neurons self-organize into fast- responding ( β < 0 . 9 , 67.3%) and slo w-memory ( β ≥ 0 . 9 , 32.7%) populations, reminiscent of 9 Figure 6: Reasoning capability assessment (28 questions). (a) Accuracy by category: arithmetic 0%, logic 83% (superficial), commonsense 25%, coherence 6/6. (b) E[K] and surprisal are flat across categories, indicating no adapti ve computation increase for harder tasks. The model has learned structural language patterns b ut not reasoning. the coexistence of fast-spiking interneurons and regular -spiking pyramidal cells in biological cor- tex. (4) Structural competence without r easoning. The model achiev es fluent Chinese generation (6/6 coherence) b ut fails at arithmetic (0/8), with E[K] flat across all task cate gories ( ∼ 7.6). This disso- ciation between structural fluency and reasoning ability , combined with the structure-driv en (not dif ficulty-dri ven) computation allocation, suggests that the model has acquired a “structural backbone” of language — analogous to early stages of biolog- ical language acquisition where grammatical pat- terns precede semantic understanding. Continued training on more data would be needed to progress from structural pattern learning to genuine seman- tic reasoning. Data efficiency . N E U RO N S PA R K acquires basic language capabilities with ∼ 14% of pretraining data and ∼ 1.2% of SFT data. The biological in- terpretability findings above suggest this ef ficiency may arise from the SNN architecture’ s inductiv e bias to ward structural pattern extraction, though controlled T ransformer baselines are needed to con- firm this hypothesis. Limitations (1) 0.9B parameters, 512-token conte xt. (2) No quantitati ve benchmarks (C-Ev al, CMMLU) or T ransformer baselines. (3) Chinese only . (4) Repe- tition artifacts and no reasoning capability . (5) In- terpretability analyses are correlational, not causal. Energy efficiency . The spike-based hidden com- putation may be amenable to deployment on neuro- morphic platforms (e.g., Intel Loihi ( Da vies et al. , 2018 )), which could yield substantial energy sav- ings. A rigorous quantitativ e ev aluation remains future work. 7 Conclusion W e presented N E U R O N S PA R K , a 0.9B-parameter spiking language model that jointly addresses three persistent gaps in prior work: distillation depen- dence, partially non-spiking pipelines, and limited model scale. By connecting SNN membrane dy- namics to selectiv e state space models and introduc- ing leakage-current inter-layer signaling, Ponder - Net adapti ve timesteps, fused T riton PLIF kernels, residual centering, lateral inhibition normalization, and natural-gradient compensation, we sho w that pure SNN architectures can learn non-tri vial lan- guage beha vior from random initialization under limited training data. Beyond architectural feasibility , our inter- pretability analyses reveal that the trained model de- velops biologically plausible computational strate- gies: structure-driv en (not difficulty-dri v en) re- source allocation, hierarchical depth-dependent processing, multi-timescale neuron specialization, and a “structure before semantics” learning progres- sion that parallels biological language acquisition. These findings suggest that SNN architectures may of fer not only energy-ef ficienc y potential b ut also a path to ward more interpretable language models grounded in neuroscience principles. Code, weights, and training infrastructure are publicly av ailable at the links in the first-page foot- note. 10 References Larry F Abbott. 1999. Lapicque’ s introduction of the integrate-and-fire model neuron (1907). Brain Re- sear ch Bulletin , 50(5-6):303–304. Malyaban Bal and Abhronil Sengupta. 2024. Spik- ingbert: Distilling bert to train spiking language models using implicit differentiation. Pr oceedings of the AAAI Confer ence on Artificial Intelligence , 38(10):10998–11006. Andrea Banino, Jan Balaguer , and Charles Blundell. 2021. Pondernet: Learning to ponder . International Confer ence on Mac hine Learning W orkshop on The- or etic F oundation, Criticism, and Application T rend of Explainable AI . BelleGroup. 2023. Bellegroup train_3.5m_cn: Chinese instruction-following dataset . Guy E Blelloch. 1990. Prefix sums and their applica- tions. T echnical Report CMU-CS-90-190, School of Computer Science, Carne gie Mellon Univer sity . Matteo Carandini and David J Heeger . 2012. Normal- ization as a canonical neural computation. Natur e Revie ws Neur oscience , 13(1):51–62. T ianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training deep nets with sublinear memory cost. arXiv pr eprint arXiv:1604.06174 . T ri Dao and Albert Gu. 2024. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality . International Confer - ence on Machine Learning . Mike Da vies, Narayan Srini vasa, Tsung-Han Lin, Gau- tham Chin ya, Y ongqiang Cao, Sri Harsha Choday , Georgios Dimou, Prasad Joshi, Nabil Imam, Shweta Jain, and 1 others. 2018. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micr o , 38(1):82–99. W ei Fang, Y anqi Chen, Jianhao Ding, Zhaofei Y u, T im- othée Masquelier , Ding Chen, Liwei Huang, Huihui Zhou, Guoqi Li, and Y onghong T ian. 2023. Spiking- jelly: An open-source machine learning infrastruc- ture platform for spike-based intelligence. Science Advances , 9(40):eadi1480. W ei Fang, Zhaofei Y u, Y anqi Chen, T imothee Masque- lier , T iejun Huang, and Y onghong T ian. 2021. In- corporating learnable membrane time constant to en- hance learning of spiking neural networks. In Pr o- ceedings of the IEEE/CVF International Confer ence on Computer V ision , pages 2661–2671. Alex Grav es. 2016. Adaptiv e computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983 . Albert Gu and T ri Dao. 2024. Mamba: Linear-time sequence modeling with selectiv e state spaces. Inter- national Confer ence on Machine Learning . Albert Gu, Karan Goel, and Christopher Ré. 2022. Ef- ficiently modeling long sequences with structured state spaces. International Conference on Learning Repr esentations . Alan L Hodgkin and Andre w F Huxley . 1952. A quan- titativ e description of membrane current and its ap- plication to conduction and e xcitation in nerve. The Journal of Physiolo gy , 117(4):500–544. Ilya Loshchilov and Frank Hutter . 2019. Decoupled weight decay regularization. International Confer- ence on Learning Repr esentations . Changze Lv , T ianlong Xu, Jianhan Li, Chenxi W ang, and Jian Liu. 2023. Spikebert: A language spik- former trained with two-stage knowledge distillation from bert. arXiv pr eprint arXiv:2308.15122 . W olfgang Maass. 1997. Networks of spiking neurons: the third generation of neural network models. Neu- ral Networks , 10(9):1659–1671. Eric Martin and Chris Cundy . 2018. Parallelizing linear recurrent neural nets ov er sequence length. Interna- tional Confer ence on Learning Repr esentations . Paulius Micike vicius, Sharan Narang, Jonah Alben, Gre- gory Diamos, Erich Elsen, David Garcia, Boris Gins- bur g, Michael Houston, Oleksii Kuchaie v , Ganesh V enkatesh, and Hao W u. 2018. Mixed precision training. International Confer ence on Learning Rep- r esentations . Mobv oi. 2023. Seq-monkey general open corpus . Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. 2019. Surrogate gradient learning in spik- ing neural networks: Bringing the power of gradient- based optimization to spiking neural networks. IEEE Signal Pr ocessing Ma gazine , 36(6):51–63. Ofir Press and Lior W olf. 2017. Using the output em- bedding to improve language models. Pr oceedings of the 15th Confer ence of the European Chapter of the Association for Computational Linguistics , pages 157–163. Rico Sennrich, Barry Haddow , and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. Proceedings of the 54th Annual Meet- ing of the Association for Computational Linguistics , pages 1715–1725. Noam Shazeer . 2020. GLU variants improve trans- former . arXiv preprint . Philippe T illet, H. T . Kung, and Da vid Cox. 2019. Tri- ton: An intermediate language and compiler for tiled neural netw ork computations. Proceedings of the 3r d MLSys Confer ence . Hugo T ouvron, Thibaut Lavril, Gautier Izacard, Xa vier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Go yal, Eric Hambro, F aisal Azhar , and 1 others. 2023. LLaMA: Open and ef- ficient foundation language models. arXiv pr eprint arXiv:2302.13971 . 11 Ashish V aswani, Noam Shazeer, Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. 2017. Attention is all you need. Advances in Neural Information Pr ocess- ing Systems , 30. An Y ang, Baosong Y ang, Beichen Zhang, and 1 oth- ers. 2025. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 . Friedemann Zenke and Tim P V ogels. 2021. The re- markable robustness of surrogate gradient learning for instilling complex function in spiking neural net- works. Neural Computation , 33(4):899–925. Biao Zhang and Rico Sennrich. 2019. Root mean square layer normalization. Advances in Neur al Information Pr ocessing Systems , 32. Rui-Jie Zhu, Qihang Zhao, Guoqi Li, and Jason K Eshraghian. 2024. Spike gpt: Generative pre-trained language model with spiking neural networks. IEEE T ransactions on Neural Networks and Learning Sys- tems . 12 A Structured Initialization Details The SNNBlock modulation parameters require careful initialization. W e tar get K ref = 16 steps and assumed input firing rate p = 0 . 15 . Multi-timescale β : β n = linspace (0 . 80 , 0 . 99 , N ) ; bias b β , n = log( β n / (1 − β n )) , repeated across D chan- nels with N (0 , 0 . 1) perturbation. α near unity : b α ∼ N (0 . 5413 , 0 . 1) , giving α ≈ 1 . 0 . Threshold calibration : σ V ( β ) = p p/ 3 · p 1 − β 2 K ref ; tar get firing rates p fire = linspace (0 . 25 , 0 . 08 , N ) ; V th ,n = σ V ( β n ) · Φ − 1 (1 − p fire ,n ) . W in scaling : ro ws scaled by p 1 − β 2 n per group. W out balancing : columns scaled by 1 / √ p fire ,n (normalized to mean 1). B Model Configuration T able 5: Detailed model configuration. Hidden dim ( D ) 896 State expansion ( N ) 8 Max SNN steps ( K ) 16 Layers ( L ) 20 FFN dim ( D ff ) 2688 V ocab 6144 Context 512 T otal params 874M Surrogate Sigmoid( α =4.0) V min 0.1 Neuron LR mult 10 × Ponder weight 0.01 Output proj init 0 . 02 / √ 2 L (GPT -2) C Parameter Br eakdown T able 6: Parameter breakdo wn. SNNBlock dominates (77.2%) due to 7 projections in D × N space. Component Params % Embedding (tied) 5.5M 0.6 SNNBlock × 20 674.8M 77.2 SNNFFN × 20 160.8M 18.4 Residual proj × 40 32.1M 3.7 Other 1.0M 0.1 T otal 874.1M 100 D Engineering Optimizations • Fused modulation : σ, softplus , | · | , × fused via torch.compile into single kernel. • Fused halt weights : PonderNet σ → log(1 − p ) → cumsum → exp → normalize fused. • Merged SNNFFN matmul : W gate , W up con- catenated into single (2 D ff , D ) matmul. • Merged PLIF scan : Gate/up neurons mer ged into single 2 D ff -dim scan. • Gradient checkpointing : Each of L =20 lay- ers checkpointed ( ∼ 60% memory reduction). E T raining Hyperparameters T able 7: Training hyperparameters. Pretrain SFT Optimizer Adam AdamW Peak LR 2 × 10 − 4 5 × 10 − 5 Neuron LR 2 × 10 − 3 5 × 10 − 4 Schedule W armup+Cosine W armup+Cosine W armup 1000 100 W eight decay 0 0.01 Eff. batch 64 64 Grad clip 1.0 1.0 Precision bf16 bf16 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment