Can LLMs Model Incorrect Student Reasoning? A Case Study on Distractor Generation
Modeling plausible student misconceptions is critical for AI in education. In this work, we examine how large language models (LLMs) reason about misconceptions when generating multiple-choice distractors, a task that requires modeling incorrect yet …
Authors: Yanick Zengaffinen, Andreas Opedal, Donya Rooein
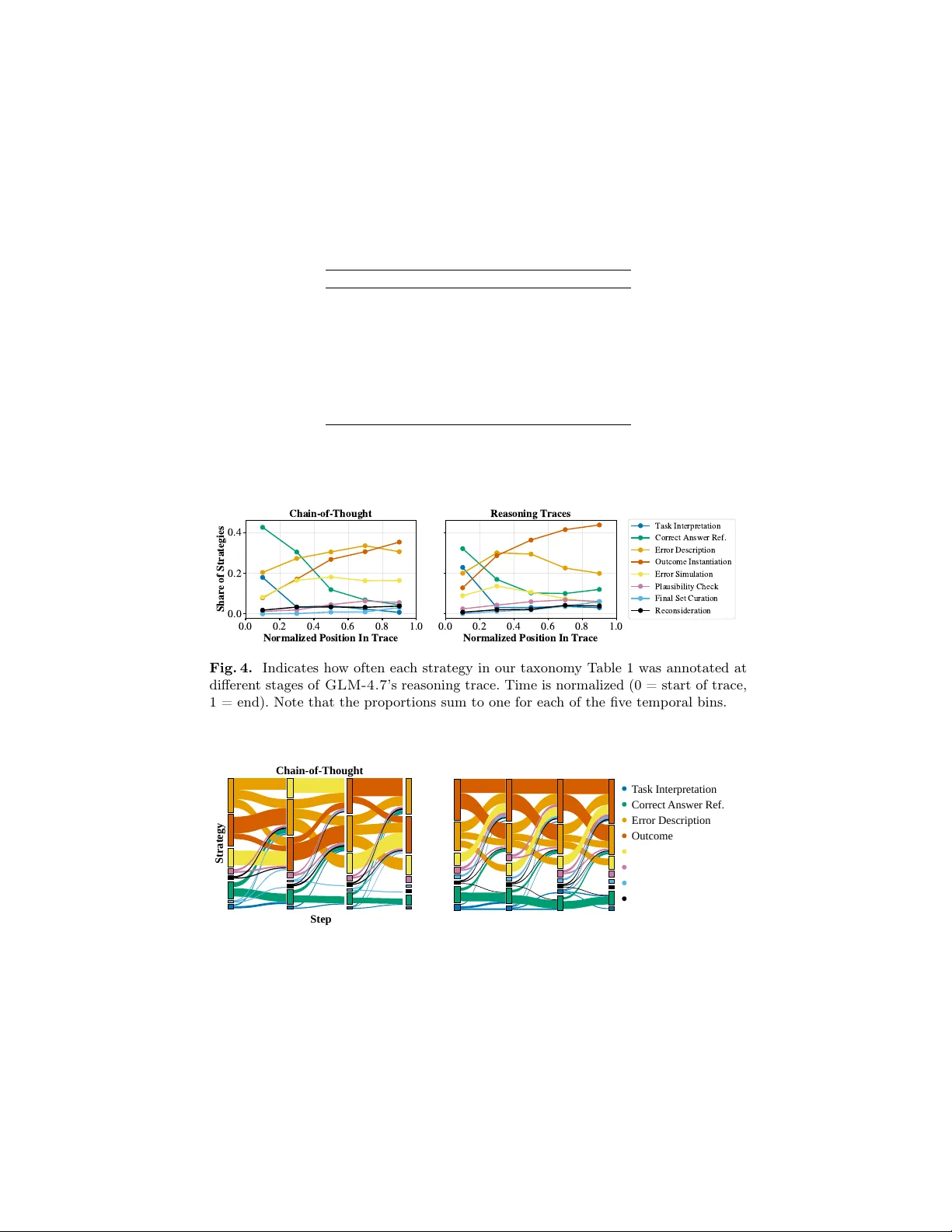
Can LLMs Mo del Incorrect Studen t Reasoning? A Case Study on Distractor Generation Y anic k Zengaffinen 1 , Andreas Op edal 1 , Dony a Ro o ein 2 , K v A dity a Sriv atsa 1 , Shashank Sonk ar 3 , and Mrinma ya Sac han 1 1 ETH Züric h, Switzerland yanick.zengaffinen@inf.ethz.ch 2 Bo cconi Univ ersity , Italy 3 Univ ersity of Central Florida, USA Abstract. Mo deling plausible student misconceptions is critical for AI in education. In this work, w e examine ho w large language mo dels (LLMs) reason ab out misconceptions when generating m ultiple-c hoice distrac- tors, a task that requires mo deling incorrect y et plausible answers by co- ordinating solution kno wledge, sim ulating studen t misconceptions, and ev aluating plausibilit y . W e introduce a taxonomy for analyzing the strate- gies used by state-of-the-art LLMs, examining their reasoning procedures and comparing them to established b est practices in the learning sci- ences. Our structured analysis rev eals a surprising alignmen t betw een their pro cesses and b est practices: the mo dels typically solve the prob- lem correctly first, then articulate and simulate multiple p oten tial mis- conceptions, and finally select a set of distractors. An analysis of failure mo des reveals that errors arise primarily from failures in recov ering the correct solution and selecting among resp onse candidates, rather than sim ulating errors or structuring the process. Consistent with these re- sults, we find that providing the correct solution in the prompt improv es alignmen t with h uman-authored distractors b y 8%, highligh ting the crit- ical role of anchoring to the correct solution when generating plausible incorrect studen t reasoning. Overall, our analysis offers a structured and in terpretable lens into LLMs’ ability to mo del incorrect student reason- ing and pro duce high-quality distractors. 4 Keyw ords: Studen t Modeling · Distractor Generation · Reasoning · Large Language Mo dels for Education 1 In tro duction Studen t mo deling is a foundational problem in AI for education [31,22], under- pinning a wide range of applications suc h as test design [3,11], diagnosis of mis- conceptions, teacher training [21,25] and dev elopmen t of targeted instructional in terven tions [20,38]. A central component of student mo deling is the ability to represen t not only what students know, but also the systematic errors and mis- conceptions that characterize incorrect but plausible reasoning. Despite rapid 4 All co de is av ailable at https://github.com/eth- lre/llm- student- modeling- strategies . 2 Y. Zengaffinen et al. T ask Interpretation Correct Answer Reference The correct simplification is: (6+9m)/3 = 3(2+3m)/3 = 2+3m We are given a question: "Simplify the following if possible: (6+9m)/3". We need to generate TWO incorrect distractor answers. High-Level Error Description Possible Errors: (1) Forgetting to divide both terms by the denominator. Error Simulation e.g., only divide 6 by 3 but not 9m. This gets us (6/3 + 9m) = Incorrect Outcome Instantiation 2 + 9m. Incorrect Outcome Instantiation or 6 + 3m Error Simulation if 3 divides only 9m and not 6. Plausibility Assessment Both count towards the same error , so they are equally likely . High-Level Error Description Next, (2) They might try to combine the constant and variable. Error Simulation So, they might add 6 and 9m to get 15m, simplifying the expression to 15m/3= Incorrect Outcome Instantiation 5m. Final Set Curation This gives us two distractors, one from each error type. Reconsideration But lets think again, are there other errors we should consider? No. Fig. 1. An LLM reasoning trace for distractor generation, annotated according to our taxonom y (T able 1). Color-coded labels sho w the model in terpreting the task, anc horing in the correct solution, generating candidate distractors based on errors, ev aluating their plausibilit y , and curating the final set-mirroring strategies identified in the learning-science literature (§ 3.1). progress in large language mo del (LLM) capabilities [48,35,9] and a growing fo- cus on using LLMs for student simulation [29,34,26,49], our understanding of whether and how LLMs can mo del incorrect student reasoning remains limited. Mo dern LLMs are trained not just to output the answer to a query , but to generate intermediate reasoning con ten t that reflects a procedure that ev en tually pro duces an answ er [48,9]. This makes it possible to analyze how LLMs construct their reasoning: whic h problem-solving strategies they follow, how these strate- gies unfold across a task, and to what extent the resulting b eha vior aligns with b est-practice cognitiv e accoun ts from learning sciences. In this work, w e inv estigate these questions in the context of a task that requires p erforming reasoning that is inc orr e ct y et plausible : generating incor- rect answ er alternativ es ( distractors ) for multiple-c hoice questions (MCQs). Distractor generation is a natural application of student models: if a model can faithfully sim ulate plausible studen t reasoning—both correct and incorrect— then distractors can b e obtained by sampling from simulated studen t solutions and selecting common incorrect outcomes. When compared to the task of solving problems, distractor generation is strictly more challenging—to pro duce high- qualit y distractors, the LLM m ust b e able to not only identify the correct so- lution, but simulate inc orr e ct student reasoning and v erify the plausibility of the resulting incorrect answ ers [15,18]. While past work has inv estigated using LLMs for automated distractor generation [13,1,10,41,36], they largely focused on p erformance measured with resp ect to the final resp onse. W e argue that it is of equal importance to ev aluate how the mo dels arriv e at distractor candidates, considering their strategies and whether those are aligned with best practices among exp erts in the field. Indeed, explainability has b een shown to play a key role for establishing trust in AI-based educational to ols among teachers [33,12]. On LLMs’ Student Mo deling Strategies 3 T o increase our understanding of ho w mo dern LLMs p erform this task, we in tro duce a broadly applicable framew ork for analyzing and comparing reasoning traces. Building on prior w ork [30], we combine open co ding—a metho d for qual- itativ e lab eling of salient concepts [7]—with guidance from the learning science literature to construct a taxonom y of strategies used in distractor generation. W e apply this taxonom y to 240 distractor-generation traces from DeepSeek- V3.2 [9] and GLM-4.7 [16], allo wing us to systematically analyze the strategies they use when generating distractors for a dataset of exp ert-written MCQs [23]. Fig. 1 illustrates the annotation of a single reasoning trace according to the strategies in our taxonomy . Although there remains substan tial ro om for impro v ement in performance, our analysis reveals a surprising alignment b et w een ho w mo dern LLMs generate distractors and b est practices from the distractor-generation literature. Sp ecifi- cally , LLMs’ pro cesses closely mirror recommended misconception-based design practices: they t ypically b egin b y solving the problem correctly , articulate p o- ten tial studen t misconceptions, instantiate them through erroneous reasoning, and select plausible incorrect answers from a broader set of candidates. The cor- rect step-by-step solution serves as an anchor from which the mo del diverges at sp ecific p oin ts to generate misconception-aligned distractors. In contrast, modi- fying surface features of the correct answ er without mo deling underlying studen t reasoning (i.e., similarit y-based heuristics) is only rarely observ ed. Bey ond c haracterizing LLMs’ pro cesses, our taxonomy also enables a diagno- sis of where and wh y distractor generation fails. W e find that some parts, suc h as error simulation and the implicit organization of multi-step reasoning, are gen- erally robust. Instead, failures arise more often in recov ering the correct solution and downstream selection of distractors. These findings also suggest concrete av- en ues for improving distractor generation such as providing additional guidance at test time. Most notably , rev ealing the correct answ er in the prompt signifi- can tly impro ves p erformance b y 8%. 5 Ov erall, our results sho w that LLMs are able to systematically mo del misconception-based distractor generation when anc hored to a correct solution, deep ening our understanding of when and ho w mo dern LLMs can model plausible incorrect student reasoning. 2 Studen t Mo deling and Distractor Generation Studen t mo deling with LLMs. A gro wing bo dy of w ork suggests LLMs as promising tools for simulating student b eha vior—they can generate student re- sp onses that exp ert annotators judge as reflective of common grade-appropriate misconceptions [29] and condition their b eha vior on a learner’s cognitive level [49] or misconceptions [27]. At the same time, recent literature suggests that LLMs may enco de common studen t error patterns [34,26], but it remains un- clear whether they can effectively leverage this implicit kno wledge. While these 5 This analysis excludes problems that rely on answer choices, e.g., “Which option out of the fol- lowing four is correct?”. 4 Y. Zengaffinen et al. findings suggest that LLMs can simulate incorrect student reasoning to some ex- ten t, prior ev aluations focus primarily on the outputs rather than the reasoning pro cesses that pro duce them. As a result, it remains unclear which reasoning strategies LLMs use to generate incorrect answ ers. Multiple-c hoice questions and distractor generation. MCQs are widely used to assess student understanding [43,6], but their effectiv eness dep ends on the qualit y of the distractors . Crafting high-quality distractors (see § 3.1) is costly and time consuming [40,37]. Prior work has therefore explored automat- ing this pro cess with LLMs [1, inter alia ], particularly for mathematical MCQs [13,19,24,36]. Some approaches decompose distractor generation into pro ducing candidate mistak es and applying them to generate plausible answers, reflecting misconception-based metho ds [14,39], while others rely on ov ergeneration fol- lo wed b y ranking [42]. Despite notable performance gains, existing approac hes dep end on human in volv emen t or large task-sp ecific datasets, limiting practi- cal deploymen t. In con trast, leveraging LLMs’ reasoning offers a complementary path to effectiv e distractor generation without these dep endencies. 3 A T axonom y of Strategies for Distractor Generation Our goal is to characterize the strategies LLMs use to generate distractors with- out access to historical student data [44]. W e develop a taxonomy (T able 1) by com bining learning-science theory with empirical analysis to capture b oth ex- p ected strategies and observed LLM b eha viour. W e first review exp ert’s strate- gies (§ 3.1) and then describ e how w e construct our taxonom y (§ 3.2). 3.1 Crafting Effectiv e Distractors Criteria for effectiv e distractor sets. When designing MCQs, distractors m ust b e plausible, i.e., likely to b e selected by students with flaw ed or incomplete understanding [18,15]. Empirical studies link plausibilit y to b oth seman tic relat- edness to the correct answ er and grounding in identifiable misconceptions [15,28]. A dditionally , functional distractors should exhibit so-called negative discrimina- tion by preferen tially attracting lo wer-performing studen ts ov er high-p erformers [45]. F urthermore, high-quality distractors must function w ell as a set . Options should b e m utually exclusive, homogeneous in form, and free of unintended cues suc h as grammatical inconsistencies, ov erlapping conten t, etc [17]. Strategies for crafting effective distractors. The literature identifies t w o main strategies for crafting high-qualit y distractors in the absence of historical data. (1) Similarity-based distractors modify surface features of the correct answ er without mo deling underlying studen t reasoning. F or example, if the cor- rect answer is 4 3 , a distractor could in vert the sign to − 4 3 . While easy to imple- men t, suc h distractors do not rev eal sp ecific student misconceptions [5,46,44]. On LLMs’ Student Mo deling Strategies 5 (2) Misconception-based distractors deriv e from common studen t errors ap- plied to the correct solution pro cess. F or example, if students forget to inv ert the divisor when dividing fractions, a distractor can b e generated by applying this error (e.g., 1 3 ÷ 1 2 ! = 1 6 ). This approac h aligns with repair theory , which ex- plains systematic errors as lo cal “repairs” students apply when their pro cedural kno wledge is incomplete or inapplicable [4]. These repairs follo w predictable pat- terns [47]. While sim ulating step-lev el buggy pro cedures is labor-intensiv e and requires kno wledge of common errors [15], such distractors are preferred because they exp ose sp ecific pro cedural gaps and are diagnostically informativ e [2,8]. 3.2 T axonom y Construction Next, we develop a taxonomy that in tegrates the ab o ve theoretical expectations with patterns observ ed in LLM distractor-generation traces. First, we summarize the relev ant theoretical princ iples, then describ e ho w w e collect and analyze LLM reasoning traces, and finally explain ho w these theoretical and empirical insights are reconciled in to a unified taxonom y . Grounding in literature. Based on the distractor generation workflo w de- scrib ed in the literature reviewed in § 3.1, w e exp ect the following strategies. Both similarity-based and misconception-based approac hes require access to the correct solution ( → CORR ). Misconception-based distractor generation can b e decomp osed into a three-step pro cess: (i) identifying a common error ( → ERR_DESC ), (ii) simulating this error within an otherwise correct step-by-step solution procedure ( → ERR_SIM ), and (iii) stating the incorrect outcome that results from instan tiating the error ( → INST ). Finally , item-writing guidelines on distractor functioning—suc h as minimum selection thresholds and negativ e discrimination—can b e op erationalized at the level of individual distractors via explicit plausibility c hecks ( → PLAUS ), while enforcing constraints o ver the full distractor set requires explicit curation or selection mechanisms ( → CURATE ). Observing LLMs’ reasoning. T o ground our taxonomy in LLMs’ actual rea- soning, w e also collect and analyze traces of their distractor-generation processes. Sp ecifically , w e use the Eedi Math MCQ Dataset [23], which con tains grade- sc ho ol l ev el math questions with four answer choices (i.e., three distractors) p er problem. W e exclude questions referencing images and only consider problems for whic h high-lev el errors are a v ailable, ensuring a misconception-based strat- egy is applicable. W e additionally remov e all problems that rely on the answ er c hoices, taking the form “Whic h of the following is correct?” (see § A.1 for further details). These filtering steps yield a dataset with N = 429 problems. W e use t wo mo dels, DeepSeek-V3.2 [9] and GLM-4.7 [16], b oth of which are reason- ing mo dels. W e consider t wo wa ys of prompting: (i) c hain-of-thought (CoT) prompting [48], where mo dels are prompted to think step-by-step b efore gen- erating distractors but reasoning is disabled; (ii) reasoning prompting , where mo dels solve the task b y generating additional reasoning tokens but output only 6 Y. Zengaffinen et al. the distractors. 6 T o capture the models’ natural distractor-generation strategies, w e use a simple prompt that av oids biasing the mo dels to ward any particular strategy and prompt the mo dels separately for each problem. 7 Grounding in observ ation. W e p erform manual op en co ding [7]—a qualita- tiv e method for breaking text into discrete concepts without predefined categories— on a curated set of 24 traces from b oth CoT and reasoning sources, co vering both LLMs and v arying in distractor generation p erformance. Half of the traces con- tain at most one matc hing distractor and half contain tw o or more, based on Eedi annotations. Because reasoning traces are highly v erb ose, w e scale our anal- ysis with mo del-assisted op en co ding. W e prompt DeepSeek-V3.2 , in reasoning mo de and without pro viding manually extracted co des, to perform sen tence-lev el op en co ding ov er an additional 500 traces and surface recurring strategies in- cluding supporting examples (prompt shown in § A.3). T races are processed in batc hes of 10 problems: the mo del first p erforms sen tence-level co ding within eac h trace and then rep orts recurring strategies across the batch, using the same stratification as for the man ual analysis. T able 1. A taxonomy for distractor generation grounded in learning-science literature and empirical observ ations of LLMs’ reasoning traces, whic h we use to annotate reasoning traces as shown in Fig. 1. Strategy Definition INTER (T ask Interpretation) Clarifying the problem statement / instruc- tions to determine the required output. CORR (Correct Answer Ref.) Computing or referencing the correct solution to the problem. ERR_DESC (Error Description) Describing common misconceptions or proce- dural errors at an abstract lev el. INST (Outcome Instantiation) Any mention of a candidate distractor or in- correct answer. ERR_SIM (Error Simulation) Any deliberate verbalization of an incorrect procedure. PLAUS (Plausibility Check) Ev aluating how likely a candidate incorrect answer is to b e chosen by a studen t. CURATE (Final Set Curation) Selecting and refining a set of distinct, incor- rect, and non-ambiguous distractors. RECON (Reconsideration) Revisiting earl ier choices by exploring alter- native interpretations or distractors. Merging theory and observ ation. Finally , w e man ually aggre- gate and reconcile con- cepts deriv ed from the literature, manual co ding, and mo del- generated proposals. Ov erlapping or re- dundan t co des are aligned and mapp ed to broader strategy categories. 8 This pro- cess yielded a uni- fied taxonom y reflect- ing b oth established theoretical insights and strategies observ ed in LLM b eha vior, presen ted in T able 1. All the strategies were first iden tified during manual open co ding. Mo del-assisted co ding indep enden tly reco vered all strategies except RECON and prop osed additional co des that w ere 6 W e set the token limits to 16k for reasoning and 8k for CoT. 7 W e use the following system prompt: “Y ou will be given a math question. Please generate 3 incor- rect distractor answers for the question to b e used as m ultiple-choice options in a m ultiple-choice exam. [TEMPLA TE] Distractor1: , Distractor2: , Distractor3:” The user prompt is “Question: . . . ”. F or the CoT prompt, w e additionally append “Think step-by-step b efore giving your final answer” b efore [TEMPLA TE]. 8 F or example, we initially obtained separate co des for utterances such as “we need to solve cor- rectly” and “but remember the correct answ er is . . . ”. As b oth refer to the same underlying concept—explicitly referencing the correct answer ( CORR ), we merged them into a single category . On LLMs’ Student Mo deling Strategies 7 excluded p ost hoc, as they captured problem-sp ecific rather than general strate- gies. Six of the eigh t strategies are directly supp orted by distractor-generation literature. The remaining tw o— INTER and RECON —reflect general reasoning pro- cesses: INTER clarifies item requirements and output constraints according to Evidence-Cen tered Design’s task model [32], while RECON represents iterativ e bac ktracking during exp ert review. Refer to § A.3 for further information ab out ho w strategies were selected. 4 Exp erimen ts In this section, we analyze LLMs’ distractor-generation strategies. W e first es- tablish that LLMs’ reasoning strategies help with distractor generation (§ 4.1). Next, we examine how LLMs use and orchestrate the strategies of our taxon- om y (§ 4.2). Finally , we discuss the extent to whic h these pro cesses align with established b est practices and identify where they fail (§ 4.3). 4.1 The Impact of Reasoning on LLM P erformance Before delving in to reasoning traces, we first examine what output-level perfor- mance metrics rev eal ab out the usefulness of LLMs for distractor generation. P erformance metrics. Our dataset { p n } N n =1 con tains N math problems p n = ( x n , y n , Z n ) , where x n is the textual description of the math problem, y n is the correct answer choice, and Z n with |Z n | = 3 is the set of (three) ground-truth distractors. W e note that the answ er choices are tok en sequences, i.e., they are not restricted to b eing numerical. Now, for the problem indexed by n , w e sample candidate distractors from an LLM, yielding a m ultiset ˆ Z n = ( ˆ Z n , m n ) , where ˆ Z n is the underlying set and m n : ˆ Z n → N is the multiplicit y of the elements in ˆ Z n (i.e., their counts). Note that in practice, w e restrict | ˆ Z n | to b e 3 ; see foot- note 7. W e use three metrics: prop ortional match |Z n ∩ ˆ Z n | / |Z n | [13,14], the n umber of candidates that equal the correct answer c hoice ( #correct ) m n ( y n ) (max v alue 3), and the num b er of redundan t candidate choices ( #rep etitions ) P z n ∈ ˆ Z n m ( z n ) −| ˆ Z n | (max v alue 2). 9 W e report the av erage across all N problem instances and confidence interv als (CIs) based on t-distributions. 9 Note that these metrics require chec king whether candidate distractors ˆ Z are equiv alent to the annotated distractors Z . Requiring exact matches—while eliminating false p ositiv es—would b e far too strict: most problems’ answers may b e expressed in multiple wa ys (e.g., 1 2 vs. 1 / 2 ) or equiv alence may depend on the problem description (e.g., 1 2 is not equivalen t to 0 . 5 if the problem asks for it to be con verted to decimal). F ollo wing prior work, we use an LLM ( gpt-4-1-mini [35], prompted to judge equiv alence of two provided answers) to judge semantic equivalence when exact matches come bac k negative [39]. The LLM achiev es 98% precision and 92% recall in equiv alence judgements ov er 500 comparisons. The full prompt is provided in § A.2. 8 Y. Zengaffinen et al. T able 2. Proportional match (mean ± 95% CI based on t-distribution) for DeepSeek-V3.2 and GLM-4.7 , under different prompting conditions. Prompt DeepSeek-V3.2 GLM-4.7 Direct 0.34 ± 0.03 0.42 ± 0.03 CoT 0.51 ± 0.03 0.50 ± 0.03 Reasoning 0.52 ± 0.03 0.52 ± 0.03 Results. W e find that prop or- tional match improv es signifi- can tly when moving from di- rect prompting —where rea- soning is disabled and the LLMs are instructed to directly out- put the distractors—to CoT and reasoning settings for b oth LLMs (T able 2). F urthermore, w e observ e that for DeepSeek-V3.2 , b oth #cor- rect and #rep etitions decrease substan tially when moving from direct prompting to reasoning. Sp ecifically , acciden tally correct resp onses drop from 0 . 39 ± 0 . 05 under direct prompting to 0 . 02 ± 0 . 01 with reasoning, and repetitions decrease from 0 . 19 ± 0 . 06 to 0 . 02 ± 0 . 02 . W e observ e similar results for GLM-4.7 . 4.2 Analyzing LLMs’ Distractor Generation Pro cess W e analyze reasoning traces in three wa ys: frequency of v arious strategies, tem- p oral evolution, and sequential organization. F requencies sho w which strategies the LLMs use (T able 3), temporal analysis captures how they unfold (Fig. 2), and transition probabilities rev eal how the reasoning is comp osed of subprocesses (Fig. 3). Annotating traces using the taxonom y . T o perform these analyses, w e first need to identify where and ho w the strategies in our taxonom y app ear in LLM reasoning traces. A ccordingly , we annotate all occurrences of each strategy in LLMs’ traces—collected in § 3.2—as depicted in Fig. 1. Because the traces are extremely long (a verage of ≈ 6,800 characters for DeepSeek reasoning), we adopt a scalable approac h that balances efficiency and annotation quality . F ol- lo wing prior w ork [30], we use an LLM as the primary annotator, 10 but v alidate man ually to ensure reasonable quality . Manual v alidation is p erformed on a rep- resen tative subset of 32 traces, stratified by mo del, CoT versus reasoning, and p erformance (prop ortional match ab o ve vs. b elo w 0.5). It is done by comparing the n umber of insertions and deletions relative to the h uman annotations. W e rep ort an av erage precision of 0.97 and recall of 0.95. 11 Our automatic annotation pro cedure prompts an LLM with (i) a description of the taxonomy , (ii) a small set of hand-pick ed general examples for eac h strat- egy tag in the taxonomy , (iii) the full reasoning trace—corresp onding to one LLM’s distractor generation on one math problem—to be annotated, and (iv) an instruction to re-generate the trace while segmen ting the text in to spans and marking each of the spans with a strategy tag. F or example, after the span “Y es, this is a plausible distractor” the mo del is expected to insert the tag . 10 W e use gpt-4.1 [35] with greedy decoding and maximum output length of 16k tok ens. 11 Per-tag averages (precision,recall) across models for both CoT and reasoning. INTER : (0.99, 0.99); CORR : (1.00, 0.98); ERR_DESC : (0.93, 0.92); ERR_SIM : (0.91, 0.96); INST : (1.00, 0.94); PLAUS : (0.97, 0.92); CURATE : (0.86, 0.91); RECON : (0.93, 0.98). On LLMs’ Student Mo deling Strategies 9 Initial exp eriments sho wed that annotating the en tire trace with all tags in a single pass yields p oor results, primarily due to the trace’s length. W e therefore split the trace into non-ov erlapping ch unks and annotate all tags jointly within eac h c hunk. The annotated ch unks are then merged to reconstruct the complete annotated trace. 12 Because c hunks may lack access to critical problem-sp ecific information established earlier in the trace (e.g., “This gets us 2 + 9 m ” could b e either INST or CORR without knowing the correct answ er), we augmen t the prompt for each c hunk with concrete, problem-sp ecific examples for eac h tag. These clarify the intended meaning of each tag, thereb y promoting consistency across ch unks. W e obtain these grounded examples by prompting the LLM with the taxonomy and the complete trace and instructing it to extract up to three represen tative examples p er tag. T ags that do not app ear in the trace are omit- ted from this example set. In total, w e apply this annotation pip eline to 240 traces, randomly sampled according to the same stratification criteria used for man ual v alidation. F urther details—including prompts—are discussed in § A.4. Occurrences of strategies. W e analyze the a verage n umber of spans anno- tated with eac h strategy tag from our taxonomy in T able 3. In b oth the CoT and reasoning settings, the most frequent strategies for DeepSeek-V3.2 are INST and ERR_DESC , follo wed by INTER , CORR , PLAUS , RECON , and ERR_SIM . CURATE oc- curs the least frequently . W e observe that LLMs frequen tly engage in the strate- gies of our taxonomy . In particular, the high prev alence of ERR_DESC suggests that LLMs explicitly base distractors on misconceptions, a p oin t we discuss in more detail in § 4.3. The more concise CoT traces naturally con tain fewer strat- egy tags than the reasoning traces. W e observ e similar trends for GLM-4.7 (see § B). T able 3. A v erage occurrences of taxonom y strategies (T able 1) in CoT and reasoning traces for DeepSeek-V3.2 (mean ± 95% CI based on t-distribution). Strategy CoT Reasoning T ask In terpretation 2.34 ± 0.43 11.37 ± 1.65 Correct Answer Ref. 4.33 ± 1.30 10.25 ± 1.62 Error Description 7.33 ± 1.29 21.58 ± 3.34 Outcome Instantiation 7.32 ± 1.13 37.43 ± 4.98 Error Simulation 2.02 ± 0.84 6.10 ± 1.45 Plausibilit y Check 1.48 ± 0.46 8.63 ± 1.47 Final Set Curation 0.63 ± 0.15 3.36 ± 0.47 Reconsideration 0.86 ± 0.38 7.36 ± 1.18 Strategies ov er time. W e trac k the prop ortion of eac h strategy within 5 discrete tem- p oral bins, normalized b y the total length of each reasoning trace. The resulting graphs in Fig. 2 rev eal clear phase tran- sitions in the reasoning process of DeepSeek-V3.2 . Reasoning t ypically b egins with task in ter- pretation ( INTER ) and identify- ing the correct answer ( CORR ), follo wed by error description ( ERR_DESC ) and instan tiation of 12 Chunks are created by splitting on double line breaks once a segment exceeds 500 characters, or by a hard split if no double line breaks o ccur within 2000 characters. Double line breaks were chosen b ecause the LLM often uses them to separate seman tic units. The thresholds of 500 and 2000 characters w ere found to balance segment length and annotation quality . 10 Y. Zengaffinen et al. incorrect outcomes ( INST ). T ow ard the end, plausibility assessmen t ( PLAUS ) and curation of the final set ( CURATE ) b ecome more frequent, while reconsidera- tion ( RECON ) persists throughout the trace. Similar trends appear in CoT, but ERR_DESC , INST , ERR_SIM , PLAUS , and CURATE are shifted later in the trace. This reflects more limited exploration, with task interpretation ( INTER ) and correct problem solving ( CORR ) occupying a larger share of the reasoning pro cess. W e observ e similar patterns for GLM-4.7 (see § B). 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Position In Trace 0.0 0.2 0.4 Share of Strategies Chain-of-Thought 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Position In Trace Reasoning Traces Task Interpretation Correct Answer Ref. Error Description Outcome Instantiation Error Simulation Plausibility Check Final Set Curation Reconsideration Fig. 2. Indicates how often each strategy in our taxonomy T able 1 was annotated at differen t stages of DeepSeek-V3.2 ’s reasoning trace. Time is normalized (0 = start of trace, 1 = end). Note that the proportions sum to one for each of the five temp oral bins. Common sequences of strategies. T o analyze the t ypical sequences in whic h strategies app ear in LLMs’ processes, w e examine the transition probabilities be- t ween strategies within annotated sequences of up to length 4, shown in Fig. 3. Sev eral consisten t patterns emerge. T ransitions within and betw een ERR_DESC and INST are common in b oth CoT and reasoning traces, indicating that error descriptions and instan tiations are often tigh tly coupled. In the v alidated traces, w e iden tified t w o common strategies for generating candidate distractors: (i) list multiple ERR_DESC b efore the corresp onding INST , and (ii) iteratively in ter- lea ve ERR_DESC and INST , sometimes with PLAUS . A frequent sequence in CoT is ERR_DESC → ERR_SIM → INST , suggesting that LLMs often explicitly verbalize the incorrect reasoning, possibly ensuring consistency b et ween the error and its outcome. Self-transitions for INTER and CORR indicate that these strategies often span multiple segmen ts. GLM-4.7 demonstrates similar patterns (see § B). 13 4.3 Discussion Understanding LLMs’ distractor-generation pro cess. Our results indi- cate that LLMs predominantly use a solve-first, misconception-based pipeline to generate distractors, rather than surface-level similarity heuristics. This mir- rors recommended human design practices, although it not alwa ys executed cor- rectly (see T able 2). Sev eral observ ations supp ort this interpretation. ERR_DESC 13 F or each step and source strategy , we iden tify the top three transitions exceeding 15% outgoing probability mass and compute the set overlap betw een DeepSeek-V3.2 and GLM-4.7 , normalized by the smaller set size. A v eraged across source strategies and steps, agreement is perfect for reasoning traces (1.00) and near-p erfect for CoT traces (0.94), indicating that the dominant transitions are largely iden tical betw een models. On LLMs’ Student Mo deling Strategies 11 Chain-of-Thought Step Strategy T ask Interpretation Correct Answer Ref. Error Description Outcome Instantiation Error Simulation Plausibility Check Final Set Curation Reconsideration Reasoning T races Step Fig. 3. Shows transition probabilities b et w een strategies in DeepSeek-V3.2 ’s traces. Sequences of strategies up to length 4 (left to right). Node height represen ts strategy share and link widths indicate the transition probabilities b etw een successive strate- gies. Only dominant (>15% outgoing mass) transitions are visualized for simplicity . is the most frequent strategy o verall, while CORR tends to app ear early . More- o ver, ERR_DESC , ERR_SIM , and INST often o ccur in sequence, suggesting a pro- cess in which a p oten tial error is articulated, instan tiated, and used to pro duce a distractor. This temp oral structure aligns with a solv e-first, error-injection ap- proac h, but not with similarity-based p erturbation. T race-level analysis further supp orts this view (refer to § C.1 for metho dology). In 92.5% of DeepSeek-V3.2 traces and 97.8% of GLM-4.7 traces, the mo del constructs a full step-b y-step solution b efore prop osing distractors. 14 In 71.2% ( DeepSeek-V3.2 ) and 76.3% ( GLM-4.7 ) of these cases, the mo del diverges at a sp ecific step to inject an er- ror, closely mirroring misconception-based design. By contrast, similarit y-based strategies are rare ( ≈ 3% of samples) and largely confined to narro w settings suc h as rounding or magnitude-estimation problems. 15 Bey ond misconception generation, LLMs also reason ab out plausibility and selection. The frequen t o c- currence of ERR_DESC b ey ond the three explicitly requested distractors suggests that the mo del migh t often explore more candidate error hypotheses than it ul- timately selects. Man ual inspection of 15 randomly selected problems confirms this: DeepSeek-V3.2 in reasoning mo de considers an av erage of 12.6 hypothet- ical studen t solution paths, compared to 5.9 in CoT. This pattern suggests that distractor construction is not single-shot, but instead resembles an exploratory b est-of-N searc h o ver candidate misconceptions prior to final selection. Over- all, misconception-based design is a central component of LLMs’ distractor- generation pro cess, alongside plausibility c hecking, candidate ov er-generation, and selection. Diagnosing failure mo des in LLMs’ distractor generation. W e analyze m ultiple stages of the distractor-generation pip eline to determine whether fail- ures stem from (i) improp er error simulation, (ii) the absence of a literature- informed reasoning structure, (iii) failure to reco ver the correct solution, or (iv) 14 Solving-first and related prop erties are detected using the same taxonom y-based annotation method, with agreemen t to manual annotation of κ = 0 . 85 ( p < 0 . 001 ). 15 This observ ation is based on manual insp ection of reasoning traces filtered for semantically similar distractor values. 12 Y. Zengaffinen et al. inaccurate plausibility assessment and selection. One potential failure p oint is error sim ulation, where the mo del generates an incorrect answer given an error description ( ERR_SIM ). Using Eedi error descriptions, we prompt DeepSeek- V3.2 to solve all 429 problems individually , sim ulating a student making a sp e- cific error sampled from each problem, and manually verify that the resulting answ ers are consistent with any faithful interpretation of that error (refer to § C.2 for further details). This yields a mean accuracy of 0.92 ± 0.02, suggesting that error sim ulation failures are rare. 16 Another h yp othesis is insufficiently struc- tured reasoning. W e compare the simple prompt (0.52 ± 0.03; see T able 2) with one enforcing a multi-step procedure (prompt in § C.3), i.e., solving, enumer- ating errors, simulating them, ev aluating outcomes, chec king plausibilit y , and selecting distractors (0.55 ± 0.02). The difference is not statistically significant, suggesting that DeepSeek-V3.2 self-organizes effective reasoning without ex- plicit guidance. By con trast, failures in recov ering the correct solution ( CORR ) propagate do wnstream. While most traces initially pro duce a correct solution, explicitly rev ealing the final answ er significan tly impro ves prop ortional match o ver the simple prompt without it (0.56 ± 0.03 vs. 0.52 ± 0.03; see T able 2). This indicates that unreliable solution recov ery degrades subsequen t distractor generation 17 . Finally , ov er-generation of candidate errors requires ranking and selection ( PLAUS , CURATE ). A man ual analysis of 30 low-performing (proportional matc h < 0.5) problems shows that mo dels discard an av erage of 0.97 candidate distractors p er problem that are incorrect yet consistent with a plausible error description. Although CURATE reduces correct answ ers and rep etitions, indicating enforcemen t of incorrectness and diversit y , it app ears o verly conserv ativ e. Th us, our analysis rules out error simulation and reasoning structure as pri- mary failure sources, instead iden tifying failures in correct-solution reco very and misalignmen t in plausibility assessment or curation as dominant causes for p er- formance drops. 5 Conclusion In this study , we examined how LLMs mo del incorrect studen t reasoning when generating math distractors, dev eloping a taxonomy grounded in learning-science literature and observ ed mo del b ehavior. Although distractor-generation p erfor- mance remains imperfect, our analysis sho ws that LLMs predominantly use a solv e-first, error-injection strategy: they first solv e the problem correctly , identify p oten tial misconceptions, simulate the resulting errors, and generate corresp ond- ing distractors. This approac h closely mirrors misconception-based methods in the educational literature, where the correct answer serv es as a critical anchor. 16 How ever, a significant prop ortion of the answers that were manually deemed to be correct dis- tractors conditioned on the error were not annotated as distractors in the Eedi dataset: The LLM-generated answer matched the human annotated Eedi distractor(s) for the same problem and error type in 62% of cases. These results are plausible b ecause the error description does not usually uniquely determine a sp ecific distractor answer for a given problem. More reliable benchmarking on the distractor generation task would therefore require access to a larger set of ground truth distractor answ ers. 17 This may be due to limited mo del comp etence or intrinsic problem am biguity . On LLMs’ Student Mo deling Strategies 13 Bey ond this, LL Ms perform explicit plausibility c hecking, curate the final dis- tractor set, and emplo y task-agnostic mec hanisms suc h as ov ergeneration and candidate ranking. Ov erall, our findings indicate that LLM reasoning aligns w ell with learning-science principles, while revealing clear opp ortunities for improv e- men t in correct answer recov ery , plausibilit y assessment, and distractor selec- tion. By isolating sp ecific failure p oin ts, our analysis highligh ts the p oten tial for targeted interv en tions with implications for automated assessment, in telligent tutoring systems, and scalable creation of high-qualit y educational conten t. References 1. Alhazmi, E., Sheng, Q.Z., Zhang, W.E., Zaib, M., Alhazmi, A.: Distractor gener- ation in multiple-c hoice tasks: A surv ey of methods, datasets, and ev aluation. In: EMNLP . pp. 14437–14458 (2024) 2. Ashlo c k, R.B.: Error patterns in computation: Using error patterns to help each studen t learn. Allyn & Bacon (2010) 3. Benedetto, L., Aradelli, G., Donvito, A., Lucc hetti, A., Capp elli, A., Buttery , P .: Using LLMs to simulate students’ resp onses to exam questions. In: EMNLP . pp. 11351–11368 (2024) 4. Bro wn, J.S., V anLehn, K.: Repair theory: A generativ e theory of bugs in pro cedural skills. Cognitive science 4 (4), 379–426 (1980) 5. Cham b erlain, D.J., Jeter, R.: Creating diagnostic assessmen ts: Automated dis- tractor generation with integrit y. The Journal of Assessment in Higher Education (2020) 6. Chingos, M.: Strength in num b ers: State sp ending on K-12 assessmen t systems. Bro wn Center on Education Policy , The Bro okings Institution (2012) 7. Corbin, J., Strauss, A.: Basics of qualitativ e research: T echniques and pro cedures for developing grounded theory. Sage publications (2014) 8. De La T orre, J.: A cognitive diagnosis mo del for cognitively based multiple-c hoice options. Applied Psychological Measurement 33 (3), 163–183 (2009) 9. DeepSeek-AI: DeepSeek-V3.2: Pushing the frontier of open large language mo dels (2025) 10. Dough ty , J., W an, Z., Bomp elli, A., Qayum, J., W ang, T., Zhang, J., Zheng, Y., Do yle, A., Sridhar, P ., Agarwal, A., Bogart, C., Keylor, E., Kultur, C., Sa velk a, J., Sakr, M.: A comparative study of AI-generated (GPT-4) and human-crafted MCQs in programming education. In: Pro ceedings of the 26th Australasian Computing Education Conference. pp. 114–123 (01 2024) 11. Ezzaki, S., Messaoudi, N., Khalid Naciri, J.: Ev aluating educational conten t through virtual studen t simulations using large language mo dels. In: International Symp osium on Generative AI and Education. pp. 241–250. Springer (2025) 12. F eldman-Maggor, Y., Cukuro v a, M., Ken t, C., Alexandron, G.: The impact of explainable AI on teachers’ trust and acceptance of AI EdT ech recommendations: The p o w er of domain-sp ecific explanations. International Journal of AIED 35 (5), 2889–2922 (Dec 2025) 13. F eng, W., Lee, J., McNichols, H., Scarlatos, A., Smith, D., W o o dhead, S., Ornelas, N., Lan, A.: Exploring automated distractor generation for math multiple-c hoice questions via large language mo dels. In: NAACL. pp. 3067–3082 (2024) 14 Y. Zengaffinen et al. 14. F ernandez, N., Scarlatos, A., F eng, W., W o odhead, S., Lan, A.: DiVER T: Distrac- tor generation with v ariational errors represen ted as text for math multiple-c hoice questions. In: EMNLP (2024) 15. Gierl, M.J., Bulut, O., Guo, Q., Zhang, X.: Developing, analyzing, and using dis- tractors for m ultiple-choice tests in education: A comprehensive review. Review of educational research 87 (6), 1082–1116 (2017) 16. GLM-4.5 T eam: GLM-4.5: Agen tic, reasoning, and co ding (AR C) foundation mod- els (2025) 17. Haladyna, T.M., Downing, S.M., Rodriguez, M.C.: A review of m ultiple-c hoice item-writing guidelines for classro om assessmen t. Applied Measuremen t in Educa- tion (2002) 18. Haladyna, T., Rodriguez, M.: Developing and v alidating test items. T a ylor & F ran- cis (2013) 19. Hang, C.N., W ei T an, C., Y u, P .D.: MCQGen: A large language mo del-driv en MCQ generator for p ersonalized learning. IEEE Access 12 , 102261–102273 (2024) 20. Jin, H., Y o o, M., P ark, J., Lee, Y., W ang, X., Kim, J.: T eac htune: Reviewing p edagogical agents against div erse studen t profiles with simulated students. In: Pro ceedings of the 2025 CHI Conference on Human F actors in Computing Systems. pp. 1–28 (2025) 21. Judge, S., Bobzien, J., Maydosz, A., Gear, S., Katsioloudis, P .: The use of visual- based sim ulated environmen ts in teac her preparation. Journal of Education and T raining Studies 1 (1) (2013) 22. Käser, T., Alexandron, G.: Simulated learners in educational tec hnology: A sys- tematic literature review and a turing-like test. International Journal of Artificial In telligence in Education 34 (2), 545–585 (2024) 23. King, J., Burleigh, L., W oo dhead, S., K on, P ., Baffour, P ., Crossley , S., Reade, W., Demkin, M.: Eedi - Mining misconceptions in mathematics (2024), k aggle 24. Lee, J., Smith, D., W o odhead, S., Lan, A.: Math m ultiple choice ques- tion generation via human-large language mo del collab oration. arXiv preprint arXiv:2405.00864 (2024) 25. Lee, U., Lee, S., Koh, J., Jeong, Y., Jung, H., Byun, G., Lee, Y., Moon, J., Lim, J., Kim, H.: Generative agent for teacher training: Designing educational problem- solving simulations with large language mo del-based agen ts for pre-service teachers. In: NeurIPS’23 W orkshop on Generativ e AI for Education (GAIED) (2023) 26. Liu, N., Sonk ar, S., Baraniuk, R.: Do LLMs make mistak es like studen ts? Explor- ing natural alignments betw een language mo dels and human error patterns. In: In ternational Conference on AIED. pp. 364–377. Springer (2025) 27. Liu, N., Sonk ar, S., W ang, Z., W oo dhead, S., Baraniuk, R.G.: Novice learner and exp ert tutor: Ev aluating math reasoning abilities of large language mo dels with misconceptions. arXiv preprint arXiv:2310.02439 (2023) 28. Ludewig, U., Sch werter, J., McElv any , N.: The features of plausible but incor- rect options: Distractor plausibility in synon ym-based v o cabulary tests. Journal of Psyc ho educational Assessment 41 (7), 711–731 (2023) 29. Macina, J., Daheim, N., Cho wdhury , S., Sinha, T., Kapur, M., Gurevyc h, I., Sac han, M.: Mathdial: A dialogue tutoring dataset with rich p edagogical prop- erties grounded in math reasoning problems. In: EMNLP . pp. 5602–5621 (2023) 30. Marjano vić, S.V., Patel, A., A dlakha, V., Agha johari, M., BehnamGhader, P ., Bhatia, M., Khandelwal, A., Kraft, A., Kro jer, B., Lù, X.H., et al.: DeepSeek-R1 though tology: Let’s think ab out LLM reasoning. arXiv preprint (2025) On LLMs’ Student Mo deling Strategies 15 31. Matsuda, N., Cohen, W.W., Sewall, J., Lacerda, G., Koedinger, K.R.: Ev aluating a sim ulated studen t using real studen ts data for training and testing. In: User Mo deling 2007. pp. 107–116 (2007) 32. Mislevy , R.J., Almond, R.G., Luk as, J.F.: A brief introduction to evidence-cen tered design. ETS Research Rep ort Series 2003 (1), i–29 (2003) 33. Nazaretsky , T., Ariely , M., Cukurov a, M., Alexandron, G.: T eachers’ trust in AI- p o w ered educational technology and a professional developmen t program to im- pro ve it. British Journal of Educational T ec hnology 53 (4), 914–931 (2022) 34. Op edal, A., Stolfo, A., Shirak ami, H., Jiao, Y., Cotterell, R., Schölk opf, B., Saparov, A., Sachan, M.: Do language mo dels exhibit the same cognitive biases in problem solving as human learners? In: ICML (2024) 35. Op enAI T eam: GPT-4 technical rep ort (2024) 36. P arikh, N., F ernandez, N., Scarlatos, A., W o odhead, S., Lan, A.: Lo okAlik e: Con- sisten t distractor generation in math MCQs. Proceedings of the 20th W orkshop on Inno v ative Use of NLP for Building Educational Applications (BEA 2025) (2025) 37. Quaigrain, K., Arhin, A.K.: Using reliability and item analysis to ev aluate a teac her-developed test in educational measurement and ev aluation. Cogen t Ed- ucation 4 (1), 1301013 (2017) 38. Ro oein, D., Cho wdhury , S.P ., Eremeev a, M., Qin, Y., Nozza, D., Sachan, M., Hovy , D.: P A TS: P ersonality-a w are teac hing strategies with large language model tutors. Findings of EACL (2026) 39. Ross, A., Andreas, J.: Learning to make MIST AKEs: Mo deling incorrect student thinking and key errors (2025) 40. Rudner, L.M.: Implementing the graduate management admission test computer- ized adaptive test. In: Elemen ts of adaptive testing, pp. 151–165. Springer (2009) 41. Säub erli, A., Clematide, S.: Automatic generation and ev aluation of reading com- prehension test items with large language mo dels. In: Proceedings of the 3rd W ork- shop on T o ols and Resources for P eople with REAding DIfficulties (READI) @ LREC-COLING 2024. pp. 22–37 (2024) 42. Scarlatos, A., F eng, W., Smith, D., W oo dhead, S., Lan, A.: Improving automated distractor generation for math multiple-c hoice questions with o v ergenerate-and- rank. arXiv preprint arXiv:2405.05144 (2024) 43. Scouller, K.: The influence of assessment metho d on studen ts’ learning approaches: Multiple c hoice question examination v ersus assignment essay. Higher education 35 (4), 453–472 (1998) 44. Shin, J., Guo, Q., Gierl, M.J.: Multiple-c hoice item distractor developmen t using topic mo deling approaches. F rontiers in psychology 10 , 825 (2019) 45. T arrant, M., W are, J., Mohammed, A.M.: An assessment of functioning and non- functioning distractors in m ultiple-choice questions: a descriptive analysis. BMC medical education 9 (1), 40 (2009) 46. T omás, A.P ., Leal, J.P .: Automatic generation and delivery of m ultiple-choice math quizzes. In: Principles and Practice of Constraint Programming. pp. 848–863 (2013) 47. V anLehn, K.: Mind bugs: The origins of procedural misconceptions. MIT press (1990) 48. W ei, J., W ang, X., Sch uurmans, D., Bosma, M., Ic hter, B., Xia, F., Chi, E.H., Le, Q.V., Zhou, D.: Chain-of-though t prompting elicits reasoning in large language mo dels. In: NeurIPS (2022) 49. W u, T., Chen, J., Lin, W., Li, M., Zhu, Y., Li, A., Kuang, K., W u, F.: Embracing imp erfection: Simulating students with div erse cognitiv e lev els using LLM-based agen ts. arXiv preprin t arXiv:2505.19997 (2025) 16 Y. Zengaffinen et al. A Supplemen tary Material - Exp erimen tal Setup A.1 Prepro cessing the Dataset Remo ving problems relying on choices. The Eedi dataset con tains prob- lems of the form “Whic h of the following is correct?”, which rely on the provided answ er c hoices to b e solv able. This is problematic for distractor generation b e- cause it implies an effectiv ely infinite answer space. Therefore, w e man ually review ed all problems in the dataset to determine whether they admit a unique solution without the provided c hoices, and remov ed those that do not. A.2 Prompts for Collecting Reasoning T races and Ev aluating Answ er Equiv alence W e pro vide the prompt used for distractor generation in both the direct and reasoning settings (T able 4), as well as the chain-of-though t prompt that enables the non-reasoning models to generate distractors step-b y-step (T able 5). W e further include the prompt used to instruct the LLM to judge whether t w o answ er c hoices are semantically equiv alen t (T able 6). T able 4. Direct prompt for generating distractors for one math problem {pr ob- lem_formulation} . Parts in blue are shown only when the correct answ er {c or- r e ct_answer} is revealed. System Prompt You will be given a math question along with the correct answer . Please generate 3 incorrect distractor answers for the question to be used as multiple-choice options in a multiple-choice exam. [ Template ] Distractor1: ... Distractor3: User Prompt Question: {problem_formulation} Answer: {correct_answer} T able 5. Chain-of-Though t (CoT) prompt for generating distractors for one math problem {pr oblem_formulation} . System Prompt You will be given a math question. Please generate 3 incorrect distractor answers for the question to be used as multiple-choice options in a multiple-choice exam. Think step-by-step before giving your final answer. Output only your step-by-step reasoning and the final distractors like so: [ Step-By-Step ] Let’s think step-by-step, ... [ Final Answer ] Distractor1: ... Distractor3: User Prompt Question: {problem_formulation} On LLMs’ Student Mo deling Strategies 17 T able 6. Prompt for judging equiv alence betw een the t w o answ ers {answer_a} and {answer_b} to a m ultiple-choice question {pr oblem_formulation} . System Prompt You are an AI assistant tasked with judging whether two answer choices to a middle-school multiple-choice math problem are semantically the same as one another. You must not solve the problem and not evaluate factual correctness –- only compare the two answers with one another relative to the problem’s formatting requirements. Your output must follow this exact structure: [ TRUE/FALSE ] [ TRUE/FALSE ] Meaning of : Output TRUE if the problem explicitly requires a specific numeric format, such as: – rounding to a given number of decimal places or significant digits – expressing the answer in scientific notation – expressing the answer as a simplified fraction – expressing the answer in terms of a constant (e.g., “in terms of π ”) – any other explicitly stated formatting requirement Ignore unit requirements (e.g., “in cm” does NOT count as a specific format). Output FALSE if the problem does not explicitly specify a numeric format. Meaning of : Determine whether answer_1 and answer_2 represent the same value or concept under the rules: If is FALSE (no required numeric format): Two answers are equivalent if: – they have the same mathematical value (e.g., 3 . 1 = 31 / 10 ) – they differ only in non-semantic aspects (e.g., LaTeX wrappers, capitalization, filler words) Examples of equivalent under = FALSE: – 10, 10.0, \ (10 \ ) – 3.1, 31/10 – fourteen, 14 – Only Bob, Bob If is TRUE (specific format required): Two answers are equivalent only if: 1. They represent the same mathematical value, AND 2. They are both expressed in the required format. This means: – 3.14 vs. 3.140 (when rounding to 2 decimal places required) → not equivalent – 4 π vs. 12.56 (when “in terms of π ” required) → not equivalent – 3.1 vs. 31/10 (when “round to one decimal place” required) → not equivalent Ignore trivial formatting wrappers (e.g., 31 / 10 = \ (31 / 10 \ ) ). General Rules: – Do not solve the problem. – Do not judge correctness of the answers. – Only compare answer_1 with answer_2. – answer_1 and answer_2 can be equivalent regardless of whether they are correct or not. User Prompt {answer_a} {answer_b} 18 Y. Zengaffinen et al. A.3 Details on T axonomy Construction During taxonomy construction, severa l additional and p oten tially complemen- tary strategies were iden tified but ultimately excluded. T able 7 summarizes these candidates, gives illustrativ e examples, their origin, and the rationale for exclu- sion. T able 7. Discarded candidate strategies during taxonomy construction. Note that both the manual open co ding as well as the LLM surfaced many additional strategies that w ere strictly captured by existing strategies; we only list the ones that might capture complemen tary asp ects compared to the strategies they were merged in to. Strategy Example / Description Iden tified By Reason for Exclusion Resp onse F or- matting “W e need to pro duce them in the format Distrac- tor1:. . . ” Both Reasoning ab out output for- mat required by our sp ecific prompt rather than a gen- eral reasoning strategy . Recall T ask- Sp ecific Kno wledge “First, let’s recall the ba- sic Roman n umeral sym- b ols . . . ” Both Explicitly observ ed only once and t ypically o ccurred implicitly within CORR or ERR_DESC . Lev eraging Domain- Sp ecific Con- strain ts En umerating limited an- sw er space (e.g., “Who out of the tw o is correct?”). Both Problem-specific en umera- tion strategy; excluded to main tain fo cus on general reasoning strategies. Exploration of Un usual Distractors Claim that highly un- usual or creativ e dis- tractors were inten tion- ally generated (no citation pro vided). LLM Conceptually ov erlaps with ERR_DESC and PLAUS ; insuf- ficien tly w ell-defined as a standalone strategy . Distractor Source Div er- sification Explicit effort to ensure distractors differ in type or origin to av oid similar- it y . LLM Strong ov erlap with CURATE . V erification and Self- Correction Revisiting earlier step-by- step reasoning tow ards distractors, p oten tially correcting issues. LLM Ov erlaps with RECON and of- ten difficult to distinguish from ERR_SIM . Detailed Error Description Captures sp ecific b ehav- iors suc h as incorrectly con verting fractions to decimals without broader strategic framing. LLM Ov erlaps with ERR_SIM . On LLMs’ Student Mo deling Strategies 19 Merging strategies and cov erage. Although the final taxonomy do es not mirror all prop osed lab els exactly , conceptual corresp ondence was alw ays clear. F or example, the LLM prop osed the strategy “Anchor on Correct Solution” whic h w e merged into CORR . In cases where titles differed, example citations from the traces frequently helped clarify the mapping. F or instance, the pro- p osed label “Con textualize to Multiple-Choice F ormat” with citation from the reasoning trace: “Usually , the options are formatted similarly to the correct answ er. Since correct is 0.256, options lik e 2.56, 0.0256, and 1.12 are all in decimal form with a few digits.” is naturally co vered b y CORR and CURATE . Gran ularity of strategies. A k ey design decision in constructing the taxonomy concerns the lev el of gran ularit y at whic h strategies are defined. F or instance, PLAUS could be sub divided in to more sp ecific assessmen ts, suc h as ev aluating ho w common an error t yp e is or identifying which constrain ts a distractor’s deriv ation violates. Although suc h finer-grained distinctions ma y offer additional analytical resolution, our ob jectiv e is to capture gener al strategy patterns rather than highly sp ecialized v arian ts. Increasing granularit y would also likely reduce annotation reliabilit y , as additional categories in tro duce greater complexity and less sharply defined decision b oundaries. Automatic op en co ding. W e show the full prompt used to let DeepSeek- V3.2 do op en coding in T able 8. Ov erview of literature sources of final taxonomy . The identified strategies largely align with prior literature. INTER and RECON are supp orted by Evidence- Cen tered Design [32], while CORR , ERR_DESC , INST , and ERR_SIM correspond to established distractor generation metho ds, mostly the misconception-based strategy [8,2,46,15,44,5,28] and repair-theory [4,47]. Plausibility c hec ks and final set curation reflect item-writing guidelines that ensure distractors are individu- ally plausible and collectively w ell-formed [17,18,15,5]. 20 Y. Zengaffinen et al. T able 8. Prompt used for op en coding of exp ert reasoning traces. {tr ac es_c onc atenated} is replaced with 10 double-new-line concatenated reason- ing traces of either DeepSeek-V3.2 or GLM-4.7 generating distractors when prompted with the simple prompt, as described in § 3.2. System Prompt You are an expert in cognitive task analysis, think-aloud protocol analysis, and grounded theory coding. Your task is to derive inductive categories of cognitive processes from reasoning traces of experts that are generating math distractors for a multiple choice exam. Follow qualitative analysis best practices: bottom-up coding, constant comparison, memoing, and grounding all claims in the data. User Prompt I will provide you with a list of reasoning traces. Your task is to discover common categories of reasoning or cognitive behaviors of the experts that are generating math distractors, using a systematic inductive approach. Your responsibilities: 1. Identify recurring cognitive behaviors or steps. 2. For every category, provide: - A clear definition (1–2 sentences) - A description of what behaviors fall under it 3. Provide 2–3 grounded citations for each category: - Verbatim excerpts from the traces - Include trace ID and step number (or text location) 4. Do not invent anything not present in the traces. 5. Focus only on recurring categories, not one-off behaviors. OUTPUT FORMAT: ## Discovered Categories ### Category 1: [Name] **Definition:** [...] **Example Citations:** - "..." (Trace X, Step Y) - "..." (Trace A, Step B) - "..." (Trace C, Step D) ### Category 2: [Name] **Definition:** [...] (Continue as needed.) After listing categories, include: ## Notes on Method & Coverage Explain how the categories were derived and how representative they are. –- Here are the reasoning traces: {traces_concatenated} A.4 Annotation of T races As outlined in § 4.2, w e annotate all reasoning traces separately . Eac h trace represen ts an LLM’s reasoning pro cess as it generated three distractors for a single math problem. Automatic annotation. W e first extract examples (T able 10) and then anno- tate ch unks of the trace individually (T able 9). Annotation quality . W e rep ort detailed annotation p erformance—comparing agreemen t b et w een h uman and DeepSeek-V3.2 ’s annotations—p er strategy for DeepSeek-V3.2 ’s (T able 12) and GLM-4.7 ’s (T able 13) traces. Note that these analyses w ere p erformed man ually on a total of 8 traces each, cov ering b oth high- and low-performance cases. As a result, strategies that the mo dels rarely engage in hav e v ery lo w supp ort. How ever, the resulting higher uncertain ty do es not meaningfully affect the analyses in § 4.2, since suc h strategies are far from playing a dominant role in the frequency analysis or dominant paths in the subpro cess analysis. On LLMs’ Student Mo deling Strategies 21 T able 9. Prompt for annotating ch unks of an LLM’s reasoning when generating dis- tractors with strategies from our taxonom y . {taxonomy_description} is replaced with the taxonomy description from T able 11 and {extr acte d_examples} with the examples extracted using the prompt in T able 10. {tr ac e_chunk} is replaced with a ch unk of the LLM’s distractor generation reasoning trace. System Prompt You are annotating a chunk of a thinking-out-loud protocol produced by an expert model with markers of a taxonomy. Context: The text is a verbalized reasoning trace of an expert generating incorrect distractor answers for a mathematics multiple-choice question. The expert’s task was: “You will be given a math question. Please generate 3 incorrect distractor answers for the question to be used as multiple-choice options in a multiple-choice exam.” The protocol contains the expert’s internal reasoning, planning, and candidate generation steps. Your job is to annotate this text by inserting taxonomy tags. Each marker marks the END of the smallest possible span that instantiates the category. TAXONOMY {taxonomy_description} EXAMPLES: {extracted_examples} User Prompt CHUNK START {trace_chunk} CHUNK END Return only the annotated chunk (no explanations). T able 10. Prompt for extracting short example spans for each strategy of the tax- onom y , if present, from a reasoning trace {trac e} . {taxonomy_description} is replaced with the taxonomy description i n T able 11. System Prompt You are a helper that extracts up to 3 short example spans for each taxonomy label from a single reasoning trace. For each tag, return a short examples block (plain text) with one line per tag in the following form: : example1; example2 If no examples exist for a tag, use: : (none) Return only the plain text block (no JSON, no commentary). TAXONOMY: {taxonomy_description} User Prompt TRACE START {trace} TRACE END Return only the examples block as described. 22 Y. Zengaffinen et al. T able 11. The description of our taxonomy (T able 1) including rules and examples. W e use this description as part of both the annotation (T able 9) and example extraction prompts (T able 10). T axonomy Description Definition: Reasoning about the task instructions or requirements –- what the question asks for and what counts as valid answers. Rules: - Only mark when the expert revisits the task description and subsequently tries to gain clarity about the task itself. - Do NOT mark execution steps, calls to produce output, or listing candidates (e.g., "I’ll produce:", "Let’s do:", "Distractor1: 0.4"). Examples: - "We are given the question: ..." - "However, the task is to generate three incorrect distractors, not the correct answer" Definition: Correct computation or reasoning toward the correct solution for the question. Rules: - Mark whenever correct reasoning or the correct answer is referenced. - If correct reasoning and errors are discussed together, mark both. Examples: - "2 ÷ 1/5 = 10" - "Multiplying both sides by 4 gives 20 = k, but a student might only multiply the numerator" Definition: High-level verbal description of a common mistake or misconception. Rules: - Mark every description of an error. Examples: - "A common mistake is forgetting to flip the fraction" - "46 (forgetting to add 2)" - "(x,y)=(-2,15)[from sign error]" - "Mis-handling the negative: -10 + 8 = 2" Definition: Explicitly simulating incorrect reasoning. Rules: - Mark when the expert simulates an incorrect calculation. - Single incorrect equations can be marked if they represent erroneous reasoning. - Mark the final incorrect outcome with . - ERR_DESC = a high level error description; ERR_SIM = a specific execution of an error Examples: - "5 - 2 = 3, then add 1 = 4" - "9 + 3 = 12, write down 2, forget to carry the 1... final result 82" - "Convert the fraction incorrectly : compute: 1 2/3 " Definition: Any incorrect outcome (number, symbol, expression). Rules: - Mark every candidate, even if later rejected. - Mark candidate values even when they appear inside task interpretation or reconsideration spans, as long as they name concrete answer options - Each value in an enumeration of candidates is marked separately; enumeration markers like 1., 2., 3. are NOT tagged. Examples: - "0.4, 0.1, 2.5" - "Possible answers could be Alice , Bob , etc" - "980might work" - "(x,y)=(-2,15)[from sign error]" Definition: Judgment of how likely a student would choose an error or candidate. Rules: - Mark plausibility comparisons or checks for incorrectness. - If also about final set, mark both PLAUS and CURATE. Examples: - "0.4is more plausible than 0.1" - "The student forgets to add?Plausibly" - "0.4is not a good distractor" - "But is a student going to make that mistake?" Definition: Evaluation or selection of the final set of distractors (coverage, diversity, redundancy). Rules: - Only mark when reasoning explicitly concerns the final set. - Otherwise, mark PLAUS. Examples: - "Keep 0.4and 2.5, drop 0.1to cover error types" - "0.4seems plausible, keep that" Definition: Reconsideration of a previous interpretation, candidate, plausibility judgment, or curation decision. Rules: - Place immediately after the cue word indicating reconsideration. - Marks the act of reconsidering, not the outcome. - Common cues: "actually", "alternatively", "instead", "however", "but wait", "on second thought", "reconsider" Examples: - "Actually, ..." - "Alternatively, 980could work" - "On second thought, that distractor is not likely" On LLMs’ Student Mo deling Strategies 23 T able 12. P erformance of LLM-based annotations per taxonom y strategy (T able 1) for DeepSeek-V3.2 with CoT vs. reasoning. Note that RECON and CURA TE hav e v ery little support in the Non-Thinking setting. CoT Reasoning Comp onen t # Precision Recall # Precision Recall T ask In terpretation 12 1.00 1.00 102 0.99 1.00 Correct Answer Ref. 33 1.00 0.92 79 1.00 1.00 Error Description 32 0.97 0.89 112 0.83 0.85 Outcome Instantiation 49 1.00 0.94 299 1.00 0.99 Error Simulation 19 1.00 1.00 55 0.95 0.95 Plausibilit y Check 13 1.00 0.93 53 0.91 0.94 Final Set Curation 4 1.00 0.80 29 0.93 0.90 Reconsideration 4 0.75 1.00 60 0.98 0.98 T able 13. P erformance of LLM-based annotations per taxonom y strategy (T able 1) for GLM-4.7 with CoT vs. reasoning. Note that RECON and CURA TE ha ve v ery little supp ort in the Non-Thinking setting. CoT Reasoning Comp onen t # Precision Recall # Precision Recall T ask In terpretation 11 1.00 1.00 30 0.97 0.97 Correct Answer Ref. 37 1.00 1.00 78 0.99 1.00 Error Description 38 0.95 0.97 159 0.97 0.96 Outcome Instantiation 34 1.00 0.87 200 1.00 0.97 Error Simulation 10 0.80 1.00 51 0.88 0.88 Plausibilit y Check 7 1.00 1.00 26 0.96 0.81 Final Set Curation 4 0.50 1.00 25 1.00 0.93 Reconsideration 1 1.00 1.00 15 1.00 0.94 24 Y. Zengaffinen et al. B GLM-4.7 Results Here we presen t all the detailed results of GLM-4.7 for the exp eriments in § 4.2 and briefly compare them to DeepSeek-V3.2 ’s results. Occurrences of strategies. T able 14 shows the o ccurrences of strategies for GLM-4.7 . Compared to DeepSeek-V3.2 (T able 3), we observe that: (i) for b oth mo dels, o ccurrences are higher in reasoning traces than in CoT. Ho wev er, GLM-4.7 has on av erage 0.55 more o ccurrences than DeepSeek-V3.2 in CoT, whereas in reasoning traces DeepSeek-V3.2 exceeds GLM-4.7 by 2.54 o ccur- rences on av erage. (ii) The a v erage ratios b etw een CoT and reasoning are of sim- ilar magnitude for b oth mo dels, except for RECON , ERR_SIM , and PLAUS , where the ratio b etw een CoT and reasoning is significantly larger for DeepSeek-V3.2 than for GLM-4.7 . Strategies ov er time. Results are sho wn in Fig. 4. Ov erall trends largely matc h those of DeepSeek-V3.2 (Fig. 2), e.g., INTER and CORR are initially frequent but decrease in relative share tow ard the end of the traces. T wo differences are notable: (i) RECON accounts for a larger share of strategies in DeepSeek-V3.2 than in GLM-4.7 , and (ii) ERR_SIM is more common in GLM-4.7 ’s CoT. Common sequences of strategies. Fig. 5 sho ws the common sequences of strategies in GLM-4.7 ’s traces. While we rep orted ov erlap in the top dominant outgoing edges, we observe sev eral minor differences compared to DeepSeek- V3.2 (Fig. 3): (i) The ordering of outgoing dominant edges may differ, e.g., the most dominant outgoing edge of GLM-4.7 in CoT from ERR_DESC is to ERR_SIM , whereas for DeepSeek-V3.2 it is to ERR_DESC . The former corresp onds to iter- ativ ely listing an error and directly simulating it, whereas the latter corresponds to listing multiple errors at once. (ii) Even when the ordering of dominan t edges is consistent, the ratios betw een transition masses can differ. F or instance , for INST in CoT, the ratio of transitions to ERR_DESC compared to INST is muc h larger for GLM-4.7 than for DeepSeek-V3.2 . (iii) The num ber of dominant edges may v ary , e.g., CORR has 4 dominant outgoing edges in DeepSeek-V3.2 ’s reasoning traces compared to just 2 in GLM-4.7 ’s. On LLMs’ Student Mo deling Strategies 25 T able 14. A verage occurrences of taxonomy strategies (T able 1) in CoT and reasoning traces for GLM-4.7 (mean ± 95% CI based on t-distribution). Strategy CoT Reasoning T ask In terpretation 1.11 ± 0.26 4.36 ± 0.79 Correct Answer Ref. 4.09 ± 0.69 11.47 ± 3.62 Error Description 9.02 ± 2.05 19.54 ± 2.73 Outcome Instantiation 8.80 ± 2.43 32.51 ± 8.62 Error Simulation 4.74 ± 1.80 7.19 ± 2.16 Plausibilit y Check 1.43 ± 0.55 4.67 ± 0.77 Final Set Curation 0.64 ± 0.28 3.46 ± 0.70 Reconsideration 0.90 ± 0.38 2.54 ± 0.51 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Position In Trace 0.0 0.2 0.4 Share of Strategies Chain-of-Thought 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Position In Trace Reasoning Traces Task Interpretation Correct Answer Ref. Error Description Outcome Instantiation Error Simulation Plausibility Check Final Set Curation Reconsideration Fig. 4. Indicates how often each strategy in our taxonomy T able 1 was annotated at differen t stages of GLM-4.7 ’s reasoning trace. Time is normalized (0 = start of trace, 1 = end). Note that the proportions sum to one for each of the five temp oral bins. Chain-of-Thought Step Strategy T ask Interpretation Correct Answer Ref. Error Description Outcome Instantiation Error Simulation Plausibility Check Final Set Curation Reconsideration Reasoning T races Step Fig. 5. Shows transition probabilities b etw een strategies in GLM-4.7 ’s traces. Sequences of strategies up to length 4 (left to right). Node height represen ts strategy share and link widths indicate the transition probabilities b etw een successive strate- gies. Only dominant (>15% outgoing mass) transitions are visualized for simplicity . 26 Y. Zengaffinen et al. C Details on Discussion Exp erimen ts This section provides a detailed description of the experiments p erformed as part of the discussion (§ 4.3). C.1 Solv e-First and Error Injection T o measure ho w frequen tly the LLM first solv es a problem correctly and then injects an error into the solution, we annotate the LLMs’ step-by-step traces at scale. F ollo wing the approac h used in our main analysis, w e first define the follo wing taxonom y: – SOLVE_FIRST : Do es the mo del systematically solve the problem to reac h the correct final answ er? – INJECT_FROM_SOLUTION : Do es the mo del refer to the correct solution or in- termediate steps to generate plausible errors, misconceptions, or distractors? W e limit the analysis to problems where the LLM generated at least tw o steps in a step-b y-step solution, ensuring that error injection is possible. Step-by-step solutions are generated using the prompt in T able 15. T able 15. Prompt for solving a math problem {pr oblem_formulation} step-b y-step, in a manner that is consistent with the ground truth answer {final_answer} . System Prompt You are a helpful assistant. User Prompt Solve the math problem. Output format (exact): [STEP-1]... ... [STEP-N]... [FINAL ANSWER]... Constraints: no fluff; only one reasoning/arithmetic step at a time; show key work. Final answer MUST equal: " {final_answer} " Problem: " {problem_formulation} " Automatic annotation. GPT 5.2 is used to automatically annotate both SOLVE_FIRST and INJECT_FROM_SOLUTION for all traces. Explanations or rele- v an t excerpts from the distractor-generation trace are also extracted to supp ort the assigned lab els (T able 18). Annotation quality . A stratified subset of 50 samples are lab eled man ually . Agreemen t b et ween man ual and automatic annotations yields κ = 0 . 85 ( p < 0 . 001 ). On LLMs’ Student Mo deling Strategies 27 C.2 Error Sim ulation Sim ulation prompt. Errors are simulated using the prompt in T able 16, with DeepSeek-V3.2 in reasoning mo de. T able 16. Prompt for generating an incorrect student answer conditioned on a specific misconception {err or} on one math word problem {pr oblem_formulation} . System Prompt You will be given a math question and specific student error. Please generate the incorrect answer that a student would give on the current question if they made the specified error. At the end, give the student’s final concise answer preceded with ‘Incorrect Student Answer:’ User Prompt Question: {problem_formulation} Student Error: {error} Man ual analysis for consistency . T o ev aluate consistency with any reason- able interpretation of the pro vided error, we first compare the generated answer against all av ailable distractors for the same question that are sourced from the same error. F or cases where the answer does not match an y a v ailable distrac- tor, we insp ect the reasoning trace step-b y-step to verify whether the error w as correctly implemented. Alb eit rarely the case, we consider examples consisten t if the error is correctly implemented but is combined with a second error. Most instances are straigh tforward to ev aluate; for example, errors such as “rounds to o m uch” are trivial to classify . C.3 Literature-Informed Reasoning Structure W e use the prompt in T able 17 to enforce a reasoning structure informed by the literature, with DeepSeek-V3.2 in reasoning mo de. 28 Y. Zengaffinen et al. T able 17. Prompt for enforcing an ideal—learning science informed—distractor gen- eration pro cedure for a single math problem {pr oblem_formulation} . System Prompt You will be given a math question. Please generate {n} incorrect distractor answers for the question to be used as multiple-choice options in a multiple-choice exam. **RULES** Solve correctly first: 1. First, solve the problem correctly and treat the most likely correct solution as fixed. 2. Identify the key concepts involved in the correct solution. 3. Specify the exact conditions that an answer must violate to be a valid distractor. Error modeling: 4. Enumerate at most 7 common error primitives relevant to this problem. Each error primitive must be either: (a) a buggy rule (an incorrect transformation or procedure), or (b) a buggy commitment (a false assumption or misclassification treated as true). 5. Each error primitive must be specific, stable, and capable of producing a concrete deterministic answer. Error simulation: 6. For each error primitive, assume the student fully commits to that single error and reasons correctly in all other respects. 7. Derive the final incorrect answer that results from that single error and collect it as a distractor candidate. - If the question is non-numerical, output the final incorrect conclusion, classification or choice that follows from the error primitive. Plausibility Assessment: 8. For each distractor candidate you assess its discriminative power: - check if the candidate can be derived deterministically - check if the candidate is truly incorrect under any reasonable interpretation - quantify how likely students are to stop here and select this candidate - make sure it is unambiguous and well-formed Selection: 9. From the remaining candidates, select the {n} most distinct plausible distractors. Output rules: 10. You should only output the final concise distractor values in the following template: [ Template ] Distractor1: ... Distractor{n}: User Prompt Question: {problem_formulation} On LLMs’ Student Mo deling Strategies 29 T able 18. Prompt for annotating solve-first and inject-from-solution b ehavior in LLMs’ traces {tr ac e} when generating distractors. System Prompt You will be given a reasoning trace whose purpose is to generate *plausible incorrect distractor answers* for a math problem (i.e., simulate student mistakes). Your job is to label two independent properties: **1. SOLVE_FIRST:** Does the trace *attempt to solve the original problem correctly step-by-step* (compute the correct answer path), even if it later discusses mistakes/distractors? - YES if it tries to lay out a solution procedure and/or computes intermediate results toward the true answer. - NO if it jumps straight to distractors/misconceptions without first doing a solution attempt. **2. INJECT_FROM_SOLUTION:** Does the trace *use the correct solution path as scaffolding* by referencing a specific step/intermediate quantity from the correct solution and then “branching off” by applying an incorrect operation/value there, propagating that error to a final distractor? - YES only if you can point to a concrete “branch point” tied to the correct solution (e.g., “Up to step X it’s correct; then it miscomputes X or applies the wrong operation to X, yielding distractor Y”). - NO if distractors are proposed without an explicit branch point from the correct solution (e.g., “a possible distractor is 30 m/s” with no tie to a specific intermediate step), OR if it only lists misconceptions abstractly without anchoring them to a step in the correct solution. These labels are **independent**: A can be YES while B is NO (solves correctly first, then proposes distractors without branching). B is unlikely if A is NO, but still label based on the text. Return output in EXACTLY this format (for regex parsing): SOLVE_FIRST_DISCUSSION: SOLVE_FIRST_LABEL: YES|NO INJECT_FROM_SOLUTION_DISCUSSION: INJECT_FROM_SOLUTION_LABEL: YES|NO **Mini-examples (for guidance only):** Example 1 (SOLVE_FIRST=YES, INJECT_FROM_SOLUTION=YES): Reasoning Trace: “Let’s solve: 30min=0.5h; v=60/0.5=120km/h; /3.6=33.3m/s. Student might incorrectly compute 60/0.5 as 30km/h, then convert...” Expected Output: “SOLVE_FIRST_DISCUSSION: Correct problem solving present. SOLVE_FIRST_LABEL: YES INJECT_FROM_SOLUTION_DISCUSSION: Branches off at the 60/0.5 step with a calculation mistake. INJECT_FROM_SOLUTION_LABEL: YES” Example 2 (SOLVE_FIRST=NO, INJECT_FROM_SOLUTION=NO): Reasoning Trace: “A potential distractor is 30 m/s.” Expected Output: “SOLVE_FIRST_DISCUSSION: No problem solving attempted. SOLVE_FIRST_LABEL: NO INJECT_FROM_SOLUTION_DISCUSSION: N/A INJECT_FROM_SOLUTION_LABEL: NO” Example 3 (SOLVE_FIRST=YES, INJECT_FROM_SOLUTION=NO): Reasoning Trace: “The correct solution is: 30min=0.5h; v=60/0.5=120km/h; /3.6=33.3m/s. One potential distractor is 45m/s.” Expected Output: “SOLVE_FIRST_DISCUSSION: Question is first solved correctly. SOLVE_FIRST_LABEL: YES INJECT_FROM_SOLUTION_DISCUSSION: No solution step is referenced and no related branching off takes place. INJECT_FROM_SOLUTION_LABEL: NO” Now label the following reasoning trace. [ BEGIN TRACE ] {trace} [ END TRACE ] 30 Y. Zengaffinen et al. D A dditional Exp eriments D.1 Co verage of strategies. Bey ond the c haracterization of LLMs’ distractor generation pro cess in § 4.2, it is also informative to examine not only how frequen tly each strategy o ccurs on a verage within a trace, but also ho w many traces contain at least one instance of that strategy . Results. In T able 19, w e observe that across b oth GLM-4.7 and DeepSeek- V3.2 , reasoning traces show substan tially higher co verage of taxonomy strategies than CoT traces, especially for ev aluativ e and iterativ e b eha viors suc h as PLAUS , CURATE , and RECON . Core generativ e steps (e.g., CORR , ERR_DESC , INST ) are nearly univ ersal across mo dels and prompting styles, suggesting they are structural comp onen ts of distractor generation. Compared to DeepSeek-V3.2 , GLM-4.7 exhibits less frequent RECON but relativ ely stronger ERR_SIM in CoT, indicating minor differences b et w een mo dels. D.2 Less capable mo dels. Our study focuses on highly capable mo dels that enable the collection of reason- ing traces. Nev ertheless, it is useful to examine whether smaller models exhibit similar patterns. W e therefore ev aluate GPT-oss-20b with deterministic sam- pling. The proportional matc h in reasoning with the simple prompt (0.30 ± 0.03) is significan tly low er than with the literature-informed reasoning structure (0.35 ± 0.03), suggesting that smaller mo dels ma y adhere less strictly to the misconception-based pro cess than larger mo dels. T able 19. Percen tage of traces containing at least one o ccurrence of each taxonomy strategy for DeepSeek-V3.2 and GLM-4.7 (reported separately for CoT and reason- ing traces). DeepSeek-V3.2 GLM-4.7 Strategy CoT Reasoning CoT Reasoning T ask In terpretation 96.7% 100.0% 56.7% 88.3% Correct Answer Ref. 100.0% 100.0% 100.0% 100.0% Error Description 92.5% 94.2% 98.3% 100.0% Outcome Instantiation 97.5% 100.0% 98.3% 100.0% Error Simulation 40.0% 62.5% 69.2% 59.2% Plausibilit y Check 65.0% 95.8% 50.8% 89.2% Final Set Curation 48.3% 92.5% 30.8% 90.8% Reconsideration 29.2% 95.8% 33.3% 67.5%
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment