SWE-QA-Pro: A Representative Benchmark and Scalable Training Recipe for Repository-Level Code Understanding
Agentic repository-level code understanding is essential for automating complex software engineering tasks, yet the field lacks reliable benchmarks. Existing evaluations often overlook the long tail topics and rely on popular repositories where Large…
Authors: Songcheng Cai, Zhiheng Lyu, Yuansheng Ni
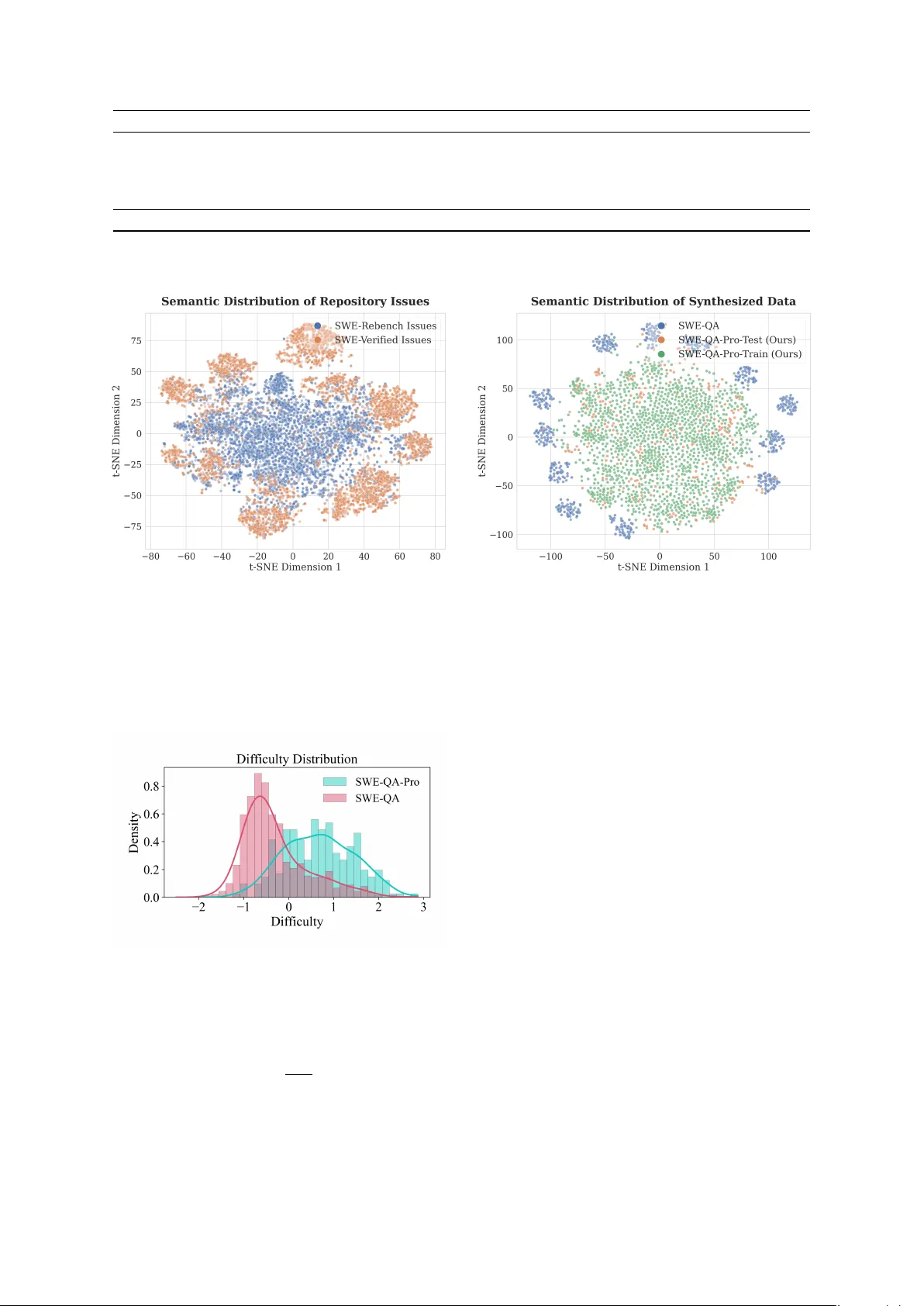
SWE-QA-Pr o: A Representati v e Benchmark and Scalable T raining Recipe f or Repository-Le vel Code Understanding Songcheng Cai 1 * Zhiheng L yu 1 * Y uansheng Ni 1 Xiangchao Chen 1 Baichuan Zhou 1 Shenzhe Zhu 2 Y i Lu 2 Haozhe W ang 3 Chi Ruan 1 Benjamin Schneider 1 W eixu Zhang 4 Xiang Li 1 Andy Zheng 1 Y uyu Zhang 5 Ping Nie 1 W enhu Chen 1 † 1 Uni versity of W aterloo 2 Uni versity of T oronto 3 The Hong K ong University of Science and T echnology 4 McGill Uni versity & MILA 5 V erdent AI, Inc. https://github.com/TIGER-AI-Lab/SWE-QA-Pro Abstract Agentic repository-level code understanding is essential for automating complex software engineering tasks, yet the field lacks reliable benchmarks. Existing e valuations often over - look the long tail topics and rely on popular repositories where Large Language Models (LLMs) can cheat via memorized kno wledge. T o address this, we introduce SWE-QA-Pro, a benchmark constructed from di verse, long-tail repositories with ex ecutable en vironments. W e enforce topical balance via issue-driv en clus- tering to cov er under-represented task types and apply a rigorous dif ficulty calibration pro- cess: questions solvable by direct-answer base- lines are filtered out. This results in a dataset where agentic workflo ws significantly outper - form direct answering (e.g., a 13-point gap for Claude Sonnet 4.5), confirming the necessity of agentic codebase exploration. Furthermore, to tackle the scarcity of training data for such complex beha viors, we propose a scalable syn- thetic data pipeline that powers a two-stage training recipe: Supervised Fine-Tuning (SFT) followed by Reinforcement Learning from AI Feedback (RLAIF). This approach allows small open models to learn ef ficient tool usage and reasoning. Empirically , a Qwen3-8B model trained with our recipe surpasses GPT -4o by 2.3 points on SWE-QA-Pro and substantially narrows the gap to state-of-the-art proprietary models, demonstrating both the validity of our ev aluation and the effecti veness of our agentic training workflo w . 1 Introduction Repository-le vel code understanding is central to LLM-assisted software engineering. Real tasks re- quire navigating many files, tracking control and data flow across modules, and verifying that im- plementations match intended designs. Snippet- * Equal contribution † Corresponding author . centric QA benchmarks do not capture these be- haviors, and kno wledge-only prompting can hide weaknesses in navigation and grounding ( Husain et al. , 2019 ; Liu and W an , 2021 ; Huang et al. , 2021 ; Lee et al. , 2022 ; Gong et al. , 2024 ; Sahu et al. , 2024 ; Li et al. , 2024 ). Recent repository QA bench- marks mov e to ward large-context, tool-using e val- uation, b ut still focus on fe w projects and include many questions solvable without interacting with the codebase. ( Abedu et al. , 2025 ; Chen et al. , 2025 ; Peng et al. , 2025 ; Rando et al. , 2025 ). W e focus on two concrete gaps. First, limited diversity : existing benchmarks concentrate on a fe w popular repositories. This leav es lar ge parts of the natural task distrib ution uncov ered and under - represents certain semantic categories of tasks (e.g., configuration, data plumbing, infrastructure glue sho wn in Appendix A ). Second, uncertain need f or tools : many benchmark questions can be an- swered from prior kno wledge or public documen- tation that is already cov ered during pretraining, so current setups do not clearly separate cases that actually requires tool-using from the cases where a single-pass, kno wledge-only model with enough context and reasoning would already succeed. As a result, it is dif ficult to tell whether a model truly understands and operates within a particular repos- itory , or simply recall generic knowledge. T o address these issues, we introduce SWE-QA- Pro, a benchmark and training recipe for repository- le vel QA. On the benchmark side, we: (i) se- lect less-studied, long-tail repositories and ensure that each one has an executable en vironment so the project can be built and explored end-to-end ( Badertdinov et al. , 2025 ); (ii) use issue texts as question seeds, embed them, and run k-means clus- tering to form topic groups, follo wed by a brief human pass to merge near-duplicates and clarify topic boundaries; and (iii) for each topic, use a tool-using code model to propose QA items and 1 Stage1: Ta xonomy Const ruct Stage3: D iffic ulty Cali bration Stage2: D ata Synthe sis Stage4: D ata Val idatio n Github Is sues Embedding Cluster Taxonomy Code Repo s Claud e C ode Generated Query Direct Answer QA Pairs Hard & B alanced Question s Claude Code Answer Annotated Ans wer Human Cros s Validat ion Questions w ith Ground - Truths Easy Questions ❌ ✅ (a) Benchmark Construction Pipeline Base Model SFT Model RL Model SFT Data RL Data Tool Server Tools Reward Mo del Rollout Reward (b) T raining Recipe Figure 1: SWE-QA-Pro Benchmark and Training Pipeline. draft answers, which are then edited by humans for correctness and repository grounding, with final benchmark QA items sampled across clusters to preserve di versity in Section 2.4 . T o reduce kno wledge-only questions and make tool usage meaningful, we add a simple filtering step. For each drafted item, we compare a direct- answer baseline (no tools, single turn) with a tool- using run. If the direct-answer baseline already achie ves a high score, we discard the item. This preserves questions that require locating and citing concrete code rather than recalling documentation. On the training side, we introduce a two-stage agentic recipe for improving small open models on repository-level QA. W e first apply SFT to match repository-grounded answer formats, then use RLAIF to fav or answers citing concrete files and symbols ( Lee et al. , 2023 ). In experiments, a tuned Qwen3-8B ( Y ang et al. , 2025 ) trained with this SFT → RLAIF recipe outperforms GPT -4o ( Hurst et al. , 2024 ) and substantially narrows the gap to state-of-the-art proprietary models shown in Section 3.2 and Section 4.2 . In summary , we make two contributions, as il- lustrated in Figure 1 : • Benchmark. W e release SWE-QA-Pro, a repository-le vel QA benchmark b uilt from long- tail repositories with ex ecutable environments. Questions are seeded from issues, then synthe- sized and grounded with a tool-using code model along with human editing, followed by filter - ing to remov e cases solv able by strong direct- answer baselines. Compared to SWE-QA, SWE- QA-Pro cov ers more diverse repositories and includes more questions that truly require code- base interaction ( Peng et al. , 2025 ). • Agent W orkflow and T raining Recipe. W e in- troduce a simple agentic workflo w for repository- le vel QA that enables iterati v e codebase explo- ration via structured actions. Building on this workflo w , we present an SFT → RLAIF training recipe that significantly improves small open- source models on SWE-QA-Pro. Using this frame work, Qwen3-8B surpasses GPT -4o on SWE-QA-Pro by 2 . 31 points and substantially narro ws the gap to se v eral state-of-the-art propri- etary models, including GPT -4.1, Claude Sonnet 4.5, and DeepSeek-V3.2 ( OpenAI , 2025 ; An- thropic , 2025 ; Liu et al. , 2025 ). 2 SWE-QA-Pro Bench SWE-QA-Pro Bench is constructed through a four-stage pipeline, as illustrated in Figure 1a : Data Sourcing and T axonomy , Data Synthesis and Sampling, Data Filtering and Difficulty Calibra- tion, and Data V alidation. This pipeline yields three ke y adv antages o ver existing benchmarks ( T able 1 ): (1) pull-request–dri ven clustering to- gether with long-tail repository sampling ensures balanced coverage across div erse software engi- neering question types; (2) systematic filtering against multiple strong proprietary models remo ves instances solvable via memorization or pretrain- ing artifacts, thereby isolating questions that re- quire genuine codebase interaction; and (3) an- swers cross-verified by Claude Code and human annotators provide high-quality gold ground truth, 2 enabling reliable multi-dimensional e v aluation. 2.1 Data Sourcing and T axonomy W e conducted a large-scale analysis of the GitHub Repositories in SWE-Rebench ( Badertdinov et al. , 2025 ). W e processed 1 , 687 , 638 issues spanning 3 , 468 repositories by concatenating their titles and bodies, specifically filtering for contexts between 10 Byte and 16KB. W e computed representations for these texts using Qwen3-8B-Embedding model. T o organize this data, we applied a hierarchical K-Means clustering algorithm, initializing with 10 clusters in the first layer and expanding to 50 in the second. W e then utilized GPT -4.1 to extract semantic labels for each resulting cluster . These labels were refined through a human-verified taxon- omy to eliminate semantic redundancy and enforce clear semantic boundaries between closely related categories, thereby reducing ambiguity and yield- ing 48 distinct task subclasses in Appendix E . This unsupervised taxonomy serves as the foundational structure for our benchmark, ensuring it covers a wide spectrum of software engineering challenges rather than a manually cherry-picked subset. 2.2 Data Synthesis and Sampling Le veraging the deriv ed semantic taxonomy , we em- ployed Claude Code to synthesize the final bench- mark data. T o guarantee the executability and v alid- ity of the problems, we repurposed the established sandbox en vironments from SWE-Rebench. For each synthesis task, we stochastically sam- pled 20 existing issues from the corresponding clus- ter and repository to serve as reference context. The agent was then tasked with automatically explor - ing the codebase to generate a ne w , self-contained problem-solution pair aligned with the specific clus- ter’ s semantics. W e adopted different sampling strate gies for the training and test sets to balance div ersity with hu- man e v aluation constraints. For the T est Set, we selected 26 repositories that efficiently cov er all 48 task categories, accommodating the cogniti ve con- straints of human annotators while ensuring com- prehensi ve ev aluation. Con versely , for the T raining Set, we applied uniform sampling across the entire dataset, achie ving cov erage of 1 , 484 repositories. Figure 2 illustrates the effecti veness of this pipeline: our synthesized data maintains a semantic distribution that is suf ficiently di verse compared to the original repository distrib ution between SWE- Rebench and SWE-V erified datasets. 2.3 Data Filtering and Difficulty Calibration T o ensure SWE-QA-Pro focuses on non-trivial, agent-essential reasoning, we apply a multi-stage filtering and calibration pipeline. W e first remov e multi-query prompts and perform semantic dedu- plication using Qwen3-8B embeddings to ensure task independence. A key challenge in ev aluat- ing repository-le vel understanding is that state-of- the-art proprietary LLMs possess extensi v e pre- training kno wledge, enabling them to answer many software engineering questions without interacting with the codebase, reading source files, or explor - ing repository structure. Such questions are often associated with widely known repositories (e.g., the canonical projects in SWE-Bench ( Jimenez et al. , 2023 )), or can be resolv ed by inspecting only one or a small number of files, without requiring multi- hop reasoning over the repository . Empirically , this issue is reflected in e xisting repo-le vel QA bench- marks, where the performance gap between mod- els answering with full repository exploration and those responding without any code context is often marginal. As a result, these benchmarks may fail to accurately measure an LLM’ s ability to explore codebases and perform grounded, repository-lev el reasoning ( Peng et al. , 2025 ). T o mitigate the influence of memorized knowl- edge and filter out trivially answerable questions, we introduce a difficulty calibration procedure based on cross-model agreement. W e ev aluate direct (no-repository) answers produced by three strong proprietary models, GPT -4o, Claude Sonnet 4.5, and Gemini 2.5 Pro ( Comanici et al. , 2025 ), and compare them against repository-grounded ref- erence answers generated by Claude Code. Each direct answer is assessed using an LLM-as-a-Judge frame work along fi ve dimensions: correctness, completeness, relev ance, clarity , and reasoning quality , as detailed in Section 4.1 . For each model m , we aggregate scores across multiple indepen- dent runs and compute the average total score ¯ s m ( q ) for question q . T o account for inter-model scale differences, we standardize the aggregated scores using z-score normalization: z m ( q ) = ¯ s m ( q ) − µ m σ m , (1) where µ m and σ m denote the mean and standard de viation of model m ’ s scores over all questions. W e then define the difficulty of a question as the 3 Benchmark Repo-level Repo Nav . Multi-hop Semantic Coverage Diff. Calibration T est Size CodeQueries ( Sahu et al. , 2024 ) ✗ ✗ ✔ ✗ ✗ 29033 InfiBench ( Li et al. , 2024 ) ✗ ✗ ✗ ✗ ✔ 234 CodeReQA ( Hu et al. , 2024 ) ✔ ✗ ✗ ✗ ✗ 1563 LongCodeQA ( Rando et al. , 2025 ) ✔ ✗ ✔ ✗ ✗ 443 SWE-QA ( Peng et al. , 2025 ) ✔ ✔ ✔ ✗ ✗ 576 SWE-QA-Pro ✔ ✔ ✔ ✔ ✔ 260 T able 1: Comparison of representativ e code benchmarks. (a) Semantic distribution of ra w Issues: SWE-Rebench (All Repos) vs. SWE-V erified. (b) Semantic distrib ution of QA Datasets: Comparison among our T raining/T est splits and SWE-QA. Figure 2: t-SNE visualization of semantic distributions. (a) Comparison of the original issue spaces, sho wing the broad co verage of SWE-Rebench compared to the manually curated SWE-V erified. (b) The distribution of our synthesized datasets (T raining and T est) demonstrates high div ersity and alignment with the semantic clusters of existing benchmarks. Figure 3: Difficulty Comparison between SWE-QA and SWE-QA-Pro. Higher difficulty indicates harder questions. negati ve consensus score across models: Difficult y( q ) = − 1 | M | X m ∈ M z m ( q ) , (2) where M denotes the set of ev aluated models. Under this definition, questions that consistently recei ve high-quality direct answers across mod- els are assigned lo w dif ficulty and are filtered out, while questions that remain challenging without repository interaction are retained. Using the cali- brated dif ficulty signal, we construct the QA pairs candidates pools with cluster-le vel coverage and approximate balance across QA types. This cali- bration step ensures that SWE-QA-Pro emphasizes questions that genuinely require repository explo- ration and multi-step reasoning, pro viding a more faithful ev aluation of LLM agent capabilities as sho wn in Figure 3 . 2.4 Data V alidation and Statistics T o ensure the quality and reliability of QA pairs and metadata, we adopt a multi-stage annotation and validation process to mitigate hallucinations and semantic ambiguity . First, C L AU D E C O D E explores each repository in a sandbox en vironment to produce repository-grounded reference answers, while assigned semantic clusters and QA types are cross-checked against the taxonomy and reused for dif ficulty calibration. Second, human annotators independently e x- 4 plore the codebase to produce answers, re vise am- biguous or underspecified questions, and verify QA types and semantic clusters. Their answers are compared against the C L AU D E C O D E refer- ences to identify missing details or errors, and only answers satisfying correctness, completeness, rel- e v ance, clarity , and reasoning quality are retained. A final expert revie w pass adjudicates remaining inconsistencies and further refines the answers. The resulting SWE-QA-Pro benchmark contains 260 questions from 26 long-tail repositories, with 4–9 questions per semantic cluster and an approx- imately balanced distrib ution of QA types. Full statistics are reported in Appendix F , with case studies in Appendix H.1 . 3 SWE-QA-Pro Agent W e introduce SWE-QA-Pro Agent, a lightweight workflo w designed for repository-lev el code un- derstanding in small open-source models. Unlike RA G-based approaches that require pre-built in- dices, our agent uses a ReAct-style loop to explore codebases directly . By combining directory traver - sal, keyword search, and scoped file inspection, the agent gathers evidence incrementally to reason across files under limited context b udgets. 3.1 Agent W orkflow W e propose SWE-QA-Pro Agent, a ReAct-based workflo w for repository-le v el code understanding. Prior agents such as SWE-QA-Agent primarily rely on RA G-style retrie v al with limited command-line support, requiring the construction of a retrie v al index while still of fering insufficient capacity for genuine repository e xploration. This limitation is particularly e vident for open-source models, where such agents often underperform strong traditional RA G baselines with offline inde xing and manually designed retrie v al pipelines. In contrast, SWE-QA-Pro Agent abandons RA G- based retrie v al entirely and does not require a pre- built index. Instead, it performs direct repository exploration using e xplicit, length-controlled Search based on keyw ord matching to locate relev ant files, V ie w for scoped inspection of file contents or direc- tory structure, and constrained read-only Comman- dLine actions for lightweight structural and pattern- based analysis (e.g., directory trav ersal, symbol matching, and line-le vel e xtraction), enabling more flexible and effecti ve context acquisition for rea- soning under limited context b udgets. The agent operates in a ReAct-style loop, where it iteratively reasons ov er the current context, freely selects an action, and incorporates the resulting observ ation until sufficient evidence is collected, at which point it terminates with Finish. Detailed algorithms are provided in the Appendix B . 3.2 Agentic T raining Recipe T o our kno wledge, e xisting efforts to enhance open- source LLMs for SWE-QA focus on SFT of agentic behaviors, without le veraging reinforcement learn- ing to optimize repository-le vel exploration and reasoning ( Rastogi et al. , 2025 ). Inspired by recent adv ances in RL for LLMs, we propose a scalable training framew ork that explicitly trains agentic interaction with code repositories, leading to im- prov ed exploration and understanding. T raining Data Construction. Starting from the benchmark question construction pipeline, we deduplicate and obtain 1,464 raw questions, which are randomly split into 1,000 questions for SFT and 464 questions for RL. For the SFT stage, we use Claude Sonnet 4.5 to generate 1,000 high- quality multi-turn con versation trajectories condi- tioned on each question and our predefined agent action space (Search, V iew , and read-only Com- mandLine tools), resulting in tool-augmented su- pervision data. For the RL stage, we assign each question a high-quality reference answer generated by Claude Code , which serves as the ground truth for re ward computation. T wo-Stage T raining. Training proceeds in two stages. In the first stage, we perform supervised fine-tuning on Qwen3-8B using 1K tool-in vocation question–answer trajectories. This stage teaches the model the tool-call syntax and instills a basic understanding of tool semantics and usage patterns. In the second stage, we apply reinforcement learn- ing to the SFT -initialized model. For each rollout, a re ward model e valuates the final answer against the ground truth along fiv e dimensions: correct- ness, completeness, rele v ance, clarity , and reason- ing quality , follo wing the same criteria used in e v al- uation. Since SWE-QA answers are often complex and cannot be reliably assessed by exact-match or rule-based rew ards, we adopt an LLM-as-Judge re ward formulation. T o mitigate reward hacking, we employ a judge model distinct from the e v alua- tion judge and assign higher weight to correctness while do wn-weighting clarity , discouraging fluent but incorrect answers. The final scalar rew ard is 5 computed as: s = RM(ˆ a, a ∗ ) ∈ [1 , 10] 5 , (3) r = w ⊤ s 10 , w = (0 . 3 , 0 . 2 , 0 . 2 , 0 . 1 , 0 . 2) . (4) where ˆ a is the generated answer , a ∗ the ground- truth reference, and s denotes scores for fi ve e v al- uation dimensions. W e optimize the policy using the GRPO algorithm ( Shao et al. , 2024 ), where re wards are normalized within each rollout group before computing polic y gradients. This stage en- courages the model to con ver ge to ward rollouts that produce high-quality , fact-grounded final answers. 4 Experiments 4.1 Experimental Setup Model selection W e e v aluate 11 LLMs, includ- ing proprietary models, GPT -4o, GPT -4.1, Claude Sonnet 4.5, Gemini 2.5 Pro, DeepSeek-V3.2, open- source models, Qwen3-8B/32B, De vstral-Small-2- 24B-Instruct ( Rastogi et al. , 2025 ), LLaMA-3.3- 70B-Instruct ( Dubey et al. , 2024 ), and two variants of SWE-QA-Pro 8B trained with SFT and SFT+RL. All models are ev aluated under both direct answer- ing and agent-based reasoning using the SWE-QA- Pro Agent workflo w . Inference and T raining Setup All inference uses temperature 0, a maximum of 25 turns, and a 32k context window on NVIDIA A100 80GB GPUs. SFT and RL are implemented using SWIFT ( Zhao et al. , 2025 ) and V erl-T ool ( Jiang et al. , 2025 ), re- specti vely . Hyperparameters are provided in Ap- pendix C . Evaluation Metrics W e follo w the LLM-as- Judge protocol of SWE-QA, including strict judge–candidate separation, anonymization, and randomized answer order . Compared to SWE-QA, we require explicit file-path and line-number ref- erences and use a stricter judge prompt to enable finer-grained score dif ferentiation. Each answer is scored independently three times, and scores are av eraged to reduce v ariance. Full prompts are pro- vided in Appendix D . 4.2 Main Results T able 2 summarizes the e valuation results across all LLMs. As shown in T able 2 , there is a substan- tial performance gap between the direct-answer set- ting and the agent-based workflo w , particularly on correctness, completeness, and reasoning quality . This gap highlights the effecti veness of our diffi- culty calibration and underscores the critical role of the SWE-QA-Pro agent in enabling high-quality , repository-grounded reasoning. Overall P erf ormance. Among all ev aluated mod- els, Claude Sonnet 4.5 achie ves the highest over - all score, reflecting strong repository-le vel code understanding and ef fecti ve tool use. Despite its smaller scale and limited training data, SWE-QA- Pro 8B outperforms many open-source baselines as well as GPT -4o with case study in Appendix H.2 , and performs competiti v ely with lar ger agen- tic models such as Devstral Small 2 24B Instruct. These results highlight that e xplicitly training agen- tic capabilities for repository-le vel QA can be more impactful than scaling model size alone. Breakdo wn Results Analysis. Appendix G de- tails model performance across repositories, seman- tic clusters, and question types. First, analyzing question types ( T able 11 , T able 12 ) re veals that localization-oriented questions yield consistently high scores with low variance, as they focus on identifying specific files, identifiers, or execution points. Con versely , causal and explanatory ques- tions are significantly more challenging, particu- larly those inv olving design rationale, trade-offs, or implicit dependencies, which require multi-file e vidence integration and global semantic reason- ing. Procedural questions fall in between: concrete implementation tasks are tractable, whereas system- le vel inquiries remain dif ficult due to their reliance on holistic understanding. Regarding repositories and semantic clusters in Appendix G.2 and G.3 , configuration and w orkflo w management areas in volving dependenc y injec- tion, CLI argument handling, and packaging prov e consistently difficult. These clusters characterize configuration-dri ven repositories lik e jsonargparse, checko v , and yt-dlp, where answering requires rea- soning ov er implicit control flo w , cross-file propa- gation, and runtime behavior not localized to single files. In contrast, clusters with e xplicitly encoded, localized logic, such as Unicode/data parsing, pro- tocol/API compatibility , filesystem config, and vi- sualization, are easier . Consequently , repositories concentrating on these areas (docker -py , pint, mk- docs, seaborn) achie ve higher , stable performance, benefiting from structurally explicit and locally grounded code. 6 Model Evaluation Metrics Overall Correctness Completeness Rele vance Clarity Reasoning Pr oprietary LLMs Gemini 2.5 Pro 2.51 2.13 8.66 8.02 4.16 25.48 Gemini 2.5 Pro + Agent 7.12 6.25 8.91 9.34 7.84 39.46 GPT -4.1 3.42 2.38 9.02 9.23 4.68 28.74 GPT -4.1 + Agent 6.86 5.90 8.89 9.13 7.68 38.47 GPT -4o 3.08 2.11 8.96 8.79 3.64 26.58 GPT -4o + Agent 5.59 4.49 8.55 8.16 6.29 33.08 DeepSeek V3.2 3.19 2.32 8.83 8.83 4.39 27.55 DeepSeek V3.2 + Agent 6.94 6.49 8.78 8.72 7.76 38.69 Claude Sonnet 4.5 3.34 2.74 8.65 8.12 4.84 27.69 Claude Sonnet 4.5 + Agent 7.34 7.36 8.88 9.03 8.06 40.67 Open-Sour ce LLMs Qwen3-8B 2.84 2.16 8.59 8.66 4.36 26.61 Qwen3-8B + Agent 4.52 3.77 8.29 7.83 5.62 30.03 Qwen3-32B 3.04 2.41 8.71 8.74 5.02 27.91 Qwen3-32B + Agent 4.99 4.21 8.50 8.16 6.22 32.08 Llama-3.3-70B-Instruct 2.34 1.75 8.68 8.47 3.08 24.32 Llama-3.3-70B-Instruct + Agent 2.84 2.11 8.09 7.18 3.51 23.73 Devstral-Small-2-24B-Instruct 2.65 2.14 8.57 8.31 3.77 25.44 Devstral-Small-2-24B-Instruct + Agent 6.61 5.66 8.81 9.09 7.13 37.30 F inetuned LLMs SWE-QA-Pro-8B (SFT) 2.56 2.01 8.37 7.93 3.55 24.42 SWE-QA-Pro-8B (SFT) + Agent 5.66 5.45 8.40 8.21 6.61 34.34 SWE-QA-Pro-8B (SFT+RL) 2.54 2.04 8.28 7.92 3.55 24.34 SWE-QA-Pro-8B (SFT+RL) + Agent 5.96 5.66 8.51 8.44 6.83 35.39 T able 2: SWE-QA-Pro Bench e valuation results. “+agent” denotes models using the SWE-QA-Pro agent frame work. Best results per scale are shown in bold , with second-best underlined. 4.3 T ool Usage Analysis Figure 4 correlates tool proficiency with repository- le vel QA performance. Models with lower scores, such as LLaMA-3.3-70B-Instruct and GPT -4o, suf fer from weak tool usage that limits context retrie v al and global understanding. Conv ersely , Claude Sonnet 4.5 excels by leveraging the high- est volume of tool calls, translating robust explo- ration into superior answer quality . Gemini 2.5 Pro, ho we ver , remains competiti ve with fe wer calls, in- dicating that internal reasoning enables ef ficient, selecti ve tool use; this underscores that reasoning is vital alongside tool capacity . Additionally , post-RL improv ements in SWE-QA-Pro 8B demonstrate that RL fosters effecti ve, judicious execution rather than merely inflating tool-call frequency . 4.4 T raining Strategy Analysis Figure 5 compares different training strate gies un- der the same model backbone. SFT -1000 and SFT - 1464 denote supervised fine-tuning on 1,000 and 1,464 tool-call trajectories, respecti vely , while SFT - 1000 + RL-464 represents a two-stage setting that initializes the model with 1,000 SFT trajectories and then applies reinforcement learning on an addi- tional 464 QA pairs. Increasing the amount of su- pervised fine-tuning data from 1,000 to 1,464 trajec- tories yields consistent b ut modest improv ements across most ev aluation dimensions. In contrast, in- troducing reinforcement learning after SFT leads to a more pronounced performance gain. In particular , SFT -1000 + RL-464 achie ves substantially higher scores in both Correctness and Completeness than SFT -only variants, including SFT -1464. This in- dicates that reinforcement learning does not sim- ply replicate the ef fect of scaling supervised data, but instead introduces a qualitati vely different op- timization signal that further unlocks the potential of the SFT -initialized model, encouraging more ac- curate and more comprehensi v e answers. Overall, these results suggest that RL provides complemen- tary supervision be yond SFT , especially ef fecti ve at refining factual precision and answer co verage. 5 Related W ork Code-centric and Repository-level QA Bench- marks. Existing code and repository QA bench- marks focus on localized or context-limited set- tings, where questions can be answered from snip- pets, APIs, or documentation. Representativ e 7 Figure 4: T ool usage behavior across models on SWE-QA-Pro. Figure 5: Effect of T raining Strate gy . W e compare SFT at different scales and a two-stage SFT → RLAIF setting. datasets such as CodeQueries, CS1QA, CoSQA, CoSQA+, and CodeSearchNet emphasize element- le vel reasoning or retriev al over individual func- tions, deliberately a voiding cross-file dependencies and repository structure ( Sahu et al. , 2024 ; Lee et al. , 2022 ; Huang et al. , 2021 ; Gong et al. , 2024 ; Husain et al. , 2019 ). InfiBench extends ev alua- tion to free-form coding-related questions across languages, but remains knowledge- and snippet- centric rather than repository-grounded ( Li et al. , 2024 ). More recent ef forts mov e to ward repository- scale ev aluation. LongCodeBench relies on long context windo ws to ingest large codebases ( Rando et al. , 2025 ), while RepoChat uses offline index- ing for structured retriev al ( Abedu et al. , 2025 ). SWE-QA formulates repository understanding as a QA task ( Peng et al. , 2025 ), but does not ex- plicitly separate cases solvable by standard re- trie v al. In contrast, SWE-QA-Pro targets long- tail, ex ecutable repositories and filters out retriev al- solv able queries, isolating scenarios that require interacti ve code e xploration. Repository-lev el Agents. Agents in software en- gineering largely tar get generati ve tasks, including issue resolution, program repair , and code genera- tion ( Jimenez et al. , 2023 ; Y ang et al. , 2024 ; Zhang et al. , 2024 ; Da et al. , 2025 ; Li et al. , 2025 ; Bi et al. , 2024 ; Bairi et al. , 2024 ). In these domains, exploration is implicitly shaped by generation ob- jecti ves rather than comprehension. Con versely , repository-le vel QA demands strict code navigation and understanding. Prior approaches, such as SWE- QA-Agent, rely on inference-time heuristics for tool use, often underperform retrie val-augmented generation (RA G) baselines due to unoptimized navig ation ( Peng et al. , 2025 ). W e address this lim- itation by explicitly training repository exploration policies, bridging the gap between passi ve retriev al and acti ve agentic na vigation. 6 Conclusion In this work, we address the challenge of e valuating and training Large Language Models for repository- le vel code understanding, where reliance on mem- orized kno wledge often masks deficits in genuine exploration capabilities. By introducing SWE-QA- Pro, we establish a rigorous testbed that enforces semantic div ersity through long-tail repositories and systematically filters out questions solvable by direct answering. The substantial performance gap observed between direct and agentic baselines on this benchmark confirms that our design success- fully isolates tasks requiring authentic codebase navig ation and e vidence grounding. Beyond ev aluation, we show that agentic capabil- ities can be learned using a scalable framework. W e 8 propose a two-stage SFT → RLAIF training recipe enabled by a synthetic data pipeline. A Qwen3-8B model trained with this recipe surpasses GPT -4o on SWE-QA-Pro and substantially narrows the gap to state-of-the-art proprietary models. W e hope SWE- QA-Pro catalyzes future research to ward activ e, grounded repository reasoning. Limitations The objectiv e of SWE-QA-Pro is to provide a chal- lenging benchmark and practical training recipe, yet we identify three limitations. First, despite employing semantic embedding clustering to max- imize topical coverage, the benchmark is con- strained to 260 questions from 26 repositories due to the high cost of expert human v erification; this scale may not fully capture the extreme long-tail di versity of the software ecosystem, and the embed- ding models used for clustering could inadv ertently introduce latent biases into the taxonomy . Second, the benchmark is currently restricted to the Python ecosystem due to the strict requirement for exe- cutable sandboxes to verify agent actions, though our data synthesis and agentic training pipeline is inherently language-agnostic and can be readily e x- tended to other languages with compatible runtime en vironments. Third, our RLAIF training objec- ti ves share a similar distribution with ev aluation metrics as both rely on LLM-as-a-Judge frame- works, creating a potential risk of re ward hacking where models optimize for judge preferences rather than objecti ve correctness. While preliminary case studies did not rev eal significant gaming behav- iors, this proximity suggests that future research should prioritize in vestigating more robust train- ing methodologies—such as process supervision or di verse re ward modeling—to mitigate such align- ment risks. References Samuel Abedu, Laurine Menneron, SayedHassan Kha- toonabadi, and Emad Shihab . 2025. Repochat: An llm-powered chatbot for github repository question- answering. In 2025 IEEE/ACM 22nd International Confer ence on Mining Softwar e Repositories (MSR) , pages 255–259. IEEE. Anthropic. 2025. Claude sonnet 4.5 system card. https://www.anthropic.com/news/ claude- sonnet- 4- 5 . Accessed: 2025-10-27. Ibragim Badertdinov , Alexander Golube v , Maksim Nekrashevich, Anton She vtsov , Simon Karasik, An- drei Andriushchenko, Maria T rofimov a, Daria Litv- intsev a, and Boris Y angel. 2025. Swe-rebench: An automated pipeline for task collection and decon- taminated ev aluation of software engineering agents. arXiv pr eprint arXiv:2505.20411 . Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, V ageesh D C, Arun Iyer, Suresh Parthasarathy , Sriram Rajamani, Balasubramanyan Ashok, and Shashank Shet. 2024. Codeplan: Repository-level coding using llms and planning. Pr oceedings of the A CM on Softwar e Engineering , 1(FSE):675–698. Zhangqian Bi, Y ao W an, Zheng W ang, Hongyu Zhang, Batu Guan, Fangxin Lu, Zili Zhang, Y ulei Sui, Hai Jin, and Xuanhua Shi. 2024. Iterativ e refinement of project-level code context for precise code gen- eration with compiler feedback. arXiv pr eprint arXiv:2403.16792 . Jialiang Chen, Kaifa Zhao, Jie Liu, Chao Peng, Jierui Liu, Hang Zhu, Pengfei Gao, Ping Y ang, and Shuiguang Deng. 2025. Coreqa: uncovering poten- tials of language models in code repository question answering. arXiv pr eprint arXiv:2501.03447 . Gheorghe Comanici, Eric Bieber , Mike Schaekermann, Ice Pasupat, No veen Sachde va, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Ev an Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with adv anced reasoning, multimodality , long context, and next generation agentic capabilities. arXiv pr eprint arXiv:2507.06261 . Jeff Da, Clinton W ang, Xiang Deng, Y untao Ma, Nikhil Barhate, and Sean Hendryx. 2025. Agent- rlvr: T raining software engineering agents via guid- ance and en vironment rew ards. arXiv preprint arXiv:2506.11425 . Abhimanyu Dubey , Abhina v Jauhri, Abhinav P ande y , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Y ang, Angela Fan, and 1 others. 2024. The llama 3 herd of models. arXiv pr eprint arXiv:2407.21783 . Jing Gong, Y anghui W u, Linxi Liang, Y anlin W ang, Jiachi Chen, Mingwei Liu, and Zibin Zheng. 2024. Cosqa+: Pioneering the multi-choice code search benchmark with test-dri ven agents. arXiv pr eprint arXiv:2406.11589 . Ruida Hu, Chao Peng, Jingyi Ren, Bo Jiang, Xiangxin Meng, Qinyun W u, Pengfei Gao, Xinchen W ang, and Cuiyun Gao. 2024. Coderepoqa: A lar ge-scale benchmark for software engineering question answer- ing. arXiv pr eprint arXiv:2412.14764 . Junjie Huang, Duyu T ang, Linjun Shou, Ming Gong, Ke Xu, Daxin Jiang, Ming Zhou, and Nan Duan. 2021. Cosqa: 20,000+ web queries for code search and question answering. arXiv pr eprint arXiv:2105.13239 . Aaron Hurst, Adam Lerer, Adam P Goucher , Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow , 9 Akila W elihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276 . Hamel Husain, Ho-Hsiang W u, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. Code- searchnet challenge: Evaluating the state of semantic code search. arXiv pr eprint arXiv:1909.09436 . Dongfu Jiang, Y i Lu, Zhuofeng Li, Zhiheng L yu, Ping Nie, Haozhe W ang, Alex Su, Hui Chen, Kai Zou, Chao Du, and 1 others. 2025. V erltool: T owards holistic agentic reinforcement learning with tool use. arXiv pr eprint arXiv:2509.01055 . Carlos E Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, K exin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language mod- els resolve real-w orld github issues? arXiv pr eprint arXiv:2310.06770 . Changyoon Lee, Y eon Seonwoo, and Alice Oh. 2022. Cs1qa: A dataset for assisting code-based question answering in an introductory programming course. arXiv pr eprint arXiv:2210.14494 . Harrison Lee, Samrat Phatale, Hassan Mansoor , Kel- lie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, V ictor Carbune, and Abhinav Rastogi. 2023. Rlaif: Scaling reinforcement learn- ing from human feedback with ai feedback. arXiv e-prints . Han Li, Y uling Shi, Shaoxin Lin, Xiaodong Gu, Heng Lian, Xin W ang, Y antao Jia, T ao Huang, and Qianx- iang W ang. 2025. Swe-debate: Competitive multi- agent debate for software issue resolution. arXiv pr eprint arXiv:2507.23348 . Linyi Li, Shijie Geng, Zhenwen Li, Y ibo He, Hao Y u, Ziyue Hua, Guanghan Ning, Siwei W ang, T ao Xie, and Hongxia Y ang. 2024. Infibench: Evaluating the question-answering capabilities of code large lan- guage models. Advances in Neural Information Pr o- cessing Systems , 37:128668–128698. Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingx- uan W ang, Bingzheng Xu, Bochao W u, Bowei Zhang, Chaofan Lin, Chen Dong, and 1 others. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv pr eprint arXiv:2512.02556 . Chenxiao Liu and Xiaojun W an. 2021. Codeqa: A question answering dataset for source code compre- hension. arXiv pr eprint arXiv:2109.08365 . OpenAI. 2025. Introducing gpt-4.1 in the api. https: //openai.com/index/gpt- 4- 1/ . Accessed: 2026- 01-06. W eihan Peng, Y uling Shi, Y uhang W ang, Xinyun Zhang, Beijun Shen, and Xiaodong Gu. 2025. Swe-qa: Can language models answer repository-le vel code ques- tions? arXiv pr eprint arXiv:2509.14635 . Stefano Rando, Luca Romani, Alessio Sampieri, Luca Franco, John Y ang, Y uta K yuragi, Fabio Galasso, and T atsunori Hashimoto. 2025. Longcodebench: Eval- uating coding llms at 1m context windows. arXiv pr eprint arXiv:2505.07897 . Abhinav Rastogi, Adam Y ang, Albert Q Jiang, Alexan- der H Liu, Alexandre Sablayrolles, Amélie Héliou, Amélie Martin, Anmol Agarwal, Andy Ehrenberg, Andy Lo, and 1 others. 2025. Devstral: Fine-tuning language models for coding agent applications. arXiv pr eprint arXiv:2509.25193 . Surya Prakash Sahu, Madhurima Mandal, Shikhar Bharadwaj, Aditya Kanade, Petros Maniatis, and Shirish Shev ade. 2024. Codequeries: A dataset of semantic queries ov er code. In Pr oceedings of the 17th Innovations in Softwar e Engineering Confer- ence , pages 1–11. Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Hao wei Zhang, Mingchuan Zhang, YK Li, Y ang W u, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv pr eprint arXiv:2402.03300 . An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , and 1 others. 2025. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 . John Y ang, Carlos E Jimenez, Alexander W ettig, Kilian Lieret, Shunyu Y ao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Pr ocessing Systems , 37:50528– 50652. Y untong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury . 2024. Autocoderover: Autonomous program improvement. In Pr oceedings of the 33r d A CM SIGSOFT International Symposium on Soft- war e T esting and Analysis , pages 1592–1604. Y uze Zhao, Jintao Huang, Jinghan Hu, Xingjun W ang, Y unlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai W u, Baole Ai, Ang W ang, and 1 others. 2025. Swift: a scalable lightweight infrastructure for fine-tuning. In Pr oceedings of the AAAI Conference on Artificial Intelligence , v olume 39, pages 29733–29735. 10 T able of Contents in A ppendix A Cluster Coverage of SWE-QA Bench 12 B SWE-QA-Pro Agent Algorithm 14 C T raining Hyperparameters 15 D Prompts 16 E Cluster and QA T ype T axonomy 21 F Statistics of SWE-QA-Pro 25 G Breakdo wn Results in SWE-QA-Pr o 27 G.1 Breakdo wn Results By QA T ype . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 G.2 Breakdo wn Results By Repository Name . . . . . . . . . . . . . . . . . . . . . . . . . 28 G.3 Breakdo wn Results By Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 H Case Study 34 H.1 Cases of Model Comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 H.2 Case Studies of Human and Model Reference Answers . . . . . . . . . . . . . . . . . . 36 I Ethics and Reproducibility Statements 39 I.1 Potential Risks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 I.2 Discuss the License for Artifacts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 I.3 Artifact Use Consistent W ith Intended Use . . . . . . . . . . . . . . . . . . . . . . . . . 39 I.4 Data Contains Personally Identifying Info or Of fensi ve Content . . . . . . . . . . . . . . 39 I.5 Documentation of Artifacts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 I.6 Parameters for P ackages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 I.7 Data Consent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 I.8 AI Assistants in Research or Writing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 11 A Cluster Coverage of SWE-QA Bench Cluster ID Cluster Name Original Ratio (%) T est Ratio (%) Coverage ( × ) Origin Count T est Count 0.0 Unicode / formatting / parsing / data validation 2.04 0.00 0.00 17,185 0 0.1 SQL / structured grammar / templating Engine 2.67 1.89 0.71 22,489 10 0.2 CLI args / syntax / re gex / com- mand completion 2.08 3.22 1.55 17,518 17 0.3 file import/export / metadata / sorting / recurrence 1.89 0.19 0.10 15,940 1 1.0 data formats / FITS / Astropy / units / WCS 0.93 8.14 8.78 7,825 43 1.1 pandas / parquet / datetime / Dask / table schema 1.77 0.57 0.32 14,917 3 1.2 numpy / dask arrays / dtype / array serialization / parallel 1.96 8.33 4.24 16,571 44 1.3 coordinate transform / image processing / IO / numeric pre- cision 3.99 0.00 0.00 33,660 0 2.0 protocol serialization / encod- ing / headers / API compatibil- ity 1.25 0.00 0.00 10,573 0 2.1 dependency injection / config / attrs / API design 2.27 7.20 3.17 19,168 38 2.2 dataclass / schema validation / enums / OpenAPI 1.68 0.76 0.45 14,190 4 2.3 type and attribute errors / ini- tialization / CLI workflo w 2.00 0.19 0.09 16,837 1 2.4 type hints / mypy / typing sys- tem / code generation 1.71 1.52 0.89 14,436 8 3.0 Python version / imports / dep- recation / conflicts 1.93 0.00 0.00 16,300 0 3.1 install / virtual en v / OS / hard- ware requirements / cloud de- ploy 2.14 0.00 0.00 18,035 0 3.2 artifacts / distrib ution format / repository management / post- install state 2.09 0.57 0.27 17,677 3 3.3 extensibility / configuration framew ork / plugin architec- ture 2.96 0.00 0.00 24,998 0 4.0 version control / Dock er / b uild cache 1.81 0.00 0.00 15,274 0 4.1 release management / changelog / license / commu- nity 1.98 0.00 0.00 16,692 0 4.2 documentation / MkDocs / user tutorials 3.11 5.30 1.70 26,274 28 4.3 async refactor / migration / log- ging infra / i18n 2.37 0.38 0.16 19,972 2 4.4 CI pipelines / coverage / lint / GitHub Actions / security checks 1.30 0.19 0.15 11,011 1 T able 3: Cluster Cov erage (1.0 - 4.4): SWE-Rebench (Original) vs. SWE-QA (T est). [Back to Appendix Contents] 12 Cluster ID Cluster Name Original Ratio (%) T est Ratio (%) Coverage ( × ) Origin Count T est Count 5.0 asyncio / async context / re- source cleanup 2.11 0.19 0.09 17,811 1 5.1 multiprocessing / advanced runtime / concurrency / hetero- geneous compute 1.07 0.00 0.00 9,034 0 5.2 runtime error handling / DB transactions / retry / logging system 2.48 0.76 0.31 20,891 4 5.3 threading / ex ecution limits / scheduling / memory / timeout 2.17 0.76 0.35 18,278 4 5.4 connection lifecycle / protocol handling / low-le vel failures 2.08 0.19 0.09 17,569 1 5.5 parallel ex ecution / distributed framew orks / task graphs 1.72 0.00 0.00 14,511 0 6.0 file paths / filesystem permis- sions / symlinks / en v config / cache system 2.13 0.76 0.36 17,982 4 6.1 unit testing / mocking / test au- tomation 2.05 8.90 4.34 17,323 47 6.2 build pipeline / doc b uilding / Sphinx / cloud provisioning 3.30 0.00 0.00 27,858 0 6.3 compiler toolchain / cross- compile / en v v ars / code qual- ity analysis 1.42 0.00 0.00 11,984 0 7.0 API integration / sync / perfor- mance / DB / SDK 2.62 0.95 0.36 22,067 5 7.1 media download / playlist / metadata / client-side proxy config 1.13 0.00 0.00 9,532 0 7.2 auth systems / deployment / extension plugins / cloud ser - vices 2.21 2.46 1.11 18,668 13 7.3 A WS / Azure / K8s / container security / IAM policy 2.20 0.00 0.00 18,531 0 7.4 rev erse proxy / URL routing / websocket / CDN / streaming 1.42 15.34 10.79 12,000 81 7.5 O Auth / JWT / SSL / access control / user sessions/ token lifecycle 4.00 1.33 0.33 33,762 7 8.0 tensors / training / GPU / ML experiment logging / tuning 2.20 2.08 0.95 18,525 11 8.1 ML analytical visualization / Fourier / ML animation / cali- bration 2.76 1.33 0.48 23,278 7 8.2 time series / feature engineer- ing / explainability methods / behavioral analysis / computa- tional semantics 0.90 2.46 2.73 7,606 13 8.3 data parallel / compression / ML plugin / indexing 2.39 2.65 1.11 20,182 14 8.4 bayesian models / MCMC / statistics / reproducibility 1.67 1.14 0.68 14,066 6 8.5 ML APIs / decorators / metrics / optimization strategies 2.15 10.61 4.94 18,116 56 9.0 UI layout / CSS / markdo wn / table extraction / frontend se- curity 2.30 0.38 0.16 19,450 2 9.1 plotting systems / widgets / maps / UI animation / usability 1.78 4.92 2.77 14,995 26 9.2 runtime UI config / UI permis- sion management / upload han- dling / customization / user- facing runtime extensibility 2.09 0.19 0.09 17,643 1 9.3 3D rendering / legends / color mapping / visualization for - matting 1.73 4.17 2.41 14,615 22 T able 4: Cluster Cov erage (5.0 - 9.3): SWE-Rebench (Original) vs. SWE-QA (T est). [Back to Appendix Contents] 13 B SWE-QA-Pro Agent Algorithm Algorithm 1 SWE-QA-Pro Agent Require: User query Q , repository R Ensure: Final answer A 1: /* Phase 1: Initialization */ 2: context ← [ ] 3: thoug ht ← Anal y z e ( Q ) 4: context ← context ∪ { S emanticS ear ch ( Q, R ) } 5: /* Phase 2: Iterative ReAct Loop */ 6: max _ iter ations ← N 7: for i ← 1 to max _ iterations do 8: thoug ht ← Reason ( context, Q ) 9: action ← S el ectAction ( thoug ht ) 10: if action = S emanticS ear ch then 11: output ← E xecute ( S emanticS ear ch ) 12: else if action = V iew C odebase then 13: output ← E xecute ( V iew C odebase ) 14: else if action = E xecuteC ommand then 15: output ← E xecute ( E xecuteC ommand ) 16: end if 17: context ← context ∪ { output } 18: if S uf f icientE v idence ( context, Q ) or i = max _ iterations then 19: break 20: end if 21: end for 22: /* Phase 3: Finalization */ 23: A ← S y nthesiz e ( context, Q ) 24: return A 14 C T raining Hyperparameters Hyperparameter V alue Precision bfloat16 Max sequence length 32,768 Optimizer AdamW Learning rate 5 × 10 − 6 W eight decay 0.05 LR scheduler Cosine W armup ratio 0.05 Batch size (per device) 1 Gradient accumulation 2 Epochs 4 Agent template Hermes T able 5: Hyperparameters for SFT of SWE-QA-Pro 8B. [Back to Appendix Contents] Hyperparameter V alue Max turns 25 Max prompt length 2,048 Max response length 8,192 Max observation length 28,000 T emperature 1.0 T op-p 1.0 Number of rollouts (n) 8 KL loss coefficient 0.02 KL loss type Low-v ariance KL Entropy coef ficient 0 Actor learning rate 1 × 10 − 6 Batch size 8 PPO mini-batch size 8 Strategy FSDP Max model length 32,768 T able 6: Hyperparameters for RL of SWE-QA-Pro 8B. [Back to Appendix Contents] 15 D Prompts Prompt T emplate for LLM-as-J udge Model: GPT -5 Y ou are a professional ev aluator . Please rate the candidate answer against the reference answer based on fi ve criteria. Ev aluation Criteria and Scoring Guidelines (each scored 1 to 10): 1. Correctness: 10 — Completely correct; core points and details are accurate with no ambiguity . 8-9 — Mostly correct; only minor details are slightly inaccurate or loosely expressed. 6-7 — Partially correct; some errors or omissions, b ut main points are generally accurate. 4-5 — Sev eral errors or ambiguities that af fect understanding of the core information. 2-3 — Many errors; misleading or fails to con vey k ey information. 1 — Serious errors; completely wrong or misleading. 2. Completeness: 10 — Cov ers all key points from the reference answer without omission. 8-9 — Cov ers most key points; only minor non-critical information missing. 6-7 — Missing sev eral ke y points; content is some what incomplete. 4-5 — Important information largely missing; content is one-sided. 2-3 — Cov ers very little rele v ant information; seriously incomplete. 1 — Cov ers almost no relev ant information; completely incomplete. 3. Rele vance: 10 — Content fully focused on the question topic; no irrelev ant information. 8-9 — Mostly focused; only minor irrelev ant or peripheral information. 6-7 — Generally on topic; some off-topic content b ut still rele v ant ov erall. 4-5 — T opic not sufficiently focused; contains considerable off-topic content. 2-3 — Content deviates from topic; includes e xcessi ve irrele vant information. 1 — Majority of content irrelev ant to the question. 4. Clarity: 10 — Fluent language; clear and precise expression; v ery easy to understand. 8-9 — Mostly fluent; clear expression with minor unclear points. 6-7 — Generally clear; some expressions slightly unclear or not concise. 4-5 — Expression somewhat a wkward; some ambiguity or lack of fluenc y . 2-3 — Language obscure; sentences are not smooth; hinders understanding. 1 — Expression confusing; very dif ficult to understand. 5. Reasoning: 10 — Reasoning is clear , logical, and well-structured; ar gumentation is excellent. 8-9 — Reasoning is clear and logical; well-structured with solid argumentation. 6-7 — Reasoning generally reasonable; mostly clear logic; minor jumps. 4-5 — Reasoning is av erage; some logical jumps or org anization issues. 2-3 — Reasoning unclear; lacks logical order; difficult to follo w . 1 — No clear reasoning; logic is chaotic. INPUT : Question:{question} Reference Answer:{reference} Candidate Answer:{candidate} OUTPUT : Please output ONL Y a JSON object with 5 integer fields in the range [1,10], corresponding to the e v aluation scores: {{ "correctness": <1-10>, "completeness": <1-10>, "relevance": <1-10>, "clarity": <1-10>, "reasoning": <1-10> }} REQUIREMENT : Y ou should assume that a score of 5 represents an a verage b ut imperfect answer . Scores abov e 7 should be reserved for answers that are clearly strong. Do not infer or assume missing information. Score strictly based on what is explicitly stated. No e xplanation, no extra te xt, no formatting other than v alid JSON 16 Prompt T emplate for Generating Answer Model: All Ev aluated Model System Prompt: Y ou are a codebase analysis agent operating in a strictly read-only en vironment. Y our task is to answer SWE-related questions by analyzing source code, configuration, documentation, and tests. Y ou must prioritize correctness, completeness, clarity , relev ance and evidence-based reasoning when answering given questions within 25 max turns. PROCESS PROTOCOL (MANDATORY) For e very question, you MUST follo w this process: 1. Planning Before calling any tools, you MUST output a short planning e xplanation at each turn. * Explain step by step what you hav e found so far from the current conte xt, and what you will inspect next and why . * This reasoning MUST be explicit and visible. 2. In vestigation * Call one or more read-only tools to gather e vidence. * Multiple tool calls in one turn are allowed. 3. Synthesis * Combine evidence acoss multiple files or components. * Do NO T rely on a single file unless clearly justified. 4. Finalization * Produce a final answer following the OUTPUT PR O TOCOL. TOOL USAGE RULES A vailable tools: * semantic_search: find rele vant files, symbols, or modules. * viewcodebase: inspect structure or specific file sections. * Prefer ‘concise=True‘ first; use ‘vie wrange‘ when needed. Prefer using vie wcodebase; avoid using ls -l or ls -R whenev er possible. Don’t use tree without -L. * ex ecutereadonlycommand: small, focused inspection tasks that require raw command output (A void using command-line operations that produce excessi ve and uncontrollable output, DON’t use ls -R path and ls -lR path as a command). Y ou may call one or more functions to assist with the user query . Y ou are provided with function signatures within {tools} OUTPUT PROTOCOL (STRICT) Y ou MUST follo w this output structure at each assitant turn: 1. Reasoning * Before any tool call, output only your step by step planning e xplanation 2. Final Answer * Output **exactly one** block in this format without an y tool calls: <finish> {Final answer’s content} Rules for ‘<finish>‘ block: * Must appear exactly once. * Must contain only the final answer’ s content. * NO code blocks or copied code such as “‘python ...““. * Cite evidence only using file paths relati ve to repo_path, in the format : line - (do not use absolute paths) e.g. responses/init.py: line 1-10. Any violation of this protocol makes the answer in valid. The working directory (where the code is e xecuted) is /data/songcheng/SWE-QA-Pro-de v/eval. Now the code repo at repopath. Please use absolute paths in all tools. User Prompt: Repository Path: repopath Question:question Instructions: - Please analyze the codebase to answer this question. - Provide a step-by-step e xplanation before calling any tools. - Follo w this workflo w: 1) Inspect the repository structure 2) Search for relev ant files and symbols 3) Examine specific implementations 4) Cross-validate your findings 5) Provide a complete answer with e vidence inside a <finish> block 17 Prompt T emplate for Generating Query Candidates Model: Claude Code Y ou are a repository-aw are planning agent. Y our job is NO T to modify code, b ut to: (1) lightly explore the local repository , (2) generate ONE high-quality dev eloper Query tailored to this repo, (3) classify it with: cluster , task_type, clarity (0–5), context (0–5), dif ficulty (0–6), (4) provide e vidence (paths, line ranges for each paths, signals) and a concise rationale summary , (5) produce a detailed NEXT_STEPS plan that explains ho w to solv e the generated Query using your general software knowledge and the repo e vidence. Each step must reference specific file paths and line ranges from the evidence. Keep internal reasoning pri vate. Output must follow the strict JSON schema at the end. [SUGGESTED — OPTION AL, USER-CUSTOMIZABLE] - Goal bias: prefer qa_verifiable tasks that ask for structural, architectural, or algorithmic explanations with standard answers - Risk preference: av oid trivial or opinion-based questions; push toward mid/high-lev el system questions (e.g., how modules interact, why design chosen) - Domain preference: explanations tied to repo internals, standardized APIs, algorithmic design, or widely accepted con ventions - Complexity tar get: cover dif ficulty 2–5 (multi-step reasoning about design/structure, not trivial lookups) - Output style: queries must include a ground_truth_answer field that captures a definiti ve, e vidence-based e xplanation [/SUGGESTED] ——————————– BUCKET / CLUSTER INDEX (L1 → L2) ——————————– Choose the tightest cluster (prefer L2; if uncertain, use L1). The “cluster” field will include [id, name]. cluster_taxonomy ——————- QA_VERIFIABLE T AXONOMY ——————- qa_type_taxonomy ——————- LABELING DEFINITIONS ——————- Clarity (0-5): 0 extremely v ague; 1 v ery vague; 2 vague; 3 w orkable with small additions; 4 clear (acceptance feasible); 5 very clear (explicit acceptance/tests). Context (0-5): 0 no repo/en v needed; 1 light reference; 2 local file/API awareness; 3 multi-file/module; 4 system-lev el; 5 deep en v/data/service coupling. Difficulty (0-6): 0 tri vial QA; 1 simple single-point; 2 routine; 3 moderately complex (multi-step or multi-file); 4 advanced (design/concurrency/test-hea vy); 5 high complexity (tradeof fs, cross-domain, higher risk); 6 extreme system-le vel with high uncertainty . ———— WORKFLO W STEPS ———— 1) Light repo scan: identify system-lev el modules, architecture diagrams, abstract base classes, registries, or pipelines. 2) Extract the repository info from the input and output it in the format: ‘"repo": ["owner/repo_name"]‘. 3) Map to cluster aligned with conceptual/system knowledge (algorithms, coordinate systems, unit registries, API design). 4) Generate the dev eloper Query: - must be a factual “what/ho w/why” about repo structures or algorithms, not tri vial docstring repeats; - answer must be checkable from code, docs, or API standards. 5) Score clarity , context, dif ficulty based on how well-defined and system-le vel the question is. 6) Evidence: point to modules, classes, or specs that define the authoritativ e structure. 7) NEXT_STEPS: describe how to cross-check the ground truth with codebase or documentation. 18 Prompt T emplate for Generating Query Candidates ————- QU ALITY RULES ————- - All queries must require an evidence-back ed, canonical answer (e.g., architecture, pipeline design, algorithm complexity). - The queries should encourage advanced analysis, integration of multiple concept, or insight beyond surface-le vel information. - All queries must contain exactly one of the following words: "What", "Why", "Where", or "How". The query must not contain more than one of these words or multiple sub-questions. For example, ’What is the architecture of chartpress’ s configuration system and how does it coordinate between chartpress.yaml parsing, image building workflows, and values.yaml modification?’ is in valid: - The evidence must e xplicitly include the rele v ant line numbers or line ranges for each repo_path. - Must include a "ground_truth_answer" string in the JSON output, summarizing the verified e xplanation. - Reject trivial “what is the type of X” unless it connects to a bigger design concept. - Prioritize non-trivial, yet v erifiable kno wledge that reflects the repo’ s system design or standards compliance. ————- USER PREFERENCE ————- W e HIGHL Y suggest you prioritize selecting problems from Cluster swe_issue_qa_1_0, since issues in this repo often fall into this domain. Since the clusters were generated through unsupervised clustering and the labels were assigned based on random sampling and manual annotation within each cluster, there may be inherent bias. If the assigned cluster label conflicts with the reference issues, always treat the reference issues as the source of truth. T o help you understand the typical patterns, here are some example issues from this repo. These are provided only as *reference context* to inform your reasoning. - If an issue has already been fixed, do not reuse it. - If an issue is still relev ant, you may paraphrase it into a fresh query . - Ideally , you should write your own problem statement, using the e xamples only as background knowledge. It is acceptable to generate a problem outside the recommended cluster if necessary — the examples are guidance, not a restriction. Repo name: {repo_name} Reference issues: {reference_issues} 19 Prompt T emplate for Generating Refer ence Answer Model: Claude Code Y ou are a repository-aw are QA answer agent. Y our job is NO T to modify code, b ut to: (1) Lightly explore the local repository at the gi ven commit using a vailable tools. (2) Understand and answer the giv en generated_query based on the actual codebase. (3) Produce a high-quality , evidence-backed gold-standard answer (refined_ground_truth) that satisfies the five dimensions: correctness, completeness, relev ance, clarity , and reasoning quality . (4) Optionally use reference_answer only as a weak hint, nev er as ground truth. ## Inputs Y ou W ill Receive * ‘repo_name‘ * ‘commit_id‘ * ‘generated_query‘ (the question you must answer) * ‘reference_answer‘ (may be partially correct, incomplete, or wrong) ## Y our Objecti ves Y ou must produce a final answer that is: * Fully verified against the repository’ s source code. * Structurally complete, cov ering all parts required by the query . * Clear and technically correct, written for dev elopers unfamiliar with the repo. * Evidence-based, with file paths and line ranges supporting your claims. * Free from speculation. ## Suggestions The following sections guide your beha vior during e xploration and answer construction. ### 1. How to Use ‘reference_answer‘ * T reat ‘reference_answer‘ as an **optional and unreliable hint**. * It may point to relev ant files or concepts, but you must verify e verything independently using the actual code. * Y ou must not summarize, lightly edit, or trust the reference answer . * If there is any contradiction between code and reference_answer , follow the code. * The correct mental model is ’ reference_answer is a hypothesis; the repository is the truth. ’ ### 2. Exploration & Evidence Collection Y ou must acti vely e xplore the repo: * Navigate to rele vant modules, subpackages, core classes, registries, and an y architecture files. * Inspect the implementations, comments, and interfaces rele v ant to the query . * T rack e verything you depend on in ‘e vidence.repo_paths‘, using e xact format: ‘"path/to/file.py: line X-Y"‘ * Collect signals, which are short text markers such as: class names, method names, configuration patterns, key comments and helper functions * Every important claim in your ‘refined_ground_truth‘ must be traceable to your collected e vidence. ### 3. Answer Style and Constraints Y our ‘refined_ground_truth‘ must obey: * No direct code quotations. * Y ou may name classes/functions/v ariables but do not cop y their bodies. * Format the answer as coherent paragraphs, not b ullet points. * The answer must be: concise but complete, technically precise, Clear for de velopers and Grounded in the repository . * Every major claim must be supported by file paths: line ranges you listed in ‘evidence‘. ## Required Output JSON Format Y ou must output **only** this JSON object: {JSON_EXAMPLE} ## W orking Procedure (Mental Checklist) 1. Read the ‘generated_query‘ and identify scope (architecture? registration? flow? algorithm?). 2. Lightly scan the repo structure to locate relev ant modules. 3. Open related files and gather evidence. 4. Build an internal understanding of the underlying architecture or behavior . 5. Compare your understanding with ‘reference_answer‘: keep what matches the repo, correct what is wrong and add missing key pieces. 6. Write a clean, well-organized gold answer in the ‘refined_ground_truth‘. 7. Fill in ‘evidence‘, ‘rationale_summary‘, and ‘ne xt_steps‘. 8. Output the JSON object. ## Input Repo Name: {repo_name} Commit ID: {commit_id} Generated Query: {generated_query} Reference Answer: {reference_answer} 20 E Cluster and QA T ype T axonomy Cluster Subcluster Description Input / Parsing / Data Con version Unicode / formatting / parsing / data validation Character encoding, string normalization, and file for- mat sanitization; focuses on correctness of raw text and low-le vel input structure. SQL / structured grammar / templat- ing engine SQL syntax, AST gram- mars, and templating sys- tems; cov ers grammar rules and templated string genera- tion. CLI ar gs / syntax / regex / command completion Argument parsing, Bash/Zsh completion, and re gex issues; applies when user input must be parsed or matched interactiv ely . File import/export / metadata / sort- ing / recurrence File loading, metadata extraction, sorting logic, and recurrence handling for structured data transfer . Data / Array / Image / Coordinate Data formats / FITS / Astrop y / units / WCS Scientific data formats and astronomy-specific coor - dinate systems, including units and world coordinate systems. Pandas / parquet / datetime / Dask / table schema T abular data manipulation, schema handling, and time- index ed datasets. NumPy / Dask arrays / dtype / seri- alization / parallel Numerical array operations, data types, chunking strate- gies, and array serialization. Coordinate transform / image pro- cessing / IO / precision Geometric transformations, image IO, and precision- sensitiv e numerical process- ing. Schema / T ypes / V alidation / Static Analysis Protocol serialization / encoding / headers / API compatibility Structured message formats and wire-lev el compatibility for APIs and protocols. Dependency injection / config / attrs / API design Software design patterns controlling configuration, object construction, and API structure. Dataclass / schema validation / enums / OpenAPI Structured field validation, enum constraints, and Ope- nAPI specifications. T ype and attribute errors / initializa- tion / CLI workflo w Runtime failures due to incorrect initialization, at- tribute access, or object life- cycle misuse. T ype hints / mypy / typing system / code generation Static typing, type check- ing, and auto-generated type stubs. Packaging / Dependency / Build Python version / imports / depreca- tion / conflicts Import errors, deprecated APIs, and Python version compatibility issues. Continued on next pa ge 21 Cluster Subcluster Description Install / virtual en v / OS / hardw are / cloud deploy En vironment setup, package installation, OS and hard- ware requirements, and de- ployment. Artifacts / distribution format / repository management Wheels, source distribu- tions, repository layout, and post-install package state. Extensibility / configuration frame- work / plugin architecture Plugin discov ery , extension mechanisms, and dynamic component loading. Docs / CI / Release / W orkflow V ersion control / Docker / build cache Git workflo ws, containeriza- tion strategies, and build cache management. Release management / changelog / license / community Release cycles, licensing policies, and community gov ernance. Documentation / MkDocs / user tu- torials Systems for generating and maintaining user-f acing doc- umentation. Async refactor / migration / logging / i18n Large-scale ref actoring, log- ging infrastructure, and in- ternationalization. CI pipelines / cov erage / lint / GitHub Actions Automated testing, linting, security checks, and CI ex e- cution. Runtime / Async / Errors / Resour ces Asyncio / async context / resource cleanup Coroutine scheduling, ev ent loops, async contexts, and cooperativ e concurrency . Multiprocessing / advanced runtime / heterogeneous compute Process pools, CPU/GPU scheduling, and multi- backend ex ecution. Runtime error handling / transac- tions / retry / logging Exception handling, roll- back mechanisms, and retry strategies. Threading / ex ecution limits / scheduling / memory OS-lev el threading, memory constraints, and timeout be- havior . Connection lifecycle / protocol han- dling / failures Socket errors, TLS issues, and low-le vel network fail- ures. Parallel ex ecution / distributed framew orks / task graphs Distributed execution mod- els such as Ray or Dask. Build En v / T esting / T oolchain File paths / filesystem / permissions / en v config OS-lev el filesystem config- uration and en vironment- dependent behavior . Unit testing / mocking / test automa- tion T est frameworks, mocks, and automated verification pipelines. Build pipeline / doc building / Sphinx / provisioning Automated build systems, documentation compilation, and provisioning. Compiler toolchain / cross-compile / static analysis Compiler behavior , environ- ment variables, and code quality analysis. API / Cloud / A uth / Network API integration / SDK / perfor- mance / DB External API usage, SDK in- tegration, and performance considerations. Media download / playlist / meta- data / proxy Media fetching, metadata extraction, and proxy config- uration. Continued on next pa ge 22 Cluster Subcluster Description Auth systems / deployment / cloud plugins Authentication services and cloud runtime behavior . A WS / Azure / Kubernetes / IAM Infrastructure orchestration and cloud security policies. Rev erse proxy / routing / websocket / CDN URL routing, real-time transport, and CDN integra- tion. O Auth / JWT / SSL / access control T oken-based authentication, certificates, and session life- cycle. ML / Algorithms / Perf ormance T ensors / training / GPU / experi- ment logging Model training, GPU exe- cution, and ML e xperiment management. ML visualization / Fourier / calibra- tion Analytical visualization and mathematical interpretation of models. T ime series / feature engineering / explainability Feature e xtraction, behav- ioral analysis, and computa- tional semantics. Data parallel / compression / ML plugins Distributed training and compressed data or model representations. Bayesian models / MCMC / statis- tics Probabilistic modeling and uncertainty-aware inference. ML APIs / metrics / optimization strategies Model interfaces, e v aluation metrics, and optimization behavior . V isualization / UI / Rendering UI layout / CSS / markdo wn / fron- tend security Layout, formatting, and se- curity of user-f acing con- tent. Plotting systems / widgets / maps / animation Charts, interactive widgets, and UI animations. Runtime UI config / permissions / uploads UI customization, permis- sion control, and file upload handling. 3D rendering / legends / color map- ping Rendering pipelines, color schemes, and legend format- ting. T able 7: Question Cluster taxonomy used in SWE-QA-Pro [Back to Appendix Contents] 23 T ype Intention Definition What Architecture exploration Identify components or structural organization of the system. Concept / Definition Understand the meaning or semantics of code elements. Dependency tracing Identify relationships or dependencies among code elements. Why Design rationale Explain why certain design decisions are made. Purpose exploration Understand the intended purpose of a function or component. Performance Understand performance considerations or trade-of fs. Where Data / Control-flow Localize variables, data flo w , or control statements. Feature location Identify where a specific feature is implemented. Identifier location Find where an identifier is defined or referenced. How System design Explain ov erall system behavior or e xecution w orkflo w . Algorithm implementation Understand algorithmic steps or logic implemented in code. API / Framew ork support Show ho w APIs or framew orks are used within the system. T able 8: T axonomy of Repository-Lev el Question Intentions [Back to Appendix Contents] 24 F Statistics of SWE-QA-Pro Cluster ID Cluster Name Count 0.0 Unicode / formatting / parsing / data validation 5 0.1 SQL / structured grammar / templating Engine 6 0.2 CLI args / syntax / re gex / command completion 8 0.3 file import/export / metadata / sorting / recurrence 6 1.0 data formats / FITS / Astropy / units / WCS 4 1.1 pandas / parquet / datetime / Dask / table schema 5 1.2 numpy / dask arrays / dtype / array serialization / parallel 6 1.3 coordinate transform / image processing / IO / numeric precision 4 2.0 protocol serialization / encoding / headers / API compatibility 4 2.1 dependency injection / config / attrs / API design 9 2.2 dataclass / schema validation / enums / OpenAPI 7 2.3 type and attribute errors / initialization / CLI w orkflow 7 2.4 type hints / mypy / typing system / code generation 7 3.0 Python version / imports / deprecation / conflicts 5 3.1 install / virtual en v / OS / hardware requirements / cloud deplo y 5 3.2 artifacts / distrib ution format / repository management / post-install state 4 3.3 extensibility / configuration frame work / plugin architecture 9 4.0 version control / Docker / b uild cache 4 4.1 release management / changelog / license / community 4 4.2 documentation / MkDocs / user tutorials 4 4.3 async refactor / migration / logging infra / i18n 5 4.4 CI pipelines / cov erage / lint / GitHub Actions / security checks 8 5.0 asyncio / async context / resource cleanup 7 5.1 multiprocessing / advanced runtime / concurrenc y / heterogeneous compute 7 5.2 runtime error handling / DB transactions / retry / logging system 8 5.3 threading / ex ecution limits / scheduling / memory / timeout 5 5.4 connection lifecycle / protocol handling / lo w-le vel f ailures 4 5.5 parallel ex ecution / distributed frame works / task graphs 4 6.0 file paths / filesystem permissions / symlinks / en v config / cache system 8 6.1 unit testing / mocking / test automation 5 6.2 build pipeline / doc b uilding / Sphinx / cloud provisioning 5 6.3 compiler toolchain / cross-compile / en v v ars / code quality analysis 6 7.0 API integration / sync / performance / DB / SDK 7 7.1 media download / playlist / metadata / client-side proxy config 5 7.2 auth systems / deployment / extension plugins / cloud services 5 7.3 A WS / Azure / K8s / container security / IAM policy 4 7.4 rev erse proxy / URL routing / websocket / CDN / streaming 5 7.5 O Auth / JWT / SSL / access control / user sessions/ token lifec ycle 4 8.0 tensors / training / GPU / ML experiment logging / tuning 4 8.1 ML analytical visualization / Fourier / ML animation / calibration 4 8.2 time series / feature engineering / explainability methods / behavioral analysis / computa- tional semantics 6 8.3 data parallel / compression / ML plugin / indexing 4 8.4 bayesian models / MCMC / statistics / reproducibility 5 8.5 ML APIs / decorators / metrics / optimization strategies 5 9.0 UI layout / CSS / markdown / table e xtraction / frontend security 4 9.1 plotting systems / widgets / maps / UI animation / usability 5 9.2 runtime UI config / UI permission management / upload handling / customization / user- facing runtime extensibility 4 9.3 3D rendering / legends / color mapping / visualization formatting 4 T able 9: Cluster Statistics (Counts per Question Cluster) [Back to Appendix Contents] 25 Class Name Sub-class Name Count T otal Num Why (Causal Queries) Performance & Scalability 33 65 Design Rationale 24 Purpose & Role 8 What (Factual Queries) Architecture & Components 20 51 Dependency & Inheritance 17 Concepts & Definitions 14 How (Pr ocedural Queries) System Design & Patterns 30 67 Algorithm Implementation 23 API & Framew ork Support 14 Where (Localization Queries) Identifier Location 32 77 Feature Location 30 Data & Control Flow 15 T able 10: QA T ype Statistics [Back to Appendix Contents] 26 G Breakdo wn Results in SWE-QA-Pr o G.1 Breakdo wn Results By QA T ype QA T ype Name Claude Sonnet 4.5 Gemini 2.5 Pro GPT 4.1 GPT -4o DeepSeek V3.2 A vg. Why (Causal Queries) 38.72 38.18 37.65 32.50 36.87 36.78 Performance & Scalability 37.27 37.32 37.69 29.34 35.30 35.39 Design Rationale 41.38 38.49 37.99 35.76 38.68 38.46 Purpose & Role 36.48 40.83 36.46 35.72 37.92 37.48 What (Factual Queries) 39.27 38.59 37.66 30.93 37.95 36.88 Architecture & Components 38.38 38.52 37.82 30.41 37.48 36.52 Dependency & Inheritance 40.57 36.73 37.65 31.78 37.04 36.75 Concepts & Definitions 38.92 40.98 37.45 30.64 39.71 37.54 How (Procedural Queries) 40.86 39.17 38.44 32.81 39.10 38.08 System Design & Patterns 39.07 38.17 37.19 32.94 37.60 36.99 Algorithm Implementation 42.85 40.42 40.45 34.00 40.62 39.67 API & Framew ork Support 41.64 39.29 37.83 30.62 39.81 37.84 Where (Localization Queries) 42.84 41.36 39.73 35.56 40.36 39.97 Identifier Location 45.32 42.46 41.44 37.59 41.85 41.73 Feature Location 41.90 41.79 39.20 36.71 40.40 40.00 Data & Control Flow 39.58 38.18 37.16 28.95 37.11 36.19 T able 11: Results across Different Question T ypes by SWE-QA-Pro [Back to Appendix Contents] QA T ype Name Qwen3 8B Qwen3 32B Devstral Small-2-24B-Ins Llama 3.3-70B-Ins SWE-QA-Pro 8B (SFT) SWE-QA-Pro 8B (SFT+RL) A vg. Why (Causal Queries) 31.52 32.83 35.52 26.66 32.35 33.54 32.07 Performance & Scalability 29.55 30.95 33.49 24.64 30.40 30.62 29.94 Design Rationale 33.74 34.68 38.56 28.39 34.66 37.42 34.57 Purpose & Role 33.04 35.00 34.75 29.71 33.46 33.96 33.32 What (Factual Queries) 29.28 30.11 36.50 21.69 32.95 34.17 30.78 Architecture & Components 28.33 29.52 36.53 20.78 32.97 34.87 30.50 Dependency & Inheritance 31.65 30.49 37.08 23.05 31.51 32.10 30.98 Concepts & Definitions 27.76 30.50 35.74 21.35 34.69 35.69 30.96 How (Procedural Queries) 28.43 31.57 37.60 22.43 35.30 35.84 31.86 System Design & Patterns 28.36 32.07 36.19 22.75 34.99 34.92 31.55 Algorithm Implementation 29.12 31.91 39.49 21.83 35.91 37.49 32.63 API & Framew ork Support 27.48 29.93 37.52 22.74 34.98 35.10 31.29 Where (Localization Queries) 30.67 33.21 39.09 23.67 36.10 37.36 33.35 Identifier Location 32.27 34.67 39.43 24.11 37.36 37.71 34.26 Feature Location 29.29 33.16 39.83 24.50 36.7 38.61 33.68 Data & Control Flow 30.02 30.20 36.89 21.08 32.18 34.13 30.75 T able 12: Results across Different Question T ypes (Open Models and SWE-QA-Pro V ariants) [Back to Appendix Contents] 27 G.2 Breakdo wn Results By Repository Name Repo Name Claude Sonnet 4.5 Gemini 2.5 Pro GPT 4.1 GPT -4o DeepSeek V3.2 A vg . PSyclone 38.37 37.97 34.53 25.68 35.20 34.35 Pillo w 39.90 37.33 39.33 33.73 37.93 37.64 cekit 42.47 39.77 39.37 32.80 38.47 38.58 checko v 37.10 36.90 34.30 28.40 36.27 34.59 docker -py 44.50 44.23 41.43 39.17 43.13 42.49 dwa ve-cloud-client 39.87 36.47 36.03 30.25 36.87 35.90 fitbenchmarking 41.47 39.63 40.33 37.83 38.63 39.58 frictionless-py 37.83 40.50 37.70 32.27 38.03 37.27 geopandas 39.80 40.70 38.83 35.42 38.63 38.68 hy 41.57 40.23 41.80 34.10 39.23 39.39 jsonargparse 37.33 33.10 33.13 31.70 34.73 34.00 mkdocs 43.20 40.97 38.83 35.12 41.97 40.02 numba 38.97 38.23 39.00 32.05 38.30 37.31 pennylane 38.37 41.47 37.60 30.48 38.30 37.24 pint 42.73 40.73 39.77 36.33 38.13 39.54 pybryt 40.33 41.77 38.97 35.80 40.43 39.46 qibo 43.27 38.90 39.53 33.48 40.50 39.14 responses 41.10 37.77 38.63 34.50 39.37 38.27 sanic 39.00 41.13 37.43 34.33 37.90 37.96 seaborn 42.97 41.73 39.07 32.95 39.87 39.32 sphinx 41.07 40.20 41.9 34.58 38.60 39.27 sqlfluf f 41.60 39.17 38.07 34.90 39.13 38.57 tox 41.07 40.67 40.00 35.40 39.03 39.23 web3.py 40.70 38.90 39.90 33.33 41.03 38.77 xarray 41.00 38.70 37.07 31.25 38.53 37.31 yt-dlp 41.97 38.83 37.70 26.24 37.73 36.49 T able 13: Results across Different Repositories by SWE-QA-Pro [Back to Appendix Contents] 28 Repo Name Qwen3 8B Qwen3 32B Devstral Small-2-24B-Ins Llama 3.3-70B-Ins SWE-QA-Pro 8B (SFT) SWE-QA-Pro 8B (SFT+RL) A vg. PSyclone 27.20 26.10 37.47 23.86 31.73 33.87 30.04 Pillow 29.60 31.80 36.27 24.50 35.37 32.70 31.71 cekit 28.07 33.27 39.57 23.07 35.87 33.83 32.28 checkov 27.47 29.20 34.43 22.68 33.62 32.73 30.02 docker -py 36.03 40.00 41.47 27.59 40.20 39.70 37.50 dwa ve-cloud-client 32.37 30.73 33.80 24.52 35.27 36.13 32.14 fitbenchmarking 32.83 34.50 38.43 22.00 38.00 38.90 34.11 frictionless-py 28.03 30.93 36.60 22.40 34.00 35.20 31.19 geopandas 29.43 33.27 37.73 25.90 34.57 35.43 32.72 hy 32.37 31.40 39.00 26.70 36.20 36.17 33.64 jsonargparse 31.17 31.10 29.20 21.35 28.93 32.87 29.10 mkdocs 32.40 33.63 41.43 23.80 36.23 38.33 34.30 numba 29.90 32.10 37.23 24.75 31.69 34.43 31.68 pennylane 28.47 32.23 33.80 18.03 33.13 32.27 29.66 pint 32.10 32.67 39.50 22.10 37.73 40.00 34.02 pybryt 31.37 34.43 39.00 23.65 35.70 37.63 33.63 qibo 26.30 30.10 37.10 22.10 35.70 37.10 31.40 responses 28.87 34.20 36.53 24.00 30.33 34.80 31.46 sanic 30.03 32.60 37.69 25.63 33.70 35.83 32.58 seaborn 30.67 33.00 37.90 24.90 34.13 35.73 32.72 sphinx 30.87 30.70 38.23 24.85 33.70 36.17 32.42 sqlfluff 28.90 30.87 36.30 22.52 33.67 36.00 31.38 tox 29.37 28.83 38.13 24.87 35.30 34.50 31.83 web3.py 28.87 33.17 38.43 23.95 33.93 33.03 31.90 xarray 29.83 31.93 38.33 22.25 34.20 34.13 31.78 yt-dlp 28.40 31.37 36.27 25.30 29.90 32.60 30.64 T able 14: Results across Different Repositories (Open Models and SWE-QA-Pro V ariants) [Back to Appendix Contents] 29 G.3 Breakdo wn Results By Cluster Cluster ID Name Claude Sonnet 4.5 Gemini 2.5 Pro GPT 4.1 GPT -4o DeepSeek V3.2 A vg. 0.0 Unicode / formatting / parsing / data valida- tion 42.73 41.07 38.07 34.20 38.00 38.81 0.1 SQL / structured grammar / templating En- gine 43.06 42.28 38.11 38.00 39.22 40.13 0.2 CLI args / syntax / rege x / command comple- tion 40.67 37.21 35.17 33.88 39.08 37.20 0.3 file import/export / metadata / sorting / recur- rence 36.20 37.17 34.06 29.75 39.17 35.27 1.0 data formats / FITS / Astropy / units / WCS 44.58 40.25 36.00 37.00 40.58 39.68 1.1 pandas / parquet / datetime / Dask / table schema 39.08 42.27 37.67 30.25 40.93 38.04 1.2 numpy / dask arrays / dtype / array serializa- tion / parallel 39.67 39.11 38.33 32.92 40.56 38.12 1.3 coordinate transform / image processing / IO / numeric precision 40.67 40.58 37.08 32.12 37.17 37.52 2.0 protocol serialization / encoding / headers / API compatibility 39.67 42.75 40.92 36.75 41.42 40.30 2.1 dependency injection / config / attrs / API design 42.42 40.19 38.37 33.86 40.19 39.00 2.2 dataclass / schema v alidation / enums / Ope- nAPI 40.95 34.10 33.67 27.96 37.29 34.79 2.3 type and attribute errors / initialization / CLI workflo w 44.14 41.90 42.81 35.54 41.33 41.15 2.4 type hints / mypy / typing system / code gen- eration 42.19 40.43 40.86 35.93 39.62 39.80 3.0 Python version / imports / deprecation / con- flicts 42.87 39.27 37.87 36.95 38.93 39.18 3.1 install / virtual env / OS / hardware require- ments / cloud deploy 39.80 35.67 38.93 29.75 36.27 36.08 3.2 artifacts / distribution format / repository management / post-install state 32.17 32.92 36.42 27.06 30.08 31.73 3.3 extensibility / configuration frame work / plu- gin architecture 38.00 39.37 38.67 34.11 38.63 37.76 4.0 version control / Docker / b uild cache 41.67 42.50 40.58 36.25 39.33 40.07 4.1 release management / changelog / license / community 37.17 41.83 39.17 34.81 35.67 37.73 4.2 documentation / MkDocs / user tutorials 40.42 39.17 37.50 29.00 39.25 37.07 4.3 async refactor / migration / logging infra / i18n 42.40 38.27 39.87 36.15 40.13 39.36 4.4 CI pipelines / coverage / lint / GitHub Actions / security checks 41.88 40.92 41.12 32.38 40.88 39.43 5.0 asyncio / async context / resource cleanup 40.10 36.38 39.95 31.07 36.48 36.80 5.1 multiprocessing / advanced runtime / concur - rency / heterogeneous compute 33.24 37.71 31.43 28.68 33.29 32.87 5.2 runtime error handling / DB transactions / retry / logging system 38.94 39.38 40.71 31.19 39.29 37.90 5.3 threading / ex ecution limits / scheduling / memory / timeout 39.33 32.33 34.27 25.20 32.40 32.71 5.4 connection lifecycle / protocol handling / low- lev el failures 44.50 43.58 41.67 41.31 41.50 42.51 5.5 parallel ex ecution / distributed frame works / task graphs 40.50 38.50 39.67 28.50 37.83 37.00 6.0 file paths / filesystem permissions / symlinks / en v config / cache system 42.50 40.83 41.50 38.03 42.83 41.14 6.1 unit testing / mocking / test automation 43.60 38.13 39.87 34.75 40.60 39.39 6.2 build pipeline / doc building / Sphinx / cloud provisioning 44.13 43.67 41.53 34.25 35.67 39.85 Continued on next pa ge 30 Cluster ID Name Claude Sonnet 4.5 Gemini 2.5 Pro GPT 4.1 GPT -4o DeepSeek V3.2 A vg. 6.3 compiler toolchain / cross-compile / env v ars / code quality analysis 42.11 39.28 40.56 36.96 41.17 40.01 7.0 API integration / sync / performance / DB / SDK 42.62 40.67 39.57 34.46 41.43 39.75 7.1 media download / playlist / metadata / client- side proxy config 38.83 38.53 33.93 18.83 35.47 33.12 7.2 auth systems / deployment / extension plug- ins / cloud services 44.47 44.07 43.00 39.15 44.27 42.99 7.3 A WS / Azure / K8s / container security / IAM policy 32.75 37.42 32.67 29.56 33.17 33.11 7.4 rev erse proxy / URL routing / websocket / CDN / streaming 44.07 43.60 40.67 39.05 43.20 42.12 7.5 O Auth / JWT / SSL / access control / user sessions / token lifecycle 33.25 33.00 36.42 27.50 36.25 33.28 8.0 tensors / training / GPU / ML experiment logging / tuning 32.56 40.00 32.42 28.44 34.00 33.48 8.1 ML analytical visualization / Fourier / ML animation / calibration 38.25 39.92 38.08 30.38 40.83 37.49 8.2 time series / feature engineering / explainabil- ity methods / behavioral analysis / computa- tional semantics 42.06 41.39 38.17 33.62 37.89 38.62 8.3 data parallel / compression / ML plugin / in- dexing 37.17 34.58 38.83 31.50 32.83 34.98 8.4 bayesian models / MCMC / statistics / repro- ducibility 42.93 38.13 38.53 30.20 38.13 37.59 8.5 ML APIs / decorators / metrics / optimization strategies 40.00 38.47 38.33 36.50 38.40 38.34 9.0 UI layout / CSS / markdown / table extraction / frontend security 41.33 38.92 39.67 34.56 39.83 38.86 9.1 plotting systems / widgets / maps / UI anima- tion / usability 43.60 44.27 42.80 40.40 42.00 42.61 9.2 runtime UI config / UI permission manage- ment / upload handling / customization / user- facing runtime extensibility 31.44 39.00 33.75 26.40 33.08 32.74 9.3 3D rendering / le gends / color mapping / vi- sualization formatting 45.92 43.83 44.50 41.44 41.58 43.45 T able 15: Results across Question Clusters (Closed Models) [Back to Appendix Contents] 31 Cluster ID Name Qwen3 8B Qwen3 32B Devstral Small- 2-24B- Ins Llama 3.3-70B- Ins SWE-QA- Pro 8B (SFT) SWE-QA- Pro 8B (SFT+RL) A vg. 0.0 Unicode / formatting / parsing / data validation 31.47 33.40 38.87 24.17 39.53 38.40 34.31 0.1 SQL / structured grammar / tem- plating Engine 30.00 32.78 39.44 21.76 35.33 38.89 33.03 0.2 CLI args / syntax / rege x / com- mand completion 29.79 30.29 31.12 22.72 33.54 35.54 30.50 0.3 file import/export / metadata / sorting / recurrence 31.33 35.61 36.28 23.67 34.00 33.00 32.31 1.0 data formats / FITS / Astropy / units / WCS 30.50 28.42 38.42 20.38 34.17 42.83 32.45 1.1 pandas / parquet / datetime / Dask / table schema 25.67 27.20 40.07 24.45 35.80 35.87 31.51 1.2 numpy / dask arrays / dtype / ar- ray serialization / parallel 30.00 34.33 38.94 24.38 37.22 34.33 33.20 1.3 coordinate transform / image pro- cessing / IO / numeric precision 28.25 31.33 36.83 20.88 34.58 33.17 30.84 2.0 protocol serialization / encoding / headers / API compatibility 30.58 36.17 40.67 20.10 36.42 35.25 33.20 2.1 dependency injection / config / at- trs / API design 31.00 33.22 38.70 23.23 35.56 36.30 33.00 2.2 dataclass / schema validation / enums / OpenAPI 25.76 29.48 35.81 23.81 30.57 31.90 29.56 2.3 type and attribute errors / initial- ization / CLI workflo w 33.57 26.38 39.10 26.45 33.86 36.62 32.66 2.4 type hints / mypy / typing system / code generation 36.19 32.95 40.19 27.53 35.05 35.62 34.59 3.0 Python version / imports / depre- cation / conflicts 37.07 35.27 41.67 21.00 34.60 33.20 33.80 3.1 install / virtual env / OS / hard- ware requirements / cloud deploy 26.40 28.80 39.60 24.36 30.80 30.33 30.05 3.2 artifacts / distribution format / repository management / post- install state 25.92 27.92 28.50 20.50 25.00 27.50 25.89 3.3 extensibility / configuration framew ork / plugin architecture 29.48 31.89 36.00 25.61 32.81 35.96 31.96 4.0 version control / Docker / build cache 31.00 27.08 41.33 25.67 38.08 40.33 33.92 4.1 release management / changelog / license / community 30.75 30.83 38.92 22.33 32.17 29.08 30.68 4.2 documentation / MkDocs / user tutorials 28.33 30.83 37.67 24.20 29.25 31.00 30.21 4.3 async refactor / migration / log- ging infra / i18n 31.87 34.07 40.60 23.20 36.67 39.67 34.34 4.4 CI pipelines / coverage / lint / GitHub Actions / security checks 27.88 31.75 37.62 22.94 39.96 38.04 33.03 5.0 asyncio / async conte xt / resource cleanup 27.05 27.48 37.52 24.00 31.71 31.48 29.87 5.1 multiprocessing / advanced run- time / concurrency / heteroge- neous compute 29.10 30.71 30.81 23.47 28.29 27.57 28.32 5.2 runtime error handling / DB trans- actions / retry / logging system 31.21 32.00 37.42 22.61 33.29 37.54 32.34 5.3 threading / ex ecution limits / scheduling / memory / timeout 30.07 32.33 29.67 24.38 28.53 28.47 28.91 5.4 connection lifecycle / protocol handling / low-le vel failures 34.83 41.92 42.91 25.00 36.75 39.08 36.75 5.5 parallel ex ecution / distributed framew orks / task graphs 27.75 32.58 38.17 22.82 32.55 36.25 31.69 Continued on next pa ge 32 Cluster ID Name Qwen3 8B Qwen3 32B Devstral Small-2- 24B-Ins Llama 3.3-70B- Ins SWE-QA- Pro 8B (SFT) SWE-QA- Pro 8B (SFT+RL) A vg. 6.0 file paths / filesystem permissions / symlinks / en v config / cache system 33.46 32.88 40.79 25.21 37.96 40.00 35.05 6.1 unit testing / mocking / test au- tomation 31.67 34.40 37.87 20.17 41.47 40.27 34.31 6.2 build pipeline / doc building / Sphinx / cloud provisioning 31.80 31.33 39.13 25.50 35.20 40.87 33.97 6.3 compiler toolchain / cross- compile / en v vars / code quality analysis 31.67 35.78 34.44 24.38 35.41 35.89 32.93 7.0 API integration / sync / perfor- mance / DB / SDK 28.00 35.00 38.05 24.33 40.00 39.24 34.10 7.1 media download / playlist / meta- data / client-side proxy config 23.60 28.60 32.67 24.64 24.53 28.07 27.02 7.2 auth systems / deployment / ex- tension plugins / cloud services 35.20 41.27 42.80 28.29 44.13 37.73 38.24 7.3 A WS / Azure / K8s / container security / IAM policy 27.08 26.67 33.83 20.22 33.08 32.00 28.81 7.4 rev erse proxy / URL routing / websocket / CDN / streaming 37.27 38.60 40.53 26.00 38.07 42.27 37.12 7.5 O Auth / JWT / SSL / access con- trol / user sessions / token lifec y- cle 25.42 30.08 28.83 24.80 25.58 29.50 27.37 8.0 tensors / training / GPU / ML ex- periment logging / tuning 28.67 27.58 28.33 17.64 28.75 33.58 27.43 8.1 ML analytical visualization / Fourier / ML animation / calibra- tion 25.50 23.17 34.08 22.25 29.58 32.50 27.85 8.2 time series / feature engineering / explainability methods / behav- ioral analysis / computational se- mantics 29.50 32.44 40.61 23.50 37.22 39.39 33.78 8.3 data parallel / compression / ML plugin / indexing 28.67 30.58 34.50 22.10 31.83 26.67 29.06 8.4 bayesian models / MCMC / statis- tics / reproducibility 29.47 32.00 31.87 22.82 31.60 31.20 29.83 8.5 ML APIs / decorators / metrics / optimization strategies 29.33 34.53 39.93 21.33 37.13 38.07 33.39 9.0 UI layout / CSS / markdo wn / ta- ble extraction / frontend security 26.50 30.58 38.33 25.56 35.17 37.58 32.29 9.1 plotting systems / widgets / maps / UI animation / usability 35.80 40.73 42.60 29.54 37.53 39.87 37.68 9.2 runtime UI config / UI permission management / upload handling / customization / user-facing run- time extensibility 26.83 33.17 33.33 22.38 31.75 33.67 30.19 9.3 3D rendering / legends / color mapping / visualization format- ting 25.92 30.50 43.92 24.09 36.83 38.58 33.31 T able 16: Results across Question Clusters (Open Models and SWE-QA-Pro V ariants) [Back to Appendix Contents] 33 H Case Study H.1 Cases of Model Comparison Comparison betwee n GPT - 4o and SWE - QA - 8B (SFT+RL) R epo N ame : d wavesyst ems/ dwave - cloud - client G enerated Q uery : Where do es cover age da ta flow from t est execut ion to the exte rnal r eporti ng service in the current CI pi peline ? Ground Truth: During test exe cution, covera ge dat a is ge nerated via the 'cove rage r un - m unittest d iscov er' command (. tr avis.y ml: l ine 46), which i nstrum ents the test ru ns to col lect c ode cov erage metri cs. The cov erage co llect ion is c onfigur ed by . coveragerc , wh ich speci fies tha t cove rage sho uld t rack the ' dwa ve.clou d ' source p ackage (line 2) while om itt ing v irtua l envi ronme nts, test files, perform ance t ests, and the package_info.py file (lines 3-6). T he necessar y dep endenci es for thi s process, i nclud ing b oth 'cov erage' an d 'cover alls' p ackage s, are in stalle d dur ing the CI setup phase as sp ecified in test s/requi rement s.txt and insta lled v ia .t ravis. yml. After succ essful test compl etion, the col lected cover age da ta is t ransmi tted to the e xternal Covera lls re porti ng serv ice throug h the 'cov erall s' comm and exec uted i n the aft er_succe ss phase (.t ravis. yml : l ine 49). Answer fro m GP T - 4o (abrid ged): In the c urrent CI pip eline … cove rage d ata flo ws … as fol lows: … The appveyor.yml file i nstall s … incl udin g cover age and cover alls. H owever, it do es not exp lici tly invok e cover alls, sug gestin g that the upl oad p rocess m ight b e hand led i mpli citl y … … No expl icit sc ript or com mand for inv oking cover alls was found i n the rep ositor y … Score : total_scor e: 22, co rrectn ess: 2, com plet eness: 2, re levanc e: 6, cla rity: 8, reaso ning: 4 Answer fro m SW E - QA - 8B (SFT+RL) (abrid ged): Coverag e dat a flows … throu gh the fol lowin g path … … The CI p ipeli ne runs t ests usin g … cov erage run - m unit test di scover … in t he .tra vis.ym l fil e (line 4 6). … After succ essful test executi on, the c overal ls com mand (line 4 9 in .tr avis.y ml) sen ds the c overag e data to Coveralls.io … The flow is: Tests → … → Covera lls CL I → Cov erall s.io Serv ice Score : total_scor e : 50 , corr ectness: 10 , c ompl eteness: 10 , rel evance: 10 , cl arity: 10 , r easoning : 10 Scoring Rationa le : SWE - QA -8B (SF T+RL) e xplici tly m atches the gro und- truth flow (cove rage run - m unittest discov er in .t ravi s.yml , then co veral ls in aft er_succe ss ). GPT -4o is not just le ss alig ned—i t is wrong: it claim s “No expl icit … com mand for inv oking cover alls was found” a nd sugg ests an “implicit” upload , even though . travis.ym l expl icit ly run s covera lls. I t also m is-cent ers appveyor.yml as t he relev ant CI path fo r uplo ading cover age, whi ch contr adict s the gr ound t ruth. Figure 6: Example of a comparison of GPT -4o and SWE-QA-8B (SFT+RL) answers against the ground-truth. [Back to Appendix Contents] 34 Comparison betwee n SWE - QA - 8B (SFT) and SWE - QA - 8B (SFT+RL) R epo N ame : pydata / xar ray G enerated Q uery : Where ar e the CR S forma t conv ersion m ethod s (PROJ.4 vs WKT strin g) define d and implemented in xarr ay's ra sterio backend? Ground Truth: The CRS fo rmat conver sion lo gic is impl ement ed in t he open_ rasteri o funct ion i n xarray /backen ds/raste rio _. py . W hen constr ucting the ou tput a ttri butes, t he cod e checks whether the raste rio d ataset h as a CRS and seri alize s it to a stri ng by first at temp ting t o call riods. crs.to_p roj4() t o obt ain a P ROJ.4 re present ation, and if t his me thod i s unava ilab le (rai sing Attrib uteErr or ), fall ing b ack t o rio ds.crs.t o_stri ng(), which retur ns a WK T repr esentati on; the resulti ng CRS string is stor ed in t he retu rned DataArray’s attri butes under t he crs key ( xarray /backen ds/raste rio _. py : line 28 4 – 291, 341 –342). A se cond CR S serial izat ion occu rs when the inp ut is a WarpedVRT , in which ca se vrt. crs.to_st ring() is used w hen bui lding the V RT param eters so that t he vir tual raster’s CR S is pr eserved duri ng reo pening ( xarray /backen ds/raste rio _. py : line 22 0 – 222). Answer fro m SW E - QA - 8B (SFT) (abridge d): The CRS fo rmat conver sion m ethods … are d efined and im plem ented in … xarray /backen ds/raste rio _. py . … The conv ersion m ethod s are: … to_p roj4() … to_str ing () … These me thods a re used in two k ey loc ations: … … WarpedVRT … the CR S is con verted to a string (PROJ.4 fo rmat ) using v rt.crs. to_str ing () … … the CR S is con verted to b oth PR OJ.4 and WKT fo rmat s using r iods.c rs.to_p roj4() a nd riods. crs.to_st ring(), and sto red as a ttri butes … The im plem entati on del egates t o raste rio’s built -in CRS metho ds … Score : total_scor e : 2 9, cor rectness: 3, compl eteness: 4 , relevance: 9, clari ty: 8, r easoning : 5 Answer fro m SW E - QA - 8B (SFT+RL) (abrid ged): The CRS fo rmat conver sion m ethods … are … in xar ray /b ackends/ rasteri o _. py . … to_pr oj4() … u sed … t o conv ert … to a PR OJ.4 str ing … to_str ing() … u sed … t o conv ert … to a W KT str ing … … when creat ing a DataArray … uses rio ds.crs.t o_proj 4() … … if to _proj 4() raises an Attri buteEr ror , i t falls back t o riod s.crs.to _strin g () for W KT fo rmat … … when creat ing a WarpedVRT … uses vrt.cr s.to_str ing () … … conv ersions a re not i mpl ement ed by xarray i tself bu t del egate t o … ra sterio … Score : total_scor e : 46 , corr ectness: 9, comp leteness: 9 , relevance: 10 , clarity: 9 , reasoni ng: 9 Scoring Rationa le : SWE - QA -8B (SF T+RL) m atche s the gro und-tr uth cont rol fl ow: it states t he try to_pr oj4() then fallb ack t o to_st ring () o n Attri buteEr ror , and it p laces v rt.crs.t o_stri ng () in the WarpedVRT path. SWE - QA -8B (SF T) is weak er aga inst th e groun d trut h and a lso int ernall y inco nsistent : it l abels vrt.cr s.to_st ring() as “PROJ.4 format ,” even though to_str ing() is t he WKT -style seriali zati on path in the g round truth . It al so clai ms the CRS is c onvert ed to “ both P ROJ.4 a nd WK T … and stored as attr ibut es,” which conflic ts with the gr ound-tr uth lo gic th at stor es one CRS string (PROJ.4 if avail able, otherwi se WKT ) under a singl e crs attribute. Figure 7: Example of Comparison between Reference Answer and Human Annotated Answer (web3.py). [Back to Appendix Contents] 35 H.2 Case Studies of Human and Model Reference Answers Session I D: ethe reum_ _web3.py - 3027 - 0773ab80 - e07c - 4730 - a349 - 6f9eef2f0c76 Ground Truth: The AF_UNIX so cket pa th val idat ion th at gener ates 'AF_ UNIX p ath to o long ' errors is not exp lici tly i mple mented in web 3.py cod e, but rath er occur s at th e opera ting sy stem level durin g socket connect ion. The error origi nates i n the get _ipc_ socket () fu nctio n (web3/pr ovid ers/ipc .py: li ne 35– 47) where socket .socket(so cket.AF _UNIX , socket.SO CK_STR EAM) cr eates a Un ix dom ain soc ket and sock.con nect( ipc_path ) attem pts the connecti on at l ine 45. When th e path exceeds th e system lim it (ty pical ly 108 charact ers on Un ix systems), the OS r aises an OSEr ror with t he messag e 'AF_UNI X pat h too l ong'. The IPC pat h itself i s constr ucted b y get_default_ipc_path () (web3/pr ovid ers/ipc. py: li ne 89–11 4) using platform -specific l ogic fo r macO S, Linu x, FreeB SD, and Wind ows. Thi s functio n is inv oked during IPC Provider initiali zati on (web3/p rovi ders/i pc.py: line 14 9– 170) when no explicit path is prov ided . The Aut oProvi der class (web3/pr ovid ers/aut o.py: l ine 63– 69) incl udes IPCProvider in its default_p roviders list and att empt s initi aliz ation throug h _ get_active_provider () (web3/pr ovid ers/aut o.py: l ine 113 – 123). The RequestMan ager (web3/m anage r.py: line 108 –111 ) uses AutoPr ovide r as the d efault when no p rovid er is specifie d. When the pat h lengt h erro r occur s, it m anifests as an OSError tha t gets caught by the JSONBaseP rovi der.is_ connecte d() met hod (web 3/prov ider s/base.py : line 111– 133), which handles OSErrors during connect ion at tempt s by ei ther r eturni ng Fal se or ra ising a ProviderConnectionE rror with traceb ack details Error Type: Fac tual Error Error Reason: The original answer fa ctuall y mi sident ified the err or hand ling m echani sm by citi ng lines 12 0– 130 in JSONBa seProvi der.i s_connect ed. Thi s code b lock is respo nsibl e for par sing application - level JSON -RPC errors (che cking for an 'err or' key in the response p ayloa d), not low- level connecti on fail ures. It faile d to l ocate t he actu al try /except b lock (lines 11 2– 115) that explici tly c aptur es the OS- level OSError tri ggered by t he socket path limi t, effect ively conflat ing proto col pay load vali datio n with transpo rt excep tion ha ndli ng. G enerated Q uery : Where is the AF_UN IX soc ket pa th val idat ion log ic im plem ented that generat es 'AF_UNI X pat h too l ong' err ors in t he IPC p rovi der syst em? Generated Answer: The AF_UN IX soc ket pat h val idati on tha t gener ates 'AF_UN IX p ath too long' er rors is not expl icitl y im plem ented i n web3 .py code, but r ather o ccurs at the op erati ng system level durin g socket connect ion. The error origi nates i n the get _ipc_ socket () fu nctio n (web3/pr ovid ers/ipc .py: li ne 35- 47) where socket. socket(soc ket.AF_ UNIX , socket.SO CK_STR EAM) cr eates a Un ix dom ain soc ket and sock.con nect( ipc_path ) attem pts the conne ction a t line 45. Whe n the pa th exceed s the syst em li mit (typi cally 108 char acters on Unix syste ms), the OS raise s an OSError wit h the m essage 'AF_ UNIX p ath to o long'. The IPC path i tself is construc ted b y get_default_ipc_path () (web3/prov ider s/ipc.p y: line 89- 114) using p latfor m-speci fic log ic for m acOS, L inux, F reeBSD , and W indows. This func tion i s invoked during IPCProvider initializa tion (w eb3/pr ovid ers/ipc. py: li ne 149- 170) when no explici t pat h is pr ovid ed. The AutoProv ider cl ass (web3/p rovi ders/au to.py: line 63 - 69) includ es IPCProvider in its default_provi ders list and at temp ts ini tiali zatio n throu gh _ get_active_provider () (web3/pr ovid ers/aut o.py: l ine 117 - 122). The RequestManag er (web3/m anage r.py: line 108 -111) uses AutoPro vider as t he defau lt when no pro vider is specifie d. When the pat h lengt h erro r occur s, it m anifests as an OSError tha t gets caught by the JSONBasePro vider .is_conn ected() m ethod (web3/p rovid ers/ba se.py: l ine 120 - 130), which handles OSErrors during connect ion at tempt s by ei ther r eturni ng Fal se or ra ising a ProviderConnectionE rror with t raceb ack det ails. Figure 8: Example of a comparison of SWE-QA-8B (SFT) and SWE-QA-8B (SFT+RL) answers. [Back to Appendix Contents] 36 Session I D: f rictionles sdata__ fric tionless - py - 1156 - b113440 4 - d537 - 4caa - 999d - 88f3b0969356 Ground Truth: The schema det ection algor ithm impl ement s field type i nference throug h a sophisti cated mult i-cand idate scoring system orchest rated by th e "det ect_schem a " method in the Det ector cl ass. The process b egins b y crea ting fi eld t ype cand idat es from "DEFA ULT_CAN DIDATE S", a p riori tized list contai ning 14 types ordere d from most specific to mo st gener al (e.g., yearmonth , geopoint ... string) (fr ictio nless/sett ings.py : line 71- 86). For each dat a colu mn, th e algor ithm init ializ es "run ners" whi ch tra ck the st ate of ev ery ca ndid ate field t ype (fri ction less/det ector/d etecto r.py: l ine 485 - 500). During inference, the algorithm processes e ach row of the da ta frag ment. It ev aluate s every candid ate ag ainst e ach cell using the " Field. read_cell ()" method, whi ch parse s the va lue and retur ns any t ype di screpan cies (fricti onless/fiel d.py : line 3 50-361). T he scori ng mec hanism award s +1 poi nt for suc cessful cel l parsing and -1 point for par sing fai lures (fr ictio nless/det ector/d etecto r.py: line 51 9).To optim ize p erform ance, th e algor ithm imp lement s earl y elim inati on by calcul ating a "thr eshold " value based o n the fra gment lengt h and co nfidence level ; candi dates d ropp ing be low thi s threshol d are skippe d in sub sequent itera tions (fri ction less/det ector/d etecto r.py: l ine 505 , 515). Finall y, a ca ndida te wins and is a ssigned as the i nferred field type wh en its sco re mee ts the confiden ce requi rement (calcu lated against a "m ax_score" that account s for mi ssing v alues) (fricti onless/de tector /detect or.py: line 5 12- 527). Error Type: Loca liza tion Hall ucinat ion Error Reason: The original answer a ccurat ely de scribe d the m ulti -candid ate sco ring l ogic b ut suffered fr om sev ere loc aliza tion ha lluci nation , citi ng the runners initi aliza tion a t lines 346- 362 based o n an out dated file v ersion. It fai led to veri fy the co de agai nst the current comm it, overl ooking signifi cant d ocstri ng add itio ns that sh ifted t he actu al im plem entati on to l ines 48 5- 500, resulti ng in a ~140-li ne di screpanc y that render ed the su pport ing ev idence inval id. G enerated Q uery : How does t he schem a detec tion a lgori thm i mpl ement fi eld t ype in ference and scor ing for tabu lar da ta in the Det ector cl ass? Generated Answer: The schem a dete ction a lgori thm i mpl ements field t ype i nference t hrough a sophist icate d mul ti-can didat e scori ng system orch estrate d by t he Dete ctor cl ass. The process b egins b y crea ting fi eld t ype can didat es from DEFAUL T_CAND IDATE S, a prior itize d list contai ning 1 4 type s order ed from most specifi c to m ost gene ral: yearmonth , geopoint , duration, geo json , obj ect, array, d atetime, t ime, dat e, integer, num ber, boolean , year, a nd stri ng (/test bed/fr iction less/sett ings.py : line 7 1- 86). For each data column, the algor ithm initi alize s runners contai ning al l cand idat e field types (/testbed /frict ionless/d etect or/det ector.p y: lin e 487- 500). During inference, the algorithm processes e ach row of the sam ple d ata an d eval uates ev ery ca ndid ate aga inst eac h cell u sing the Field.read_cell () method (/test bed/fr ictio nless/fiel d.py: line 3 23-362). T he scori ng mechani sm awa rds +1 p oint fo r successful cell parsin g (when read_cell retur ns no err or note s) and -1 point for pa rsing fa ilures (/testbe d/frict ionless/ detect or/det ector.p y: li ne 519). T he algor ithm impl ement s early elim inati on opt imiz ation by cal culat ing a t hreshold val ue as len (fragment ) * (fiel d_co nfidenc e - 1) and skippi ng cand idat es whose sco res fall below this threshol d (/test bed/fri ction less/det ector/d etecto r.py: l ine 50 5, 515). A candid ate wi ns and becom es the in ferred fi eld t ype whe n its scor e reach es or exceed s max_p ossibl e_score * field _confid ence , where m ax_possi ble_sc ore acco unts for missin g val ues in th e data (/testbed /frict ionless/d etect or/det ector.p y: lin e 520- 527). The default field _confi dence i s 0.9, meani ng a cand idat e must successful ly par se 90% o f vali d (non-m issing) c ells to be sele cted. This ap proach ensures r obust t ype i nference whi le m aintai ning p erform ance thr ough ea rly eliminat ion of poorly -perform ing ca ndid ates. Figure 9: Example of Comparison between Reference Answer and Human Annotated Answer (fritionless-py). [Back to Appendix Contents] 37 Session I D: hylang_ _hy - 2514 - 955a46b9 - 91d6 - 46ec - 98cb - 2a41fbff46bd Ground Truth: Hy's conditio nal com pil ation sy stem g enerate s redund ant an onymo us vari able assignm ents pr imar ily b ecause t he " cond " macro recursi vely expands into nest ed "i f" expressio ns (hy/core /macro s.hy : line 36 -41) that do not util ize the compi ler's i nternal "if*" optim izat ion sym bol. Whil e the " com pile_if " function (hy/core/ result_ macr os.py: l ine 643 - 707) includ es logi c to r euse tem porar y var iabl es for nest ed cond ition als (speci ficall y check ing for "if*" at li ne 652), t he stand ard " cond " ma cro em its sta ndard "if" forms, c ausing t his opt imi zatio n to be skippe d. Consequ ently, " compil e_if " trea ts each n esting l evel a s a separ ate sta tement - to - expressio n conver sion con text. To brid ge Hy's e xpression -orient ed sema ntics wi th Pyt hon's statem ent-ori ented a rchit ecture, the com piler is forc ed to c reate a new tem porar y var iabl e via " get_anon_var " (line 6 81) and generat e expli cit assi gnment statem ents (l ines 685- 689) for each level . This b ehavio r is str uctur ally e nforced by the "Resul t" cl ass (hy/com pil er.py: l ine 14 4- 309), which sep arates st atem ents from expressi on cont exts, necessi tati ng these a ssignm ents to maint ain cor rect ev alua tion sem anti cs across ne sted sta temen t blo cks. Error Type: Reas oning De pth Error Reason: The original answer su perfici ally blam ed de sign ph ilosop hy, ove rlooki ng the compi ler's in ternal if* opt imi zation mechan ism. I t fail ed to i denti fy the r oot cau se: the cond macro expands i nto sta ndard if form s, inad vert ently b ypassi ng the b uilt -in opt imi zation path d esigned to prevent redun dancy. G enerated Q uery : Why doe s Hy's cond ition al com pila tion sy stem g enerate redund ant anonym ous var iabl e assignm ents i nstead of opti mizi ng nested condi tiona ls int o efficien t elif chains? Generated Answer: Hy's condi tiona l com pilat ion syst em ge nerates r edund ant ano nymou s varia ble assi gnme nts due to a fund ament al ar chitect ural d ecisio n that prior itize s semant ic correct ness over perfor mance o ptim izat ion. The redund ancy st ems fro m two key desi gn patter ns. Fir st, the cond m acro recursi vely e xpands i nto de eply ne sted if expressio ns rather than a f lat elif -like st ructur e. The _ cond functi on in hy/cor e/ macr os.hy : line 3 6 - 41 demon strates this rec ursiv e expansio n where ea ch cond ition-r esult p air g enerate s a nested if form t hat cal ls _ cond ag ain for remai ning c ondit ions. Thi s creat es a tre e of nested condit ional s rather than a linear chain. Second, t he compi le_if functi on in hy/core/r esult_ macro s.py: l ine 643-7 07 hand les the fu ndam ental m isma tch be tween Hy 's everything - is - an -expr ession ph ilosop hy and Python's se parat ion of st atemen ts and expressio ns. When c ondit ional b odie s contai n statem ents r ather t han pur e expressi ons, the compi ler cr eates ano nymou s vari ables using get_anon_var () (line 681) and generat es assignm ent stat ement s (lines 6 85-689) t o store interm edia te resul ts. Ea ch nested condi tional receiv es its ow n temp orary vari able a nd assig nment rather than b eing op tim ized i nto a single el if chain b ecause t he com piler must ensure t hat each branch can be used in both expressio n and st atemen t conte xts. The R esult c lass arc hitect ure in h y/comp iler .py: li ne 144- 309 enfor ces this separat ion by mai ntaini ng bot h a stat ement s list a nd an exp ression context, requir ing assi gnment s to br idge between them. This d esign cho ice ensur es that compl ex nested co nditi onals w ith m ixed st atemen ts and e xpression s main tain co rrect evalua tion semanti cs, but at th e cost of g enerat ing ad diti onal t empor ary v ariab les and assignm ents th at could theoret icall y be o ptim ized away in simpl er cases. Figure 10: Example of Comparison between Reference Answer and Human Annotated Answer (hy). [Back to Appendix Contents] 38 I Ethics and Reproducibility Statements I.1 Potential Risks This work focuses on training and ev aluating large language models for repository-lev el code understanding and question answering, using real-world open-source project code. While all questions are grounded in executable repositories and paired with validated reference answers, models may still produce incomplete or misleading responses when codebase exploration or tool usage fails, particularly in cases of implicit reasoning errors or silent failures. This work in volv es only publicly a vailable open-source repositories and does not include any personal, sensiti ve, or user -generated content. I.2 Discuss the License f or Artifacts All released artifacts are provided under permissi ve licenses suitable for academic research. License terms permit use, modifica- tion, and redistribution in accordance with each license’ s conditions. I.3 Artifact Use Consistent With Intended Use All external datasets and software components were used in accordance with their original license agreements and intended purposes. Deriv ed artifacts are intended solely for research and educational use, and are not authorized for commercial deployment or redistrib ution. I.4 Data Contains Personally Identifying Inf o or Offensive Content All data was either synthetically generated or obtained from public sources. Automated filters and manual re vie w were applied to ensure that no samples contain personally identifying information or of fensi ve content. All instructions and tables are free of references to real individuals, groups, or sensiti ve contexts. I.5 Documentation of Artifacts All released artifacts are accompanied by documentation describing their structure, content format, intended use, and ev aluation methodology . Sufficient metadata and usage instructions are provided to support inspection, reproduction, and downstream research use. I.6 Parameters f or Packages All external packages used during training and evaluation were applied in accordance with standard practices. Default parameters were used unless otherwise specified. Any deviations from default settings are documented in the accompanying implementation materials. I.7 Data Consent This work exclusi v ely uses data deriv ed from publicly av ailable open-source software repositories and their associated issue trackers. All data was collected in accordance with the repositories’ publicly stated licenses and terms of use, which permit research, analysis, and redistrib ution. As no priv ate, restricted, or user-submitted personal data is included, e xplicit indi vidual consent was not required. The data collection and curation process does not inv olve interaction with repository contrib utors, nor does it introduce new uses be yond the original public and open-source context. I.8 AI Assistants in Research or Writing Used ChatGPT to capture grammar errors in the manuscript. 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment