Brain-Inspired Graph Multi-Agent Systems for LLM Reasoning
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of language tasks, yet complex multi-step reasoning remains a fundamental challenge. While Large Reasoning Models (LRMs) equipped with extended chain-of-though…
Authors: Guangfu Hao, Yuming Dai, Xianzhe Qin
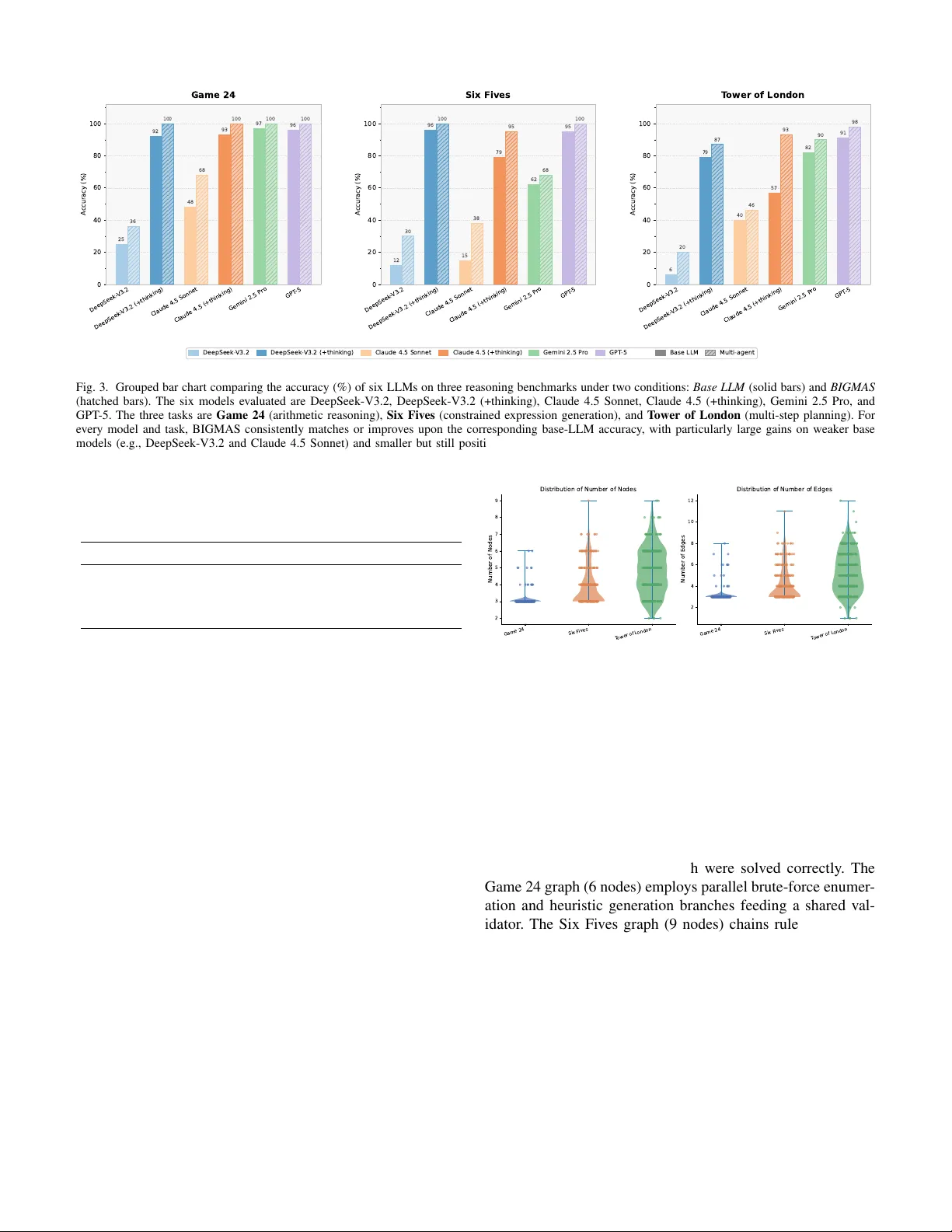
1 Brain-Inspired Graph Multi-Agent Systems for LLM Reasoning Guangfu Hao 1,2,† , Y uming Dai 3,† , Xianzhe Qin 4 , Shan Y u 1,2,5,* 1 Laboratory of Brain Atlas and Brain-inspired Intelligence, Institute of Automation, Chinese Academy of Sciences (CASIA) 2 School of Artificial Intelligence, Uni versity of Chinese Academy of Sciences (UCAS) 3 Uni versity of the Chinese Academy of Sciences (UCAS) 4 College of Softw are (CS), T aiyuan Univ ersity of T echnology 5 School of Future T echnology , Uni v ersity of Chinese Academy of Sciences (UCAS) Abstract —Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of language tasks, yet complex multi-step reasoning remains a fundamental chal- lenge. While Large Reasoning Models (LRMs) equipped with extended chain-of-thought mechanisms demonstrate improv ed performance over standard LLMs, both model types still suffer from accuracy collapse on sufficiently complex tasks [1], [2], suggesting that scaling model-level reasoning alone is insufficient. Inspired by the global workspace theory of human cognition, we propose Brain-Inspired Graph Multi-Agent Systems (BIGMAS), in which specialized LLM agents are organized as nodes in a dynamically constructed directed graph and coordinate ex- clusively through a centralized shared workspace. A problem- adaptive GraphDesigner constructs task-specific agent topologies, while a global Orchestrator leverages the complete shared state for routing decisions, over coming the local-view bottleneck of reacti ve approaches. Experiments on Game24, Six Fives, and T ower of London across six frontier LLMs demonstrate that BIGMAS consistently improves reasoning performance for both standard LLMs and LRMs, outperf orming existing multi-agent baselines including ReAct and T ree of Thoughts, showing that multi-agent architectural design pro vides complementary gains orthogonal to model-level reasoning enhancements. Index T erms —Multi-agent systems, large language models, graph-based reasoning, shared workspace coordination, dynamic graph design, complex problem solving I . I N T R O D U C T I O N Recent generations of frontier models ha ve introduced Lar ge Reasoning Models (LRMs) such as OpenAI o1/o3 [3], [4], DeepSeek-R1 [5], Claude Sonnet Thinking [6], and Gem- ini Thinking [7], characterized by extended chain-of-thought (CoT) [8] mechanisms with self-reflection [9]. While these models demonstrate improved performance on standard rea- soning benchmarks [10], [11], recent systematic inv estigations rev eal that both standard LLMs and LRMs suffer from ac- curacy collapse beyond certain problem complexity thresh- olds [12]. Moreov er , providing explicit solution algorithms to LRMs does not alleviate this collapse, suggesting the limi- tation lies not merely in solution discovery but in consistent logical execution—pointing to a fundamental bottleneck that model-lev el scaling alone cannot resolve. This observ ation motiv ates a complementary perspecti ve: rather than continuing to scale individual model reasoning, can we design multi-agent arc hitectures that distribute cognitive †These authors contributed equally to this work. *Corresponding authors: shan.yu@nlpr .ia.ac.cn load across specialized components and externalize interme- diate reasoning state? While multi-agent LLM framew orks hav e emerged as a promising direction [13]–[16], existing ap- proaches share a critical structural limitation: agent communi- cation is either point-to-point or encoded in fix ed, pre-specified topologies, leaving global task state fragmented across indi- vidual agents, preventing both full-state visibility and dynamic adaptation of their collaborative organization [17], [18] to the specific demands of each problem. A deeper inspiration comes from the organizational prin- ciples of the human brain. Under Global W orkspace Theory (GWT) [19], [20], flexible cognition emerges from the dy- namic formation of coalitions among distributed specialized processors, coordinated through a shared central workspace. Critically , both the composition of the coalition and the topology of their interactions are determined by task demands rather than hardwired in advance. Translating these principles into a multi-agent system suggests an architecture in which: (i) a meta-lev el agent designs a task-specific graph of spe- cialized agents per problem; (ii) the resulting graph is adap- tiv e—different problems yield different node compositions and topologies; and (iii) all agents coordinate through a shared workspace that maintains a globally consistent view of task state. In this paper , we present Brain-Inspired Graph Multi- Agent Systems (BIGMAS) , a novel framew ork that instan- tiates these principles for LLM reasoning. A GraphDesigner agent autonomously constructs a task-specific directed agent graph together with a shared workspace schema for each problem. All agent nodes interact exclusiv ely through the centralized shared workspace, ensuring e very intermediate result is globally visible. A global Orc hestrator observes the complete workspace state and full execution history at each routing step, eliminating the local-view bottleneck of reactiv e paradigms. Agent outputs are validated against workspace constraints, with a self-correction loop that resolves errors without aborting ex ecution. W e ev aluate BIGMAS on three reasoning benchmarks—Game24, Six Fiv es, and T o wer of London—across six frontier LLMs (DeepSeek, Claude, GPT , and Gemini). BIGMAS consistently improv es performance for both standard LLMs and LRMs. The gains are largest precisely where individual models struggle most, suggesting that multi-agent coordination provides a structural remedy 2 Game of 24 2 6 6 7 ( 7 - 6 ÷ 2 ) x 6 = 24 ( 7 - 3 ) x 6 = 24 4 x 6 = 24 + - × ÷ Mathematical Reasoning T arget: 24 Given Numbers Solution Available Operations T ower of London Initial State Planning & Executive Function Minimum moves: 4 T arget State Source Numbers Solution Available Operations Game of Six Five Mathematical Reasoning T arget: 108 5! - 5 - 5 - (5+5)/5 = 108 + - × ÷ ! !! 5 5 5 5 5 5 Fig. 1. Three cognitive reasoning tasks used in evaluation. Left: T ower of London task requires planning optimal moves to reach target configuration. Middle: Six Fives requires constructing arithmetic expressions using exactly six 5s to reach a target value. Right: Game24 demands mathematical reasoning to combine four numbers reaching target value 24. for reasoning collapse that is orthogonal to model-lev el capability . BIGMAS also outperforms established multi-agent baselines—ReAct and Tree of Thoughts—across all three tasks, confirming that the gains stem from the synergy of adaptiv e topology and global workspace coordination rather than from more extensi ve search alone. Our key contributions are as follo ws: • Brain-Inspired Dynamic Graph Architecture. W e pro- pose BIGMAS, grounded in global workspace theory . A GraphDesigner agent autonomously constructs a task- specific directed agent graph with a shared workspace schema per problem, replacing static topologies with problem-adaptiv e structures. • Global-State Orchestration with Robust Execution. A global Orchestrator makes routing decisions based on the complete shared workspace state and full ex ecution history , overcoming the local-view bottleneck of reactiv e paradigms. A self-correction loop with multi-strate gy f all- back parsing ensures execution integrity without aborting on transient node failures. • Comprehensiv e Empirical V alidation. Experiments across three reasoning benchmarks and six frontier LLMs demonstrate consistent and substantial improv ements ov er single-model baselines for both standard LLMs and LRMs, establishing complementary gains orthogonal to model-lev el enhancements. I I . R E L ATE D W O R K A. LLM Reasoning and Multi-Agent F rameworks Improv ements in LLM reasoning hav e followed two broad trajectories. The first scales inference-time computation through prompting strategies such as Chain-of-Thought [8] and self-consistency [21], decomposition strategies such as least-to-most prompting [22] and Program of Thoughts [23], or iterativ e self-refinement approaches [24], or through reinforce- ment learning from verifiable re wards [5], yielding LRMs that generate extended reasoning traces before producing answers. Shojaee et al. [12] provide a systematic characterization of LRM limitations: accuracy collapses beyond problem-specific complexity thresholds, reasoning effort counterintuiti vely de- creases near the collapse point, and the collapse persists ev en when explicit solution algorithms are provided. These findings establish that model-lev el scaling hits a fundamental ceiling on sufficiently complex tasks. The second trajectory dev elops multi-agent framew orks that distribute reasoning across specialized components. Re- Act [25] interleav es reasoning and action in a reactive loop; Reflexion [26] augments this with verbal self-reflection; T ree of Thoughts [27] broadens exploration via tree search. Graph of Thoughts [28] extends this further by modeling LLM- generated information as an arbitrary graph where units of rea- soning are vertices and dependencies are edges, enabling feed- back loops and thought merging. Buf fer of Thoughts [29] pro- poses a meta-buf fer of reusable thought-templates to improv e accuracy , efficienc y and robustness across div erse reasoning tasks. These approaches improv e on single-pass inference but remain limited by incremental, partial-information decision- making or by operating within a single model’ s context. Role- specialized frame works such as MetaGPT [13] introduce struc- tured collaboration, while planning-execution decoupling via D AG structures—LLMCompiler [30] and the planner-centric paradigm of W ei et al. [31]—demonstrates the advantage of global upfront planning over reactiv e approaches. Multi- agent con versation frameworks such as AutoGen [32] and role-playing framew orks such as CAMEL [33] enable flexible agent orchestration through programmable interaction patterns. Multiagent debate [34] demonstrates that having multiple model instances propose and critique each other’ s reasoning can substantially improve factual accuracy and mathematical reasoning. Dynamic agent team selection approaches such as DyLAN [35] and graph-based optimization frameworks such as GPTSwarm [36] show that v arying agent composition and 3 communication topology according to the task improv es ov er fixed-structure alternativ es. Despite this progress, all existing framew orks share the limitation that coordination graphs are fixed and agent state is not globally shared, preventing dy- namic adaptation to problem structure. BIGMAS addresses this gap by combining per-problem graph construction with a centralized shared workspace, connecting both trajectories into a unified architecture. B. Neur oscience F oundations: Dynamic Networks and Global W orkspace Systems neuroscience has established that the brain does not use a fixed processing pipeline. Large-scale functional networks reconfigure dynamically according to task de- mands [37], [38], with prefrontal hub regions orchestrating the selective recruitment of specialized areas [39]. T ask com- plexity modulates the degree of cross-network coordination re- quired: routine tasks engage relativ ely isolated modules, while complex or novel problems necessitate broader functional coalitions [40]. Recent neuroimaging studies confirm that these functional network reconfigurations are not merely structural but reflect training-induced plasticity [41], further supporting the view that task-adaptiv e topology is a core computational principle of flexible cognition. Global W orkspace Theory (GWT) [19], [20] formalizes this observation. Under GWT , flexible cognition arises when spe- cialized processors form a task-driv en coalition and communi- cate through a central workspace that broadcasts information globally to all recruited modules. The three core properties of GWT—processor specialization, dynamic coalition formation, and global broadcast—map directly onto design principles for multi-agent systems: distinct agent roles, per-problem graph construction, and a centralized shared workspace visible to all agents. Existing LLM frameworks instantiate specialization but not the other two properties; BIGMAS is the first to operationalize all three within a unified architecture, grounding its design in an empirically supported theory of flexible cognition. C. Reasoning Benchmarks and Evaluation W idely used benchmarks such as GSM8K [42], MA TH [43], and HumanEval [44] have driv en LLM progress but present two well-kno wn limitations for systematic analysis: sus- ceptibility to data contamination in frontier model training corpora [12], and fixed problem complexity that precludes controlled study of performance scaling. Evaluation is also typically restricted to final answer accuracy , obscuring inter- mediate reasoning quality . Controllable puzzle environments overcome these limi- tations by enabling precise complexity manipulation and simulator-based step-level verification [12], [45]. The three benchmarks in this work—Game24 [27], Six Fives, and T o wer of London [46]—provide contamination-resistant, verifiable tasks spanning arithmetic reasoning, combinatorial search, and sequential planning. Unlike tool-augmented e valuations such as T oolBench [47] and StableT oolBench [48], where task success conflates reasoning quality with tool reliability , these benchmarks isolate the reasoning contribution directly , enabling a clean measurement of architectural gains across both standard LLMs and LRMs. I I I . M E T H O D A. Pr oblem F ormulation W e consider a class of combinatorial reasoning tasks that require multi-step logical deduction, constraint satisfaction, or sequential planning. Formally , a reasoning problem instance is defined as a tuple P = ( x, C , y ∗ ) , where x denotes the problem input (e.g., a set of numbers, an initial board configuration, or a hidden code), C denotes the set of task- specific constraints (e.g., operator restrictions, move legality rules, or capacity limits), and y ∗ denotes the target output (e.g., a valid expression, a mov e sequence, or a sequence of guesses). The goal is to produce a solution ˆ y that satisfies all constraints in C and achieves the target y ∗ . The three tasks considered in this work instantiate this formulation as follo ws. Game24. Gi ven four integers { n 1 , n 2 , n 3 , n 4 } ⊂ [1 , 13] , find an arithmetic expression using each number exactly once with operators { + , − , × , ÷} and parentheses such that the result equals 24. Formally , find ˆ y = f ( n 1 , n 2 , n 3 , n 4 ) such that e val ( ˆ y ) = 24 . Six Fives. Giv en a tar get integer t , construct an arith- metic expression using exactly six instances of the digit 5—with concatenation (e.g., 55 , 555 ) permitted—and oper- ators { + , − , × , ÷ , ! , !! } such that the expression ev aluates to t . The constraint set C requires that the count of digit 5 used equals exactly six. T ower of London. Giv en three pegs with capacities (3 , 2 , 1) and three colored beads { r, g , b } , find a minimum-length sequence of moves ˆ y = ( m 1 , m 2 , . . . , m k ) that transforms an initial peg configuration s 0 into a goal configuration s ∗ . Each mov e m i transfers the topmost bead of one peg to another, subject to peg capacity constraints. B. BIGMAS Arc hitectur e Overview BIGMAS solves a reasoning problem P through a three- phase pipeline: graph design , gr aph execution , and answer extr action . The system maintains a centralized W orkspace B as the single source of truth throughout execution. All agent nodes interact exclusi vely with B ; no point-to-point commu- nication between nodes occurs. The complete framew ork is illustrated in Figure 2. The W orkspace is structured as a four-partition data object: B = ( B ctx , B work , B sys , B ans ) (1) where B ctx stores the read-only problem context (input x and constraints C ); B work is the read-write working area for intermediate results; B sys records system metadata including ex ecution step count and routing history; and B ans holds the final answer written by the terminal node. 4 Problem Instance Agent Graph 𝒢 𝒫 = ( x, 𝒞, y* ) W orkspace Contract κ append / update / replace v src v snk v 1 v 2 v 3 v 4 Generator V eri�ier Optimizer Sink (a) Graph Design (c) Graph Ex ecu�on (b) W orkspace GraphDesigner 𝒟 𝒢, 𝒮work, κ = 𝒟(𝒫) Single Source of T ruth Read-Only ℬ ctx input x, constraints 𝒞 immutable System ℬ sys step t, history ℋ Sink-Only ℬ ans written by v_snk only Read-Writ e ℬ work intermediate results ω = ( π, α, δ ) append / update / replace δ = ast.literal_eval v snk Vt ρ κ LLM call DSL α( π, δ ) ω t Apply V alidate ω, ℬ, 𝒢 pass fail no LLM / deterministic |succ|=1 v v ’ LLM on ℬ / global routing |succ|>1 v v ’ v ’’ v snk t ≥ T max return ℬ ans t ≥ Tmax : F allbackResolver(ℬ, ℋ) Halt when or Fig. 2. Overview of the BIGMAS framework. (a) Graph Design : A GraphDesigner agent D analyzes the problem instance P = ( x, C , y ∗ ) and produces a task-specific directed agent graph G together with a W orkspace contract κ . (b) W orkspace B : A centralized shared workspace partitioned into read-only context B ctx , read-write working area B work , system metadata B sys , and sink-only answer store B ans ; all agent nodes interact exclusiv ely through B . (c) Graph Execution : Each activ e node v t produces a structured write instruction ω t = ( π , α, δ ) via an LLM call; the instruction is validated against B and G , with a self-correction loop on failure. A global Orchestrator routes execution based on the complete workspace state; the system halts when the sink node v snk is reached or the step budget T max is exhausted. C. Phase 1: Pr oblem-Adaptive Graph Design Giv en a problem instance P , a GraphDesigner agent D analyzes the problem structure and produces a task-specific directed agent graph together with a W orkspace working-area schema: ( G , S work , κ ) = D ( P ) (2) where G = ( V , E , v src , v snk ) is a directed graph with node set V , edge set E , a designated source node v src , and a sink node v snk ; S work is the initial template for B work ; and κ is a natural- language W orkspace contract specifying each node’ s read and write responsibilities. Each node v i ∈ V is characterized by a role descriptor ρ i (e.g., expr ession generator , validator , strate gy updater ) and a set of W orkspace interaction permissions derived from κ . The graph G may contain cycles to support iterativ e refinement. Different problem instances yield structurally distinct graphs, reflecting the dynamic coalition formation principle of Global W orkspace Theory . D. Phase 2: Graph Execution Execution proceeds as an iterative read-execute-write loop driv en by a GraphExecutor . Let v t denote the activ e node at step t , and let B ( t ) denote the W orkspace state at the beginning of step t . The executor maintains an execution history H ( t ) = { ( v τ , ω τ ) } t − 1 τ =1 , where ω τ records the write operation performed at step τ . 1) Node Execution and Write Pr otocol: Each node v t receiv es B ( t ) , its role descriptor ρ t , and contract κ as context, and produces a structured write instruction: ω t = v t B ( t ) , ρ t , κ (3) Each write instruction ω t = ( π t , α t , δ t ) specifies a target path π t within B work , an action α t ∈ { append , update , replace } , and a payload δ t containing the node’ s output data. The append action adds an element to a list field; update merges ke y-value pairs into a dict field; and replace overwrites a field entirely . Node outputs are produced in a structured natural-language format that explicitly declares the target path, action type, and payload, which a multi-strategy parser with fallback decoding extracts into ω t , maximizing robustness across output format variations. 2) Write V alidation and Self-Correction: Before applying ω t to the W orkspace, the ex ecutor performs a validation check: ( σ t , ϵ t ) = V alidate ( ω t , B ( t ) , G ) (4) where σ t ∈ { pass , fail } and ϵ t is a structured error message. V alidation enforces three conditions: (i) the target path π t exists in B work or equals B ans for the sink node; (ii) the action α t is compatible with the type of the target field ( append requires a list, update requires a dict); and (iii) the payload δ t is non-empty . If σ t = fail , a self-correction loop re-inv okes node v t with ϵ t appended to its context, at most R times: ω ( r +1) t = v t B ( t ) , ρ t , κ, ϵ ( r ) t , r = 0 , 1 , . . . , R − 1 (5) If validation passes after correction, ω t is applied and B ( t ) is updated to B ( t +1) . The W orkspace state is nev er modified by a failed write, preserving integrity throughout execution. 3) Global Orc hestration and Routing: After each success- ful write, a global Or chestr ator O determines the next acti ve node. For nodes with a unique successor , routing is determinis- 5 Algorithm 1 BIGMAS Execution Require: Problem P , step budget T max , correction budget R Ensure: Final answer B ans 1: ( G , S work , κ ) ← D ( P ) { Graph design } 2: Initialize W orkspace B with B ctx ← P , B work ← S work 3: v ← v src ; t ← 0 ; H ← {} 4: while v = v snk and t < T max do 5: ω ← v ( B , ρ v , κ ) { Node ex ecution } 6: for r = 0 to R − 1 do 7: ( σ , ϵ ) ← V alidate ( ω , B , G ) 8: if σ = pass then 9: break 10: end if 11: ω ← v ( B , ρ v , κ, ϵ ) { Self-correction } 12: end f or 13: if σ = pass then 14: B ← Apply ( ω , B ) 15: H ← H ∪ { ( v , ω ) } 16: v ← O ( B , H , succ ( v ) , G ) { Orchestrator routing } 17: else 18: v ← v snk { Route to sink on repeated failure } 19: end if 20: t ← t + 1 21: end while 22: if t ≥ T max then 23: B ans ← FallbackResolver ( B , H ) 24: end if 25: retur n B ans tic. For branching nodes with | succ ( v t ) | > 1 , the Orchestrator conditions on the full W orkspace state and ex ecution history: v t +1 = O B ( t +1) , H ( t ) , succ ( v t ) , G (6) This global conditioning allo ws the Orchestrator to detect con vergence (e.g., a validated solution already exists in B work ), identify unproductive cycles, and route to fallback nodes when needed. T o prev ent non-termination, a step budget T max is enforced; if t > T max , a F allbackResolver directly extracts the best av ailable answer from B ( t ) . The FallbackResolver is in vok ed when the step budget T max is exhausted before the sink node is reached. It scans B work for any candidate answer written during execution—prioritizing entries that pass constraint verification—and writes the best a v ailable candidate to B ans . If no v alid candidate exists, it returns the most recent non-empty output as a best-effort answer . The complete ex ecution procedure is summarized in Algorithm 1. E. Experimental Setup T asks and Datasets. W e ev aluate on three reasoning bench- marks. Game 24 : 100 instances sampled from the original 1,362 problems [27] using stratified sampling within one stan- dard deviation of problem difficulty . Six Fives : 100 instances with integer targets drawn uniformly from the range [1 , 100] . T ower of London : 100 instances sampled uniformly across optimal solution lengths of 1 to 8 moves. BIGMAS Configuration. The GraphDesigner is con- strained to produce graphs with at most MAX_NODES = 10 nodes and paths of at most MAX_PATH_LENGTH = 15 steps. All LLM calls within BIGMAS use a sampling temperature of 0 . 7 . Baselines. W e compare against three baselines using DeepSeek-V3.2 as the backbone model. Base LLM : di- rect single-call inference with no additional scaffolding. ReAct [25]: a reactiv e reasoning-and-acting loop with a maximum of 10 turns and temperature 0 . 7 . T r ee of Thoughts [27]: tree-structured search with max_rounds = 4 , n_thoughts = 3 , and temperature 0 . 7 . Evaluation Metric. All methods are ev aluated using accu- racy (%), defined as the percentage of instances for which the system produces a solution that satisfies all task constraints and achie ves the specified target value. I V . R E S U LT S A. Overall P erformance Figure 3 summarizes the accuracy of all six frontier LLMs on three reasoning benchmarks under two conditions: direct single-model inference ( Base LLM ) and our proposed multi- agent frame work ( BIGMAS ). BIGMAS consistently improv es performance across all models and tasks without exception. The gains are most pronounced for weak er base models: DeepSeek-V3.2 impro ves from 25.0% to 36.0% on Game 24, from 12.0% to 30.0% on Six Fiv es, and from 6.0% to 20.0% on T o wer of Lon- don. Similarly , Claude 4.5 Sonnet improves from 48.0% to 68.0%, 15.0% to 38.0%, and 40.0% to 46.0% respectively . For already-strong models, BIGMAS still provides meaningful increments: GPT -5 reaches 100.0% on both Game 24 and Six Fiv es (up from 96.0% and 95.0%), and 98.0% on T o wer of London (up from 91.0%). Notably , BIGMAS pushes four out of six models to perfect accuracy on Game 24 (100%), con- firming that multi-agent coordination saturates performance ev en on tasks where individual models already score near - ceiling. For Large Reasoning Models (LRMs), the gains are also consistent and substantial. DeepSeek-V3.2 (+thinking) ad- vances from 92.0% to 100.0% on Game 24, from 96.0% to 100.0% on Six Fives, and from 79.0% to 87.0% on T o wer of London. Claude 4.5 (+thinking) shows the most dramatic im- prov ement on T o wer of London, rising from 57.0% to 93.0%, suggesting that BIGMAS is particularly effecti ve at compen- sating for the planning failures of LRMs on sequential multi- step tasks. These results establish that multi-agent architectural design provides complementary gains that are orthogonal to model-lev el reasoning enhancements via extended chain-of- thought. B. Comparison with Existing Multi-Agent F rameworks T o situate BIGMAS within the landscape of existing multi- agent approaches, we compare it against two representati ve baselines—ReAct [25] and T ree of Thoughts [27]—using DeepSeek-V3.2 as the backbone model. 6 DeepSeek- V3.2 DeepSeek- V3.2 (+thinking) Claude 4.5 Sonnet Claude 4.5 (+thinking) Gemini 2.5 P r o GPT -5 0 20 40 60 80 100 A ccuracy (%) 25 36 92 100 48 68 93 100 97 100 96 100 Game 24 DeepSeek- V3.2 DeepSeek- V3.2 (+thinking) Claude 4.5 Sonnet Claude 4.5 (+thinking) Gemini 2.5 P r o GPT -5 0 20 40 60 80 100 A ccuracy (%) 12 30 96 100 15 38 79 95 62 68 95 100 Six Fives DeepSeek- V3.2 DeepSeek- V3.2 (+thinking) Claude 4.5 Sonnet Claude 4.5 (+thinking) Gemini 2.5 P r o GPT -5 0 20 40 60 80 100 A ccuracy (%) 6 20 79 87 40 46 57 93 82 90 91 98 T ower of London DeepSeek- V3.2 DeepSeek- V3.2 (+thinking) Claude 4.5 Sonnet Claude 4.5 (+thinking) Gemini 2.5 P r o GPT -5 Base LLM Multi-agent Fig. 3. Grouped bar chart comparing the accuracy (%) of six LLMs on three reasoning benchmarks under two conditions: Base LLM (solid bars) and BIGMAS (hatched bars). The six models ev aluated are DeepSeek-V3.2, DeepSeek-V3.2 (+thinking), Claude 4.5 Sonnet, Claude 4.5 (+thinking), Gemini 2.5 Pro, and GPT -5. The three tasks are Game 24 (arithmetic reasoning), Six Fives (constrained expression generation), and T ower of London (multi-step planning). For ev ery model and task, BIGMAS consistently matches or improv es upon the corresponding base-LLM accuracy , with particularly large gains on weaker base models (e.g., DeepSeek-V3.2 and Claude 4.5 Sonnet) and smaller but still positi ve gains on already strong models (e.g., GPT -5 and Gemini 2.5 Pro). T ABLE I A C C U RA CY ( % ) O F D E E P S EE K - V 3. 2 U ND E R F O U R R E AS O N I NG F R AM E W OR K S A CR OS S T HR E E TA SK S . Method Game 24 Six Fives T ower of London Base LLM 25.0 12.0 6.0 ReAct 26.0 18.0 10.0 T ree of Thoughts 30.0 25.0 18.0 BIGMAS (Ours) 36.0 30.0 20.0 As shown in T able I, BIGMAS outperforms both ReAct and T ree of Thoughts across all three tasks. ReAct pro- vides only marginal gains over the base model (1.0%–6.0%), consistent with prior observations that reactiv e single-model loops are limited by partial-information decision-making. Tree of Thoughts improves substantially over ReAct by enabling broader search, but remains constrained by the absence of a globally shared workspace and dynamic graph construction. BIGMAS surpasses T ree of Thoughts by 6.0%, 5.0%, and 2.0% on Game 24, Six Fives, and T o wer of London, re- spectiv ely , demonstrating that problem-adaptiv e graph design combined with centralized workspace coordination provides a structural adv antage ov er fixed-topology framew orks. C. Graph T opology Analysis Figure 4 reports the distribution of graph complex- ity—measured by node count and directed edge count—across all problem instances for each task. The G R A P H D E S I G N E R produces task-appropriate topolo- gies without any explicit complexity constraints. Game 24 graphs cluster tightly around three nodes (mean 3 . 07 ± 0 . 38 ), reflecting the sufficienc y of a compact generate – validate – format pipeline for arithmetic search. Six Fives graphs span three to nine nodes (mean 3 . 87 ± 1 . 12 ), with the higher variance indicating that the model selectively employs richer expression-search pipelines for harder target v alues. T ower Game 24 Six F ives T ower of L ondon 2 3 4 5 6 7 8 9 Number of Nodes Distribution of Number of Nodes Game 24 Six F ives T ower of L ondon 2 4 6 8 10 12 Number of Edges Distribution of Number of Edges Fig. 4. Distribution of graph complexity across three reasoning tasks, shown as violin plots overlaid with jittered individual observations. The left panel reports the number of nodes and the right panel the number of directed edges in each agent graph automatically designed by the G R A PH D E S IG N E R . of London exhibits the broadest distribution (two to nine nodes, mean 4 . 82 ± 1 . 47 ), consistent with the richer state- space reasoning required for multi-step planning. Across all tasks, edge counts closely track node counts (mean degree > 1 ), confirming that the designed graphs are relati vely dense. Figure 5 presents the highest-node-count representative graph for each task, all of which were solved correctly . The Game 24 graph (6 nodes) employs parallel brute-force enumer - ation and heuristic generation branches feeding a shared val- idator . The Six Fiv es graph (9 nodes) chains rule-compliance validation, strategy selection, and v alue ev aluation into a multi- stage refinement pipeline. The T o wer of London graph (9 nodes) orchestrates BFS-style move enumeration, candidate selection, and move validation in a cyclic structure suited to state-space search. D. Node Role Distribution Figure 6 presents a heatmap of the node role distribution across tasks, quantifying how G R A P H D E S I G N E R allocates functional responsibilities. Role allocations reflect task-specific reasoning require- ments. Game 24 graphs are dominated by Generator (34%), 7 task initialize heuristic generator expression validator strategy switcher brute force answer formatter Game 24 2-5-6-11 task initialize strategy selector candidate generator expression normalizer deduplicat rule compliance value evaluator optimizer refiner integrator Six Fives target_60 problem parser frontier selector move enumerator candidate pick er move validator successor generator goal check er frontier updater plan writer T ower of London 1g-2br-3_to_1bg-2-3r Node R ole Sour ce Sink Generator V alidator Optimizer Analyzer F or matter Other Fig. 5. Representative agent graph structures automatically designed for each of the three reasoning tasks. Each panel displays the highest-node-count graph produced by the system for that task; all three instances were solved correctly (indicated by ✓ ). Game 24 Six F ives T ower of L ondon T ask Generator V alidator Optimizer Analyzer F or matter Other R ole Category 34% n = 343 29% n = 278 15% n = 183 32% n = 323 29% n = 273 19% n = 230 1% n = 6 5% n = 49 12% n = 145 1% n = 9 11% n = 100 24% n = 292 31% n = 309 24% n = 227 19% n = 227 1% n = 6 2% n = 20 11% n = 134 0 5 10 15 20 25 30 P r oportion of nodes (%) Fig. 6. Heatmap of agent node role distribution across three reasoning tasks. Each cell reports the proportion (%) of nodes assigned to a given functional role category within all graphs produced for that task; raw node counts are shown in italics belo w each percentage. Color intensity encodes the proportion on a white-to-navy scale. V alidator (32%), and Formatter (31%) nodes, encoding the straightforward propose – verify – format pattern suf ficient for arithmetic search. Six Fiv es shows a similar pattern but with a notable increase in Analyzer (11%) and Optimizer (5%) nodes, indicating that the system introduces expression-search heuristics for the more constrained generation task. T o wer of London exhibits the most diverse role composition: An- alyzer nodes rise to 24% and Optimizer nodes to 12%, while Generator and Formatter proportions decrease substantially , reflecting the rich state-space reasoning required for multi-step planning. The consistent presence of Formatter nodes across all tasks ( ≥ 19% ) confirms that the system reliably designates a dedicated output-formatting stage regardless of task type. T ogether, these patterns demonstrate that G R A P H D E S I G N E R implicitly learns task-appropriate functional decompositions from problem structure alone, without any role specification in the design prompt. E. T oken Consumption Analysis Figure 7 reports token consumption broken down by archi- tectural phase: Graph Design, Orchestrator Routing, and Node Execution. Node Execution dominates total tok en e xpenditure across all tasks, accounting for 46.4%, 50.9%, and 55.5% of total tokens for Game 24, Six Fives, and T o wer of London, respectively . This confirms that the majority of computational resources are allocated to substanti ve problem-solving rather than system co- ordination. Orchestrator Routing consumes a bounded b ut non- trivial share (16.9%–25.2%), growing with task complexity as broader inter-agent coordination is required. Graph Design incurs a one-time up-front cost that shrinks as a proportion of total tokens when execution runs are lengthy (T ower of London: 18.9% vs. Game 24: 36.7%). The wide interquartile ranges observed for DS-V3.2 and Gemini 2.5 Pro on Six Fives and T ower of London reflect high variance in the number of agent-loop iterations triggered for harder instances, consistent with the routing count analysis below . F . Or chestrator Routing Behavior Figure 8 presents the distribution of orchestrator routing decisions per run, serving as a proxy for ex ecution-time complexity . Routing counts scale naturally with task dif ficulty without any hard-coded scheduling. Game 24 concentrates near one decision per run (mean 1 . 3 ), consistent with its compact three- node pipelines. Six Fiv es shows moderate spread (mean 2 . 6 ), with DS-V3.2 as a notable outlier (mean 5 . 7 ) due to its ten- dency to design lar ger iterativ e graphs. T ower of London yields the highest and most v ariable counts (mean 7 . 9 , maximum 49), reflecting the iterativ e state-space search required for multi- step planning. Figure 9 further rev eals a characteristic failure mode: in- correct runs consistently require mor e routing decisions than correct ones. The gap between failed and successful runs is modest for Game 24 ( 1 . 2 vs. 1 . 6 decisions on average), pronounced for Six Fi ves ( 1 . 9 vs. 4 . 5 ), and substantial for T o wer of London ( 7 . 3 vs. 9 . 4 ). This pattern exposes a characteristic failure mode: when an agent graph fails to find a valid solution, the Orchestrator continues cycling through nodes until the step budget is exhausted, accumulating routing calls without con verging. Con versely , successful runs terminate earlier be- cause the Orchestrator correctly detects a validated solution and routes to the sink node. This finding suggests that routing- count thresholds could serve as lightweight early-stopping signals to curtail unproductiv e ex ecution on hard instances, a direction we leave for future work. V . D I S C U S S I O N A N D C O N C L U S I O N This work introduced BIGMAS, a brain-inspired graph multi-agent frame work grounded in Global W orkspace Theory , in which specialized LLM agents are organized as nodes in a dynamically constructed directed graph and coordinate ex- clusiv ely through a centralized shared workspace. The frame- work instantiates three principles drawn from flexible human 8 Graph Design Orch. Routing Node Execution 2k 5k 7k 10k 12k 15k 17k 20k 22k T okens per run Game 24 Graph Design Orch. Routing Node Execution 0 50k 100k 150k 200k Six Fives Graph Design Orch. Routing Node Execution 0 100k 200k 300k 400k 500k 600k T ower of London DS-V3.2 DS-V3.2+think Claude 4.5 Claude 4.5+think Gemini 2.5 Pro GPT -5 Fig. 7. Absolute token consumption per architectural phase across three reasoning tasks, shown as grouped box plots (one box per model per phase, outliers omitted). Node Execution dominates in all tasks, accounting for 46.4%, 50.9%, and 55.5% of total tokens for Game 24, Six Fiv es, and T ower of London respectiv ely . Orchestrator Routing consumes a bounded but non-trivial share (16.9%–25.2%), growing with task complexity . Graph Design incurs a fixed up-front cost that shrinks as a proportion of total tokens when execution steps are numerous. DS-V3.2 DS-V3.2+think Claude 4.5 Claude 4.5+think Gemini 2.5 Pro GPT -5 2 4 6 8 10 12 14 Routing decisions per run Game 24 DS-V3.2 DS-V3.2+think Claude 4.5 Claude 4.5+think Gemini 2.5 Pro GPT -5 0 6 12 18 24 30 36 42 48 Six Fives DS-V3.2 DS-V3.2+think Claude 4.5 Claude 4.5+think Gemini 2.5 Pro GPT -5 0 6 12 18 24 30 36 42 48 T ower of London Fig. 8. Distribution of orchestrator routing decisions per run across three reasoning tasks, displayed as violin plots overlaid with jittered individual observations. Routing count serves as a proxy for ex ecution-time complexity . Game 24 concentrates near one decision per run (mean 1 . 3 ), Six Fives shows moderate spread (mean 2 . 6 ), and T ower of London yields the highest and most variable counts (mean 7 . 9 , maximum 49 ). DS-V3.2 DS-V3.2+think Claude 4.5 Claude 4.5+think Gemini 2.5 Pro GPT -5 0 1 2 3 Mean routing decisions Game 24 Correct Incorrect DS-V3.2 DS-V3.2+think Claude 4.5 Claude 4.5+think Gemini 2.5 Pro GPT -5 0 3 6 9 12 15 18 21 Six Fives Correct Incorrect DS-V3.2 DS-V3.2+think Claude 4.5 Claude 4.5+think Gemini 2.5 Pro GPT -5 0 4 8 12 16 20 24 28 32 T ower of London Correct Incorrect Fig. 9. Mean number of orchestrator routing decisions for correctly solved (green bars) versus incorrectly solved (red bars) instances, broken down by model and task. Error bars denote 95% confidence intervals. Incorrect runs consistently require more routing calls than correct ones across all three tasks. cognition: processor specialization through role-specific agent nodes, dynamic coalition formation through per -problem graph construction by a GraphDesigner agent, and global broadcast through a workspace that maintains a consistent view of task state across all agents. A central finding is that multi-agent architectural coordi- nation provides gains that are orthogonal to model-level rea- soning capability . Prior systematic inv estigations hav e shown that LRMs suffer accuracy collapse beyond task-specific com- plexity thresholds [12], and that providing explicit solution algorithms does not alleviate this collapse—pointing to con- sistent logical ex ecution, not solution discovery , as the funda- mental bottleneck. Our results directly support this diagnosis: BIGMAS improves performance across all six frontier models tested, including LRMs already equipped with self-reflection and extended reasoning traces. The most striking instance is Claude 4.5 (+thinking) on T o wer of London, where BIGMAS deliv ers a 36-percentage-point gain despite the model already performing extended internal reasoning. This indicates the benefit of BIGMAS is structural: by decomposing a prob- lem into specialized subagents coordinated through a global workspace, the system reduces the per-agent cognitiv e burden and externalizes intermediate state in a form that is globally visible, writable, and verifiable—a mechanism that is unav ail- able to any single-model approach regardless of reasoning depth. The graph topology and node role analyses provide em- pirical support for these design principles. The GraphDe- signer does not produce a fixed pipeline applied uniformly across problems; rather , it constructs structurally distinct graphs whose complexity tracks task demands—from compact three-node generate–validate–format pipelines for Game 24 to nine-node cyclic structures for T ower of London. This mirrors the brain’ s dynamic large-scale network reconfig- uration [40], [41]: routine tasks engage relativ ely isolated modules, while complex problems recruit broader functional coalitions. The autonomous emer gence of task-appropriate role distributions—with Analyzer and Optimizer nodes rising sub- stantially from arithmetic to planning tasks, without any task- specific engineering—further suggests that the GraphDesigner is sensitiv e to the underlying reasoning demands of each problem class in a way that parallels prefrontal orchestration of specialized cortical areas. This parallels findings in compu- tational neuroscience showing that task-appropriate functional modules emerge spontaneously from connectivity constraints rather than explicit programming [49], and is consistent with 9 hierarchical society-of-mind principles in which specialized sub-agents cooperate without centralized role assignment. The orchestrator routing analysis re veals an additional emer - gent property: routing count functions as a natural proxy for instance-lev el difficulty , arising without explicit scheduling logic purely from global conditioning on workspace state and ex ecution history . The systematic di ver gence between correct and incorrect runs—most pronounced on T o wer of London (7.3 vs. 9.4 routing decisions)—exposes a characteristic failure mode in which the orchestrator continues cycling when no valid solution has been found. This connects to broader findings on LLM self-ev aluation and the dif ficulty of knowing when to stop in iterativ e refinement [24], [50], [51]: global workspace visibility is necessary but not sufficient for reliable termination, and detecting non-con vergence remains an open problem. The token consumption analysis complements this picture: Node Execution accounts for 46.4%–55.5% of total tokens across tasks, confirming that coordination overhead remains bounded and that BIGMAS is most token-ef ficient precisely on the hard tasks—T o wer of London at 18.9% Graph Design ov erhead—where it is most needed. Compared to existing multi-agent frameworks, BIGMAS advances the state of the art along two dimensions simulta- neously . Reactiv e approaches such as ReAct and Reflexion operate with partial information and fixed decision loops; planning-ex ecution frame works [52] such as LLMCompiler [30] introduce upfront global planning but use static, pre- specified topologies. BIGMAS combines the benefits of both: per-problem graph construction provides the structural flex- ibility that static framew orks lack, while global workspace coordination provides the full-state visibility that reacti ve framew orks lack. The gains over Tree of Thoughts—which already incorporates broad search—further confirm that the advantage of BIGMAS does not reduce to more extensiv e exploration, but stems from the synergy between adaptive topology and shared state. T aken together , these results establish that the architectural organization of reasoning systems—not merely the capacity or reasoning strategy of individual model components—is a fundamental determinant of performance on complex tasks. Multi-agent coordination and model-level scaling are com- plementary rather than competing inv estments: the former provides a structural remedy for the accuracy collapse that the latter cannot resolve alone. As frontier models continue to improv e, BIGMAS-style architectures of fer a principled, neuroscience-grounded path for extracting further gains from those models on the hardest reasoning problems—a path that becomes more, not less, valuable as individual model ceilings are approached. V I . L I M I TA T I O N S A N D F U T U R E D I R E C T I O N S The current ev aluation is limited to three combinatorial reasoning benchmarks; extending BIGMAS to open-domain question answering, mathematical competition problems, and code generation remains important future work. The GraphDe- signer operates without memory of prior designs, treating each instance independently; incorporating episodic memory or meta-learned graph construction could improve both efficienc y and quality across recurring problem families. The step budget T max and self-correction limit R are fixed hyperparameters, though the routing dynamics analysis suggests that routing- count signals could support adaptive early stopping to curtail non-con verging runs. Finally , while per-agent reasoning bur- den is reduced through decomposition, total token cost exceeds single-model inference; token-aw are graph design and learned role specialization via fine-tuned specialist agents represent promising directions tow ard more efficient and capable het- erogeneous multi-agent systems. R E F E R E N C E S [1] T . Zheng, Y . Chen, C. Li, C. Li, Q. Zong, H. Shi, B. Xu, Y . Song, G. Y . W ong, and S. See, “The curse of cot: On the limitations of chain-of- thought in in-context learning, ” arXiv preprint , 2025. [2] Y . He, S. Li, J. Liu, W . W ang, X. Bu, G. Zhang, Z. Peng, Z. Zhang, Z. Zheng, W . Su et al. , “Can large language models detect errors in long chain-of-thought reasoning?” in Pr oceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , 2025, pp. 18 468–18 489. [3] A. Jaech, A. Kalai, A. Lerer , A. Richardson, A. El-Kishky , A. Low , A. Helyar, A. Madry , A. Beutel, A. Carney et al. , “Openai o1 system card, ” arXiv pr eprint arXiv:2412.16720 , 2024. [4] OpenAI, “Introducing OpenAI o3 and o4-mini, ” https://openai.com/ index/o3- o4- mini- system- card/, April 2025, accessed: 2025-04-16. [5] D. Guo, D. Y ang, H. Zhang, J. Song, P . W ang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi et al. , “Deepseek-r1 incentivizes reasoning in llms through reinforcement learning, ” Natur e , vol. 645, no. 8081, pp. 633–638, 2025. [6] Anthropic, “Introducing Claude Sonnet 4.5, ” 2025, accessed: 2025-09-29. [Online]. A vailable: https://www .anthropic.com/news/ claude- sonnet- 4- 5 [7] G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdev a, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen et al. , “Gem- ini 2.5: Pushing the frontier with advanced reasoning, multimodality , long context, and next generation agentic capabilities, ” arXiv preprint arXiv:2507.06261 , 2025. [8] J. W ei, X. W ang, D. Schuurmans, M. Bosma, F . Xia, E. Chi, Q. V . Le, D. Zhou et al. , “Chain-of-thought prompting elicits reasoning in large language models, ” Advances in neural information pr ocessing systems , vol. 35, pp. 24 824–24 837, 2022. [9] M. Renze and E. Guven, “Self-reflection in llm agents: Effects on problem-solving performance, ” arXiv pr eprint arXiv:2405.06682 , 2024. [10] M. A. Ferrag, N. Tihanyi, and M. Debbah, “From llm reasoning to autonomous ai agents: A comprehensiv e revie w , ” arXiv preprint arXiv:2504.19678 , 2025. [11] Y . Cao, S. Hong, X. Li, J. Y ing, Y . Ma, H. Liang, Y . Liu, Z. Y ao, X. W ang, D. Huang et al. , “T oward generalizable ev aluation in the llm era: A survey beyond benchmarks, ” arXiv preprint , 2025. [12] P . Shojaee, I. Mirzadeh, K. Alizadeh, M. Horton, S. Bengio, and M. Farajtabar , “The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity , ” arXiv preprint arXiv:2506.06941 , 2025. [13] S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. W ang, C. Zhang, Z. W ang, S. K. S. Y au, Z. Lin et al. , “Metagpt: Meta programming for a multi-agent collaborati ve frame work, ” in The twelfth international confer ence on learning repr esentations , 2023. [14] X. Liu, H. Y u, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Y ang et al. , “ Agentbench: Evaluating llms as agents, ” arXiv pr eprint arXiv:2308.03688 , 2023. [15] L. W ang, C. Ma, X. Feng, Z. Zhang, H. Y ang, J. Zhang, Z. Chen, J. T ang, X. Chen, Y . Lin et al. , “ A survey on large language model based autonomous agents, ” F rontier s of Computer Science , vol. 18, no. 6, p. 186345, 2024. [16] Z. Xi, W . Chen, X. Guo, W . He, Y . Ding, B. Hong, M. Zhang, J. W ang, S. Jin, E. Zhou et al. , “The rise and potential of large language model based agents: A survey , ” Science China Information Sciences , vol. 68, no. 2, p. 121101, 2025. [17] K. Dong, “Large language model applied in multi-agent systema survey , ” Applied and Computational Engineering , 2024. 10 [18] C. Jimenez-Romero, A. Y egenoglu, and C. Blum, “Multi-agent systems powered by large language models: applications in swarm intelligence, ” F rontier s in artificial intelligence , vol. 8, p. 1593017, 2025. [19] B. J. Baars, A Cognitive Theory of Consciousness . New Y ork: Cambridge University Press, 1988. [20] S. Dehaene and J.-P . Changeux, “Experimental and theoretical ap- proaches to conscious processing, ” Neuron , vol. 70, no. 2, pp. 200–227, 2011. [21] X. W ang, J. W ei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdh- ery , and D. Zhou, “Self-consistency improves chain of thought reasoning in language models, ” arXiv pr eprint arXiv:2203.11171 , 2022. [22] D. Zhou, N. Sch ¨ arli, L. Hou, J. W ei, N. Scales, X. W ang, D. Schu- urmans, C. Cui, O. Bousquet, Q. Le et al. , “Least-to-most prompting enables complex reasoning in large language models, ” arXiv pr eprint arXiv:2205.10625 , 2022. [23] W . Chen, X. Ma, X. W ang, and W . W . Cohen, “Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks, ” arXiv preprint , 2022. [24] A. Madaan, N. T andon, P . Gupta, S. Hallinan, L. Gao, S. Wiegref fe, U. Alon, N. Dziri, S. Prabhumoye, Y . Y ang et al. , “Self-refine: Iter- ativ e refinement with self-feedback, ” Advances in neural information pr ocessing systems , vol. 36, pp. 46 534–46 594, 2023. [25] S. Y ao, J. Zhao, D. Y u, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models, ” in The eleventh international conference on learning repr esentations , 2022. [26] N. Shinn, F . Cassano, A. Gopinath, K. Narasimhan, and S. Y ao, “Re- flexion: Language agents with v erbal reinforcement learning, ” Advances in neural information processing systems , vol. 36, pp. 8634–8652, 2023. [27] S. Y ao, D. Y u, J. Zhao, I. Shafran, T . Griffiths, Y . Cao, and K. Narasimhan, “T ree of thoughts: Deliberate problem solving with lar ge language models, ” Advances in neural information pr ocessing systems , vol. 36, pp. 11 809–11 822, 2023. [28] M. Besta, N. Blach, A. Kubicek, R. Gerstenberger , M. Podstawski, L. Gianinazzi, J. Gajda, T . Lehmann, H. Niewiadomski, P . Nyczyk et al. , “Graph of thoughts: Solving elaborate problems with large language models, ” in Pr oceedings of the AAAI confer ence on artificial intellig ence , vol. 38, no. 16, 2024, pp. 17 682–17 690. [29] L. Y ang, Z. Y u, T . Zhang, S. Cao, M. Xu, W . Zhang, J. E. Gonzalez, and B. Cui, “Buffer of thoughts: Thought-augmented reasoning with large language models, ” Advances in Neural Information Pr ocessing Systems , vol. 37, pp. 113 519–113 544, 2024. [30] S. Kim, S. Moon, R. T abrizi, N. Lee, M. W . Mahoney , K. Keutzer , and A. Gholami, “ An llm compiler for parallel function calling, ” in F orty- first International Conference on Machine Learning , 2024. [31] X. W ei, Y . Dong, X. W ang, X. Zhang, Z. Zhao, D. Shen, L. Xia, and D. Yin, “Beyond react: A planner-centric framework for complex tool- augmented llm reasoning, ” arXiv pr eprint arXiv:2511.10037 , 2025. [32] Q. W u, G. Bansal, J. Zhang, Y . W u, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu et al. , “ Autogen: Enabling next-gen llm applications via multi-agent con versations, ” in Fir st conference on language modeling , 2024. [33] G. Li, H. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “Camel: Communicativ e agents for” mind” exploration of large language model society , ” Advances in neural information pr ocessing systems , vol. 36, pp. 51 991–52 008, 2023. [34] Y . Du, S. Li, A. T orralba, J. B. T enenbaum, and I. Mordatch, “Improving factuality and reasoning in language models through multiagent debate, ” in F orty-first international conference on machine learning , 2024. [35] Z. Liu, Y . Zhang, P . Li, Y . Liu, and D. Y ang, “Dynamic llm-agent network: An llm-agent collaboration framework with agent team op- timization, ” arXiv pr eprint arXiv:2310.02170 , 2023. [36] M. Zhuge, W . W ang, L. Kirsch, F . Faccio, D. Khizbullin, and J. Schmid- huber , “Gptswarm: Language agents as optimizable graphs, ” in F orty- first International Conference on Machine Learning , 2024. [37] O. Sporns, “Networks of the brain: quantitativ e analysis and modeling, ” Analysis and function of lar ge-scale brain networks , vol. 7, pp. 7–13, 2010. [38] E. Bullmore and O. Sporns, “Complex brain networks: graph theoretical analysis of structural and functional systems, ” Natur e revie ws neuro- science , vol. 10, no. 3, pp. 186–198, 2009. [39] M. W . Cole, J. R. Re ynolds, J. D. Power , G. Repo vs, A. Antice vic, and T . S. Braver , “Multi-task connectivity re veals flexible hubs for adapti ve task control, ” Nature neur oscience , vol. 16, no. 9, pp. 1348–1355, 2013. [40] D. S. Bassett, N. F . W ymbs, M. A. Porter, P . J. Mucha, J. M. Carlson, and S. T . Grafton, “Dynamic reconfiguration of human brain networks during learning, ” Proceedings of the National Academy of Sciences , v ol. 108, no. 18, pp. 7641–7646, 2011. [41] K. Finc, K. Bonna, X. He, D. M. Lydon-Stale y , S. K ¨ uhn, W . Duch, and D. S. Bassett, “Dynamic reconfiguration of functional brain networks during working memory training, ” Natur e communications , vol. 11, no. 1, p. 2435, 2020. [42] K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. T worek, J. Hilton, R. Nakano et al. , “Training verifiers to solve math word problems, ” arXiv preprint , 2021. [43] D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. T ang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the math dataset, ” arXiv preprint , 2021. [44] M. Chen, J. T worek, H. Jun, Q. Y uan, H. P . D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman et al. , “Evaluating large language models trained on code, ” arXiv preprint , 2021. [45] K. V almeekam, M. Marquez, S. Sreedharan, and S. Kambhampati, “On the planning abilities of large language models-a critical investig ation, ” Advances in neur al information processing systems , vol. 36, pp. 75 993– 76 005, 2023. [46] T . Shallice, “Specific impairments of planning, ” Philosophical T ransac- tions of the Royal Society of London. B, Biological Sciences , vol. 298, no. 1089, pp. 199–209, 1982. [47] Y . Qin, S. Liang, Y . Y e, K. Zhu, L. Y an, Y . Lu, Y . Lin, X. Cong, X. T ang, B. Qian et al. , “T oolllm: Facilitating large language models to master 16000+ real-world apis, ” arXiv pr eprint arXiv:2307.16789 , 2023. [48] Z. Guo, S. Cheng, H. W ang, S. Liang, Y . Qin, P . Li, Z. Liu, M. Sun, and Y . Liu, “Stabletoolbench: T owards stable large-scale benchmarking on tool learning of large language models, ” in Findings of the Association for Computational Linguistics: ACL 2024 , 2024, pp. 11 143–11 156. [49] M. Minsky , Society of mind . Simon and Schuster, 1986. [50] Y . Zeng, X. Cui, X. Jin, Q. Mi, G. Liu, Z. Sun, M. Y ang, D. Li, W . Ma, N. Y ang et al. , “Evolving llms’ self-refinement capability via synergis- tic training-inference optimization, ” arXiv pr eprint arXiv:2502.05605 , 2025. [51] J. Han, X. W ang, H. Zhao, Z. Jiang, S. Jiang, J. Liang, X. Lin, W . Zhou, Z. Sun, F . Y u et al. , “ A stitch in time saves nine: Proactive self-refinement for language models, ” arXiv pr eprint arXiv:2508.12903 , 2025. [52] L. E. Erdogan, N. Lee, S. Kim, S. Moon, H. Furuta, G. Anumanchipalli, K. Keutzer , and A. Gholami, “Plan-and-act: Improving planning of agents for long-horizon tasks, ” arXiv pr eprint arXiv:2503.09572 , 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment