Ethical Fairness without Demographics in Human-Centered AI
Computational models are increasingly embedded in human-centered domains such as healthcare, education, workplace analytics, and digital well-being, where their predictions directly influence individual outcomes and collective welfare. In such contex…
Authors: Shaily Roy, Harshit Sharma, Daniel A. Adler
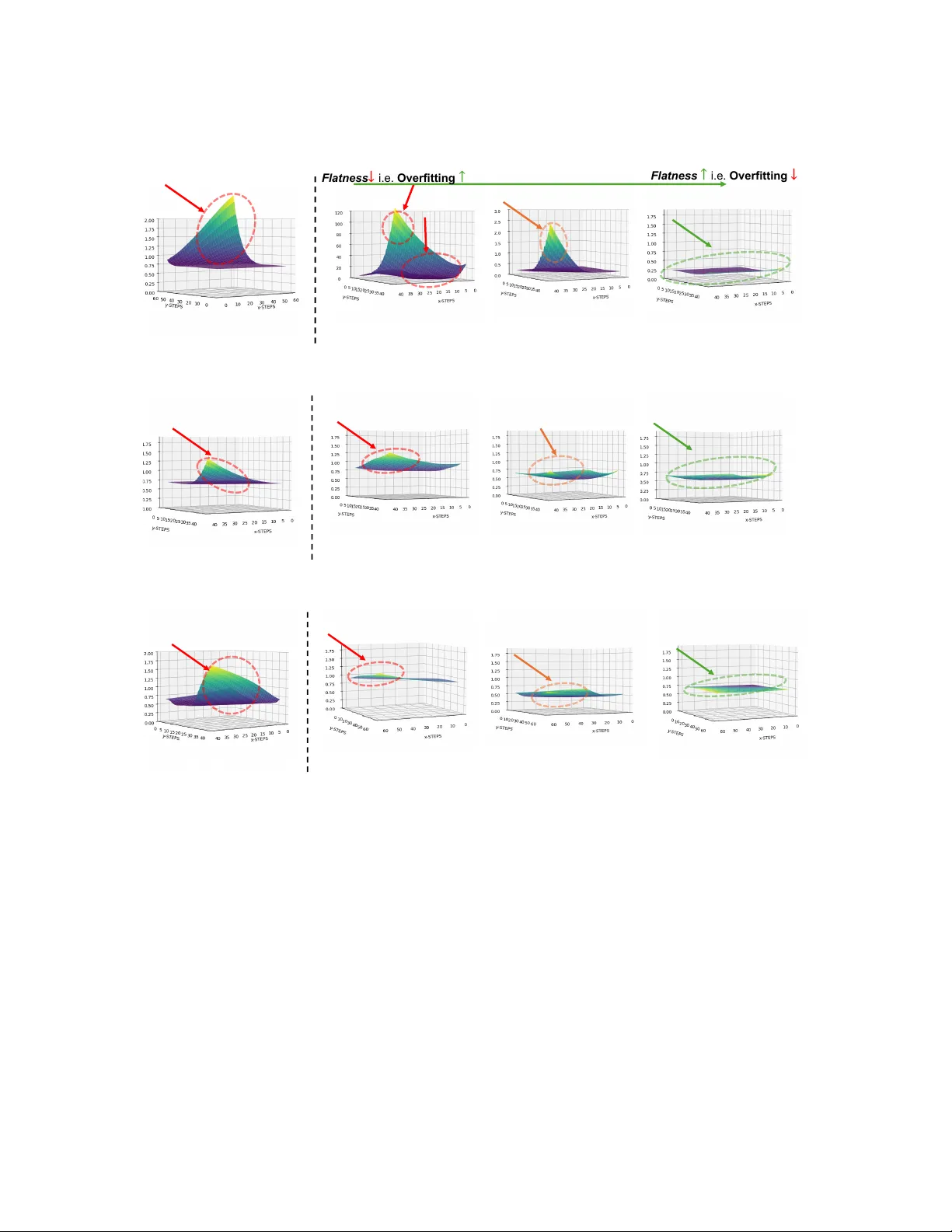
Ethical Fairness without Demographics in Human-Centered AI SHAIL Y RO Y, Ira A. Fulton Schools of Engineering, Arizona State University, USA HARSHI T SHARMA, Ira A. Fulton Schools of Engineering, Arizona State University, USA D ANIEL A. ADLER, Information Science, Cornell University, USA T ANZEEM CHOUDH URY, Cornell University, USA ASIF SALEKIN, Ira A. Fulton Schools of Engine ering, Arizona State University, USA Computational models are increasingly embedded in human-centered domains—healthcare, education, workplace analytics, and digital w ell-being—where their pr edictions directly inuence individual outcomes and collective w elfare. In such conte xts, achieving high accuracy alone is insucient; models must also act ethically and equitably across diverse populations. How- ever , fair AI approaches that r ely on demographic attributes are often impractical, as such information is often unavailable, privacy-sensitive, or r estricted by regulatory frameworks. Moreover , conventional parity-based fairness approaches, while aiming for equity , can inadvertently violate core ethical principles—by trading o subgroup p erformance or stability . T o address this challenge, we present Flare —Fisher-guided LAtent-subgroup learning with do-no-harm REgularization, the rst demographic-agnostic framework that aligns algorithmic fairness with ethical principles through the ge ometry of optimization. Flare leverages Fisher Information to regularize curvature, uncovering latent disparities in model behavior without access to demographic or sensitive attributes. By integrating representation, loss, and curvature signals, it identies hidden performance strata and adaptively renes them through collab orativ e but do-no-harm optimization—enhancing each subgroup ’s performance while preserving global stability and ethical balance. W e also introduce BHE (Benecence–Harm A voidance–Equity), a novel metric suite that operationalizes ethical fairness e valuation beyond statistical parity . Extensive evaluations across diverse physiological (ED A), behavioral (IHS), and clinical (Ohio T1DM) datasets show that Flare consis- tently enhances ethical fairness compared to state-of-the-art baselines. Comprehensive ablation and loss-landscape analyses validate its design principles, and runtime evaluations conrm its practicality for resource-constrained edge deployment. A CM Reference Format: Shaily Ro y, Harshit Sharma, Daniel A. Adler, T anzeem Choudhury , and Asif Salekin. 2024. Ethical Fairness without Demograph- ics in Human-Centered AI. ACM J. A uton. T ransp ort. Syst. 0, 0, Article 0 ( 2024), 32 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Articial intelligence (AI) is rapidly becoming a cornerstone of modern healthcar e, integrating data-driven intelligence across human-sensing domains to enhance diagnosis, risk prediction, and continuous monitor- ing—transforming raw multimodal data from health records, medical images, and wearables into actionable, personalized insights [ 53 , 71 , 87 , 88 , 100 , 103 ]. Y et these gains come with a persistent risk: performance is not uni- form. Hidden heterogeneity in physiology , behavior , context, and device usage often yields uneven performance A uthors’ Contact Information: Shaily Roy, shailyro@asu.edu, Ira A. Fulton Schools of Engineering, Arizona State University, T empe, Arizona, USA; Harshit Sharma, hsharm62@asu.e du, Ira A. Fulton Schools of Engineering, Arizona State University, T empe, Arizona, USA; Daniel A. Adler, daa243@cornell.edu, Information Science, Cornell University, New Y ork, New Y ork, USA; Tanzeem Choudhury, tanzeem.choudhury@cornell.edu, Cornell University, Ithaca, New Y ork, USA; Asif Salekin, asalekin@asu.edu, Ira A. Fulton Schools of Engineering, Arizona State University, T empe, Arizona, USA. Permission to make digital or hard copies of all or part of this work for p ersonal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is p ermitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specic permission and /or a fee. Request p ermissions from permissions@acm.org. © 2024 Copyright held by the owner/author(s). Publication rights licensed to A CM. A CM 2833-0528/2024/0- ART0 https://doi.org/XXXXXXX.XXXXXXX A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:2 • Tro vato et al. across subgroups, many of which ar e latent [ 2 , 24 , 90 ]. Consequently , models that perform well on average can still systematically underserve spe cic groups, embedding inequities into de cision pipelines and emphasizing the need for subgroup-aware fairness-driven learning approaches [5]. Recent U.S. p olicy dev elopments—such as updates to the Health and Human Services (HHS) nondiscrimination rule and new federal AI governance frameworks—emphasize equitable and privacy-oriented ML in healthcare [ 4 , 85 ]. This vision is echoed in the 2025 Executive Order [ 34 ], which calls for bias-resistant, innovation-driven AI that advances fairness through principled optimization rather than demographic categorization , fostering equity without reinforcing engineered social constructs. In human-centered AI—especially in healthcare—fairness is deeply intertwined with ethics. Ethical AI must not only ensure equitable performance but also uphold the principles of benecence (promoting overall benet), non-malecence (avoiding harm), justice (ensuring equitable treatment), and autonomy (maintaining stability) [ 8 , 23 , 36 ]. Y et, conventional fairness-driven optimization often overlooks these broader ethical dimensions. Methods that focus narrowly on e qualizing performance can inadvertently mask subgroup failures, reduce collective benet, and erode trust in human-centered applications [ 72 ]. This underscores a critical need: fairness and ethical principles must be systematically integrated into AI mo del design and optimization to ensure reliable, trustworthy , and impactful use in sensitive human-centered domains such as healthcare. Guided by these imperatives, this pap er’s goal is to develop human-centered AI models that (i) maximize b oth overall and subgroup-wise accuracy , (ii) reduce disparities, thus improving stability across both subgroups and individuals—without relying on sensitive demographic information or prior knowledge of those subgroups, and (iii) enforce non-degradation so that no subgroup performs worse than a baseline . A central challenge in attaining this goal , as discussed above, is that the information on demographics or sensitive attributes may b e unavailable, or undesirable due to privacy , regulatory , or ethical concerns [ 9 , 21 , 70 , 80 ]. Fairness, therefore , should be pursued through mo del b ehavior rather than demographic super vision. W e appr oach this through the lens of optimization geometr y: the curvature of the loss landscape is tightly linked to robustness, i.e., stability and subgroup disparities. Loss-landscape sharp regions—captured by the high Hessian—are associated with parameters that are highly sensitive to perturbations; subgroups concentrated near such regions tend to lie closer to decision boundaries and experience less stable performance than others [ 17 , 39 , 84 ]. Because computing full Hessians is prohibitive at scale, following the literature [ 51 , 62 , 83 , 96 ], we adopt Fisher Information as a tractable surrogate that preserves key curvature properties. Thus, to attain the ab ov e-discussed goal, this paper introduces Flare —Fisher-guide d LAtent-subgroup learning with do-no-harm REgularization. This demographic agnostic framework aligns fairness with ethical principles by explicitly shaping and leveraging the loss landscape: Through Fisher-informed curvature regularization, Flare learns smoother loss landscapes and more stable decision b oundaries, r educing sensitivity to perturbations and enhancing generalizability—thus reinforcing the ethical principle of autonomy (goal-ii) through stability and reliability . Next, it discovers latent subgroups through joint analysis of embe dding similarity , prediction loss, and curvature response—exposing where model behavior diverges acr oss populations. In doing so, Flare re veals the disparities in model behavior across latent subgr oups, even in the absence of demographic labels—thereby advancing the ethical principle of justice (goal-ii) . Finally , Flare renes mo del behavior by training latent subgroup-specic extensions through a conditional aggr egation, enhancing inter- and intra- subgroup perfor- mance, fairness, and stability , while ensuring that no subgr oup deteriorates as fairness impr oves. This design operationalizes benecence (goal-i) and justice (goal-ii) by improving colle ctive performance and equity , and non-malecence (goal-iii) by safeguarding against subgroup harm. T ogether , these mechanisms yield ethically grounded AI systems that balance ecacy , fairness, and stability across diverse human populations. This work’s primary contributions, embodie d in Flare , are: A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:3 • Ethical fairness without demographics: It introduces Flare , the rst human-centered framework that enforces fairness and ethical consistency without relying on demographic attributes. By integrating model representation–behavior fusion —combining embeddings, cross-entropy loss, and Fisher Information— Flare uncovers latent performance strata, identies underserved subgroups, and promotes ethically constrained fairness across them, all while remaining agnostic to demographic or other sensitive attributes. • Do-no-harm adaptation: It presents a nov el do-no-harm training mechanism that enhances the perfor- mance of underserved or underperforming subgroups without degrading others. This design operationalizes the ethical principles of benecence (improving outcomes) and non-malecence (avoiding harm), while maintaining global equity and model stability . • Ethics-grounded evaluation metrics: T o address the lack of principled e valuation tools, it introduces the BHE (Benet, Harm-avoidance, Equity ), a new metric suite , which directly ties empirical model behavior to core AI ethics principles—quantifying how well a model balances colle ctive impro vement, subgroup protection, and equity in performance variance. • Comprehensive Empirical V alidation and Justication. Through extensive e valuation across phys- iological (ED A), behavioral (IHS), and clinical (Ohio T1DM) datasets, Flare demonstrates that fairness, constrained by ethics, can b e seamlessly integrated into real-world human-centered AI systems. These e xper- iments conrm that Flare achiev es its ab ov e-mentioned goals: (goal-i) improved ov erall and subgroup-wise accuracy (Section 6.2.1), (goal-ii) reduced disparities, thus enhance d stability across subgr oups (Section 6.2.2) and individuals (Section 6.2.3), while ( goal-iii) ensuring non-degradation of any subgroup , both internal to Flare steps (Section 6.2.4), and compared to established baselines (Se ction 6.2.2). Ablation and loss-landscape analyses validate its principled design (Section 6.3), while runtime evaluations on diverse edge platforms (Section 7) conrm its scalability and readiness for trustworthy , e quitable deployment. 2 Related W ork This section reviews related work on algorithmic fairness and ethical AI. W e begin with methods that r ely on demographic information, then discuss fairness approaches that operate without sensitive attributes, subgroup- oriented fairness techniques, and recent eorts to align fairness with ethical and human-centered principles in healthcare. 2.1 Fairness through Demographic Information Early algorithmic fairness methods relied on demographic attributes to constrain predictions[ 9 , 25 , 70 ]. Preprocess- ing methods, such as reweighting or relabeling, reduced training data bias but did not ensure fair representations or predictions under complex decision boundaries [ 42 ]. In-processing techniques addressed this by incorporating fairness directly into the learning objective by modifying loss functions or adding regularizers, enforcing parity in error rates or decision boundaries [ 98 , 99 ]. These metho ds oered ner control but often traded o with overall accuracy . Post-processing strategies adjusted outputs after training, for example by shifting thresholds or randomizing predictions, to satisfy criteria like demographic parity or equalized odds [ 28 , 64 , 89 ]. While simple and exible, the y left underlying representations unchanged and were unstable in deployment [ 22 , 28 ]. Overall, demographic-based methods establishe d the foundation of fairness research but remain limited by their dependence on sensitive attributes—often unavailable or undesirable in domains such as human sensing [ 21 , 70 ]. 2.2 Fairness without Demographic (F WD ) The growing need for fairness without relying on sensitive demographic attributes has driven ne w approaches to mitigate bias [ 14 , 46 , 49 ]. Adversarial re weighting dynamically adjusts instance weights during training to emphasize underperforming or misclassied samples, thereby mitigating disparities across hidden subgroups [ 49 ]. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:4 • Tro vato et al. Howev er , such re weighting can destabilize optimization and often reduces overall accuracy , since amplifying dicult instances may distort the training objective. Another direction is knowledge distillation (KD), where a complex teacher model transfers knowledge to a simpler student mo del. Adapted to fairness, this approach allows the student to inherit subgroup performance improvements from the teacher without requiring access to demographic attributes [ 14 ]. Y et KD-based methods remain highly dependent on the quality of the teacher model; if the teacher encodes biased representations, those biases may be propagated or ev en amplied in the student. Furthermore, distillation often struggles to generalize to underrepresented subgroups, limiting its ability to ensure equitable outcomes. Ni et al. propose Reckoner [ 68 ], a condence-based hierarchical framework for fairness without sensitive attributes. Reckoner partitions data into high- and low-condence subsets and trains dual models that exchange pseudo-label information to r educe the inuence of biased features. Learnable noise is injected to mitigate lab el bias, and the framework achie ves improv ed fairness–accuracy trade-os across tabular datasets. Despite these gains, Reckoner’s reliance on condence-based partitioning can make its performance sensitive to threshold selection and mo del initialization. Luo et al. introduce Graph of Gradients (GoG) [ 59 ], showing that last-layer gradients corr elate more strongly with unobserved sensitive subpopulations than raw features. GoG formulates a Rawlsian max–min objective through an adversarial reweighting game: for each minibatch, it computes per-example losses and last-layer gradients, constructs a 𝑘 -NN graph in gradient space, and passes these node features through a one-lay er GCN to produce instance weights. This design enables the adversary to emphasize locally coherent “gradient neighborhoods” instead of isolate d har d samples, stabilizing training compared to instance-wise reweighting. How ever , GoG’s success dep ends heavily on the stability of 𝑘 -NN graph construction and the expr essivity of its shallow GCN, which can suer from ov er-smoothing and sensitivity to noise [ 35 , 43 ]. While prior approaches aim to make model behavior uniformly fair , such unguided optimization often complicates training and risks degrading performance. Our perspective instead is that fairness can b e achieved more eectively by identifying and addressing latent disparities —hidden dierences in how models treat similar and dissimilar instances. This targeted strategy simplies optimization, provides structure to fairness adjustments, and enables more stable learning. Given their relevance and demonstrated impact, we adopt adversarial reweighting ( ARL), knowledge distillation (KD), Graph of Gradients (GoG), and Reckoner as our baselines for comparison in this study . 2.3 Subgroup-oriented Fairness Beyond methods that rely on e xplicit demographics or av oid them entirely , a gr owing line of work targets subgroup-oriented fairness by enforcing equity across diverse population partitions. However , Kearns et al. [ 45 ] showed that optimizing fairness for a small set of protected groups can yield “fairness gerrymandering, ” where other subgroups suer large disparities. Hébert-Johnson et al. [ 31 ] addressed this via multicalibration, enforcing predictive calibration across broad subgr oup families. Another related line of research focuses on achieving equitable subgroup performance through distributionally robust optimization (DRO ). Given access to gr oup annotations, these methods aim to minimize the worst-case subgroup error . For example, Group DRO (Group Distributionally Robust Optimization) [ 75 ] achieves this by dynamically adjusting the training objective to focus on the gr oups with the highest loss. Building on this, Liu et al. [ 58 ] proposed Just Train Twice ( JT T), which removes the nee d for explicit group labels by rst using a baseline model to identify high-loss or misclassied samples as latent hard subgroups, then retraining a new model that upweights these samples to boost performance on the worst-performing groups. Despite gains, two limits remain: (i) dependence on predene d or pro xy groupings that may be unavailable or too coarse for ne-grained heterogeneity , and (ii) objectives centered on the worst group, leaving non-worst disparities unresolved. Howe ver , in practical settings, subgroup gaps often persist even when average or worst- group accuracy improv es [48]. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:5 Additionally , Sohoni et al. [ 78 ] investigated hidden stratication , where a single class label conceals multiple unlabeled subclasses with var ying diculty . Their approach clusters data within each class to identify these subclasses and then applies Group-DRO to optimize the worst-case subclass accuracy . The clustering is strictly class-conditional—each subclass remains tied to its original class—and the objective is to impr ove within-class robustness. In contrast, our work does not operate through class-conditioned subclass formation. W e examine model b ehavior using latent, class-agnostic clusters that capture variations in repr esentation and sensitivity , allowing ethically constrained fairness evaluation beyond demographics and class-specic partitions. 2.4 Ethical AI in healthcare and aligning with human-centered modeling Ethical AI in healthcare centers on four principles: benecence (promote patient w ell-being), non-malecence (avoid foreseeable harm), justice (ensure equitable treatment across groups), and autonomy (enable informed, voluntary choices) [ 8 , 23 , 36 ]. These principles are e choed across international AI ethics guidelines and form a shared foundation for trustworthy AI [ 19 , 41 ]. Howev er , principles alone are insucient—they must be translated into practical design and evaluation steps for real-w orld systems [ 65 ]. In healthcare, wher e AI models are incrementally inuencing patient outcomes and clinical decisions, such alignment with human-center ed modeling becomes critical. Particularly: • Benecence emphasizes the obligation to design and implement systems that activ ely promote overall well-being and deliver measurable improv ements[82]. • Non-malecence focuses on minimizing risks and preventing harm, supported by frameworks that identify and mitigate potential harms throughout the machine learning lifecycle [82]. • Justice requires that algorithms perform equitably across diverse populations, avoiding systematic disad- vantages to specic subgroups [41]. • A utonomy promotes consistent and stable model b ehavior , enabling users to rely on AI outcomes and making informed decision-making in line with ethical standards [19, 38, 65]. These principles anchor ethical AI in human-centered computing, ensuring that technical performance is balanced with fairness, safety , and trustworthiness. 2.5 Ethical AI vs fairness While fairness has b ecome one of the most prominent concerns in machine learning, it represents only one dimension of ethical AI [ 26 ]. Fairness typically refers to the equitable treatment of individuals or subgroups, often quantied through statistical metrics across groups [ 22 , 28 ]. These measures addr ess the principle of justice , ensuring that no population is disproportionately disadvantaged by algorithmic predictions. Howev er , this narrow focus creates a gap between fairness as currently dened in machine learning and the broader requirements of ethical AI, a concern raised in r ecent ethical AI literature [ 6 , 15 , 18 , 77 , 86 ]. Principles such as benecence and non-malecence demand that systems not only avoid disparities but also improve outcomes while causing no harm for any subgroup [ 8 ]. A utonomy requires consistency so that users can rely on the AI system. Y et, these dimensions are rarely embedded into fairness framew orks, leaving critical ethical concerns unaddressed. Such a gap is particularly critical to address in healthcar e, where fairness is necessary but not sucient [ 41 ]: predictive models must not only perform equitably across patients but also improve health outcomes, avoid harmful decisions, and support trustworthiness. T o the b est of our knowledge, no prior work has jointly operationalized fairness and core ethical principles in model development. This pap er directly tackles the above-discussed gaps—advancing the goal of ethical fairness in human-centered AI. In the absence of established ethical fairness baselines, we consider state-of-the-art (So T A) fairness-without-demographics (FWD) approaches as baselines. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:6 • Tro vato et al. 3 Fairness Metrics Although fairness is a major focus in machine learning, no existing metric adequately captures the broader scope of ethical fairness [ 13 ]. This section re views the commonly used fairness metrics and then introduces a new framework for compr ehensive ethical fairness e valuation, aligning fairness assessment more closely with the core principles of ethical AI. 3.1 Limitations of existing fairness metrics Fairness in machine learning is typically assessed using statistical measures that quantify disparities in mo del outcomes across protected groups. Common binary metrics include Demographic Parity (DP)—which measures whether positive prediction rates are equal across subgr oups—and Equal Opportunity Dierence (EOD), which compares true positive rates to ensure equitable treatment [22, 28, 101]. Howev er , these binar y metrics capture only pairwise group dierences (e.g., male vs. female) and fail to reect disparities across multiple subgroups. T o overcome this limitation, multi-gr oup extensions such as generalized EOD [ 69 ] and Relative Disparity (RD) [ 3 ] have been intr oduced. These metrics aggregate performance gaps across all subgroups to pro vide a broader view of fairness. For instance , RD measures the ratio between the best- and worst-performing subgroups ( e.g., by recall or F1-score), with values closer to 1 indicating greater equity . Despite these advances, these metrics still fall short in key ways. Metrics that rely solely on aggregated performance (e.g., overall accuracy or AUC) or extr eme-value summaries (e.g., max–min ratios) can obscure systematic harm—masking whether certain subgroups consistently underp erform [ 29 , 45 , 75 ]. A model may achieve parity in statistical terms yet still produce outcomes that disproportionately burden specic populations, conicting with the ethical principles of justice and non-malecence . Moreover , existing fairness metrics do not assess whether model improvements benet all subgr oups and the overall population. They equalize outcomes without ensuring collective ecacy , overlooking the ethical principle of b enecence . 3.2 BHE: Fairness Metrics Aligned with Bioethics T o bridge the gap between technical fairness and ethical accountability , we introduce the BHE Metrics ( Benet , Harm- A voidance , Equity ), derived from known-demographic-wise F1-scor es, such as age , sex, sensor , disorder scores like PhQ10, and more, aggregated across 𝑁 folds. Moreover , each fold’s test set is person-disjoint from the others, and together they encompass the entire population, ensuring a comprehensive and unbiased evaluation. Notably , demographic information is used exclusively during evaluation; during model training, no demographic information is used. T o meaningfully evaluate whether Flare enhances ethical fairness, it is essential to use datasets that include known demographic or sensitive attribute labels. Such datasets pro vide the necessar y ground truth for quantifying ethical principles and fairness across dened subgroups and verifying whether Flare can indeed promote ethically constrained equitable outcomes. However , most human-centered datasets lack this information, making direct fairness evaluation challenging. Ther efore, demonstrating consistent ethical fairness improvements on datasets with available demographic annotations, lev eraged in this paper for evaluation, ser ves as a proxy validation—establishing condence that Flare can generalize ethical fairness across broader human-centered applications and domains where demographic data are unavailable or impractical to collect. BHE metrics compare the fair solutions ( Flare and other fair AI approaches) with So T A b enign baseline approaches, and measure the changes in ethical principles, outlined below: Let S denote the set of all demographic subgroups, and 𝐹 1 𝑚 𝑠 ( 𝜃 ) the F1-score of model 𝑚 ( 𝑚 ∈ { Flare , Base } ) on subgroup 𝑠 . W e dene the BHE deltas Δ as follows: Δ 𝐵 = 1 | S | 𝑠 ∈ S ( 𝐹 1 Flare 𝑠 ( 𝜃 ) ) − 1 | S | 𝑠 ∈ S ( 𝐹 1 Base 𝑠 ( 𝜃 ) ) , Δ 𝐻 = min 𝑠 ∈ S 𝐹 1 Flare 𝑠 ( 𝜃 ) − 𝐹 1 Base 𝑠 ( 𝜃 ) , A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:7 Δ 𝐸 = Std { 𝐹 1 Base 𝑠 ( 𝜃 ) } 𝑠 ∈ S − Std { 𝐹 1 Flare 𝑠 ( 𝜃 ) } 𝑠 ∈ S . • Benet ( Δ 𝐵 ): Reects the change in average predictive performance across subgroups, corresponding to the ethical principle of benecence —higher Δ 𝐵 promotes the greatest overall benet to the population [ 36 ]. • Harm- A voidance ( Δ 𝐻 ): Captures the smallest subgr oup-level improvement, emphasizing protection against systematic disadvantage and embodying non-malecence —the obligation to avoid harm [ 8 ]. By taking the minimum subgroup-wise F1 impr ovement ( which can b e negativ e according to the equation- indicating harm), Δ 𝐻 ensures that even the most vulnerable subgroup is considered; when Δ 𝐻 ≥ 0 , no subgroup experiences a decline in performance, ther eby guaranteeing that the model does not introduce harm to any population segment, adhering to non-malecence principle. • Equity ( Δ 𝐸 ): Quanties the reduction in performance variability across subgroups—typically expressed as a lower standard deviation of model accuracy or outcomes among demographic categories. A low er standard deviation indicates that the AI system performs consistently and reliably across diverse populations, ensuring that no group is systematically advantaged or disadvantaged [ 11 ]. This uniformity of performance embodies a commitment to justice , as it upholds fairness and equal treatment in decision-making. At the same time, it reinforces autonomy , since consistent model behavior enhance stability i.e. reliable decision making [ 12 , 23 ]. Reliable and equitable outputs reduce uncertainty , build condence in human oversight, and preserve meaningful human control—core elements of autonomy in the WHO’s ethical framework for AI in health[44]. Higher Δ 𝐵 and Δ 𝐻 indicate greater benet and stronger safeguards for vulnerable subgroups, corresponding to goals-i and -iii in Se ction 1. Similarly , a higher Δ 𝐸 (reecting reduced disparity) signies improved equity and stability , aligning with goals-ii in Section 1. This formulation ensures that, for all thr ee metrics, larger positive Δ values consistently represent ethically superior outcomes—enhanced colle ctiv e utility , minimized harm to disadvantage d groups, and diminished disparities in model performance. 4 Design Choice Optimization theory background that supports Flare . Fairness in machine learning can be examined through the geometr y of optimization. Specically , the Hessian matrix of the loss function pro vides insights into the curvature of the loss landscap e, wher e sharp minima—characterized by a large top eigenvalue of the Hessian—indicate higher sensitivity to parameter perturbations and instability in generalization [ 17 , 39 ]. Recent work has shown that subgroups associated with sharper regions in the loss surface tend to lie closer to the model’s decision boundaries. A s a result, these groups experience less stable and less accurate mo del p erformance than others. This nding suggests that cur vature disparities, as captured by the top eigenvalue of the Hessian of the loss, can serve as a useful proxy for identifying fairness gaps across demographic subgroups [84]. Since computing the full Hessian is computationally prohibitiv e in high-dimensional models, following the literature [ 51 , 83 , 96 ], we adopt Fisher information as a tractable surrogate to measure the mo del’s loss-landscape curvature. Under standard r egularity conditions, the Fisher information matrix (FIM) coincides with the e xpected Hessian of the negative log-likelihood [62], capturing similar curvature characteristics in a more scalable form. Consequently , a lower top eigenvalue of the FIM reects atter minima and smoother curvature—implying greater generalizability [ 57 , 97 ], as the model’s decisions remain stable across unseen or noisy conditions. Moreover , when FIM disparities across subgroups are reduced, the mo del achieves more uniform curvature and decision-boundar y distances among groups, promoting r obustness and fairness through consistent decision boundaries across subgroups. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:8 • Tro vato et al. Fig. 1. Proposed Approach: (1) Base pre-training learns embeddings with Fisher penalty regularization, (2) UMAP+GMM clustering captures behavior-based similarity , and (3) cluster models are fine-tune d and aggregated with stability constraints Building on these insights, Flare unies Fisher-based cur vature information, loss dynamics, and embedding- space structure to reveal latent subgroups that exhibit disproportionate model performance. By identifying these hidden disparities, Flare guides optimization towar d atter and mor e equitable loss landscapes across the discovered subgroups. This promotes fairness without relying on demographic attributes (F WD), while enhancing generalizability through improved model stability—thereby advancing the ethical principles of justice and autonomy . Simultaneously , Flare enhances overall model ecacy without compromising any subgr oup’s performance, balancing colle ctive improvement with individual protection in line with the principles of benecence (promoting good) and non-malecence (preventing harm). Flare ’s design choices comprise three modules shown in Figure 1, and discussed below: 4.1 Base pretraining. As we can see from Figur e 1 (step 1), the rst module involv es training an encoder–decoder–classier framework ( 𝑒 𝜃 𝑒 , 𝑑 𝜃 𝑑 , 𝑔 𝜃 𝑐 ) to learn model-behavior-aware comprehensive representations of the data. Given an input sample 𝑥 with ground-truth label 𝑦 , the encoder 𝑒 𝜃 𝑒 maps the input into a latent representation 𝑧 = 𝑒 𝜃 𝑒 ( 𝑥 ) . The classier 𝑔 𝜃 𝑐 produces a label prediction ˆ 𝑦 = 𝑔 𝜃 𝑐 ( 𝑧 ) from the latent code, while the de coder 𝑑 𝜃 𝑑 reconstructs the input as ˜ 𝑥 = 𝑑 𝜃 𝑑 ( 𝑧 ) . The classier is trained using a joint obje ctive that balances reconstruction, classication, and stability: L pre ( 𝜃 ) = ( 1 − 𝛼 ) ∥ 𝑥 − ˜ 𝑥 ∥ 2 2 + 𝛼 𝛽 ℓ CE ( ˆ 𝑦, 𝑦 ) + ( 1 − 𝛽 ) F ( 𝑥 , 𝑦 ; 𝜃 ) I { ˆ 𝑦 = 𝑦 } . (1) Here: the rst term, ∥ 𝑥 − ˜ 𝑥 ∥ 2 2 is the mean-squared error (MSE) reconstruction loss, encouraging the latent representation 𝑧 to retain as much information from 𝑥 as possible. ℓ CE ( ˆ 𝑦, 𝑦 ) is the cross-entropy loss between the predicted label ˆ 𝑦 and the true label 𝑦 , which drives the model to make accurate classications. And, F ( 𝑥 , 𝑦 ; 𝜃 ) denotes Fisher penalty , i.e., promoting reduction of the top eigenvalue of the FIM, which measures the sensitivity of the model’s loss around correctly classied samples [ 55 ]. Minimizing this term r educes the local curvature of the loss landscape, encouraging the model to converge toward atter minima, which correspond to more stable generalization behavior , thereby enhancing autonomy . I { ˆ 𝑦 = 𝑦 } is an indicator function that equals 1 if the sample is classied correctly and 0 otherwise, ensuring that Fisher penalty regularization is applied only to correctly predicted samples. This training avoids penalizing the curvature of misclassied samples, since they are already penalized to encourage crossing the de cision boundaries via the ℓ CE ( ˆ 𝑦, 𝑦 ) loss. 𝛼 ∈ [ 0 , 1 ] balances A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:9 reconstruction against super vised objectives. 𝛽 ∈ [ 0 , 1 ] controls the trade-o between classication accuracy (cross-entr opy ) and stability (Fisher penalty) within the supervised comp onent. In this module, intuitively , minimizing the Fisher Penalty across all samples lowers its ov erall upper bound and variance, aligning curvature more evenly throughout the population. A s discussed above, equitable loss-landscap e curvature promotes fair predictions across inputs, thereby enhancing justice . Thus, this curvature regularization acts as a fairness-promoting me chanism, improving justice and autonomy of the base-pretrained model 𝜃 ∗ ’s predictions without requiring access to sensitive demographic attributes. Howev er , as prior work on fairness without demographics has shown ( discussed in Section 2.2), enforcing such uniform regularization globally can yield suboptimal results—since it fails to capture nuance d dierences in how the model interacts with diverse subgroups [ 14 , 49 ]. T o overcome these limitations, our encoder–deco der design in the pretraining module explicitly structures the model to dierentiate samples based on b oth repr esentational and model behavioral similarity . The encoder captures latent features, i.e., embeddings that reveal which samples share similar representational structure—meaning the model is likely to apply similar decision rules to them. Simultaneously , the classier’s cross-entropy loss captures each sample’s classication ecacy (how condently it is predicted), while the Fisher penalty captur es each sample’s sensitivity to perturbation and its proximity to the decision boundar y . T ogether , these metrics characterize the model’s behavior for each data point, which informs the following module to identify latent subgroups that experience disproportionate model treatment and, through the last module, attain latent subgroup-guided optimization to promote ethical fairness. 4.2 Latent Clustering Building upon the baseline mo del 𝜃 ∗ ’s behavior-informed representations learned during pretraining, this module seeks to rev eal hidden stratication—that is, dierences in model treatment (i.e., performance and behavior) across latent subgroups that are not e xplicitly dened by demographic attributes. While the pretraining module encourages atter loss surfaces and wider decision margins globally , such uniform regularization may mask local disparities: some samples may still reside near sharper regions of the loss landscape, corr esponding to smaller decision boundar y margins and higher predictive uncertainty . T o uncover these disparities, we perform model behavioral clustering, grouping samples not only by how they are represented in the latent space but also by how the model 𝜃 ∗ ’s loss landscape behaves around them. For each input 𝑥 with label 𝑦 : we form a v ector 𝑠 = [ 𝑧 , ℓ CE , F ] , where, 𝑧 = 𝑒 𝜃 𝑒 ( 𝑥 ) is the encoder embedding, ℓ CE = ℓ CE ( ˆ 𝑦, 𝑦 ) is the cross-entropy loss, and F is the Fisher penalty around this input. T o form coherent behavioral clusters, we rst employ Uniform Manifold Appr oximation and Projection ( UMAP) [ 30 ] to reduce 𝑠 to a lower dimension, follo wed by a Gaussian Mixture Model (GMM) [ 74 ] that partitions samples into 𝐶 clusters, with 𝐶 chosen to avoid degenerate (empty) groups. This approach yields clusters r eecting behavioral similarity under the model, not just raw input features. Each cluster thus r epresents a group of samples that are similar in both their feature representation and the model’s local loss landscape cur vatur e and ecacy , eectively dening b ehaviorally homogeneous subgr oups. Importantly , this clustering is performed at the sample level, not at the individual or demographic level. A s a result, multiple samples from the same subject can belong to dierent clusters dep ending on how the model’s decision geometry interacts with each instance. This property is critical for identifying subtle, data-driven fairness gaps that demographic-based methods may overlook. In essence, this module reframes ethical fairness as a loss landscape analysis problem. By gr ouping samples based on their shared curvature characteristics, classication dynamics, and representational traits, it identies latent subgroups that dier systematically in model ecacy , robustness, stability , or margin distance. These behaviorally coherent clusters expose where the model performs inconsistently , providing a principled basis for targeted adaptation promoting ethically guided fairness attainment in the subsequent module. Throughout the rest of the paper , identie d clusters will be used synonymously with latent subgroups. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:10 • Tro vato et al. 4.3 Cluster-specific Adaptation and Aggregation After revealing latent subgroups through cur vature- and behavior-aware clustering, this module of Flare fo cuses on ethically fair adaptation. It ensures that each cluster , i.e., latent subgroup, r eceives tailored optimization that respects both performance equity and ethical constraints. This se ction’s training is performed on a disjoint hold-out dataset from the prior modules, ensuring unbiased model optimization. 4.3.1 Cluster Adaptation: Once clusters are identied, we specialize models for each cluster 𝑐 by adapting the pretrained model 𝜃 ∗ . The early encoder layers are frozen to preserve generic knowledge learned during pretraining, while the later encoder and classier parameters are ne-tuned to capture cluster-specic patterns. This hierarchical adaptation enables localized fairness correction without sacricing generalizability . The training objective for cluster 𝑐 spe cic model is L cl ( 𝜃 𝑐 ) = 𝛼 × ℓ CE ( ˆ 𝑦, 𝑦 ) | {z } accuracy + ( 1 − 𝛼 ) × F ( 𝑥 , 𝑦 ; 𝜃 𝑐 ) | {z } stability on corrects + max { ℓ CE ( ˆ 𝑦, 𝑦 ) − ℓ pre CE , 0 } | {z } do-no-harm vs. baseline . (2) Here: ℓ CE ( ˆ 𝑦, 𝑦 ) is the cross-entrop y loss between the prediction ˆ 𝑦 and the ground truth 𝑦 , measuring classication error . F ( 𝑥 , 𝑦 ; 𝜃 𝑐 ) is the Fisher penalty under 𝜃 𝑐 , quantifying sensitivity of the model to parameter perturbations specic to cluster 𝑐 samples, encouraging atter minima and improving decision b oundary margins within each cluster . Similar to Section 4.1, Fisher p enalty is computed only on correctly classied samples , ensuring that curvature smoothing focuses on reliable decision regions, while misclassied samples are handled through the cross-entropy term that encourages boundary correction. This separation promotes accuracy and stability for the correct samples, promoting benecence and autonomy , while preventing enhancement of stability of misclassied samples, promoting non-malecence. Moreover , just as in Section 4.1, lowering the Fisher p enalty promotes more uniform curvature—yielding fairer , more consistent performance across cluster 𝑐 samples, promoting justice . Given, ℓ pre CE is the cross-entrop y loss of the cluster 𝑐 samples under the pretrained model 𝜃 ∗ , the term max { ℓ CE ( ˆ 𝑦, 𝑦 ) − ℓ pre CE , 0 } represents a “do-no-harm” regularizer . It is positive only if the cluster-specic mo del performs worse than the pretrained baseline 𝜃 ∗ , preventing harmful updates, promoting non-malecence ; if the performance is improving, this term vanishes. A dditionally , 𝛼 ∈ [ 0 , 1 ] balances accuracy ( cross-entropy ) against stability and fairness (Fisher regularization). Through this design, each cluster-specic model evolv es within a locally fairer loss ge ometry , improving ecacy for underperforming subgroups while safeguarding others from degradation. 4.3.2 Aggregation: While local adaptation renes each subgroup, independent optimization can cause clusters to drift apart, creating uneven de cision geometries and potentially new disparities. T o counter this, Flare introduces a p eriodic running-average aggregation mechanism that promotes equilibrium across clusters, ensuring that improvements r emain shared and harmonized. At scheduled inter vals, parameters from all cluster-specic models are aggregated through a running mean: ¯ 𝜃 = 1 𝐶 𝐶 𝑐 = 1 𝜃 𝑐 , where 𝐶 denotes the number of clusters and 𝜃 𝑐 the parameter vector associated with cluster 𝑐 . The aggregated model ¯ 𝜃 represents a consensus parameterization, capturing shared curvature and decision geometry across subgroups [ 27 , 37 , 102 ]. It is then redistributed to all clusters, ser ving as a synchronized initialization for subsequent adaptation. Each cluster evaluates whether adopting ¯ 𝜃 improves its o wn validation F1 score. If the update yields improvement, ¯ 𝜃 replaces the prior model; other wise, the cluster retains its previous parameters. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:11 Formally , the best model for cluster 𝑐 , upon each aggregation step is dened as: 𝜃 ∗ 𝑐 = arg max 𝜃 𝑐 , ¯ 𝜃 F1 val ( 𝐷 𝑐 ) , where 𝐷 𝑐 represents cluster 𝑐 ’s data distribution, sampled from its validation set. This procedure balances knowledge sharing [ 81 ] and sp ecialization [ 33 ]: clusters b enet from colle ctive information through ¯ 𝜃 while retaining the ability to reject it if it degrades local performance. By comparing the validation F1 scores between ¯ 𝜃 and the previous cluster mo del 𝜃 𝑐 , each cluster ee ctively performs a lo cal model selection step that guards against utility drop, pr omoting non-malecence . The nal system is given by { 𝜃 ∗ 𝑐 } 𝐶 𝑐 = 1 , ensuring that each cluster settles on the parameter conguration—either its adapted version or the aggregated one—that maximizes its local validation performance. O verall, by coupling lo cal specialization with global reconciliation, the model converges toward a fair curvature across subgroups—atter , more robust, and more equitable in its decision geometry —while adhering to ethical constraints. 5 Approach Following the design principles described in Section 4, Flare operationalizes the propose d framew ork through two main algorithmic steps: (Algorithm 1 - modules 1,2) Base Pretraining and Latent Clustering , and (Algorithm 2 - module 3) Cluster-specic Adaptation and Aggregation . These algorithmic steps correspond directly to the components illustrated in Figure 1, where Module 1 and 2 produce Fisher-regularized embeddings and behaviorally meaningful clusters, and Module 3 renes model performance on those clusters through stability-aware adaptation. 5.1 Algorithm 1 − Modules 1,2: Base Pretraining and Latent Clustering Algorithm 1 Modules 1–2: Base Pretraining and Latent Clustering Require: Fold 𝑘 ∈ { 1 , . . . , 𝐾 } with train+holdout train (80%/20%) and person-disjoint test ; hyperparameters 𝛼 , 𝛽 , 𝜂, 𝐸, 𝐶 . 1: Initialize encoder–decoder–classier 𝑀 𝜃 . 2: for epo ch = 1 to 𝐸 do 3: for each batch ( 𝑥 , 𝑦 ) ∈ train do 4: ( 𝑧 , ˜ 𝑥 , ˆ 𝑦 ) ← 𝑀 ( 𝑥 ) ⊲ For ward pass: embeddings, reconstruction, predictions 5: Compute Fisher penalty F 𝑐 for correctly classied samples only . 6: L pre ← ( 1 − 𝛼 ) ∥ 𝑥 − ˜ 𝑥 ∥ 2 2 + 𝛼 [ 𝛽 ℓ CE ( ˆ 𝑦, 𝑦 ) + ( 1 − 𝛽 ) F 𝑐 ] 7: 𝜃 ← 𝜃 − 𝜂 ∇ 𝜃 L pre ⊲ Parameter up date 8: end for 9: Evaluate on test ; save 𝜃 ∗ if validation improves. 10: end for 11: Feature Extraction: Using 𝜃 ∗ , compute ( 𝑧, ℓ CE , F ) for all samples. 12: Combine descriptors 𝑠 = [ 𝑧, ℓ CE , F ] into sets 𝑆 corr (correct) and 𝑆 all . 13: Clustering: Fit UMAP 𝜑 on 𝑆 corr ; train GMM( 𝐶 ) on 𝜑 ( 𝑆 corr ) . 14: Assign cluster IDs to all samples using GMM posterior probabilities. Ensure: Che ckpoint 𝜃 ∗ , UMAP 𝜑 , GMM mo del, and cluster assignments. Module 1 trains an encoder–deco der–classier network using the Fisher-r egularized composite loss introduced earlier . The objective balances reconstruction delity , predictive accuracy , and curvature regularization. During training (Lines 3–10 in Algorithm 1), each batch is passe d through the encoder to obtain latent representations 𝑧 , reconstructed outputs ˜ 𝑥 , and class predictions ˆ 𝑦 . Fisher penalty is compute d only for correctly classied samples and combined with the reconstruction and classication losses to form the total obje ctive . After every epo ch A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:12 • Tro vato et al. (Line 11), model performance on the person-disjoint test set is evaluated, and the best-performing checkpoint 𝜃 ∗ is retained for downstream clustering. Using 𝜃 ∗ , we e xtract three descriptors for each sample: latent emb edding ( 𝑧 ), cross-entropy loss ( ℓ CE ), and Fisher penalty ( F ). These features are combined to form a joint representation 𝑠 = [ 𝑧 , ℓ CE , F ] . In Module 2 (Lines 17–20), UMAP is applied to the correctly classie d subset to preserve local geometr y in a lower-dimensional manifold. A Gaussian Mixture Model (GMM) is then tted on this manifold to partition the samples into 𝐶 clusters. Finally , each sample is assigned a cluster label based on its GMM posterior pr obability . Module 1 ensures the encoder learns comprehensive embeddings, while Mo dule 2 identies latent model-behavioral-wise clusters based on geometry , loss dynamics, and cur vature sensitivity . 5.2 Algorithm 2 - Module 3: Cluster-specific Adaptation and Aggregation Algorithm 2 Module 3: Cluster-specic Adaptation and Conditional Aggregation 1: Inputs: pr etrained 𝜃 ∗ ; clusters { D 𝑐 train2 , D 𝑐 val , D 𝑐 test } 𝐶 𝑐 = 1 ; fr eeze depth 𝐿 ; w eights 𝛼 , 𝜆 ; lr 𝜂 ; epochs 𝐸 ; aggr egation interval 𝜏 . 2: Initialize 𝜃 𝑐 ← 𝜃 ∗ ; freeze rst 𝐿 encoder layers for all 𝑐 . 3: Set bestF1 ( 𝑐 ) ← −∞ for each cluster . 4: for epo ch = 1 to 𝐸 do 5: for 𝑐 = 1 to 𝐶 do 6: for mini-batch ( 𝑥 , 𝑦 ) ⊂ D 𝑐 train2 do 7: ˆ 𝑦 ← 𝑀 𝜃 𝑐 ( 𝑥 ) , ˆ 𝑦 ∗ ← 𝑀 𝜃 ∗ ( 𝑥 ) 8: Compute CE , CE ∗ , and F ; apply F only on correct samples. 9: Compute loss: L cl = 𝛼 CE + ( 1 − 𝛼 ) F + 𝜆 [ CE − CE ∗ ] + 10: 𝜃 𝑐 ← 𝜃 𝑐 − 𝜂 ∇ 𝜃 𝑐 L cl 11: end for 12: Evaluate F1 ( 𝑐 ) val ; if improved, save best checkpoint. 13: end for 14: if epoch mo d 𝜏 = 0 then 15: ¯ 𝜃 ← 1 𝐶 Í 𝐶 𝑐 = 1 𝜃 𝑐 ⊲ Compute running average 16: for 𝑐 = 1 to 𝐶 do 17: Evaluate ¯ 𝜃 on D 𝑐 val ; if F1 ( 𝑐 ) val ( ¯ 𝜃 ) > F1 ( 𝑐 ) val ( 𝜃 𝑐 ) , set 𝜃 𝑐 ← ¯ 𝜃 18: end for 19: end if 20: Stop when 1 𝐶 Í 𝐶 𝑐 = 1 F1 ( 𝑐 ) val converges. ⊲ Early stopping 21: end for 22: for 𝑐 = 1 to 𝐶 do 23: Reload best checkpoint 𝜃 ∗ 𝑐 and evaluate on D 𝑐 test . 24: end for Module 3 ne-tunes cluster-specic mo dels and performs conditional aggregation to achiev e a balance between local specialization and global stability . Each cluster model is initialized from the shared checkpoint 𝜃 ∗ and partially frozen (Line 2 in Algorithm 2) to retain domain-invariant generic structure learned during pretraining. This module is trained on the holdout training split to prevent overtting and ensur e that adaptation remains generalizable across participants and clusters. Fine-tuning proceeds (Lines 5–12) with the cluster-specic objective L cl dened in Section 4, which integrates accuracy , Fisher-based stability , and the one-sided “ do-no-harm” A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:13 constraint. Fisher penalty terms are again computed only on correctly classied samples. V alidation F1 scores are tracked per cluster (Line 13), and the best-p erforming checkpoint is saved. T o maintain coherence across clusters, perio dic aggregation is applied every 𝜏 epochs (Lines 15–23). The average model ¯ 𝜃 = 1 𝐶 Í 𝐶 𝑐 = 1 𝜃 𝑐 is computed and oered to all clusters. Each cluster 𝑐 tests ¯ 𝜃 on its validation data; if adopting ¯ 𝜃 improves validation F1, the cluster updates its parameters; other wise , it continues training with its own 𝜃 𝑐 . This conditional aggregation (Lines 18–21) enables positive transfer between clusters while preventing negative interference. Early stopping (Line 24) is triggered when the mean validation F1 across all clusters stabilizes, ensuring convergence to balanced, stable solutions. Finally , each cluster reloads its b est checkpoint for testing (Lines 26–27), and the ensemble { 𝜃 ∗ 𝑐 } 𝐶 𝑐 = 1 forms the nal output. Module 3 renes each cluster’s model through targeted, Fisher-regularized adaptation while ensuring fairness and stability via the “do-no-harm” constraint and conditional aggregation. The resulting ensemble preser ves global robustness while allowing local specialization, achieving fairness without demographic supervision. 6 Experimental Results This section evaluates Flare to assess its ability to enhance ethical fairness without relying on e xplicit demo- graphic or sensitive attribute information, while maintaining high predictive accuracy across diverse behavioral and physiological sensing tasks. W e begin by describing the datasets and model congurations. Next, we assess the eectiveness of Flare . Finally , we provide an empirical validation of the design choices. 6.1 Datasets and Models Flare is teste d on three multimodal datasets: Ohio T1DM [ 61 ]—continuous glucose and insulin pump data from 11 participants (normal vs. hyperglycemia, processed per [ 10 ]); Intern Health Study (IHS) [ 1 ]—a 14- month study of 85 medical interns combining PHQ-9 scores, daily mood, and Fitbit-derived features, labels are derived from moo d thresholds ( >8 positive, <3 negative) in line with [ 60 ]; and Electrodermal Activity (ED A) [ 90 , 91 ]—multimodal physiological signals (ED A, HR, A CC, TEMP, HRV) from 76 participants with 340 handcrafted features for stress detection. Known Demographics for Evaluating Subgroup-wise Ethical Fairness through BHE Metrics. For Ohio T1DM [ 61 ], we evaluate along attributes reported in the dataset and prior work, including Sex (male/female), Age (20–40, 40–60, 60–80), insulin Pump and Model (e .g., 530G, 630G), Sensor Band (Empatica, Basis), and Cohort (2018 vs. 2020); data processing follows Appendix 2.4 of [10]. For EDA [90, 91], we assess BHE Metrics across Medication and disorder Groups (control/pre-dose/post-dose) and Sex . For IHS [ 1 ], available BHE Metrics evaluation attributes include Sex , Age , Ethnicity , Residency Spe cialty (12+ categories), and a baseline mental-health indicator PHQ10 > 0 . Evaluation Setup. All datasets use an 𝑁 -fold evaluation setup in which the train and test sets are p erson-disjoint within each fold. The training participants are further divided 80:20 into train and holdout-train subsets. The train split is used for pr etrained classier training and clustering (Sections 4.1 and 4.2), while the holdout-train split supports Cluster-specic Adaptation and Aggregation (Section 4.3). As noted in Section 3.2, each fold’s test set is mutually exclusive and collectiv ely spans the entire population, ensuring a comprehensiv e and unbiased evaluation. The conguration of folds across datasets is as follows: IHS: 5 folds with 17 users in test set per fold. ED A: 4 folds with 19 users in the test set per fold. Ohio T1DM: 4 folds with test sets containing 3, 3, 2, and 3 users, respectively . Models. Each dataset employs an autoencoder–classier backbone tailored to its feature dimensionality and domain characteristics. Specically , DNN model (use d for OHIO- T1DM ) consists of a 256–128–64–32 enco der and a 32–8–2 classier head. The DNN model (for IHS) follows a compact 128–64–32 encoder with a 32–16–8–2 classier . For ED A DNN model, the encoder compresses the input into a 128-dimensional latent representation A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:14 • Tro vato et al. using three linear layers with a deeper 128–64–64–2 classier . Each model integrates a symmetric de coder for reconstruction learning, enabling joint representation regularization. These ‘pr etrained autoencoder–classier’ networks (from module 1 in Section 4.1) serve as the initialization stage for Flare , on which it p erforms cluster-specic adaptation and cross-cluster aggregation. Benign Baseline Models. The b enign baseline refers to standard super vised mo dels trained without fairness or ethical regularization, serving as reference p oints for e valuating the BHE metrics of Flare and other FWD approaches. These baselines adopt established architectures and hyperparameter congurations from prior work. For the Ohio T1DM dataset, we followed the models and parameter settings of Marling and Bunescu [ 61 ] and Arefeen and Ghasemzadeh [ 10 ]. For the EDA dataset, we implemented the congurations proposed by Xiao et al. [ 90 , 91 ]. For the IHS dataset, since model conguration was not provided in the literature [ 1 ], the baseline was optimized through a combination of Optuna [ 76 ] hyperparameter tuning and iterative manual renement to obtain the highest benign performance. Hyperparameter Optimization. T o ensure optimal and reproducible performance, all hyp erparameters—including learning rate, batch size, w eight decay , and the r egularization coecients 𝛼 , 𝛽 , and 𝛾 —are tuned using the Optuna hyperparameter optimization framework. Optuna employs Bay esian optimization with early stopping and dy- namic pruning to eciently explore the search space , automatically selecting the conguration that maximizes validation performance while maintaining fairness and stability objectives [ 16 ]. Comprehensive architectural, training, and preprocessing specications are detailed in Appendix A.1. 6.2 Evaluation of Flare ’s Ee ctiv eness W e evaluate the ethical fairness of Flare through a multi-stage analysis. First, we assess its Benecence —b oth overall and across demographic subgroups—by comparing performance against a benign baseline and recent state-of-the-art fairness-without-demographics (F WD) models. Next, we conduct comprehensive BHE evaluation to compare Flare with the same So T A F WD baselines, quantifying its r elative advantages in achieving balanced improvements acr oss ethical dimensions. Finally , we empirically validate two core ethical pr operties of Flare : its ability to achieve user-level autonomy , enabling consistent behaviour across users, promoting stability; and its adherence to the Do No Harm principle, ensuring that adaptation never reduces performance while promoting fairness across the population. Fig. 2. Overall F1-scores acr oss all models for each dataset. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:15 6.2.1 Beneficence Comparison for Baselines vs. Flare . Benecence is a core principle of ethical AI, empha- sizing the enhancement of overall w ell-being through improved model performance. Ther efore, any decline in predictive performance—either overall or across subgroups—when using Flare compared to baselines would contradict this principle. T o assess benecence , we compare the proposed Flare model with the Benign Baseline and four representative So TA FWD baselines— Adversarial Rew eighting Learning (ARL) [ 49 ], Knowledge Distilla- tion (KD) [ 14 ], Reckoner [ 68 ], and Graph of Gradients (GoG) [ 59 ]. These methods capture distinct paradigms of fairness optimization, as discussed in Section 2.2. Figure 2 shows the ov erall F1-scores for all models across datasets. Flare consistently achieves the highest performance— 73.0% on the Ohio T1DM dataset, 89.1% on ED A, and 63.5% on IHS—demonstrating that its optimization strategy enhances predictive quality , ensuring benecence . ARL attains competitive scores, which are still not as go od as Flare , while KD and Reckoner uctuate notably across datasets, and GoG tends to underperform, indicating weaker adaptability . These results conrm that Flare sustains reliable predictive strength across domains of varying complexity and data heterogeneity . T able 1 extends this analysis to the subgroup level, revealing that Flare maintains superior benecence across known sensitiv e demographic partitions. In the Ohio T1DM dataset, Flare achieves signicant improvements for Pump ( 73.62% ) and Age ( 74.36% ), outperforming ARL and KD by 5–10 percentage points. In the high-performing ED A dataset, where most models already approach saturation, Flare still attains the best subgroup-wise scores ( 89.1–89.5% ), conrming its robustness under low-variance conditions. Within the IHS dataset, which exhibits greater heterogeneity , Flare achieves the highest F1-scores across all subgroups, ranging from 63.3% to 63.4% . In comparison, ARL spans 62.5% to 62.7% , while KD lags further behind at 58.0%–58.1% . This evaluation demonstrates that Flare achieves stable and superior performance, both overall and across diverse subgroups, due to its architectural and training design. As discussed in Section 4.1, it employs an encoder–decoder architecture that captures temporal and contextual dependencies, combined with a Fisher-based penalty that stabilizes parameter updates during training—enhancing generalizability to unseen individuals and settings, measured through p erson-disjoint evaluations, while maintaining pr edictive reliability where other approaches often degrade. Moreover , the extended cluster adaptation and aggregation frame work (Section 4.3) further impro ves ecacy by learning latent subgroup–specic rules, thereby promoting benecence , while preserving stability , fairness, and preventing degradation. A more detailed subgroupwise analysis is shown in Appendix A.3. 6.2.2 BHE Comparison of Flare with So T A FWD Baselines . Comparing So T A FWD approaches with Flare through the lens of benet ( 𝐵 ) , harm avoidance ( 𝐻 ) , and equity ( 𝐸 ) —collectively the BHE dimensions—is essential to evaluate not only predictive accuracy but also ethical r eliability . Improvements in one dimension at the expense of another lead to ethical inconsistencies, yielding models that appear accurate o verall yet still propagate subgroup harm or inequity . Therefore, BHE metric pro vides a principled measure of whether fairness interventions genuinely improve ethical alignment. T o assess this, we evaluated three datasets—Ohio T1DM, IHS, and ED A —reporting p er centage-point changes ( Δ 𝐵, Δ 𝐻 , Δ 𝐸 ) relative to the Benign Baseline (T able 2). Across datasets, Flare achiev es the most coherent improvements acr oss all BHE dimensions. On the Ohio T1DM dataset, it records the highest mean deltas ( +12.46, +3.79, +11.50 ), outperforming ARL ( +8.67, +3.19, +7.09 ) and Reckoner ( +5.52, +1.81, +4.43 ), while KD ( +4.83, +1.89, +0.01 ) and GoG ( +0.18, –0.26, –0.14 ) show minimal or unstable gains. Subgr oup-level analysis r eveals particularly strong impro vements for Pump ( +20.03, +5.41, +19.41 ) and Age ( +15.14, +5.35, +15.37 ), demon- strating Flare ’s ability to correct high-variance bias sources without overcompensation. In the IHS dataset, which is more heterogeneous, Flare sustains robust mean impro vements ( +4.09, +1.26, +3.09 ) while other FWD baselines regress in at least one dimension. Similarly , in the fairness-saturate d ED A dataset, it continues to achieve balanced positive deltas ( +2.36, +0.69, +0.31 ), whereas ARL and KD both exhibit degradation. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:16 • Tro vato et al. T able 1. F1 scores (%) across demographic subgroups for dier ent models in the Ohio T1DM, EDA, and IHS datasets. Subgroup Benign Baseline (%) KD (%) ARL (%) Re ckoner (%) GOG (%) Flare (%) Ohio T1DM Dataset Age 59.23 65.01 70.16 66.42 59.12 74.36 Cohort 63.31 67.33 70.46 67.57 63.50 72.91 Sex 64.79 68.08 70.71 68.51 65.09 72.72 Pump 53.59 60.66 65.80 61.74 53.92 73.62 Sensor Band 63.31 67.33 70.46 67.57 63.50 72.91 ED A Dataset Group_label 86.91 69.20 87.61 85.55 87.03 89.08 Sex 86.92 69.20 87.61 85.84 87.04 89.47 IHS Dataset Sex 59.66 58.12 62.69 57.52 59.93 63.40 Age 57.37 57.90 62.54 53.34 54.83 63.29 Ethnicity 56.37 58.06 62.66 52.85 57.67 63.30 Specialty 60.27 58.01 62.62 56.94 60.56 63.30 PHQ10>0 62.52 58.09 62.68 58.85 59.35 63.37 These results indicate that Flare is uniquely capable of maintaining stability while improving fairness across multiple ethical axes, unlike adversarial or distillation-based approaches that tend to oscillate or ov ercorrect under imbalance. The reasons for this robustness align with Flare ’s theor etical design. Existing So T A F WD methods enforce fairness globally—through uniform r eweighting or adversarial gradients—without accounting for local heterogeneity in data geometr y . In contrast, Flare operates locally by identifying clusters of samples with similar geometric and model behavioral properties. Fisher penalty guides this process by capturing cur vature- driven sensitivity , revealing which samples lie in unstable regions of the loss landscape. The cluster adaptation mechanism then ne-tunes these regions individually , while conditional aggregation transfers knowledge only when it demonstrably improves validation performance , avoiding the destructive averaging common in global aggregation. This balance between local specialization and controlled sharing explains why Flare achieves both higher fairness and more stable optimization, as reected by its consistently superior BHE scor es across datasets. 6.2.3 Empirical V alidation of Aaining Autonomy at the User Level . Autonomy requires AI systems to deliver consistent and stable b ehavior [ 19 , 38 , 65 ]. In this section, we extend the concept of autonomy to the user level, examining whether Flare maintains stable and reliable performance across individual users. Real-world human-sensing data often exhibit substantial heterogeneity in physiology , b ehavior , context, and device use—factors that commonly lead to une ven performance across individuals [ 24 , 90 ]. By evaluating user- level consistency , we assess Flare ’s ability to mitigate inter-user variability and sustain uniform accuracy and stability . T o this end, Fig. 3 compares six r epresentative models—Benign Baseline, KD, ARL, Reckoner , GOG, and Flare —across three datasets ( Ohio T1DM, EDA, and IHS). Each subplot reports the user-le vel F1 mean and F1 standard deviation ( F1 std ), representing predictive accuracy and consistency , respectively . Including the Benign Baseline enables us to assess whether advanced fairness-oriented methods and Flare improv e upon a simple, unregularized model both in accuracy and reliability—key aspects of practical autonomy . Across all datasets, Flare demonstrates sup erior predictive performance while maintaining the lowest or among the lowest F1 variability across users: A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:17 T able 2. Model-wise p er centage changes ( Δ 𝐵, Δ 𝐻 , Δ 𝐸 ) for ARL, KD, Reckoner , GoG, and Flare across datasets. V alues represent percentage-point impro vements, where larger deltas indicate stronger fairness performance and greater ethical consistency across subgroups. Subgroup ARL (%) KD (%) Reckoner (%) GoG (%) Flare (%) Δ 𝐵 Δ 𝐻 Δ 𝐸 Δ 𝐵 Δ 𝐻 Δ 𝐸 Δ 𝐵 Δ 𝐻 Δ 𝐸 Δ 𝐵 Δ 𝐻 Δ 𝐸 Δ 𝐵 Δ 𝐻 Δ 𝐸 Ohio T1DM Dataset Age 10.93% 3.98% 6.55% 5.78% 2.53% 4.82% 7.19% 2.08% 5.05% -0.11% -1.26% 0.52% 15.14% 5.35% 15.37% Cohort 7.15% 2.32% 6.83% 4.01% 1.39% -17.27% 4.26% 0.53% 3.90% 0.19% -0.22% -0.58% 9.60% 2.64% 9.83% Sex 5.92% 2.46% 4.89% 3.29% 1.47% 2.58% 3.72% 2.98% 1.57% 0.30% 0.18% -0.18% 7.93% 2.89% 3.04% Pump 12.20% 4.86% 10.38% 7.07% 2.66% 6.23% 8.15% 2.92% 7.75% 0.32% 0.24% 0.12% 20.03% 5.41% 19.41% Sensor Band 7.15% 2.32% 6.83% 4.01% 1.39% 3.72% 4.26% 0.53% 3.90% 0.19% -0.22% -0.58% 9.60% 2.64% 9.83% mean 8.67% 3.19% 7.09% 4.83% 1.89% 0.01% 5.52% 1.81% 4.43% 0.18% -0.26% -0.14% 12.46% 3.79% 11.50% EDA Dataset Group_label 0.70% -0.42% 1.13% -17.72% -13.86% 2.06% -1.37% -23.22% -2.36% 0.12% -1.95% -0.11% 2.16% 0.70% 0.57% Sex 0.69% -0.48% -1.48% -17.72% -12.93% -0.17% -1.08% -34.15% 2.30% 0.12% -1.63% 0.22% 2.55% 0.68% 0.06% mean 0.69% -0.45% -0.18% -17.72% -13.39% 0.94% -1.22% -28.69% -0.03% 0.12% -1.79% 0.06% 2.36% 0.69% 0.31% IHS Dataset Sex 3.03% 2.28% -0.73% -1.54% -2.81% -1.40% -2.14% -2.84% -1.51% 0.27% -1.18% -1.79% 3.74% 2.72% 0.04% Age 5.18% 0.28% -27.07% 0.54% -22.67% 1.95% -4.03% -14.04% 5.03% -2.54% -31.82% 3.71% 5.92% 0.00% 8.95% Ethnicity 6.29% 1.84% -1.21% 1.69% -9.20% 1.81% -3.52% -4.21% -0.86% 1.30% -3.08% -6.76% 6.94% 0.00% 2.08% Specialty 2.36% 0.00% 0.94% -2.26% -6.07% 0.59% -3.32% -7.69% 2.03% 0.29% -2.95% -0.25% 3.03% 0.68% 1.16% PHQ10>0 0.15% 0.57% 1.88% -4.43% -4.90% 2.55% -3.68% -4.21% 2.34% -3.17% -7.34% 3.60% 0.85% 2.92% 3.25% mean 3.40% 0.99% -5.24% -1.20% -9.13% 1.10% -2.06% -3.03% 0.08% 0.62% 4.12% 0.09% 4.09% 1.26% 3.09% • On Ohio T1DM , Flare achieves the highest F1 mean of 73.32% , outperforming the Benign Baseline ( 61.80% ), KD (66.63%), and ARL (69.56%), while reducing F1 std to 7.38% compared to 12–18% for the baselines. • On EDA, Flare attains 88.86% mean F1 with an F1 std of only 11.09% , improving upon the Benign Baseline ( 86.92%, 13.39% ) and surpassing other fairness-oriented models such as ARL (87.67%, 11.38%) and GOG (87.06%, 13.67%). • On IHS, Flare achieves 62.57% mean F1, outperforming the Benign Baseline ( 57.41% ), KD (56.92%), and Reckoner (55.43%), with a comparable F1 std of 14.60% . These results indicate that Flare ’s autonomy enhancement extends to the user level, addressing the inherent human heterogeneity . 6.2.4 Empirical V alidation of the “Do Not Harm” Strategy . This section serves as an internal non-malecence validation of the Flare framework, conrming that the adaptive clustering and aggregation mechanisms behave as intended—enhancing local sp ecialization while ensuring that no cluster experiences a reduction in predictive performance compared to the pretrained classier . It analyzes the change in F1-scores b etw een the intermediate ‘Base Pretrained (Bp T) ’ classier (Section 4.1), and the nal Flare model for every dataset, fold, and cluster (Figure 4). Across all datasets, the obser ved Δ F1 values are non-negative , indicating that Flare consistently maintains or improves performance relative to the intermediate Bp T stage. This stability veries that the adaptiv e training dynamics of Flare adhere to the Do Not Harm principle: the nal model strengthens fairness and representation quality without introducing any degradation across clusters, folds, or subgroups. In the Ohio T1DM dataset, several clusters show pronounced gains (e.g., Fold 3—Cluster 1: +44.65%, Cluster 2: +38.81%), indicating that the nal-stage adaptation enhances generalization without sacricing performance. For ED A, impro vements are mo derate yet consistent, demonstrating that even in already high-performing conditions, Flare renes decision boundaries and sustains comparable or improved accuracy ( e.g., Fold 2—Cluster 0: +8.81%, A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:18 • Tro vato et al. Fig. 3. User-level F1 mean and F1 standard deviation across all models for the Ohio T1DM, EDA, and IHS datasets. Lower F1 std indicates more consistent model behavior , supporting user-level autonomy . Fold 3—Cluster 0: +7.73%). In the more heter ogeneous IHS dataset, stable positive shifts (e .g., Fold 3—Cluster 0: +17.14%) further demonstrate that the cluster-level adaptation sustains or improves accuracy within clusters, validating the do-no-harm objective. 6.3 V alidating Design Choices W e validate Flare ’s design choices through two complementary analyses, ensuring that its observed improve- ments directly result from the intende d design principles. First, we visualize and compare the loss landscapes of models trained with and without Fisher penalty regularization to examine how curvature control inuences optimization stability and generalization. Se cond, we perform a detailed component-level ablation of the network structure to isolate the contribution of Fisher regularization, cluster adaptation, and conditional aggregation. T ogether , these analyses clarify why Flare converges to atter , more stable minima and how each architectural element contributes to improved ethical fairness. 6.3.1 Analyzing Optimization Geometry through Loss Landscapes . T o substantiate the design choices underpinning Flare and to interpret its b ehavior from an optimization–geometry persp ective , we visualize the loss landscapes [ 54 ] corresponding to the best-performing Flare models across all three datasets—Ohio T1DM, ED A, and IHS. Specically , we examine how each design component ( base pretraining, Fisher penalty regulariza- tion, and cluster-level adaptation with do-no-harm aggregation) shapes the curvature and smo othness of the resulting optimization surface. Prior research has established that the geometry of the loss landscape encodes valuable generalization pr operties: models converging to atter minima exhibit better generalization performance [ 52 , 54 , 73 ]. In contrast, sharper minima indicate higher curvature regions that correspond to overtting and unstable learning dynamics. Following [ 54 ], we visualize the loss by sweeping along two random, lter-normalized orthogonal directions (denoted as 𝑋 - and 𝑌 -steps), with the 𝑍 -axis repr esenting the corresponding loss surface centered at the nal conv erged weights. Figure 5 illustrates the comparative loss landscapes for four ablated variants—(i) the benign baseline model, (ii) base pr etraining without the Fisher penalty ( Bp T -wo Fisher ), (iii) base pretraining with Fisher p enalty regularization ( Bp T -w Fisher ), and (iv) Flare ( Bp T -w Fisher + Adaptation ). These are shown separately for the EDA (Figur e 5a), IHS (Figure 5b), and Ohio T1DM datasets (Figure 5c), each generate d using identical folds and cluster data for fair , unbiased comparison. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:19 (a) Ohio T1DM: Bp T vs. Flare per fold–cluster . (b) EDA: Bp T vs. Flare per fold–cluster . (c) IHS: Bp T vs. Flare per fold–cluster . Fig. 4. Fold and Cluster-wise F1 comparison across datasets within the propose d Flare framework. Bars show F1-scores for Base pre Training (Bp T , light brown) as the interme diate module (1) and Flare (dark brown) as the final module (3) across all fold–cluster pairs. V alues above each pair ( Δ ) indicate the change from Bp T to Flare . Across all datasets, we consistently observe that the b enign baseline e xhibits a turbulent and sharp loss surface (highlighted with red arrows and dotted cir cles), characterized by steep valleys and narrow basins . Such sharp curvature regions imply higher local sensitivity to parameter perturbations and are indicative of overtting [52] . Introducing the base pretraining step without Fisher penalty regularization (second subgure, red arrows) results in a visibly smoother surface, but it still retains local irregularities. Incorporating the Fisher penalty (orange arr ows and dotted circles) further stabilizes the curvature, reducing sharpness and yielding a broader , lower-energy basin that captures the eect of curvature-aware regularization [20]. The full Flare model (rightmost panels, highlighted with green arrows and dotted circles) demonstrates a consistently atter and wider basin across all datasets, r epresenting a near-at optimum. This outcome r eects the synergistic eect of cluster-sp ecic adaptation and stability-preserving aggregation—where the do-no-harm regularizer ensures local ne-tuning benets subgroups without regr essing from the baseline. The atter landscape empirically supports our claim of Flare achieving a Par eto-optimal [ 67 ], i.e., "Do not harm" balance between performance improvement and fairness preservation. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:20 • Tro vato et al. (i ) Benign Baseline (ii) Base pretraining without Fisher penalty (BpT- wo Fisher) (iii) Base pretraining with Fisher Penalty (BpT- w Fisher) (iv) FLARE ( BpT - w Fisher + Adaptation ) Fl at ness ↑ i. e . Ov e r f i t t i n g ↓ Fl at ness ↓ i. e . Ov e r f i t t i n g ↑ (a) ED A dataset (i ) Benign Baseline (ii) Base pretraini ng without Fisher penalty ( BpT - wo Fisher) (iii) Base pretraining with Fisher Penalty (BpT- w Fisher) (iv) FLARE ( BpT - w Fisher + Adaptation ) (b) IHS dataset (i ) Benign Baseline (ii) Base pretraini ng without Fisher penalty ( BpT - wo Fisher) (iii) Base pretraining with Fisher Penalty (BpT- w Fisher) (iv) FLARE ( BpT- w Fisher + Adapt ation ) (c) Ohio T1DM dataset Fig. 5. Loss landscap e visualizations for the b enign baseline, base Pre-training without Fisher penalty , base pretraining with Fisher penalty regularization, and Flare across three datasets. The red , orange , and green arrows and doed circles respectively highlight curvature transitions, showing how Fisher regularization and cluster adaptation progressively flaen the optimization landscape. These r esults suggest that Flare , eectively steers the optimization towards smoother and more generalizable minima by penalizing cur vatur e (via Fisher penalty) and harmonizing subgroup-spe cic ne-tuning through adaptive aggregation. The observed attening across datasets pr ovides geometric evidence that our design enhances both robustness and fairness, aligning with the intended Pareto-optimal learning objectives. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:21 6.3.2 Assessing Structural Contributions via Detailed Ablation . W e conducted an ablation study to assess the contribution of each structural comp onent within Flare , specically examining the individual and combined eects of Fisher penalty regularization and the Cluster A daptation and Aggregation (CAA) module. This analysis disentangles how each element inuences fairness, stability , and overall p erformance across datasets. T able 3 summarizes the results, demonstrating that Fisher penalty regularization enhances representational smoothness and equity , while CAA enhances performance, while avoiding harm across latent clusters. The full Flare conguration—combining b oth components—consistently achieves the most balanced and consistent improv ements, conrming their complementary roles in achieving ethical fairness without demographic supervision. W e compare four congurations: • Bp T -w Fisher , base pretraining with Fisher penalty regularization; • Bp T -wo Fisher , the same base pretraining procedure without Fisher penalty; • CAA -wo Fisher , which uses the same Cluster Adaptation and Aggregation (CAA ) module as Flare , but initializes from a non-Fisher penalty base; and • the full Flare mo del, combining both. Across all datasets, Fisher penalty regularization during base pretraining improves representational stability and equity . In the Ohio T1DM dataset, Bp T -w Fisher produces modest gains ( Δ 𝐵 = + 0 . 74 , Δ 𝐻 = − 2 . 13 , Δ 𝐸 = − 1 . 27 ) , while removing Fisher (Bp T -wo Fisher) increases benecence ( + 7 . 96 ) but with uctuating harm and equity ( + 0 . 80 , + 9 . 05 ) , indicating less controlled adaptation. Introducing the CAA module without Fisher further raises Δ 𝐸 ( + 5 . 62 ) but amplies harm variability ( Δ 𝐻 = − 9 . 53 ) , highlighting its sensitivity to unstable initializa- tion. When both components are integrated, Flare achieves the strongest and most consistent improv ements ( + 12 . 46 , + 3 . 79 , + 11 . 50 ) , demonstrating that Fisher penalty regularization and CAA work synergistically—one stabilizing the base representation and the other rening subgr oup alignment. In the ED A dataset, all congurations improve slightly , but Flare attains the highest overall balance ( + 2 . 36 , + 0 . 69 , + 0 . 31 ) , whereas Bp T -w Fisher ( + 1 . 49 , − 0 . 32 , + 1 . 22 ) and Bp T -wo Fisher ( + 1 . 91 , − 0 . 51 , + 1 . 08 ) show smaller or inconsistent changes. This pattern r einforces that the Fisher penalty-informed base provides a smoother optimization surface for subsequent cluster adaptation. The IHS dataset, characterized by high heter ogeneity , further conrms this trend. Bp T -w Fisher achie ves minor positive benecence ( + 0 . 65 ) but negative harm and equity values, while Bp T -wo Fisher and CAA-w o Fisher exhibit larger oscillations in Δ 𝐻 ( − 4 . 90 and − 5 . 10 respectively). Only Flare yields consistent positive deltas across all three dimensions ( + 4 . 09 , + 6 . 00 , + 3 . 09 ) , indicating stable adaptation under complex population shifts. These ndings collectively demonstrate that Fisher regularization establishes a stable and equitable representa- tional foundation, while the Cluster Adaptation and Aggregation ( CAA) module leverages this stability to rene subgroup alignment and performance. 7 On-device Eiciency during W earable Mo del Infer ence Evaluating on-device inference eciency is critical for human sensing systems, particularly those that r ely on resource-constrained wearables such as the Empatica E4 used in our EDA dataset. In such systems, inference latency and memory consumption directly determine the feasibility of real-time feedback and energy sustainability [ 50 , 79 ]. Therefore, to evaluate the practical feasibility of Flare during deployment, we benchmarked its on-device inference eciency against the baselines (Benign, ARL, KD , Reckoner , GoG) across ve har dware platforms—from high-end GP Us (N VIDIA RTX 4090, Quadro RTX 5000) to desktop-class CP Us (Intel i9-9900K, AMD Ryzen 9 7950X, Apple M1) for the EDA dataset. W e measured the average inference time, r esident set size (RSS) memory usage, and resour ce utilization percentage (CP U/GP U utilization) over v e runs per platform. T able 4 presents the results for the EDA dataset. Flare maintains similar inference latency and memor y consumption across A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:22 • Tro vato et al. T able 3. Ablation study showing p ercentage changes ( Δ 𝐵, Δ 𝐻 , Δ 𝐸 ) for Base-T raining with Fisher (Bp T -w Fisher), Base- Training without Fisher (Bp T -wo Fisher), Cluster Adaptation and Aggr egation without base-trained Fisher (CAA -wo Fisher), and Flare across datasets. V alues are percentage points. Subgroup Bp T -w Fisher (%) Bp T -wo Fisher (%) CAA -wo Fisher (%) Flare (%) Δ 𝐵 Δ 𝐻 Δ 𝐸 Δ 𝐵 Δ 𝐻 Δ 𝐸 Δ 𝐵 Δ 𝐻 Δ 𝐸 Δ 𝐵 Δ 𝐻 Δ 𝐸 Ohio T1DM Dataset Age 2.21% -2.26% 0.68% 10.23% 2.29% 12.65% 5.61% -7.75% 9.69% 15.14% 5.35% 15.37% Cohort 0.16% -2.72% -16.92% 5.78% -0.08% 8.29% 1.52% -11.25% 2.92% 9.60% 2.64% 9.83% Sex -0.39% -2.10% 2.41% 4.13% -0.54% -0.21% -2.02% -9.13% 0.11% 7.93% 2.89% 3.04% Pump 1.56% -0.85% 3.40% 13.90% 2.41% 16.25% 11.24% -8.29% 12.47% 20.03% 5.41% 19.41% Sensor Band 0.16% -2.72% 4.07% 5.78% -0.08% 8.29% 1.52% -11.25% 2.92% 9.60% 2.64% 9.83% mean 0.74% -2.13% -1.27% 7.96% 0.80% 9.05% 3.58% -9.53% 5.62% 12.46% 3.79% 11.50% EDA Dataset Group_label 1.50% -0.51% 2.13% 1.98% 0.03% 0.96% 1.97% 0.11% 2.13% 2.16% 0.70% 0.57% Sex 1.49% -0.13% 0.31% 1.83% -1.06% 1.19% 1.97% 0.46% 0.47% 2.55% 0.68% 0.06% mean 1.49% -0.32% 1.22% 1.91% -0.51% 1.08% 1.97% 0.28% 1.30% 2.36% 0.69% 0.31% IHS Dataset Sex 0.07% -0.33% -0.57% 0.92% 0.48% -0.37% 0.65% 0.03% -0.36% 3.74% 2.90% 0.04% Age 3.78% -3.14% 1.39% 2.45% -9.77% 2.20% 2.83% -9.77% 7.94% 5.92% 12.42% 8.95% Ethnicity 0.29% -2.23% -2.74% -0.85% -2.11% -9.45% -0.06% -2.27% 2.38% 6.94% 5.22% 2.08% Specialty -0.06% -2.75% -0.35% 0.68% -7.25% 0.94% 3.78% -7.37% 1.07% 3.03% 5.66% 1.16% PHQ10>0 -0.82% -1.81% 1.40% 1.62% -5.85% -1.07% -2.22% -6.09% 2.89% 0.85% 3.79% 3.25% mean 0.65% -2.05% -0.17% 0.96% -4.90% -1.55% 0.99% -5.10% 2.78% 4.09% 6.00% 3.09% all devices with consistently low latency— 0 . 001 s on the RTX 4090, 0 . 006 s on the Ryzen 9, and 0 . 04 s on the Apple M1 while consuming mo dest memory ( ∼ 826 Mbs on av erage). Resource utilization r emains minimal ( ≤ 4% GP U and ≤ 3 . 5% CP U), demonstrating ecient hardware usage even on edge devices. The lo w CP U utilization reects measurements normalized across all available cores on multi-core pr ocessors, where lightw eight inference workloads engage only a subset of threads, an expe cted behavior in energy-ecient human-sensing models [ 32 , 40 ]. Notably , Flare , with its two-stage learning process, learns cluster memberships once during the base-pretraining phase and only uses them during inference, thus ensuring ecient inference time performance without compromising deployability on heterogeneous systems. 8 Discussions and Limitations While Flare advances ethical, demographic-agnostic fairness, it also presents computational and metho dological considerations that open avenues for future research and r enement. (1) Training- Time Overhead and Practical Feasibility . While Flare ’s inference-time performance matches So T A baselines (refer to Section 7), our approach incurs additional training-time overhead due to the base pre-training phase for latent subgroup identication and clustering. Our Train time evaluation in Appendix A.4 shows that for the EDA dataset, although the training latency is higher , the CP U and memory utilization remain comparable to other appr oaches. In practice, this o verhead is manageable since most human- sensing systems rely on centralized or edge/cloud-based training pipelines capable of handling increased computational demands [ 7 , 47 , 63 , 66 ]. Hence, Flare ’s added training cost is a reasonable trade-o for its fairness and ethical consideration gains, especially since deployment emphasizes lightweight inference rather than on-device training. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:23 T able 4. Inference Time ( s), Inference Process (RSS) Memory Usage (MB), and Inference Resour ce Usage (%) for baselines and Flare across dierent platforms e valuated for the EDA dataset. Platform Benign Baseline ARL KD Reckoner GoG Flare Infer (s) RSS (MB) Usage (%) Infer (s) RSS (MB) Usage (%) Infer (s) RSS (MB) Usage (%) Infer (s) RSS (MB) Usage (%) Infer (s) RSS (MB) Usage (%) Infer (s) RSS (MB) Usage (%) EDA Dataset NVIDIA GeForce RTX 4090 0.001 1214.7 21 0.006 1256.6 26 0.077 1269.3 28 0.01 1288 13.8 0.01 1625 18.4 0.001 1070 4 AMD Ryzen 9 7950X 16-Core Processor 0.01 1219.6 0.78 0.006 1263 0.79 0.005 1274.7 0.82 0.01 1351.7 0.78 0.01 1648 1.09 0.006 1073 1.13 Quadro RTX 5000 0.12 983.7 7.90 0.02 1020.1 11.7 0.02 1031.3 10.90 0.05 1146.4 5.0 0.03 1414.1 34.8 0.02 818.8 2.40 Intel i9-9900K Processor 0.07 1133.4 3.11 0.08 1129 3.12 0.0541 1143 3.12 0.27 1234.7 3.01 0.09 1515.8 3.68 0.02 840.1 3.12 Apple M1 0.02 133.3 0.72 0.017 157.0 0.65 0.01 135.8 0.59 0.03 98.1 0.25 0.02 173.4 0.74 0.04 331.9 0.20 (2) Inuence of Person-Disjoint Splits on Reported Accuracy . Notably , our results on the Ohio T1DM dataset show lo wer accuracy than those reporte d in prior w ork [ 61 ]; this dierence stems fr om this paper’s stricter and more realistic e valuation protocol. Unlike previous studies that used ov erlapping user data, our person-disjoint evaluation ensures complete subject-level separation between the training and testing sets. This setup prevents information leakage and provides a more faithful estimate of real-world generalization to unseen individuals, reecting robustness rather than overtting to user-specic patterns. (3) Interpretability of Latent Subgroups. Flare identies latent subgroups through clustering based on model embeddings and instance-level loss and landscape curvature, without relying on explicit demographic or sensitive attributes. How ever , this optimization-driven process makes it dicult to determine which demographic or sensitive factors—or their combinations—underlie the observed disparities. As noted in Section 3.2, we assess ethical fairness using known demographic attributes only as proxies for unobserved ones. This limitation is not unique to our frame work; existing fairness-without-demographics (F WD) approaches [ 14 , 49 , 59 , 68 ] face the same challenge. Nevertheless, identifying the hidden social or contextual factors behind such latent disparities remains a valuable dir ection for future resear ch, as doing so could inform more transparent, data-aware , and so cially responsible AI interventions. (4) Experiment at Scale. Due to the scarcity of large, demographically annotated human-sensing datasets, our evaluation could not be conducted on broader-scale cohorts. While our experiments spanned diverse domains—wearable sensing (ED A), mobile sensing in the wild (IHS), and clinical monitoring (Ohio T1DM)— datasets encompassing multiple sensitive attributes remain rare in the human-sensing domain [ 94 ]. Even recent large-scale initiatives such as GLOBEM [ 92 ] omit demographic or sensitive information due to privacy , consent, and ethical constraints [ 56 ], a gap also noted across ubiquitous and mobile sensing research [ 93 , 95 ]. Developing ethically curated datasets that balance participant privacy with the inclusion of demographic or sensitive information will be essential for futur e large-scale validation of Flare and broader fairness research in human-center ed AI. 9 Conclusion This paper introduced Flare —the rst principled framework for achieving ethical fairness without access to demographic information. It pro vides a demographic-agnostic and ethically gr ounded foundation for human- centered AI, dete cting and mitigating latent disparities through geometry-aware collaboration rather than A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:24 • Tro vato et al. demographic super vision. Comprehensiv e evaluations across diverse human-centered datasets and its com- putational eciency on e dge devices demonstrate Flare ’s practicality for real-world, resource-constrained deployment. As AI systems increasingly inuence critical decisions that shape human welfare, embedding fairness and ethics into their cor e design is essential for building systems that ar e trustworthy , inclusive, and account- able. Flare represents a step towar d this future—realizing practical, ethically aligned AI with transformativ e implications for sensitive and high-impact domains such as healthcare , education, and behavioral sensing. References [1] Adler, D. A., Tseng, V . W .-S., Qi, G., Scarp a, J., Sen, S., and Choudhury, T . Identifying mobile sensing indicators of stress-resilience. Proceedings of the ACM on Interactive, Mobile, W earable and Ubiquitous T echnologies 5 , 2 (2021), 1–32. [2] Adler, D. A., Y ang, Y ., Viranda, T ., Xu, X., Mohr, D. C., V an Meter, A. R., T art aglia, J. C., Ja cobson, N. C., W ang, F., Estrin, D ., et al. Beyond detection: T owards actionable sensing research in clinical mental healthcar e. Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies 8 , 4 (2024), 1–33. [3] Afrose, S., Song, W ., Nemeroff, C. B., Lu, C., and Y ao, D . Subpopulation-specic machine learning prognosis for underrepresented patients with double prioritized bias correction. Communications medicine 2 , 1 (2022), 111. [4] AI, N. Articial intelligence risk management framework (ai rmf 1.0). URL: https://nvlpubs. nist. gov/nistpubs/ai/nist. ai (2023), 100–1. [5] Akande, O. A. Architecting decentralized ai frameworks for multi-modal health data fusion to advance equitable and personalized medicine. [6] Alabi, M. Ethical implications of ai: Bias, fairness, and transparency , 2024. [7] Ala wneh, L., Al-A yyoub, M., Al-Sharif, Z. A., and Sha tna wi, A. Personalize d human activity recognition using deep learning and edge-cloud architecture. Journal of Ambient Intelligence and Humanized Computing 14 , 9 (2023), 12021–12033. [8] Andersson, G. B., Chapman, J. R., Dekutoski, M. B., Dettori, J., Fehlings, M. G., Fourney, D. R., Norvell, D ., and Weinstein, J. N. Do no harm: the balance of “benecence” and “non-malecence ” , 2010. [9] Andrus, M., and Villeneuve, S. Demographic-reliant algorithmic fairness: Characterizing the risks of demographic data collection in the pursuit of fairness. In Proceedings of the 2022 ACM Conference on Fairness, Accountability , and Transpar ency (2022), pp. 1709–1721. [10] Arefeen, A., and Ghasemzadeh, H. Designing user-centric behavioral interventions to prevent dysglycemia with novel counterfactual explanations. arXiv preprint arXiv:2310.01684 (2023). [11] Arize AI . Evaluating mo del fairness, May 2023. Responsible AI. Discusses bias and fairness in machine learning, including sensitive and non-sensitive group bias, and approaches to mitigate bias in model dev elopment. [12] Benzinger, L., Ursin, F., Balke, W .-T ., Kacprowski, T ., and Salloch, S. Should articial intelligence be used to support clinical ethical decision-making? a systematic review of reasons. BMC medical ethics 24 , 1 (2023), 48. [13] Beutel, A., Chen, J., Doshi, T ., Qian, H., W oodruff, A., Luu, C., Kreitmann, P., Bischof, J., and Chi, E. H. Putting fairness principles into practice: Challenges, metrics, and improvements. In Proce edings of the 2019 AAAI/A CM Conference on AI, Ethics, and Society (2019), pp. 453–459. [14] Chai, J., Jang, T ., and W ang, X. Fairness without demographics through knowledge distillation. Advances in Neural Information Processing Systems 35 (2022), 19152–19164. [15] Chint a, S. V ., W ang, Z., Yin, Z., Ho ang, N., Gonzalez, M., y, T . L., and Zhang, W . Fairaie d: Navigating fairness, bias, and ethics in educational ai applications. arXiv preprint arXiv:2407.18745 (2024). [16] Dada, B. A., Nwulu, N. I., and Olukanmi, S. O. Bayesian optimization with optuna for enhanced soil nutrient prediction: A comparative study with genetic algorithm and particle swarm optimization. Smart Agricultural T e chnology (2025), 101136. [17] Da uphin, Y. N., A garw ala, A., and Mobahi, H. Neglected hessian component explains mysteries in sharpness regularization. arXiv preprint arXiv:2401.10809 (2024). [18] Emma, L. The ethical implications of articial intelligence: A deep dive into bias, fairness, and transpar ency . Retriev ed from Emma, L.(2024). The Ethical Implications of A rticial Intelligence: A Deep Dive into Bias, Fairness, and Transpar ency (2024). [19] Floridi, L., and Cowls, J. A unied framework of ve principles for ai in society . Machine learning and the city: Applications in architecture and urban design (2022), 535–545. [20] Foret, P., Kleiner, A., Mobahi, H., and Neyshabur, B. Sharpness-aware minimization for eciently improving generalization. arXiv preprint arXiv:2010.01412 (2021). [21] Friedler, S. A., Scheidegger, C., and Venka t asubramanian, S. The (im) possibility of fairness: Dierent value systems require dierent mechanisms for fair decision making. Communications of the A CM 64 , 4 (2021), 136–143. [22] Friedler, S. A., Scheidegger, C., Venka t asubramanian, S., Choudhary, S., Hamilt on, E. P., and Roth, D . A comparative study of fairness-enhancing interventions in machine learning. In Proceedings of the conference on fairness, accountability , and transparency (2019), pp. 329–338. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:25 [23] Gabriel, I. T oward a theory of justice for articial intelligence. Dae dalus 151 , 2 (2022), 218–231. [24] Giblon, R., Gao, C., Liu, K., Ouy ang, Y., Cunningham, J., Pimient a, A., Goligher, E., and Hea th, A. Who benets? uncovering hidden heterogeneity of treatment eects in adaptive trials using bayesian methods: A systematic re view . [25] Giguere, S., Metevier, B., Brun, Y ., Da Silv a, B. C., Thomas, P. S., and Niekum, S. Fairness guarante es under demographic shift. In Proceedings of the 10th International Conference on Learning Representations (ICLR) (2022). [26] Giov anola, B., and Tiribelli, S. Beyond bias and discrimination: redening the ai ethics principle of fairness in healthcare machine- learning algorithms. AI & society 38 , 2 (2023), 549–563. [27] Gu, X., Zhang, Z., Jin, R., Goh, R. S. M., and Luo, T . Self-distillation with model averaging. Information Sciences 694 (2025), 121694. [28] Hardt, M., Price, E., and Srebro, N. Equality of opportunity in sup ervised learning. Advances in neural information processing systems 29 (2016). [29] Hashimot o, T ., Sriv ast a v a, M., Namkoong, H., and Liang, P. Fairness without demographics in repeated loss minimization. In International Conference on Machine Learning (2018), PMLR, pp. 1929–1938. [30] Healy, J., and McInnes, L. Uniform manifold approximation and projection. Nature Reviews Methods Primers 4 , 1 (2024), 82. [31] Hebert-Johnson, U ., Kim, M., Reingold, O., and Rothblum, G. Multicalibration: Calibration for the (computationally-identiable) masses. In Procee dings of the 35th International Conference on Machine Learning (ICML) (2018), pp. 1939–1948. [32] Hirsch, M., Mateos, C., and Majchrzak, T . A. Exploring smartphone-based edge ai inferences using real testbeds. Sensors 25 , 9 (2025), 2875. [33] Hod, S., Filan, D ., Casper, S., Crit ch, A., and Russell, S. Quantifying local specialization in deep neural networks. arXiv preprint arXiv:2110.08058 (2021). [34] House, T . W . Removing barriers to american leadership in articial intelligence. Executive Order 23 (2025). [35] Hu ang, W ., Rong, Y ., Xu, T ., Sun, F ., and Hu ang, J. T ackling over-smoothing for general graph convolutional networks. arXiv preprint arXiv:2008.09864 (2020). [36] Hurley, P. Fairness and benecence. Ethics 113 , 4 (2003), 841–864. [37] Izmailov, P., P odoprikhin, D., Garipov, T ., Vetrov, D., and Wilson, A. G. A veraging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407 (2018). [38] Jahn, W . T . The 4 basic ethical principles that apply to forensic activities are respect for autonomy , benecence, nonmalecence, and justice. Journal of chiropractic medicine 10 , 3 (2011), 225. [39] Jastrzębski, S., Kenton, Z., Ballas, N., Fischer, A., Bengio, Y ., and Storkey, A. On the relation between the sharpest directions of dnn loss and the sgd step length. arXiv preprint arXiv:1807.05031 (2018). [40] Jin, X., Li, L., Dang, F., Chen, X., and Liu, Y. A survey on edge computing for wearable technology . Digital Signal Processing 125 (2022), 103146. [41] Jobin, A., Ienca, M., and V ayena, E. The global landscape of ai ethics guidelines. Nature Machine Intelligence 1 , 9 (2019), 389–399. [42] Kamiran, F., and Calders, T . Data preprocessing techniques for classication without discrimination. In Knowledge and Information Systems (2012), vol. 33, pp. 1–33. [43] Kang, S. K-nearest neighbor learning with graph neural networks. Mathematics 9 , 8 (2021), 830. [44] Ka tirai, A. The ethics of advancing articial intelligence in healthcare: analyzing ethical considerations for japan’s innovative ai hospital system. Frontiers in Public Health 11 (2023), 1142062. [45] Kearns, M., Neel, S., Roth, A., and W u, Z. S. Preventing fairness gerrymandering: Auditing and learning for subgroup fairness. In Proceedings of the 35th International Conference on Machine Learning (ICML) (2018), pp. 2564–2572. [46] Kenf ack, P . J., Kahou, S. E., and Aïvodji, U. A survey on fairness without demographics. Transactions on Machine Learning Research (2024). [47] Khan, A. R., Manzoor, H. U ., A y az, F., Imran, M. A., and Zoha, A. A privacy and energy-aware federated framework for human activity recognition. Sensors 23 , 23 (2023), 9339. [48] K oh, P . W ., Saga w a, S., Marklund, H., Xie, S. M., Zhang, M., Balsubramani, A., Hu, W ., Y asunaga, M., Phillips, R. L., Gao, I., et al. Wilds: A benchmark of in-the-wild distribution shifts. In International conference on machine learning (2021), PMLR, pp. 5637–5664. [49] Lahoti, P., Beutel, A., Chen, J., Lee, K., Prost, F., Thain, N., W ang, X., and Chi, E. Fairness without demographics through adversarially reweighted learning. Advances in neural information processing systems 33 (2020), 728–740. [50] Lane, N. D., and Georgiev, P . Can deep learning revolutionize mobile sensing? In Proceedings of the 16th international workshop on mobile computing systems and applications (2015), pp. 117–122. [51] Lee, B.-K., Kim, J., and Ro, Y . M. Masking adversarial damage: Finding adv ersarial saliency for robust and sparse network. In Pr oceedings of the IEEE/CVF Conference on Computer Vision and Pattern Re cognition (2022), pp. 15126–15136. [52] Li, A., Zhuang, L., Long, X., Y ao, M., and W ang, S. Seeking consistent at minima for better domain generalization via rening loss landscapes. In Proceedings of the Computer Vision and Pattern Recognition Conference (2025), pp. 15349–15359. [53] Li, C., Cao, Z., and Liu, Y . Deep ai enabled ubiquitous wireless sensing: A sur v ey . A CM Computing Surveys (CSUR) 54 , 2 (2021), 1–35. [54] Li, H., Xu, Z., T a ylor, G., Studer, C., and Goldstein, T . Visualizing the loss landscape of neural nets. Advances in neural information A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:26 • Tro vato et al. processing systems 31 (2018). [55] Li, Y ., Dangel, F., T am, D., and Raffel, C. Fishers for free? appro ximating the sher information matrix by r ecycling the squared gradient accumulator . arXiv preprint arXiv:2507.18807 (2025). [56] Linna Jr, D. W ., and Muchman, W . J. Ethical obligations to protect client data when building articial intelligence tools: Wigmore meets ai. Prof. Law . 27 (2020), 27. [57] Liu, C. C., Pfeiffer, J., Vulić, I., and Gurevych, I. Fun with sher: Improving generalization of adapter-based cross-lingual transfer with scheduled unfreezing. arXiv preprint arXiv:2301.05487 (2023). [58] Liu, E. Z., Haghgoo, B., Chen, A. S., Raghuna than, A., K oh, P. W ., Saga w a, S., Liang, P., and Finn, C. Just train twice: Improving group robustness without training group information. In International Conference on Machine Learning (2021), PMLR, pp. 6781–6792. [59] Luo, Y ., Li, Z., Liu, Q., and Zhu, J. Fairness without demographics through learning graph of gradients. In Procee dings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1 (2025), pp. 918–926. [60] Manjuna th, N., Li, Z. Y ., Choi, E. S., Sen, S., W ang, F., and Adler, D. A. Can data augmentation improve daily mood prediction from wearable data? an empirical study . In Adjunct Procee dings of the 2023 A CM International Joint Conference on Pervasive and Ubiquitous Computing & the 2023 ACM International Symposium on W earable Computing (2023), pp. 632–637. [61] Marling, C., and Bunescu, R. The ohiot1dm dataset for blood glucose level prediction: Update 2020. In CEUR workshop proceedings (2020), vol. 2675, p. 71. [62] Martens, J. New insights and perspectives on the natural gradient method. Journal of Machine Learning Research 21 , 146 (2020), 1–76. [63] Messer, A., Greenberg, I., Bernada t, P., Milojicic, D., Chen, D., Giuli, T . J., and Gu, X. T owards a distributed platform for resource-constrained devices. In Proceedings 22nd International Conference on Distributed Computing Systems (2002), IEEE, pp. 43–51. [64] Mishler, A., Kennedy, E. H., and Chouldechov a, A. Fairness in risk assessment instruments: Post-pr ocessing to achieve counterfactual equalized odds. In Proceedings of the 2021 ACM conference on fairness, accountability , and transparency (2021), pp. 386–400. [65] Mittelst adt, B. Principles alone cannot guarante e ethical ai. Nature machine intelligence 1 , 11 (2019), 501–507. [66] Mosha wrab, M., Adda, M., Bouzou ane, A., Ibrahim, H., and Raad, A. Reviewing federated machine learning and its use in diseases prediction. Sensors 23 , 4 (2023), 2112. [67] Nagp al, R., Shahsa v arifar, R., Goy al, V ., and Gupt a, A. Optimizing fairness and accuracy: a pareto optimal approach for decision- making. AI and Ethics 5 , 2 (2025), 1743–1756. [68] Ni, H., Han, L., Chen, T ., Sadiq, S., and Demartini, G. Fairness without sensitive attributes via knowledge sharing. In Proce edings of the 2024 ACM Conference on Fairness, Accountability , and T ransparency (2024), pp. 1897–1906. [69] Opoku, R. A., Pei, B., and Xing, W . Unveiling accuracy-fairness trade-os: Investigating machine learning models in student performance prediction. Journal of Learning A nalytics 12 , 2 (2025), 125–139. [70] Pessach, D., and Shmueli, E. Algorithmic fairness. In Machine Learning for Data Science Handb ook: Data Mining and Knowledge Discovery Handbook . Springer , 2023, pp. 867–886. [71] Puccinelli, D., and Haenggi, M. Wireless sensor networks: applications and challenges of ubiquitous sensing. IEEE Circuits and systems magazine 5 , 3 (2005), 19–31. [72] Rajk omar, A., Hardt, M., Howell, M. D ., Corrado, G., and Chin, M. H. Ensuring fairness in machine learning to advance health equity . A nnals of internal me dicine 169 , 12 (2018), 866–872. [73] Rangamani, A., et al. Loss landscap es and generalization in neural networks: Theor y and applications . PhD thesis, Johns Hopkins University , 2020. [74] Ra uf, H. T ., Boga tu, A., P a ton, N. W ., and Freit as, A. Gem: Gaussian mixture model embeddings for numerical feature distributions. arXiv preprint arXiv:2410.07485 (2024). [75] Saga w a, S., Koh, P . W ., Hashimoto, T . B., and Liang, P. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv preprint arXiv:1911.08731 (2019). [76] Shekhar, S., Bansode, A., and Salim, A. A comparative study of hyper-parameter optimization to ols. In 2021 IEEE Asia-Pacic Conference on Computer Science and Data Engineering (CSDE) (2021), IEEE, pp. 1–6. [77] Singh, J. P. Ai ethics and societal perspectives: a comparative study of ethical principle prioritization among diverse demographic clusters. Journal of Advanced A nalytics in Healthcare Management 5 , 1 (2021), 1–18. [78] Sohoni, N., Dunnmon, J., Angus, G., Gu, A., and Ré, C. No subclass left behind: Fine-graine d robustness in coarse-grained classication problems. Advances in Neural Information Processing Systems 33 (2020), 19339–19352. [79] Stisen, A., Blunck, H., Bha tt achary a, S., Prent ow, T . S., Kjærgaard, M. B., Dey, A., Sonne, T ., and Jensen, M. M. Smart devices are dierent: Assessing and mitigatingmobile sensing heterogeneities for activity recognition. In Proceedings of the 13th A CM conference on embedded networked sensor systems (2015), pp. 127–140. [80] Stopczynski, A., Pietri, R., Pentland, A., Lazer, D ., and Lehmann, S. Privacy in sensor-driven human data collection: A guide for practitioners. arXiv preprint arXiv:1403.5299 (2014). [81] Supeksala, Y ., Nguyen, D. C., Ding, M., Ranbaduge, T ., Chua, C., Zhang, J., Li, J., and Poor, H. V . Private knowledge sharing in distributed learning: A survey . arXiv preprint arXiv:2402.06682 (2024). A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:27 [82] Suresh, H., and Gutt ag, J. A framework for understanding sources of harm thr oughout the machine learning life cy cle. In Proceedings of the 1st ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (2021), pp. 1–9. [83] Thomas, V ., Pedregosa, F., Merriënboer, B., Manzagol, P .-A., Bengio, Y ., and Roux, N. L. On the interplay b etween noise and curvature and its eect on optimization and generalization. In Proceedings of the Tw enty Third International Conference on A rticial Intelligence and Statistics ( June 2020), PMLR, pp. 3503–3513. ISSN: 2640-3498. [84] Tran, C., Fioretto, F ., Kim, J.-E., and Naidu, R. Pruning has a disparate impact on mo del accuracy . Advances in Neural Information Processing Systems 35 (2022), 17652–17664. [85] U.S. Dep artment of Health and Human Services . Nondiscrimination in health programs and activities. Fe deral Register , May 2024. [86] Venka t asubbu, S., and Krishnamoorthy, G. Ethical considerations in ai addressing bias and fairness in machine learning models. Journal of Knowledge Learning and Science T echnology ISSN: 2959-6386 (online) 1 , 1 (2022), 130–138. [87] V os, G., Trinh, K., Sarny ai, Z., and Azghadi, M. R. Generalizable machine learning for stress monitoring from wearable devices: A systematic literature review . International Journal of Medical Informatics (2023), 105026. [88] W ang, H., Zhou, M., Jia, X., Wei, H., Hu, Z., Li, W ., Chen, Q., and W ang, L. Recent progress on articial intelligence-enhanced multimodal sensors integrated devices and systems. Journal of Semiconductors 46 , 1 (2025), 011610. [89] Xian, R., Yin, L., and Zhao, H. Fair and optimal classication via post-processing. In International conference on machine learning (2023), PMLR, pp. 37977–38012. [90] Xiao, Y ., Sharma, H., Kaur, S., Bergen-Cico, D ., and Salekin, A. Human heterogeneity invariant stress sensing. Proceedings of the A CM on Interactive, Mobile, W earable and Ubiquitous T echnologies 9 , 3 (2025), 1–42. [91] Xiao, Y ., Sharma, H., Zhang, Z., Bergen-Cico, D ., Rahman, T ., and Salekin, A. Reading between the heat: Co-teaching body thermal signatures for non-intrusive stress detection. Procee dings of the A CM on Interactive, Mobile, W earable and Ubiquitous T echnologies 7 , 4 (2024), 1–30. [92] Xu, X., Liu, X., Zhang, H., W ang, W ., Nepal, S., Sefidgar, Y ., Seo, W ., Kuehn, K. S., Huckins, J. F., Morris, M. E., et al. Glob em: Cross-dataset generalization of longitudinal human behavior modeling. Procee dings of the A CM on Interactive, Mobile, W earable and Ubiquitous T echnologies 6 , 4 (2023), 1–34. [93] Yf antidou, S., Const antinides, M., Spa this, D., V akali, A., ercia, D ., and Ka wsar, F. Beyond accuracy: A critical revie w of fairness in machine learning for mobile and wearable computing. arXiv preprint arXiv:2303.15585 (2023). [94] Yf antidou, S., Const antinides, M., Spa this, D., V akali, A., ercia, D ., and Ka wsar, F. The state of algorithmic fairness in mobile human-computer interaction. In Proceedings of the 25th International Conference on Mobile Human-Computer Interaction (2023), pp. 1–7. [95] Yf antidou, S., Sermpezis, P., V akali, A., and Baeza-Y a tes, R. Uncovering bias in personal informatics. Proceedings of the A CM on Interactive, Mobile, W earable and Ubiquitous T echnologies 7 , 3 (2023), 1–30. [96] Yu, X., Serra, T ., Ramalingam, S., and Zhe, S. The combinatorial brain surgeon: Pruning weights that cancel one another in neural networks. In International Conference on Machine Learning (2022), PMLR, pp. 25668–25683. [97] Yu, Y ., Chen, B., and Lu, W . On the eigenstructure of the sher information matrix and its r ole in generalization error . In 2025 40th Y outh Academic A nnual Conference of Chinese Association of Automation (Y AC) (2025), IEEE, pp. 3026–3033. [98] Zaf ar, M. B., V alera, I., Gómez-Rodríguez, M., and Gummadi, K. P. Fairness constraints: Mechanisms for fair classication. In Proceedings of the 20th International Conference on Articial Intelligence and Statistics (AIST A TS) (2017), pp. 962–970. [99] Zaf ar, M. B., V alera, I., Gómez-Rodríguez, M., and Gummadi, K. P. Fairness constraints: A exible approach for fair classication. Journal of Machine Learning Research 20 , 75 (2019), 1–42. [100] Zhang, A., Wu, Z., W u, E., Wu, M., Snyder, M. P ., Zou, J., and Wu, J. C. Leveraging physiology and articial intelligence to deliver advancements in health care. Physiological Reviews 103 , 4 (2023), 2423–2450. [101] Zhang, J., and Bareinboim, E. Equality of opportunity in classication: A causal approach. Advances in neural information processing systems 31 (2018). [102] Zhang, T ., Xue, M., Zhang, J., Zhang, H., W ang, Y ., Cheng, L., Song, J., and Song, M. Generalization matters: Loss minima attening via parameter hybridization for ecient online knowledge distillation. In Proce e dings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023), pp. 20176–20185. [103] Zhang, Y ., Zheng, Y., Qian, K., Zhang, G., Liu, Y ., Wu, C., and Y ang, Z. Widar3. 0: Zero-eort cross-domain gestur e recognition with wi-. IEEE Transactions on Pattern Analysis and Machine Intelligence 44 , 11 (2021), 8671–8688. A Methodological Transparency & Repr oducibility Appendix (MET A) A.1 Data and Model Details This section provides additional details on the datasets, preprocessing pipelines, feature composition, and neural architectures used in Flare . All datasets wer e standardized to support a consistent autoencoder–classier A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:28 • Tro vato et al. formulation and trained under identical preprocessing and optimization protocols, ensuring comparability across sensing domains. A.1.1 Ohio T1DM Dataset. The Ohio T1DM dataset [ 61 ] includes multimodal records from individuals with T ype 1 Diabetes collected in 2018 and 2020. The data contain continuous glucose monitoring ( CGM) readings, insulin pump records, and contextual annotations (e.g., meals, work, and exercise events). W e use 11 participants (4 folds)—with demographic and device information reported in [ 61 ]. Preprocessing follows Appendix 2.4 of Arefeen and Ghasemzadeh [ 10 ], including temporal alignment of CGM and pump data, removal of incomplete sequences, and normalization within each participant session. Feature Representation. Each instance consists of sev en features: (1) basal_insulin — continuous basal insulin deliver y rate; (2) insulin_bolus — short-acting b olus insulin dosage; (3) time_since_last_bolus — elapse d time since pre vious insulin injection; (4) meal_intake — carb ohydrate content of meals ( grams); (5) work — binary contextual indicator of work activity; (6) exercise — binar y contextual indicator of exer cise activity; (7) three_hour_glucose — CGM measurement three hours post-meal. The binary prediction label indicates normal glucose ( ≤ 180 mg/dL) or hyperglycemia ( > 180 mg/dL). Demographic and Device Attributes. The following attributes wer e used for subgroup evaluation: • Sex: male, female (six male and six female participants); • Age: 20–40, 40–60, and 60–80 years (participant-level groups); • Pump Mo del: Medtronic 530G or 630G (two generations of insulin pumps); • Sensor Band: Empatica or Basis (wrist-worn sensor brands); • Cohort: 2018 vs. 2020 (two data-collection cohorts). These subgroups capture both physiological (sex, age) and technical (pump, sensor ) variation, which often drive systematic performance dierences in glucose prediction tasks. Model A rchitecture (ExActModel). ExActModel is a fully connected autoencoder–classier netw ork. The encoder has four layers (256–128–64–32) with Tanh activations and dropout rates of 0.5, 0.3, and 0.3, respectively . The decoder mirrors this structure, and the classier is a two-layer MLP (32–8–2) with ReLU and dropout (0.3). Training minimizes a weighted combination of reconstruction loss (MSE) and cross-entropy loss. A.1.2 Intern Health Study (IHS) Dataset. The Intern Health Study (IHS) [ 1 ] is a 14-month longitudinal dataset tracking medical interns fr om two months before internship thr ough the end of their rst year . It includes demographics, PHQ-9 mental health assessments, and daily mood self-reports (1–10). Fitbit data provide daily summaries of sleep, step count, and heart rate. W e analyze cohorts from 2018–2022. Data Preprocessing. W e use 85 participants (17 p er fold). Daily mood labels are binarized following Manjunath et al. [ 60 ]: moods > 8 are labeled positive (1), moods < 3 negative (0), and interme diate values e xcluded. Sensor data are aggregated to daily averages; missing values are imputed with mean substitution, and binary “missing-indicator” ags are added. All numeric features are z-normalized per participant. Feature Representation. Eighteen input features are used: 9 Fitbit-derived measures ( e.g., sleep duration, sleep phases, resting heart rate, step count) and 9 corr esponding missing-indicator variables. These features capture daily physical activity and rest patterns linked to stress and mood variation. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:29 Demographic and Behavioral Attributes. Subgroups for model evaluation include: • Sex: male, female (self-identied at baseline); • Age: 24–29, 30–34, and 35+ years (age at baseline); • Ethnicity: Caucasian, African American, Latino/Hispanic, Asian, Mixed/Other; • Residency Spe cialty: Internal Medicine, Surgery , Obstetrics/Gynecology (Ob/Gyn), Pediatrics, Psychiatry , Neurology , Emergency Medicine, Medicine/Pe diatrics (Med/Peds), Family Practice, Transitional, Anesthesi- ology , Otolaryngology; • Baseline Depression (PHQ10 > 0): yes, no (presence of depressive symptoms prior to internship). These attributes represent both demographic diversity and occupational heterogeneity , capturing psychosocial and contextual factors associated with stress, sleep, and mood variation among medical interns. Model A rchitecture (IHS_MLP).. The IHS_MLP encoder uses thr ee layers (128–64–32) with ReLU activations and dropout (0.1); the decoder mirrors this structure. The classier has three layers (32–16–8–2) with ReLU and dropout (0.1). Models are optimized using Adam ( 𝜂 = 10 − 3 ), and hyperparameters are tuned via Optuna [ 76 ] to maximize F1 performance. A.1.3 EDA Dataset. The EDA dataset [ 90 , 91 ] captures multimodal physiological signals, including electrodermal activity (ED A), heart rate (HR), temperature (TEMP), acceleration ( ACC), and heart rate variability (HRV). Data were collected from 76 participants under both control and intervention conditions, producing 340 handcrafted features for binary stress classication. Feature Composition. Features cover tonic and phasic components of ED A and higher-order statistics such as mean, variance, ske wness, kurtosis, peak count, energy , and entropy (permutation and SVD entr opy). Similar features are extracted for HR, TEMP , ACC, and HRV modalities. All features are z-normalized per participant. Demographic and Experimental Attributes. Evaluation subgroups are dened as: • Group: control, pre-dose, and post-dose (e xperimental conditions); • Sex: male, female. These categories quantify fairness across both experimental interventions and intrinsic biological variation. Model A rchitecture (ED A_MLP).. The encoder maps the 340-dimensional input into a 128-dimensional latent space using three fully connecte d layers with ReLU activations and dropout (0.1). The de coder reconstructs the input, and the classier (128–64–64–2) outputs str ess vs. non-stress logits. T raining minimizes a combined reconstruction and cross-entropy loss with Fisher penalty-based stability regularization. For all three datasets, we include User Heterogeneity (UH) : per-participant slices capturing subject-level disparities in physiological response and signal quality . A.2 Training Pr otocol and Implementation Details All models were trained with the Adam optimizer and early stopping base d on validation F1. The total loss com- bined r econstruction, cr oss-entropy , and Fisher penalty terms, with dataset-specic weighting. Fisher information was computed only on correctly classied samples, as describe d in Algorithm 1. Random seeds were xed for reproducibility , and all results were av eraged acr oss folds. This unied framework ensures that cross-dataset dierences observed under Flare reect true sensing heterogeneity rather than architectural variation. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:30 • Tro vato et al. T able 5. Summary of datasets and base model configurations. Dataset Participants Features T ask Model (Encoder–Classier) Ohio T1DM [61] 11 7 Glucose (binary) input–256–128–64–32 / 32–8–2 IHS [1] 85 18 Mood (binar y) input–128–64–32 / 32–16–8–2 ED A [90, 91] 76 340 Stress (binary) input–128 / 128–64–64–2 A.3 Subgroup-Lev el Performance Analysis T ables 6 and 7 summarize the subgroup-le vel F1 scores for the Baseline , KD , ARL, Reckoner , GoG, and Flare models across the Ohio T1DM, ED A, and IHS datasets. Each table reports performance disaggregated by demo- graphic attributes (e .g., sex, age, ethnicity , specialty), allowing evaluation of both model utility and consistency across heterogeneous populations. Across all datasets, Flare consistently attains the highest or among the highest F1 scores within each subgroup, indicating improved predictive stability relativ e to all baselines. In the Ohio T1DM dataset, Flare yields notable gains across age and device-r elated gr oups, demonstrating robustness to variation in sensor type and user cohort. In the EDA dataset, wher e the baseline performance is already strong, Flare maintains stable accuracy across experimental conditions (Control, Pr edose, Postdose) and between sexes, outperforming adversarial and distillation-based approaches that exhibit inconsistent subgroup behavior . Finally , in the more heter ogeneous IHS dataset, Flare achieves superior F1 scores across sex, age, ethnicity , and specialty subgroups, reecting its capacity to generalize across diverse populations. These results highlight that Flare not only improves ov erall utility but also reduces variability acr oss subgroups compared with fairness-oriented baselines such as ARL and GoG. T able 6. F1 scores across subgroups for dierent models (Baseline, KD , ARL, Reckoner , GOG, Flare ) in the OhioT1DM and ED A datasets. Dataset Group Baseline F1 KD F1 ARL F1 Reckoner F1 GOG F1 Flare F1 Ohio T1DM Dataset Sex Female 0.6839 0.6985 0.7085 0.7136 0.6882 0.7127 Male 0.6119 0.6631 0.7057 0.6937 0.6137 0.7417 Age 20–40 0.3942 0.5089 0.5896 0.6922 0.3983 0.7407 40–60 0.6723 0.6976 0.7121 0.6931 0.6776 0.7263 60–80 0.7103 0.7437 0.8030 0.7815 0.6976 0.7638 Pump 530G 0.6777 0.7043 0.7263 0.7069 0.6800 0.7318 630G 0.3942 0.5089 0.5896 0.6922 0.3983 0.7407 Sensory Band Basis 0.7073 0.7212 0.7305 0.7126 0.7133 0.7337 Empatica 0.5589 0.6253 0.6786 0.6884 0.5567 0.7244 ED A Dataset Group_label Control 0.8822 0.7436 0.8779 0.9706 0.8627 0.8899 Predose 0.8367 0.7425 0.8420 0.4952 0.8315 0.8550 Postdose 0.9194 0.7996 0.9271 0.8645 0.9217 0.9264 Sex Female 0.8789 0.7496 0.8741 0.7439 0.8626 0.8857 Male 0.8973 0.7743 0.9025 0.6651 0.8894 0.9057 A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. Ethical Fairness without Demographics in Human-Centered AI • 0:31 T able 7. F1 scores across subgroups for dier ent models (Baseline, KD , ARL, Reckoner , GOG, Flare ) in the IHS dataset. Subgroup Group Baseline F1 KD F1 ARL F1 Reckoner F1 GOG F1 Flare F1 Sex Male 0.5975 0.5694 0.6203 0.5764 0.5857 0.6247 Female 0.5957 0.5910 0.6324 0.5673 0.6128 0.6418 Age 23 0.8151 0.5884 0.8182 0.7273 0.4969 0.9091 24 0.3194 0.2941 0.4158 0.3678 0.3529 0.4436 25 0.5872 0.5772 0.5901 0.6101 0.5756 0.6033 26 0.6515 0.6071 0.6588 0.5803 0.6635 0.6915 27 0.6517 0.6339 0.6651 0.6024 0.6095 0.6716 28 0.5617 0.5374 0.6156 0.5382 0.6139 0.5910 29 0.5195 0.5490 0.5887 0.5305 0.5685 0.5856 30 0.5635 0.5846 0.6239 0.5386 0.5575 0.6177 32 0.6057 0.5785 0.6513 0.6136 0.5909 0.6627 33 0.5086 0.5441 0.5441 0.4256 0.3285 0.5810 34 0.3565 0.3565 0.4706 0.3934 0.5569 0.5505 38 0.7980 0.8356 0.8380 0.6576 0.7340 0.8044 51 0.4793 0.4793 0.5084 0.5084 0.4793 0.4793 Ethnicity White 0.6099 0.5889 0.6407 0.5860 0.6062 0.6435 Black / African American 0.5085 0.5548 0.5788 0.4957 0.4778 0.5085 Latino / Hispanic 0.6283 0.5364 0.7110 0.5892 0.7692 0.7110 Asian 0.5823 0.5730 0.6007 0.5587 0.5868 0.6205 Multi-racial 0.5768 0.5773 0.6197 0.5347 0.6189 0.6543 Arab / Middle Eastern 0.2262 0.4762 0.4954 0.3174 0.4012 0.3174 Specialty Internal Me dicine 0.5893 0.5617 0.6175 0.5730 0.5840 0.6379 Surgery 0.6014 0.6113 0.6161 0.5667 0.6238 0.6247 Ob/Gyn 0.6078 0.5549 0.6834 0.5368 0.7281 0.6834 Pediatrics 0.6324 0.6101 0.6666 0.5869 0.6320 0.6767 Psychiatry 0.6377 0.5770 0.6377 0.5608 0.6377 0.6445 Neurology 0.5685 0.6522 0.6072 0.5934 0.6033 0.6522 Emergency Medicine 0.5042 0.5816 0.6263 0.5976 0.5723 0.5967 Med/Peds 0.5723 0.6213 0.6955 0.5404 0.6234 0.6963 Family Practice 0.4791 0.4955 0.5825 0.4999 0.5607 0.5828 Other 0.6199 0.6272 0.6353 0.6215 0.5904 0.6522 Transitional 0.6191 0.6469 0.6722 0.5892 0.6148 0.6890 Anesthesiology 0.4504 0.5424 0.5467 0.5586 0.4966 0.5358 PHQ10>0 Y es 0.6588 0.6098 0.6645 0.6167 0.5854 0.6880 No 0.5916 0.5787 0.6239 0.5677 0.6017 0.6295 A.4 Training Eiciency and Runtime Analysis of Flare T o complement our inference analysis, we further benchmarked the training-time performance of Flare against baseline models. T able 8 summarizes the average training latency , memor y fo otprint (RSS), and resource utilization across multiple hardware platforms. A s shown, the base pretraining phase of Flare (Bp T) introduces a higher runtime overhead—e .g., 799.97 s on the RTX 4090 and 847.83 s on the Ryzen 9—due to latent subgroup identication and Fisher-guided clustering. However , the CP U utilization (0.8–3.0%) and memor y usage ( ∼ 1400 Mb) remain on A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024. 0:32 • Tro vato et al. T able 8. T rain Time (s), Train Pr ocess (RSS) Memory Usage (MB), and Train Resource Usage (%) for baselines and Flare during Base pretraining (Bp T) and Adapation (A dapt) phases across dierent platforms. Platform ARL KD Reckoner GoG Flare (Bp T) Flare (Adapt.) Train (s) RSS (MB) Usage (%) Train (s) RSS (MB) Usage (%) Train (s) RSS (MB) Usage (%) Train (s) RSS (MB) Usage (%) Train (s) RSS (MB) Usage (%) Train (s) RSS (MB) Usage (%) EDA Dataset NVIDIA GeForce RTX 4090 7.348 1256 5.23 11.86 1264 25 170 1286.2 12.3 22.58 1618.5 16 799.97 1412 16.20 0.12 1035 4 AMD Ryzen 9 7950X 16-Core Processor 10.446 1263.2 0.78 14.95 1274.7 1.72 159.32 1351.7 0.79 16.96 1648 0.78 847.83 1428.4 0.86 0.5 1073 0.66 Quadro RTX 5000 21.65 1020.3 12 71.06 1030.4 29.30 721.78 1146.4 2.50 72.7 1431.9 8.50 694.84 1285.3 4.0 0.54 818.8 1.80 Intel i9-9900K Processor 106.7 1111.2 3.11 157.8 1143.6 3.12 2205.04 1234.7 3.04 151.8 1712.8 3.75 1481.6 1341.8 3.12 0.1 840.1 2.96 Apple M1 26.01 157.7 1.41 45.13 142.5 1.27 354.278 72.6 1.99 46.92 95.4 2.16 461.17 67.1 5.80 0.1320 331.5 0.42 par with other baselines such as ARL and KD, indicating that the additional computation arises from algorithmic complexity rather than hardware ineciency . This overhead is acceptable in practice, as human-sensing systems typically perform model training or personalization on centralized ser vers or cloud-based infrastructures before on-device deployment [ 7 , 47 , 63 , 66 ]. Consequently , Flare maintains energy and resour ce eciency during training while providing impro ved robustness and fairness benets in deployment. A CM J. Auton. Transport. Syst., V ol. 0, No. 0, Article 0. Publication date: 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment