KEEP: A KV-Cache-Centric Memory Management System for Efficient Embodied Planning
Memory-augmented Large Language Models (LLMs) have demonstrated remarkable capability for complex and long-horizon embodied planning. By keeping track of past experiences and environmental states, memory enables LLMs to maintain a global view, thereb…
Authors: Zebin Yang, Tong Xie, Baotong Lu
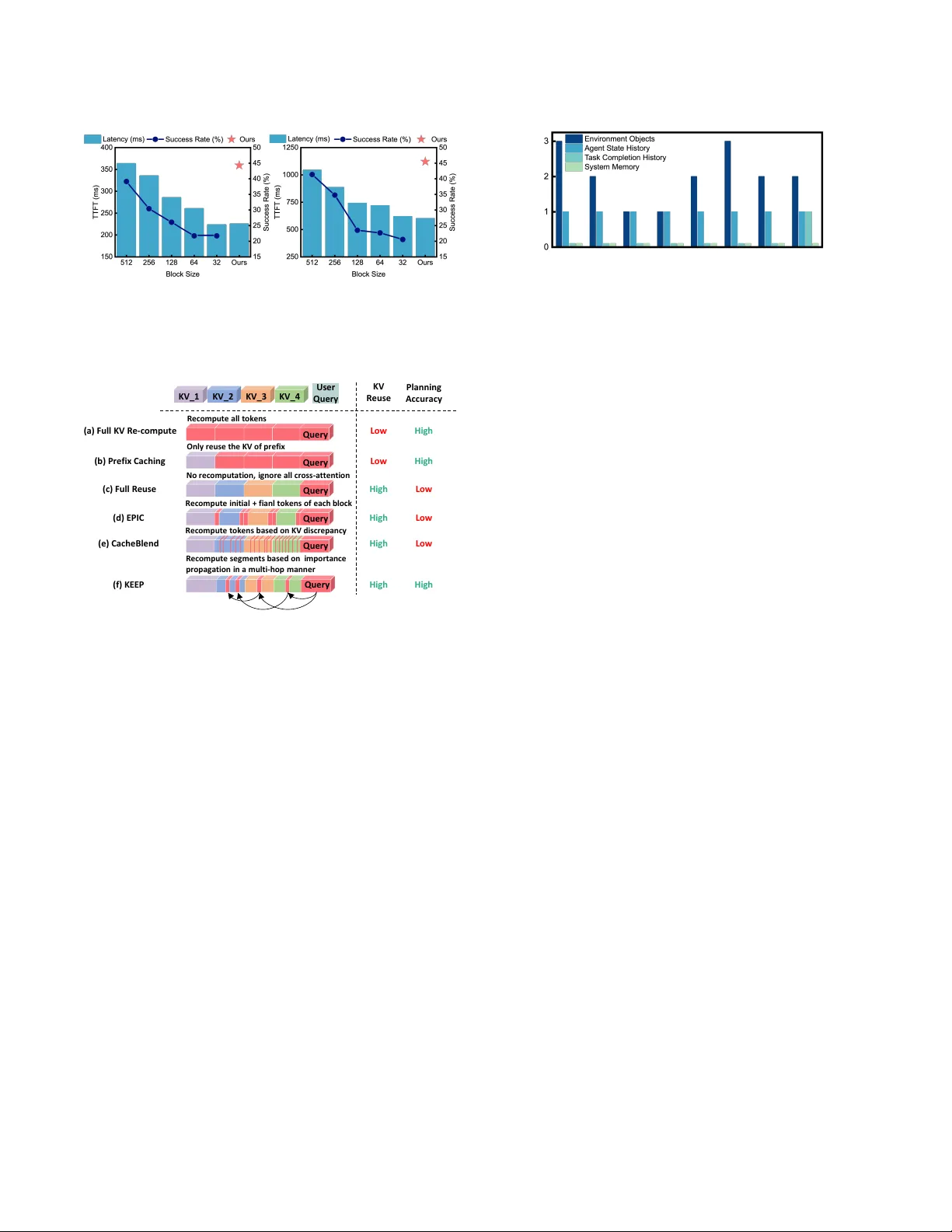
KEEP: A KV -Cache-Centric Memor y Management System for Eicient Embo died Planning Zebin Y ang 1 , 2 , T ong Xie 1 , 2 , Baotong Lu 4 , Shaoshan Liu 3 , Bo Y u 3 ∗ , Meng Li 1 , 2 , 5 ∗ 1 Institute for Articial Intelligence, 2 School of Integrated Circuits, Peking University , Beijing, China 3 Shenzhen Institute of Articial Intelligence and Robotics for Society , Shenzhen, China 4 Microsoft Research, 5 Beijing Advanced Innovation Center for Integrated Circuits, Beijing, China Abstract Memory-augmented Large Language Models (LLMs) have demon- strated remarkable capability for complex and long-horizon em- bodied planning. By keeping track of past experiences and en- vironmental states, memory enables LLMs to maintain a global view , thereby avoiding repetitive exploration. Howev er , e xisting ap- proaches often stor e the memory as raw text, leading to excessively long prompts and high prell latency . While it is possible to store and reuse the KV caches, the eciency b enets are greatly under- mined due to frequent KV cache updates. In this paper , we propose KEEP, a K V -cache-centric memor y management system for ecient embodied planning. KEEP features 3 key innovations: (1) a Static- Dynamic Memory Construction algorithm that reduces K V cache recomputation by mixed-granularity memory group; (2) a Multi- hop Memory Re-computation algorithm that dynamically identies important cross-attention among dierent memory groups and re- constructs memory interactions iteratively; (3) a Layer-balanced Memory Loading that eliminates unbalanced KV cache loading and cross-attention computation across dier ent layers. Extensive e x- perimental results have demonstrated that KEEP achieves 2.68 × speedup with negligible accuracy loss compared with text-based memory methods on ALFRED dataset. Compared with the K V re- computation method CacheBlend (EuroSys’25), KEEP shows 4.13% success rate improvement and 1.90 × time-to-rst-token (T TFT) reduction. Our code is available on https://github .com/PKU-SEC- Lab/KEEP_Embodied_Memor y. Ke ywords Embodied P lanning, Memory System, KV Cache Management, K V Recomputation 1 Introduction Embodied planning tasks agents predicting sequences of actions to achieve long-term goals in real-w orld scenarios [ 11 , 36 ]. Large Lan- guage Models (LLMs), with extensive encoding of world knowledge and common sense, oer a promising pathway to endow agents with such advanced planning skills [ 4 , 9 ]. As shown in Figure 1 (a), at each step, a prompt composed of the current memory (including the status of the agent, status of environment obje cts, records of past robot actions and tasks, and etc.) and the instruction will be fed to the planner to guide the next action decision [ 6 , 13 ]. Among them, the structured memory provides a global viewpoint to avoid repeated observation and exploration, which is instrumental in improving the task completion eciency of the agent [25, 28]. ∗ Corresponding author . Emails: boyu@cuhk.edu.cn, meng.li@pku.e du.cn (b ) ( c) Environment Description : {'object': 'Egg', 'state': 'cooked', 'position': 'on countertop’} {‘object’: ‘Pan’, ‘state’: ‘heated’, ‘position’: ‘on stove‘} … Instruction: T ask: Place a sliced potato in the sink. Te l l the sequence of actions to accomplish the task. Step 1: find a knife, Ta s k History : Human: T o heat a slice of potato and place it in t he sink. Robot: 1. find a knife, …, 20. put down the potato Human: Put a cooked potato slice in to the sink. Robot: 1. find a butter knife, …, 14. put down the potato Output : Step 2: find a potato Agent Stat us Environment Instruction Ta s k Histor y LLM Planner Action Co mpletion & Memory Update Agent Status : Hi there, I‘m a robot operating in a home. … Her e is a description of different objects in the environment: Memory for Embodied Planning Latency ( s) Success Rat e (%) Latency (s) Success Rate (%) (a) Relevant Segments Retrieval Figure 1: (a) An example of embo died planning with LLM planner . In each step, a prompt composed of retrie ved mem- ory and instruction is given to the LLM planner . With the number of retrieved memor y segments increasing, the suc- cess rate and prelling latency both increase, evaluated on ALFRED dataset with (b) Q wen-14B and (c) Qwen-32B (IN T4). Howev er , in contrast to the relatively short generated action (less than 10 tokens), the comprehensiv e memory can result in extremely long pr ompts, which can be up to tens of thousands of tokens [ 31 , 34 ]. A s shown in Figure 1 (b) and (c), although more retrieved memor y segments 1 can provide more information to the LLM and lead to a higher success rate (SR), it also leads to substantial prelling time, which becomes the dominant factor in planning latency . T o accelerate this process, a key observation is that the same memory segments are frequently accessed across dierent queries and planning steps [ 2 , 27 , 32 ]. For instance, the location and state of a foundational object like a table might b e relevant to multiple actions, such as placing a cup on it or cleaning it. In LLM inference domain, a common optimization is to cache the Key- V alue (KV) pairs upon their rst computation [ 5 , 17 ]. In subsequent reasoning steps, the system can directly retrieve these pre-computed KV pairs for the memory blo cks. This is widely used in applications such as Retrieval- Augmented Generation (RA G) to avoid redundant computation [10, 32]. 1 Following [ 3 , 9 , 13 , 36 ], embodied memory is highly structured and can be divided into memor y segments. As shown in Figure 1(a), according to memor y categor y , a memory segment can be the status of one environment object, the recording of one history task, and so on. Through promising, this caching paradigm faces a fundamental challenge when applied to emb odied planning. Unlike the typi- cal LLM inference, which usually processes static text blocks, the various forms of memory in embodied scenarios are often highly dynamic and fr equently updated [ 13 , 28 ]. For instance , after a robot executes the action “pick milk from the table” , the memory related to the milk changes, and the state of the table also changes (it no longer holds the milk). After each action, only the pr ex before the updated memory segment can be reused, while the cache for all subsequent tokens contains invalid information and must be recal- culated [ 10 , 32 ]. This sever ely undermines the acceleration benets. T o this end, this paper tackles a core problem: within embo died scenarios, how to construct and manage memory eciently in the face of its frequent updates, thereby impr oving planning eciency . T o address these challenges, we propose a KV -Cache-Centric memory management system for ecient embodied planning. First, in terms of memory construction, we de vise a Static-dynamic Mem- ory Management scheme to mitigate KV cache invalidation caused by memory updates. This me chanism groups memory segments by their changing frequency and performs K V computation for dier- ent groups at dierent granularities. Second, to reduce the impact of cross-attention ignorance between dierent groups, we propose Multi-hop Memory Re-computation to recover the interactions be- tween important memories. Dierent from pre vious methods that recompute tokens at specic p ositions, this technique dynamically selects important memor y segments for re-computation according to current quer y and environmental context. Third, we nd that under K V recomputation paradigm, the cost of K V loading and recomputation is highly imbalance d across LLM layers, creating pipeline bubbles in traditional loading-computation-parallel sched- ules. T o tackle this, we design a Layer-balanced Memory Loading strategy that orchestrates the workload across layers, eectively minimizing idle time and maximizing hardware utilization. Our main contributions can be summarized as follows: • W e provide a detailed analysis of the fundamental dier- ences in memor y construction and management between embodied planning and conventional LLM inference. • W e propose static-dynamic memor y construction to mini- mize K V cache invalidation, a multi-hop memory re-computation mechanism to preser ve memor y interconnection, and a layer- balanced loading scheduler to optimize hardwar e utilization. • Extensive experiments show that KEEP achieves 2.68 × speedup over text-based memory methods on ALFRED benchmark. Compared with K V re-computation method CacheBlend, KEEP also achieves 4.13% SR impro vement and 1.90 × time- to-rst-token (T TFT) reduction. 2 Background The design of memory is pivotal for enabling agents to learn from past experiences and improv e planning performance [ 13 , 30 ]. Ex- isting memory construction approaches can be broadly categorized into thr ee paradigms: i) Parametric Memory involves ne-tuning models on data collected from sp ecic tasks or environments to embed memor y directly into the model weights [ 33 ]. But it incurs signicant training ov erhead and often leads to catastrophic for- getting and generalization loss [ 35 ]. ii) Context Memor y stores In v al i d M e m o r y (a) Fu l l K V R e - c o m p u te : sav e r aw te xt as m e m o r y M e m o r y Ch an g e (b ) Pr efi x Cach i n g : c al cu l ate th e K V cac h e of t h e wh ole m em or y (c ) Ful l Re u se / K V r e - co m p u tati on : cal cu l ate K V cac h e i n d i v i d u al l y i n fi xed - si ze b l oc ks (d ) K E E P: c al c u l ate K V c ac h e o f stat i c / d y n am i c m e m o r y i n d i ff e r e n t g r an u l ar i ty KV R e u se M em or y In v al i d ation D y n am i c g r ou p s S tat i c gr o u p s D y n am i c gr o u p s S tat i c gr o u p s --- High High Low Text B l o c k K V Cac h e B l o c k M e m o r y Ch an g e Posi tion Figure 2: Comparison with previous K V reuse metho ds on memory construction. memory directly as textual information [ 13 , 28 ]. Although straight- forward and training-free, the long context length results in sub- stantial computational redundancy during prelling [ 2 , 15 ]. iii) Latent Memory compresses memory into a xed-size latent state, such as representative summary tokens [ 29 , 34 , 35 ]. Howev er , the limited representational capacity often leads to inevitable loss of details and premature forgetting of critical past ev ents [19]. In contrast to the abov e, this work employs a KV -Centric Mem- ory , storing memory as Key- V alue (K V) cache pairs of the LLM, which is training-free and maintains memory integrity . However , its scalability becomes a challenge: the memory storage gro ws linearly with the number of memory tokens, which can quickly exceed the capacity of device memory (e.g., GP U HBM) [ 8 , 16 , 17 ]. T o address this, following [ 17 , 24 , 32 ], our system utilizes slower but higher-capacity memory (e.g., CP U RAM) for KV storage and only loads KV pairs of relevant memory segments to the GPU in each inference. For ecient KV loading, we orchestrate a layer-grained pipeline to overlap KV loading and computation, thereby mitigating the latency cost. W e will further discuss this in Section 4.3. 3 When K V Reuse Me ets Embo died P lanning As established in Section 1 and 2, a common optimization for reusable memory is to cache its KV to avoid repeated computa- tion. Existing KV reuse methods can be categorized as follows. i) Prex Caching reuses the K V cache only for the identical prex of the LLM input, which guarantees output quality but requires an exact match of the prex [ 12 , 37 ]. For scenarios like RAG, where memory selection varies with dierent queries (which is also the case in embodied planning), ii) Full KV Reuse segments long context into xed-length blocks and calculates their KV states in- dividually , enabling more exible KV reuse [ 5 , 10 ]. T o address the loss of cross-attention between these independently cache d blocks, iii) K V Recomputation methods identify a small ratio of impor- tant tokens in model inference and selectively recompute their KV cache in subsequent layers [ 1 , 7 , 32 ], thus increasing model accu- racy with negligible extra computation cost. While these methods have shown great success in general LLM inference, the y face two stability challenges in embodied planning. (a) (b) Figure 3: Impact of dierent block sizes for K V recompu- tation metho ds, evaluated on ALFRED with CacheBlend method using (a) Qwen-14B and (b) Qwen-32B (IN T4). Us e r Qu e r y Pl an n i n g A c c u r ac y K V_ 1 K V_ 2 K V_ 3 K V_ 4 KV R e u se (a) Ful l K V Re - co m p u te R e c o mp u te al l to ke n s O n l y r e u se th e KV o f p r e f i x (b ) Pr e fi x Cac h i n g No r e c o mp u tati o n , i g n o r e al l c r o ss - attenti o n (c ) Fu l l R e u se R e c o mp u te i n i ti al + f i an l to ke n s o f e ac h b l o c k (d ) E PI C R e c o mp u te to ke n s b ase d o n KV d i sc r e p an c y (e ) Cac h e B l e n d (f) KE E P High Low High Low High High High Low Low High Low High Qu e r y Qu e r y Qu e r y Qu e r y Qu e r y Qu e r y R e c o mp u te se g me n ts ba se d o n i mp o r tan c e p r o p ag ati o n i n a mu l ti - h o p man n e r Figure 4: Metho d comparison on K V recomputation. Challenge 1: For memor y construction, the coarse-grained, xed-sized block partitioning fails to align with the ne- grained and rapid updating embodie d memory . As shown in Figure 2, for prex caching, a single memor y update will make the whole following memory invalid. For full reuse or KV recomputa- tion methods, which use xed-size coarse-grained blocks to save KV , for a minor update, the K V after the update position in the same block must be invalidated and recomputed. While decreasing the block size could reduce this invalidation, it severs the cross- attention ignorance between dierent blo cks, leading to a drop in planning accuracy , which is shown in Figure 3. So a trade-o between memory management granularity and memory intercon- nection preservation is nee ded. Challenge 2: For K V recomputation, the static recompu- tation paradigm of existing methods fails to adapt to the dynamic and context-dependent memory imp ortance in em- bodied scenarios. As shown in Figure 4, in planning process, full KV re-computation and prex caching show lo w KV reuse , leading to repeated computation and high T TFT . Full reuse methods [ 5 ] ignores all cr oss-attention between groups, leading to lo w accuracy . KV recomputation approaches like EPIC [ 7 ], heuristically recom- pute tokens at xed positions ( e.g., the start and end of a block). And CacheBlend [ 32 ] selects tokens based on the discrepancy be- tween the full-attention KV state and the cached K V state , in which the recomputation token is only decided by its prex. However , in embodied planning, the memory relevance is highly dependent on 1 2 3 7 4 8 5 6 Step ID Memory Updates per Ste p Figure 5: Dierent memories show dierent update frequen- cies. Here we use a coarse-graine d memory classication as an example. the query and the whole memory context. For instance, a memory segment {“object”:“key” , “p osition”:“on the table” , ...} is critically im- portant for the task “unlock the door” but only marginally relevant for the task “nd the door” . A static K V recomputation mechanism might overlook important memor y interconnections or waste com- putation regardless of the memory rele vance in current situation. So a dynamic recomputation strategy that actively chooses impor- tant memory interconnections is essential for achieving both high accuracy and eciency . W e will further discuss this in Se ction 4.2. Overview . In this work, we propose a KV -centric memory man- agement system for ecient embodied planning. T o minimize K V cache invalidation while preserving interconnections, we propose Static-Dynamic Memor y Construction (Section 4.1) to group mem- ory by update frequency and manage dier ent groups with dierent granularities. T o recover critical memory interactions, we propose Multi-hop Memory Re-computation (Section 4.2) to conduct mem- ory recomputation based on the quer y and current context. For the large K V cache footprint, we propose a hierarchical storage strategy with Layer-balanced Memory Loading (Section 4.3) that leverages a pipelined schedule for better scalability and eciency . 4 Method 4.1 Static-dynamic Memory Construction Motivation. As discussed in Section 3, existing K V reuse methods split long context into xed-length blocks to construct memory . In embodied planning, with dierent block sizes, this strategy either shows high re-computation costs because of memor y updates or shows planning accuracy drops because of sev ere cross-attention ignorance. Howev er , we nd that the up date frequency of dierent embodied memories actually varies a lot. As shown in Figure 5, memories such as the status of environmental objects usually show a high updating frequency . And memories such as completed tasks change rarely , as it is just a record of the agent’s working history . In addition, even the memory segments within the same cluster have various changing fr e quencies. For e xample, the changing frequency of the position of a table is much lower than the position of a book. So, for dierent memory , using xed memor y management granularity is sub-optimal. Based on this, we propose the Static-Dynamic Memor y Con- struction mechanism. Its core principle is to manage memory based on changing frequency: highly dynamic memory segments are cal- culated separately to preve nt unnecessary K V cache invalidation, while relatively static memories are grouped and calculated KV together to preserve their intrinsic contextual relationships. T o b e specic, we employ a sentence enco der to cluster memor y into groups base d on semantics 2 . A group is classied as static if all its memor y segments have remained unchanged for the recent 𝑡 steps. For these groups, the KV cache is computed with full cross- attention between segments within the group, thereby pr eserving their rich interconnections. Conversely , a group is labeled as dy- namic if any of its memory has been updated within the last 𝑡 steps. The K V cache for a dynamic group is compute d individually p er segment, preventing a single update from invalidating the cache of the entire gr oup. A static group will transition to a dynamic state if any of its members are update d. Conversely , a dynamic group that remains stable for 𝑡 steps will be changed to a static group. When a group ’s category changes, we recompute its K V cache according to the new computation paradigm. This will not introduce much cost, as it happens at a low frequency (usually once in tens of steps). In practice, we set 𝑡 = 10 , which is a typical length of one task. T o adapt to the dierent KV computation mechanisms for dier- ent groups, during the retrieval phase for a given query , we also apply dierent strategies. For static groups, retrieval is performed at the group lev el; the entire group is selected as an interconnected unit. For dynamic groups, it is performed at the memory segment level for better exibility . This hybrid strategy eectively avoids the huge KV invalidation caused by dynamic memory and the memory interconnection igno- rance between memory segments in static groups. How ever , the interconnection between dynamic memor y segments and dierent groups is still not considered. W e solve this by K V re-computation on important memories, further discussed in Section 4.2. 4.2 Multi-hop Memory Re-computation Motivation. As discussed in Section 3, existing K V reuse methods use static paradigms to select important memories for recomputa- tion. Howev er , in embodied planning, a single memor y segment’s importance often depends on the query and memor y context. For example, as shown in Figur e 6, the important memory segment of “table” is hard to nd unless the logic chain “Locked Door -> K ey -> T able” is fully used. So, a multi-hop evaluation me chanism is necessary for accurately quantifying memor y importance. Based on this, we propose Multi-hop Memory Re-computation to identify and recompute critical memories. Following prior work [ 32 ], we utilize attention distributions to evaluate memory im- portance. Howe ver , unlike methods that study the attention dis- tribution at xed p ositions [ 7 ]. Our approach evaluates memor y importance using importance propagation. As sho wn in gure 6, according to attention distribution, it rst identies memories im- portant to the query , then uses these memories to nd secondary important memories critical to them, and iterates this process to uncover crucial inter-memor y relationships. T o be spe cic, after obtaining the attention scores at layer 𝑖 , we proceed as follows: • Initialization : The average attention scores between the query and all memories to be evaluated ar e used as the initial importance scores for the memories. • Importance Propagation : A ratio of top 𝑟 𝑖 memories based on current importance scores is selected as the relevant set. 2 Here we use sentence-transformers-mpnet-base-v2 [ 22 ] as the sentence encoder . Actually , any widely used sentence encoder is reasonable here. {“ object ” : “ k e y ” , “ posi t i on” : “ on t he t ab l e” } {“ ob ject ” : “ do or ” , “ s t a t us” : “ l ock ed” } {“ object ” : “ t ab l e” , “ posi t i on” : “ i n t he k i t chen” } {“ object ” : “ TV ” , “ s t a t us” : “ …” } {“ object ” : “ t oil e t ” , “ posi t i on” : “ …” } O pe n the do or 0 . 7 7 0 . 0 1 0.02 0 . 6 6 0 . 0 2 0 . 0 1 0 . 2 1 0 . 6 0 0 . 0 3 0 . 0 2 ME M 1 ME M 2 MEM 3 ME M 4 ME M 5 Quer y Gr ou n d truth actio n : “ Go t o the kit ch e n ” Figure 6: The memory importance evaluation works in a multi-hop manner . Here we show an example of imp ortance propagation with ve memory segments. The numb er above the memory connection is the normalize d cross-attention score between two memor y segments (some minor attention score is not shown). The red arrows show that we nd impor- tant memories in a multi-hop manner . The importance scores of all memories are then updated by averaging the cross-attention w eights from the curr ent relevant memory set. This step eectively allows important memories to “propagate ” their imp ortance to other memories critical to them. • Convergence Check : Steps of importance propagation are repeated until the composition of the relevant memory set stabilizes between iterations. • Selective Recomputation : In layer 𝑖 + 1 , only KV cache for memories in the nal stabilized relevant set is recomputed. Following CacheBlend [ 32 ], we recompute all memories in the rst layer and gradually reduce the recomputation ratio 𝑟 𝑖 of subsequent layers. Finally , we maintain a r elatively lo w average r ecomputation ratio 𝑟 while preserving accuracy by focusing recomputation on the most critical memory discovered through multi-hop importance propagation. W e will discuss the impact of 𝑟 in the ablation study . System advantage : Another key dierence between our strat- egy and e xisting kv recomputation methods [ 10 ] is on the recompu- tation granularity . W e evaluate memory importance and conduct recomputation in memory segment granularity , rather than to- ken granularity [ 32 ]. This enables ecient, contiguous loading of only the non-r ecomputed K V blocks. In contrast, token-granularity methods must load the entire cache and perform in-place updates for recomputed tokens to preserve storage continuity , incurring signicantly higher I/O overhead. Crucially , our method maintains accuracy despite the coarser granularity by accurately identifying critical memory by importance propagation. And the propagation process will not introduce much latency cost, and it can be calcu- lated in parallel with the MLP of the same layer . 4.3 Layer-balanced Memory Loading Motivation. As discussed in Section 2, we store the KV cache memory on slower but higher-capacity memory (e.g., CPU RAM) to solve the scalability problem. Howev er , this will introduce extra KV loading cost before the attention computation of each layer . T o hide this cost, a common technique [17, 18, 23] is to parallelize the computation of the current lay er with the KV loading for the (a) (b) Figure 7: Unbalanced K V loading and computation cost of dierent layers for (a) Qwen-14B and (b) Q wen-32B (IN T4). 7* KV Loading Computation 1 1 2 2 3 3 4 4 5 5 6 6 1 2 1 † 7 7 1 2 3 3 4 4 5 † 5 6 7 7 1 3* 2 4* 3 7* 4 6 † 7 † 7 (a) (b) (c) 5 6 5 6 KV Loading Computation KV Loading Computation 2 † 5* 3 † 7* 4 † 5* 6* Figure 8: Pipeline comparison b etween (a) separate KV load- ing and computation, (b) computation parallel with KV load- ing of the next layer , and (c) layer-balanced memory loading. Here we use a 7-layer mo del as an example . 𝑛 ∗ means load the memory which is guaranteed not to be recompute d in layer 𝑛 . 𝑛 † means nish loading the K V needed in layer 𝑛 . next layer 3 . Howev er , we nd that this strategy becomes inecient when combined with our recomputation mechanism. As shown in Figure 7, the workload across layers is highly imbalanced: earlier layers, which recompute a larger proportion of memories, have less KV data to load. Conversely , later layers, with a lower r ecom- putation ratio, must load a much larger portion of KV cache. As illustrated in Figure 8 (b), this imbalance creates pipeline bubbles both in K V loading for early layers and computation in later lay- ers. Consequently , the inherent imbalance prevents the standard pipeline from fully amortizing the loading overhead. T o address this, we propose Layer-balanced Memor y Loading. Our approach is grounded in a key obser vation: for any given memory segment, if it is not recomputed in an earlier layer , it will not be recomputed in any subsequent layers. This is because the input hidden state corresponding to that memory is discarded after the not-to-r ecompute decision. This makes it imp ossible to generate new KV cache for this memory in later layers. Consequently , K V cache for such memories must be loaded for all subsequent layers. Leveraging this, our strategy proactively manages the KV load- ing pipeline, which is shown in Figure 8 (c). In earlier layers, if the KV loading for the next lay er nishes before the current layer’s com- putation, the idle loading engine immediately begins pre-loading the K V cache for memories guaranteed not to be recompute d in 3 In fact, when combined with KV re-computation, we can not know the KV to load next layer before KV importance evaluation of this layer . Here we just load the memor y of the next layer according to current layer, as the memory to recompute will not change much between adjacent layers. However , for later layers, the memory nee ded to load will be more dierent. T able 1: Evaluation on ALFRED dataset. Methods Model SR T TFT LLM-Planner [21] GPT -3 16.45% - FLARE [11] GPT -4 40.05% - KARMA [28] GPT -4o 43.00% - Lo TA (Full Recompute) [3] Qwen-2.5-14B 44.63% 0.410s Lo TA + Full Reuse [5] Qwen-2.5-14B 34.41% 0.210s Lo TA + CacheBlend [32] Qwen-2.5-14B 39.36% 0.363s Lo TA + KEEP Qwen-2.5-14B 44.30% 0.236s Lo TA (Full Recompute) [3] Qwen-2.5-32B (IN T4) 45.81% 1.213s Lo TA + Full Reuse [5] Qwen-2.5-32B (IN T4) 35.72% 0.602s Lo TA + CacheBlend [32] Qwen-2.5-32B (IN T4) 41.37% 1.209s Lo TA + KEEP Qwen-2.5-32B (IN T4) 45.50% 0.635s future layers. This pre-loading continues until current layer’s com- putation nishes. This strategy both eliminates the loading bubble in the early stages and reduces the K V loading burden for later layers, thus also eliminating the computation bubble for later lay- ers. This cross-layer , proactive pre-loading mechanism eectively redistributes the loading overhead from later layers to underutilized earlier layers, resulting in a more balanced execution pipeline. 5 Implementation W e implement KEEP on top of vLLM [ 12 ] with about 2.8K lines of code in Python based on PyT orch v2.0. W e integrate our metho d into the LLM serving engine through three interfaces: • load_memory(memory_id, layer_id) -> KV Cache: given a memory id, KEEP loads its KV cache of an indicated layer . • prefill_layer(input, layer_id, KV cache) -> output, updated KV cache: KEEP takes the input and KV cache for an indicated layer to recompute K V of important memories. Then it outputs the input hidden state for the next lay er and the updated K V cache for decoding process. • importance_evaluation(layer_id, memory_ids, attention) -> memory_ids: KEEP uses the attention scores to identify the important memories to be re-computed in the next layer . For load_memory , we use a hash table to record the storage place of each memory . If a nee ded memor y is not in GP U, we use torch.cuda() to load it from CP U RAM. In model inference , thr ee threads are used to pipeline the computation ( prefill_layer ) of layer 𝑖 , the mem- ory importance evaluation ( importance_evaluation ) of layer 𝑖 , and the KV cache loading ( load_memory ) of layer 𝑖 + 1 and the not- recomputed memories in future layers. W e also call a synchronize() function to ensure two dependencies: 1) the memory importance evaluation for layer 𝑖 and memor y loading for layer 𝑖 + 1 should nish before the computation of layer 𝑖 + 1 ; 2) the attention com- putation of layer 𝑖 should nish before the memory importance evaluation of layer 𝑖 . 6 Experiments 6.1 Experiment Setup W e evaluate KEEP on ALFRED [ 20 ] and W AH-NL [ 3 ] benchmark, using the Qwen-2.5 model family [ 26 ]. In each step, the agent can access the obje ct states in the environment, the agent state, and the task history [ 3 ]. Then the agent updates its memory and uses T able 2: Evaluation on W AH-NL dataset. Methods Model Sub-SR TTFT Lo TA (Full Recompute) [3] Qwen-2.5-14B 19.58% 0.362s Lo TA + Full Reuse [5] Qwen-2.5-14B 9.08% 0.203s Lo TA + CacheBlend [32] Qwen-2.5-14B 16.21% 0.341s Lo TA + KEEP Qwen-2.5-14B 19.52% 0.226s Lo TA (Full Recompute) [3] Qwen-2.5-32B (IN T4) 20.48% 1.221s Lo TA + Full Reuse [5] Qwen-2.5-32B (IN T4) 12.74% 0.578s Lo TA + CacheBlend [32] Qwen-2.5-32B (IN T4) 16.88% 1.148s Lo TA + KEEP Qwen-2.5-32B (IN T4) 20.25% 0.601s LLM planner to predict the next action. For action completion, we follow [ 3 ] and [ 31 ], using the agent action APIs embedde d in the platform. Following [ 20 ] and [ 3 ], we evaluate planning accuracy using Success Rate (SR) and Subgoal success rate (Sub-SR), which means the ratio of tasks/sub-tasks that the agent can complete. For planning eciency , we evaluate T TFT , as prelling time accounts for over 90% of the planning latency . Our memory retrieval strategy follows [ 3 ]. Each mo del is deployed on one NVIDIA A6000 GP U. For Qwen-32B model, we use IN T4 weight-only quantization [ 14 ]. 6.2 Main Results T able 1 and 2 show the evaluation r esults on ALFRED and W AH- NL benchmark. On ALFRED, compared with traditional methods FLARE [ 11 ] and KARMA [ 28 ], KEEP shows 4.25% SR and 1.30% SR improvement with a much smaller LLM planner , by timely record- ing and updating memory in each action step. Compared with LOT A (full recompute) [ 3 ], KEEP shows 1.74 × and 1.91 × T TFT reduc- tion using Qwen-14B and Q wen-32B, with negligible accuracy loss. Compared with the full r euse method [ 5 ] and CacheBlend, KEEP shows 9.89% and 4.94% SR improvement on 14B model and 9.78% and 4.13% on 32B mo del, by using importance propagation to re- cover cross-attention between important memories. Compared with CacheBlend, KEEP also shows 1.54 × and 1.90 × T TFT reduction on 14B and 32B models, by using static-dynamic memory construction to avoid KV invalidation. On W AH-NL, compared with CacheBlend, KEEP also shows 3.31% and 3.37% Sub-SR improvement, and 1.51 × and 1.91 × T TFT reduction. Latency comparison with dierent numb ers of retrieved memory segments. As discussed in Section 1, more retrieved memory segments can provide more information to the LLM plan- ner , while it will also introduce a longer prompt and higher latency . Here we e valuate how T TFT scales with the number of retrieved memory segments on ALFRED benchmark. As shown in Figure 9, the latency of full computation and prex caching increases rapidly with segments number . The latency of CacheBlend also gr ows as more memory segments contain more memory updates, causing more K V invalidation. How ever , the T TFT of KEEP increases slower than other methods, as static-dynamic memory construction can reduce memory invalidation. With 40 segments, KEEP shows 2.19 × and 2.68 × T TFT reduction ov er full recomputation, and 1.56 × and 2.17 × T TFT reduction over CacheBlend, on 14B and 32B model. 5 10 20 30 40 5 10 20 30 40 5 10 20 30 40 7B 14B 32B # R e trieved Memory Segments Figure 9: Latency comparison with dierent numbers of re- trieved memor y segments. T able 3: Individual inuence of our methods. Methods SR T TFT KEEP 44.30% 0.230s w/o static-dynamic memory construction 37.36% 0.355s w/o multi-hop memory re-computation 41.78% 0.228s w/o layer-balanced memory loading 44.30% 0.273s Figure 10: Ablation study on dierent recomputation ratios. 6.3 Ablation Study Individual inuence of our methods. The individual inuence of our methods is shown in T able 3, evaluated on ALFRED . Miss- ing static-dynamic memory construction will introduce a 6.94% SR drop, because of ignoring cross-attention between static memory segments. It will also introduce 1.54 × T TFT increase, as manag- ing K V in xed-size blo cks will introduce high KV invalidation, which ne eds to be re-computed. Missing multi-hop memor y re- computation introduces a 2.52% SR drop, as the cross-attention between importance memory can not be fully recovered without importance propagation. Missing layer-balanced memory loading introduces 1.20 × T TFT increase, which comes from memory load- ing bubbles in early layers and computation bubbles in latter layers. Impact of recomputation ratios. The individual inuence on recomputation ratios is shown in Figure 10, evaluated on ALFRED using Qwen-14B. KEEP shows robust performance across dier- ent recomputation ratios. KEEP maintains high SR even with a low recomputation ratio, as the cross-attention between the most important memories can b e recover ed by multi-hop memor y recom- putation. KEEP maintains a low T TFT for a high recomputation ratio, as the latency of recomputation is eectively o verlapped with KV loading process, r educing the impact on overall inference speed. 7 Conclusion W e propose KEEP, a KV -Cache-centric memor y management sys- tem for ecient embodie d planning. T o avoid high memory invali- dation caused by memory update in embodie d scenarios, we pro- pose static-dynamic memory management to manage dynamic and static memory at dierent granularities. T o recov er cross-attention between important memories, we propose multi-hop memory re- computation to nd important memories by importance propaga- tion and recompute their KV cache. W e also propose layer-balanced memory loading to balance the K V loading and computation over- head in dierent layers. Compared with CacheBlend, KEEP shows 4.13% SR improvement and 1.90 × T TFT reduction on ALFRED. 8 Acknowledgments This work was supported in part by New Generation Articial Intelligence-National Science and T echnology Major Project (No. 2025ZD0122502), in part by Beijing Municipal Science and T ech- nology Program under Grant Z241100004224015, in part by NSFC (No. 92464104, 62495102), in part by the National K ey Research and Development Program under Grant 2024YFB4505004, and in part by Shenzhen Key Industr y R&D Project (No. ZDCY20250901105036006): Research and Dev elopment of High-Eciency Edge Chips for "Brain- Cerebellum" Coordination in Embodied Intelligence. References [1] Ziyi Cao, Qingyi Si, Jingbin Zhang, and Bingquan Liu. 2025. Sparse Attention across Multiple-context KV Cache. arXiv preprint arXiv:2508.11661 (2025). [2] Y aoqi Chen, Jinkai Zhang, Baotong Lu, Qianxi Zhang, Chengruidong Zhang, Jingjia Luo, Di Liu, Huiqiang Jiang, Qi Chen, Jing Liu, et al . 2025. RetroInfer: A V ector-Storage Approach for Scalable Long-Context LLM Inference. arXiv preprint arXiv:2505.02922 (2025). [3] Jae- W o o Choi, Y oungwoo Y oon, Hyobin Ong, Jaehong Kim, and Minsu Jang. 2024. Lota-bench: Benchmarking language-oriented task planners for embodied agents. arXiv preprint arXiv:2402.08178 (2024). [4] Huang Fang, Mengxi Zhang, Heng Dong, W ei Li, Zixuan W ang, Qifeng Zhang, Xueyun Tian, Y ucheng Hu, and Hang Li. 2025. Robix: A unied model for robot interaction, reasoning and planning. arXiv preprint arXiv:2509.01106 (2025). [5] In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. 2024. Prompt cache: Modular attention reuse for lo w-latency inference. Proceedings of Machine Learning and Systems 6 (2024), 325–338. [6] Ran Gong, Qiuyuan Huang, Xiaojian Ma, Y usuke Noda, Zane Durante, Zilong Zheng, Demetri T erzopoulos, Li Fei-Fei, Jianfeng Gao, and Hoi V o. 2024. Minda- gent: Emergent gaming interaction. In Findings of the A ssociation for Computa- tional Linguistics: NAACL 2024 . 3154–3183. [7] Junhao Hu, W enrui Huang, W eidong W ang, Haoyi W ang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and T ao Xie. 2024. EPIC: Ecient Position-Independent Caching for Serving Large Language Models. arXiv preprint arXiv:2410.15332 (2024). [8] Jie Hu, Shengnan Wang, Yutong He, Ping Gong, Jiawei Yi, Juncheng Zhang, Y ouhui Bai, Renhai Chen, Gong Zhang, Cheng Li, et al . 2025. Ecient Long- Context LLM Inference via KV Cache Clustering. arXiv preprint (2025). [9] Y uheng Ji, Huajie T an, Jiayu Shi, Xiaoshuai Hao, Y uan Zhang, Hengyuan Zhang, Pengwei W ang, Mengdi Zhao, Y ao Mu, Pengju An, et al . 2025. Robobrain: A uni- ed brain model for robotic manipulation from abstract to concrete. In Proceedings of the Computer Vision and Pattern Re cognition Conference . 1724–1734. [10] Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Shufan Liu, Xuanzhe Liu, and Xin Jin. 2024. Ragcache: Ecient knowledge caching for retrieval-augmented generation. A CM Transactions on Computer Systems (2024). [11] T aewoong Kim, Byeonghwi Kim, and Jonghyun Choi. 2025. Multi-Modal Grounded Planning and Ecient Replanning For Learning Embodied A gents with A Few Examples. In Proceedings of the AAAI Conference on A rticial Intelligence , V ol. 39. 4329–4337. [12] W oosuk K won, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Ecient memory management for large language model serving with pagedattention. In Proceedings of the 29th symp osium on operating systems principles . 611–626. [13] Mingcong Lei, Honghao Cai, Binbin Que, Zezhou Cui, Liangchen T an, Junkun Hong, Gehan Hu, Shuangyu Zhu, Yimou Wu, Shaohan Jiang, et al . 2025. RoboMemory: A Brain-inspired Multi-memor y Agentic Framework for Lifelong Learning in Physical Embodie d Systems. arXiv e-prints (2025), arXiv–2508. [14] Ji Lin, Jiaming Tang, Haotian T ang, Shang Yang, W ei-Ming Chen, W ei-Chen W ang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. A wq: Activation-aware weight quantization for on-device llm compr ession and accel- eration. Proceedings of machine learning and systems 6 (2024), 87–100. [15] Guangda Liu, Chengwei Li, Zhenyu Ning, Jing Lin, Yiwu Y ao, Danning K e, Minyi Guo, and Jieru Zhao. 2025. FreeK V: Boosting K V Cache Retrieval for Ecient LLM Inference. arXiv preprint arXiv:2505.13109 (2025). [16] Xiang Liu, Zhenheng T ang, Peijie Dong, Zeyu Li, Yue Liu, Bo Li, Xuming Hu, and Xiaowen Chu. 2025. Chunkkv: Semantic-preserving kv cache compression for ecient long-context llm inference. arXiv preprint arXiv:2502.00299 (2025). [17] Y uhan Liu, Hanchen Li, Kuntai Du, Jiayi Y ao, Yihua Cheng, Y uyang Huang, Shan Lu, Michael Maire, Henry Homann, Ari Holtzman, et al . 2023. Cachegen: Fast context loading for language model applications. CoRR (2023). [18] Zaifeng Pan, Ajjkumar Patel, Zhengding Hu, Yipeng Shen, Y ue Guan, W an-Lu Li, Lianhui Qin, Yida W ang, and Yufei Ding. 2025. K VFlow: Ecient Prex Caching for Accelerating LLM-Based Multi-Agent W orkows. arXiv preprint arXiv:2507.07400 (2025). [19] Y aorui Shi, Yuxin Chen, Siyuan W ang, Sihang Li, Hengxing Cai, Qi Gu, Xiang W ang, and An Zhang. 2025. Look Back to Reason For ward: Revisitable Memory for Long-Context LLM Agents. arXiv preprint arXiv:2509.23040 (2025). [20] Mohit Shridhar, Jesse Thomason, Daniel Gordon, Y onatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoy er , and Dieter Fox. 2020. Alfred: A b enchmark for interpreting grounded instructions for ev eryday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 10740–10749. [21] Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, W ei-Lun Chao, and Y u Su. 2023. Llm-planner: Few-shot grounded planning for embodied agents with large language models. In Proceedings of the IEEE/CVF international conference on computer vision . 2998–3009. [22] Kaitao Song, Xu T an, Tao Qin, Jianfeng Lu, and Tie-Y an Liu. 2020. Mpnet: Masked and permuted pre-training for language understanding. Advances in neural information processing systems 33 (2020), 16857–16867. [23] Hanshi Sun, Li-W en Chang, W enlei Bao, Size Zheng, Ningxin Zheng, Xin Liu, Harry Dong, Yuejie Chi, and Beidi Chen. 2024. Shadowkv: Kv cache in shadows for high-throughput long-context llm inference. arXiv preprint (2024). [24] He Sun, Li Li, Mingjun Xiao, and Chengzhong Xu. 2025. Breaking the Bound- aries of Long-Context LLM Inference: Adaptive K V Management on a Single Commodity GP U. arXiv preprint arXiv:2506.20187 (2025). [25] Huajie T an, Xiaoshuai Hao, Cheng Chi, Minglan Lin, Y aoxu Lyu, Mingyu Cao, Dong Liang, Zhuo Chen, Mengsi Lyu, Cheng Peng, et al . 2025. Roboos: A hierar- chical embodied framew ork for cross-embodiment and multi-agent collab oration. arXiv preprint arXiv:2505.03673 (2025). [26] Qwen T eam et al . 2024. Qwen2 technical report. arXiv preprint 2, 3 (2024). [27] Zishen W an, Yuhang Du, Mohamed Ibrahim, Jiayi Qian, Jason Jabbour , Y ang Zhao , T ushar Krishna, Arijit Raychowdhury , and Vijay Janapa Reddi. 2025. Reca: Inte- grated acceleration for real-time and ecient cooperative embodied autonomous agents. In Proceedings of the 30th A CM International Conference on A rchitectural Support for Programming Languages and Operating Systems, V olume 2 . 982–997. [28] Zixuan W ang, Bo Yu, Junzhe Zhao, W enhao Sun, Sai Hou, Shuai Liang, Xing Hu, Yinhe Han, and Yiming Gan. 2025. Karma: A ugmenting emb odied ai agents with long-and-short term memory systems. In 2025 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 1–8. [29] Renjie W ei, Songqiang Xu, Linfeng Zhong, Zebin Yang, Qingyu Guo, Y uan W ang, Runsheng W ang, and Meng Li. 2025. Lightmamba: Ecient mamba acceleration on fpga with quantization and hardware co-design. In 2025 Design, A utomation & T est in Europe Conference (D ATE) . IEEE, 1–7. [30] Wujiang Xu, K ai Mei, Hang Gao, Juntao T an, Zujie Liang, and Y ongfeng Zhang. 2025. A-mem: Agentic memory for llm agents. arXiv preprint (2025). [31] Zebin Y ang, Sunjian Zheng, T ong Xie, Tianshi Xu, Bo Y u, Fan Wang, Jie T ang, Shaoshan Liu, and Meng Li. 2025. EcientNav: T owards On-Device Object- Goal Navigation with Navigation Map Caching and Retrieval. arXiv preprint arXiv:2510.18546 (2025). [32] Jiayi Y ao, Hanchen Li, Y uhan Liu, Siddhant Ray , Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast large language model serving for RAG with cached knowledge fusion. In Proce edings of the T wentieth European Conference on Computer Systems . 94–109. [33] W eiran Y ao, Shelby Heinecke, Juan Carlos Niebles, Zhiwei Liu, Yihao Feng, Le Xue, Rithesh Murthy , Zeyuan Chen, Jianguo Zhang, Devansh Arpit, et al . 2023. Retroformer: Retrospective large language agents with p olicy gradient optimization. arXiv preprint arXiv:2308.02151 (2023). [34] Hongli Y u, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, W einan Dai, Qiying Y u, Y a-Qin Zhang, W ei-Ying Ma, Jingjing Liu, Mingxuan Wang, et al . 2025. MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent. arXiv preprint arXiv:2507.02259 (2025). [35] Guibin Zhang, Muxin Fu, and Shuicheng Y an. 2025. MemGen: W eaving Genera- tive Latent Memory for Self-Evolving Agents. arXiv preprint (2025). [36] Hongxin Zhang, W eihua Du, Jiaming Shan, Qinhong Zhou, Yilun Du, Joshua B T enenbaum, Tianmin Shu, and Chuang Gan. 2023. Building co operative embodie d agents modularly with large language models. arXiv preprint (2023). [37] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Je Huang, Chuyue Sun, Cody_Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al . 2023. Eciently Programming Large Language Mo dels using SGLang. (2023).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment