CLAG: Adaptive Memory Organization via Agent-Driven Clustering for Small Language Model Agents
Large language model agents heavily rely on external memory to support knowledge reuse and complex reasoning tasks. Yet most memory systems store experiences in a single global retrieval pool which can gradually dilute or corrupt stored knowledge. Th…
Authors: Taeyun Roh, Wonjune Jang, Junha Jung
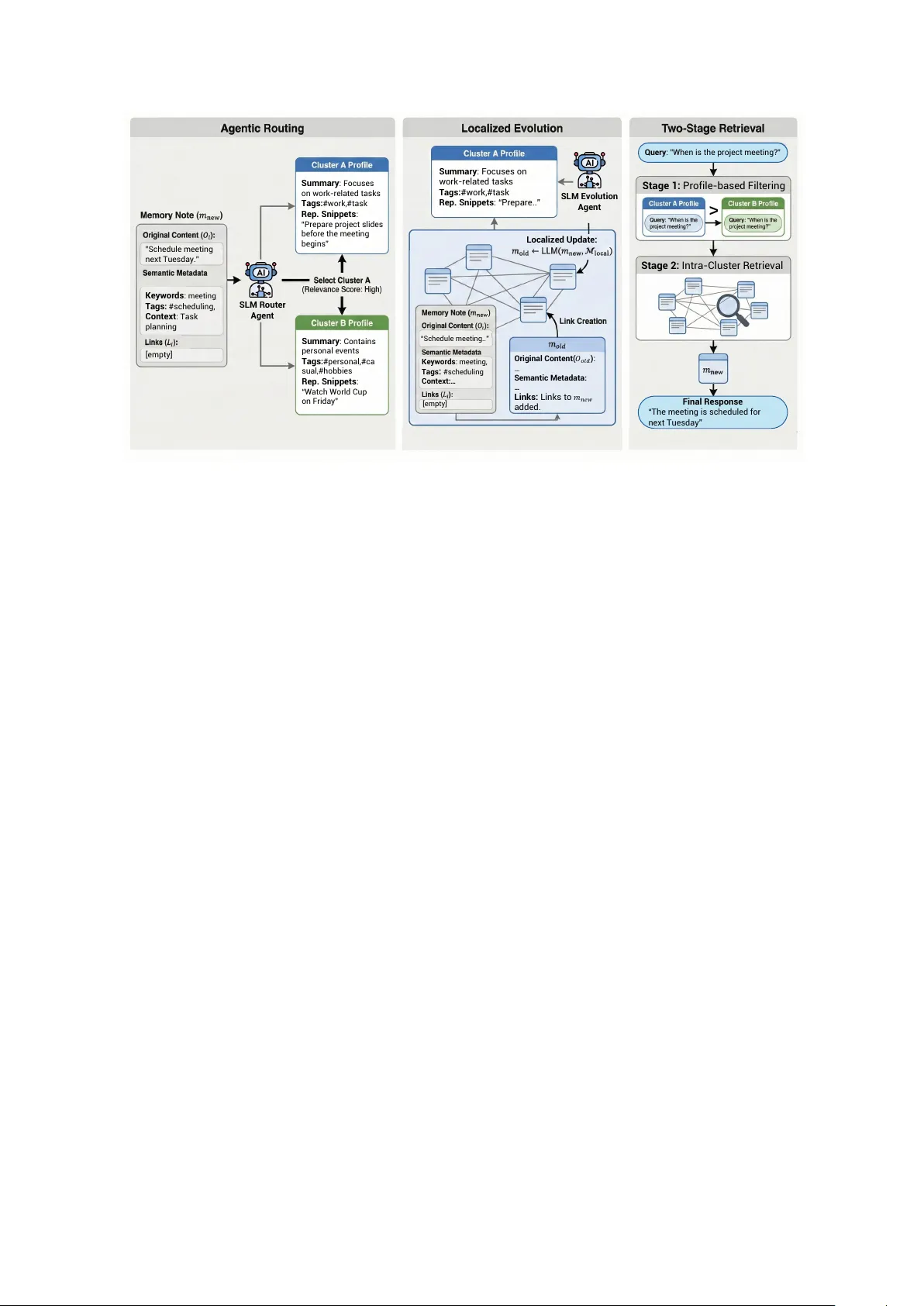
CLA G: Adaptiv e Memory Organization via Agent-Dri ven Clustering f or Small Language Model Agents T aeyun Roh 1 W onjune Jang 2 Junha J ung 1,3 Jaew oo Kang 1,3, † 1 K orea Uni v ersity 2 Myongji Uni versity 3 AIGEN Sciences {nrbsld, goodjungjun, kangj}@korea.ac.kr dnjswnswkd03@mju.ac.kr Abstract Large language model agents heavily rely on external memory to support kno wledge reuse and complex reasoning tasks. Y et most memory systems store experiences in a single global retriev al pool which can gradually di- lute or corrupt stored knowledge. This prob- lem is especially pronounced for small lan- guage models (SLMs), which are highly vul- nerable to irrelev ant conte xt. W e introduce CLA G , a CL ustering-based A G entic memory framew ork where an SLM agent activ ely or- ganizes memory by clustering. CLA G em- ploys an SLM-dri ven router to assign incoming memories to semantically coherent clusters and autonomously generates cluster-specific pro- files—including topic summaries and descrip- tiv e tags—to establish each cluster as a self- contained functional unit. By performing local- ized e v olution within these structured neighbor - hoods, CLA G ef fectiv ely reduces cross-topic interference and enhances internal memory den- sity . During retriev al, the framework utilizes a two-stage process that first filters relev ant clusters via their profiles, thereby excluding distractors and reducing the search space. Ex- periments on multiple QA datasets with three SLM backbones show that CLA G consistently improv es answer quality and robustness ov er prior memory systems for agents, remaining lightweight and efficient. 1 Introduction AI agents are becoming the primary paradigm for deploying Lar ge Language Models (LLMs) in real- world, long-horizon tasks ( Xi et al. , 2023 ; Zhou et al. , 2023 ; Li et al. , 2023 ; W ang et al. , 2024 ). T o succeed in these settings, LLMs rely on internal memory mechanisms to support kno wledge reuse, † Corresponding author . Our code is available at https://github.com/ dmis- lab/CLAG multi-session coherence, and complex reasoning tasks ( W ang et al. , 2024 ; Xi et al. , 2025 ). Conv en- tionally , basic memory systems for AI agents ad- here to a standard Retrie v al Augmented Generation (RA G) ( Le wis et al. , 2020 ) paradigm. In this setup, memory functions essentially as a static reposi- tory designed to overcome fixed conte xt window limitations. Agents sequentially record raw inter- action logs, cov ering en vironmental observations, ex ecuted actions, tool output, and feedback loops during task execution ( Shinn et al. , 2023 ; Y ao et al. , 2023 ). When faced with a new state, the agent simply retrie ves rele v ant historical snippets based on semantic similarity to ground its current input, treating memory merely as a fixed-access database of past episodes. Consequently , this static approach pre vents the agent from learning from subsequent feedback or refining outdated information based on ne w experiences ( Zhong et al. , 2023 ; W ang et al. , 2023a ). Moving beyond static storage, frame w orks demonstrating a gentic memory ( Xu et al. , 2025 ; Kang et al. , 2025 ; Y an et al. , 2025 ) integrate acti ve agents into memory management to enable con- tinuous self-ev olution. Howe ver , as illustrated in Figure 1 , these systems typically operate within a single global memory pool , where both ev olu- tion and retrie v al processes are conducted across the entire unstructured storage. Consequently , as a memory b uffer gro ws, retriev al becomes vulner- able to two coupled issues: (i) the search space expands, increasing the probability of retrie ving se- mantically plausible but task-irrele vant memories, and (ii) memory e volution mechanisms are exposed to topic-mixed neighborhoods, which can misguide updates and gradually degrade the memory store. These problems are especially salient for small lan- guage models (SLMs), which are highly vulnerable to irrelev ant context ( Mallen et al. , 2023 ; Shi et al. , 2023 ; Y oran et al. , 2023 ; Lu et al. , 2024 ). T o address these limitations, we propose CLA G , a CL ustering-based A G entic memory frame work 1 H i gh Int er fer ence & F o r ge tti ng Gl o b al Ev o l utio n & R etr i ev al Lo cal i zed Ev o l utio n & R etr i ev al (a) E xisting Glo ba l M e mo r y Sy st e ms (b) C L AG (Ours) C l u s ter B Cl u st e r A Cl u st e r C C oh e r e nt U pd ates (T op ic 2 – T ar get) (T op ic 3 ) (T op ic 1 ) Figure 1: Conceptual comparison between e xisting global memory systems and CLA G. (Left) Traditional approaches manage memories in a single global pool, where topic-mixed updates and retrie val lead to high interference and noise accumulation. (Right) CLAG employs agent-dri ven clustering to or ganize memories into semantically coherent neighborhoods. By confining ev olution and retriev al to these local clusters, our framew ork significantly reduces cross-topic interference and enhances memory stability . that imposes lightweight structure on long-horizon memory while preserving the self-e volving nature of modern agentic systems. The core idea is to treat clustering as an agent-contr olled operation rather than a static offline preprocessing step. Upon memory write, the agent assigns each ne w memory to a semantically coherent cluster through SLM- agent guided routing and maintains cluster-specific profiles. This process establishes topic-consistent neighborhoods where memory e volution is con- ducted locally . This design aligns with cogniti ve principles suggesting that new information should refine relev ant schemas without perturbing unre- lated memory structures ( Tse et al. , 2007 ; K umaran et al. , 2016 ; Gilboa and Marlatte , 2017 ). By con- fining e volution to these semantic neighborhoods, CLA G prev ents noisy updates from propagating across the global store, allowing each cluster to act as a self-organizing unit that continuously enhances its internal coherence through local interactions. At inference time, CLA G adopts a two-stage retrie val strategy . Gi ven a query , the agent first se- lects a small set of relev ant clusters using centroid- based filtering and an agentic cluster-selection mod- ule, and then retriev es fine-grained memories only within the selected clusters. This hierarchical de- sign reduces the retriev al scope and excludes se- mantically plausible b ut task-irrele vant memories that are more likely to appear under global retriev al. Across multiple QA benchmarks and three SLM backbones, we find that this structured control loop yields consistent improvements in answer qual- ity and robustness compared to prior agent mem- ory baselines, while remaining lightweight in both computation and storage. These gains align with our analysis: clustering produces cleaner semantic neighborhoods for e volution and retrie val, and the two-stage retrie val pipeline mitigates the distractor exposure inherent in global retrie val. Our contributions are threefold: • W e introduce an agent-driven clustering mechanism that organizes memories into se- mantically coherent groups via SLM-agent- based routing, ensuring rob ust long-horizon org anization. • W e propose localized memory evolution that updates and consolidates memories within topic-consistent neighborhoods to stabilize long-term memory quality and mitigate cross- topic interference. • W e dev elop a two-stage cluster-a ware re- trie val scheme that improves robustness for limited-capacity models by reducing the search space, suppressing distractors, and lo w- ering retrie v al noise. 2 2 Related W ork 2.1 Retriev al A ugmented Generation Retrie val Augmented Generation (RAG) ( Le wis et al. , 2020 ) extends the conte xt window of LLMs by coupling a parametric model with a non- parametric external knowledge base. In agentic settings, the knowledge base is replaced by a mem- ory serving as a repository for interaction histories with the en vironment. T ypically , agents rely on retrie v al ov er these accumulated records to inform current decision-making ( Park et al. , 2023 ; Zhang et al. , 2025 ; Y ao et al. , 2023 ). While variants such as hierarchical index- ing ( Sarthi et al. , 2024 ; Rezazadeh et al. , 2024 ; Edge et al. , 2025 ; W ang et al. , 2025a ; Xi et al. , 2023 ) or query rewriting ( Ma et al. , 2023 ; W ang et al. , 2023b , 2025b ) improve co verage, most stan- dard RA G systems operate on a r ead-only basis ov er a static index. They typically process queries as independent, stateless e vents, lacking the mech- anism to dynamically consolidate or restructure memory based on the agent’ s continuous experi- ence ( Pack er et al. , 2024 ). 2.2 Memory system f or LLM agents As LLMs are increasingly deployed as AI agents in long-horizon settings, retriev al has been repurposed into memory for LLM agents: storing interaction traces (observations, actions, tool outputs, feed- back) and retrieving rele vant past snippets to guide current decisions ( Y ao et al. , 2023 ; Zhang et al. , 2025 ). Early agent memories largely follo wed a static RA G-style design, treating memory as an append-only repository queried by global similar - ity search, which limits learning from feedback and consolidation ov er time. Recent agentic and ev olv- ing memory systems (e.g., A-mem ( Xu et al. , 2025 ), MemoryOS ( Kang et al. , 2025 ), GAM ( Y an et al. , 2025 )) introduce maintenance operations such as reflection, compression, and rewriting, b ut typi- cally still rely on a single global memory pool. In contrast, we reduce reliance on global search by agentically clustering memories online and routing ne w entries to an appropriate cluster , conditioning retrie val and memory operations on cluster -level structure. 3 CLA G As illustrated in Figure 2 , the CLAG frame work comprises three core components designed to struc- ture and manage long-horizon memory: (1) Agen- tic Routing , which assigns incoming memories to semantically coherent clusters; (2) Localized Evolution , which consolidates information within specific clusters to maintain topic consistency; and (3) Cluster -A ware T wo-Stage Retrieval , which filters irrelev ant clusters to suppress noise during inference. All agentic decisions in CLA G (routing, e volution, and cluster selection) are produced by the same backbone SLM, inv oked multiple times with role-specific prompts (router/e volver/selector), rather than separate learned models. 3.1 Memory Structuring Inspired by recent agentic memory frame works such as A-mem ( Xu et al. , 2025 ), we represent an agent’ s long-term memory as a collection of struc- tured memory notes that encode both the raw inter- action trace and SLM-agent generated semantic an- notations. Formally , let M = { m 1 , m 2 , . . . , m N } denote the set of all memory notes. Each note m i is represented as m i = { O i , C i , t i , K i , G i , X i , L i } (1) where O i is the original interaction content, C i is the cluster that the memory belongs to, t i is the timestamp, K i is a set of SLM-agent generated ke ywords that summarize salient concepts, G i is a set of SLM-agent generated tags for additional information, X i is an SLM-generated contextual description that captures higher -level semantics, and L i stores links to other notes that are semanti- cally related. 3.2 Memory Routing W e employ an SLM agent to route each incoming memory to the most semantically relev ant clus- ter . The procedure detailed in Algorithm 1 oper- ates in two phases based on the number of pro- cessed memories N processed . During the initial "cold-start" phase (when N processed < n ), memo- ries are b uffered until sufficient data is collected to establish the initial cluster structure C via the InitializeClusters routine. Once initialized, subse- quent memories undergo a routing process. First, a coarse filtering step identifies the top- k candidate clusters ( C topK ) closest to the ne w memory based on vector distance. Giv en the candidate clusters, the final selection is dele gated to the SLM agent, which re views the semantic profiles of these candi- dates to select the most appropriate cluster C routed . Finally , a cosine similarity check against a thresh- old τ determines if the memory is routed to C routed 3 ” S c h e d u l e me e ti n g n e xt Tu e s d ay .” Ke y w o rds : m e e t i n g T ags : #sc h e d u l i n g , Co nt ex t : T as k p l an n i n g [e mp ty] Su mmary : Fo c u s e s o n w o rk - re l ate d tas k s T ags : # w o rk, # tas k Re p . Sn ip p et s : “Pre p are p ro je c t s l i d e s b e f o re th e me e ti n g b e g i n s ” Su mmary : C o n tai n s p e rs o n al e ve n ts T ags : # p e rs o n al , # c a s u al , # h o b b i e s Rep . Snip pe ts : “Watc h Wo rl d C u p o n F ri d ay ” Su mmary : F ocus es on w ork - re l a t ed t a sk s T ags: # w ork,# t a sk Re p . Sn ip p et s : “ P re pa re ..” “S c he dul e mee t i ng. . ” Ke y w ords : mee t i ng, Ta gs : # s c he dul i ng Cont e x t :… [empt y ] Or igi nal C on te nt( 𝑂 𝑜 𝑙𝑑 ) : … Se manti c M e tadat a : … Lin ks: L i nks t o 𝑚 𝑛𝑒 𝑤 a dd ed. Q ue r y : ” W h e n i s th e p ro je c t me e ti n g ? ” Fin al Re spo n se “T he m e e t i ng i s s c he du l e d f or ne xt Tue sd ay ” S tage 2 : Int ra - Clu s t e r R e t ri e v al S tage 1 : P r of il e - ba s e d Fi l t e ri ng SLM Ro u te r Agent SLM Ev o lu ti o n Agent Lo caliz ed Up d ate : > Figure 2: Overview of the pr oposed CLA G framework. Left: Agentic Routing . An SLM router assigns each incoming memory note m new to the most rele vant cluster using semantic metadata, and updates the corresponding cluster profile P . Middle: Localized Evolution. An e volution agent performs consolidation (e.g., linking, re writing, strengthening) within the r outed cluster to maintain topic-consistent neighborhoods and reduce cross-topic interference. Right: T wo-Stage Retriev al. Gi ven a query , CLA G first filters clusters using profile-based selection (Stage 1), then retrie ves fine-grained memories only inside the selected clusters (Stage 2), reducing the ef fective search space and suppressing retriev al noise. or if it represents nov el information requiring the creation of a ne w cluster C new . T o ensure scalability and prev ent semantic drift, we employ an adapti ve clustering mechanism (Al- gorithm 3 ). When a cluster C targ et exceeds a size threshold τ split , it is dynamically bisected into two sub-clusters via K-Means. This on-the-fly refine- ment mitigates o ver-saturation, k eeping the mem- ory structure adaptiv e to the agent’ s ev olving expe- riences. 3.3 Localized Evolution within Clusters A distinct advantage of CLA G is that both link generation and memory e volution operate strictly within the assigned cluster C routed . This local- ized strategy not only ensures that connections are formed within a coherent semantic context b ut also reduces computational overhead by precluding global pairwise comparisons. Upon the assignment of a newly routed memory m new to C routed , CLA G identifies the top- k most rele vant neighbors within the cluster . W e denote this subset of semantically aligned memories as M local , defined via cosine similarity: M local = { m j ∈ C routed | rank ( s new ,j ) ≤ k } (2) where s new ,j is the cosine similarity between m new and m j . Intra-Cluster Linking CLA G establishes ex- plicit connections between the ne w memory and the retrie ved candidates. Since M local is constructed via cluster routing and similarity ranking, it inher - ently contains memories that are semantically prox- imate yet often dif ficult to distinguish by vector similarity alone. T o address this, SLM agent ana- lyzes the fine-grained relationships (e.g., causality , temporal sequence) between m new and M local to generate a set of links L new : L new ← SLM ( m new ∥ M local ) (3) Localized Evolution F ollowing link generation, the system creates a feedback loop to refine e xisting kno wledge. For each neighbor m j in M local , the system determines if its attrib utes require an update to reflect the ne w information: m ∗ j ← SLM ( m new ∥ M local \ { m j } ∥ m j ) (4) The e volved memory m ∗ j then replaces m j within the cluster . Concurrently , the cluster profile is up- dated to maintain alignment with the refined se- mantic state of the cluster . This localized evolu- tion mimics human cogniti ve processes, where new 4 Algorithm 1: Agentic Routing for Ne w Memory 1 Input: Ne w memory data m new , Current set of clusters C , Count of processed memories N processed 2 Parameters: Initialization size n , Routing top-k k , Similarity threshold τ , SLM client S LM 3 if N processed < n then 4 Add m new to initialization buf fer B ; 5 if |B | == n then 6 C ← InitializeClusters ( B ) ; 7 else 8 Identify set C topK containing k closest clusters; 9 C routed ← S LM . SelectCluster ( m new , C topK ) ; 10 sim = CosineSimilarity ( m new , C routed ) ; 11 if sim < τ then 12 Create ne w cluster C new initialized with m new ; 13 C ← C ∪ { C new } ; 14 else 15 Add m new to C routed ; 16 N processed ← N processed + 1 ; experiences primarily reshape our understanding of related concepts (i.e., the cluster) without dis- rupting unrelated kno wledge domains ( Tse et al. , 2007 ; Kumaran et al. , 2016 ; Gilboa and Marlatte , 2017 ). Consequently , each cluster functions as a self-refining module that iterativ ely enhances its semantic density and internal coherence through localized updates. 3.4 Cluster -A war e T wo-Stage Retrie val At inference time, CLA G replaces flat global re- trie val with a cluster-a ware two-stage retrie val pipeline. Giv en a user query q , the system initially identifies a candidate subs et of relev ant clusters and subsequently performs retrie val only within those clusters. Stage 1: Agentic Cluster Selection. The query and its tags are concatenated and embedded into a vector e q . Based on the distance to cluster cen- troids { c k } , a candidate set C cand of the K clos- est clusters is identified. Instead of a determinis- tic top- K selection, the final decision is deleg ated to the SLM agent. By ev aluating cluster profiles against the query , agent returns a variable-size sub- set C selected ⊆ C cand , constraining the search space and suppressing irrele vant noise, which mitigates vulnerability to distractors. Stage 2: Intra-Cluster Retriev al. Gi ven the selected cluster set C selected , CLA G performs re- trie val only within the union of their members M cand = S C ∈C selected C . By restricting retriev al to cluster-local neighborhoods, CLA G reduces the ef fecti ve search space and suppresses semantically plausible but task-irrelev ant memories that com- monly arise under global similarity search. This hierarchical procedure is particularly beneficial for SLM agents: the agentic cluster-selection step pro- vides a high-level semantic filter , improving robust- ness to retrie v al noise. 4 Experiment 4.1 Datasets W e ev aluate CLA G on three benchmarks. W e employ LoCoMo ( Maharana et al. , 2024 ) and HotpotQA ( Y ang et al. , 2018 ), which are widely adopted benchmarks for ev aluating memory sys- tems for LLM agents, to assess con versational gen- eralization and reasoning under noise ( Hu et al. , 2025 ). Additionally , to ev aluate domain adaptabil- ity , we utilize BioASQ ( Tsatsaronis et al. , 2015 ), which we adapted into a HotpotQA-style format to simulate noisy retrie val in specialized domains. De- tailed dataset construction protocols are pro vided in Appendix A . 4.2 Baselines W e compare our framew ork against a standard RA G ( Lewis et al. , 2020 ) baseline and represen- tati ve agentic memory architectures including A- mem ( Xu et al. , 2025 ), MemoryOS ( Kang et al. , 2025 ), and GAM ( Y an et al. , 2025 ); detailed im- plementation settings are provided in Appendix B . 4.3 Implementation Details In our experiments, we employ Llama-3.2- 1B-Instruct ( Grattafiori et al. , 2024 ), Qwen3- 0.6B ( Y ang et al. , 2025 ), and DeepSeek-R1-Distill- Qwen-1.5B ( Guo et al. , 2025 ) as the backbone mod- els for both CLAG and all baselines. For seman- tic embedding and retriev al tasks, we utilize the MiniLM-L6-v2 model. Further details reg arding hyperparameter configurations and implementation specifics are provided in Appendix E . 5 Model Method LoCoMo HotpotQA BioASQ F1 BLEU-1 F1 BLEU-1 F1 BLEU-1 Qwen3-0.6B RA G 12.9 10.39 11.75 11.17 2.4 1.71 A-mem 14.29 11.8 12.04 10.65 3.61 2.83 GAM 16.05 13.24 7.81 6.69 3.40 3.37 MemoryOS 4.30 3.24 9.02 7.34 3.12 1.29 CLA G (Ours) 20.99 17.88 15.50 14.33 22.01 17.23 Llama3.2-1B Instruct RA G 18.04 15.29 9.46 8.19 5.12 3.42 A-mem 14.80 12.20 11.19 10.01 5.38 4.95 GAM 22.63 19.85 13.85 12.84 6.52 4.71 MemoryOS 9.67 6.03 6.43 4.76 3.55 2.52 CLA G (Ours) 21.05 18.16 14.20 12.30 10.16 8.08 DeepSeek-R1 Distill-Qwen 1.5B RA G 11.54 9.13 5.54 4.41 2.81 2.12 A-mem 12.50 9.83 6.06 4.81 4.45 3.07 GAM 12.34 9.27 6.45 4.55 2.78 2.19 MemoryOS 6.41 4.76 4.51 2.84 2.93 1.63 CLA G (Ours) 15.46 12.6 9.12 6.63 6.18 4.42 T able 1: Overall results on LoCoMo, HotpotQA, and BioASQ across three backbone models. Best results are marked in bold , 2nd-best results are marked in underline. Method Retrieval (ms) End-to-End (ms) RA G 17.80 289.60 A-mem 18.54 408.68 GAM 8303.41 17934.32 MemoryOS 220.79 968.75 CLA G (Ours) 142.43 514.14 T able 2: Latency comparison on Qwen3-0.6B backbone. All measurements were conducted on a single NVIDIA A100 GPU. V alues represent the average time in mil- liseconds (ms). 4.4 Main Results Analysis Backbone-wise trends and rob ustness T able 1 sho ws that CLA G yields consistent gains across backbones and datasets, with particularly strong improv ements on kno wledge-intensiv e and domain- shift settings. For Qwen3-0.6B, CLA G achiev es the best F1/BLEU-1 on all three benchmarks, indi- cating that cluster -based routing reliably suppresses distractor retriev al and improves faithfulness un- der long-context noise. For DeepSeek-R1-Distill- Qwen-1.5B, CLAG again provides the strongest ov erall results, suggesting that the proposed rout- ing mechanism remains ef fective e ven when the backbone is changed. Accuracy–efficiency trade-off Be yond accu- racy , CLAG is designed to avoid the high com- putational o verhead typical of multi-step agentic memory pipelines. As quantified in T able 2 , on LoCoMo with the Qwen3-0.6B backbone, CLA G achie ves orders-of-magnitude lo wer end-to-end la- tency than GAM, while maintaining strong accu- racy . Therefore, ev en in regimes where CLA G and GAM are close in LoCoMo accurac y (e.g., under Llama3.2-1B-Instruct), CLAG pro vides a markedly better operating point in practice, achie ving a de- cisi ve balance between model performance and computational cost. 4.5 Perf ormance Analysis across Question Categories W e analyze CLA G’ s performance across the sub- categories of the LoCoMo dataset (T able 3 ). In complex reasoning tasks ( T emporal and Multi- Hop ), CLA G deliv ers consistent gains, indicat- ing that cluster -lev el or ganization helps preserv e long-range dependencies while reducing distrac- tion from irrele vant memory . CLAG achieves the best Multi-Hop F1 across all backbones and im- prov es T emporal performance for two models (e.g., Qwen3-0.6B: 11.53; DeepSeek-R1-Distill-Qwen- 1.5B: 8.92), with BLEU-1 showing a similar trend. For Adver sarial questions, CLA G yields strong improv ements, supporting our claim that localized retrie val mitigates distractor-hea vy failure modes. 6 Model Method Multi Hop T emporal Open Domain Single-Hop Adversarial F1 BLEU-1 F1 BLEU-1 F1 BLEU-1 F1 BLEU-1 F1 BLEU-1 Qwen3-0.6B RA G 6.11 6.04 8.34 7.41 9.07 7.92 8.09 5.52 30.35 24.90 A-mem 6.80 6.34 2.34 2.37 9.97 7.58 8.16 6.00 40.11 33.85 GAM 8.46 7.08 6.50 6.78 10.92 8.45 9.41 6.92 41.25 34.60 MemoryOS 2.29 1.99 7.19 5.60 8.93 7.68 3.58 2.53 3.85 2.72 CLA G 10.08 8.80 11.53 9.39 8.68 6.57 14.10 11.07 50.34 45.00 Llama3.2-1B Instruct RA G 5.78 6.56 2.64 2.54 12.13 9.34 8.73 5.95 55.71 48.88 A-mem 4.91 4.19 2.65 2.76 8.02 6.07 5.92 3.68 47.87 41.51 GAM 10.88 8.94 5.81 3.45 16.06 12.62 11.48 8.76 63.30 59.75 MemoryOS 8.97 6.64 10.34 6.21 9.44 6.66 10.36 6.14 8.40 5.18 CLA G 11.24 10.12 9.00 6.05 9.38 7.31 11.52 8.77 56.41 52.02 DeepSeek-R1 Distill-Qwen-1.5B RA G 4.62 4.40 2.95 2.15 7.49 6.77 6.42 4.31 32.64 26.77 A-mem 5.73 5.70 2.21 1.95 10.55 8.84 7.78 5.27 33.52 26.92 GAM 6.87 6.62 5.53 4.96 9.10 7.94 8.21 5.39 29.65 21.65 MemoryOS 4.74 5.20 6.51 5.26 8.02 6.19 6.64 4.36 6.63 4.59 CLA G 6.99 7.02 8.92 8.02 11.70 10.78 8.58 5.87 39.33 32.53 T able 3: Detailed e xperimental results on the LoCoMo dataset across fiv e categories. Results are reported in F1 and BLEU-1 (%). Best results are marked in bold , 2nd-best results are marked in underline. In contrast, Open Domain results are more mixed: methods with broader retrie v al (e.g., GAM) can outperform CLA G for some backbones, suggest- ing a trade-of f between localization and cov erage. Overall, this category-wise breakdo wn highlights where CLA G is most effecti ve (hard reasoning and robustness) and moti vates adapti ve broadening as a potential extension for open-domain queries. 4.6 Retriev al Perf ormance and Memory Quality Analysis T o in vestigate the sources of our performance gains, we analyze the retriev al quality across three bench- marks with Qwen3-0.6B. T able 4 presents the com- parati ve results on evidence retriev al (E-F1) and ranking metrics (Recall@K, nDCG@K). W e ex- clude MemoryOS and GAM from this specific retrie val-quality analysis because the y do not ad- here to a standard K -bounded raw-evidence re- trie val interface. Both systems yield a dynamic, v ariable number of retriev ed items driv en by ar- chitectural design, rendering them incompatible with standard K -bounded ev aluation protocols. De- tailed results of b udget-aware retrie val quality ex- periments, including these two baselines, are pro- vided in Appendix J . Structural Advantage in Retrieval On the Lo- CoMo and BioASQ benchmarks, CLA G demon- strates the clear structural advantage of Agen- tic Clustering and T wo-Stage Retrieval . In Lo- CoMo, which in volv es long con versational his- tories, CLA G achiev es an E-F1 of 2.07, signif- icantly outperforming A-mem (1.17) and RA G (1.12). This indicates that the agent-driv en rout- ing effecti vely filters out irrele vant interaction logs that often confuse global retriev ers. The advantage is e ven more pronounced in the biomedical domain (BioASQ), where CLA G e xhibits a decisive lead with an E-F1 of 25.11, exceeding baselines (RA G: 2.29, A-mem: 2.20) by an order of magnitude. In domains laden with dense terminology , global sim- ilarity search often struggles to distinguish relev ant context from distractor passages. By le veraging the agentic router to narrow the search space to seman- tically coherent clusters, CLA G ef fectively filters out domain-specific noise, ensuring high-fidelity retrie v al. Localized Evolution Gains In the HotpotQA benchmark, CLA G achiev es retriev al performance comparable to the RA G baseline (E-F1 11.17 vs. 11.44) and slightly better than A-mem (9.60), while securing the highest ranking score (nDCG@10 23.98). Despite the similarity in raw retrie val met- rics, CLA G demonstrates superior final answer quality (as shown in T able 1 ). This discrepancy highlights the critical contribution of Localized Evolution . CLA G continuously consolidates and re writes memories within topic-consistent neigh- 7 Dataset Method E-Prec E-Recall E-F1 R@5 R@10 nDCG@10 LoCoMo RA G 0.66 4.83 1.12 3.12 4.83 3.26 A-mem 0.68 5.50 1.17 3.86 5.50 3.62 CLA G (Ours) 1.20 9.74 2.07 7.18 9.74 6.89 HotpotQA RA G 9.75 14.71 11.44 10.71 14.71 23.71 A-mem 8.05 12.63 9.60 8.38 12.63 22.56 CLA G (Ours) 9.86 14.20 11.17 9.94 14.20 23.98 BioASQ RA G 4.60 1.65 2.29 1.48 1.65 20.19 A-mem 4.40 1.59 2.20 1.48 1.59 21.27 CLA G (Ours) 33.35 32.64 25.11 25.90 32.64 56.17 T able 4: Retriev al performance analysis across three datasets (Backbone: Qwen3-0.6B). Metrics include Evidence Precision (E-Prec), Recall (E-Recall), F1 (E-F1), Recall at k (R@k), and nDCG@10. Best results are marked in bold , 2nd-best results are marked in underline. Clustering Strategy F1 BLEU-1 Cosine-based Clustering 14.78 12.53 K-Means Clustering 15.64 13.36 CLA G (Ours) 22.01 17.23 T able 5: Impact of different clustering method on BioASQ (Qwen3-0.6B). borhoods. This process increases the information density of each memory note. Consequently , ev en when the retrie val recall is on par with baselines, the retriev ed content in CLA G provides a synthe- sized context, enabling the agent to generate ac- curate reasoning steps. Detailed ablation study quantifying the specific contrib utions of localized e volution and two-stage retrie v al is pro vided in Ap- pendix C . 4.7 Agentic vs. Geometric Clustering Moti vated by the retriev al-quality findings in Sec- tion 4.6 , we further isolate the contrib ution of Agen- tic Clustering . In particular, the retriev al analysis re veals that CLA G deliv ers the largest gain in e vi- dence retriev al on BioASQ (E-F1: 25.11), where dense biomedical terminology and frequent lexi- cal ov erlap make global similarity search prone to retrie ving high-similarity yet irrele v ant passages. This suggests that the primary challenge in special- ized domains lies in the pre-retrie val or ganization of the search space, not in the capability of the retrie ver itself. T o directly test this hypothesis, we replace CLA G’ s agentic clustering with representati ve non- agentic clustering strategies while keeping the rest of the pipeline unchanged, and e va luate on BioASQ. Specifically , we compare our approach against two geometric baselines: (1) Cosine-based Clustering , which greedily assigns each incoming memory to the cluster centroid yielding the high- est cosine similarity , and (2) K-Means Clustering , which partitions the memory space based purely on geometric proximity in the embedding space. As shown in T able 5 , non-agentic clustering pro- vide limited gains. In contrast, CLA G achiev es a substantial leap in final answer quality (F1: 22.01, BLEU-1: 17.23), far exceeding the best non-agentic alternati ve (K-Means: 15.64/13.36). These results indicate that simply grouping mem- ories by geometric similarity is insufficient in domains with heavy jargon and ambiguous sur- face cues. Combined with the e vidence from Section 4.6 , this controlled ablation supports the vie w that Agentic Clustering is a central dri ver of CLA G’ s robustness in specialized retrie val settings. 5 Conclusion W e introduce CLA G , a framew ork that structures long-horizon agentic memory through agent-driven clustering and localized ev olution. By shifting from a static global pool to dynamic semantic neighbor- hoods, CLA G ensures that memory updates refine rele v ant schemas while minimizing cross-topic in- terference. Furthermore, our cluster-aw are two- stage retriev al mechanism effecti vely suppresses noise, addressing the critical vulnerability of SLMs to distractor-hea vy contexts. Experiments confirm that this unified approach significantly improv es robustness and scalability , offering a lightweight yet high-performing memory solution tailored for limited-capacity agents. Overall, CLA G is a practi- cal memory layer for limited-capacity agents, im- proving rob ustness without introducing substantial 8 runtime latency . W e also anticipate extensions to safer deployment, including access control and re- tention policies for persistent memory . Limitations A primary technical limitation of CLAG is its re- liance on prompt-based cluster profile generation and agentic beha vior . Consequently , performance can be sensiti ve to specific prompt designs and vari- ations in the underlying language model v ersions. Furthermore, the quality of routing decisions may v ary under significant distribution shifts, such as ne wly emerging topics or drastic changes in writ- ing style, which were not systematically e valuated in this study . From a broader perspectiv e, the organization and persistent storage of user memories raise impor- tant pri vac y and data governance questions. While this work focuses on the retrie val and org anization mechanisms rather than deployment policies, prac- tical application requires rob ust safeguards. Real- world deployment must incorporate strict access controls, clear retention and deletion policies, and transparent user consent mechanisms, especially when handling sensiti ve or personally identifiable information. References Satanjeev Banerjee and Alon La vie. 2005. Meteor: An automatic metric for mt ev aluation with impro ved cor- relation with human judgments. In Proceedings of the A CL W orkshop on Intrinsic and Extrinsic Evalua- tion Measur es for Machine T ranslation and/or Sum- marization . Darren Edge, Ha T rinh, Ne wman Cheng, Joshua Bradley , Alex Chao, Apurva Mody , Ste ven T ruitt, Dasha Metropolitansky , Robert Osazuwa Ness, and Jonathan Larson. 2025. From local to global: A graph rag approach to query-focused summarization . Pr eprint , Asaf Gilboa and Hannah Marlatte. 2017. Neurobiology of schemas and schema-mediated memory . T rends in cognitive sciences , 21(8):618–631. Aaron Grattafiori, Abhimanyu Dube y , Abhinav Jauhri, Abhinav Pande y , Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex V aughan, and 1 others. 2024. The llama 3 herd of models. arXiv pr eprint arXiv:2407.21783 . Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi W ang, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 . Y uyang Hu, Shichun Liu, Y anwei Y ue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun T an, Y an- bin Y in, Jiongnan Liu, Ze yu Zhang, Zhongxiang Sun, Y utao Zhu, Hao Sun, Boci Peng, and 28 others. 2025. Memory in the age of ai agents . Preprint , Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumu- lated gain-based ev aluation of ir techniques. In A CM T ransactions on Information Systems , pages 422– 446. Jiazheng Kang, Mingming Ji, Zhe Zhao, and T ing Bai. 2025. Memory os of ai agent. arXiv pr eprint arXiv:2506.06326 . Dharshan Kumaran, Demis Hassabis, and James L Mc- Clelland. 2016. What learning systems do intelligent agents need? complementary learning systems the- ory updated. T r ends in cognitive sciences , 20(7):512– 534. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler , Mik e Lewis, W en-tau Y ih, T im Rock- täschel, and 1 others. 2020. Retriev al-augmented gen- eration for knowledge-intensi ve nlp tasks. Advances in neural information pr ocessing systems , 33:9459– 9474. Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. Camel: Communicativ e agents for" mind" exploration of large language model society . Advances in Neural Information Pr ocessing Systems , 36:51991–52008. Zhenyan Lu, Xiang Li, Dongqi Cai, Rongjie Y i, Fang- ming Liu, Xiwen Zhang, Nicholas D Lane, and Mengwei Xu. 2024. Small language models: Sur- ve y , measurements, and insights. arXiv preprint arXiv:2409.15790 . Xinbei Ma, Y eyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023. Query re writing in retriev al- augmented large language models. In Pr oceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 5303–5315. Adyasha Maharana, Dong-Ho Lee, Sergey T ulyakov , Mohit Bansal, Francesco Barbieri, and Y uwei F ang. 2024. Ev aluating very long-term conv ersational memory of llm agents . Preprint , arXi v:2402.17753. Alex Mallen, Akari Asai, V ictor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: In vestigating ef fectiv eness of parametric and non-parametric mem- ories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V ol- ume 1: Long P apers) , pages 9802–9822. 9 Charles Pack er , Sarah W ooders, Ke vin Lin, V i vian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. Memgpt: T owards llms as operating systems . Pr eprint , Kishore Papineni, Salim Roukos, T odd W ard, and W ei- Jing Zhu. 2002. Bleu: a method for automatic ev alu- ation of machine translation. In Pr oceedings of the 40th Annual Meeting of the Association for Compu- tational Linguistics (A CL) , pages 311–318. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bern- stein. 2023. Generativ e agents: Interacti ve simulacra of human behavior . In Pr oceedings of the 36th an- nual acm symposium on user interface softwar e and technology , pages 1–22. Pranav Rajpurkar , Jian Zhang, K onstantin Lopyrev , and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Pr oceedings of the 2016 Confer ence on Empirical Methods in Natu- ral Language Processing (EMNLP) . Alireza Rezazadeh, Zichao Li, W ei W ei, and Y ujia Bao. 2024. From isolated con versations to hierarchical schemas: Dynamic tree memory representation for llms. arXiv pr eprint arXiv:2410.14052 . Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. Raptor: Recursiv e abstracti ve processing for tree-organized retrie val . Preprint , arXi v:2401.18059. Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelev ant conte xt. In Inter- national Conference on Machine Learning , pages 31210–31227. PMLR. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Y ao. 2023. Re- flexion: Language agents with verbal reinforcement learning. Advances in Neural Information Pr ocess- ing Systems , 36:8634–8652. George Tsatsaronis, Georgios Balikas, Prodromos Malakasiotis, Ioannis Partalas, Matthias Zschunk e, Michael R Alvers, Dirk W eissenborn, Anastasia Krithara, Sergios Petridis, Dimitris Polychronopou- los, and 1 others. 2015. An overvie w of the bioasq large-scale biomedical semantic indexing and ques- tion answering competition. BMC bioinformatics , 16(1):138. Dorothy Tse, Rosamund F Langston, Masaki Kakeyama, Ingrid Bethus, Patrick A Spooner, Emma R W ood, Menno P W itter, and Richard GM Morris. 2007. Schemas and memory consolidation. Science , 316(5821):76–82. Bing W ang, Xinnian Liang, Jian Y ang, Hui Huang, Shuangzhi W u, Peihao W u, Lu Lu, Zejun Ma, and Zhoujun Li. 2025a. Scm: Enhancing lar ge lan- guage model with self-controlled memory framework . Pr eprint , Guanzhi W ang, Y uqi Xie, Y unfan Jiang, Ajay Man- dlekar , Chaowei Xiao, Y uke Zhu, Linxi Fan, and Anima Anandkumar . 2023a. V oyager: An open- ended embodied agent with large language models . Pr eprint , Lei W ang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Y ang, Jingsen Zhang, Zhiyuan Chen, Jiakai T ang, Xu Chen, Y ankai Lin, and 1 others. 2024. A surve y on large language model based autonomous agents. F rontier s of Computer Science , 18(6):186345. Liang W ang, Nan Y ang, and Furu W ei. 2023b. Query2doc: Query expansion with lar ge language models. arXiv pr eprint arXiv:2303.07678 . Zilong W ang, Zifeng W ang, Long Le, Huaixiu Ste ven Zheng, Swaroop Mishra, V incent Perot, Y uwei Zhang, Anush Mattapalli, Ankur T aly , Jingbo Shang, Chen-Y u Lee, and T omas Pfister . 2025b. Specula- tiv e rag: Enhancing retriev al augmented generation through drafting . Preprint , arXi v:2407.08223. Zhiheng Xi, W enxiang Chen, Xin Guo, W ei He, Y iwen Ding, Boyang Hong, Ming Zhang, Junzhe W ang, Sen- jie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao W ang, Limao Xiong, Y uhao Zhou, W eiran W ang, Changhao Jiang, Y icheng Zou, Xiangyang Liu, and 10 others. 2023. The rise and potential of large language model based agents: A surve y . Pr eprint , Zhiheng Xi, W enxiang Chen, Xin Guo, W ei He, Y i- wen Ding, Boyang Hong, Ming Zhang, Junzhe W ang, Senjie Jin, Enyu Zhou, and 1 others. 2025. The rise and potential of large language model based agents: A survey . Science China Information Sci- ences , 68(2):121101. W ujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao T an, and Y ongfeng Zhang. 2025. A-mem: Agentic memory for llm agents . Pr eprint , BY Y an, Chaofan Li, Hongjin Qian, Shuqi Lu, and Zheng Liu. 2025. General agentic memory via deep research. arXiv pr eprint arXiv:2511.18423 . An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bo wen Y u, Chang Gao, Chengen Huang, Chenxu Lv , and 1 others. 2025. Qwen3 technical report. arXiv pr eprint arXiv:2505.09388 . Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengio, W illiam Cohen, Ruslan Salakhutdinov , and Christo- pher D Manning. 2018. Hotpotqa: A dataset for div erse, e xplainable multi-hop question answering. In Proceedings of the 2018 conference on empiri- cal methods in natural languag e pr ocessing , pages 2369–2380. Shunyu Y ao, Jef frey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik Narasimhan, and Y uan Cao. 2023. React: Syner gizing reasoning and acting in language models . Preprint , arXi v:2210.03629. 10 Ori Y oran, T omer W olfson, Ori Ram, and Jonathan Berant. 2023. Making retrie val-augmented language models rob ust to irrele vant context. arXiv pr eprint arXiv:2310.01558 . Hongli Y u, T inghong Chen, Jiangtao Feng, Jiangjie Chen, W einan Dai, Qiying Y u, Y a-Qin Zhang, W ei- Y ing Ma, Jingjing Liu, Mingxuan W ang, and 1 others. 2025. Memagent: Reshaping long-context llm with multi-con v rl-based memory agent. arXiv pr eprint arXiv:2507.02259 . T ianyi Zhang, V arsha Kishore, Felix W u, Kilian Q. W einberger , and Y oav Artzi. 2020. Bertscore: Ev al- uating text generation with bert. In International Confer ence on Learning Representations (ICLR) . Zeyu Zhang, Quan yu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong W en. 2025. A survey on the memory mechanism of large language model-based agents. ACM T ransac- tions on Information Systems , 43(6):1–47. W anjun Zhong, Lianghong Guo, Qiqi Gao, He Y e, and Y anlin W ang. 2023. Memorybank: Enhancing large language models with long-term memory . Pr eprint , Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar , Xianyi Cheng, Tian yue Ou, Y onatan Bisk, Daniel Fried, and 1 others. 2023. W ebarena: A realistic web en vironment for building autonomous agents. arXiv pr eprint arXiv:2307.13854 . 11 A Dataset Details W e ev aluate our method on three benchmarks— LoCoMo, HotpotQA, and BioASQ—chosen to cov er con versational long-term memory , reasoning under noisy contexts, and domain-specific adapta- tion. LoCoMo W e use LoCoMo ( Maharana et al. , 2024 ), one of the longest and most comprehensiv e benchmarks for memory for agents in long-context dialogue settings. Unlike prior datasets that are typically limited to fiv e chat sessions, LoCoMo features very long-term con versations spanning up to 35 sessions, with an a verage of 300 turns and 9K tokens per dialogue. These con versations are generated via a human-machine pipeline grounded on temporal e vent graphs and rigorously verified by human annotators to ensure long-range consistency . This dataset is specifically designed to challenge models in comprehending long-range temporal and causal dynamics, making it a rigorous testbed for e v aluating the robustness of our memory system. HotpotQA W e build on HotpotQA ( Y ang et al. , 2018 ) under the distractor construction used in MemAgent and GAM ( Y u et al. , 2025 ; Y an et al. , 2025 ), where each query is paired with gold sup- porting documents and additional irrelev ant pas- sages sampled from the same corpus to form a long noisy context. For reproducibility and fair comparison in the small-agent regime, we use a fixed-passage (bounded-context) setting with 20 passages per question (gold e vidence + distrac- tors). In our HotpotQA-20 construction, concate- nating the chunked passages results in approxi- mately 33–39k tokens per query (median ≈ 35k; 25–75%: 34–37k), which is substantially shorter than the 56K/224K/448K variants in MemAgent and av oids small-model context collapse. BioASQ T o e valuate domain adaptability , we adapt BioASQ T ask 10b ( Tsatsaronis et al. , 2015 ) using the same distractor construction protocol as HotpotQA. W e filtered the dataset to retain only factoid and list types compatible with standard QA metrics (e.g., F1, BLEU-1). Specifically , we ran- domly sampled 200 questions (140 factoid and 60 list items) from this subset to form our e valuation benchmark. For reproducibility and fair compari- son in the small-agent regime, we use a bounded- context setting with 20 passages per question (gold e vidence + distractors). In our BioASQ-20 con- struction, concatenating these passages yields in- puts of approximately 5–16k tokens (median ≈ 10.7k; 25–75%: 9.4–12.9k), keeping the context length within the range where small models remain stable. B Baseline Details B.1 Baselines Description W e provide descriptions of each baseline to clarify their memory assumptions and architectural differ - ences from our approach. RA G RA G ( Lewis et al. , 2020 ) augments a lan- guage model with an external retriev er that fetches semantically relev ant documents for each query . Follo wing the setting used in the LoCoMo bench- mark, the retriev ed passages are concatenated with the query and pro vided to the model as additional context. GAM General Agentic Memory (GAM) ( Y an et al. , 2025 ) is a just-in-time (JIT) memory frame- work that builds task-specific context at runtime instead of relying on heavily pre-compressed static memory . It uses a Memorizer to maintain lightweight cues while storing full histories in a page-store, and a Researcher to retrie ve and in- tegrate relev ant information from the page-store for each query , guided by those cues. Criti- cally , the Researcher operates through an iterati ve loop—planning search actions, retrieving data, and reflecting on the results—until the internal infor- mation need is fully satisfied. This dynamic ter- mination criterion results in a variable number of retrie ved contexts per query , making the system incompatible with standard fixed- K ranking e valu- ations. MemoryOS MemoryOS ( Kang et al. , 2025 ) pro- poses an operating-system-inspired memory archi- tecture that or ganizes information into short-term, mid-term, and long-term memory layers. It em- ploys automated memory promotion, decay , and summarization strategies to manage memory per - sistence, enabling scalable long-term interaction without explicit agentic routing decisions. During retrie val, MemoryOS aggregates hierarchical out- puts and persona information from these multiple tiers to construct the final context. Since the vol- ume of retrie ved information is determined by the system’ s architectural depth and the current state of the hierarchy rather than a user -defined budget, it cannot be aligned with standard K -bounded re- trie v al metrics. 12 Method LoCoMo HotpotQA BioASQ F1 BLEU-1 F1 BLEU-1 F1 BLEU-1 RA G 19.06 15.93 23.66 21.33 22.21 20.19 A-mem 21.44 18.35 22.73 20.94 18.59 15.86 GAM 19.55 17.26 22.09 19.30 22.96 19.42 MemoryOS 19.60 15.89 24.64 22.37 28.83 22.48 CLA G (Ours) 21.50 17.94 25.40 23.53 25.40 23.54 T able 6: Results on the stronger backbone Qwen3-8B. C L A G remains competitiv e as model scale increases, achieving the best results on LoCoMo and HotpotQA and the best BLEU-1 on BioASQ. Best results are marked in bold , and second-best results are marked in underline. V ariant F1 BLEU-1 CLA G (full) 22.01 17.23 w/ Global Evolution 19.55 17.25 w/ Global Retriev al 20.25 16.56 T able 7: Ablation on BioASQ (Qwen3-0.6B). Replac- ing localized e volution with global e volution drops F1 by 2.46, and replacing two-stage retriev al with global retriev al drops F1 by 1.76. A-mem A-mem ( Xu et al. , 2025 ) introduces an agentic memory framework in which a dedicated memory agent dynamically decides what informa- tion to store, update, or retriev e based on task re- quirements. The system relies on LLM-driv en rea- soning for memory management, providing flexibil- ity at the cost of increased computational overhead. C Impact of Localized Evolution and T wo-Stage Retrieval Experimental Setup. W e quantify the contribu- tion of (i) Localized Evolution and (ii) Cluster- awar e T wo-Stage Retrie val using BioASQ under the Qwen3-0.6B backbone. W e compare the full system ( CLA G ) against two controlled ablations: (a) Global Evolution which ev olves memories beyond the assigned local neighborhood, and (b) Global Retriev al which replaces the two-stage pipeline with a flat global similarity search. W e report answer quality with F1 and BLEU-1. C.1 Localized Evolution Impr oves Answer Quality with Local Computation Replacing localized evolution with global ev olu- tion reduces F1 from 22.01 to 19.55 ( − 2 . 46 ). This indicates that continuously consolidating memo- ries within topic-consistent neighborhoods is a key dri ver of final answer quality , likely by increas- ing the information density and coherence of notes before retrie v al and generation. Cost-efficiency via local neighborhood updates. Localized e volution re writes only the memories within the assigned cluster (local neighborhood), av oiding a global update over the entire memory store. Conceptually , Cost local ∝ | M local | ≪ Cost global ∝ | M | . (5) In our runs, the clustering structure is moderate in granularity: the number of clusters is 5 . 6 ± 3 . 56 (min 3, max 13; count 10), with mean cluster size 67 . 99 ± 41 . 90 and max cluster size 139 . 5 ± 38 . 47 (min 85, max 210; count 10). These statistics sup- port that ev olution can be restricted to a bounded topic neighborhood rather than the full memory set, enabling more cost-ef ficient continual refinement. C.2 T wo-Stage Retrie val: Modest Pruning, Consistent Gains Replacing two-stage retrie val with global retrie val decreases F1 from 22.01 to 20.25 ( − 1 . 76 ) and BLEU-1 from 17.23 to 16.56 ( − 0 . 67 ), showing that structuring the search space before fine-grained retrie v al is beneficial. Search-space r eduction. W e measure search- space reduction as r = 1 − | S searched | | S all | , (6) where S searched denotes the set of memories e xam- ined after Stage-1 cluster selection (i.e., the union of memories within the selected clusters), and S all is the full memory pool. Across 200 BioASQ queries, we observe mean r = 0 . 0802 ( ≈ 8 . 02%) , std = 0 . 1729 , min = 0 . 0 , max = 0 . 8957 ( ≈ 89 . 57%) . 13 While the av erage pruning is modest, the high vari- ance indicates that for a subset of queries the tw o- stage mechanism substantially narro ws the candi- date pool. Importantly , ev en this conserv ativ e prun- ing yields consistent answer-quality impro vements, suggesting that the main benefit stems from reduc- ing domain-specific distractors and impro ving the rele vance of the candidate set rather than aggres- si vely shrinking it. D Effect of Model Scale Our primary focus is on resource-constrained SLMs ( < 2 B parameters), where retriev al noise and irrele v ant context more easily de grade reason- ing. This regime is especially important for on- de vice and cost-sensiti ve agentic applications, as smaller backbones are generally less robust to dis- tractors than larger models. T o test whether C L AG remains ef fectiv e be yond this setting, we additionally e valuate Qwen3-8B. T able 6 sho ws that C L A G remains competiti ve, achie ving the best results on LoCoMo and Hot- potQA and comparable performance on BioASQ. W e further observe that the relativ e gap between C L AG and the baselines narro ws as model scale increases. W e attribute this trend to the stronger intrinsic robustness of lar ger backbones, which are better able to tolerate noisy evidence. In contrast, C L AG ’ s retriev al filtering is particularly valuable for SLMs, where suppressing distractors is essen- tial for stable agentic reasoning. E Hyperparameter Details W e provide the detailed hyperparameter configu- rations used in our experiments to ensure repro- ducibility . The specific v alues for memory ini- tialization, dynamic clustering, and retrie val are summarized in T able 8 . For the initialization phase in Algorithm 2 , we set the buf fer size n = 100 to accumulate sufficient data before performing the initial K-Means cluster- ing. During the online routing process Algorithm 1 , the SLM router is presented with k route = 3 candidate clusters based on embedding similarity . W e employ a similarity threshold of τ to determine whether to instantiate a new cluster and a maximum capacity threshold of τ split = 300 to trigger cluster splitting (Algorithm 3). T o v alidate the stability of our proposed frame work, we conducted additional ablation studies on the impact of these hyperparam- eter v alues. The experimental results exhibit small v ariance across a wide range of settings, demon- strating the rob ustness of the architectural struc- ture of CLA G . This consistenc y indicates a low dependency on specific hyperparameter configu- rations , confirming that the system’ s performance is driv en by the agentic mechanism itself rather than heuristic tuning. Impact of Initial Cluster Count ( n init ) T o as- sess the system’ s sensitivity to the initial memory structure, we e valuated performance with v arying numbers of initial clusters ( n init ∈ { 3 , 5 , 10 } ). As sho wn in T able 9 , increasing n init from 3 to 5 yields a slight performance gain, achieving the best F1 score of 22.71 and BLEU-1 of 19.01. Further in- creasing the count to 10 results in a mar ginal de- cline, yet the system maintains high stability across all metrics. While n init = 5 yields the peak score, we selected n init = 3 as the default to align with the intrinsic semantic dimensionality of the dataset, where we observed the agent naturally gravitates to wards approximately three dominant topic clus- ters regardless of initialization. This suggests that CLA G’ s continuous e volution mechanism effec- ti vely compensates for initialization choices. Impact of New-Cluster Thr eshold ( τ ) W e fur- ther analyzed the impact of the similarity thresh- old τ , which gov erns the propensity to create new clusters. T able 10 demonstrates the relationship between τ , the resulting cluster granularity , and retrie val performance. As e xpected, increasing τ makes the system stricter about mer ging ne w mem- ories into existing clusters, leading to a significant increase in the av erage number of clusters (from 4.7 to 47.5). W e prioritized structural parsimony by selecting τ = 0 . 10 (Default) despite the peak performance at τ = 0 . 15 ; this setting prev ents over - segmentation into numerous micro-clusters and minimizes management ov erhead while maintain- ing competiti ve accurac y . Remarkably , despite the drastic change in cluster count at higher thresholds, the retriev al performance remains robust. The F1 score peaks at τ = 0 . 15 (22.41) and degrades only slightly ev en at τ = 0 . 30 (21.94). This resilience confirms the ef ficacy of our Ag entic Cluster Selec- tion (Stage 1 retriev al): e ven when the memory space is fragmented into many fine-grained clus- ters, the agent successfully identifies the relev ant neighborhoods, pre venting performance collapse. 14 Hyperparameter Meaning V alue n Init buf fer size (min memories before initial KMeans) 100 n init Initial clusters for KMeans initialization 3 τ split Cluster split threshold (split if size > τ split ) 300 k route Routing candidate clusters shown to SLM 3 τ New-cluster threshold (min cosine sim to accept a cluster) 0.1 k local Intra-cluster neighbors for ev olution/linking 5 K stage1 Candidate clusters for Stage-1 selection 3 k retrieve Final retriev al top- k memories 10 T able 8: Hyperparameters used in our CLA G implementation. Unless stated otherwise, all experiments use the values sho wn abov e. Initial Clusters ( n init ) F1 BLEU-1 3 (Default) 20.99 17.88 5 22.71 19.01 10 21.71 18.50 T able 9: Sensitivity analysis of the initial cluster count ( n init ) on LoCoMo (Qwen3-0.6B). The system main- tains high performance across all metrics, regardless of initialization settings. Threshold ( τ ) F1 BLEU-1 A vg. # Clusters 0.10 (Default) 20.99 17.88 4.7 0.15 22.41 18.93 6.9 0.20 21.68 18.29 15.6 0.25 21.99 18.35 26.5 0.30 21.94 18.73 47.5 T able 10: Sensitivity analysis of the new-cluster thresh- old ( τ ) on LoCoMo (Qwen3-0.6B). While the number of clusters increases significantly with higher thresholds, retriev al performance remains robust. F Case Study: Mystery Novel Inquiry T o further illustrate the adv antage of C L A G , we present a qualitati ve case study from the LoCoMo benchmark using the Qwen3-0.6B backbone. The query and ground-truth answer are taken verbatim from LoCoMo Sample 4. Query . “Which two mystery novels does T im par - ticularly enjoy writing about?” Ground T ruth. Harry P otter and Game of Thr ones T able 11 compares model predictions for this query . Among all methods, only C L A G correctly identifies both titles. In contrast, the baseline methods either abstain or generate ov erly vague responses that fail to recover the exact two-item answer required by the query . Method Prediction Result C L AG (Ours) “Harry Potter and Game of Thrones” Correct ✓ RA G “Not mentioned in the con versation. ” Wrong ✗ A-mem “T im’ s fav orite two mys- tery nov els are not men- tioned. ” Wrong ✗ GAM “Not mentioned in the con versation. ” Wrong ✗ MemoryOS “T im writes about both fantasy and mystery nov- els. ” Wrong ✗ T able 11: Comparison of generated responses F or the query “Which two mystery novels does T im particularly enjoy writing about?” , only C L AG correctly identifies the two titles mentioned in the dialogue. F .1 Agentic Memory Organization and Pruning The memory pool for this sample contains 680 notes spanning di verse topics, including literature, sports, and social interactions. Rather than re- trie ving directly from the full mixed memory pool, C L AG ’ s agentic router first organizes notes into semantically coherent clusters and then performs Stage-1 selection to identify the most relev ant re- gion for the query . As sho wn in T able 12 , this step selects only the literature-related cluster and prunes the others, re- ducing the effecti ve search space from 680 notes to 119 notes. This corresponds to an 82.5% re- duction in candidate memories before fine-grained retrie val. By filtering out unrelated clusters in ad- v ance, C L A G is able to focus on the e vidence di- rectly tied to Tim’ s writing preferences and recov er the correct titles. 15 Cluster ID Profile Count Status 0 Speaker discusses how books create new w orlds 119 Selected ✓ 1 Impact of basket- ball on commu- nity growth 231 Pruned ✗ 2 Experience of meeting team- mates after a trip 330 Pruned ✗ T able 12: Semantic clustering and pruning f or the case study sample. C L AG selects the literature-related cluster and prunes aw ay unrelated clusters, reducing the search space from 680 to 119 notes before fine-grained retriev al. G Algorithmic Details In this section, we pro vide the detailed procedure for cluster initialization and splitting, which are core components of our agentic memory mainte- nance. Specifically , Algorithm 2 details the boot- strapping of the initial memory hierarchy through semantic partitioning, while Algorithm 3 go verns the dynamic refinement of clusters to ensure high- granularity memory maintenance. Algorithm 2: Initialize Clusters 1 Input: Initialization b uffer of memories B 2 Parameters: T arget number of initial clusters n init , SLM client S LM 3 Output: Initialized set of clusters C 4 Extract embeddings E from memories in B ; 5 Partition E into n init sets using KMeans: { M 1 , M 2 , . . . , M n init } ; 6 C ← ∅ ; 7 for i ← 1 to n init do 8 Calculate centroid c i of memories in M i ; 9 Generate Cluster profile pr of ile i ← S LM . GenerateProfile ( M i ) ; 10 Create cluster C i ← { memories : M i , centroid : c i , profile : prof ile i } ; 11 C ← C ∪ { C i } ; 12 return C ; H F ailure Analysis of Agentic Components W e analyze failure cases of the agentic router and selector in C L AG on LoCoMo with Qwen3-0.6B. Algorithm 3: Split Cluster 1 Input: T arget cluster ID cid , Global set of clusters C , Memory storage M 2 Parameters: Split threshold τ split 3 Output: Updated set of clusters C 4 Retrieve cluster info C targ et ← C [ cid ] ; 5 if | C targ et . members | ≤ τ split then 6 retur n C 7 Extract embeddings E from all memories m ∈ C targ et . members; 8 Partition E into 2 sets using KMeans: { M A , M B } with centroids c A , c B ; 9 Define new cluster IDs id A , id B ; 10 Create cluster C A ← { members : M A , centroid : c A , id : id A } ; 11 Create cluster C B ← { members : M B , centroid : c B , id : id B } ; 12 C ← C ∪ { C A , C B } 13 Remove C targ et from C ; 14 return C ; Specifically , we examine examples where C L A G underperforms the global-retriev al baseline, i.e., EM = 0 and F1 C L AG ≤ F1 Baseline . H.1 F ailure T axonomy W e build a heuristic labeler based on query cues and retriev al diagnostics to group failures into se ven cate gories (T able 13 ). H.2 F ailure Distrib ution As sho wn in T able 14 , Entity confusion is the most frequent failure pattern (46.2%), follo wed by T emporal-slot ambiguity (19.3%). These results indicate that improving sensiti vity to fine-grained entity and temporal cues is a promising direction for future work. I Comparison Details In the main text, we primarily reported F1 and BLEU-1 scores to assess lexical ov erlap and re- trie val accuracy . T o provide a more comprehen- si ve ev aluation of semantic coherence and gener - ation quality , we additionally report BER TScore (BER T -F1) and METEOR metrics in T able 15 . BER T -F1 captures semantic similarity using con- textual embeddings, while METEOR accounts for synonyms and stemming, often correlating better with human judgment regarding fluenc y . 16 Category Description Entity confusion Routed to a cluster anchored to the wrong entity . T emporal-slot ambiguity Routed to profiles lacking temporal cues. Stale/drift Baseline retriev es more temporally relev ant evidence. Compositional/Multi-hop miss Query requires composition, but too fe w clusters are selected ( n ≤ 1 ). Location ambiguity Routed to profiles lacking spatial cues. Numeric-slot ambiguity Routed to profiles lacking numeric evidence. Residual ambiguity Remaining underspecified or overlapping cases. T able 13: Failure taxonomy for C L A G . Pattern Count % Entity confusion 110 46.2 T emporal-slot ambiguity 46 19.3 Stale / drift 34 14.3 Compositional / Multi-hop miss 17 7.1 Residual ambiguity 13 5.5 Location ambiguity 9 3.8 Numeric-slot ambiguity 9 3.8 T otal 238 100.0 T able 14: Failure distribution ( N = 238 ). Consistent with the main results, CLA G demon- strates superior performance across most settings, particularly when using the Qwen3-0.6B back- bone. • Semantic Robustness: On the BioASQ dataset with Qwen3-0.6B, CLA G achie ves a METEOR score of 17.75 , drastically outper - forming the baselines (which remain below 3.03). This suggests that CLA G’ s agentic clus- tering and cluster-a ware retrie val enable the agent to generate responses that are linguisti- cally richer and semantically more accurate, rather than merely copying ke ywords. • Consistency across Backbones: Even with larger backbones like Llama3.2-1B-Instruct and DeepSeek-R1-Distill, CLA G maintains competiti ve or superior performance. For instance, on HotpotQA with Llama3.2-1B- Instruct, CLA G achiev es the highest ME- TEOR score (8.64), indicating better handling of multi-hop reasoning contexts compared to GAM and MemoryOS. J Retriev al quality under controlled evidence b udgets. W e further compare C L A G with GAM and Mem- oryOS under budget-aw are retriev al-quality e val- uation. Because GAM retrie ves page-le vel e vi- dence, its output is not directly compatible with the fixed- K raw-e vidence setting used in our main comparison, and exact character -budget matching is infeasible. W e therefore report the av erage num- ber of retriev ed characters actually passed to QA. For MemoryOS, whose final e vidence length is in- directly controlled by se gment selection, we raise the segment-selection threshold to 0 . 7 to obtain a budget comparable to C L AG , A-mem, and RA G. As shown in T able 16 , C L A G does not outperform competitors by retrie ving more text; rather , it con- sistently retrie ves more rele v ant e vidence under a controlled b udget, with especially large gains on BioASQ. K Evaluation Metric W e ev aluate our system using complementary met- rics that assess both question answering quality and retrie val ef fectiv eness. For question answering, we employ lexical- and semantic-lev el metrics to measure answer correctness and meaning similar - ity , while retriev al performance is e valuated using e vidence-le vel precision, recall, and ranking-based metrics. Question Answering Evaluation F1 Score. The F1 score ( Rajpurkar et al. , 2016 ) e valuates answer accuracy by jointly considering precision and recall. In span-based question an- swering, it is computed at the token le vel to rew ard partial overlap between predicted and reference answer spans. F1 = 2 · P rec · Recal l P r ec + Recal l (7) P r ec = TP TP + FP , Recal l = TP TP + FN (8) where TP , FP , and FN denote true positives, false positi ves, and f alse negati ves at the token le vel. 17 Model Method LoCoMo HotpotQA BioASQ BER T -F1 METEOR BER T -F1 METEOR BER T -F1 METEOR Qwen3-0.6B RA G 85.07 12.78 82.11 7.07 78.89 2.68 A-mem 85.04 12.85 82.20 6.13 79.04 3.03 GAM 84.91 14.39 82.57 6.33 77.05 2.66 MemoryOS 84.15 2.68 84.39 5.02 80.65 1.11 CLA G (Ours) 85.45 18.57 82.47 10.10 83.56 17.75 Llama3.2-1B Instruct RA G 85.52 16.09 84.70 6.15 79.25 3.52 A-mem 85.10 14.10 85.44 6.52 80.37 3.43 GAM 87.85 17.61 77.23 8.07 73.63 5.04 MemoryOS 84.08 7.48 82.23 4.73 80.23 2.71 CLA G (Ours) 86.80 18.13 84.78 8.64 80.92 7.14 DeepSeek-R1 Distill-Qwen 1.5B RA G 84.28 8.91 82.97 3.63 79.30 2.11 A-mem 84.38 13.11 83.05 4.06 80.08 4.67 GAM 86.21 11.73 84.78 4.85 81.10 2.53 MemoryOS 85.09 4.99 81.82 3.96 81.12 2.51 CLA G (Ours) 85.33 14.74 83.38 6.03 79.90 4.78 T able 15: Detailed experimental results on LoCoMo, HotpotQA, and BioASQ: BER T -F1 and METEOR scores. Best results are marked in bold , 2nd-best results are marked in underline. BLEU-1. BLEU-1 ( Papineni et al. , 2002 ) mea- sures unigram-lev el lexical precision between gen- erated answers and references, while applying a brevity penalty to discourage o verly short re- sponses. BLEU - 1 = BP · exp(log p 1 ) (9) BP = ( 1 , c > r exp(1 − r /c ) , c ≤ r (10) where c and r denote candidate and reference lengths, and p 1 is unigram precision. METEOR. METEOR ( Banerjee and Lavie , 2005 ) e valuates answer quality based on aligned unigrams while accounting for synonym matching and fragmentation penalties. This allows the metric to capture semantic similarity beyond exact lexical ov erlap. METEOR = F mean · (1 − Penalt y) (11) F mean = 10 P R R + 9 P , Penalt y = 0 . 5 ch m 3 (12) where P and R denote unigram precision and re- call, m is the number of matched unigrams, and ch is the number of contiguous matched chunks. BER T -F1. BER T -F1 ( Zhang et al. , 2020 ) ev al- uates semantic similarity between predicted and reference answers using contextualized tok en em- beddings from BER T . It computes precision and re- call based on maximum cosine similarity between tokens, and reports their harmonic mean, enabling robust e valuation even when e xact lexical o verlap is limited. BER T - F1 = 2 · P BER T · R BER T P BER T + R BER T (13) where P BER T and R BER T denote tok en-level preci- sion and recall, computed using maximum cosine similarity between contextualized BER T embed- dings of predicted and reference tokens. Retriev al Evaluation Evidence Precision and Recall. W e ev aluate re- trie val quality using e vidence-le vel precision and recall. E - Prec = |R ∩ E | |R| , E - Recall = |R ∩ E | |E | (14) where R is the set of retrie ved memories, E is the set of gold evidence items, and R ∩ E denotes the set of retriev ed memories that match at least one gold evidence item (determined by normalized substring matching). 18 Dataset Method Evidence Quality Ranking Chars E-Prec E-F1 R@5 nDCG@10 LoCoMo GAM 1.97 3.01 7.50 6.93 17,198.04 RA G 0.66 1.12 3.12 3.26 1,389.43 A-mem 0.68 1.17 3.86 3.62 1,483.91 MemoryOS 3.24 2.87 2.72 3.35 1,373.48 CLA G 1.20 2.07 7.18 9.74 1,465.65 HotpotQA GAM 14.44 6.50 5.38 15.00 1,234.70 RA G 9.75 11.44 10.71 23.71 1,196.73 A-mem 8.05 9.60 8.38 22.56 1,826.13 MemoryOS 19.10 6.44 4.04 19.85 1,549.99 CLA G 9.86 11.17 9.94 23.98 1,844.98 BioASQ GAM 22.90 5.73 4.27 25.06 913.45 RA G 4.60 2.29 1.48 20.19 1,564.12 A-mem 4.40 2.20 1.48 21.21 1,318.54 MemoryOS 28.50 9.27 6.72 29.40 1,228.24 CLA G 33.65 25.90 32.64 56.17 1,465.65 T able 16: Retriev al-quality comparison with GAM and MemoryOS. Best results are marked in bold , and second-best results are marked in underline. Evidence F1. The harmonic mean of evidence precision and recall. E - F1 = 2 · E - Prec · E - Recall E - Prec + E - Recall (15) where E - Prec and E - Recall are defined in Equa- tion ( 14 ). Recall@K. Recall@K ( Järvelin and K ekäläinen , 2002 ) measures the fraction of gold e vidence re- trie ved within the top-K results. Recall@ K = 1 |E | |E | X i =1 1 [rank( e i ) ≤ K ] (16) where E is the set of gold evidence items, e i de- notes an evidence item, rank( e i ) is the rank of the retrie ved memory containing e i (or ∞ if absent), K is the cutoff rank, and 1 [ · ] denotes the indicator function. nDCG@K. Normalized Discounted Cumulativ e Gain ( Järvelin and Kekäläinen , 2002 ) e valuates ranking quality . nDCG@ K = DCG@ K IDCG@ K (17) DCG@ K = K X i =1 rel i log 2 ( i + 1) (18) where rel i ∈ { 0 , 1 } denotes the relev ance of the item at rank i , K is the cutof f rank, and IDCG@ K is the ideal DCG obtained by ranking all rele vant items at the top positions. L SLM Prompts This appendix provides the exact prompt templates used for SLM-agent based routing and cluster pro- filing. L.1 Prompt f or SLM Cluster Selection This prompt is used in the ‘SLM.SelectCluster‘ function to determine the best-fitting cluster for a ne w memory from a list of candidates. Prompt template f or Cluster Selection You are a memory routing assistant. A new memory has arrived: - Content: {note.content} - Context: {note.context} - Tags: {note.tags} 19 Here are candidate clusters (pre-selected by vector similarity) that might relate to this memory: {candidates_text} Your task: 1. Analyze the topics and contexts of the candidate clusters provided above. 2. Select the single cluster_id that exhibits the highest semantic relevance and thematic alignment with the new memory. 3. You MUST choose exactly one cluster_id from the candidate list. - Do NOT output any text that is not a valid cluster_id. Return ONLY a JSON object in this format (this is an example): {{ "choice": "cluster_1" }} Where: - cluster_1 must be replaced with one of the actual cluster ids from the candidate list above. - Do not include comments or extra fields. L.2 Prompt f or Cluster Profile Generation This prompt is used to generate a semantic summary and representativ e tags for a cluster based on its member memories. The placeholder {samples_text} is populated with actual text snip- pets from memories within the cluster . Prompt template f or Cluster Profile Genera- tion You are a memory clustering assistant. Below are several memory snippets that belong to the SAME cluster: {samples_text} Your task: 1. Write ONE short sentence summary that best describes the main topic of this cluster. 2. Return EXACTLY 3 tags. - Each tag must be a single word. - Do NOT repeat the same tag. Return ONLY a JSON object with the following KEYS (this is a schema, not the actual content): {{ "summary": "...your one-sentence summary here...", "tags": ["tag_1", "tag_2", "tag_3"] }} L.3 Prompt f or Retrieval Stage Cluster Selection This prompt is employed during the first stage of the retriev al pipeline (Agentic Cluster Selec- tion). The SLM ev aluates the semantic relev ance of candidate clusters—identified via centroid dis- tance—against the user’ s query . By allowing the agent to select a variable number of clusters, this step acts as a semantic gatekeeper , filtering out ir- rele v ant topics before fine-grained retriev al ensues. Prompt template f or Retrieval stage cluster selection You are an AI memory router that selects the most relevant memory clusters for a given query. You will be given several candidate clusters. Each cluster has: • cluster_id • one-sentence summary • optional tags • one or more representative memory examples Your task: 1. Analyze the user query and query_tags. 2. For each candidate cluster, judge how relevant it is. 3. Decide how many clusters are actually needed. You should return between 0 and {top_n} clusters. • If one cluster is definitely sufficient for answering the query, return just that one. • Include additional clusters if they are needed for answering the query. 4. If none of the clusters are meaningfully related, return an empty list. Return ONLY JSON with this format: { "selected_clusters": [ "cluster_id_1", "cluster_id_2" ] } If no cluster is relevant, return: { "selected_clusters": [] } User query: {query} Query tags: {query_tags} Candidate clusters: {candidate_clusters_text} 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment