POaaS: Minimal-Edit Prompt Optimization as a Service to Lift Accuracy and Cut Hallucinations on On-Device sLLMs
Small language models (sLLMs) are increasingly deployed on-device, where imperfect user prompts--typos, unclear intent, or missing context--can trigger factual errors and hallucinations. Existing automatic prompt optimization (APO) methods were desig…
Authors: Jungwoo Shim, Dae Won Kim, Sun Wook Kim
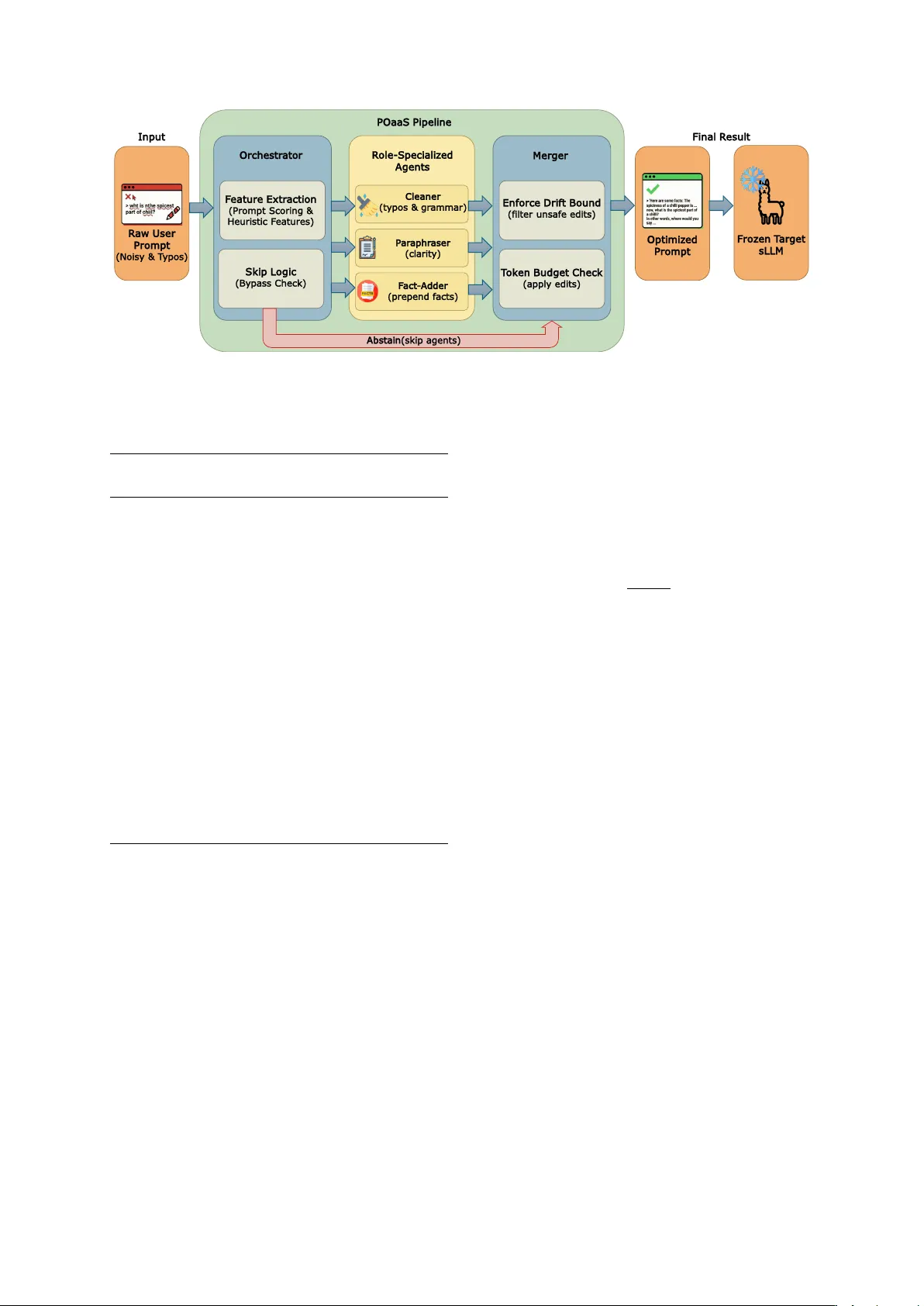
POaaS: Minimal-Edit Pr ompt Optimization as a Service to Lift Accuracy and Cut Hallucinations on On-Device sLLMs Jungw oo Shim Dae W on Kim Sun W ook Kim Soo Y oung Kim Myungcheol Lee Jae-geun Cha Hyunhwa Choi † Electronics and T elecommunications Research Institute, Republic of K orea {right_rain,won22,swkim99,sykim,mclee,jgcha,hyunwha}@etri.re.kr Abstract Small language models (sLLMs) are increas- ingly deployed on-de vice, where imperfect user prompts–typos, unclear intent, or miss- ing context–can trigger f actual errors and hal- lucinations. Existing automatic prompt opti- mization (APO) methods were designed for large cloud LLMs and rely on search that often produces long, structured instructions; when ex ecuted under an on-de vice constraint where the same small model must act as optimizer and solver , these pipelines can waste context and ev en hurt accuracy . W e propose POaaS , a minimal-edit prompt optimization layer that routes each query to lightweight specialists (Cleaner , Paraphraser , Fact-Adder) and merges their outputs under strict drift and length con- straints, with a conserv ati ve skip policy for well-formed prompts. Under a strict fixed- model setting with Llama-3.2-3B-Instruct and Llama-3.1-8B-Instruct, POaaS improv es both task accuracy and factuality while representa- tiv e APO baselines degrade them, and POaaS recov ers up to +7.4% under token deletion and mixup. Overall, per-query conservati ve optimization is a practical alternative to search- heavy APO for on-de vice sLLMs. 1 Introduction Large language models (LLMs) hav e rapidly be- come the default interface for knowledge work, question answering, and decision support. Al- though early deployments relied on large, server - hosted models ( Leon , 2025 ; Sparkman and W itt , 2025 ), recent advances are pushing small language models (sLLMs) onto phones, bro wsers, and edge de vices ( Gunter et al. , 2024 ; Grattafiori et al. , 2024 ; Roh et al. , 2024 ). The first line of defense has been manual pr ompt engineering ( Reynolds and McDonell , 2021 ), b ut it is labor -intensi ve and brittle, and small changes † Corresponding author . in domain, user intent, or input quality often re- quire re-design. T o reduce this overhead, au- tomatic pr ompt optimization (APO) frame works emerged ( W an et al. , 2024 ). Systems such as OPR O ( Y ang et al. , 2023 ), PromptW izard ( Agarwal et al. , 2025 ), and EvoPrompt ( T ong et al. , 2025 ) use iterati ve search and ev olution to discover prompts that help large cloud LLMs. Ho we ver , these as- sumptions mismatch on-de vice sLLMs. The search itself is expensi ve, optimized prompts can become long and structured, and increased prompt complex- ity can raise verbose eneration and hallucination risk in smaller models ( Li et al. , 2025b ; Ramnath et al. , 2025 ). This motiv ates a different design point: per-query , conservative edits that fix obvious input issues while av oiding unnecessary rewriting. Our appr oach: POaaS. W e introduce Prompt Optimization as a Service (POaaS) , a lightweight layer between the user prompt and the target model. POaaS uses three specialists– Cleaner (ty- pos/grammar), Paraphraser (clarity/fluenc y), and F act-Adder (concise contextual facts)–b ut applies them selecti vely via CPU-only routing. It can skip r efinement for well-formed prompts, and a drift- controlled merger rejects edits that de viate too far from the user’ s intent. GPU time remains domi- nated by the specialist calls that are actually used. Empirical findings. Under a strict fix ed-model policy , we compare POaaS to APO base- lines on reasoning tasks (BBH ( Suzgun et al. , 2023 ), GSM8K ( Cobbe et al. , 2021 ), Common- senseQA ( T almor et al. , 2019 )) and factuality benchmark datasets (HaluEval ( Li et al. , 2023 ), HalluLens ( Bang et al. , 2025 ), F ActScore ( Min et al. , 2023 )), under clean and degraded inputs. POaaS yields consistent gains on both Llama- 3.2-3B-Instruct and Llama-3.1-8B-Instruct, while APO baselines degrade performance and add large prompt ov erheads; under 5–15% tok en dele- tion/mixup, POaaS recov ers up to +7.4% over No Optimization. Contributions. • W e introduce POaaS , a minimal-edit, microservice-style optimization layer for sLLMs that sits between user prompts and the target model, and sho w that it consistently improv es accurac y where state-of-the-art APO methods reduces instead. • W e sho w that POaaS is particularly ef fectiv e under realistic input de gradations that mimic human error (typos, deletions, and missing information), recov ering performance on both reasoning and factuality benchmarks where APO baselines further amplify degradation. • W e provide a capacity-a ware design to deli ver these gains with zero of fline optimization cost and modest per-query latenc y , making POaaS suitable for on-de vice and edge deployments. 2 Related W ork 2.1 A utomatic Prompt Optimization (APO) Automatic prompt optimization methods treat prompts as objects of search, typically optimiz- ing performance through iterati ve re writing, scor - ing, and selection ( Ramnath et al. , 2025 ). A re- cent survey characterizes APO along dimensions such as candidate generation, ev aluation strategy , and search depth, spanning gradient-free methods, meta-prompt design, and program-synthesis-style pipelines ( Chang et al. , 2024 ). Representati ve systems include OPR O, which conditions on pre viously generated prompts and their scores in a meta-prompt to propose new instructions; PromptW izard, which uses a self- e volving loop of LLM-dri ven mutation, critique, and in-conte xt example optimization; and Ev o- Prompt, which connects LLMs with e volutionary algorithms implementing mutation and crossov er operators. Other v ariants explore self-referential prompt e volution (PromptBreeder ( Fernando et al. , 2023 )), gradient-like te xtual feedback with bandit- style candidate selection and Monte Carlo search (ProT eGi ( Pryzant et al. , 2023 )), Monte Carlo Tree Search–based strate gic planning ov er prompt states (PromptAgent ( W ang et al. , 2023 )), and pipeline- le vel prompt and weight optimization for multi- stage LM programs (DSPy ( Khattab et al. , 2024 )). These methods have shown strong gains on cloud-scale LLMs, but their assumptions dif fer from our target setting. They typically ev aluate many candidates, require substantial compute, and often yield long, highly structured prompts that consume scarce tokens on small models. Moreover , most APO work focuses on task accuracy rather than hallucination robustness, and the resulting prompt complexity can increase ov er-generation in sLLMs ( Cui et al. , 2025 ). 2.2 Hallucination Mitigation Prompting Hallucinations—fluent, but unsupported statements—pose critical reliability risks, especially for smaller models with limited contex- tual and reasoning capacity . Sev eral benchmarks provide complementary vie ws of this phenomenon: F ActScore decomposes generations into atomic claims and measures e vidential support; HaluEv al of fers a di verse hallucination test suite with LLM- as-judge ev aluation; and HalluLens or ganizes intrinsic vs. extrinsic hallucinations and provides fine-grained error profiles. Most hallucination mitigation techniques operate after generation, using retriev al-augmented gener- ation (RA G) ( Lewis et al. , 2020 ), v erifier models, or domain guardrails. While effecti ve for large server -hosted LLMs, these methods increase sys- tem comple xity and latency and may be impractical for resource-constrained sLLM deployments. By contrast, much less work focuses on pr e -generation mitigation at the prompt lev el, such as cleaning noisy inputs, clarifying underspecified instructions, or injecting lightweight context before decoding. Such approaches are attracti ve for on-device or latency-sensiti ve settings, because they can wrap a fixed sLLM with a small controller and compose with RA G or verification when av ailable. Our work follo ws this direction: we vie w hal- lucination risk as partly induced by imperfect user prompts and introduce a modular prompt- optimization layer that edits inputs within a fix ed token budget, positioning prompt-le vel optimiza- tion as a complementary b uilding block alongside post-hoc retrie v al and verification. 3 Method POaaS places a lightweight, minimal-edit optimiza- tion layer in front of a frozen target sLLM f θ (Llama-3.2-3B-Instruct and Llama-3.1-8B-Instruct; decoding fixed across all runs: temperature 0 . 2 , top- p 0 . 9 , fixed seed; max generation budget). Gi ven a prompt x , POaaS (i) scores prompt quality with R a w U s e r P r omp t ( Noi sy & T y p os) O r c he s tr at o r R o le - S pe c i al i z e d A ge nts M e rg er O p ti mi z ed P r omp t F r o z en T a rg et sLLM F in al R e s ul t I n put P O aa S P ip el i ne C le a n e r ( ty p os & g r am ma r ) P a r aph r as e r ( cl ari ty ) F a c t - Ad d er ( p r ep en d fact s) T o k en B u d ge t C h eck ( app l y ed i ts ) E n f orc e D r if t B o und ( fi l ter u n sa fe ed i ts ) F e a ture E x tr ac ti on ( P r ompt Scor i n g & H eu r i st i c F eatur es) S k i p L o g i c ( By p as s Che ck ) A b st a i n ( ski p ag e n ts) Figure 1: POaaS pipeline overvie w . First, the orchestrator analyzes input prompts using lightweight heuristics, routes to appropriate specialists (Cleaner , Paraphraser , Fact-Adder), and then the Merger applies drift-controlled merging to produce optimized prompts. Algorithm 1 POaaS Minimal-Edit Optimization Pipeline Require: Prompt x ; routing thresholds τ typo , τ comp , τ flu , τ skip Require: Drift/length caps δ clean , δ para , δ max ; length cap ρ max Require: Drift params θ drift = ( δ clean , δ para , δ max , ρ max ) Ensure: Optimized prompt ˜ x 1: ϕ ← A NA L Y Z E P R O M P T x, τ typo , τ comp , τ flu , τ skip 2: if S H O U L D S K I P ( ϕ ) then 3: retur n x 4: end if 5: A ← S E L E C T A G E N T S ( ϕ ) ▷ Selected agents 6: C ← ∅ ▷ Candidates 7: for each a ∈ A do 8: x ′ ← a ( x ) 9: ok ← W I T H I N D R I F T ( x, x ′ ; θ drift ) 10: if ok then 11: C ← C ∪ { ( a, x ′ ) } 12: end if 13: end for 14: if C = ∅ then 15: retur n x 16: end if 17: ˜ x ← M E R G E ( x, C ) ▷ Compose edits + context 18: return ˜ x CPU-only heuristics and may skip optimization, (ii) selecti vely calls role-specialized agents (Cleaner, Paraphraser , Fact-Adder), and (iii) merges their outputs under strict drift/length and safety guards to produce ˜ x , which is sent to f θ . W e illustrate POaaS’ s pipeline ov ervie w in Figure 1 . 3.1 T ask Setup Gi ven a prompt x and frozen f θ , POaaS seeks an optimized prompt ˜ x that impro ves do wnstream util- ity while av oiding intent drift. W e enforce: Drift bound. W e use a CPU-only lexical similar- ity ensemble and define D ( x, x ′ ) = 1 − sim ( x, x ′ ) ∈ [0 , 1] , (1) accepting edits only if D ( x, x ′ ) ≤ δ (details and ablations in Appendix C ). Length cap. W e cap expansion by the character- length ratio ρ ( x, ˜ x ) = len ( ˜ x ) len ( x ) ≤ ρ max , (2) and also cap specialist outputs (Fact-Adder: ≤ 120 tokens, up to 3 facts). Full budgets appear in Ap- pendix A . 3.2 Prompt Analysis and Routing The orchestrator computes lightweight CPU scores (typo, completeness, fluency , clarity; all nor- malized to [0 , 1] ) and applies threshold routing: Cleaner for high typo, Fact-Adder for lo w com- pleteness, and Paraphraser for lo w fluency (Ap- pendix B ). Critically , POaaS uses a conserv ati ve skip gate: if the prompt is already high-quality , POaaS returns x unchanged to av oid harmful over - editing. Skip logic. W e compute an ov erall quality score q ( x ) = 1 − max typo ( x ) , [ τ comp − comp ( x )] + , [ τ flu − flu ( x )] + , [0 . 70 − clar ( x )] + , (3) and skip refinement when q ( x ) > 1 − τ skip and typos are low , with def aults τ skip = 0 . 25 (so q ( x ) > 0 . 75 ) and typo ( x ) < 0 . 20 . This design is intentionally conserv ative: POaaS prefers false negati ves (missing a small potential improv ement) ov er false positi ves (unnecessary edits) to preserve intent on already well-formed prompts. 3.3 Role-Specialized Agents All agents run as vLLM-served ( Kwon et al. , 2023 ) LoRA adapters ( Hu et al. , 2021 ) on frozen Llama backbones. Each specialist is trained to produce one transformation and then a secondary guard model verifies f aithfulness: • Cleaner (fine-tuned with JFLEG ( Napoles et al. , 2017 )): fixes typos/grammar with a minimal-change instruction. A guard rejects candidates that introduce ne w information, re- verting to the original prompt if unsafe. Exam- ples and guard details appear in Appendix D . • Paraphraser (fine-tuned with P A WS ( Zhang et al. , 2019 ) and QQP ( Sharma et al. , 2019 )): re writes for fluency while preserving meaning. A fidelity guard re writes or vetoes unfaithful paraphrases. Examples and thresholds appear in Appendix D . • F act-Adder (fine-tuned with Wikipedia and W ikidata-derived corpora ( Vrande ˇ ci ´ c and Krötzsch , 2014 )): generates up to three concise factual bullets (total ≤ 120 tokens under the target tok enizer) that are directly related to the user’ s input entities/task, providing lightweight contextual support for the do wnstream sLLM. If no high-confidence facts can be produced, it outputs NONE and is skipped during merg- ing. A grounding/answer-leakage guard re- jects reasoning-like content and remov es unsup- ported statements before any fact is prepended. 3.4 Agent Selection Gi ven the four scores from § 3.2 , POaaS uses thresholded routing: Cleaner if typo ( x ) > τ typo ; Fact-Adder if comp ( x ) < τ comp (underspecified prompts); and Paraphraser if flu ( x ) < τ flu . Multi- ple agents may be in voked in parallel; their outputs are accepted only if they satisfy drift/length and safety guards, otherwise they are discarded and POaaS falls back to the original prompt. 3.5 Drift-Controlled Mer ging POaaS merges specialist edits only when they are prov en to be low-risk under cheap, determinis- tic checks. Concretely , each candidate x ′ is sani- tized (meta-commentary removed), scored for drift D ( x, x ′ ) , checked for preservation of ke y content (entities/numbers/quotes), and rejected if it violates drift/length caps. Accepted edits are then com- posed into a single ˜ x with a fix ed precedence: ap- ply Cleaner edits first, then P araphraser , and finally prepend up to three Fact-Adder facts ( ≤ 120 to- kens total) ahead of the user request. For few-shot prompts, POaaS isolates and edits only the final question span, reattaching the untouched prefix. Safety and guards. POaaS uses layered fail- safes: per-agent guard models to reject unfaith- ful edits (adding facts, dropping constraints, or answering the question), orchestrator-side sanitiza- tion that strips meta-commentary , and strict struc- tural preservation (e.g., few-shot exemplars are kept intact by editing only the final query span). If all candidates fail checks, POaaS returns the original prompt. Implementation. POaaS is implemented as a FastAPI ( Lubanovic , 2023 ) orchestrator (CPU) that routes to vLLM+LoRA specialist services (GPU) and logs per-stage latency/tokens with determin- istic configs for reproducibility are listed in Ap- pendix F . 4 Experiments W e ev aluate POaaS against state-of-the-art APO baselines on both task accuracy and factuality met- rics, under clean and degraded input conditions. All experiments use fixed target models (Llama- 3.2-3B-Instruct and Llama-3.1-8B-Instruct) with frozen weights and identical decoding parameters (temperature=0.2, top- p =0.9, max tokens= 512), ensuring that any dif ferences are attributable solely to prompt optimization rather than model or decod- ing changes. 4.1 Experimental Setup Baselines. W e focus on three representati ve APO frame works that we can apply under our fixed- model, on-device constraint (i.e., all LLM calls made inside each APO pipeline are ex ecuted us- ing the same 3B/8B backbone and matched de- coding): Length policy: we do not impose an explicit prompt-length cap on APO baselines; they may generate arbitrarily long optimized instruc- tions (prompt/input tokens). By contrast, POaaS remains budgeted and we fix the target model’ s gener ated output to a maximum of 512-tokens. • EvoPr ompt : An ev olutionary search method that maintains a population of prompt candi- dates and applies mutation/crossov er operators T able 1: T ask accuracy and factuality benchmark results (%) for POaaS and APO baselines. Green / red show change vs No Optimization. Best in bold . T ask Accuracy Factuality Model Method BBH GSM8K CSQA A vg. HaluEval HalluLens F ActScore A vg. Llama-3.2-3B No Optimization 42.2 77.2 71.6 63.7 68.2 48.8 16.6 44.5 EvoPrompt 35.8 (-6.4) 75.4 (-1.8) 68.2 (-3.4) 59.8 67.6 (-0.6) 46.8 (-2.0) 16.4 (-0.2) 43.6 OPR O 32.4 (-9.8) 74.2 (-3.0) 65.8 (-5.8) 57.5 66.8 (-1.4) 45.6 (-3.2) 15.8 (-0.8) 42.7 PromptW izard 10.4 (-31.8) 72.4 (-4.8) 63.6 (-8.0) 48.8 65.2 (-3.0) 43.8 (-5.0) 14.8 (-1.8) 41.3 POaaS (Ours) 46.0 (+3.8) 79.0 (+1.8) 73.0 (+1.4) 66.0 70.2 (+2.0) 52.0 (+3.2) 22.0 (+5.4) 48.1 Llama-3.1-8B No Optimization 51.8 82.4 76.2 70.1 74.6 56.2 24.8 51.9 EvoPrompt 44.2 (-7.6) 80.6 (-1.8) 73.4 (-2.8) 66.1 74.0 (-0.6) 54.2 (-2.0) 24.4 (-0.4) 50.9 OPR O 40.6 (-11.2) 79.2 (-3.2) 70.8 (-5.4) 63.5 73.0 (-1.6) 52.8 (-3.4) 23.6 (-1.2) 49.8 PromptW izard 18.6 (-33.2) 77.8 (-4.6) 68.2 (-8.0) 54.9 71.4 (-3.2) 50.2 (-6.0) 22.6 (-2.2) 48.1 POaaS (Ours) 54.0 (+2.2) 83.2 (+0.8) 77.2 (+1.0) 71.5 76.0 (+1.4) 57.6 (+1.4) 26.2 (+1.4) 53.3 to generate v ariants; candidates are scored and the best-performing prompts are retained across generations. W e run EvoPrompt with 20 gener- ations and otherwise follo w the authors’ recom- mended settings, using the same 3B/8B sLLM for all internal calls. • OPR O : A meta-prompt optimization frame- work that treats prompt optimization as black- box search: a meta-prompt summarizes prior candidate instructions and their scores, and the optimizer proposes the next candidate condi- tioned on this trajectory . W e cap the optimiza- tion b udget at 10 iterations and replace all op- timizer/e v aluator calls with the same 3B/8B backbone used for task inference. • PromptW izard : A critique-and-synthesis ap- proach that iterates between generating candi- date instructions, critiquing them, and synthe- sizing re vised prompts (often with more struc- ture). W e follow the official hyperparameters with 10 iterations and run both generator and critic roles on the same 3B/8B backbone. W e start from the official repositories and rec- ommended optimization b udgets, modifying only (i) the choice of backbone (our 3B/8B sLLMs), and (ii) the matching decoding parameters. For each backbone, we adapt all LLM calls inside each APO pipeline to that backbone, so that the same sLLM acts as optimizer , critic, and task model. This restriction makes the comparison realistic for on-de vice scenarios where larger cloud models are costly and ensures that any observed degradation is a property of the APO design rather than access to a stronger teacher . Benchmarks. W e ev aluate on three task- accuracy benchmarks (BBH, GSM8K, Common- senseQA) and three factuality datasets (HaluEv al, HalluLens, F ActScore). W e treat the latter as datasets and e v aluate hallucination av oidance with GPT -5-as-a-judge. W e provide benchmark prov enance, split choices, and prompt templates in Appendix G . • T ask Accur acy : BBH, GSM8K, and Common- senseQA. These cover multi-step reasoning, arithmetic reasoning, and multiple-choice com- monsense reasoning. W e use standard fe w-shot prompting formats where applicable (BBH: task-specific 3-shot CoT prefix; GSM8K: 8- shot CoT prefix), but under our strict 512-tok en generation cap and fixed decoding; as a result, absolute scores are belo w leaderboard/of ficial reports that use larger b udgets and dif ferent de- coding. The prompts used in e v aluation are provided in Appendix I • F actuality : HaluEv al, HalluLens, and F ActScore. W e use the dataset-provided inputs and any av ailable reference context/e vidence, and score whether model outputs are hal- lucinated via GPT -5-as-a-judge (binary non-hallucination rate; details and judge prompt in Appendix H ). For each benchmark, we randomly sample 500 examples from the of ficial training or ev aluation splits. This choice balances three factors: (i) the need to co v er di verse phenomena within each dataset, (ii) the computational cost of running 5 methods × 7 conditions (clean + 6 noise lev els) × 6 benchmarks × 2 models, and (iii) comparability with prior prompt-optimization and hallucination studies that commonly report 100–1,000 examples per setting ( Opsahl-Ong et al. , 2024 ; Ravi et al. , 2024 ). Sampling is deterministic gi ven a fix ed seed; for BBH we stratify across subtasks to preserve task di versity . Full sampling details are in Appendix G . Evaluation. • T ask Accuracy : For GSM8K, we e xtract the fi- nal numeric answer from the model output (e.g., “The answer is X” / last number) and score e xact match against the gold answer (after normal- ization). For CommonsenseQA, we e xtract an answer letter (A–E) and score e xact match. For BBH, we extract the final short answer (e.g., T rue/False or option letter depending on the task) and score e xact match. The exact extrac- tion patterns and normalization rules are listed in Appendix G . • F actuality : W e e v aluate hallucination av oid- ance using GPT -5-as-a-judge on the under- lying datasets. For each sample, we pro- vide GPT -5 with the dataset-provided refer- ence context/e vidence (when av ailable) and the model answer , and ask for a strict binary la- bel ( hallucinated vs not hallucinated ). W e compute factuality as the percentage of an- swers labeled not hallucinated . Prompts used (judge + generation templates) are listed in Appendix H . • Input De gradation : T o approximate typos and noisy user text, we inject token-le vel noise us- ing two processes following prior robustness work ( Ishibashi et al. , 2023 ). For token dele- tion , we randomly delete 5%, 10%, or 15% of word tokens. For token mixup , we ran- domly replace 5%, 10%, or 15% of word to- kens with unrelated content words from a fixed vocab ulary ( Xie et al. , 2017b ). In both cases, we perturb only the user prompt (not the ref- erence answers/labels), and perturbations are deterministic giv en a fixed seed. Full details are in Appendix J . Metrics. W e report: • T ask accuracy (%) on BBH, GSM8K, and CSQA, computed as mean exact-match accuracy over 500 samples per bench- mark after benchmark-specific answer extrac- tion/normalization. • F actuality (%, higher is better) on HaluE- v al, HalluLens, and F ActScore datasets, com- puted as the proportion of outputs judged not hallucinated by GPT -5 given reference con- text/e vidence. • Efficiency : (i) one-time offline optimization time and internal LLM calls for APO methods, and (ii) per-query refinement latency , special- ist calls, and added prompt tokens for POaaS. Measurement protocol and prompts are listed in Appendix K . 4.2 Main Results T able 1 summarizes accuracy and f actuality under clean conditions. POaaS consistently impr oves or at least preserves the No Optimization baseline on all benchmarks and both model sizes: for POaaS with the 3B backbone, av erage accuracy increases from 63.7% to 66.0% (+2.3%), and for POaaS with the 8B backbone from 70.1% to 71.5% (+1.4%). Factuality also impro ves, with g ains of +2.0–5.4% for POaaS with the 3B backbone and +1.4% across all three factuality datasets for POaaS with the 8B backbone. By contrast, we found that directly applying these APO methods to small models hurts perfor - mance. Among the APO baselines, EvoPrompt degrades the least overall, OPRO degrades more, and PromptW izard degrades the most. PromptWiz- ard is especially harmful on BBH: it drives BBH accuracy do wn from 42.2% to 10.4% on the 3B backbone (and from 51.8% to 18.6% on the 8B backbone). W e observed a similar pattern on the factuality datasets: all three APO baselines reduce factuality scores compared to No Optimization, whereas POaaS consistently improves them. In short, our findings back up the main hypothesis: the heavy search-based prompt optimizations de- signed for large cloud LLMs don’t transfer well to small on-de vice models, whereas a more capacity- aw are approach with minimal edits produces gains that, while modest, are consistent. 4.3 Robustness Under Input Degradation T able 2 sho ws that POaaS is consistently the most robust method under both token deletion and token mixup. For the Llama-3.2-3B, at 15% deletion, No Optimization drops to 40.2% while POaaS recov- ers accuracy to 47.6% (+7.4%); for Llama-3.1-8B, the corresponding impro vement is from 45.6% to 52.8% (+7.2%). Under mixup, POaaS similarly T able 2: Rob ustness under input degradation. T ask accuracy (%) averaged across BBH, GSM8K, and CSQA. Green / red show change vs No Optimization at each noise le vel. Best in bold . T oken Deletion T oken Mixup Model Method Clean 5% 10% 15% 5% 10% 15% Llama-3.2-3B No Optimization 63.7 52.4 45.8 40.2 59.2 54.6 48.8 EvoPrompt 59.8 (-3.9) 46.8 (-5.6) 39.2 (-6.6) 32.4 (-7.8) 54.6 (-4.6) 48.2 (-6.4) 41.6 (-7.2) OPR O 57.5 (-6.2) 44.2 (-8.2) 36.4 (-9.4) 29.2 (-11.0) 52.0 (-7.2) 45.2 (-9.4) 38.4 (-10.4) PromptW izard 48.8 (-14.9) 35.6 (-16.8) 27.2 (-18.6) 20.4 (-19.8) 42.8 (-16.4) 34.6 (-20.0) 28.2 (-20.6) POaaS 66.0 (+2.3) 58.4 (+6.0) 52.8 (+7.0) 47.6 (+7.4) 63.2 (+4.0) 59.4 (+4.8) 54.6 (+5.8) Llama-3.1-8B No Optimization 70.1 58.2 51.4 45.6 65.4 60.8 55.2 EvoPrompt 66.1 (-4.0) 53.0 (-5.2) 45.2 (-6.2) 38.4 (-7.2) 60.6 (-4.8) 54.4 (-6.4) 47.8 (-7.4) OPR O 63.5 (-6.6) 49.8 (-8.4) 41.6 (-9.8) 34.2 (-11.4) 57.4 (-8.0) 50.6 (-10.2) 43.6 (-11.6) PromptW izard 54.9 (-15.2) 41.2 (-17.0) 32.4 (-19.0) 25.6 (-20.0) 48.4 (-17.0) 40.2 (-20.6) 33.4 (-21.8) POaaS 71.5 (+1.4) 64.0 (+5.8) 58.2 (+6.8) 52.8 (+7.2) 68.6 (+3.2) 64.2 (+3.4) 59.0 (+3.8) narro ws the degradation: at 15% token mixup, POaaS improv es from 48.8% to 54.6% (+5.8%) on Llama-3.2-3B and from 55.2% to 59.0% (+3.8%) on Llama-3.1-8B. APO baselines not only start from lower clean accuracy but also degrades more steeply as noise increases. PromptW izard is the most fragile, los- ing nearly 20% relativ e to No Optimization at 15% deletion and 17–22% under mixup; OPR O sho ws intermediate de gradation, and Ev oPrompt de grades most moderately b ut still underperforms No Opti- mization across all noise le vels. Overall, POaaS makes the performance drop un- der input noise much less sev ere than what we see with No Optimization or the APO baselines – an outcome that makes sense gi ven ho w POaaS works. Its Cleaner agent directly fixes corrupted tokens when needed, and the system only turns that agent on when it detects input degradation, so it ef fec- ti vely counteracts the noise especially at higher corruption le vels. 4.4 Efficiency Analysis T able 3 highlights the core deployment tradeof f be- tween offline pr ompt sear ch (APO) and online per- query refinement (POaaS). APO baselines spend minutes of offline search (hundreds of internal LLM calls under our capped budgets) to produce a single static optimized instruction; this instruction is then reused at inference time with no additional per-query compute, b ut it typically introduces thou- sands of extra prompt tokens that compete with user content under tight context budgets. In con- trast, POaaS uses fixed agent templates and routing thresholds (no per-benchmark search), and pays a small incr emental latency only when refinement is triggered. In the 3B setting, we measure POaaS re- finement ov erhead as end-to-end additional latency T able 3: Efficienc y summary (3B setting). “Opt. Time (s)” is the wall-clock pr ompt-impro vement time : for APO methods, the of fline optimization runtime to pro- duce a single static instruction; for POaaS, the incr emen- tal per-query refinement latency (routing + specialist calls) averaged over ev aluation queries. “LLM calls” counts internal optimizer calls for APO and specialist calls per query for POaaS. “ Added tokens” is the aver - age additional pr ompt/input tokens injected at inference time. Method Opt. Time (s) Added T okens LLM Calls No Optimization 0 0 0 OPR O 455 2,840 130 PromptW izard 336 3,520 96 EvoPrompt 602 4,180 172 POaaS (Ours) 0.95 48 1.4 for the refinement stage (router + specialist calls) with batch=1 on a warmed inference server; this measurement excludes the target model’ s answer- generation time and excludes an y GPT -judge cost. A veraged ov er ev aluation queries (including cases where refinement is skipped), POaaS adds ∼ 0.95s of refinement ov erhead, in v okes ∼ 1.4 specialist calls, and injects ∼ 48 additional prompt tokens. Clarifying notes. (1) “Opt. Time” for APO methods reflects our e valuation-time configurations (budget-capped steps/candidates and a fixed de v subset) rather than the much larger default b udgets sometimes used in original papers. (2) “ Added T o- kens” counts additional pr ompt/input tokens only; all methods share the same decoding configuration and an identical cap on generated output tokens (512). 4.5 Ablation Studies For ablations, we reuse the full experimental set- ting: all datasets used from the six benchmarks, T able 4: Ablation study of POaaS components. T ask ac- curacy (%) av eraged over all six benchmarks, with green sho wing improv ement vs No Optimization. Degradation results are a veraged o ver 10% token deletion (Del-10%) and 10% token mixup (Mix-10%). Model Configuration Clean Del-10% Mix-10% Llama-3.2-3B No Optimization 63.7 45.8 54.6 Full POaaS 66.0 (+2.3) 52.8 (+7.0) 59.4 (+4.8) w/o Cleaner 65.6 (+1.9) 46.4 (+0.6) 55.2 (+0.6) w/o Paraphraser 64.8 (+1.1) 51.4 (+5.6) 57.8 (+3.2) w/o Fact-Adder 64.2 (+0.5) 52.2 (+6.4) 58.8 (+4.2) Cleaner only 63.9 (+0.2) 51.6 (+5.8) 58.4 (+3.8) Paraphraser only 65.0 (+1.3) 46.6 (+0.8) 55.4 (+0.8) Fact-Adder only 65.6 (+1.9) 46.2 (+0.4) 55.0 (+0.4) Llama-3.1-8B No Optimization 70.1 51.4 60.8 Full POaaS 71.5 (+1.4) 58.2 (+6.8) 64.2 (+3.4) w/o Cleaner 71.2 (+1.1) 52.0 (+0.6) 61.2 (+0.4) w/o Paraphraser 70.6 (+0.5) 57.0 (+5.6) 63.2 (+2.4) w/o Fact-Adder 70.4 (+0.3) 57.6 (+6.2) 63.8 (+3.0) Cleaner only 70.2 (+0.1) 57.2 (+5.8) 63.4 (+2.6) Paraphraser only 70.8 (+0.7) 52.2 (+0.8) 61.4 (+0.6) Fact-Adder only 71.0 (+0.9) 51.8 (+0.4) 61.0 (+0.2) both models, and the same clean samples, but a v- eraged the degraded samples to 10% deletion and 10% mixup conditions. T able 4 shows that the full POaaS configuration yields the largest gains on both Llama-3.2-3B and Llama-3.1-8B, with es- pecially strong improvements under degradation (+7.0%/+6.8% at 10% token deletion). Cleaner - only v ariants recov er most of the rob ustness gains but improv e clean accurac y only mar ginally , indi- cating that surface-le vel repair is the primary dri ver of robustness. Removing the Fact-Adder sharply reduces clean gains while preserving most rob ust- ness, suggesting that fact priming mainly benefits clean queries. The Paraphraser contrib utes moder - ate gains in both regimes. Overall, the full system consistently outperforms any single-agent or ab- lated v ariant, indicating that the three specialists provide complementary benefits that are best real- ized when combined with routing and drift control. 5 Conclusion W e studied prompt-side refinement for capacity- constrained sLLMs under a strict fixed-model pol- icy . Across task-accuracy and factuality datasets, POaaS—a minimal-edit, drift-guarded, per -input refinement layer—consistently improv es ov er a no- optimization baseline while remaining robust un- der prompt corruption. In contrast, representativ e search-based APO framew orks, when ported so that the same 3B/8B model must serve as optimizer and solver , often degrade performance and pro- duce long prompts that are poorly matched to tight token budgets. These findings suggest that, for on-de vice sLLM deployments, lightweight conser - v ati ve refinement with explicit drift/length controls is a practical alternativ e to heavy global prompt search. Limitations POaaS has three key limitations. (1) English-only: heuristics, corruption detectors, and specialists are tuned for English; multilingual extension (e.g., K orean/Japanese/Chinese) will require re-deriving routing/drift metrics and retraining specialists. (2) Empirical tuning: thresholds and caps are set em- pirically; more principled or automated calibra- tion would improve portability and interpretabil- ity . (3) Limited agent set: we study three special- ists; future work should explore broader palettes (domain-specific or retriev al-backed) while preserv- ing minimal-edit guarantees and on-de vice budgets. Acknowledgments This work was supported by the Institute of In- formation & Communications T echnology Plan- ning & Ev aluation(IITP) grant funded by the K orea gov ernment(MSIT) (No.RS-2025-02263869, De- velopment of AI Semiconductor Cloud Platform Establishment and Optimization T echnology . References Eshaan Agarwal, Raghav Magazine, Joykirat Singh, V iv ek Dani, T anuja Ganu, and Akshay Nambi. 2025. Promptwizard: Optimizing prompts via task-a ware, feedback-dri ven self-ev olution. In F indings of the As- sociation for Computational Linguistics: A CL 2025 , pages 19974–20003. Y ejin Bang, Ziwei Ji, Alan Schelten, Anthony Hartshorn, T ara Fowler , Cheng Zhang, Nicola Cancedda, and Pascale Fung. 2025. Hallulens: Llm hallucination benchmark. arXiv pr eprint arXiv:2504.17550 . Andrei Z. Broder . 1997. On the resemblance and con- tainment of documents. In Pr oceedings of the Com- pr ession and Complexity of Sequences 1997 . Andharini Dwi Cahyani, Moh Fathoni, Fika Hastarita Rachman, Ari Basuki, Salman Amin, Bain Khusnul Khotimah, and 1 others. 2025. Automatic essay scor- ing: leveraging jaccard coefficient and cosine sim- ilaritywith n-gram variation in vector space model approach. arXiv preprint . Kaiyan Chang, Songcheng Xu, Chenglong W ang, Y ingfeng Luo, Xiaoqian Liu, T ong Xiao, and Jingbo Zhu. 2024. Efficient prompting methods for large language models: A survey . arXiv pr eprint arXiv:2404.01077 . Karl Cobbe, V ineet K osaraju, Mohammad Ba v arian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems. arXiv pr eprint arXiv:2110.14168 . W endi Cui, Jiaxin Zhang, Zhuohang Li, Hao Sun, Damien Lopez, Kamalika Das, Bradley A Malin, and Sricharan Kumar . 2025. Automatic prompt optimiza- tion via heuristic search: A survey . arXiv pr eprint arXiv:2502.18746 . Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and T im Rock- täschel. 2023. Promptbreeder: Self-referential self-improv ement via prompt ev olution. arXiv pr eprint arXiv:2309.16797 . W ael H. Gomaa and Aly A. Fahmy . 2013. A surve y of text similarity approaches. International J ournal of Computer Applications , 68(13). Aaron Grattafiori, Abhimanyu Dube y , Abhinav Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur , Alan Schel- ten, Alex V aughan, Amy Y ang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Y ang, Archi Mi- tra, Archie Srav ankumar , Artem K orenev , Arthur Hinsvark, and 542 others. 2024. The llama 3 herd of models . T om Gunter , Zirui W ang, Chong W ang, Ruoming Pang, Andy Narayanan, Aonan Zhang, Bo wen Zhang, Chen Chen, Chung-Cheng Chiu, David Qiu, Deepak Gopinath, Dian Ang Y ap, Dong Y in, Feng Nan, Floris W eers, Guoli Y in, Haoshuo Huang, Jianyu W ang, Jiarui Lu, and 136 others. 2024. Apple intel- ligence foundation language models . arXiv preprint arXiv:2407.21075 . Edward J. Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. 2021. Lora: Low-rank adap- tation of large language models. arXiv pr eprint arXiv:2106.09685 . Y oichi Ishibashi, Danushka Bollegala, Katsuhito Su- doh, and Satoshi Nakamura. 2023. Evaluating the robustness of discrete prompts . arXiv pr eprint arXiv:2302.05619 . Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Kesha v Santhanam, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, Heather Miller , and 1 others. 2024. Dspy: Compiling declarativ e language model calls into state-of-the-art pipelines. In The T welfth International Conference on Learning Repr esentations . W oosuk Kwon, Zhuohan Li, Siyuan Zhuang, Y ing Sheng, Lianmin Zheng, Cody Hao Y u, Joseph Gon- zalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serv- ing with pagedattention. In Pr oceedings of the 29th symposium on operating systems principles , pages 611–626. Maikel Leon. 2025. Gpt-5 and open-weight large lan- guage models: Advances in reasoning, transparenc y , and control. Information Systems , page 102620. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler , Mike Lewis, W en-tau Y ih, Tim Rock- täschel, and 1 others. 2020. Retriev al-augmented gen- eration for knowledge-intensi ve nlp tasks. Advances in neural information pr ocessing systems , 33:9459– 9474. Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen T an, Amrita Bhat- tacharjee, Y uxuan Jiang, Canyu Chen, Tianhao W u, and 1 others. 2025a. From generation to judgment: Opportunities and challenges of llm-as-a-judge. In Pr oceedings of the 2025 Confer ence on Empirical Methods in Natural Language Processing , pages 2757–2791. Junyi Li, Xiaoxue Cheng, W ayne Xin Zhao, Jian-Y un Nie, and Ji-Rong W en. 2023. Halue val: A large- scale hallucination ev aluation benchmark for large language models. arXiv preprint . W enwu Li, Xiangfeng W ang, W enhao Li, and Bo Jin. 2025b. A survey of automatic prompt engineer- ing: An optimization perspectiv e. arXiv preprint arXiv:2502.11560 . Bill Lubanovic. 2023. F astAPI . " O’Reilly Media, Inc.". Sew on Min, Kalpesh Krishna, Xinxi L yu, Mike Le wis, W en-tau Y ih, Pang K oh, Mohit Iyyer , Luke Zettle- moyer , and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic e valuation of factual precision in long form text generation. In Pr oceedings of the 2023 Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 12076–12100. Courtney Napoles, Keisuke Sakaguchi, and Joel T etreault. 2017. JFLEG: A fluency corpus and bench- mark for grammatical error correction. In Pr oceed- ings of the 15th Conference of the Eur opean Chap- ter of the Association for Computational Linguistics: V olume 2, Short P apers , pages 229–234. Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab . 2024. Optimizing instructions and demon- strations for multi-stage language model programs . In Proceedings of the 2024 Conference on Empiri- cal Methods in Natural Languag e Pr ocessing , pages 9340–9366, Miami, Florida, USA. Association for Computational Linguistics. Reid Pryzant, Dan Iter , Jerry Li, Y in T at Lee, Chen- guang Zhu, and Michael Zeng. 2023. Automatic prompt optimization with" gradient descent" and beam search. arXiv preprint . Python Software Foundation. 2023. dif flib — helpers for computing deltas (python documenta- tion). Python 3 documentation . SequenceMatcher (Ratcliff/Obershelp-style matching). Kiran Ramnath, Kang Zhou, Sheng Guan, Soumya Sm- ruti Mishra, Xuan Qi, Zhengyuan Shen, Shuai W ang, Sangmin W oo, Sullam Jeoung, Y awei W ang, and 1 others. 2025. A systematic surve y of automatic prompt optimization techniques. CoRR . John W . Ratclif f and Da vid E. Metzener . 1988. Pattern matching: The gestalt approach. Dr . Dobb’s J ournal . Selvan Sunitha Ravi, Bartosz Mielczarek, Anand Kan- nappan, Douwe Kiela, and Rebecca Qian. 2024. L ynx: An open source hallucination ev aluation model. arXiv preprint . Laria Reynolds and K yle McDonell. 2021. Prompt pro- gramming for large language models: Beyond the few-shot paradigm. In Extended Abstracts of the 2021 CHI Confer ence on Human F actors in Comput- ing Systems . Denis (derenrich) Richter . 2023. wikidata-en- descriptions: English descriptions for wikidata entities. https://huggingface.co/datasets/ derenrich/wikidata- en- descriptions . Hug- ging Face dataset, CC BY -SA 4.0, accessed 2025- 12-11. Jihyeon Roh, Minho Kim, and K youngman Bae. 2024. T owards a small language model powered chain- of-reasoning for open-domain question answering. ETRI Journal , 46(1):11–21. Lakshay Sharma, Laura Graesser, Nikita Nangia, and Utku Evci. 2019. Natural language understanding with the quora question pairs dataset. arXiv pr eprint arXiv:1907.01041 . Max Sparkman and Alan W itt. 2025. Claude ai and lit- erature revie ws: An experiment in utility and ethical use. Library T rends , 73(3):355–380. Mirac Suzgun, Nathan Scales, Nathanael Schärli, Se- bastian Gehrmann, Y i T ay , Hyung W on Chung, Aakanksha Chowdhery , Quoc Le, Ed Chi, Denny Zhou, and 1 others. 2023. Challenging big-bench tasks and whether chain-of-thought can solv e them. In F indings of the Association for Computational Linguistics: ACL 2023 , pages 13003–13051. Alon T almor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. Commonsenseqa: A question answering challenge targeting commonsense kno wl- edge. In Pr oceedings of the 2019 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T ech- nologies, V olume 1 (Long and Short P apers) , pages 4149–4158. Zeliang T ong, Zhuojun Ding, and W ei W ei. 2025. Evo- prompt: Evolving prompts for enhanced zero-shot named entity recognition with lar ge language models. In Pr oceedings of the 31st International Conference on Computational Linguistics , pages 5136–5153. Denny Vrande ˇ ci ´ c and Markus Krötzsch. 2014. Wiki- data: A free collaborativ e knowledge base. Commu- nications of the A CM , 57(10):78–85. Xingchen W an, Ruoxi Sun, Hootan Nakhost, and Sercan Arik. 2024. T each better or sho w smarter? on instruc- tions and exemplars in automatic prompt optimiza- tion. Advances in Neural Information Processing Systems , 37:58174–58244. Xinyuan W ang, Chenxi Li, Zhen W ang, Fan Bai, Haotian Luo, Jiayou Zhang, Nebojsa Jojic, Eric P Xing, and Zhiting Hu. 2023. Promptagent: Strategic planning with language models enables expert-le vel prompt optimization. arXiv preprint arXiv:2310.16427 . Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large language models. Advances in neural information pr ocessing systems , 35:24824– 24837. Jun Xie, Zhaopeng W ang, Zhen Li, and 1 others. 2017a. Data noising as smoothing in neural machine trans- lation. In Pr oceedings of the 2017 Confer ence on Empirical Methods in Natural Languag e Pr ocessing . Ziang Xie, Sida I. W ang, Jiwei Li, Daniel Lévy , Aiming Nie, Dan Jurafsky , and Andrew Y . Ng. 2017b. Data noising as smoothing in neural network language models . In International Confer ence on Learning Repr esentations (ICLR) . Chengrun Y ang, Xuezhi W ang, Y ifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. 2023. Large language models as optimizers. In The T welfth International Conference on Learning Repr esentations . Y uan Zhang, Jason Baldridge, and Luheng He. 2019. P A WS: Paraphrase adversaries from word scrambling. In Pr oceedings of NAA CL-HLT , pages 1298–1308. Y ao wei Zheng, Richong Zhang, Junhao Zhang, Y an- han Y e, Zheyan Luo, Zhangchi Feng, and Y ongqiang Ma. 2024. Llamafactory: Unified efficient fine- tuning of 100+ language models. arXiv preprint arXiv:2403.13372 . A POaaS Hyperparameters: Thresholds and Budgets Heuristic scores (CPU-only). POaaS computes four scalar scores in [0 , 1] : typo ( x ) (higher-w orse); comp ( x ) , flu ( x ) , clar ( x ) (higher -better). T able 5: Default POaaS hyperparameters used across experiments unless stated otherwise. Component Default Routing thresholds τ typo = 0 . 30 , τ comp = 0 . 70 τ flu = 0 . 80 , τ skip = 0 . 25 Skip gate q ( x ) > 0 . 75 and typo ( x ) < 0 . 20 Length cap ρ max =2 . 4 (character ratio) Specialist gen cap 512 output tokens / call Fact-Adder cap ≤ 3 bullets, ≤ 120 tokens total Default routing thr esholds. W e use: τ typo = 0 . 30 , τ comp = 0 . 70 , τ flu = 0 . 80 , τ skip = 0 . 25 . and additionally require typo ( x ) < 0 . 20 to en- able skipping. Prompt-length budget. W e cap prompt expan- sion using a character-length ratio ρ ( x, ˜ x ) = len( ˜ x ) len( x ) ≤ ρ max , ρ max = 2 . 4 . Here len( · ) is character length (CPU-cheap); we report token-based added prompt tok ens using the target tok enizer in experiments. Specialist output caps. Each specialist call is capped at 512 generated output tokens. This bounds cost and pre vents runa way re writes. F act-Adder budget. When inv oked, the Fact- Adder emits up to thr ee factual b ullets, capped at ≤ 120 tokens total (tar get tokenizer). The merger prepends these b ullets and rejects an y output that (i) exceeds the cap or (ii) contains reasoning/answer - like content (Appendix D ). Summary table (defaults). B Prompt Quality Scor es (CPU-only Heuristics) All scores are clipped to [0 , 1] . W e use whitespace tokenization plus lightweight re gex patterns. B.1 T ypo score T ypo starts at 0 and adds penalties; final score is typo ( x ) = clip [0 , 1] X k p k ( x ) . W e use: • Misspellings / character noise : let m be the number of matches against a compact list of common misspellings and noise re gex es (re- peated letters, dropped vo wels, ke yboard ad- jacency patterns). Add p noise ( x ) = 0 . 04 · min( m, 8) (cap 0 . 32 ). • Missing question punctuation : if the prompt begins with a wh-word ( what/why/how/when/where/who ) and does not end with ? s, add p ? ( x ) = 0 . 05 . • Case anomalies : if ≥ 90% alphabetic char- acters are uppercase (ALL CAPS) or lower - case for prompts longer than 20 characters, add p case ( x ) = 0 . 05 . • Short-word ratio : let r ≤ 2 be the fraction of non-stopword tokens with length ≤ 2 . If r ≤ 2 > 0 . 35 , add p short ( x ) = 0 . 08 . B.2 Completeness score Completeness starts at 1 . 0 and subtracts penalties: comp ( x ) = clip [0 , 1] 1 . 0 − X k p k ( x ) . W e use: • V ery short prompts : if token count < 5 , sub- tract 0 . 25 ; else if < 10 , subtract 0 . 15 . • Missing detail cues : if token count < 15 and the prompt contains no detail-seeking cues (e.g., explain/describe/context/assumptions ), subtract 0 . 10 . • V ague templates : if the prompt matches a v ague template like what is X / tell me about X without any constraints (no time scope, format, audience, or objecti ve), subtract 0 . 10 . B.3 Fluency score Fluency starts at 1 . 0 and subtracts penalties: flu ( x ) = clip [0 , 1] 1 . 0 − X k p k ( x ) . W e use: • Fragments : if token count < 3 , subtract 0 . 25 . • Degenerate repetition : if an y exact repeated bi- gram occurs ≥ 2 times (e.g., the the ), subtract 0 . 15 . • Surface capitalization cues : if token count ≥ 12 and the first token is lowercase while the prompt contains sentence-ending punctuation, subtract 0 . 10 . B.4 Clarity score Clarity starts at 1 . 0 and subtracts penalties: clar ( x ) = clip [0 , 1] 1 . 0 − X k p k ( x ) . W e use: • Low lexical div ersity : for prompts with ≥ 12 tokens, compute type-token ratio (TTR). If TTR < 0 . 35 , subtract 0 . 15 . • Ambiguous leading pronouns : if the prompt begins with it/this/that/they/them , sub- tract 0 . 10 . • Overlong, unf ocused prompts : if token count > 200 , subtract 0 . 08 (mild; primarily discour- ages unnecessary re writes). B.5 Overall quality and skip gate Let [ z ] + = max( z , 0) . W e compute: q ( x ) = 1 − max typo ( x ) , [ τ comp − comp ( x )] + , [ τ flu − flu ( x )] + , [0 . 70 − clar ( x )] + , (4) and skip refinement when q ( x ) > 0 . 75 and typo ( x ) < 0 . 20 . This is intentionally conserv a- ti ve: POaaS prefers missing marginal improve- ments over risking harmful edits on already well- formed prompts. C Lexical Drift and Length Guards C.1 Drift calculation W e define lexical similarity as a weighted ensemble of standard string/document similarity primitives (SequenceMatcher / Ratclif f–Obershelp matching; n-gram Jaccard/shingling; and weighted token o ver - lap) commonly used in text similarity pipelines. ( Ratclif f and Metzener , 1988 ; Broder , 1997 ; Go- maa and Fahmy , 2013 ) sim ( x, x ′ ) = 0 . 5 S seq ( x, x ′ ) + 0 . 3 S jac ( x, x ′ ) + 0 . 2 S tok ( x, x ′ ) , S jac = 0 . 6 J c 3 ( x, x ′ ) + 0 . 4 J w 2 ( x, x ′ ) . (5) where: • S seq is the Python difflib.SequenceMatcher ratio computed on lowercased, whitespace- normalized strings. ( Ratclif f and Metzener , 1988 ; Python Software F oundation , 2023 ) • J char-3 is Jaccard similarity ov er sets of character trigrams; J word-2 is Jaccard similarity o ver sets of word bigrams. ( Cahyani et al. , 2025 ) • S tok is a weighted token-o v erlap score: P t ∈∩ w ( t ) / P t ∈∪ w ( t ) with w ( t )=1 for con- tent tokens and w ( t )=0 . 2 for stopwords. W e define drift as D ( x, x ′ ) = 1 − sim ( x, x ′ ) . C.2 Content preser vation penalty W e extract ke y items from the original prompt x : numbers (regex for integers/decimals), quoted spans (text inside quotes), URLs/emails, and cap- italized entity-like spans (two consecuti ve capi- talized tokens). Let this multiset be K ( x ) = { k 1 , . . . , k M } (after normalization: lo wercasing URLs/emails, stripping punctuation around num- bers/quotes). W e compute an absolute match count c ( x, x ′ ) = M X i =1 1 [ k i occurs in x ′ ] , and define the preserv ation ratio P content ( x, x ′ ) = ( 1 . 0 if M = 0 , c ( x, x ′ ) / M otherwise. If P content < 0 . 8 , we increase drift: D final = min 1 . 0 , D ( x, x ′ ) + 0 . 2 · 1 − P content ( x, x ′ ) (6) C.3 Default drift caps Defaults: • Cleaner : accept if D final ≤ 0 . 15 on clean prompts; relax progressively for high-typo prompts. • Paraphraser : accept if D final ≤ 0 . 08 (relax to 0.13 when clarity is lo w). • Global clean-regime fail-safe : reject any can- didate with D final > δ max , where δ max = 0 . 18 . C.4 Length cap W e enforce ρ ( x, ˜ x ) ≤ ρ max with ρ max = 2 . 4 and also reject any specialist output that exceeds 2 × the original character length after sanitization. D Safety and Guardrails D.1 Per -agent guard checks • Cleaner guard : rejects edits that add ne w con- tent or remove explicit constraints; otherwise returns the corrected prompt. • Paraphraser guard : rejects/repairs para- phrases that change meaning, drop constraints, or inject ne w facts. • F act-Adder grounding guard : filters out un- supported statements and returns NONE if no high-confidence facts remain. D.2 Merger -level filters • Sanitization : strip meta-commentary (e.g., Here is the rewrite ), formatting artifacts, and enclosing quotes if the entire output is quoted. • Question structure : for question prompts, re- ject edits that remov e a trailing ? . • Answer leakage : reject Fact-Adder context containing explicit answer phrases (e.g., the answer is ), stepwise reasoning mark ers (e.g., step 1 ), or standalone option letters/numeric answers likely to leak the solution. • F ew-shot pr eservation : when few-shot ex em- plars are detected, only the final query span is editable; ex emplars are preserved v erbatim. • F ail-safe fallback : if all candidates fail, return the original prompt unchanged. E Specialist Fine-T uning and LoRA Settings LoRA configuration. All specialists are LoRA adapters on frozen Llama backbones using the open-source LlamaFactory frame work ( Zheng et al. , 2024 ) with r = 16 , α = 32 , dropout 0 . 05 , trained for 3 epochs (AdamW , cosine schedule). W e keep decoding fixed across conditions in the main experiments. T raining data. W e train each specialist on task- aligned pairs (or synthetic pairs) that match the specialist’ s contract: minimal edits, strict mean- ing preservation, and no answer leakage. W e de- duplicate across sources and create a held-out v al- idation split for early stopping / threshold tuning. W e do not use any samples from the six ev aluation benchmarks for specialist training. • Cleaner (error -correction pairs). W e use sentence-lev el correction pairs from JF- LEG ( Napoles et al. , 2017 ), treating the noisy sentence as input and the corrected sentence as target. W e conv ert each pair into an instruction- style example that explicitly enforces minimal edits : (i) fix typos/spacing/punctuation, (ii) preserve numbers, entities, URLs, and quoted spans verbatim, and (iii) ne ver add new f acts or constraints. T o better match our inference-time corruptions, we optionally augment a fraction of inputs with light synthetic noise (random dele- tion/replacement at lo w rates) while keeping the original JFLEG correction as the target, and we discard examples where the tar get substantially rephrases content (to av oid training the Cleaner to paraphrase). • Paraphraser (semantic-equivalence pairs). W e use paraphrase pairs from P A WS ( Zhang et al. , 2019 ) and QQP ( Sharma et al. , 2019 ), keeping only pairs labeled as semantically equi v alent. Each example is formatted as: (in- put pr ompt → clear er re write) with constraints: preserve intent, entities, numerals, and e xplicit constraints; keep the question type (question vs. instruction); and improve clarity/fluency with- out length inflation (we filter or do wnweight pairs whose target is excessi vely longer). W e also include a small portion of NONE -style neg- ati ves where the input is already well-formed, training the Paraphraser to output the original text unchanged (or a special NO_CHANGE token) to support conserv ati ve beha vior . • F act-Adder (short grounded fact bullets). W e construct a lightweight fact corpus from W ikipedia and W ikidata-style resources ( Vran- de ˇ ci ´ c and Krötzsch , 2014 ; Richter , 2023 ) by extracting high-confidence atomic facts (e.g., entity definitions, key attributes, and simple relational triples) and con verting them into short declarative sentences. T raining inputs are prompts paired with r elevant fact bullets selected using lexical ov erlap between prompt ke yphrases (entities, nouns, and numbers) and the fact corpus entries. T argets are capped to at most three bullets and a strict token budget, and we exclude f acts that look like solutions to benchmark-style questions (to a void answer leakage). W e additionally include NONE targets when no high-confidence matching facts are found, teaching the F act-Adder to abstain rather than hallucinate. Splits are de-duplicated; a held-out slice is used for threshold selection. F Implementation and Instrumentation POaaS is deployed as FastAPI microservices: an orchestrator ( POST /infer ) dispatches to special- ist workers ( POST /clean , POST /paraphrase , POST /fact ). Routing/scoring/drift checks run on CPU; specialists run on GPU via vLLM with LoRA adapters. Each service exposes Prometheus met- rics at GET /metrics and logs per-stage latency , token usage, and error counts. Runs are tracked via run_id and persisted artifacts (inputs, inter- mediate outputs, merge decisions, timing) with a deterministic configuration hash. G Benchmarks, Sampling, and Metrics Benchmarks. W e ev aluate task accuracy on BBH, GSM8K, and CommonsenseQA, and f actu- ality on HaluEv al, HalluLens, and F ActScore. W e follo w each benchmark’ s of ficial splits and stan- dard ev aluation con ventions from the dataset papers and widely used LLM e v aluation practice. ( Cobbe et al. , 2021 ; Suzgun et al. , 2023 ) Sampling. For each benchmark we sample n = 500 examples deterministically (fixed seed) from the official e valuation split. For BBH, we strat- ify across subtasks to preserv e task di versity . The same sampled indices are reused across all methods and corruption conditions. Subsampled e v aluation is common in prompt-optimization pipelines un- der b udget constraints (small de v/ev al subsets per setting). ( Agarwal et al. , 2025 ) G.1 T ask accuracy W e report exact-match accuracy (%) using benchmark-specific answer e xtraction consistent with common practice: • GSM8K : normalize by e xtracting the final nu- meric answer (model outputs are normalized to the last numeric span; gold answers use the dataset’ s canonical final answer format). ( Cobbe et al. , 2021 ) • CSQA : extract a single option letter A–E near the end of the output (after stripping punctua- tion/whitespace). ( T almor et al. , 2019 ) • BBH : extract the task-appropriate short answer (e.g., True/F alse, option letter , or short span) and normalize whitespace/casing, following BBH’ s per-task e valuation con ventions. ( Suzgun et al. , 2023 ) G.2 F actuality / hallucination a voidance For HaluEv al, HalluLens, and F ActScore, we ev al- uate non-hallucination rate (%) using an LLM- as-a-judge protocol: giv en dataset-provided con- text/e vidence when av ailable, the judge outputs a strict binary label. This follo ws established practice in LLM ev aluation with strong constraints (temper- ature 0, fixed output space). ( Li et al. , 2025a ) H GPT -5-as-a-Judge Protocol W e use GPT -5 with temperature 0.0 and a small output budget. The judge must output exactly one label. Judge system pr ompt. You are a strict hallucination judge. Given a model answer and optional reference context, output exactly one token: ˋ hallucinatedìf the answer introduces unsupported or contradicted facts; ˋ not_hallucinatedìf it is supported by the context/evidence. Do not explain. Judge user pr ompt template. Task: {task} Evidence (if any): {evidence} Gold / reference answer (if provided): {gold} Model answer: {answer} Output exactly one token: ‘hallucinated’ or ‘not_hallucinated’. I Evaluation Pr ompt T emplates T arget model system prompt. You are a helpful assistant. BBH template (3-shot CoT ; per -task prefix). W e use the task-specific 3-shot CoT prompt prefix released with BBH-style e valuations, and append the test question in the same format. ( Suzgun et al. , 2023 ; W ei et al. , 2022 ) {BBH_3shot_cot_prefix} Q: {question} A: Let’s think step by step. GSM8K template (common 8-shot CoT ; “The final answer is”). W e follow the widely used GSM8K 8-shot CoT template used in common e val- uation harnesses. ( Cobbe et al. , 2021 ; W ei et al. , 2022 ) As an expert problem solver, solve step by step the following mathematical questions. {GSM8K_8shot_cot_demos} Q: {question} A: Let’s think step by step. CommonsenseQA template (multiple-choice; letter output). CommonsenseQA is nati vely a multiple-choice classification task; for a generation- style interface we constrain outputs to a single op- tion letter . ( T almor et al. , 2019 ) Q: {question} (A) {choiceA} (B) {choiceB} (C) {choiceC} (D) {choiceD} (E) {choiceE} Answer (A/B/C/D/E): HaluEval / HalluLens / F ActScor e template. W e keep a minimal context+prompt+answer for - mat aligned with common benchmark usage. ( Li et al. , 2023 ; Bang et al. , 2025 ; Min et al. , 2023 ) HaluEval-QA template (evidence-gr ounded QA). Knowledge (may be empty): {knowledge} Question: {question} Answer: HaluEval-Dialogue template (multi-tur n). Conversation: {dialogue} Assistant: HalluLens PreciseW ikiQA / LongWiki template (wiki-grounded QA). Context: {wiki_context} Question: {question} Answer (do not invent facts not supported by the context): HalluLens NonExistentRefusal template (refuse if non-existent). User request: {prompt} Answer. If the entity or requested information does not exist or cannot be verified, say you do not know rather than guessing: F ActScor e biography prompt (official query f orm). Tell me a bio of {entity}. J Input Degradation Protocol W e perturb the user pr ompt only and keep labels/answers unchanged. W e follow prior robustness-style tok en deletion, and implement to- ken replacement (mixup) as random word replace- ment from a fixed vocab ulary . ( Ishibashi et al. , 2023 ; Xie et al. , 2017a ) • T oken deletion : delete r ∈ { 0 . 05 , 0 . 10 , 0 . 15 } of word tokens uniformly at random. • T oken mixup : replace r ∈ { 0 . 05 , 0 . 10 , 0 . 15 } of word tokens with content words sampled from a fixed v ocabulary . Perturbations are deterministic under a fixed seed and applied consistently across methods. K Efficiency Measurement Pr otocol W e report: • Opt. time and internal calls (APO) : of- fline wall-clock time and the number of opti- mizer/critic/e v aluator calls required to produce one optimized prompt per benchmark. • Specialist calls (POaaS) : a verage number of specialist calls per query (often < 1 due to skip- ping). • Added prompt tokens : additional input tokens prepended at inference time (tokenized with the target tokenizer), distinct from the fixed 512- token gener ation cap.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment