Frequency Matters: Fast Model-Agnostic Data Curation for Pruning and Quantization
Post-training model compression is essential for enhancing the portability of Large Language Models (LLMs) while preserving their performance. While several compression approaches have been proposed, less emphasis has been placed on selecting the mos…
Authors: Francesco Pio Monaco, Elia Cunegatti, Flavio Vella
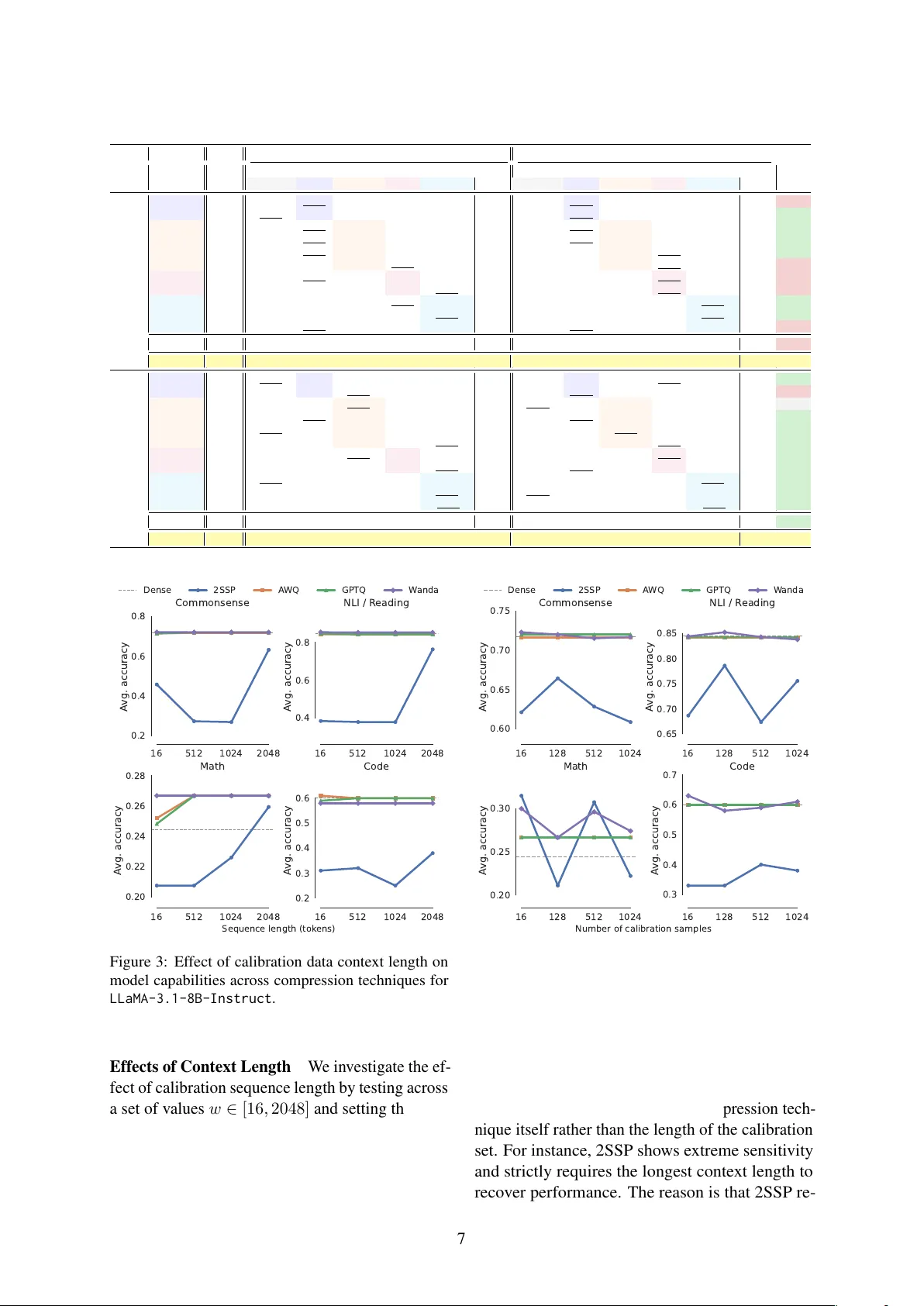
Fr equency Matters: F ast Model-Agnostic Data Curation f or Pruning and Quantization Francesco Pio Monaco Elia Cunegatti Fla vio V ella Giovanni Iacca Uni versity of T rento {francescopio.monaco, elia.cunegatti, flavio.vella, giovanni.iacca}@unitn.it Abstract Post-training model compression is essential for enhancing the portability of Large Lan- guage Models (LLMs) while preserving their performance. While sev eral compression ap- proaches ha ve been proposed, less emphasis has been placed on selecting the most suitable set of data (the so-called calibr ation data ) for finding the compressed model configuration. The choice of calibration data is a critical step in preserving model capabilities both intra- and inter-tasks. In this work, we address the chal- lenge of identifying high-performance calibra- tion sets for both pruning and quantization by analyzing intrinsic data properties rather than model-specific signals. W e introduce ZipCal , a model-agnostic data curation strategy that maximizes lexical di versity based on Zipfian power la ws. Experiments demonstrate that our method consistently outperforms standard uni- form random sampling across v arious pruning benchmarks. Notably , it also performs on par , in terms of downstream performance, with a state-of-the-art method that relies on model per - plexity . The latter becomes prohibiti vely expen- siv e at lar ge-scale models and datasets, while ZipCal is on average ∼ 240 × faster due to its tractable linear complexity 1 . 1 Introduction In recent years, considerable effort has been put into alleviating the significant computational re- quirements of Large Language Models (LLMs) ( Xia et al. , 2024 ; Muralidharan et al. , 2024 ; Lee et al. , 2025 ). T o facilitate the deplo yment of such models, researchers have de veloped v arious post- training compression techniques that reduce mem- ory and compute overhead while striving to pre- serve the original model’ s capabilities. In this work, we mainly focus on two such compression tech- niques, which are pruning and quantization. The 1 W e make the code and the e xperiments av ailable at https: //anonymous.4open.science/r/zipcal- 71CD/ . former compresses the model by removing part of its parameters, with earlier approaches requiring expensi ve retraining ( Han et al. , 2015 ; Frankle and Carbin , 2019 ), and more modern approaches sim- ply removing weights in a gradient-free manner ( Frantar and Alistarh , 2023 ; Sun et al. , 2024b ), or enforcing hardware-friendly sparsity patterns ( Sun and Sakuma , 2026 ) without the need for param- eter updates ( Zhang et al. , 2024 ; Cuneg atti et al. , 2025 ). Quantization, on the other hand, compresses the model by reducing the numerical precision of weights and activ ations ( Frantar et al. , 2023 ; Lin et al. , 2024 ; Huang et al. , 2025 ). The latest ap- proaches are based on ternary quantized models ( W ang et al. , 2023 ; Ma et al. , 2024 ) or ef ficient bi- nary MatMul techniques ( Dehghankar et al. , 2025 ). Beyond the choice of the compression approach, recent works ( Bandari et al. , 2024 ; W illiams and Aletras , 2024 ; Oh and Oh , 2025 ) explored how the selection of the data used for gathering model statistics during the compression process, called calibration data , can influence the process and, as a result, the final compressed model capabili- ties. While the majority of compression techniques ( Frantar and Alistarh , 2023 ; Lin et al. , 2024 ) rely on general-purpose datasets, such as C4 ( Raffel et al. , 2020 ) or Pile ( Gao et al. , 2020 ), the impact of domain-specific calibration remains an underin- vestigated problem, with fe w exceptions ( Bandari et al. , 2024 ). T o analyze the impact of selected data for com- pression, we le verage se veral studies on statistical linguistics that sho w that human languages sho w a structure in the frequency distribution of words ( Zipf , 2013 ; Piantadosi , 2014 ). Specifically , we in vestigate whether this statistical observ ation can be exploited for data curation of calibration sets for model compression. W e hypothesize that a set of data samples maximizing le xical di v ersity , cap- turing the sparse tail of the Zipfian distribution, can provide much richer and more representati ve 1 information for compression algorithms. By fo- cusing on these intrinsic linguistic properties, we propose a sampling strategy that identifies high- utility , model-agnostic data with negligible com- putational overhead. Our results show that this linguistically-informed approach performs on par with more expensi ve, model-dependent curation methods, of fering a scalable and rob ust solution for billion-parameter model compression that general- izes across di verse do wnstream tasks. Data Curation Goals An ideal technique for data curation must be scalable ( G1 ), i.e., capa- ble of processing massiv e corpora with minimal computational ov erhead; model-agnostic ( G2 ), i.e., capable of identifying the most informati ve exam- ples from a corpus without relying on expensi ve model passes; and address inter-domain general- ization ( G3 ), i.e., being capable of synthesizing both Single-Domain and Multi-Domain corpora settings by design. Existing data curation tech- niques only fulfill a subset of these goals, and, to our best kno wledge, none hav e yet explored ( G3 ). Core Contributions W e propose a sampling strategy rooted in Zipfian statistics that identifies high-utility calibration samples by maximizing lex- ical diversity . This approach sidesteps the need for model-dependent metrics (e.g., perplexity or gradient information), achie ving goals ( G1 ) and ( G2 ). Moreover , we provide a framew ork for ex- tracting representativ e samples from Multi-Domain datasets, ensuring the calibration set is balanced, meeting goal ( G3 ). W e empirically e v aluate our proposed method, called ZipCal , against SoT A techniques for data curation for compression al- gorithms. W e conduct a comprehensi ve analysis against baselines based on alternativ e data prop- erties, proving that capturing le xical di versity is a stable and scalable proxy for data curation. 2 Related W ork Model Compression Pruning methods aim to remov e parameters to reduce the size of the mod- els. The first approaches to pruning in v olved es- timating the contribution of each neuron to the fi- nal loss using the magnitude of the weights and gradient information ( Molchanov et al. , 2019 ; Ma et al. , 2023 ). More recently , different gradient- free no-retraining pruning modalities have been ex- plored. Unstructured approaches zero-out individ- ual weights ( Frantar and Alistarh , 2023 ; Sun et al. , 2024b ; Y ang et al. , 2025 ), while semi-structured methods enforce specific sparsity patterns to en- sure hardware compatibility ( Zhou et al. , 2021 ). Structured approaches, instead, remov e entire ar- chitectural components, such as attention heads or layer rows/columns ( Ashkboos et al. , 2024 ; Sandri et al. , 2025 ; Guo et al. , 2025 ). On the other hand, quantization methods reduce the numerical precision of weights and/or activ a- tions to reduce the memory footprint and accelerate inference. These methods range from Round-T o- Nearest (R TN) ( Nagel et al. , 2020 ) to more sophisti- cated error-minimization strate gies ( Nahshan et al. , 2021 ; Chen et al. , 2025 ). Other works focus on reducing degradation in extreme quantization sce- narios ( Dettmers et al. , 2022 ), employ optimized kernels like LUT -GEMM ( Park et al. , 2024 ), or acti v ation-aw are scaling ( Lin et al. , 2024 ). Calibration Data Almost every compression al- gorithm relies on a small, representati ve calibra- tion set to estimate the information flow through the network. These statistics guide the compression process, determining quantization thresholds ( Lin et al. , 2024 ) or pruning s cores ( Sun et al. , 2024b ). Recent studies hav e shown that the choice of the calibration source significantly impacts the perfor- mance of the compressed model ( W illiams and Aletras , 2024 ), re vealing that general-purpose cor - pora like C4 ( Raf fel et al. , 2020 ) are not the optimal choice for downstream tasks ( Bandari et al. , 2024 ). This suggests that calibration data should mirror the target domain to pre vent activ ation distribution shifts, which can lead to suboptimal quantization thresholds or pruning masks. Researchers hav e proposed more sophisticated calibration data curation strategies. Marion et al. ( Marion et al. , 2023 ) demonstrate that perplexity serves as a robust metric to rank and select the most impactful samples for pruning, essentially using the model’ s o wn likelihood as a proxy for quality . Extending this logic, COLA ( He et al. , 2025 ) in- troduces a hybrid approach that selects samples by balancing the magnitude of model activ ations with intrinsic data statistics. While ef fecti ve, these meth- ods are inherently model-dependent and computa- tionally intensi ve. Moreover , these techniques are typically ev aluated on single-source datasets and do not address the challenge of heterogeneous com- posability ( G3 ), while it would be desirable to hav e stable, cross-task performance post-compression. 2 3 Zipf Sampling Natural languages are characterized by a Zipfian distribution ( Piantadosi , 2014 ), where a small num- ber of words appear with high frequency , while most of the vocab ulary resides in an increasingly sparse long tail. Not acknowledging this sparsity implies potentially omitting the rare tokens and di verse semantic contexts that trigger critical acti- v ation outliers in LLMs. 3.1 Single-Domain Sampling W e propose to sample calibration data from a dataset by maximizing the le xical diver sity of the calibration set within a constrained number of sam- ples. Specifically , we apply a sanitization pass to the dataset where tokens are con verted to lo wer- case to form a vocabulary V and special tokens (i.e., EOS) are removed. W e then employ a ran- domized greedy selection heuristic to iterati vely populate the calibration set. In each iteration, we select a sample s from a candidate pool P that maximizes the gain of the sample’ s vocabulary: s ∗ = arg max s ∈ P | V ( s ) \ V cov ered | (1) where V cov ered is the vocab ulary of sanitized tokens already present in pre viously selected samples. In the ev ent of a tie, we prioritize the sample with the highest total number of unique tokens to maximize information density . This approach ensures that the resulting calibration data provides a high-fidelity approximation of the full dataset’ s vocab ulary man- ifold. W e present the procedure, named ZipCal , in Algorithm 1 . Lemma 3.1. When ZipCal is used to extr act a cali- bration set of k samples on dataset D of n elements, it completes the pr ocedur e in O ( nk ) time . Pr oof. The selection process, lines 4 to 7 of Al- gorithm 1 , consists of k iterations to construct the calibration set. At any iteration i ∈ (1 , k ) , we hav e to carry out T i = N − i + 1 e v aluations. T o find out the total number of ev aluations required to construct a calibration set of k samples, we hav e: T tot = k X i =1 T i = k · n − k ( k + 1) 2 + k (2) During each e v aluation, we compute the set dif fer- ence between the candidate’ s vocabulary V s and the cumulati ve vocab ulary V cov ered . This cost scales with the number of unique elements in a sample, Algorithm 1: ZipCal Input: Dataset D ; Number of samples k Output: Set of calibration samples S 1 S , V cov ered ← ∅ ; // Precalculate the full vocabulary 2 f or each sample s ∈ D do 3 V s ← { sanitize ( t ) | t ∈ s, t / ∈ SpecialT okens } ; 4 f or i = 1 to k do // Select sample with maximum marginal vocabulary gain 5 s ∗ ← arg max s ∈D\ S | V s \ V cov ered | ; 6 S ← S ∪ { s ∗ } ; 7 V cov ered ← V cov ered ∪ V s ∗ ; 8 r eturn S ; which is bounded by the context window size w . Since w is fixed a priori, its contribution to the asymptotic complexity is constant. Consequently , summing these contributions, the o verall comple x- ity is O ( kn ) . 3.2 Multi-Domain Sampling When calibrating models for general-purpose use or Multi-Domain applications, a single source of data is often insuf ficient. T o address goal ( G3 ), we extend our approach to support heteroge- neous multi-domain settings. Simply concatenating datasets and applying ZipCal ov er the joint dataset is suboptimal, as a single large or linguistically dense corpus might dominate the selection process. T o address this, we propose a hierarchical selection strategy . First, we apply ZipCal to each dataset D i ∈ D , to extract a local representativ e pool P i of size k . This ensures each domain’ s unique vo- cabulary is captured. Second, we consolidate these pools into a candidate set P = S P i and apply a greedy k -centers selection algorithm. By represent- ing each sample using a lightweight embedding, the k -centers objectiv e selects a final set S that maximizes the distance between samples, ensuring the calibration data is semantically spread across all provided domains. Lemma 3.2. The Multi-Domain ZipCal pr ocedur e extr acts k samples fr om m datasets, each of length n m , in O ( mN k ) time, wher e N = max m ( n m ) . 3 1 0 1 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 F r equency (log) GSM8K 1 0 0 1 0 1 1 0 2 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 W inoGrande 1 0 0 1 0 1 1 0 2 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 HellaSwag F ull Dataset R andom ZipCal COL A Theor etical Zipf Figure 1: T oken frequency distrib ution of the original datasets and the random, COLA, and ZipCal calibration sets. T able 1: Comparison of COLA vs. ZipCal calibration data under W anda unstructured pruning at 25% sparsity . COLA ZipCal Calibration Category Calibration Category Model T ask Dense LangMod Math CommQA NLI KnowT ran Mean LangMod Math CommQA NLI KnowTran Mean Delta MMLU-M 24.44 23.33 24.44 23.01 21.85 23.33 23.19 23.01 26.29 21.24 22.02 23.01 23.11 -0.08 GSM8k 78.09 76.55 75.70 74.40 76.54 75.89 75.82 76.88 76.27 75.82 75.70 76.61 76.25 +0.43 HellaSwag 71.71 72.03 72.09 71.76 71.67 71.86 71.88 71.78 71.90 71.83 71.59 71.80 71.78 -0.10 W inoGr . 69.46 68.93 68.51 67.93 68.03 68.07 68.30 67.88 68.43 68.82 68.15 68.03 68.26 -0.04 OBQA 47.80 46.67 47.30 46.67 46.20 47.10 46.79 47.90 47.50 48.10 47.30 47.80 47.72 +0.93 BoolQ 84.46 84.99 84.74 84.41 84.85 84.91 84.78 84.50 84.45 84.83 84.60 84.48 84.57 -0.21 R TE 74.73 72.32 72.20 71.96 72.38 72.38 72.25 72.20 72.38 72.74 72.74 73.10 72.64 +0.39 ANLI 58.40 56.37 59.00 59.33 57.10 57.80 57.92 61.50 58.50 59.80 59.65 61.95 60.28 +2.36 ARC-C 51.71 51.54 50.30 50.28 51.24 50.77 50.82 51.45 50.98 51.58 51.32 51.11 51.29 +0.47 ARC-E 73.86 73.27 73.46 73.13 73.21 73.74 73.36 73.86 74.05 73.74 73.84 73.93 73.88 +0.52 MMLU-K 62.28 62.08 62.51 62.04 61.94 61.56 62.02 62.23 62.68 62.70 62.44 62.58 62.53 +0.51 Mean 63.36 62.55 62.75 62.27 62.27 62.49 62.47 63.02 63.04 62.84 62.67 63.13 62.94 +0.47 Llama-3.1-8B-Instruct Runtime 5400s 36s 3240s 2160s 1380s 2443s 15.2s 2.3s 12.3s 9.3s 14.5s 10.7s 228 × MMLU-M 21.48 24.44 23.01 22.02 21.24 21.85 22.51 27.40 24.44 26.29 28.79 24.44 26.27 +3.76 GSM8k 75.44 74.05 74.34 74.98 74.30 73.88 74.31 74.32 74.41 75.09 74.26 74.37 74.49 +0.18 HellaSwag 67.24 67.11 67.23 67.08 67.06 67.22 67.14 67.27 67.15 67.23 67.34 67.34 67.27 +0.13 W inoGr . 70.48 69.24 69.06 68.82 69.26 69.65 69.21 69.11 68.63 69.18 69.34 68.82 69.02 -0.19 OBQA 45.40 46.07 46.10 46.40 45.70 46.30 46.11 45.33 45.60 45.40 45.20 45.40 45.39 -0.72 BoolQ 88.59 88.92 88.62 88.65 88.81 88.64 88.73 88.80 88.79 88.79 88.72 88.98 88.81 +0.08 R TE 78.34 78.22 78.88 77.80 78.34 78.70 78.39 78.46 78.34 78.52 78.52 78.34 78.44 +0.05 ANLI 72.80 72.37 73.30 73.05 72.40 72.15 72.65 73.27 73.15 72.60 73.05 73.00 73.01 +0.36 ARC-C 51.79 52.13 51.37 51.71 51.62 51.83 51.73 51.48 51.54 51.54 51.79 51.32 51.53 -0.20 ARC-E 66.79 67.51 67.09 66.94 67.28 67.23 67.21 66.72 66.75 66.90 66.96 66.90 66.85 -0.36 MMLU-K 33.83 35.90 33.53 32.94 36.80 33.94 34.62 36.95 36.07 36.42 35.88 35.63 36.19 +1.57 Mean 61.11 61.45 61.14 60.94 61.16 61.04 61.15 61.74 61.35 61.63 61.80 61.32 61.57 +0.42 gemma-2-9b-it Runtime (sec) 6231s 149s 3400s 2671s 1500s 2790s 15.2s 2.3s 12.3s 9.3s 14.5s 10.7s 260 × 4 Experiments W e present below the details of the experimental setup and the experimental results. 4.1 Experimental Setup Post-training Compressions W e v alidate ZipCal across a number of post-training compres- sion techniques that rely on calibration data. For pruning, we consider W anda ( Sun et al. , 2024b ), an unstructured approach which scores weight importance via the product of magnitudes and input activ ation norms | W ij | · ∥ X j ∥ 2 , and 2SSP ( Sandri et al. , 2025 ), a two-stage framework for structured pruning that balances width and depth reduction. For quantization, we ev aluate GPTQ ( Frantar et al. , 2023 ), which minimizes layer -wise reconstruction error ∥ W X − ˆ W X ∥ 2 2 , and A WQ ( Lin et al. , 2024 ), which preserves salient weights critical to model performance by scaling them according to acti v ation magnitude | X | . Experimental En vironment W e use two LLMs to perform our ev aluation of downstream tasks: Llama-3.1-8B-Instruct ( Grattafiori et al. , 2024 ) and Gemma-2-9B-it ( T eam et al. , 2024 ). For lan- guage modeling e v aluation, we use two base mod- els, namely Llama-3.1-8B and Gemma-2-9B 2 . Un- less otherwise specified, we set the conte xt length to w = 2048 and the number of calibration samples k = 128 . 2 Due to the number of combinations (calibration, down- stream) tasks, executing the complete set of experiments o ver these models requires ≈ 1200 GPU hours. 4 Baselines W e benchmark ZipCal firstly against random sampling, the standard approach used by almost any compression algorithm ( Ashkboos et al. , 2024 ; Sun et al. , 2024b ; Lin et al. , 2024 ). Then, we e v aluate whether our lightweight, model-agnostic approach can match or exceed the performance of a computationally expensi ve, model-dependent technique. Hence, we more extensi vely compare against COLA ( He et al. , 2025 ), a recent state- of-the-art data curation method for compression algorithms that relies on both acti v ation influence and data div ersity metrics. W e compare the per- formance e v aluation of both intra- (i.e., when the e v aluation tasks match with the calibration domain) and inter- (i.e., when the e v aluation tasks do not match with the calibration domain) tasks, as well as the runtime between ZipCal and COLA. Evaluation T o assess do wnstream performance post-compression, we use the LM-Evaluation- Harness framew ork ( Gao et al. , 2023 ) across five functional domains. Results are reported on the subset of datasets that support standardized zero or few-shot metrics. W e categorize the datasets in functional domains as follows. (i) Language Modeling : zero-shot perplexity is measured on W ikiT ext ( Merity et al. , 2016 ), C4 ( Raffel et al. , 2020 ), and Pile ( Gao et al. , 2020 ), which are gen- eral datasets that have commonly been used for model compression. (ii) Mathematical Reason- ing : ev aluated via GSM8k (5-shot) ( Cobbe et al. , 2021 ), SV AMP ( P atel et al. , 2021 ), and MMLU-M the subset of math tasks in MMLU. (iii) Common- sense Reasoning & QA : zero-shot assessed us- ing W inoGrande ( Keisuke et al. , 2021 ), Common- senseQA ( T almor et al. , 2019 ), HellaSwag ( Zellers et al. , 2019 ), and OpenBookQA ( Mihaylov et al. , 2018 ). (iv) Natural Language Inference (NLI) : tested in zero-shot on R TE ( W ang et al. , 2018 ) and the adversarial ANLI ( Nie et al. , 2020 ) benchmarks. (v) Kno wledge & T ranslation : general world kno wledge and reasoning are measured via MMLU- K, the MMLU corpus with math tasks excluded ( Hendrycks et al. , 2021 ) and ARC ( Clark et al. , 2018 ), while translation capabilities are tested on WMT14 ( Bojar et al. , 2014 ). 4.2 Experimental Results Better than Random The purpose of this ex- periment is to verify the hypothesis that ZipCal identifies higher-utility data compared to standard uniform random sampling. Random sampling is T able 2: Performance comparison against random sam- pling across different tasks and compression techniques for Meta-Llama-3.1-8B-Instruct . W anda (25%) GPTQ (W4A16) A WQ (W4A16) T ask Dense Rand. ZipCal Rand. ZipCal Rand. ZipCal MMLU-M 24.44 23.33 24.14 23.33 24.07 23.12 24.07 GSM8K 78.08 74.98 77.17 70.12 70.63 36.13 38.46 HellaSwag 71.70 64.49 64.28 64.23 64.20 64.85 64.85 W inoGr . 73.56 67.86 68.07 67.21 67.39 67.48 68.71 OBQA 47.80 41.83 42.42 42.02 41.10 40.90 40.45 BoolQ 85.41 84.80 84.64 83.53 83.44 83.98 84.36 R TE 74.37 72.39 72.77 71.75 73.06 74.73 73.47 ANLI 58.40 57.90 60.64 46.50 53.90 51.10 53.20 ARC-C 53.75 50.33 50.89 50.03 50.37 51.41 51.54 ARC-E 82.24 76.48 76.67 76.27 76.22 76.47 76.49 MMLU-K 62.28 62.24 62.46 57.73 58.08 56.51 57.49 Mean 64.73 61.51 62.20 59.34 60.22 56.97 57.55 statistically prone to ov errepresent high-frequency tokens while failing to capture the Zipfian tail com- posed of tokens that are an integral part of the corpora, as can be seen from Figure 1 . More- ov er , as numerically shown in T able 2 , ZipCal consistently outperforms random selection across the different compression techniques. In the few occasions where random selection performs best, it does so by a small margin ( < 1% ). Most notably , we observe significant gains in reasoning-intensi ve tasks: on ANLI, our method improves accuracy by 7 . 4% for GPTQ and 2 . 7% for W anda. Similarly , in GSM8K, we achie ve a 2 . 1% boost in the pruning setting with W anda. This increased lexical rep- resentation correlates directly with performance; by forcing the calibration set to cov er a broader vocab ulary manifold, Zipf Sampling provides the compression algorithms with a more representa- ti ve set of acti v ation outliers ( Sun et al. , 2024a ; An et al. , 2025 ). This leads to more robust statistics, ef fecti vely bridging the gap between the original dense model and its compressed counterpart. Evaluating Single-Domain Data Curation W e no w discuss the ev aluation against COLA on mod- els compressed using a Single-Domain calibration source (i.e, the calibration data are extracted from a single domain). T ables 1 and 3 shows ho w our pro- posed approach achiev es on-par performance w .r .t. the baselines. Considering only the mean across all possible < task,domain > pairs, ZipCal performs better than COLA in 3 out of 4 cases. More im- portantly , as stated at the beginning of the paper , it reduces the data curation bottleneck from o ver an hour to mere seconds, yielding a 228 − 260 × accel- eration while preserving do wnstream capabilities on par with computationally expensi ve baselines. Furthermore, the results in T ables 1 and 3 demon- 5 strate that Single-Domain compression is highly sensiti ve to the choice of calibration data. Contrary to intuition, matching the calibration source do- main to the task domain (e.g., using Commonsense Reasoning & QA for BoolQ) does not uni versally hold the best performance (best is underlined in the T ables 1 and 3 , while domain-task match cells are colored). The results are also in line with ( Ban- dari et al. , 2024 ), where the authors showed how Language Modeling corpora are not inherently the optimal calibration source for di verse do wnstream tasks. This domain sensitivity finding introduces a form of intra-task sub-optimality that limits the pos- sibility of deploying a unique compressed model that can achie ve reasonable performance on a pre- defined do wnstream domain task. Evaluating Multi-Domain Data Curation W e tested our Multi-Domain approach of ZipCal , Sec- tion 3.2 , to see if it can ef fecti v ely bypass the afore- mentioned intra-task sub-optimality , as well as the inter-task limitations of real-world model deploy- ment, where the specific downstream task domain will be used is unkno wn a priori . By aggregating Zipfian subsets from multiple domains, we pro- duce a single general calibration set. W e sho w in T able 4 that models compressed using a Multi- Domain source perform better ov erall on a verage across dif ferent tasks. Most notably , Multi-Domain calibration deliv ers a model that achiev es a score of 64 . 48 for Llama-3.1-8B with W anda pruning, which is a higher score than any individual calibra- tion domain within the Single-Domain compressed models within ZipCal and COLA groups. These results highlight that the Multi-Domain version of ZipCal can solve both the intra-suboptimality issue as well as the inter-task deplo yment. Evaluating Scalability W e ev aluated the compu- tational efficienc y of ZipCal against COLA across v arious dataset scales, to assess its scalability ( G1 ). While already in tables 1 and 3 the runtime supe- riority of ZipCal is clear , we also tried v arying the number of calibration samples k from 16 to 2048 on two downstream tasks, such as ARC-C and W inoGrande, to better understand the compu- tational complexity trade-of f between ZipCal and COLA. Results are reported in Figure 2 . On a small dataset like ARC-C, COLA needs from a fe w sec- onds with a small 3B model to some minutes using a large 70B model, with the forward pass becom- ing a bottleneck e ven on a dataset of this size. W e observe a similar trend with W inogGande, which is an order of magnitude lar ger than ARC-C. COLA with a 70B model requires ov er 3 hours, while ZipCal takes just 9 seconds. Overall, ZipCal is 104 × faster ov er the 3B model, and achiev es up to 1330 × speed up ov er the 70B model. 0.25 0.5 1 1s 1m 1h T otal selection time AR C-C (n 10 ) 0.25 0.5 1 W inoGrande (n 10 ) F raction of dataset ZipCal COL A Llama-3.1-70B COL A Llama-3.1-8B COL A Llama-3.2-3B Figure 2: Running time (log-scale) for calibration data selection. The COLA COLA COLA COLA COLA COLA COLA COLA COLA COLA COLA COLA COLA COLA COLA COLA COLA baseline is run for models of dif- ferent sizes; whereas, ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal ZipCal is model-agnostic, thus we report the measurement of the only run. Remarks T o conclude, the results highlight that while model-based curation becomes computa- tionally prohibitiv e as LLMs scale in size, our model-agnostic approach ( G2 ) pro vides a near- zero-ov erhead solution ( G1 ) that maintains high- fidelity calibration without requiring inference. Crucially , it is important to notice that the efficienc y gain is model-agnostic; once a calibration set is computed, it is fixed and reusable across dif ferent models and compressi on techniques. Moreover , the Multi-Domain version of ZipCal ov ercomes the ne- cessity of a luc ky pick from a plethora of datasets and samples. In contrast, the proposed hierarchical sampling approach pro vides a compressed model that, on a verage, outperforms models compressed separately on single domains ( G3 ). 5 Further Experiments Effects of Compression on Perplexity Along with the downstream e valuation ov er Instruct mod- els, we also e v aluate ZipCal against COLA over the Language Modeling task (i.e., perplexity). The results reported in T able 5 show that Single- Domain and Multi-Domain ZipCal performances are once again on par with COLA. W e want to high- light that the calibration sets e xtracted by ZipCal are shared across dif ferent models without adapta- tion, confirming that lexically div erse calibration sets preserve compression quality . 6 T able 3: Comparison of COLA vs. ZipCal calibration data under GPTQ W4A16 quantization. COLA ZipCal Calibration Category Calibration Category Model T ask Dense LangMod Math CommQA NLI KnowT ran Mean LangMod Math CommQA NLI KnowT ran Mean Delta MMLU-M 24.44 23.33 24.44 23.01 21.85 23.33 23.19 23.01 26.29 21.24 22.02 23.01 23.11 -0.08 GSM8k 78.09 71.75 68.46 68.84 63.99 65.01 67.61 71.99 74.60 65.13 70.96 67.32 70.00 +2.39 HellaSwag 71.71 72.07 72.14 71.91 72.06 71.54 71.94 71.84 72.71 71.46 71.89 72.37 72.05 +0.11 W inoGr . 69.46 66.75 68.15 66.34 66.30 66.73 66.85 66.34 67.40 66.69 67.05 67.32 66.96 +0.11 OBQA 47.80 45.60 46.40 46.20 43.90 45.90 45.60 45.20 47.20 45.60 47.50 46.20 46.34 +0.74 BoolQ 84.46 84.70 84.08 84.08 84.74 83.53 84.23 82.63 82.68 83.79 83.91 83.35 83.27 -0.96 R TE 74.73 74.61 75.63 71.30 74.91 74.37 74.16 72.38 70.76 71.84 73.10 72.92 72.20 -1.96 ANLI 58.40 57.47 52.85 53.55 54.40 58.25 55.30 53.45 51.90 55.20 56.25 55.05 54.37 -0.93 ARC-C 51.71 50.14 50.38 50.21 50.77 50.64 50.43 50.21 50.34 50.17 49.66 51.96 50.47 +0.04 ARC-E 73.86 73.55 73.76 72.62 73.30 73.88 73.42 72.73 74.07 74.33 72.90 75.48 73.90 +0.48 MMLU-K 62.28 57.46 60.45 57.48 58.45 58.35 58.44 54.42 58.64 57.40 56.96 58.12 57.11 -1.33 Mean 63.36 61.58 61.52 60.50 60.42 61.05 61.02 60.38 61.51 60.26 61.11 61.19 60.89 -0.13 Llama-3.1-8B-Instruct Runtime 5400s 36s 3240s 2160s 1380s 2443s 15.2s 2.3s 12.3s 9.3s 14.5s 10.7s 228 × MMLU-M 21.48 24.44 23.01 22.02 21.24 21.85 22.44 27.40 24.44 26.29 28.79 24.44 26.27 +3.83 GSM8k 75.44 74.12 74.30 74.41 74.18 73.81 74.16 73.67 73.92 73.39 73.81 73.54 73.66 -0.50 HellaSwag 67.24 67.43 67.56 68.23 67.43 67.48 67.63 68.02 67.61 67.81 67.36 67.37 67.63 +0.00 W inoGr . 70.48 69.93 70.01 69.69 69.34 69.61 69.72 69.69 70.60 70.38 70.01 69.02 69.92 +0.20 OBQA 45.40 45.47 44.50 44.20 44.10 45.40 44.73 45.07 44.90 45.20 45.00 45.00 45.03 +0.30 BoolQ 88.59 88.66 88.62 88.32 88.50 88.76 88.57 88.64 88.62 88.58 89.07 88.49 88.68 +0.11 R TE 78.34 78.10 76.53 78.34 77.26 77.62 77.57 77.26 77.80 77.80 78.16 78.52 77.91 +0.34 ANLI 72.80 71.07 71.75 71.80 71.90 72.00 71.70 72.20 72.90 70.30 72.55 71.95 71.98 +0.28 ARC-C 51.79 52.28 50.77 51.79 51.32 51.41 51.51 52.22 52.09 52.43 51.45 52.52 52.14 +0.63 ARC-E 66.79 67.31 66.50 66.73 66.22 67.66 66.88 68.83 67.82 68.81 66.41 68.22 68.02 +1.14 MMLU-K 33.83 33.23 26.74 29.17 29.70 37.46 31.26 36.76 30.64 34.03 28.79 41.04 34.25 +2.99 Mean 61.11 61.09 60.03 60.43 60.11 61.19 60.56 61.80 61.03 61.37 61.04 61.83 61.41 +0.85 gemma-2-9b-it Runtime 6231s 149s 3400s 2671s 1500s 2790s 15.2s 2.3s 12.3s 9.3s 14.5s 10.7s 260 × 16 512 1024 2048 0.2 0.4 0.6 0.8 A vg. accuracy Commonsense 16 512 1024 2048 0.4 0.6 0.8 A vg. accuracy NLI / R eading 16 512 1024 2048 0.20 0.22 0.24 0.26 0.28 A vg. accuracy Math 16 512 1024 2048 0.2 0.3 0.4 0.5 0.6 A vg. accuracy Code Sequence length (tok ens) Dense 2SSP A WQ GPTQ W anda Figure 3: Effect of calibration data context length on model capabilities across compression techniques for LLaMA-3.1-8B-Instruct . Effects of Context Length W e in vestigate the ef- fect of calibration sequence length by testing across a set of values w ∈ [16 , 2048] and setting the num- ber of samples k = 128 . As sho wn in Figure 3 , we find that for most compression techniques, no significant improv ement is observ ed by increasing the context window . Performance is flat ev en at 16 128 512 1024 0.60 0.65 0.70 0.75 A vg. accuracy Commonsense 16 128 512 1024 0.65 0.70 0.75 0.80 0.85 A vg. accuracy NLI / R eading 16 128 512 1024 0.20 0.25 0.30 A vg. accuracy Math 16 128 512 1024 0.3 0.4 0.5 0.6 0.7 A vg. accuracy Code Number of calibration samples Dense 2SSP A WQ GPTQ W anda Figure 4: Effect of the number of calibration data sam- ples on model capabilities across compression tech- niques for LLaMA-3.1-8B-Instruct . w = 16 , which suggests that lexically di v erse cali- bration sets work e ven at small scales. This trend seems to be characterized by the compression tech- nique itself rather than the length of the calibration set. For instance, 2SSP sho ws e xtreme sensiti vity and strictly requires the longest context length to recov er performance. The reason is that 2SSP re- 7 T able 4: Comparison of COLA vs. ZipCal (Multi-Domain) performance across W anda and 2SSP at 25% sparsity , and GPTQ and A WQ using W4A16 compression scheme. W anda (25%) 2SSP (25%) GPTQ (W4A16) A WQ (W4A16) Model T ask Dense COLA ZipCal ∆ COLA ZipCal ∆ COLA ZipCal ∆ COLA ZipCal ∆ Llama-3.1-8B-Instruct MMLU-M 24.44 23.19 24.00 +0.81 22.22 22.54 +0.32 23.19 23.01 -0.18 24.44 24.44 0.00 GSM8k 78.09 75.82 75.80 -0.02 4.88 4.13 -0.75 67.61 74.07 +6.46 68.98 70.50 +1.52 HellaSwag 71.71 71.88 71.86 -0.02 59.41 59.16 -0.25 71.94 71.73 -0.21 71.68 71.95 +0.27 W inoGr . 69.46 68.30 68.82 +0.52 60.03 59.68 -0.35 66.85 67.95 +1.10 66.75 68.10 +1.35 OBQA 47.80 46.79 47.90 +1.11 40.25 40.92 +0.67 45.60 44.40 -1.20 45.90 45.90 0.00 BoolQ 84.46 84.78 85.23 +0.45 72.57 73.12 +0.55 84.23 85.38 +1.15 84.07 84.60 +0.53 R TE 74.73 72.25 72.82 +0.57 67.04 68.02 +0.98 74.16 74.72 +0.56 73.10 74.50 +1.40 ANLI 58.40 57.92 61.50 +3.58 44.50 43.87 -0.63 55.30 56.90 +1.60 53.56 55.00 +1.44 ARC-C 51.71 50.82 51.11 +0.29 39.71 39.75 +0.04 50.43 49.31 -1.12 50.21 50.30 +0.09 ARC-E 73.86 73.36 73.86 +0.50 63.21 62.47 -0.74 73.42 72.97 -0.45 72.55 72.80 +0.25 MMLU-K 62.28 62.02 76.37 +14.35 35.59 36.07 +0.48 58.44 55.86 -2.58 58.52 58.60 +0.08 Mean 63.36 62.47 64.48 +2.01 46.31 46.34 +0.03 61.02 61.48 +0.46 60.89 61.52 +0.63 gemma-2-9b-it MMLU-M 21.48 22.51 27.40 +4.89 19.26 23.33 +4.07 22.44 26.29 +3.85 21.40 21.30 -0.10 GSM8k 75.44 74.31 74.75 +0.44 3.30 3.51 +0.21 74.16 73.61 -0.55 74.22 74.10 -0.12 HellaSwag 67.24 67.14 67.25 +0.11 55.48 54.73 -0.75 67.63 67.55 -0.08 67.58 67.50 -0.08 W inoGr . 70.48 69.21 68.98 -0.23 59.06 58.66 -0.40 69.72 69.61 -0.11 69.58 69.40 -0.18 OBQA 45.40 46.11 45.60 -0.51 38.14 38.64 +0.50 44.73 45.40 +0.67 45.17 46.10 +0.93 BoolQ 88.59 88.73 89.08 +0.35 72.78 73.07 +0.29 88.57 88.04 -0.53 88.57 89.00 +0.43 R TE 78.34 78.39 79.06 +0.67 66.00 65.64 -0.36 77.57 79.06 +1.49 77.58 78.50 +0.92 ANLI 72.80 72.65 72.60 -0.05 51.90 52.28 +0.38 71.70 72.90 +1.20 71.76 72.10 +0.34 ARC-C 51.79 51.73 52.21 +0.48 39.80 40.62 +0.82 51.51 51.11 -0.40 51.28 51.20 -0.08 ARC-E 66.79 67.21 67.84 +0.63 59.22 58.43 -0.79 66.88 68.22 +1.34 66.66 66.80 +0.14 MMLU-K 33.83 34.62 36.96 +2.34 22.77 22.41 -0.36 31.26 35.19 +3.93 32.00 34.00 +2.00 Mean 61.11 61.15 61.98 +0.83 44.34 44.67 +0.33 60.56 61.54 +0.98 60.53 60.91 +0.38 T able 5: Language modeling perplexity ( ↓ ). Com- parison between COLA, ZipCal , and ZipCal (Multi- Domain). ∆ indicates the dif ference between our best and COLA on A vg. ov er C4, W ikiT ext, and Pile. Model Method COLA ZipCal -SD ZipCal -MD ∆ Llama-3.1-8B Dense 7.15 7.15 7.15 W anda (25%) 7.77 7.76 7.67 -0.10 2SSP (25%) 16.32 15.81 18.52 -0.51 GPTQ (W4A16) 8.09 8.09 8.67 +0.00 A WQ (W4A16) 7.35 7.40 7.40 +0.05 gemma-2-9B Dense 7.93 7.93 7.93 W anda (25%) 8.13 8.22 8.13 0.00 2SSP (25%) 12.74 12.41 14.18 -0.33 GPTQ (W4A16) 8.27 8.27 8.67 0.00 A WQ (W4A16) 15.84 15.75 15.73 -0.11 mov es entire attention submodules, which requires capturing long-range relationships; at small con- text length, this information is remov ed and leads to biased pruning. Our results are in line with the comprehensi ve analysis of ( Oh and Oh , 2025 ). Effects of Calibration Sample Size T o further highlight the ef ficiency of ZipCal , we analyze the impact of the number of samples in the calibration set by testing k ∈ [16 , 2048] with context length w = 2048 . The results in Figure 4 sho w great stability among capabilities and the number of sam- ples. Once again, 2SSP shows greater sensitivity to sample count. Surprisingly , Code and Math ca- pabilities actually benefit from a smaller number of samples (38% vs. 31% using 16 vs. 1024 sam- ples, respecti vely , for Math capabilities after 2SSP), finding a negligible decrease. When compared to baselines like COLA ( He et al. , 2025 ), which ex- hibit some capability shifts at higher sample sizes, ZipCal provides a f ar more stable and predictable function. 6 Conclusion In this paper , we highlighted the limitations of cur- rent calibration data selection strategies for com- pression algorithms, which are either based on pure random sampling or use expensi ve, model- and task- dependent calibration strategies, limit- ing performance across multiple models and tasks. T o address these issues, we proposed ZipCal , a model-agnostic, computationally cheap data cura- tion strategy for both pruning and quantization ap- proaches, which selects calibration data by follo w- ing a linguistics-principled Zipfian distribution. Re- sults sho w that the proposed method performs bet- ter than random, and more importantly , on par with state-of-the-art data curation approaches while re- quiring minimal overhead. Furthermore, we also in- troduced a multi-domain version of ZipCal , which applies Zipf sampling hierarchically across dif fer - ent calibration datasets. Results show that the re- sulting unified multi-domain calibration dataset al- lo ws for outperforming single-domain calibration, proving a solution to the aforementioned problem of inter-task sub-optimality . 8 Limitations While we provide extended e xperimental insights on choosing calibration data based on linguistic di- versity , we ackno wledge the follo wing limitations to the current study . W e mainly relied on English calibration data and ev aluation tasks due to com- putational limitations. Although Zipf ’ s Law is a cross-linguistic phenomenon ( Piantadosi , 2014 ), the specific “sanitization” process (e.g., lowercase con version and subword marker stripping) may re- quire tuning for morphologically rich languages or non-alphabetic scripts. Our experiments focus on two specific families of LLMs (LLama-3.1-8B, Gemma-2-9B) and four compression methods. It remains to be seen ho w le xical di versity as a cura- tion proxy beha ves for Mixture-of-Experts (MoE) models, where activ ation routing might necessitate a different balance of data to ensure all “experts” are adequately calibrated. Similarly , extending this approach to Multimodal Lar ge Language Models (MLLMs) would require a multimodal analogue of lexical di versity that captures the distrib utional properties of non-textual tokens, such as visual, audio, or video modality . Ethics Statement This work focuses on efficient data curation for model compression. All models, datasets, and benchmarks used in this research are publicly av ail- able with appropriate licenses. W e credit original authors throughout the manuscript and acknowl- edge their contributions. W e ackno wledge that data selection processes can inadv ertently amplify e xist- ing biases in the source data, and we hav e reported detailed performance statistics across our bench- marks. W e also recognize that efficient techniques for deploying LLMs accelerate AI adoption, po- tentially leading to misuse. Howe ver , our focus remains on the foundational technical aspects of data curation rather than specific do wnstream ap- plications of AI. References Y ongqi An, Xu Zhao, T ao Y u, Ming T ang, and Jinqiao W ang. 2025. Systematic Outliers in Large Language Models . In The Thirteenth International Conference on Learning Repr esentations . Saleh Ashkboos, Maximilian L. Croci, Marcelo Gennari do Nascimento, T orsten Hoefler , and James Hensman. 2024. SliceGPT: Compress Large Language Models by Deleting Rows and Columns . In The T welfth In- ternational Confer ence on Learning Repr esentations . Abhinav Bandari, Lu Y in, Cheng-Y u Hsieh, Ajay Ku- mar Jaiswal, T ianlong Chen, Li Shen, Ranjay Kr- ishna, and Shiwei Liu. 2024. Is C4 Dataset Optimal for Pruning? An In v estigation of Calibration Data for LLM Pruning . arXiv preprint . [cs]. Ond ˇ rej Bojar, Christian Buck, Christian Federmann, Barry Haddow , Philipp Koehn, Johannes Leveling, Christof Monz, Pa vel Pecina, Matt Post, Herve Saint- Amand, Radu Soricut, Lucia Specia, and Aleš T am- chyna. 2014. Findings of the 2014 W orkshop on Sta- tistical Machine Translation . In Proceedings of the Ninth W orkshop on Statistical Machine T ranslation , pages 12–58, Baltimore, Maryland, USA. Associa- tion for Computational Linguistics. Mengzhao Chen, W enqi Shao, Peng Xu, Jiahao W ang, Peng Gao, Kaipeng Zhang, and Ping Luo. 2025. Ef- ficientQA T : Efficient Quantization-A ware Training for Large Language Models . In Proceedings of the 63r d Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long P apers) , pages 10081–10100, V ienna, Austria. Association for Com- putational Linguistics. Peter Clark, Isaac Co whey , Oren Etzioni, T ushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind T afjord. 2018. Think you hav e Solved Question An- swering? Try ARC, the AI2 Reasoning Challenge . arXiv pr eprint . ArXiv:1803.05457 [cs]. Karl Cobbe, V ineet Kosaraju, Mohammad Bav arian, Mark Chen, Heew oo Jun, Lukasz Kaiser , Matthias Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training V erifiers to Solve Math W ord Prob- lems . arXiv pr eprint . ArXiv:2110.14168 [cs]. Elia Cunegatti, Leonardo Lucio Custode, and Giov anni Iacca. 2025. Zeroth-Order Adaptive Neuron Align- ment Based Pruning without Re-T raining . T ransac- tions on Machine Learning Resear ch . Mohsen Dehghankar , Mahdi Erfanian, and Abolfazl Asudeh. 2025. An Efficient Matrix Multiplica- tion Algorithm for Accelerating Inference in Bi- nary and T ernary Neural Networks . arXiv preprint . ArXiv:2411.06360 [cs]. T im Dettmers, Mike Le wis, Y ounes Belkada, and Luke Zettlemoyer . 2022. LLM.int8(): 8-bit Matrix Multi- plication for T ransformers at Scale. In Pr oceedings of the 36th International Confer ence on Neural In- formation Pr ocessing Systems , NIPS ’22, Red Hook, NY , USA. Curran Associates Inc. Jonathan Frankle and Michael Carbin. 2019. The Lot- tery Tick et Hypothesis: Finding Sparse, Trainable Neural Networks . In International Conference on Learning Repr esentations . 9 Elias Frantar and Dan Alistarh. 2023. SparseGPT: Mas- siv e Language Models Can be Accurately Pruned in One-Shot . In Pr oceedings of the 40th Inter- national Confer ence on Machine Learning , pages 10323–10337. PMLR. ISSN: 2640-3498. Elias Frantar , Saleh Ashkboos, T orsten Hoefler , and Dan Alistarh. 2023. GPTQ: Accurate Post-T raining Quantization for Generati ve Pre-trained T ransform- ers . arXiv pr eprint . ArXiv:2210.17323 [cs]. Leo Gao, Stella Biderman, Sid Black, Laurence Gold- ing, T ravis Hoppe, Charles Foster , Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser , and Connor Leahy . 2020. The Pile: An 800GB Dataset of Div erse T ext for Language Model- ing . arXiv pr eprint . ArXiv:2101.00027 [cs]. Leo Gao, Jonathan T ow , Baber Abbasi, Stella Bider- man, Sid Black, Anthony DiPofi, Charles Foster , Laurence Golding, Jeffre y Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Haile y Schoelkopf, A viya Sko wron, Lintang Sutawika, and 5 others. 2023. A framework for fe w-shot language model ev aluation . Aaron Grattafiori, Abhimanyu Dube y , Abhinav Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex V aughan, Amy Y ang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Y ang, Archi Mi- tra, Archie Srav ankumar, Artem K orenev , Arthur Hinsvark, and 181 others. 2024. The Llama 3 Herd of Models . arXiv pr eprint . ADS Bibcode: 2024arXiv240721783G. Jialong Guo, Xinghao Chen, Y ehui T ang, and Y unhe W ang. 2025. SlimLLM: Accurate Structured Prun- ing for Large Language Models . arXiv pr eprint . ArXiv:2505.22689 [cs]. Song Han, Jeff Pool, John Tran, and W illiam Dally . 2015. Learning both weights and connections for efficient neural network. Advances in neural infor- mation pr ocessing systems , 28. Bowei He, Lihao Y in, Huiling Zhen, Shuqi Liu, Han W u, Xiaokun Zhang, Mingxuan Y uan, and Chen Ma. 2025. Preserving LLM Capabilities through Calibra- tion Data Curation: From Analysis to Optimization . arXiv pr eprint . ArXiv:2510.10618 [cs]. Dan Hendrycks, Collin Burns, Saura v Kadav ath, Akul Arora, Steven Basart, Eric T ang, Dawn Song, and Jacob Steinhardt. 2021. Measuring Mathematical Problem Solving W ith the MA TH Dataset . arXiv pr eprint . ArXiv:2103.03874 [cs]. W ei Huang, Haotong Qin, Y angdong Liu, Y awei Li, Qinshuo Liu, Xianglong Liu, Luca Benini, Michele Magno, Shiming Zhang, and Xiaojuan Qi. 2025. SliM-LLM: Salience-Driv en Mixed-Precision Quan- tization for Large Language Models. In International Confer ence on Machine Learning , pages 25672– 25692. PMLR. Sakaguchi K eisuke, BrasRonan Le, Bhaga vatulaChan- dra, and ChoiY ejin. 2021. W inoGrande . Commu- nications of the A CM . Publisher: ACMPUB27Ne w Y ork, NY , USA. Banseok Lee, Dongkyu Kim, Y oungcheon you, and Y oung-Min Kim. 2025. LittleBit: Ultra Low-Bit Quantization via Latent Factorization . In The Thirty- ninth Annual Conference on Neur al Information Pr o- cessing Systems . Ji Lin, Jiaming T ang, Haotian T ang, Shang Y ang, W ei- Ming Chen, W ei-Chen W ang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. A WQ: Acti v ation-aware W eight Quantization for On- Device LLM Compression and Acceleration . Pr o- ceedings of Machine Learning and Systems , 6:87– 100. Shuming Ma, Hongyu W ang, Lingxiao Ma, Lei W ang, W enhui W ang, Shaohan Huang, Li Dong, Ruiping W ang, Jilong Xue, and Furu W ei. 2024. The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits . arXiv pr eprint . ArXiv:2402.17764 [cs]. Xinyin Ma, Gongfan Fang, and Xinchao W ang. 2023. Llm-pruner: On the structural pruning of large lan- guage models. Advances in neural information pr o- cessing systems , 36:21702–21720. Max Marion, Ahmet Üstün, Luiza Pozzobon, Alex W ang, Marzieh F adaee, and Sara Hooker . 2023. When Less is More: Inv estigating Data Pruning for Pretraining LLMs at Scale . arXiv pr eprint . ArXiv:2309.04564 [cs]. Stephen Merity , Caiming Xiong, James Bradbury , and Richard Socher . 2016. Pointer Sentinel Mixture Mod- els . arXiv pr eprint . ArXiv:1609.07843 [cs]. T odor Mihaylov , Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a Suit of Armor Conduct Elec- tricity? A New Dataset for Open Book Question An- swering . In Pr oceedings of the 2018 Conference on Empirical Methods in Natural Languag e Pr ocessing , pages 2381–2391, Brussels, Belgium. Association for Computational Linguistics. Pa vlo Molchanov , Arun Mallya, Stephen T yree, Iuri Frosio, and Jan Kautz. 2019. Importance estima- tion for neural network pruning. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pages 11264–11272. Saurav Muralidharan, Sharath T uruvek ere Sreeniv as, Raviraj Bhuminand Joshi, Marcin Chochowski, Mostofa P atwary , Mohammad Shoe ybi, Bryan Catan- zaro, Jan Kautz, and P a vlo Molchanov . 2024. Com- pact Language Models via Pruning and Kno wledge Distillation . In The Thirty-eighth Annual Confer ence on Neural Information Pr ocessing Systems . Markus Nagel, Rana Ali Amjad, Mart V an Baalen, Christos Louizos, and Tijmen Blanke voort. 2020. Up or Do wn? Adaptiv e Rounding for Post-T raining 10 Quantization . In Pr oceedings of the 37th Interna- tional Confer ence on Machine Learning , pages 7197– 7206. PMLR. Y ury Nahshan, Brian Chmiel, Chaim Baskin, Evgenii Zheltonozhskii, Ron Banner , Alex M. Bronstein, and A vi Mendelson. 2021. Loss aware post-training quan- tization . Machine Learning , 110(11):3245–3262. Y ixin Nie, Adina W illiams, Emily Dinan, Mohit Bansal, Jason W eston, and Douwe Kiela. 2020. Adversar - ial NLI: A New Benchmark for Natural Language Understanding . In Proceedings of the 58th Annual Meeting of the Association for Computational Lin- guistics , pages 4885–4901, Online. Association for Computational Linguistics. Jaehoon Oh and Dokwan Oh. 2025. Beyond Fixed- Length Calibration for Post-T raining Compression of LLMs . In F indings of the Association for Compu- tational Linguistics: EMNLP 2025 , pages 19355– 19366, Suzhou, China. Association for Computa- tional Linguistics. Gunho P ark, Baeseong P ark, Minsub Kim, Sungjae Lee, Jeonghoon Kim, Beomseok Kwon, Se Jung Kwon, Byeongwook Kim, Y oungjoo Lee, and Dongsoo Lee. 2024. LUT-GEMM: Quantized Matrix Multiplica- tion based on LUTs for Ef ficient Inference in Lar ge- Scale Generati ve Language Models . arXiv pr eprint . ArXiv:2206.09557 [cs]. Arkil Patel, Satwik Bhattamishra, and Navin Goyal. 2021. Are NLP Models really able to Solv e Simple Math W ord Problems? arXiv pr eprint . ArXiv:2103.07191 [cs]. Stev en T . Piantadosi. 2014. Zipf ’ s word frequenc y law in natural language: A critical revie w and future di- rections . Psychonomic bulletin & r eview , 21(5):1112– 1130. Colin Raffel, Noam Shazeer , Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Y anqi Zhou, W ei Li, and Peter J. Liu. 2020. Exploring the Lim- its of T ransfer Learning with a Unified T ext-to-T ext T ransformer . Journal of Machine Learning Resear ch , 21(140):1–67. Fabrizio Sandri, Elia Cunegatti, and Giov anni Iacca. 2025. 2SSP: A T wo-Stage Framew ork for Structured Pruning of LLMs . T ransactions on Machine Learn- ing Resear c h . Lu Sun and Jun Sakuma. 2026. Learning Semi- Structured Sparsity for LLMs via Shared and Context- A ware Hypernetwork . In The F ourteenth Interna- tional Confer ence on Learning Repr esentations . Mingjie Sun, Xinlei Chen, J Zico Kolter , and Zhuang Liu. 2024a. Massiv e Activ ations in Large Language Models . In F irst Confer ence on Language Modeling . Mingjie Sun, Zhuang Liu, Anna Bair , and J. Zico K olter . 2024b. A Simple and Effecti ve Pruning Ap- proach for Large Language Models . arXiv pr eprint . ArXiv:2306.11695 [cs]. Alon T almor , Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. CommonsenseQA: A Ques- tion Answering Challenge T argeting Commonsense Knowledge . In Pr oceedings of the 2019 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T ech- nologies, V olume 1 (Long and Short P apers) , pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics. Gemma T eam, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupati- raju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya T afti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ra vin Kumar , Charline Le Lan, Sammy Jerome, and 179 others. 2024. Gemma 2: Improving Open Language Models at a Practical Size . arXiv pr eprint . ArXiv:2408.00118 [cs]. Alex W ang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy , and Samuel Bo wman. 2018. GLUE: A Multi-T ask Benchmark and Analysis Platform for Natural Language Understanding . In Pr oceedings of the 2018 EMNLP W orkshop BlackboxNLP: An- alyzing and Interpreting Neur al Networks for NLP , pages 353–355, Brussels, Belgium. Association for Computational Linguistics. Hongyu W ang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie W ang, Lingxiao Ma, Fan Y ang, Ruiping W ang, Y i W u, and Furu W ei. 2023. BitNet: Scal- ing 1-bit T ransformers for Large Language Models . arXiv pr eprint . ArXiv:2310.11453 [cs]. Miles W illiams and Nikolaos Aletras. 2024. On the Impact of Calibration Data in Post-training Quanti- zation and Pruning . In Pr oceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 10100– 10118, Bangkok, Thailand. Association for Compu- tational Linguistics. Mengzhou Xia, T ianyu Gao, Zhiyuan Zeng, and Danqi Chen. 2024. Sheared LLaMA: Accelerating Lan- guage Model Pre-training via Structured Pruning . In The T welfth International Confer ence on Learning Repr esentations . Y ifan Y ang, Kai Zhen, Bhavana Ganesh, Aram Gal- styan, Goeric Huybrechts, Markus Müller , Jonas M. Kübler , Rupak V ignesh Swaminathan, Athanasios Mouchtaris, Srav an Babu Bodapati, Nathan Susanj, Zheng Zhang, Jack FitzGerald, and Abhishek Kumar . 2025. W anda++: Pruning Large Language Models via Regional Gradients . In F indings of the Associa- tion for Computational Linguistics: ACL 2025 , pages 4321–4333, V ienna, Austria. Association for Compu- tational Linguistics. Row an Zellers, Ari Holtzman, Y onatan Bisk, Ali Farhadi, and Y ejin Choi. 2019. HellaSwag: Can a Machine Really Finish Y our Sentence? arXiv pr eprint . ArXiv:1905.07830 [cs]. 11 Y uxin Zhang, Lirui Zhao, Mingbao Lin, Sun Y unyun, Y iwu Y ao, Xingjia Han, Jared T anner, Shiwei Liu, and Rongrong Ji. 2024. Dynamic Sparse No Train- ing: Training-Free Fine-tuning for Sparse LLMs . In The T welfth International Confer ence on Learning Repr esentations . Aojun Zhou, Y ukun Ma, Junnan Zhu, Jianbo Liu, Zhijie Zhang, Kun Y uan, W enxiu Sun, and Hongsheng Li. 2021. Learning N:M Fine-grained Structured Sparse Neural Networks From Scratch . In International Confer ence on Learning Repr esentations . George Kingsle y Zipf. 2013. Relativ e Frequency , Ab- brevi ation, and Semantic Change . In Selected Studies of the Principle of Relative F requency in Language , pages i–iv . Harvard Uni versity Press. 12 A Detailed Algorithms and Proofs Multi-Domain Sampling W e present here the pseudocode for the Multi-Domain selection pro- cedure, Algorithm 2 , and prov e Theorem 3.2 , the time complexity of ZipCal in this setting. Pr oof. Gi ven m datasets D i : i ∈ (1 , m ) . In the first stage, Single-Domain ZipCal is ex ecuted for each dataset. Let n i be the size of dataset D i . From Theorem 3.1 , the complexity for each source is O ( n i k ) . An upper bound to this operation is mk N , where N = max D i ( n i ) The second stage in v olves the k -centers greedy selection on a pool of size mk . At each of the k iterations, we calculate the distance between the remaining candidates and the current set S . The cost of this stage is O ( k · ( mk ) · d ) , where d is the dimensionality of the sample representation. Since m and k are typically << N , the term mk d is negligible. Thus, the overall complexity is dominated by the initial ZipCal pass, yielding O ( mkN ) . Algorithm 2: Multi-Domain ZipCal Input: Collection of datasets D = {D 1 , . . . , D m } ; Final budget k Output: Multi-Domain calibration set S 1 P ← ∅ ; 2 f or each D i ∈ D do // Step 1: Single-Domain ZipCal 3 P i ← ZipCal ( D i , k ) ; 4 P ← P ∪ P i ; // Step 2: Global K-Centers Greedy Selection 5 s 1 ← select random s ∈ P ; 6 S ← { s 1 } ; 7 f or j = 2 to k do 8 s ∗ ← arg max s ∈P \ S (min z ∈ S dist ( s, z )) ; 9 S ← S ∪ { s ∗ } ; 10 r eturn S ; B Additional Results W e report here additional tables that were omitted from the main paper due to length constraints. In particular T ables 6 and 7 show the comparison be- tween COLA and Single-Domain ZipCal under A WQ and 2SSP compression, respecti v ely . Zipf Coverage As illustrated in Figure 1 , ZipCal achie ves a vo- cabulary cov erage that better reflects the original dataset. When restricted to a standard budget of 128 samples, ZipCal identifies by construction the subset that yields the longest possible Zipfian tail. On the other hand, random sampling would need a significantly higher number of samples in order to cover the same vocabulary space. COLA ’ s se- lection criterion leads to a similar distribution to random sampling. This advantage in cov erage is especially noticeable in lexically rich corpora lik e W inoGrande and HellaSwag, where the gap be- tween ZipCal and competing baselines reaches up to half an order of magnitude. At extremely tiny samples (i.e., 16), Figure 5 , the dif ference is ev en more pronounced, with ZipCal being the only one capable of cov ering more than half of the original vocab ulary . For large amounts of samples, Figure 6 , ZipCal actually cov ers the whole v ocab ulary space compared to the other baselines. 13 1 0 1 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 F r equency (log) GSM8K 1 0 0 1 0 1 1 0 2 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 W inoGrande 1 0 0 1 0 1 1 0 2 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 HellaSwag F ull Dataset R andom ZipCal COL A Theor etical Zipf Figure 5: T oken frequency distribution of the original datasets and the random, COLA, and ZipCal sampling calibration sets using 16 samples. 1 0 1 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 F r equency (log) GSM8K 1 0 0 1 0 1 1 0 2 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 W inoGrande 1 0 0 1 0 1 1 0 2 1 0 3 R ank (log) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 HellaSwag F ull Dataset R andom ZipCal COL A Theor etical Zipf Figure 6: T oken frequency distribution of the original datasets and the random, COLA, and ZipCal sampling calibration sets using 1024 samples. T able 6: Comparison of COLA vs. ZipCal calibration data under A WQ W4A16 compression. COLA ZipCal Calibration Category Calibration Category Model T ask Dense LangMod Math CommQA NLI KnowT ran Mean LangMod Math CommQA NLI KnowTran Mean Delta Llama-3.1-8B-Instruct MMLU-M 24.44 24.40 24.60 24.30 24.40 24.50 24.44 24.50 24.30 24.40 24.20 24.70 24.42 -0.02 GSM8k 78.09 72.35 62.51 69.67 69.60 70.77 68.98 71.80 63.10 68.90 70.10 70.50 68.88 -0.10 HellaSwag 71.71 72.20 71.38 71.28 72.10 71.45 71.68 72.40 71.10 71.50 71.80 71.60 71.68 0.00 W inoGr . 69.46 67.19 67.05 67.52 65.98 66.02 66.75 66.90 67.30 67.20 66.50 65.80 66.74 -0.01 OBQA 47.80 46.60 44.90 46.50 45.20 46.30 45.90 46.80 44.50 46.10 45.50 46.50 45.88 -0.02 BoolQ 84.46 83.92 84.28 84.20 83.70 84.24 84.07 83.50 84.40 83.80 84.10 84.00 83.96 -0.11 R TE 74.73 74.01 72.92 73.47 72.02 73.10 73.10 73.80 73.10 73.00 72.50 73.30 73.14 +0.04 ANLI 58.40 56.33 50.95 53.40 53.30 53.80 53.56 55.80 51.50 53.10 53.90 53.40 53.54 -0.02 ARC-C 51.71 50.03 51.41 49.62 50.04 49.96 50.21 50.50 50.80 49.90 49.70 50.30 50.24 +0.03 ARC-E 73.86 73.36 71.72 72.14 72.69 72.85 72.55 72.90 71.90 71.80 72.80 72.50 72.38 -0.17 MMLU-K 62.28 58.52 58.52 58.31 58.11 59.12 58.52 58.10 58.80 58.15 58.30 58.90 58.45 -0.07 Mean 63.36 60.81 59.97 60.84 60.72 61.13 60.89 60.64 60.07 60.67 60.85 61.17 60.85 -0.04 Runtime 5400s 36s 3240s 2160s 1380s 2443s 15.2s 2.3s 12.3s 9.3s 14.5s 10.7s 228 × gemma-2-9b-it MMLU-M 21.48 21.40 21.40 21.35 21.45 21.40 21.40 21.40 21.35 21.30 21.45 21.45 21.39 -0.01 GSM8k 75.44 74.17 74.91 74.07 73.96 74.00 74.22 74.50 74.50 73.80 74.20 73.70 74.14 -0.08 HellaSwag 67.24 67.25 67.81 68.04 67.39 67.42 67.58 66.90 67.90 67.50 67.50 67.20 67.40 -0.18 W inoGr . 70.48 69.53 69.65 69.73 69.34 69.65 69.58 69.80 69.20 69.90 69.10 69.40 69.48 -0.10 OBQA 45.40 45.47 44.70 45.20 45.50 45.00 45.17 45.10 45.00 44.90 45.80 44.80 45.12 -0.05 BoolQ 88.59 88.53 88.53 88.61 88.58 88.59 88.57 88.70 88.40 88.50 88.70 88.40 88.54 -0.03 R TE 78.34 79.06 77.26 76.90 77.26 77.44 77.58 78.50 77.50 76.50 77.00 77.60 77.42 -0.16 ANLI 72.80 71.77 72.10 71.90 70.70 72.35 71.76 72.00 71.80 72.10 70.50 72.10 71.70 -0.06 ARC-C 51.79 51.11 51.49 51.41 51.58 50.81 51.28 50.80 51.70 51.20 51.80 50.50 51.20 -0.08 ARC-E 66.79 66.40 66.35 67.09 66.88 66.58 66.66 66.60 66.10 66.80 67.10 66.30 66.58 -0.08 MMLU-K 33.83 35.73 28.90 30.12 31.79 33.46 32.00 35.10 29.50 29.80 32.10 33.10 31.92 -0.08 Mean 61.11 60.95 60.26 60.22 60.40 60.61 60.53 61.03 60.27 60.21 60.48 60.41 60.44 -0.09 Runtime 6231s 149s 3400s 2671s 1500s 2790s 15.2s 2.3s 12.3s 9.3s 14.5s 10.7s 260 × 14 T able 7: Comparison of COLA vs. ZipCal under 2SSP compression at 25% sparsity . COLA ZipCal Calibration Category Calibration Category Model T ask Dense LangMod Math CommQA NLI KnowT ran Mean LangMod Math CommQA NLI KnowTran Mean Delta Llama-3.1-8B-Instruct MMLU-M 24.44 22.30 23.40 21.80 21.10 22.50 22.22 22.10 22.90 21.50 21.30 22.00 21.96 -0.26 GSM8k 78.09 6.34 13.68 0.00 0.00 4.36 4.88 4.98 8.42 0.23 3.87 5.65 4.63 -0.25 HellaSwag 71.71 61.32 60.53 60.66 57.32 57.21 59.41 60.26 61.29 58.73 59.30 59.23 59.76 +0.35 W inoGr . 69.46 60.69 58.68 59.04 60.18 61.56 60.03 61.69 59.63 60.62 61.80 61.72 61.09 +1.06 OBQA 47.80 41.93 38.10 41.80 40.50 38.90 40.25 40.60 39.90 41.60 40.80 40.70 40.72 +0.47 BoolQ 84.46 75.64 71.36 69.36 71.64 74.85 72.57 74.01 72.66 67.06 75.46 70.60 71.96 -0.61 R TE 74.73 66.43 65.52 63.00 71.12 69.13 67.04 67.99 59.93 64.98 65.34 71.12 65.87 -1.17 ANLI 58.40 47.63 39.75 45.00 45.85 44.25 44.50 40.53 35.10 37.30 36.05 39.05 37.61 -6.89 ARC-C 51.71 39.51 39.04 42.15 39.16 38.69 39.71 38.88 37.03 39.51 36.22 38.44 38.01 -1.70 ARC-E 73.86 61.91 62.61 65.85 63.97 61.70 63.21 63.13 58.92 64.27 57.47 60.71 60.90 -2.31 MMLU-K 62.28 39.87 34.59 33.25 37.68 32.54 35.59 38.27 26.98 29.89 29.85 31.30 31.26 -4.33 Mean 63.36 47.60 46.12 45.63 46.23 45.97 46.31 46.59 43.89 44.15 44.31 45.50 44.89 -1.42 Runtime 5400s 36s 3240s 2160s 1380s 2443s 15.2s 2.3s 12.3s 9.3s 14.5s 10.7s 228 × gemma-2-9b-it MMLU-M 21.48 19.50 20.40 18.90 18.40 19.10 19.26 19.10 20.00 18.50 18.70 18.80 19.02 -0.24 GSM8k 75.44 4.50 7.80 1.20 0.50 2.50 3.30 3.20 5.40 0.00 2.10 3.10 2.76 -0.54 HellaSwag 67.24 56.40 55.20 57.10 54.80 53.90 55.48 54.10 55.60 53.20 55.00 54.80 54.54 -0.94 W inoGr . 70.48 59.50 57.80 58.40 59.10 60.50 59.06 60.20 58.10 59.30 60.50 59.90 59.60 +0.54 OBQA 45.40 39.50 36.40 38.20 39.10 37.50 38.14 38.10 37.50 39.20 38.60 38.90 38.46 +0.32 BoolQ 88.59 76.20 72.10 69.50 71.80 74.30 72.78 74.50 73.20 68.10 75.10 71.20 72.42 -0.36 R TE 78.34 67.50 65.20 62.80 68.40 66.10 66.00 68.10 63.40 65.70 66.80 67.50 66.30 +0.30 ANLI 72.80 54.20 48.50 51.30 53.10 52.40 51.90 49.50 45.20 47.80 46.90 48.50 47.58 -4.32 ARC-C 51.79 40.10 39.50 41.20 39.80 38.40 39.80 39.20 38.10 40.50 37.60 39.10 38.90 -0.90 ARC-E 66.79 59.20 58.40 60.50 59.80 58.20 59.22 60.10 57.50 61.20 56.40 59.30 58.90 -0.32 MMLU-K 33.83 24.12 21.45 22.10 25.30 20.90 22.77 23.10 19.80 20.45 21.00 21.50 21.17 -1.60 Mean 65.07 45.52 43.88 43.75 44.55 43.98 44.34 44.47 43.07 43.10 43.52 43.88 43.61 -0.73 Runtime 6231s 149s 3400s 2671s 1500s 2790s 15.2s 2.3s 12.3s 9.3s 14.5s 10.7s 260 × T able 8: Language modeling perplexity ( ↓ ). Comparison between standard COLA, Single-Domain ZIPCAL, and Multi-Domain ZIPCAL. ∆ indicates the difference between ZIPCAL (Multi-Domain) and COLA on A vg. Model Method COLA ZipCal ZipCal (Multi-Domain) ∆ A vg W iki C4 Pile A vg Wiki C4 Pile A vg Wiki C4 Pile A vg Llama-3.1-8B Dense 7.03 9.71 4.71 7.15 7.03 9.71 4.71 7.15 7.03 9.71 4.71 7.15 W anda (25%) 7.62 10.70 4.98 7.77 7.60 10.71 4.98 7.76 7.52 10.54 4.94 7.67 -0.10 2SSP (25%) 18.53 21.09 9.36 16.32 17.34 21.09 9.00 15.81 19.53 25.80 10.22 18.52 +2.20 GPTQ (W4A16) 7.71 11.42 5.13 8.09 7.71 11.40 5.15 8.09 8.59 12.08 5.34 8.67 +0.58 A WQ (W4A16) 7.21 10.04 4.79 7.35 7.31 10.09 4.81 7.40 7.32 10.07 4.82 7.40 +0.05 Gemma-2-9B Dense 7.63 11.53 4.63 7.93 7.63 11.53 4.63 7.93 7.63 11.53 4.63 7.93 W anda (25%) 7.87 11.78 4.74 8.13 7.92 11.99 4.76 8.22 7.86 11.82 4.72 8.13 0.00 2SSP (25%) 12.56 19.20 6.47 12.74 11.68 19.08 6.47 12.41 14.14 21.55 6.86 14.18 +1.44 GPTQ (W4A16) 7.93 12.05 4.82 8.27 7.93 12.06 4.81 8.27 8.44 12.59 4.99 8.67 +0.40 A WQ (W4A16) 16.01 21.87 9.64 15.84 16.01 21.54 9.71 15.75 16.01 21.51 9.67 15.73 -0.11 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment