CATFormer: When Continual Learning Meets Spiking Transformers With Dynamic Thresholds
Although deep neural networks perform extremely well in controlled environments, they fail in real-world scenarios where data isn't available all at once, and the model must adapt to a new data distribution that may or may not follow the initial dist…
Authors: Vaishnavi Nagabhushana, Kartikay Agrawal, Ayon Borthakur
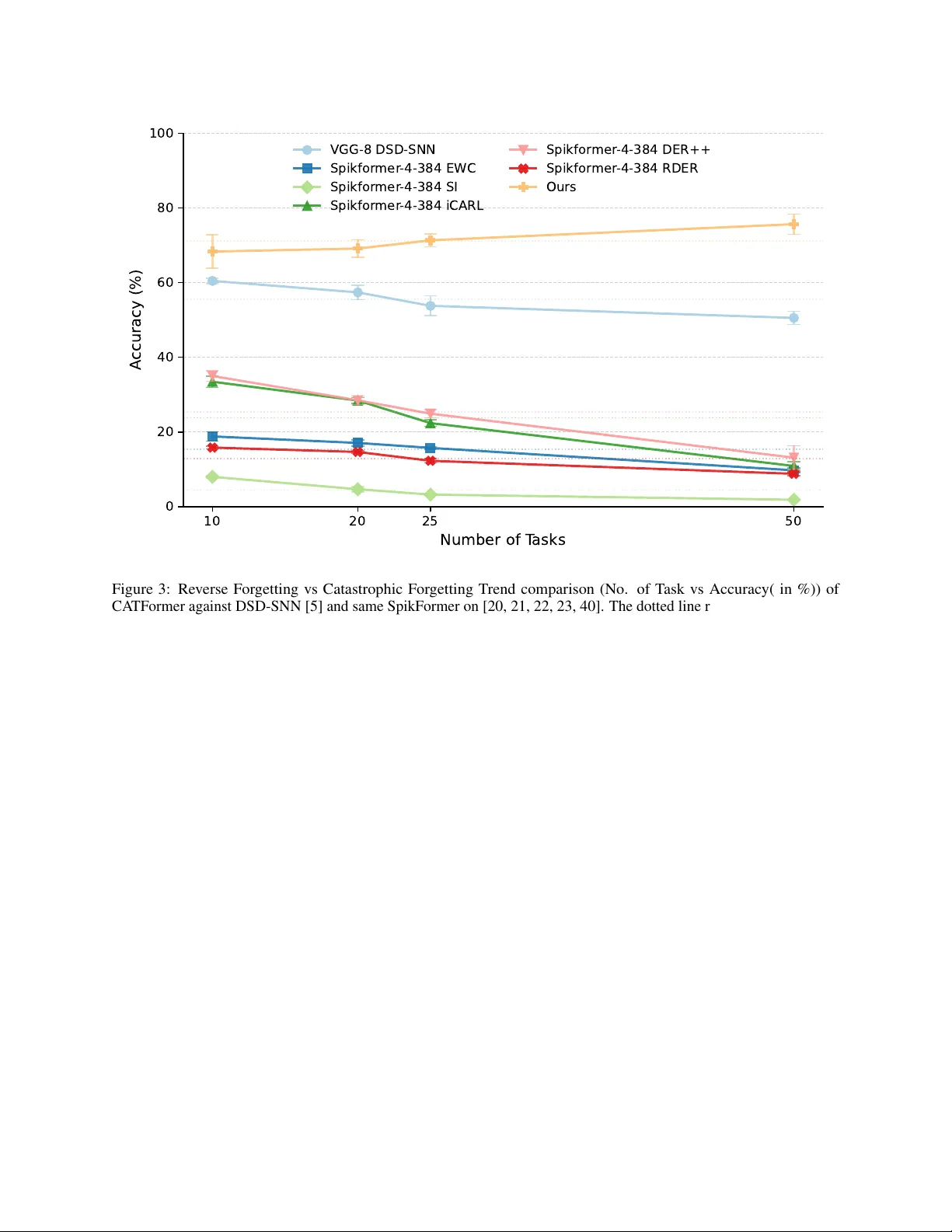
C A T F O R M E R : W H E N C O N T I N UA L L E A R N I N G M E E T S S P I K I N G T R A N S F O R M E R S W I T H D Y N A M I C T H R E S H O L D S ∗ V aishnavi Nagabhushana SustainAI Lab, MFSDS&AI IIT Guwahati n.vaishnavi@iitg.ac.in Kartikay Agrawal SustainAI Lab, MFSDS&AI IIT Guwahati a.kartikay@iitg.ac.in A yon Borthakur SustainAI Lab, MFSDS&AI IIT Guwahati ayon.borthakur@iitg.ac.in A B S T R AC T Although deep neural networks perform extremely well in controlled en vironments, they fail in real-world scenarios where data isn’t a vailable all at once, and the model must adapt to a ne w data distribution that may or may not follow the initial distribution. Previously acquired kno wledge is lost during subsequent updates based on new data. a phenomenon commonly known as catastrophic forgetting. In contrast, the brain can learn without such catastrophic forgetting, irrespecti ve of the number of tasks it encounters. Existing spiking neural networks (SNNs) for class-incremental learning (CIL) suffer a sharp performance drop as tasks accumulate. W e here introduce CA TFormer (Context Adaptiv e Threshold T ransformer), a scalable framework that o vercomes this limitation. W e observe that the key to pre venting forgetting in SNNs lies not only in synaptic plasticity but also in modulating neuronal excitability . At the core of CA TF ormer is the Dynamic Threshold Leak y Integrate-and-Fire (DTLIF) neuron model, which le verages conte xt-adaptive thresholds as the primary mechanism for knowledge retention. This is paired with a Gated Dynamic Head Selection (G-DHS) mechanism for task-agnostic inference. Extensi ve ev aluation on both static (CIF AR-10/100/Tin y-ImageNet) and neuromorphic (CIF AR10-D VS/SHD) datasets rev eals that CA TFormer outperforms existing rehearsal-free CIL algorithms across various task splits, establishing it as an ideal architecture for energy-ef ficient, true-class incremental learning. 1 Introduction Progress in physical AI holds immense promise for enhancing real-world capabilities across robotics, near -sensor edge devices, and autonomous systems. A critical challenge on these platforms is learning and predicting cyclically across extended deployments with minimal resource utilisation. Model updates are often essential due to sequentially arriving data and distributional shifts [ 1 , 2 ]. But naively training standard deep neural networks (MLPs, CNNs, or ev en modern transformers) from scratch repeatedly typically results in catastr ophic for getting of pre viously acquired knowledge. In battery-operated, memory or bandwidth-constrained physical agents, data rehearsal (i.e., storage and replay of past data during training on new data) is often infeasible due to ener gy , onboard memory , priv acy , or regulatory constraints [3]. Energy-ef ficient learning architectures are essential in these applications, and Spiking neural networks (SNNs) hav e become a well-established solution, of fering e vent-dri ven sparse computations. Recent adv ances hav e brought class- incremental learning (CIL) to SNNs with early ef forts mainly on small-scale tasks (e.g., CIF AR-10) and, more recently , on larger , more realistic benchmarks like CIF AR-100 using various incremental task re gimes [ 4 , 5 ]. Howev er , prior efforts in SNN-based CL ha ve predominantly relied on con v olutional (CNN) architectures. Recently , transformers and their v ariants hav e dominated performance in numerous AI applications. V ision transformers [ 6 ] can also capture global dependencies and contextual understanding. And, SpikFormer [ 7 ] extends the standard vision transformer paradigm to SNNs by combining its strengths with ener gy ef ficiency . Y et, its potential for continual learning remains largely untapped. Hence, we here design CA TF ormer , a SNN-based transformer for long class incremental learning. CA TF ormer is inspired by the brain, where resistance to for getting has been proposed to be closely linked to neuromodulation [ 8 , 9 ]. ∗ This version has been accepted for publication in the proceedings of the Neuro for AI & AI for Neuro W orkshop at AAAI 2026 (PMLR). CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds 0 10 20 30 40 50 Number of T asks 0 20 40 60 80 100 A ccuracy (%) EWC SI iCaRL DER++ RDER Ours Figure 1: T est performance v ariation with respect to the progress in the number of trained tasks (for a maximum of 50 tasks). CA TFormer (ours) maintains consistent performance with other existing CIL methods when implemented on a Spiking T ransformer . All methods are ev aluated on CIF AR 100. Neuromodulators such as acetylcholine, dopamine, serotonin, and norepinephrine mediate changes in neural circuit behaviour by altering plasticity or excitability . For instance, acetylcholine plays a central role by modulating membrane excitability and synaptic plasticity in hippocampal and cortical netw orks, thereby enabling the rapid encoding of new memories while transiently lowering neuronal firing thresholds to suppress interference from prior information [ 10 , 11 ]. Similar cholinergic modulation of plasticity is also observed in rodent piriform corte x [ 12 ]. These processes in the brain dynamically regulate neuronal e xcitability and firing thresholds [ 13 , 14 ], enabling selecti ve pathway activ ation and memory consolidation while prev enting interference [ 15 , 16 ]. Computational models and experimental studies further demonstrate that neuromodulators broadly demonstrate task and conte xt-specific routing of information by reshaping network dynamics [ 17 , 8 , 18 ]. Although we don’t claim that CA TFormer is completely biologically plausible, these multi-scale neuromodulatory effects inspire our approach to implement adaptiv e thresholds within CA TFormer , serving as an analogy to support plasticity in ex emplar-free continual learning. In this work, we systematically study class incremental learning in a spiking vision transformer [ 7 ]. W e analyse how biologically inspired, dynamic spiking thresholds influence continual learning and propose mechanisms that foster robustness across encountered tasks. This is crucial for physical AI and r obotics : real-world robots and edge agents must adapt over months or years, often encountering dozens or even hundreds of dif ferent skills or operating re gimes [ 3 ]. Thus, we rigorously ev aluate our approach at unprecedented scales, including challenging 50 and 100-task sequences, providing a rigorous testbed for long-term continual learning relev ant to autonomous robotics and physical edge applications. Moreover , our data rehearsal-free protocol ensures that results directly reflect core algorithmic adv ances, rather than storage-based workarounds. This can be observed in Figure 1, where the model maintains its accuracy across longer task sequences. W e observe a phenomenon we call r everse for getting , where the model actually learns more ef fectiv ely when exposed to fe wer classes per task. This scenario is more reflectiv e of real-world settings—for example, in robotics or lifelong learning, the model is unlikely to encounter 20 or 50 ne w classes all at once [3, 8]. W e make the f ollowing advances in this work: • T o the best of our kno wledge, we present the first CIL frame work designed for spiking vision transformers, closing a major gap in the field. 2 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds • W e propose a no vel, biologically-inspired adaptation mechanism where a frozen backbone learns ne w tasks primarily through task-specific dynamic thresholds. This approach serves as the core mechanism for pre venting catastrophic forgetting without requiring netw ork growth or storing ra w data exemplars. • W e demonstrate state-of-the-art performance among ex emplar-free SNNs and, critically , show that CA TF ormer is uniquely scalable to long task sequences. Unlike prior methods that degrade, our model maintains, or e ven improv es, its accuracy on challenging benchmarks comprising up to 100 incremental tasks, i.e., e xhibiting a re verse f orgetting trend. 2 Related W ork 2.1 Continual Learning Paradigms Continual learning methods often fall into three main approaches [ 19 ]. Regularisation-based methods mitigate forgetting by constraining updates to parameters deemed important for pre vious tasks, thus preventing o verwriting of past knowledge [ 20 , 21 ]. Rehearsal-based methods maintain a buf fer of stored pre vious data samples either as original images or as representations for replay during training, impro ving memory retention but incurring increased storage and pri vac y concerns [ 22 , 23 , 24 , 25 ]. Architecture-based methods adapt the network structure dynamically[ 5 , 26 ], such as by adding modules or selecting task-specific sub-networks, balancing plasticity and stability at the cost of computational ov erhead [ 27 , 28 ]. While these architecture-based continual learning methods are ef fective, they ha ve scalability limitations and memory ov erhead as the task count increases. In the brain, context-dependent signals from regions lik e the prefrontal cortex project across cortical areas, allo wing neural circuits to adaptively process information based on the task at hand [ 29 , 30 ]. Previous techniques lev eraged EWC [20] with a gating mechanism to stabilise training for feedforward and recurrent architectures [8]. 2.2 T ransformers in Continual Lear ning T ransformers, with their self-attention mechanisms, hav e recently emerged as a po werful alternativ e to con volutional neural networks (CNNs) for continual learning due to their ability to model long-range dependencies and the ease with which pretrained architectures can be e xtended [ 26 , 31 ]. Recent work has focused on parameter -efficient fine-tuning techniques like Lo w-Rank Adaptation (LoRA) [ 32 , 31 ] to update large pre-trained transformers continually with limited ov erhead [ 26 , 33 ]. Howe ver , these standard vision transformers require attention computations, which in turn lead to energy inef ficiency due to their heavy matrix multiplications. Hence, we move to wards spiking vision transformers (3.31 times more energy ef ficient) [ 7 ], which can eliminate these hea vy computations. Continual learning research on spiking vision transformers remains unexplored. Our work presents a data rehearsal-free continual learning on spiking vision transformers trained from scratch, addressing these challenges and expanding the landscape of SNN continual learning. 2.3 Spiking Neural Networks f or Continual Learning and Neur omodulation Inspiration Early SNN continual learning methods adapted classical regularisation and rehearsal methods that are limited to CNNs [ 5 , 34 ]. Recent work [ 4 ] sho ws significant improv ement by incorporating rehearsal buf fers into a method inspired by DER++ [ 23 ] to enhance performance, b ut it violates data privac y and is memory inefficient. Preliminary work on con verting the idea of neuromodulation to the circuit le vel w as demonstrated by [ 18 ], where the thresholds of the current layer were modulated based on the pre vious layer’ s excitation. Our model introduces adapti ve, task-specific dynamic thresholds. This mimics neuromodulatory circuits that release context signals, modulating downstream neurons’ responses, corresponding to our task-ID routing mechanism that dynamically tunes neuron thresholds per task to enable data-replay-free continual adaptation. 2.4 Dynamic Thresholds in Spiking Neural Netw orks Adaptiv e firing thresholds have been shown to improv e temporal precision and robustness in SNNs [ 35 , 36 , 37 ]. Although many mechanisms ha ve been extensi vely studied in neuroscience, only a handful of works ha ve in vestigated bioinspired dynamic threshold rules to improv e SNN generalisation. Existing approaches include a dynamic threshold update rule that adaptively scales firing thresholds to prev ent excessi ve activity cite hao2020biologically, double exponential functions for threshold decay [ 38 ], and predefined target firing counts [ 39 ]. BDETT computes thresholds via av erage membrane potentials for neuronal homeostasis [ 35 ], but excessi ve spiking from highly active neurons reduces sparsity . Howe ver , prior work has predominantly focused on single-task adaptation rather than task-specific thresholding for continual learning. By freezing synaptic weights after the initial task and relying solely on learnable, 3 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds per-task thresholds for plasticity , our approach introduces a no vel mechanism to pre vent catastrophic for getting in a rehearsal-free framew ork. T ogether with lightweight task gating, this enables stable continual learning across up to 100 tasks on static and neuromorphic datasets, setting a ne w standard in memory and energy-ef ficient SNN continual learning. 3 Methodology W e introduce a data rehearsal-free frame work for class-incremental learning (CIL) in Spiking Neural Networks (SNNs) that robustly accommodates ne w classes ov er time without catastrophic forgetting. Unlike existing systems, our entire system is trained without a separate ex emplar representation buf fer from pre vious learning across tasks [ 4 , 23 ]. The proposed architecture lev erages two key innov ations: task-specific (Context Adaptive) dynamic neur onal thr esholds and a gated infer ence mechanism , combined through a two-stage training protocol. Spiking Patch Splitting Spiking Self Attention Spiking Encoder Blocks Linear BN Linear BN Representation of internal blocks in spiking encoder . Representation of DTLIF DTLIF DTLIF DTLIF DTLIF x N Blocks . . . . . . . . . . . . Gating MLP Block Dynamic task heads Backbone Parameters of Encoder . Gating MLP and heads Parameters of DTLIF (thresholds) Backbone Parameters of Encoder Gating MLP and heads Static Datasets CIF AR10 / 100 Neuromorphic Datasets SHD / CIF AR10 DVS All Params jointly optimized Only heads to MLP and thresholds optimized Parameters of DTLIF (thresholds) (or) Figure 2: The diagram depicts the full architecture and workflow of CA TFormer . Algorithm 1 CA TFormer T raining Protocol 1: Input: T ask sequence {T k , D k } T k =1 2: Initialize: Backbone θ , base threshold ϕ init = 0 . 5 , gating MLP G , buffers F gate , L gate 3: f or k = 0 to T − 1 do 4: Add head W k (Xavier init), set ϕ ( k ) ← ϕ init 5: if k = 0 then 6: T rain { θ , ϕ (0) , W 0 } jointly with L CE 7: else 8: all previous parameters are frozen; initialize W k for optimization. 9: Jointly optimize { W k , ϕ ( k ) } , i.e min { ϕ ( k ) ,W k } E ( x,y ) ∼D k L CE ( W k · f ( x ; θ, ϕ ( k ) ) , y ) 10: end if 11: Extract features f ( x ) using ϕ init ; add ( f ( x ) , k ) to buf fers (local scope not across tasks) . 12: T rain gating MLP G on accumulated data with L CE 13: end f or 4 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds Algorithm 2 Gated Inference 1: Input: T est sample x , trained model { θ , Φ , { W 0 · · · W k } , G } , seen tasks k 2: Output: Predicted class ˆ y 3: if T = 0 then 4: Set thresholds to ϕ (0) and reset SNN state 5: Extract features: f ( x ) ← SpikFormer ( x ) 6: retur n arg max( W 0 f ( x )) 7: else 8: T ask Prediction: 9: Set all thresholds to base ϕ init and reset SNN state 10: Extract base features: f base ( x ) ← SpikF ormer ( x ) 11: Predict task: k ∗ ← arg max( G ( f base ( x ))) 12: Classification(once the head is selected): 13: Set thresholds to ϕ ( k ∗ ) and reset SNN state 14: Extract task-specific features: f k ∗ ( x ) ← SpikF ormer ( x ) 15: retur n arg max( W k ∗ f k ∗ ( x )) 16: end if 3.1 Problem F ormulation and Notation In CIL, the model is exposed to T number of tasks {T 0 , T 1 , . . . , T T − 1 } sequentially , each with dataset D k = { ( x k i , y k i ) } N k i =1 and disjoint label sets Y k (i.e., Y i ∩ Y j = ∅ for i = j ). At each task k , the model must classify samples ov er the cumulativ e label space Y 1: k , having access solely to the current task’ s train data during, and without the any task oracle or pr evious task samples at test time. 3.2 Context Adaptive Dynamic Thr eshold Neurons Dynamic Threshold LIF Neuron Model: T o enable task-adapti ve spiking dynamics, we extend the standard Leaky Inte grate-and-Fire (LIF) neuron with context adaptive, learnable thr esholds . Updation of thresholds : ˜ V ( t ) j = 1 − 1 τ V ( t − 1) j + 1 τ I ( t ) j where τ is the membrane time constant, I ( t ) j is the input current. S ( t ) j = Θ ˜ V ( t ) j − ϕ ( k ) j here Θ( · ) is the Heaviside step function and S ( t ) j is the spike output. W e use soft reset Mechanism V ( t ) j = ˜ V ( t ) j − S ( t ) j ϕ ( k ) j . Updation of Dynamic thresholds: During training on task k , the threshold ϕ ( k ) c is updated via gradient descent: ϕ ( k ) j ← ϕ ( k ) j − η ∂ L ∂ ϕ ( k ) j where η is the learning rate and L is the loss function. This mechanism allows each channel to adjust its firing threshold for different tasks, supporting task-adapti ve spiking in continual learning. 3.3 T wo-Stage T raining Protocol Our training protocol balances plasticity and stability by freezing and updating components, using threshold adaptation as the key mechanism to pre vent catastrophic forgetting. Algorithm 1 outlines the complete training mechanism. 3.4 Inference via Dynamic Head Routing During inference, we employ our Gated Dynamic Head Selection (G-DHS) mechanism to ef ficiently route inputs to appropriate task-specific heads. Gating MLP Architectur e. The gating network is used as the Gated Dynamic Head Selection (G- DHS), which consists of a two-layer MLP that maps feature embeddings to task predictions: G ( f ) = Linear ( ReLU ( Linear ( f ))) , where f ∈ R D → R D/ 4 → R k . Given an input x and D is the dimension of the fea- ture vector , the inference mechanism is done for this as described by the algorithm 2 5 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds 10 20 25 50 Number of T asks 0 20 40 60 80 100 A ccuracy (%) VGG-8 DSD-SNN Spikfor mer -4-384 EWC Spikfor mer -4-384 SI Spikfor mer -4-384 iCARL Spikfor mer -4-384 DER++ Spikfor mer -4-384 RDER Ours Figure 3: Reverse Forgetting vs Catastrophic For getting Trend comparison (No. of T ask vs Accuracy( in %)) of CA TFormer ag ainst DSD-SNN [ 5 ] and same SpikFormer on [ 20 , 21 , 22 , 23 , 40 ]. The dotted line represents the a verage accuracy across tasks as the number of tasks increases. 4 Results 4.1 Dataset and Experimental Setup T o e valuate the ef fecti veness of our context-adapti ve dynamic threshold mechanism in a spiking T ransformer (CA T - Former), we conducted e xtensiv e experiments across a range of static and neuromorphic datasets. W e ev aluate on CIF AR-10/100 (10/100 classes) [ 41 ]: standard 32 × 32 RGB image benchmarks, tiny-ImageNet (200 classes) [ 42 ]: subset of ImageNet with 64 × 64 images, CIF AR10-D VS (10 classes) [ 43 ]: a neuromorphic, ev ent-based version of CIF AR-10 captured with Dynamic V ision Sensors, and SHD (20 classes) [ 44 ]: a neuromorphic auditory dataset of spiking ev ent sequences preprocessed into fixed-length frames. 4.2 Experimental Observations 4.2.1 Perf ormance in Extended T ask Sequences on static datasets W e compared CA TFormer with state-of-the-art methods for class incremental learning in spiking neural networks. For a fair comparison, we e valuated other methods on the same SpikFormer backbone and with respect to re verse for getting. Further compared T iny-ImageNet with a non-spiking benchmark with the same SpikFormer backbone. T able 1 presents our class incremental learning (CIL) performance on Split CIF AR-100. Classical regularisation-based methods like EWC [ 20 ], MAS [ 45 ], and SI [ 21 ] suffer from se vere catastrophic forgetting. Rehearsal-based approaches such as iCaRL [ 22 ] and DER++ [ 23 ] offer better retention, but their memory requirements are often constrained on hardware like the Lakemont x86 processors and neuromorphic cores in Loihi 2 [ 46 ], making e ven the 2000 samples proposed by ALADE-SNN [ 4 ] pretty dif ficult. Among data rehearsal-free SNN baselines, pre vious state-of-the-art DSD-SNN [ 5 ] achie ves moderate performance but exhibits a consistent for getting pattern. The accuracy consistently degrades from 60.47% at 10 tasks to 50.55% at 50 tasks. T o confirm the trend, we e xtended the original DSD-SNN 6 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds Backbone Methods Number of T asks Parameters (M) T raditional 1 T ask (Full dataset) T otal VGG-11 Hybrid 67.87 9.27 ResNet-19 TET 74.47 12.63 SpikFormer -4-384 BPTT 77.86 9.32 Class incremental Lear ning 10 T asks 20 T asks 25 T asks 50 T asks T ask 0 T ask k VGG-8 DSD-SNN 60.47 ± 0.72 57.39 ± 1.97 53.79 ± 2.67 50.55 ± 1.76 14.2 14.2 SpikFormer -4-384 EWC 18.81 ± 1.22 17.06 ± 0.83 15.73 ± 0.38 9.73 ± 0.62 9.32 18.64 SI 7.98 ± 0.33 4.66 ± 0.74 3.22 ± 0.14 1.84 ± 0.09 9.32 27.96 iCARL 33.46 ± 1.52 28.42 ± 0.77 22.37 ± 0.90 10.89 ± 1.19 9.32 9.32 DER++ 34.99 ± 1.39 28.48 ± 1.16 24.9 ± 1.07 13.12 ± 3.2 9.32 9.32 RDER 15.82 ± 0.36 14.65 ± 0.27 12.28 ± 0.59 8.8 ± 0.47 11.06 11.06 Ours 68.33 ± 4.51 69.13 ± 2.36 71.34 ± 1.75 75.66 ± 2.72 10.5 1.4 T able 1: Comparison of standard CIL accurac y (%) on Split CIF AR-100 across dif ferent task granularities. Reported av erage test accuracy after all tasks. DSD-SNN results (25/50 tasks)[ 5 ]; other CIL baselines [ 20 , 21 , 22 , 23 , 40 ] are ev aluated on SpikF ormer [ 7 ]. T ask 0 and T ask k describe the total number of parameter updates during the 0 th and k th training tasks, respectiv ely . repository 2 to generate 25 and 50 task results. On the contrary , CA TF ormer fundamentally breaks this degradation pattern. Our model not only surpasses the classical CIL baselines by substantial mar gins but also demonstrates the unprecedented behaviour of impr oving accuracy with increasing tasks from 68.33% at 10 tasks to 75.66% at 50 tasks. This is a counter -intuitive ‘rev erse for getting’ trend, as illustrated in Figure 3. This effect stems from our dynamic threshold adaptation with the g ating mechanism, which optimises neuronal firing for ne w tasks without o verwriting prior knowledge. This trend tow ard long task sequences is crucial for real-world applications, as highlighted in robotics and embodied AI research [ 3 , 47 ], which in volve continuous adaptation and data drift. W e e valuated our model performance on the 10-class count CIF AR-10 dataset. The comparative results in T able 2, with the best-performing model, DSD-SNN [ 48 ], serving as the baseline, demonstrate CA TFormer’ s superior performance on Split CIF AR-10, achieving an accurac y of 89.29% for the 5-task split. Comparison of parameter updates at k th task In terms of model size, our proposed architecture is parameter- efficient. The base SpikFormer [ 7 ] has a base size of 9.32M parameters, while our model has a base size of 10.5M, of which 1.2M is attributed to the routing mechanism. Although there is a minimal increase in the number of parameters, it is comparable to other methods using the same SpikFormer backbone. For instance, a task 0 CA TFormer is comparable to most of the current training paradigms presented in T able 1. Our approach becomes significantly parameter -efficient once we mov e to tasks T k , where k > 0 , where we approximately train only 1.4 million parameters, while the other model actually updates the entire model’ s parameters and also utilises a rehearsal b uffer in some cases (which can also lead to unwanted priv acy breaches). The total parameter count for our model scales efficiently with the term count ( ϕ k ), where approximately 16,032 thresholds per task are stored, requiring no more than 64.2 KB of memory when FP32 is used for storage. This can e ventually be reduced to FP16, since we hardly need many decimal places, indicating that only a small number of task-specific parameters are added as new tasks are learned, while achie ving state-of-the-art performance. 4.2.2 Perf ormance on tiny-ImageNet Dataset W e further e valuate CA TFormer’ s performance on the 200-class count Tin y-ImageNet dataset. Since CIF AR-100 allows up to 50 task training, we test the efficac y of our model on 100 tasks that were not possible earlier . Due to the unav ailability of a previous similar CIL implementation of SNNs on ImageNet, we compare performance to an ANN baseline [ 49 ], which features a non-transformer backbone [ 50 ] on [ 51 ]. W e observe 8.45% improvement ov er the baselines (T able 2). Hence, CA TFormer achie ves better o verall performance than non-spiking models across a lar ger number of tasks. 4.2.3 Perf ormance on Spiking Datasets Neuromorphic datasets pose challenges due to their spatiotemporal dynamics and e vent-dri ven inputs, making them ideal testbeds for our dynamic threshold hypothesis. T able 2 demonstrates CA TFormer’ s efficacy on SHD (with only timesteps of 16) and CIF AR10-D VS benchmarks, achieving 84.48% / 87.85% and 83.21% / 87.14% for 5/10 and 2/5 task splits, respecti vely . Notably , unlike our other computer vision ev aluation datasets, namely CIF AR-10/100, 2 https://github.com/BrainCog- X/Brain- Cog.git 7 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds CIF AR10-D VS, SHD is an audio-based classification dataset. W e observe that, e ven without any data rehearsal strategy , CA TFormer’ s 83.21% performance on CIF AR10-D VS (2 tasks) closely matches the rehearsal augmented performance of ALADE-SNNs [ 4 ], 83.5%. CA TFormer thereby establishes a new standard for data rehearsal-free neuromorphic continual learning. The consistent performance gains across neuromorphic datasets v alidate that our context-adaptiv e threshold mechanism naturally aligns with the temporal processing characteristics inherent to spiking neural networks, enabling more effecti ve utilisation of the temporal dimension for task differentiation. This neuromorphic compatibility represents a significant advancement, as these datasets remain undere xplored in data rehearsal-free continual learning scenarios. Dataset T ask Model Accuracy CIF AR10 5 SA-SNN+EWC 80.39 ± 1.84 CA TFormer 89.29 ± 2.53 CIF AR10 2 DSD-SNN 80.90 ± 1.20 -D VS CA TFormer 83.21 ± 2.33 5 DSD-SNN 76.57 ± 0.96 CA TFormer 87.14 ± 2.78 SHD 5 DSD-SNN 82.56 ± 1.15 (T=16) CA TFormer 84.48 ± 1.62 10 DSD-SNN 80.47 ± 1.03 CA TFormer 87.85 ± 1.20 T iny Im-Net 100 S6MOD * 40.11 ± 0.26 CA TFormer 48.56 ± 0.81 T able 2: T ask-wise accuracy (%) of CA TF ormer with respect to the state-of-the-art SNNs on static and neuromorphic datasets. Methods marked with * denote online continual learning approaches. 4.3 Ablation Studies W e conducted targeted ablation e xperiments on Split CIF AR-10 (5 tasks, 2 classes per task) to isolate the impact of each core component in CA TFormer . The ablated variants and their a verage accuracy (in %) a fter all tasks are described in T able 3. The Fixed Threshold variant, where all neurons use their initial firing threshold for all tasks, leads to pronounced catastrophic forgetting, with accuracy dropping to 42.87%. In this configuration, performance on the first task is reasonable, but subsequent tasks trigger a consistent 15–18% degradation after each increment, mirroring classical for getting patterns in SNNs without adapti ve mechanisms. Hence, we observ e that, when studying catastrophic forgetting in brain-inspired SNNs, it is important to pay close attention to the role of spiking thresholds, unlike pre vious studies [ 4 , 5 , 48 ]. Biologically , such dynamic threshold behavior can potentially be mediated by neuromodulation [17, 14, 13, 15]. Ablation V ariant Accuracy Acc. on task 0 Fixed Threshold 42.87 ± 1.26 72.59 ± 1.86 SpikIdentityFormer 59.38 ± 0.98 70.62 ± 1.75 Random Identity Former 53.17 ± 2.13 62.43 ± 0.99 FFN Frozen 63.24 ± 1.78 72.17 ± 1.59 CA TFormer 89.29 ± 2.53 93.87 ± 0.45 T able 3: Ablation study of CA TFormer e valuated on CIF AR-10 (5 tasks). Recent works on vision transformer [ 52 , 53 ] sho w that its performance is not significantly impacted by the choice of token mixers. In f act, they show that even after removing all v anilla attention token mixers, the V iT achie ves good baseline performance. Driv en by these observ ations, we e valuate the performance of our spiking vision transformer (CA TFormer) on the CIF AR-10 (5 tasks) platform. As part of this, we design SpikIdentityFormer by either replacing all spike attention with identity mapping in CA TFormer ( SpikIdentityFormer ) or replacing spike attention with uniformly distrib uted random numbers in CA TF ormer ( Random Identity F ormer ). Both the SpikIdentityF ormer (removing all attention) and Random Identity Former (disrupting transformer blocks) yield similar, mark edly reduced accuracy , confirming that structured feature transformation is crucial for rob ust continual learning. Significantly , a Random Identity Former performs lower (53.17%) than a SpikIdentityFormer (59.38%). Moreov er , freezing the feed-forward network ( FFN Fr ozen ) provides only moderate improvement (63.24%), indicating that adaptiv e intermediate representations are also necessary for ef fectiv e knowledge retention ov er time. Compared to only FFN learning in SpikIdentityFormer , a learnable token mix er in FFN Frozen (with FFN frozen) performs better by 3.86%. 8 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds A similar trend is observed in first-task learning. These results demonstrate that both the transformer’ s structured feature extraction and, critically , its dynamic, task-specific threshold modulation are essential for effecti ve, data-rehearsal-free continual learning, thereby justifying our design choices. Overall, CA TFormer surpasses prior rehearsal-free methods on static and neuromorphic benchmarks, achie ving stable or improved accurac y as the task count increases. This makes it well-suited for continual learning on embedded, memory-constrained robotic and autonomous systems that must adapt to dynamic, unpredictable en vironments. Unlike con ventional rehearsal-based methods, which face prohibiti ve storage, energy , pri vac y , and bandwidth constraints, CA TFormer almost eliminates the need for memory buf fers by lev eraging dynamic, task-specific neuronal plasticity . This biologically inspired and hardware-ef ficient design aligns with practical constraints highlighted in robotics and embodied AI research [ 3 , 47 ], enabling robust lifelong continual learning in real-world deployment. 5 Discussion CA TFormer demonstrates that biologically inspired dynamic threshold adaptation enables rehearsal-free continual learning in spiking neural networks, maintaining or improving accurac y across up to 50 tasks. This is especially rele vant for robotics and physical AI, where limited onboard memory mak es storing replay buf fers impractical—for instance, retaining 2,000 CIF AR-100 images for rehearsal consumes [ 4 ] approximately 25–30MB, a significant ov erhead for resource-constrained hardware. Moreov er, continual network gro wth or pruning introduces complexity and unstable resource demands, hindering deployment on embedded or neuromorphic platforms. By le veraging intrinsic neuronal modulation through task-specific dynamic thresholds, CA TFormer provides a memory and computation-efficient solution that a voids these pitfalls while sustaining robust, scalable continual learning. Future work should explore adaptiv e threshold learning in streaming, non-stationary en vironments for lifelong learning and in vestigate direct hardware implementations on Loihi 2 [46] to accelerate the real-world deplo yment of lifelong SNN agents. 6 Acknowledgments This work was supported by the F aculty Startup Grant from IIT Guwahati. References [1] Arslan Chaudhry , Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny . Efficient lifelong learning with a-gem. arXiv pr eprint arXiv:1812.00420 , 2018. [2] Liyuan W ang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensi ve surve y of continual learning: Theory , method and application. IEEE transactions on pattern analysis and machine intelligence , 46(8):5362–5383, 2024. [3] T imothée Lesort, V incenzo Lomonaco, Andrei Stoian, Davide Maltoni, David Filliat, and Natalia Díaz-Rodríguez. Continual learning for robotics: Definition, framew ork, learning strategies, opportunities and challenges. Informa- tion fusion , 58:52–68, 2020. [4] W enyao Ni, Jiangrong Shen, Qi Xu, and Huajin T ang. Alade-snn: Adapti ve logit alignment in dynamically expandable spiking neural networks for class incremental learning. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , v olume 39, pages 19712–19720, 2025. [5] Bing Han, Feifei Zhao, Y i Zeng, W enxuan Pan, and Guobin Shen. Enhancing ef ficient continual learning with dynamic structure dev elopment of spiking neural networks. arXiv preprint , 2023. [6] Alex ey Dosovitskiy , Lucas Be yer , Alexander K olesnikov , Dirk W eissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylv ain Gelly , et al. An image is worth 16x16 words: T ransformers for image recognition at scale. arXiv pr eprint arXiv:2010.11929 , 2020. [7] Zhaokun Zhou, Y uesheng Zhu, Chao He, Y aowei W ang, Shuicheng Y AN, Y onghong T ian, and Li Y uan. Spik- former: When spiking neural netw ork meets transformer . In The Eleventh International Confer ence on Learning Repr esentations , 2023. [8] Nicolas Y Masse, Gre gory D Grant, and David J Freedman. Alle viating catastrophic for getting using conte xt- dependent gating and synaptic stabilization. Pr oceedings of the National Academy of Sciences , 115(44):E10467– E10475, 2018. [9] Shawn Beaulieu, Lapo Frati, Thomas Miconi, Joel Lehman, K enneth O Stanley , Jef f Clune, and Nick Cheney . Learning to continually learn. arXiv pr eprint arXiv:2002.09571 , 2020. 9 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds [10] Michael E Hasselmo and Edi Barkai. Choliner gic modulation of activity-dependent synaptic plasticity in the piriform cortex and associati ve memory function in a netw ork biophysical simulation. Journal of Neur oscience , 15(10):6592–6604, 1995. [11] Stephen Grossberg. Acetylcholine neuromodulation in normal and abnormal learning and memory: vigilance control in waking, sleep, autism, amnesia and alzheimer’ s disease. F rontier s in neural cir cuits , 11:82, 2017. [12] Michael E Hasselmo. The role of acetylcholine in learning and memory . Curr ent opinion in neur obiology , 16(6):710–715, 2006. [13] Y uhan Helena Liu, Stephen Smith, Stefan Mihalas, Eric Shea-Brown, and Uygar Sümbül. Biologically-plausible backpropagation through arbitrary timespans via local neuromodulators. Advances in Neural Information Pr ocess- ing Systems , 35:17528–17542, 2022. [14] M Matthe w Oh and John F Disterhoft. Increased excitability of both principal neurons and interneurons during associativ e learning. The Neur oscientist , 21(4):372–384, 2015. [15] Jun Xu, Ning Kang, Li Jiang, Maiken Neder gaard, and Jian Kang. Activity-dependent long-term potentiation of intrinsic excitability in hippocampal ca1 pyramidal neurons. Journal of Neur oscience , 25(7):1750–1760, 2005. [16] George E F armer and Lucien T Thompson. Learning-dependent plasticity of hippocampal ca1 pyramidal neuron postburst afterhyperpolarizations and increased excitability after inhibitory av oidance learning depend upon basolateral amygdala inputs. Hippocampus , 22(8):1703–1719, 2012. [17] Ben Tsuda, Stefan C Pate, Kay M T ye, Hav a T Siegelmann, and T errence J Sejno wski. Neuromodulators generate multiple context-rele vant beha viors in recurrent neural networks. Neural Computation , pages 1–36, 2026. [18] Ilyass Hammouamri, Timothée Masquelier , and Dennis George Wilson. Mitigating catastrophic forgetting in spiking neural networks through threshold modulation. T ransactions on Machine Learning Resear ch , 2022. [19] Gido M V an de V en and Andreas S T olias. Three scenarios for continual learning. arXiv preprint , 2019. [20] James Kirkpatrick, Razvan Pascanu, Neil Rabino witz, Joel V eness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, T iago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences , 114(13):3521–3526, 2017. [21] Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. In International confer ence on machine learning , pages 3987–3995. Pmlr , 2017. [22] Sylvestre-Alvise Rebuf fi, Alexander Kolesnik ov , Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. In Pr oceedings of the IEEE confer ence on Computer V ision and P attern Recognition , pages 2001–2010, 2017. [23] Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: a strong, simple baseline. Advances in neural information processing systems , 33:15920–15930, 2020. [24] Kai Zhu, W ei Zhai, Y ang Cao, Jiebo Luo, and Zheng-Jun Zha. Self-sustaining representation expansion for non-ex emplar class-incremental learning. In Proceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pages 9296–9305, 2022. [25] Fei Y e and Adrian G Bors. Online task-free continual learning via dynamic expansionable memory distrib ution. In Pr oceedings of the Computer V ision and P attern Recognition Conference , pages 20512–20522, 2025. [26] Huiyi W ang, Haodong Lu, Lina Y ao, and Dong Gong. Self-e xpansion of pre-trained models with mixture of adapters for continual learning. In Pr oceedings of the Computer V ision and P attern Recognition Conference , pages 10087–10098, 2025. [27] Andrei A Rusu, Neil C Rabino witz, Guillaume Desjardins, Hubert Soyer , James Kirkpatrick, K oray Ka vukcuoglu, Razvan P ascanu, and Raia Hadsell. Progressi ve neural networks. arXiv preprint , 2016. [28] Chrisantha Fernando, Dylan Banarse, Charles Blundell, Y ori Zwols, David Ha, Andrei A Rusu, Alexander Pritzel, and Daan W ierstra. Pathnet: Evolution channels gradient descent in super neural networks. arXiv preprint arXiv:1701.08734 , 2017. [29] Andreas K Engel, Pascal Fries, and W olf Singer . Dynamic predictions: oscillations and synchrony in top–do wn processing. Natur e Revie ws Neur oscience , 2(10):704–716, 2001. [30] Earl K Miller and Jonathan D Cohen. An integrati ve theory of prefrontal cortex function. Annual r evie w of neur oscience , 24(1):167–202, 2001. 10 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds [31] Y an-Shuo Liang and W u-Jun Li. Inflora: Interference-free low-rank adaptation for continual learning. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition , pages 23638–23647, 2024. [32] Jiangpeng He, Zhihao Duan, and Fengqing Zhu. Cl-lora: Continual low-rank adaptation for rehearsal-free class-incremental learning. In Pr oceedings of the Computer V ision and P attern Recognition Confer ence , pages 30534–30544, 2025. [33] Jiashuo Li, Shaokun W ang, Bo Qian, Y uhang He, Xing W ei, Qiang W ang, and Y ihong Gong. Dynamic integration of task-specific adapters for class incremental learning. In Proceedings of the Computer V ision and P attern Recognition Confer ence , pages 30545–30555, 2025. [34] Erliang Lin, W enbin Luo, W ei Jia, Y u Chen, and Shaofu Y ang. Online continual learning via spiking neural networks with sleep enhanced latent replay . arXiv pr eprint arXiv:2507.02901 , 2025. [35] Jianchuan Ding, Bo Dong, Felix Heide, Y ufei Ding, Y unduo Zhou, Baocai Y in, and Xin Y ang. Biologically inspired dynamic thresholds for spiking neural networks. Advances in neural information pr ocessing systems , 35:6090–6103, 2022. [36] Chao Huang, Andrey Resnik, T ansu Celikel, and Bernhard Englitz. Adaptiv e spike threshold enables robust and temporally precise neuronal encoding. PLoS computational biology , 12(6):e1004984, 2016. [37] W enjie W ei, Malu Zhang, Hong Qu, Ammar Belatreche, Jian Zhang, and Hong Chen. T emporal-coded spiking neural networks with dynamic firing threshold: Learning with e vent-driv en backpropagation. In Pr oceedings of the IEEE/CVF international confer ence on computer vision , pages 10552–10562, 2023. [38] Ahmed Shaban, Sai Sukruth Bezugam, and Manan Suri. An adaptiv e threshold neuron for recurrent spiking neural networks with nanode vice hardware implementation. Natur e Communications , 12(1):4234, 2021. [39] T aeyoon Kim, Suman Hu, Jae wook Kim, Joon Y oung Kwak, Jongkil Park, Suyoun Lee, Inho Kim, Jong-K euk Park, and Y eonJoo Jeong. Spiking neural netw ork (snn) with memristor synapses ha ving non-linear weight update. F r ontiers in computational neur oscience , 15:646125, 2021. [40] Quanziang W ang, Renzhen W ang, Y uexiang Li, Dong W ei, Hong W ang, Kai Ma, Y efeng Zheng, and De yu Meng. Relational experience replay: Continual learning by adaptively tuning task-wise relationship. IEEE T ransactions on Multimedia , 26:9683–9698, 2024. [41] Alex Krizhevsk y , Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. [42] Y ann Le, Xuan Y ang, et al. T iny imagenet visual recognition challenge. CS 231N , 7(7):3, 2015. [43] Hongmin Li, Hanchao Liu, Xiangyang Ji, Guoqi Li, and Luping Shi. Cifar10-dvs: an ev ent-stream dataset for object classification. F r ontiers in neur oscience , 11:244131, 2017. [44] Benjamin Cramer , Y annik Stradmann, Johannes Schemmel, and Friedemann Zenke. The heidelberg spiking data sets for the systematic e v aluation of spiking neural networks. IEEE T ransactions on Neural Networks and Learning Systems , 33(7):2744–2757, 2020. [45] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny , Marcus Rohrbach, and T inne T uytelaars. Memory aware synapses: Learning what (not) to forget. In Pr oceedings of the Eur opean confer ence on computer vision (ECCV) , pages 139–154, 2018. [46] Sumit Bam Shrestha, Jonathan T imcheck, Paxon Frady , Leobardo Campos-Macias, and Mike Da vies. Ef ficient video and audio processing with loihi 2. In ICASSP 2024-2024 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 13481–13485. IEEE, 2024. [47] Elvin Hajizada, P atrick Berggold, Massimiliano Iacono, Arren Glov er , and Y ulia Sandamirskaya. Interactiv e continual learning for robots: a neuromorphic approach. In Pr oceedings of the international confer ence on neur omorphic systems 2022 , pages 1–10, 2022. [48] Jiangrong Shen, W enyao Ni, Qi Xu, and Huajin T ang. Efficient spiking neural networks with sparse selectiv e activ ation for continual learning. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , v olume 38, pages 611–619, 2024. [49] Sihao Liu, Y ibo Y ang, Xiaojie Li, David A Clifton, and Bernard Ghanem. Enhancing online continual learning with plug-and-play state space model and class-conditional mixture of discretization. In Proceedings of the Computer V ision and P attern Recognition Confer ence , pages 20502–20511, 2025. [50] Albert Gu and T ri Dao. Mamba: Linear -time sequence modeling with selective state spaces. In F irst confer ence on language modeling , 2024. 11 CA TFormer: When Continual Learning Meets Spiking T ransformers W ith Dynamic Thresholds [51] Hongwei Y an, Liyuan W ang, Kaisheng Ma, and Y i Zhong. Orchestrate latent expertise: Advancing online continual learning with multi-le vel supervision and reverse self-distillation. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pages 23670–23680, 2024. [52] W eihao Y u, Mi Luo, Pan Zhou, Chenyang Si, Y ichen Zhou, Xinchao W ang, Jiashi Feng, and Shuicheng Y an. Metaformer is actually what you need for vision. In Pr oceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pages 10819–10829, June 2022. [53] W eihao Y u, Chenyang Si, Pan Zhou, Mi Luo, Y ichen Zhou, Jiashi Feng, Shuicheng Y an, and Xinchao W ang. Metaformer baselines for vision. IEEE T ransactions on P attern Analysis and Mac hine Intelligence , 46(2):896–912, 2023. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment