Seismic full-waveform inversion based on a physics-driven generative adversarial network
Objectives: Full-waveform inversion (FWI) is a high-resolution geophysical imaging technique that reconstructs subsurface velocity models by iteratively minimizing the misfit between predicted and observed seismic data. However, under complex geologi…
Authors: Xinyi Zhang, Caiyun Liu, Jie Xiong
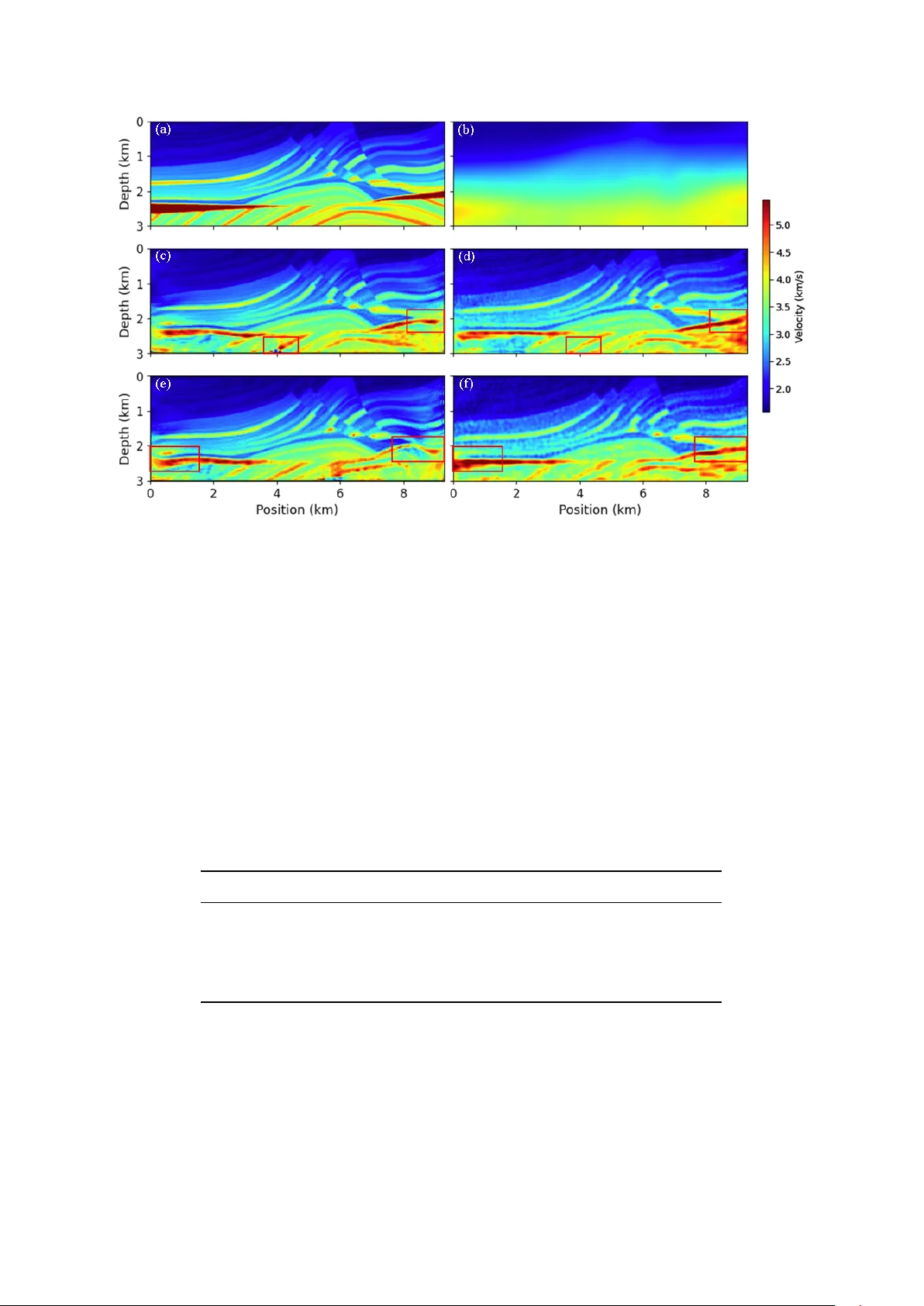
Seismic full-wa vef orm in version based on a ph ysics-driven generati ve adv ersarial network Xinyi Zhang, Caiyun Liu * , Jie Xiong, Qingfeng Y u School of Electr onic Information and Electrical Engineering, Y angtze University Jingzhou, Hubei 434023, P .R.China Abstract Objectives: Full-wa veform in version (FWI) is a high-resolution geophysical imaging technique that reconstructs subsurface v elocity models by iteratively minimizing the misfit between predicted and observed seismic data. Ho wever , under complex geological condi- tions, conv entional FWI suffers from strong dependence on the initial model and tends to produce unstable results when the data are sparse or contaminated by noise. Methods: T o address these limitations, this paper proposes a physics-driv en generative adversarial network–based full-wav eform in version method. The proposed approach in- tegrates the data-driven capability of deep neural networks with the physical constraints imposed by the seismic wa ve equation, and emplo ys adv ersarial training through a discrim- inator to enhance the stability and robustness of the in v ersion results. Results: Experimental results on two representati ve benchmark geological models demon- strate that the proposed method can effecti vely recov er complex velocity structures and achie ves superior performance in terms of structural similarity (SSIM) and signal-to-noise ratio (SNR). Conclusions: This method provides a promising solution for alleviating the initial-model dependence in full-wav eform in version and shows strong potential for practical applica- tions. K eywords: deep learning; seismic full-wav eform inv ersion; generati ve adversarial net- work; unsupervised learning 1 Intr oduction Seismic in version is an essential tool for studying the Earth’ s internal structure and exploring natural resources. The velocity model plays a critical role in seismic data processing and inter- pretation, particularly in migration imaging, structural interpretation, and attribute analysis [ 1 ]. T raditional velocity modeling methods mainly include velocity spectrum analysis [ 2 ], tomog- raphy [ 3 ], and full-wa veform in version (FWI) [ 4 ]. V elocity spectrum analysis estimates layer velocities from reflection arriv al times; it is simple but has low resolution. T omography in verts trav el-time residuals based on ray theory , improving accuracy but still limited in characteriz- ing complex structures. FWI fully utilizes all wav efield information in seismic records and can in vert high-resolution subsurface velocity structures, making it a focal point of current research. * Corresponding author 1 Since T arantola [ 5 ] proposed FWI, it has shown significant advantages in high-resolution imaging due to its ability to iterati vely update subsurface velocity structures using full wav efield information. Howe ver , traditional FWI usually relies on a good initial model and low-frequenc y data, easily falling into local minima and suf fering from noise, cycle skipping, and other issues in practical applications, which limits its accuracy and stability [ 6 , 7 ]. T o address these nonlinear problems, Akcelik [ 8 ] introduced a Gauss–Newton optimization method and applied it to a 2D acoustic wa ve synthetic model, impro ving in version accurac y . Ren et al. [ 9 ] systematically studied the Hessian operator in seismic in version imaging. W ang and Dong [ 10 ] implemented multi-parameter acoustic FWI in VTI media using a truncated Newton method and obtained relati vely accurate results. Liu et al. [ 11 ] introduced a modified quasi-Newton condition in frequency-domain FWI, accelerating con v ergence. Miao [ 12 ] applied the L-BFGS algorithm to time-domain FWI. Zhang et al. [ 13 ] implemented multi-scale FWI. Furthermore, to overcome the local-minimum problem, simulated annealing [ 14 , 15 ], ge- netic algorithms [ 16 ], and particle swarm optimization [ 17 ] ha ve been introduced into FWI to reduce dependence on the initial model. Pan et al. [ 18 ] proposed a hybrid adaptiv e genetic al- gorithm (HA GA) to further improve search ef ficiency . Ov erall, although global optimization methods can partially overcom e cycle skipping and reduce initial model dependence, they are computationally expensiv e and con ver ge slowly , often requiring combination with local opti- mization strategies in practice. In recent years, deep learning has been rapidly applied in seismic exploration, especially in velocity model building. Y ang and Ma [ 19 ] proposed a modified U-Net framew ork that can ef fectiv ely predict velocity models from multiple seismic data, approximating the nonlinear relationship between seismic data and models. W u and McMechan [ 20 ] introduced a deep im- age prior (DIP)-based CNN-domain FWI method, updating network parameters by minimizing the error between simulated and observed data. Recurrent neural networks (RNNs) [ 21 ] hav e been applied to seismic data reconstruction [ 22 ] and impedance in version [ 23 ], demonstrating their advantages in handling variable-length input sequences. Howe ver , most of these methods rely heavily on large amounts of labeled data and lack physical constraints, which may lead to inconsistencies between generated results and actual observ ations, limiting generalization. In addition, Raissi et al. [ 24 ] proposed physics-informed neural networks (PINNs), which effi- ciently solve nonlinear partial differential equations (PDEs) by combining mathematical models with data, and ha ve been successfully applied to wa veform in version. Under an unsupervised learning frame work, PINNs incorporate physical constraints to generate velocity models that both fit observed seismic data and satisfy physical laws, but they still depend on training data quality and network architecture design. Based on the idea of physical constraints, Y ang and Ma [ 25 ] proposed physics-informed generati ve adversarial networks (FWIGAN), which apply adv ersarial constraints through a dis- criminator to traditional FWI results and achiev ed good in version performance. Ho wev er , in that method, the generator consists only of traditional FWI, and model updates rely mainly on physical gradient information; no learnable velocity model mapping is established, so under complex geological conditions, it is still ine vitably constrained by the initial model. T o address this problem, this paper improves the generator structure by introducing a deep neural network to parameterize the generator , enabling it to learn structural features of subsurface velocity models from observed seismic data and collaborati vely optimize with the FWI iteration process under wa ve-equation constraints. On one hand, the deep neural network provides a structurally reasonable initial model for FWI, ef fectiv ely reducing the sensitivity of in version to the ini- tial model. On the other hand, the physical inv ersion process corrects the network predictions under wav e-equation constraints, ensuring the physical consistency of the generated velocity 2 model. Meanwhile, FWI also provides additional training data for the deep neural network, gi ving the generator a ”learnable” characteristic, and the deep neural network prediction and physical in version process mutually promote each other , achie ving joint optimization. 2 Basic Principles 2.1 T raditional FWI Full-wa veform inv ersion (FWI) [ 4 ] is a method for high-resolution reconstruction of subsurface velocity models by minimizing the difference between simulated and observed seismic data. This paper adopts the 2D constant-density acoustic wa ve equation (A WE) to describe wav e propagation, expressed in the time domain as: ∂ 2 u ( x , t ) ∂ t 2 − v 2 ( x ) ∇ 2 u ( x , t ) = f ( t ) δ ( x − x s ) , (1) where u ( x , t ) represents the seismic wa vefield, v ( x ) is the velocity model, f ( t ) is the source term, and δ ( x − x s ) is the Dirac function indicating the source location. The forward modeled data are d syn ( x r , t ; x s ) = R u , where R is a sampling operator , and the observed seismic data are denoted as d obs ( x r , t ; x s ) . The least-squares misfit function is constructed as: E ( v ) = 1 2 N s X s =1 N r X r =1 Z T 0 d syn ( x r , t ; x s ) − d obs ( x r , t ; x s ) 2 dt, (2) where T is the maximum recording time, and N s and N r are the numbers of sources and re- cei vers, respecti vely . The goal of FWI is to iterati vely update the velocity model v by minimizing E ( v ) . In numerical implementation, the domain Ω of the velocity model v is discretized into an N x × N z pixel grid, and the corresponding discretized model and data can be e xpressed as: v ∈ R N x N z , d syn = F ( v ) , d obs ∈ R N s N r N t , (3) where v is the discretized velocity model, d syn is the simulated seismic data, d obs is the observed data, and F is the forward modeling operator constrained by the wa ve equation. 2.2 GAN Ar chitectur e Generati ve adversarial networks (GANs) [ 28 ] are a typical class of generativ e deep learning models, consisting of two neural networks: a generator and a discriminator . The generator aims to generate samples that approximate the real data distribution from an input space, while the discriminator’ s task is to distinguish whether an input sample comes from real data or from the generator’ s fake data. The two networks are optimized through adversarial training, ev entually enabling the generator to produce highly realistic samples. The o verall loss consists of a gener - ator loss and a discriminator loss, with opposing objectiv es. The overall optimization objecti ve of GAN can be expressed as the follo wing minimax problem: min G max D V ( D , G ) = E x ∼ p data [log D ( x )] + E z ∼ p z [log(1 − D ( G ( z )))] , (4) 3 where x represents real samples, z is a noise vector , p data and p z are the distributions of real data and noise, respecti vely , D ( x ) is the probability output by the discriminator , and G ( z ) is the generator output. Correspondingly , the loss functions of the discriminator and generator can be written as: L D = − E x ∼ p data [log D ( x )] − E z ∼ p z [log(1 − D ( G ( z )))] , (5) L G = − E z ∼ p z [log D ( G ( z ))] . (6) The discriminator improv es its ability to distinguish between real and generated samples by minimizing Eq. ( 5 ), while the generator continuously adjusts its parameters by minimizing Eq. ( 6 ) so that its generated samples approach the real data distribution under the discriminator’ s judgment. 3 Model Design 3.1 Overall W orkflo w The ov erall workflow of the proposed physics-driv en generative adversarial network in version method is shown in Fig. 1 . The observed seismic shot gather data are first input into the physics- dri ven generator G , which produces a subsurface velocity model prediction that conforms to the physical laws of seismic wa ve propagation. Based on this predicted model, forward wav e- equation modeling yields corresponding predicted seismic data, which are then input together with the observed seismic data into the discriminator D . The discriminator judges the authen- ticity of the input data, distinguishing between observed and predicted seismic data. During adversarial training, the optimization goal of G is to reduce the probability that its generated results are judged as ”fake” by D , thereby guiding the generated velocity model to gradually approach the true subsurface structure. The goal of D is to improve its ability to distinguish between observed and predicted seismic data, thereby forcing G to further improve generation quality (i.e., in version quality). Through alternating optimization between G and D , the model continuously updates the generator parameters during iterations, achie ving high- precision in version of subsurf ace velocity models. Figure 1: Overall w orkflo w 3.2 Physics-Dri ven Generator The physics-dri ven generator G consists of a U-Net structured deep neural netw ork and an FWI solver , as sho wn in Fig. 2 . Unlike Y ang and Ma [ 25 ], who used the traditional FWI iterati ve process as the generator , this paper parameterizes the generator by combining a deep neural network with the physical inv ersion process, constructing a learnable physics-dri ven generator structure. 4 The deep neural network in G adopts the U-Net architecture, consisting of an encoder and a decoder . The encoder comprises four con volutional blocks, each containing two con volutional layers, ReLU activ ation, and max-pooling operations, extracting high-lev el semantic features through successiv e downsampling. A center layer is set at the end of the encoder to further enhance feature representation. The decoder consists of four upsampling blocks that progres- si vely restore spatial resolution via transposed con volution or bilinear interpolation, and skip connections link feature maps from corresponding encoder layers to the decoder to fuse low- le vel detail information with high-level semantic information. Finally , a 1 × 1 con volutional layer outputs the predicted velocity model. Before adversarial training, we first pre-train the U-Net in generator G using only observed seismic data as input and the corresponding initial velocity model v init (obtained by linear in- terpolation or Gaussian smoothing) as the target, optimized with an L2 loss. This enables the network to learn generating a reasonable background velocity model from seismic data until the loss con ver ges. The adversarial training procedure of G is as follows: First, observed seismic data are fed into the pre-trained U-Net, extracting multi-scale features from the seismic data through multi- layer nonlinear mappings, yielding an initial predicted subsurface velocity model v pre . Then, v pre is used as the initial velocity model and input together with the observed seismic data into the traditional FWI process, obtaining a physically corrected velocity model v corr . Figure 2: Architecture of the physics-dri ven generator 3.3 Discriminator The discriminator D adopts a con volutional neural network (CNN) structure, as shown in Fig. 3 , consisting of six con volutional blocks and two fully connected layers. Each conv olutional block comprises a 3 × 3 con volutional layer , a Leaky ReLU activ ation with a negati ve slope of 0.1, and a 2 × 2 max-pooling layer that do wnsamples the feature maps to reduce spatial resolution. The first con volutional block has 32 channels, and the number of channels doubles in subsequent blocks. The input channel number is set according to the number of rays per batch of seismic data. The output of the last con volutional block is flattened into a vector and fed into fully connected layers, with neuron numbers set to 2000, 1000, and 1500 in dif ferent experiments (corresponding to FcX in Fig. 3 (a), where X indicates the number of neurons), processed by Leaky ReLU, and finally outputting a scalar representing the discrimination result. T o ensure the ef fectiv eness of the gradient penalty strategy , batch normalization is not used. The discriminator extracts features layer by layer and provides feedback, effecti vely pushing the generator to optimize its output and thus generate more realistic subsurface v elocity models. 5 Figure 3: Architecture of the discriminator: (a) Discriminator structure; (b) Con volutional block structure. 4 Experiments 4.1 Experimental Setup The experiments in this paper were implemented using the PyT orch deep learning framework, and model training was conducted on a Linux system. The experimental platform was equipped with an NVIDIA T esla P40 GPU (24GB memory) and 96GB of system RAM. The generator and discriminator were trained for 300 epochs with a batch size of 15 and a learning rate of 0.001. All networks were optimized using the Adam optimizer , with a training strategy of training the discriminator six times follo wed by training the generator once. 4.2 Evaluation Metrics T o quantitativ ely ev aluate the in version performance of the proposed method, the consistency between the predicted velocity model ˆ v and the true velocity model v must be analyzed. The main ev aluation metrics include structural similarity (SSIM) and signal-to-noise ratio (SNR), which comprehensi vely reflect the quality of the in verted model in terms of structural fidelity and noise suppression. Structural similarity (SSIM) measures the similarity between the inv erted model and the true model in terms of structure and texture features, defined as: SSIM ( v , ˆ v ) = (2 µ v µ ˆ v + C 1 )(2 σ v ˆ v + C 2 ) ( µ 2 v + µ 2 ˆ v + C 1 )( σ 2 v + σ 2 ˆ v + C 2 ) , (7) where µ v and µ ˆ v are the local means of the two models, σ v and σ ˆ v are their standard de viations, and the regularization constants are C 1 = (0 . 01 L ) 2 , C 2 = (0 . 03 L ) 2 (with L being the dynamic range of the grayscale values). A higher SSIM value indicates greater consistency in structural features between the in verted and true models. T o assess the impact of noise in the model, the signal-to-noise ratio (SNR) is introduced, 6 defined as: SNR = 10 log 10 ∥ v ∥ 2 2 ∥ v − ˆ v ∥ 2 2 (dB) . (8) A larger SNR value indicates a higher proportion of effecti ve signal in the in version result, implying better model quality and stability . 4.3 Marmousi Model Experiments The Marmousi model [ 26 ] is one of the most representati ve acoustic velocity models in seismic forward and in verse modeling research. In this paper , a downsampled version of the Marmousi model was used as the research object, with a model size of 191 × 51 , a spatial grid spacing of 0.03 km, and a velocity range of 1472 m/s to 5772 m/s. The true velocity distribution is sho wn in Fig. 4 (a). Under noise-free observation data conditions, the result of Y ang and Ma [ 25 ] (Fig. 4 (c)) obtained a relati vely reasonable velocity model with a good initial model, but there were still noticeable artifacts and local anomalies in the deep region (indicated by the red box in Fig. 4 (c)), de viating somewhat from the true model. In contrast, the proposed method (Fig. 4 (d)) recovers the velocity structure more accurately and continuously; the in version result not only clearly reconstructs the main geological interfaces but also preserves subsurface details well. When additi ve white Gaussian noise (A WGN) with an SNR of 10 dB was added to the observation data, the differences between the two methods became more pronounced. The method of Y ang and Ma [ 25 ] (Fig. 4 (e)) is sensiti ve to noise, and the in version result exhibits local lo w-velocity anomalies and structural discontinuities (indicated by the red box in Fig. 4 (e)). In contrast, the proposed framework (Fig. 4 (f)) demonstrates stronger robustness and denoising capabil- ity under noise interference, yielding a smoother and more reasonable velocity distribution. The SSIM and SNR results between the true velocity model and the in verted velocity models are sho wn in T able 1 . The proposed method outperforms that of Y ang and Ma in all metrics, demonstrating its ef fectiv eness. T able 1: Statistical performance of Marmousi model in version Noise condition Metric Proposed method Y ang et al. ’ s method Noise-free SSIM 0.7092 0.6802 SNR 19.37 17.29 Noisy SSIM 0.6652 0.6301 SNR 21.42 16.71 4.4 Overthrust Model Experiments The Overthrust model [ 27 ] is a typical 3D geological velocity model. In this paper , the central slice of this 3D model was selected as the 2D research object. After do wnsampling, the model size is 251 × 81 , with a spatial step of 0.05 km and a velocity range of 2360 m/s to 6000 m/s. The true velocity distrib ution is shown in Fig. 5 (a). Figure 5 displays the in version results of the Overthrust model. This model contains distinct ov erthrust structures and a deep high-velocity basement, posing high demands on the structural resolution capability of the in version method. The comparison results show that, in both noise- free and noisy cases, the imaging quality of Y ang and Ma’ s method [ 25 ] is limited in deep 7 Figure 4: In version results of the Marmousi model: (a) T rue v elocity model; (b) Gaussian- smoothed initial velocity model; (c) In version result by Y ang et al. using noise-free seismic data; (d) In version result by the proposed method using noise-free seismic data; (e) In version result by Y ang et al. using noisy seismic data; (f) In version result by the proposed method using noisy seismic data. and laterally v arying regions (indicated by red boxes in Fig. 5 (c) and (e)), with insufficiently clear local structural shapes. In contrast, the proposed method recov ers a more continuous velocity distribution beneath the ov erthrust structures and in the deep high-velocity zone, with more complete representation of structural interfaces, indicating better imaging stability under complex structural conditions. The SSIM and SNR ev aluations of the in verted models are gi ven in T able 2 . T able 2: Statistical performance of Overthrust model in version Noise condition Metric Proposed method Y ang et al. ’ s method Noise-free SSIM 0.7842 0.7270 SNR 28.57 25.83 Noisy SSIM 0.7286 0.6889 SNR 27.52 23.88 4.5 In version Experiments with a Linear Initial V elocity Model Figure 6 shows the in version results of dif ferent methods on the two complex models (Mar- mousi and Overthrust) when using a linear initial velocity model. Because the initial model significantly deviates from the true model, the method of Y ang and Ma [ 25 ] has limitations in depicting structural details in fault-dense zones and deep regions (indicated by red boxes in 8 Figure 5: Inv ersion results of the Overthrust model: (a) T rue velocity model; (b) Gaussian- smoothed initial velocity model; (c) In version result by Y ang et al. using noise-free seismic data; (d) In version result by the proposed method using noise-free seismic data; (e) In version result by Y ang et al. using noisy seismic data; (f) In version result by the proposed method using noisy seismic data. Fig. 6 (c1) and (c2)), with relativ ely weak continuity of local velocity structures. In contrast, the proposed method, under the same initial conditions, gradually con verges to a reasonable velocity distribution and obtains clearer imaging results at multiple key structural locations, demonstrating lower dependence on the initial model and better adaptability in complex in ver - sion problems. The SSIM and SNR e v aluations of the in verted models are giv en in T able 3 . T able 3: Statistical performance of in version using a linear initial model Model Metric Proposed method Y ang et al. ’ s method Marmousi SSIM 0.6582 0.6550 SNR 18.21 15.35 Overthrust SSIM 0.7607 0.7377 SNR 28.50 23.92 5 Conclusions This paper proposes a physics-dri ven generati ve adv ersarial network for seismic full-w av eform in version. By combining traditional FWI with generativ e adversarial networks, the method achie ves high-precision velocity model in version. The approach effecti vely alleviates the de- pendence of deep learning methods on large amounts of labeled data and reduces the sensitivity of traditional FWI to the initial model. Numerical experiments on two typical complex mod- 9 Figure 6: In version results using a linear initial model: (a1–d1) T rue velocity model, linear initial velocity model, in version result by Y ang et al., and in version result by the proposed method for the Marmousi model; (a2–d2) T rue velocity model, linear initial velocity model, in version result by Y ang et al., and in version result by the proposed method for the Overthrust model. els, Marmousi and Overthrust, demonstrate that the proposed method can stably recov er com- plex geological structures under both noise-free and noisy conditions, exhibiting better imaging quality and robustness in fault-dense zones, deep high-velocity regions, and areas with strong lateral v elocity v ariations. Comprehensiv e qualitativ e comparisons and quantitativ e ev aluations indicate that the proposed method out performs the compared method in in version accuracy , sta- bility , and noise resistance, showing great potential for high-precision velocity in version under complex geological conditions. Acknowledgements This paper is the result of the National Natural Science Foundation of China funded project (No. 62273060). Refer ences [1] Y ang W Y , W ang X W , Y ong X S, Chen Q Y . 2013. Revie w of seismic full-wa veform in version methods. Progress in Geophysics, 28(2): 766-776 (in Chinese). [2] Berkhout A J. 1997. Pushing the limits of seismic imaging, P art II: Inte gration of prestack migration, velocity estimation, and A V O analysis. Geophysics, 62(3): 954-969. [3] Iyer H M, Hirahara K. 1993. Seismic T omography: Theory and Practice. Springer Science & Business Media. [4] V irieux J, Operto S. 2009. An ov ervie w of full-wav eform inv ersion in exploration geo- physics. Geophysics, 74(6): WCC127-WCC152. [5] T arantola A. 1984. In version of seismic reflection data in the acoustic approximation. Geo- physics, 49(8): 1259-1266. [6] Koren Z, Mose gaard K, Landa E, Thore P , T arantola A. 1991. Monte Carlo estimation and resolution analysis of seismic background velocities. Journal of Geophysical Research, 96: 20289-20299. 10 [7] W ang Q, Zhang J Z, Huang Z L. 2015. Adv ances in time-domain seismic full-wa veform in version methods. Progress in Geophysics, 30(6): 2797-2806 (in Chinese). [8] Akcelik V . 2002. Multiscale Newton–Krylo v methods for in verse acoustic wa ve propaga- tion. Ph.D. thesis, Carnegie Mellon Uni versity . [9] Ren H R, Huang G H, W ang H Z, Chen S C. 2013. Study of Hessian operator in seismic in version imaging. Chinese Journal of Geophysics, 56(7): 2429-2436 (in Chinese). [10] W ang Y , Dong L G. 2015. Multi-parameter acoustic full-wav eform in version in VTI media based on the truncated Newton method. Chinese Journal of Geophysics, 58(8): 2873-2885 (in Chinese). [11] Liu L, Liu H, Zhang H, Cui Y F , Li F , Duan W S, Peng G X. 2013. Full-wa veform in version based on a modified quasi-Ne wton formula. Chinese Journal of Geophysics, 56(7): 2447- 2451 (in Chinese). [12] Miao Y K. 2015. Time-domain full-wa veform in version based on the L-BFGS algorithm. Oil Geophysical Prospecting, 50(3): 469-474 (in Chinese). [13] Zhang S Q, Liu C C, Han L G, Y ang X C. 2013. Frequency multi-scale full-wa veform in version based on the L-BFGS algorithm and simultaneous source excitation. Journal of Jilin Uni versity (Earth Science Edition), 43(3): 1004-1012 (in Chinese). [14] Y ang W Y . 2010. Pre-stack A V A synchronous in version method based on simulated an- nealing. Progress in Geophysics, 25(1): 219-224 (in Chinese). [15] Han X Y , Y in X Y , Cao D P , Liang K. 2019. Zero-offset VSP full-wa veform in version based on segmental fast simulated annealing. Geophysical Prospecting for Petroleum, 58(1): 103-111 (in Chinese). [16] Kirkpatrick S, Gelatt C D Jr , V ecchi M P . 1983. Optimization by simulated annealing. Science, 220(4598): 671-680. [17] Zhu T , Li X F , W ang W S, Li M. 2013. Application of particle swarm–gradient algorithm in frequency-domain seismic wa veform in version. Progress in Geophysics, 28(1): 180-189 (in Chinese). [18] Pan D X, Zhang P , Han L G. 2021. Robust full-wav eform in version based on a hybrid adapti ve genetic algorithm. Progress in Geophysics, 36(2): 636-643 (in Chinese). [19] Y ang F , Ma J. 2019. Deep-learning in version: A next-generation seismic velocity model building method. Geoph ysics, 84(4): R583-R599. [20] W u Y , McMechan G A. 2019. Parametric con volutional neural network-domain full- wa veform in version. Geophysics, 84(6): R881-R896. [21] Mikolov T , Kombrink S, Bur get L, ˇ Cernock ` y J, Khudanpur S. 2011. Extensions of re- current neural network language model. In: Proceedings of the 36th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Re- public, 22-27 May 2011, 5528-5531. 11 [22] Y oon D, Y eeh Z, Byun J. 2020. Seismic data reconstruction using deep bidirectional long short-term memory with skip connections. IEEE Geoscience and Remote Sensing Letters, 18(7): 1298-1302. [23] Alfarraj M, AlRegib G. 2019. Semisupervised sequence modeling for elastic impedance in version. Interpretation, 7(3): SE237-SE249. [24] Raissi M, Perdikaris P , Karniadakis G E. 2019. Physics-informed neural netw orks: A deep learning framework for solving forward and in verse problems in volving nonlinear partial dif ferential equations. Journal of Computational Physics, 378: 686-707. [25] Y ang F , Ma J. 2023. FWIGAN: Full-w av eform in version via a physics-informed generati ve adversarial network. Journal of Geophysical Research: Solid Earth, 128, e2022JB025493. https://doi.org/10.1029/2022JB025493 [26] V ersteeg R. 1994. The Marmousi experience: V elocity model determination on a synthetic complex data set. The Leading Edge, 13(9): 927-936. [Alternatively: Martin G S, W iley R, Marfurt K J. 2006. Marmousi2: An elastic upgrade for Marmousi. The Leading Edge, 25(2): 156-166.] [27] Aminzadeh F , Burkhard N, Nicoletis L, Rocca F , W yatt K. 1994. SEG/EAEG 3-D model- ing project: 2nd update. The Leading Edge, 13(9): 949-952. [28] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, W arde-Farle y D, Ozair S, Courville A, Bengio Y . 2014. Generati ve adversarial nets. In: Advances in Neural Information Process- ing Systems, 2672-2680. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment