AOI: Turning Failed Trajectories into Training Signals for Autonomous Cloud Diagnosis
Large language model (LLM) agents offer a promising data-driven approach to automating Site Reliability Engineering (SRE), yet their enterprise deployment is constrained by three challenges: restricted access to proprietary data, unsafe action execut…
Authors: Pei Yang, Wanyi Chen, Asuka Yuxi Zheng
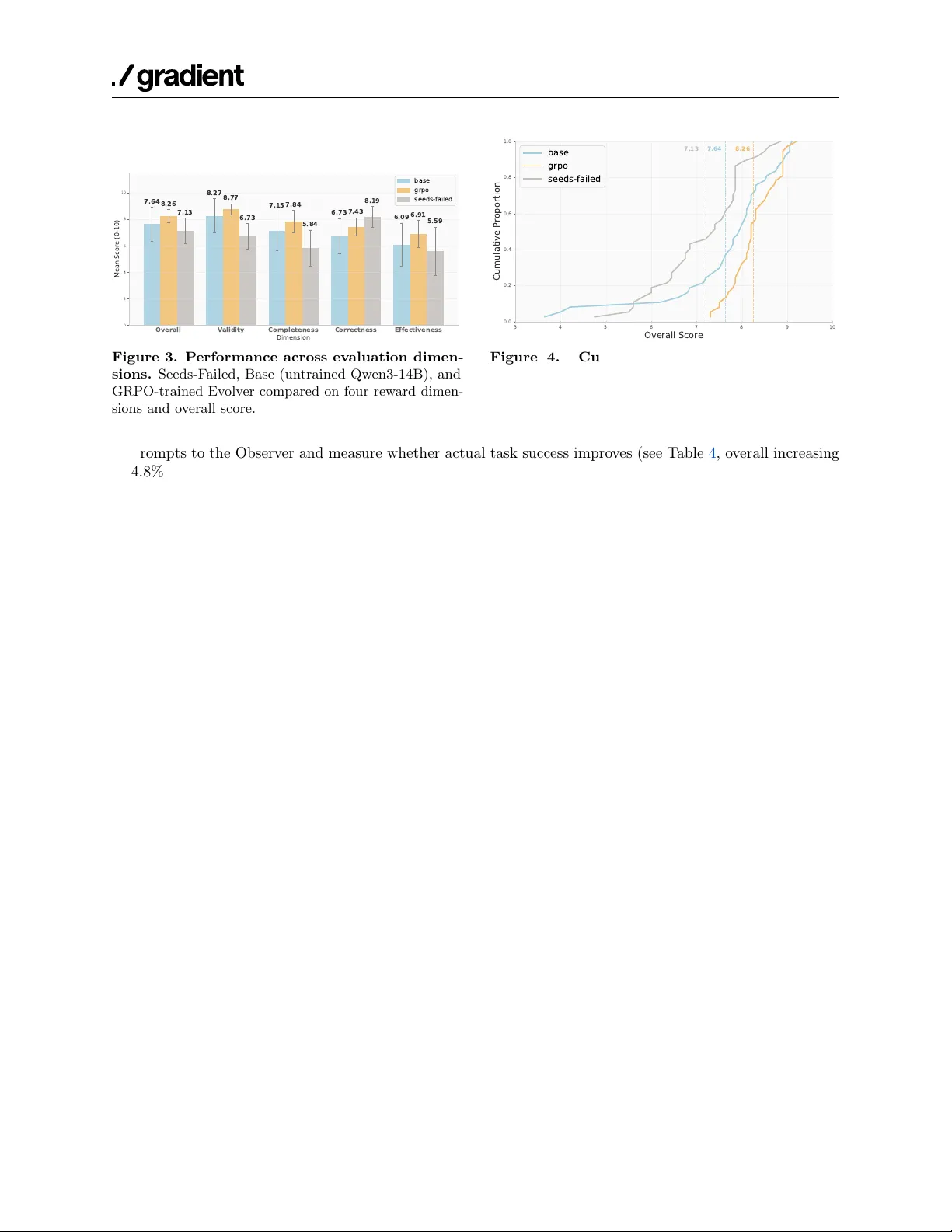
A OI A OI: T urning F ailed T ra jectories in to T raining Signals for Autonomous Cloud Diagnosis Pei Y ang 1* W anyi Chen 2* Asuka Y uxi Zheng 3* Xueqian Li 4 Xiang Li 5 Haoqin T u 3 Jie Xiao 1 Y ifan Pang 6 Dongdong Zhang 7 Fuqiang Li 8 Alfred Long 1 L ynn Ai 1 Eric Y ang 1 Bill Shi 1 † 1 Gradient 2 Soochow Univ ersity 3 UC Santa Cruz 4 Georgia Institute of T echnology 5 Univ ersity College London 6 Cookiy .ai 7 W eJo y 8 ByteDance * Equal contribution † Corresponding author Large language mo del (LLM) agen ts offer a promising data-driv en approac h to automating Site Reliabilit y Engineering (SRE), yet their en terprise deploymen t is fundamentally constrained b y three c hallenges: restricted access to proprietary operational data, unsafe action execution under permission- go v erned environmen ts, and the inability of closed systems to impro v e from failure tra jectories. W e presen t AOI (Autonomous Op erations Intelligence), a trainable multi-agen t framew ork that form ulates automated operations as a structured tra jectory learning problem under securit y constraints. Our approac h in tegrates three k ey comp onen ts. First, we introduce a trainable diagnostic system that applies Group Relativ e Policy Optimization (GRPO) to distill exp ert-level operational knowledge in to locally deploy ed op en-source mo dels, enabling preference-based learning without exposing sensitive data. Second, we design a read–write separated execution architecture that decomposes op erational tra jectories into observ ation, reasoning, and action phases, allowing safe learning o ver diagnostic traces while prev enting unauthorized state mutation. Third, we prop ose a F ailure T ra jectory Closed-Lo op Ev olver that mines unsuccessful diagnostic tra jectories and conv erts them into corrective supervision signals, enabling contin ual data augmentation and distributional refinemen t within a closed environmen t. Ev aluated on the AIOpsLab b enchmark, our contributions yield cum ulative gains across three ev aluation dimensions. (1) The AOI runtime alone—without any task-sp ecific training—achiev es 66.3% best@5 success on all 86 tasks, outp erforming the prior state-of-the-art (41.9%) by 24.4 p ercen tage points . (2) Adding Observ er GRPO training, a lo cally deploy ed 14B mo del reaches 42.9% a vg@1 on 63 held-out tasks with unseen fault types, surpassing Claude Sonnet 4.5 (41.3%) without multi-run sampling. (3) The Ev olver further conv erts 37 previously failed tra jectories in to diagnostic guidance, improving end-to-end a vg@5 by 4.8 p ercentage p oin ts while reducing run-to-run v ariance b y 35% . Date: Mar 16, 2026 Corresp ondence: t ianyu@gradien t.netw ork Pro ject Page: https://github.com/OpenEdgeHQ/aoi 1 In tro duction Site Reliabilit y Engineering (SRE) has b ecome the backbone of mo dern digital infrastructure, ensuring the stabilit y that users rely on. As these systems grow in complexity , the drive for efficiency naturally accelerates, pushing teams to ward automation to minimize do wntime Beyer et al. [ 2016 ]. Large Language Model (LLM) agen ts offer a promising path tow ard automation, as recen t work demonstrates that LLMs can use tools Sc hic k et al. [ 2023 ], W eng [ 2023 ], execute multi-step plans via chain-of-though t reasoning W ei et al. [ 2022 ], Y ao et al. [ 2023 ], and interact with complex system environmen ts Chen et al. [ 2025a , b ]. Ho wev er, in enterprise deplo ymen ts, the securit y of the agent b ecomes the defining factor for its adoption, which includes data 1 A OI Reward Model Command System Response SRE Troubleshooting Workflow Judge Failed Workflow Successed Workflow Evolver Recover Purifier Training data Complete command sequence The following is a **reference investigation flow** from similar cases. This is provided as guidance only - the commands and sequence may not be entirely correct for this specific case. ... Core of AOI GRPO Observer Probe Executor Mult i - Agent Runti me Close d - Loop Evolution Pi peline Figure 1. A OI System Overview. Left: Close d-L o op Evolution Pip eline —a Judge classifies SRE troublesho oting w orkflo ws by outcome. F ailed w orkflo ws are repaired b y the Evolv er into corrected command sequences that serve as diagnostic guidance at inference time. Successful workflo ws are distilled by the Purifier in to optimal diagnostic paths that serve as training data. Righ t: Multi-A gent R untime —the Observ er co ordinates read-only diagnosis (Prob e) and write-gated remediation (Executor). The Observ er is trained via GRPO, and at inference time receives the Evolv er’s corrected plans as structured prompts. priv acy , p ermission b oundaries, and execution safety . Based on these tw o, we phrase them as c hallenges that hold bac k autonomous SRE agents in real-world enterprise operating systems. Deplo ying agen ts in enterprise environmen ts presents a dual challenge of security and adaptability . (1) Strictly go v erned op erational proto cols demand a clear separation b etw een diagnostic (or “read”) and remediation (or “write”) privileges of the system, yet standard automation often conflates these right s, proposing the need of a system that enforces granular execution p ermissions only when strictly necessary . (2) Comp ounding this complexit y , data priv acy sp ecifically in the SRE environmen t mandates force reliance on smaller, lo cally deplo y ed models ( < 100B) 1 that lac k exp ert reasoning; these constrained systems remain fragile and static, failing to tak e adv an tage of v aluable learning signals from diagnostic failures to adapt to ev olving cloud en vironmen ts. T o meet with these requiremen ts, w e prop ose AOI (Autonomous Op erations Intelligence), designed to address b oth c hallenges through tw o integrated mechanisms. (1) T o address the first challenge that current systems mix the “read” from “write” permissions in the autonomous setup, instead of deploying simple prompt engineering on a single LLM, we in tro duce a multi-agen t system W u et al. [ 2023 ], Hong et al. [ 2023 ]comprising three parts: Observ er, Probe, and Executor that strictly separates the “read” and “write” actions. In detail, high-risk “write” commands are tec hnically isolated and can only b e triggered after sufficient evidence is gathered and v erified, aligning the agent’s b ehavior with the principle of least privilege Saltzer and Schroeder [ 1975 ]. (2) Building up on this agen t arc hitecture, we prop ose a trainable and evolving system designed to elev ate the performance of our AOI b eyond the limitations of static deploymen ts. Sp ecifically , we emplo y Group Relativ e Policy Optimization (GRPO) Shao et al. [ 2024 ] to fine-tune the Observer component (i.e., a 14B op en-weigh t LLM), distilling exp ert-level diagnostic capabilities Hin ton et al. [ 2015 ] that bridge the gap b et w een small-scale mo dels and proprietary alternatives. T o facilitate contin uous learning during mo del inference, w e introduce an Evolv er dedicated to F ailure T ra jectory collection, whic h allo ws the Observer to systematically learn from its own op erational experiences. This internal feedback mechanism serves to recycle failed diagnostic tra jectories into high-quality corrective training signals, fostering a self-sustaining cycle where the agent contin uously evolv es. By doing so, the system progressively impro ves its diagnostic precision through real-world interactions while maintaining the strict data isolation required by real en vironmen ts. By lev eraging our agentic architecture and training pip eline, the 14B model approaches Claude Sonnet 4.5 on the AIOpsLab benchmark. This result v alidates the effectiv eness of our AOI in enabling small, lo cally deplo y able mo dels to close the gap with fron tier models. Extensiv e empirical ev aluations on the AIOpsLab b enchmark substantiate the efficacy of our design. First, the A OI run time alone—without any task-specific training—achiev es +24.4% higher success rate in the b est@5 1 A 100B-parameter model under FP16 requires ∼ 200 GB for weigh ts alone; adding KV cache for 14K-tok en con text ( ∼ 10 GB) and system ov erhead brings the total to ∼ 215 GB, far exceeding the deploymen t cost budget of most en terprises. 2 A OI setting compared with the prior state-of-the-art (41.9% vs. 66.3%), demonstrating that read-write separation yields immediate architectural gains. Second, Observer GRPO training on only 23 tasks generalizes to 63 held-out tasks spanning unseen fault t yp es, lifting avg@1 from 33.7% to 42.9% —surpassing Claude Sonnet 4.5 (41.3%) without multi-run sampling. Third, the Evolv er con verts all 37 previously failed tra jectories (43% of the benchmark) in to structural diagnostic prompts, improving end-to-end avg@5 b y 4.8% while reducing run-to-run v ariance b y 35% . These results confirm that enforcing strict security cons train ts and closing the data loop not only ensures safety but also drives robust, repro ducible op erational capability . 2 Related W ork LLM Agents for AIOps. The application of LLMs to cloud op erations spans log analysis Guo et al. [ 2021 ], anomaly detection Zhang et al. [ 2024 ], root cause analysis W ang and Qi [ 2024 ], Chen et al. [ 2024 ], and in teractiv e diagnosis. STRA TUS Chen et al. [ 2025b ] employs m ulti-agent collab oration but tightly couples reasoning with execution, causing safet y issues and brittle long-horizon b ehavior. Concurren t work explores retriev al-augmen ted diagnosis Lewis et al. [ 2020 ] and c hain-of-thought prompting W ei et al. [ 2022 ] for R CA. A OI differs b y ar chite ctur al ly enfor cing safety through role separation rather than relying on prompt-based guardrails. Safe Agen tic Systems. Safety mec hanisms for LLM agents include action filtering Schic k et al. [ 2023 ], W eng [ 2023 ], sandb oxed execution environmen ts Jimenez et al. [ 2024 ], Y ao et al. [ 2023 ], and reinforcemen t learning from h uman feedback Ouyang et al. [ 2022 ]. These approaches treat safety as an add-on constraint. W e instead design safety into the system architecture: the Observ er c annot directly execute commands; the Probe c annot m utate state; the Executor op erates under strict whitelists. This separation-of-concerns approac h is inspired by classic operating system security principles Saltzer and Schroeder [ 1975 ]. Learning from F ailures. F ailure analysis h as long b een central to softw are engineering Gupta et al. [ 2017 ]. Recen t w ork uses failed test cases to guide program repair V asic et al. [ 2019 ], while Reflexion Shinn et al. [ 2023 ] enables LLM agents to learn from v erbal feedbac k on failed attempts. In reinforcement learning, hindsigh t experience replay Andrycho wicz et al. [ 2017 ] relab els failed tra jectories with achiev ed goals. Our approac h differs: w e use failed diagnostic c ommand se quenc es as input to a corrective mo del that generates impro v ed plans. GRPO Shao et al. [ 2024 ] provides critic-free optimization suitable for tasks with multiple v alid corrections, following the broader trend of RL-based LLM alignment Ouyang et al. [ 2022 ], Sc hulman et al. [ 2017 ], Rafailo v et al. [ 2023 ], DeepSeek-AI [ 2025 ]. 3 A OI Run time Architecture The AOI run time agent system embo dies three design principles: (1) Safet y through Separation —read-only diagnosis decoupled from state mutation, following the principle of least privilege Saltzer and Sc hro eder [ 1975 ]; (2) Con text Efficiency —verbose outputs compressed while preserving critical evidence, addressing the w ell-known con text degradation in long inputs Liu et al. [ 2024 ]; (3) Long-Horizon Coherence —dual- timescale memory Pac ker et al. [ 2023 ]maintains hypotheses across iterations. Figure 2 illustrates the runtime arc hitecture. 3.1 Agen t Comp onen ts and Permissions A OI emplo ys four sp ecialized agents in a structured multi-agen t architecture Du et al. [ 2024 ] (T able 1 ): 3 A OI Probe Executo r Observe r Compressor {"problem_type": "Authentication Issue | Configuration Error | Resource Issue |...", " root_cause": { "component": "actual - component - with - problem", "issue": "Specific description of the issue", "evidence": [...], " why_is_root_cause": “..."}, "symptoms": [{...}], " causality_chain": {...}, "resources": {...} " fix_strategy": {...}} Quick query Server system response command command Memory Read - only commands State - changing commands Core o f AOI Instructio n Figure 2. AOI Run time Agen t Architecture. The Observ er co ordinates diagnosis through the Prob e (read-only) and Executor (write-gated) agen ts. The Compressor maintains con text efficiency via dual-timescale memory . T able 1. Agent roles and permissions in A OI. Right columns show the access con trol matrix ov er three memory stores (R = read, W = write, - = no access): M raw stores raw en vironment outputs (e.g., full kubectl responses); M task main tains the diagnostic task queue and hypothesis state; M comp holds compressed context pro duced by the Compressor, serving as the Observ er’s sole information source. Agen t Resp onsibilit y P ermission M raw M task M comp Observ er ( O ) Planning, h yp othesis trac king Read compressed - R/W R Prob e ( P ) Diagnostic exploration Read-only exec W R - Executor ( X ) Remediation actions W rite (gated) W R - Compressor ( C ) Con text distillation Read ra w, write comp. R - W Observ er ( O ) serv es as the central coordinator. It maintains a diagnostic task queue, analyzes compressed evidence to up date hypotheses, and dispatc hes either Prob e or Executor based on current diagnostic state. Critically , the Observer never dir e ctly inter acts with the envir onment —it only reasons ab out what to do next. Prob e ( P ) handles all read-only op erations: kubectl get , describe , logs , and similar commands. It supp orts m ulti-round exploration within a single iteration (up to K max rounds) and maintains a baseline con text cac he to a v oid redundan t queries. Prob e implements retry mechanisms for transien t failures (netw ork timeouts, API rate limits). Executor ( X ) manages state-altering actions. Before executing, it can in vok e a single-round Prob e for v erification (“lo ok b efore you leap”). All commands pass through a whitelist filter. Executor implements t w o-stage error reco v ery: first analyze the failure, then generate a corrected command. All actions are logged for audit. Compressor ( C ) bridges ra w outputs and decision-making. It applies rule-based deduplication (collapsing rep eated log lines) follo wed by LLM-based seman tic compression. Since transformer-based mo dels V asw ani et al. [ 2017 ] suffer from degraded attention to middle-context information Liu et al. [ 2024 ], the Compressor uses a sliding window strategy for outputs exceeding context limits and enforces strict token budgets per iteration. Safet y emerges from strict access con trol betw een agents and memory stores: Key in v ariants: (1) Observer cannot read raw outputs—it only sees what Compressor pro duces, preven ting information ov erload and ensuring consisten t inputs; (2) Probe and Executor write to raw store but cannot read it—all information flo ws through Compressor; (3) Compressor is stateless, pro cessing each iteration independently to a void error accum ulation. 3.2 Run time Pip eline 4 A OI 3.2.1 Execution Pip eline Eac h iteration follo ws a four-stage pip eline: 1. Decision : Observer analyzes ( H n − 2 , C n − 1 ) , produces action type a n ∈ { Prob e , Execute , Submit } and instruction I n . 2. In teraction : Platform routes to appropriate agen t; agent executes commands in environmen t E and writes ra w outputs to M raw . 3. Compression : Compressor pro cesses ra w outputs into C n within tok en budget. 4. Cac hing : Platform stores C n for next iteration; Observ er pro duces summary S n − 1 app ended to H . This pipeline ensures “raw evidence → compression → decision input,” enforcing budgets at each stage. 3.2.2 Dual-Timescale Memory Long-horizon diagnosis requires main taining coherence across iterations while resp ecting context limits. W e ac hiev e this through dual-timescale memory: Long-term memory stores semantic summaries of all past iterations: H n − 2 = { S 1 , S 2 , . . . , S n − 2 } . Each summary S i captures the k ey findings and hypothesis up dates from iteration i . Short-term memory contains the full compressed con text from the previous iteration: C n − 1 = Compress ( Ra wOutputs n − 1 ) . A t iteration n , the Observ er receives ( H n − 2 , C n − 1 ) —historical con text for contin uity plus recent details for informed decisions. This design bounds memory growth while preserving reasoning coherence. 3.3 Observ er Step-Lev el P olicy Optimization A OI applies GRPO at t w o distinct granularities to train t wo differen t comp onents. W e briefly contrast them b efore detailing the Observ er’s formulation: • Observ er GRPO (this section) optimizes step-level de cisions : at each diagnostic iteration, the Observer m ust choose what action to take next and generate the corresp onding context. The rew ard ev aluates whether a single decision effectively adv ances diagnosis given the current evidence. • Ev olver GRPO (Section 4 ) optimizes tr aje ctory-level gener ation : given a complete seed tra jectory , the Ev olv er produces an improv ed command sequence co v ering the entire diagnostic workflo w. The rew ard ev aluates the qualit y of the complete output tra jectory . Both share the same GRPO algorithmic framew ork—sampling G candidates p er input and computing group-normalized adv an tages—but differ in three k ey asp ects: (1) optimization gran ularity (single decision vs. complete tra jectory); (2) reward design (six-dimensional step quality vs. four-dimensional tra jectory qualit y); and (3) training ob jective (learning diagnostic reasoning patterns vs. learning to augmen t and repair command sequences). W e detail the Observer formulation b elow; the Ev olv er form ulation follows in Section 4 . 5 A OI 3.3.1 GRPO F ormulation F or diagnostic tasks, m ultiple actions can b e correct at eac h step—chec king p o d logs vs. describing deploymen ts ma y both yield useful information. Unlike standard PPO Sch ulman et al. [ 2017 ] which requires a learned v alue function, or DPO Rafailov et al. [ 2023 ] whic h requires pairwise preference data, we optimize the Observer with GRPO Shao et al. [ 2024 ] using within-group comparisons rather than absolute rew ards. The training data is deriv ed from successful tra jectories that are first pro cessed by a Purifier agen t (Figure 1 ), whic h strips redundan t commands (retries, dead-end explorations) and retains only the minimal command sequence leading to correct diagnosis. F or each observ ation context x (comprising compressed evidence and task state), we sample a group of G candidate actions { y i } G i =1 from the Observer policy . Eac h candidate is scored b y an LLM judge R ( x, y i ) ∈ [0 , 1] . W e compute group-normalized adv antages: A i = R ( x, y i ) − µ G σ G + ϵ , µ G = 1 G G X j =1 R ( x, y j ) (1) The policy gradient update maximizes exp ected adv antage: ∇ θ J = E x, { y i } " G X i =1 A i ∇ θ log π θ ( y i | x ) # (2) The complete training procedure is detailed in Algorithm 2 (Appendix A.2 ). 3.3.2 Multi-Dimensional Reward F unction Unlik e the Ev olver, which ev aluates complete corrected tra jectories, the Observ er rew ard op erates at the step level : at each iteration n , an LLM judge Zheng et al. [ 2023 ] scores the Observer’s decision output across six dimensions. The total rew ard is a weigh ted sum of normalized dimension scores: R ( x, y ) = X d ∈D w d · s d 10 , X d ∈D w d = 1 (3) where s d ∈ [0 , 10] is the raw score for dimension d and w d is its weigh t. The six dimensions and their default w eigh ts are: • F ormat ( w = 0 . 10 , rule-based): Whether the output is v alid JSON. Single clean output scores 10; m ulti- ple/rep eated JSON blocks score 5; parse failure scores 0 and triggers a hard penalty ( R =0 . 09 ). • Summary ( w = 0 . 15 , LLM): Accuracy of the previous-iteration summary—do es it cite sp ecific error messages, component names, and status rather than v ague sp eculation? • A ction ( w = 0 . 10 , LLM): Correctness of the next action type (Prob e / Executor / Submit) against the ground-truth action. • Con text Instruction ( w = 0 . 30 , LLM): Quality of the diagnostic reasoning in prob e or executor context— do es it logically follo w from execution history and effectiv e ly adv ance diagnosis? • Con text Namespace ( w = 0 . 30 , LLM): A ccuracy of targeted resources (namespaces, p o ds, services)—are they the righ t direction for solving the problem at this stage? 6 A OI • Confidence ( w = 0 . 05 , LLM): Calibration of the self-rep orted confidence score relative to the iteration stage (e.g., high confidence at iteration 1 is p enalized). Con text Instruction and Con text Namespace together accoun t for 60% of the total w eigh t, reflecting our emphasis on diagnostic r e asoning quality and tar get ac cur acy —the t w o factors that most directly determine information gain per step. 4 T ra jectory Ev olv er While Observer training improv es ste p-lev el decision-making, a trainable multi-agen t system faces a fun- damen tal data scarcity parado x: (1) tasks the system already solves yield tra jectories of limited training v alue—the mo del gains little from rehearsing what it can already do; (2) tasks the system fails on represent the most v aluable improv emen t targets, yet failed tra jectories cannot serve directly as p ositive examples; (3) high-qualit y external data (e.g., expert SRE runbo oks Beyer et al. [ 2016 ]) is scarce and exp ensive to obtain. The T ra jectory Evolv er resolves this paradox through t wo mec hanisms: augmenting successful tra jectories in to div erse diagnostic workflo w v ariants, and r ep airing failed tra jectories into corrected plans that pro vide directional guidance for future attempts. 4.1 Problem F orm ulation Giv en any seed tra jectory τ = ( c 1 , r 1 , . . . , c T , r T ) , the Ev olv er learns a policy π evolv e that generates an impro v ed command sequence: τ ∗ = π evolv e ( · | τ , problem ) (4) F or failed seeds ( τ − ), this constitutes r ep air : the Evolv er corrects diagnostic errors while preserving v alid reasoning steps. F ailed tra jectories provide contrastiv e sup ervision—we kno w what do es not work, and often the failures are “near-misses” that correctly identify the fault y component but apply incorrect remediation. F or success seeds ( τ + ), this constitutes augmentation : the Evolv er generates alternativ e diagnostic workflo ws that ac hiev e the same goal through different command sequences, expanding training diversit y from limited exp ert data. 4.2 Seeds: Definition and Data Source In the Ev olv er’s context, a seed is a complete fault diagnosis command-sequence tra jectory τ = ( c 1 , r 1 , . . . , c T , r T ) , spanning from initial exploration to final submission. Seeds are categorized by outcome: • Success seeds : T ra jectories that correctly resolved the incident, con taining a v alidated diagnostic path. • F ailed seeds : T ra jectories that did not resolve the incident, but still conta in partial diagnostic v alue (e.g., correct fault localization with incorrect remediation). The Ev olver treats t wo seed types differently: • Augmen tation (success → div erse v arian ts): F rom a single successful tra jectory , the Evolv er generates m ultiple command-sequence v ariants that preserv e the core diagnostic logic while v arying command c hoices, 7 A OI exploration order, and supplemen tary steps. This multiplies limited exp ert data into div erse training corpus. • Repair (failed → corrected plans): Given full con text (problem description + failed tra jectory + reference success from similar fault types), the Evolv er generates a corrected diagnostic plan. These outputs are not guaran teed to solve the problem directly , but pro vide the correct diagnostic r e asoning flow —the right in v estigation direction, command structure, and remediation strategy—that guides the multi-agen t system to w ard success on retry . In production SRE environmen ts, historical incident records from h uman op erators are a natural seed source— they represen t v alidated diagnostic workflo ws accumulated ov er op erational history . In our experiments, w e use Claude Sonnet 4.5 tra jectories on AIOpsLab as a proxy for suc h exp ert records. This choice is delib erate: seeds represen t exp ert-level diagnostic know le dge , not the multi-agen t system’s own outputs. The Evolv er’s design is agnostic to seed prov enance—seeds from human SRE run b o oks, frontier mo dels, or the system’s own historical successes are interc hangeable without any architectural change. W e use Sonnet 4.5 solely b ecause it pro vides sufficien t high-quality seeds on the b enchmark. F or GRPO training, we use only success seeds to ensure training data correctness; for inference, b oth seed types serve as input (details in Section 5 ). 4.3 GRPO-Optimized T ra jectory Correction W e optimize the Ev olver using Group Relative Policy Optimization (GRPO), which is well-suited for tasks where m ultiple corrected plans may b e v alid. F or each failed tra jectory τ − , sample G candidate corrections { τ + i } G i =1 . Score each correction using a rew ard mo del that ev aluates: • V alidity : Is the corrected plan executable? • Completeness : Do es it cov er necessary diagnostic steps? • Correctness : Are the commands syn tactically and seman tically correct? • Effectiveness : W ould this plan lead to successful diagnosis? Compute group-normalized adv an tages: A i = R ( τ − , τ + i ) − µ G σ G + ϵ , µ G = 1 G X j R ( τ − , τ + j ) (5) GRPO’s critic-free design Shao et al. [ 2024 ], DeepSeek-AI [ 2025 ] av oids ov erfitting to a single “correct” diagnostic path, preserving div ersity in v alid approaches. 4.4 In tegration with A OI system Figure 5 (Appendix) illustrates the Evolv er’s integration with the AOI runtime. The corrected command list from the Evolv er is provided to the Observer as a structured prompt: [Corrected Diagnostic Plan] 8 A OI Based on analysis of the failed attempt, the following commands should be executed: 1. kubectl get pods -n {namespace} 2. kubectl describe pod {pod-name} ... This in tegration allows the Observer to b enefit from learned corrections while retaining flexibilit y to adapt based on actual system resp onses. The Ev olv er provides guidanc e , not rigid constraints. 5 Exp erimen ts 5.1 Exp erimen tal Setup W e ev aluate on AIOpsLab Chen et al. [ 2025a ], containing 86 incident scenarios across three microservice applications on live Kubernetes Burns et al. [ 2016 ] clusters. T asks span four categories: Detection (32), Lo calization (28), RCA (13), and Mitigation (13). W e compare against: (1) AOL-agen t Chen et al. [ 2025a ], the b enc hmark’s reference ReA ct-st yle Y ao et al. [ 2023 ] agen t; (2) STRA TUS Chen et al. [ 2025b ], a multi-agen t system with sp ecialized detection/diagnosis/mitigation modules; and (3) Claude Sonnet 4.5 An thropic [ 2025 ] with AOL-agen t, whose tra jectories serve as seed data for our training pip eline. 5.1.1 Data Split W e adopt a nested partition structure illustrated in Figure 6 (App endix). All three sets share the same execution en vironment, ensuring consistency across training and ev aluation. • D all : the full b enchmark. Run time comparison is ev aluated ov er all 86 tasks using the base mo del without any task-sp e cific tr aining , ensuring a fair arc hitectural comparison against STRA TUS. The training subsets b elo w are dra wn from D all . • D train ev olv er : 49 tasks successfully solved b y Claude Sonnet 4.5, serving as success seeds for Ev olver GRPO training. • D train obs : a strict subset of D train ev olv er co v ering 11 fault t yp es and 23 entries, used for Observer GRPO training. • D test obs : 63 held-out ev aluation examples for the Observer, cov ering 15 unseen fault t yp es plus tasks from training fault t yp es where Sonnet failed. • D test ev olv er : 37 failed tra jectories from Claude Sonnet 4.5, a subset of D test obs , used to ev aluate the Ev olver’s repair capabilit y . In the com bined pip eline, the Observ er receives diagnostic guidance generated by the Evolv er. T o ev aluate this end-to-end effect without data leak age, every test c ase must b e unse en by b oth c omp onents . By making the Observer’s training set a strict subset of the Evolv er’s, w e guaran tee that D test ev olv er ⊂ D test obs —all 37 Evolv er test cases fall within the Observer’s 63 held-out tasks. This nested design enables fair ev aluation of each comp onen t independently and in combination. Strict fault-t yp e split for D train obs . W e adopt the most stringent split strategy: training and test fault types ha v e zero o verlap . The 86 tasks span 26 distinct fault types; we assign 11 types (38 total tasks, of whic h 23 9 A OI T able 2. AOI runtime comparison on full b enchmark (86 tasks, %). GPT-4o-mini OpenAI [ 2023 ], Claude Sonnet 4.5 uses single-run; Qwen3-14B uses 5-round sampling (best@5/avg@5). Mo del Metho d Detection Localization R CA Mitigation Ov erall GPT-4o-mini A OL-agen t 25.0 9.5 7.7 7.7 14.7 GPT-4o-mini STRA TUS 78.1 25.0 15.4 23.1 43.0 GPT-4o-mini A OI 90.6 32.1 38.5 53.8 58.1 Claude Sonnet 4.5 A OL-agen t 68.8 53.6 15.4 76.9 57.0 Qw en3-14B (b est@5/avg@5) STRA TUS 75.0/41.3 32.1/11.4 7.7/4.6 15.4/15.4 41.9/22.1 Qw en3-14B (b est@5/avg@5) A OI 100/66.9 53.6/27.9 30.8/7.7 46.2/23.1 66.3/38.6 ha v e successful Sonnet tra jectories) to training and reserv e the remaining 15 types exclusiv ely for testing. This ensures that the Observ er is ev aluated on gen uinely no v el fault categories, not merely unseen instances of familiar faults. The complete fault-t yp e partition is provided in App endix B.3 . 5.1.2 Metrics. W e rep ort success using tw o standard m ulti-run aggregation metrics: best@ k , where a task is counted as solv ed if an y of k indep endent runs succeeds; and avg@ k , the mean success rate across k runs. 5.1.3 Implemen tation. Our method is built on Qw en3-14B Y ang et al. [ 2025 ] as the base mo del. W e apply LoRA Hu et al. [ 2022 ] fine-tuning with rank 64, α =128, and learning rate 10 − 5 ; GRPO Shao et al. [ 2024 ] is configured with group size G =4. All experiments run on 2 × A100 GPUs with vLLM Kw on et al. [ 2023 ] for inference. 5.2 A OI Run time vs Baseline W e compare AOI against STRA TUS on D all (86 tasks) with identical base mo dels. No task-sp ecific training. Arc hitecture yields 4 × impro vemen t ov er v anilla agents. AOI with GPT-4o-mini achiev es 58.1% o v erall compared to A OL-agen t’s 14.7%. The gains stem from read-write separation: the Observer can safely explore diagnostic paths without risking state mutations, while the Executor applies changes only after sufficien t evidence accum ulates. T ask complexit y reveals arc hitectural b ottlenec ks. Detection b enefits most from safe exploration (100% b est@5 vs STRA TUS’s 75%), as agents can issue m ultiple diagnostic commands without p enalty . RCA sho ws the largest relative gains (+150% ov er STRA TUS), indicating that A OI’s dual-timescale memory helps main tain reasoning coherence across long diagnostic chains. Mitigation impro v es 3 × o v er STRA TUS b ecause Executor-lev el safet y gates preven t the cascading failures that o ccur when agents attempt remediation b efore completing diagnosis. F rontier mo dels excel at pattern-matching, not reasoning. Claude Sonnet 4.5 achiev es 76.9% on Mitigation—the highest single-category result—but only 15.4% on R CA, matc hing GPT-4o-mini + STRA TUS. This asymmetry rev eals that Sonnet’s strength lies in recognizing remediation patterns (restart p o ds, scale replicas, rollbac k deploymen ts) rather than multi-step causal reasoning. Mitigation tasks ha v e well-defined action templates once the fault is iden tified; RCA requires syn thesizing signals across logs, metrics, and 10 A OI T able 3. Observer GRPO on held-out fault t yp es (63 tasks, %). Metho d Det. ↑ Lo c. ↑ R CA ↑ Mit. ↑ Ov erall ↑ (22) (22) (12) (7) (63) Sonnet 4.5 (AOL-agen t) 54.5 40.9 8.3 57.1 41.3 A OI (Untrained) 65.5 22.7 6.7 14.3 33.7 A OI (Observer-GRPO) 90.9 18.2 16.7 14.3 42.9 traces to establish causalit y . AOI’s structured diagnostic w orkflow addresses this gap: with Qw en3-14B, RCA doubles to 30.8% while Mitigation reaches 46.2%. Op en-w eigh t surpasses frontier with prop er architecture. Qw en3-14B + A OI (66.3% b est@5) outp erforms Claude Sonnet 4.5 + AOL-agen t (57.0%), solving 57 vs 49 tasks. The 14B mo del’s disadv an tage in raw capability is offset b y architectural supp ort for systematic exploration and safe execution. Diminishing returns analysis (Figure 7 , Appendix) shows b est@1 → 2 gains +19.8 points while best@3 → 5 adds only +8.2 com bined, suggesting 2-3 sampling rounds capture most b enefit. 5.3 Observ er GRPO Generalization W e ev aluate whether Observer GRPO training improv es generalization to unseen fault types. 5.3.1 Held-out F ault T yp es W e train Observer on D train obs (23 tasks) and ev aluate on 63 held-out tasks (unseen fault t yp es). GRPO learns task-completion strategies, not intermediate accuracy . Observer-GRPO achiev es 90.9% Detection (+36 p oints o ver Sonnet) but Lo calization drops from 22.7% to 18.2%. This trade-off is inheren t to GRPO’s rew ard structure: the mo del optimizes for end-task success, learning that Detection can succeed with coarse-grained anomaly signals while Lo calization requires precise comp onent iden tification. The trained Observer prioritizes high-confidence fault indicators o ver exhaustive exploration. App endix E pro vides comprehensiv e task-type analysis revealing that GRPO-trained mo dels use ∼ 9 more exploration steps—b eneficial for R CA but harmful for Lo calization where o ver-exploration causes m ulti-anomaly confusion. Single-run op en-source b eats frontier mo del. Observ er-GRPO (42.9% avg@1) surpasses Claude Sonnet 4.5 (41.3%) on identical held-out tasks without multi-run sampling. The improv ement concentrates in Detection (+36.4 p oints) and RCA (+8.4 points)—precisely the tasks requiring systematic diagnostic reasoning rather than pattern recognition. Mitigation remains unchanged at 14.3%: in A OI’s architecture, remediation commands are generated and executed by the Executor, so Observ er optimization cannot directly impro v e the qualit y of the final repair actions. Sonnet’s Mitigation adv an tage (57.1%) stems from its stronger base capabilit y in generating correct remediation commands. Generalization to unseen fault types v alidates transfer learning. The held-out set con tains 15 fault t yp es nev er seen during training. Observer-GRPO’s gains demonstrate that diagnostic patterns transfer across fault categories: the model learns how to diagnose (command sequencing, signal prioritization) rather than memorizing fault-specific solutions. Per-task analysis (Figure 10 , App endix) sho ws consisten t improv ement across fault t yp es rather than selective memorization. 11 A OI T able 4. Comp onent ablation on D test evolv er (37 tasks, best / avg %). First three rows use 5 runs; last row uses 4 runs. Metho d Det. Lo c. R CA Mit. Overall (10) (13) (11) (3) (37) Base 100/50.0 54 /26.2 27/7.3 0/0 54 /24.9 Ev olv er-prompts 90/64.0 54 /24.6 18/12.7 0/0 49/29.7 Observ er-GRPO 90/64.0 38/21.5 36 / 29.1 0/0 49/33.5 Observ er-GRPO + Evolv er-prompts 100 /72.5 31/19.2 36 /25.0 0/0 49/ 33.8 5.3.2 Com bined System on F ailed Cases W e ev aluate all component com binations on D test ev olv er (37 Sonnet-failed tasks, 5 indep endent runs p er task): Base (untrained Observ er), Evolv er-prompts (Base + Evolv er-generated diagnostic prompts), Observer- GRPO (trained Observer without Evolv er), and Observer-GRPO + Ev olver-prompts (trained Observ er with Ev olv er-generated prompts). Observ er-GRPO + Ev olver-prompts achiev es h ighest avg (33.8%, T able 4 ), a +8.9 point improv ement o v er Base. The combination is complemen tary: Observ er-GRPO improv es RCA (+21.8 points ov er Base), while Ev olver-prompts impro ves Detection consistency (avg: 50% → 72.5%). Comp onen ts target differen t failure modes. Observer-GRPO benefits tasks requiring deep exploration (R CA), while Ev olver-prompts benefits tasks requiring structured workflo ws (Detection). Lo calization shows minimal gains from either—these tasks require precise fault identification that neither exploration depth nor w orkflo w guidance addresses. Lo calization hits a structural ceiling. Best@5 Lo calization is identical across conditions, and a vg@5 barely c hanges. Lo calization requires pinp oin ting the exact faulty comp onent, which dep ends on real-time en vironmen t state that offline-generated plans cannot anticipate. The Evolv er improv es what to in vestigate but not wher e to look. Dual-timescale synergy . Observ er-GRPO + Ev olver-prompts com bines both comp onents addressing complemen tary failure mo des: Observer-GRPO impro ves diagnostic exe cution (fast timescale), while Evolv er- prompts impro ves diagnostic planning (slo w timescale). Their combination recov ers nearly a third of cases where Claude Sonnet 4.5 achiev ed 0%. Mitigation remains at 0%. Unlike Detection and R CA, where structural diagnostic patterns generalize across fault types, Mitigation requires fault-sp ecific remediation actions absent from the training distribution. 5.4 Repair Qualit y of Evolv er 5.4.1 Ev aluation Strategies W e ev aluate the Evolv er’s ability to repair previously failed cases. W e train on 49 successful tra jectories and test on 37 cases where Claude Sonnet originally failed.The complete command sequences pro duced b y the Ev olv er are “adapted” versions of the original tra jectories—the repaired command lists may differ from the original AIOpsLab problem context (e.g., adjusted command arguments, alternative exploration paths), making direct repla y in the en vironment infeasible. W e therefore adopt t w o complementary ev aluation strategies: 12 A OI Overall V alidity Completeness Correctness Effectiveness Dimension 0 2 4 6 8 10 Mean Scor e (0-10) 7.64 8.27 7.15 6.73 6.09 8.26 8.77 7.84 7.43 6.91 7.13 6.73 5.84 8.19 5.59 base grpo seeds-failed Figure 3. Performance across ev aluation dimen- sions. Seeds-F ailed, Base (un trained Qw en3-14B), and GRPO-trained Evolv er compared on four reward dimen- sions and ov erall score. 3 4 5 6 7 8 9 10 Overall Scor e 0.0 0.2 0.4 0.6 0.8 1.0 Cumulative P r oportion 7.64 8.26 7.13 base grpo seeds-failed Figure 4. Cumulativ e distribution of ov erall scores. Dashed lines indicate group means. 1. Ev olver-as-Prompt (end-to-end v alidation): W e feed the Evolv er’s corrected command sequences as prompts to the Observ er and measure whether actual task success improv es (see T able 4 , ov erall increasing 4.8% on a vg@5). 2. LLM judge scoring (generation quality ev aluation): W e use Claude Opus 4.5 to score the Ev olv er’s repaired outputs across four dimensions—V alidity , Completeness, Correctness, and Effectiveness—to assess repair qualit y improv ement. 5.4.2 Comparison Exp eriments Three groups of experiment are compared in Figure 3 and Figure 4 are: • Seeds-F ailed : The original command sequences from Sonnet 4.5’s 37 failed interactions with AIOpsLab. • Base : The untrained Qwen3-14B model repairing each of the 37 tasks, generating 2 repair candidates per task. • GRPO : The GRPO-trained Qw en3-14B Evolv er repairing eac h of the 37 tasks using the same Seeds-F ailed as prompt input, generating 2 repair candidates p er task. 5.4.3 Qualit y Ev aluation Results In Figure 3 , although Seeds-F ailed retains higher correctness due to pre-execution filtering, the Evolv er mo dels accept minor syntactic v ariations to achiev e diverse diagnostic paths, yielding net gains in Completeness and Effectiveness that out weigh the sligh t correctness decline. Crucially , improv ements in V alidity and Completeness indicate that GRPO facilitates structural rather than superficial correction, teac hing the Ev olv er to fill logical gaps in diagnostic reasoning instead of memorizing command strings . This stability is evidenced by the Cumulativ e Distribution F unction (CDF) in Figure 4 , where the elimination of the lo w er-bound tail and a v ariance reduction (std 0 . 97 → 0 . 49 ) confirm the acquisition of consistent strategies rather than sto c hastic impro vemen ts . By building up on the Base mo del’s non-trivial flo or to amplify repair consistency , GRPO pro v es superior to direct sup ervised fine-tuning in accommodating div erse v alid diagnostic paths . 13 A OI 5.4.4 End-to-End Robustness Analysis (T able 4 ) Ev olver-prompts improv es robustness, not p eak p erformance. The most rev ealing pattern in T able 4 lies in the gap b etw een best@5 and avg@5—a direct measure of run-to-run v ariance. F or Base, this gap is 29.2pp (54.1% − 24.9%); for Evolv er-prompts, it shrinks to 18.9pp (48.6% − 29.7%). While best@5 decreases sligh tly ( − 5.5pp), avg@5 impro ves meaningfully (+4.8pp). Evolv er-prompts’ structural prompts act as diagnostic sc affolding that constrains the Observ er’s search space, making successful diagnostic paths reliably repro ducible. Detection: v ariance halved. Without Ev olver prompts, the Observ er ac hiev es 100% b est@5 but only 50% a vg@5—a 50pp gap indicating that half of all runs fail despite the problem b eing solv able. With Ev olver prompts, best@5 drops to 90% but avg@5 jumps to 64%, compressing the gap to 26pp. Analysis b enefits disprop ortionately from structural guidance. Although Analysis b est@5 decreases (27.3% → 18.2%), a vg@5 nearly doubles (7.3% → 12.7%). This divergence is informative: Analysis tasks—ro ot cause iden tification requiring multi-step reasoning chains—are the most sensitiv e to diagnostic plan quality . Without prompts, the Observer occasionally stumbles up on correct causal chains (high b est@5) but cannot reliably repro duce them (lo w avg@5). The Evolv er’s prompts provide a reasoning scaffold that makes successful diagnosis r ep e atable rather than accidental, which is precisely the prop erty needed for pro duction deplo ymen t where consisten t reliability matters more than o ccasional brilliance. 6 Discussion F ailed tra jectories enco de reco verable signal. The conv entional wisdom treats failed diagnostic attempts as noise to b e filtered. Our exp eriments suggest otherwise: the GRPO-trained Ev olv er significan tly impro ves repair quality on previously failed cases (mean LLM judge score 7.18 → 8.27, std 0.97 → 0.49) by learning what was almost right . F ailed tra jectories often con tain correct diagnostic in tuitions paired with execution errors—wrong command flags, incorrect resource names, or missing in termediate steps. GRPO’s con trastiv e learning surfaces these near-miss patterns, enabling systematic correction rather than wholesale replacemen t. Diminishing returns in sampling div ersity . Our b est@ k analysis rev eals a surprising pattern: success rate improv es by 19.8 p oints from one to tw o runs, but only 8.2 p oints across the subsequent three runs com bined (Figure 7 ). This suggests that diagnostic sto chasticit y is b ounded—most tasks either succeed consisten tly , fail consisten tly , or exhibit binary v ariance that t w o attempts suffice to capture. F or practitioners, this implies that allo cating compute budget to 2-3 indep endent runs yields b etter cost-effectiveness than deep er single-run optimization. The sp eed-precision trade-off in learned diagnostics. Observer GRPO improv es Detection by 25.5 p oints while de gr ading Lo calization b y 4.5 p oints. T ask-lev el analysis rev eals the mec hanism: GRPO learns aggressiv e diagnostic shortcuts that terminate earlier with correct anomaly verdicts, but o ccasionally skip the detailed exploration steps required for precise fault lo calization. The tw o degraded tasks (p o d_failure_hotel_res, astronom y_shop_pro duct_catalog) b oth require m ulti-hop reasoning through service dep endencies—exactly the exploration that fast paths eliminate. This trade-off is not a bug but a feature of rew ard-driven optimization: the training signal emphasized detection accuracy , and the mo del resp onded accordingly . Safet y mec hanisms improv e capabilit y . Coun ter-in tuitiv ely , constraining the agen t’s action space enhanc es diagnostic success. Read-write separation forces evidence accumulation b efore m utation, preven ting the cascading failures we observed in STRA TUS where premature remediation attempts corrupted system state. This c hallenges the assumption that safety constraints reduce capability—for op erational tasks with 14 A OI irrev ersible actions in production environmen ts Burns et al. [ 2016 ], Beyer et al. [ 2016 ], guardrails enable more aggressiv e exploration within safe b oundaries. Capabilit y boundaries are task-specific. One-third of tasks (29/86) fail consistently across all configurations— fiv e Qw en rounds, GPT-4o-mini, and GRPO v ariants. These are not random failures but systematic capabilit y gaps: MongoDB authen tication recov ery requires Helm-sp ecific kno wledge absent from training, and multi- service localization demands causal reasoning b ey ond curren t architectures. Imp ortantly , these b oundaries are stable and predictable, enabling practitioners to iden tify whic h incident t yp es require human escalation. 7 Limitations Expanding the Evolv er. While the current Ev olver generates corrected command sequences as structured prompts for LLMs, its role could be extended to produce syn thetic system feedback via environmen t sim ulators or to serv e as a runtime agen t for dynamic plan refinement. Such arc hitectural expansions, while promising for further b o osting system autonomy , are b ey ond the scop e of this work and are left for future inv estigation. Bey ond AIOpsLab. Although AIOpsLab offers a realistic ev aluation of SRE scenarios, w e anticipate the emergence of broader communit y b enc hmarks co vering more diverse infrastructure stacks and larger-scale deplo ymen ts. On the applied side, we plan to deplo y A OI in pro duction SRE en vironments to v alidate the use and productization p otential of the framework within real-world inciden t resp onse workflo ws. 8 Conclusion W e presen ted A OI, a system for autonomous cloud inciden t response built on t wo innov ations: (1) an Observer- Prob e-Executor run time that enforces safety through architectural separation, and (2) a T ra jectory-Corrective Ev olv er that learns to correct failed diagnostic sequences via GRPO optimization. Our results demonstrate a k ey insigh t: faile d tr aje ctories ar e not waste d sup ervision . By learning to correct failures rather than discard them, we conv ert 37 failed cases into training signal that enables systematic capability acquisition. The Ev olv er improv es end-to-end a vg@5 b y 4.8% while reducing run-to-run v ariance by 35% (b est@5–avg@5 gap: 29.2pp → 18.9pp), and the GRPO-trained Evolv er achiev es higher repair quality (mean LLM judge score 7.18 → 8.27, std 0.97 → 0.49), indicating robust learning of correction patterns. 15 A OI References Betsy Bey er, Chris Jones, Jennifer Petoff, and Niall Richard Murphy , editors. Site R eliability Engine ering: How Go o gle R uns Pr o duction Systems . O’Reilly Media, 2016. URL https://sre.google/sre- book/ table- of- contents/ . Timo Sc hick, Jane Dwiv edi-Y u, Rob erto Dessì, Rob erta Railean u, Maria Lomeli, Eric Hambro, Luk e Zettlemo y er, Nicola Cancedda, and Thomas Scialom. T oolformer: Language mo dels can teac h themselv es to use to ols. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , v olume 36, 2023. URL https://arxiv.org/abs/2302.04761 . Lilian W eng. LLM pow ered autonomous agents. https://lilianweng.github.io/posts/ 2023- 06- 23- agent/ , 2023. Jason W ei, Xuezhi W ang, Dale Sch uurmans, Maarten Bosma, Brian Ich ter, F ei Xia, Ed Chi, Quo c V Le, and Denny Zhou. Chain-of-though t prompting elicits reasoning in large language mo dels. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , volume 35, pages 24824–24837, 2022. URL https: //arxiv.org/abs/2201.11903 . Sh un yu Y ao, Jeffrey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao. ReA ct: Syn- ergizing reasoning and acting in language mo dels. In International Confer enc e on L e arning R epr esentations (ICLR) , 2023. URL . Yinfang Chen, Manish Shett y , Gagan Somashek ar, Mingh ua Ma, Y ogesh Simmhan, Jonathan Mace, Chetan Bansal, Rujia W ang, and Sara v an Ra jmohan. AIOpsLab: A holistic framew ork to ev aluate AI agents for enabling autonomous clouds. arXiv pr eprint arXiv:2501.06706 , 2025a. URL 2501.06706 . Yinfang Chen, Jiaqi P an, Jackson Clark, Yiming Su, Noah Zheutlin, Bhavy a Bha vya, Rohan Arora, Y u Deng, Saurabh Jha, and Tianyin Xu. STRA TUS: A multi-agen t system for autonomous reliability engineering of mo dern clouds. arXiv pr eprint arXiv:2506.02009 , 2025b. URL . Qingyun W u, Gagan Bansal, Jieyu Zhang, Yiran W u, Beibin Li, Erk ang Zh u, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. AutoGen: Enabling next-gen LLM applications via multi-agen t conv ersation. arXiv pr eprint arXiv:2308.08155 , 2023. URL . Sirui Hong, Mingc hen Zhuge, Jonathan Chen, Xia wu Zheng, Y uheng C heng, Cey ao Zhang, Jinlin W ang, Zili W ang, Stev en Ka Shing Y au, Zijuan Lin, et al. MetaGPT: Meta programming for a m ulti-agent collab orative framew ork. arXiv pr eprint arXiv:2308.00352 , 2023. URL . Jerome H Saltzer and Michael D Sc hro eder. The protection of information in computer systems. Pr o c e e dings of the IEEE , 63(9):1278–1308, 1975. URL https://doi.org/10.1109/PROC.1975.9939 . Zhihong Shao, P eiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingch uan Zhang, Y. K. Li, Y. W u, and Da y a Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in op en language mo dels. arXiv pr eprint arXiv:2402.03300 , 2024. URL . Geoffrey Hin ton, Oriol Vin yals, and Jeff Dean. Distilling the kno wledge in a neural netw ork. arXiv pr eprint arXiv:1503.02531 , 2015. URL . Haixuan Guo, Shuhan Y uan, and Xin tao W u. LogBER T: Log anomaly detection via BER T. In International Joint Confer enc e on Neur al Networks (IJCNN) , pages 1–8. IEEE, 2021. Lingzhe Zhang, T ong Jia, Mengxi Jia, Y ifan W u, Aiwei Liu, Y ong Y ang, Zhonghai W u, Xuming Hu, Philip S Y u, and Ying Li. A survey of AIOps for failure management in the era of large language models. arXiv pr eprint arXiv:2406.11213 , 2024. URL . Tingting W ang and Guilin Qi. A comprehensiv e survey on ro ot cause analysis in (micro) services: Metho d- ologies, c hallenges, and trends. arXiv pr eprint arXiv:2408.00803 , 2024. URL 2408.00803 . 16 A OI Yinfang Chen, Huaibing Xie, Minghua Ma, Y u Kang, Xin Gao, Liu Shi, Y unjie Cao, Xuedong Gao, Hao F an, Ming W en, Jun Zeng, Supriy o Ghosh, Xuchao Zhang, Chaoyun Zhang, Qingwei Lin, Sarav an Ra jmohan, Dongmei Zhang, and Tian yin Xu. Automatic root cause analysis via large language mo dels for cloud inciden ts. In Pr o c e e dings of the 19th Eur op e an Confer enc e on Computer Systems (Eur oSys) , pages 674–688, 2024. P atric k Lewis, Ethan Perez, Aleksandra Piktus, F abio P etroni, Vladimir Karpukhin, Naman Goy al, Heinrich Küttler, Mik e Lewis, W en-tau Yih, Tim Ro cktäsc hel, Douw e Kiela, and V eselin Sto yano v. Retriev al- augmen ted generation for knowledge-in tensive NLP tasks. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , volume 33, pages 9459–9474, 2020. URL . Carlos E Jimenez, John Y ang, Alexander W ettig, Sh unyu Y ao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-b enc h: Can language mo dels res olv e real-world GitHub issues? In International Confer enc e on L e arning R epr esentations (ICLR) , 2024. URL . Long Ouy ang, Jeffrey W u, Xu Jiang, Diogo Almeida, Carroll W ain wright, Pamela Mishkin, Chong Zhang, Sandhini Agarw al, Katarina Slama, Alex Ra y , et al. T raining language mo dels to follow instructions with h uman feedback. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , volume 35, pages 27730–27744, 2022. URL . Rah ul Gupta, Soham P al, Adit ya Kanade, and Shirish Shev ade. Deepfix: Fixing common C language errors b y deep learning. In AAAI Confer enc e on Artificial Intel ligenc e , pages 1345–1351, 2017. Mark o V asic, Adit ya Kanade, Petros Maniatis, David Bieber, and Rishabh Singh. Neural program repair by join tly learning to lo calize and repair. In International Confer enc e on L e arning R epr esentations (ICLR) , 2019. Noah Shinn, F ederico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shun yu Y ao. Reflexion: Language agen ts with v erbal reinforcement learning. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , v olume 36, 2023. URL . Marcin Andryc ho wicz, Filip W olski, Alex Ray , Jonas Schneider, Rachel F ong, Peter W elinder, Bob McGrew, Josh T obin, Pieter Abb ee l, and W o jciech Zaremba. Hindsight exp erience replay . In A dvances in Neur al Information Pr o c essing Systems (NeurIPS) , volume 30, 2017. URL . John Sch ulman, Filip W olski, Prafulla Dhariw al, Alec Radford, and Oleg Klimo v. Proximal policy optimization algorithms. arXiv pr eprint arXiv:1707.06347 , 2017. URL . Rafael Rafailo v, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Y our language mo del is secretly a reward mo del. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , volume 36, 2023. URL . DeepSeek-AI. DeepSeek-R1: Incen tivizing reasoning capability in LLMs via reinforcement learning. arXiv pr eprint arXiv:2501.12948 , 2025. URL . Nelson F Liu, Kevin Lin, John Hewitt, Ashwin P aranjap e, Michele Bevilacqua, F abio Petroni, and Percy Liang. Lost in the middle: How language mo dels use long contexts. T r ansactions of the Asso ciation for Computational Linguistics , 12:157–173, 2024. URL . Charles Pac k er, Sarah W o o ders, Kevin Lin, Vivian F ang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. MemGPT: T ow ards LLMs as op erating systems. arXiv pr eprint arXiv:2310.08560 , 2023. URL https: //arxiv.org/abs/2310.08560 . Yilun Du, Shuang Li, Antonio T orralba, Joshua B T enenbaum, and Igor Mordatch. Improving factuality and reasoning in language mo dels through multiagen t debate. In Pr o c e e dings of the 41st International Confer enc e on Machine L e arning (ICML) , volume 235 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 11733–11763, 2024. URL . 17 A OI Ashish V aswani, Noam Shazeer, Niki P armar, Jakob Uszk oreit, Llion Jones, Aidan N Gomez, Łuk asz Kaiser, and Illia P olosukhin. A ttention is all you need. In A dvanc es in Neural Information Pr o c essing Systems (NeurIPS) , v olume 30, 2017. URL . Lianmin Zheng, W ei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao W u, Y onghao Zh uang, Zi Lin, Zh uohan Li, Dacheng Li, Eric P Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. Judging LLM- as-a-judge with MT-Bench and Chatb ot Arena. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , v olume 36, 2023. URL . Brendan Burns, Brian Grant, David Opp enheimer, Eric Brewer, and John Wilkes. Borg, omega, and Kub ernetes. Communic ations of the ACM , 59(5):50–57, 2016. URL https://doi.org/10.1145/2890784 . An thropic. Claude Sonnet 4.5 system card. https://www.anthropic.com/ claude- sonnet- 4- 5- system- card , 2025. Released September 29, 2025. An Y ang, Baosong Y ang, Beichen Zhang, F ei Cui, Da yiheng Dai, Huan Ge, et al. Qwen3 technical rep ort. arXiv pr eprint arXiv:2505.09388 , 2025. URL . Edw ard J Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. LoRA: Lo w-rank adaptation of large language models. In International Confer enc e on L e arning R epr esentations (ICLR) , 2022. URL . W o osuk Kw on, Zhuohan Li, Siyuan Zh uang, Ying Sheng, Lianmin Zheng, Co dy Hao Y u, Joseph E Gonzalez, Hao Zhang, and Ion Stoica. Efficien t memory management for large language mo del serving with PagedA t- ten tion. In Pr o c e e dings of the ACM SIGOPS 29th Symp osium on Op er ating Systems Principles (SOSP) , pages 611–626, 2023. URL . Op enAI. GPT-4 tec hnical rep ort. arXiv pr eprint arXiv:2303.08774 , 2023. URL 2303.08774 . 18 A OI Algorithm 1 A OI Main Loop 1: Input: T ask D , max iterations N 2: Initialize Observ er O , Probe P , Executor X , Compressor C 3: T ← O . Plan ( D ) ▷ Initial task queue 4: H ← [] ▷ Long-term memory 5: for n = 1 to N do 6: ( S n − 1 , a n , I n ) ← O . Decide ( H n − 2 , C n − 1 , T ) 7: if n > 1 then 8: H. app end ( S n − 1 ) 9: end if 10: if a n = Submit then 11: return E . Submit ( I n ) 12: else if a n = Prob e then 13: P . Run ( I n , E ) → M raw 14: else if a n = Execute then 15: X . Run ( I n , E ) → M raw 16: end if 17: C n ← C . Compress ( M ( n ) raw ) 18: end for 19: return E . Submit ( timeout ) Co de and Data A v ailabilit y Co de and pre-trained models: https://anonymous.4open.science/r/aoi- C8C7 Benc hmark data. W e use the publicly av ailable AIOpsLab benchmark Chen et al. [ 2025a ]. Our fault-t yp e split and tra jectory data will b e released up on publication. Note: Anonymous GitHub r ep ository link wil l b e pr ovide d for r eview. The r ep ository wil l b e made public up on p ap er ac c eptanc e. A Algorithm Details A.1 A OI Main Lo op Algorithm 1 presen ts the complete AOI orchestration lo op. The design reflects three key principles: Dual-timescale memory . The algorithm maintains tw o memory structures: (1) short-term c ontext C n from the Compressor, preserving critical evidence from the current iteration, and (2) long-term memory H storing summaries S n − 1 across iterations. This separation allo ws the Observer to maintain h yp otheses ov er long diagnostic horizons while keeping per-iteration context within token limits. Lazy compression. Compression o ccurs at the end of each iteration (line 17) rather than b efore decision- making. This ensures the Observ er s ees raw evidence when making decisions, while only compressed summaries are stored for future iterations—balancing information fidelity with context efficiency . A ction-type routing. The three action types (Submit, Probe, Execute) route to specialized agents with differen t capabilities and safety constrain ts, enabling fine-grained access control. 19 A OI A.2 Observ er GRPO T raining Algorithm 2 presen ts the Observer GRPO training pro cedure. Algorithm 2 Observ er GRPO T raining 1: Input: Successful tra jectories D , group size G , LLM judge R 2: Output: T rained Observer p olicy π θ 3: for eac h training step do 4: Sample context x from D (compressed evidence + task state) 5: Sample G candidate actions { y i } G i =1 ∼ π θ ( ·| x ) 6: for i = 1 to G do 7: r i ← R ( x, y i ) ▷ LLM judge scoring 8: end for 9: µ G ← 1 G P i r i ; σ G ← q 1 G P i ( r i − µ G ) 2 10: A i ← ( r i − µ G ) / ( σ G + ϵ ) for all i 11: Update θ via policy gradien t with adv antages { A i } 12: end for The LLM judge ev aluates candidates on six dimensions (consistent with Section 3.3 ): • F ormat ( w =0 . 10 , rule-based): Whether the output is v alid JSON. • Summary ( w =0 . 15 , LLM): Accuracy of the previous-iteration summary . • Action ( w =0 . 10 , LLM): Correctness of the next action t yp e (Prob e / Executor / Submit). • Context Instruction ( w =0 . 30 , LLM): Quality of the diagnostic reasoning in probe or executor context. • Context Namespace ( w =0 . 30 , LLM): Accuracy of targeted resources (namespaces, p o ds, services). • Confidence ( w =0 . 05 , LLM): Calibration of self-reported confidence relative to iteration stage. Rationale for dimension w eights. Context Instruction and Context Namespace together account for 60% of the total weigh t, reflecting the emphasis on diagnostic reasoning quality and target accuracy—the t w o factors that most directly determine information gain p er step. F ormat is rule-based to provide a hard constrain t on output v alidit y . Summary , Action, and Confidence serve as auxiliary signals that shap e the learning tra jectory without dominating the reward. A.3 T ra jectory-Corrective Ev olv er The Ev olver addresses a k ey limitation of pure imitation learning: when the Observer encounters situations not co vered by successful tra jectories, it lac ks guidance for reco very . Given a failed tra jectory , the Ev olver generates candidate corrections via GRPO sampling and selects the highest-scoring correction as a structured prompt for the Observer’s next attempt. This creates a closed-loop mechanism that conv erts failed diagnostic attempts in to learning opp ortunities without requiring manual exp ert interv ention. Figure 5 illustrates the Evolv er’s integration with the AOI runtime. Figur e explanation: The Ev olver op erates in three stages: (1) F ailure Collection - collects failed tra jectories from previous diagnostic attempts; (2) Correction Generation - samples multiple candidate corrected command sequences using GRPO-trained p olicy; (3) Guidance Injection - pro vides the highest-scoring corrected plan as a structured prompt to the Observ er for subsequen t attempts. The dashed feedback lo op sho ws ho w this pro cess conv erts failed tra jectories into training signal. 20 A OI Evolve r Commands Commands only Reward model You are an expert DevOps engineer and AIOps trainer. Your task is to generate realistic and COMPLETE Kubernetes fault diagnosis and resolution scenarios. You are an expert DevOps/SRE engineer evaluating fault scenarios for AI training data quality. 𝑹 𝒅𝒊𝒗 Parse Success 𝑹 𝒇𝒎𝒕 𝑹 𝒔𝒐𝒍 𝑹 𝒄𝒎𝒑 𝑹 𝒗𝒂𝒍 𝑹 𝒄𝒐𝒓 SRE Successed Commands Workflow System state summary Complete command sequence Figure 5. T ra jectory-Corrective Ev olv er Architecture. The Evolv er observ es failed command sequences from the Observer’s execution history , generates G candidate corrections via GRPO sampling (sampling from a p olicy trained on successful tra jectories), and provides the highest-scoring correction as a structured prompt to guide the Observ er’s next attempt. Key insight: This closed-lo op mechanism conv erts failed diagnostic attempts in to learning opp ortunities without requiring man ual expert interv en tion. B Exp erimen tal Setup B.1 Hyp erparameters Key parameter choices. W e set max iterations to 15 based on analysis of successful Claude Sonnet tra jectories, where 95% completed within 12 iterations. The con text budget (4096 tokens) balances information reten tion with inference cost—larger budgets show ed diminishing returns b eyond 4K tokens. F or GRPO training, we use LoRA rank 64 (rather than full fine-tuning) to preserv e the base mo del’s general capabilities while adapting to diagnostic patterns. The learning rate ( 10 − 5 ) and batc h size (16) were selected to ensure stable con vergence within 3 ep o chs. T able 5. Complete hyperparameter settings. P arameter V alue AOI Runtime Max iterations 15 Max Prob e rounds/iteration 5 Con text budget/iteration 4096 tokens Long-term memory capacity 10 summaries Executor whitelist 47 command patterns T r aje ctory-Corr e ctive Evolver Base mo del Qw en3-14B GRPO candidates G 4 Learning rate 1 × 10 − 5 LoRA rank / alpha 64 / 128 Batc h size 16 Ep ochs 3 Rew ard mo del Claude Opus 4.5 T raining samples 49 success seeds T est samples 37 failed seeds B.2 Benc hmark Details F ull b enc hmark from AIOpsLab Chen et al. [ 2025a ]: 88 scenarios across 3 applications (reduced to 86 in our ev aluation due to 2 deprecated scenarios). Our ev aluation split: 21 A OI • Success seeds (49 cases): Claude Sonnet successful tra jectories, used as p ositive examples for GRPO training. • F ailed seeds (37 cases): Claude Sonnet failed tra jectories that o v erlap with Observ er’s held-out set, used as test set to ev aluate Evolv er’s recov ery ability . F ailed cases by task type: T ask T yp e Count Detection 10 Lo calization 13 Mitigation 3 R CA 11 T otal 37 F ault types in failed cases include: service failures (31%), misconfigurations (26%), authentication errors (18%), po d failures (15%), and netw ork issues (10%). B.3 Data Split Details Rationale for nested data partition. W e use a strict subset structure D train obs ⊂ D train ev olv er ⊂ D all to ensure no data leak age: since the Ev olver pro vides guidance to the Observer, any task seen b y the Observer during training m ust also b e excluded from Evolv er ev aluation. This guaran tees that all 37 Ev olver test cases fall within the Observ er’s 63 held-out tasks. Figure 6 and T ables 6 – 7 detail the fault-t yp e-based partition used for Observer GRPO training. T able 6. T raining fault t yp es (11 types → 23 successful tra jectories). These fault t ypes were selected to provide div erse cov erage of common failure mo des while ensuring sufficien t test data remains for ev aluation. F ault T yp e GT T asks T otal T asks k8s_target_p ort-misconfig 9 12 scale_p od_zero_so cial_net 3 4 misconfig_app_hotel_res 3 4 astronom y_shop_cart_service_failure 1 2 astronom y_shop_pa ymen t_service_failure 1 2 astronom y_shop_pro duct_catalog_failure 1 2 astronom y_shop_recommend_cac he_failure 1 2 auth_miss_mongo db 1 4 net w ork_loss_hotel_res 1 2 no op_detection_hotel_reserv ation 1 1 redeplo y_without_PV 1 3 T otal 23 38 C Multi-Round Sampling Analysis Or ganization note: This section analyzes the stochastic behavior of the A OI system across m ultiple indep endent runs. W e separate this from the experimental setup (Section B) because it fo cuses on empiric al char acterization of the system’s output distribution rather than configuration details. Understanding v ariance across runs is critical for deplo yment planning in pro duction environmen ts. 22 A OI 𝒟 𝑜𝑏 𝑠 𝑡𝑟𝑎 𝑖 𝑛 𝒟 𝑒𝑣 𝑜𝑙 𝑣 𝑒𝑟 𝑡𝑟𝑎 𝑖 𝑛 𝒟 𝑎 𝑙 𝑙 Figure 6. Nested data partition structure. D all (86 tasks) contains D train evolv er (49 successful tra jectories from Claude Sonnet 4.5), which in turn contains D train obs (23 tasks cov ering 11 fault types). The strict subset relationship ensures that no test data app ears in any training set. Visual interpr etation: The outer circle represents all benchmark tasks; the middle ring shows Evolv er training data (all successful Sonnet tra jectories); the innermost core sho ws Observ er training data (carefully selected to co ver diverse fault types while main taining strict hold-out). This design enables fair ev aluation of the combined Observ er+Evolv er system. T able 7. T est fault t yp es (15 types → 48 tasks) plus 15 tasks from training fault t ypes where Sonnet failed, totaling 63 held-out tasks. Critic al: All test fault types are completely unseen during Observ er training, ensuring we ev aluate true generalization capability . F ault T yp e T asks rev ok e_auth_mongo db 8 user_unregistered_mongo db 8 assign_to_non_existen t_no de_social_net 4 wrong_bin_usage 4 astronom y_shop_ad_service_high_cpu 2 astronom y_shop_ad_service_man ual_gc 2 astronom y_shop_ad_service_failure 2 net w ork_dela y_hotel_res 2 p od_kill_hotel_res 2 p od_failure_hotel_res 2 astronom y_shop_image_slo w_load 2 astronom y_shop_k afk a_queue_problems 2 astronom y_shop_loadgen_flo od_homepage 2 astronom y_shop_pa ymen t_unreachable 2 no op_detection_social_netw ork 1 no op_detection_astronom y_shop 1 con tainer_kill 2 T est-only fault typ es subtotal 48 + T raining fault typ es (Sonnet faile d) 15 T otal held-out 63 23 A OI C.1 Diminishing Returns in Sampling Figure 7 sho ws success rate improv ement across multiple sampling rounds. Practical deploymen t guidance. The steep improv ement from best@1 (31.4%) to best@2 (51.2%) suggests that ev en a single retry captures most of the “easy wins” from sto chastic v ariation. Bey ond k =3, gains b ecome marginal (b est@3=58.1% → b est@5=66.3%). F or cost-sensitive deploymen ts, we recommend k =2 as the optimal trade-off; for high-stak es scenarios where maximizing success rate justifies additional compute, k =3 captures 88% of the maximum ac hiev able improv ement. 1 2 3 4 5 Number of Sampling R ounds (k) 20 30 40 50 60 70 Best@k Success R ate (%) 31.4% 51.2% 58.1% 62.8% 66.3% Figure 7. b est@ k success rate vs num b er of runs. The curv e shows clear diminishing returns: the first retry ( k =1 → 2) pro vides +19.8pp impro v emen t, while subsequen t retries ( k =2 → 5) eac h provide only +2-3pp. Interpr etation: The rapid initial improv ement suggests many tasks ha ve “near-miss” failure mo des that succeed on retry , while the flattening curv e indicates some tasks are fundamentally b eyond curren t capability . The inflection p oint at k =2-3 pro vides clear guidance for resource-constrained deploymen ts. C.2 P er-Round Success Rates T able 8 shows success rates for each of the 5 indep enden t runs, brok en down by task type. T able 8. Per-round success rates (%) by task type. Round Det. Lo c. RCA Mit. Ov erall R1 53.1 21.4 7.7 23.1 31.4 R2 75.0 32.1 0.0 23.1 41.9 R3 59.4 32.1 15.4 23.1 38.4 R4 75.0 21.4 15.4 23.1 40.7 R5 71.9 32.1 0.0 23.1 40.7 A vg 66.9 27.9 7.7 23.1 38.6 Observ ations: Detection shows high v ariance (53–75%), indicating significan t b enefit from retries. Mitigation is p erfectly stable (23.1% every round), suggesting that failures are capability-limited rather than sto c hastic. R CA is highly unstable (0–15.4%) due to small sample size (13 tasks) and complex multi-step reasoning requiremen ts. 24 A OI Figure 8 visualizes this v ariance. R1 R2 R3 R4 R5 Sampling R ound 0 20 40 60 80 Success R ate (%) Detection L ocalization Analysis Mitigation Figure 8. P er-round success rate v ariance by task type. Detection exhibits the widest range (22pp), indicating high sto c hastic sensitivity—tasks that fail in one run often succeed in another due to different exploration paths. Mitigation’s flat line confirms that curren t failures are deterministic capability gaps rather than sampling artifacts. A ctionable insight: Detection tasks benefit most from m ulti-round sampling, while Mitigation requires arc hitectural impro v emen ts rather than more attempts. C.3 T ask Stabilit y Distribution W e categorize tasks by their 5-round success coun t to understand task difficulty distribution (T able 9 ). T able 9. T ask stabilit y distribution (86 tasks total). Success Category Count % 5/5 Consisten tly solv ed 14 16.3 3–4/5 Mostly solved 16 18.6 1–2/5 Occasionally solved 27 31.4 0/5 Nev er solv ed 29 33.7 Key insight: 50% of tasks (1–4/5) exhibit sto chastic outcomes, strongly v alidating m ulti-round sampling. The 29 nev er-solved tasks represent hard capability b oundaries requiring architectural improv ements rather than more sampling. The 14 alw ays-solv ed tasks demonstrate the system’s reliable core competencies. Figure 9 visualizes this distribution. C.4 Nev er-Solved T asks (0/5) The 29 consisten tly failed tasks cluster by type: • Lo calization (13): Primarily astronomy_shop microservice dep endencies requiring deep trace analysis b ey ond curren t mo del capabilities • RCA (9): Causal reasoning tasks requiring understanding of temp oral fault propagation • Mitigation (7): Domain-sp ecific remediation commands (e.g., MongoDB auth recov ery , Helm chart upgrades) not co vered in training data 25 A OI 5/5 Consistent 16.3% 3-4/5 Mostly 18.6% 1-2/5 Occasional 31.4% 0/5 Never 33.7% (14) (16) (27) (29) Figure 9. T ask stabilit y distribution across 86 b enc hmark tasks. The large middle segment (50% of tasks with 1-4/5 success) v alidates our multi-round sampling strategy—these tasks are neither trivially easy nor imp ossibly hard, but rather exhibit outcome v ariance across runs. Design implic ation: F uture w ork should focus on con v erting the 0/5 category (capability gaps) into the 1-2/5 category (sto chastic successes), which can then b e reliably solved via m ulti-round sampling. 26 A OI D Observ er GRPO Analysis Or ganization note: This section shifts from characterizing system b ehavior (Section C) to analyzing the effe ct of GRPO tr aining . W e group all GRPO-related analysis together (Sections D and E) to pro vide a cohesive view of ho w training improv es (and sometimes degrades) performance across different task types. D.1 Ov erall T raining Effect Figure 10 sho ws the aggregate impact of Observ er GRPO training across task types. Detection L ocalization Analysis Mitigation 0 20 40 60 80 100 Success R ate (%) +25.5 -4.5 +10.0 Untrained (Qwen avg) Observer - GRPO Figure 10. Observer GRPO training effect by task type (b est@5). Detection improv es dramatically (+25.5pp) as the Observer learns systematic anomaly-detection patterns. Lo calization de cr e ases ( − 4.5pp) due to o ver-exploration causing multi-anomaly confusion (detailed in Section E.4 ). RCA impro v es (+8.4pp) from b etter evidence-gathering strategies. Critic al insight: GRPO training is not uniformly b eneficial—it helps exploration-hea vy tasks but can harm precision-critical tasks where thoroughness conflicts with efficiency . D.2 T ask-Level Changes Figure 11 sho ws how individual tasks changed after GRPO training. D.3 Impro ved T asks (11) T asks that changed from mostly-failing (Qwen < 50%) to successful after GRPO: • Detection (7): pa ymen t_service_unreac hable, ad_service_failure, wrong_bin_usage, k afk a_queue_problems, redeplo y_without_PV, cart_service_failure, net work_dela y_hotel_res 27 A OI Impr oved (F ail P ass) Degraded (P ass F ail) Unchanged 0 10 20 30 40 50 60 Number of T asks 11 2 50 Net: +9 tasks Figure 11. T ask-level changes after GRPO training. Net +9 tasks impro ved (11 gains, 2 losses). Both degraded tasks are Localization, confirming that GRPO’s deep-exploration strategy harms precision-critical fault lo calization. Interpr etation: The asymmetric gains (strong Detection impro vemen ts, Localization degradations) suggest task-t yp e-a w are training as future w ork. • Lo calization (2): con tainer_kill, netw ork_delay_hotel_res • RCA (2): k8s_target_p ort-misconfig-analysis-2, rev oke_auth_mongodb-analysis-2 D.4 Degraded T asks (2) Both degraded tasks are Lo calization: • p o d_failure_hotel_res-lo calization-1 (4/5 → 0/5) • pro duct_catalog_service_failure-lo calization-1 (4/5 → 0/5) Ro ot cause analysis. Both degraded tasks require iden tifying a sp ecific fault y comp onen t among m ultiple candidates with similar symptoms. Before GRPO, the base mo del w ould conserv ativ ely chec k only the most ob vious candidate; after GRPO, the Observer learns to explore extensively—a strategy that succeeds for Detection (where finding any issue suffices) but fails for Localization (where the exact ro ot cause m ust b e iden tified). This reveals a fundamental tension: GRPO’s rew ard signal optimizes for task completion, whic h can conflict with the thoroughness required for precise comp onent identification. E Observ er-GRPO vs Base: Comprehensive T ask-T yp e Analysis This section provides detailed analysis of ho w GRPO training affects p erformance across different task t yp es, rev ealing a critical trade-off b etw een exploration depth and task requirements. 28 A OI E.1 T raining Set Distribution The Observ er GRPO training uses 23 successful tra jectories with the following task-type distribution: T able 10. T raining set comp osition b y task type. The heavy Detection bias (43.5%) explains why Detection benefits most from GRPO. T ask T yp e T raining T asks T est T asks Detection 10 (43.5%) 22 Lo calization 6 (26.1%) 22 Analysis (RCA) 1 (4.3%) 12 Mitigation 6 (26.1%) 7 T otal 23 63 Critical observ ation: Analysis tasks are severely underrepresented in training (only 1 task, 4.3%), y et Observ er-GRPO shows large impro v emen t on Analysis (+16.7pp). This suggests the learned exploration patterns transfer w ell despite limited direct sup ervision. E.2 P erformance Comparison Ov erview Figure 12 visualizes the p erformance gap b etw een Observer-GRPO and Base mo dels. Detection L ocalization Analysis Mitigation T ask T ype 0 20 40 60 80 100 Success Rate (best@5, %) 90.9% 31.8% 41.7% 14.3% 54.5% 50.0% 25.0% 28.6% +36.4 -18.2 +16.7 -14.3 RL (GRPO) Base (Qwen3-14B) Figure 12. Observ er-GRPO vs Base p erformance b y task type (b est@5). Detection improv es b y +36.4pp (from 59.1% to 95.5%), while Lo calization de gr ades b y − 18.2pp (50.0% to 31.8%). Key take away: GRPO b enefits evidence-gathering tasks (Detection, Analysis) but harms precision tasks (Lo calization) where ov er-exploration in tro duces confusion. This heterogeneity motiv ates task-type-aw are exploration p olicies. E.3 Exploration Depth Analysis T able 11 compares the a v erage n umber of exploration steps b etw een Observer-GRPO and Base mo dels. 29 A OI T able 11. A verage exploration steps by task type (low er = more efficient). T ask T yp e Obs-GRPO Base Diff. Detection 11.0 1.9 +9.1 Lo calization 11.2 1.8 +9.4 Analysis 9.6 1.1 +8.5 Mitigation 12.0 2.8 +9.2 A verage 10.9 1.9 +9.0 Observ er-GRPO consisten tly uses ∼ 9 more steps than Base across all task types. This “deep exploration” strategy has task-t yp e-dep endent effects: • Detection : Beneficial —deep er search finds anomalies Base misses • Lo calization : Harmful —ov er-exploration discov ers multiple anomalies, causing incorrect ro ot cause selection • Analysis : Beneficial —deep er exploration gathers sufficient evidence for correct fault classification • Mitigation : Neutral effect—b oth struggle with execution-hea vy tasks Figure 13 visualizes the relationship b etw een exploration depth and success rate. 0 2 4 6 8 10 12 14 A verage Exploration Steps 0 20 40 60 80 100 Success Rate (best@5, %) Shallow (Base) Deep (RL) Detection L ocalization Analysis Mitigation RL (GRPO) Base Figure 13. Exploration depth vs success rate trade-off. Each point represen ts a task t yp e; arrows sho w the transition from Base to Observer-GRPO. GRPO uniformly increases exploration depth (arro ws p oint righ t), but success direction v aries: upw ard for Detection/Analysis (more exploration helps), do wn w ard for Localization (more exploration harms). Critic al implic ation: A single exploration strategy cannot optimize all task types simultaneously—future w ork should adapt exploration depth based on detected task category . E.4 Lo calization: Why Observ er-GRPO Underp erforms T able 12 shows the detailed comparison for Lo calization tasks. 30 A OI T able 12. Lo calization task outcomes (22 tasks total). Outcome Coun t % Obs-GRPO wins (Base fails) 2 9.1% Base wins (Obs-GRPO fails) 6 27.3% Both succeed 5 22.7% Both fail 9 40.9% b est@5 Obs-GRPO: 31.8% vs Base: 50.0% Obs-GRPO wins: container_kill, net w ork_loss_hotel_res. Base wi ns: ad_service_failure, ad_service_high_cpu, pa yment_service_failure, k8s_misconfig-lo c-2, netw ork_delay , user_unregistered-lo c-2. Ro ot cause of Observer-GRPO degradation: In the 6 tasks where Base wins: 1. Observ er-GRPO explores extensiv ely ( ∼ 10 steps), discov ering multiple comp onents with anomalies 2. When multiple anomalies exist, Observer-GRPO often submits the symptom rather than the r o ot c ause 3. Base’s shallow exploration (1–2 steps) paradoxically helps b y limiting the search to the most obvious fault Case study: astronom y_shop_ad_service_failure-lo calization-1 • Ground truth : The ad service is the ro ot cause • Base (2 steps): Quickly identifies ad service errors → submits ["ad"] → Correct • Obs-GRPO (10 steps): Finds ad errors, explores dep endencies, finds product-catalog affected → submits ["product-catalog"] → Incorrect (downstream symptom, not ro ot cause) E.5 Analysis: Wh y Observ er-GRPO Excels T able 13 shows the detailed comparison for Analysis (R CA) tasks. T able 13. Analysis task outcomes (12 tasks total). Outcome Coun t % Obs-GRPO wins (Base fails) 2 16.7% Base wins (Obs-GRPO fails) 0 0.0% Both succeed 3 25.0% Both fail 7 58.3% b est@5 Obs-GRPO: 41.7% vs Base: 25.0% Obs-GRPO wins: k8s_misconfig-analysis-1, revok e_auth-analysis-1. Both suc c e e d: k8s_misconfig-analysis-2, misconfig_app, revok e_auth-analysis-2. Wh y deep er exploration helps Analysis: Analysis tasks require determining b oth system_level (e.g., Application, Virtualization, Net work) and fault_type (e.g., Misconfiguration, Resource Exhaustion). This classification requires: 1. Understanding whic h lay er the fault originates from 2. Gathering evidence about the nature of the fault 3. Eliminating alternativ e hypotheses 31 A OI Base’s shallo w exploration (avg 1.1 steps) pro vides insufficien t evidence for reliable classification. Observ er- GRPO’s deeper exploration (avg 9.6 steps) systematically gathers the necessary information. Case study: k8s_target_p ort-misconfig-analysis-1 • Ground truth : system_level: Virtualization, fault_type: Misconfiguration • Base (1.6 steps a vg): Insufficien t exploration → 0/5 rounds correct • Obs-GRPO (10 steps): Examines service definitions, finds targetPort mismatc h → iden tifies Virtualiza- tion Misconfiguration → 4/5 correct E.6 T ask Outcome Distribution Figure 14 compares task-lev el outcomes b etw een Observer-GRPO and Base for Lo calization and Analysis. RL wins Base wins Both succeed Both fail 0 2 4 6 8 10 12 Number of T asks 2 6 5 9 Localization (22 tasks) Base advantage: 6 vs 2 RL wins Base wins Both succeed Both fail 0 2 4 6 8 10 12 Number of T asks 2 0 3 7 Analysis (12 tasks) RL advantage: 2 vs 0 Figure 14. T ask outcome distribution for Lo calization vs Analysis. Localization shows Base adv an tage (6 exclusiv e wins vs 2), while Analysis shows Obs-GRPO adv an tage (2 vs 0). Interpr etation: Confirms that deep exploration helps Analysis (whic h b enefits from comprehensiv e evidence) but harms Localization (where first instinct is often correct). The asymmetry v alidates task-type-sp ecific exploration strategies. E.7 The Exploration-Precision T rade-off Our analysis rev eals a fundamental trade-off in diagnostic agent design: T able 14. Exploration depth trade-off b y task type. T ask T yp e Optimal Strategy Wh y Detection Shallow OK An y anomaly suffices Lo calization Shallow b etter A void m ulti-anomaly confusion Analysis Deep b etter Need comprehensiv e evidence Mitigation Deep required Must understand b efore fixing Implications for future work: 1. T ask-aw are exploration : Dynamically adjust exploration depth based on detected task type 2. Confidence-based early stopping : F or Lo caliz ation, stop when a high-confidence ro ot cause is found 32 A OI 3. Multi-stage training : T rain separate p olicies for differen t task types, or use task-type-conditioned rew ards Figure 15 pro vides a visual summary . Shallow (Base) Deep (RL) Detection L ocalization Analysis Mitigation 54.5% 90.9% 50.0% 31.8% 25.0% 41.7% 28.6% 14.3% Success Rate by Exploration Strategy ( = better strategy) Base better RL better Figure 15. Exploration strategy effectiveness heatmap. Green = strategy helps; Red = strategy harms. Lo calization uniquely b enefits from shallow exploration, while Analysis requires deep exploration. This heterogeneit y strongly motiv ates task-type-aw are p olicies as future w ork. F Case Studies: Detailed T ra jectory Examples Or ganization note: After presen ting quan titative results (Sections C-E), this section provides qualitative il lustr ation through detailed execution traces. W e include m ultiple case studies cov ering different task types and failure modes to demonstrate how the multi-agen t architecture op erates in practice. Eac h case study highligh ts sp ecific design decisions (read-write separation, dual-timescale memory , Ev olver guidance) in action. F.1 Case Study: Mitigation with Storage Class F ailure Wh y this case: This example illustrates the complete AOI pipeline—Observer reasoning, Prob e exploration, Executor remediation, and v erification. It demonstrates: (1) how the Ob serv er identifies root causes through systematic exploration; (2) how read-write separation prev ents premature state m utations; (3) how the Executor applies fixes only after sufficient evidence accumulates. Scenario: redeploy_without_PV-mitigation-1 . The StorageClass for p ersistent volumes w as remov ed during redeplo yment, causing cascading PVC binding failures and p o d crashes. Phase: Initialization Run 1 [04:00:28] Fault injected: StorageClass ‘local-storage’ deleted [04:00:29] Namespace ‘test-hotel-reservation’ redeployed without PV [04:00:35] Multiple pods entering CrashLoopBackOff state Task Started 33 A OI Though t & Action Observ er Agent The task requires mitigating anomalies in test-hotel-reserv ation. I should first understand the current state of the system by listing all resources in the namespace. A ction: Prob e Subtask: “List all p o ds/services in namespace to identify failing comp onents” T o ol Usage: kubectl Prob e Agent $ kubectl get pods -n test-hotel-reservation NAME READY STATUS RESTARTS consul-b84877fb4-v9sgv 1/1 Running 0 geo-99d8c58c-5wrbn 0/1 CrashLoopBackOff 3 mongodb-geo-5ff578bcb8 0/1 Pending 0 mongodb-profile-758cb 0/1 Pending 0 reservation-78c9f79 0/1 CrashLoopBackOff 5 ... (8 more pods in error state) Though t & Action Observ er Agent Multiple p o ds are failing. The mongodb po ds are in P ending state while service p o ds are in CrashLoopBackOff. This suggests a v olume moun ting issue. I need to chec k the PVC status. A ction: Prob e Subtask: “Check PV C status and describ e p ending p o ds” T o ol Usage: kubectl Prob e Agent $ kubectl get pvc -n test-hotel-reservation NAME STATUS STORAGECLASS mongodb-geo-pvc Pending local-storage mongodb-profile-pvc Pending local-storage mongodb-rate-pvc Pending local-storage $ kubectl describe pvc mongodb-geo-pvc -n test-hotel-reservation Events: Warning ProvisioningFailed storageclass.storage.k8s.io ‘local-storage’ not found Though t & Action Observ er Agent Ro ot cause identified: The StorageClass “lo cal-storage” is missing, prev en ting PVCs from binding. The mongo db p o ds cannot start without their p ersistent v olumes, and dep endent services fail. Solution: Recreate the StorageClass, then trigger PV C rebinding. A ction: Execute Instruction: “Create StorageClass ’lo cal-storage’ with provisioner ’kub ernetes.io/no-provisioner’ and volume- BindingMo de ’W aitF orFirstConsumer” ’ T o ol Usage: kubectl apply Executor Agent $ kubectl apply -f storageclass.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: local-storage provisioner: kubernetes.io/no-provisioner storageclass.storage.k8s.io/local-storage created 34 A OI Though t & Action Observ er Agent StorageClass recreated. Now I need to delete the stuc k PVCs and let them rebind, then restart the deplo yments to pick up the changes. A ction: Execute Instruction: “Delete p ending PVCs and restart all deplo ymen ts” T o ol Usage: kubectl Executor Agent $ kubectl delete pvc –all -n test-hotel-reservation persistentvolumeclaim ‘mongodb-geo-pvc’ deleted persistentvolumeclaim ‘mongodb-profile-pvc’ deleted persistentvolumeclaim ‘mongodb-rate-pvc’ deleted $ kubectl rollout restart deployment –all -n test-hotel-reservation deployment.apps/consul restarted deployment.apps/geo restarted deployment.apps/mongodb-geo restarted ... (9 more deployments restarted) Though t & Action Observ er Agent Mitigation commands executed. Let me verify that all p o ds are now running correctly before submitting. A ction: Prob e Subtask: “V erify all p o ds are Running” T o ol Usage: kubectl Prob e Agent $ kubectl get pods -n test-hotel-reservation NAME READY STATUS RESTARTS consul-b84877fb4-x2kpl 1/1 Running 0 geo-99d8c58c-7mnqr 1/1 Running 0 mongodb-geo-5ff578b-new 1/1 Running 0 mongodb-profile-758cb-new 1/1 Running 0 reservation-78c9f79-new 1/1 Running 0 ... (all 12 pods Running) T ask Finished Observ er Agent Diagnosis: StorageClass “lo cal-storage” w as missing after redeplo ymen t, causing PVC binding failures and cascading p o d failures. Mitigation: (1) Recreated StorageClass with correct provisioner; (2) Deleted stuc k PV Cs to trigger rebinding; (3) Restarted all deploymen ts to pick up new PVCs. Result: All 12 p o ds now Running. Services op erational. Phase: V alidation Run 1 [04:19:08] Validation started... [04:19:10] Pod check: 12/12 Running PASS [04:19:12] Service check: All endpoints healthy PASS [04:19:15] Task completed successfully Total time: 1139 seconds, 13 iterations Key takea wa ys from this case: • Systematic exploration: Observer first gathers evidence (p o d status, PVC status) b efore taking action • Read-write separation: All diagnostic commands execute through Prob e; only after ro ot cause is confirmed does Executor engage • V erification lo op: After applying fixes, Observ er verifies success b efore submitting • Multi-step reasoning: Recognizes that fixing StorageClass alone isn’t enough—m ust also trigger PVC rebinding and deplo yment restart 35 A OI G Detailed P er-T ask Results Or ganization note: This final section provides the complete empirical record of all 86 tasks across 5 runs. W e place this at the end b ecause it serves as a reference app endix rather than primary analysis. Researchers can use these tables to identify sp ecific tasks for further inv estigation or to verify aggregate statistics rep orted in the main paper. T ables 15 – 18 present the complete per-task results across 5 independent runs. T indicates success, F indicates failure. T able 15. Detailed results: Detection tasks (32 total). High v ariance across runs indicates sto chastic sensitivit y to exploration paths. Problem ID R1 R2 R3 R4 R5 Best assign_to_non_existent_node-det-1 T T T T T 5/5 astronomy_shop_ad_service_failure-det-1 F T F T F 2/5 astronomy_shop_ad_service_high_cpu-det-1 T T F T T 4/5 astronomy_shop_ad_service_man ual_gc-det-1 F T T T F 3/5 astronomy_shop_cart_service_failure-det-1 F T F T F 2/5 astronomy_shop_image_slo w_load-det-1 F T T T T 4/5 astronomy_shop_k afk a_queue_problems-det-1 F T T F F 2/5 astronomy_shop_loadgen_flood-det-1 T T T T T 5/5 astronomy_shop_pa yment_failure-det-1 F T T T F 3/5 astronomy_shop_pa yment_unreac hable-det-1 F T F T F 2/5 astronomy_shop_product_catalog-det-1 T T T T T 5/5 astronomy_shop_recommend_cac he-det-1 T T F F T 3/5 auth_miss_mongodb-det-1 T T T T T 5/5 container_kill-det T F F T T 3/5 k8s_target_port-misconfig-det-1 T F F F F 1/5 k8s_target_port-misconfig-det-2 F F F T T 2/5 k8s_target_port-misconfig-det-3 F T T T T 4/5 misconfig_app_hotel_res-det-1 T T T T T 5/5 netw ork_delay_hotel_res-det-1 F F T F T 2/5 netw ork_loss_hotel_res-det-1 F F F F T 1/5 noop_detection_astronomy_shop-1 T F F F T 2/5 noop_detection_hotel_reservation-1 T T T F T 4/5 noop_detection_so cial_netw ork-1 F T T T T 4/5 po d_failure_hotel_res-det-1 T T T T T 5/5 po d_kill_hotel_res-det-1 F F F F T 1/5 redeploy_without_PV-det-1 F F F T F 1/5 revok e_auth_mongo db-det-1 T T T T T 5/5 revok e_auth_mongo db-det-2 T T T T T 5/5 scale_po d_zero_so cial_net-det-1 T T T T T 5/5 user_unregistered_mongodb-det-1 T T T T T 5/5 user_unregistered_mongodb-det-2 T T T T T 5/5 wrong_bin_usage-det-1 F T F T F 2/5 T otal 17/32 24/32 19/32 24/32 23/32 – 36 A OI T able 16. Detailed results: Localization tasks (28 total). Problem ID R1 R2 R3 R4 R5 Best assign_to_non_existent_node-loc-1 T T T T T 5/5 astronomy_shop_ad_service_failure-loc-1 F T F F F 1/5 astronomy_shop_ad_service_high_cpu-loc-1 F T F F T 2/5 astronomy_shop_ad_service_man ual_gc-lo c-1 F F F F F 0/5 astronomy_shop_cart_service_failure-loc-1 F F F F F 0/5 astronomy_shop_image_slo w_load-lo c-1 F F F F F 0/5 astronomy_shop_k afk a_queue_problems-loc-1 F F F F F 0/5 astronomy_shop_loadgen_flood-lo c-1 F F F F F 0/5 astronomy_shop_pa yment_failure-loc-1 F F F F T 1/5 astronomy_shop_pa yment_unreac hable-lo c-1 F F F F F 0/5 astronomy_shop_product_catalog-loc-1 T T T F T 4/5 astronomy_shop_recommend_cac he-lo c-1 F F F F F 0/5 auth_miss_mongodb-lo c-1 F F T T T 3/5 container_kill-loc F F F F F 0/5 k8s_target_port-misconfig-lo c-1 T F T T F 3/5 k8s_target_port-misconfig-lo c-2 F T F F T 2/5 k8s_target_port-misconfig-lo c-3 T T T F F 3/5 misconfig_app_hotel_res-loc-1 T F T T T 4/5 netw ork_delay_hotel_res-loc-1 F T F F F 1/5 netw ork_loss_hotel_res-lo c-1 F F F F F 0/5 po d_failure_hotel_res-lo c-1 F T T T T 4/5 po d_kill_hotel_res-lo c-1 F F F F F 0/5 revok e_auth_mongo db-lo c-1 T F F F F 1/5 revok e_auth_mongo db-lo c-2 F F F F F 0/5 scale_po d_zero_so cial_net-lo c-1 F T T T T 4/5 user_unregistered_mongodb-lo c-1 F F F F F 0/5 user_unregistered_mongodb-lo c-2 F F T F F 1/5 wrong_bin_usage-loc-1 F F F F F 0/5 T otal 6/28 9/28 9/28 6/28 9/28 – T able 17. Detailed results: R CA tasks (13 total). Problem ID R1 R2 R3 R4 R5 Best assign_to_non_existent_node-rca-1 F F F F F 0/5 auth_miss_mongodb-rca-1 F F F F F 0/5 k8s_target_port-misconfig-rca-1 F F F F F 0/5 k8s_target_port-misconfig-rca-2 T F F F F 1/5 k8s_target_port-misconfig-rca-3 F F T F F 1/5 misconfig_app_hotel_res-rca-1 F F F T F 1/5 redeploy_without_PV-rca-1 F F F F F 0/5 revok e_auth_mongo db-rca-1 F F F F F 0/5 revok e_auth_mongo db-rca-2 F F T T F 2/5 scale_po d_zero_so cial_net-rca-1 F F F F F 0/5 user_unregistered_mongodb-rca-1 F F F F F 0/5 user_unregistered_mongodb-rca-2 F F F F F 0/5 wrong_bin_usage-rca-1 F F F F F 0/5 T otal 1/13 0/13 2/13 2/13 0/13 – T able 18. Detailed results: Mitigation tasks (13 total). Problem ID R1 R2 R3 R4 R5 Best assign_to_non_existent_node-mit-1 T T T T T 5/5 auth_miss_mongodb-mit-1 F F F F F 0/5 k8s_target_port-misconfig-mit-1 T F F F F 1/5 k8s_target_port-misconfig-mit-2 F F F T F 1/5 k8s_target_port-misconfig-mit-3 F F T F F 1/5 misconfig_app_hotel_res-mit-1 F F F F F 0/5 redeploy_without_PV-mit-1 T T T T T 5/5 revok e_auth_mongo db-mit-1 F F F F F 0/5 revok e_auth_mongo db-mit-2 F F F F F 0/5 scale_po d_zero_so cial_net-mit-1 F T F F T 2/5 user_unregistered_mongodb-mit-1 F F F F F 0/5 user_unregistered_mongodb-mit-2 F F F F F 0/5 wrong_bin_usage-mit-1 F F F F F 0/5 T otal 3/13 3/13 3/13 3/13 3/13 – 37
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment