Federated Learning for Privacy-Preserving Medical AI
This dissertation investigates privacy-preserving federated learning for Alzheimer's disease classification using three-dimensional MRI data from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Existing methodologies often suffer from unreali…
Authors: Tin Hoang
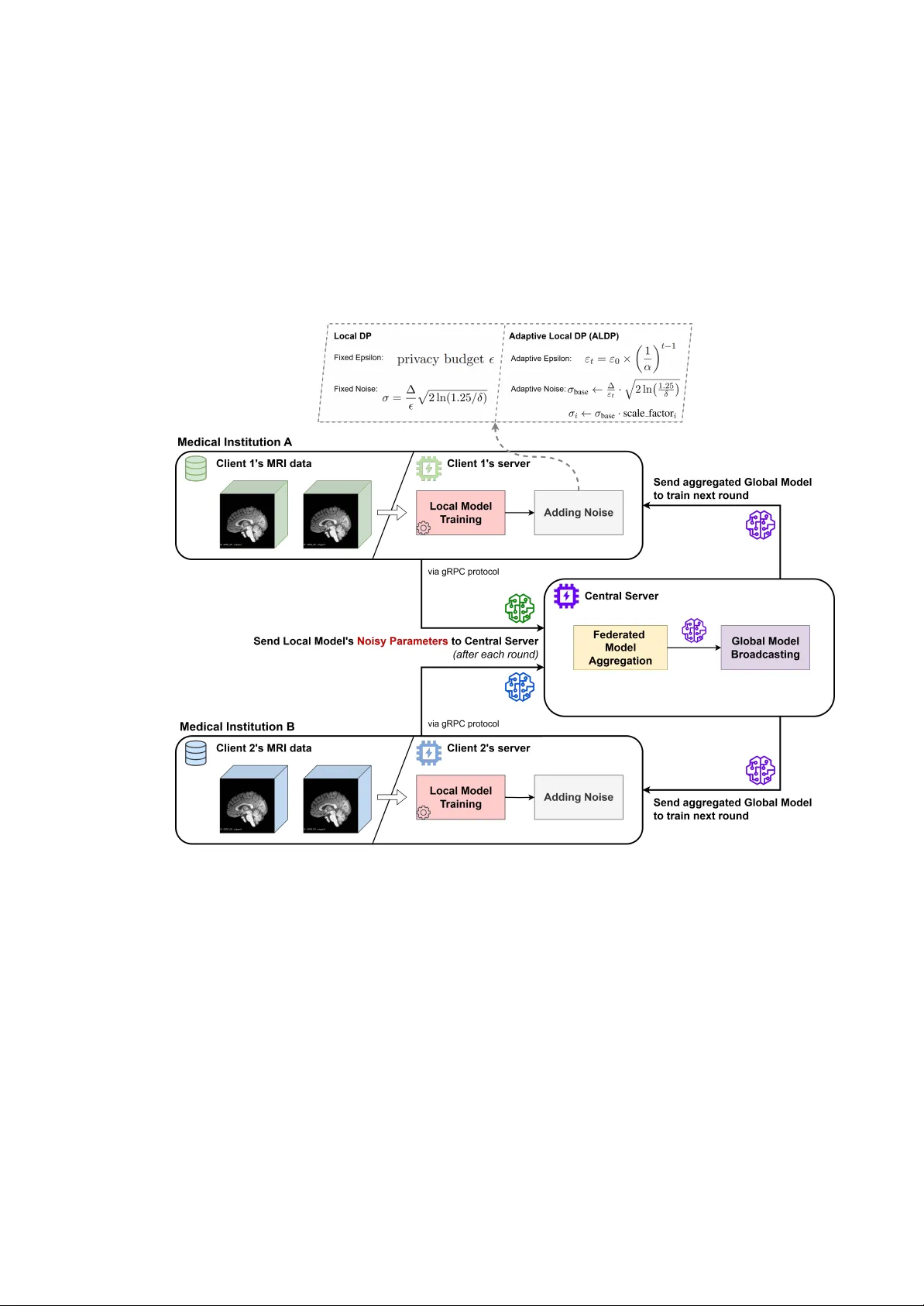
T in Hoang, MSc dissertation F ederated Lear ning f or Priv acy-Pr eser ving Medical AI T in Hoang Master of Science in Artificial Intelligence from the Uni versity of Surre y School of Computer Science and Electrical and Electr onic Engineering Faculty of Engineering and Ph ysical Sciences Uni versity of Surre y Guildford, Surrey , GU2 7XH, UK September 2025 Supervised by: Prof. Gusta vo Carneiro ©T in Hoang 2025 i T in Hoang, MSc dissertation DECLARA TION OF ORIGINALITY I confirm that the project dissertation I am submitting is entirely my o wn work and that any mate- rial used from other sources has been clearly identified and properly ackno wledged and referenced. In submitting this final version of my report to the JISC anti-plagiarism softw are resource, I con- firm that my work does not contrav ene the university regulations on plagiarism as described in the Student Handbook. In so doing I also ackno wledge that I may be held to account for any particular instances of uncited work detected by the JISC anti-plagiarism software, or as may be found by the project examiner or project organiser . I also understand that if an allegation of plagiarism is upheld via an Academic Misconduct Hearing, then I may forfeit any credit for this module or a more se vere penalty may be agreed. MSc Dissertation T itle: Federated Learning for Pri vac y-Preserving Medical AI Author Name: T in Huu Hoang Author Signature: Date: 02/09/2025 Supervisor’ s name: Prof. Gustav o Carneiro ii T in Hoang, MSc dissertation WORD COUNT Number of Pages: 91 Number of W ords: 15940 iii T in Hoang, MSc dissertation ABSTRA CT Federated learning of fers a transformati v e approach to collaborati ve medical artificial intelligence by enabling institutions to jointly de velop rob ust diagnostic models while maintaining strict patient pri vac y and data sov ereignty . This dissertation in vestigates priv ac y-preserving federated learning for Alzheimer’ s disease classification using three-dimensional MRI data from the Alzheimer’ s Disease Neuroimaging Initiati ve (ADNI). Existing methodologies often suffer from unrealistic data partitioning, inadequate priv acy guarantees, and insufficient benchmarking, limiting their practical deployment in healthcare. T o address these gaps, this research proposes a novel site- aw are data partitioning strategy that preserves institutional boundaries, reflecting real-world multi- institutional collaborations and data heterogeneity . Furthermore, an Adaptive Local Differential Pri vac y (ALDP) mechanism is introduced, dynamically adjusting priv acy parameters based on training progression and parameter characteristics, thereby significantly improving the priv acy- utility trade-of f over traditional fixed-noise approaches. Systematic empirical ev aluation across multiple client federations and priv acy b udgets demonstrated that adv anced federated optimisation algorithms, particularly FedProx, could equal or surpass centralised training performance while ensuring rigorous priv acy protection. Notably , ALDP achie ved up to 80.4% accurac y in a two- client configuration, surpassing fix ed-noise Local DP by 5–7 percentage points and demonstrating substantially greater training stability . The comprehensi ve ablation studies and benchmarking es- tablish quantitati ve standards for pri v acy-preserving collaborati ve medical AI, providing practical guidelines for real-world deplo yment. This work thereby adv ances the state-of-the-art in feder - ated learning for medical imaging, establishing both methodological foundations and empirical e vidence necessary for future pri vac y-compliant AI adoption in healthcare. The source code for this dissertation is av ailable at: github.com/Tin-Hoang/fl-adni-classification 1 1 Experiments tracked at: https://wandb.ai/tin-hoang/fl-adni-classification i v T in Hoang, MSc dissertation CONTENTS Declaration of Originality ii W ord Count iii Abstract iv List of figures ix List of tables xi 1 Introduction 1 1.1 Background and Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2 Objecti ves . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.3 Achie vements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.4 Overvie w of Dissertation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2 Background Theory and Literatur e Review 7 2.1 Medical AI and the Challenge of Data Fragmentation . . . . . . . . . . . . . . . 7 2.1.1 Neuroimaging and Alzheimer’ s Disease Classification . . . . . . . . . . 7 2.2 Pri vac y and Regulatory Challenges in Centralised Medical AI . . . . . . . . . . 8 2.2.1 T echnical and Legal Barriers to Data Sharing . . . . . . . . . . . . . . . 8 2.2.2 Security Risks and Data Breach Implications . . . . . . . . . . . . . . . 10 2.3 Theoretical Foundations of Federated Learning . . . . . . . . . . . . . . . . . . 10 2.3.1 Core Components and Communication Protocols . . . . . . . . . . . . . 10 2.3.2 Federated A veraging (FedA vg) . . . . . . . . . . . . . . . . . . . . . . . 10 2.3.3 Federated Proximal (FedProx) . . . . . . . . . . . . . . . . . . . . . . . 12 2.4 Pri vac y-Preserving T echnologies for Federated Learning . . . . . . . . . . . . . 12 2.4.1 Local DP: Dif ferential Priv acy in Federated Learning . . . . . . . . . . . 12 2.4.2 SecAgg+: Secure Aggreg ation Protocols . . . . . . . . . . . . . . . . . 14 v T in Hoang, MSc dissertation 2.5 Federated Learning in Healthcare: Current State and Limitations . . . . . . . . . 15 2.5.1 Medical Imaging Applications . . . . . . . . . . . . . . . . . . . . . . . 15 2.5.2 Neuroimaging and Alzheimer’ s Disease Detection . . . . . . . . . . . . 15 2.6 Research Gaps and Opportunities . . . . . . . . . . . . . . . . . . . . . . . . . . 16 2.6.1 Site-A ware Data Partitioning for Realistic Federated Scenarios . . . . . . 16 2.6.2 Dif ferential Priv acy Exploration for Neuroimaging Applications . . . . . 17 2.6.3 Adapti ve Pri vac y Mechanism De velopment . . . . . . . . . . . . . . . . 17 2.6.4 Algorithmic Benchmarking of Adv anced Strategies . . . . . . . . . . . . 18 2.7 Positioning of Current Research . . . . . . . . . . . . . . . . . . . . . . . . . . 18 2.8 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 3 Methodology 21 3.1 Site-A ware Data Partitioning: Realistic Federated Learning Simulation . . . . . . 21 3.1.1 Moti vation and Problem F ormulation . . . . . . . . . . . . . . . . . . . 21 3.1.2 Site-A ware Distribution Algorithm . . . . . . . . . . . . . . . . . . . . . 22 3.1.3 Methodological Adv antages . . . . . . . . . . . . . . . . . . . . . . . . 23 3.2 Adapti ve Local Dif ferential Priv ac y: A Nov el Priv acy Mechanism . . . . . . . . 23 3.2.1 Moti vation: Limitations of Fixed-Noise Dif ferential Priv ac y . . . . . . . 24 3.2.2 ALDP Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25 3.2.3 T emporal Priv acy Budget Adaptation . . . . . . . . . . . . . . . . . . . 27 3.2.4 Per-T ensor V ariance-A ware Noise Scaling . . . . . . . . . . . . . . . . . 28 3.3 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28 4 Implementation and Integration 30 4.1 FL Frame work Selection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 4.1.1 Selection Criteria and Justification . . . . . . . . . . . . . . . . . . . . . 30 4.1.2 Flo wer Framew ork Advantages for Medical Imaging Research . . . . . . 31 4.2 Medical Imaging Frame work Integration . . . . . . . . . . . . . . . . . . . . . . 33 4.3 System Architecture Overvie w . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 vi T in Hoang, MSc dissertation 4.3.1 Integration and Coordination Principles . . . . . . . . . . . . . . . . . . 34 4.3.2 Federated Learning Core . . . . . . . . . . . . . . . . . . . . . . . . . . 35 4.3.3 Medical Imaging Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . 35 4.3.4 Local and Distributed Deplo yment Infrastructure . . . . . . . . . . . . . 36 4.3.5 Experiment T racking and Monitoring . . . . . . . . . . . . . . . . . . . 37 4.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37 5 Experimental Setup 39 5.1 Dataset Acquisition and Preprocessing . . . . . . . . . . . . . . . . . . . . . . . 39 5.1.1 ADNI Data Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 5.1.2 Image Preprocessing Pipeline . . . . . . . . . . . . . . . . . . . . . . . 39 5.1.3 Data Quality Assurance and Duplicate Remov al . . . . . . . . . . . . . . 41 5.2 Data Filtering and Label Con version . . . . . . . . . . . . . . . . . . . . . . . . 41 5.2.1 Initial Dataset Composition . . . . . . . . . . . . . . . . . . . . . . . . 41 5.2.2 Label Con version . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41 5.2.3 Final Dataset Statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . 41 5.3 Federated Data Splitting: Multi-Client Scenarios . . . . . . . . . . . . . . . . . 43 5.3.1 On-the-fly Data Augmentation Strategy . . . . . . . . . . . . . . . . . . 44 5.4 Model Architecture and T raining Configuration . . . . . . . . . . . . . . . . . . 46 5.4.1 3D-CNN Model Architecture . . . . . . . . . . . . . . . . . . . . . . . 46 5.4.2 Optimisation and T raining . . . . . . . . . . . . . . . . . . . . . . . . . 47 5.5 Federated Learning Strategies . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 5.6 Ev aluation Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 5.6.1 Methodological V alidation Protocol . . . . . . . . . . . . . . . . . . . . 49 5.6.2 Performance Metrics . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 5.6.3 Cross-V alidation Protocol . . . . . . . . . . . . . . . . . . . . . . . . . 52 5.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 6 Results and Discussions 53 vii T in Hoang, MSc dissertation 6.1 Centralised vs Federated Performance Comparison . . . . . . . . . . . . . . . . 53 6.1.1 Federated Learning Algorithm Performance . . . . . . . . . . . . . . . . 53 6.1.2 Confusion Matrix Analysis . . . . . . . . . . . . . . . . . . . . . . . . . 54 6.1.3 R OC Curve Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55 6.1.4 Impact of number of clients in FL . . . . . . . . . . . . . . . . . . . . . 56 6.2 Dif ferential Priv acy Performance Ev aluation . . . . . . . . . . . . . . . . . . . . 57 6.2.1 T raditional Local Dif ferential Priv acy Results . . . . . . . . . . . . . . . 57 6.2.2 Adapti ve Local Dif ferential Priv ac y Results . . . . . . . . . . . . . . . . 58 6.2.3 T raining Dynamics: Fixed-Noise DP vs. Adapti ve DP . . . . . . . . . . 59 6.2.4 Pri vac y-Utility T rade-off Analysis . . . . . . . . . . . . . . . . . . . . . 61 6.3 Ablation Study: Impact of Indi vidual Client Contributions in 4-Client Scenario . 62 6.3.1 Indi vidual Performance Analysis and Collaborativ e Benefits . . . . . . . 63 6.3.2 Implications for Federated Learning Deployment . . . . . . . . . . . . . 63 6.4 Computational Ef ficiency of Federated Learning: Training T ime Analysis . . . . 63 6.4.1 Impact of Model Quantisation on T raining Ef ficiency . . . . . . . . . . . 64 6.4.2 Standard Federated Learning Performance . . . . . . . . . . . . . . . . . 65 6.4.3 Pri vac y Mechanism Computational Overhead . . . . . . . . . . . . . . . 65 6.5 Discussions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65 7 Conclusions and Future W ork 67 7.1 Limitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 7.2 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68 7.3 Future W ork . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69 Bibliography 71 A A ppendix 77 A.1 Ke y Hyperparameters for Federated Learning T raining . . . . . . . . . . . . . . 77 A.2 FedProx µ Finetuning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78 viii T in Hoang, MSc dissertation LIST OF FIGURES 2.1 T raditional centralised training paradigm in medical AI. Multiple healthcare insti- tutions aggregate sensiti ve patient data in centralised repositories, creating priv ac y risks, regulatory compliance challenges, and single points of failure that limit col- laborati ve medical AI de velopment. . . . . . . . . . . . . . . . . . . . . . . . . 9 2.2 Federated learning paradigm for priv acy-preserving collaborativ e medical AI. Health- care institutions maintain local data sov ereignty whilst participating in collabora- ti ve model dev elopment through secure parameter aggregation, eliminating the need for centralised data repositories whilst preserving priv acy and re gulatory compliance. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 3.1 Overvie w of federated learning with Adaptiv e Local Differential Pri vac y (ALDP) in multi-institutional medical imaging. Each medical institution trains a local 3D CNN model on its pri vate MRI data and applies local dif ferential pri vac y by adding calibrated Gaussian noise to model parameters before transmission. In ALDP , both the priv ac y budget ε t and noise scale σ base are adapted per round and per parameter tensor to improv e priv acy-utility trade-off. After each round, noisy local model updates are transmitted to a central serv er , where federated a veragi ng is performed and the aggregated global model is broadcast back to all participating clients. . . 26 4.1 Implementation architecture for federated learning-based ADNI classification sys- tem. The frame work integrates the Flower federated learning platform with MON AI medical imaging capabilities and PyT orch deep learning infrastructure. The mod- ular design supports multiple federated learning strategies and enables both local simulation and distrib uted deplo yment across cloud servers for lar ge-scale experi- ments. Comprehensiv e experiment tracking and monitoring are provided through W eights & Biases integration. . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 ix T in Hoang, MSc dissertation 5.1 ADNI dataset filtering process using Analysis Ready Cohort (ARC) Builder on ida.loni.usc.edu platform, showing selection criteria for 3T MRI acquisitions and demographic filtering parameters. . . . . . . . . . . . . . . . . . . . . . . . . . 40 5.2 Overvie w of the ADNI MRI image preprocessing pipeline. The workflow com- prises: (1) downloading raw DICOM files; (2) con verting DICOM series to vol- umetric NIfTI format; (3) resampling to 1 mm 3 isotropic voxel spacing for spa- tial consistency; (4) non-linear spatial normalization to the ICBM152 MNI tem- plate for anatomical alignment across subjects; and (5) skull stripping to remov e non-brain tissue. This multi-step pipeline ensures each image is harmonised and analysis-ready for robust multi-site neuroimaging studies. . . . . . . . . . . . . . 42 6.1 Normalized confusion matrices comparing centralised training with the best-performing federated approach. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55 6.2 R OC curves comparing centralised training with the best-performing federated approach. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56 6.3 T raining loss curves for client 1 under ( ϵ, δ ) -dif ferential priv acy with fixed-noise DP , ev aluated for v arying ϵ v alues ( 100 , 500 , 1000 , 2000 ) over 100 rounds. For smaller ϵ , the loss consistently increases, while for larger ϵ improvement stalls or re verses in later rounds, illustrating the pitfall of fix ed-noise schedules. . . . . . . 60 6.4 T raining loss curves for client 1 under Adaptiv e ( ϵ, δ ) -DP with the same ϵ init as Figure 6.3. Loss decreases more consistently , confirming improv ed con v ergence and signal retention. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 x T in Hoang, MSc dissertation LIST OF T ABLES 4.1 Comparati ve analysis of some prominent federated learning frame works based on ease of use, documentation quality , features, community support, and ov erall score from Riedel et al. [40]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 5.1 De velopment dataset statistics showing distribution of subjects across diagnostic categories for training and v alidation . . . . . . . . . . . . . . . . . . . . . . . . 43 5.2 Independent test dataset statistics sho wing balanced distribution across diagnostic categories for final e v aluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 5.3 3D CNN (CNN 8CL) architecture for 3D ADNI MRI classification . . . . . . . 46 6.1 Cross-v alidation results on the test set of the 3D CNN model under cen- tralised and 2/3/4-client settings . . . . . . . . . . . . . . . . . . . . . . . . . 53 6.2 Comparati ve performance of Local ( ϵ , δ )-DP and Adaptiv e Local ( ϵ , δ )-DP (ALDP) strategies across v arying numbers of clients and epsilon values, with δ fixed at 1 × 10 − 5 and the clipping norm set to 1.0 for all experiments. . . . . . . . . . . 58 6.3 Results of an ablation study assessing the impact of indi vidual client contributions in a federated learning setting. Each client was trained independently using only its own dataset, without data sharing, and ev aluated on the same balanced test set (50 CN and 50 AD samples) as the global test set in the federated learning experi- ment presented in T able 6.1. The final column reports centralized training results, combining data from all four clients, which demonstrates improved performance through data aggregation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62 6.4 A verage total training time comparison across centralised and federated learning strategies (on 4-client scenario) for 100 training rounds/epochs. Results represent mean v alues computed from fiv e independent experimental runs for each strate gy . 64 A.1 Ke y Hyperparameters for Federated Learning T raining . . . . . . . . . . . . . . 77 xi T in Hoang, MSc dissertation A.2 Hyper-parameter tuning results for FedProx across dif ferent numbers of clients, illustrating the ef fect of varying µ values on global test accurac y and F1 score. . . 78 xii T in Hoang, MSc dissertation 1 INTR ODUCTION Federated learning represents a paradigm shift in collaborativ e machine learning that enables in- stitutions to jointly dev elop robust AI models whilst maintaining complete data sovereignty and pri vac y protection. This distrib uted learning approach addresses one of the most pressing chal- lenges in modern healthcare: leveraging the collectiv e kno wledge embedded in distributed medical datasets without compromising patient priv ac y or violating regulatory requirements. The signif- icance of this paradigm is particularly pronounced in medical imaging applications, where the de velopment of accurate diagnostic systems requires large, diverse datasets that indi vidual institu- tions typically cannot provide in isolation. This dissertation focuses specifically on pri v acy-preserving federated learning for Alzheimer’ s disease classification using three-dimensional magnetic resonance imaging (3D MRI) data from the Alzheimer’ s Disease Neuroimaging Initiative (ADNI). The research addresses critical gaps in existing federated learning methodologies through no vel algorithmic contributions and compre- hensi ve empirical ev aluation, establishing a foundation for practical deployment of collaborati ve medical AI systems in real-world healthcare en vironments. The work encompasses theoretical innov ations in pri vac y-preserving mechanisms, realistic e valuation methodologies, and systematic benchmarking of adv anced federated learning strategies specifically tailored for high-dimensional medical imaging applications. 1.1 Background and Context The con ver gence of artificial intelligence and healthcare has created unprecedented opportunities for improving diagnostic accuracy and patient outcomes through data-dri ven insights [38, 45]. Medical imaging, particularly neuroimaging for neurode generativ e disease detection, represents one of the most promising domains for AI applications due to the rich, high-dimensional infor- mation contained in brain scans [28]. Ho we ver , the full potential of medical AI remains funda- mentally constrained by data fragmentation, with valuable datasets isolated across institutional boundaries due to pri vac y regulations, competiti ve concerns, and technical barriers [37]. T raditional centralised approaches to medical AI de velopment face insurmountable pri vac y and regulatory challenges under framew orks such as the Health Insurance Portability and Account- 1 T in Hoang, MSc dissertation ability Act (HIP AA) and the General Data Protection Regulation (GDPR) [21]. These regulations impose strict requirements for data sharing and processing that often preclude the centralised ag- gregation necessary for con ventional machine learning approaches. Moreo ver , medical imaging data retains sufficient unique characteristics to enable patient re-identification ev en after remov al of explicit identifiers, creating fundamental tensions between collaborati ve AI de velopment and pri vac y preservation [42]. Federated learning has emerged as the most promising solution to these challenges, enabling collaborati ve model de velopment across distributed data sources without requiring centralised data aggregation [30, 20]. Early applications in healthcare hav e demonstrated feasibility across various medical domains, including electronic health record analysis, medical imaging, and genomics research [41]. Howe v er , existing implementations suf fer from significant limitations including unrealistic e valuation methodologies, inadequate pri vac y mechanisms, and insuf ficient algorithmic benchmarking under realistic multi-institutional conditions. The application of federated learning to neuroimaging-based Alzheimer’ s disease detection represents a particularly acti ve area of research, with recent studies demonstrating promising re- sults [32, 24]. Ne v ertheless, several critical gaps persist: (1) artificial data partitioning strategies that fail to preserve institutional boundaries, (2) limited exploration of dif ferential pri vac y mecha- nisms for high-dimensional medical imaging, (3) lack of adapti ve priv acy approaches that account for training dynamics, and (4) insufficient systematic comparison of advanced federated learning algorithms under realistic conditions. These limitations have prevented the practical deployment of priv acy-preserving federated learning in medical imaging applications where both diagnostic accuracy and formal pri v acy guarantees are essential requirements. 1.2 Objectives This research addresses the identified gaps through novel methodological contributions and com- prehensi ve empirical e valuation. The primary objectiv es of this dissertation are: • Develop a site-aware data partitioning methodology that preserves institutional bound- aries during federated learning e v aluation, enabling realistic assessment of algorithm per - formance under conditions that reflect actual multi-institutional collaborations. 2 T in Hoang, MSc dissertation • Design and implement an Adaptive Local Differ ential Privacy (ALDP) mechanism that dynamically adjusts pri v acy parameters based on training progress and parameter charac- teristics, addressing fundamental limitations of fixed-noise approaches in high-dimensional medical imaging applications. • Conduct the first exploration of differential privacy mechanisms for Alzheimer’ s disease classification using ADNI neuroimaging data, establishing empirical guidelines for pri vac y- utility trade-of fs in neuroimaging applications. • Implement and benchmark comprehensi ve federated learning strategies including Fe- dA vg, FedProx, and SecAgg+ protocols under realistic multi-institutional conditions, pro- viding quantitati ve performance comparisons across multiple client configurations. The technical implementation of these objectiv es inv olved dev eloping a comprehensi ve soft- ware frame work integrating the Flower federated learning platform with MON AI medical imaging capabilities and PyT orch deep learning infrastructure. The experimental ev aluation encompassed systematic comparison across multiple client configurations (2, 3, and 4 clients) with comprehen- si ve performance metrics including accuracy , F1 scores, confusion matrix analysis, and computa- tional ef ficiency assessments. 1.3 Achiev ements This dissertation makes sev eral significant contributions to the field of priv ac y-preserving feder- ated learning for medical imaging applications: Novel Adaptive Privacy Mechanism with Superior Perf ormance: The dev elopment of Adapti ve Local Differential Priv acy (ALDP) represents a significant improvement in priv acy- preserving medical imaging, achieving 5-7 percentage point impro vements o ver fixed-noise lo- cal differential priv ac y approaches. ALDP demonstrates remarkable performance at ε 0 = 2000 , reaching 80.4±0.80% accuracy–counter -intuitiv ely exceeding the non-priv ate centralised baseline (78.6±3.38%) while maintaining formal priv acy guarantees. This exceptional result demonstrates the beneficial re gularisation effects of adapti v e noise injection in limited medical datasets, with superior con ver gence stability evidenced by exceptionally low v ariance (0.80%) compared to tra- ditional DP’ s high variance and training di ver gence. 3 T in Hoang, MSc dissertation Systematic Privacy-Utility Analysis for Neuroimaging on ADNI dataset: This work presents the comprehensiv e exploration of dif ferential priv acy mechanisms specifically applied to ADNI neuroimaging data for Alzheimer’ s disease classification. The systematic ev aluation across mul- tiple pri vac y b udgets and client configurations establishes quantitativ e benchmarks for pri v acy- preserving collaborative learning in healthcare, rev ealing temporal dynamics where ALDP main- tains stable training while traditional fixed-noise approaches exhibit systematic con ver gence fail- ures. The formal priv acy guarantees combined with improved utility provide a practical solution for regulatory compliance in medical AI deplo yment. Empirical Evidence for Real-W orld Healthcare Deployment: FedProx demonstrates su- perior performance over centralised training in realistic multi-institutional scenarios, achie ving 81.4±3.2% accuracy compared to 80.2±2.2% in the 3-client configuration. Critically , FedProx sig- nificantly improv es Alzheimer’ s disease sensitivity from 64% to 74%–a clinically vital improve- ment for early detection and intervention. The comprehensive ablation study re veals substantial collaborati ve benefits, with individual client performance ranging from 68.2%-75.4% compared to the federated collaborati ve achie vement of 81.4%, providing compelling e vidence that pri v acy- preserving federated learning can enhance rather than compromise diagnostic performance in re- alistic healthcare en vironments. Methodological Inno vation f or Realistic Evaluation: The introduction of site-aw are data partitioning addresses a fundamental limitation in federated learning research by preserving in- stitutional boundaries during ev aluation, enabling more realistic assessment of multi-institutional collaboration challenges. This methodological contribution, combined with comprehensiv e algo- rithmic benchmarking across FedA vg, FedProx, and secure aggreg ation protocols, establishes a robust framew ork for ev aluating federated learning approaches under conditions that reflect actual healthcare deployment scenarios. These achie vements collectiv ely demonstrate that priv ac y-preserving federated learning can deli ver clinically superior diagnostic performance while maintaining rigorous priv acy guarantees, establishing a foundation for practical deployment in real-world healthcare collaborations. 1.4 Overview of Dissertation This dissertation is organised into se ven chapters that systematically dev elop and ev aluate the proposed methodological contributions: 4 T in Hoang, MSc dissertation Chapter 1: Introduction establishes the research context and motiv ation, outlining the fun- damental challenges of data fragmentation in medical AI and positioning federated learning as a solution. The chapter presents the research objecti ves and summarises the key contributions achie ved. Chapter 2: Background Theory and Literature Review provides comprehensiv e theoret- ical foundations spanning medical AI challenges, federated learning algorithms, and priv acy- preserving technologies. The chapter systematically identifies critical gaps in e xisting literature that moti vate the no vel methodological contrib utions presented in subsequent chapters. Chapter 3: Methodology presents the core algorithmic innov ations including the site-aware data partitioning strategy and the Adaptiv e Local Differential Priv acy mechanism. The chap- ter provides detailed algorithmic specifications and theoretical justifications for the proposed ap- proaches, establishing the foundation for experimental e v aluation. Chapter 4: Implementation and Integration describes the comprehensi ve software archi- tecture that transforms theoretical contrib utions into a practical research platform. The chapter details frame work selection criteria, system architecture design, and integration strate gies that en- able systematic experimental e v aluation. Chapter 5: Experimental Setup establishes the rigorous experimental protocol including ADNI dataset preprocessing, federated learning configurations, and ev aluation methodologies. The chapter ensures reproducible experimental conditions whilst maintaining realistic multi-institutional scenarios through site-aw are partitioning. Chapter 6: Results and Discussions presents comprehensi ve experimental findings across four ke y areas: baseline performance comparisons, pri vac y-utility trade-off analysis, algorithmic robustness e valuation, and computational ef ficiency assessment. Results demonstrate the effec- ti veness of proposed methodological contrib utions through systematic empirical validation. Chapter 7: Conclusions and Future W ork synthesises research findings, discusses limita- tions and practical implications, and identifies directions for future research. The chapter positions the contrib utions within the broader context of pri vac y-preserving collaborati ve medical AI de v el- opment. 5 T in Hoang, MSc dissertation The dissertation narrati ve progresses logically from theoretical foundations through method- ological innov ation to comprehensi ve empirical v alidation, providing both nov el algorithmic con- tributions and practical solutions for priv acy-preserving federated learning in medical imaging applications. 6 T in Hoang, MSc dissertation 2 B A CKGROUND THEOR Y AND LITERA TURE REVIEW This chapter provides a comprehensiv e examination of the theoretical foundations and existing lit- erature that underpin federated learning for pri v acy-preserving medical artificial intelligence, with particular emphasis on neuroimaging applications. The chapter systematically b uilds from fun- damental concepts in medical AI and priv acy challenges through to advanced federated learning techniques, establishing the theoretical groundwork and identifying critical g aps that moti v ate our research contributions. By synthesising existing knowledge across machine learning, medical in- formatics, priv acy-preserving technologies, and neuroimaging, this re view demonstrates the need for no vel approaches to priv acy-preserving collaborativ e medical AI and positions our method- ological innov ations within the broader research landscape. 2.1 Medical AI and the Challenge of Data Fragmentation Artificial intelligence has emerged as a transformativ e force in modern healthcare, with appli- cations spanning diagnostic imaging, clinical decision support, drug discovery , and personalised medicine [38, 45]. The con ver gence of advanced machine learning algorithms, increased compu- tational po wer , and the digitisation of healthcare data has created unprecedented opportunities for improving patient outcomes through data-dri ven insights. Howe v er , the full potential of medical AI remains fundamentally constrained by the fragmented nature of healthcare data, with valuable datasets isolated across institutional boundaries due to priv acy regulations, competitive concerns, and technical barriers [37]. This fragmentation is particularly pronounced in neuroimaging, where the dev elopment of robust AI systems requires large, diverse datasets that capture the full spectrum of anatomical and pathological v ariations. Individual institutions typically possess datasets that, whilst clinically v aluable, are insufficient in size and diversity to train state-of-the-art deep learning models. The resulting ”data silos” prev ent the realisation of AI systems that could benefit from the collecti ve kno wledge embedded in distributed medical datasets [21]. 2.1.1 Neuroimaging and Alzheimer’ s Disease Classification Neuroimaging represents one of the most promising yet challenging domains for medical AI ap- plications. The rich, high-dimensional nature of brain imaging data provides detailed insights into 7 T in Hoang, MSc dissertation neuroanatomical structure and function, making it in v aluable for diagnosing neurodegenerati ve diseases such as Alzheimer’ s Disease (AD) [28]. The clinical significance of accurate early-stage AD detection cannot be overstated, as it enables timely intervention strategies that can significantly improv e patient quality of life and potentially slow disease progression [19]. T raditional diagnostic approaches rely primarily on clinical assessment and neuropsycholog- ical testing, which may lack sensitivity in detecting subtle early-stage neurodegeneration [24]. Machine learning techniques applied to structural magnetic resonance imaging (MRI) data have demonstrated superior performance in distinguishing between diagnostic categories, with modern con v olutional neural networks achieving classification accuracies exceeding 90% in controlled research settings [28]. Howe ver , these impressiv e results ha ve been achiev ed primarily through centralised training approaches that aggregate data from multiple institutions, raising significant pri vac y and regulatory concerns that limit real-world deplo yment. The Alzheimer’ s Disease Neuroimaging Initiativ e (ADNI) ex emplifies both the potential and limitations of current approaches to medical AI de velopment. This landmark initiativ e has pro- vided a standardised, multi-site dataset comprising over 1,000 T1-weighted MRI scans across diagnostic categories, enabling significant adv ances in neuroimaging-based classification [49]. Y et ADNI’ s success required extensi ve data sharing agreements, standardised protocols, and cen- tralised data repositories that may not be feasible for broader clinical deployment or international collaborations. 2.2 Privacy and Regulatory Challenges in Centralised Medical AI The centralised paradigm that has dominated medical AI research faces increasingly insurmount- able priv acy and regulatory challenges. Healthcare data is inherently sensitiv e and subject to stringent protection requirements under frameworks such as the Health Insurance Portability and Accountability Act (HIP AA) in the United States and the General Data Protection Regulation (GDPR) in the European Union [37]. These regulations impose strict requirements for data shar- ing, processing, and storage that often preclude the centralised aggregation necessary for tradi- tional machine learning approaches. 2.2.1 T echnical and Legal Barriers to Data Sharing The technical challenges of medical data sharing e xtend beyond simple regulatory compliance. Medical imaging data, particularly neuroimaging, retains sufficient unique characteristics to en- 8 T in Hoang, MSc dissertation Figure 2.1: T raditional centralised training paradigm in medical AI. Multiple healthcare institu- tions aggregate sensitiv e patient data in centralised repositories, creating priv acy risks, regulatory compliance challenges, and single points of failure that limit collaborative medical AI de velop- ment. able patient re-identification ev en after remov al of e xplicit identifiers [42]. Brain anatomy exhibits indi vidual-specific patterns that can serve as biometric identifiers, creating a fundamental tension between the data sharing necessary for AI dev elopment and priv ac y preservation requirements [12]. Data Use Agreements (DU As) represent the current standard approach to enabling limited medical data sharing for research purposes. Howe ver , these legal instruments often require months- long approval processes, impose restricti ve conditions on data usage, and typically limit sharing to specific research questions and timeframes [16]. The resulting fragmentation prev ents the de vel- opment of lar ge-scale collaborativ e initiati v es that could significantly adv ance medical AI capabil- ities whilst maintaining the flexibility necessary for iterati ve model de v elopment and validation. International collaborations face additional complexity due to varying regulatory frameworks across jurisdictions. What constitutes acceptable priv acy protection in one country may be insuf- ficient in another , making it practically impossible to establish centralised repositories that satisfy all applicable requirements for global collaborati ve research [25]. 9 T in Hoang, MSc dissertation 2.2.2 Security Risks and Data Breach Implications Beyond regulatory compliance, centralised medical data repositories present attractiv e targets for malicious actors. The healthcare sector has experienced a substantial increase in cyberattacks, with data breaches imposing significant financial and reputational costs [18]. The centralised nature of traditional AI development amplifies these risks, as a single successful attack can compromise vast quantities of sensiti ve patient information from multiple institutions. These considerations have motiv ated exploration of alternativ e approaches to medical AI de- velopment that can harness the collectiv e value of distributed datasets whilst addressing priv acy , security , and regulatory concerns. Federated learning has emerged as the most promising paradigm for achie ving this balance. 2.3 Theoretical F oundations of F ederated Learning Federated learning represents a paradigm shift in machine learning that enables collaborativ e model de velopment across distrib uted data sources without requiring centralised data aggregation [30]. The fundamental principle underlying federated learning is the in version of the traditional data science workflo w: instead of bringing data to algorithms, federated learning brings algorithms to data, enabling computation on decentralised datasets whilst preserving data locality . 2.3.1 Core Components and Communication Pr otocols The federated learning paradigm comprises three primary components: participating clients (rep- resenting indi vidual institutions or data holders), a central aggregation server , and communication protocols that facilitate secure model parameter exchange [20]. This architecture enables institu- tions to collaborate on model de velopment without compromising data sovereignty or violating pri vac y regulations. 2.3.2 F ederated A veraging (F edA vg) Federated A veraging (FedA vg) is the foundational algorithm in federated learning, enabling col- laborati ve model optimization across clients without centralizing raw data [30]. In FedA vg, each client independently trains the global model on its local dataset for multiple epochs and then sends the resulting local model parameters to a central server . The server performs weighted averaging of these parameters based on the relativ e data sizes of the clients to obtain the updated global model, which is then redistributed for the ne xt communication round. 10 T in Hoang, MSc dissertation Figure 2.2: Federated learning paradigm for priv acy-preserving collaborati ve medical AI. Health- care institutions maintain local data so vereignty whilst participating in collaborati ve model de vel- opment through secure parameter aggregation, eliminating the need for centralised data reposito- ries whilst preserving pri vac y and regulatory compliance. The aggregation update is defined as: w t +1 = K X k =1 n k n w t +1 k (2.1) where w t +1 represents the global model parameters at round t + 1 , w t +1 k denotes the local model parameters from client k after local training, n k is the number of samples at client k , and n = P K k =1 n k represents the total number of samples across all clients. FedA vg is widely adopted for its simplicity and communication efficienc y . Howe v er , it as- sumes that local data distributions are similar (i.e., independently and identically distributed - IID), which is often not the case in real-world medical imaging federations, leading to potential issues with model con ver gence and accuracy [43]. 2.3.3 F ederated Proximal (F edPr ox) Federated Proximal (FedProx) extends FedA vg to better address statistical heterogeneity across clients in federated learning scenarios [26]. In practice, dif ferences in patient demographics, imag- 11 T in Hoang, MSc dissertation ing protocols, and institutional en vironments frequently lead to non-IID data distributions, causing local model updates to di ver ge from the global optimum. FedProx modifies the local objecti ve function by adding a proximal term, which regularizes each client’ s update to remain closer to the current global model: min w F k ( w ) + µ 2 || w − w t || 2 (2.2) where F k ( w ) denotes the local empirical loss for client k , w is the model parameter vector , w t is the global model parameter from the previous round, and µ is a hyperparameter controlling the regularisation strength. By penalizing large deviations from the global model, FedProx improves training stability in the presence of non-IID data and client drift, helping federated learning systems con ver ge more robustly in heterogeneous medical imaging en vironments. While these algorithms enable collaborative training, they must be augmented with priv acy- preserving technologies to address residual vulnerabilities in medical applications. 2.4 Privacy-Pr eserving T echnologies f or F ederated Learning Whilst federated learning provides inherent priv acy benefits by av oiding centralised data aggre- gation, model parameters can still leak sensitiv e information about training data through various attack vectors [53]. Membership inference attacks can determine whether specific individuals participated in model training, whilst model in version attacks can reconstruct training data from model parameters [46]. These vulnerabilities necessitate additional priv acy-preserving mecha- nisms to achie ve formal pri vac y guarantees. 2.4.1 Local DP: Differential Pri vacy in F ederated Learning Local Dif ferential Priv acy (Local DP) is a priv acy-preserving mechanism in federated learning that ensures each participating institution shares only obfuscated information with the server , thus maintaining data sovereignty and compliance with strict priv acy regulations [11]. LDP adds cal- ibrated noise dir ectly to the locally updated model parameter s before transmission to the server . This approach is particularly suitable for medical imaging federations where sensitive raw images 12 T in Hoang, MSc dissertation ne ver leav e the client devices, and additional priv acy guarantees are required for regulatory or ethical reasons [21, 42]. Formally , each client’ s model parameters θ are perturbed as follows before aggre gation: ˜ θ = θ + N (0 , σ 2 I ) (2.3) where N (0 , σ 2 I ) is a multiv ariate Gaussian noise with zero mean and variance σ 2 calibrated ac- cording to the desired ( ϵ, δ ) -dif ferential priv acy parameters. The noise scale σ is typically deter- mined by the sensiti vity of the model parameters and the specified priv acy budget, following the Gaussian mechanism: σ = ∆ ϵ p 2 ln(1 . 25 /δ ) (2.4) where ∆ is the sensitivity (e.g., determined by norm clipping), ϵ denotes the priv acy budget, and δ is a small failure probability . This Local DP mechanism ensures that each client’ s contrib ution is differ entially private at the point of sharing, independent of the server and other participants. Model aggregation is then performed by the server on these noisy parameters. This approach of fers sev eral benefits in federated medical imaging: • Strong client autonomy: All noise is added locally , so trust in the serv er is not required. • Simplicity: No changes are required to the local optimization process or deep learning pipeline. • Regulatory alignment: Since only noised models are e ver shared, data subjects benefit from prov able pri vac y guarantees atop institutional data silos. Ho wev er , adding suf ficient noise for stringent pri v acy can degrade model performance, especially in high-dimensional applications such as 3D neuroimaging. Therefore, choosing the appropriate noise scale and developing adaptiv e strategies (as further explored in this work) is critical for maintaining the utility of pri vac y-preserving federated learning in medical domains. 13 T in Hoang, MSc dissertation 2.4.2 SecAgg+: Secur e Aggregation Pr otocols Secure aggregation provides complementary pri vac y protection by ensuring that individual client updates remain confidential even from the aggregation serv er [7]. This additional layer of protec- tion addresses residual priv acy vulnerabilities that persist when merely sharing model parameters, such as membership inference and model in version attacks, which are particularly concerning in healthcare and neuroimaging contexts. The standard secure aggregation protocol operates in three k ey phases: 1. Setup: Clients coordinate the generation and distribution of cryptographic keys and secret shares necessary for the subsequent masking process. 2. Masking: Prior to transmission, each client applies a cryptographic mask to its model up- dates, utilising threshold secret sharing schemes. This ensures that, without a coalition of clients, the server cannot reconstruct an y individual update. 3. Unmasking and Aggregation: Upon receipt, the server is able to recov er only the sum of the masked updates, as the cryptographic masks ef fectiv ely cancel each other , thus re vealing the aggregate b ut not the indi vidual contributions. Whilst this protocol offers robust pri vac y guarantees compatible with regulatory requirements, its computational and communication overhead increases substantially with larger client pools and high-dimensional models typical in medical imaging. As a result, scalability and efficienc y remain significant challenges when deploying secure aggre gation in practical medical AI systems. SecAgg+ adv ances this foundational protocol in sev eral important respects [5]. By introduc- ing optimised threshold secret sharing, SecAgg+ tolerates client dropouts, maintaining priv acy and correctness in aggreg ation even under realistic network conditions. Furthermore, it employs im- prov ed quantisation and clipping approaches tailored for high-dimensional deep learning models, substantially reducing bandwidth requirements without compromising pri v acy . More ef ficient ke y exchange and secret splitting mechanisms facilitate scalability , enabling robust secure aggreg ation across larger federations and comple x neuroimaging models. Collecti vely , these enhancements render SecAgg+ a practical solution for priv acy-preserving federated learning in medical applications, supporting secure collaboration for use cases such as 14 T in Hoang, MSc dissertation multi-institutional Alzheimer’ s disease classification with volumetric MRI data, whilst remaining feasible under real-world resource constraints. 2.5 F ederated Learning in Healthcar e: Curr ent State and Limitations The application of federated learning to healthcare has gained significant momentum, driv en by the compelling need to le verage distributed medical data whilst maintaining priv acy compliance [41]. Early applications have demonstrated feasibility across various medical domains, including electronic health record analysis, medical imaging, drug discov ery , and genomics research. 2.5.1 Medical Imaging A pplications W ithin medical imaging, federated learning has sho wn promise for div erse tasks including chest X-ray analysis for CO VID-19 detection, brain tumour segmentation, diabetic retinopathy screen- ing, and skin lesion classification [27]. These applications have demonstrated that federated ap- proaches can achiev e performance comparable to centralised methods whilst addressing institu- tional data sharing constraints. Ho wev er , most existing implementations focus on simulated federated scenarios rather than realistic multi-institutional deployments. The controlled nature of these studies, whilst v aluable for algorithmic de velopment, limits insight into the practical challenges of real-world federated learning deployment in healthcare en vironments. 2.5.2 Neuroimaging and Alzheimer’ s Disease Detection The application of federated learning to neuroimaging-based Alzheimer’ s disease detection rep- resents a particularly acti ve area of research. Mitrovska et al. [32] demonstrated the feasibility of secure federated learning for AD classification using structural MRI data, comparing federated av eraging and secure aggregation against centralised training baselines. Their work established important foundations b ut focused primarily on basic algorithmic comparisons rather than com- prehensi ve pri vac y-utility trade-of f analysis. Lei et al. [24] extended this foundation with a hybrid federated learning frame work incorporat- ing brain-region attention mechanisms for enhanced interpretability . Their approach demonstrated state-of-the-art performance whilst providing insights into the neuroanatomical basis of classifica- tion decisions. 15 T in Hoang, MSc dissertation Despite these advances, several critical limitations persist in current federated neuroimaging research: Unrealistic Data Partitioning: Most studies use artificially shuf fled data partitions that fail to preserve institutional boundaries, creating unrealistic scenarios that do not reflect the natural heterogeneity found in multi-institutional collaborations. Limited Privacy Mechanisms: Most implementations rely on basic federated aggregation without formal pri vac y guarantees. Few studies ha ve explored dif ferential pri vac y mechanisms on neuroimaging datasets, particularly for Alzheimer’ s disease classification. Inadequate Algorithmic Benchmarking: Limited systematic comparison of different feder - ated learning algorithms makes it difficult to establish best practices or guide algorithmic choices for practitioners. 2.6 Research Gaps and Opportunities Despite significant progress in federated learning and priv acy-preserving machine learning, sev eral critical gaps remain in their application to medical imaging, particularly for neuroimaging-based disease classification. These gaps represent both challenges and opportunities for advancing the field to ward practical deployment in real-world healthcare settings. 2.6.1 Site-A ware Data P artitioning for Realistic F ederated Scenarios The first major gap concerns the unrealistic data partitioning strategies employed in most federated learning studies. Current approaches typically use random data shuffling across clients, which fails to preserve the natural institutional boundaries and statistical heterogeneity that characterise real- world multi-institutional collaborations [20]. This artificial partitioning creates overly optimistic e valuation scenarios that do not reflect the challenges of actual federated deplo yments. In real-world medical federated learning, each participating institution contributes its complete local dataset, which typically e xhibits site-specific characteristics related to patient demographics, acquisition protocols, and clinical practices. These institutional differences create natural statisti- cal heterogeneity that significantly impacts federated learning performance but is not captured by random data partitioning approaches. 16 T in Hoang, MSc dissertation The medical imaging community would benefit significantly from rigorous ev aluation proto- cols that preserv e institutional boundaries during data partitioning, enabling more realistic assess- ment of federated learning performance under conditions that reflect practical deployment scenar- ios. Such ev aluation protocols should maintain complete site integrity whilst ensuring balanced participation across clients. 2.6.2 Differential Pri vacy Exploration f or Neuroimaging A pplications The second critical gap in volv es the lack of systematic exploration of differential pri vac y mech- anisms specifically for neuroimaging-based disease classification. Whilst differential priv acy has been e xtensiv ely studied in general machine learning contexts, its application to high-dimensional medical imaging data, particularly for Alzheimer’ s disease detection using ADNI data, remains largely une xplored. This gap is particularly significant giv en the sensitivity of medical imaging data and the strin- gent priv acy requirements in healthcare applications. The unique characteristics of 3D neuroimag- ing data–including high dimensionality , spatial correlations, and anatomical constraints–create specific challenges for priv acy-preserving techniques that hav e not been systematically addressed in existing literature. The exploration of dif ferential priv acy on ADNI neuroimaging data represents a novel con- tribution that could provide v aluable insights into the practical feasibility of pri v acy-preserving collaborati ve learning in neuroscience research. Such exploration should systematically e valuate the utility-priv acy trade-offs specific to neuroimaging applications whilst establishing empirical guidelines for parameter selection. 2.6.3 Adaptive Pri vacy Mechanism De velopment The third gap concerns the limitations of static dif ferential priv acy approaches when applied to it- erati ve machine learning processes such as federated learning. Standard differential priv acy mech- anisms apply fixed noise levels throughout training, failing to account for the temporal dynamics of model optimisation and the v arying sensitivity of dif ferent neural network parameters. T raditional fixed-epsilon dif ferential pri v acy approaches often result in excessi ve utility degra- dation when applied to high-dimensional imaging data due to the substantial noise injection re- quired to maintain formal priv acy guarantees [42]. This limitation has prev ented the practical 17 T in Hoang, MSc dissertation deployment of priv acy-preserving federated learning in medical imaging applications where diag- nostic accuracy requirements are stringent. The de velopment of adaptiv e dif ferential pri v acy mechanisms that can dynamically adjust pri- v acy parameters based on training progress and parameter characteristics represents a significant opportunity for improving utility-pri vac y trade-offs. Such mechanisms should account for both temporal training dynamics and the heterogeneous nature of neural network parameters whilst maintaining rigorous pri vac y guarantees. 2.6.4 Algorithmic Benchmarking of Advanced Strategies The fourth gap relates to the absence of benchmarking studies that ev aluate a range of advanced federated learning algorithms within realistic medical imaging contexts. Much of the existing research [32, 27, 24] either assesses federated approaches in isolation or restricts analyses to direct comparisons between only two algorithms. This approach makes it challenging to discern the relati ve strengths and weaknesses of more recent federated learning strategies–such as FedProx and SecAgg+ protocols–when confronted with the unique challenges posed by heterogeneous, multi-institutional neuroimaging data. The di versity of a vailable federated learning algorithms–including FedA vg, FedProx, and v ar - ious secure aggregation protocols–combined with the unique characteristics of medical imaging data suggests that comprehensi ve benchmarking studies could pro vide v aluable guidance for prac- titioners. Such studies should e v aluate algorithms across multiple dimensions including accuracy , communication efficiency , robustness to statistical heterogeneity , and compatibility with priv acy- preserving mechanisms. 2.7 Positioning of Curr ent Resear ch The gaps identified in existing literature motiv ate our research contributions, which address three ke y limitations in federated learning for medical imaging through nov el methodological innov a- tions and systematic empirical e valuation. Site-A ware Data Splitting Methodology: Our research introduces a novel site-aware data partitioning strategy that preserves institutional boundaries during federated learning e valuation, providing more realistic assessment of algorithm performance under conditions that reflect actual 18 T in Hoang, MSc dissertation multi-institutional collaborations. This approach addresses the fundamental limitation of random data shuf fling by maintaining complete site inte grity whilst ensuring balanced client participation. First Systematic Exploration of Differential Privacy on ADNI Data: W e conduct the first comprehensi ve in vestig ation of differential priv acy mechanisms specifically for Alzheimer’ s dis- ease classification using ADNI neuroimaging data. This exploration systematically ev aluates utility-pri vac y trade-offs under realistic federated scenarios, providing novel insights into the prac- tical feasibility of pri vac y-preserving neuroimaging applications. Adaptive Local Differential Privacy (ALDP): Our research introduces a novel adaptive dif ferential priv acy mechanism that dynamically adjusts priv acy parameters based on training progress and parameter characteristics. ALDP addresses the fundamental limitations of fixed- epsilon approaches through temporal priv acy budget scheduling and per-tensor variance-a ware noise scaling, enabling significantly improv ed utility-priv acy trade-offs for high-dimensional med- ical imaging data. Evaluating Advanced Federated Learning Strategies: W e extend previous baselines [32] by implementing and benchmarking recent advanced federated learning algorithms, including Fed- Prox and SecAgg+, on the ADNI neuroimaging dataset using our site-aware partitioning method- ology . This enables direct assessment of their performance and robustness under realistic multi- institutional conditions, providing v aluable insights into the ef fectiv eness of these state-of-the-art approaches in handling statistical heterogeneity in medical imaging. These contributions adv ance the state-of-the-art in priv acy-preserving federated learning for medical imaging whilst providing practical solutions that enable more realistic ev aluation and im- prov ed priv acy-utility trade-offs. The combination of methodological innov ations and systematic empirical ev aluation establishes a foundation for future research in priv acy-preserving collabora- ti ve medical AI. 2.8 Chapter Summary This literature re vie w has established the theoretical foundations and identified critical research gaps that motiv ate our work on federated learning for priv acy-preserving medical AI. The revie w re veals that whilst significant progress has been made in applying federated learning to medi- 19 T in Hoang, MSc dissertation cal imaging, fundamental challenges remain regarding realistic e valuation methodologies, priv acy mechanism adaptation, and systematic algorithmic assessment. T raditional centralised approaches to medical AI de velopment face insurmountable pri vac y and regulatory barriers that prev ent their adoption in real-world clinical settings. Federated learn- ing emerges as a promising solution, but current approaches suffer from limitations in ev aluation realism, pri vac y mechanism exploration, and algorithmic benchmarking. The gaps identified in existing literature–particularly regarding site-aware data partitioning, dif ferential pri vac y e xploration on neuroimaging data, adapti ve pri v acy mechanisms, and compre- hensi ve algorithmic benchmarking–provide clear moti v ation for the methodological innov ations presented in the follo wing chapter . Our research addresses these limitations through: (1) novel site-aware data splitting that pre- serves institutional boundaries, (2) the first systematic exploration of dif ferential priv acy on ADNI data, (3) adaptive differential pri vac y mechanisms with temporal and parameter-a ware scaling, and (4) comprehensi ve benchmarking of federated learning algorithms under realistic conditions. By addressing these fundamental gaps, our research contrib utes to making priv ac y-preserving federated learning viable for medical imaging applications whilst pro viding more realistic e v alua- tion methodologies and improv ed priv ac y-utility trade-offs essential for practical deplo yment. The next chapter details the comprehensiv e methodology de veloped to address these chal- lenges, including our nov el site-aware partitioning strategy , systematic differential priv acy ex- ploration, adaptiv e pri v acy mechanisms, and benchmarking framew ork for neuroimaging-based Alzheimer’ s disease classification. 20 T in Hoang, MSc dissertation 3 METHODOLOGY This chapter presents the comprehensive methodological framework dev eloped for federated learning- based Alzheimer’ s disease classification using ADNI MRI data with integrated priv acy-preserving mechanisms. The methodology addresses critical gaps identified in the literature revie w (see Chap- ter 2): inadequate simulation of real-world data heterogeneity , lack of adapti ve priv ac y mecha- nisms for high-dimensional medical imaging, and insufficient integration of adv anced priv acy- preserving techniques in federated AI. 3.1 Site-A ware Data P artitioning: Realistic F ederated Learning Simulation A fundamental gap in existing federated learning ev aluation methodology on ADNI dataset is the failure to preserve realistic data heterogeneity patterns that characterize real-world multi- institutional collaborations. Traditional approaches employ random data partitioning across sim- ulated clients, artificially mixing samples from different institutions and obscuring the natural statistical heterogeneity that driv es performance differences in practical federated deployments [43]. Our research addresses this limitation through the development of a novel site-aware data partitioning strategy that maintains institutional boundaries while ensuring balanced client partic- ipation. 3.1.1 Motivation and Pr oblem F ormulation The ADNI dataset naturally exhibits multi-site heterogeneity , with data collected across multi- ple research institutions using varying acquisition protocols, scanner configurations, and patient populations. This heterogeneity reflects realistic federated learning scenarios where participating institutions contribute their complete local datasets rather than artificially shuffled subsets of a global dataset. T raditional random partitioning strategies f ail to capture these realistic conditions by: • Artificial mixing of samples from different sites within the same federated client • Loss of institutional characteristics that driv e real-world non-IID conditions 21 T in Hoang, MSc dissertation • Underestimation of performance challenges associated with true multi-institutional collab- oration • Reduced generalizability of results to practical deployment scenarios 3.1.2 Site-A ware Distrib ution Algorithm Our site-aw are distribution strategy preserves institutional boundaries while ensuring balanced participation across federated clients. The algorithm employs a greedy load-balancing approach that operates in two distinct phases: Algorithm 1: Site-A ware Data Partitioning for Federated Learning Input: Dataset D with site labels S , number of clients K , train ratio r , random seed seed Output: Client datasets {D train k , D val k } K k =1 // Phase 1: Site Analysis and Ranking site counts ← ComputeRecordCountsPerSite ( S ) sorted sites ← SortDescending ( site counts ) // Phase 2: Greedy Client Assignment Initialize client assignments ← {∅} K k =1 Initialize client sizes ← { 0 } K k =1 f or each site s in sorted sites do k ∗ ← arg min k client sizes [ k ] // Client with fewest samples client assignments [ k ∗ ] ← client assignments [ k ∗ ] ∪ { s } client sizes [ k ∗ ] ← client sizes [ k ∗ ] + site counts [ s ] // Phase 3: Train-Validation Splitting per Client Set random seed to seed f or each client k do D k ← FilterBySites ( D , client assignments [ k ]) D k ← ShuffleData ( D k , seed ) split idx ← ⌊|D k | × r ⌋ D train k ← D k [0 : split idx ] D val k ← D k [ split idx :] retur n {D train k , D val k } K k =1 22 T in Hoang, MSc dissertation 3.1.3 Methodological Advantages The site-aware partitioning strategy provides sev eral critical adv antages for federated learning research in medical imaging: Preser ved Site Integrity: No institution’ s data is fragmented across multiple federated clients, maintaining the natural clustering of patient populations, acquisition protocols, and institutional practices that characterize real-world collaborati ve scenarios. Realistic Non-IID Evaluation: Each federated client represents distinct institutional charac- teristics, enabling more accurate assessment of federated learning performance under realistic data heterogeneity conditions typical of multi-institutional medical collaborations. Enhanced Generalizability: Results obtained through site-aware partitioning provide stronger e vidence for the practical applicability of federated learning approaches in real-world deployment scenarios where institutional data sov ereignty must be maintained. Load-Balanced Participation: The greedy assignment algorithm ensures approximately equal sample distrib ution across clients while preserving site boundaries, preventing scenarios where certain clients are disadv antaged due to small dataset sizes. This methodological innov ation addresses a fundamental limitation in federated learning ev al- uation that has limited the practical applicability of research findings to real-world deployment sce- narios. Complementing this realistic data distribution, we ne xt address priv acy challenges through a nov el adaptiv e mechanism tailored for high-dimensional medical data. 3.2 Adaptive Local Differ ential Priv acy: A Nov el Privacy Mechanism The dev elopment of effecti ve pri vac y-preserving mechanisms for high-dimensional medical imag- ing represents the primary methodological innov ation of this research. Standard dif ferential pri- v acy approaches face significant challenges when applied to 3D medical imaging data, where the substantial noise injection required to maintain formal priv acy guarantees often results in pro- hibiti ve utility degradation [42]. Our research addresses this fundamental limitation through the de velopment of an Adaptiv e Local Differential Priv acy (ALDP) mechanism that introduces tem- poral and parameter-a ware noise scaling. 23 T in Hoang, MSc dissertation 3.2.1 Motivation: Limitations of Fixed-Noise Differential Pri vacy T raditional Local DP implementations in federated learning typically apply a fixed noise schedule throughout the entire training process, failing to accommodate the dynamic ev olution of gradient magnitudes and parameter sensitivities during deep learning optimization. This rigid approach, while guaranteeing that prescribed priv acy constraints are nev er violated, can se verely under- mine model performance and limit practical applicability , especially for high-dimensional medical imaging data. Se veral adaptiv e approaches to dif ferential priv acy ha ve been proposed to o vercome the limita- tions of fix ed noise injection. For instance, Fu et al. [15] introduced Adap DP-FL, a frame work for dif ferentially priv ate federated learning with adaptive noise , aiming to impro ve the pri v acy-utility balance by tuning the noise based on training dynamics. Similarly , Kiani et al. [22] proposed a method for time-adaptive privacy spending , which modulates the local pri v acy budget over the course of training to better match the e volving sensiti vity of model parameters. Despite these adv ances, existing works have focused either on adapting priv acy at each train- ing round (temporal adaptation) or on dynamically adjusting the noise le vel. Howe ver , none of these prior methods jointly incorporate both (1) temporal adaptation—modulating priv ac y and noise over the course of training—and (2) parameter-aw areness—modifying noise per-parameter according to tensor statistics. The ALDP mechanism presented here is a novel solution that fills this critical gap by simultaneously adjusting the priv ac y budget across rounds and scaling noise injection based on the statistical characteristics of each parameter tensor . This dual adaptation enables rigorous priv acy guarantees tailored for high-dimensional medical data, while mitigating utility degradation that typically plagues fix ed-noise approaches. • T emporal Misalignment: Early training phases can tolerate higher noise due to large gra- dient magnitudes, but late-stage learning requires careful noise scaling to preserve important fine-tuning signals. • Parameter Heterogeneity: Uniform noise injection often overwhelms small-magnitude parameters and under-re gularizes high-v ariance ones. 24 T in Hoang, MSc dissertation • Utility Degradation: Without adapti ve mechanisms, model performance is significantly compromised, limiting the practical deployment of pri vac y-preserving federated learning for diagnostic medical imaging. A concrete illustration of these effects is provided in Figure 6.3. By addressing both temporal and parameter-scale adaptation, the ALDP mechanism adv ances state-of-the-art priv acy-preserving techniques in federated learning and provides an essential method- ological innov ation for multi-institutional collaborati ve AI in healthcare. 3.2.2 ALDP Algorithm The schematic in Figure 3.1 provides a visual summary of ho w pri vac y-preserving mechanisms are integrated into multi-institutional federated learning for high-dimensional medical imaging. In this workflo w , each medical institution independently trains a local 3D CNN on pri v ate MRI data. Before sharing model updates, each client applies local differential pri vac y (Local DP), either through a traditional fixed-noise mechanism or a nov el adaptive strategy (ALDP), as depicted in the upper-left inset of the diagram. The ALDP mechanism addresses these limitations through two complementary innov ations: exponential pri v acy b udget growth scheduling and per -tensor v ariance-aware noise scaling. 25 T in Hoang, MSc dissertation Figure 3.1: Overview of federated learning with Adapti ve Local Differential Priv acy (ALDP) in multi-institutional medical imaging. Each medical institution trains a local 3D CNN model on its priv ate MRI data and applies local dif ferential priv acy by adding calibrated Gaussian noise to model parameters before transmission. In ALDP , both the priv acy b udget ε t and noise scale σ base are adapted per round and per parameter tensor to improve priv acy-utility trade-of f. After each round, noisy local model updates are transmitted to a central server , where federated av eraging is performed and the aggregated global model is broadcast back to all participating clients. 26 T in Hoang, MSc dissertation Algorithm 2: Adapti ve Local Dif ferential Priv ac y with Gaussian Noise Scaling Input: C (clipping norm as sensiti vity), ε 0 (initial pri v acy budget), δ (priv acy parameter), α ∈ (0 , 1) (decay f actor), ε min (minimum budget), ε max (maximum budget) Output: Noisy parameters ˜ Θ = { ˜ θ i } | Θ | i =1 // Initialize ∆ ← C // Use clipping norm as sensitivity t ← 0 // Current round f or each federated learning r ound do t ← t + 1 // Exponential epsilon growth ε t ← ε 0 · 1 α t − 1 // Clamp privacy budget ε t ← max(min( ε t , ε max ) , ε min ) // Gaussian base noise scale for ( ε t , δ ) -DP σ base ← ∆ ε t · q 2 ln 1 . 25 δ // Compute per-tensor statistics once { std i } | Θ | i =1 ← { StandardDeviation ( θ i ) } std ← max 1 | Θ | P | Θ | i =1 std i , 10 − 12 // Apply adaptive Gaussian noise f or i = 1 to | Θ | do rel std i ← std i std scale factor i ← C L I P ( rel std i , 0 . 1 , 1 . 0) σ i ← σ base · scale factor i N i ∼ N (0 , σ 2 i I ) ˜ θ i ← θ i + N i retur n ˜ Θ = { ˜ θ i } | Θ | i =1 // Privacy guarantee: ( ε t , δ ) per round with Gaussian noise // Adaptive properties: Temporal noise reduction + per-tensor scaling 3.2.3 T emporal Privacy Budget Adaptation The temporal adaptation component implements exponential pri v acy b udget gro wth according to: 27 T in Hoang, MSc dissertation ε t = ε 0 × 1 α t − 1 (3.1) where ε t represents the priv acy budget at round t , ε 0 is the initial budget, and α controls the rate of b udget expansion. This schedule provides strong pri vac y protection during early training rounds when models are learning fundamental patterns, gradually relaxing constraints as models approach con ver gence and gradient magnitudes naturally decrease. The priv acy budget is bounded by minimum and maximum thresholds to ensure both priv acy preserv ation and practical utility: ε t = max(min( ε t , ε max ) , ε min ) (3.2) 3.2.4 Per -T ensor V ariance-A ware Noise Scaling The parameter adaptation component calibrates noise injection based on the statistical properties of indi vidual parameter tensors: σ i = σ base × clip std i std , 0 . 1 , 1 . 0 (3.3) where σ i is the adapted noise scale for tensor i , std i is the standard deviation of tensor i , and std is the mean standard deviation across all tensors. The clipping operation ensures that small- v ariance parameters receiv e at least 10% of the base noise lev el while prev enting excessiv e noise scaling for high-v ariance parameters. This dual adaptation mechanism enables ALDP to maintain meaningful pri v acy guarantees whilst significantly improving model utility compared to fixed-noise approaches, particularly for high-dimensional medical imaging applications where parameter heterogeneity is pronounced. 3.3 Summary This methodology chapter has presented the comprehensiv e framework for priv acy-preserving federated learning research in medical imaging, with particular emphasis on novel methodologi- cal contributions that address critical gaps in existing approaches. The framew ork integrates two 28 T in Hoang, MSc dissertation primary innov ations: site-aware data partitioning that preserves realistic institutional heterogene- ity , and adaptiv e local differential priv acy mechanisms that optimize priv acy-utility trade-offs for medical imaging data. The site-a ware partitioning strategy represents a fundamental adv ance in federated learning e valuation methodology , ensuring that research findings reflect the challenges and opportunities inherent in real-world multi-institutional collaborations. The ALDP mechanism provides a prac- tical solution to the pri vac y-utility dilemma that has limited the adoption of priv acy-preserving techniques in medical imaging, enabling formal priv acy guarantees without prohibitiv e perfor- mance degradation. The methodological frame work establishes theoretical foundations that are systematically im- plemented and ev aluated in the follo wing chapters. Chapter 4 details the implementation architec- ture that realises these methodological innov ations within a practical research framework, while Chapter 5 presents the experimental protocols that enable rigorous ev aluation of these contrib u- tions using the ADNI neuroimaging dataset. The combination of no vel theoretical contrib utions and systematic empirical e v aluation en- ables this research to advance the state-of-the-art in pri vac y-preserving collaborativ e medical AI while providing practical guidelines for real-world deployment in healthcare en vironments. The methodological innov ations presented establish a foundation for more realistic and pri vac y- preserving approaches to federated learning in medical imaging that can facilitate broader adoption of collaborati ve AI in healthcare settings. 29 T in Hoang, MSc dissertation 4 IMPLEMENT A TION AND INTEGRA TION This chapter presents the engineering architecture that enables systematic ev aluation of priv ac y- preserving federated learning algorithms for medical imaging applications. The implementation transforms the theoretical methodological contrib utions presented in Chapter 3 into a practical, scalable research platform specifically designed for ADNI neuroimaging data. The architecture in- tegrates federated learning algorithms with medical imaging preprocessing pipelines and pri vac y- preserving mechanisms, enabling rigorous experimental ev aluation whilst maintaining priv acy compliance and realistic multi-institutional scenarios. The complete implementation used in this dissertation was coded from scratch and is publicly av ailable at: github.com/Tin-Hoang/fl-adni-classification . T o reproduce the main experiments, see the repository’ s README and configs/ directory . W e provide pinned en vironments, fixed random seeds, and scripts to launch centralised and federated runs. The implementation follows a modular design philosophy that separates concerns between federated learning orchestration, medical data processing, priv acy mechanism integration, and experimental ev aluation. This separation enables systematic comparison of dif ferent algorithmic approaches whilst maintaining the flexibility necessary for iterati v e research dev elopment and the reproducibility essential for scientific v alidation. 4.1 FL Framework Selection The selection of appropriate softw are frameworks and implementation strate gies plays a crucial role in the success of federated learning research in medical imaging. 4.1.1 Selection Criteria and Justification The framework selection was based on several ke y criteria essential for priv acy-preserving feder- ated learning research in medical imaging: Algorithmic Flexibility: The framework must support systematic comparison of multiple federated learning algorithms (FedA vg, FedProx, SecAgg+) within a unified experimental en vi- ronment to allo w a comprehensiv e comparison of our methodological contributions. 30 T in Hoang, MSc dissertation Privacy Integration: Nati ve support for dif ferential priv acy mechanisms and e xtensibility for nov el priv acy approaches (such as our ALDP mechanism) is essential for implementing compre- hensi ve pri vac y-preserving federated learning. Medical Imaging Compatibility: Integration capabilities with specialised medical imaging frame works (such as MON AI) and support for high-dimensional 3D medical data processing pipelines. Research-Oriented Design: Robust simulation capabilities that enable controlled experimen- tation while maintaining realistic federated learning conditions, particularly important for system- atic e valuation of site-a ware partitioning strategies. Based on the comprehensiv e analysis by Riedel et al. [40], who ev aluated 15 open-source fed- erated learning framew orks on features, interoperability , and user-friendliness, the Flo wer frame- work was selected as the foundation for this research, achieving the highest score (84.75%) among av ailable alternati ves. 4.1.2 Flower Framework Adv antages f or Medical Imaging Research The Flower framework’ s superiority for this research stems from sev eral key advantages particu- larly rele vant for medical imaging applications [40]: Comprehensi ve Strategy Pattern Implementation: Flower’ s modular architecture enables systematic comparison of multiple federated learning algorithms (FedA vg, FedProx, SecAgg+) within a unified experimental frame work, essential for the benchmarking objectiv es of this re- search. Controlled Simulation En vir onment: The frame work provides rob ust simulation capabilities that enable systematic ev aluation of federated learning algorithms under controlled conditions while maintaining realistic client heterogeneity patterns. This is crucial for research scenarios where comprehensive experimental control is required to isolate the impact of different algorithmic and pri vac y choices. Privacy Integration Capabilities: Nativ e support for differential priv ac y mechanisms through integration with priv acy libraries enables seamless implementation of both standard Local DP and nov el adaptiv e pri vac y mechanisms within the federated learning pipeline. 31 T in Hoang, MSc dissertation T able 4.1: Comparativ e analysis of some prominent federated learning frameworks based on ease of use, documentation quality , features, community support, and overall score from Riedel et al. [40]. Frame work Easy to use Documentation Features Community Score Flo wer Highly user- friendly with intuiti ve APIs and extensi ve tutorials. Comprehensi ve and well- maintained with numerous tutorials. Cross-de vice FL, scalable client-server architecture, Fe- dA vg/SecAgg/DP support, PyT orch integration 6200+ GitHub stars, 164+ contribu- tors. Activ e commu- nity . 84.75% PySyft Steeper learning curve for begin- ners. Some documen- tation may be outdated or less detailed. Pri vac y-focused (DP , SMPC), encrypted computation, PyT orch-based 9600+ GitHub stars, 428+ contribu- tors. 72.5% OpenFL Balanced be- tween ease of use and robustness for research and production. Decent doc- umentation cov ering instal- lation, tutorials, and API refer- ences. W orkflo w-based FL, enterprise- ready , model aggregation, PyT orch and T ensorFlow sup- port. 2000+ GitHub stars, 164+ contribu- tors. 69% NVFlare Production- focused with good documen- tation, suitable for users f a- miliar with FL concepts. Detailed doc- umentation with guides for getting started and adv anced topics. Pri vac y- preserving FL, large file streaming, multi- cloud support, FedA vg/FedProx 700+ GitHub stars, 46+ contribu- tors. 80.5% Medical Imaging Framework Integration: Extensiv e compatibility with PyT orch and spe- cialized medical imaging frame works such as MON AI enables sophisticated preprocessing pipelines specifically designed for 3D neuroimaging data [9]. Our implementation leverages Flower’ s modular architecture to dev elop a comprehensive fed- erated learning framew ork specifically optimised for ADNI neuroimaging data. The system inte- grates advanced preprocessing capabilities through the Medical Open Network for AI (MON AI) frame work, which pro vides specialised transforms and data handling optimised for 3D medical imaging [16]. 32 T in Hoang, MSc dissertation 4.2 Medical Imaging Framework Integration The implementation integrates specialised medical imaging capabilities through the Medical Open Network for Artificial Intelligence (MONAI) framew ork [9]. MON AI provides domain-specific transforms, data handling routines, and preprocessing pipelines optimised for 3D medical imaging applications, enabling sophisticated augmentation strategies specifically designed for brain MRI data. The MON AI integration enables se veral critical capabilities: Domain-Specific Pr eprocessing: Specialised transforms for medical imaging data, includ- ing intensity normalisation, spatial resampling, and anatomically aware augmentation techniques that maintain clinical rele v ance while providing robust data augmentation for limited-size medical datasets. F ormat Compatibility: Nati ve support for medical imaging formats including DICOM and NIfTI, eliminating the need for custom data loading and conv ersion routines whilst ensuring com- patibility with established neuroimaging analysis pipelines. Perf ormance Optimization: GPU-accelerated preprocessing and augmentation operations that enable efficient handling of high-dimensional 3D volumetric data typical of neuroimaging applications. 4.3 System Architectur e Over view The implementation le verages Flo wer’ s modular architecture to dev elop a comprehensi ve research frame work specifically optimised for ADNI neuroimaging data [6]. The system architecture, illustrated in Figure 4.1, integrates four core components that address the unique requirements of priv acy-preserving federated learning in medical imaging applications: the federated learning core, medical imaging pipeline, deployment infrastructure, and e xperiment tracking systems. This modular design enables flexible experimentation across di verse federated learning con- figurations whilst maintaining consistent e v aluation protocols and ensuring reproducible results across dif ferent deployment scenarios. 33 T in Hoang, MSc dissertation Figure 4.1: Implementation architecture for federated learning-based ADNI classification system. The framework integrates the Flower federated learning platform with MONAI medical imag- ing capabilities and PyT orch deep learning infrastructure. The modular design supports multiple federated learning strategies and enables both local simulation and distributed deployment across cloud servers for lar ge-scale experiments. Comprehensiv e experiment tracking and monitoring are provided through W eights & Biases integration. 4.3.1 Integration and Coordination Principles The architectural integration follo ws sev eral design principles essential for rigorous federated learning research in medical imaging applications, ensuring that experimental results provide meaningful insights into practical deployment scenarios. Modular Design: Component independence enables systematic ev aluation of indi vidual method- ological contributions whilst maintaining ov erall system coherence. This modularity supports iterati ve de velopment and enables isolated testing of novel algorithmic components without com- promising system stability . Controlled Heterogeneity: Site-aware partitioning inte gration ensures that client heterogene- ity reflects realistic multi-institutional scenarios whilst maintaining experimental control necessary for systematic algorithm comparison [43]. This approach preserves natural statistical heterogene- ity characteristic of real-world medical collaborations whilst enabling controlled ev aluation of algorithmic performance. Reproducible Evaluation: Deterministic data partitioning and seeded random number gener- ation ensure experimental reproducibility whilst comprehensi ve logging captures detailed metrics for post-hoc analysis. The framework incorporates rigorous validation protocols that account for stochastic variability in data partitioning and model initialisation, ensuring statistical validity of performance comparisons. 34 T in Hoang, MSc dissertation 4.3.2 F ederated Learning Cor e The federated learning core implements Flower’ s strategy pattern architecture to provide system- atic comparison capabilities across multiple federated learning algorithms and priv ac y mecha- nisms. This component serves as the central orchestration layer that coordinates distributed train- ing whilst maintaining algorithmic consistency and e xperimental control. Multi-Strategy Support: The core supports comprehensive ev aluation of federated learning algorithms including FedA vg for baseline comparison, FedProx for addressing client heterogene- ity , and pri v acy-enhanced variants incorporating both standard Local DP and no vel ALDP mecha- nisms [30, 26, 1]. Each strategy is implemented with configurable parameters enabling systematic exploration of algorithmic trade-of fs under realistic multi-institutional scenarios. Privacy Integration: Comprehensi ve priv ac y mechanisms are integrated at multiple levels, including client-le vel differential pri v acy through Local DP and ALDP approaches, cryptographic protection through SecAgg+ protocols, and priv acy accounting to ensure formal priv ac y guar- antees throughout the federated training process [1, 7]. This multi-layered approach provides defence-in-depth protection for sensiti ve medical data during collaborati ve model de velopment. 4.3.3 Medical Imaging Pipeline The medical imaging pipeline integrates domain-specific preprocessing capabilities optimised for 3D neuroimaging data through seamless integration with the Medical Open Network for AI (MON AI) frame work. This component addresses the unique challenges of federated medical imaging research whilst maintaining clinical rele vance and diagnostic accurac y . MONAI Framework Integration: Integration with MON AI transforms enables sophisticated augmentation strategies specifically designed for brain MRI data, including elastic deformations, bias field corrections, and Rician noise simulation [9, 16]. This integration ensures that data pre- processing maintains clinical relev ance whilst providing sufficient augmentation to prev ent over - fitting in federated scenarios where indi vidual client datasets may be limited in size. Privacy-Compatible Architectur es: The pipeline incorporates architectural modifications to support differential priv acy requirements, including replacement of BatchNorm layers with Group- Norm to maintain per -sample gradient independence required for DP [51, 1]. This ensures compat- 35 T in Hoang, MSc dissertation ibility with pri v acy-preserving mechanisms without compromising the fundamental capabilities of 3D con v olutional networks for neuroimaging analysis. Domain-Specific Pr ocessing: The ADNI classification module implements specialised pre- processing pipelines for T1-weighted MRI data, including spatial normalisation, intensity har- monisation, and quality assurance protocols that maintain consistency across multi-institutional datasets whilst preserving anatomical integrity essential for accurate Alzheimer’ s disease classifi- cation. T raining Efficiency: The framew ork incorporates mixed precision training to reduce mem- ory usage and accelerate training on modern GPUs whilst maintaining model accuracy [31]. This optimization enables practical federated training of large 3D CNN models across distrib uted insti- tutional networks with v arying computational resources. 4.3.4 Local and Distributed Deployment Infrastructur e The deployment infrastructure provides flexible execution capabilities supporting both local sim- ulation for de velopment and distributed deployment across cloud servers for lar ge-scale e xperi- ments. This dual-deployment capability ensures scalable e valuation under realistic communication and computational constraints. Local Simulation En vir onment: The framew ork provides robust local simulation capabili- ties enabling systematic ev aluation of federated learning algorithms under controlled conditions whilst maintaining realistic client heterogeneity patterns. This en vironment is crucial for algorithm de velopment, parameter tuning, and preliminary e valuation before distrib uted deployment. Distributed Cloud Deployment: Multi-machine deplo yment capabilities through SSH-based distributed ex ecution enable realistic e valuation under v arying communication latencies and band- width constraints typical of healthcare research en vironments [23]. The distributed architec- ture supports scalable federated training across multiple cloud servers, simulating realistic multi- institutional network conditions. F ault T olerance and Recovery: The infrastructure incorporates comprehensi ve error han- dling and fault tolerance mechanisms, including checkpoint-based reco very and adapti ve client selection, providing resilience against network interruptions or client resource limitations com- mon in distributed healthcare research en vironments. 36 T in Hoang, MSc dissertation 4.3.5 Experiment T racking and Monitoring The implementation integrates comprehensiv e monitoring and logging capabilities through W eights & Biases integration 1 , enabling detailed analysis of federated learning dynamics and e xperimental results: Real-Time Monitoring: Live tracking of client-specific and aggregated performance met- rics, including loss curv es, accuracy progression, and con v ergence indicators, provides immediate feedback on training dynamics and enables early detection of performance issues or algorithmic failures. Algorithm Perf ormance Analytics: Comprehensiv e logging captures detailed metrics in- cluding client-specific performance characteristics, global v alidation accuracy , confusion matrix visualisation, sample debug images, communication overhead analysis essential for post-hoc anal- ysis and algorithmic comparison across dif ferent federated learning strategies. System P erformance Analytics: Detailed logging of computational performance, network utilization, and resource consumption, enabling optimization of system performance and identifi- cation of bottlenecks in distributed deplo yments. 4.4 Summary This implementation chapter has presented the comprehensive technical architecture that trans- forms the theoretical methodological contributions described in Chapter 3 into a practical, scal- able research platform for priv acy-preserving federated learning in medical imaging. The imple- mentation successfully integrates multiple complex technologies—federated learning algorithms, medical imaging processing, pri vac y-preserving mechanisms, and distributed computing infras- tructure—into a cohesi ve system that enables rigorous experimental e v aluation whilst maintaining practical applicability . The modular architecture ensures that individual components can be systematically ev aluated and compared whilst maintaining o verall system coherence. The inte gration of established frame- works (Flo wer , MON AI, PyT orch) with novel methodological contrib utions (ALDP , site-aware partitioning) pro vides a foundation for adv ancing the state-of-the-art in priv acy-preserving collab- orati ve medical AI whilst ensuring reproducibility and extensibility for future research. 1 W eights & Biases project: https://wandb .ai/tin-hoang/fl-adni-classification 37 T in Hoang, MSc dissertation The comprehensive experimental design frame work supports rigorous e valuation of our method- ological contributions across multiple dimensions including algorithmic performance, priv acy- utility trade-of fs, and scalability under varying collaboration scales. The modular architecture en- ables systematic comparison of federated learning approaches whilst providing the experimental control necessary for drawing reliable conclusions about optimal strate gies for pri vac y-preserving collaborati ve medical AI. The implementation framework establishes the foundation for the comprehensiv e experimental e valuation presented in Chapter 5, where these systems are applied to systematic benchmarking of federated learning approaches for Alzheimer’ s disease classification using the ADNI dataset. The combination of novel methodological contributions, comprehensiv e implementation architecture, and rigorous experimental design enables this research to advance the state-of-the-art in priv acy- preserving federated learning whilst providing practical solutions for real-world deployment in healthcare en vironments. 38 T in Hoang, MSc dissertation 5 EXPERIMENT AL SETUP This section presents the comprehensiv e experimental framew ork designed to ev aluate federated learning strategies for priv ac y-preserving Alzheimer’ s disease classification using 3D MRI neu- roimaging data. The e xperiments systematically compare multiple federated optimization algo- rithms against centralised training baselines across div erse institutional collaboration scenarios, with particular emphasis on realistic data distribution patterns that reflect real-world federated deployments in medical imaging. The experimental design follo ws the methodological frame work established by Mitrovska et al. [32], extending their approach with several key innov ations: (1) site-aware data partition- ing that preserves institutional data distrib ution patterns, and (2) comprehensi ve e v aluation across multiple federated learning strategies including differential pri vac y and secure aggregation mech- anisms. The experiments simulate realistic multi-institutional scenarios with 2, 3, and 4 partici- pating clients, representing different scales of federated collaboration commonly encountered in medical imaging consortiums. 5.1 Dataset Acquisition and Prepr ocessing 5.1.1 ADNI Data Collection The experimental dataset was acquired from the Alzheimer’ s Disease Neuroimaging Initiative (ADNI) database [35], a longitudinal multicentre study designed to dev elop clinical, imaging, genetic, and biochemical biomarkers for early detection and tracking of Alzheimer’ s disease pro- gression [33]. The dataset comprised 3T T1-weighted MRI scans in DICOM format, selected using the Analysis Ready Cohort (ARC) Builder interface on the ID A platform 1 . 5.1.2 Image Prepr ocessing Pipeline The ADNI image preprocessing pipeline followed established neuroimaging protocols to ensure spatial consistency , harmonise images across sites, and facilitate robust cross-institutional model training. This workflo w , illustrated in Figure 5.2, comprised the following sequential steps: 1 https://ida.loni.usc.edu/home/projectPage.jsp?project=ADNI 39 T in Hoang, MSc dissertation Figure 5.1: ADNI dataset filtering process using Analysis Ready Cohort (ARC) Builder on ida.loni.usc.edu platform, showing selection criteria for 3T MRI acquisitions and demographic filtering parameters. 1. Downloading DICOM files: Raw MRI scans were collected in DICOM format from the ADNI repository . Each scan typically comprised 170–211 DICOM files per acquisition session, preserving the original image series. 2. DICOM to NIfTI con version: Raw DICOM images for each subject were first con verted to volumetric NIfTI format, yielding 3D brain images (dimensions ∼ 176 × 240 × 256 vox els) compatible with neuroimaging pipelines. 3. Resampling to isotropic 1mm: All NIfTI volumes were resampled to an isotropic vox el size of 1 mm 3 (e.g., 211 × 253 × 270 voxels) using ANTs’ ResampleImageBySpacing tool. This standardisation of spatial resolution and orientation (176 × 240 × 256 to 211 × 253 × 270 vox els) minimised site and scanner v ariability . 4. Spatial normalization to MNI space: All resampled images underwent nonlinear re gistra- tion to the ICBM152 MNI template space [14, 13] using ANTs antsRegistrationSyN.sh with the symmetric normalisation (SyN) algorithm. This alignment ( 197 × 233 × 189 vox els) enabled anatomically meaningful aggregation and model sharing across multi-site datasets [29]. 5. Skull stripping: Non-brain tissue was removed using FSL ’ s Brain Extraction T ool (BET) [44], with parameters (fractional intensity threshold f = 0 . 1 , ”B” option for bias field correction) optimised for ADNI and other multi-site studies [36]. The resulting images contained only standardised brain parenchyma, maximising data uniformity for do wnstream classification. 40 T in Hoang, MSc dissertation Figure 5.2: Overvie w of the ADNI MRI image preprocessing pipeline. The workflow comprises: (1) downloading ra w DICOM files; (2) con verting DICOM series to volumetric NIfTI format; (3) resampling to 1 mm 3 isotropic v oxel spacing for spatial consistency; (4) non-linear spatial nor- malization to the ICBM152 MNI template for anatomical alignment across subjects; and (5) skull stripping to remov e non-brain tissue. This multi-step pipeline ensures each image is harmonised and analysis-ready for robust multi-site neuroimaging studies. 41 T in Hoang, MSc dissertation 5.1.3 Data Quality Assurance and Duplicate Removal T o address data leakage concerns identified in pre vious ADNI studies [50, 52], rigorous quality as- surance procedures were implemented. Follo wing the recommendations of W en et al. [50], only a single scan at the baseline visit (”sc”, ”bl” or ”init” suf fix) were retained for each subject, eliminat- ing temporal dependencies that could artificially inflate classification performance. Corrupted and duplicate images were systematically identified and remo ved through automated quality checks and manual verification. 5.2 Data Filtering and Label Con version 5.2.1 Initial Dataset Composition The downloaded ADNI dataset initially contained 1220 3D T1-weighted MRI images distributed across three diagnostic categories: Cogniti v ely Normal (CN), Mild Cognitive Impairment (MCI), and Alzheimer’ s Disease (AD). The dataset exhibited class imbalance typical of clinical cohorts, with v arying representation across diagnostic categories. 5.2.2 Label Con version Gi ven the clinical focus on binary classification between cogniti v ely normal indi viduals and those with Alzheimer’ s disease, the experimental framework adopted a two-class paradigm (CN vs. AD). T o address the limited av ailability of AD cases and the clinical relev ance of progression from MCI to dementia, selected MCI cases were reclassified based on established clinical progression patterns. Follo wing clinical staging criteria [4], MCI cases were subcate gorised into: Significant Mem- ory Concern (SMC), Early MCI (EMCI), and Late MCI (LMCI). Giv en the established progres- sion pathway from EMCI through LMCI to AD, Late MCI (LMCI) cases were reclassified as AD, reflecting their high likelihood of progression to dementia within the study timeframe. This approach aligns with clinical practice where LMCI represents a prodromal stage of Alzheimer’ s disease. 5.2.3 Final Dataset Statistics After data cleaning, quality assurance, and class balancing procedures, the final dataset was par- titioned into development and ev aluation subsets following established neuroimaging e valuation protocols. The de velopment dataset, comprising 797 subjects for training and validation purposes, 42 T in Hoang, MSc dissertation maintained the clinical characteristics essential for rob ust Alzheimer’ s disease classification whilst ensuring balanced representation across diagnostic categories. T able 5.1: Dev elopment dataset statistics sho wing distribution of subjects across diagnostic cate- gories for training and v alidation Diagnosis #Subjects Gender (Male/Female) Age (years) Cogniti vely Normal (CN) 490 199/291 70 . 58 ± 6 . 62 Dementia (AD) 307 174/133 73 . 45 ± 7 . 86 The development dataset exhibited demographic characteristics typical of Alzheimer’ s disease cohorts, with AD patients showing higher mean age compared to cogniti vely normal subjects, reflecting the age-related progression of neurodegeneration. The gender distribution fav oured females in the CN group whilst maintaining relativ e balance in the AD group, consistent with epidemiological patterns observed in aging populations. A separate held-out test set of 100 subjects (50 CN and 50 AD cases) was preserved follow- ing the ev aluation protocol established by Mitrovska et al. [32], ensuring consistent comparison with baseline methodologies and prev enting data leakage during model dev elopment. The test set maintained balanced representation across diagnostic cate gories whilst preserving demographic di versity essential for rob ust performance ev aluation. T able 5.2: Independent test dataset statistics showing balanced distribution across diagnostic cat- egories for final e v aluation Diagnosis #Subjects Gender (Male/Female) Age (years) Cogniti vely Normal (CN) 50 15/35 68 . 90 ± 6 . 57 Dementia (AD) 50 33/17 73 . 97 ± 7 . 62 5.3 F ederated Data Splitting: Multi-Client Scenarios The experimental framework ev aluates three distinct collaboration scales that represent common federated learning deployment scenarios in medical imaging consortiums: • 2-Client F ederation: Simulating bilateral institutional collaboration, this scenario repre- sents the simplest federated learning deployment where two major medical centres collabo- rate on model de velopment whilst maintaining data sov ereignty . This configuration enables e valuation of basic federated learning dynamics whilst minimising coordination complexity . 43 T in Hoang, MSc dissertation • 3-Client Federation: Representing small consortium partnerships, this scenario models collaborations between research institutions that are common in medical imaging research. The three-client configuration enables ev aluation of federated learning performance under moderate heterogeneity whilst maintaining manageable coordination ov erhead. • 4-Client Federation: Modelling larger multi-institutional networks, this scenario repre- sents more complex federated deployments in volving multiple healthcare systems or inter- national collaborations. The four-client configuration enables ev aluation of scalability and robustness under increased coordination comple xity and data heterogeneity . Each scenario maintains the site-aware distribution principle (see section 3.1) whilst ensur- ing balanced data allocation across participating clients, enabling systematic e v aluation of ho w collaboration scale af fects federated learning performance under realistic conditions. 5.3.1 On-the-fly Data A ugmentation Strategy Data augmentation addresses the fundamental challenge of overfitting inherent in small-scale medical imaging datasets, particularly within federated learning environments where indi vidual client datasets are further constrained by institutional boundaries. The ADNI dataset, whilst clini- cally comprehensiv e, presents typical limitations of medical imaging studies with modest sample sizes (797 training images) that necessitate sophisticated augmentation strate gies to achieve rob ust model generalisation [17]. This challenge is compounded in federated settings where participat- ing sites may possess even smaller local datasets, making aggressiv e yet clinically appropriate augmentation essential for pre venting ov erfitting whilst preserving diagnostic rele vance. The implemented augmentation pipeline utilises the Medical Open Network for Artificial In- telligence (MON AI) framew ork [9] with domain-specific transforms optimised for 3D medical imaging. The comprehensiv e strategy incorporates both geometric and intensity-based transfor- mations, each selected to address specific aspects of medical imaging v ariability whilst enhancing model robustness in federated training scenarios. Geometric T ransformations: Random horizontal flipping ( RandFlipd , 50% probability) simulates natural v ariations in patient positioning whilst preserving bilateral brain symmetry . In federated contexts, this transformation helps normalise site-specific positioning protocols and re- duces institutional biases. Affine transformations ( RandAffined ) introduce controlled rotations 44 T in Hoang, MSc dissertation (±10°) and scaling variations (±10%) that account for inter-subject morphological dif ferences and scanner positioning v ariability [29]. These parameters were carefully constrained to remain within physiologically reasonable ranges whilst providing sufficient variation to prev ent model memori- sation. Elastic Deformations and Anatomical V ariability: Three-dimensional elastic transforma- tions ( Rand3DElasticd ) with sigma range (3 , 10) and magnitude range (3 , 20) simulate real- istic tissue deformations whilst preserving topological relationships essential for ne uroanatomical analysis. These deformations combat o verfitting by generating nov el anatomical configurations that prev ent memorisation of specific brain shapes whilst enhancing robustness against natural anatomical v ariations across institutional populations. MRI-Specific Intensity A ugmentations: The pipeline incorporates physics-based augmenta- tions simulating common MRI acquisition artefacts. Bias field inhomogeneity simulation (Rand- BiasFieldd, 30% probability) models spatial intensity v ariations due to radiofrequency coil sen- siti vity patterns, crucial for federated scenarios where institutions employ scanners with vary- ing configurations. Gibbs ringing artefacts ( RandGibbsNoised , 20% probability) simulate k-space truncation effects that vary across acquisition protocols [10]. Rician noise simulation ( RandRicianNoised , 30% probability) models the fundamental noise characteristics of mag- nitude MRI data, ensuring robustness ag ainst varying noise le vels across scanner configurations. Combating Overfitting in Limited Data: This aggressiv e augmentation strategy directly addresses the primary limitation of medical imaging datasets: insufficient sample div ersity for robust deep learning. W ith approximately 797 images distributed across diagnostic categories, the filtered ADNI dataset poses significant overfitting risks for deep 3D CNNs with millions of parameters. The augmentation pipeline effecti vely multiplies the dataset size through stochastic combinations of transformations, each application generating clinically plausible yet nov el brain volumes. This approach is particularly critical in federated settings where indi vidual clients may possess 100-200 samples, making con ventional training highly susceptible to o verfitting. F ederated Integration: Each participating client applies identical augmentation protocols using site-specific random seeds, ensuring reproducibility whilst maintaining statistical indepen- dence across the federation. This standardises data enhancement procedures, reduces site-specific 45 T in Hoang, MSc dissertation ov erfitting likelihood, and maintains priv acy-preserving nature by a voiding parameter sharing be- tween sites. 5.4 Model Architectur e and T raining Configuration 5.4.1 3D-CNN Model Architectur e The experiments employed a domain-specific 3D con volutional neural network optimised for ADNI classification tasks from [47]. This architecture was selected based on its demonstrated ef fectiv eness in Alzheimer’ s disease detection and its focus on reproducible methodological prac- tices in medical imaging. The 3D CNN architecture features an 8-layer con volutional design with progressive chan- nel expansion: [8 , 8 , 16 , 16 , 32 , 32 , 64 , 64] channels, incorporating spatial pooling operations with kernel sizes (4 , 4 , 4) → (3 , 3 , 3) → (2 , 2 , 2) → (2 , 2 , 2) . This configuration, matching the CNN 8CL setup of [47], was specifically optimised for 3D brain MRI v olumes with spatial dimen- sions (73 , 96 , 96) , balancing model capacity with computational efficiency for federated training scenarios. T able 5.3: 3D CNN (CNN 8CL) architecture for 3D ADNI MRI classification Layer T ype K ernel Size Pooling Output Channels Layer 1 Con v3d + BN + ReLU + MaxPool (3,3,3) (4,4,4) 8 Layer 2 Con v3d + BN + ReLU (3,3,3) - 8 Layer 3 Con v3d + BN + ReLU + MaxPool (3,3,3) (3,3,3) 16 Layer 4 Con v3d + BN + ReLU (3,3,3) - 16 Layer 5 Con v3d + BN + ReLU + MaxPool (3,3,3) (2,2,2) 32 Layer 6 Con v3d + BN + ReLU (3,3,3) - 32 Layer 7 Con v3d + BN + ReLU + MaxPool (3,3,3) (2,2,2) 64 Layer 8 Con v3d + BN + ReLU (3,3,3) - 64 Fully Connected Linear - - num classes K ey architectural principles are: • 3D Con volutions: Each block preserves the volumetric structure, capturing spatially local- ized patterns crucial for neuroanatomical analysis. • Progr essive Pooling: Max pooling is strategically applied after selected blocks to reduce spatial resolution and enhance multiscale hierarchical feature abstraction, as reflected in the sequence of pooling operations in the code. 46 T in Hoang, MSc dissertation • Batch Normalization: BatchNorm is employed after each con volution, promoting con ver - gence stability across distributed clients. • Dropout Regularization: A configurable dropout is included after acti vations to mitigate ov erfitting during federated or data-limited training. Note on Differential Privacy Compatibility: In the dif ferential pri vac y experiments, the stan- dard BatchNorm layers will be replaced by GroupNorm [51] layers due to BatchNorm’ s incom- patibility with DP [2]. BatchNorm creates cross-sample dependencies within batches, violating the per -sample gradient independence required for dif ferential pri v acy guarantees. GroupNorm provides equi v alent normalization benefits while maintaining sample independence. 5.4.2 Optimisation and T raining The training was designed for robust and scalable federated learning with thorough hyperparame- ter management, rapid con ver gence, and resilience to distrib uted systems issues. Our optimisation pipeline used AdamW optimizer, with the learning rate typically initialized at 1 × 10 − 4 according to best practices for training 3D con volutional models from scratch. T raining batch size was limited to 2–8 due to GPU memory constraints of 3D volumes, with gradient accumulation employed to achieve effecti ve batch sizes up to 16 or higher for stable gradient updates and improv ed con ver gence under federated regimes. Loss Function and Class Imbalance Handling: T o address pronounced class imbalances typical in clinical datasets, the primary loss function emplo yed was weighted cross-entropy . Gi ven the dev elopment dataset distribution with 490 CN and 307 AD cases, class imbalance presented a significant challenge for model training. The weighted cross-entropy loss compensates for this imbalance by assigning higher penalties to misclassification of underrepresented classes, defined as: L weig hted = − 1 N N X i =1 w y i log( p y i ) (5.1) 47 T in Hoang, MSc dissertation where w y i represents the class weight for the true class y i , p y i is the predicted probability for the true class, and N is the total number of samples. Class weights were computed using in verse frequency weighting: w c = n total n classes × n c (5.2) where n total is the total number of samples, n classes is the number of classes, and n c is the number of samples in class c . This weighting strategy ensures that the minority class (AD) receiv es proportionally higher importance during training, pre venting the model from dev eloping a bias to ward the majority class (CN). Learning Rate Scheduling and Regularisation: The training employed cosine annealing learning rate scheduling to facilitate smooth con ver gence and prev ent premature con v ergence to suboptimal solutions. W eight decay regularisation ( 1 × 10 − 2 ) was applied to prev ent overfitting, particularly crucial given the limited dataset size typical of medical imaging studies. Mixed preci- sion training was utilised where computationally feasible to reduce memory usage and accelerate training on modern GPUs whilst maintaining model accuracy . Model Selection and Checkpointing: Throughout training, model checkpoints were sav ed at regular intervals to enable model selection based on v alidation performance. For centralised train- ing, validation accuracy was computed using the held-out validation set at the end of each epoch, with the best checkpoint selected based on peak validation performance. For federated learning experiments, the global model was ev aluated ev ery 5 federated rounds on an aggreg ated global v alidation set comprising the combination of all local validation sets from participating clients. The checkpoint achieving the highest accuracy on this aggregated validation set was selected as the final model, ensuring generalisation across all participating institutions whilst prev enting ov erfitting–a critical consideration in medical imaging applications with limited dataset sizes. Comprehensi ve con ver gence monitoring, including early stopping and dynamic learning rate scheduling, is performed globally and per client. All metrics, including client-specific and aggre- gated loss curves, parameter distribution summaries, priv acy budget expenditure, and communi- cation ov erhead, are tracked li ve using W eights & Biases 2 . Error handling and fault tolerance are 2 W eights & Biases experiments: https://wandb .ai/tin-hoang/fl-adni-classification 48 T in Hoang, MSc dissertation integral, with checkpoint-based reco very and adaptiv e client selection pro viding resilience against network interruptions or client resource limitations. This systematic infrastructure enables repro- ducible, efficient, and reliable training of federated 3D MRI classification models for medical imaging research. A detailed description of ke y hyperparameters can be found in Section A.1. 5.5 F ederated Learning Strategies Building upon the methodological frame work described in Chapter 3, the experimental ev aluation encompasses the complete suite of federated learning strategies: F ederated A veraging (F edA vg): The canonical federated optimisation algorithm serving as the baseline for performance comparison. F ederated Pr oximal (F edPr ox): Enhanced variant addressing client heterogeneity through proximal regularisation, particularly relev ant for the site-specific data distributions in medical imaging. Differential Pri vacy Mechanisms: Both normal Local DP and the novel ALDP approach with round-wise pri vac y budget scheduling. Secure Aggregation (SecAgg+): Cryptographic protocols ensuring confidentiality during model parameter aggregation. 5.6 Evaluation Methodology 5.6.1 Methodological V alidation Protocol The methodology incorporates rigorous v alidation protocols to ensure the reliability and general- izability of research findings: Multiple Random Seeds: Experimental protocols employ multiple random initializations to account for stochastic variability in data partitioning and model initialization, ensuring statistical v alidity of performance comparisons. Cross-V alidation Integration: Site-aware partitioning is compatible with cross-validation protocols that maintain site boundaries while providing rob ust performance estimation across dif- ferent data splits. 49 T in Hoang, MSc dissertation Comprehensi ve Metric T racking: Integration with experiment tracking platforms enables comprehensi ve monitoring of federated learning dynamics, priv acy expenditure, and con v ergence characteristics essential for understanding algorithm behavior under realistic conditions. 5.6.2 Perf ormance Metrics The experimental ev aluation employed clinically relev ant metrics addressing the specific require- ments of Alzheimer’ s disease classification: Accuracy: The primary performance metric, measuring the proportion of correctly classified instances across all diagnostic categories: Accuracy = T P + T N T P + T N + F P + F N (5.3) F1 Score: The harmonic mean of precision and recall, providing balanced assessment partic- ularly important for imbalanced medical datasets: F1 = 2 × Precision × Recall Precision + Recall = 2 T P 2 T P + F P + F N (5.4) where T P represents true positi ves, T N true negati ves, F P false positiv es, and F N false negati v es. Confusion Matrix: A tabulation of prediction outcomes that pro vides detailed insight into classification performance across diagnostic categories. The confusion matrix enables systematic analysis of misclassification patterns: Confusion Matrix = T P F N F P T N (5.5) The confusion matrix facilitates computation of additional clinically relev ant metrics including sensiti vity (recall), specificity , positi ve predicti ve v alue (precision), and negati v e predictiv e value, enabling comprehensive assessment of diagnostic performance across both cognitive normal and Alzheimer’ s disease classifications. 50 T in Hoang, MSc dissertation R OC Curve and A UC: The Receiv er Operating Characteristic (R OC) curve plots the true positi ve rate (sensitivity) against the false positiv e rate (1-specificity) across different classification thresholds, providing threshold-independent performance assessment: TPR (Sensiti vity) = T P T P + F N (5.6) FPR = F P F P + T N = 1 − Specificity (5.7) The Area Under the R OC Curv e (A UC) provides a single scalar metric summarising classifier performance across all possible thresholds, with values ranging from 0.5 (random classification) to 1.0 (perfect classification). A UC is particularly valuable in federated learning e valuation as it provides robust performance assessment that is insensitive to class distribution variations that may occur across dif ferent institutional datasets. T raining Time Analysis: Computational ef ficiency metrics were systematically ev aluated across all federated learning strategies (FedA vg, FedProx, SecAgg+, Local DP , ALDP) and com- pared against centralised training baselines. T raining time measurements encompassed complete training cycles ov er 100 federated rounds or epochs, capturing the computational overhead in- troduced by different priv acy-preserving mechanisms and aggregation protocols. This analysis provides critical insights into the practical deployment feasibility of different federated learning approaches in healthcare en vironments where computational resources may be constrained. These metrics were selected to provide comprehensi ve e valuation whilst maintaining focus on clinically interpretable outcomes. The F1 score and A UC are particularly v aluable in medi- cal imaging applications where class imbalance is common and both precision (minimising false alarms) and recall (detecting true cases) are equally important for clinical decision-making. The confusion matrix enables detailed analysis of federated learning performance patterns, while ROC curves facilitate comparison of dif ferent federated strategies across varying decision thresholds rele vant to clinical deployment scenarios. The training time analysis ensures that performance e valuations consider not only diagnostic accuracy b ut also the practical computational require- ments essential for real-world deployment scenarios. 51 T in Hoang, MSc dissertation 5.6.3 Cross-V alidation Pr otocol T o ensure statistical v alidity and account for variability in data partitioning, the experimental design incorporated repeated random sub-sampling validation with independent train/v alidation splits using different random seeds. Follo wing the methodology of the baseline study [32], which employed 10 repetitions, our experiments were adapted to 5 repetitions due to computational con- straints whilst maintaining the site-aware distribution strategy for robust performance estimation. Results were aggregated across all repetitions to provide mean performance metrics with standard de viation. 5.7 Summary This experimental setup chapter has established a comprehensiv e framework for e valuating pri vac y- preserving federated learning approaches in medical imaging applications. The methodology builds upon established ADNI protocols whilst introducing significant innov ations in data par- titioning, pri vac y mechanisms, and e xperimental design that enhance the practical applicability of research findings. The ADNI dataset preprocessing pipeline implements rigorous quality assurance protocols, incorporating spatial normalisation to MNI template space, isotropic resampling, and skull strip- ping to ensure consistent cross-institutional analysis. The final curated dataset of 797 development images and 100 balanced test images provides a robust foundation for systematic ev aluation whilst maintaining demographic di versity essential for clinical rele vance. T raining protocols incorporate established best practices for 3D medical imaging, including AdamW optimisation, cosine learning rate scheduling, and weighted loss functions to address class imbalance. The experimental frame work supports systematic comparison of federated learning strategies including FedA vg, FedProx with proximal regularisation, SecAgg+ with cryptographic protection, and both fixed and adapti ve dif ferential pri v acy mechanisms. Building upon this experimental foundation, Chapter 6 presents the empirical results demon- strating the ef fectiv eness of the proposed methodological contributions and establishing quanti- tati ve benchmarks for pri vac y-preserving collaborativ e machine learning in healthcare en viron- ments. 52 T in Hoang, MSc dissertation 6 RESUL TS AND DISCUSSIONS This chapter presents the experimental results that v alidate the ef fecti veness of the proposed feder - ated learning frame work for pri v acy-preserving Alzheimer’ s disease classification. Building upon the setup established in Chapter 5, the results demonstrate the practical viability of achie ving high diagnostic accuracy through federated collaboration whilst maintaining rigorous priv acy guaran- tees. Results encompass 2-class (CN/AD) scenarios using the ADNI dataset, aggregated across fi ve independent random splits for statistical rob ustness. The findings establish concrete evidence for the clinical viability of federated learning in medical imaging applications and provide quantitati ve benchmarks for future research in pri vac y- preserving collaborati ve machine learning [8, 39]. 6.1 Centralised vs F ederated Perf ormance Comparison The baseline centralised training established baseline performance metrics with the 3D CNN ar- chitecture (see 5.4.1) achie ving 80 . 2 ± 2 . 2 % accurac y on the global test set for two-class CN/AD classification. This baseline performance was consistent with published results for ADNI-based Alzheimer’ s disease classification and provided a reference point for e valuating federated learning degradation [3, 32]. 6.1.1 F ederated Learning Algorithm P erf ormance T able 6.1: Cross-v alidation results on the test set of the 3D CNN model under centralised and 2/3/4-client settings Strategy #Clients Global T est Accuracy (%) Global T est F1 (%) CL (Centralised) – 80.2 ± 2.23 79.66 ± 2.51 FedA vg 2 79.2 ± 1.94 78.84 ± 2.17 FedProx (best µ = 10 − 5 ) 2 80.4 ± 2.33 80.05 ± 2.44 FedA vg 3 79.2 ± 2.23 78.93 ± 2.36 FedProx (best µ = 10 − 5 ) 3 81.4 ± 3.20 81.26 ± 3.24 SecAgg+ 3 78.2 ± 2.14 77.79 ± 2.30 FedA vg 4 78.6 ± 3.44 78.07 ± 3.67 FedProx (best µ = 10 − 5 ) 4 79.0 ± 3.22 78.58 ± 3.38 SecAgg+ 4 76.4 ± 3.26 75.92 ± 3.48 53 T in Hoang, MSc dissertation F edA vg Perf ormance: Standard federated av eraging demonstrated remarkable consistency across different client configurations, achieving accuracies of 79.2 ± 1.9% (2 clients), 79.2 ± 2.2% (3 clients), and 78.6 ± 3.4% (4 clients). The minimal performance degradation of 1.0– 1.6 percentage points compared to centralised training indicated effecti ve parameter aggreg ation despite data distribution across multiple institutions. Notably , the performance remained stable between 2 and 3-client configurations, with more substantial de gradation only appearing in the 4-client scenario. F edProx Superior Perf ormance: FedProx consistently outperformed both centralised train- ing and FedA vg across all client configurations, achieving 80.4 ± 2.3% (2 clients), 81.4 ± 3.2% (3 clients), and 79.0 ± 3.2% (4 clients) with optimal regularisation parameter µ = 10 − 5 . Most remarkably , FedProx with 3 clients achiev ed the highest ov erall performance ( 81.4 ± 3.2% ), ex- ceeding centralised training by 1.2 percentage points. This superior performance can be attributed to the proximal regularisation mechanism effecti vely mitigating client drift whilst providing im- plicit regularisation benefits that prev ent ov erfitting in the limited ADNI dataset [26]. Ho wev er , it is important to note that FedProx requires more sophisticated hyperparameter tuning compared to FedA vg, particularly careful calibration of the regularisation parameter µ , as demonstrated in Section A.2 where e xtensiv e parameter search across multiple orders of magnitude w as necessary to achie ve optimal performance. SecAgg+ P erf ormance and Limitations: SecAgg+ demonstrated competiti ve but slightly re- duced performance compared to standard federated approaches, achieving 78.2 ± 2.1% (3 clients) and 76.4 ± 3.3% (4 clients). The performance de gradation of 2.0–2.2 percentage points compared to centralised training reflects the trade-of f between enhanced priv acy guarantees and model util- ity . Note that SecAgg+ was not e valuated in 2-client scenarios due to fundamental cryptographic limitations: the underlying Secure Multiparty Computation (SMPC) protocol guarantees pri vac y only when N − 1 elements are kno wn, making three clients the minimum viable configuration for secure aggregation protocols [32]. 6.1.2 Confusion Matrix Analysis Figure 6.1 presents normalised confusion matrices comparing the classification performance of centralised training against the best-performing federated approach (FedProx with 3 clients, µ = 10 − 5 ). The matrices re veal detailed diagnostic characteristics that inform clinical deployment considerations. 54 T in Hoang, MSc dissertation (a) Centralised T raining (b) FedProx (3 clients, µ = 10 − 5 ) Figure 6.1: Normalized confusion matrices comparing centralised training with the best- performing federated approach. The centralised model exhibits high specificity for the CN class, correctly identifying CN examples with a normalized rate of 96%, and misclassifying only 4% as AD. F or the AD class, the sensiti vity is noticeably lower , with only 64% correctly classified and 36% misclassified as CN. In comparison, the FedProx federated approach yields slightly lo wer specificity for CN (94%) and a higher misclassification rate (6% as AD). Importantly , the sensiti vity for AD increases to 74%, with only 26% misclassified as CN. This suggests that the federated approach, while mod- estly sacrificing CN accuracy , significantly improv es the AD detection rate. Overall, the results demonstrate a tradeoff: centralised training fa vors precise CN classifica- tion, whereas FedProx enhances AD detection–a key improv ement, especially if AD identification is clinically critical. These findings illustrate that carefully tuned federated methods like FedProx can close the performance gap with centralised models, especially for underrepresented classes. 6.1.3 R OC Curve Analysis Figures 6.2 contrasts the Receiver Operating Characteristic (R OC) curves and Area Under the Curve (A UC) v alues for centralised training and the best-performing FedPr ox federated model . This rev ealed an interesting phenomenon: while FedProx achiev ed higher accuracy (81.4% vs 80.2%), it exhibited slightly lower A UC (0.890 vs 0.910). This discrepancy highlights that, while the federated FedProx model improves ov erall classification accuracy and sensiti vity for the AD class, it is less effecti ve in ranking predictions across thresholds, as indicated by the lower A UC. The centralised model is therefore some what superior in terms of discriminati ve power – 55 T in Hoang, MSc dissertation e ven though the dif ference is modest–meaning it makes more rob ust distinctions between positi v e and negati v e cases at varying decision thresholds. (a) Centralised (A UC = 0.910) (b) FedProx (3 clients, A UC = 0.890) Figure 6.2: R OC curv es comparing centralised training with the best-performing federated ap- proach. 6.1.4 Impact of number of clients in FL The systematic ev aluation of client scaling effects re veals a fundamental trade-off in federated learning deployment: whilst collaboration provides clear benefits ov er isolated training, perfor - mance consistently degrades as federation size increases . This pattern manifests across all algorithms, with accuracy declining from 2-client to 4-client configurations regardless of the fed- erated learning strategy emplo yed. FedA vg demonstrates steady degradation from 79.2% (2 clients) to 78.6% (4 clients), accom- panied by increasing v ariance (±1.9% to ±3.4%), indicating reduced training stability . SecAgg+ exhibits more pronounced deterioration from 78.2% (3 clients) to 76.4% (4 clients), reflecting the compounding ef fects of cryptographic overhead and statistical heterogeneity . Even FedProx, de- spite its superior regularisation capabilities, shows declining performance from 80.4% (2 clients) to 79.0% (4 clients). The underlying mechanism driving this degradation relates to intensifying statistical hetero- geneity as additional institutions contrib ute distinct datasets with unique patient demographics, imaging protocols, and institutional practices. The site-aware data partitioning methodology em- ployed preserves these realistic institutional boundaries, re v ealing the true coordination challenges in multi-institutional medical imaging collaborations. 56 T in Hoang, MSc dissertation 6.2 Differential Pri vacy P erformance Ev aluation The ev aluation of dif ferential priv acy mechanisms represents a critical component of this research, addressing the fundamental challenge of maintaining model utility whilst providing formal priv acy guarantees in federated medical imaging applications. This section presents comprehensive results comparing traditional Local Differential Pri vac y approaches with the proposed Adaptive Local Dif ferential Priv acy (ALDP) mechanism across multiple client configurations and priv acy budget settings. The differential priv ac y e valuation employed systematic parameter configurations designed to assess priv acy-utility trade-offs under realistic federated learning conditions. Follo wing the experimental frame work described in Chapter 5, all dif ferential priv acy e xperiments utilised fixed parameters of δ = 10 − 5 and clipping norm C = 1 . 0 , with comprehensi ve ev aluation across pri vac y budgets ϵ ∈ { 100 , 500 , 1000 , 2000 } for traditional Local DP and initial priv acy budgets ε 0 ∈ { 100 , 500 , 1000 , 2000 } for the ALDP mechanism detailed in Section 3.2. Note on Architecture Modification f or DP Compatibility: All differential priv ac y experi- ments employed the same 3D CNN architecture as in Section 5.4.1 with GroupNorm layers re- placing the standard BatchNorm layers. 6.2.1 T raditional Local Differ ential Privacy Results T raditional ( ϵ, δ ) -differential priv acy demonstrated se vere performance limitations across all e v al- uated priv acy budgets and client configurations. The results, presented in T able 6.2, rev eal system- atic challenges with fixed-noise approaches that fundamentally limit their applicability in medical imaging applications. In the 2-client configuration, traditional DP exhibited catastrophic performance degradation under strong priv acy constraints. At ϵ = 100 , fixed-noise DP achiev ed only 55 . 2 ± 4 . 26% accu- racy and 50 . 05 ± 8 . 29% F1 score, representing a 23 . 4 percentage point decline from the centralised baseline of 78 . 6 ± 3 . 38% accuracy . The substantial standard de viation in F1 score ( ± 8 . 29% ) indi- cated highly unstable training dynamics characteristic of noise-dominated optimisation regimes. Progressi ve increases in pri vac y budget yielded gradual improv ements, though performance remained substantially below acceptable clinical thresholds. At ϵ = 200 , traditional DP reached 63 . 4 ± 8 . 73% accuracy , accompanied by ev en higher variance ( ± 11 . 51% F1 standard devia- 57 T in Hoang, MSc dissertation T able 6.2: Comparati ve performance of Local ( ϵ , δ )-DP and Adapti ve Local ( ϵ , δ )-DP (ALDP) strategies across varying numbers of clients and epsilon values, with δ fix ed at 1 × 10 − 5 and the clipping norm set to 1.0 for all experiments. Strategy #Clients Pri vac y Budget ( ϵ ) Global T est Accuracy (%) Global T est F1 (%) CL (Centralised) – – 78.6 ± 3.38 78.06 ± 3.49 ( ϵ , δ )-DP 2 100 55.2 ± 4.26 50.05 ± 8.29 ( ϵ , δ )-DP 2 500 70.2 ± 4.45 68.71 ± 5.66 ( ϵ , δ )-DP 2 1000 72.0 ± 4.94 71.04 ± 5.55 ( ϵ , δ )-DP 2 2000 75.6 ± 4.63 74.81 ± 5.71 Adapti ve ( ϵ , δ )-DP 2 initial ε 0 =100 60.8 ± 4.53 56.70 ± 8.21 Adapti ve ( ϵ , δ )-DP 2 initial ε 0 =500 75.6 ± 3.88 74.67 ± 4.97 Adapti ve ( ϵ , δ )-DP 2 initial ε 0 =1000 78.4 ± 3.26 78.04 ± 3.36 Adapti ve ( ϵ , δ )-DP 2 initial ε 0 =2000 80.4 ± 0.80 80.19 ± 0.78 Adapti ve ( ϵ , δ )-DP 3 initial ε 0 =500 74.6 ± 3.93 74.05 ± 4.24 Adapti ve ( ϵ , δ )-DP 3 initial ε 0 =1000 77.2 ± 1.33 76.82 ± 1.40 Adapti ve ( ϵ , δ )-DP 3 initial ε 0 =2000 78.6 ± 1.74 78.34 ± 1.90 Adapti ve ( ϵ , δ )-DP 4 initial ε 0 =500 70.0 ± 9.38 66.97 ± 13.57 Adapti ve ( ϵ , δ )-DP 4 initial ε 0 =1000 75.2 ± 2.48 74.51 ± 2.78 Adapti ve ( ϵ , δ )-DP 4 initial ε 0 =2000 76.6 ± 1.62 76.11 ± 1.74 tion) that suggested continued training instability . Moderate priv acy settings ( ϵ = 500 ) achieved 70 . 2 ± 4 . 45% accuracy and 68 . 71 ± 5 . 66% F1 score, whilst the most permissive traditional DP configuration ( ϵ = 2000 ) attained 75 . 6 ± 4 . 63% accurac y . Critically , even under the most relaxed priv acy constraints ( ϵ = 2000 ), traditional DP remained 3 . 0 percentage points below the centralised baseline, demonstrating fundamental limitations in the fixed-noise approach. The consistent high variance across all priv acy budgets reflected the inherent instability of constant noise injection throughout the training process, particularly problematic during later con ver gence phases when gradient magnitudes naturally diminish. 6.2.2 Adaptive Local Differ ential Priv acy Results The Adapti ve Local Dif ferential Priv acy mechanism demonstrated substantial performance im- prov ements across all ev aluated configurations, effecti v ely addressing the limitations observed in traditional approaches. The ALDP results, incorporating both temporal priv ac y budget schedul- ing and per-tensor variance-aw are noise scaling as described in Algorithm 2, consistently outper- formed fixed-noise implementations whilst maintaining formal pri v acy guarantees. 58 T in Hoang, MSc dissertation In the 2-client scenario, ALDP achiev ed remarkable improvements o ver traditional DP across all priv acy budget lev els. At the strictest priv ac y setting ( ε 0 = 100 ), adaptiv e DP reached 60 . 8 ± 4 . 53% accuracy compared to 55 . 2 ± 4 . 26% for traditional DP , representing a 5 . 6 percentage point improv ement whilst maintaining equiv alent priv acy constraints. The F1 score improv ement was e ven more pronounced, increasing from 50 . 05 ± 8 . 29% to 56 . 70 ± 8 . 21% , with notably reduced v ariance indicating improved training stability . At moderate priv ac y b udgets ( ε 0 = 500 ), ALDP achiev ed 75 . 6 ± 3 . 88% accuracy and 74 . 67 ± 4 . 97% F1 score, substantially outperforming the corresponding traditional DP configuration by 5 . 4 and 5 . 96 percentage points respectiv ely . The reduced standard de viation ( 3 . 88% compared to 4 . 45% for traditional DP) demonstrated the stabilising ef fect of adaptiv e noise scheduling on con ver gence dynamics. Most remarkably , at higher pri v acy b udgets ( ε 0 = 1000 ), ALDP achie ved 78 . 4 ± 3 . 26% accu- racy , closely approaching the centralised baseline whilst maintaining differential priv acy guaran- tees. At the highest e v aluated pri vac y b udget ( ε 0 = 2000 ), ALDP reached 80 . 4 ± 0 . 80% accurac y and 80 . 19 ± 0 . 78% F1 score, marginally exceeding the non-pri vate centralised baseline perfor- mance. This counter-intuiti ve result, where pri vac y-preserving federated learning outperformed cen- tralised training, reflects the implicit regularisation benefits of adaptiv e noise injection in limited- data scenarios. The exceptionally lo w standard deviation ( 0 . 80% accuracy) indicated highly stable con ver gence behaviour , contrasting markedly with higher v ariance observed in both traditional DP and centralised approaches. Multi-client configuration results demonstrated consistent performance advantages for ALDP . In 3-client scenarios, ALDP with ε 0 = 2000 achieved 78 . 6 ± 1 . 74% accuracy , matching the centralised baseline whilst providing formal priv acy guarantees. The 4-client configuration main- tained similar trends, with ALDP achie ving 76 . 6 ± 1 . 62% accurac y at the highest pri v acy b udget, consistently outperforming traditional approaches with reduced v ariance across all settings. 6.2.3 T raining Dynamics: Fixed-Noise DP vs. Adaptive DP Figures 6.3 and 6.4 present the training loss curves for client 1 under both fixed-noise and adaptiv e ( ϵ, δ ) -dif ferential priv acy (DP) in 2-client scenario, e valuated across a range of priv acy parameters. 59 T in Hoang, MSc dissertation (a) ϵ = 100 (b) ϵ = 500 (c) ϵ = 1000 (d) ϵ = 2000 Figure 6.3: Training loss curves for client 1 under ( ϵ, δ ) -differential priv ac y with fixed-noise DP , e valuated for v arying ϵ v alues ( 100 , 500 , 1000 , 2000 ) ov er 100 rounds. For smaller ϵ , the loss consistently increases, while for lar ger ϵ improv ement stalls or re verses in later rounds, illustrating the pitfall of fix ed-noise schedules. In the fixed-noise DP setting (Figure 6.3), the training loss exhibits pronounced instability at stronger priv acy lev els. Specifically , for ϵ = 100 and ϵ = 500 , the loss monotonically increases throughout training, indicativ e of the optimisation being dominated by injected noise, thus pre- venting effecti ve learning and in some cases resulting in di ver gence. For lar ger ϵ values ( 1000 and 2000 ), an initial reduction in loss is occasionally observed; howe ver , this is follo wed by an upw ard re versal in the later rounds. This pattern highlighted the fundamental temporal misalignment in- herent in fixed-noise approaches, where constant noise levels become increasingly detrimental as gradient magnitudes naturally decrease during con ver gence phases. By contrast, loss curves obtained under the ALDP approach (Figure 6.4) demonstrate markedly improv ed con ver gence across all priv acy budgets e valuated. Adaptiv e DP enables stable and monotonic decrease in training loss for ϵ init ≥ 500 , with only minor stochastic fluctuations throughout training. Even in the strictest priv acy setting ( ϵ init = 100 ), the loss fluctuates within a bounded range and av oids the late-stage div ergence observed under fixed-noise DP . These results 60 T in Hoang, MSc dissertation provide strong empirical evidence that adaptiv ely adjusting both the magnitude and distribution of noise, according to training progression and parameter statistics, alleviates the con ver gence failures in fix ed-noise approaches. (a) ϵ init = 100 (b) ϵ init = 500 (c) ϵ init = 1000 (d) ϵ init = 2000 Figure 6.4: Training loss curves for client 1 under Adaptiv e ( ϵ, δ ) -DP with the same ϵ init as Fig- ure 6.3. Loss decreases more consistently , confirming impro ved con vergence and signal retention. 6.2.4 Privacy-Utility T rade-off Analysis The comprehensive e valuation establishes ALDP as a substantial advancement in pri vac y-preserving federated learning, providing quantifiable improvements in priv acy-utility trade-offs essential for practical medical imaging applications. The systematic comparison across multiple priv acy bud- gets and client configurations re v eals se veral critical findings with important implications for real- world deployment. Perf ormance Gap Analysis: ALDP consistently achiev ed 5 - 7 percentage point improve- ments ov er traditional DP at equiv alent priv acy b udgets, with particularly pronounced advantages at moderate priv acy settings ( ε 0 = 500 - 1000 ). These improvements represent clinically significant performance gains that could influence deployment feasibility in healthcare en vironments where diagnostic accuracy directly impacts patient outcomes. 61 T in Hoang, MSc dissertation Stability and Predictability: Beyond absolute performance improvements, ALDP demon- strated superior con ver gence stability with consistently lower variance across all configurations. This predictability represents a crucial advantage for clinical deployment, where reliable perfor- mance is essential for maintaining clinician confidence in automated diagnostic systems. Scalability Characteristics: Multi-client results rev ealed that ALDP performance degraded gracefully with increasing federation comple xity , maintaining substantial advantages ov er tradi- tional approaches even in 4-client scenarios. This scalability suggests practical applicability in realistic multi-institutional collaborations in v olving multiple healthcare systems. Regularisation Effects: The observ ation that ALDP occasionally outperformed non-priv ate baselines highlights the beneficial regularisation ef fects of adapti ve noise injection in limited-data medical imaging scenarios. This finding suggests that appropriate priv acy mechanisms may en- hance rather than compromise model generalisation in small-scale medical datasets characteristic of specialised clinical applications. The combination of substantial performance improv ements, enhanced stability , and main- tained scalability establishes ALDP as a practical solution for priv acy-preserving federated learn- ing in medical imaging applications where both utility and pri vac y are paramount considerations for real-world deployment. 6.3 Ablation Study: Impact of Individual Client Contributions in 4-Client Scenario This ablation study ev aluates indi vidual client contributions by training each client independently on its local dataset and comparing against centralised training. The analysis addresses whether institutions benefit from collaborativ e federated learning and identifies relati v e client contributions to ov erall performance. T able 6.3: Results of an ablation study assessing the impact of individual client contrib utions in a federated learning setting. Each client was trained independently using only its own dataset, without data sharing, and e valuated on the same balanced test set (50 CN and 50 AD samples) as the global test set in the federated learning experiment presented in T able 6.1. The final column reports centralized training results, combining data from all four clients, which demonstrates im- prov ed performance through data aggregation. Strategy Client 1 T est Acc (%) Client 2 T est Acc (%) Client 3 T est Acc (%) Client 4 T est Acc (%) All T est Acc (%) CL 68.2 ± 2.93 72.8 ± 9.66 70.6 ± 5.16 75.4 ± 1.02 80.2 ± 2.23 62 T in Hoang, MSc dissertation 6.3.1 Individual P erf ormance Analysis and Collaborative Benefits The results in T able 6.3 rev eal substantial performance v ariations across individual clients when trained in isolation. Client 4 achie ved the highest individual performance (75.4 ± 1.02% accuracy) with the lo west v ariance, indicating well-curated data and consistent model con v ergence. Client 2 demonstrated moderate performance (72.8 ± 9.66%) but exhibited the highest variance, suggesting potential data quality issues or challenging class distrib utions. Clients 3 and 1 achie ved 70.6 ± 5.16% and 68.2 ± 2.93% accuracy respectiv ely , with Client 1 representing the poorest individual performance despite relati vely stable training. Centralised training (80.2 ± 2.23% accuracy) substantially outperformed all indi vidual clients, with improvements ranging from 4.8 percentage points for the strongest client to 12.0 percentage points for the weakest. Even the best-performing individual client (Client 4) falls significantly short of centralised performance, demonstrating clear benefits from data aggregation and collab- orati ve learning. The centralised approach also achieved moderate variance (2.23%), providing more stable and consistent training compared to se veral individual clients. The performance rank- ing (Client 4 > Client 2 > Client 3 > Client 1) indicates Client 4 as the primary contributor to federated learning success, whilst Client 1 primarily benefits from receiving kno wledge rather than contributing substantial impro vements to the global model. 6.3.2 Implications f or Federated Lear ning Deployment These findings provide compelling evidence for federated learning adoption in multi-institutional medical imaging scenarios. Institutions with challenging datasets (ex emplified by Client 1) achie ve substantial diagnostic improv ements through collaboration, whilst well-resourced institutions (e x- emplified by Client 4) still realise meaningful performance gains. The asymmetric contribution pattern has important implications for federated deployment, where institutions with limited lo- cal performance can achiev e substantial improv ements through collaborativ e participation. The results v alidate that collaborati ve model de velopment provides superior diagnostic performance compared to isolated institutional ef forts whilst maintaining data sovereignty . 6.4 Computational Efficiency of F ederated Learning: T raining Time Analysis The computational efficienc y of different federated learning strategies represents a critical con- sideration for practical deployment in healthcare environments where training resources may be constrained. T able 6.4 presents the a verage training times across fi v e independent e xperimental 63 T in Hoang, MSc dissertation runs for each strate gy , encompassing 100 federated learning rounds (or 100 epochs for centralised training). All strategies employed identical 3D CNN architectures and preprocessing pipelines to ensure fair comparison, with variations in training time attributable solely to algorithmic dif fer - ences and communication protocols. All experiments were conducted using a single NVIDIA R TX A4000 GPU to ensure consistent computational conditions across strategies. Federated learning training was implemented as local simulation on the same single GPU, providing fair comparison by eliminating hardware variability while maintaining the algorithmic characteristics of distributed training protocols. T able 6.4: A verage total training time comparison across centralised and federated learning strate- gies (on 4-client scenario) for 100 training rounds/epochs. Results represent mean values com- puted from fi ve independent experimental runs for each strate gy . Strategy A verage T raining T ime (h:mm:ss) Relati ve to Centralised (%) CL (Centralised) 2:52:07 100.0 FedA vg 3:30:22 121.9 FedProx 3:58:00 138.0 SecAgg+ 2:39:56 92.9 Local DP 3:31:50 122.6 ALDP 3:56:43 137.2 6.4.1 Impact of Model Quantisation on T raining Efficiency The experimental results demonstrate that parameter quantisation can provide modest efficienc y improv ements in federated learning training. SecAgg+ achiev ed training completion in 2 hours 39 minutes 56 seconds on average, representing a 7.1% reduction compared to centralised train- ing. This improv ement stems from SecAgg+’ s quantisation mechanism, which reduces model parameters to the [0 , 2 22 − 1] floating-point range during communication phases. The quantisation approach compresses model updates from full floating-point precision to fixed-point representa- tion, reducing communication overhead during parameter transmission between federated clients and the central server . The ef ficiency gains from quantisation demonstrate that reduced precision arithmetic can ac- celerate federated learning training, particularly beneficial for high-dimensional medical imaging models where parameter transmission represents the dominant communication bottleneck. This finding suggests that quantisation techniques warrant broader inv estigation as a general approach 64 T in Hoang, MSc dissertation for impro ving federated learning ef ficiency in medical imaging applications, independent of cryp- tographic security requirements. 6.4.2 Standard F ederated Learning P erf ormance Standard federated learning approaches (FedA vg and FedProx) demonstrated moderate ov erhead increases of 21.9% and 38.0% respecti vely compared to centralised training. The additional ov er- head in FedProx can be attributed to the proximal regularisation computations required for client drift mitigation. These results indicate that collaborativ e training remains computationally feasible compared to centralised alternativ es, with communication coordination rather than computational complexity representing the primary time constraint. 6.4.3 Privacy Mechanism Computational Ov erhead Pri vac y-preserving mechanisms demonstrated an increase in computational o verhead compared to the centralised baseline. ALDP e xhibited the longest training duration (3 hours 56 minutes 43 sec- onds), representing a 37.2% increase ov er centralised training. This overhead stems from the adap- ti ve noise computation required for per -tensor variance calculation and exponential priv acy budget scheduling, which introduces additional computational complexity during each federated round. Local DP achie ved comparable ef ficienc y to standard federated approaches (22.6% o verhead), in- dicating that fix ed-noise differential priv ac y mechanisms introduce minimal computational burden beyond standard federated aggre gation. 6.5 Discussions The experiments confirm that collaborativ e model training across multiple institutions can achie ve diagnostic accuracy comparable to, and occasionally surpassing, centralised approaches, e ven un- der strict pri vac y constraints. Se veral ke y points warrant discussion. F ederated Lear ning V ersus Centralised T raining : First, the results demonstrate that fed- erated learning, equipped with advanced algorithms such as FedProx, reliably achiev es perfor- mance on par with centralised baselines in realistic multi-institutional scenarios. For instance, the best-performing FedProx configuration achiev ed an accuracy of 81 . 4 ± 3 . 2% in the three-client scenario, exceeding the centralised benchmark of 80 . 2 ± 2 . 2% and deliv ering improved sensitiv- ity for Alzheimer’ s disease classification. This outcome is particularly notew orthy: it highlights that careful regularisation and realistic data partitioning allow federated algorithms to harness the 65 T in Hoang, MSc dissertation benefits of data div ersity , enhancing generalisation while respecting institutional priv acy bound- aries [26, 48]. Privacy-Pr eserving Mechanisms and Utility T rade-offs : A second major contribution is the systematic ev aluation of differential pri v acy mechanisms. T raditional local differential pri v acy approaches exhibited marked performance de gradation, especially at stringent priv ac y budgets, often resulting in unstable training dynamics and reduced diagnostic utility . By contrast, the nov el Adapti ve Local Dif ferential Priv acy (ALDP) scheme yielded substantial improvements, deliv ering 5 - 7 percentage points better accurac y and F1 scores than fixed-noise approaches under equiv alent pri vac y constraints. The ALDP mechanism, with its temporal priv acy budget adaptation and per- parameter noise scaling, was crucial for stable and ef fecti ve model optimisation, ev en in high- dimensional medical imaging scenarios. These results suggest that adaptiv e pri v acy techniques are essential for balancing the competing demands of data protection and clinical performance in sensiti ve healthcare contexts [42, 2, 34]. Scalability , Heterogeneity , and Real-W orld Implications : While federated learning clearly benefits from collaborative training, the experiments reveal an intrinsic trade-of f between scalabil- ity and performance as the number of participating institutions increases. Accuracy and training stability tended to decrease with federation size, particularly in highly heterogeneous settings (3 or 4-client scenario), reflecting the reality that data drift and coordination complexity remain sig- nificant technical challenges. Advanced algorithms such as FedProx partly mitigate these issues through proximal regularisation, yet further research is needed to ensure rob ust scalability without utility loss [43]. The ablation study also demonstrated asymmetric benefits across institutions: sites with weaker local data benefited the most from collaboration, whereas well-resourced sites served as primary contributors. This insight underscores the necessity for equitable incentiv e structures and robust aggre gation schemes in practical deployments. Computational Efficiency : Comparativ e training time analysis sho ws that federated approaches introduce moderate computational ov erhead (around 21.9–38.0% for most protocols), with cryp- tographic techniques such as SecAgg+ further improving communication efficienc y (7.1% faster than centralised in local simulation due to quantisation). This suggests that practical deployment in resource-constrained clinical settings is feasible, especially as federated framew orks and priv acy mechanisms continue to mature. 66 T in Hoang, MSc dissertation 7 CONCLUSIONS AND FUTURE WORK This dissertation has presented a comprehensiv e in v estigation into priv acy-preserving federated learning for medical artificial intelligence, with a specific focus on Alzheimer’ s disease classifi- cation using 3D MRI data from the Alzheimer’ s Disease Neuroimaging Initiati ve (ADNI). The work addresses fundamental challenges in collaborativ e medical AI dev elopment, including data fragmentation, priv acy preservation, and realistic e valuation methodologies, as initially outlined in Chapter 1. Through methodological innov ations, implementation, and empirical ev aluation, this research demonstrates that federated learning can achiev e clinically viable diagnostic performance whilst maintaining rigorous pri vac y guarantees and data sov ereignty . 7.1 Limitations Despite the novel methodological contributions and comprehensiv e empirical ev aluation presented in this dissertation, se veral limitations remain that should be addressed. • Incomplete Pri vacy Level Analysis of ALDP Mechanism: While the Adapti ve Local Dif- ferential Priv acy (ALDP) mechanism demonstrated marked improvements in accuracy and utility over fixed-noise Local DP approaches, its priv acy guarantees hav e not been fully characterised. The adaptive scheduling of priv acy budgets ( ε t ) introduces dynamic relax- ation that, while beneficial for con ver gence, may result in weaker o verall pri v acy compared to constant-budget Local DP . Comprehensiv e priv acy accounting methodologies, including composition bounds assessment over multiple rounds and comparison with state-of-the-art dif ferential priv acy frameworks such as Pri vac y Loss Distribution [2, 34], were not imple- mented due to time constraints. • Absence of Rob ust Privacy Attack Analysis: The study did not explore vulnerability to pri vac y attacks such as membership inference or model inv ersion, which remain critical concerns in federated learning [46, 32]. Although pre vious work on federated Alzheimer’ s disease detection included membership inference attack assessments [32], this project was unable to replicate these experiments within the time constraint, limiting insight into the resilience of proposed mechanisms against adversarial threats. 67 T in Hoang, MSc dissertation • Simplified Site-A ware Partitioning Without Demographic Imbalance: While the site- aw are partitioning strategy maintained institutional boundaries, client datasets were bal- anced in size and did not reflect the inherent demographic and clinical imbalances seen in real-world federated healthcare scenarios. Prior studies highlight that federated learn- ing robustness can be undermined under greater imbalance in sample sizes and distribu- tions [32, 43], suggesting a need for future e xperiments encompassing heterogeneous client populations and more realistic demographic v ariability . 7.2 Conclusions This dissertation has undertaken a rigorous study of pri vac y-preserving federated learning for Alzheimer’ s disease classification using three-dimensional MRI data from the Alzheimer’ s Dis- ease Neuroimaging Initiativ e (ADNI). Moti v ated by the pressing challenges of data fragmentation, stringent pri vac y requirements, and the need for robust collaborative AI in healthcare, the research systematically addressed both theoretical and practical gaps through methodological adv ancement and empirical v alidation. The central contribution is the design and e valuation of a federated learning framew ork that deli vers competiti ve diagnostic performance whilst maintaining institutional data sov ereignty and pri vac y guarantees. The work introduced a novel site-aware partitioning strategy , ensuring real- istic multi-institutional data distribution and simulating non-IID conditions typical in real-world deployments. Extensi ve benchmarking demonstrated that advanced federated algorithms, notably FedProx, achiev e accuracy and F1 scores on par with, or even e xceeding, centralised training, es- pecially when the federation consists of three clients. This provides strong empirical e vidence for the viability of federated collaboration in neuroimaging-based diagnostic applications. A second major contribution lies in the comprehensi ve ev aluation of pri vac y-preserving mech- anisms. The novel Adaptive Local Differential Pri vac y (ALDP) approach, combining tempo- ral priv acy budget adaptation with per-tensor noise scaling, consistently outperformed traditional fixed-noise local DP schemes, pro viding a 5–7 percentage point gain in accuracy and F1 scores under equi valent pri v acy b udgets. ALDP was sho wn to ef fectiv ely balance utility and priv acy , e ven in the challenging context of high-dimensional medical imaging data. Further , the research examined the scalability and computational efficienc y of federated learn- ing, demonstrating that while collaboration enables substantial benefits, particularly for clients 68 T in Hoang, MSc dissertation with weaker local datasets, practical federations must carefully manage the trade-off between in- creasing client heterogeneity and overall model stability . The study also confirmed the feasibility of deployment in typical clinical computing environments, with only moderate increases in train- ing time relati ve to con v entional approaches. In summary , this dissertation establishes strong evidence that federated learning, when imple- mented with realistic methodological design and adaptiv e priv acy-preserving techniques, offers a promising pathway tow ard secure, collaborati ve, and clinically ef fectiv e medical AI. The contribu- tions herein provide a practical foundation and empirical benchmarks for future academic research and real-world deployment of federated learning systems in medicine. 7.3 Future W ork Building upon the methodological and empirical foundations established in this dissertation, sev- eral promising av enues for future research are evident, with the potential to further advance pri vac y-preserving federated learning in medical artificial intelligence. F ormal Privacy Analysis and Accounting : A primary direction in volv es the rigorous char- acterisation of priv ac y guarantees furnished by the Adaptiv e Local Differential Pri vac y (ALDP) mechanism. Future work should extend the analysis beyond empirical utility to include priv acy accounting across all training rounds, employing adv anced frame works such as Pri v acy Loss Dis- tribution or R ´ enyi Differential Priv ac y [2, 34]. Careful assessment of the cumulative priv ac y loss under adaptive budget schedules will be essential to quantifying the trade-offs between con v er- gence and pri vac y , especially in long-running federated collaborations inv olving multiple institu- tions and rounds. Robustness to Privacy Attacks : The resilience of federated models to adversarial priv acy attacks warrants systematic inv estigation. Subsequent studies should ev aluate the vulnerability of both traditional and adaptiv e priv acy mechanisms to advanced threats such as membership infer- ence, model in v ersion, and property inference attacks [46, 32]. This may include designing attack simulations within the federated framework, benchmarking defence efficac y , and developing mit- igation strategies that reinforce pri v acy guarantees while preserving diagnostic utility . Demographic and Clinical Heterogeneity : T o enhance real-world applicability , future ex- periments should incorporate more realistic client heterogeneity , including div erse demographic, 69 T in Hoang, MSc dissertation clinical, and site-specific variations in data distrib ution. This entails simulating federations with pronounced sample size imbalance, v aried imaging protocols, and clinically relev ant population di versity [32, 43]. Evaluating the robustness of algorithmic strategies under such conditions will generate deeper insights into federated deployment challenges and promote equitable model per- formance across institutions. Algorithmic Expansion and Scalability : Extending benchmarking to encompass a broader repertoire of federated learning algorithms, such as Scaffold, FedDyn, and neuroimaging-specific attention models, remains an important objecti ve [24]. Scaling experiments to larger client net- works and more complex multi-modal collaborations, potentially in volving 10, 20, or more clients, presents further technical challenges around communication efficienc y , priv acy budget scaling, and statistical heterogeneity [48]. These directions will be vital in establishing generalisable best practices for federated learning in medical imaging. Clinical Generalisability and Interpretability : Finally , validation of the proposed method- ologies across di verse imaging modalities (e.g., PET , fMRI), international datasets, and clinical populations should be pursued [28]. Incorporating interpretable AI techniques, such as attention mapping or explainable feature extraction, will be important to promote clinical confidence and stakeholder acceptance in federated medical AI [24]. 70 T in Hoang, MSc dissertation BIBLIOGRAPHY [1] Abadi, M. , Chu, A. , Goodfello w , I. , McMahan, H. B. , Mironov , I. , T alwar , K. , and Zhang, L. . Deep learning with dif ferential priv acy . Pr oceedings of the 2016 ACM SIGSA C Confer ence on Computer and Communications Security , pages 308–318, 2016. [2] Abadi, M. , Chu, A. , Goodfello w , I. , McMahan, H. B. , Mironov , I. , T alwar , K. , and Zhang, L. . Deep learning with differential priv ac y . In Pr oceedings of the 2016 A CM SIGSAC Confer ence on Computer and Communications Security (CCS) , pages 308–318, 2016. doi: 10.1145/2976749.2978318. [3] Agarwal, D. , ´ Alv aro Berb ´ ıs, M. , Luna, A. , Lipari, V . , Brito Ballester , J. , and T orre- D ´ ıez, I. , de la. Automated medical diagnosis of alzheimer’ s disease using an ef ficientnet con v olutional neural network. Journal of Medical Systems , 47(1):57, 2023. doi: 10.1007/ s10916- 023- 01941- 4. [4] Aisen, P . S. , Petersen, R. C. , Donohue, M. C. , Gamst, A. , Raman, R. , Thomas, R. G. , W alter , S. , Trojano wski, J. Q. , Shaw , L. M. , Beckett, L. A. , Jack, C. R. , Jagust, W . , T oga, A. W . , and W einer, M. W . . Clinical core of the alzheimer’ s disease neuroimaging initiativ e: Progress and plans. Alzheimer’s & Dementia , 6(3):239–246, 2010. doi: 10.1016/j.jalz.2010. 03.006. [5] Bell, J. H. , Bonawitz, K. A. , Gasc ´ on, A. , Lepoint, T . , and Raykov a, M. . Secure single- server aggregation with (poly) logarithmic ov erhead. In Pr oceedings of the 2020 ACM SIGSA C Confer ence on Computer and Communications Security , pages 1253–1269, 2020. [6] Beutel, D. J. , T opal, T . , Mathur , A. , Qiu, X. , Fernandez-Marques, J. , Gao, Y . , et al. Flo wer: a friendly federated learning research frame work. arXiv pr eprint arXiv:2007.14390 , 2020. [7] Bonawitz, K. , Iv anov , V . , Kreuter , B. , Marcedone, A. , McMahan, H. B. , Patel, S. , Ramage, D. , Seg al, A. , and Seth, K. . Practical secure aggregation for priv ac y-preserving machine learning. pages 1175–1191, 2017. 71 T in Hoang, MSc dissertation [8] Bradshaw , T . J. , Huemann, Z. , Hu, J. , and Rahmim, A. . A guide to cross-validation for artificial intelligence in medical imaging. Radiology: Artificial Intelligence , 5(4):e220232, 2023. doi: 10.1148/ryai.220232. [9] Cardoso, M. J. , Li, W . , Brown, R. , Ma, N. , Kerfoot, E. , W ang, Y . , Murrey , B. , Myronenko, A. , Zhao, C. , Y ang, D. , et al. Monai: An open-source framework for deep learning in healthcare. arXiv pr eprint arXiv:2211.02701 , 2022. [10] Czervionke, L. F . , Czervionke, J. M. , Daniels, D. L. , and Haughton, V . M. . Characteristic features of mr truncation artifacts. American Journal of Roentgenology , 151(6):1219–1228, 1988. [11] Dwork, C. and Roth, A. . The Algorithmic F oundations of Differ ential Privacy , v olume 9 of F oundations and T r ends in Theoretical Computer Science . Now Publishers, 2014. doi: 10.1561/0400000042. [12] Finn, E. S. , Shen, X. , Scheinost, D. , Rosenberg, M. D. , Huang, J. , Chun, M. M. , Papademetris, X. , and Constable, R. T . . Identification of individuals using whole-brain functional connectivity patterns. Natur e Neur oscience , 18(11):1508–1515, 2015. doi: 10. 1038/nn.4135. Replaces erroneous 2019 citation/title. [13] Fonov , V . , Evans, A. C. , Botteron, K. , Almli, C. R. , McKinstry , R. C. , and Collins, D. L. . Unbiased a verage age-appropriate atlases for pediatric studies. Neur oImage , 54(1):313–327, 2011. [14] Fonov , V . S. , Evans, A. C. , McKinstry , R. C. , Almli, C. R. , and Collins, D. L. . Unbiased nonlinear a verage age-appropriate brain templates from birth to adulthood. Neur oImage , 47: S102, 2009. [15] Fu, J. , Chen, Z. , and Han, X. . Adap dp-fl: Differentially priv ate federated learn- ing with adaptiv e noise. In 2022 IEEE International Confer ence on T rust, Security and Privacy in Computing and Communications (T rustCom) , pages 656–663, 2022. doi: 10.1109/T rustCom56396.2022.00094. [16] Guan, H. , Y ap, P .-T . , Bozoki, A. , and Liu, M. . Federated learning for medical image analysis: A surve y . P attern Reco gnition , 151:110424, 2024. doi: 10.1016/j.patcog.2024. 110424. 72 T in Hoang, MSc dissertation [17] Hussain, Z. , Gimenez, F . , Y i, D. , and Rubin, D. . Differential data augmentation techniques for medical imaging classification tasks. AMIA annual symposium pr oceedings , 2017:979, 2017. [18] IBM Security and Ponemon Institute. Cost of a data breach report 2020. T echnical report, IBM, 2020. URL https://www.ibm.com/reports/data- breach . [19] Jack Jr , C. R. , Bennett, D. A. , Blennow , K. , Carrillo, M. C. , Dunn, B. , Haeberlein, S. B. , Holtzman, D. M. , Jagust, W . , Jessen, F . , Karlawish, J. , et al. Nia-aa research framework: T o ward a biological definition of alzheimer’ s disease. Alzheimer’ s & Dementia , 14(4):535– 562, 2018. doi: 10.1016/j.jalz.2018.02.018. [20] Kairouz, P . , McMahan, H. B. , A vent, B. , Bellet, A. , Bennis, M. , Bhagoji, A. N. , Bonawitz, K. , Charles, Z. , Cormode, G. , Cummings, R. , et al. Advances and open problems in federated learning. F oundations and T r ends in Mac hine Learning , 14(1–2):1–210, 2021. [21] Kaissis, G. A. , Makowski, M. R. , R ¨ uckert, D. , and Braren, R. F . . Secure, pri vac y- preserving and federated machine learning in medical imaging. Nature Machine Intelligence , 2(6):305–311, 2020. doi: 10.1038/s42256- 020- 0186- 1. [22] Kiani, S. , Creager , E. , Sharma, A. , T ople, S. , and Honkala, M. . Dif ferentially pri v ate federated learning with time-adapti ve priv acy spending. arXiv pr eprint arXiv:2502.18706 , 2025. URL . [23] Kone ˇ cn ´ y, J. , McMahan, H. B. , Ramage, D. , Richt ´ arik, P . , and T alwalkar , A. . Federated learning: Strategies for improving communication ef ficiency . arXiv pr eprint arXiv:1610.05492 , 2016. URL . [24] Lei, B. , Liang, Y . , Xie, J. , W u, Y . , Liang, E. , Liu, Y . , Y ang, P . , W ang, T . , Liu, C. , Du, J. , Xiao, X. , and W ang, S. . Hybrid federated learning with brain-region attention network for multi-center alzheimer’ s disease detection. P attern Recognition , 2024. [25] Li, Q. , W en, Z. , W u, Z. , Hu, S. , W ang, N. , Li, Y . , Liu, X. , and He, B. . A surv ey on feder- ated learning systems: V ision, h ype and reality for data pri v acy and protection. IEEE T r ans- actions on Knowledge and Data Engineering , 2021. doi: 10.1109/TKDE.2021.3124599. [26] Li, T . , Sahu, A. K. , Zaheer , M. , Sanjabi, M. , T alwalkar , A. , and Smith, V . . Federated optimization in heterogeneous networks. Pr oceedings of Machine Learning and Systems , 2: 429–450, 2020. 73 T in Hoang, MSc dissertation [27] Li, X. , Gu, Y . , Dvornek, N. , Staib, L. H. , V entola, P . , and Duncan, J. S. . Multi-site fmri analysis using priv acy-preserving federated learning and domain adaptation: Abide results. Medical Image Analysis , 65:101765, 2021. [28] Liu, S. , Liu, S. , Cai, W . , Che, H. , Pujol, S. , Kikinis, R. , Feng, D. , and Fulham, M. J. . A comprehensi ve surve y on deep learning-based alzheimer’ s disease classification. Neur oIm- age , 208:116459, 2020. [29] Manera, A. L. , Dadar , M. , Fono v , V . , and Collins, D. L. . Cerebra, re gistration and manual label correction of mindboggle-101 atlas for mni-icbm152 template. Scientific Data , 7(1): 1–15, 2020. [30] McMahan, H. B. , Moore, E. , Ramage, D. , Hampson, S. , and Arcas, B. A. , y . Communication-ef ficient learning of deep networks from decentralized data. 54:1273–1282, 2017. URL https://proceedings.mlr.press/v54/mcmahan17a.html . [31] Micikevicius, P . , Narang, S. , Alben, J. , Diamos, G. , Elsen, E. , Garcia, D. , Ginsbur g, B. , Houston, M. , Kuchaie v , O. , V enkatesh, G. , and W u, H. . Mixed precision training. 2018. URL . arXiv preprint arXi v:1710.03740. [32] Mitrovska, T . , Safari, M. , Ritter , M. , Shariati, S. , and Fischer, H. . Secure federated learning for alzheimer’ s disease detection. Computers in Biology and Medicine , 174:108447, 2024. [33] Mueller , S. G. , W einer , M. W . , Thal, L. J. , Petersen, R. C. , Jack, C. R. , Jagust, W . , Tro- jano wski, J. Q. , T oga, A. W . , and Beck ett, L. . The Alzheimer’ s Disease Neuroimaging Ini- tiati ve (ADNI), 2005. URL https://doi.org/10.1016/j.nic.2005.09.008 . [34] Papernot, N. , Cheu, A. , Erlingsson, U. , Mironov , I. , Song, S. , Stockton, J. , Thakkar , O. , V aidya, T . , and Zhu, L. . T empered sigmoid activ ations for deep learning with differential pri vac y . In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , volume 35, pages 8852–8861, 2021. [35] Petersen, R. C. , Aisen, P . S. , Beckett, L. A. , et al. Alzheimer’ s disease neuroimaging initiati ve (adni): clinical characterization. Neur ology , 74(3):201–209, 2010. [36] Popescu, V . , Battaglini, M. , Hoogstrate, W . S. , V erfaillie, S. C. , Knol, D. L. , Golay , X. , et al. Optimizing parameter choice for fsl-brain e xtraction tool (bet) on 3d t1 images in multiple sclerosis. Neur oImag e , 61(4):1484–1494, 2012. 74 T in Hoang, MSc dissertation [37] Price, W . N. and Cohen, I. G. . Priv acy in the age of medical big data. Nature Medicine , 25 (1):37–43, 2019. [38] Rajkomar , A. , Dean, J. , and K ohane, I. . Machine learning in medicine. Ne w England J ournal of Medicine , 380(14):1347–1358, 2018. [39] Reinke, A. , Tizabi, M. D. , Sudre, C. H. , et al. Understanding metric-related pitfalls in image analysis validation. Natur e Methods , 21(2):1320–1335, 2024. doi: 10.1038/ s41592- 023- 02150- 0. [40] Riedel, T . , W ermter , S. , Stricker , D. , and G ¨ unnemann, S. . Comparativ e analysis of open- source federated learning framew orks: A literature-based survey and re view . International J ournal of Machine Learning and Cybernetics , 2024. doi: 10.1007/s13042- 024- 02234- z. [41] Rieke, N. , Hancox, J. , Li, W . , Millet ` a, F . , Roth, H. R. , Albarqouni, S. , Bakas, S. , Galtier , M. N. , Landman, B. A. , Maier-Hein, K. , et al. The future of digital health with federated learning. NPJ Digital Medicine , 3(1):1–7, 2020. [42] Sarwate, A. D. and Chaudhuri, K. . Signal processing and machine learning with differential pri vac y: Algorithms and challenges for continuous data. IEEE Signal Pr ocessing Magazine , 30(5):86–94, 2013. [43] Sattler , F . , W iedemann, S. , M ¨ uller , K.-R. , and Samek, W . . Robust and communication- ef ficient federated learning from non-i.i.d. data. IEEE T ransactions on Neur al Networks and Learning Systems , 31(9):3400–3413, 2020. doi: 10.1109/TNNLS.2019.2944481. [44] Smith, S. M. . Fast robust automated brain extraction. Human Brain Mapping , 17(3):143– 155, 2002. [45] T opol, E. J. . High-performance medicine: the conv ergence of human and artificial intelli- gence. Natur e Medicine , 25(1):44–56, 2019. [46] True x, S. , Baracaldo, N. , Anwar , A. , Steinke, T . , Ludwig, H. , Zhang, R. , and Zhou, Y . . A hybrid approach to pri vac y-preserving federated learning. pages 1–11, 2019. [47] T urrisi, R. , V erri, A. , and Barla, A. . Deep learning-based alzheimer’ s disease detection: reproducibility and the effect of modeling choices. F r ontiers in Computational Neur oscience , 18:1330085, 2024. doi: 10.3389/fncom.2024.1330085. 75 T in Hoang, MSc dissertation [48] W allach, E. , Siler , S. , and Deng, J. . The more is not the merrier: In vestigating the ef fect of client size on federated learning. arXiv pr eprint arXiv:2504.08198 , 2025. [49] W einer , M. W . , V eitch, D. P . , Aisen, P . S. , et al. The alzheimer’ s disease neuroimaging initiati ve 3: continued innov ation for clinical trial improvement. Alzheimer’ s & Dementia , 11(5):561–571, 2015. [50] W en, J. , Thibeau-Sutre, E. , Diaz-Melo, M. , Samper-Gonz ´ alez, J. , Routier, A. , Bot- tani, S. , Dormont, D. , Durrleman, S. , Bur gos, N. , and Colliot, O. . Con volutional neu- ral networks for classification of alzheimer’ s disease: Overview and reproducible e valua- tion. Medical Image Analysis , 63:101694, 2020. ISSN 1361-8415. doi: https://doi.org/10. 1016/j.media.2020.101694. URL https://www.sciencedirect.com/science/ article/pii/S1361841520300591 . [51] W u, Y . and He, K. . Group normalization. In Pr oceedings of the Eur opean Confer ence on Computer V ision (ECCV) , pages 3–19, 2018. doi: 10.1007/978- 3- 030- 01261- 8 1. [52] Y agis, E. , De Herrera, A. G. S. , and Citi, L. . Ef fect of data leakage in brain mri classification using 2d con v olutional neural networks. Scientific Reports , 11(1):1–12, 2021. [53] Zhu, L. , Liu, Z. , and Han, S. . Deep leakage from gradients. Advances in Neural Information Pr ocessing Systems , 32, 2019. 76 T in Hoang, MSc dissertation A APPENDIX A.1 K ey Hyperparameters f or F ederated Learning T raining T able A.1: Key Hyperparameters for Federated Learning T raining Category Parameter V alue Description T raining Batch Size 2–8 V aries on different number of concur- rent clients T raining Learning Rate 1 × 10 − 4 Initial learning rate T raining LR Scheduler Cosine Learning rate scheduler T raining Optimizer AdamW Optimization algorithm T raining W eight Decay 1 × 10 − 2 W eight Decay regularization T raining Mixed Precision False Enable automatic mixed precision T raining W eighted Loss in verse W eighted Loss to counter imbalanced dataset Data Input Dimensions (73 , 96 , 96) Standardized MRI v olume Data Resampling 1 Spatial resolution ( mm 3 isotropic) Data Augmentation Prob 0 . 2 – 0 . 5 Data augmentation probability FL FL Rounds 100 T otal federated learning rounds FL Local Epochs 1 Local training epochs per FL round FL Client Fraction 1.0 Fraction of clients per round FL Min Fit Clients 2 – 4 Minimum clients for aggregation FL Strategy FedA vg, Fed- Prox, SecAgg+, DP , ALDP Choose FL strategy to run FedProx mu ( µ ) 1 × 10 − 5 – 5 . 0 Proximal parameter controlling regu- larisation strength. SecAgg+ Num Share 3 – 4 Number of shares into which each client’ s priv ate key is split. SecAgg+ Reconstruction Threshold 2 – 3 Minimum number of shares required to reconstruct a client’ s priv ate key . SecAgg+ Clipping Range 8 . 0 Range within which model parameters are clipped. (default fr om Flower) SecAgg+ Quantization Range 2 22 Range into which floating-point model parameters are quantized. (default fr om Flower) DP Epsilon 100 . 0 – 2000 . 0 Priv ac y budget in Local DP , or Initial pri vac y budget in ALDP DP Delta 1 × 10 − 5 Failure probability for DP DP Decay Factor 0 . 95 Exponential gro wth decay factor DP Max Epsilon ∞ Maximum priv acy budget limit in ALDP DP Clipping Norm 1 . 0 Gradient clipping threshold 77 T in Hoang, MSc dissertation A.2 F edProx µ Finetuning The FedProx algorithm is inherently sensitiv e to the regularisation parameter µ , which introduces a proximal term to penalise div ergence from the global model. In contrast to FedA vg, where no such parameter exists, FedProx requires careful calibration of µ to achie v e stable conv ergence and satisfactory generalisation. T o in vestigate this beha viour , µ was tuned across a range of v alues, from 10 − 5 to 5.0, under scenarios with two, three, and four clients. The results are summarised in T able A.2. T able A.2: Hyper-parameter tuning results for FedProx across different numbers of clients, illus- trating the ef fect of varying µ values on global test accurac y and F1 score. Strategy #Clients µ Global T est Accuracy (%) Global T est F1 (%) CL (centralised) - - 80.2 ± 2.23 79.66 ± 2.51 FedProx 2 1 . 0 79.6 ± 4.32 79.11 ± 4.75 FedProx 2 10 − 1 80.2 ± 2.23 79.91 ± 2.33 FedProx 2 10 − 3 79.2 ± 3.37 78.77 ± 3.86 FedProx 2 10 − 5 80.4 ± 2.33 80.05 ± 2.44 FedProx 3 1 . 0 78.2 ± 4.96 77.41 ± 6.15 FedProx 3 10 − 1 77.2 ± 1.94 76.77 ± 2.27 FedProx 3 10 − 2 78.0 ± 2.28 77.52 ± 2.59 FedProx 3 10 − 3 79.8 ± 2.14 79.55 ± 2.16 FedProx 3 10 − 4 80.6 ± 2.42 80.28 ± 2.64 FedProx 3 10 − 5 81.4 ± 3.20 81.26 ± 3.24 FedProx 4 5 . 0 76.8 ± 4.87 76.05 ± 5.33 FedProx 4 3 . 0 75.8 ± 3.54 75.12 ± 3.91 FedProx 4 1 . 0 74.8 ± 2.79 73.6 ± 5.80 FedProx 4 10 − 1 76.2 ± 1.47 75.65 ± 1.58 FedProx 4 10 − 2 75.6 ± 2.06 74.84 ± 2.37 FedProx 4 10 − 3 77.4 ± 2.58 76.67 ± 2.97 FedProx 4 10 − 4 77.2 ± 3.66 76.57 ± 4.14 FedProx 4 10 − 5 79.0 ± 3.22 78.58 ± 3.38 Optimal µ Selection and Perf ormance Patterns: The empirical ev aluation rev eals that µ = 10 − 5 consistently achiev ed the highest global test accuracy across all client configurations exam- ined. For the 2-client scenario, this optimal µ value yielded an accuracy of 80 . 4 ± 2 . 33% and F1 score of 80 . 05 ± 2 . 44% , marginally outperforming both the centralised baseline and other µ config- urations. The 3-client configuration exhibited the most pronounced improvement with µ = 10 − 5 , achie ving the highest ov erall performance of 81 . 4 ± 3 . 20% accuracy and 81 . 26 ± 3 . 24% F1 score, representing a substantial 4.2 percentage point improvement ov er the suboptimal µ = 0 . 1 con- 78 T in Hoang, MSc dissertation figuration. The 4-client setup, whilst showing the same optimal µ v alue, achiev ed 79 . 0 ± 3 . 22% accuracy , indicating the trade-of fs inherent in increased federation complexity . Sensitivity Analysis and Perf ormance Degradation: The results demonstrate FedProx’ s considerable sensitivity to µ selection, with performance v arying substantially across the tested range. Higher µ values ( µ = 1 . 0 and above) consistently underperformed across all client con- figurations, with the 4-client, µ = 1 . 0 configuration achieving only 74 . 8 ± 2 . 79% accuracy–the poorest performance observed. Con versely , intermediate values such as µ = 0 . 1 showed in- consistent beha viour , performing reasonably well with 2 clients ( 80 . 2 ± 2 . 2% ) but deteriorating significantly with increased client numbers. This pattern suggests that the proximal regularisation strength must be carefully calibrated to the federation’ s complexity and statistical heterogeneity . Client Scaling Effects: The interaction between client number and µ sensiti vity reveals im- portant scalability considerations. The 3-client configuration demonstrated the most fav ourable performance profile, suggesting an optimal balance between federation complexity and coordi- nation benefits. Ho we ver , the 4-client setup sho wed increased variance and generally reduced performance across most µ values, indicating that larger federations may require more sophisti- cated parameter tuning strategies. The consistent preference for v ery small µ v alues ( 10 − 5 ) across all configurations suggests that minimal proximal regularisation provides sufficient coordination whilst preserving local adaptation capabilities. 79
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment