Make it SING: Analyzing Semantic Invariants in Classifiers
All classifiers, including state-of-the-art vision models, possess invariants, partially rooted in the geometry of their linear mappings. These invariants, which reside in the null-space of the classifier, induce equivalent sets of inputs that map to…
Authors: Harel Yadid, Meir Yossef Levi, Roy Betser
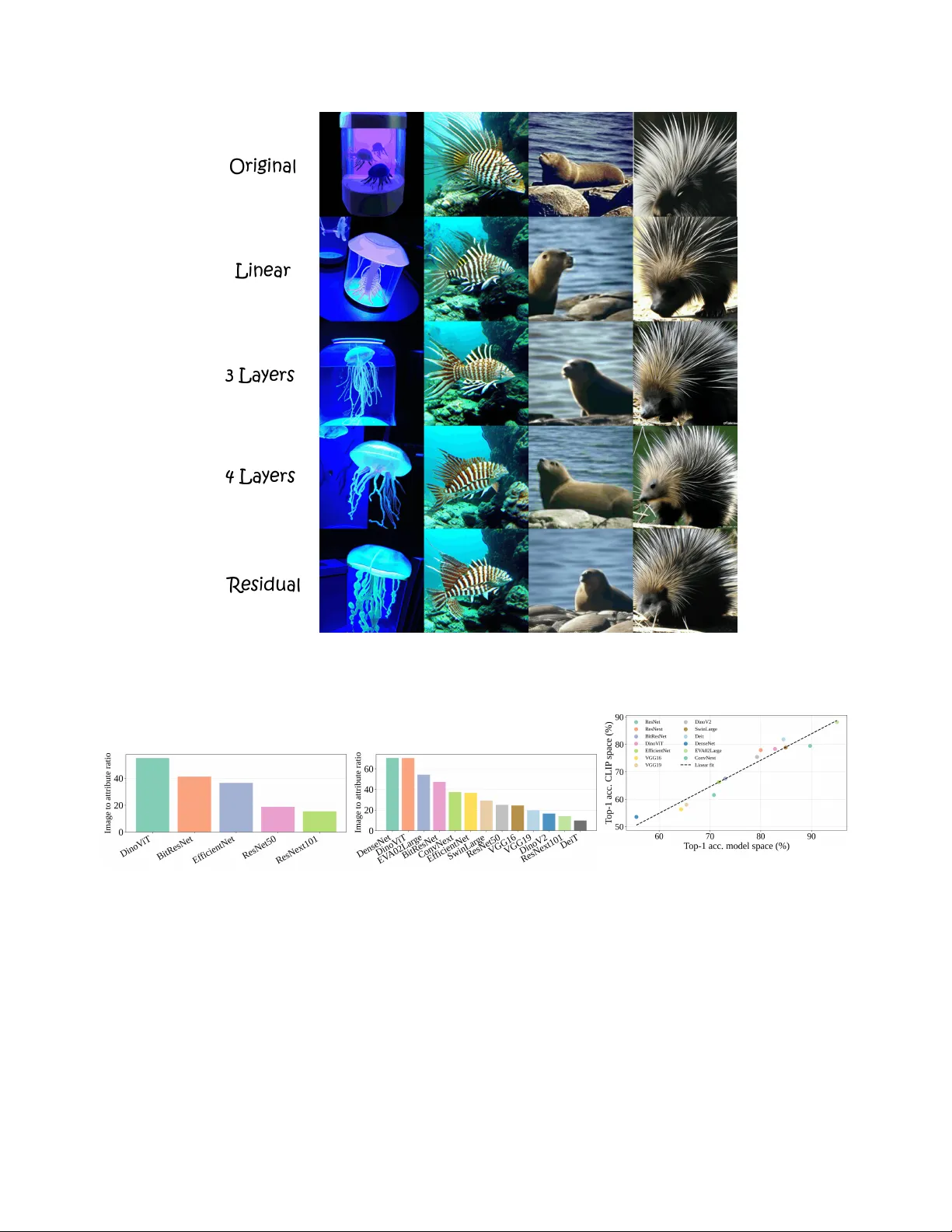
Make it SING: Analyzing Semantic In variants in Classifiers Harel Y adid, Meir Y ossef Le vi, Roy Betser , Guy Gilboa V iterbi Faculty of Electrical and Computer Engineering T echnion – Israel Institute of T echnology , Haifa, Israel {harel.yadid,roybe,me.levi}@campus.technion.ac.il; guy.gilboa@ee.technion.ac.il Figure 1. V isualization of benign and problematic in variants. The four images at the center correspond to certain features taken from a pretrained ResNet50. On the left and right columns their equiv alent images are shown, follo wing null-space removal. Each pair yields the same logits after passing through the linear head. The left side (green) demonstrates robustness, with little semantic change. The right side (red) incurs lar ge semantic de viations. Our framew ork quantifies these changes statistically , diagnosing semantic in variants at the class and network le vel. Abstract All classifiers, including state-of-the-art vision models, pos- sess in variants, partially rooted in the geometry of their lin- ear mappings. These in variants, which r eside in the null- space of the classifier , induce equivalent sets of inputs that map to identical outputs. The semantic content of these in- variants r emains vague, as existing appr oaches struggle to pr ovide human-interpr etable information. T o addr ess this gap, we present Semantic Interpr etation of the Null-space Geometry (SING), a method that constructs equivalent im- ages, with r espect to the network, and assigns semantic in- terpr etations to the available variations. W e use a map- ping from network featur es to multi-modal vision languag e models. This allows us to obtain natural language descrip- tions and visual examples of the induced semantic shifts. SING can be applied to a single image, uncovering local in variants, or to sets of images, allowing a breadth of sta- tistical analysis at the class and model le vels. F or e xam- ple, our method re veals that ResNet50 leaks rele vant se- mantic attributes to the null space, wher eas DinoV iT , a V iT pr etrained with self-supervised DINO, is superior in main- taining class semantics acr oss the invariant space. Code is available at https : / / tinyurl . com / github - SING . 1. Introduction State of the art networks, especially vision classifiers, learn internal representations with complex geometry . while this correlates with strong performance on recognition bench- marks, it makes mechanistic interpretability difficult [ 1 , 14 ]. For example, inv ariants, derived from the null space of the model’ s linear layers, lead to sets of inputs with identical outputs. W e refer to these sets as equivalent sets . Whereas nonsemantic in variants such as background or illumination are generally beneficial, in v ariants that carry semantic in- formation may harm the classifier . Howe ver , although users can often introduce image augmentations to increase in vari- ants of certain attrib utes, they cannot easily determine what the model has actually learned, only via rigorous testing. This moti vates approaches that interpret neural networks while focusing on their geometry . A natural starting point would be the geometry of the classification head, where the last decision is made. A related line of research applies sin- gular v alue decomposition (SVD) to the latent space based on representati ve data in the latent feature space [ 3 , 19 , 25 ]; howe ver , these methods are prone to the data co variances rather than network mechanism. Other methods operate di- rectly in the weight-induced null space [ 11 , 32 , 47 ]. For example, the classifier head can be decomposed into two space components:(i) principal directions, associated with dominant singular values that influence the logits; (ii) null directions, the complementary space that keeps the inputs unchanged [ 2 , 43 ]. While they are able to identify the ex- istence of inv ariant directions, they fail to explain seman- tically what they represent, and often rely on task-specific data to demonstrate these directions [ 32 ]. Recent advances in mechanistic interpretability [ 15 , 24 , 28 , 38 ] lev erage the translation of latent features from a giv en model into a multi-modal vision language space, most notably CLIP [ 44 ]. The use of CLIP to compute seman- tic correlations between text and images facilitates ne w sets of techniques that focus on producing human-readable concepts and counterfactual examples to aid interpretation. Howe ver , to the best of our knowledge, we are the first to map a classifier’ s in variant directions into a multi modal net- work for systematic analysis, providing textual descriptions and visual examples. W e propose a Semantic Interpretation of the Null-space Geometry (SING), a method grounded in SVD of the fea- ture layer to probe the latent feature space of a target clas- sifier and identify the representations of equiv alent pairs. The rev ealed null-space structure is then mapped to CLIP’ s vision-language space through linear translators, yielding quantifiable semantic analysis. Our method provides a gen- eral framework for measuring human-readable e xplanations of data in variants, spanning from image and class le vels up to entire model assessments. It supports probing, de- bugging, and comparing these in variants across vulnerable classes and spurious correlations such as background cues, as well as measuring how much a specific concept is ignored by the model. W e demonstrate the effecti veness of SING through cross-architecture measurements, per-class analy- sis, and individual image breakdown. In the last section of our experiments we present a promising direction for null space manipulation, creating features with hidden seman- tics that the model ignores. Our main contributions are: • A semantic tool for interpreting invariants . SING links classifier geometry , specifically the null space and the in- variants it induces, to meaningful human-readable expla- nations using equiv alent pairs analysis. • Model comparison . W e introduce a protocol to compare different architectures by measuring the leakage of their semantic information into their null space. Our analysis found that DinoV iT , among the examined networks, had the least class-relev ant leakage into its null space while al- lowing broad permissible in variants, such as background or color . • Open vocabulary class analysis . Our framework allows for systematic inv estigations of the sensitivity of classes to certain concepts. It can discover spurious correlations and assess their contrib ution. For example, our e xperi- ments show that for some spurious attributes in the Di- noV iT model the classifier head considers them as in vari- ants. 2. Related W ork 2.1. Explainability through decomposition Decomposing latent spaces using SVD is a foundational approach for studying their inv ariances [ 18 ]. Aubry and Russell [ 3 ] used this technique to probe dominant modes of v ariation in CNN embeddings, for e xample illumina- tion and viewpoint, under controlled synthetically rendered scenes. Härkönen et al. [ 25 ] applied it to GAN latent spaces for interpretable controls, and more recently Haas et al. [ 19 ] used it to present consistent editing directions in diffusion model latent spaces. Howe ver , feature-space decomposition is inherently data-dependent: its axes reflect the cov ariance of the measured dataset rather than the classifier’ s decision geometry . Notably , it may miss in variants residing in the classifier’ s null space itself. A complementary study inv olves decomposing the model weights directly . This line of w ork includes early low-rank decompositions of con volutional weights for ac- celeration [ 27 ], SVD analyzes of con volutional filters for interpretability [ 43 ], and decomposition of the final lin- ear layer to identify the direction rele vant to the task and the direction in variant to the task [ 2 ]. Null space analysis has been explored across several directions in deep learn- ing. Some works leverage it for information removal: Rav- fogel et al. [ 46 ] iteratively projected representations onto the null space of a linear attribute classifier to remov e pro- tected information while preserving task predictions, while Li and Short [ 32 ] exploited null space properties for im- age steganography , masking images that leave logits un- changed. Others use it as a diagnostic tool: Cook et al. [ 11 ] Figure 2. Method Overview . The approach consists of: (a) decomposing the final linear weights to obtain principal and null projectors; (b) training a translator that maps features from the network embedding space to the CLIP image space; (c) creating an equivalent pair to the feature we want to examine. (d) translate the set into CLIP image embedding space, and apply our metrics and visualizations. deriv ed OOD detection scores from null space projections, and Idnani et al. [ 26 ] explained OOD failures via null-space occupancy , showing that features drifting into the readout’ s null space lead to misclassification. Rezaei and Sabokrou [ 47 ] further analyzed the last layer null space to quantify ov erfitting through changes in its structure. Collecti vely , these methods treat the null space as an operational inv ari- ance set for control, detection, and manipulation. Howe ver , as far as we know , no current research managed to assign semantic meaning to null directions, as our approach does. 2.2. Projecting featur es to a vision-language space Contrastiv e Language–Image Pretraining (CLIP) [ 44 ] learns a rich joint embedding space for images and text, enabling a wide range of vision-language applications. A characteristic property of this space is the presence of a modality gap between image and text embeddings [ 33 ]. Be- yond its empirical success, the geometry of the CLIP latent space has been studied from multiple perspectives, includ- ing geometric analyses [ 31 ], probabilistic modeling [ 6 , 7 ], and asymptotic theoretical analysis [ 5 ]. Sev eral methods hav e lev eraged CLIP representations for interpretability , either by mapping classifier features into CLIP’ s vision- language space or by using CLIP as supervision to train concept vectors within the target model’ s feature space. T ext2Concept [ 38 ] learns a linear map from any vision en- coder to CLIP’ s space, turning text prompts directly into concept acti vation vectors, while CounTEX [ 28 ] introduces a bidirectional projection between classifier and CLIP to generate counterf actual explanations. CLIP-Dissect [ 39 ] extends this direction to the neuron lev el, automatically as- signing open-vocab ulary concept labels to individual neu- rons by matching their activ ation patterns to CLIP embed- dings. Rather than projecting into CLIP , LG-CA V [ 24 ] uses CLIP’ s text-image scores on unlabeled probe images as su- pervision to train concept vectors directly within the target model’ s feature space. T aking a broader view , DrML [ 53 ], MUL TIMON [ 50 ], and MDC [ 10 ] use language to probe, mine, and correct vision model failures across a range of failure modes. Despite the breadth of these approaches, they all focus on the activ e feature subspace of the classi- fier , leaving the null space une xplored. 3. Method Our method contains sev eral components as can be seen in Figure 2 . W e begin by decomposing the tar get layer into principal and null subspaces and building projection oper- ators that isolate each space. On the second component, we learn a linear mapping that translates the layer’ s fea- tures into the shared multi-modal space, specifically the im- age space. W e then select a feature and perturb it along a specified semantic direction projected to a chosen subspace, creating the equiv alent feature pair . After perturbing, we translate the feature using our translator to observe ho w its representation changed semantically with visualization and textual measurements. In this section we develop each com- ponent in detail, with particular attention to the null space and to the classifier head. 3.1. Setup In our w ork, we focus on the last fully connected layer W ∈ R c × m , which maps the penultimate features f ∈ R m to a logit vector in the dimension of the number of classes c . W e decompose it with SVD and specifically extract the null space projection matrix Π n , which contains all the in variants of the layer . In the translation step we denote T Θ ( f ) as the T ranslator , and we use CLIP as our multi-modal model space. W e denote z img and z text as the image and text latent features in CLIP space. W e define ˜ f as the equiv alent pair of f after perturbation in the null space. 3.2. SVD on the classifier head W can be decomposed into its principal and null spaces via SVD: W = U Σ V ⊤ , V = V p V n , (1) where Σ ∈ R c × m is a rectangle diagonal matrix contain- ing the singular values in descending order, and U ∈ R c × c and V ∈ R m × m contain the left and right singular vectors, respectiv ely . W e tak e rank( W ) , and use it to break the right singular v ectors V into the two subspace components, prin- cipal space , denoted V p (associated with non-zero singular values), and the remaining columns V n that span the null space . Any perturbation ν ∈ span( V n ) lea ves the logits unchanged: W ( f + ν ) = W f + W ν = W f , (2) since W ν = 0 for all ν in the null space. Consequently , our projector matrices are: Π p = V p V ⊤ p , Π n = V n V ⊤ n . (3) 3.3. T raining a translator Follo wing Moayeri et al. [ 38 ] and justified by Lähner and Moeller [ 30 ], we define a linear mapping operator T : R m → R n . Recall that f ∈ R m is the classifier feature and z img ∈ R n the corresponding image feature in CLIP . W e fit T Θ for a certain pretrained model by minimizing a loss combining mean squared error , and weight decay: L = ∥ T Θ ( f ) − z img ∥ 2 2 + λ ∥ Θ ∥ 2 2 , (4) where Θ is the parameters of the translator and λ is a balancing coef ficient. Detailed explanations on the train- ing procedure can be found in the supplementary mate- rials. Note that since the translator is linear , it admits T Θ ( f + v ) = T Θ ( f ) + T Θ ( v ) for any f , v , hence natu- rally fits additive feature decompositions, as our framework suggests. The translator is validated to preserve relative classification performance across models, and while we use CLIP as the tar get space, we demonstrate in the supplemen- tary that other vision-language models can serve this role as well. Although our frame work is not limited to linear trans- lators, we empirically verified that this linear map fits well in our setting. 3.4. Metrics Attribute score. An angle between two nonzero vectors x, y of the same dimension is defined by: ∠ ( x, y ) := arccos x · y ∥ x ∥∥ y ∥ . (5) CLIP Score, as described in Hessel et al. [ 22 ], is the co- sine similarity of the angle between a CLIP feature in image space z img , and a feature in the text space, z text . W e write this angle as follows: ∠ ( z img , z text ) (6) Recall that f and ˜ f are the original and its equi v alent pair . W e define Attribute Scor e (AS) for text target z text as the difference between tw o angles: AS ( f , ˜ f | z text , T Θ ) := ∠ ( T Θ ( f ) , z text ) − ∠ ( T Θ ( ˜ f ) , z text ) . (7) A positive AS indicates that the equiv alent image is se- mantically closer to the text and vice versa. In our frame- work, the text prompts are chosen as “ an image of a ” to analyze how null remov al affects classifica- tion. Ho wev er , this metric is general and can be applied with any prompt selection. Image scor e. While AS quantifies how the image de vi- ates from its current semantics, the image may be altered in appearance without af fecting AS. Such differences in over - all appearance can be measured directly by the angular dis- tance related to the original and its equiv alent pair . we de- fine it as Image Scor e (IS): IS ( f , ˜ f | T Θ ) := ∠ ( T Θ ( f ) , T Θ ( ˜ f )) . (8) Intuitiv ely , AS captures the effects of null spaces on the alignment of text-image, whereas IS reflects general seman- tic changes in the image. When the text is in the correct image class we would like low AS, and hence null-space changes should not affect class distinction. Howe ver , a good classifier should allo w high IS, and hence large se- mantic changes that do not affect class distinction, such as background change and other allowed semantic inv ariants. Details on image synthesis for visualization are provided in the supplementary materials, howe ver it’ s highly important to note that those visualizations are used only for qualitative illustration; all quantitativ e claims rely on logits and CLIP embeddings. 3.5. A pplications Our main focus is on removing the null component from an image feature f . This way , the equiv alent pair is ˜ f = f − Π n f . (9) Both f and ˜ f produce the same logit vector under the ex- amined network, yet the semantic content can be changed as a result of the null-remov al process. In the following, we describe how to quantify semantic information leakage at different levels: model, attrib ute, and image, using the proposed metrics (AS and IS). Model-level comparison. A desirable property of well- performing classifiers is to maintain a rich inv ariant space, while ensuring that this richness does not compromise class preservation. For instance, there exists a wide v ariety of dogs dif fering in breed, pose, size, color , background and more, all of which should be classified consistently with high confidence. Hence, the in variant space should sup- port such di versity . Howe ver , if perturbations along in v ari- ant directions lead to changes in classification confidence or e ven alter the predicted class, this indicates that class- specific information has leaked into the in variant space - a highly undesirable property that also exposes the model to adversarial vulnerabilities. T o e v aluate this, we collect a representativ e set of images (16 ImageNet classes, serv- ing as a proof of concept), compute the AS and IS metrics (with respect to the real class prompt; “ an image of a ”) on all null-remo ved pairs, and perform a statistical analysis across models. An effec- tiv e model should exhibit a broad range of IS values, reflect- ing rich in variance, while maintaining a narrow distribution of AS values, ensuring semantic consistenc y . Class and Attribute analysis. The same methodology can be applied to analyze inter-class behavior by selecting representativ e sets from different classes. W e conducted two complementary variants. First, we collected images from each class independently and computed the absolute Attribute Score (AS) after null-remov al, relative to the true label prompt. Higher AS values indicate that the classi- fier contains more semantic information within the inv ariant space for that class. This provides a practical diagnostic tool for practitioners when choosing networks suited to specific classes or domains. Second, we e xpanded the vocab ulary to an open set of concepts. W e quantified the distance (angles) between the original and the null-remov ed features, ov er a broad set of phrases, re vealing ho w semantic correlations emerge between the null space and di verse concepts. Single image analysis. Follo wing the same logic, leakage can also be examined at the image le vel. This provides a fine-grained diagnostic tool for identifying and debugging failure cases. Null perturbations. While null remov al is useful for fair comparisons across classes, attributes, or images, feature manipulation need not be restricted to a single inv ariant di- rection. W e propose a more principled selection of pertur- bation directions. W e formalize perturbations that target a specific concept while remaining confined to the model’ s in variant (null) subspace. Let f ∈ R d be an image fea- ture, T Θ : R d → R n the translator into the CLIP image- embedding space, and z text ∈ R n the CLIP text embedding of a prompt (e.g., “ an image of a jellyfish ”). Define the cosine-similarity score s ( f ; z text ) := ⟨ z , z text ⟩ ∥ z ∥ ∥ z text ∥ , z := T Θ ( f ) . (10) The semantic dir ection toward the prompt is the gradient through the translator , g text ( f ) := ∇ f s ( f ; z text ) . (11) Let Π n denote the orthogonal projector onto the null space (( 3 )). Projecting this direction onto the null space isolates the component that liv es in the in variant subspace: d null ( f ) := P N g text ( f ) , ˆ d null ( f ) := d null ( f ) ∥ d null ( f ) ∥ . (12) One can control the extent of semantic change via a scalar step size ε applied to the normalized null direction ˆ d null : f ε = f + ε ˆ d null ( f ) . (13) By choosing the prompt to correspond to another class or attrib ute, this construction probes a class’ s sensitivity within the in variant subspace to concepts associated with other classes, thereby rev ealing “confusing” inter-class re- lationships. 4. Experiments 4.1. Dataset and models W e base our analysis on fiv e models pretrained on ImageNet-1k [ 12 ] spanning div erse architectures and train- ing paradigms: DinoV iT [ 9 ], ResNet50 [ 20 ], ResNext101 (a) (b) Figure 3. Model-level comparison (1,000 classes). (a) At- tribute Score (AS) quantifies class-dependent semantic leakage into the null space; Image Score (IS) quantifies tolerance to class- independent (non–class-dependent) semantic variation within the in variant subspace. Desirably , AS is low and IS is high (relati ve to AS). In our results, DinoV iT performs best in this regard. (b) W e summarize the trade-off with the IS / AS ratio (higher is better), DinoV iT has the highest ratio and ResNext101 the lowest. with weakly supervised pretraining [ 37 ], EfficientNetB4 trained with Noisy Student [ 52 ], and BiTResNetv2 [ 29 ]. For statistical analyses, we collect 10k feature vectors per model from all 1,000 ImageNet classes. For each model, we then train a dedicated translator in the same 1,000-class set- ting. W e also empirically confirm that null-space remov al leav es logits nearly unchanged, whereas equal-norm pertur- bations in other directions induce substantial logit and CLIP drift (see supplementary material). 4.2. Model comparison W e compare models globally across all tested classes, mea- suring AS and IS after null remov al. Figure 3 displays the joint distributions of AS and IS across fiv e models. Di- noV iT attains the best IS/AS trade-off, consistent with its foundation-scale pretraining on a large, diverse corpus be- yond ImageNet prior to fine-tuning. This trade-off is evi- dent both in the IS/AS ratio bar plot (panel (b)) and in the orientation of the confidence ellipses in panel (a). By con- trast, ResNe xt101 sho ws high AS with substantial variance, which we interpret as class-dependent semantic leakage into its null space. Repeating the comparison with EV A02 [ 17 ] as the tar get multimodal space preserves the same model ordering in the ratio analysis (see supplementary material). T o further validate the translator, we train classifier heads on principal features before and after translation to CLIP space, obtaining a high Pearson correlation of 0.972 across models (see supplementary material). W e also include an extended 12-model sweep as additional coverage across a broader architectural variety . 4.3. Class analysis W e present per class statistics of AS for two of our models, ResNet50 and DinoV iT , and report them class by class; see Figure 4 . For each class, AS is measured after null removal. A complete analysis of the other models can be found in the supplementary materials. DinoV iT exhibits stable behavior with very small AS magnitudes (typically | AS | < 1 ), con- sistent with minimal class-dependent leakage into the null space. By contrast, ResNet50 shows larger and more vari- able AS across classes. This contrast suggests that DinoV iT tends to retain class-relev ant semantics within its in variant subspace, whereas ResNet50 appears to possibly rely also on spurious cues, leaving some class-relev ant information in the null space. Finally , we observe no significant corre- lation between the per-class AS rank orderings of the two models, indicating that the effect is model-dependent rather than driv en by dataset class structure. In Fig. 5 , W e extend the class analysis to an open vocab- ulary of concepts. Focusing on DinoV iT , we examine two classes, “ Arabian Camel” and “Jellyfish”. W e measure two quantities: 1) The angle between the translated feature and the CLIP concept embedding; 2) the Attribute Score (AS), quantifies how much content related to a concept resides in the null space; A small AS for loosely related concept can indicate a spurious correlation. Both classes are analyzed through a set contains of 30 concepts, the extreme weak- est and strongest are presented. “ Arabian Camel” features exhibit little to no AS (short green lines), while Desert at- tains the smallest CLIP angle among the tested concepts. By contrast, “Jellyfish” features have substantially larger AS, indicating that concepts are tightly coupled to in vari- ances related to this class in the classifier head. The results on the full set of open-vocab ulary concepts and intuition for the scale of AS v alues is provided in the supplementary ma- terials. 4.4. Gradient direction analysis In the pre vious e xperiments, we restricted our analysis to equiv alent pairs obtained by removing the null component. Howe ver , our method supports any null-space direction, in- (a) ResNet50 (b) DinoV iT Figure 4. Class Comparison. DinoV iT consistently preserves low semantic leakage across classes, whereas ResNet50 exhibits a pronounced imbalance, with certain classes, such as Porcupine and Sports-Car, leaking substantially more semantic information into the null space. cluding text-conditioned perturbations. In Figure 6 , we il- lustrate concept-directed perturbations confined to the null space of the ResNet50 classifier head. For each original im- age (left), we follo w the CLIP similarity gradient to ward a target prompt, project it onto the null space, and take a step in this direction to obtain an equiv alent feature. By construction, the perturbed feature leav es the head logits unchanged. The synthesized renderings, generated with UnCLIP [ 45 ] for visualization, reveal pronounced seman- tic shifts tow ard Arabian Camel , Starfish , Pirate , Jellyfish , and Jeep . This demonstrates the diagnostic value of null- space steering and highlights a security risk: semantics can be manipulated at a single layer while the classifier’ s deci- sion remains unaffected. T able 1 summarizes null-space steps (calibrated to IS = 40 ◦ ) from Sports Car tow ard the prompt “ an image of a jellyfish ”. In this setting, DinoV iT exhibits low AS, (a) ‘ Arabian Camel‘ class (b) ‘Jellyfish‘ class Figure 5. Open-vocabulary concept analysis. For DinoV iT , we sample ∼ 1300 images per class and compute the CLIP angle (de- grees; lower is more similar) to a set of concepts for (a) “ Arabian Camel” class and (b) “Jellyfish” class. Blue dots denote origi- nal features; red dots denote null-removed (equiv alent) features. Green arrows connect each pair and represent the Attribute Score after null removal. Longer arrows indicate larger | AS | (greater class-dependent semantic leakage); shorter arrows indicate mini- mal leakage. indicating resilience to directed null manipulation. By con- trast, EfficientNet and ResNet50 show large AS, suggest- ing that their null components are easier to steer and that directed in variant perturbations can alter semantics while leaving the logits unchanged. 5. Discussion and Conclusion W e introduced SING, a nov el approach for analyzing inv ari- ances in classification networks. Our method systematically generates equiv alent images whose logits are, by construc- Figure 6. Null-space semantic steering (ResNet50). From each original image (left), we add a small perturbation aligned with the indicated prompt (column headers) but constrained to the classifier head’ s null space (projected-gradient direction). Although only the in variant component is modified, the feature’ s semantics shift toward the target concepts, illustrating ho w null-space directions can alter meaning without changing the discriminativ e subspace. T able 1. T ext-gradient null perturbations. For a f air comparison, each model is perturbed by a fixed null-space step calibrated to IS = 40 ◦ . W e report | AS | toward the tar get prompt (mean ± standard de viation; lo wer is better). DinoV iT attains the lowest value (marked in bold), indicating the greatest resistance to directed null-space manipulation, whereas ResNext101 remains comparati vely susceptible. ResNet50 EfficientNet BiT resnet DinoV iT ResNext101 | AS | to wards target 12.04 ± 0.25 12.38 ± 0.52 9.19 ± 0.31 5.0 ± 0.59 11.15 ± 0.53 tion, identical to those of the original image. W e demon- strated a wide range of possible analyses: at the model lev el, SING facilitates f air sensiti vity comparisons across archi- tectures; at the class level, it highlights classes that are less robust to semantic shifts; and at the image lev el, it aids in debugging failure cases. SING transforms the null space into measurable and human-readable evidence by construct- ing equiv alent pairs, projecting features into a joint vision- language space, and perturbing only the in variant compo- nent. In doing so, it reveals how semantics can drift while logits remain fixed, providing a compact diagnostic that complements accuracy at the levels of models, classes, and individual images. Looking ahead, two research directions may help control the null space more directly: (i) Directed augmentation during fine-tuning, encouraging small AS for essential concepts; (ii) Linear-algebraic control, using pro- jector regularization, rank adjustment, or constrained up- dates to move useful semantics from the null space to the principal space while preserving logits. SING exposes in- variant geometry in a simple, interpretable form, clarifying how semantics can shift while logits remain fix ed. Acknowledgments W e would like to acknowledge support by the Israel Science Foundation (Grant 1472/23) and by the Ministry of Innov ation, Science and T echnology (Grant 8801/25). References [1] Alessio Ansuini, Alessandro Laio, Jak ob H. Macke, and Da- vide Zoccolan. Intrinsic dimension of data representations in deep neural networks, 2019. 1 [2] Daniel Anthes, Sushrut Thorat, Peter König, and T im C Kiet- zmann. K eep moving: identifying task-rele vant subspaces to maximise plasticity for newly learned tasks. arXiv pr eprint arXiv:2310.04741 , 2023. 2 [3] Mathieu Aubry and Bryan C Russell. Understanding deep features with computer-generated imagery . In Pr oceedings of the IEEE international confer ence on computer vision , pages 2875–2883, 2015. 2 [4] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hin- ton. Layer normalization. arXiv pr eprint arXiv:1607.06450 , 2016. 2 [5] Roy Betser, Eyal Gofer, Meir Y ossef Levi, and Guy Gilboa. Infonce induces gaussian distribution. In The F ourteenth In- ternational Confer ence on Learning Representations . 3 [6] Roy Betser, Meir Y ossef Levi, and Guy Gilboa. Whitened clip as a likelihood surrogate of images and captions. In Pr o- ceedings of the 42nd International Conference on Machine Learning , V ancouver , Canada, 2025. PMLR. 3 [7] Roy Betser , Omer Hofman, Roman V ainshtein, and Guy Gilboa. General and domain-specific zero-shot detection of generated images via conditional likelihood. In Pr oceed- ings of the IEEE/CVF W inter Conference on Applications of Computer V ision , pages 7809–7820, 2026. 3 [8] Lukas Biewald. Experiment tracking with weights and bi- ases, 2020. Software a vailable from https : / / www . wandb.com/ . 2 [9] Mathilde Caron, Hugo T ouvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emer g- ing properties in self-supervised vision transformers. In Pr o- ceedings of the IEEE/CVF international confer ence on com- puter vision , pages 9650–9660, 2021. 5 , 6 , 7 [10] Xuanbai Chen, Xiang Xu, Zhihua Li, T ianchen Zhao, Pietro Perona, Qin Zhang, and Y ifan Xing. Model diagnosis and correction via linguistic and implicit attribute editing. In Pr oceedings of the Computer V ision and P attern Reco gnition Confer ence , pages 14281–14292, 2025. 3 [11] Matthew Cook, Alina Zare, and Paul Gader . Outlier detec- tion through null space analysis of neural networks. arXiv pr eprint arXiv:2007.01263 , 2020. 2 [12] Jia Deng, W ei Dong, Richard Socher , Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE confer ence on computer vision and pattern r ecognition , pages 248–255. Ieee, 2009. 5 [13] Lee Donghoon, Kim Jiseob, Choi Jisu, Kim Jongmin, Byeon Minwoo, Baek W oonhyuk, and Kim Saehoon. Karlo- v1.0.alpha on coyo-100m and cc15m. https://github. com/kakaobrain/karlo , 2022. 4 [14] Finale Doshi-V elez and Been Kim. T o wards a rigorous sci- ence of interpretable machine learning, 2017. 1 [15] Maximilian Dreyer , Jim Berend, T obias Labarta, Johanna V ielhaben, Thomas W iegand, Sebastian Lapuschkin, and W ojciech Samek. Mechanistic understanding and validation of large ai models with semanticlens. Natur e Machine Intel- ligence , pages 1–14, 2025. 2 [16] Y uxin Fang, Quan Sun, Xinggang W ang, T iejun Huang, Xin- long W ang, and Y ue Cao. EV A-02: A visual representation for neon genesis. arXiv preprint , 2023. 6 [17] Y uxin Fang et.al. Eva-02: A visual representation for neon genesis. Image and V ision Computing , 149:105171, 2024. 6 [18] Gene H. Golub and Christian Reinsch. Singular value de- composition and least squares solutions. Numerische Math- ematik , 14:403–420, 1970. 2 [19] René Haas, Inbar Huberman-Spiegelglas, Rotem Mulayoff, Stella Graßhof, Sami S Brandt, and T omer Michaeli. Dis- cov ering interpretable directions in the semantic lat ent space of diffusion models. In 2024 IEEE 18th International Con- fer ence on Automatic F ace and Gesture Recognition (FG) , pages 1–9. IEEE, 2024. 2 [20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceed- ings of the IEEE confer ence on computer vision and pattern r ecognition , pages 770–778, 2016. 5 , 6 [21] Dan Hendrycks and Ke vin Gimpel. Gaussian error linear units (gelus). arXiv preprint , 2016. 2 [22] Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Y ejin Choi. Clipscore: A reference-free ev aluation met- ric for image captioning. arXiv pr eprint arXiv:2104.08718 , 2021. 4 [23] Gao Huang, Zhuang Liu, Laurens V an Der Maaten, and Kil- ian Q W einberger . Densely connected con volutional net- works. In Proceedings of the IEEE conference on computer vision and pattern r ecognition , pages 4700–4708, 2017. 6 [24] Qihan Huang, Jie Song, Mengqi Xue, Haofei Zhang, Bingde Hu, Huiqiong W ang, Hao Jiang, Xingen W ang, and Mingli Song. Lg-ca v: Train any concept activ ation vector with lan- guage guidance. Advances in Neural Information Pr ocessing Systems , 37:39522–39551, 2024. 2 , 3 [25] Erik Härkönen, Aaron Hertzmann, Jaakko Lehtinen, Sylv ain Paris, and Michaël Gharbi. Ganspace: Disco vering inter- pretable gan controls. In Advances in Neural Information Pr ocessing Systems , 2020. 2 [26] Daksh Idnani, V i vek Madan, Naman Go yal, David J Schwab, and Shanmukha Ramakrishna V edantam. Don’t forget the nullspace! nullspace occupancy as a mechanism for out of distribution failure. In The Eleventh International Confer- ence on Learning Repr esentations , 2023. 3 [27] Max Jaderberg, Andrea V edaldi, and Andrew Zisserman. Speeding up con volutional neural networks with low rank expansions. In British Machine V ision Conference (BMVC) , pages 3.1–3.12, 2014. 2 [28] Siwon Kim, Jinoh Oh, Sungjin Lee, Seunghak Y u, Jaeyoung Do, and T ara T agha vi. Grounding counterfactual e xplanation of image classifiers to te xtual concept space. In Proceedings of the IEEE/CVF Conference on Computer V ision and P at- tern Recognition , pages 10942–10950, 2023. 2 , 3 [29] Alexander K olesnikov , Lucas Beyer , Xiaohua Zhai, Joan Puigcerver , Jessica Y ung, Sylvain Gelly , and Neil Houlsby . Big transfer (bit): General visual representation learning. In Eur opean conference on computer vision , pages 491–507. Springer , 2020. 6 , 7 [30] Zorah Lähner and Michael Moeller . On the direct alignment of latent spaces. In Pr oceedings of UniReps: the F irst W ork- shop on Unifying Repr esentations in Neural Models , pages 158–169. PMLR, 2024. 4 [31] Meir Y ossef Levi and Guy Gilboa. The double ellipsoid ge- ometry of clip. In Pr oceedings of the 42nd International Confer ence on Machine Learning , V ancouv er, Canada, 2025. PMLR. 3 [32] Xiaolong Li and Katherine Short. Null space properties of neural networks with applications to image steganography . arXiv pr eprint arXiv:2401.12345 , 2024. 2 [33] V ictor W eixin Liang, Y uhui Zhang, Y ongchan Kwon, Ser- ena Y eung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Pr ocessing Sys- tems , 35:17612–17625, 2022. 3 [34] Ze Liu, Y utong Lin, Y ue Cao, Han Hu, Y ixuan W ei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Pr oceedings of the IEEE/CVF International Conference on Computer V ision (ICCV) , pages 9992–10002, 2021. 6 [35] Zhuang Liu, Hanzi Mao, Chao-Y uan Wu, Christoph Feicht- enhofer , T rev or Darrell, and Saining Xie. A Con vNet for the 2020s. In Proceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2022. 6 [36] Ilya Loshchilo v and Frank Hutter. Decoupled weight de- cay regularization. In International Conference on Learning Repr esentations , 2019. 2 [37] Dhruv Mahajan, Ross Girshick, V ignesh Ramanathan, Kaiming He, Manohar Paluri, Y ixuan Li, Ashwin Bharambe, and Laurens V an Der Maaten. Exploring the limits of weakly supervised pretraining. In Pr oceedings of the Eur opean con- fer ence on computer vision (ECCV) , pages 181–196, 2018. 6 , 7 [38] Mazda Moayeri, Kei van Rezaei, Maziar Sanjabi, and So- heil Feizi. T ext2concept: Concept activ ation vectors directly from text. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pages 3744– 3749, 2023. 2 , 3 , 4 [39] T uomas Oikarinen and Tsui-W ei W eng. Clip-dissect: Au- tomatic description of neuron representations in deep vision networks. arXiv pr eprint arXiv:2204.10965 , 2022. 3 [40] Maxime Oquab, T imothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, V asil Khalidov , Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby , Mah- moud Assran, Nicolas Ballas, W ojciech Galuba, Russell Howes, Po-Y ao Huang, Shang-W en Li, Ishan Misra, Michael Rabbat, V asu Sharma, Gabriel Synnaev e, Hu Xu, Hervé Jé- gou, Julien Mairal, Patrick Labatut, Armand Joulin, and Pi- otr Bojanowski. DINOv2: Learning robust visual features without supervision. T ransactions on Mac hine Learning Re- sear ch (TMLR) , 2024. 6 [41] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Y ang, Zachary DeV ito, Zeming Lin, Al- ban Desmaison, Luca Antiga, Adam Lerer , James Massa, T ete Liskovich, W ojciech Chmiel, Roman Serdyuk, Mengjia Y ang, Marcin K opacz, Piotr Sal Pietrek, Franz Zesch, Jonas Schick, Jeff Dearing, Alban Bhargav a, Kai Wu, W ojciech Zaremba, Da vid Killeen, Jie Sun, Y ang Liu, Y e W ang, Peizhao Ma, Rong Huang, V aibhav Pratap, Y ing Zhang, Ab- hishek Kumar , Ching-Y i Y u, Cong Zhu, Chang Liu, Jeremy Kahn, Mirco Ravanelli, Peng Sun, Shinji W atanabe, Y ang Shi, T ao T ao, Raphael Scheibler , Stephen Cornell, Sanghyun Kim, and Stavros Petridis. Pytorch: An imperative style, high-performance deep learning library . Advances in Neural Information Pr ocessing Systems , 32:8024–8035, 2019. 2 [42] F . Pedre gosa, G. V aroquaux, A. Gramfort, et al. Scikit-learn: Machine learning in Python. Journal of Machine Learning Resear ch , 12:2825–2830, 2011. 2 [43] Marek Praggastis, Daniel Hampson, and K e vin Lee. The svd of con volutional weights: A cnn interpretability framework. T ech. Report, ResearchGate, 2022. 2 [44] Alec Radford, Jong W ook Kim, Chris Hallac y , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, P amela Mishkin, and Jack Clark. Learn- ing transferable visual models from natural language super- vision. arXiv preprint , 2021. 2 , 3 , 4 [45] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Case y Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents. arXiv preprint , 1 (2):3, 2022. 7 , 4 [46] Shauli Ravfogel, Y air Elazar , and Jacob Goldberger . Null it out: Guarding protected attributes by iterativ e nullspace projection. In Pr oceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 1688– 1703, 2020. 2 [47] Hossein Rezaei and Mohammad Sabokrou. Quantifying ov erfitting: Evaluating neural network performance through analysis of null space. arXiv preprint , 2023. 2 , 3 [48] Karen Simonyan and Andrew Zisserman. V ery deep con- volutional networks for lar ge-scale image recognition. In In- ternational Confer ence on Learning Representations (ICLR) , 2015. 6 [49] Nitish Sri vasta va, Geof frey Hinton, Alex Krizhevsky , Ilya Sutske ver , and Ruslan Salakhutdinov . Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Resear ch , 15(1):1929–1958, 2014. 2 [50] Shengbang T ong, Erik Jones, and Jacob Steinhardt. Mass- producing failures of multimodal systems with language models. Advances in neural information processing systems , 36:29292–29322, 2023. 3 [51] Hugo T ouvron, Matthieu Cord, and Hervé Jégou. DeiT III: Rev enge of the V iT. In Computer V ision – ECCV 2022 , pages 516–533. Springer , Cham, 2022. 6 [52] Qizhe Xie, Minh-Thang Luong, Eduard Hovy , and Quoc V Le. Self-training with noisy student impro ves imagenet classification. In Proceedings of the IEEE/CVF confer ence on computer vision and pattern recognition , pages 10687– 10698, 2020. 6 , 7 [53] Y uhui Zhang, Jef f Z HaoChen, Shih-Cheng Huang, Kuan- Chieh W ang, James Zou, and Serena Y eung. Diagnosing and rectifying vision models using language. arXiv pr eprint arXiv:2302.04269 , 2023. 3 Make it SING: Analyzing Semantic In variants in Classifiers Supplementary Material Contents 1. Setup and repr oducibility 2 1.1 . T ranslator training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2. Null space validation 3 3. Image-level and visualization details 4 3.1 . Angle visual interpretation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3.2 . V isualization with UnCLIP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 4. Model-level r esult extensions 5 5. Class-level analyses 6 6. DinoV iT feature wrapper 7 1. Setup and repr oducibility 1.1. T ranslator training As described in the paper , each translator trained on a specific classifier and its task is to map features from the penultimate layer f ∈ R d to a CLIP image feature e ∈ R d e . Nonlinear translators were trained directly in PyT orch [ 41 ], while linear translators were fitted by ridge regression using scikit-learn [ 42 ] and then ported to PyT orch for unified inference. The hyperparameters were chosen using sweeps logged in W eights & Biases [ 8 ]. W e compared three training objectiv es: 1. Mean squared error (MSE) loss: L MSE ( f , e ) = ∥ T θ ( f ) − e ∥ 2 2 . (14) 2. Cosine similarity loss: L cos ( f , e ) = 1 − T θ ( f ) · e ∥ T θ ( f ) ∥ 2 ∥ e ∥ 2 . (15) 3. MSE + Cosine loss For all three cases, we applied L 2 regularization. In practice, minimizing L MSE alone proved sufficient to achieve high co- sine similarity , whereas optimizing L cos alone does not reliably reduce MSE, suggesting an asymmetric relationship between the two objecti ves. This trend is illustrated in Figure 7 . (a) Cosine-only loss L cos . (b) MSE-only loss L MSE . (c) Joint loss L joint . Figure 7. T raining losses for the different translator objectiv es. Minimizing the MSE loss also improv es cosine similarity , whereas cosine- only training leav es the MSE substantially higher . Our baseline translator is a linear map chosen for stability . T o compare linear and non-linear translators, we ev aluate three additional. As for Nonlinear architectures, we tried the following combinations: 1. A 3-layer MLP with blocks of the form LayerNorm–GELU–Dropout-FC [ 4 , 21 , 49 ] 2. A 4-layer MLP with the same block. 3. A residual MLP with one residual blocks and one projection layer . All nonlinear translators were optimized with AdamW [ 36 ]. with learning rate 1 × 10 − 4 and weight decay λ = 0 . 1 . W e report validation results over a 2,000-image subset in T able 2 and Figure 8 showing no significant advantage of any non-linear variant o ver the linear translator . T able 2. V alidation results for different translator architectures on a 2 000-image validation subset from 16 classes. None of the non-linear architectures shows a significant adv antage ov er the linear translator . Architecture Mean cosine similarity V alidation MSE 3-layer MLP 0.9049 0.082246 Residual MLP 0.9045 0.082366 4-layer MLP 0.9023 0.084346 Linear 0.8946 0.091355 Figure 8. Cosine similarity distrib ution of different architectures between the translated and the original CLIP features, o ver 2k ImageNet features from 16 classes. All the histograms are leaned to wards high correlation 2. Null space validation Let f denote the penultimate classifier feature and ℓ ( f ) ∈ R C the corresponding vector of logits for C classes. W e define the logit change induced by a perturbation δ as ∆ ℓ ( f , δ ) = ∥ ℓ ( f + δ ) − ℓ ( f ) ∥ 2 . (16) W e compare three types of perturbations with matched ℓ 2 -norm: (i) a null perturbation δ null in the approximate null space of the classifier head, satisfying W δ null ≈ 0 , (17) where W are the head weights; (ii) a random perturbation δ rand sampled from an isotropic Gaussian and rescaled to the same norm; and (iii) a principal perturbation δ principal chosen along a direction that strongly affects the logits (e.g. a leading sensitiv e direction for the predicted class) rescaled as well to the null perturbation magnitude. For each type we compute the logit change in L2-norm ov er a validation set and summarize the distrib ution in Figure 9 . As expected, null-space perturbations produce negligible logit changes, while random and principal perturbations have a noticeable shifts. In Figure 13 we illustrate the corresponding UnCLIP generations for a single feature under these three perturbations and multiple seeds. (a) Logit change under null vs. random perturbations. (b) Logit change under principal vs. random perturbations. Figure 9. Distribution of logit changes ∆ ℓ ( f , δ ) for null-space, random, and principal perturbations. Null-space perturbations leave logits almost unchanged, whereas principal perturbations induce large logit shifts. Image AS ( ◦ ) IS ( ◦ ) I 0 0.00 0.0 I 1 1.58 4.0 I 2 3.80 10.8 I 3 4.70 23.0 I 4 9.48 29.0 I 5 11.29 36.2 Figure 10. Example images with dif ferent attrib ute scores (AS) and image scores (IS), illustrating the relationship between angular distance and perceived semantic change. Small angles correspond to nearly identical images, while larger angles reflect more significant semantic changes. 3. Image-lev el and visualization details 3.1. Angle visual interpr etation For the readers con venience, we provide a visual interpretation of the angles we measured along the paper . For two non-zero vectors u and v we define the angle in degrees θ ( u, v ) = arccos u · v ∥ u ∥ 2 ∥ v ∥ 2 · 180 π . (18) The attribute score (AS) and image score (IS) used in the main paper are instances of θ ( · , · ) applied in CLIP image-embedding space. Figure 10 provides a concrete mapping between AS/IS v alues and visual changes for a single example. Angles below roughly 3 ◦ in AS and 10 ◦ in IS correspond to barely perceptible changes, while larger angles produce clear semantic differences such as pose or shape v ariations. 3.2. V isualization with UnCLIP UnCLIP is a two-stage image generator: a prior maps text to a CLIP image embedding, and a diffusion-based decoder with super-resolution modules synthesizes the corresponding image [ 45 ]. CLIP encoders normalize image and te xt embeddings to unit length and compare them using cosine similarity , so semantic information is primarily encoded in the angular component on the unit hypersphere [ 44 ]. W e use trained translators T Θ to map classifier features f and their perturbed variants ˜ f into the CLIP image-embedding space. Giv en a feature and its equi valent feature set translated to CLIP , T Θ ( f ) and T Θ ( ˜ f ) , we rescale the translated equiv alent feature to match the norm of the original: ˆ T Θ ( ˜ f ) = T Θ ( ˜ f ) ∥ T Θ ( f ) ∥ 2 T Θ ( ˜ f ) 2 . (19) This preserv es the angular relationships while restoring the radial component, pre venting distortions in the visualizations due to radial drift. T o ensure that observed visual differences are solely attributable to changes in the classifier feature f , we remov e the stochasticity in the diffusion sampling process. W e fix the random seed, draw a single Gaussian noise tensor with randn_tensor , scale it by the scheduler’ s init_noise_sigma , and reuse this tensor for all images in the batch and for both the decoder and super-resolution stages. For a fixed CLIP image embedding, this procedure yields deterministic outputs. Our implementation uses the Karlo-v1.0.alpha UnCLIP model [ 13 ], which follo ws the original OpenAI frame- work [ 45 ]. The system includes frozen CLIP text and image encoders, a projection layer into the decoder space, a UNet2DConditionModel decoder, two UNet2DModel super-resolution networks, and UnCLIPScheduler instances for both stages. A generation example of the same feature translated by different translators is sho wn in Figure 11 . Figure 11. UnCLIP generations from a single classifier feature translated by different translator architectures. Despite small quantitativ e differences in cosine similarity , the resulting visualizations are qualitati vely consistent. (a) 5-model ratio comparison in EV A02 space. (b) Extended ratio comparison over 12 models. (c) T ranslator robustness on principal features (Pearson 0.972). Figure 12. Additional model-le vel validations used in the camera-ready update. 4. Model-lev el result extensions W e include three additional checks requested during rebuttal integration. First, we repeat the 5-model ratio comparison with EV A02 as the target multimodal space. Second, we expand the ratio comparison from 5 models to 13 models pretrained on ImageNet [ 12 ] to increase architectural variety . the list of all models can be found in 3 . Third, we ev aluate translator robustness by training classifier heads on 500k principal features before and after translation to CLIP space, and computing the model-wise Pearson correlation of classification accuracy . 12 . The resulting Pearson score is 0.972, indicating strong consistency between the original-principal and translated-principal feature spaces. T able 3. List of models from CNNs to V iTs that we used as our test subjects. Model ImageNet T op-1 Acc (%) VGG-16 [ 48 ] 71.6 VGG-19 [ 48 ] 72.4 DenseNet-121 [ 23 ] 74.4 ResNet50 [ 20 ] 76.1 DinoV iT [ 9 ] 84.0 EfficientNet-B0 (NS) [ 52 ] 78.7 BiT -ResNet (M-R50x1) [ 29 ] 80.4 ResNeXt-101 32x8d (WSL) [ 37 ] 82.6 Con vNeXt-Base [ 35 ] 85.8 Swin-L [ 34 ] 86.3 DINOv2-L [ 40 ] 86.5 DeiT -3-L/16 [ 51 ] 87.7 EV A-02-L [ 16 ] 89.9 5. Class-lev el analyses W e provide violin plots for all models that participated in our experiments (Figures 14a to 14c ). Each violin summarizes the distribution of semantic angle changes (in degrees) under null-space perturbations for a giv en class. Figures 15 and 16 provide extended open-vocab ulary concept lists used in the class analyses of the “ Arabian Camel” and “Jellyfish” classes in Figure 13. UnCLIP generations of a single feature under three perturbation types (null, random, principal) across four random seeds. Null-space perturbations preserve the global class semantics, while random and principal perturbations produce more noticeable semantic changes. (a) BiT -ResNet [ 29 ]. (b) ResNeXt [ 37 ]. (c) EfficientNet [ 52 ]. Figure 14. Per-class distrib ution of null-space semantic angle changes across three architectures. Each violin corresponds to a single class; narrow distributions around zero indicate classes largely in variant to null-space perturbations. The consistent pattern across architectures with different inducti ve biases confirms the generality of our observ ations. DinoV iT . Nodes correspond to text prompts and the target class, and edge strengths reflect CLIP similarity between image and text embeddings. These plots show that the concepts we highlight in the main paper are representative of broader open- vocab ulary neighborhoods. 6. DinoV iT feature wrapper W e use a wrapper around a pre-trained DinoV iT backbone [ 9 ] to expose the penultimate feature f and the classifier head weights W . W e extract the sequence of tokens from the layer immediately before the classifier head (denoted "encoder.ln" in our implementation), take the class token as f , and apply the original head to obtain logits ℓ ( f ) = W f . c l a s s S e l e c t C l a s s T o k e n ( n n . M o d u l e ) : d e f _ _ i n i t _ _ ( s e l f , f ) : s u p e r ( ) . _ _ i n i t _ _ ( ) s e l f . f , s e l f . B = f , 1 d e f f o r w a r d ( s e l f , x ) : # x : ( B * n u m _ t o k e n s , f ) ; r e s h a p e a n d s e l e c t c l a s s t o k e n ( i n d e x 0 ) r e t u r n x . r e s h a p e ( s e l f . B , − 1 , s e l f . f ) [ : , 0 , : ] d e f s e t _ B ( s e l f , B = 1 ) : s e l f . B = B c l a s s D i n o H o o k a b l e ( n n . M o d u l e ) : d e f _ _ i n i t _ _ ( s e l f , b a s e : n n . M o d u l e , e x t r a c t o r , f e a t u r e _ d i m = 1 0 2 4 ) : s u p e r ( ) . _ _ i n i t _ _ ( ) s e l f . e x t r a c t o r = e x t r a c t o r s e l f . f c = b a s e . h e a d s . h e a d # c l a s s i f i e r h e a d ; w e i g h t s a r e W ^ T s e l f . p e n u l t i m a t e = S e l e c t C l a s s T o k e n ( f = f e a t u r e _ d i m ) d e f f o r w a r d ( s e l f , x : t o r c h . T e n s o r ) − > t o r c h . T e n s o r : s e l f . p e n u l t i m a t e . s e t _ B ( x . s i z e ( 0 ) ) # t o k e n s e q u e n c e b e f o r e t h e c l a s s i f i e r h e a d x = s e l f . e x t r a c t o r . e x t r a c t ( x , " e n c o d e r . l n " ) # p e n u l t i m a t e f e a t u r e f ( c l a s s t o k e n ) x = s e l f . p e n u l t i m a t e ( x ) # l o g i t s ; p e n u l t i m a t e f e a t u r e f i s a v a i l a b l e f o r a n a l y s i s r e t u r n s e l f . f c ( x ) This wrapper allows us to reuse the original DinoV iT classifier while directly accessing the feature space in which we construct translators and null-space perturbations. Figure 15. Open-vocab ulary analysis for the “ Arabian Camel” class in DinoV iT . W e show a lar ger set of prompts and their CLIP similarities to the class, illustrating the semantic neighborhood used in our analysis. Figure 16. Open-vocab ulary analysis for the “Jellyfish” class in DinoV iT . The graph highlights related concepts and their CLIP similarities, showing that the concepts discussed in the main paper are part of a consistent semantic cluster .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment