VIGIL: Towards Edge-Extended Agentic AI for Enterprise IT Support
Enterprise IT support is constrained by heterogeneous devices, evolving policies, and long-tail failure modes that are difficult to resolve centrally. We present VIGIL, an edge-extended agentic AI system that deploys desktop-resident agents to perfor…
Authors: Sarthak Ahuja, Neda Kordjazi, Evren Yortucboylu
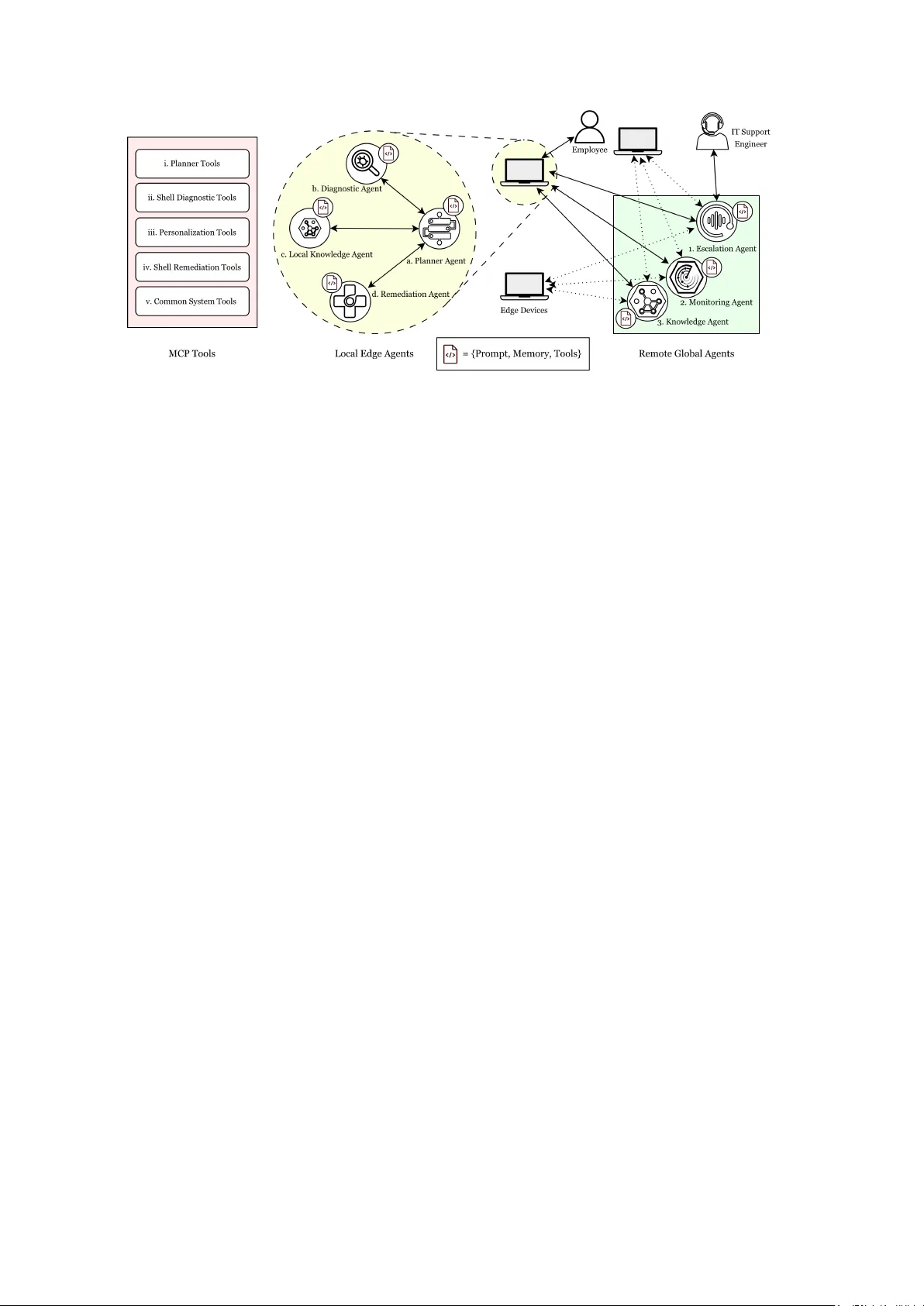
VIGIL: T owards Edge-Extended Agentic AI f or Enterprise IT Support Sarthak Ahuja * Neda K ordjazi * Evren Y ortucboylu * V ishaal Kapoor Mariam Dundua Y iming Li Derek Ho V aibhavi Padala Jennifer Whitted Rebecca Steinert Amazon Engine, AI Center of Excellence {sarahuja,nedakord,yortuc,vishaalk,madundua}@amazon.com {yimingll,derekjho,vapadala,jenwhitt,rsteinrt}@amazon.com * Equal contribution Abstract Enterprise IT support is constrained by het- erogeneous devices, ev olving policies, and long-tail failure modes that are dif ficult to resolve centrally . W e present VIGIL, an edge-extended agentic AI system that deplo ys desktop-resident agents to perform situated di- agnosis, retriev al ov er enterprise knowledge, and polic y-governed remediation directly on user devices with explicit consent and end- to-end observability . In a 10-week pilot of VIGIL ’ s operational loop on 100 resource- constrained endpoints, VIGIL reduces inter- action rounds by 39%, achiev es at least 4 × faster diagnosis, and supports self-service res- olution in 82% of matched cases. Users re- port excellent usability , high trust, and low cognitiv e workload across four validated in- struments, with qualitativ e feedback highlight- ing transparency as critical for trust. Notably , users rated the system higher when no histor- ical matches were available, suggesting on- device diagnosis provides value independent of kno wledge base coverage. This pilot estab- lishes safety and observ ability foundations for fleet-wide continuous improv ement. 1 Introduction Large enterprise IT ecosystems comprise vast fleets of heterogeneous devices, networks, and policies operating under partial observ ability ( Li et al. , 2021 ). F ailures often emerge from subtle local interactions rather than clear global faults, making diagnosis reactiv e and slow . Operational knowl- edge remains fragmented, and support workflo ws continue to rely on centralized human intervention and static playbooks, with AI chatbots offering limited post-incident assistance ( Reinhard et al. , 2024 ). In parallel, AI systems are ev olving beyond con- versational assistants to ward agentic, computer -use models capable of acting within software en viron- ments through terminal interfaces and operational tools ( Anthropic ; Kiro , 2025 ; Shen et al. , 2024 ; Zhuang et al. , 2023 ). Enterprise platforms are be- ginning to incorporate such capabilities into struc- tured IT service workflows ( Zhang , 2025 ; Servi- ceNo w and Accenture , 2025 ), typically through centrally orchestrated agents within predefined au- tomation boundaries rather than distrib uted, on- de vice execution across heterogeneous endpoints. Executing bounded actions directly on edge de vices can enable lower -latency remediation, access to fine-grained local context, and improved resilience under partial connecti vity , but such distributed au- tonomy requires mechanisms that prevent out-of- bounds behavior . VIGIL explores this opportunity by bringing agentic and computer-use capabilities into enter- prise IT through an emerging edge-extended ar- chitecture that combines on-device autonomy with cloud coordination and continuous improvement. At its core, VIGIL relies on language understand- ing, retriev al-augmented generation, and natural language reasoning to interpret user-reported is- sues, ground diagnosis in enterprise knowledge, and communicate remediation steps transparently . VIGIL treats each endpoint as an intelligent par- ticipant running specialized agents for diagnosis, kno wledge access, and remediation, while cloud services provide model inference, fleet-le vel ob- serv ability , and structured escalation to human op- erators. Each interaction produces structured experience signals that form the basis for future learning at the context and prompt lev els without requiring model retraining. This paper makes the follo wing contributions: • A distrib uted architecture for enterprise IT support in which endpoints perform situ- ated diagnosis and remediation under cloud- coordinated gov ernance and observability • An edge-de vice controller that integrates on- de vice diagnostic and remediation agents with enterprise knowledge access, observability , and structured escalation to human operators • A proof-of-value pilot e valuating the edge con- troller component on real IT support scenarios, providing early e vidence on efficienc y , usabil- ity , and user trust. 2 Related W ork LLM-enhanced IT operations. Recent work demonstrates that large language models can en- hance AIOps by structuring logs and incidents for improv ed detection and decision-making ( V i- tui and Chen , 2025 ), and surveys document both the promise of such techniques and the persistence of centralized, human-mediated workflo ws ( de la Cruz Cabello et al. , 2025 ). Agent-oriented efforts explore partial autonomy in detection, classifica- tion, and remediation ( Zota et al. , 2025 ), while ev al- uation frameworks probe the reliability of LLM- based operational agents ( Chen et al. , 2025 ). How- e ver , these systems retain centralized architectures in which endpoints serve as passiv e telemetry sources rather than activ e participants in diagnosis and resolution. Agentic and tool-augmented systems. The broader agentic AI landscape has adv anced rapidly , with surve ys characterizing the design space of au- tonomous agents and their orchestration patterns ( Acharya et al. , 2025 ; Sapk ota et al. , 2025 ). T ool- augmented language models enable structured in- teraction with external systems through learned or specified tool interfaces ( Schick et al. , 2023 ; Patil et al. , 2023 ), and standardized protocols such as MCP ( PBC , 2024 ) and A2A ( Agent2Agent W ork- ing Group , 2025 ) provide interoperability across agent boundaries. Retriev al-augmented generation grounds model outputs in curated knowledge ( Gao et al. , 2023 ). VIGIL builds on these capabilities but is the first to integrate them into a governed, edge-deployed IT operations system. Edge and distrib uted AI. Recent proposals ad- vocate distributing intelligence across edge de vices rather than concentrating it in centralized services ( Luo et al. , 2025 ; T allam , 2025 ). While these works establish architectural principles for multi-LLM edge systems, they remain largely theoretical and do not address the go vernance, observ ability , and safety constraints required for enterprise IT . VIGIL Figure 1: Operational and self-improvement loops within VIGIL. De vice-level cognition, the focus of this paper , executes locally on endpoints (shown in blue ), while cloud-le vel reflection, designed for future activ a- tion, refines policies, memory , and prompts ov er time (shown in r ed ). Monitoring at the fleet le vel operates in parallel across both loops (shown in black ). addresses this gap by operating under deterministic policy control. 3 VIGIL V ision and Architectur e VIGIL is organized around two tightly coupled control loops that together define how intelligence, action, and adaptation are distributed across the enterprise (depicted in figure 1 ). Operational loop. The operational loop governs real-time diagnosis and remediation directly on endpoint de vices, and is the primary focus of this paper . On each endpoint, the loop follo ws a struc- tured diagnose, retrie ve, and remediate w orkflow: when anomalies are detected through telemetry , scheduled checks, or user -reported issues, the sys- tem collects evidence, retrie ves rele vant enterprise kno wledge, and executes bounded remediation ac- tions. All steps are logged as structured traces for do wnstream analysis and monitoring. Execution is resilient to partial connectivity , allo wing devices to continue troubleshooting using cached knowl- edge and locally enforced policies ev en when cloud services are unav ailable. Self-impro vement loop. The self-improv ement loop operates ov er structured experience produced by the operational loop. Rather than retraining foundation models, it refines the contextual scaf- folding that shapes agent behavior , including mem- Figure 2: VIGIL ’ s agentic architecture integrating local edge agents and remote cloud agents. Edge agents execute diagnosis and remediation on-de vice, while cloud agents provide coordination, gov ernance, and observability across the fleet. ory ( Ouyang et al. , 2025 ), retriev al strategies ( Gao et al. , 2023 ), prompts and workflows ( Agrawal et al. , 2025 ), and governance policies ( Santurkar et al. , 2023 ). This loop reflects the broader VIGIL vision and is left as future work, to be activ ated once suf ficient safety and observability guarantees are established. 3.1 Agent Roles VIGIL realizes the operational loop through a small set of coordinated agents running on each endpoint (figure 2 ). These agents are tightly integrated com- ponents of a single control system, sharing state and operating over constrained, auditable tool inter- faces ( Y ao et al. , 2023b ; Schick et al. , 2023 ; Patil et al. , 2023 ; W ang et al. , 2023 ). Planner Agent. The planner agent orchestrates the local workflo w . It decomposes troubleshooting goals into diagnostic steps and remediation plans, employing structured reasoning methods such as ReAct-style deliberation and multi-step reasoning ( Y ao et al. , 2023c , a ). The planner reasons ov er de- vice context, episodic history , and enterprise poli- cies, delegat ing e vidence collection and actuation to specialized agents while keeping decision logic explicit and governable ( Agent2Agent W orking Group , 2025 ). Diagnosis Agent. The diagnosis agent gathers structured e vidence about local system state using tools exposed through the Model Context Protocol (MCP). T ool usage is constrained by purpose, pre- conditions, and safety annotations, consistent with modern tool-augmented language model systems ( Schick et al. , 2023 ; Patil et al. , 2023 ). Probe selec- tion is informed by uncertainty-aware debugging and information-gain-driv en exploration ( Kirsch et al. , 2022 ; Agraw al et al. , 2024 ; Gupta et al. , 2023 ; Moshko vich and Zeltyn , 2025 ). The output is a structured diagnostic profile. Knowledge Agent. The knowledge agent man- ages contextual information used throughout the loop. Locally , it maintains compact episodic mem- ory capturing de vice-specific history . Remotely , it interfaces with curated enterprise knowledge and federated summaries from other devices. T ogether , these form a hybrid memory substrate integrating episodic, semantic, and causal structure ( Anokhin et al. , 2025 ; Cai et al. , 2025 ; Fiorini et al. , 2025 ). Remediation Agent. The remediation agent ex e- cutes bounded, rev ersible interventions such as ser- vice restarts, configuration changes, or rollbacks. Actions are validated against deterministic safety and compliance constraints, gated by user con- sent. Execution follo ws stepwise verification and self-correction paradigms drawn from recent work on automated repair and safe actuation ( Bouzenia et al. , 2025 ; Santurkar et al. , 2023 ; Madaan et al. , 2023 ; Zhu et al. , 2023 ). All actions produce au- ditable traces. While ex ecution remains local, the VIGIL de- sign includes cloud-based agents for fleet-lev el co- ordination, observ ability , and gov ernance, enabling cross-de vice pattern discovery ( Lapte v et al. , 2023 ; Y u et al. , 2022 ) and structured escalation to human operators ( Miller , 2019 ). 4 Implemented Edge System VIGIL ’ s deployed edge layer is implemented as a standalone desktop application built on top of Strands ( Amazon W eb Services , 2024b ) and Bedrock ( Amazon W eb Services , 2024a ) that ex- ecutes diagnosis, reasoning, and remediation di- rectly on endpoint de vices. Upon a user-reported issue, the system first in- vok es a bounded set of operating-system-specific diagnostic tools exposed through the Model Con- text Protocol (MCP) ( PBC , 2024 ) to collect evi- dence and produce a structured diagnostic profile (refer T able 1 . Based on this profile, the system performs retrie val-augmented reasoning o ver two enterprise-curated sources: a knowledge base of IT portal articles and a repository of previously resolved cases authored by support engineers. Re- trie ved artifacts are assembled into a grounded con- text package, from which a stepwise remediation plan is synthesized and executed locally under pol- icy control and continuous v erification. T ool Purpose system_uptime Retriev es device uptime to identify reboots security_updates Detects pending enterprise security updates cpu_process Retriev es top running processes by CPU usage disk_usage Reports disk usage across all mount points. network_status Retriev es network connectivity sta- tus T able 1: Illustrativ e diagnostic tools used in the diagnose–retriev e–remediate loop. All state-changing actions are mediated locally by a deterministic policy engine based on Open Pol- icy Agent (OP A) ( Open Policy Agent Contributors , 2024 ). Generated commands are ev aluated against declarati ve policies and classified into one of three tiers: allow , warn, or deny . Low-risk actions exe- cute automatically; moderate-risk actions require explicit user consent with a natural-language ex- planation of purpose and impact; and high-risk actions are blocked. Remediation is e xecuted incre- mentally with verification after each step; if health signals regress, the system adapts its plan or esca- lates, and where possible selects rev ersible actions to enable rollback. 5 Evaluation W e conducted a proof-of-v alue (PoV) pilot to ev al- uate VIGIL under real enterprise operating condi- tions. The ev aluation combines LLM-based auto- mated assessment of operational effecti veness with direct human e valuation through v alidated user ex- perience instruments. 5.1 Deployment Setting The pilot was conducted ov er a 10-week period across 100 enterprise endpoints running a single hardware and software configuration (W indows- based HP G8 devices). This device category was selected because it is among the highest dri vers of IT support contacts in the org anization: the devices are resource-constrained and frequently exhibit is- sues related to the proprietary enterprise software stack required on each machine. Participants were instructed to use VIGIL as their first point of con- tact for IT issues they would otherwise escalate to human support, and all interaction traces were recorded for subsequent analysis. 5.2 Operational T race Analysis T o quantify VIGIL ’ s impact relativ e to con ventional IT support, we performed a retrospecti ve case- matching analysis against a centralized graph repos- itory (CGR) containing over 60,000 pre-resolved IT support interactions authored by human support engineers. Each VIGIL session was matched to historically similar CGR cases using a two-step process: semantic similarity via dense embeddings (threshold 0.55), follo wed by language-model ver- ification of full case details (confidence ≥ 7/10). This yielded 826 confirmed matches spanning 60 of 153 VIGIL sessions (39%). For matched cases, we compared interaction efficienc y and response time, assessed response quality across fi ve dimen- sions (issue understanding, root cause accuracy , rele vance, actionability , completeness) using auto- mated ev aluation, and estimated self-service poten- tial. 5.3 User Experience Evaluation At the conclusion of the pilot, participants com- pleted a structured questionnaire comprising four v alidated instruments: • System Usability Scale (SUS) ( Brooke et al. , 1996 ): a 10-item Likert scale pro viding a com- posite usability score (0–100), with an estab- lished industry av erage of 68. Metric SHIELD Human Support Interaction rounds (median) 11 cycles 18 turns ∗ Diagnosis time (median) 36.5 s ≥ 2.7 min † Response quality (median) 8.0 / 10 — Self-service potential 82% (high + medium confidence) T ool success rate 95.3% across 1,586 calls T able 2: Operational metrics on matched cases (n=60). ∗ Human support rounds reflect full con versational turns between user and support engineer . Interaction rounds were reduced by 39% (83% of cases). † Conservati ve lower bound assuming 10% of median contact duration (26.5 min) reflects active w ork; realistic estimates yield 4–17 × speedup. • NASA T ask Load Index (NASA-TLX) ( Hart and Stav eland , 1988 ): a six-dimensional work- load assessment cov ering mental demand, physical demand, temporal demand, perfor- mance, ef fort, and frustration. • T rust in A utomation ( Jian et al. , 2000 ): a scale measuring user confidence in automated system decision-making and reliability . • T echnology Acceptance Model (T AM) ( Davis , 1989 ): items assessing perceiv ed use- fulness, percei ved ease of use, and behavioral intention to adopt. All rev erse-scored items were handled according to each instrument’ s standard scoring procedure. Of the 100 pilot participants, 23 completed the full surve y . Respondents also provided optional open- ended feedback on their experience. 6 Results and Discussion W e report results along two complementary axes: operational ef fectiveness of the edge component measured through trace analysis against historical IT support records, and user experience assessed through v alidated survey instruments. 6.1 Operational Effectiveness T able 2 summarizes key metrics from the case- matching analysis described in Section 5 . Of 153 VIGIL sessions recorded during the pilot, 60 (39%) were matched to historically similar cases in the centralized graph repository . Instrument Score SUS 86.2 ± 15.7 T rust in Automation 4.29 / 5.0 T AM 4.41 / 5.0 N ASA-TLX 2.53 / 7.0 T able 3: User experience scores across four validated instruments (n=23). SUS industry average is 68.0. Efficiency . VIGIL required a median of 11 au- tonomous reasoning cycles to produce a com- plete diagnosis, compared to 18 back-and-forth exchanges between users and human agents for matched cases, a 39% reduction observed in 50 of 60 matched pairs. VIGIL ’ s cycles are internal (tool in vocation, reasoning, v erification) and require no user interaction beyond the initial problem state- ment. Median diagnosis time w as 36.5 seconds; for example, when a user reported persistent applica- tion crashes, the diagnosis agent identified memory pressure from a background process, retriev ed a matching resolution, and executed a targeted ser- vice restart within this windo w . Ev en conserva- ti vely assuming only 10% of recorded human con- tact time (median 26.5 minutes) is acti ve diagnostic work, VIGIL is at least 4 × faster . Response quality . Automated ev aluation across fi ve dimensions- issue understanding (8.5), re- sponse rele vance (8.1), actionability (7.8), com- pleteness (7.4), and root cause accuracy (7.1), yielded a median ov erall score of 8.0 / 10, with 81% of sessions rated Good or Excellent. Reso- lution confidence analysis estimated that 82% of cases could be resolved through self-service (39% high confidence, 43% medium), suggesting that the majority of issues handled by VIGIL would not re- quire human escalation. Root cause accuracy was the lowest-scoring dimension, indicating an area for tar geted improv ement through richer diagnostic tooling and kno wledge coverage. Operational reliability . Across all 153 sessions, VIGIL in vok ed diagnostic tools in 95.4% of cases with a 95.3% tool ex ecution success rate ov er 1,586 total calls, confirming that the MCP-based tool in- terface operates reliably under real enterprise con- ditions. 6.2 User Experience T able 3 and Figure 4 summarize responses from 23 participants who completed the post-pilot question- naire. Figure 3: User experience surv ey: (a) SUS score distri- bution, (b) N ASA-TLX workload, (c) user trust (bottom- left) and (d) technology acceptance As shown in Figure 3 , the SUS score of 86.2 places VIGIL 18 points above the industry av erage of 68.0, in the Excellent tier corresponding to the 90th percentile of ev aluated systems ( Brooke et al. , 1996 ).High trust (4.29/5.0) and technology accep- tance (4.41/5.0) scores indicate that users found VIGIL ’ s recommendations reliable and belie ved it improv ed their productivity . The low N ASA-TLX workload score (2.53/7.0) confirms that the sys- tem reduces rather than adds cogniti ve burden, a common concern with AI assistance tools. Situated diagnosis exceeds retriev al alone. A stratified analysis re vealed that the 16 respondents who experienced sessions without matching his- torical cases rated VIGIL higher across all instru- ments (SUS 89.2, T rust 4.44, T AM 4.55, TLX 2.29) compared to the ov erall population. This suggests that VIGIL ’ s on-de vice diagnostic capabilities and transparent reasoning provide v alue independent of kno wledge base coverage, supporting the architec- tural decision to in vest in situated diagnosis rather than relying solely on retrie val. Figure 4: Normalized summary of the user experience surve y across the four validated instruments (n=23) Qualitative feedback. Open-ended responses (n=8) highlighted three themes: (1) users valued the transparency of VIGIL ’ s actions and reasoning as critical for trust; (2) se veral requested ele vated permissions for autonomous task completion, in- dicating demand for broader actuation scope; and (3) multiple respondents requested continued ac- cess and wider rollout. 6.3 Limitations Se veral factors qualify these results. The case- matching analysis cov ers only 39% of VIGIL ses- sions; unmatched cases may dif fer systematically in complexity . Response quality was assessed via automated LLM-based ev aluation rather than hu- man expert judgment. The survey response rate (23 of 100 participants) introduces potential self- selection bias. Finally , the pilot was conducted on a single de vice category; generalization to hetero- geneous fleets remains to be v alidated. 7 Conclusion W e presented VIGIL, an edge-extended agentic AI architecture for enterprise IT support, and ev alu- ated its on-de vice diagnosis and remediation com- ponent through a real-world pilot. Across 100 resource-constrained endpoints over 10 weeks, the system reduced interaction rounds by 39%, achie ved at least 4 × faster diagnosis, and demon- strated high response quality , user trust, and low cogniti ve workload. Notably , users rated the sys- tem higher when no historical matches were a vail- able, indicating that on-device reasoning adds value beyond kno wledge base lookup. By colocating reasoning and actuation with the en vironment where failures occur , VIGIL reduces latency , preserves fine-grained conte xt, and enables resilient operation under partial connectivity . At the same time, distrib uting autonomy to heteroge- neous endpoints introduces architectural challenges in gov ernance, monitoring, and deciding when lo- cal adaptations should generalize across the fleet. Although VIGIL is designed to support improve- ment through context refinement and prompt opti- mization rather than model retraining, these mecha- nisms were not exercised in the current deplo yment. Overall, our findings suggest that distributing agen- tic intelligence to the edge under deterministic pol- icy control offers a viable architectural direction for scalable, gov erned autonomy in enterprise IT operations. Ethical Considerations All 100 pilot participants provided informed con- sent prior to enrollment. Interaction traces col- lected during the pilot were anonymized before analysis, with no personally identifiable informa- tion retained. The system’ s policy engine ensures that all state-changing actions on user de vices are gov erned by deterministic safety constraints, with moderate-risk actions requiring explicit user ap- prov al and high-risk actions block ed uncondition- ally . No actions are executed without user aware- ness, and all agent reasoning and actions are logged transparently for auditability . References Deepak Bhaskar Acharya, Karthigeyan Kuppan, and B Di vya. 2025. Agentic ai: Autonomous intelligence for complex goals–a comprehensiv e surve y . IEEE Access . Agent2Agent W orking Group. 2025. Agent2Agent (A2A) Protocol Specification, V ersion 1.0. https: //a2a- protocol.org/latest/specification/ . Open standard for interoperability between AI agents. Aditi Agrawal, Xuechen Li, Caiming Xiong, and Aditi Raghunathan. 2024. Deep uncertainty quantification for decision-making with large language models . In International Confer ence on Learning Repr esenta- tions . Lakshya A. Agrawal, Shangyin T an, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arna v Singhvi, Herumb Shandilya, Michael J. Ryan, Meng Jiang, Christopher Potts, K oushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab . 2025. Gepa: Reflective prompt e vo- lution can outperform reinforcement learning. arXiv pr eprint arXiv:2507.19457 . Amazon W eb Services. 2024a. Amazon bedrock documentation. https://docs.aws.amazon.com/ bedrock/ . Accessed: 2026-02-11. Amazon W eb Services. 2024b. Strands agents documentation. https://strandsagents.com/ latest/documentation/docs/ . Accessed: 2026- 02-11. Petr Anokhin, Nikita Semenov , Artyom Sorokin, Dmitry Evseev , Mikhail Burtse v , and Evgeny Burnae v . 2025. Arigraph: Learning knowledge graph world models with episodic memory for llm agents . In Pr oceedings of IJCAI 2025 . Anthropic. Claude code ov erview . https://code. claude.com/docs/en/overview . Accessed: 2026- 02-08. Ilias Bouzenia, Marcel Böhme, Cristian Cadar, and 1 others. 2025. An autonomous, llm-based agent for program repair . In ICSE . John Brooke and 1 others. 1996. Sus-a quick and dirty usability scale. volume 189, pages 4–7. London, England. Linyue Cai, Chaojia Y u, Y ongqi Kang, Y u Fu, Heng Zhang, and Y ong Zhao. 2025. Practices, opportuni- ties and challenges in the fusion of knowledge graphs and large language models . F r ontiers in Computer Science . Y infang Chen, Manish Shetty , Gagan Somashekar , Minghua Ma, Y ogesh Simmhan, Jonathan Mace, Chetan Bansal, Rujia W ang, and Sarav an Rajmohan. 2025. Aiopslab: A holistic framew ork to e valuate ai agents for enabling autonomous clouds . arXiv pr eprint arXiv:2501.06706 . Fred D Davis. 1989. Perceived usefulness, perceiv ed ease of use and user acceptance of information tech- nology . MIS quarterly . M. de la Cruz Cabello and 1 others. 2025. Aiops in the era of large language models . ACM Computing Surve ys . Sandro Rama Fiorini, Leonardo G Aze vedo, Raphael M Thiago, V alesca M de Sousa, Anton B Labate, and V iviane T orres da Silv a. 2025. Episodic memory in agentic frameworks: Suggesting next tasks. arXiv pr eprint arXiv:2511.17775 . Y unfan Gao, Y un Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Y uxi Bi, Y i Dai, Jiawei Sun, Meng W ang, and Haofen W ang. 2023. Retriev al-augmented gen- eration for large language models: A survey . arXiv pr eprint arXiv:2312.10997 . Pranay Gupta, Anirudh Suresh, Damanpreet Singh, and 1 others. 2023. Llm-debugger: Autonomous de- bugging with tool-inte grated large language models . arXiv pr eprint arXiv:2311.07480 . Sandra G Hart and Lowell E Sta veland. 1988. Dev elop- ment of nasa-tlx (task load index): Results of empiri- cal and theoretical research. In Advances in psychol- ogy , v olume 52, pages 139–183. Elsevier . Jiun-Y in Jian, Ann M Bisantz, and Colin G Drury . 2000. Foundations for an empirically determined scale of trust in automated systems. International journal of cognitive er gonomics , 4(1):53–71. Kiro. 2025. Bring kiro agents to your termi- nal with kiro cli. https://kiro.dev/blog/ introducing- kiro- cli/ . Accessed: 2026-02-08. Andreas Kirsch, Joost van Amersfoort, and Y arin Gal. 2022. Minimizing epistemic uncertainty in deep learning . Advances in Neural Information Pr ocess- ing Systems . Nikolay Lapte v and 1 others. 2023. Multi variate time- series anomaly detection with llm-augmented fore- casting . arXiv pr eprint arXiv:2310.06745 . Liqun Li, Xu Zhang, Xin Zhao, Hongyu Zhang, Y u Kang, Pu Zhao, Bo Qiao, Shilin He, Pochian Lee, Jeffre y Sun, Feng Gao, Li Y ang, Qingwei Lin, Sara- vanakumar Rajmohan, Zhangwei Xu, and Dongmei Zhang. 2021. Fighting the fog of war: Automated in- cident detection for cloud systems . In 2021 USENIX Annual T echnical Conference (USENIX A TC 21) , pages 131–146. USENIX Association. Haoxiang Luo, Y inqiu Liu, Ruichen Zhang, Jiacheng W ang, Gang Sun, Dusit Niyato, Hongfang Y u, Zehui Xiong, Xianbin W ang, and Xuemin Shen. 2025. T o- ward edge general intelligence with multiple-large language model (multi-llm): architecture, trust, and orchestration. IEEE T ransactions on Cognitive Com- munications and Networking . Anirudh Madaan, Shuyan Liu, Amir Y azdanbakhsh, Xinyun Chen, Xi V ictoria Lin, and Y uandong Zhou. 2023. Self-refine: Iterati ve refinement with large language models . In Advances in Neural Information Pr ocessing Systems . T im Miller . 2019. Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelli- gence . Dany Moshko vich and Sergey Zeltyn. 2025. T aming uncertainty via automation: Observing, analyzing, and optimizing agentic ai systems. arXiv preprint arXiv:2507.11277 . Open Policy Agent Contributors. 2024. Open pol- icy agent. https://openpolicyagent.org/ . Ac- cessed: 2026-02-11. Sherry Ouyang and 1 others. 2025. Scaling agent self- ev olving with reasoning memory . arXiv preprint arXiv:2509.25140 . Introduces the ReasoningBank memory framew ork. Shishir G. Patil, Eric W allace Hu, and 1 others. 2023. Gorilla: Large language model connected with mas- siv e apis . arXiv preprint . Anthropic PBC. 2024. Introducing the model context protocol . Philipp Reinhard and 1 others. 2024. Generative ai in customer support services: A framework for aug- menting the routines of frontline service employ- ees. https://papers.ssrn.com/sol3/papers. cfm?abstract_id=4862940 . Accessed: 2026-02- 08. Shashank Santurkar , Esin Durmus, F aisal Ladhak, Percy Liang, and T atsunori Hashimoto. 2023. Whose opin- ions do language models reflect? In International Confer ence on Machine Learning . Ranjan Sapkota, K onstantinos I Roumeliotis, and Manoj Karkee. 2025. Ai agents vs. agentic ai: A concep- tual taxonomy , applications and challenges. arXiv pr eprint arXiv:2505.10468 . T imo Schick, Jane Dwivedi-Y u, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luk e Zettle- moyer , Nicola Cancedda, and Thomas Scialom. 2023. T oolformer: Language models can teach themselv es to use tools . In Advances in Neural Information Pr o- cessing Systems . ServiceNo w and Accenture. 2025. Bring ai to e very cor - ner of your business with servicenow and accenture . White paper . Accessed 2026-02-11. Y ongliang Shen, Kaitao Song, Xu T an, W enqi Zhang, Kan Ren, Siyu Y uan, W eiming Lu, Dongsheng Li, and Y ueting Zhuang. 2024. T askbench: Benchmark- ing large language models for task automation . In Advances in Neural Information Pr ocessing Systems , volume 37. NeurIPS 2024 Datasets and Benchmarks T rack. Krti T allam. 2025. From autonomous agents to integrated systems, a new paradigm: Orches- trated distributed intelligence. arXiv preprint arXiv:2503.13754 . Arthur V itui and Tse-Hsun Chen. 2025. Empow- ering aiops: Lev eraging large language models for it operations management . arXiv pr eprint arXiv:2501.12461 . W eizhe W ang, Lili Y u, Jason W eston, and Sainbayar Sukhbaatar . 2023. Augmenting language models with long-term memory . In Advances in Neural In- formation Pr ocessing Systems . Shunyu Y ao, Dian Y u, Jef frey Zhao, Izhak Shafran, Thomas L. Grif fiths, Y uan Cao, and Karthik Narasimhan. 2023a. T ree of thoughts: Deliberate problem solving with large language models . In Ad- vances in Neural Information Pr ocessing Systems . Shunyu Y ao, Jeffre y Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao. 2023b. React: Synergizing reasoning and acting in language models . In International Confer ence on Learning Repr esentations . Shunyu Y ao, Jeffre y Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao. 2023c. React: Synergizing reasoning and acting in language models . In International Confer ence on Learning Repr esentations . Jing Y u and 1 others. 2022. Gdn: Graph neural net- works for multiv ariate time-series anomaly detection . AAAI . John Zhang. 2025. Agentic ai (ai agent) de velopment guidelines and use cases (hands-on experience) . Ser- viceNow Community (Blog). Accessed 2026-02-11. Liang Zhu, Zhe Y e, Y ingjun Li, and Jian Sun. 2023. Repairagent: Fixing softw are b ugs with llm-based au- tonomous agents . arXiv pr eprint arXiv:2307.10779 . Y uchen Zhuang, Y ue Y u, Kuan W ang, Haotian Sun, and Chao Zhang. 2023. T oolqa: A dataset for llm ques- tion answering with external tools . In Advances in Neural Information Pr ocessing Systems , volume 36. NeurIPS 2023 Datasets and Benchmarks T rack. R ˘ azvan Daniel Zota, Corneliu B ˘ arbulescu, and Radu Constantinescu. 2025. A practical approach to defin- ing a framew ork for developing an agentic aiops sys- tem . Electr onics , 14(9):1775. 8 A ppendix 8.1 T echnology Stack Layer T echnology Agent Framew ork A WS Strands (Python) LLM Inference Claude Opus 4.1 Inter-Agent Protocol Agent2Agent (A2A) Packaging PyInstaller Observability OpenT elemetry tracing Policy Enforcement Open Policy Agent (OP A) Authentication Enterprise SSO T able 4: Core implementation components of VIGIL 8.2 Example Execution Summaries After each session, we con vert the e xecution trace into human-readable summaries. A few examples are provided belo w . 8.2.1 No Issue Case User Request: "How can I make my computer faster?" VIGIL Execution Trace: 1. Invoked system diagnostics: - CPU utilization: 9% - Disk utilization: 0.6% - No abnormal processes detected 2. Evaluated performance indicators against policy thresholds. 3. Determined system operating within normal parameters. 4. No remediation actions executed. Resolution: VIGIL concluded that the system was performing normally and avoided unnecessary troubleshooting or state-changing actions. This is considered a successful resolution because it correctly diagnosed "no issue" rather than applying unnecessary fixes. 8.2.2 Failur e Case User Request: "my headset mic is not working" VIGIL Execution Trace: 1. Opened Sound Control Panel. 2. Launched built-in Audio Troubleshooter. 3. Attempted to restart audio service (failed – requires admin privileges). 4. Detected that the headset was not recognized by the operating system. Resolution: VIGIL determined that the issue could not be resolved remotely. It generated a structured escalation path including: - Manual physical troubleshooting steps. - Request for administrative access to reinstall drivers. - Recommendation to visit IT vending machine for hardware replacement. 8.2.3 Success Case User Request: "My laptop doesn’t respond after waking from sleep and requires a hard reboot." VIGIL Execution Trace: Diagnosis Phase: 1. Invoked system uptime check to detect abnormal reboot patterns. 2. Retrieved relevant enterprise knowledge base articles. 3. Verified hardware specifications, driver versions, and pending updates. Remediation Phase: 4. Synthesized stepwise remediation plan grounded in retrieved guidance. 5. Executed bounded shell commands to adjust power management settings. 6. Disabled fast startup configuration. 7. Updated advanced power configuration parameters. 8. Re-validated system state after each step. Execution Summary: - Total shell commands executed: 11. - Successful command rate: 90.9%. - All actions executed under policy constraints with user consent. Resolution: VIGIL systematically diagnosed a Windows sleep/wake configuration issue. It applied targeted power-management adjustments under policy control. Continuous verification ensured safe execution and avoided unnecessary or high-risk interventions. 8.3 Evaluation Prompts ========================== EVALUATION PROMPT A: RESPONSE QUALITY ========================== You are an expert IT support quality evaluator. Evaluate the following automated IT assistant (VIGIL) response. » User Issue {user_input} » VIGIL’s Diagnostic Process Tools used: {tools_used} Total cycles: {total_cycles} Duration: {duration} seconds Execution trace: {trace_summary} » VIGIL’s Final Response {response} — » Evaluation Criteria Please evaluate the response on the following criteria (1-10 scale, where 10 is excellent): 1. Issue Understanding: Did VIGIL correctly understand what the user was asking about? 2. Root Cause Accuracy: Did VIGIL identify the correct root cause or relevant factors? 3. Response Relevance: Is the response directly relevant to the user’s issue? 4. Actionability: Are the suggested steps clear, specific, and actionable? 5. Completeness: Does the response address all aspects of the issue? Also assess: 6. Resolution Confidence: How confident are you that following VIGIL’s guidance would resolve the issue? - "high": Very likely to resolve - "medium": Likely to help but may need follow-up - "low": Unlikely to fully resolve - "unable": VIGIL could not provide a resolution Output: JSON with scores and assessment. Prompt A. LLM-as-judge prompt used to score response quality for VIGIL interactions. ========================== EVALUATION PROMPT B: CASE SIMILARITY MATCHING ========================== You are an IT support case analyst. Compare the following two IT support cases and determine if they are similar in terms of: 1. Issue type (the fundamental problem being addressed) 2. Root cause (the underlying cause of the issue) 3. Resolution actions (the steps taken to resolve, if available) » VIGIL Case (Automated IT Assistant) User Issue: {user_input} Final Response: {response} » CGR Case (Human Agent IT Support) Issue Description: {issue_description} Chat Transcript (excerpt): {chat_transcript} Resolution Summary: {resolution_Summary} Root Cause: {resolution_RootCause} Resolution Steps: {resolution_ResolutionAgent} » Your Task Analyze both cases and provide your assessment in the following JSON format: { "is_similar": true/false, "confidence": 1-10, "issue_type_match": true/false, "root_cause_match": true/false, "resolution_match": true/false, "reasoning": "Brief explanation of your assessment" } Prompt B. Prompt used to assess similarity between VIGIL-resolv ed cases and matched human support cases. 8.4 Example OP A Policies ========================== DENY (Blocked - Never Execute) ========================== 1. Command: format C: Description: Attempts to format the C: drive, erasing the system disk including the OS, user files, and installed programs. Catastrophically destructive and irreversible. 2. Command: deny[msg] { contains(input.command, "net user") contains(input.command, "/add") msg := "Blocked: User creation command detected" } Description: Blocks creation of new user accounts that could establish unauthorized persistent access. 3. Command: deny[msg] { lower_cmd := lower(input.command) contains(lower_cmd, "netsh") contains(lower_cmd, "firewall") contains(lower_cmd, "delete") msg := "Blocked: Firewall rule deletion command detected" } Description: Prevents deletion of firewall rules that protect the system from network threats. Captures syntactic variations to avoid bypass. ========================== ALLOW (Execute Immediately) ========================== 1. Command: Get-Process Description: Lists running processes with CPU/memory usage. Read-only diagnostic command. 2. Command: systeminfo Description: Displays system configuration details including hardware, OS version, and network settings. Read-only diagnostic command. ========================== WARN (Requires User Approval) ========================== 1. Command: Stop-Process -Name chrome Description: Terminates Chrome and may close unsaved work. Requires user confirmation. 2. Command: winget install 7zip Description: Installs software via Windows Package Manager. System-modifying but legitimate and reversible; requires approval. Illustrativ e OP A-based command classification examples used in the deployed system. Figure 5: Item-level SUS score breakdo wn (1–5 scale). Positiv e-framed items (higher is better) and negativ e- framed items (lower is better) are sho wn separately . The dashed line indicates the neutral midpoint (3.0). 8.5 Expanded SUS Item-Level Analysis T o provide greater transparency into the System Usability Scale (SUS) results reported in the main te xt, we include an item-lev el breakdown of all ten SUS questions in Figure 5 . Positiv e-framed items (Q1, Q3, Q5, Q7, Q9) are sho wn di- rectly , where higher scores indicate stronger agreement and better usability perception. Negati ve-framed items (Q2, Q4, Q6, Q8, Q10) are sho wn in their original form (lo wer is better), allowing inspection of percei ved complexity and friction. The neutral midpoint (3.0) is included for reference. This break- down highlights consistenc y across usability dimensions and helps interpret the aggre gate SUS score of 86.2. The questions are enumerated below for reference: Q1. I think that I would like to use this system frequently . Q2. I found the system unnecessarily complex. Q3. I thought the system was easy to use. Q4. I think that I would need the support of a technical person to be able to use this system. Q5. I found the various functions in this system were well integrated. Q6. I thought there was too much inconsistency in this system. Q7. I w ould imagine that most people would learn to use this system very quickly . Q8. I found the system very cumbersome to use. Q9. I felt very confident using the system. Q10. I needed to learn a lot of things before I could get going with this system.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment