Latent-Mark: An Audio Watermark Robust to Neural Resynthesis
While existing audio watermarking techniques have achieved strong robustness against traditional digital signal processing (DSP) attacks, they remain vulnerable to neural resynthesis. This occurs because modern neural audio codecs act as semantic fil…
Authors: Yen-Shan Chen, Shih-Yu Lai, Ying-Jung Tsou
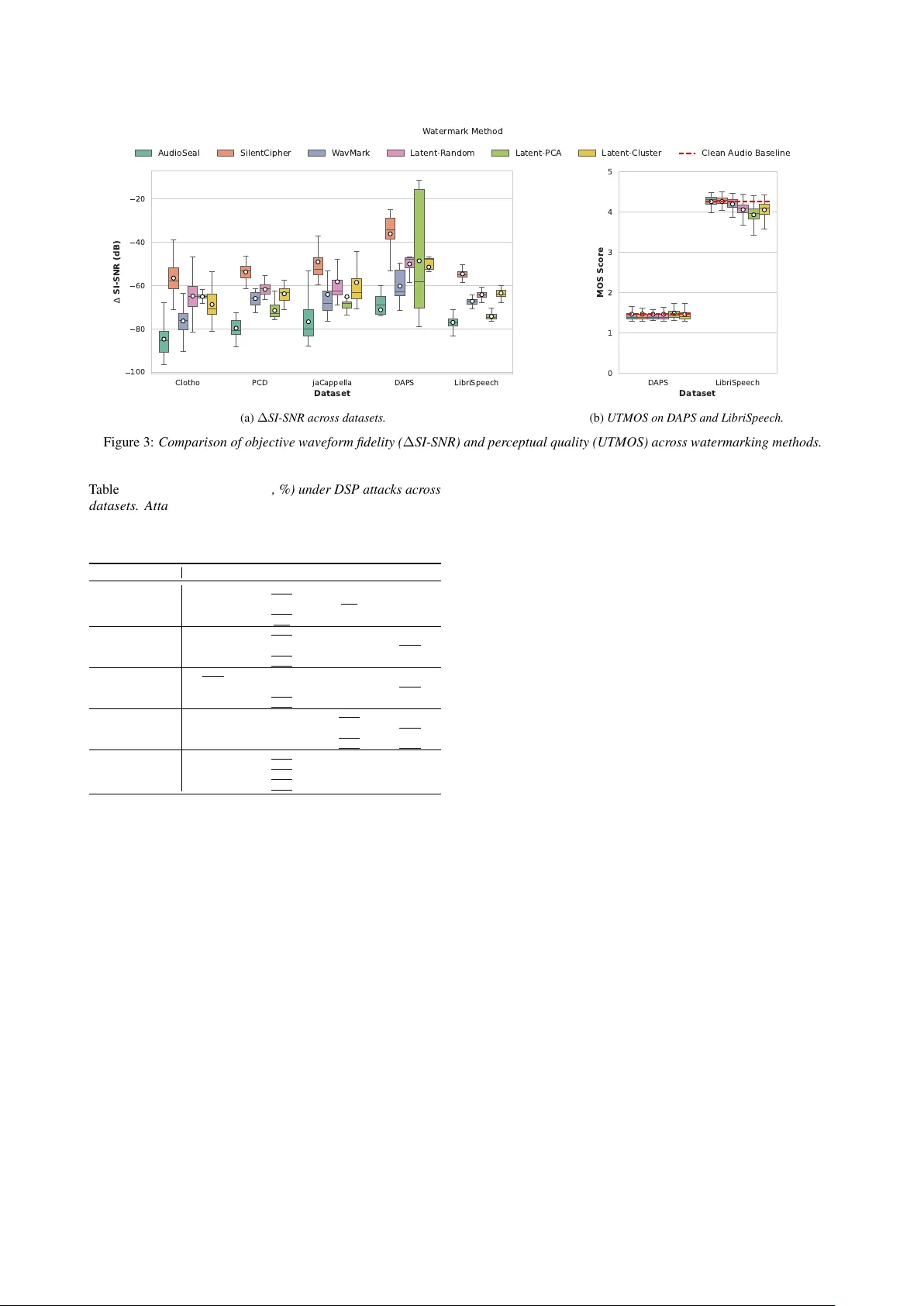
L A T E N T - M A R K : An A udio W atermark Rob ust to Neural Resynthesis Y en-Shan Chen 1 , 2 , ∗ , Shih-Y u Lai 1 , 3 , 4 , ∗ , Y ing-Jung Tsou 1 , Y i-Cheng Lin 1 , Bing-Y u Chen 1 , Y un-Nung Chen 1 , Hung-yi Lee 1 , Shang-Tse Chen 1 , ∗∗ 1 National T aiwan Uni versity , T aiwan 2 CyCraft AI Lab, T aiwan 3 RIKEN Center for Computational Science (RIKEN-CCS), Japan 4 MoonShine Animation Studio, T aiwan { r14922018, r13922a22, r14922076 } @csie.ntu.edu.tw, f12942075@ntu.edu.tw, robin@ntu.edu.tw, y.v.chen@ieee.org, hungyilee@ntu.edu.tw, stchen@csie.ntu.edu.tw Abstract While existing audio watermarking techniques ha ve achie ved strong robustness against traditional digital signal processing (DSP) attacks, the y remain vulnerable to neural resynthesis. This occurs because modern neural audio codecs act as semantic fil- ters and discard the imperceptible wav eform variations used in prior watermarking methods. T o address this limitation, we propose L A T E N T - M A R K , the first zero-bit audio watermarking framew ork designed to surviv e semantic compression. Our key insight is that robustness to the encode-decode process requires embedding the watermark within the codec’ s inv ariant latent space. W e achie ve this by optimizing the audio waveform to induce a detectable directional shift in its encoded latent represen- tation, while constraining perturbations to align with the natural audio manifold to ensure imperceptibility . T o prev ent overfitting to a single codec’ s quantization rules, we introduce Cross-Codec Optimization, jointly optimizing the wa veform across multiple surrogate codecs to target shared latent inv ariants. Extensi ve ev al- uations demonstrate robust zero-shot transferability to unseen neural codecs, achieving state-of-the-art resilience against tradi- tional DSP attacks while preserving perceptual imperceptibility . Our work inspires future research into uni versal watermarking framew orks capable of maintaining integrity across increasingly complex and di verse generati ve distortions. Index T erms : Audio W atermarking, Neural Resynthesis, Latent- Space Shift, Manifold Alignment, Cross-Codec T ransferability 1. Introduction Audio w atermarking has emer ged as a critical tool for intellectual property protection. Recent state-of-the-art methods, such as Au- dioSeal [ 1 ], W avMark [ 2 ], and T imbre [ 3 ], demonstrate strong resilience against a broad spectrum of con ventional digital signal processing (DSP) distortions [ 4 ], including compression, filter - ing, resampling, and sample suppression. In such settings, water - mark robustness has lar gely been framed as survi ving wav eform- or spectrogram-lev el perturbations while remaining impercepti- ble to human listeners. Howe ver , the rapid adoption of neural network-based com- pression and resynthesis models introduces a qualitativ ely differ - ent threat surface that breaks this traditional notion of rob ustness. Modern neural audio codecs, such as EnCodec [ 5 ] and SN AC [ 6 ], reconstruct audio by mapping wa veforms into discrete latent to- kens and decoding them back under a strict bitrate constraint. This encode–quantize–decode pass, which we refer to as Neural * These authors contributed equally . ** indicates the corresponding author . 0 10000 20000 30000 40000 50000 60000 0.4 0.2 0.0 0.2 0.4 Original W ater mark ed (a) Original vs. W atermarked 0 10000 20000 30000 40000 50000 60000 0.4 0.2 0.0 0.2 0.4 W ater mark ed P ost-SNA C (b) W atermarked vs. P ost-SN AC Figure 1: W aveform comparisons at differ ent pr ocessing stag es using AudioSeal. (a) The original and watermarked waveforms lar gely overlap, showing minimal differ ences. (b) Substantial amplitude distortion and phase shifts occur after the SN AC encoding–decoding pr ocess. Resynthesis , is not a localized DSP distortion but a highly non- linear projection through a learned latent bottleneck. As a result, existing watermarks that are highly r obust to DSP transf or - mations can fail catastr ophically after a single codec pass . W e in vestigated this impact through a preliminary analysis using Au- dioSeal [ 1 ], the SN AC [ 6 ] codec, and the LibriSpeech [ 7 ] dataset. As illustrated in Figure 1a , while a w atermarked wav eform ini- tially exhibits no visible deviation from the original signal, a single neural encode–decode pass ( Figure 1b ) introduces ex- tensiv e phase shifts and amplitude distortions that completely misalign with the source watermark. W e attribute this behavior to the inherent design of neural codecs, which act as a semantic pr ojection mapping input sig- nals onto the latent space of v alid audio representations. Under this projection, traditional watermarks—typically embedded as imperceptible, non-semantic noise—are treated as off-manifold residuals and discarded during reconstruction. Despite the output remaining perceptually transparent, these structural modifica- tions effecti vely strip away the fine-grained signals of water- marks required for detection. This elev ates neural resynthesis from a routine compression task to a potent watermark remov al attack, representing a pressing real-world vulnerability as codec- based pipelines become the de facto standard for generative modeling and audio distribution. T o withstand this regime, we propose Latent-Mark , the first zer o-bit audio watermarking framework (i.e., it encodes only pr esence rather than a payload) explicitly designed to with- stand neural resynthesis under semantic bottlenecks. Our core insight is that only featur es embedded in a codec’ s in variant latent space can survive its encode–quantize–decode pro- cess . Accordingly , we formulate watermark embedding as a latent-targeted optimization problem: we apply gradient-based updates directly to the input wav eform to induce a detectable dir ectional shift in the codec latent space, while constraining wa veform perturbations so that the watermark remains impercep- tible. By embedding the mark into the latent manifold itself, it becomes a feature the codec is designed to preserve, rather than a wa veform-lev el artifact neural codecs are trained to discard. A practical watermark must satisfy more than surviving neural codec distortions. First , it must remain imperceptible. W e ensure this by constraining the latent shift to align with the codec’ s learned representation space—specifically along direc- tions defined by codebook centroids. This alignment lev erages the decoder to naturally regularize the watermark, preserving acoustic fidelity . Second , it must generalize beyond a single codec. Building on the above white-box embedding strategy , we further introduce cross-codec optimization across div erse surro- gate codecs. By enforcing the watermark objective simultane- ously under multiple quantization rules, the framework captures shared semantic structures across different codecs and av oids ov erfitting to a single architecture. This ensures zero-shot trans- ferability to unseen black-box codecs. Finally , the watermark should remain robust to traditional DSP distortions: in addition to neural resynthesis, we ev aluate Latent-Mark and find that it maintains state-of-the-art resilience against a wide range of ana- lytic attacks, including adding Gaussian noise, scaling amplitude, filtering, and resampling. Our primary contributions are as follo ws: • W e identify neural r esynthesis as a fundamentally differ - ent attack regime for audio watermarking, and ar gue that neural codecs act as semantic projections that can erase the imperceptible, non-semantic noise patterns used by prior watermarking methods. • W e propose Latent-Mark , the first zero-bit audio wa- termarking framework explicitly designed to withstand neural resynthesis by inducing a detectable latent direc- tional shift via gradient-based waveform optimization. W e show that latent space-aligned shifts enhance acous- tic imperceptibility (Sections 5.1, 5.3). • Building on the white-box formulation, we introduce cross-codec optimization across multiple codecs to achiev e strong zero-shot transferability to unseen black- box codecs. Ultimately , Latent-Mark provides a balance of perceptual fidelity and surviv ability to semantic bottle- necks, while maintaining highly competitiv e rob ustness against prior DSP attacks (Section 5.4). 2. Related W ork 2.1. Mechanisms of Neural W atermarking Across audio, image, te xt, and multi-modal domains, watermark- ing methods are categorized by the space in which they embed signals [ 8 , 9 , 10 , 11 , 12 , 13 , 14 , 15 , 16 , 17 ]. A recurring theme is that robustness depends on how watermark signals interact with model-internal representations and survi ve distortions. T o formalize this, we categorize se veral core concepts commonly employed in the design of rob ust watermarking algorithms: Post-Hoc A udio Signal and Additive Perturbations. While traditional watermarking treats signals as additi ve perturbations across modalities [ 12 ], audio presents a uniquely stringent setting due to the ubiquity of lossy compression and model- mediated transformations [ 18 ]. In contrast to image or text modalities, audio watermarks f ace the unique challenge of sur - viving the complex digital signal processing (DSP) inherent to audio production workflo ws, followed by subsequent degrada- tion across distrib ution channels. Specifically , they face repeated neural codec r e-synthesis and quantization (e.g., SN A C [ 6 ], APCodec [ 19 ], and FunCodec [ 20 ], etc.), which the RA W -Bench [ 9 ] identifies as the most formidable challenge to bit-string in- tegrity . Furthermore, ¨ Ozer et al. [ 9 ] emphasize that practical audio watermarks must withstand an extensi ve battery of studio- standard manipulations—including dynamic range compr ession, limiting, equalization, and re verberation —alongside en viron- mental degradation like background noise. Audio watermarking methods like AudioSeal [ 1 ], SilentCipher [ 21 ], T imbre [ 3 ], and W avMark [ 2 ] address these vulnerabilities by incorporating psy- choacoustic masking and noise-to-mask ratio losses [ 22 ] to hide information within inaudible frequency bands. Latent and Manifold-A ware Embedding. Recognizing that deep generativ e models manipulate semantic concepts rather than raw signals, recent work has shifted tow ard embedding marks directly into continuous latent spaces or discrete codec tokens [ 11 , 23 , 10 ]. Building on classical manifold learning [ 24 , 25 ] and vector -quantized representations [ 26 ], these meth- ods inject structured perturbations into deep features to find a subspace separable from natural content variations. In this paradigm, a watermark’ s survi val depends on aligning with model-internal structural in variances—such as pitch or speaker identity—rather than superficial signal details [ 27 , 28 ]. T o en- sure rob ustness against the quantization and re-synthesis inherent in model-mediated transformations, current strategies include training-time codec augmentation [ 29 ] or integrating watermark- ing objectiv es directly into neural codecs via end-to-end joint training [ 10 ]. This motiv ates ev aluating watermark schemes explicitly under latent representations, such as those used in multi-modal or diffusion-based frame works [16, 17]. A udio Latent-Space A pproaches and Their Limitations. Most recently , highly concurrent works ha ve attempted to tackle the neural codec bottleneck by operating near or within latent spaces, though they rely on fundamentally dif ferent paradigms. For in- stance, Roman et al. [ 30 ] explore watermarking the training data of audio generativ e models such that the trained model inherently emits watermarked codec tokens. Howe ver , this as- sumes white-box control over the model training pipeline and fails to address the post-hoc marking of arbitrary audio assets in the wild. Alternativ ely , Liu et al. [ 31 ] propose an end-to-end framew ork utilizing cross-attention mechanisms for robust em- bedding. While effecti ve against known distortions, it relies on training a static, feed-forward neural embedder against a prede- fined attack set. This risks overfitting to the specific quantization rules seen during training, fundamentally limiting its zer o-shot transfer ability to unseen, proprietary neural codecs. Further- more, without explicit geometric constraints, modifying latent representations can easily push the signal off the natural audio manifold, introducing perceptible artifacts upon decoding. In contrast, our Latent-Mark overcomes these limitations. Rather than training a static embedder or altering generative models, we employ test-time Cr oss-Codec Optimization across surrogate codecs to induce a measurable directional shift in shared seman- tic structures. This ensures zero-shot surviv al against black-box neural resynthesis while enforcing natural manifold constraints to guarantee imperceptibility . 2.2. W atermark Robustness and the Threat of Distortions The definition of a “robust” watermark has ev olved significantly , shifting from algorithmic signal degradations to complete se- mantic reconstruction. T raditional DSP , Channel Distortions, and Rob ustness. Ro- bustness is increasingly defined by rigorous e valuation protocols that transition from algorithmic signal-lev el corruptions to com- plex semantic reconstructions. Historically , benchmarks like AudioMarkBench [ 8 ] and RA W -Bench [ 9 ] systematize a wide array of remov al and forgery attacks, including MP3 compres- sion, bandpass filtering, added noise, rev erberation, and modern neural codec chains. T o counter these, researchers have de- veloped v arious defensiv e mechanisms, such as noise-to-mask ratio (NMR) losses [ 22 ], training-time codec augmentation [ 29 ], and end-to-end deepfak e verification pipelines [ 32 ]. Beyond generic perturbations, contemporary systems must withstand adaptiv e and model-aware threats, including ov erwriting, own- ership conflicts, and spoofing [ 33 ]. These security challenges hav e prompted the integration of defensi ve cryptographic hash- ing and filter -based mechanisms to pre vent for gery within neural watermarking frame works [34]. The Paradigm Shift to Neural Resynthesis. The landscape of distortions fundamentally changed with the introduction of high- fidelity neural audio codecs (e.g., SoundStream [ 35 ], EnCodec [ 5 ], D A C [ 36 ]). Unlike MP3, which remov es psychoacoustically masked frequencies, neural codecs completely deconstruct the wa veform into discrete semantic tokens—typically utilizing con- volutional architectures and Residual V ector Quantization (R VQ) to capture coarse-to-fine structure—and re-synthesize it from scratch. Because neural resynthesis acts as an e xtreme, structure- aware information bottleneck [ 4 ], it explicitly discards the “of f- manifold” residual noise that traditional additiv e methods rely upon. Compounding this threat, these discrete codec tokens now serve as the foundational vocab ulary for modern generati ve se- quence models [ 37 , 38 , 39 ]. Large audio language models treat quantized indices as linguistic sequences for zero- or fe w-shot speech synthesis [ 18 , 40 , 41 , 42 , 43 ]. Thus, signal-space mod- ifications must surviv e this encode–quantize–decode pipeline. Recent benchmarks like RA W -Bench [ 9 ] confirm neural codecs are the primary threat to audio watermarks, necessitating a shift tow ard latent-aware strate gies. 3. Methodology 3.1. Preliminaries The Gap. The vulnerability of traditional audio watermarking to neural resynthesis stems from a fundamental repr esentation mismatch . Con ventional methods typically embed watermarks as non-semantic residuals or psychoacoustic masking patterns at the wa veform le vel. Howe ver , modern neural codecs process audio through a lossy reconstruction operator: R ( s ) = D ( Q ( E ( s )))) (1) where E is the encoder mapping the time-domain audio s to a continuous feature space; Q is the vector quantizer that dis- cretizes these features by mapping them to the nearest entries in a codebook W ; and D is the decoder that reconstructs the signal back into the original audio space. Because traditional watermarks are designed to be imperceptible, they often man- ifest as subtle signal variations that are effecti vely treated as quantization noise. During resynthesis, these “off-manifold” details are discarded. Consequently , the core challenge stems from detectability : the basic ability to extract the watermark from an unattacked signal, and surviv ability : the capacity of the watermark to endure the lossy quantization of resynthesis. The intuition. Assuming a white-box setting where we have parameter access to the codec’ s encoder E , we propose Latent- Mark : a framework ( Figure 2 ) that identifies and leverages latent properties in variant to the quantization process. Rather than injecting waveform-le vel noise, we induce a directional shift in the continuous latent representation z tow ard a secret manifold axis v c before it enters the quantizer Q . This modification is designed to surviv e resynthesis by “steering” the latent tokens into a distribution with a persistent directional bias. While the perceiv ed audio remains unchanged, this shift remains detectable ev en after the signal is decoded and subsequently re-encoded. W e formulate this as a zero-bit watermarking challenge , where the goal is to induce a statistically significant shift in the latent sequence along a designated secret axis , ensuring the perturbation surviv es the semantic bottleneck. 3.2. Problem F ormulation Let s ∈ R T be the input audio wa veform, where T denotes the total number of temporal samples. A neural codec c maps s to a latent representation: z c = Q ( E ( s )) ∈ R d × L (2) where d is the codebook dimension and L is the sequence length of the latent frames. Our frame work consists of an Encoder E wm and a Detector Det wm . W e generate a watermarked wa veform s w = s + δ by solving a gradient-based optimization over the perturbation δ . The Detector determines the presence of the mark by computing a scalar score y based on the latent projection of a suspect signal s ′ onto a secret manifold vector v c ∈ R d . T o induce the desired shift while maintaining perceptual transparency , we formulate the embedding as a constrained op- timization problem. W e solve for the perturbation δ that max- imizes the alignment with the manifold vector v c subject to a small wa veform distortion: min δ L wm ( s + δ, v c ) s.t. || δ || ∞ ≤ ϵ (3) where ϵ is a dynamic threshold determined by the target Signal- to-Distortion Ratio (SDR). This prevents the watermark from introducing audible artifacts into the original audio s . The Latent-Mark framework consists of an optimization- based Embedder and a statistical Detector . For an y giv en codec c , the presence of a watermark is defined by the alignment of the signal’ s latent representation z c with a secret manifold axis v c ∈ R d . W e measure this alignment via the projection score Quantization discrete tokens shifted latent representation latent representation R V Q specific shift detected? watermarking (add perturbation δ) A u d i o L a t e n t S p a c e Original Audio W atermark Detector A. Macro Pipeline: End-to-End Latent-Mark Framework B. Micro Mechanism: Latent Space Shift Audio Encoder Audio Decoder Watermarked Audio detectable shift Watermarked Audio Watermarked Audio ( attacked ) C. Withstand Attack: Watermark Detectability and Survivability C o d e c s D A C , E n c o d e c , S N A C . . . Resynthesized Audio Figure 2: Overview of Latent-Mark. (A) Macro end-to-end pipeline. The lower blue and gray components illustrate the standar d neural r esynthesis pipeline; The orange components highlight our pr oposed additions: adding an optimized perturbation δ to the original audio to intentionally induce a constrained shift in its latent r epr esentation prior to quantization and decoding. (B) Micro mechanism for the r obust latent space shift, driven by a pr edefined shifting vector v = µ B − µ A between cluster centr oids. (C) W atermark detectability and survivability against attacks . The watermarked audio under goes destructive neural codec pipelines (encoding, RVQ, and decoding), after which a detector ( E ) verifies if the latent shift persists. ¯ p c ( s ) , defined as the temporal mean of the latent projections ov er the sequence length L : ¯ p c ( s ) = 1 L L X t =1 ⟨ z c,t , v c ⟩ (4) W atermark Optimization. Embedding is formulated as a con- strained optimization problem. Given an input audio s , we solve for a wa veform perturbation δ that steers the latent representation into the target direction. W e minimize a hinge loss objective: min δ ReLU ( γ c − ¯ p c ( s + δ )) s.t. || δ || ∞ ≤ ϵ (5) where γ c represents the tar get alignment scor e (set to 1 . 5 in our implementation). The intuition behind γ c is to create a “safety margin” that pushes the latent projection far enough into the target manifold so that the shift survi ves the rounding ef fects of the quantization bottleneck. T o maintain imperceptibility , we enforce a dynamic threshold ϵ = β · RMS ( s ) · 10 − SDR / 20 , where RMS denotes the root mean square function. W e solve this via the Adam optimizer for 150 steps, applying a hard clip to δ at each iteration to strictly satisfy the perceptual boundary . W atermark Detection. Detection is a statistical verification process performed in the latent domain. For a suspect signal s ′ , we first compute the raw projection score ¯ p c ( s ′ ) , which corre- sponds to the temporal mean of the projected latent sequence. T o ensure robustness across different codec architectures with varying latent scales, we compute a Normalized Mar gin m c : m c ( s ′ ) = ¯ p c ( s ′ ) − τ c σ c (6) where τ c is the detection threshold ( µ c + k σ c ) and σ c is the standard de viation of projections deri ved from a null distrib ution of clean audio. A watermark is detected if m c > 0 . Shifting Axis Selection. While v c can be any arbitrary unit vector , for the main experiment, we design its selection with the intention of improving survi vability through the quantization bottleneck Q , and term this the Latent-Cluster variant. Aiming to guide the shift tow ard high-density regions of the latent space, we deriv e v c by partitioning the codebook weights W ∈ R K × d into two primary groupings via K -means clustering ( k = 2 ). Letting µ 0 and µ 1 be the resulting centroids, we define the axis as the unit-normalized vector between them: v c = µ 1 − µ 0 || µ 1 − µ 0 || 2 (7) By aligning v c with the codebook distribution, our inten- tion is for the perturbation to act more like a structural feature rather than stochastic noise, hypothesizing that this alignment increases its likelihood of preserv ation during discretization. A comparativ e analysis of alternativ e directions is in Section 5.1. 3.3. Joint Cr oss-Codec Optimization A fundamental limitation of single-codec optimization is the lack of transferability; a watermark optimized for one specific codec’ s latent representation may be treated as stochastic noise and dis- carded by another . T o achieve zero-shot robustness against unseen black-box models, we introduce Joint Manifold Op- timization . Instead of targeting a single bottleneck, we identify a semantic intersection : a directional shift that a committee of heterogeneous surrogate codecs C collectiv ely agree is structural. Framework Overview . Our joint optimization pipeline con- sists of four integrated stages: (1) a multi-rate resampling loop to synchronize heterogeneous codec views; (2) a calibration phase to balance gradients across different latent scales; (3) a constrained optimization loop that induces a structurally in vari- ant latent shift; and (4) an ensemble detection mechanism that aggregates e vidence for robust v erification. Stage 1. Cross-Codec Resampling Pipeline. Because the committee members operate at different sampling rates, we im- plement a synchronized resampling loop. During each optimiza- tion step, the perturbation δ is maintained in a high-resolution workspace at rate f work . For each codec c ∈ C , the perturbed signal s + δ is resampled to the codec’ s native rate f c before latent extraction. W aveforms are padded to satisfy a temporal constraint T pad to ensure stable optimization across all views. In our implementation, we set f work = 44 . 1 kHz and T pad to multiples of 4096 samples. Stage 2. Gradient Balancing via Calibration. Different archi- tectures operate on vastly dif ferent latent scales, which can lead to “gradient dominance” where one codec’ s loss overwhelms others. T o counter this, we use a Baseline Calibration method to calculate a target threshold τ c = µ c + k σ c and a normalization scale α c deriv ed from a null distribution of clean audio: α c = E [ ReLU ( τ c − ¯ p c ( s ))] (8) where α c represents the av erage projection gap of clean audio. W e set the calibration constant k = 1 . 5 . By dividing each per-codec hinge loss by its respective α c , we ensure the opti- mization assigns equal importance to satisfying the manifolds of all committee members regardless of their latent v ariance. Stage 3. Joint Manifold Injection Objecti ve. W e solve for the optimal perturbation δ by minimizing the ensemble normalized hinge loss ov er N steps using the Adam optimizer: min δ 1 |C | X c ∈C ReLU ( τ c − ¯ p c ( s + δ )) α c s.t. || δ || ∞ ≤ ϵ (9) The budget ϵ is dynamically adjusted as ϵ = clip ( β · RMS ( s ) · 10 − SDR / 20 , ϵ min , ϵ max ) . W e set N steps = 150 , β = 2 . 5 , ϵ min = 10 − 4 , and ϵ max = 0 . 1 . This objective effecti vely induces a directional bias into the shared semantic features of the committee, increasing the likelihood that the mark will surviv e resynthesis by an unseen attacker codec a / ∈ C . Stage 4. Ensemble Detection and ∆ -Score. Detection is per- formed by aggre gating e vidence across the committee. For a sus- pect signal s ′ , we compute the Normalized Margin m c ( s ′ ) = ( ¯ p c ( s ′ ) − τ c ) /α c for each view . Let { m (1) , m (2) , . . . , m ( |C | ) } denote the margins sorted in ascending order . T o ensure ro- bustness against outlier distortions, the final detection score is defined as: score ( s ′ ) = m l |C| 2 m ( s ′ ) (10) Notably , taking the mean of normalized margins is suscepti- ble to e xtreme outliers caused by scale v ariations across dif ferent codec geometries, while the median acts as a robust statistic. It effecti vely functions as a majority voting mechanism, ensuring that even if an attack completely obliterates the watermark in a minority of vie ws (resulting in unbounded negati ve margins), the global detection remains stable as long as the structural bias persists in the remaining surrogate spaces. T o evaluate transferability under attack, we utilize a ∆ -Score metric, which measures the shift in detection score relati ve to a clean baseline: ∆ = score ( R a ( s wm )) − score ( R a ( s )) , where R a is the resynthesis operator of an unseen attack codec. A positiv e ∆ indicates that the watermark’ s directional bias has successfully transferred through the black-box bottleneck. 4. Experiments The primary objecti ve of our study is to verify whether Latent- Mark retains its embedded signal through the e xtreme bottleneck of neural resynthesis, and investig ate if cross-codec joint opti- mization enables better transferability to unseen codecs. 4.1. Experimental Setup Datasets. W e ev aluate our method across seven di verse datasets spanning three primary acoustic domains: ambient and en- vironmental sound (AIR [ 44 ], Clotho [ 45 ]), human speech (LibriSpeech [ 7 ], DAPS [ 46 ]), and music and vocals (PCD [ 47 ], jaCappella [ 48 ], MAESTRO [ 49 ]). T o ensure statistical consistency and balanced e valuation, we uniformly sample 120 instances from each dataset, randomly subsampling those that exceed this threshold. Baselines. W e compare Latent-Mark against three state-of-the- art watermarking models: W a vMark [ 2 ], SilentCipher [ 21 ], and A udioSeal [ 1 ]. F or the single-codec variant of Latent- Mark , we utilize SN A C as the primary surrogate model. For the cross-codec v ariant ( Latent-Mark-Joint ), we optimize across an ensemble of models with div erse architectures and sampling frequencies (SNA C 32 kHz, DA C 16 kHz, and DA C 44 kHz), testing cross-family codecs transferability on APCodec [ 19 ] and FunCodec [ 20 ], as formulated in Section 3.3. An extended anal- ysis of this surrogate model selection is provided in Section 5.2. Evaluation Metrics. W e ev aluate watermark performance us- ing two primary metrics. Detectability (Det.) ev aluates the detector’ s fundamental accuracy on clean, unperturbed audio. W e assess watermark performance using a balanced test set comprising 50 watermarked and 50 unwatermarked (original audio) samples per dataset. Alongside overall classification ac- curacy , we explicitly report the True Positive Rate (TPR) and the False Positive Rate (FPR). Survivability (Sur .) quantifies the robustness of the embedded signal against se vere compres- sion bottlenecks. It is defined strictly as the successful detection rate on the watermarked samples after they ha ve been processed through the neural resynthesis attack. Attacker Models. In these primary ev aluations, we utilize the SN A C [ 6 ] architecture (with frequency 24kHz) as the surrogate model for Latent-Mark’ s detector . While our main experiments focus on surviv ability against SN A C resynthesis, we further in vestigate the zero-shot transferability of our embedded marks in Section 5.2, where we test rob ustness against attacks from a variety of other unseen neural codecs in different codec types and sampling rates. 4.2. Results T able 1 (Left) summarizes the performance of our proposed Latent-Mark variants against state-of-the-art watermarking baselines across eight di verse datasets. From these ev aluations, we draw three primary findings: First, in terms of detectability on unperturbed audio, both the prior baselines and our Latent-Mark variants (with or without joint optimization) maintain highly competiti ve performance, consistently e xceeding 0.95 accuracy across most datasets. This confirms that Latent-Mark, similar to prior base- lines, reliably triggers the detector under standard conditions. Second, a stark contrast emerges regarding survivability against the neural codec bottleneck. While prior watermark- ing methods experience catastrophic failure —dropping to T able 1: Benchmark r esults acr oss datasets. Detectability (Det.) is presented as Accur acy (TPR/FPR), while Survivability (Sur .) reports the detection rate after neural r esynthesis with SNA C (24kHz). F or simplicity , the original version of our Latent-Mark is shown as Latent-Cluster , and Latent-Mark-J oint is abbre viated to Latent-J oint . Left: Comparison of Latent-Mark and its joint-optimization variant against prior baselines (Section 4.2). Right: Evaluation of our method using alternative secret ke y directions (Section 5.1). Best and second-best values ar e highlighted in bold and underlined. Main Experiment Dir ectional V ariants Dataset Metric W avMark SilentCipher AudioSeal Latent-Cluster Latent-Joint Latent-PCA Latent-Random AIR Det. 95.0 (99.2/9.2) 93.3 (95.0/9.2) 96.7 (97.5/4.2) 95.8 (95.8/4.2) 100.0 (100.0/0.0) 95.8 (99.2/6.7) 100.0 (100.0/0.0) Sur . 0.0 0.0 0.0 61.7 53.3 60.8 66.7 Clotho Det. 93.3 (95.0/9.2) 96.7 (100.0/5.8) 94.2 (94.2/5.8) 92.5 (91.7/7.5) 96.7 (95.8/3.3) 93.3 (92.5/7.5) 93.3 (95.0/9.2) Sur . 0.0 0.0 0.0 58.3 58.3 61.7 61.7 D APS Det. 100.0 (100.0/0.0) 93.3 (97.5/11.7) 100.0 (100.0/0.0) 99.2 (100.0/1.7) 83.3 (85.0/20.0) 95.0 (99.2/9.2) 95.8 (96.7/5.0) Sur . 0.0 0.0 8.3 93.3 76.7 88.3 65.0 LibriSpeech Det. 96.7 (96.7/3.3) 96.7 (97.5/4.2) 91.7 (91.7/7.5) 100.0 (100.0/0.0) 93.3 (95.0/10.0) 95.8 (95.0/3.3) 95.0 (95.0/5.0) Sur . 4.2 0.0 5.0 80.8 74.2 65.8 76.7 jaCappella Det. 96.7 (96.7/3.3) 100.0 (100.0/0.0) 100.0 (100.0/0.0) 100.0 (100.0/0.0) 95.0 (98.3/8.3) 95.8 (95.8/4.2) 100.0 (100.0/0.0) Sur . 0.0 0.0 0.0 75.8 75.8 77.5 70.8 PCD Det. 90.8 (90.8/9.2) 96.7 (94.2/0.0) 90.8 (91.7/10.0) 90.8 (90.8/9.2) 88.3 (91.7/16.7) 95.8 (94.2/1.7) 100.0 (100.0/0.0) Sur . 0.0 0.0 1.7 81.7 78.3 71.7 75.8 MAESTR O Det. 96.7 (99.2/5.0) 96.7 (95.0/0.8) 95.0 (99.2/9.2) 100.0 (100.0/0.0) 89.2 (95.0/16.7) 95.0 (98.3/8.3) 95.8 (95.0/3.3) Sur . 0.0 0.0 0.0 80.8 71.7 65.0 83.3 GuitarSet Det. 100.0 (100.0/0.0) 100.0 (100.0/0.0) 100.0 (100.0/0.0) 96.7 (95.0/0.8) 85.0 (90.0/20.0) 95.0 (95.0/5.0) 97.5 (100.0/4.2) Sur . 0.0 0.0 0.0 86.7 68.3 85.0 61.7 near-zero detection rates across the board— Latent-Mark ro- bustly pr eserves the embedded signal , achie ving surviv ability scores consistently abo ve 0.58 and peaking at 0.93 on the Clotho dataset (using Latent-Cluster). W e note that Latent-J oint e xhibits slightly lo wer performance compared to its single-codec coun- terparts; this is expected, as performing white-box optimization against multiple codecs simultaneously necessitates a trade-of f in specialized robustness. Nev ertheless, its performance remains highly competiti ve, maintaining accuracy rates abo ve 0.58 across all tested configurations. Finally , we observe that the audio domain influences re- tention. Speech and vocal datasets (e.g., DAPS, LibriSpeech) generally exhibit more stable survi vability , frequently exceeding 0.70. In contrast, certain en vironmental noise distributions lik e AIR show slightly lower retention ranges (between 0.50 and 0.70). Notably , among the baselines, only AudioSeal demon- strated any mar ginal resilience to neural resynthesis (retaining a mere 0.08 on D APS and 0.05 on LibriSpeech), further under - scoring the critical necessity of our latent-space formulation. 5. Ablation and Analysis Having demonstrated the primary robustness and detectability of Latent-Mark under neural resynthesis, we no w present a series of analyses to validate our design. Our evaluation is tw ofold. First, we conduct architectural ablations to justify our core hyperpa- rameter choices, specifically inv estigating the selection of secret ke y directions within the latent space (Section 5.1) and the im- pact of surr ogate model combinations (Section 5.2) Second, we ev aluate Latent-Mark against established baselines to compare the acoustic imperceptibility (Section 5.3) of the watermarks and verify that optimizing for neural codec bottlenecks does not inadvertently compromise r obustness against traditional digital signal pr ocessing attacks (Section 5.4). 5.1. Choice of Secret K ey Direction W e first discuss how the direction of the secret key (see Sec- tion 3.2, Choice of Shifting Axis ) influences watermarking performance and survi vability . T o isolate the impact of this ge- ometric choice, we compare three distinct v ariants for deriving the target axis: Latent-Cluster (our primary method, which utilizes the vector connecting the centroids of a k = 2 clustering of the codebook), Latent-PCA , which deri ves the axis from the first principal component (the direction of maximum vari- ance) of the centered codebook weights using Singular V alue Decomposition, and Latent-Random , which simply samples a uniformly random, unit-normalized vector within the latent dimension space. Comparing the post-resynthesis surviv ability of these ap- proaches in T able 1 (Right) , Latent-Cluster yields the most robust performance, ranking first in four of the eight datasets. Latent-Random follows closely , securing first place in three datasets and second place in one. Conv ersely , Latent-PCA con- sistently performs the worst across the e valuations. This hierarchy stems from how each strate gy interacts with the quantization bottleneck Q . Latent-Cluster explicitly guides the watermark to ward high-density regions of the codebook; by mimicking a structural transition between mass centers, the per- turbation is effecti vely preserv ed by the nearest-neighbor quan- tizer as a valid semantic shift. Con versely , the poor performance of Latent-PCA rev eals that shifting along the axis of maximum variance is detrimental. Because the first principal component represents the most continuous variations in the feature space, the quantizer likely treats such shifts as standard signal variance rather than a distinct structural feature, causing the watermark to be aggressiv ely washed out during discretization. Further comparisons regarding the acoustic imperceptibil- ity of the watermarks generated by these distinct directional methods are detailed in Section 5.3. T able 2: T ransfer ability under codec resynthesis attac ks acr oss all optimization settings and three acoustic domain datasets. V alues are survivability pass rates (%). The best and second-best values per column are highlighted in bold and underlined. Ambient & En vironmental Human Speech Music & V ocals Method Clotho LibriSpeech DAPS PCD jaCappella SNA C44 EnCodec48 D AC24 SNA C44 EnCodec48 D AC24 SNA C44 EnCodec48 D AC24 SNA C44 EnCodec48 D AC24 SNA C44 EnCodec48 D AC24 Latent-Joint (Opt C1) 92.50 97.50 93.33 100.00 85.00 100.00 90.83 100.00 100.00 95.00 100.00 90.00 92.00 100.00 68.00 Latent-Joint (Opt C2) 100.00 98.33 79.17 80.00 100.00 79.17 100.00 100.00 77.50 100.00 100.00 100.00 100.00 100.00 98.00 Latent-Joint (Opt F1) 79.17 95.83 57.50 100.00 91.67 100.00 98.33 100.00 69.17 77.50 100.00 97.50 96.00 100.00 88.00 Latent-PCA (snac24) 69.00 63.17 83.67 66.83 28.00 69.17 84.00 89.83 99.33 100.00 100.00 100.00 71.20 58.00 76.00 Latent-Cluster (snac24) 94.67 95.33 97.16 100.00 100.00 97.50 100.00 100.00 100.00 97.50 100.00 100.00 100.00 100.00 100.00 Latent-Random (snac24) 66.00 55.33 75.33 76.83 54.17 83.33 88.50 53.67 99.00 2.50 0.00 10.00 77.20 44.00 98.00 Latent-Joint (Opt D1) 60.00 55.80 59.20 65.67 70.80 73.33 79.20 95.80 72.50 37.50 37.50 50.00 60.00 62.00 80.00 Latent-Joint (Opt D2) 70.80 63.30 61.70 47.50 69.17 44.17 90.80 100.00 82.50 55.00 52.50 52.50 40.00 44.00 56.00 5.2. Surrogate Model Selection f or Joint Optimization W e next discuss ho w the model combination used for joint opti- mization (Section 3.3) affects performance and transferability . Throughout this section, codec shorthand (e.g., snac32 ) denotes the architecture ( snac ) operating at a specific sampling frequency ( 32 kHz). W e select fiv e optimization combinations targeting two orthogonal generalization axes: cr oss-codec archi- tecture shifts and cr oss-sampling-rate v ariations. • Opt C1 { snac32, dac16, dac44 } and Opt C2 { snac32, encodec24, encodec32 } focus on intra-family gener- alization. By optimizing against “architecturally c loser” relativ es sharing a hierarchical R VQ structure, we test if the watermark generalizes to unseen members of the same lineage across varying sampling rates. • Opt F1 { snac24, dac24, encodec24 } ev aluates cross- family transferability under a controlled f requency con- straint by fixing all codecs at 24 kHz. • Opt D1 { snac24, dac44, funcodec } and Opt D2 { snac24, funcodec, apcodec } explore extreme cross- family scenarios. These “ d istant” groups incorporate heterogeneous architectures (e.g., FunCodec, APCodec) to stress-test rob ustness against radical domain shifts in unrelated neural synthesis pipelines. W e compare these against single-optimization baselines (Latent-Cluster , PCA, and Random, optimized on snac24 ). T o test transferability , we use snac44 , encodec48 , and dac24 for neural resynthesis. Experimental results are summarized in T able 2 . W e de- fine transferability as the success rate of w atermark perturba- tions—initially optimized to survi ve a specific codec resynthe- sis—when ev aluated against unseen codec architectures. Specifi- cally , we first identify watermark perturbations that successfully surviv e snac24 resynthesis (the common optimization target across all settings) and subsequently assess whether this robust- ness generalizes to disparate codec environments. W e present results for two representativ e datasets from each audio category: en vironmental noise, human speech, and music. Sev eral key observations can be dra wn from these results: Architectural pr oximity serves as the primary determi- nant of transfer success, as evidenced by the significant per- formance gap between intra-family and cross-family transfers. Specifically , configurations optimized for architectures similar to the target (e.g., C 1 , C 2 , F 1 ) outperform distant-family trans- fers by approximately 20%. While identifying shared semantic features across disparate architectures remains a challenge, our method maintains a baseline transferability between 50–70%, indicating that the learned perturbations are not strictly ov er- fitted to a single decoder’ s bias. Furthermore, intra-family generalization is significantly increased by including at least one repr esentative codec from the target family during op- timization. For instance, the inclusion of D A C variants in C 1 leads to high robustness for the unseen dac24 , while EnCodec- inclusiv e optimization in C 2 excels on encodec48 , suggesting that structural commonalities, such as shared Residual V ector Quantization (R VQ) hierarchies, are more critical for transfer than matching bitrates or sampling frequencies. Third, joint optimization configurations consistently demonstrate superior rob ustness compared to single-variant baselines, provided that the optimization set includes at least one representativ e from the target codec’ s architectural family . By comparing the joint frameworks ( C 1 , C 2 , F 1 ) against the single-variant baselines ( Latent-Cluster , PCA , and Random ), we observe that exposure to diverse neural resynthesis processes prev ents the watermark from occupying narro w , codec-specific latent regions, ef fecti vely cov ering a broader spectrum of unseen codecs than the individual semantic-mapping strate gies. Finally , structural architecture remains a more signifi- cant bottleneck for watermark survival than sampling fre- quency , a fact highlighted by the F 1 configuration. Despite F 1 being optimized for 24kHz targets, it fails to provide dis- proportionate gains for the 24kHz dac24 variant compared to other families. This indicates that the specific inductiv e bias of the neural synthesis layers—rather than the frequency response of the signal—is the dominant factor that the watermark must navigate to remain imperceptible yet detectable. 5.3. A udio Quality and Imperceptibility T o ev aluate the impact of watermark embedding on percep- tual quality , we utilize two metrics: ∆ SI-SNR (Scale-In variant Signal-to-Noise Ratio change) [ 50 ] to measure mathematical wa veform fidelity , and UTMOS (UT okyo-SaruLab MOS Predic- tion System) [ 51 ], a neural-based Mean Opinion Score (MOS) predictor for human-like perceptual assessment. As illustrated in Figure 3a, the observed change in wave- form fidelity ( ∆ SI-SNR) follows the trend: SilentCipher > Latent-Cluster , Latent-Random > Latent-PCA , AudioSeal , W av- Mark . Of our proposed variants, Cluster and Random demon- strate comparable stability , likely due to their uniform treatment of the latent space. In contrast, the PCA variant e xhibits higher variance, reflecting greater sensiti vity to the underlying data. W ater mark Method AudioSeal SilentCipher W avMark Latent-R andom Latent-PCA Latent-Cluster Clean Audio Baseline Clotho PCD jaCappella D APS LibriSpeech Dataset 100 80 60 40 20 S I - S N R ( d B ) (a) ∆ SI-SNR acr oss datasets. D APS LibriSpeech Dataset 0 1 2 3 4 5 MOS Score (b) UTMOS on D APS and LibriSpeech. Figure 3: Comparison of objective waveform fidelity ( ∆ SI-SNR) and per ceptual quality (UTMOS) acr oss watermarking methods. T able 3: Survivability (pass rates, %) under DSP attacks acr oss datasets. Attacks: GA U = Gaussian noise (SNR=60), AMP = Amplitude scaling (0.5), LPF = Low-pass filtering (4kHz), and RSM = Resampling (16kHz). Dataset Attack AudioSeal [1] SilentCipher [21] W avMark [2] Latent-Mark AIR GA U 100.00 18.60 3.33 100.00 AMP 100.00 0.00 3.49 100.00 LPF 100.00 10.17 3.49 100.00 RSM 100.00 9.30 3.49 100.00 Freischuetz GA U 68.49 97.26 100.00 69.86 AMP 100.00 0.00 100.00 71.23 LPF 100.00 93.15 100.00 56.16 RSM 100.00 95.89 100.00 64.38 GuitarSet GA U 90.00 100.00 100.00 67.78 AMP 100.00 0.00 100.00 91.11 LPF 100.00 94.44 100.00 100.00 RSM 100.00 92.22 100.00 100.00 jaCappella GA U 20.00 46.00 84.00 100.00 AMP 100.00 0.00 84.00 88.00 LPF 100.00 38.00 84.00 78.00 RSM 100.00 34.00 84.00 84.00 LibriSpeech GA U 100.00 99.19 100.00 100.00 AMP 100.00 98.39 100.00 100.00 LPF 100.00 89.52 100.00 75.81 RSM 100.00 91.13 100.00 100.00 As for perceptual quality (UTMOS) , despite the differ - ences captured by ∆ SI-SNR, the UTMOS results in Figure 3b indicate that the perceptual quality across all methods is nearly indistinguishable, suggesting that the artifacts introduced by our semantic-based embedding are effecti vely masked and maintain a high lev el of imperceptibility to the human ear . 5.4. Robustness to Prior Attacks Besides imperceptibility , we extend our comparisons to ev aluate the robustness of Latent-Mark against traditional digital signal processing (DSP) distortions, benchmarking against the same three baselines: AudioSeal, W avMark, and SilentCipher . Fol- lowing the e valuation protocol outlined in SoK [ 4 ], we subject the watermarked audio to four highly diverse signal distortion attacks to cov er a wide spectrum of degradation: Gaussian noise, amplitude scaling, low-pass filtering, and resampling. The hy- perparameters are set consistently with prior work. As sho wn in T able 3 , AudioSeal consistently achiev es the highest robustness across these traditional distortions, which is expected given that it is explicitly trained on augmented au- dio editing data to ensure resilience against such modifications. Meanwhile, Latent-Mark and W a vMark exhibit competitive, dataset-dependent performance; our method outperforms W a v- Mark on the AIR and jaCapella datasets, whereas W avMark holds an advantage on Freischuetz and GuitarSet. This indicates that while Latent-Mark is primarily designed to survive neu- ral codec bottlenecks, it successfully retains rob ustness against con ventional attacks, performing on par with dedicated robust watermarking methods. Finally , SilentCipher yields the lo west detection rates in this setting—dropping to as lo w as 0.00% un- der amplitude scaling attacks across several datasets—which we attribute to its reliance on delicate temporal and phase alignments that are easily disrupted by broad signal distortions. Summary of T rade-offs. Concluding from Sections 5.3 and 5.4, Latent-Mark establishes a balance between acoustic trans- parency and rob ustness. While AudioSeal and W avMark e xhibit strong resilience to traditional DSP distortions, they do so at the sev ere expense of audio quality and completely fail under neu- ral resynthesis. Conv ersely , while SilentCipher maintains high imperceptibility , it remains vulnerable to both DSP attacks and codec bottlenecks. Latent-Mark deliv ers acoustic fidelity com- parable to the highly constrained SilentCipher , while uniquely surviving the e xtreme bottleneck of neural resynthesis and main- taining competitiv e defense against standard DSP perturbations. 6. Conclusion W e propose Latent-Mark , the first watermarking framework specifically engineered to survi ve neural resynthesis, a process that causes catastrophic failure in traditional methods. Using the insight that watermark information must be embedded directly into the semantic latent space to na vigate quantization bottle- necks, we successfully bridge the gap between DSP robustness and neural codec surviv ability . Our findings indicate that latent-space alignment is critical in robustness to wards neural resynthesis; specifically , perturbations guided by the codebook’ s topological clusters achie ve higher imperceptibility while maintaining high detection accuracy . Be- yond its specialized resilience to neural synthesis, Latent-Mark achiev es state-of-the-art performance in both perceptual trans- parency and rob ustness against DSP attacks. Finally , we show that black-box transferability can be achieved by jointly optimiz- ing across di verse codec architectures and inspire future research on de veloping unified watermarking methods to adapt to the ev olving landscape of generativ e neural synthesis. 7. References [1] R. San Roman, P . Fernandez, H. Elsahar, A. D ´ efossez, T . Furon, and T . T ran, “Proacti ve detection of v oice cloning with localized watermarking, ” ICML , 2024. [2] G. Chen, Y . W u, S. Liu, T . Liu, X. Du, and F . W ei, “W a v- mark: W atermarking for audio generation, ” 2023. [3] C. Liu, J. Zhang, T . Zhang, X. Y ang, W . Zhang, and N. Y u, “Detecting voice cloning attacks via timbre watermarking, ” in Network and Distributed System Security Symposium , 2024. [4] Y . W en, A. Innuganti, A. B. Ramos, H. Guo, and Q. Y an, “Sok: How robust is audio watermarking in generati ve ai models?” 2025. [5] A. D ´ efossez, J. Copet, G. Synnae ve, and Y . Adi, “High fidelity neural audio compression, ” 2022. [6] H. Siuzdak, F . Gr ¨ otschla, and L. A. Lanzend ¨ orfer , “Snac: Multi-scale neural audio codec, ” 2024. [7] V . Panayoto v , G. Chen, D. Pove y , and S. Khudanpur , “Lib- rispeech: An asr corpus based on public domain audio books, ” in 2015 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP) , 2015, pp. 5206–5210. [8] H. Liu, M. Guo, Z. Jiang, L. W ang, and N. Gong, “ Au- diomarkbench: Benchmarking robustness of audio water - marking, ” in NeurIPS , 2024. [9] Y . ¨ Ozer , W . Choi, J. Serr ` a, M. K. Singh, W .-H. Liao, and Y . Mitsufuji, “ A comprehensi ve real-world assessment of audio watermarking algorithms: W ill they survi ve neural codecs?” 2025. [10] J. Zhou, J. Y i, Y . Ren, J. T ao, T . W ang, and C. Y . Zhang, “Wmcodec: End-to-end neural speech codec with deep watermarking for authenticity verification, ” 2024. [11] L. Zhang, X. Liu, A. V . Martin, C. X. Bearfield, Y . Brun, and H. Guan, “ Attack-resilient image watermarking using stable diffusion, ” in Pr oceedings of the 38th International Confer ence on Neural Information Pr ocessing Systems , ser . NIPS ’24. Red Hook, NY , USA: Curran Associates Inc., 2024. [12] Y . Hu, Z. Jiang, M. Guo, and N. Z. Gong, “ A transfer at- tack to image watermarks, ” in The Thirteenth International Confer ence on Learning Repr esentations , 2025. [13] A. Diaa, T . Aremu, and N. Lukas, “Optimizing adaptive attacks against watermarks for language models, ” 2025. [14] R. Chen, Y . W u, J. Guo, and H. Huang, “De-mark: W ater- mark remov al in large language models, ” 2025. [15] S. Rastogi, P . Maini, and D. Pruthi, “Stamp your content: Proving dataset membership via watermarked rephrasings, ” 2025. [16] J. Qiu, W . Han, X. Zhao, S. Long, C. Faloutsos, and L. Li, “Ev aluating durability: Benchmark insights into multimodal watermarking, ” 2024. [17] S. Liu, Q. Zheng, J. J. Xu, Y . Y an, J. Zhang, H. Geng, A. Liu, P . Jiang, J. Liu, Y .-C. T am, and X. Hu, “Vla-mark: A cross modal watermark for lar ge vision-language align- ment model, ” 2025. [18] C. W ang, S. Chen, Y . W u, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. W ang, J. Li, L. He, S. Zhao, and F . W ei, “Neural codec language models are zero-shot text to speech synthesizers, ” 2023. [19] Y . Ai, X.-H. Jiang, Y .-X. Lu, H.-P . Du, and Z.-H. Ling, “ Apcodec: A neural audio codec with parallel amplitude and phase spectrum encoding and decoding, ” IEEE/A CM T rans. Audio, Speech and Lang. Proc. , vol. 32, p. 3256–3269, Jun. 2024. [Online]. A v ailable: https://doi.org/10.1109/T ASLP .2024.3417347 [20] Z. Du, S. Zhang, K. Hu, and S. Zheng, “Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec, ” ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pp. 591–595, 2023. [Online]. A vailable: https://api.semanticscholar .org/ CorpusID:261823065 [21] M. K. Singh, N. T akahashi, W . Liao, and Y . Mitsufuji, “Silentcipher: Deep audio watermarking, ” in Interspeec h 2024 . ISCA, Sep. 2024, p. 2235–2239. [22] M. Moritz, T . Ol ´ an, and T . V irtanen, “Noise-to-mask ratio loss for deep neural network based audio watermarking, ” in 2024 IEEE 5th International Symposium on the Internet of Sounds (IS2) . IEEE, Sep. 2024, p. 1–6. [23] C.-H. Huang and J.-L. W u, “Slic: Secure learned image codec through compressed domain watermarking to defend image manipulation, ” in Pr oceedings of the 6th ACM Inter- national Confer ence on Multimedia in Asia , ser . MMAsia ’24. New Y ork, NY , USA: Association for Computing Machinery , 2024. [24] J. B. T enenbaum, V . de Silv a, and J. C. Langford, “ A global geometric frame work for nonlinear dimensionality reduc- tion, ” Science , vol. 290, no. 5500, pp. 2319–2323, 2000. [25] S. T . Roweis and L. K. Saul, “Nonlinear dimensionality reduction by locally linear embedding, ” Science , vol. 290, no. 5500, pp. 2323–2326, 2000. [26] A. van den Oord, O. V inyals, and K. Kavukcuoglu, “Neu- ral discrete representation learning, ” in Proceedings of the 31st International Confer ence on Neural Information Pr o- cessing Systems , ser . NIPS’17. Red Hook, NY , USA: Curran Associates Inc., 2017, p. 6309–6318. [27] S. Sadok, J. Hauret, and ´ E. Ba vu, “Bringing interpretability to neural audio codecs, ” in Interspeech 2025 . ISCA, Aug. 2025, p. 5023–5027. [28] N. T okui and T . Baker , “Latent granular resynthesis using neural audio codecs, ” 2025. [29] L. Juvela and X. W ang, “ Audio codec augmentation for robust collaborative watermarking of speech synthesis, ” 2024. [30] R. S. Roman, P . Fernandez, A. Deleforge, Y . Adi, and R. Serizel, “Latent watermarking of audio generative models, ” in ICASSP 2025 - 2025 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2025, pp. 1–5. [31] Y . Liu, L. Lu, J. Jin, L. Sun, and A. Fanelli, “XAt- tnmark: learning robust audio watermarking with cross- attention, ” in F orty-second International Conference on Machine Learning , 2025. [Online]. A v ailable: https://openrevie w .net/forum?id=zuOKPHHfEr [32] A. Pujari and A. Rattani, “W a vev erify: A nov el audio wa- termarking framew ork for media authentication and com- batting deepf akes, ” in IEEE International J oint Confer ence on Biometrics (IJCB) , 2025. [33] L. Y ao, C. Huang, S. W ang, J. Xue, H. Guo, J. Liu, P . Lin, T . Ohtsuki, and M. Pan, “Y ours or mine? overwriting attacks against neural audio watermarking, ” 2025. [34] Y . Y ao, J. Song, and J. Jin, “Hashed watermark as a filter: Defeating forging and ov erwriting attacks in weight-based neural network watermarking, ” 2025. [35] N. Ze ghidour , A. Luebs, A. Omran, J. Skoglund, and M. T agliasacchi, “Soundstream: An end-to-end neural au- dio codec, ” IEEE/ACM T rans. Audio, Speech and Lang. Pr oc. , vol. 30, p. 495–507, No v . 2021. [36] R. Kumar , P . Seetharaman, A. Luebs, I. Kumar , and K. Ku- mar , “High-fidelity audio compression with improved rvq- gan, ” in Pr oceedings of the 37th International Conference on Neural Information Pr ocessing Systems , ser . NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023. [37] Z. Borsos, R. Marinier, D. V incent, E. Kharitonov , O. Pietquin, M. Sharifi, D. Roblek, O. T eboul, D. Grangier , M. T agliasacchi, and N. Zeghidour , “ Audiolm: A language modeling approach to audio generation, ” IEEE/A CM T rans. Audio, Speec h and Lang. Pr oc. , vol. 31, p. 2523–2533, Jun. 2023. [38] A. Agostinelli, T . I. Denk, Z. Borsos, J. Engel, M. V erzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. T agliasac- chi, M. Sharifi, N. Zeghidour , and C. Frank, “Musiclm: Generating music from text, ” 2023. [39] J. Copet, F . Kreuk, I. Gat, T . Remez, D. Kant, G. Synnae ve, Y . Adi, and A. D ´ efossez, “Simple and controllable mu- sic generation, ” in Pr oceedings of the 37th International Confer ence on Neural Information Pr ocessing Systems , ser . NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023. [40] S. Chen, S. LIU, L. Zhou, E. Liu, X. T an, J. Li, sheng zhao, Y . Qian, and F . W ei, “V ALL-e 2: Neural codec lan- guage models are human parity zero-shot text to speech synthesizers, ” 2025. [41] M. Le, A. Vyas, B. Shi, B. Karrer , L. Sari, R. Moritz, M. W illiamson, V . Manohar, Y . Adi, J. Mahadeokar , and W .-N. Hsu, “V oicebox: text-guided multilingual univ ersal speech generation at scale, ” in Pr oceedings of the 37th In- ternational Confer ence on Neural Information Pr ocessing Systems , ser . NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023. [42] P . K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsos, F . de Chaumont Quitry , P . Chen, D. E. Badawy , W . Han, E. Kharitonov , H. Muckenhirn, D. P adfield, J. Qin, D. Rozenberg, T . Sainath, J. Schalkwyk, M. Sharifi, M. T . Ramanovich, M. T agliasacchi, A. T udor , M. V elimirovi ´ c, D. V incent, J. Y u, Y . W ang, V . Zayats, N. Zeghidour , Y . Zhang, Z. Zhang, L. Zilka, and C. Frank, “ Audiopalm: A large language model that can speak and listen, ” 2023. [43] P . Peng, P .-Y . Huang, S.-W . Li, A. Mohamed, and D. Har - wath, “V oiceCraft: Zero-shot speech editing and text-to- speech in the wild, ” in Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (V olume 1: Long P apers) , L.-W . Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 12 442–12 462. [44] M. Jeub, M. Sch ¨ afer , and P . V ary , “A binaural room impulse response database for the ev aluation of dereverberation algorithms, ” in Pr oceedings of International Confer ence on Digital Signal Pr ocessing (DSP) , IEEE, IET , EURASIP . Santorini, Greece: IEEE, Jul. 2009, pp. 1–4. [45] K. Drossos, S. Lipping, and T . V irtanen, “Clotho: an au- dio captioning dataset, ” in ICASSP 2020 - 2020 IEEE In- ternational Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2020, pp. 736–740. [46] G. J. Mysore, “Daps (device and produced speech) dataset, ” May 2014. [47] Y . ¨ Ozer , S. Schw ¨ ar , V . Arifi-M ¨ uller , J. Lawrence, E. Sen, and M. M ¨ uller , “Piano Concerto Dataset (PCD): A mul- titrack dataset of piano concertos, ” T rans. of the Int. Soc. for Music Inf. Retrie v . (TISMIR) , vol. 6, no. 1, pp. 75–88, 2023. [48] T . Nakamura, S. T akamichi, N. T anji, S. Fukayama, and H. Saruwatari, “jaCappella corpus: A Japanese a cappella vocal ensemble corpus, ” in Pr oc. of the IEEE Int. Conf. on Acoust., Speech, and Signal Pr ocess. (ICASSP) , 2023. [49] C. Hawthorne, A. Stasyuk, A. Roberts, I. Simon, C.-Z. A. Huang, S. Dieleman, E. Elsen, J. Engel, and D. Eck, “En- abling factorized piano music modeling and generation with the MAESTR O dataset, ” in International Conference on Learning Repr esentations , 2019. [50] Y . Luo and N. Mesgarani, “T aSNet: Time-Domain Audio Separation Network for Real-T ime Speech Separation in the T ime Domain, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2019, pp. 6470–6474. [51] T . Saeki, D. Xin, T . Koriyama, S. T akamichi, and H. Saruwatari, “UTMOS: UT okyo-SaruLab System for V oiceMOS Challenge 2022, ” in Pr oc. Interspeech 2022 , 2022, pp. 1632–1636.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment