CTI-REALM: Benchmark to Evaluate Agent Performance on Security Detection Rule Generation Capabilities
CTI-REALM (Cyber Threat Real World Evaluation and LLM Benchmarking) is a benchmark designed to evaluate AI agents' ability to interpret cyber threat intelligence (CTI) and develop detection rules. The benchmark provides a realistic environment that r…
Authors: Arjun Chakraborty, S, ra Ho
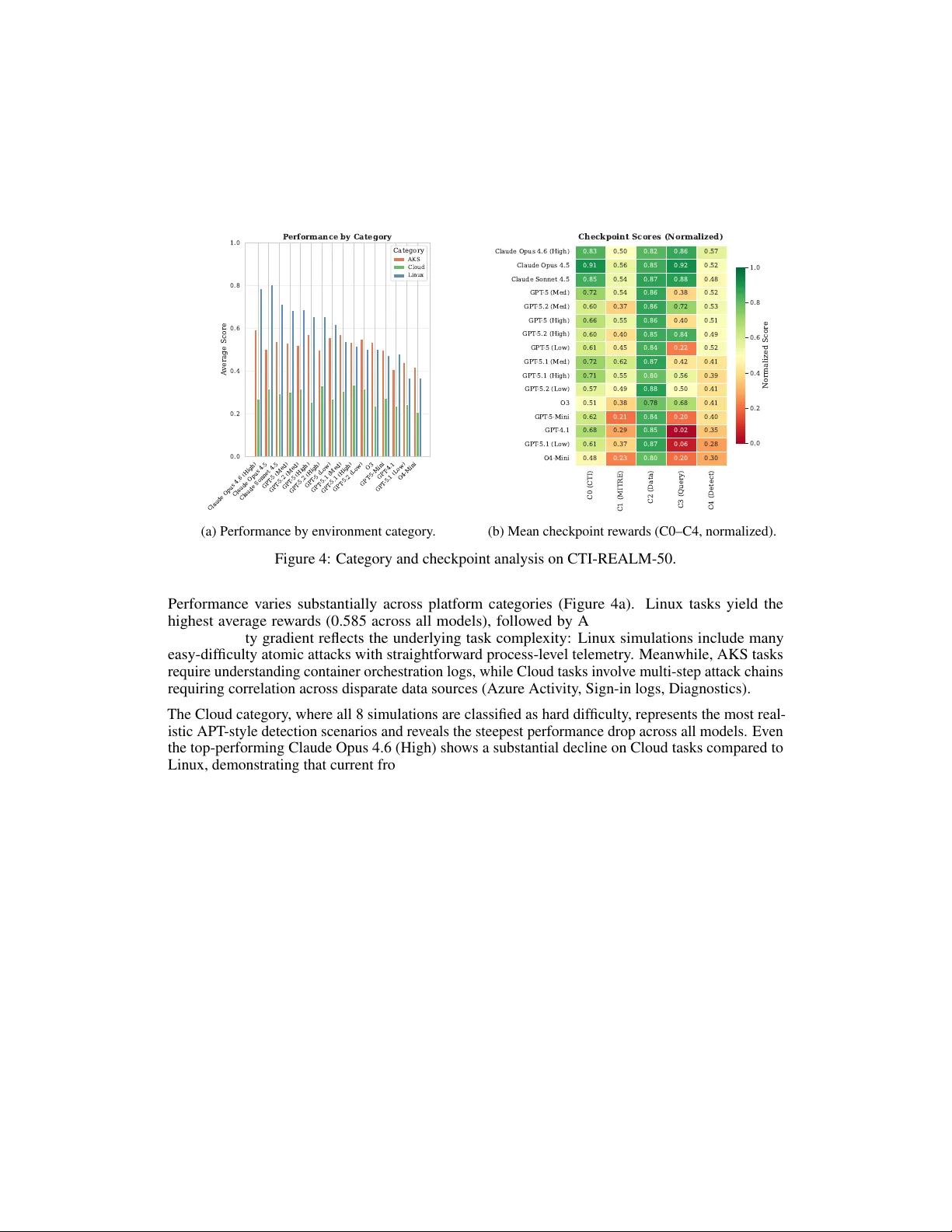
CTI-REALM : Benchmark to Evaluate Agent P erf ormance on Security Detection Rule Generation Capabilities Arjun Chakraborty Microsoft Security AI arjunc@microsoft.com Sandra Ho Microsoft Security AI sandraho@microsoft.com Adam Cook Microsoft Security AI cookadam@microsoft.com Manuel Meléndez Microsoft Security AI mmelndezlujn@microsoft.com Abstract CTI-REALM (Cyber Threat Real W orld Evaluation and LLM Benchmarking) is a benchmark designed to ev aluate AI agents’ ability to interpret c yber threat intelligence (CTI) and dev elop detection rules. The benchmark provides a realistic en vironment that replicates the security analyst w orkflow . This enables agents to examine CTI reports, ex ecute queries, understand schema structures, and construct detection rules. Evaluation in v olves emulated attacks of varying comple xity across Linux systems, cloud platforms, and Azure K ubernetes Service (AKS), with ground truth data for accurate assessment. Agent performance is measured through both final detection results and trajectory-based re wards that capture decision-making effecti v eness. This work demonstrates the potential of AI agents to support labor -intensi ve aspects of detection engineering. Our comprehensive e valuation of 16 frontier models shows that Claude Opus 4.6 (High) achie ves the highest ov erall re ward (0.637), followed by Claude Opus 4.5 (0.624) and the GPT -5 family . An ablation study confirms that CTI-specific tools significantly improve agent performance, a v ari- ance analysis across repeated runs demonstrates result stability . Finally , a memory augmentation study sho ws that seeded context can close 33% of the performance gap between smaller and larger models. 1 Introduction Detection engineering is the process of creating rules and queries to identify malicious acti vity in security telemetry . It remains a cornerstone of blue team operations. There are tw o primary challenges that make it dif ficult: (1) enterprise environments are heterogeneous, spanning endpoints, cloud infrastructure, and containerized workloads, and (2) analysts must interpret threat intelligence, understand div erse data schemas, and iterati vely refine detection logic. Existing cybersecurity benchmarks primarily e v aluate parametric kno wledge or isolated subtasks such as rule synthesis, TTP classification, and threat actor attribution. None address the end-to- end detection engineering w orkflow , where an analyst must interpret threat intelligence, explore heterogeneous telemetry , iterativ ely construct queries, and produce validated detection rules. This gap leav es the field without a principled way to measure whether AI agents can perform the complete analytical pipeline that security teams rely on daily . Preprint. Under re vie w . W e introduce CTI-REALM (Cyber Threat Real W orld Evaluation and LLM Benchmarking), a benchmark that ev aluates AI agents on end-to-end detection engineering in realistic settings. The benchmark is grounded in authentic telemetry from real attack emulations e xecuted on sandboxed Azure infrastructure, where agents use specialized tools to analyze CTI reports and construct queries to produce detection rules. W e introduce two benchmarks : CTI-REALM-25 and CTI-REALM-50, with task difficulty ranging from atomic attacks to complex multi-step intrusion scenarios. The benchmark ev aluates both final detection quality and decision-making processes through trajectory- based rew ards. Our ev aluation of 16 frontier models reveals significant performance v ariation, with Claude Opus 4.6 (High) achie ving the highest rew ard (0.637), followed by Claude Opus 4.5 (0.624) and GPT -5 variants. Our contributions are as follo ws: • A realistic e valuation en vironment with authentic attack telemetry , containerized sandbox, queryable logs across Linux/AKS/Cloud, and reference databases for MITRE techniques and Sigma rules. • A trajectory-based ev aluation frame work combining deterministic checkpoints with LLM- as-judge assessment. The fine-grained re ward structure at intermediate checkpoints pro vides training signals suitable for reinforcement learning approaches, enabling hill climbing and RL-based policy optimization for detection engineering. • Comprehensiv e ground-truth-annotated benchmark dataset spanning three platforms at varying dif ficulty le vels. • Empirical ev aluation of 16 frontier models with ablation and v ariance analyses. 2 Background and Pr e vious W ork Detection engineering has become a focal point for LLM-based automation in c ybersecurity . This section re views relev ant work around LLM-driv en detection rule generation, threat intelligence, cybersecurity benchmarks, and situates CTI-REALM in this landscape. 2.1 LLM-Based Detection Rule Generation Sev eral systems ha ve e xplored automating detection rule creation. LLMCloudHunter [1] generates Sigma rules from unstructured CTI reports with multimodal analysis, achieving 92 percent precision for API call e xtraction. IntelEX [2] extracts attack-level TTPs using in-context learning, while SigmaGen [3] fine-tunes LLMs specifically for Sigma rule generation. RuleGenie [4] addresses rule set optimization to reduce redundancy , and Sublime Security’ s ADÉ [5] introduced agentic workflo ws for email threat detection. Bertiger et al. [15] present an ev aluation frame work for LLM-generated detection rules, comparing automated outputs ag ainst human-written rule corpora. Ho wev er , these systems focus on isolated rule synthesis or e v aluation rather than end-to-end detection engineering workflo ws. 2.2 Threat Intelligence Extraction Upstream from rule generation, research has addressed e xtracting structured intelligence from CTI sources. Rule-A TT&CK Mapper [6] uses multi-stage LLM pipelines to map SIEM rules to MITRE A TT&CK techniques, while comparati ve studies [7] hav e ev aluated encoder-based models versus decoder-based LLMs with RA G for TTP classification. These approaches demonstrate LLM potential but rely on static e v aluation without iterati ve refinement. 2.3 Cybersecurity Benchmarks CTIBench [8] e valuates LLMs on CTI tasks including root cause mapping and threat actor attrib ution under closed-book settings. AthenaBench [9] extends this with dynamic data from liv e CTI sources, while ExCyTIn-Bench [10] ev aluates agents on threat in v estigation using Microsoft Sentinel logs. CAIBench [11] rev ealed that models achieving 70 percent on kno wledge benchmarks degrade to 20- 40 percent on multi-step adversarial scenarios, highlighting gaps between kno wledge and capability . 2 CyberSOCEval [16] benchmarks LLMs on malware analysis and threat intelligence reasoning within a SOC context, finding that reasoning models do not achiev e the same performance boost as in coding and math domains. CTIArena [18] ev aluates LLMs across heterogeneous CTI tasks under both closed-book and knowledge-augmented settings, demonstrating significant gains from retrie v al augmentation. These benchmarks primarily test parametric kno wledge rather than tool-augmented detection engineering. 2.4 Attack Simulation Frameworks CTI-REALM leverages established adversary emulation tools as inspiration for ground truth gen- eration. Atomic Red T eam [12] pro vides a library of small, portable tests mapped to the MITRE A TT&CK framework, enabling reproducible simulation of individual attack techniques. Se veral of our simulations adapt Atomic Red T eam test cases to produce realistic telemetry in controlled en vironments. CTI-REALM dif fers from prior work by: (1) e valuating complete detection engineering workflows rather than isolated rule synthesis; (2) providing realistic tools for acti ve data exploration rather than testing parametric kno wledge; (3) introducing trajectory-based ev aluation capturing decision- making processes; and (4) grounding ev aluation in authentic telemetry from attacks executed on real infrastructure across Linux, AKS, and Azure cloud en vironments. 3 Benchmark Design and Methodology CTI-REALM is designed to e valuate AI agents on the complete detection engineering workflow . This extends from interpreting threat intelligence to producing v alidated detection rules. The benchmark presents objectiv es deriv ed from real-world CTI reports and requires agents to analyze rele vant threat intelligence, identify appropriate data sources, iterati vely construct and test queries, and produce both Sigma rules and ex ecutable KQL queries. 3.1 T ask Formulation The core task in CTI-REALM mirrors the workflow of SOC analysts. Giv en a CTI report describing an attack, the goal is to dev elop detection logic that identifies the threat in production en vironments. Each task instance presents an agent with: • Input : CTI references from public detection repositories and threat research blogs, plus telemetry logs from the attack emulation. • Output : Detection rules in Sigma and KQL 1 formats that identify the described attack patterns while minimizing false positi ves. • Constraints : Agents operate within the containerized en vironment using pro vided tools only . They cannot modify telemetry or access external resources. Figure 1 illustrates two representati ve tasks. 3.2 Simulation and Data Collection CTI-REALM’ s dataset comprises attack simulations executed across three distinct en vironments: Linux endpoints, Azure Kubernetes Service (AKS), and Azure cloud infrastructure. These simulations were deriv ed from 37 publicly av ailable CTI reports and detection references sourced from Microsoft Security , Datadog Security Labs, Palo Alto Netw orks and Splunk Security Content. The selection criteria prioritized (1) variation in attack comple xity , (2) feasibility of accurate recreation, (3) viability for detection rule dev elopment, and (4) representation across dif ficulty lev els. Difficulty and Dataset Composition : Simulations span three dif ficulty tiers - easy (atomic single- step attacks), medium (multi-step sequences), and hard (complex attack chains requiring cross-source correlation). Cloud simulations are e xclusi vely hard, reflecting real-world APT campaign complexity . 1 Kusto Query Language (KQL) is Microsoft’ s query language for Azure Data Explorer , Microsoft Sentinel, and other Azure services. See https://learn.microsoft.com/en- us/kusto/query/ . 3 Example 1: Linux Endpoint Detection (Easy) T ask: Write a detection rule to identify scheduled task cr eation using at command by monitoring for shell commands piped to at, indicating attempts to establish persistence or delayed execution of malicious commands. Ground T ruth — MITRE: T1053 (Scheduled T ask/Job) Sources: DeviceProcessEvents Fields: filename matches at , processcommandline matches pipe-to-at patterns Example 2: Cloud Multi-Step Attack (Hard) T ask: Write a detection rule to identify the creation of r estricted management Administrative Units wher e privile ged administrator s cr eate organizational containers with mana gement restriction pr operties enabled, then add user accounts as members. Monitor for A U cr eation through dir ectory manag ement APIs, followed by member addition activities. Ground T ruth — MITRE: T1078, T1069, T1098, T1484, T1136 Sources: SigninLogs, MicrosoftGraphActivityLogs, AuditLogs Fields: RequestUri matches /directory/administrativeUnits , OperationName ∈ {Add administrativ e unit, Add member to restricted management administrativ e unit} Figure 1: Representativ e CTI-REALM tasks spanning the difficulty spectrum. Linux Endpoints AKS Clusters Azure Cloud 37 CTI Reports T elemetry Collection Cleaning & Anonymization CTI Repository Kusto Cluster T elemetry Logs MITRE A TT&CK DB Sigma Rules DB T ool API (8 functions) LLM Agent (ReAct) Inspect AI Scoring C0 → C1 → C2 → C3 → C4 Sigma Rule KQL Query Figure 2: CTI-REALM en vironment architecture. From the full simulation pool, we construct two stratified e v aluation sets: CTI-REALM-25 (12 Linux, 9 AKS, 4 Cloud) and CTI-REALM-50 (25 Linux, 17 AKS, 8 Cloud). CTI-REALM-25 is a subset of CTI-REALM-50. The smaller set enables rapid iteration and dev elopment testing with lower cost, while CTI-REALM-50 provides a more rob ust ev aluation surface with greater co verage across difficulty le v els and platform categories. Attack Execution and Log Collection : An important architectural distinction in CTI-REALM is the separation between attack e xecution and agent e v aluation en vironments. Simulations are ex ecuted on actual infrastructure, including Linux endpoints, AKS clusters, and other Azure cloud infrastructure hosted on an isolated sandboxed Azure tenant to maintain security and traceability . Realistic telemetry is collected through the Azure Monitor Agent and MDE (Microsoft Defender for Endpoint). Prior to e v aluation, logs undergo cleaning and anonymization to remo ve personally identifiable information (PII). W e also sanitize sensitive infrastructure details and pre vent benchmark contamination by remo ving resource group names, ke y vault identifiers etc. The cleaned logs are then transferred to the containerized ev aluation en vironment where agents perform analysis. 3.3 En vironment Ar chitecture The CTI-REALM ev aluation en vironment is implemented as a containerized Docker system that replicates the operational workspace of security detection engineers. It is inte grated with Inspect AI [14]-a framew ork for LLM agent ev aluation to provide standardized interfaces for task e xecution and scoring. This architecture provides agents with the necessary tools and data to analyze threat intelligence and de v elop detection rules while maintaining isolation and reproducibility . Figure 2 illustrates the end-to-end system. En vironment Components : The container hosts se veral k ey resources : • CTI repository : 37 source reports from Microsoft Security , Datadog Security Labs, P alo Alto Networks, and Splunk Security Content that served as the basis for attack simulations 4 • Kusto Cluster : A query engine enabling agents to execute KQL (K usto Query Language) queries against telemetry data • T elemetry logs : Multi-source security logs collected from the attack simulations • MITRE A TT&CK Database [17] : T echniques and tactic mappings for threat contextual- ization • Sigma rules database : A reference collection of existing detection rules to prevent duplication and provide conte xt T elemetry Data Sour ces : The en vironment contains 12 log sources collected through MDE, Azure Monitor , and Azure AD: endpoint telemetry ( deviceprocessevents , devicefilevents ), AKS logs ( aksaudit , aksauditadmin ), Azure cloud operations ( azureactivity , azurediagnostics ), identity and authentication ( signinlogs , auditlogs , aadserviceprincipalsigninlogs ), and application-layer logs ( officeactivity , microsoftgraphactivitylogs , storagebloblogs ). Each source contains 1–3 days of telemetry incorporating both attack-generated ev ents and benign background acti vity . Agent T ools : Agents interact with the environment through a structured API providing eight special- ized functions, detailed in the appendix. These tools support CTI report retrie val, data exploration, query ex ecution, and threat context mapping. 3.4 Evaluation Framework CTI-REALM frames detection rule development as a sequential decision-making task within a reinforcement learning en vironment. Rather than treating detection engineering as a single-step generation problem, the benchmark models it as a multi-stage process where agents recei ve re ward signals at intermediate checkpoints corresponding to natural progression points in the analytical workflo w . Reinf orcement Learning F ormulation: W e model each detection task as a Marko v Decision Process (MDP) [21] where: • State space S captures the agent’ s current understanding (CTI reports retrie ved, TTPs identified, data sources explored, query results obtained) • Action space A consists of tool in vocations (CTI retriev al, schema inspection, query ex ecution, etc.) • Reward function R provides feedback at fi ve checkpoints throughout the trajectory The total rew ard for a task is computed as: R total = X i ∈{ C 0 ,C 1 ,C 2 ,C 3 ,C 4 } w i · r i (1) where w i represents the weight assigned to checkpoint i (with P w i = 1 ) and r i ∈ [0 , 1] is the normalized reward achiev ed at that checkpoint, yielding R total ∈ [0 , 1] . This decomposes into checkpoint and ground truth components: R total = R checkpoint + R ground truth (2) where: • R checkpoint = P i ∈{ C 0 ,C 1 ,C 2 ,C 3 } w i · r i (35% total weight) • R ground truth = w C 4 · r C 4 (65% total weight) Checkpoint Reward Signals: Each checkpoint ev aluates a distinct aspect of the detection dev elop- ment process: • C0 - CTI Report Analysis ( w C 0 = 0 . 125 , LLM-as-judge): Rewards correct identification and retriev al of rele v ant threat intelligence reports 5 • C1 - Threat Context ( w C 1 = 0 . 075 , Jaccard similarity): Rew ards accurate extraction and mapping of MITRE A TT&CK techniques • C2 - Data Exploration ( w C 2 = 0 . 10 , Jaccard similarity): Rewards identification of rele v ant telemetry sources through schema exploration • C3 - Query Execution ( w C 3 = 0 . 05 , binary): Rewards iterati ve query refinement beha vior ( ≥ 2 successful queries) • C4 - Detection Quality ( w C 4 = 0 . 65 , F1 + LLM-as-judge): Rewards detection rule effecti v eness (KQL correctness via F1-score, Sigma rule quality via judge) This formulation serves dual purposes: (1) enabling comparative e v aluation of reasoning capabilities across agent architectures, and (2) providing training signals for reinforcement learning approaches that lev erage intermediate re wards to learn ef fectiv e security analysis policies. Evaluation Methodologies: The frame work uses both deterministic and non-deterministic ev aluation. The deterministic section includes tool usage verification (for C0 and C3), Jaccard similarity for comparing identified TTPs and data sources against ground truth (C1, C2). Finally , for detection accuracy we use re gexes and F1-score. Non-deterministic e valuation utilizes GPT -5-Mini as an LLM- as-a-judge [19] for assessing report relev ance and detection rule quality . T o validate judge reliability , a sample of LLM-as-judge outputs was manually revie wed by security researchers, confirming alignment between automated rew ards and expert assessment. Full details on ground truth structure, judge prompts, and scoring calibration are provided in Appendix C and Appendix E. 4 Experimental Setup W e e valuate agent performance on CTI-REALM using a ReAct agent framew ork implemented on the Inspect AI [14] platform. This section describes the models tested, agent architecture, and experimental configurations. Models Evaluated: W e assess 16 model configurations: three Anthropic Claude models (Opus 4.6 at the default high reasoning effort [22], Opus 4.5, Sonnet 4.5), nine OpenAI GPT -5 family variants (GPT -5, 5.1, 5.2 each at high/medium/low reasoning ef fort), GPT -5-Mini, GPT -4.1, and two reasoning models (O3, O4-Mini). The reasoning ef fort lev els control the computational b udget for e xtended thinking, enabling analysis of how reasoning depth af fects detection performance. Agent Architectur e: All ev aluations employ a ReAct [13] agent that interleaves reasoning traces with tool in v ocations, mirroring how security analysts alternate between analytical thinking and practical in vestigation. W e use a single agent architecture to isolate model capability dif ferences under controlled conditions; comparing multiple agent frameworks (e.g., plan-and-ex ecute, tree-of-thought) is left to future work. Agents are permitted a maximum of 70 messages per task. Each model is ev aluated on CTI-REALM-50 using identical configurations. Evaluation Protocol: W e conduct ev aluation in four phases to balance comprehensive model cov erage with statistical rigor . In the initial phase, all 16 model configurations are ev aluated on CTI-REALM-50 to establish baseline rankings. In the second phase, we select the top fi ve models for repeated e valuation (three epochs) on CTI-REALM-25 to assess variance and establish confidence intervals. In the third phase, we conduct an ablation study on the same top fi ve models using CTI- REALM-25 with minimal tools (removing CTI-specific capabilities) to measure the impact of tool augmentation. In the fourth phase, we inv estigate memory augmentation by comparing GPT -5-Mini with and without seeded memory conte xt against the full GPT -5 model at multiple reasoning ef fort lev els. This approach enables broad comparison across model families. 5 Results W e present results across four experimental setups: comprehensive model comparison on CTI- REALM-50 (Sections 5.1 – 5.4), variance analysis with repeated runs (Section 5.5), an ablation study examining the impact of CTI-specific tools (Section 5.6), and a memory augmentation study (Section 5.7). 6 T able 1: CTI-REALM Model Performance Summary . All scores normalized to [0,1]. CI = 95% confidence interval. Checkpoint Re ward + Ground T ruth Re ward = Re wards. Model Provider Rewards StdErr 95% CI Checkpoint Reward Ground Truth Rew ard C0 C1 C2 C3 Steps Claude Opus 4.6 (High) Anthropic 0.6373 0.0374 [0.562, 0.712] 0.266 0.372 0.83 0.50 0.82 0.86 31 Claude Opus 4.5 Anthropic 0.6244 0.0338 [0.556, 0.692] 0.287 0.337 0.91 0.56 0.85 0.92 32 Claude Sonnet 4.5 Anthropic 0.5872 0.0328 [0.521, 0.653] 0.278 0.310 0.85 0.54 0.87 0.88 37 GPT -5 (Med) OpenAI 0.5720 0.0337 [0.504, 0.640] 0.235 0.337 0.72 0.54 0.86 0.38 32 GPT -5.2 (Med) OpenAI 0.5716 0.0325 [0.506, 0.637] 0.226 0.346 0.60 0.37 0.86 0.72 31 GPT -5 (High) OpenAI 0.5633 0.0329 [0.497, 0.629] 0.230 0.333 0.66 0.55 0.86 0.40 32 GPT -5.2 (High) OpenAI 0.5513 0.0367 [0.478, 0.625] 0.232 0.319 0.60 0.40 0.85 0.84 35 GPT -5 (Low) OpenAI 0.5413 0.0315 [0.478, 0.605] 0.204 0.337 0.61 0.45 0.84 0.22 25 GPT -5.1 (Med) OpenAI 0.5133 0.0300 [0.453, 0.574] 0.244 0.269 0.72 0.62 0.87 0.42 26 GPT -5.1 (High) OpenAI 0.4946 0.0373 [0.420, 0.570] 0.238 0.256 0.71 0.55 0.80 0.56 29 GPT -5.2 (Low) OpenAI 0.4898 0.0248 [0.440, 0.540] 0.221 0.269 0.57 0.49 0.88 0.50 27 O3 OpenAI 0.4707 0.0281 [0.414, 0.527] 0.204 0.267 0.51 0.38 0.78 0.68 33 GPT -5-Mini OpenAI 0.4506 0.0292 [0.392, 0.509] 0.188 0.263 0.62 0.21 0.84 0.20 27 GPT -4.1 OpenAI 0.4186 0.0235 [0.371, 0.466] 0.193 0.225 0.68 0.29 0.85 0.02 21 GPT -5.1 (Low) OpenAI 0.3731 0.0211 [0.331, 0.415] 0.194 0.179 0.61 0.37 0.87 0.06 22 O4-Mini OpenAI 0.3602 0.0238 [0.312, 0.408] 0.167 0.193 0.48 0.23 0.80 0.20 26 5.1 Overall Model P erformance T able 1 presents the complete results for all 16 model configurations e valuated on CTI-REALM-50. Claude Opus 4.6 (High) achieves the highest normalized rew ard of 0.637 ( ± 0.037 SE), followed closely by Claude Opus 4.5 at 0.624 ( ± 0.034). Anthropic models occupy the top three positions, with Claude Sonnet 4.5 at 0.587. Among OpenAI models, GPT -5 (Med) leads at 0.572, closely followed by GPT -5.2 (Med) at 0.572. 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Rewards O4-Mini GPT -5.1 (Low) GPT -4.1 GPT -5-Mini O3 GPT -5.2 (Low) GPT -5.1 (High) GPT -5.1 (Med) GPT -5 (Low) GPT -5.2 (High) GPT -5 (High) GPT -5.2 (Med) GPT -5 (Med) Claude Sonnet 4.5 Claude Opus 4.5 Claude Opus 4.6 (High) 0.360 0.373 0.419 0.451 0.471 0.490 0.495 0.513 0.541 0.551 0.563 0.572 0.572 0.587 0.624 0.637 CTI-REALM Model P erformance OpenAI Anthropic Figure 3: Model performance on CTI-REALM-50, sorted by normalized reward. The results rev eal several notable patterns across the 0.637–0.419 performance range. Anthropic Claude models occupy the top three positions, with a clear separation from the best OpenAI result (GPT -5 Med, 0.572). This advantage appears driven by stronger tool-use and agentic capabilities, with particularly large gaps in query ex ecution (C3) and CTI comprehension (C0), as detailed in Section 5.3. W ithin the GPT -5 family , medium reasoning effort achie ves the best results across all three generations (GPT -5, 5.1, 5.2), while high reasoning consistently underperforms medium. This pattern is consistent with ov erthinking: higher reasoning b udgets may cause the agent to o ver -elaborate on analytical steps or second-guess effecti ve query strategies, a phenomenon observ ed in other agentic benchmarks where additional reasoning computation yields diminishing or ne gati ve returns. The dedicated reasoning models O3 and O4-Mini similarly underperform general-purpose models, reinforcing that e xtended chain-of-thought reasoning does not directly translate to improved detection engineering capabilities. Of the 120 pairwise comparisons, 71 (59.2%) are statistically significant ( α = 0 . 05 ), with 34 (28.3%) remaining significant after Bonferroni correction. T able 1 also reports per-checkpoint re wards: C0 7 (CTI report analysis), C1 (MITRE technique mapping), C2 (data source exploration), and C3 (query ex ecution rate). 5.2 Category Perf ormance Claude Opus 4.6 (High) Claude Opus 4.5 Claude Sonnet 4.5 GPT -5 (Med) GPT -5.2 (Med) GPT -5 (High) GPT -5.2 (High) GPT -5 (Low) GPT -5.1 (Med) GPT -5.1 (High) GPT -5.2 (Low) O3 GPT -5-Mini GPT -4.1 GPT -5.1 (Low) O4-Mini 0.0 0.2 0.4 0.6 0.8 1.0 A verage Score P erformance by Category Category AKS Cloud Linux (a) Performance by en vironment category . C0 (CTI) C1 (MITRE) C2 (Data) C3 (Query) C4 (Detect) Claude Opus 4.6 (High) Claude Opus 4.5 Claude Sonnet 4.5 GPT -5 (Med) GPT -5.2 (Med) GPT -5 (High) GPT -5.2 (High) GPT -5 (Low) GPT -5.1 (Med) GPT -5.1 (High) GPT -5.2 (Low) O3 GPT -5-Mini GPT -4.1 GPT -5.1 (Low) O4-Mini 0.83 0.50 0.82 0.86 0.57 0.91 0.56 0.85 0.92 0.52 0.85 0.54 0.87 0.88 0.48 0.72 0.54 0.86 0.38 0.52 0.60 0.37 0.86 0.72 0.53 0.66 0.55 0.86 0.40 0.51 0.60 0.40 0.85 0.84 0.49 0.61 0.45 0.84 0.22 0.52 0.72 0.62 0.87 0.42 0.41 0.71 0.55 0.80 0.56 0.39 0.57 0.49 0.88 0.50 0.41 0.51 0.38 0.78 0.68 0.41 0.62 0.21 0.84 0.20 0.40 0.68 0.29 0.85 0.02 0.35 0.61 0.37 0.87 0.06 0.28 0.48 0.23 0.80 0.20 0.30 Checkpoint Scores (Normalized) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Score (b) Mean checkpoint rew ards (C0–C4, normalized). Figure 4: Category and checkpoint analysis on CTI-REALM-50. Performance v aries substantially across platform categories (Figure 4a). Linux tasks yield the highest av erage rewards (0.585 across all models), follo wed by AKS (0.517) and Cloud (0.282). This dif ficulty gradient reflects the underlying task comple xity: Linux simulations include many easy-difficulty atomic attacks with straightforward process-le vel telemetry . Meanwhile, AKS tasks require understanding contai ner orchestration logs, while Cloud tasks in volv e multi-step attack chains requiring correlation across disparate data sources (Azure Activity , Sign-in logs, Diagnostics). The Cloud category , where all 8 simulations are classified as hard difficulty , represents the most real- istic APT -style detection scenarios and rev eals the steepest performance drop across all models. Even the top-performing Claude Opus 4.6 (High) shows a substantial decline on Cloud tasks compared to Linux, demonstrating that current frontier models struggle with the correlation and contextualization demands of advanced cloud threat detection. 5.3 Checkpoint Analysis Figure 4b shows normalized mean rew ards for each checkpoint. C3 (query execution) is the most discriminating - Claude models score 0.86–0.92 while most OpenAI models f all below 0.50, with GPT -4.1 at just 0.02. C1 (MITRE mapping) varies widely (0.21–0.56), with Claude Opus 4.5 leading at 0.56, suggesting that strong CTI knowledge does not guarantee do wnstream performance. C0 (CTI report analysis) separates Claude (0.85–0.91) from most OpenAI models (0.49–0.70), reflecting differences in threat intelligence comprehension that propag ate through subsequent stages. 5.4 Efficiency Analysis Figure 5a illustrates the cost-performance tradeof f using total tokens per sample (a full input/output breakdo wn is provided in T able 6, Appendix A). GPT -4.1 is the most tok en-efficient at ∼ 120K tokens (rew ard 0.419), while GPT -5 (Lo w) offers the best Pareto-frontier balance at ∼ 179K tokens (re ward 0.541). The Anthropic models achieve top re wards with moderate consumption ( ∼ 442–524K). Step counts (Figure 5b) sho w that top-performing models use 30–37 steps on av erage versus 20–27 for weaker models, suggesting ef fecti ve detection engineering requires sustained iterati ve in v estigation. 8 100000 200000 300000 400000 500000 A verage T otal T okens per Sample 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Rewards Claude Opus 4.6 (High) Claude Opus 4.5 Claude Sonnet 4.5 GPT -5 (Med) GPT -5.2 (Med) GPT -5 (High) GPT -5.2 (High) GPT -5 (Low) GPT -5.1 (Med) GPT -5.1 (High) GPT -5.2 (Low) O3 GPT -5-Mini GPT -4.1 GPT -5.1 (Low) O4-Mini Cost-P erformance T radeoff P areto frontier (a) T oken usage vs. rew ard with Pareto frontier . 0 5 10 15 20 25 30 35 A verage Steps per Sample O4-Mini GPT -5.1 (Low) GPT -4.1 GPT -5-Mini O3 GPT -5.2 (Low) GPT -5.1 (High) GPT -5.1 (Med) GPT -5 (Low) GPT -5.2 (High) GPT -5 (High) GPT -5.2 (Med) GPT -5 (Med) Claude Sonnet 4.5 Claude Opus 4.5 Claude Opus 4.6 (High) Agent Steps vs P erformance 0.0 0.2 0.4 0.6 0.8 1.0 Reward Reward (b) A verage steps per sample vs. rew ard. Figure 5: Cost and interaction efficienc y on CTI-REALM-50. T able 2: Score variance across repeated e v aluation runs (CTI-REALM-25). Model Mean Std Min Max 95% CI Claude Opus 4.6 (High) 0.6130 0.2626 0.0000 0.9426 [0.553, 0.673] Claude Opus 4.5 0.6124 0.2522 0.0000 0.9655 [0.554, 0.670] GPT -5 (Med) 0.5454 0.2159 0.2406 0.9002 [0.496, 0.595] GPT -5.2 (Med) 0.5331 0.2254 0.0000 0.9456 [0.481, 0.585] GPT -5.1 (Med) 0.4815 0.1958 0.2416 0.9195 [0.436, 0.527] 5.5 V ariance and Reproducibility T o assess reproducibility , we ev aluated the top fi ve models on CTI-REALM-25 across three epochs (T able 2, Figure 6). The rankings remain stable across runs: Claude Opus 4.6 (High) (mean 0.613, std 0.263) and Claude Opus 4.5 (0.612, std 0.252) maintain their leading positions. The within-model variance is substantial (standard de viations of 0.196–0.263),and is primarily driv en by task difficulty variation. Notably , GPT -5 (Med) shows the most consistent performance with a minimum rew ard of 0.241 (no zero-re ward samples), while the Claude models occasionally receiv e zero re wards on the most dif ficult tasks. This suggests Claude models take higher -risk analytical approaches that either succeed well or fail completely . The full reward distrib utions are visualized in Figure 6 (Appendix A). 5.6 Ablation: Impact of CTI T ools T o validate that agents genuinely lev erage CTI-specific tools rather than relying on parametric knowledge, we conducted an ablation study removing CTI report retriev al and threat conte xt tools from the agent’ s toolkit. T able 3 summarizes the results. All fiv e models show performance degradation without CTI tools. Claude Opus 4.5 shows the largest absolute drop ( ∆ = − 0 . 150 ), falling from 0.612 to 0.462. GPT -5 (Med) drops by 0.134, and GPT -5.1 (Med) by 0.117. Even the top model, Claude Opus 4.6 (High), drops by 0.077. Since removing CTI tools mechanically zeroes C0, we exclude it from the per-checkpoint com- parison. The right side of T able 3 sho ws the remaining deltas (positiv e = full toolkit bet- ter). C1 (MITRE mapping) is negativ e for all models, indicating agents compensate by calling search_mitre_techniques more aggressiv ely without CTI context. C3 (query ex ecution) is posi- tiv e for three of fiv e models, suggesting agents struggle to construct effecti v e queries without CTI guidance. C4 (detection quality) is non-negativ e across all models, confirming that the overall re ward drop is driv en by degraded detection rule quality . CTI context is essential for producing high-quality detections, ev en if intermediate checkpoints can be reached through alternati ve paths. 9 T able 3: Ablation study: impact of remo ving CTI-specific tools. ∆ = Full − Minimal. Per-checkpoint deltas are normalized; C0 excluded (mechanically zeroed without CTI tools). Model Full Score Minimal Score ∆ Cohen’ s d ∆ C1 ∆ C2 ∆ C3 ∆ C4 Claude Opus 4.6 (High) 0.6130 0.5358 +0.0772 0.30 -0.17 -0.13 -0.12 +0.01 Claude Opus 4.5 0.6124 0.4624 +0.1500 0.59 -0.06 +0.04 +0.03 +0.06 GPT -5 (Med) 0.5454 0.4120 +0.1335 0.64 -0.07 -0.02 +0.16 +0.07 GPT -5.2 (Med) 0.5331 0.4555 +0.0776 0.35 -0.14 -0.03 +0.04 +0.02 GPT -5.1 (Med) 0.4815 0.3641 +0.1174 0.61 -0.05 +0.02 -0.04 +0.04 T able 4: Memory augmentation study results. Seeded = with memory context. Model Score Checkpoint Re ward Ground Truth Re ward C0 C1 C2 C3 C4 GPT -5 (Med) 0.5556 0.229 0.326 0.72 0.54 0.80 0.40 0.50 GPT -5 (Low) 0.5478 0.217 0.331 0.64 0.60 0.81 0.20 0.51 GPT -5 (High) 0.5348 0.249 0.286 0.73 0.58 0.83 0.64 0.44 GPT -5-Mini (Memory) 0.4324 0.207 0.225 0.66 0.44 0.86 0.12 0.35 GPT -5-Mini 0.3714 0.182 0.189 0.66 0.22 0.78 0.12 0.29 5.7 Memory A ugmentation: Closing the Gap with Larger Models W e in vestig ate whether smaller models can be augmented to approach larger model performance by providing GPT -5-Mini with seeded memory context. The seeded content consists of human-authored domain guidance: a structured detection engineering w orkflow , tool-specific usage tips (e.g., KQL query patterns, common deb ugging strategies), and template patterns for Sigma rules and KQL queries (see Appendix H for e xamples). Importantly , this is expert-distilled kno wledge rather than extracted model trajectories, so the augmentation does not constitute model-to-model distillation. T able 4 compares GPT -5-Mini without memory (0.371), with memory (0.432), and GPT -5 at three reasoning lev els as upper bounds. Memory augmentation closes 33% of the 0.184-point gap to GPT -5 (Med). The improvement is concentrated in knowledge-dependent checkpoints: C1 (MITRE mapping) doubles from 0.22 to 0.44, and the ground truth re ward improv es by 19%. Howe v er , C3 (query ex ecution) remains unchanged at 0.12, suggesting query construction is an inherent model capability rather than a knowledge g ap. The remaining gap to GPT -5 lies primarily in C3 (GPT -5 Med achieves 0.40) and detection quality , indicating the lar ger model’ s adv antage is in iterativ e query refinement rather than domain knowledge. 6 Use Cases CTI-REALM serves multiple purposes beyond model comparison. Security teams can use it for model selection , identifying which models best suit operational needs. Our results suggest Claude Opus for quality , GPT -5 (Low) for cost-efficienc y . The checkpoint-based evaluation enables capability gap analysis : a model scoring high on C2 but low on C3 would benefit from query construction improv ements rather than additional CTI context. The ablation and memory studies provide a framew ork for tool and augmentation design , measuring whether ne w tools or retrie val strategies meaningfully improv e outcomes. Finally , the checkpoint re ward structure pro vides training signals for RL-based appr oaches to detection engineering. 7 Limitations (1) No full SOC r eplication. CTI-REALM cannot replicate a production-scale SOC en vironment, so it does not e valuate query optimization ag ainst real telemetry volumes or long-baseline anomaly detection ov er extended time windo ws. (2) Azure-centric. The benchmark targets Azure-native telemetry (MDE, Azure Monitor , Azure AD) and KQL; results may not generalize to A WS/GCP en vironments or alternative SIEM query languages. 10 8 Discussion and Conclusion W e introduced CTI-REALM, a benchmark for e valuating AI agents on realistic detection engineering workflo ws. Our ev aluation of 16 frontier models rev eals that medium reasoning ef fort consistently outperforms high and lo w settings. Anthropic Claude models lead overall (Opus 4.6 High: 0.637), and CTI tools provide genuine augmentation (0.019–0.038 point improv ements) that propagates through the entire workflo w . W e also saw that memory augmentation closes 33% of the gap between GPT -5- Mini and GPT -5 through improved MITRE mapping, while query construction remains an inherent model capability . Cloud-based multi-step detection remains the most significant challenge (0.282 vs 0.585 for Linux). Future work includes expanding platform co verage and data size, incorporating more tooling systems and exploring dif ferent types of agentic harnesses. Acknowledgements The authors would like to thank the Microsoft Security AI Benchmarking and Evaluation team and the broader Microsoft Security (MSEC) organization for their support and contrib utions to this work. 11 References 1. Adar , E., & Dankwa, R. (2024). LLMCloudHunter: Harnessing LLMs for Automated KQL-Based Cloud Threat Hunting and Sigma Rule Generation. arXiv preprint . 2. Mitra, S., et al. (2024). IntelEX: A LLM-dri ven Attack-le vel Threat Intelligence Extraction Frame work. arXiv pr eprint arXiv:2407.11191 . 3. Mukherjee, A., et al. (2024). SigmaGen: Automated Generation of Sigma Rules from Threat Reports. Pr oceedings of the AAAI Confer ence on Artificial Intelligence . 4. Gao, P ., et al. (2024). RuleGenie: Optimizing Detection Rule Sets with Large Language Models. IEEE Symposium on Security and Privacy . 5. Hall, J. (2024). ADÉ: Agentic Detection Engineering for Email Security . Sublime Security T echnical Report. 6. Al-Shaer , R., et al. (2024). Rule-A TT&CK Mapper: Mapping SIEM Rules to MITRE A TT&CK Using Multi-Stage LLM Pipelines. Digital Threats: Researc h and Practice . 7. Orbinato, V ., et al. (2024). Comparative Study on LLMs for TTP Classification: Encoder-Based vs. Decoder-Based Models with RA G. ACM CCS W orkshop on AI Security . 8. Alam, M., et al. (2024). CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence. arXiv pr eprint arXiv:2406.07599 . 9. Gylling, A., et al. (2024). AthenaBench: Evaluating LLMs on Cyber Threat Intelligence with Dynamic Data. Conference on Applied Mac hine Learning in Information Security (CAMLIS) . 10. T undis, A., et al. (2025). ExCyTIn-Bench: An Extensible Cyber Threat In vestigation Benchmark. arXiv pr eprint arXiv:2502.13379 . 11. Sanz-Gómez, M., Mayoral-V ilches, V ., et al. (2025). Cybersecurity AI Benchmark (CAIBench): A Meta-Benchmark for Evaluating Cybersecurity AI Agents. arXiv pr eprint arXiv:2510.24317 . 12. Red Canary . (2024). Atomic Red T eam. https://github.com/redcanaryco/ atomic- red- team . 13. Y ao, S., et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. International Confer ence on Learning Repr esentations (ICLR) . 14. UK AI Safety Institute. (2024). Inspect: A Frame work for Large Language Model Evaluations. https://inspect.ai- safety- institute.org.uk/ . 15. Bertiger , A., et al. (2025). Evaluating LLM Generated Detection Rules in Cybersecurity . Confer ence on Applied Machine Learning in Information Security (CAMLIS) . arXi v:2509.16749. 16. Deason, L., et al. (2025). CyberSOCEval: Benchmarking LLMs Capabilities for Malware Analysis and Threat Intelligence Reasoning. CyberSecEval 4 . 17. Strom, B.E., et al. (2018). MITRE A TT&CK: Design and Philosophy . MITRE T echnical Report MTR180312 . 18. Cheng, Y ., et al. (2025). CTIArena: Benchmarking LLM Knowledge and Reasoning Across Heteroge- neous Cyber Threat Intelligence. arXiv preprint . 19. Zheng, L., et al. (2024). Judging LLM-as-a-Judge with MT -Bench and Chatbot Arena. Advances in Neural Information Pr ocessing Systems (NeurIPS) . 20. Jimenez, C.E., et al. (2024). SWE-bench: Can Language Models Resolve Real-W orld GitHub Issues? International Confer ence on Learning Repr esentations (ICLR) . 21. Sutton, R.S. and Barto, A.G. (2018). Reinfor cement Learning: An Introduction . MIT Press, 2nd edition. 22. Anthropic. (2025). Adaptive Thinking (Extended Thinking). https://platform.claude.com/ docs/en/build- with- claude/adaptive- thinking . 12 A Additional Results Claude Opus 4.6 (High) Claude Opus 4.5 GPT -5 (Med) GPT -5.2 (Med) GPT -5.1 (Med) 0.0 0.2 0.4 0.6 0.8 1.0 Score Score Distribution (Repeated Runs) Figure 6: Reward distrib utions across three repeated runs on CTI-REALM-25. B Agent T ools T able 5 describes the eight specialized tools av ailable to agents during e v aluation. T able 5: Agent tool API. T ool Description list_cti_report_tags Lists all av ailable CTI report tags with metadata get_cti_reports_by_tag Retriev es full CTI reports filtered by tag identifier list_kusto_tables Lists a v ailable telemetry tables and their schemas get_table_schema Returns column definitions for a specific table execute_kql_query Ex ecutes KQL queries against the Kusto cluster get_mitre_techniques Retriev es MITRE A TT&CK technique details by ID search_sigma_rules Searches the Sigma rule database by keyw ord submit_detection Submits final Sigma rule and KQL query for ev aluation C Evaluation Details Ground T ruth Structure. Each task includes a structured ground truth object with three components: • mitre_techniques — A list of expected MITRE A TT&CK technique IDs (e.g., ["T1115"] ). Used for C1 scoring via Jaccard similarity between the agent’ s identified techniques and the ground truth set. • data_sources — A list of expected telemetry tables the agent should explore (e.g., ["deviceprocessevents"] ). Used for C2 scoring via Jaccard similarity between ta- bles the agent queried or inspected and the expected set. • regex_patterns — A dictionary mapping field names to re gex patterns that capture k ey indicators of compromise (e.g., {"filename": "wl-paste|xclip|xsel"} ). Used for C4 F1 scoring: each row in the agent’ s KQL query results is matched against these patterns. A row is a true positiv e if all field patterns match; precision, recall, and F1 are computed across all returned rows. The complete structure per task is: {"ground_truth": { 13 "mitre_techniques": ["T1115"], "data_sources": ["deviceprocessevents"], "regex_patterns": { "filename": "wl-paste|xclip|xsel", "initiatingprocessfilename": "bash|sh|dash" } }} LLM-as-Judge Configuration. C0 (CTI report analysis) and C4 (Sigma rule quality) use GPT -5-Mini as an automated judge. For C0, the judge e v aluates tag rele vance, report selection appropriateness, and reasoning quality on a 0–1 scale. F or Sigma quality , the judge assesses syntax correctness (weight 0.25) and detection specificity (weight 0.75), producing a weighted quality rew ard. D Agent Prompts D.1 Standard Agent Prompt The follo wing system prompt is used for all standard e v aluations (CTI-REALM-25, CTI-REALM-50) and the ablation study . In the ablation variant, the CTI-specific tools ( list_cti_report_tags , get_cti_reports_by_tag ) are remo ved from the agent’ s toolkit, but the prompt text remains identical. Standard Agent System Prompt You are a cybersecurity analyst creating detection rules from threat intelligence. ## Mission 1. **Find and analyze relevant CTI report**: Search available threat intelligence reports and explain why the selected report relates to your detection objective 2. **Create detection capability** with: (1) Sigma rule, (2) KQL query, (3) Query results ## Resources You have access to various tools for threat intelligence analysis, detection rule development, and data querying. Use your available tools to explore capabilities and complete the mission. ## Output Format (JSON only, no extra text) { "sigma_rule": "", "kql_query": "", "query_results": [{"column1": "value1", ...}, ...] } Note: query_results must be the actual array returned by execute_kql_query. D.2 Memory-A ugmented Agent Prompt The memory v ariant adds a Memory section to the standard prompt, instructing the agent to consult pre-loaded guidance files before beginning its in vestigation. Memory A ugmentation Addition (inserted between Resour ces and Output Format) ## Memory You have a ‘memory‘ tool with pre-loaded guidance in /memories/. **Before starting any investigation, use the memory tool to view /memories/ and read the files there.** They contain workflow steps, tool tips, and common patterns that will help you work more effectively. Refer back to your memory notes when you get stuck. 14 E LLM-as-Judge Pr ompts E.1 C0: CTI Threat Alignment Judge This judge ev aluates whether the agent’ s threat intelligence research is rele vant to the detection objectiv e and whether the agent clearly e xplained the connection. The judge scores on a 0.0–1.0 scale. C0 Judge System Pr ompt You are evaluating whether an AI agent’s threat intelligence research is relevant to the detection objective and whether they clearly explained the connection between selected CTI reports and the detection task. C0 Judge Instructions (abbr eviated) Consider these aspects: 1. Did the agent search for tags that match the detection objectiv e? 2. Did they identify specific CTI reports or threat intelligence? 3. Did they e xplain WHY the reports are relev ant to the detection task? Scoring calibration (from few-shot examples): • 1.0 : Highly relev ant tags, specific report found, outstanding reasoning connecting report to objectiv e with MITRE technique references • 0.8 : Relevant tags, good report selection, solid reasoning about rele v ance • 0.5 : Adequate tags, reports found but not specified, very weak reasoning • 0.2 : Mismatched tags, no evidence of report analysis, no explanation of rele v ance E.2 C4: Sigma Rule Quality Judge This judge ev aluates Sigma rules for production readiness across two dimensions: syntax correctness (weight 0.25) and detection specificity (weight 0.75). C4 Sigma Judge System Pr ompt You are a Sigma rule evaluator. C4 Sigma Judge Instructions (abbr eviated) Evaluate Sigma rules for production readiness: Syntax score (0.0–1.0, weight 0.25): • Is the Y AML valid and parseable? • Are critical fields present (title, logsource, detection, condition)? • Are recommended fields included (id, status, description, lev el)? Specificity score (0.0–1.0, weight 0.75): • Does the rule match the detection objectiv e precisely? • Are there specific conditions that reduce false positiv es? • W ould this rule be effecti ve in a production en vironment? Scoring calibration (from few-shot examples): • Syntax 1.0 / Specificity 0.95 : All required fields, proper Y AML, MITRE tags, specific operation names for target beha vior • Syntax 1.0 / Specificity 0.75 : All required fields, tar gets correct operation but could add contextual filters 15 • Syntax 0.7 / Specificity 0.2 : Missing metadata fields; triggers on broad cate gory (e.g., any PowerShell) rather than specific beha vior • Syntax 0.3 / Specificity 0.0 : Missing detection section entirely • Syntax 0.1 / Specificity 0.0 : Malformed Y AML, cannot parse Final Sigma quality score: 0 . 25 × syntax + 0 . 75 × specificity F T oken Usage T able 6: Per-sample token usage breakdo wn on CTI-REALM-50, sorted by re ward. Model Input Output Reasoning T otal Claude Opus 4.6 2,269 7,116 — 472,352 Claude Opus 4.5 2,437 7,434 — 441,915 Claude Sonnet 4.5 71 9,528 — 523,693 GPT -5 (Med) 326,535 9,975 4,858 336,510 GPT -5.2 (Med) 367,329 8,129 3,095 375,457 GPT -5 (High) 390,512 11,990 6,729 402,501 GPT -5.2 (High) 528,312 11,022 5,701 539,333 GPT -5 (Lo w) 172,250 6,863 1,857 179,113 GPT -5.1 (Med) 243,210 14,054 7,745 257,265 GPT -5.1 (High) 420,308 24,100 17,359 444,408 GPT -5.2 (Lo w) 220,518 5,432 1,123 225,950 O3 360,962 7,685 3,259 368,647 GPT -5-Mini 238,206 14,056 5,958 252,263 GPT -4.1 116,855 3,468 — 120,323 GPT -5.1 (Lo w) 135,373 6,077 1,026 141,450 O4-Mini 185,854 6,931 4,214 192,784 G Example Agent T rajectory The following sho ws an abbreviated trajectory from Claude Opus 4.6 (High) on a Linux endpoint task (sample linux_041 , rew ard: 0.552). The agent completed the task in 11 reasoning steps across 36 messages. T ask Objective Write a detection rule to identify scheduled task creation using at command by monitoring for shell commands piped to at , indicating attempts to establish persistence or delayed execution of malicious commands. Agent Steps Step 1 — list_cti_report_tags , search_mitre_techniques , list_kusto_tables “I’ll start by resear ching the thr eat landscape, available data, and rele vant detection techniques for scheduled task creation using the at command. ” → Found T1053 (Scheduled T ask/Job) as the relev ant MITRE technique; listed av ailable tables. Step 2 — get_cti_reports_by_tag × 2, search_sigma_rules × 2, get_table_schema “T1053 is the r elevant technique. Let me get CTI reports for scheduled tasks and e xamine the data tables. ” → Retrie ved CTI reports on Linux crontab; no Sigma rules for at specifically; obtained DeviceProcessEvents schema. Step 3 — get_cti_reports_by_tag , search_sigma_rules × 2, sample_table_data “Let me sear ch for mor e specific CTI reports and Sigma rules, and look at the data. ” → Found rele vant CTI report from Elastic Security Labs co vering T1053.002; sampled telemetry . Step 4 — search_sigma_rules × 2, execute_kql_query “F ound the Elastic report specifically co vering T1053.002 (At). Let me searc h for existing Sigma rules. ” → Found e xisting Sigma rule “Scheduled T ask/Job At”; initial query returned at command activity . Step 5 — execute_kql_query “F ound data with at command usage. Let me run a more focused query for piped commands to at. ” → Identified specific patterns in process command lines. Step 6–9 — execute_kql_query × 4 “Iteratively r efining queries to captur e pipe-to-at patterns, file input (-f flag), and en v wrapper patterns. ” → Found k ey attack pattern: echo ’command’ | at now + 3 minutes ; identified three distinct attack variants. 16 Step 10 — execute_kql_query “Building the compr ehensive detection query covering all three attac k patterns. ” → Final query returned 10 results cov ering pipe-to-at, file input, and en v wrapper patterns. Step 11 — validate_output_json “V alidating the final output JSON. ” → Output v alidated successfully . Final Output (abbr eviated) Sigma Rule: title: Scheduled Task Creation via Shell Command Piped to At status: experimental description: Detects scheduled task creation using ’at’ where shell commands are piped to ’at’ via echo/printf/cat, or ’at’ is invoked with -f flag for script execution. tags: [attack.persistence, attack.t1053.002] logsource: {category: process_creation, product: linux} detection: selection: Image|endswith: ’/at’ CommandLine|contains|any: [’| at ’,’at -f’,’-c at’] condition: selection level: medium KQL Query: DeviceProcessEvents | where (ProcessCommandLine matches regex @"\|\s*at\s+(now|noon|midnight|\d{1,2}:\d{2})") or (ProcessCommandLine has "| at " and ProcessCommandLine has_any ("echo","printf","cat","bash","sh")) or (FolderPath endswith "/at") | project Timestamp, DeviceName, AccountName, FileName, ProcessCommandLine, InitiatingProcessFileName Scoring Breakdo wn Rewards sho wn as weighted checkpoint rew ards ( w i × r i scaled to 10 points); individual r i ∈ [0 , 1] . C0 CTI Report Analysis: 1.12/1.25 C1 MITRE Mapping: 0.75/0.75 C2 Data Exploration: 1.00/1.00 C3 Query Execution: 0.50/0.50 C4 Detection Quality: 2.65/6.50 (F1: 0.35, Sigma: 0.61) T otal: 5.52/10.0 → Normalized Reward: 0.552 H Seed Memory Content The memory augmentation study (Section 5.7) provides the agent with three pre-loaded guidance files. Excerpts from each are shown belo w . H.1 W orkflow Guidance Provides a structured step-by-step detection engineering workflo w . workflow .md (excerpt) # CTI Detection Rule Development Workflow ## Critical: Always Start With CTI Reports Successful investigations begin by understanding the threat BEFORE exploring data. Do NOT jump straight to data tables. ## Recommended Steps 1. Discover CTI reports –- use list_cti_report_tags() to see available tags, then get_cti_reports_by_tag(tag) to pull reports matching your detection objective. 2. Map MITRE techniques –- use search_mitre_techniques(tactic) to find technique IDs. 3. Search Sigma rules –- use search_sigma_rules() to find existing detection logic to adapt. 4. Explore data –- use list_kusto_tables(), get_table_schema(table), sample_table_data(table). 17 5. Write & test KQL –- use execute_kql_query(query). 6. Build Sigma rule –- write a YAML Sigma rule. 7. Validate & submit –- call validate_output_json(). H.2 T ool Usage Tips Provides specific guidance on each tool function, including common f ailure modes and deb ugging strategies. tool_tips.md (excerpt) # Tool Usage Tips ## CTI Report Tools (use these FIRST) - list_cti_report_tags(): Returns all available tags with report counts. Start here to find matching tags. - get_cti_reports_by_tag(tag): Returns full reports with id, title, link, tags, and content. ## Kusto/KQL Tools - list_kusto_tables(): Discover available tables. Do not guess table names. - get_table_schema(table): Get exact column names and types. Always check BEFORE writing any query. - execute_kql_query(query): If 0 rows returned: 1. Check column names match the schema exactly 2. Use ‘contains‘ instead of ‘==‘ for string filters 3. Remove time filters to broaden results H.3 Common Patterns Provides template patterns for Sigma rules and KQL queries, plus an in vestigation decision tree for debugging. patterns.md (excerpt) # Common Patterns ## Sigma Rule Skeleton title: status: experimental tags: - attack. - attack. logsource: category: product: detection: selection: FieldName|: condition: selection ## Investigation Decision Tree - Query returns 0 rows? → Check column names against schema → Broaden filters: contains instead of == → Sample the table to see actual values - Query returns errors? → Verify table name via list_kusto_tables() → Check KQL syntax 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment