Noisy Data is Destructive to Reinforcement Learning with Verifiable Rewards
Reinforcement learning with verifiable rewards (RLVR) has driven recent capability advances of large language models across various domains. Recent studies suggest that improved RLVR algorithms allow models to learn effectively from incorrect annotat…
Authors: Yuxuan Zhu, Daniel Kang
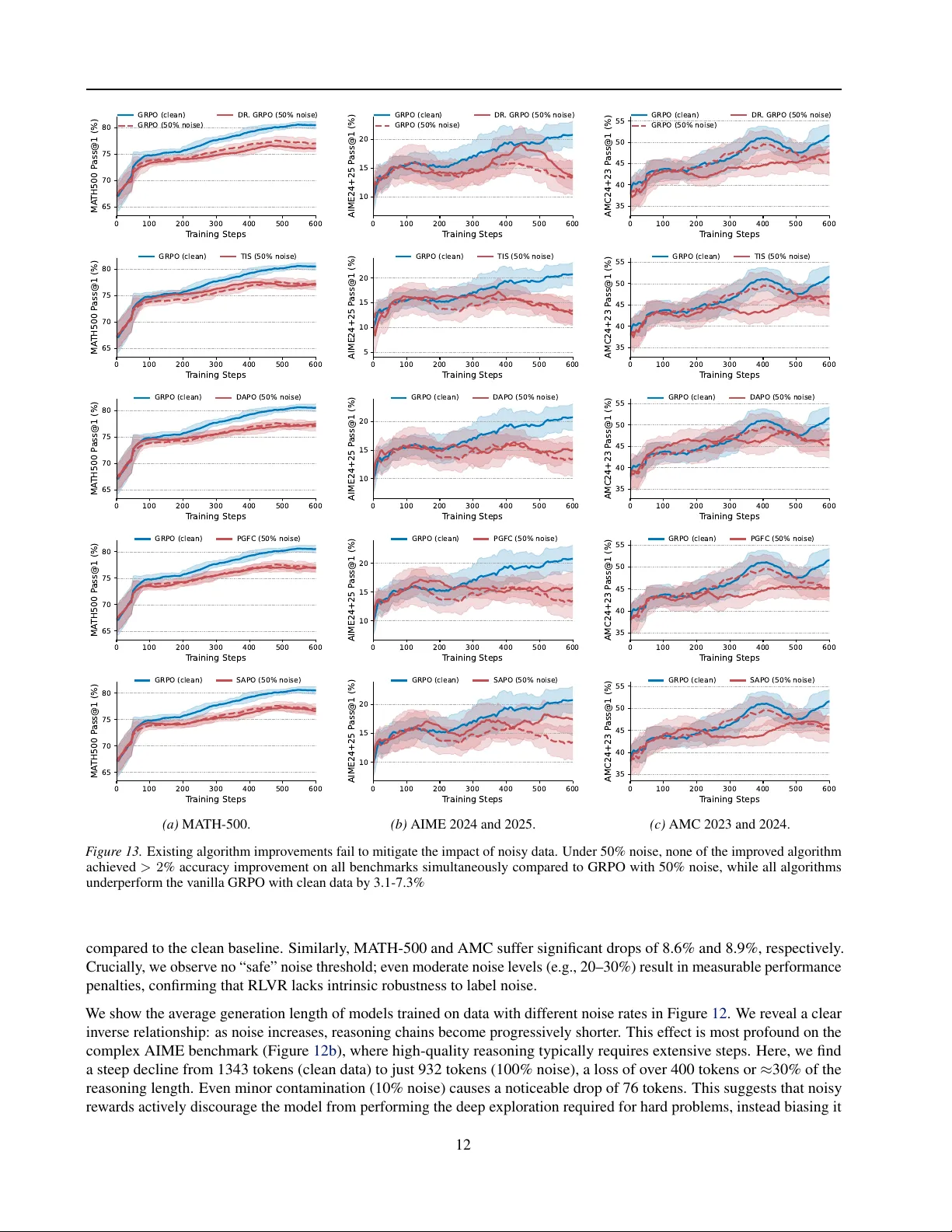
Noisy Data is Destructiv e to Reinf or cement Lear ning with V erifiable Rewards Y uxuan Zhu 1 Daniel Kang 1 Abstract Reinforcement learning with verifiable re wards (RL VR) has dri ven recent capability adv ances of large language models across various domains. Recent studies suggest that improved RL VR algo- rithms allo w models to learn ef fecti vely from in- correct annotations, achieving performance com- parable to learning from clean data. In this work, we sho w that these findings are in valid because the claimed 100% noisy training data is “con- taminated” with clean data. After rectifying the dataset with a rigorous re-verification pipeline, we demonstrate that noise is destructi ve to RL VR. W e show that e xisting RL VR algorithm improv e- ments fail to mitigate the impact of noise, achie v- ing similar performance to that of the basic GRPO. Furthermore, we find that the model trained on truly incorrect annotations performs 8–10% w orse than the model trained on clean data across math- ematical reasoning benchmarks. Finally , we show that these findings hold for real-world noise in T ext2SQL tasks, where training on real-world, hu- man annotation errors cause 5–12% lower accu- racy than clean data. Our results sho w that current RL VR methods cannot yet compensate for poor data quality . High-quality data remains essential. 1. Introduction Reinforcement learning with verifiable re wards (RL VR) is a widely used post-training paradigm ( Guo et al. , 2025 ; OpenAI , 2025 ), improving the reasoning capabilities of large language models (LLMs) ( Shao et al. , 2024 ; Luo et al. , 2025a ; b ; c ; W ei et al. , 2025 ; W en et al. , 2025 ; Ma et al. , 2025 ; Su et al. , 2025 ). Ho wev er , obtaining verifiable annotations at scale for rew ard calculation is labor-intensi ve, and ensuring their quality is dif ficult ( Wretblad et al. , 2024 ; Chen et al. , 2025 ; T eam et al. , 2025 ). Recent studies suggest that data quality is secondary , arguing that models can learn equally 1 Siebel School of Computing and Data Science, Univ ersity of Illinois Urbana Champaign, USA. Correspondence to: Daniel Kang < ddkang@illinois.edu > . Preliminary work under re vie w . 0 100 200 300 400 500 600 700 T raining Steps 60 65 70 75 80 MA TH500 P ass@1 (%) 41% 9% 3% GRPO (clean) GRPO (for mat) GRPO (random) GRPO (100% incor r ect) best alg. (50% incor r ect) GRPO (50% incor r ect) F igur e 1. Noisy data significantly degrades RL VR performance, and existing algorithmic improv ements fail to mitigate this impact. Using Qwen2.5-Math-7B as a base model, we sho w that training on 100% incorrect annotations sampled from the base model (red line) leads to performance similar to training with format-only rew ards (purple line) and underperforms training on clean data (blue line) by 9%. Ev en with the best-performing algorithm among D APO ( Y u et al. , 2025b ), SAPO ( Gao et al. , 2025 ), Dr . GRPO ( Liu et al. , 2025c ), TIS ( Y ao et al. , 2025 ), and PGFC ( Cai et al. , 2025 ), training on 50% incorrect annotations yields performance similar to GRPO ( Shao et al. , 2024 ) and underperforms clean data. effecti vely from cheaper , noisy data, lev eraging algorithmic tweaks such as re ward shaping ( Cai et al. , 2025 ), objecti ve correction ( Mansouri et al. , 2025 ), and clipping mechanisms ( Park et al. , 2025 ). This raises a fundamental question for the future of post-training: T o what extent can RL VR, with algorithmic impr ovements, tolerate annotation noise? A growing body of recent literature suggests a promising, yet counter-intuiti ve answer: RL VR appears surprisingly robust to data noise. Sev eral studies claim that LLMs can learn effecti vely from low-quality data or even random noise, achieving performance comparable to models trained on clean data ( Shao et al. , 2025 ; Park et al. , 2025 ; Lv et al. , 2025 ). For instance, Shao et al. ( 2025 ) report that RL VR with 100% incorrect data annotations achieves accuracy on MA TH-500 within 5% of the same model trained on clean data. Similarly , Lv et al. ( 2025 ) suggest that clipped objectiv es allow learning from random rew ards with only 3% performance loss. These findings increasingly imply that data quality is secondary to algorithmic design. 1 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards In this work, we argue that these findings are inv alid by showing that the noisy data used in prior w ork is not 100% noisy . Through a rigorous empirical study , we demonstrate that high-quality data remains necessary and cannot be re- placed by existing algorithmic impro vements. Re-verifying data re veals sev ere impact of noise. W e iden- tify a critical contamination issue in the training datasets used in prior work. Using a data re-verification pipeline lev eraging GPT -5 Pro and manual verification (Section 3.3 ), we find that at least 16% of annotations labeled as “incor- rect” in prior work are actually correct (Figure 2 ). This contamination inflated the performance of models trained on noise. After correcting for this, we find that training on 100% incorrect annotations degrades MA TH-500 accuracy by 9% (8-10% on other benchmarks) compared to clean data (Figure 1 ). This performance is similar to training with format-only re wards (rew arding \ boxed {} ), empiri- cally showing that RL VR with pure noise reinforces format adherence and fails to boost reasoning. Furthermore, we show that training on pure random annotations results in performance lower than the base model (Figure 1 ). Existing algorithms fail to compensate f or noisy data. W e tested state-of-the-art algorithmic improv ements, including bias mitigation ( Liu et al. , 2025c ; Y ao et al. , 2025 ; Cai et al. , 2025 ), adaptiv e clipping ( Gao et al. , 2025 ), and dynamic sampling ( Y u et al. , 2025b ), on noisy data. Contrary to prior work, we find that these carefully designed algorithms f ail to compensate for true data noise. Under synthetic noise, these algorithms perform similarly to GRPO ( Shao et al. , 2024 ) and underperform GRPO with clean data by ov er 3% on MA TH-500 (Figure 1 ). W e attribute the contradiction with prior work to the fact that their synthetic noisy training data contained hidden correct annotations. Real-world annotation noise is destructiv e to RL VR. Moving beyond synthetic noise, we use T ext2SQL (i.e., translating natural language questions to SQL queries) tasks as a case study to illustrate the impact of real-world annota- tion errors. T ext2SQL datasets contain naturally occurring human annotation errors due to the ambiguity of natural language and the multidimensionality of data. W e manually corrected a T ext2SQL dataset, BIRD ( Li et al. , 2023 ), which is known to contain substantial annotation noise ( Wretblad et al. , 2024 ; Liu et al. , 2025b ; Pourreza & Rafiei , 2023 ). W e find that training on the original, noisy dataset degrades per- formance by 5–12% compared to training on our corrected dataset across different base model architectures. W e summarize our contributions as follo ws: 1. W e construct a truly noisy dataset of mathematical rea- soning for RL training. This provides the community with a reliable dataset to rigorously in v estigate the impact of data noise in RL VR. 2. W e sho w that existing algorithmic improv ements for RL VR fail to mitigate the impact of noise. With 50% noise, the best-performing algorithm achie ves similar accuracy to that of GRPO and 3% lower than clean data. 3. W e demonstrate that the impact of data noise is more sev ere than previously reported. T raining with 100% noise leads to similar or lo wer performance than training with format rew ards and 8-10% lo wer than clean data. 4. Using T ext2SQL as an example, we show that the pres- ence of real-world data noise is destructiv e to RL VR. Compared to a cleaned dataset, the real-world, noisy dataset lowers performance by up to 12%. 2. Background Reinfor cement learning with verifiable r ewards. RL VR has emer ged as a dominant paradigm for post-training LLMs, with recent large-scale successes achie ving state-of- the-art results in various domains ( Guo et al. , 2025 ; OpenAI , 2025 ). Group relativ e policy optimization (GRPO) is the first algorithmic instantiation of RL VR ( Shao et al. , 2024 ). In each iteration, for a question-answer pair ( q , a ), GRPO samples a group of outputs { τ 1 , . . . , τ G } from the model π θ old and estimates the advantage of output τ i as follows: ˆ A i = R ( τ i , a ) − mean { R ( τ j , a ) } G j =1 std { R ( τ j , a ) } G j =1 (1) Then, GRPO optimizes the model by maximizing the fol- lowing clipped objecti ve: E 1 G G X i =1 1 | τ i | | τ i | X t =1 min r i,t ˆ A i , clip ( r i,t , 1 ± ϵ ) ˆ A i where r i,t = π θ ( τ i,t | x, τ i, 1 , showing that noise does not improve reasoning boundary . 0% 10% 20% 30% 40% 50% 100% P r oportion of Noise in Data 30 35 40 45 50 A verage P ass@1 (%) 45.1% -1.5% -1.5% -2.3% -4.8% -6.2% -9.8% F igur e 5. T raining on noisy data results in increasing performance degradation (1.5– 9.8%) as the noise proportion increases. 0% 10% 20% 30% 40% 50% 100% P r oportion of Noise in Data 400 600 800 1000 A vg. R esponse L ength 1024 -53 -97 -131 -136 -175 -245 F igur e 6. Training on noisy data results in shorter responses (5.2–23.9%), indicating that noise induces weaker reasoning. Evaluation. W e performed all e v aluations using greedy decoding (temperature=0). W e include fi ve benchmarks for e valuation: MA TH-500 ( Lightman et al. , 2023 ), AIME 2024 and 2025 ( Community , 2025a ), AMC 2023 and 2024 ( Community , 2025b ). Among them, the AIME 2025 and AMC 2024 datasets were released after the last update date of the model weights of our base model, Qwen2.5-Math-7B, ensuring a contamination-free ev aluation environment. 4.2. Findings Answer to RQ1 . Noisy data impacts learning signifi- cantly , r esulting in 8-10% lower accuracy than training on clean data and failing to outperform tr aining with pur e format r ewar ds. Noisy data causes significant perf ormance degradation. W e quantify the performance gap between training on clean data and training on noisy data. As shown in Figure 3 , train- ing on 100% noise (red lines) yields a substantially lower performance compared to the clean baseline (blue lines), de- grading accuracy by 9.0% on MA TH-500, 10.0% on AIME, and 8.5% on AMC. W e also find that training on 100% noise fails to outperform the format-re ward baseline (purple lines), suggesting that noisy data does not improve the capability of the base model, but only strengthens format adherence. Furthermore, training on random annotations (gray lines) leads to catastrophic collapse, causing performance to drop significantly below that of the base model. Noisy data decreases pass@ k . T o determine if noisy data affects the range of problems a model can solve gi ven mul- tiple attempts, we ev aluate the pass@ k of models trained on noisy data. W e find that clean data expands the set of solvable problems, while noisy data shrinks it. As shown in Figure 4 , the model trained on clean data consistently outperforms all other baselines by 4.6–16.6% in terms of pass@ k . Howe ver , the model trained on noisy data only outperforms the base model when k = 1 , while underper- forming the base model by up to 6.1% when k > 1 . This indicates that incorrect annotations reduce both sampling efficienc y and the number of solvable problems, damaging the model’ s “reasoning boundary” ( Y ue et al. , 2025 ). Noisy data leads to shorter reasoning. Noise induces a collapse in reasoning length, leading to not only lo wer ac- curacy but also shorter responses. In Figure 5 , we show a monotonic drop in accuracy as noise increases, with de gra- dation ranging from 1.5% (at 10% noise) to 9.8% (at 100% noise). This loss in accuracy is accompanied by a significant reduction in generation length. In Figure 6 , we show that models trained on noisy data produced responses that were 5.2% to 23.9% shorter than the model trained on clean data. This reduction implies that noisy data discourages complex reasoning chains, which weakens the reasoning capability . 5. Algorithm Impro vements F ail to Mitigate the Impact of Data Noise In this section, we inv estigate whether existing algorithm improv ements mitigate the impact of data noise on RL VR. W e first introduce our selected algorithms and then discuss our experimental settings and findings. 5.1. Algorithm Selection W e ev aluated a set of state-of-the-art RL VR variants. W e categorized these methods into three algorithmic changes that hypothetically improv es stability and rob ustness: 1. Gradient bias mitigation : GRPO suf fers from bias caused by inherent policy loss ( Liu et al. , 2025c ), training-inference shifts ( Y ao et al. , 2025 ), and noisy data ( Cai et al. , 2025 ). Therefore, we include Dr . GRPO ( Liu et al. , 2025c ), truncated importance sampling (TIS) ( Y ao et al. , 2025 ), and polic y gradient with forward correction (PGFC) designed to address these bias, respectiv ely . 2. Dynamic sampling : GRPO suffers from v anishing gra- dients when a rollout group has uniform rewards (all correct or all wrong). T o address this, prior work pro- posed dynamic sampling, which discard uniform groups to focus on informativ e groups. Dynamic sampling may implicitly filter out failures caused by noise. Thus, we ev aluate TIS ( Y ao et al. , 2025 ) and D APO ( Y u et al. , 2025b ), both of which incorporate dynamic sampling. 6 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards GRPO (cor r ect) S APO (50% noise) D APO (50% noise) TIS (50% noise) DR . GRPO (50% noise) PGFC (50% noise) GRPO (50% noise) 70 75 80 P ass@1 (%) -3.9% -2.9% -3.1% -4.1% -3.5% -3.2% (a) MA TH-500. GRPO (cor r ect) S APO (50% noise) D APO (50% noise) TIS (50% noise) DR . GRPO (50% noise) PGFC (50% noise) GRPO (50% noise) 5 10 15 20 P ass@1 (%) -3.6% -5.0% -7.4% -6.7% -3.8% -7.3% (b) AIME 2024 and 2025. GRPO (cor r ect) S APO (50% noise) D APO (50% noise) TIS (50% noise) DR . GRPO (50% noise) PGFC (50% noise) GRPO (50% noise) 35 40 45 50 55 P ass@1 (%) -6.6% -4.6% -5.3% -4.4% -7.1% -6.2% (c) AMC 2023 and 2024. F igure 7. Existing algorithmic improvements fail to mitigate the impact of noisy data. Under 50% noise, none of the improved algorithms achiev ed a > 2 % accuracy impro vement on all benchmarks simultaneously compared to GRPO with 50% noise, while all algorithms underperform the vanilla GRPO with clean data by 3.1–7.3%. 1 2 4 8 16 32 64 128 Number of Samples k 40 50 60 70 80 A verage P ass@k (%) Algorithms (50% noise) GRPO (clean) GRPO (50% noise) Base F igure 8. None of the e v aluated algorithmic impro vements achieve a higher pass@ k score than GRPO under 50% noise. 3. Clipping mechanisms : Prior research suggests that asymmetric clipping can improve learning from noisy data by regulating entropy ( Lv et al. , 2025 ). Further- more, adaptive clipping ratios based on group advan- tage can stabilize gradient updates when a batch of roll- outs exhibit a variance of rewards. Therefore, we as- sess D APO (asymmetric clipping) ( Y u et al. , 2025b ) and SAPO (adaptiv e clipping) ( Gao et al. , 2025 ). In summary , we e valuate fiv e algorithms to achiev e a full cov erage of the categories of state-of-the-art algorithmic improv ements: Dr . GRPO (bias mitigation), TIS (bias miti- gation + dynamic sampling), PGFC (bias mitigation), D APO (dynamic sampling + clipping), and SAPO (clipping). 5.2. Experimental Settings In addition to the settings of Section 4 , we use the default hyperparameter recommendations for each algorithm based on their original publications. For TIS and D APO, we used asymmetric clipping with an upper ratio of 0.28 and a lo wer ratio of 0.2, alongside an ov erlong buf fer threshold of 2,048 tokens and a penalty factor of 1.0. Additionally , for TIS, we applied an importance sampling cap of 2.0. For SAPO, we configured the adaptiv e clipping with a positiv e clip- ping parameter of 1.0 and a ne gati ve clipping parameter of 1.05. For PGFC, we used the ground-truth noise rates as the correction factors, measuring the method’ s upper-bound performance. 5.3. Results Answer to RQ2 . Algorithmic impr ovements fail to com- pensate for the noise in data. None of the SO T A variants (TIS, D APO, SAPO, Dr . GRPO) outperformed GRPO by mor e than 1% under the 50% noise. None of them con- sistently achieved performance within 5% of GRPO on clean data. Algorithmic improvements fail to mitigate accuracy degradation. In Figure 7 , we summarize the final accu- racy achie ved by each algorithm. Under 50% noise, none of the e v aluated algorithms achie ved a consistent impro ve- ment ov er the GRPO (50% noise) baseline. Specifically , no algorithm yielded more than a 2% accurac y gain across all benchmarks simultaneously . Furthermore, all algorithmic vari ants underperform the model trained on clean data, with accuracy gaps ranging from 3.1% to 7.3%. This suggests that current algorithmic interventions are insuf ficient to com- pensate for the destructi ve ef fects of noise. W e defer a de- tailed analysis of the accuracy of intermediate checkpoints to Appendix A.3 , which shows similar trends to Figure 7 . Algorithmic improv ements fail to recov er pass@ k . T o determine if algorithmic improv ements could enable the models to solve a wider range of problems gi v en multiple attempts, we analyzed the av erage pass@ k performance of these methods across all benchmarks. In Figure 8 , we demonstrate that the performance of the improv ed algo- rithms (represented by the shaded red region) ov erlaps with the GRPO (50% noise) baseline. None of the algorithmic im- prov ements achie ved a higher pass@ k score than the v anilla baseline, and all remained significantly below the GRPO with clean data. Additionally , we analyzed the response length of the trained models. W e found that none of the 7 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards Qwen3-235B- A22B -Instruct-2507 DeepSeek- V3.1 Qwen3-32B GPT - OSS-120B- A5B Llama-3.3-70B -Instruct 50 55 60 65 70 75 80 Ex ecution A ccuracy (%) -10.0 -10.4 -6.0 -7.0 -5.7 -5.1 -10.2 -16.3 -12.1 -7.8 GRPO (BIRD-Cor r ected-600) PGFC (BIRD- Original-600) GRPO (BIRD- Original-600) F igur e 9. Real-world noise significantly degrades RL VR perfor- mance, while algorithmic intervention f ails to recov er it. Models trained on the original, noisy BIRD dataset (BIRD-Original-600) via GRPO suffers a 5.7–12.1% accurac y drop compared to BIRD- Corrected-600. The PGFC algorithm, specifically designed to handle noisy data, fails to consistently improve over GRPO and remains 5.1–16.3% behind the clean data baseline. models trained via improved algorithms consistently gener - ates longer response than GRPO. These results indicate that improv ed algorithms fail to impro ve the model’ s reasoning boundary under noisy data. W e defer more detailed results and analysis in Appendix A.4 and A.5 . 6. Impact of Real-world Annotation Noise Moving beyond synthetic noisy data, we extend our anal- ysis to the annotation errors found in real-world datasets. Specifically , we inv estigate the impact of naturally occur- ring annotation errors within the BIRD dataset ( Li et al. , 2023 ) on RL VR performance. 6.1. Experimental Settings T raining. W e used the state-of-the-art multi-turn RL VR tailored for T ext2SQL tasks, allowing the model to inter- act with the database for iterative refinement ( Liu et al. , 2025a ). W e define a tri-le vel re ward function R ( τ , a ) giv en a generated SQL τ and a gold SQL a : R ( τ , a ) = 1 , τ and a have the same e xecution result − 1 , τ misses 〈 solution 〉 tags 0 , otherwise W e applied the GRPO and set the batch size to 64, the group size to 16, the learning rate to 5 × 10 − 5 , and the LoRA rank to 32. Based on our con vergence analysis (Appendix C ), we trained all models for 10 epochs. Evaluation. Existing T ext2SQL benchmarks suffer from substantial annotation errors ( Liu et al. , 2025b ; Pourreza & Rafiei , 2023 ; Wretblad et al. , 2024 ; Jin et al. , 2026 ). T o en- sure our reported performance dif ference come from noisy training data rather than benchmark errors, we used the BIRD Mini-Dev set independently v erified by Arcwise ( Ar- cwise , 2025 ). This benchmark contains corrections for 161 (32.3%) of the original 498 instances. After independent, manual inspection by two of our authors, we find that the corrections by Arcwise are valid and sound. W e performed all ev aluations using greedy decoding (temperature=0). 6.2. Findings Answer to RQ3 . Real-world noisy data is destructive to RL VR. Acr oss differ ent base models ranging fr om 32B to 685B parameter s, training on noisy data r esults in up to 12% lower accuracy compar ed to training on clean data. Real-world noise leads to significant degradation. As shown in Figure 9 , we find that training on BIRD-Corrected- 600 demonstrates consistent and significant superiority over training on BIRD-Original-600. Models trained on the BIRD-Corrected-600 consistently outperform those trained on the original noisy data, with performance gaps ranging from a minimum of 5.7% to a maximum of 12.1%. This confirms that the impact of noisy data observed in synthetic settings transfers directly to realistic domains. Algorithmic mitigation fails to handle r eal-world noise. W e also tested whether PGFC ( Cai et al. , 2025 ), an algo- rithm specifically designed to mitigate impact of noise on RL VR, could recover the performance lost to real-world noise. Consistent with our findings from synthetic noise, we show that PGFC f ailed to yield consistent improvements ov er the GRPO. On GPT -OSS-120B-A5B, PGFC performed significantly worse than GRPO on noisy data. Overall, mod- els trained with PGFC on BIRD-Original-600 remained 5.1-16.3% less accurate than those trained on clean data. 7. Conclusion In this work, we demonstrate the significant impact of noisy data on RL VR, which cannot be mitigated by existing al- gorithmic improvements. Contrary to prior studies, we dev eloped and used a rigorous data re-verification pipeline to synthesize a set of truly noisy data and in vestig ated real- world noisy data by correcting a subset of the noisy BIRD dataset. In our experiments, we show that SOT A RL VR algorithms (e.g., TIS, DAPO) result in performance indistin- guishable from the basic GRPO. Furthermore, we identify a consistent performance collapse of 8-10% due to synthetic noise and up to 12% due to real-world noise. These findings highlight that, without high-quality data, RL VR risks yield- ing suboptimal models, a phenomenon that has not yet been addressed by existing algorithmic interv entions. 8 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards 8. Impact Statement This work adv ances the understanding of robustness in re- inforcement learning from v erifiable re wards (RL VR). By demonstrating that current algorithmic interventions f ail to mitigate the effects of noisy data, our findings emphasize the critical necessity of high-quality data curation for de- veloping reliable reasoning models. This insight has impli- cations for the allocation of research resources, suggesting that efforts should prioritize data quality over algorithmic complexity to prevent the deployment of models with de- graded reasoning capabilities. This is particularly rele v ant for high-stakes domains such as code generation and scien- tific discov ery , where trust in the model is paramount. References Arcwise. Bird minidev - corrections, 2025. URL https: / /d o c s. g o og l e .c o m /s p r ea d s he e t s/ d / 1I G m9 O t ru e y6 0 u jU n l8 A Ok e p Y3 q gW H d F J H nX 7 hQ GUeCw . Accessed: 2025-09-15. Beyer , L., H ´ enaff, O. J., K olesnikov , A., Zhai, X., and Oord, A. v . d. Are we done with imagenet? arXiv preprint arXiv:2006.07159 , 2020. Cai, X.-Q., W ang, W ., Liu, F ., Liu, T ., Niu, G., and Sugiyama, M. Reinforcement learning with verifiable yet noisy rew ards under imperfect verifiers. arXiv pr eprint arXiv:2510.00915 , 2025. Chen, A., Li, A., Gong, B., Jiang, B., Fei, B., Y ang, B., Shan, B., Y u, C., W ang, C., Zhu, C., et al. Minimax- m1: Scaling test-time compute efficiently with lightning attention. arXiv pr eprint arXiv:2506.13585 , 2025. Community , A. O. Aime problems and solutions, 2025a. URL h t t ps : / / a r t o f p r o bl e m s o l v i n g . c o m / w i k i /i n d ex . p h p / AI M E _P r ob l e ms _ a nd _ S o l utions . Accessed Dec. 10, 2025. Community , A. O. Amc problems and solutions, 2025b. URL h t t ps : / / a r t o f p r o bl e m s o l v i n g . c o m / w i k i /i n d ex . p h p ? ti t l e= A MC _ P ro b l em s _ a n d_Solutions . Accessed Dec. 10, 2025. Gao, C., Zheng, C., Chen, X.-H., Dang, K., Liu, S., Y u, B., Y ang, A., Bai, S., Zhou, J., and Lin, J. Soft adaptiv e policy optimization. arXiv pr eprint arXiv:2511.20347 , 2025. Griggs, T ., Hegde, S., T ang, E., Liu, S., Cao, S., Li, D., Ruan, C., Moritz, P ., Hakhamaneshi, K., Liaw , R., Malik, A., Zaharia, M., Gonzalez, J. E., and Stoica, I. Evolving skyrl into a highly-modular rl framework, 2025. Notion Blog. Guo, D., Y ang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., W ang, P ., Bi, X., et al. Deepseek-r1: In- centi vizing reasoning capability in llms via reinforcement learning. arXiv pr eprint arXiv:2501.12948 , 2025. Jin, T ., Choi, Y ., Zhu, Y ., and Kang, D. Pervasi ve annotation errors break text-to-sql benchmarks and leaderboards. VLDB 2026 , 2026. Kydl ´ ı ˇ cek, H., Gandenber ger , G., and Maksin, L. Math verify , 2025. URL http s:// gith u b.co m/hu g gi ngface/Math- Verify . Accessed Dec. 10, 2025. Li, J., Hui, B., Qu, G., Y ang, J., Li, B., Li, B., W ang, B., Qin, B., Geng, R., Huo, N., et al. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Pr ocessing Systems , 36:42330–42357, 2023. Lightman, H., K osaraju, V ., Burda, Y ., Edwards, H., Baker , B., Lee, T ., Leike, J., Schulman, J., Sutske ver , I., and Cobbe, K. Let’ s verify step by step. In ICLR , 2023. Liu, S., He gde, S., Cao, S., Zhu, A., Li, D., Griggs, T ., T ang, E., Malik, A., Hakhamaneshi, K., Liaw , R., Moritz, P ., Zaharia, M., Gonzalez, J. E., and Stoica, I. Skyrl-sql: Matching gpt-4o and o4-mini on text2sql with multi-turn rl, 2025a. Notion Blog. Liu, X., Shen, S., Li, B., T ang, N., and Luo, Y . Nl2sql- bugs: A benchmark for detecting semantic errors in nl2sql translation. In Proceedings of the 31st ACM SIGKDD Confer ence on Knowledge Discovery and Data Mining V . 2 , pp. 5662–5673, 2025b. Liu, Z., Chen, C., Li, W ., Qi, P ., P ang, T ., Du, C., Lee, W . S., and Lin, M. Understanding r1-zero-like training: A critical perspectiv e. arXiv pr eprint arXiv:2503.20783 , 2025c. Luo, M., Jain, N., Singh, J., T an, S., Patel, A., W u, Q., Ariyak, A., Cai, C., V enkat, T ., Zhu, S., Athiwaratkun, B., Roongta, M., Zhang, C., Li, L. E., Popa, R. A., Sen, K., and Stoica, I. Deepswe: Training a state-of-the-art coding agent from scratch by scaling rl. h t t p s : / / pre tty - r adi o- b7 5.n oti on. sit e/D ee pSW E- T ra i n ing - a - F ul l y - O p en- s o ur c e d- S t at e - of - t h e - A r t - C o d i ng - A g e n t - by - S c a l i n g - RL - 2 2 2 8 1 9 0 2 c 1 4 6 8 1 9 3 a a b b e 9 a 8 c 5 9 b b e 33 , 2025a. Notion Blog. Luo, M., T an, S., Huang, R., P atel, A., Ariyak, A., W u, Q., Shi, X., Xin, R., Cai, C., W eber , M., Zhang, C., Li, L. E., Popa, R. A., and Stoica, I. Deepcoder: A fully open-source 14b coder at o3-mini level. https://pr etty - rad io - b 75. not io n.s ite /De epC ode r- A - F u l l y - O pen - So u r ce- 1 4B - C o d er - at - O3 - 9 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards mini- Leve l- 1c f81902c 14680b3 bee5eb 349a 512a51 , 2025b. Notion Blog. Luo, M., T an, S., W ong, J., Shi, X., T ang, W . Y ., Roongta, M., Cai, C., Luo, J., Li, L. E., Popa, R. A., and Stoica, I. Deepscaler: Surpassing o1-previe w with a 1.5b model by scaling rl. ht tps :// pr etty - ra d io - b 75 .no t i o n . s i t e / D e e p S c a l eR - S u r p a s s i ng - O1 - Previ ew- w ith- a - 1- 5B- Mode l- by- Sc a ling- RL - 1 9 6 8 1 9 0 2 c 1 4 6 8 0 0 5 b e d 8 c a 3 0 3 0 1 3 a 4 e2 , 2025c. Notion Blog. Lv , A., Xie, R., Sun, X., Kang, Z., and Y an, R. The climb carves wisdom deeper than the summit: On the noisy re wards in learning to reason. arXiv preprint arXiv:2505.22653 , 2025. Ma, X., Liu, Q., Jiang, D., Zhang, G., Ma, Z., and Chen, W . General-reasoner: Advancing llm reasoning across all domains. arXiv pr eprint arXiv:2505.14652 , 2025. Mansouri, O. E., Seddik, M. E. A., and Lahlou, S. Noise- corrected grpo: From noisy rewards to unbiased gradients. arXiv pr eprint arXiv:2510.18924 , 2025. Natarajan, N., Dhillon, I. S., Ravikumar , P . K., and T ew ari, A. Learning with noisy labels. Advances in neural infor - mation pr ocessing systems , 26, 2013. Newcombe, R. G. T wo-sided confidence intervals for the single proportion: comparison of se ven methods. Statis- tics in medicine , 17(8):857–872, 1998. OpenAI. Introducing openai o3 and o4-mini, 2025. URL ht tps :/ /o pen ai .c om/ in de x/i nt ro duc ing - o3- and- o4- mini/ . Accessed Dec. 10, 2025. Park, J. R., Kim, J., Kim, G., Jo, J., Choi, S., Cho, J., and Ryu, E. K. Clip-low increases entropy and clip-high decreases entropy in reinforcement learning of lar ge lan- guage models. arXiv pr eprint arXiv:2509.26114 , 2025. Pourreza, M. and Rafiei, D. Ev aluating cross-domain text-to- sql models and benchmarks. In Proceedings of the 2023 Confer ence on Empirical Methods in Natur al Language Pr ocessing , pp. 1601–1611, 2023. Schulman, J. and Lab, T . M. Lora without regret. Thinking Machines Lab: Connectionism , 2025. doi: 10.64434/tml .20250929. https://thinkingmachines.ai/blog/lora/. Shao, R., Li, S. S., Xin, R., Geng, S., W ang, Y ., Oh, S., Du, S. S., Lambert, N., Min, S., Krishna, R., et al. Spu- rious re wards: Rethinking training signals in rlvr . arXiv pr eprint arXiv:2506.10947 , 2025. Shao, Z., W ang, P ., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., W u, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models. arXiv pr eprint arXiv:2402.03300 , 2024. Su, Y ., Y u, D., Song, L., Li, J., Mi, H., Tu, Z., Zhang, M., and Y u, D. Crossing the rew ard bridge: Expanding rl with verifiable rewards across diverse domains. arXiv pr eprint arXiv:2503.23829 , 2025. T eam, K., Bai, Y ., Bao, Y ., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y ., Chen, Y ., Chen, Y ., et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534 , 2025. T eam, T . M. Tink er , 2025. URL htt ps: //th ink ing machines.ai/tinker/ . Accessed Dec. 10, 2025. W ei, Y ., Duchenne, O., Copet, J., Carbonneaux, Q., Zhang, L., Fried, D., Synnaev e, G., Singh, R., and W ang, S. I. Swe-rl: Advancing llm reasoning via reinforcement learning on open software e volution. arXiv pr eprint arXiv:2502.18449 , 2025. W en, X., Liu, Z., Zheng, S., Y e, S., W u, Z., W ang, Y ., Xu, Z., Liang, X., Li, J., Miao, Z., et al. Reinforcement learn- ing with verifiable rew ards implicitly incentivizes correct reasoning in base llms. arXiv preprint , 2025. Wretblad, N., Riseby , F ., Biswas, R., Ahmadi, A., and Holm- str ¨ om, O. Understanding the effects of noise in text-to-sql: An examination of the bird-bench benchmark. In Pr o- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 2: Short P apers) , pp. 356–369, 2024. Y ao, F ., Liu, L., Zhang, D., Dong, C., Shang, J., and Gao, J. Y our ef fi cient rl framew ork secretly brings you off-policy rl training, August 2025. URL ht tp s: // fe ng ya o. notion.site/off- policy- rl . Y u, B., Zhu, Y ., He, P ., and Kang, D. Utboost: Rigorous ev aluation of coding agents on swe-bench. ACL 2025 , 2025a. Y u, Q., Zhang, Z., Zhu, R., Y uan, Y ., Zuo, X., Y ue, Y ., Dai, W ., Fan, T ., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv pr eprint arXiv:2503.14476 , 2025b. Y ue, Y ., Chen, Z., Lu, R., Zhao, A., W ang, Z., Song, S., and Huang, G. Does reinforcement learning really incenti vize reasoning capacity in llms be yond the base model? arXiv pr eprint arXiv:2504.13837 , 2025. Zhang, Z. and Sabuncu, M. Generalized cross entropy loss for training deep neural netw orks with noisy labels. Advances in neural information pr ocessing systems , 31, 2018. 10 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards 1 2 4 8 16 32 64 128 Number of Samples k 70 80 90 A verage P ass@k (%) (a) MA TH-500. 1 2 4 8 16 32 64 128 Number of Samples k 10 20 30 40 50 60 A verage P ass@k (%) GRPO (clean) GRPO (100% noise) Base (no training) GRPO (for mat) (b) AIME 2024 and 2025. 1 2 4 8 16 32 64 128 Number of Samples k 40 50 60 70 80 90 A verage P ass@k (%) (c) AMC 2023 and 2024. F igure 10. Noise leads to lower pass@ k than the base model when k > 1 , showing that noise does not improv e capability boundary . 0% 10% 20% 30% 40% 50% 100% P r oportion of Noise in Data 0 20 40 60 80 A verage P ass@1 (%) 80.8% -0.5% -1.9% -1.4% -3.0% -3.8% -8.6% (a) MA TH-500. 0% 10% 20% 30% 40% 50% 100% P r oportion of Noise in Data 0 5 10 15 20 A verage P ass@1 (%) 20.2% -1.2% 0.0% -2.3% -4.5% -6.8% -11.4% (b) AIME 2024 and 2025. 0% 10% 20% 30% 40% 50% 100% P r oportion of Noise in Data 0 10 20 30 40 50 A verage P ass@1 (%) 52.2% -2.7% -3.1% -3.5% -6.0% -6.9% -8.9% (c) AMC 2023 and 2024. F igure 11. Training on noisy data results in increasing performance degradation (by up to 11.4%) as the noise proportion increases. 0% 10% 20% 30% 40% 50% 100% P r oportion of Noise in Data 300 400 500 600 A vg. R esponse L ength 577 -24 -40 -45 -13 -21 -18 (a) MA TH-500. 0% 10% 20% 30% 40% 50% 100% P r oportion of Noise in Data 600 800 1000 1200 1400 A vg. R esponse L ength 1343 -76 -144 -196 -221 -285 -411 (b) AIME 2024 and 2025. 0% 10% 20% 30% 40% 50% 100% P r oportion of Noise in Data 400 600 800 1000 A vg. R esponse L ength 928 -45 -78 -110 -113 -141 -191 (c) AMC 2023 and 2024. F igure 12. Training on noisy data results in shorter responses, indicating that noise induces weaker reasoning. A. Detailed Experimental Results A.1. Pass@k Results of Models T rained on Noisy Data W e show the pass@ k performance of models trained on noisy data in Figure 10 . While the model trained on correct annotations (blue) consistently expands the solution space across all k , the model trained on 100% noise (red) exhibits failures consistently . On easier benchmarks like MA TH-500 (Figure 10a ), the noisy model performs comparably to the base model at k = 1 , but falls behind as k increases. This trend is even more se vere on complex reasoning benchmarks like AIME (Figure 10b ) and AMC (Figure 10c ), where the base model (gre y) consistently outperforms the noisy model across nearly all values of k . This crossov er indicates that while noise might improv e greedy decoding ( k = 1 ) slightly , it degrades the model’ s reasoning capabilities in general. Furthermore, training with format-only rew ards (purple) consistently outperforms training with verifiable noise, confirming that the “signal” in noisy data is negati ve, dragging performance below what could be achie ved by simply teaching the model the correct output format. A.2. Results of T raining on Different Noise Rates W e show the performance of models trained on data with different noise rates in Figure 11 . As shown, we find a strict negati ve correlation: as the proportion of incorrect annotations rises, accuracy consistently declines. This degradation is most sev ere on the challenging AIME benchmark (Figure 11b ), where 100% noise precipitates an 11.4% collapse in accurac y 11 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards 0 100 200 300 400 500 600 T raining Steps 65 70 75 80 MA TH500 P ass@1 (%) GRPO (clean) GRPO (50% noise) DR . GRPO (50% noise) 0 100 200 300 400 500 600 T raining Steps 10 15 20 AIME24+25 P ass@1 (%) GRPO (clean) GRPO (50% noise) DR . GRPO (50% noise) 0 100 200 300 400 500 600 T raining Steps 35 40 45 50 55 AMC24+23 P ass@1 (%) GRPO (clean) GRPO (50% noise) DR . GRPO (50% noise) 0 100 200 300 400 500 600 T raining Steps 65 70 75 80 MA TH500 P ass@1 (%) GRPO (clean) TIS (50% noise) 0 100 200 300 400 500 600 T raining Steps 5 10 15 20 AIME24+25 P ass@1 (%) GRPO (clean) TIS (50% noise) 0 100 200 300 400 500 600 T raining Steps 35 40 45 50 55 AMC24+23 P ass@1 (%) GRPO (clean) TIS (50% noise) 0 100 200 300 400 500 600 T raining Steps 65 70 75 80 MA TH500 P ass@1 (%) GRPO (clean) D APO (50% noise) 0 100 200 300 400 500 600 T raining Steps 10 15 20 AIME24+25 P ass@1 (%) GRPO (clean) D APO (50% noise) 0 100 200 300 400 500 600 T raining Steps 35 40 45 50 55 AMC24+23 P ass@1 (%) GRPO (clean) D APO (50% noise) 0 100 200 300 400 500 600 T raining Steps 65 70 75 80 MA TH500 P ass@1 (%) GRPO (clean) PGFC (50% noise) 0 100 200 300 400 500 600 T raining Steps 10 15 20 AIME24+25 P ass@1 (%) GRPO (clean) PGFC (50% noise) 0 100 200 300 400 500 600 T raining Steps 35 40 45 50 55 AMC24+23 P ass@1 (%) GRPO (clean) PGFC (50% noise) 0 100 200 300 400 500 600 T raining Steps 65 70 75 80 MA TH500 P ass@1 (%) GRPO (clean) S APO (50% noise) (a) MA TH-500. 0 100 200 300 400 500 600 T raining Steps 10 15 20 AIME24+25 P ass@1 (%) GRPO (clean) S APO (50% noise) (b) AIME 2024 and 2025. 0 100 200 300 400 500 600 T raining Steps 35 40 45 50 55 AMC24+23 P ass@1 (%) GRPO (clean) S APO (50% noise) (c) AMC 2023 and 2024. F igure 13. Existing algorithm improv ements fail to mitigate the impact of noisy data. Under 50% noise, none of the improved algorithm achiev ed > 2 % accuracy improvement on all benchmarks simultaneously compared to GRPO with 50% noise, while all algorithms underperform the vanilla GRPO with clean data by 3.1-7.3% compared to the clean baseline. Similarly , MA TH-500 and AMC suf fer significant drops of 8.6% and 8.9%, respecti vely . Crucially , we observe no “safe” noise threshold; ev en moderate noise le vels (e.g., 20–30%) result in measurable performance penalties, confirming that RL VR lacks intrinsic rob ustness to label noise. W e show the a verage generation length of models trained on data with different noise rates in Figure 12 . W e re veal a clear in verse relationship: as noise increases, reasoning chains become progressively shorter . This effect is most profound on the complex AIME benchmark (Figure 12b ), where high-quality reasoning typically requires extensi ve steps. Here, we find a steep decline from 1343 tok ens (clean data) to just 932 tokens (100% noise), a loss of o ver 400 tokens or ≈ 30% of the reasoning length. Even minor contamination (10% noise) causes a noticeable drop of 76 tokens. This suggests that noisy rew ards acti vely discourage the model from performing the deep e xploration required for hard problems, instead biasing it 12 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards 1 2 4 8 16 32 64 128 Number of Samples k 70 80 90 A verage P ass@k (%) (a) MA TH-500. 1 2 4 8 16 32 64 128 Number of Samples k 20 30 40 50 60 A verage P ass@k (%) Algorithms (50% noise) GRPO (clean) GRPO (50% noise) Base (b) AIME 2024 and 2025. 1 2 4 8 16 32 64 128 Number of Samples k 40 50 60 70 80 90 A verage P ass@k (%) (c) AMC 2023 and 2024. F igure 14. None of the evaluated algorithmic impro vements achie ve higher pass@ k score than GRPO under 50% noise. GRPO (cor r ect) S APO (50% noise) D APO (50% noise) TIS (50% noise) DR .GRPO (50% noise) PGFC (50% noise) GRPO (50% noise) 300 400 500 600 A vg. R esponse L ength 577 -37 -34 -93 -57 -16 -21 (a) MA TH-500. GRPO (cor r ect) S APO (50% noise) D APO (50% noise) TIS (50% noise) DR .GRPO (50% noise) PGFC (50% noise) GRPO (50% noise) 600 800 1000 1200 1400 A vg. R esponse L ength 1343 -327 -349 -422 -400 -268 -285 (b) AIME 2024 and 2025. GRPO (cor r ect) S APO (50% noise) D APO (50% noise) TIS (50% noise) DR .GRPO (50% noise) PGFC (50% noise) GRPO (50% noise) 400 600 800 1000 A vg. R esponse L ength 928 -169 -166 -223 -201 -135 -141 (c) AMC 2023 and 2024. F igure 15. Training on noisy data with improv ed algorithms still results in shorter responses. tow ard shorter and likely incorrect solutions. A.3. Results of Different RL VR Algorithms In Figure 13 , we show the test accurac y trajectories (pass@1) ov er all training steps for all algorithms. W e first show a sharp contrast between clean and noisy supervision. Across all fiv e algorithmic variants (ro ws) and three benchmarks (columns), the model trained on clean data establishes a clear performance upper bound, maintaining a steady upward trajectory . In contrast, the adv anced algorithms (solid red) fail to dif fer from the GRPO baseline trained on the same noisy data (dashed red). The trajectories are nearly indistinguishable, with overlapping confidence interv als throughout the process. Specifically , on the challenging AIME benchmark (middle column), both the advanced algorithms and the vanilla noisy baseline exhibit signs of training collapse after 400 steps, whereas the clean model continues to improv e. This confirms that current algorithmic state-of-the-art methods, including Dr . GRPO, TIS, D APO, PGFC, and SAPO, offer no significant robustness against v alidated label noise. A.4. Pass@k Results of Differ ent RL VR Algorithms In Figure 14 , we show the pass@ k results of models trained via improved algorithms. W e find that the shaded region (range of improv ed algorithms) effecti vely collapses onto the GRPO curve (50% noise), indicating that no algorithmic intervention successfully expands the set of solvable problems beyond the naive baseline. As sampling budget k increases, the gap between these algorithms and the clean-data model (blue) widens, particularly on the rigorous AIME benchmark (Figure 14b ). This demonstrates that while these algorithms might stabilize training metrics, they fail to repair the fundamental damage noise inflicts on the model’ s ability to explore and find correct solutions. A.5. Generation Length Analysis of Different RL VR Algorithms In Figure 15 , we sho w the a verage response length across all trained models. W e demonstrate a significant contraction in reasoning depth when noise is introduced. On the complex AIME benchmark (Figure 15b ), the model trained on clean data generates long, detailed chains of thought (a vg. 1343 tokens). In contrast, models trained on noisy data, regardless of 13 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards the algorithm used, exhibits a massi ve reduction in length, dropping by ov er 300 tokens. This suggests that noisy rewards penalize complex exploration, encouraging the model to con ver ge on shorter reasoning paths. Specifically , advanced algorithms like TIS and DAPO fail to rev erse this trend, often producing responses ev en shorter than the GRPO baseline. This confirms that current algorithmic improvements do not restore the depth of thought characteristic of models trained on high-quality data. B. Prompts Used in the Re-v erification Pipeline W e used the following prompt when acquiring annotations from GPT -5 Pro. Question: { question } If the question have multiple distinct and correct answers, provide all the answers. Write the answers in LaTeX format. Do not include any explanations. Answer(s): W e used the following prompt as the final prompt for judging the correctness of answers with GPT -5. You are a highly intelligent and accurate math grader. Given a math question, a ground truth answer, and a student’s answer, determine whether the student’s answer is correct. You must follow the following guidelines: 1. If the question has multiple distinct but correct answers, the student only needs to provide one of them to be considered correct. For example, if the ground truth answer is "(k in 12, -12)" and the student’s answer is "11", the student’s answer should be considered correct. 2. Ignore any format mistakes and only grade the mathematical meaning of the answer. For example, if the ground truth answer is "(11) 6" and the student’s answer is "11", the student’s answer should be considered correct. Another example is if the ground truth answer is latex formatted and the student’s answer is not latex formatted but is mathematically equivalent, the student’s answer should be considered correct. Vice versa is also true. 3. If the student’s answer is mathematically equivalent to the ground truth answer, it should be considered correct. 4. If the student’s answer uses fractions, decimals, or different representations that are mathematically equivalent to the ground truth answer, it should be considered correct. For example, if the ground truth answer is "4 \ sqrt { 2 } " and the student’s answer is "5.656854249492381", the student’s answer should be considered correct. 5. If the question is an Yes/No question and the ground truth answer is an exact solution, the student’s answer is correct as long as they answers "Yes" or anything equivalent to "Yes". For example, for the question "Does there exist a fraction equivalent to $ \ frac { 7 }{ 13 } $ such that the difference between the denominator and the numerator is 24?", the ground truth answer is " \ frac { 28 }{ 52 } " and the student’s answer is "Yes", the student’s answer should be considered correct. 6. If the student’s answer is a simplification of the ground truth answer, it should be considered correct. For example, if the ground truth answer is "2 + 2" and the student’s answer is "4", the student’s answer should be considered correct. Vice versa is also true. 7. If the student’s answer is mathematically inequivalent to the ground truth answer, it should be considered incorrect. For example, if the ground truth answer is "5" and the student’s answer is "-5", the student’s answer should be considered incorrect. Question: { question } Ground Truth: { ground truth } Student Answer: { student answer } Is the student’s answer correct? Answer ’Yes’ or ’No’. Answer: 14 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards 0 100 200 300 400 500 600 T raining Steps 35 40 45 A verage P ass@1 (%) GRPO (clean) 0 100 200 300 400 500 600 T raining Steps 34 36 38 40 42 A verage P ass@1 (%) GRPO (100% noise) 0 100 200 300 400 500 600 T raining Steps 32.5 35.0 37.5 40.0 42.5 A verage P ass@1 (%) GRPO (for mat) F igure 16. After three epochs (600 steps), no model shows improvements of average pass@1 of all benchmarks in the subsequent 50 steps. C. Determination of T raining Duration T o establish a rigorous stopping criterion for math reasoning training, we monitored the average performance across all benchmarks o ver nearly 600 training steps. As illustrated in Figure 16 , the model trained on clean data (left) exhibits a steady ascent, reaching peak performance stability around 600 steps (3 epochs). In contrast, the model trained on 100% noise (right) peaks early (approx. step 200) before degrading, confirming that prolonged exposure to noise leads to ov erfitting and performance collapse. The format-only model (center) stabilizes quickly and maintains a consistent pass@1. Consequently , we set the training duration to 600 steps for all experiments, as no model demonstrated significant improv ements in the subsequent 50 steps. Similarly , to determine the stopping criterion for T ext2SQL training, we monitored the average training re wards. W e did not monitor test accuracy on BIRD mini-De v to pre vent o verfitting to a single benchmark. As illustrated in Figure 17 , starting the tenth epoch, no model shows improv ements in training rewards. Consequently , we set the training duration to 10 epochs for all T ext2SQL experiments. 15 Noisy Data is Destructive to Reinf orcement Learning with V erifiable Rewards 1 2 3 4 5 6 7 8 9 10 T raining Epochs 60 70 80 90 R ewar d GRPO (BIRD-Cor r ected-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 50 55 60 65 70 R ewar d GRPO (BIRD- Original-600) (a) Qwen3-235B-A22B-Instruct-2507. 1 2 3 4 5 6 7 8 9 10 T raining Epochs 15 20 25 30 35 40 R ewar d PGFC (BIRD- Original-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 60 70 80 R ewar d GRPO (BIRD-Cor r ected-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 40 50 60 70 R ewar d GRPO (BIRD- Original-600) (b) DeepSeek-V3.1. 1 2 3 4 5 6 7 8 9 10 T raining Epochs 0 10 20 R ewar d PGFC (BIRD- Original-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 30 40 50 60 70 R ewar d GRPO (BIRD-Cor r ected-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 20 30 40 50 R ewar d GRPO (BIRD- Original-600) (c) Qwen3-32B. 1 2 3 4 5 6 7 8 9 10 T raining Epochs 0 5 10 15 20 R ewar d PGFC (BIRD- Original-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 40 60 80 R ewar d GRPO (BIRD-Cor r ected-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 20 30 40 50 60 70 R ewar d GRPO (BIRD- Original-600) (d) GPT -OSS-120B-A5. 1 2 3 4 5 6 7 8 9 10 T raining Epochs 10 20 30 R ewar d PGFC (BIRD- Original-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 0 20 40 60 80 R ewar d GRPO (BIRD-Cor r ected-600) 1 2 3 4 5 6 7 8 9 10 T raining Epochs 0 20 40 60 R ewar d GRPO (BIRD- Original-600) (e) Llama-3.3-70B-Instruct. 1 2 3 4 5 6 7 8 9 10 T raining Epochs 0 10 20 30 R ewar d PGFC (BIRD- Original-600) F igure 17. Starting the tenth epoch, no model shows improv ements in terms of rew ard. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment