APEX-Searcher: Augmenting LLMs' Search Capabilities through Agentic Planning and Execution
Retrieval-augmented generation (RAG), based on large language models (LLMs), serves as a vital approach to retrieving and leveraging external knowledge in various domain applications. When confronted with complex multi-hop questions, single-round ret…
Authors: Kun Chen, Qingchao Kong, Zhao Feifei
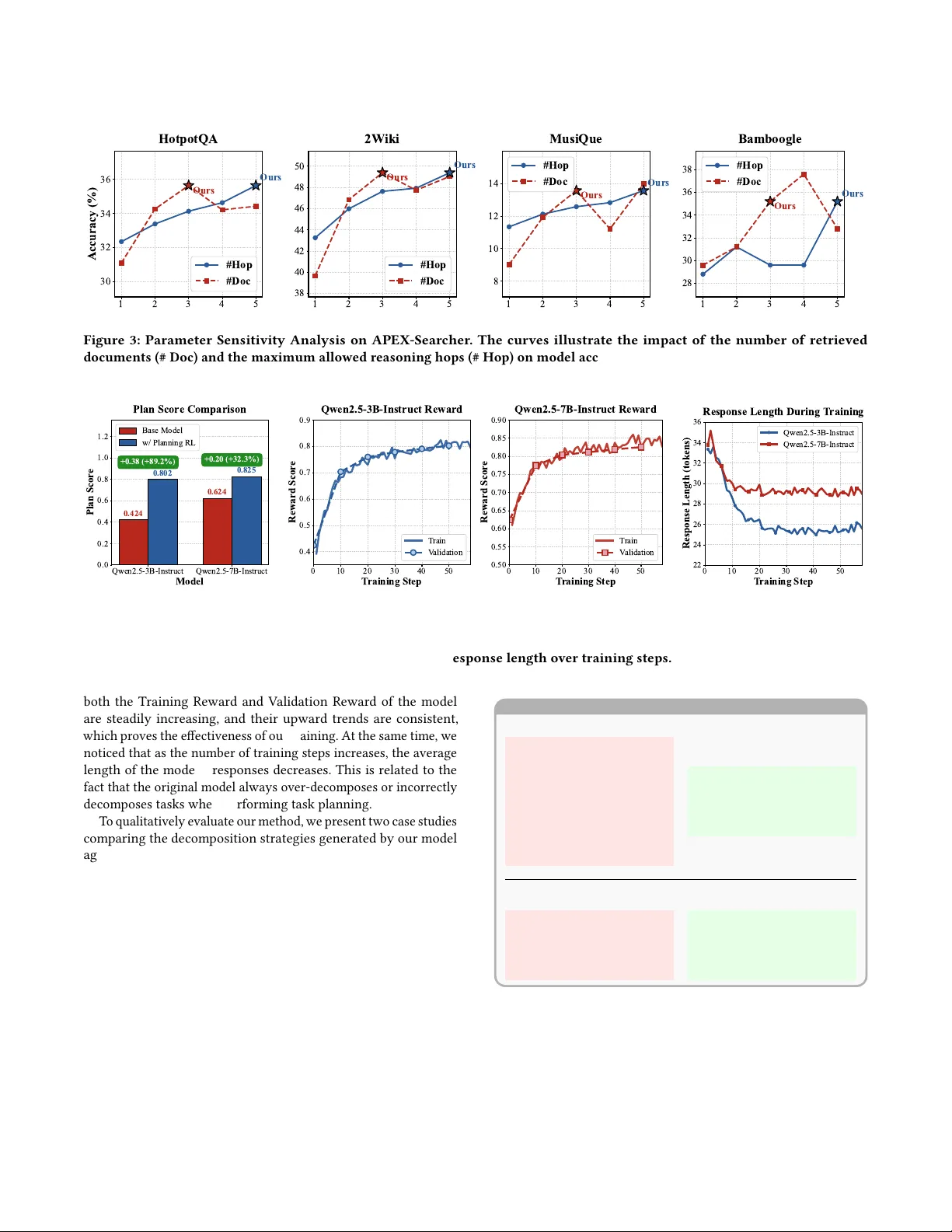
APEX -Searcher: A ugmenting LLMs’ Search Capabilities through Agentic Planning and Exe cution Kun Chen University of Chinese Academy of Sciences Institute of A utomation, Chinese Academy of Sciences Beijing, China chenkun2024@ia.ac.cn Qingchao Kong ∗ Institute of A utomation, Chinese Academy of Sciences Beijing, China qingchao.kong@ia.ac.cn Feifei zhao W enge T echnology Co., Ltd Beijing, China feifei.zhao@wenge.com W enji Mao Institute of A utomation, Chinese Academy of Sciences Beijing, China wenji.mao@ia.ac.cn Abstract Retrieval-augmented generation (RA G), based on large language models (LLMs), serves as a vital approach to r etrieving and lever- aging external knowledge in various domain applications. When confronted with complex multi-hop questions, single-round re- trieval is often insucient for accurate reasoning and problem solving. T o enhance search capabilities for complex tasks, most existing works integrate multi-round iterative retrieval with rea- soning processes via end-to-end training. While these approaches signicantly improve pr oblem-solving performance, they are still faced with challenges in task reasoning and model training, espe- cially ambiguous retrieval e xecution paths and sparse rewards in end-to-end reinforcement learning (RL) process, leading to inaccu- rate r etrieval results and p erformance degradation. T o address these issues, in this paper , we proposes APEX -Searcher , a novel Agentic Planning and Execution framework to augment LLM search capa- bilities. Specically , we introduce a tw o-stage agentic framework that decouples the retrieval process into planning and execution: It rst employs RL with decomposition-specic rewards to optimize strategic planning; Built on the sub-task decomp osition, it then applies supervise d ne-tuning on high-quality multi-hop trajecto- ries to equip the model with robust iterative sub-task execution capabilities. Extensive experiments demonstrate that our propose d framework achiev es signicant improvements in both multi-hop RA G and task planning p erformances across multiple benchmarks. CCS Concepts • Information systems → Information retrieval . ∗ Corresponding author . Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commer cial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honor ed. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specic p ermission and /or a fee. Request p ermissions from permissions@acm.org. Conference acronym ’XX, W oodstock, NY © 2018 Copyright held by the owner/author(s). Publication rights licensed to ACM. ACM ISBN 978-1-4503-XXXX -X/2018/06 https://doi.org/XXXXXXX.XXXXXXX Ke y words LLM Search, Retrieval- A ugmented Generation, T ask Planning, Multi-hop Reasoning, A CM Reference Format: Kun Chen, Qingchao Kong, Feifei zhao, and W enji Mao. 2018. APEX-Searcher: A ugmenting LLMs’ Search Capabilities through Agentic Planning and Exe- cution. In Proceedings of Make sure to enter the correct conference title from your rights conrmation email (Conference acronym ’XX) . A CM, New Y ork, NY, USA, 11 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Large Language Models (LLMs) have shown remarkable ability to process, generate, and comprehend human language acr oss a vast spectrum of applications [ 52 ]. They are trained on massive text corpora and have demonstrated emergent capabilities in reason- ing, summarization, and few-shot learning, fundamentally altering the landscape of natural language processing [ 23 ]. Howev er , The knowledge possessed by the model is related to the model’s pa- rameters during the pre-training phase[ 27 ]. This reliance on static, parametric knowledge introduces two critical vulnerabilities. First, the model’s knowledge is frozen at the time of training, rendering it incapable of accessing information beyond its " cut-o date" and unable to incorporate real-time or rapidly evolving facts [ 13 , 19 ]. Second, when confronted with queries that fall outside their train- ing distribution or require precise, veriable facts, LLMs are prone to generating plausible but factually incorrect information—a phe- nomenon widely termed "hallucination" [3, 9]. Recently , Retrieval- A ugmented Generation (RAG) has emerged as the canonical approach for connecting LLMs to external knowl- edge sources [ 19 ]. The RA G systems typically consist of multiple components, such as query generation, document retrieval and answer extraction. By elegantly combining a pre-trained language model with an information retrieval system, RAG has been proven highly eective in mitigating hallucinations and providing access to up-to-date information (e.g., Wikipedia or a proprietary data- base) for a wide range of knowledge-intensive tasks [ 6 ]. Howev er , the standard RA G is largely conned to the tasks where necessar y information can be located within a single retrie val pass. It reaches a distinct breaking point when faced with complex queries (i.e., Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Trovato et al. multi-hop questions) [ 22 ] that necessitate the synthesis of infor- mation from multiple, often interdependent, pieces of evidence to derive a nal answer [8, 36, 46]. T o address these limitations, iterative RAG [ 20 , 26 , 37 , 47 ] has emerged as the prevailing approach for multi-hop question answer- ing. In this paradigm, the model engages in multiple rounds of retrieval and generation. T ypically , the output from one iteration, such as an intermediate answer or a generated thought, is used to formulate a new query for the subsequent retrieval step , creating a chain of information gathering. Inspired by these w orks, recent studies have explor ed agentic RAG [ 18 , 43 ], which treat retrie val as a callable tool, enabling large models to indep endently decide when to invoke the retrieval tool and dynamically adjust strate- gies. Reinforcement learning (RL) based on LLM is often used as a training method to improve the search capabilities of agentic RA G, aiming to equip LLMs with combine d reasoning and search ability through RL [2, 11, 32, 33, 40, 50, 53]. Although existing iterative RA G and agentic RA G methods can enhance search performances by integrating multi-round iterative retrieval with reasoning pr ocesses, they are faced with substantial challenges. First, existing retrieval processes may generate ambigu- ous execution trajectories, lacking a global view in task reasoning and sub-task structure to guide the retrieval. Consequently , it is liable to cause innite reasoning loops (e.g., repetitive keyword querying) that prevent the system fr om converging to a nal result. Second, the over-reliance on end-to-end training often results in ill-dened optimization objectives due to error accumulation, and sparse rewards further aect learning eciency . As a result, these issues may lead to inaccurate retrieval results and performance degradation of RA G systems. In this paper , we propose APEX -Searcher , a novel frame work that augments LLM search capabilities through A gentic P lanning and EX ecution. T o address the ambiguity associate d with reasoning execution paths, we separate the r etrieval-reasoning process into two phases: planning and execution, which are trained with distinct objectives. Specically , we enhance the model’s agentic planning capabilities using RL with task decomposition-based re wards, as RL processes the eective reasoning skills necessary for accurate task planning and decomp osition. Conversely , we employ super- vised ne-tuning (SFT) to improve iterative sub-task execution capabilities. SFT provides explicit supervision, enabling the model to solve sub-tasks characterized by ’weak reasoning’ but ’strong structural patterns, ’ such as query generation and information ex- traction. Extensive experiments show that our method improves the performances of complex retrieval problem-solving, as w ell as agentic planning and execution. The main contributions of our work are summarized as follows: • W e propose APEX-Searcher , a novel RA G framework consisted of agentic planning and sub-task execution, to reduce ambigui- ties in execution trajectories and impro ve overall performances. • W e introduce a hybrid training strategy that divides the training process into two stages to clarify learning objectives and im- prove learning eciency . Specically , we employ RL with task decomposition rewards to facilitate agentic planning, and SFT on multi-turn retrieval datasets to optimize agentic execution. • Extensive experimental results on multiple challenging multi- hop Q A b enchmarks demonstrate the superior performance of APEX-Sear cher in solving complex multi-hop problems, fur- ther validating the critical importance of planning in retrieval- augmented models. 2 Related W orks 2.1 Standard Retrieval- A ugmented Generation Standard RA G, often referred to as "Naive RA G" in recent literature [ 6 ], emerged as a foundational paradigm to address critical limita- tions of LLMs, such as hallucinations [ 3 , 9 ], outdated knowledge, and knowledge-intensive tasks [ 13 ]. Rooted in the integration of external knowledge bases with LLMs, this framework follows a three-stage pipeline: indexing, retrieval, and generation [ 14 , 19 ]. Early implementations of traditional RAG focused on improving knowledge-intensive tasks such as open-domain question answer- ing [ 49 ]. For instance, [ 19 ] demonstrated that RA G outperforms vanilla LLMs on ODQ A benchmarks (e.g., Natural Questions [ 16 ], TriviaQ A [ 12 ]) by leveraging Wikipedia as an external knowledge source. Similarly , Dense Passage Retrieval [ 14 ] introduced dense retrievers to impr ove retrieval precision, laying the foundation for subsequent RAG advances. Despite its success, traditional RA G faces notable limitations: retrieval often suers from low preci- sion/recall (e .g., retrieving irrelevant or redundant chunks), genera- tion may produce hallucinations inconsistent with retrieved context [6, 31, 48]. 2.2 Iterative Retrieval- A ugmented Generation Iterative Retrieval- A ugmented Generation was proposed to over- come the limitations of traditional RA G’s one-time retrieval, which often fails to provide sucient context for complex, multi-step rea- soning tasks [ 29 ]. Iterative RA G adopts a cyclic pipeline: it repeat- edly retrieves information from external knowledge bases based on the initial query and intermediate generation outputs, enabling the model to accumulate incremental context and rene its under- standing of the task [ 1 , 5 , 17 , 29 , 37 , 45 ]. Key contributions to Itera- tive RA G include frameworks that synergize retrieval and genera- tion to enhance mutual performance. For example, I TER-RETGEN [ 29 ] introduces a "retrieval-enhanced generation" and "generation- enhanced retrie val" loop to ensur e that each new chunk aligns with the evolving task context. IRCo T [ 37 ] is a new multi-step QA ap- proach that uses chains of thought (Co T) to guide the retrieval and takes advantage of the retrieved results to impr ove Co T . Evaluations on benchmarks like HotpotQA [ 46 ] (multi-hop QA ) have shown that Iterative RA G outperforms traditional RAG by capturing nuanced, multi-step dependencies in information. How- ever , challenges persist, including potential semantic discontinuity across iterations and accumulation of irrelevant information, which have spurred research into adaptive stopping criteria (e.g., con- dence thresholds) to balance retrieval depth and eciency [10]. 2.3 Agentic Retrieval- A ugmented Generation Recent surveys dene an agentic RAG as a system that can au- tonomously reason, act, and interact with its environment to achieve a goal [ 25 ]. Unlike passive models that simply respond to prompts, an agentic system can decide when and how to use e xternal tools APEX-Searcher: Augmenting LLMs’ Search Capabilities thr ough Agentic Planning and Execution Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY (like a search engine or a retrie val engine), and adapt its strategy based on fee dback [ 20 , 26 , 37 , 43 , 47 ]. This paradigm shift is mo- tivated by the need to address complex, long-horizon tasks that require more than a single inference pass. For e xample, Search-o1 [ 43 ] framework extends the agentic RA G mechanism by incor- porating a Reason-in-Documents module. Building on this foun- dation, some agentic RA G work has focused on improving the model’s reasoning ability during the search process through RL [ 2 , 11 , 32 , 33 , 40 , 50 , 53 ]. For example, Search-R1 [ 11 ] optimizes LLM reasoning paths through multi-round search interactions and achieves stable RL training with the help of retrie val token mask- ing. Although curr ent agentic RA G has demonstrated strong search capabilities, due to the lack of clear task planning before retrieval, phenomena such as task forgetting and repeated retrie val can occur . 2.4 Planning in Agentic Systems T o enhance the planning ability of agents, a signicant amount of research has utilized explicit or implicit structured kno wledge to guide the planning process during the reasoning stage [ 4 , 7 , 15 , 39 ]. Many works have also focused on making planning ability a learning objective for the agent, enabling it to optimize its decision- making process through sear ch, feedback, or large-scale training [ 24 , 34 , 44 ]. Howev er , few studies have explored the integration of planning in complex multi-round retrieval. While the agentic RA G mentioned in Section 2.3 has achieved remarkable performance, none of them have considered the agent’s planning ability as a crucial aspect for improving retrieval accuracy . In fact, planning is a fundamental stage for an LLM-based agent b efore retrieval execution, and it is an important step in breaking down a complex retrieval problem into primitiv e sub-tasks [42, 51]. 3 Methodology In this section, we present APEX-Sear cher ( A gentic P lanning & EX ecution Searcher ), a novel frame work designed to solve com- plex, multi-hop questions. At its core, our approach decouples rea- soning into two specialized phases as shown in Figure 1: • Agentic Planning: Responsible for decomposing complex queries into strategic sub-goals. • Iterative Sub- T ask Execution: Responsible for interacting with external knowledge bases to retrie ve and synthesize informa- tion. Based on the sub-answers of each subtask, comprehensively provide the answer to the original multi-hop comple x task. Unlike relying on generic prompting, we introduce a hybrid training framework to specialize these phases, employing Group Relative Policy Optimization (GRPO ) [ 30 ] for strategic planning (Section 3.1) and a specialized SFT curriculum to master iterative execution (Section 3.2). Finally , we detail the systematic Inference Pipeline where these trained agents collaborate to solve user queries (Section 3.3). 3.1 RL-based Agentic P lanning The initial phase of our methodology focuses on decomposing a complex, multi-hop question, 𝑄 , into a coherent and solvable exe- cution plan, denoted as 𝑆 = { 𝑠 1 , 𝑠 2 , . . ., 𝑠 𝑛 } . W e frame this decompo- sition task as a sequential decision-making pr oblem and employ RL to train a "Planning Agent. " This agent, implemented as a large lan- guage model, learns an optimal p olicy , 𝜋 𝑝𝑙 𝑎𝑛 for generating logical and ecient reasoning plans. 3.1.1 Policy Optimization with Group Relative Policy Optimization. T o optimize the Planning Agent’s policy , we employ GRPO [ 30 ], an algorithm that obviates the need for an auxiliary value function, a common component in actor-critic methods like Proximal Pol- icy Optimization(PPO) [ 28 ]. Instead, GRPO establishes a dynamic baseline by using the average rewar d of multiple outputs sampled in response to the same prompt. GRPO optimizes the policy by maximizing the following objective function: 𝐽 𝐺 𝑅 𝑃 𝑂 ( 𝜃 ) = E [ 𝑞 ∼ 𝑃 ( 𝑄 ) , { 𝑜 𝑖 } 𝐺 𝑖 = 1 ∼ 𝜋 𝜃 old ( 𝑂 | 𝑞 ) ] 1 𝐺 𝐺 𝑖 = 1 1 | 𝑜 𝑖 | | 𝑜 𝑖 | 𝑡 = 1 min 𝑟 𝑡 ( 𝜃 ) ˆ 𝐴 𝑖 ,𝑡 , clip ( 𝑟 𝑡 ( 𝜃 ) , 1 − 𝜖 , 1 + 𝜖 ) ˆ 𝐴 𝑖 ,𝑡 − 𝛽 𝐷 KL ( 𝜋 𝜃 | | 𝜋 ref ) where 𝑟 𝑡 ( 𝜃 ) = 𝜋 𝜃 ( 𝑜 𝑖 ,𝑡 | 𝑞,𝑜 𝑖 , < 𝑡 ) 𝜋 𝜃 old ( 𝑜 𝑖 ,𝑡 | 𝑞,𝑜 𝑖 , < 𝑡 ) is the probability ratio, ˆ 𝐴 𝑖 ,𝑡 is the advantage calculated based on relative rewards within the sampled group, and 𝛽 is the KL-divergence coecient. 3.1.2 T raining Prompt T emplate. T o guide the Planning Agent in generating well-structured and syntactically correct plans, we uti- lize a specialized training template. The agent is prompted with a set of instructions that dene the expected output format and constraints. The prompt used in the training process is as follows. This structured prompting ensures that the agent’s outputs ar e constrained to a manageable number of steps and explicitly mod- els dependencies between sub-questions through the #n reference mechanism. Prompt for Agentic P lanning RL You are an assistant who is good at decomposing complex problems into simple sub-problems. 1. Please decompose the problem directly into 2-4 sub-problems, with each sub-problem on a new line, separated by ' \n ' . Do not add any serial numbers. 2. Use ' #1 ' , ' #2 ' , etc. to refer to the answers of previous sub-problems, where ' #1 ' represents the answer to the first sub-problem, for example, ' What city is #1 from? ' represents asking which country the answer to the first sub-question comes from. 3. Generally, the answer to the last sub-problem should be the final answer to this complex question. The question you need to break down is: 3.1.3 Reward Function Design. A robust rewar d function s critical tor guiding the RL agent toward generating high-quality plans. The reward, 𝑅 𝑝𝑙 𝑎𝑛 , is a terminal reward granted at the end of a full decomposition episo de. It is calculated by comparing the agent- generated plan, 𝑆 𝑔𝑒𝑛 against a human-annotated, gold-standard decomposition, 𝑆 𝑔𝑜𝑙 𝑑 . The core of our re ward function is an F1-scor e that measures the semantic alignment between the two plans. The calculation involves three key steps: Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Trovato et al. ST AGE I: Agentic Planning Pol ic y LL M Question Embedding S gen = { p 1 , . . . , p n } S gold = { g 1 , . . . , g n } ⊗ C ij = 1 − e g i ⋅ e p j | | e g i | | ⋅ | | e p j | | ST AGE II: Iter ative Sub-T ask Execution Pol ic y LL M Corpus Query Info Rollout Advanced LLM Question Answer Gener ation Optimal Bipartite Mat ching Final Reward Pol ic y LL M Answer RL-Based Primitive Sub-task Dat a for SFT Actor LLM RL Optimization Actor LLM Pol icy L LM SFT -Based System Planning User User User Assistant … User User Assistant … … Sub-answer 1 Sub-answer n w/o loss w / loss Assistant Assistant Path 1 Path n Sub-answer #1 Sub-answer #2 Sub-answer #n Sub-answers Sub-task #2 Sub-task #n Sub-task #1 … … … … R = F 1( S gen , S gold ) Figure 1: O verview of the APEX-Searcher framework. The architecture utilizes RL-driven agentic planning in Stage I to decompose a complex question into a multi-step plan. Subse quently , Stage II employs SFT -guided execution to solve each sub-question using an iterative retrieval loop that features dynamic continuation decisions and context management for nal synthesis. See Figure 2 for an example. Semantic Similarity Calculation. T o account for linguistic variations, we rst measur e the semantic similarity between sub- questions. Each sub-question from 𝑆 𝑔𝑒𝑛 = { 𝑝 1 , . . ., 𝑝 𝑛 } and 𝑆 𝑔𝑜𝑙 𝑑 = { 𝑔 1 , . . ., 𝑔 𝑚 } is encoded into a high-dimensional vector using a sentence- transformer model. , chosen for its established performance on semantic textual similarity tasks to minimize embe dding-based variance. The similarity between a predicted sub-question 𝑝 𝑗 and a ground-truth sub-question 𝑔 𝑖 is then computed using cosine simi- larity: sin ( 𝑔 𝑖 , 𝑝 𝑗 ) = ® 𝑒 𝑔 𝑖 · ® 𝑒 𝑝 𝑗 | | ® 𝑒 𝑔 𝑖 | | · | | ® 𝑒 𝑝 𝑗 | | where ® 𝑒 𝑔 𝑖 and ® 𝑒 𝑝 𝑗 are the vector embeddings of the respective sub- questions. Optimal Bipartite Matching. T o establish the most accurate correspondence between sub- questions in 𝑆 𝑔𝑒𝑛 and 𝑆 𝑔𝑜𝑙 𝑑 , we for- mulate it as an assignment problem. W e construct a cost matrix 𝐶 where each element 𝐶 𝑖 𝑗 = 1 − sin ( 𝑔 𝑖 , 𝑝 𝑗 ) . The Hungarian algorithm is then employed to nd the one-to-one matching that minimizes the total cost, yielding a set of matched pairs, M , where the sim- ilarity of each pair exceeds a predene d threshold 𝜏 = 0 . 8 . This matching strategy ensures the metric is robust to step ordering, while the threshold was empirically tuned to lter low-condence matches without penalizing valid paraphrases. F1-Score as the Final Reward. Base d on the set of matched pairs M , the generated set 𝑆 𝑔𝑒𝑛 , and the gold set 𝑆 𝑔𝑜𝑙 𝑑 , the nal reward signal 𝑅 𝑝𝑙 𝑎𝑛 is computed directly . W e dene the rewar d as the harmonic mean based on the cardinalities of these sets: 𝑅 𝑝𝑙 𝑎𝑛 = 2 · | M | | 𝑆 𝑔𝑒𝑛 | + | 𝑆 𝑔𝑜𝑙 𝑑 | This formulation serves as the reward for the GRPO algorithm, guiding the Planning Agent to learn a policy that produces logically sound, complete, and ecient reasoning plans. 3.2 SFT -based Agentic Execution T o enhance the mo del’s performance in multi-round retrieval, we constructed a batch of multi-round ne-tuning datasets which have undergone accuracy screening consistent with the reasoning of APEX-Sear cher through Self-instruct [ 38 ]. These datasets are fur- ther trained on the Execution Agent via SFT , enabling the model to learn how to accurately solve problems in accordance with this set of reasoning paradigms. The data generation pipeline involved the following steps: Seed T ask Collect: W e sample d and constructed a set of ques- tion instructions from the multi-hop task data training sets 2Wiki- MultiHopQ A [8], HotpotQA [46], and MuSiQue [36]. Instruction Generation: W e asked the advanced model such as Qwen2.5-32B-Instruct [ 35 ] and Deepse ek-v3 [ 21 ] to generate instructions in accordance with the aforementioned multi-round reasoning paradigm based on task planning, and generate d a batch of multi-round instruction data as shown in Figure 1. Filtering and V alidation: The generate d data under went a rigorous automated ltering pr ocess to ensure its quality and align- ment with our framework’s logic. W e discar ded instances that were trivial, contained awed reasoning, or produced factually incor- rect answers. This step was crucial for preventing the model from learning erroneous patterns. Through this process, we sampled data from the 2WikiMulti- HopQ A, HotpotQA, and MuSiQue training sets to construct a nal ne-tuning dataset of 14,604 high-quality , multi-turn retrieval in- struction instances. By ne-tuning on this specialized dataset, we eectively teach the Execution Agent to internalize the comple x, iterative logic of the APEX -Searcher framework. This training enables the model to learn not just what information to retrieve, but how to strate- gically explore a knowledge base, manage context acr oss multiple APEX-Searcher: Augmenting LLMs’ Search Capabilities thr ough Agentic Planning and Execution Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Q3: Are #1 and #2 the same? Q2: What is Ed Wood’ s nationality? Q1: What is Scott Derrickson’s nationality? Question: Were Scott Derrickson and Ed W ood of the same nationality? Agentic Planning Sufficiency Evaluation No Knowledge Query Generation Query: “Scott Derrickson biography” Document Retrieval Retrieved: “Scott Derrickson (born July 16, 1966) is an American film director” Knowledge Augmentation Answer : Scott Derrickson is American Sufficiency Evaluation Context : Scott Derrickson is American Query Generation Query: “Nationality of Ed Wood” Document Retrieval Retrieved: “No Related Info” Query Generation Query: “Ed Wood’s background” Document Retrieval Retrieved: “ Ed Wood is a 1994 American Biographical … ” Knowledge Augmentation Answer: Ed Wood is American Decision: Retry Sufficiency Evaluation Context: Scott Derrickson is American; Ed Wood is American Knowledge Augmentation Answer: #1 and #2 are the same Answer Synthesis #1 -> American; #2 -> American #3 -> Y es Final Answer : Ye s Decision: Answer Decision: Answer Decision: Answer Next Iteration T ask decomposition Figure 2: An example of two stage walkthrough of the APEX-Searcher pipeline, demonstrating the planning and execution processes on a sample complex question. turns, and synthesize information to accurately solve problems in accordance with our dened reasoning paradigm. 3.3 The APEX-Sear cher Inference Pipeline Let a complex, multi-hop question be denoted by 𝑄 . Answering 𝑄 requires synthesizing information from a large-scale external knowledge corpus, 𝐶 . The primary objective is to generate a nal answer , 𝐴 𝑓 𝑖 𝑛𝑎𝑙 , that is both correct and faithful to the information contained within 𝐶 . The process to achieve this is modeled as a stateful, sequential task. The core of our approach involv es two foundational stages: (1) Planning: The initial complex question 𝑄 is transformed into an order ed sequence of sub-questions, denoted as 𝑆 = { 𝑠 1 , 𝑠 2 , . . ., 𝑠 𝑛 } , which are the leaf nodes of the sub-task structure. This sequence constitutes a strategic plan, where the answer to a later sub-question 𝑠 𝑗 may be conditionally dependent on the answer of a preceding sub-question 𝑠 𝑖 , where 𝑖 < 𝑗 . This dependency can be represented as 𝑠 𝑗 = 𝑓 ( 𝑠 ′ 𝑗 | 𝑎 𝑖 ) , where 𝑠 ′ 𝑗 is the template for the sub-question and 𝑎 𝑖 is the answer to 𝑠 𝑖 . (2) Sequential Answering: For each sub-question 𝑠 𝑖 ∈ 𝑆 , the system retrieves a set of rele vant documents 𝐷 𝑖 = { 𝑑 1 , 𝑑 2 , . . ., 𝑑 𝑘 } ⊂ 𝐶 to synthesize a sub-answer , 𝑎 𝑖 . The process maintains a dynami- cally updated set of all question-answer pairs, terme d the accumu- lated knowledge base, 𝐾 𝑎𝑐𝑐 = { ( 𝑠 1 , 𝑎 1 ) , ( 𝑠 2 , 𝑎 2 ) , .. ., ( 𝑠 𝑖 , 𝑎 𝑖 ) } , which provides context for subsequent steps. The framework op erates through a systematic, multi-phase pipeline, beginning with planning and proceeding through iterative execu- tion for each sub-question (as illustrated in Figure 2). W e show the pseudo-code of APEX-Searcher pipeline in Algorithm 1. 3.3.1 Phase 1: Agentic Planning . Upon receiving the complex question 𝑄 , the Planning Agent is invoked. It analyzes the quer y’s Algorithm 1 APEX-Sear cher Inference Pipeline Require: Question 𝑄 , Decomposition Model 𝑀 𝑑 , Main Model 𝑀 𝑚 , Max Hops 𝐻 𝑚𝑎𝑥 Ensure: Final Answer 𝐴 𝑓 𝑖 𝑛𝑎𝑙 , Condence Score 𝐶 1: 𝑠𝑢𝑏 𝑡 𝑎𝑠 𝑘 𝑠 − 𝑡 𝑟 𝑒 𝑒 ← estionDecomposition ( 𝑄 , 𝑀 𝑑 ) 2: 𝑘 𝑛𝑜𝑤 𝑙 𝑒 𝑑 𝑔𝑒 ← ∅ 𝑎𝑛𝑠𝑤 𝑒 𝑟 𝑠 ← [ ] 3: for 𝑖 = 1 to | 𝑠 𝑢𝑏 𝑡 𝑎𝑠𝑘 𝑠𝑇 𝑟 𝑒 𝑒 .𝑙 𝑒 𝑎 𝑓 𝑠 | do 4: 𝑠𝑢𝑏 𝑡 𝑎𝑠 𝑘 ← Resol veReferences ( 𝑠 𝑢𝑏 𝑡 𝑎𝑠𝑘 𝑠𝑇 𝑟 𝑒 𝑒 .𝑙 𝑒 𝑎 𝑓 𝑠 [ 𝑖 ] , 𝑎𝑛𝑠𝑤 𝑒 𝑟 𝑠 ) 5: ( 𝑎𝑛𝑠𝑤 𝑒 𝑟 𝑖 , 𝑐 𝑜 𝑛𝑡 𝑒 𝑥 𝑡 𝑖 ) ← ProcessSubqestion ( 𝑠 𝑢𝑏 𝑡 𝑎𝑠 𝑘 , 𝑘 𝑛𝑜𝑤 𝑙 𝑒𝑑 𝑔𝑒 , 𝑀 𝑚 , 𝐻 𝑚𝑎𝑥 ) 6: 𝑎𝑛𝑠𝑤 𝑒 𝑟 𝑠 . append ( 𝑎𝑛𝑠𝑤 𝑒 𝑟 𝑖 ) 7: 𝑘 𝑛𝑜𝑤 𝑙 𝑒 𝑑 𝑔𝑒 ← 𝑘 𝑛𝑜𝑤 𝑙 𝑒𝑑 𝑔𝑒 ∪ { ( 𝑠𝑢𝑏 𝑡 𝑎𝑠 𝑘 , 𝑎𝑛𝑠 𝑤 𝑒 𝑟 𝑖 ) } 8: end for 9: ( 𝐴 𝑓 𝑖 𝑛𝑎𝑙 , 𝐶 ) ← FinalSynthesis ( 𝑄 , 𝑘 𝑛𝑜 𝑤 𝑙 𝑒 𝑑 𝑔𝑒, 𝑀 𝑚 ) 10: return ( 𝐴 𝑓 𝑖 𝑛𝑎𝑙 , 𝐶 ) complexity , identies implicit dependencies, and decomposes it into a chain of logically sequenced sub-questions, 𝑆 . T o manage depen- dencies, sub-questions can contain placeholders (e .g, #1 , #2 ) that refer to the answers of preceding sub-questions. If the decomposi- tion fails or is unnecessar y for a simple query , the system defaults to treating 𝑄 as a single-step task. 3.3.2 P hase 2: Agentic Execution & Iterative Retrieval . Each sub-question 𝑠 𝑖 ∈ 𝑆 is processed sequentially by the Execution Agent. Before pr ocessing, a Reference Resolution step is performed, where any placeholders in 𝑠 𝑖 are substitute d with the concrete answers from the accumulated knowledge base 𝐾 𝑎𝑐𝑐 . W e show the pseudo-code of sub-questions processing in Algorithm 2. For each resolved sub-question, the following iterativ e process is executed: Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Trovato et al. Algorithm 2 Process Sub-question Require: Sub-question 𝑠 , Accumulated Knowledge 𝐾 , Main Model 𝑀 𝑚 , Max Hops 𝐻 𝑚𝑎𝑥 Ensure: Sub-question Answer 𝑎 , Retrieved Context 𝑐𝑡 𝑥 1: Step 1: Initial Knowledge Check 2: 𝑠𝑢 𝑓 𝑓 𝑖 𝑐 𝑖 𝑒 𝑛𝑡 ← 𝑀 𝑚 . CheckKnowledgeSufficiency ( 𝑠 , 𝐾 ) 3: if 𝑠 𝑢 𝑓 𝑓 𝑖 𝑐 𝑖 𝑒 𝑛𝑡 then 4: 𝑎 ← 𝑀 𝑚 . AnswerFromKnowledge ( 𝑠 , 𝐾 ) 5: return ( 𝑎, ∅) 6: end if 7: Step 2: Multi-Hop Retrieval Lo op 8: 𝑐𝑡 𝑥 ← ∅ 𝑑 𝑜 𝑐 𝑠 𝑠𝑒 𝑒 𝑛 ← ∅ 𝑞𝑢𝑒 𝑟 𝑖 𝑒 𝑠 𝑡 𝑟 𝑖 𝑒𝑑 ← ∅ 9: for ℎ𝑜 𝑝 = 1 to 𝐻 𝑚𝑎𝑥 do 10: A. Continuation Decision (if ℎ𝑜 𝑝 > 1 and ℎ 𝑜 𝑝 < 𝐻 𝑚𝑎𝑥 ) 11: if ¬ 𝑀 𝑚 . ShouldContinueRetriev al ( 𝑠 , 𝑐 𝑡 𝑥 , 𝐾 ) then 12: break 13: end if 14: B. Query Generation 15: 𝑞𝑢𝑒 𝑟 𝑦 ← 𝑀 𝑚 . Genera teery ( 𝑠 , 𝑐 𝑡 𝑥 , 𝑞𝑢𝑒 𝑟 𝑖 𝑒 𝑠 𝑡 𝑟 𝑖 𝑒𝑑 , 𝐾 ) 16: 𝑞𝑢𝑒 𝑟 𝑖 𝑒 𝑠 𝑡 𝑟 𝑖 𝑒𝑑 ← 𝑞𝑢𝑒 𝑟 𝑖 𝑒 𝑠 𝑡 𝑟 𝑖 𝑒𝑑 ∪ { 𝑞𝑢𝑒 𝑟 𝑦 } 17: C. Document Retrieval 18: 𝑑𝑜 𝑐 𝑠 𝑛𝑒 𝑤 ← Retrieve ( 𝑞𝑢𝑒 𝑟 𝑦 ) 19: 𝑑𝑜 𝑐 𝑠 𝑛𝑒 𝑤 ← Fil terDuplica tes ( 𝑑 𝑜 𝑐 𝑠 𝑛𝑒 𝑤 , 𝑑 𝑜𝑐 𝑠 𝑠𝑒 𝑒 𝑛 ) 20: if | 𝑑 𝑜 𝑐 𝑠 𝑛𝑒 𝑤 | = 0 then 21: break ⊲ No new documents 22: end if 23: D . Context Management 24: 𝑐 𝑡 𝑥 ← 𝑐 𝑡 𝑥 ∪ Forma t ( 𝑑 𝑜 𝑐 𝑠 𝑛𝑒 𝑤 ) 25: 𝑑𝑜 𝑐 𝑠 𝑠𝑒 𝑒 𝑛 ← 𝑑 𝑜 𝑐 𝑠 𝑠𝑒 𝑒 𝑛 ∪ GetIDs ( 𝑑 𝑜 𝑐 𝑠 𝑛𝑒 𝑤 ) 26: end for 27: Step 3: Sub-question Answer Generation 28: 𝑎 ← 𝑀 𝑚 . Genera teAnswer ( 𝑠 , 𝑐 𝑡 𝑥 , 𝐾 ) 29: return ( 𝑎, 𝑐 𝑡 𝑥 ) (1) Knowledge Suciency Evaluation. The agent rst as- sesses whether the current sub-question 𝑠 𝑖 can be answer ed suf- ciently using only the existing accumulated knowledge, 𝐾 𝑎𝑐𝑐 . A decision function, 𝛿 𝑘𝑛𝑜 𝑤𝑙 𝑒𝑑 𝑔𝑒 , is invoked: 𝛿 𝑘 𝑛𝑜 𝑤𝑙 𝑒𝑑 𝑔𝑒 ( 𝑠 𝑖 , 𝐾 acc ) → Retrieve/Retry , Answer If the knowledge is deemed sucient( Answer ), the agent proceeds directly to Step "Sub- Answer Synthesis" . Otherwise ( Retrieve ), it initiates the multi-hop retrieval loop. (2) Adaptive Multi-Hop Retrieval Lo op. The agent enters an iterative loop to gather external information, with a predened maximum numb er of hops (iterations), 𝐻 𝑚𝑎𝑥 . For each hop ℎ ∈ [ 1 , 𝐻 𝑚𝑎𝑥 ] : A. Dynamic Query Generation : The agent formulates a search query , 𝑞 𝑖 , ℎ , tailored to the current information gap. T o ensure nov- elty , the generation is conditioned on previously generated queries for the same sub-question, 𝑄 ℎ𝑖𝑠 𝑡 = { 𝑞 𝑖 , 1 , . . ., 𝑞 𝑖 , ℎ − 1 } . 𝑞 𝑖 , ℎ = 𝜋 𝑒 𝑥 𝑒 𝑐 ( "generate query for 𝑠 𝑖 " | 𝐾 𝑎𝑐𝑐 , 𝐷 𝑟 𝑒 𝑡 𝑟 𝑖 𝑒 𝑣𝑒 𝑑 , 𝑄 ℎ𝑖𝑠 𝑡 ) B. Document Retrieval & Filtering : The query 𝑞 𝑖 , ℎ is dispatched to the search index over corpus 𝐶 , retrieving a ranked list of doc- uments. A crucial de-duplication step is applie d to lter out doc- uments that have b een previously retrieved in any hop for any sub-question. C. Continuation De cision : For ℎ > 1 , the agent decides whether to continue retrieving information. This decision, 𝛿 𝑐𝑜 𝑛𝑡 𝑖 𝑛𝑢𝑒 , is base d on the completeness of the information gathered thus far . D . Loop T ermination : The loop terminates if (a) the maximum hop limit 𝐻 𝑚𝑎𝑥 is reached, or (b) the agent’s continuation decision 𝛿 𝑐𝑜 𝑛𝑡 𝑖 𝑛𝑢𝑒 is to stop. (3) Knowledge Base Augmentation . The newly generated question-answer pair is appended to the accumulated knowledge base: 𝐾 𝑎𝑐𝑐 ← 𝐾 𝑎𝑐𝑐 ∪ ( 𝑠 𝑖 , 𝑎 𝑖 ) This updated knowledge base ser ves as the context for the next sub-question in the sequence, 𝑠 𝑖 + 1 . 3.3.3 Final Answer Synthesis . After all sub-questions in the sequence 𝑆 have been answered, the Execution A gent performs the nal synthesis step. It receives the complete accumulated knowl- edge base 𝐾 𝑎𝑐𝑐 and the original question 𝑄 to generate the nal, comprehensive answer , 𝐴 𝑓 𝑖 𝑛𝑎𝑙 . 𝐴 𝑓 𝑖 𝑛𝑎𝑙 = 𝜋 𝑒 𝑥 𝑒 𝑐 ( "comprehensiv ely answer 𝑄 " | 𝐾 𝑎𝑐𝑐 ) Alongside the textual answer , the system calculates a condence score, 𝑐 ( 𝐴 𝑓 𝑖 𝑛𝑎𝑙 ) ∈ [ 0 , 1 ] , based on the spe cicity of the answer , the completeness of the information collected and the absence of markers of linguistic uncertainty . The nal output includes the answer and condence score. 4 Experiments 4.1 Experimental Setup 4.1.1 Evaluation Benchmark and Datasets. W e use four multi-hop question answering tasks as b enchmarks, including 2WikiMulti- HopQ A [ 8 ], HotpotQ A [ 46 ], MuSiQue [ 36 ], and Bambo ogle [ 26 ]. The questions in these benchmarks are constructed by combining information from multiple Wikipedia articles. Therefor e, a single retrieval is often unable to obtain all relevant do cuments, which puts higher demands on the ability of methods to solve complex tasks. W e utilize Exact Match (EM) as our primary evaluation met- ric. Given that the target answers in this dataset are pr edominantly short, factoid entities, we nd that F1 scores ar e highly correlated with EM and provide marginal additional signal. Consequently , we focus on EM to provide the strictest assessment of model perfor- mance. For the RL-based Agentic Planning phase, we utilized 10,473 ex- amples from the MuSiQue training set to enable the agent to learn robust task decomposition strategies from complex reasoning tra- jectories. In terms of data processing, we used De epSeek- V3[ 21 ] to rewrite the original planning of symbolic language for task decom- position into natural language. In the SFT -based Agentic Execution phase, we sampled training set data from 2WikiMultiHopQ A, Hot- potQA, and MuSiQue to construct 14,604 pieces of multi-round retrieval instruction data, and strict data ltering has been carried out to ensure that there is no leakage from the training set to the test set, thus guaranteeing the fairness of the evaluation.. APEX-Searcher: Augmenting LLMs’ Search Capabilities thr ough Agentic Planning and Execution Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY T able 1: Main results comparison between Qwen2.5-7B-Instruct and Qwen2.5-3B-Instruct across dierent benchmarks. The highest score for each Benchmark is marked in b old. Methods T ype HotpotQA 2Wiki MuSiQue Bamboogle A vg. 7B 3B 7B 3B 7B 3B 7B 3B 7B 3B Direct Inference Non-Retrieval 0.183 0.149 0.250 0.244 0.031 0.020 0.120 0.024 0.146 0.109 Co T Non-Retrieval 0.092 0.021 0.111 0.021 0.022 0.002 0.232 0.000 0.114 0.011 RA G Standard RA G 0.299 0.255 0.235 0.226 0.058 0.047 0.208 0.080 0.200 0.152 IRCo T Iterative RA G 0.133 0.164 0.149 0.171 0.072 0.067 0.224 0.240 0.145 0.161 Search-o1 Agentic RA G 0.187 0.221 0.176 0.218 0.058 0.054 0.296 0.320 0.179 0.203 ZeroSearch-instruct Agentic RA G 0.346 0.274 0.352 0.300 0.184 0.098 0.278 0.111 0.290 0.195 Search-R1-Instruct Agentic RA G 0.370 0.284 0.414 0.273 0.146 0.049 0.368 0.088 0.324 0.174 StepSearch-instruct Agentic RA G 0.386 0.345 0.366 0.320 0.226 0.174 0.400 0.328 0.345 0.296 ReasonRA G Agentic RA G 0.384 - 0.436 - 0.128 - 0.360 - 0.327 - DecEx-RA G Agentic RA G 0.377 - 0.500 - - - 0.376 - - - Apex-Searcher Agentic RA G 0.402 0.356 0.540 0.494 0.164 0.136 0.400 0.352 0.376 0.335 4.1.2 Baselines. W e compare our method against the following baselines: (1)Non-Retrieval Methods: Direct Inference and Co T rea- soning [ 41 ]. (2) Standard RA G: A standard Retrieval-A ugmented Generation [ 19 ]. (3) Iterative RAG: IRCo T [ 37 ]. (4) Agentic RAG: Search-o1 [ 43 ], Search-r1 [ 11 ], ZeroSearch-instruct [ 33 ], StepSearch- instruct [40], ReasonRA G [50] and DecEx-RAG [18]. W e use the same environment as most of the compared base- lines [ 11 , 18 , 40 ], including the retrieval corpus, the numb er of retrieved documents, and the construction scheme of the retrieval environment to ensure the fairness of the evaluation. 4.2 Implementation Details W e conducted experiments on Qwen-2.5-3B-Instruct and Qwen- 2.5-7B-Instruct [35] respectively . For RL-based agentic planning experiment, W e utilized the verl 1 framework to implement a GRPO algorithm for 3 epochs. Ke y hy- perparameters for the training process were congured as follows: The learning rate was set to 5 × 10 − 6 . W e used a global training batch size of 512 , with a PPO mini-batch size of 128 and a micro-batch size of 16 per GP U. The maximum prompt and response lengths were both capped at 1024 tokens. T o regularize the policy updates and prevent divergence fr om the reference model, we incorporate d a KL divergence loss with a coecient of 0 . 01 . Furthermore, an entropy coecient of 0 . 01 was applied to encourage exploration. T o optimize for memory and computational eciency , the training was conducted with boat16 precision. Gradient che ckpointing was enabled to reduce memory consumption. The GRPO algorithm generates 8-tone trajectories in one group, with gradient retention clipping 𝜖 = 0 . 2 . For SFT -based agentic execution experiment, we performed full- parameter SFT using the 360Llamafactor y 2 framework. The model was trained for 2 epochs. The training was congured with a learn- ing rate of 5 × 10 − 6 and a cosine learning rate scheduler , with a warmup ratio of 0 . 03 . W e set a per-device training batch size of 1 1 https://github.com/volcengine/v erl 2 https://github.com/Qihoo360/360-LLaMA -Factory and used 2 gradient accumulation steps. The maximum sequence length was set to 32 , 768 tokens. Several optimization techniques wer e employed to ensure e- cient training. W e utilized DeepSpeed 3 with a ZeRO stage 3 con- guration to optimize memory usage across devices. The training was performed using boat16 precision, and Flash Attention 2 4 was enabled to accelerate the attention mechanism computations. Gra- dient checkpointing was also activated to further conserve memory . The model was trained with a sequence parallel size of 2 . 4.3 Main Results The main experimental results are compar ed in Table 1. From the results, we can see that Ap ex-Searcher performs well on multi- ple baselines. Compared with the original mo dels Qwen-2.5-3B- Instruct and Qwen-2.5-7B-Instruct Standard RA G, we achieved an average performance impr ovement of 0.230 and 0.226 respectively . In addition, it can be se en from the experimental results that the performance gap between our method and the strongest baseline ( +8.2%, +13.1% EM) suggests a robust improvement. 4.4 Ablation Study T o demonstrate the eectiveness of RL-based A gentic Planning and SFT -based Agentic Execution, we conducted ablation experiments on Qwen2.5-7B-Instruct and Qwen2.5-3B-Instruct. W e tested the dierences in the model’s performance on various b enchmarks with dierent combinations of method components (including whether to adopt Planning, whether to use RL to train the Planning process, and whether to use SFT to train the Execution process). It can be seen from T able 2 that our training of the model on both A gentic Planning and Agentic Execution is ee ctive and necessar y . Both contribute to the impro vement of the nal performance of Apex- Searcher . The specic conclusions of the ablation study are as follows: 3 https://github.com/deepspeedai/DeepSpee d 4 https://github.com/Dao- AILab/ash-attention Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Trovato et al. T able 2: Ablation study of dierent comp onents on 7B and 3B models. Plan: P lanning module; RL: Planning with RL; SFT: Execution via Super vised Fine- T uning. Model Method (Components) HotpotQA 2Wiki MuSiQue Bamboogle Eval Plan Plan RL Exp SFT Qwen-2.5-7B-Instruct ✗ - ✗ 35.11 31.27 8.61 35.20 27.55 ✗ - ✓ 35.18 35.69 9.56 36.00 29.11 ✓ ✗ ✗ 33.52 42.92 11.50 33.60 30.39 ✓ ✓ ✗ 36.79 46.30 12.99 39.20 33.82 ✓ ✗ ✓ 35.76 48.72 12.12 37.60 33.55 ✓ ✓ ✓ 40.15 54.04 16.38 40.00 37.64 Qwen-2.5-3B-Instruct ✗ - ✗ 19.88 12.65 3.56 17.60 13.42 ✗ - ✓ 29.97 30.58 7.12 26.40 23.52 ✓ ✗ ✗ 16.73 14.73 3.06 16.00 12.63 ✓ ✓ ✗ 20.58 25.00 6.00 20.80 18.10 ✓ ✗ ✓ 26.77 33.43 7.74 28.80 24.19 ✓ ✓ ✓ 35.64 49.38 13.57 35.20 33.45 • Synergy of Components: The model achieves optimal per- formance across both scales when all components are simul- taneously enabled. Specically , the 7B model improves from a baseline of 27.55 to 37.64, repr esenting an increase of approxi- mately 36.6%. The 3B model advances from a baseline of 13.42 to 33.45, reecting a substantial improvement of 149%. • Fundamental Role and Limitations of the P lanning Mod- ule: Introducing the "Plan" mo dule in isolation, without RL optimization or SFT , yields limited performance gains and may even negatively impact smaller models. When only the Plan module is enable d, the Eval score is 30.39 (an improvement over the 27.55 baseline). However , for the smaller model, the Eval score drops to 12.63, falling below the baseline of 13.42. This indicates that merely requiring the model to perform com- plex task decomposition (Planning) incr eases task diculty . For the less capable 3B model, the absence of targeted training to guide plan execution results in forced decomposition, which introduces noise or leads to error accumulation. • Eect of planning RL: Incorp orating RL on top of the plan- ning module signicantly enhances the mo del’s ability to solve complex problems. A comparison between "Plan only" and "P lan + RL" reveals the following: the 7B model impro ves from 30.39 to 33.82, and the 3B model improv es from 12.63 to 18.10. This demonstrates that RL optimization ee ctively improves the quality of plan generation. On the other hand, the ablation experiments also fully demonstrate the generalization of the planning ability of the RL-trained model. On out-of-domain test sets such as HotpotQA, 2Wiki, and Bamboogle, the model still shows signicant performance impro vements brought by the planning ability . • Eect of Execution SFT: SFT is critical for enhancing retrie val and reasoning capabilities on specic sub-problems, particularly for smaller models. In the absence of planning, enabling only Exp SFT causes the 3B model’s Eval score to surge fr om 13.42 to 23.52. This suggests that SFT signicantly compensates for the foundational deciencies of smaller models. By enabling the model to better utilize tools or corpora for reasoning, SFT serves as a key factor in improving " execution capabilities. " 4.5 Parameter Sensitivity Analysis W e analyze the impact of two key parameters used in our experi- ments: the number of retrieved documents ( 𝑁 𝑢𝑚 ) and the maximum allowed reasoning hops ( 𝐻 𝑜 𝑝 ). The experiments are conducted on Qwen2.5-3B-Instruct. Figure 3 presents the mo del’s accuracy across four benchmarks under varying parameter settings. Based on the experimental results, we draw the following ke y observations: 1) Diminishing returns or noise interference in document retrieval: Across all datasets, accuracy signicantly improves as the number of retrieved documents increases from 1 to 3, indicating that augmenting context is crucial for problem- solving. However , as the number exceeds 3, performance gains tend to plateau or even exhibit a distinct decline. This suggests that an excessive number of documents may introduce irr elevant information or noise, which disrupts the model’s reasoning process and degrades performance. 2) Positive correlation between rea- soning hops and performance: Generally , the model’s accuracy demonstrates a continuous improvement as the maximum allowed reasoning hops increase from 1 to 5. 4.6 Analysis on T ask P lanning T o conduct an in-depth analysis of the model’s P lanning Learning, we tested the reward scores related to task decomposition on the test sample set of the dataset for Qwen2.5-3B-Instruct and Q wen2.5- 7B-Instruct that has undergone agentic Planning RL. As shown in Figure 4a, it can be observed that the traine d model shows a signicant impro vement in the accuracy of task decomposition and planning, and this improv ement will also lead to higher accuracy in subsequent Multi-hop QA answ ers. Furthermore, we paid additional attention to the changes in the model’s Training Rewar d, V alidation Reward, and Mean Response Length during the training process, as shown in Figur e 4b, Figure 4c and Figure 4d. W e can observe that during the training process, APEX-Searcher: Augmenting LLMs’ Search Capabilities thr ough Agentic Planning and Execution Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY 1 2 3 4 5 30 32 34 36 Accuracy (%) Ours Ours HotpotQA #Hop #Doc 1 2 3 4 5 38 40 42 44 46 48 50 Ours Ours 2W iki #Hop #Doc 1 2 3 4 5 8 10 12 14 Ours Ours MusiQue #Hop #Doc 1 2 3 4 5 28 30 32 34 36 38 Ours Ours Bamboogle #Hop #Doc Figure 3: Parameter Sensitivity Analysis on APEX-Searcher . The curves illustrate the impact of the number of retrieved documents (# Doc) and the maximum allowed reasoning hops (# Hop) on model accuracy across four benchmarks. The asterisk ( ★ ) denotes the optimal parameter conguration selected for this study and its corresponding p erformance. Qwen2.5-3B-Instruct Qwen2.5-7B-Instruct Model 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Plan Scor e 0.424 0.624 0.802 0.825 +0.38 (+89.2%) +0.20 (+32.3%) Plan Scor e Comparison Base Model w/ Planning RL (a) 0 10 20 30 40 50 T raining Step 0.4 0.5 0.6 0.7 0.8 0.9 Reward Scor e Qwen2.5-3B-Instruct Reward T rain V alidation (b) 0 10 20 30 40 50 T raining Step 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 Reward Scor e Qwen2.5-7B-Instruct Reward T rain V alidation (c) 0 10 20 30 40 50 T raining Step 22 24 26 28 30 32 34 36 Response Length (tokens) Response Length During T raining Qwen2.5-3B-Instruct Qwen2.5-7B-Instruct (d) Figure 4: (a) shows the Plan score improvements over base models, (b-c) show the reward score convergence during training for the 3B and 7B variants, and (d) shows the optimization of response length over training steps. both the Training Reward and V alidation Reward of the mo del are steadily increasing, and their upward trends are consistent, which prov es the eectiveness of our training. At the same time, w e noticed that as the numb er of training steps increases, the average length of the mo del’s responses decreases. This is related to the fact that the original model always over-decomposes or incorrectly decomposes tasks when performing task planning. T o qualitatively evaluate our method, we present two case studies comparing the decomposition strategies generated by our model against the Qwen2.5-7B-Instruct baseline. As shown in Figure 5, Our method can de compose tasks accurately without incorporating redundant subtasks. At the same time, the trained task planning capabilities will use #n instead of relying on question answers. 5 Conclusion In this paper , we focus on the limitations of existing RAG frame- works in handling complex, multi-hop questions. W e introduced APEX-Sear cher , a novel framework that enhances an LLM’s search capabilities by explicitly separating strategic planning from itera- tive execution. Case Study: Question Decomposition Comparison Question 1: Who is the maternal grandfather of A ntiochus X Eusebes? Qwen2.5-7B-Instruct: (1) Who is the mother of Anti- ochus X Eusebes? (2) Who is the father of Anti- ochus X Eusebes’s mother? (3) What is the relationship of the answer to #2 to Anti- ochus X Eusebes? Ours: (1) Who is the mother of Anti- ochus X Eusebes? (2) Who is the father of #1? Question 2: Which country Audoeda’s husband is from? Qwen2.5-7B-Instruct: (1) Which country Audoeda’s husband is from? (No decomposition) Ours: (1) Who is A udoeda’s hus- band? (2) Which countr y is #1 from? Figure 5: Comparison of question decomp osition strategies. Our methodology employs a Planning A gent, trained with RL, to decomp ose a complex query into a logical sequence of sub- questions. Subsequently , an Execution Agent, trained via SFT , sys- tematically solves each sub-question using a robust multi-round Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY Trovato et al. retrieval and e xecution process. Our experiments across multiple benchmarks demonstrate that APEX-Searcher signicantly outper- forms existing methods. Ablation studies further conrmed that both the RL-based planning and SFT -based execution stages are crucial for the mo del’s nal p erformance. This work highlights the immense potential of equipping LLMs with e xplicit planning capabilities, paving the way for more sophisticated and ee ctive agentic systems in complex information-seeking tasks. In the future, 1) w e consider discussing whether the performance of the model in multi-round retrieval can be continuously improved through multi-r ound RL during the execution phase of multi-round retrieval; 2) expand local database retrieval to web search, and further broaden application scenarios starting from task planning. Acknowledgments T o Rob ert, for the bagels and explaining CMYK and color spaces. References [1] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-rag: Learning to r etrieve, generate, and critique through self-reection. (2024). [2] Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Je Z Pan, W en Zhang, Huajun Chen, et al . 2025. Learn- ing to reason with search for llms via reinforcement learning. arXiv preprint arXiv:2503.19470 (2025). [3] Manuel Cossio. 2025. A comprehensive taxonomy of hallucinations in Large Language Models. arXiv preprint arXiv:2508.01781 (2025). [4] Lut Eren Erdogan, Nicholas Le e, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anumanchipalli, Kurt K eutzer , and Amir Gholami. 2025. P lan-and-act: Im- proving planning of agents for long-horizon tasks. arXiv preprint (2025). [5] Jinyuan Fang, Zaiqiao Meng, and Craig MacDonald. 2025. KiRAG: Knowledge- Driven Iterative Retriev er for Enhancing Retrieval-A ugmented Generation. In Proceedings of the 63rd A nnual Me eting of the Association for Computational Linguistics (V olume 1: Long Pap ers) , W anxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad T aher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, 18969–18985. doi:10.18653/v1/2025.acl- long.929 [6] Y unfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen W ang, and Haofen W ang. 2023. Retrieval-augmented generation for large language models: A survey . arXiv preprint 2, 1 (2023). [7] Y u Gu, Boyuan Zheng, Boyu Gou, Kai Zhang, Cheng Chang, Sanjari Srivastava, Y anan Xie, Peng Qi, Huan Sun, and Y u Su. 2024. Simulate Before Act: Model-Based Planning for W eb Agents. https://openreview .net/forum?id=JDa5RiTIC7 [8] Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. arXiv preprint arXiv:2011.01060 (2020). [9] Lei Huang, W eijiang Yu, W eitao Ma, W eihong Zhong, Zhangyin Feng, Haotian W ang, Qianglong Chen, W eihua Peng, Xiaocheng Feng, Bing Qin, et al . 2025. A survey on hallucination in large language models: Principles, taxonomy, chal- lenges, and open questions. ACM Transactions on Information Systems 43, 2 (2025), 1–55. [10] Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Y u, Yiming Y ang, Jamie Callan, and Graham Neubig. 2023. A ctive retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing . 7969–7992. [11] Bowen Jin, Hansi Zeng, Zhenrui Y ue, Jinsung Y oon, Sercan Arik, Dong W ang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516 (2025). [12] Mandar Joshi, Eunsol Choi, Daniel W eld, and Luke Zettlemoyer . 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th A nnual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) . 1601–1611. [13] Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric W allace, and Colin Raf- fel. 2023. Large Language Models Struggle to Learn Long- T ail Knowledge. In Procee dings of the 40th International Conference on Machine Learning (Pro- ceedings of Machine Learning Research, V ol. 202) . PMLR, 15696–15707. https: //proceedings.mlr .press/v202/kandpal23a.html [14] Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Le dell Wu, Sergey Edunov , Danqi Chen, and W en-tau Yih. 2020. Dense Passage Retrie val for Open-Domain Question Answering.. In EMNLP (1) . 6769–6781. [15] Michael Katz, Harsha K okel, Kavitha Srinivas, and Shirin Sohrabi Araghi. 2024. Thought of search: Planning with language models through the lens of eciency . Advances in Neural Information Processing Systems 37 (2024), 138491–138568. [16] T om K wiatkowski, Jennimaria Palomaki, Olivia Redeld, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al . 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7 (2019), 453–466. [17] Jakub Lála, Odhran O’Donoghue, Aleksandar Shtedritski, Sam Cox, Samuel G Rodriques, and Andrew D White. 2023. Pap erqa: Retrie val-augmented generative agent for scientic research. arXiv preprint arXiv:2312.07559 (2023). [18] Y ongqi Leng, Yikun Lei, Xikai Liu, Meizhi Zhong, Bojian Xiong, Y urong Zhang, Y an Gao, Y ao Hu, Deyi Xiong, et al . 2025. DecEx-RAG: Boosting A gentic Retrieval- Augmented Generation with Decision and Execution Optimization via Pr ocess Supervision. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track . 1412–1425. [19] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, W en-tau Yih, Tim Ro cktäschel, et al . 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33 (2020), 9459–9474. [20] Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025. Search-o1: Agentic search-enhanced large reasoning models. arXiv preprint arXiv:2501.05366 (2025). [21] Aixin Liu, Bei Feng, Bing Xue, Bingxuan W ang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al . 2024. Deepse ek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024). [22] V aibhav Mavi, Anubhav Jangra, Adam Jatowt, et al . 2024. Multi-hop question answering. Foundations and Trends ® in Information Retrieval 17, 5 (2024), 457– 586. [23] Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar , Nick Barnes, and Ajmal Mian. 2025. A com- prehensive overview of large language models. ACM Transactions on Intelligent Systems and T echnology 16, 5 (2025), 1–72. [24] Ajay Patel, Markus Hofmarcher , Claudiu Leoveanu-Condrei, Marius-Constantin Dinu, Chris Callison-Burch, and Sepp Hochreiter . 2024. Large language models can self-improve at web agent tasks. arXiv preprint arXiv:2405.20309 (2024). [25] Aske Plaat, Max van Duijn, Niki van Stein, Mike Preuss, Peter van der Putten, and Kees Joost Batenburg. 2025. Agentic large language models, a survey . arXiv preprint arXiv:2503.23037 (2025). [26] Or Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2023. Measuring and Narrowing the Compositionality Gap in Language Models. arXiv:2210.03350 [cs. CL] [27] Adam Roberts, Colin Rael, and Noam Shazeer . 2020. How much knowledge can you pack into the parameters of a language model? arXiv preprint (2020). [28] John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . 2017. Proximal policy optimization algorithms. arXiv preprint (2017). [29] Zhihong Shao, Y eyun Gong, Y elong Shen, Minlie Huang, Nan Duan, and W eizhu Chen. 2023. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy . arXiv preprint arXiv:2305.15294 (2023). [30] Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y ang Wu, et al . 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024). [31] Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning . PMLR, 31210–31227. [32] Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong W en. 2025. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint (2025). [33] Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Y ong Jiang, Pengjun Xie, Y an Zhang, Fei Huang, and Jingren Zhou. 2025. Zerosearch: Incentivize the search capability of llms without searching. arXiv preprint (2025). [34] Shuang Sun, Huatong Song, Yuhao W ang, Ruiyang Ren, Jinhao Jiang, Jun- jie Zhang, Fei Bai, Jia Deng, W ayne Xin Zhao, Zheng Liu, et al . 2025. Sim- pleDeepSearcher: Deep information seeking via web-powered reasoning trajec- tory synthesis. arXiv preprint arXiv:2505.16834 (2025). [35] Qwen T eam. 2024. Q wen2.5: A Party of Foundation Models. https://qwenlm. github.io/blog/qwen2.5/ [36] Harsh Trivedi, Niranjan Balasubramanian, T ushar Khot, and Ashish Sabharwal. 2022. ♪ MuSiQue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics 10 (2022), 539–554. APEX-Searcher: Augmenting LLMs’ Search Capabilities thr ough Agentic Planning and Execution Conference acronym ’XX, June 03–05, 2018, W oodsto ck, NY [37] Harsh Trivedi, Niranjan Balasubramanian, T ushar Khot, and Ashish Sabharwal. 2023. Interleaving Retrieval with Chain-of- Thought Reasoning for Knowledge- Intensive Multi-Step Questions. In Proceedings of the 61st A nnual Me eting of the Association for Computational Linguistics (V olume 1: Long Papers) . 10014–10037. [38] Yizhong W ang, Y eganeh K ordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. Self-instruct: Aligning language mod- els with self-generated instructions. arXiv preprint arXiv:2212.10560 (2022). [39] Zheng W ang, Shu Xian T e o, Jun Jie Chew , and W ei Shi. 2025. InstructRAG: Le ver- aging Retrieval- Augmented Generation on Instruction Graphs for LLM-Based T ask Planning. In Procee dings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (Padua, Italy). 1413–1422. [40] Ziliang W ang, Xuhui Zheng, Kang An, Cijun Ouyang, Jialu Cai, Y uhang W ang, and Yichao Wu. 2025. StepSearch: Igniting LLMs Search Ability via Step- Wise Proximal Policy Optimization. arXiv preprint arXiv:2505.15107 (2025). [41] Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al . 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824–24837. [42] Renjun Xu and Jingwen Peng. 2025. A Comprehensive Survey of Deep Research: Systems, Methodologies, and Applications. arXiv preprint arXiv:2506.12594 (2025). [43] Shicheng Xu, Liang Pang, Huawei Shen, Xueqi Cheng, and T at-Seng Chua. 2024. Search-in-the-chain: Interactively enhancing large language models with search for knowledge-intensive tasks. In Proceedings of the ACM W eb Conference 2024 . 1362–1373. [44] Shicheng Xu, Liang Pang, Huawei Shen, Xueqi Cheng, and T at-Seng Chua. 2024. Search-in-the-Chain: Interactively Enhancing Large Language Models with Search for Knowledge-intensive Tasks. In Proceedings of the ACM W eb Conference 2024 . 1362–1373. [45] Ruiyi Y ang, Hao Xue, Imran Razzak, Hakim Hacid, and Flora D Salim. 2025. Beyond Single Pass, Looping Through Time: KG-IRA G with Iterative Knowledge Retrieval. arXiv preprint arXiv:2503.14234 (2025). [46] Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengio, William W Cohen, Ruslan Salakhutdinov , and Christopher D Manning. 2018. HotpotQA: A dataset for di- verse, explainable multi-hop question answering. arXiv preprint (2018). [47] Shunyu Y ao, Jerey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao . 2023. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR) . [48] W enhao Yu, Hongming Zhang, Xiaoman Pan, Kaixin Ma, Hongwei W ang, and Dong Yu. 2023. Chain-of-note: Enhancing robustness in retrieval-augmented language models. arXiv preprint arXiv:2311.09210 (2023). [49] Qin Zhang, Shangsi Chen, Dongkuan Xu, Qingqing Cao, Xiaojun Chen, T revor Cohn, and Meng Fang. 2022. A sur vey for ecient op en domain question an- swering. arXiv preprint arXiv:2211.07886 (2022). [50] W enlin Zhang, Xiangyang Li, Kuicai Dong, Yichao Wang, Pengyue Jia, Xiaopeng Li, Yingyi Zhang, Derong Xu, Zhaocheng Du, Huifeng Guo, et al . 2025. Process vs. Outcome Reward: Which is Better for Agentic RA G Reinforcement Learning. arXiv preprint arXiv:2505.14069 (2025). [51] W enlin Zhang, Xiaop eng Li, Yingyi Zhang, Pengyue Jia, Yichao W ang, Huifeng Guo, Y ong Liu, and Xiangyu Zhao . 2025. Deep Research: A Survey of A utonomous Research Agents. arXiv preprint arXiv:2508.12752 (2025). [52] W ayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi T ang, Xiaolei W ang, Y upeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al . 2023. A sur vey of large language models. arXiv preprint arXiv:2303.18223 1, 2 (2023). [53] Y uxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Y e, Pengrui Lu, and Pengfei Liu. 2025. Deepresearcher: Scaling deep research via reinforce- ment learning in r eal-world environments. arXiv preprint arXiv:2504.03160 (2025).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment