Attention Sinks Are Provably Necessary in Softmax Transformers: Evidence from Trigger-Conditional Tasks
Transformers often display an attention sink: probability mass concentrates on a fixed, content-agnostic position. Are sinks a byproduct of the optimization/training regime? Or are they sometimes functionally necessary in softmax Transformers? Are si…
Authors: Yuval Ran-Milo
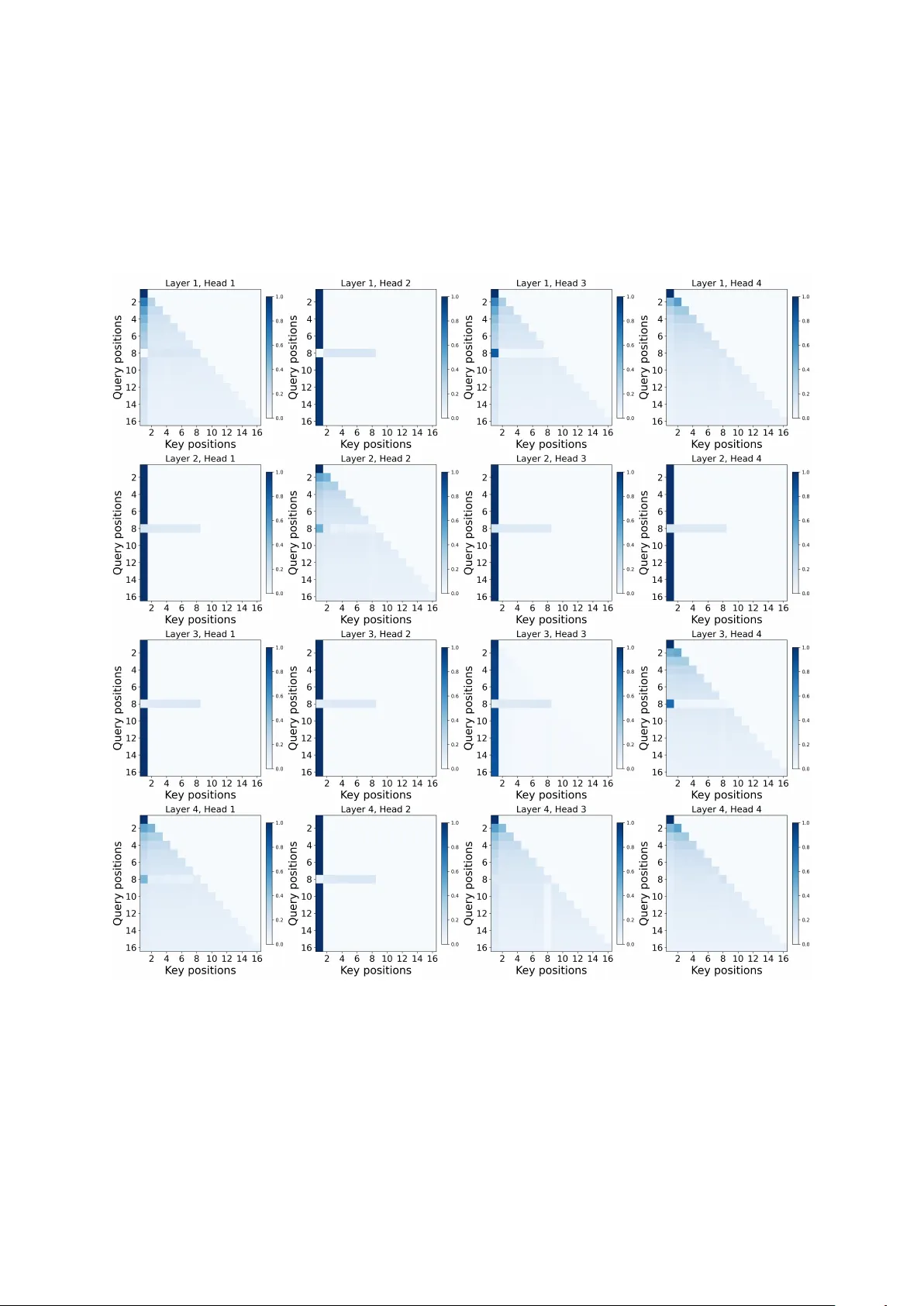
Attention Sinks Ar e Pr ov ably Necessary in Softmax T ransf ormers: Evidence fr om T rigger -Conditional T asks Y uval Ran-Milo T el A viv Uni v ersity yuvalmilo@mail.tau.ac.il Abstract T ransformers often display an attention sink : probability mass concentrates on a fixed, content-agnostic position. Are sinks a byprod- uct of the optimization/training regime? Or are they sometimes functionally necessary in soft- max T ransformers? W e prove that, in some set- tings, it is the latter: computing a simple trigger- conditional behavior necessarily induces a sink in softmax self-attention models. Our results formalize a familiar intuition: normalization ov er a probability simplex must force attention to collapse onto a stable anchor to realize a de- fault state (e.g., when the model needs to ignore the input). W e instantiate this with a concrete task: when a designated trigger token appears, the model must return the averag e of all pr e- ceding tok en r epr esentations , and otherwise output zero, a task which mirrors the function- ality of attention heads in the wild ( Barbero et al. , 2025 ; Guo et al. , 2024 ). W e also prove that non-normalized ReLU attention can solve the same task without any sink, confirming that the normalization constraint is the fundamental driv er of sink behavior . Experiments validate our predictions and demonstrate they extend beyond the theoretically analyzed setting: soft- max models dev elop strong sinks while ReLU attention eliminates them in both single-head and multi-head variants. 1 Introduction T ransformers ( V asw ani et al. , 2017 ) frequently con- centrate attention on an early position in a way that is largely insensitiv e to content. This atten- tion sink has been reported for small and lar ge models alike ( Xiao et al. , 2024 ; Gu et al. , 2024 ; Guo et al. , 2024 ). It occurs under a v ariety of positional schemes—absolute/learned embeddings, ALiBi, RoPE, and ev en without explicit positional encodings ( Press et al. , 2021 ; Su et al. , 2021 ; Gu et al. , 2024 )—and similar behavior sho ws up in multimodal and vision settings, as well as in dif- fusion language models ( Kang et al. , 2025 ; W ang et al. , 2025 ; Feng and Sun , 2025 ; Rulli et al. , 2025 ). The breadth of contexts points to a perv asi ve pat- tern, not a peculiarity of any single model or train- ing regime. This pattern has significant practical conse- quences. When probability mass concentrates on a fixed position, attention can be div erted away from other tokens and do wnstream accuracy can be af fected ( Y u et al. , 2024 ). Sinks can also worsen numerical issues rele v ant to compression and quan- tization ( Sun et al. , 2024 ; Lin et al. , 2024 ; Bon- darenko et al. , 2023 ; Son et al. , 2024 ), distort attention-based interpretability analyses ( Guo et al. , 2024 ), and complicate streaming and long-context inference ( Xiao et al. , 2024 ). Analogous sink ef- fects ha v e also been documented in vision and mul- timodal settings, where they w aste representational capacity on irrelev ant visual tok ens ( Kang et al. , 2025 ; W ang et al. , 2025 ; Feng and Sun , 2025 ). (See Appendix B for an extended discussion on the prac- tical moti v ations for mitigating attention sinks.) Why is sink behavior so common? One plausible account is an inductive bias —a phenomenon docu- mented in other settings ( Soudry et al. , 2024 ; Arora et al. , 2019 ; Ran-Milo et al. , 2026 )— whereby the learning setup (model class and optimization pro- cedure) steers solutions toward models that exhibit attention sinks, e ven when sink-free alternativ es exist. In this w ork we ar gue that, in certain settings, this isn’t the case, and sink behavior is functionally essential : all models that successfully compute a natural class of functions must exhibit sinks. 1 W e in vestigate this claim theoretically by intro- ducing a trigger -conditional task : a model must output the mean of past tokens at a designated trig- ger position, and output zero (a no-op) everywhere else. This formulation captures the core mecha- nism of empirically observed attention heads “in the wild” ( Barbero et al. , 2025 ; Guo et al. , 2024 ) 1 W e do not claim sinks are unav oidable in all architectures (e.g., sinks do not appear in gated attention or Mamba-based models ( Qiu et al. , 2025 ; Endy et al. , 2025 )). Rather, we prov e they are a necessary consequence of softmax attention. 1 which aggregate context when triggered and use a sink to remain dormant otherwise (see section 2 for more details). W e prov e that attention sinks are necessary for softmax attention to solve this task. Specifically , we consider a synthetic, trigger- conditional task on sequences in which each to- ken representation consists of: (i) a BOS indicator equal to one only for the first token; (ii) a trigger indicator equal to one only at the trigger position; (iii) a non-trigger non-BOS indicator equal to one for all remaining tokens; and (iv) i.i.d. samples from a continuous distribution in the content coor - dinates. The target is intuiti ve: the model writes nothing to the residual stream at e very position (i.e., outputs the zero v ector), except at the unique trig- ger position where it should write the mean of all pr eceding non- BOS 2 token vectors . Our main results are necessity theorems for soft- max self-attention: for single-layer models (theo- rem 1 ), any model that achiev es v anishing error on this task must place attention arbitrarily close to 1 (the maximal possible v alue) on a fixed sink token (the BOS token) at all non-trigger positions; for multi-layer models (theorem 2 ), we sho w that at least one layer must e xhibit sink behavior at some non-trigger position 3 . At a high level, we formalize a widely held intuition: normalization of attention scores forces the model to concentrate probability mass on a stable anchor whene v er it needs to produce a def ault output, independent of the variable input content. W e complement these necessity theorems with a constructi v e result (the- orem 3 ): ReLU attention can solve the same task with zero attention on the BOS token, demonstrat- ing that the normalization constraint is the primary dri ver of sink formation. Experiments on both single-layer and multi-layer models provide supporting evidence (section 4 ). Single-layer softmax T ransformers trained on the task de velop attention sinks with near -unit mass on BOS when no trigger is present, aligning with our theoretical analysis. Swapping softmax for ReLU attention eliminates sink formation while preserv- ing task accuracy , confirming that the softmax nor- malization constraint—rather than the task struc- ture or optimization dynamics—is the fundamen- tal driv er of the sink behavior . W e observe these patterns across both single-layer and deeper multi- 2 W e exclude BOS from the av erage because it contains no input-dependent content. 3 Indeed, we empirically see in section 4 that sinks do form, but not in all positions and layers (see fig. 6 ). Figure 1: Reproduced from Barbero et al. ( 2025 ) 4 : an attention head that fires on an apostrophe trigger and otherwise attends to BOS . head multi-layer architectures, demonstrating that our theoretical insights capture fundamental proper- ties of normalization-based attention mechanisms. Overall, our contrib utions are as follo ws: 1. W e introduce a trigger-conditional task that models the mechanism of attention heads ob- served “in the wild” ( Barbero et al. , 2025 ; Guo et al. , 2024 ) (section 3.2 ). 2. W e prove that an y single-layer softmax atten- tion model achie ving v anishing error on this task must place nearly all attention on a fixed sink token (the BOS token) at e very non-trigger position (theorem 1 ). 3. W e e xtend this to multi-layer models, sho wing that at least one layer must place nearly all attention on the BOS token at some non-trigger position 3 (theorem 2 ). 4. W e show that the softmax normalization is the driv er of sink formation by showing the existence of a ReLU attention model that per- fectly solves the same task without any sink formation (theorem 3 ). 2 Sinks Empirically Enable No-Op Beha viors in Real Models In realistic empirical settings, attention sinks fre- quently appear in attention heads implementing a no-op beha vior in the absence of specific trig- gers. Barbero et al. ( 2025 ) demonstrate this di- rectly: their case study of an “apostrophe head” in Gemma 7B shows two operating modes—firing on apostrophe triggers and otherwise attending 4 Licensed under Creati ve Commons Attrib ution 4.0 (CC BY 4.0). Minor cropping for layout; no other changes. License: https://creativecommons.org/licenses/by/4. 0/ . 2 Figure 2: Reproduced from Guo et al. ( 2024 ) 5 : an active– dormant attention head in Llama 2–7B. On code-like inputs (GitHub, top), the head exhibits di verse attention patterns; on text-like inputs (W ikipedia, bottom), it col- lapses to an attention sink on position 0. to BOS as a default no-operation (no-op) (fig. 1 ) 4 . Similarly , Guo et al. ( 2024 ) document an ac- ti ve–dormant head in Llama 2–7B that switches be- tween acti ve computation on code-lik e inputs and dormant sink beha vior on te xt-like inputs (fig. 2 ) 5 . Notably , Guo et al. ( 2024 ) report that sink beha vior diminishes under certain non-softmax/activ ation v ariants; in particular , replacing softmax with ReLU attention eliminates sinks, consistent with our theoretical result (theorem 3 ). These works complement our theoretical per- specti ve. Barbero et al. ( 2025 ) argue that sinks enable controlled information mixing, with BOS serving as a stable anchor . Guo et al. ( 2024 ) an- alyze the training dynamics behind sink forma- tion—ho w these patterns emerge during optimiza- tion. In contrast, our work establishes a theoretical necessity of sink behavior in softmax attention and its absence in ReLU attention via expressi v eness analyses re gardless of optimization and training schemes . W e include illustrativ e figures from Bar - bero et al. ( 2025 ) (fig. 1 ) 4 and Guo et al. ( 2024 ) (fig. 2 ) 5 to highlight that our synthetic task captures ke y aspects of real sink behavior—sinks emerge to implement a no-op when no trigger fires. See Appendix H for more related works. 3 Theory and Results W e now set up our analysis. W e introduce the task in section 3.2 , explain why this task is meaningful and ho w its assumptions match realistic modeling in section 3.3 , introduce the model architectures in 5 Reproduced with written permission of the au- thors from https://github.com/GuoTianYu2000/ Active- Dormant- Attention . section 3.4 , and state our main necessity claims in section 3.5 . 3.1 Notation and Setup W e write R > 0 for the positiv e reals and N ≥ k for the natural numbers at least k . W e use 1 {·} for the indicator function and denote [ k ] = { 1 , . . . , k } . Let n ∈ N ≥ 5 be the input dimension and L ∈ N ≥ 4 denote the sequence length. W e write sequences as x = ( x (1) , . . . , x ( L ) ) ⊤ ∈ R L × n with tokens vectors x ( i ) ∈ R n × 1 . 3.2 T ask Definition W e define a synthetic task designed to capture the mechanism of attention sinks “in the wild”. Em- pirical studies sho w that attention heads in LLMs frequently implement trigger-conditional behavior: they aggregate context upon detecting a specific trigger , and attend to a sink token to ef fecti v ely “switch of f ” otherwise ( Barbero et al. , 2025 ; Guo et al. , 2024 ) (see section 2 for more details). Our task isolates this structure: the model must detect a trigger tok en and, only at the trigger position , write to the residual stream the mean of prior content, and write the zero vector at all other positions. 3.2.1 Input Distribution Input tokens lie in R n (for some n ∈ N ≥ 5 ) and consist of four coordinate types: (i) a BOS indica- tor (coordinate 1), equal to one only for the first token; (ii) a trigg er indicator (coordinate 2), equal to one only for the trigger token; (iii) a non-trigger non- BOS indicator (coordinate 3), equal to one for all remaining tokens; and (i v) content coor dinates ( 4 ≤ k ≤ n ), drawn i.i.d. from some continuous distribution (except for the BOS token, for which the content coordinates are fixed to zero, as this token contains no input-dependent content). Formally , we construct our input distribution D as follows. W e sample a trigger position j uni- formly from { 2 , . . . , L } , and construct a sequence as follo ws: • Position 1 ( BOS ): Coordinate 1 is one; all other coordinates are zero. • Position j (T rigger token): Coordinate 2 is one; coordinates 4 ≤ k ≤ n are i.i.d. from some continuous distribution. All other coordinates are zero. • Positions i = 1 , j : Coordinate 3 is one; coordi- nates 4 ≤ k ≤ n are i.i.d. from some continuous distribution. All other coordinates are zero. 3 Figure 3: V alidation of theorem 1 and theorem 3 . (a) Mean attention weights for softmax attention across 1000 test examples with trigger at position 8. Dark regions indicate high attention mass concentrated on BOS (position 1) at non-trigger positions. (b) Standard deviation of softmax attention weights shows negligible v ariance, confirming stable sink behavior . (c) Mean attention weights for ReLU attention show no sink formation—attention on BOS remains near zero. (d) Standard deviation for ReLU attention confirms consistent beha vior across e xamples. 3.2.2 T arget Output The tar get output y ( i ) is the zero vector 0 at all positions e xcept the trigger position i = j , where it equals ( j − 1) − 1 P j k =2 x ( k ) , the mean of all preced- ing non- BOS tokens (including the trigger itself). 3.2.3 Loss Function W e e v aluate hypotheses using the ℓ ∞ loss: L ( f ) = sup ( x , y ) ∈ support ( D ) max i ∈ [ L ] y ( i ) − f ( x ) ( i ) 2 . 3.3 T ask Motivation and J ustification This setup captures a basic and pervasi v e pattern in sequence modeling: aggr e gate context upon a trigger , otherwise perform a no-op ( Barbero et al. , 2025 ; Guo et al. , 2024 ) (see section 2 for more details). Our task distills this to its minimal form: detect a trigger and compute the mean of prior content, or , otherwise, output zero. 6 The design choices we make are less arbitrary than they may appear . Man y aspects are without loss of generality: the BOS indicator , the trigger indicator , and the non-trigger non-BOS indicator channels can be an y three mutually orthogonal v ec- tors via a change of basis; we fix them to coordi- nates 1, 2, and 3 for simplicity . While having such fixed indicator channels feels some what arbitrary , it is a natural way to model position-type information that an MLP layer can easily learn to inject into the residual stream in practice (e.g., by writing a constant vector). 6 Our analysis applies almost as-is to a broader class of trigger-conditional problems, such as ke y-query retriev al where a query must extract a specific previous token (e.g., marked by a feature bit) while ignoring others, resembling the apostrophe head in fig. 1 4 . W e analyze the averaging task for clarity , leaving the formal characterization of the full class of tasks necessitating sinks to future work. 3.4 Model Architectur e W e study self-attention models with two variants of attention mechanisms. W e denote the learn- able parameter of a single-layer attention model by W Q , W K , W V , W O ∈ R n × n for queries, ke ys, v alues, and output projection respecti vely . For in- put sequence x = ( x (1) , . . . , x ( L ) ) ⊤ ∈ R L × n , we calculate the attention weights α i,j as defined be- lo w for each attention variant (softmax or ReLU). The model output is then computed as f ( x ) ( i ) = W O P i j =1 α i,j W V x ( j ) . Softmax Attention. The attention weight from position i to position j ≤ i is giv en by: α i,j = exp( x ( i ) W Q W ⊤ K ( x ( j ) ) ⊤ ) P i k =1 exp( x ( i ) W Q W ⊤ K ( x ( k ) ) ⊤ ) ReLU Attention. F or ReLU attention, we re- place the softmax normalization with element- wise ReLU. W e divide the scores by the num- ber of positions up to the current position i , ex- cluding the BOS token 7 . Namely , if we de- fine n i = max { i − 1 , 1 } , then we hav e α i,j = ReLU( x ( i ) W Q W ⊤ K ( x ( j ) ) ⊤ ) /n i . Multi-Layer Attention. A D -layer soft- max/ReLU model is the composition f = f ( D ) ◦ · · · ◦ f (1) , where each f ( d ) is a single-layer softmax/ReLU attention model. W e denote by α ( d ) i,j the attention weight at position i attending to position j in layer d . 7 This scaling is necessary because ReLU attention cannot naturally compute averages: concatenating the input sequence to itself would double the output at the final position while keeping the average the same. Alternativ ely , we could have defined the task to sum ov er past tokens for the ReLU model instead of averaging , which w ould yield an analogous theorem without requiring scaling. Moreov er, a similar scaling would not work for softmax attention , as our analysis would hold for any such v ariant. 4 Figure 4: Multi-layer multi-head validation. Attention patterns for a 2-layer 2-head softmax model on a random input (with trigger at position 8). All heads exhibit strong sink beha vior . 3.5 Main Result W e are no w ready to state our theoretical results. Our central contrib ution is threefold: (i) we estab- lish that an attention sink is necessary at every non- trigger position for single-layer softmax attention to solve the trigger-conditional task (theorem 1 ); (ii) we prov e that in multi-layer softmax attention, at least one position must exhibit sink behavior (theorem 2 ); 8 and (iii) we prove constructively that ReLU attention can solve the same task without any sink behavior (theorem 3 ). This contrast di- rectly demonstrates that the softmax normalization constraint—not the task structure or optimization dynamics—is the fundamental dri ver of attention sinks. Theorem 1 (Single-Layer Attention Sink Neces- sity) . F or any ε, δ ∈ R > 0 , L ∈ N ≥ 4 , n ∈ N ≥ 5 , and a bounded pr obability density function P , ther e ex- ists a constant η ∈ R > 0 such that the following holds. Consider any single-layer softmax atten- tion 9 model f with loss L ( f ) ≤ η on sequences with length L and dimension n wher e content coor - dinates ar e drawn fr om P . 10 Then with pr obability at least 1 − δ , for all non-trigger positions i = j , we have α i, 1 ≥ 1 − ε . Pr oof sketch (full pr oof in section D ). Suppose for contradiction that α i, 1 ≤ 1 − ε at some non-trigger position i with probability at least δ > 0 , ev en as η := L ( f ) → 0 . On this event a constant amount of attention mass falls on non- BOS tokens; by pi- geonhole there exist indices i 0 , h 0 and a constant γ > 0 such that α i 0 ,h 0 ≥ γ on a positi ve-measure set. 8 Indeed, we empirically see in section 4.2 (e.g., fig. 6 ) that sinks do form, but not in all positions and layers. 9 Our analysis immediately extends to any attention mechanism whose weights α i,j satisfy: (i) normalization — P j ≤ i α i,j ≥ c for some constant c > 0 ; and (ii) monotonic- ity —inserting an additional key into positions 1 , . . . , i does not increase α i,j for any e xisting key j . 10 It is easy to show that such an f exists for any η ∈ R > 0 . Since e very non-trigger position must output 0 with error at most η , and adding more ke ys can only decrease any fixed softmax weight, one can reduce to short prefixes and sho w that whenev er h ≤ i are both non-trigger positions, ∥ α i,h Vx ( h ) ∥ 2 ≤ O ( η ) . On the positi ve-measure set where α i,h ≥ γ , this giv es ∥ Vx ( h ) ∥ 2 = O ( η /γ ) : the v alue map must crush a positiv e-probability set of non-trigger tokens. By bounded density and independence of the content coordinates, for ev ery content coordinate m ≥ 4 this crushed set contains two tokens z , z ′ that agree on all coordinates except m , where they dif fer by at least a constant. T ransplant them into two sequences with trigger at position 3 : ( BOS , z , t ) and ( BOS , z ′ , t ) . The targets at the trigger posi- tion differ by 1 2 ( z − z ′ ) , which has a Ω(1) com- ponent along e m . The prediction at position 3 is ˆ y (3) ( z ) = α 3 , 1 V e 1 + α 3 , 2 Vz + α 3 , 3 Vt ; the first two terms are O ( η ) by the crushing bound, and the third lies in the span of the fix ed vector v := Vt . Projecting onto v ⊥ remov es the trigger contribution entirely , so the two projected predic- tions are O ( η ) -close, while the projected tar gets re- main Ω(1) -apart (choosing m so e m has a nontri v- ial component in v ⊥ ). This contradicts η → 0 . Theorem 2 (Multi-Layer Attention Sink Neces- sity) . F or any ε, δ ∈ R > 0 , L ∈ N ≥ 4 , n ∈ N ≥ 5 and a bounded pr obability density function P , ther e exists a constant η ∈ R > 0 such that the following holds. Consider any D -layer softmax attention 9 model f with loss L ( f ) ≤ η on sequences with length L and dimension n wher e content coor- dinates are drawn fr om P . 11 Then over all in- puts with trigg er position j ≥ 3 , with pr obabil- ity at least 1 − δ , ther e exists at least one layer d ∈ { 1 , . . . , D } and a non- BOS non-trigger posi- tion i = j such that α ( d ) i, 1 ≥ 1 − ε . 11 It is easy to show that such an f exists for any η ∈ R > 0 . 5 Figure 5: ReLU attention: 2-layer 2-head model. Attention patterns on a single test input (trigger at position 8). No sink formation occurs in any head; attention on BOS remains near zero throughout. Pr oof sketch (full pr oof in section E ). W e unroll the multi-layer network and apply similar rea- soning as in theorem 1 : if no layer exhibits sink behavior , the effecti ve attention weights on content tokens remain large, forcing the value map to crush them to zero, which again contradicts the sensiti vity required at the trigger position. Theorem 3 (ReLU Attention W ithout Sinks) . F or any L ∈ N ≥ 4 and n ∈ N ≥ 3 , ther e exists a one- layer ReLU attention model f with loss L ( f ) = 0 such that for any input sequence x with trigger position j , and any non-trig ger position i = j we have α i, 1 = 0 . Pr oof sketch (full pr oof in section F ). W e provide a simple explicit construction. By choosing query and ke y weights to align with the trigger indicator coordinate and non-trigger non-BOS indicator co- ordinate, we ensure that attention scores are equal to some positi ve constant at the trigger position (where they compute the av erage) and zero other- wise. Since ReLU does not enforce normalization, the model can output the zero vector by simply having zero attention weights, without needing a sink. 4 Experiments W e validate our theoretical predictions on the syn- thetic trigger-conditional task. In section 4.1 , we train single-layer single-head models to v alidate theorem 1 and theorem 3 . In section 4.2 , we vali- date our multi-layer findings (theorem 2 ) in more realistic settings by training multi-layer multi-head models with residual connections. All experiments use sequences of length L = 16 ; training details are in Appendix A . Code for reproducing our ex- periments is av ailable at https://github.com/ YuvMilo/sinks- are- provably- necessary . 4.1 Single-Layer Models W e first v alidate theorem 1 and theorem 3 on single- layer single-head models. Experiment 1: Softmax Attention F orms Sinks. Theorem 1 predicts that softmax attention models achie ving low loss must hav e a strong attention sink at all non-trigger positions. T o test this, we visualize the mean and standard deviation of atten- tion weights across 1000 test examples with trigger position j = 8 (fig. 3 , panels a and b). The model places near-unit attention mass on position 1 at e v- ery non-trigger position, with negligible variance across examples. Experiment 2: ReLU Attention A voids Sinks. Theorem 3 establishes that ReLU attention can solve the same task with zero attention on BOS . W e replace softmax with ReLU attention while keep- ing all other parameters identical (fig. 3 , panels c and d). The ReLU model achieves comparable task accuracy without dev eloping sink behavior: attention weights on position 1 remain near zero throughout the sequence. This observation rein- forces that sinks are not a byproduct of the task or training dynamics, but a direct consequence of the normalization geometry . 4.2 Multi-Layer Multi-Head Models Figure 4 shows attention patterns for a 2-layer 2- head softmax model: all heads exhibit strong sink behavior across non-trigger positions. In deeper models, sinks appear in some but not all heads, con- sistent with theorem 2 , which guarantees existence rather than ubiquity . Figure 6 shows an example: in a 4-layer 4-head softmax model that achieves lo w loss, head 3 in layer 4 places near-zero atten- tion on BOS , while other heads in the same netw ork de velop clear sinks (fig. 7 in Appendix C ). Finally , replacing softmax with ReLU attention eliminates sink formation entirely in multi-layer models as 6 well: fig. 5 shows that no head of a 2-layer 2-head ReLU model de velops a sink, and the same holds for a 4-layer 4-head ReLU model (see fig. 8 in Appendix C ). 5 Conclusions and Practical Implications Our results sho w that for trigger-conditional beha v- iors, attention sinks are not an optimization artifact but a structural necessity: when a model must main- tain a stable default (no-op) output on typical inputs while performing a content-dependent computation upon a recognizable trigger , softmax normalization forces sink formation. This has direct practical consequences: it can help practitioners distinguish between mitigation strategies that are fundamen- tally limited and those that address the root cause. Specifically , sink-remov al interventions operat- ing within the softmax mechanism may be inher- ently limited for such computations. Penalizing BOS attention, spreading attention mass, or post- hoc re weighting may degrade the no-op guarantee, or cause the model to recreate an equiv alent anchor else where (a different position, head, or layer). In this sense, our results pro vide a principled reason to expect that simply “fighting” sinks without relax- ing the simplex constraint can be counterproducti ve for trigger -conditional circuits: the sink may be the very mechanism that mak es the circuit possible. At the same time, the contrast with ReLU at- tention (theorem 3 ) clarifies a more promising di- rection. If sinks are undesirable for a do wnstream goal—e.g., they waste representational capacity ( Y u et al. , 2024 ), confound attention-based anal- yses ( Guo et al. , 2024 ), or create quantization- unfriendly outliers ( Sun et al. , 2024 )—the right le ver is to change how “of f ” states are represented, via non-normalized attention, explicit gating, or other mechanisms that can output zero without al- locating probability mass. More broadly , we hope our results can help guide future work on designing sink-free attention mech- anisms that directly support no-op operations. 6 Limitations The synthetic trigger-conditional task, while em- pirically grounded in real sink behavior ( Barbero et al. , 2025 ; Guo et al. , 2024 ), represents a specific computational pattern within a broader class of trigger-conditional problems. Our analysis likely extends to related tasks such as key-query retrie val where a query must e xtract a specific previous to- Figure 6: A softmax head without a sink in mu ltilayer T ransformer . Attention pattern of head 3, layer 4 in a 4- layer 4-head softmax model that achiev es lo w loss. This head places near-zero attention on BOS at all non- BOS positions, while other heads in the same network exhibit strong sinks (see fig. 7 for all heads). This confirms the existential nature of theorem 2 : a sink must exist somewher e in the network, b ut not in every head. ken (e.g., mark ed by a feature bit) while ignoring others—resembling the apostrophe head in fig. 1 . W e leave the formal characterization of the full class of tasks necessitating sinks to future work. For multi-layer models, our necessity result (the- orem 2 ) guarantees that at least one layer must exhibit sink beha vior at some non-trigger position, but does not characterize which specific layer this must be. Our experiments extend this to multi-head architectures and confirm that sinks indeed do not form in all heads or layers (section C ), consistent with the existential nature of the theorem; under - standing exactly where sinks emer ge would likely require a dynamical analysis of ho w optimization selects among valid solutions, which we leav e to future work. Finally , it would be interesting to in vestigate whether other special tokens that are stable and always present in the input (e.g., <|think|> in reasoning models) exhibit similar sink behavior , and to in vestigate the relativ ely newly disco vered phenomenon of “secondary attention sinks” ( W ong et al. , 2026 ). W e leave this direction for future work as well. Acknowledgments I thank Y otam Alexander , Amit Elhelo, Daniela Gottesman, Eden Lumbroso and Y oni Slutsky for il- luminating discussions. Special thanks to my advi- sor Nadav Cohen for his guidance and mentorship. W e used AI assistance for writing and code de vel- opment. This work was supported by the European 7 Research Council (ERC) grant NN4C 101164614, a Google Research Scholar A ward, a Google Re- search Gift, Meta, the Y andex Initiative in Machine Learning, the Israel Science F oundation (ISF) grant 1780/21, the T el A viv Uni versity Center for AI and Data Science, the Adelis Research Fund for Artifi- cial Intelligence, Len Bla vatnik and the Bla vatnik Family F oundation, and Amnon and Anat Shashua. References Anand, Umberto Cappellazzo, Sta vros Petridis, and Maja Pantic. 2026. Mitigating attention sinks and massiv e activ ations in audio-visual speech recogni- tion with llms . Preprint , arXi v:2510.22603. Sanjeev Arora, Nada v Cohen, W ei Hu, and Y uping Luo. 2019. Implicit regularization in deep matrix factor - ization . Preprint , arXi v:1905.13655. Federico Barbero, Álv aro Arroyo, Xiangming Gu, Christos Periv olaropoulos, Michael Bronstein, Petar V eli ˇ ckovi ´ c, and Razvan Pascanu. 2025. Why do llms attend to the first token? Pr eprint , Y elysei Bondarenko, Markus Nagel, and T ijmen Blanke voort. 2023. Quantizable transformers: Re- moving outliers by helping attention heads do noth- ing . Preprint , arXi v:2306.12929. Nicola Cancedda. 2024. Spectral filters, dark signals, and attention sinks . Preprint , arXi v:2402.09221. Enrique Queipo de Llano, Álvaro Arro yo, Federico Bar- bero, Xiaowen Dong, Michael Bronstein, Y ann Le- Cun, and Ra vid Shwartz-Ziv . 2026. Attention sinks and compression valle ys in llms are two sides of the same coin . Preprint , arXi v:2510.06477. Nir Endy , Idan Daniel Grosbard, Y uval Ran-Milo, Y onatan Slutzky , Itay Tshuva, and Raja Giryes. 2025. Mamba knockout for unra veling factual information flow . Pr eprint , W enfeng Feng and Guoying Sun. 2025. Edit: Enhanc- ing vision transformers by mitigating attention sink through an encoder-decoder architecture . Pr eprint , Zichuan Fu, W entao Song, Y ejing W ang, Xian W u, Y efeng Zheng, Y ingying Zhang, Derong Xu, Xue- tao W ei, T ong Xu, and Xiangyu Zhao. 2025. Sliding windo w attention training for efficient lar ge language models . Preprint , arXi v:2502.18845. Zizhuo Fu, W enxuan Zeng, Runsheng W ang, and Meng Li. 2026. Attention sink forges native moe in at- tention layers: Sink-aware training to address head collapse . Preprint , arXi v:2602.01203. Xiangming Gu, Tian yu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Y e W ang, and Min Lin. 2024. When attention sink emerges in language models: An empirical view . Pr eprint , T ianyu Guo, Druv Pai, Y u Bai, Jiantao Jiao, Michael I. Jordan, and Song Mei. 2024. Activ e-dormant attention heads: Mechanistically demystifying extreme-token phenomena in llms . Preprint , V ictoria Hankemeier and Malte Schilling. 2026. Stochastic parroting in temporal attention – re gulat- ing the diagonal sink . Preprint , arXi v:2602.10956. Jonghyun Hong and Sungyoon Lee. 2025. V ariance sensitivity induces attention entrop y collapse and in- stability in transformers . In Pr oceedings of the 2025 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , pages 8360–8378, Suzhou, China. Association for Computational Linguistics. Sayed Mohammadreza T ayaranian Hosseini, Amir Ardakani, and W arren J. Gross. 2026. In- nerq: Hardware-aw are tuning-free quantization of kv cache for lar ge language models . Preprint , Xingyue Huang, Xueying Ding, Mingxuan Ju, Y ozen Liu, Neil Shah, and T ong Zhao. 2026. Thresh- old differential attention for sink-free, ultra-sparse, and non-dispersiv e language modeling . Pr eprint , Mingyu Jin, Kai Mei, W ujiang Xu, Mingjie Sun, Ruix- iang T ang, Mengnan Du, Zirui Liu, and Y ongfeng Zhang. 2025. Massiv e v alues in self-attention mod- ules are the key to conte xtual knowledge understand- ing . Preprint , arXi v:2502.01563. Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. 2025. See what you are told: V isual at- tention sink in lar ge multimodal models . ArXiv , abs/2503.03321. Haokun Lin, Haobo Xu, Y ichen W u, Jingzhi Cui, Y ing- tao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Y ing W ei. 2024. Duquant: Distributing outliers via dual transformation makes stronger quantized llms . Preprint , arXi v:2406.01721. Ziyong Lin, Haoyi W u, Shu W ang, Ke wei T u, Zilong Zheng, and Zixia Jia. 2025. Look both ways and no sink: Conv erting LLMs into text encoders without training . In Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V ol- ume 1: Long P apers) , pages 22839–22853, V ienna, Austria. Association for Computational Linguistics. Guozhi Liu, W eiwei Lin, Tiansheng Huang, Ruichao Mo, Qi Mu, Xiumin W ang, and Li Shen. 2026. Surgery: Mitigating harmful fine-tuning for lar ge language models via attention sink . Preprint , 8 Andrew Lu, W entinn Liao, Liuhui W ang, Huzheng Y ang, and Jianbo Shi. 2025. Artifacts and attention sinks: Structured approximations for efficient vision transformers . Preprint , arXi v:2507.16018. Jiayun Luo, W an-Cyuan Fan, L yuyang W ang, Xi- angteng He, T anzila Rahman, Purang Abolmaesumi, and Leonid Sigal. 2025. T o sink or not to sink: V i- sual information pathways in lar ge vision-language models . Preprint , arXi v:2510.08510. Aidar Myrzakhan, T ianyi Li, Bo wei Guo, Shengkun T ang, and Zhiqiang Shen. 2026. Si nk-aware pruning for diffusion language models . Pr eprint , Ofir Press, Noah A. Smith, and Mike Le wis. 2021. T rain short, test long: Attention with linear bi- ases enables input length extrapolation . Preprint , Zihan Qiu, Zeyu Huang, Kaiyue W en, Peng Jin, Bo Zheng, Y uxin Zhou, Haofeng Huang, Zekun W ang, Xiao Li, Huaqing Zhang, Y ang Xu, Haoran Lian, Siqi Zhang, Rui Men, Jianwei Zhang, Ivan T itov , Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2026. A unified view of attention and residual sinks: Outlier-dri ven rescaling is essential for transformer training . Preprint , arXi v:2601.22966. Zihan Qiu, Zekun W ang, Bo Zheng, Zeyu Huang, Kaiyue W en, Songlin Y ang, Rui Men, Le Y u, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2025. Gated attention for large lan- guage models: Non-linearity , sparsity , and attention- sink-free . Preprint , arXi v:2505.06708. Y uv al Ran-Milo, Y otam Ale xander , Shahar Mendel, and Nadav Cohen. 2026. Outcome-based rl prov ably leads transformers to reason, b ut only with the right data . Preprint , arXi v:2601.15158. Oliv er Richter and Roger W attenhofer . 2020. Normal- ized attention without probability cage . Pr eprint , Maximo Eduardo Rulli, Simone Petruzzi, Edoardo Michielon, Fabrizio Silvestri, Simone Scardapane, and Alessio De voto. 2025. Attention sinks in diffu- sion language models . Preprint , arXi v:2510.15731. V aleria Ruscio, Umberto Nanni, and Fabrizio Silvestri. 2025. What are you sinking? a geometric approach on attention sink . Preprint , arXi v:2508.02546. Pedro Sandov al-Segura, Xijun W ang, Ashwinee Panda, Micah Goldblum, Ronen Basri, T om Goldstein, and David Jacobs. 2025. Using attention sinks to identify and ev aluate dormant heads in pretrained llms. arXiv pr eprint arXiv:2504.03889 . Bingqi Shang, Y iwei Chen, Y ihua Zhang, Bingquan Shen, and Sijia Liu. 2025. Forgetting to for get: At- tention sink as a gatew ay for backdooring llm un- learning . Preprint , arXi v:2510.17021. Jaew on Sok, Jewon Y eom, Seonghyeon P ark, Jeongjae Park, and T aesup Kim. 2026. Garbage attention in large language models: Bos sink heads and sink- aware pruning . Pr eprint , Seungwoo Son, W onpyo Park, W oohyun Han, Kyuyeun Kim, and Jaeho Lee. 2024. Prefixing attention sinks can mitigate activ ation outliers for large language model quantization . In Pr oceedings of the 2024 Con- fer ence on Empirical Methods in Natural Langua ge Pr ocessing , pages 2242–2252, Miami, Florida, USA. Association for Computational Linguistics. Daniel Soudry , Elad Hoffer , Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. 2024. The implicit bias of gradient descent on separable data . Pr eprint , Jianlin Su, Y u Lu, Shengfeng Pan, Ahmed Murtadha, Bo W en, and Y unfeng Liu. 2021. Roformer: En- hanced transformer with rotary position embedding . Pr eprint , Zunhai Su and Kehong Y uan. 2025. Kvsink: Under- standing and enhancing the preservation of attention sinks in kv cache quantization for llms . Preprint , Mingjie Sun, Xinlei Chen, J. Zico Kolter , and Zhuang Liu. 2024. Massiv e activ ations in large language models . Preprint , arXi v:2402.17762. Shangwen Sun, Alfredo Canziani, Y ann LeCun, and Jiachen Zhu. 2026. The spike, the sparse and the sink: Anatomy of massi ve activ ations and attention sinks . Preprint , arXi v:2603.05498. Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser , and Illia Polosukhin. 2017. Attention is all you need . Preprint , arXi v:1706.03762. Petar V eli ˇ ckovi ´ c, Christos Perivolaropoulos, Federico Barbero, and Razvan Pascanu. 2025. Softmax is not enough (for sharp size generalisation) . Pr eprint , Y ining W ang, Mi Zhang, Junjie Sun, Chenyue W ang, Min Y ang, Hui Xue, Jialing T ao, Ranjie Duan, and Jiexi Liu. 2025. Mirage in the eyes: Hallucination attack on multi-modal large language models with only attention sink . Preprint , arXi v:2501.15269. Jef frey T . H. W ong, Cheng Zhang, Louis Mahon, W ayne Luk, Anton Isopoussu, and Y iren Zhao. 2026. On the existence and beha vior of secondary attention sinks . Pr eprint , Guangxuan Xiao, Y uandong T ian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient streaming language models with attention sinks . Preprint , Jing Xiong, Liyang F an, Hui Shen, Zunhai Su, Min Y ang, Lingpeng Kong, and Ngai W ong. 2026. Dope: Denoising rotary position embedding . Pr eprint , 9 Itay Y ona, Ilia Shumailov , Jamie Hayes, Federico Bar- bero, and Y ossi Gandelsman. 2025. Interpreting the repeated token phenomenon in lar ge language mod- els . Preprint , arXi v:2503.08908. Zhongzhi Y u, Zheng W ang, Y onggan Fu, Huihong Shi, Khalid Shaikh, and Y ingyan Celine Lin. 2024. Un veiling and harnessing hidden attention sinks: Enhancing large language models without training through attention calibration . Pr eprint , Stephen Zhang, Mustafa Khan, and V ardan Papyan. 2025. Attention sinks: A ’catch, tag, release’ mecha- nism for embeddings . Preprint , arXi v:2502.00919. Xiaofeng Zhang, Y ihao Quan, Chaochen Gu, Chen Shen, Xiaosong Y uan, Shaotian Y an, Hao Cheng, Kaijie W u, and Jieping Y e. 2024. Seeing clearly by layer two: Enhancing attention heads to alleviate hallucination in lvlms . Preprint , arXi v:2411.09968. Zihou Zhang, Zheyong Xie, Li Zhong, Haifeng Liu, Y ao Hu, and Shaosheng Cao. 2026. One token is enough: Improving dif fusion language models with a sink token . Preprint , arXi v:2601.19657. Zayd M. K. Zuhri, Erland Hilman Fuadi, and Al- ham Fikri Aji. 2026. Softpick: No attention sink, no massiv e activ ations with rectified softmax . Pr eprint , A T raining Details All models are trained using the Adam optimizer ( β 1 =0 . 9 , β 2 =0 . 95 ) with batch size 128 ov er the ℓ 2 loss until the ℓ ∞ loss is less than 10 − 2 for the entire batch. Single-layer models use learning rate 10 − 3 ; multi-layer models use learning rate 10 − 4 . W e use input dimension n = 16 and sample content coordinates i.i.d. from U ( − 1 , 1) . B Practical Impact of Attention Sinks The goal of this section is to detail the empirical mo- ti vation for our theoretical study . Attention sinks hav e been shown to affect se veral aspects of model performance and deployment. W e briefly surve y the e vidence here to moti vate the practical impor - tance of understanding their origin. Accuracy and context utilization. When prob- ability mass concentrates on a fix ed position, at- tention can be div erted away from other tokens and downstream accuracy can be af fected ( Y u et al. , 2024 ). Guo et al. ( 2024 ) document “activ e– dormant” heads in which dormant sink behavior ef fectively w astes representational capacity . Compression and quantization. Attention sinks are correlated with outlier acti vations that compli- cate model compression. Sun et al. ( 2024 ) identify massi ve activ ations tied to sink tokens, and Lin et al. ( 2024 ) sho w that these outliers are a key challenge for quantization. Streaming and long-context inference. At- tention sinks complicate streaming and rolling- windo w KV -cache strategies: Xiao et al. ( 2024 ) sho w that e victing sink tokens from the cache causes catastrophic performance degradation, and that explicitly retaining them is necessary for sta- ble generation on sequences far beyond the training length. V ision and multimodal models. Analogous sink ef fects appear in vision T ransformers and multi- modal models. Kang et al. ( 2025 ) show that visual attention sinks allocate high attention weights to irrele vant visual tokens, wasting representational capacity . W ang et al. ( 2025 ) demonstrate that atten- tion sinks in multimodal models can be exploited to induce hallucinations, and Feng and Sun ( 2025 ) propose architectural modifications to mitigate sink behavior in vision T ransformers. Interpr etability . Sinks distort attention-based analyses by concentrating probability mass on to- kens that carry no content-relev ant information, complicating efforts to use attention patterns for model interpretation ( Guo et al. , 2024 ). C Additional Experimental Results T o further validate our findings at lar ger scale, we train 4-layer 4-head models with both softmax and ReLU attention. All models use the same training configuration described in Appendix A . Figures 7 and 8 sho w representativ e attention patterns. The softmax v ariant exhibits strong sink beha vior in at least one head per layer in the no-trigger regime, while the ReLU v ariant maintains near-zero atten- tion on BOS throughout. These results pro vide addi- tional evidence that the necessity of attention sinks in softmax models persists in deeper , wider archi- tectures. D Proof of theor em 1 W e prove theorem 1 by establishing two separate necessity results: one for pre-trigger positions (the- orem 4 ) and one for post-trigger positions (theo- rem 5 ). Combining these two results directly yields 10 the statement of theorem 1 , which asserts necessity at all non-trigger positions i = j . Theorem 4 (Pre-T rigger Necessity) . F or any ε, δ ∈ R > 0 , L ∈ N ≥ 4 , n ∈ N ≥ 5 , and a bounded pr oba- bility density function P , ther e e xists a constant η ∈ R > 0 such that the following holds. Con- sider any single-layer softmax attention model f with loss L ( f ) ≤ η on sequences with length L and dimension n wher e non-trigger coor dinates ar e drawn fr om P . Then with pr obability at least 1 − δ over the choice of x with trigger position j , for all pre-trig ger positions 1 < i < j , we have α i, 1 ≥ 1 − ε . Pr oof. Step 1: W e can assume that W K = I and W O = I . Let B := W Q W ⊤ K , V := W O W V . For an y input, the scores and outputs are s i,k = x ( i ) B ( x ( k ) ) ⊤ , ˆ y ( i ) = X k ≤ i α i,k V x ( k ) , with α i,k = exp( s i,k ) P ℓ ≤ i exp( s i,ℓ ) . Thus the attention depends on ( W Q , W K ) only through B , and the output depends on ( W O , W V ) only through V . Reparameterizing by setting W K := I , W Q := B , W O := I , W V := V leav es α i,k and ˆ y ( i ) unchanged, hence the loss is unchanged. Therefore, we will assume without loss of generality that W K = I and W O = I , write Q for the query map, and V for the (combined) value map. Step 2: Setup and pigeonhole principle. Fix ε 0 , δ 0 ∈ R > 0 and suppose by contradiction that there exists a sequence of one-layer softmax mod- els { f t } ∞ t =1 with η t := L ( f t ) → 0 such that, for each t , with probability at least δ 0 ov er ( x , j ) ∼ P there is a pre-trigger position i < j violating the sink condition: α i, 1 ≤ 1 − ε 0 . (1) Since P k ≤ i α i,k = 1 , ( 1 ) implies that the total mass on non- BOS ke ys is at least ε 0 . There are only finitely many position triples ( i, h, j ) with 2 ≤ h ≤ i < j ≤ L . By a pigeonhole principle, there exist infinitely many times t a 1 , t a 2 , . . . and fixed indices 2 ≤ i ⋆ < j ⋆ ≤ L and 2 ≤ h ⋆ ≤ i ⋆ , and a constant γ ∈ R > 0 (e.g., γ = ε 0 /L 2 ), such that P α i ⋆ , 1 ≤ 1 − ε 0 and α i ⋆ ,h ⋆ ≥ γ ≥ δ (2) for some δ ∈ R > 0 independent of t . By relabel- ing this subsequence, we assume without loss of generality that ( 2 ) holds for all t . Step 3: Constructing tokens via Lemma 7 . Since the ev ent in ( 2 ) has positi ve probability at least δ , by Lemma 7 (applied to content coordi- nates) there exists ε ′ ∈ R > 0 (independent of t ) such that for ev ery content coordinate m ∈ { 4 , . . . , n } there exist tokens x ( m ) , y ( m ) with the following properties: (i) x ( m ) k = y ( m ) k for all k = m , and x ( m ) m − y ( m ) m ≥ ε ′ ; and (ii) there e xist sequences with either x ( m ) or y ( m ) at position h ⋆ and with trigger position j satisfying i ⋆ < j , such that α i ⋆ ,h ⋆ ≥ γ . (3) Step 4: Positi ve weight implies small values. By Lemma 5 (applied with the pair ( h ⋆ , i ⋆ ) in the case where h ⋆ = i ⋆ ) and Lemma 4 (applied with h ⋆ whene ver h ⋆ = i ⋆ ), for every choice of token at position h ⋆ we hav e α i ⋆ ,h ⋆ Vx ( h ⋆ ) 2 ≤ 4 η t . Combining with ( 3 ) yields that for any content co- ordinate m and any z ∈ { x ( m ) , y ( m ) } , Vz 2 ≤ 4 γ η t . (4) That is, the lo wer bound on α i ⋆ ,h ⋆ directly forces the value projections to be small for all tokens con- structed in Step 2. Step 5: T ransplanting to j = 3 and deriving a contradiction. Fix t and abbre viate η := η t . Pick a content coordinate m ∈ { 4 , . . . , n } and let x t := x ( m ) and y t := y ( m ) be the two tok ens from Step 2 satisfying | x ( m ) t − y ( m ) t | ≥ ε ′ . Instantiate two sequences by setting the trigger at j = 3 , taking x (2) ∈ { x t , y t } , and fixing the trigger token x (3) to any arbitrary v alue t such that the sequence is in the support of D . At position i = 3 the target is y (3) = 1 2 ( x (2) + t ) . (5) 11 For any z ∈ { x t , y t } , let β t ( z ) be the atten- tion weight α 3 , 3 computed on the sequence where x (2) = z and x (3) = t . Define the fixed v alue vector v t := V t t . (6) By Lemma 1 and ( 4 ) , at position 3 we can decom- pose ˆ y (3) ( z ) = α 3 , 1 V e 1 + α 3 , 2 Vz | {z } =: r t ( z ) + β t ( z ) v t , (7) ∥ r t ( z ) ∥ 2 ≤ C 0 η , (8) with C 0 := 1 + 4 γ independent of t . Consider coordinate 3 (the non-trigger non-BOS indicator). Since ( y (3) ) 3 = 1 2 (( x (2) ) 3 + ( t ) 3 ) = 1 2 (1 + 0) = 0 . 5 and 0 < β t ( z ) ≤ 1 , from ( 7 ) and the uniform loss bound we obtain β t ( z ) ( v t ) 3 − 0 . 5 ≤ ˆ y (3) 3 ( z ) − 0 . 5 + ( r t ( z )) 3 ≤ η + C 0 η = C 1 η , (9) where C 1 := 1 + C 0 . Hence, for all sufficiently large t , ( v t ) 3 ≥ 0 . 5 − C 1 η β t ( z ) ≥ 0 . 5 − C 1 η > 0 , (10) so v t = 0 . Let P t denote the orthogonal projection onto v ⊥ t . Since P t is an orthogonal projection onto an ( n − 1) -dimensional subspace, there must be at least one coordinate m 0 ∈ { 4 , 5 } such that ∥ P t e m 0 ∥ 2 ≥ 1 / √ 2 ; fix m to be that coordinate. Now , applying P t to ( 7 ) kills the v t component: P t ˆ y (3) ( z ) = P t r t ( z ) , (11) ∥ P t ˆ y (3) ( z ) ∥ 2 ≤ ∥ r t ( z ) ∥ 2 ≤ C 0 η . (12) Therefore, for the two choices z = x t , y t , P t ˆ y (3) ( x t ) − P t ˆ y (3) ( y t ) 2 ≤ ∥ P t r t ( x t ) ∥ 2 + ∥ P t r t ( y t ) ∥ 2 ≤ 2 C 0 η . (13) On the other hand, we ha ve y (3) ( z ) = 1 2 ( z + t ) , so P t y (3) ( z ) = 1 2 P t z + 1 2 P t t . Since the t term is constant in z , it cancels in the dif ference: P t y (3) ( x t ) − P t y (3) ( y t ) 2 = 1 2 ∥ P t ( x t − y t ) ∥ 2 = 1 2 ∥ P t (( x t,m − y t,m ) e m ) ∥ 2 = 1 2 | x t,m − y t,m | ∥ P t e m ∥ 2 ≥ 1 2 ε ′ ∥ P t e m ∥ 2 ≥ 1 2 √ 2 ε ′ . (14) where the third equality uses the fact that x t and y t dif fer only on coordinate m . Finally , by the triangle inequality and the uni- form loss bound, P t y (3) ( x t ) − P t y (3) ( y t ) 2 ≤ P t ˆ y (3) ( x t ) − P t ˆ y (3) ( y t ) 2 + 2 η ≤ (2 C 0 + 2) η , (15) which contradicts ( 14 ) for all suf ficiently small η , because ε ′ ∥ P t e m ∥ 2 > 0 is independent of t . Theorem 5 (Post-Trigger Necessity) . F or any ε, δ ∈ R > 0 , L ∈ N ≥ 4 , n ∈ N ≥ 5 , and a bounded pr obability density function P , ther e exists a con- stant η ∈ R > 0 such that the following holds. Con- sider any single-layer softmax attention model f with loss L ( f ) ≤ η on sequences with length L and dimension n wher e non-trigger coor dinates ar e drawn fr om P . Then with pr obability at least 1 − δ over the choice of x with trigger position j , for all post-trigger positions j < i ≤ L , we have α i, 1 ≥ 1 − ε . Pr oof. Step 1: The trigger receiv es arbitrarily small attention post-trigger . Fix any trigger to- ken t and any non-trigger tok en z , and consider the length- 3 prefix ( BOS , t , z ) (so the trigger posi- tion is j = 2 and position 3 is post-trigger). Let e α 3 , 1 , e α 3 , 2 , e α 3 , 3 be the attention weights at position 3 . W e first bound the self term e α 3 , 3 Vz using Lemma 4 . Embed the pair ( BOS , z ) as the first two tokens of an y valid sequence from D whose trigger position satisfies j ≥ 3 (so position 2 is pre-trigger and non-trigger). Applying Lemma 4 at i = 2 gi ves ∥ α 2 , 2 Vz ∥ 2 ≤ 2 η for that sequence, and by Lemma 2 (adding the extra ke y t can only decrease 12 the probability assigned to z ) we hav e e α 3 , 3 ≤ α 2 , 2 , hence ∥ e α 3 , 3 Vz ∥ 2 ≤ 2 η . Also, Lemma 1 giv es ∥ e α 3 , 1 V e 1 ∥ 2 ≤ η . Since the target at position 3 is 0 , we hav e ∥ ˆ y (3) ∥ 2 ≤ η , and therefore ∥ e α 3 , 2 Vt ∥ 2 ≤ ∥ ˆ y (3) ∥ 2 + ∥ e α 3 , 1 V e 1 ∥ 2 + ∥ e α 3 , 3 Vz ∥ 2 ≤ 4 η . Finally , Lemma 6 (applied to any valid sequence with trigger at position 2 ) gi ves ∥ Vt ∥ 2 ≥ 1 − 2 η , so e α 3 , 2 ≤ 4 η 1 − 2 η . (16) No w fix any valid sequence x with trigger posi- tion j and any i > j . By Lemma 3 (2), α i,j ≤ b α 3 , 2 where b α 3 , 2 is the attention weight on the second token in the prefix ( BOS , x ( j ) , x ( i ) ) , and applying ( 16 ) to that prefix yields α i,j ≤ 4 η 1 − 2 η for all i > j . (17) Step 2 (contradiction via shifting the trigger). Fix ε 0 , δ 0 ∈ R > 0 and suppose, for contradiction, that the theorem is false. Then there exists a se- quence of one-layer softmax models { f t } t ≥ 1 with η t := L ( f t ) → 0 such that for e very t , P ( x ,j ) ∼D ∃ i > j : α ( t ) i, 1 ( x ) ≤ 1 − ε 0 ≥ δ 0 . (18) By Step 1 (i.e., ( 17 ) ), for all x in supp ort( D ) and all i > j , α ( t ) i,j ( x ) ≤ 4 η t 1 − 2 η t . Fix t large enough so that 4 η t 1 − 2 η t ≤ ε 0 / 2 . Let E t be the ev ent in ( 18 ) . For each ( x , j ) ∈ E t there e xists i ( x ) > j with α ( t ) i ( x ) , 1 ( x ) ≤ 1 − ε 0 . For that i ( x ) we also ha ve α ( t ) i ( x ) ,j ( x ) ≤ ε 0 / 2 , hence X k ≤ i ( x ) , k / ∈{ 1 ,j } α ( t ) i ( x ) ,k ( x ) = 1 − α ( t ) i ( x ) , 1 ( x ) − α ( t ) i ( x ) ,j ( x ) ≥ ε 0 / 2 . (19) No w define the shift map Shift that moves the trigger token to the end: x ′ = Shift( x , j ) , where x ′ ( k ) = x ( k ) for 1 ≤ k < j (positions before the trigger are unchanged), x ′ ( k ) = x ( k +1) for j ≤ k ≤ L − 1 (positions after the trigger shift left by one), and x ′ ( L ) = x ( j ) (trigger mov es to the end). Then x ′ ∈ supp ort( D ) with trigger position L , and moreov er, by the definition of the task (sec- tion 3.2 ), we have that the probability density of x ′ is the same as that of x : P ( x ) = P ( x ′ ) . (20) Fix ( x , j ) ∈ E t . Applying Lemma 2 we get that removing the ke y j can only incr ease the attention weight of each remaining key (at position i ( x ) in x , the “candidate” key set is { 1 , . . . , i ( x ) } ; at po- sition i ( x ) − 1 in x ′ , the “candidate” key set is { 1 , . . . , i ( x ) } \ { j } , the same set with the trigger ke y removed.) Therefore, X r ≤ i ( x ) − 1 , r =1 α ′ ( t ) i ( x ) − 1 ,r ( x ′ ) ≥ X k ≤ i ( x ) , k / ∈{ 1 ,j } α ( t ) i ( x ) ,k ( x ) ≥ ε 0 / 2 , where the last inequality is ( 19 ). Equi v alently , α ′ ( t ) i ( x ) − 1 , 1 ( x ′ ) ≤ 1 − ε 0 / 2 . (21) Since this holds for every ( x , j ) ∈ E t , by the Pigeonhole Principle, there e xist fixed indices j ∗ ∈ { 1 , . . . , L } and r ∗ < L and a constant c 1 ∈ R > 0 such that for infinitely many t , P ( x ,j ) ∼D α ′ ( t ) r ∗ , 1 ( x ′ ) ≤ 1 − ε 0 / 2 and j = j ∗ ≥ c 1 δ 0 , (22) where x ′ = Shift( x , j ) . Finally , consider the bijection x 7→ Shift( x , j ∗ ) from the set of sequences with trigger at j ∗ to the set of sequences with trigger at L . By eq. ( 20 ), this map preserves probability density . Thus, the e vent in ( 22 ) has the exact same probability as the corresponding e vent for sequences with trigger at L : P ( z ,j ) ∼D α ( t ) r ∗ , 1 ( z ) ≤ 1 − ε 0 / 2 and j = L ≥ c 1 δ 0 . Conditioning on j = L , this implies that for in- finitely many t , P α ( t ) r ∗ , 1 ( z ) ≤ 1 − ε 0 / 2 j = L ≥ c 1 δ 0 P ( j = L ) . Since r ∗ < L , this contradicts Theorem 4 , as needed. 13 E Proof of theor em 2 Step 1: Setup and contradiction assumption. Fix ε 0 , δ 0 ∈ R > 0 . Suppose for contradiction that there exists a sequence of D -layer softmax models { f t } ∞ t =1 with η t := L ( f t ) − → 0 such that, for e very t , P ∀ d ∈ { 1 , . . . , D } , ∀ 1 < i < j : α ( d ) i, 1 ≤ 1 − ε 0 j ≥ 3 ≥ δ 0 . (23) Let E t denote the e vent inside the probability in ( 23 ) intersected with the ev ent j ≥ 3 . For each t , let V t be the combined v alue map from Lemma 8 , and write β ( t ) i,k ( · ) for the corresponding coef ficients. Step 2: No sink implies small value pr ojections. On the ev ent E t , position 2 is pre-trigger (since j ≥ 3 ) and for ev ery layer d , α ( d ) 2 , 2 = 1 − α ( d ) 2 , 1 ≥ ε 0 . Therefore, by Lemma 9 conditioned on E t we ha ve that β ( t ) 2 , 2 ( x ) ≥ ε D 0 (24) Moreov er, Lemma 11 applied to f t yields β ( t ) 2 , 2 ( x ) V t x (2) 2 ≤ 2 η t . Combining with ( 24 ) gi ves ∥ V t x (2) ∥ 2 ≤ 2 ε D 0 η t on E t . (25) Define the measurable set S t := n z ∈ R n : ∥ V t z ∥ 2 ≤ 2 ε D 0 η t o . Since E t ⊆ { x (2) ∈ S t } by ( 25 ), ( 23 ) implies P x (2) ∈ S t j ≥ 3 ≥ δ 0 . (26) By Lemma 7 (applied to content coordinates) and ( 26 ) , there e xists ε ′ ∈ R > 0 (independent of t ) such that for ev ery content coordinate m ∈ { 4 , . . . , n } there exist tok ens x ( m ) t , y ( m ) t ∈ S t sat- isfying x ( m ) t,k = y ( m ) t,k for all k = m, x ( m ) t,m − y ( m ) t,m ≥ ε ′ . (27) Step 3: T ransplanting to j = 3 and deriving a contradiction. Fix t and abbreviate η := η t . Pick a content coordinate m ∈ { 4 , . . . , n } and let x t := x ( m ) t and y t := y ( m ) t be the two tokens from Step 2 satisfying | x t,m − y t,m | ≥ ε ′ . Instantiate two sequences by setting the trigger at j = 3 , taking x (2) ∈ { x t , y t } , and fixing the trigger token x (3) to an arbitrary v alue t such that the sequence is in the support of D . At position i = 3 the target is y (3) = 1 2 ( x (2) + t ) . (28) For any z ∈ { x t , y t } , let β t ( z ) be the coefficient β ( t ) 3 , 3 ( z ) computed on the sequence where x (2) = z and x (3) = t . Define the fixed v alue vector v t := V t t . (29) By Lemma 8 , for each choice x (2) = z we can decompose ˆ y (3) ( z ) = β ( t ) 3 , 1 ( z ) V t e 1 + β ( t ) 3 , 2 ( z ) V t z | {z } =: r t ( z ) + β t ( z ) v t . (30) Since β ( t ) 3 , 1 ( z ) , β ( t ) 3 , 2 ( z ) ≤ 1 , Lemma 10 gi ves ∥ V t e 1 ∥ 2 ≤ η , and z ∈ S t implies ∥ V t z ∥ 2 ≤ 2 ε D 0 η . Therefore ∥ r t ( z ) ∥ 2 ≤ C 0 η , C 0 := 1 + 2 ε D 0 . (31) Consider coordinate 3 (the non-trigger non-BOS indicator). For the j = 3 construction, we hav e ( y (3) ) 3 = 0 . 5 . Using ( 30 ) and the uniform loss bound, β t ( z ) ( v t ) 3 − 0 . 5 ≤ ˆ y (3) 3 ( z ) − 0 . 5 + ( r t ( z )) 3 ≤ η + C 0 η = C 1 η , where C 1 := 1+ C 0 . Hence ( v t ) 3 ≥ 0 . 5 − C 1 η > 0 for all suf ficiently large t , so v t = 0 . Let P t denote the orthogonal projection onto v ⊥ t . Since dim( v ⊥ t ) = n − 1 , there exists at least one coordinate m 0 ∈ { 4 , 5 } such that ∥ P t e m 0 ∥ 2 ≥ 1 / √ 2 . (32) Fix such an m , and take x t := x ( m ) t and y t := y ( m ) t from ( 27 ). 14 Applying P t to ( 30 ) kills the v t component, giv- ing P t ˆ y (3) ( z ) = P t r t ( z ) . Therefore, P t ˆ y (3) ( x t ) − P t ˆ y (3) ( y t ) 2 ≤ ∥ P t r t ( x t ) ∥ 2 + ∥ P t r t ( y t ) ∥ 2 ≤ 2 C 0 η , (33) using ( 31 ) . On the other hand, by ( 28 ) we have P t y (3) ( z ) = 1 2 P t ( z + t ) , so P t y (3) ( x t ) − P t y (3) ( y t ) 2 = 1 2 ∥ P t ( x t − y t ) ∥ 2 = 1 2 | x t,m − y t,m | · ∥ P t e m ∥ 2 ≥ 1 2 √ 2 ε ′ , (34) using ( 27 ) and ( 32 ). Finally , by the triangle inequality and the uni- form loss bound, P t y (3) ( x t ) − P t y (3) ( y t ) 2 ≤ P t ˆ y (3) ( x t ) − P t ˆ y (3) ( y t ) 2 + 2 η ≤ (2 C 0 + 2) η , which contradicts ( 34 ) for all sufficiently small η . This contradiction completes the proof. F Proof of theor em 3 W e giv e an explicit zero-loss construction with α i, 1 = 0 for all i . Parameters. Set W K = I , W V = I , and W O = I . Let e r denote the r -th standard basis vector . Recall from section 3.2 : coordinate 1 is the BOS indicator; coordinate 2 is the trigger indicator; coordinate 3 is the non-trigger non-BOS indicator , with x (1) 3 = x ( j ) 3 = 0 and x ( i ) 3 = 1 for i = 1 , j . Define W Q = e 2 ( e 2 + e 3 ) ⊤ . Computing the attention weights. Using the ReLU attention formula from section 3.4 , the un- normalized score from position i to position k is x ( i ) W Q W ⊤ K ( x ( k ) ) ⊤ = x ( i ) 2 · ( x ( k ) 2 + x ( k ) 3 ) . Fix a trigger position j ∈ { 2 , . . . , L } . For any non-trigger position i = j , we ha ve x ( i ) 2 = 0 , so all scores are zero and hence α i,k = ReLU(0) /n i = 0 for all k ≤ i . In particular , α i, 1 = 0 . For the trigger position i = j , we hav e x ( j ) 2 = 1 . The score to position k equals x ( k ) 2 + x ( k ) 3 . This is 1 for non-trigger non-BOS tokens (if such exist) k ∈ { 2 , . . . , j − 1 } (where x ( k ) 3 = 1 ) and for the trigger token k = j (where x ( k ) 2 = 1 ). It is 0 for k = 1 ( BOS ). After applying ReLU and dividing by n j = j − 1 , we obtain α j,k = 1 j − 1 for 2 ≤ k ≤ j, α j,k = 0 otherwise . V erifying the output. At non-trigger positions, all attention weights are zero, so f ( x ) ( i ) = 0 = y ( i ) . At the trigger position i = j , using W O = W V = I : f ( x ) ( j ) = W O j X k =1 α j,k W V x ( k ) = 1 j − 1 j X k =2 x ( k ) = x = y ( j ) . Thus L ( f ) = 0 and α i, 1 = 0 for all i , completing the proof. G Lemmas Lemma 1. Let f be a single-layer softmax self- attention model as in § 3.4 and write V := W O W V . If the loss L ( f ) (see section 3.2 ) sat- isfies L ( f ) ≤ η , then ∥ V e 1 ∥ 2 ≤ η . Pr oof. By causality , at position i = 1 we hav e α 1 , 1 = 1 , hence ˆ y (1) = V e 1 . Since y (1) = 0 and ∥ ˆ y (1) − y (1) ∥ 2 ≤ L ( f ) ≤ η , the claim follows. Lemma 2. Assume the attention mechanism is soft- max. F ix any query q ∈ R n and two candidate sets of ke ys S ⊆ T ⊂ R n . F or the softmax pr obabilities σ S ( k ) = exp( q ⊤ k ) P r ∈ S exp( q ⊤ r ) , σ T ( k ) = exp( q ⊤ k ) P r ∈ T exp( q ⊤ r ) , we have σ T ( k ) ≤ σ S ( k ) for every k ∈ S . Pr oof. The denominators satisfy X r ∈ T exp( q ⊤ r ) = X r ∈ S exp( q ⊤ r ) + X r ∈ T \ S exp( q ⊤ r ) ≥ X r ∈ S exp( q ⊤ r ) , 15 while the numerator for a fix ed k ∈ S is the same in both fractions. Lemma 3. Assume the attention mechanism is soft- max. Consider any sequence fr om D (section 3.2 ) and any indices 1 < i and 1 < i < h . Then: 1. (Self-r eduction) Let e α 2 , 2 denote the attention weight on the second token in the length- 2 pr efix ( BOS , x ( i ) ) , computed with the same ( W Q , W K ) . Then α i,i ≤ e α 2 , 2 . 2. (P airwise r eduction) Let e α 3 , 2 denote the at- tention weight on the second token in the length-3 pr efix ( BOS , x ( i ) , x ( h ) ) , computed with ( W Q , W K ) . Then α h,i ≤ e α 3 , 2 . Pr oof. For (1), at real position i the query equals x ( i ) W Q . Let S be the two keys { W K x (1) , W K x ( i ) } and T = { W K x ( k ) : k ≤ i } . Lemma 2 (with this fixed query) gi ves the claim, noting that e α 2 , 2 = σ S ( W K x ( i ) ) and α i,i = σ T ( W K x ( i ) ) . For (2), at real position h the query equals x ( h ) W Q . Let S = { W K x (1) , W K x ( i ) , W K x ( h ) } and T = { W K x ( k ) : k ≤ h } ; apply Lemma 2 as before. Lemma 4. In the setting of lemma 1 , assume the attention mechanism is softmax. F or every se- quence in supp ort( D ) and every non-trigg er posi- tion 1 < i = j , α i,i Vx ( i ) 2 ≤ 2 η . Pr oof. Fix i and consider the length-2 prefix ( BOS , x ( i ) ) . At its position 2 (which is pre-trigger), the output equals ˆ y (2) = e α 2 , 1 V e 1 + e α 2 , 2 Vx ( i ) , with target y (2) = 0 . Hence e α 2 , 2 Vx ( i ) 2 ≤ ∥ ˆ y (2) ∥ 2 + ∥ e α 2 , 1 V e 1 ∥ 2 ≤ η + η = 2 η , using Lemma 1 for the BOS term. By Lemma 3 (1), α i,i ≤ e α 2 , 2 , and multiplying both sides by the fixed vector Vx ( i ) yields the result. Lemma 5. In the setting of lemma 1 , assume the at- tention mechanism is softmax. F or every sequence in supp ort( D ) and e very pair of non-trig ger in- dices 1 < i < h with i, h = j : α h,i Vx ( i ) 2 ≤ 4 η . Pr oof. Consider first the length-3 prefix ( BOS , x ( i ) , x ( h ) ) . At position 3 (pre-trigger), with target y (3) = 0 , ˆ y (3) = e α 3 , 1 V e 1 + e α 3 , 2 Vx ( i ) + e α 3 , 3 Vx ( h ) . Therefore, e α 3 , 2 Vx ( i ) 2 ≤ ∥ ˆ y (3) ∥ 2 + ∥ e α 3 , 1 V e 1 ∥ 2 + ∥ e α 3 , 3 Vx ( h ) ∥ 2 ≤ η + η + 2 η = 4 η , using Lemma 1 for the BOS term and Lemma 4 for the self term. By Lemma 3 (2), α h,i ≤ e α 3 , 2 . Multiplying by Vx ( i ) gi ves the result. Lemma 6. In the setting of lemma 1 , assume the at- tention mechanism is softmax. F or every sequence in supp ort( D ) with trigger at position j , ∥ Vx ( j ) ∥ 2 ≥ 1 − 2 η . Pr oof. Consider a sequence where the trigger is at position j = 2 . The target output at position 2 is y (2) = x (2) . The model output is ˆ y (2) = α 2 , 1 V e 1 + α 2 , 2 Vx (2) . W e know ∥ y (2) − ˆ y (2) ∥ 2 ≤ η and ∥ V e 1 ∥ 2 ≤ η (lemma 1 ). By triangle inequality , ∥ y (2) − α 2 , 2 Vx (2) ∥ 2 ≤ 2 η . Since ( y (2) ) 2 = 1 (trigger in- dicator), we ha ve | 1 − α 2 , 2 ( Vx (2) ) 2 | ≤ 2 η . Since α 2 , 2 ≤ 1 , this implies ( Vx (2) ) 2 ≥ 1 − 2 η , so ∥ Vx (2) ∥ 2 ≥ 1 − 2 η . Lemma 7. Let n ∈ N ≥ 1 and X = ( X 1 , . . . , X n ) ∼ µ ⊗ n , wher e µ has a density g bounded by M := sup x ∈ R g ( x ) < ∞ . F ix δ ∈ (0 , 1] . Then ther e exists some ε ′ ∈ R > 0 such that if a measurable set E ⊂ R n satisfies P ( X ∈ E ) ≥ δ , then for every coordinate j ∈ { 1 , . . . , n } ther e exist x, y ∈ E such that x k = y k for all k = j, and | x j − y j | ≥ ε ′ , Pr oof. Fix j and, for z ∈ R n − 1 , set E j ( z ) := { t ∈ R : ( z 1 , . . . , z j − 1 , t, z j +1 , . . . ) ∈ E } . By Fubini and independence, P ( X ∈ E ) = Z µ ( E j ( z )) dµ ⊗ ( n − 1) ( z ) . Since µ has density g bounded by M , for any mea- surable A ⊂ R we have µ ( A ) ≤ M λ ( A ) , where 16 λ is the Lebesgue measure. Hence δ ≤ Z µ ( E j ( z )) dµ ⊗ ( n − 1) ( z ) ≤ M Z λ ( E j ( z )) dµ ⊗ ( n − 1) ( z ) . Therefore there exists z with λ ( E j ( z )) ≥ δ / M . Any set A ⊂ R with Lebesgue measure λ ( A ) has diameter at least λ ( A ) − η for any η ∈ R > 0 , so we can choose t 1 , t 2 ∈ E j ( z ) with | t 1 − t 2 | ≥ δ / M − η with η < δ / 2 M . Setting ε ′ = δ / 2 M and taking x, y to match z on all coordinates k = j and hav e j -th coordinates t 1 , t 2 respecti vely giv es the claim. Lemma 8. Let f = f ( D ) ◦ · · · ◦ f (1) be a D -layer causal softmax self-attention model as in § 3.4 . F or each layer d ∈ { 1 , . . . , D } write V ( d ) := W ( d ) O W ( d ) V . V := V ( D ) V ( D − 1) · · · V (1) Then for e very input sequence x and every position i ∈ [ L ] , ther e exist coefficients β i, 1 ( x ) , . . . , β i,i ( x ) such that f ( x ) ( i ) = i X k =1 β i,k ( x ) Vx ( k ) . (35) Mor eover , for each i we have β i,k ( x ) ≥ 0 for all k ≤ i and i X k =1 β i,k ( x ) = 1 . Pr oof. Let z (0) := x and for d ≥ 1 let z ( d ) := f ( d ) ( z ( d − 1) ) . Write α ( d ) i,k for the (softmax) attention weight in layer d from position i to ke y k ≤ i . By definition of a single layer , z ( d ) ( i ) = X k ≤ i α ( d ) i,k V ( d ) z ( d − 1) ( k ) . Define β (1) i,k := α (1) i,k , and for d ≥ 2 define recur - si vely β ( d ) i,k := X ℓ : k ≤ ℓ ≤ i α ( d ) i,ℓ β ( d − 1) ℓ,k . A direct induction on d gi ves z ( d ) ( i ) = X k ≤ i β ( d ) i,k V ( d ) · · · V (1) x ( k ) . Nonnegati vity and the row-sum identity follow since each α ( d ) i, · is a probability vector . T aking d = D and setting β i,k := β ( D ) i,k yields ( 35 ). Lemma 9. In the setting of Lemma 8 , for any input sequence x we have β 2 , 2 ( x ) = D Y d =1 α ( d ) 2 , 2 ( x ) , wher e α ( d ) 2 , 2 ( x ) is the attention weight at position 2 attending to position 2 in layer d . Pr oof. In the recursion from the proof of Lemma 8 , note that position 1 is causal and thus ne ver de- pends on tok en 2 , directly yielding the product formula. Lemma 10. In the setting of Lemma 8 , if the loss L ( f ) (see section 3.2 ) satisfies L ( f ) ≤ η then ∥ V e 1 ∥ 2 ≤ η . Pr oof. By causality , at position i = 1 e very layer attends only to position 1 , hence f ( x ) (1) = Vx (1) = V e 1 . Since y (1) = 0 and ∥ f ( x ) (1) − y (1) ∥ 2 ≤ L ( f ) ≤ η , the claim follo ws. Lemma 11. In the setting of Lemma 8 , assume softmax attention and that the loss L ( f ) (see sec- tion 3.2 ) satisfies L ( f ) ≤ η . Then for every x in supp ort( D ) with trigger position j ≥ 3 we have that β 2 , 2 ( x ) Vx (2) 2 ≤ 2 η . Pr oof. Since j ≥ 3 , position 2 is pre-trigger and the target satisfies y (2) = 0 . By Lemma 8 with i = 2 , f ( x ) (2) = β 2 , 1 ( x ) V e 1 + β 2 , 2 ( x ) Vx (2) . Thus β 2 , 2 ( x ) Vx (2) 2 ≤ ∥ f ( x ) (2) ∥ 2 + β 2 , 1 ( x ) ∥ V e 1 ∥ 2 ≤ η + η = 2 η , using ∥ f ( x ) (2) − y (2) ∥ 2 ≤ η , β 2 , 1 ( x ) ≤ 1 , and Lemma 10 . H Related W ork Theory and analyses of attention sinks. Several recent works study attention sinks directly , aiming to characterize why they arise and what they cor- relate with. Barbero et al. ( 2025 ) argue (theoret- ically and empirically) that first-token sinks can act as a stabilizing mechanism against over -mixing, 17 and analyze how f actors like depth, context length, and packing influence sink strength. Cancedda ( 2024 ) connect sink beha vior to spectral structure in the vocab ulary embedding/unembedding oper- ators, attributing sinking to “dark” (tail-spectrum) components. Ruscio et al. ( 2025 ) view sinks as learned “reference-frame anchors” in representa- tion space and sho w that the resulting anchoring pattern depends strongly on architectural choices, especially the positional encoding. de Llano et al. ( 2026 ) connect attention sinks to “compression v al- leys” (layers where token representations become unusually low-entrop y/compressed), showing both tend to emerge when the BOS token de velops ex- tremely large residual-stream acti vations. Qiu et al. ( 2026 ) study attention sinks together with “residual sinks” (persistent large activ ations in a few residual- stream dimensions) and argue these outliers in- teract with normalization (softmax/RMSNorm) to rescale the remaining components, supporting sta- ble training. Sok et al. ( 2026 ) treat strong BOS- focused heads—especially in later layers—as a marker of functional redundancy and propose a pruning criterion based on sink scores. Hong and Lee ( 2025 ) attrib ute softmax-driv en attention en- tropy collapse (attention concentrating onto a sin- gle token) to v ariance sensiti vity of the logits and propose entropy-stable alternati ves. Zhang et al. ( 2025 ) link sink tokens to large-norm outlier direc- tions in LLM representations and RoPE-focused analyses similarly tie sink behavior to structured frequency artif acts and Q/K “massiv e values” ( Jin et al. , 2025 ; Xiong et al. , 2026 ). These “massive v alues” were recently revisited in Sun et al. ( 2026 ), which argues that massi ve acti vations and atten- tion sinks are largely decoupled: spikes can be suppressed via normalization changes while sinks persist. W e complement these with a different an- gle: rather than studying how sinks emer ge during training, we ask whether the y are structurally nec- essary for certain computations. W e prove that an y softmax attention model solving a natural trigger- conditional task must dev elop a sink, regardless of the training procedure or optimization dynamics (theorems 1 and 2 ). Softmax normalization implications. In stan- dard attention, the softmax turns scores into non- negati ve weights that sum to one. Richter and W attenhofer ( 2020 ) analyze how this simple x con- straint can restrict attention behavior and discuss alternati ves that relax or replace softmax normal- ization. V eli ˇ cko vi ´ c et al. ( 2025 ) pro ve that softmax- based mechanisms can fail to maintain increasingly sharp selection as the problem size gro ws, leading to degraded beha vior under distribution shift when near-ar gmax behavior is required. W e pro vide a concrete natural task where this constraint is prov- ably the cause of sink formation: a model that must aggregate conte xt on a trigger token and output zero otherwise cannot a void a sink under softmax normalization (theorem 1 ), whereas ReLU atten- tion—which lacks the simplex constraint—solves the same task without any sink (theorem 3 ). Mitigating sinks. Alongside analyses, multiple papers propose sink-targeted interventions. This in- cludes modified attention normalizations explicitly designed to av oid sinks ( Zuhri et al. , 2026 ; Huang et al. , 2026 ), as well as training procedures tailored to long-context regimes, including sliding-windo w attention that explicitly addresses attention-sink is- sue( Fu et al. , 2025 ). For inference-time ef ficiency , Su and Y uan ( 2025 ); Hosseini et al. ( 2026 ) analyze ho w KV -cache quantization can disrupt sink be- havior and propose predicting and preserving sink tokens during quantization. Mitigation has also been studied for closely related collapse modes of attention: Hong and Lee ( 2025 ) analyze softmax- dri ven entropy collapse (attention concentrating onto a single tok en) and propose alternati ves aimed at stabilizing attention entropy , while Hankemeier and Schilling ( 2026 ) study diagonal/temporal self- attention sinks and introduce regularizers to counter them. In a dif ferent setting, Lin et al. ( 2025 ) sho w that attention sinks degrade training-free con ver - sion of decoder-only LLMs into te xt encoders, and reduce this effect by enabling bidirectional atten- tion and masking the first token in attention. In mul- timodal and A V settings, sink patterns have simi- larly motiv ated mitigation strategies aimed at reduc- ing hallucination and stabilizing acti vations ( Zhang et al. , 2024 ; Anand et al. , 2026 ). Lu et al. ( 2025 ) analyze attention sinks as a structured artifact in V ision T ransformers and lev erage this structure to deri ve efficient approximation schemes. More- ov er, in these settings, sinks have been explicitly regularized in the context of harmful fine-tuning ( Liu et al. , 2026 ). Sinks ha ve also been studied in alignment and security contexts where Shang et al. ( 2025 ) leverage sink behavior as a pathway for backdooring unlearning procedures. Finally , circuit-le vel interventions ha ve also been explored in regimes where sink-related circuitry correlates 18 with repeated-token failures ( Y ona et al. , 2025 ). Our necessity results of fer a principled lens for ev al- uating such interventions: for trigger-conditional circuits, the sink is the mechanism enabling the computation, so strategies that operate within soft- max (penalizing BOS attention, spreading mass, post-hoc reweighting) risk degrading the circuit without addressing the root cause. The contrast with ReLU attention (theorem 3 and section 5 ) sug- gests that relaxing the normalization constraint is the more fundamental direction. Usefulness of sinks. Other work treats sinks as a useful computational primiti ve rather than an ar- tifact to eliminate. Our work formalizes this intu- ition: for trigger-conditional beha viors—where a model must aggregate context on a trigger while outputting zero else where—the sink is not merely a con venient implementation choice but a pr ovably necessary consequence of softmax normalization (theorems 1 and 2 ). Zhang et al. ( 2025 ) link sink tokens to representation outliers and ar gue that sim- ple structural conditions (e.g., low-rank attention structure) can be suf fi cient to induce sinks that sup- port concrete computations such as a veraging and retrie val—a vie wpoint that is closely aligned with our trigger -conditional setting. Sinks ha ve been argued to induce or support attention-layer special- ization, including MoE-like ef fects within attention ( Fu et al. , 2026 ). Sandov al-Segura et al. ( 2025 ) use sink dominance to identify “dormant” heads and v alidate their redundancy via head ablations. In addition, BOS-sink heads ha ve been treated as a locus of redundancy that can be targeted for model simplification via sink-aware pruning ( Sok et al. , 2026 ). In large vision-language models ( Luo et al. , 2025 ) sho w that high-norm V iT sink tok ens encode high-le vel semantic concepts and serve as impor- tant visual information pathways into the LLM, and propose methods to better le verage them. Related ideas appear in diffusion LMs as well, where in- troducing an explicit sink token is used to stabilize sink behavior across steps ( Zhang et al. , 2026 ) and where sink locations can be transient across de- noising steps, moti vating sink-a ware pruning that targets unstable sinks ( Myrzakhan et al. , 2026 ). 19 Figure 7: Softmax attention: 4-layer 4-head model. Representativ e attention patterns on a single test input showing strong sink at least in one head across all layers. 20 Figure 8: ReLU attention: 4-layer 4-head model. Representati ve attention patterns on a single test input sho wing absence of sink behavior across all layers. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment