TinyIO: Lightweight Reparameterized Inertial Odometry
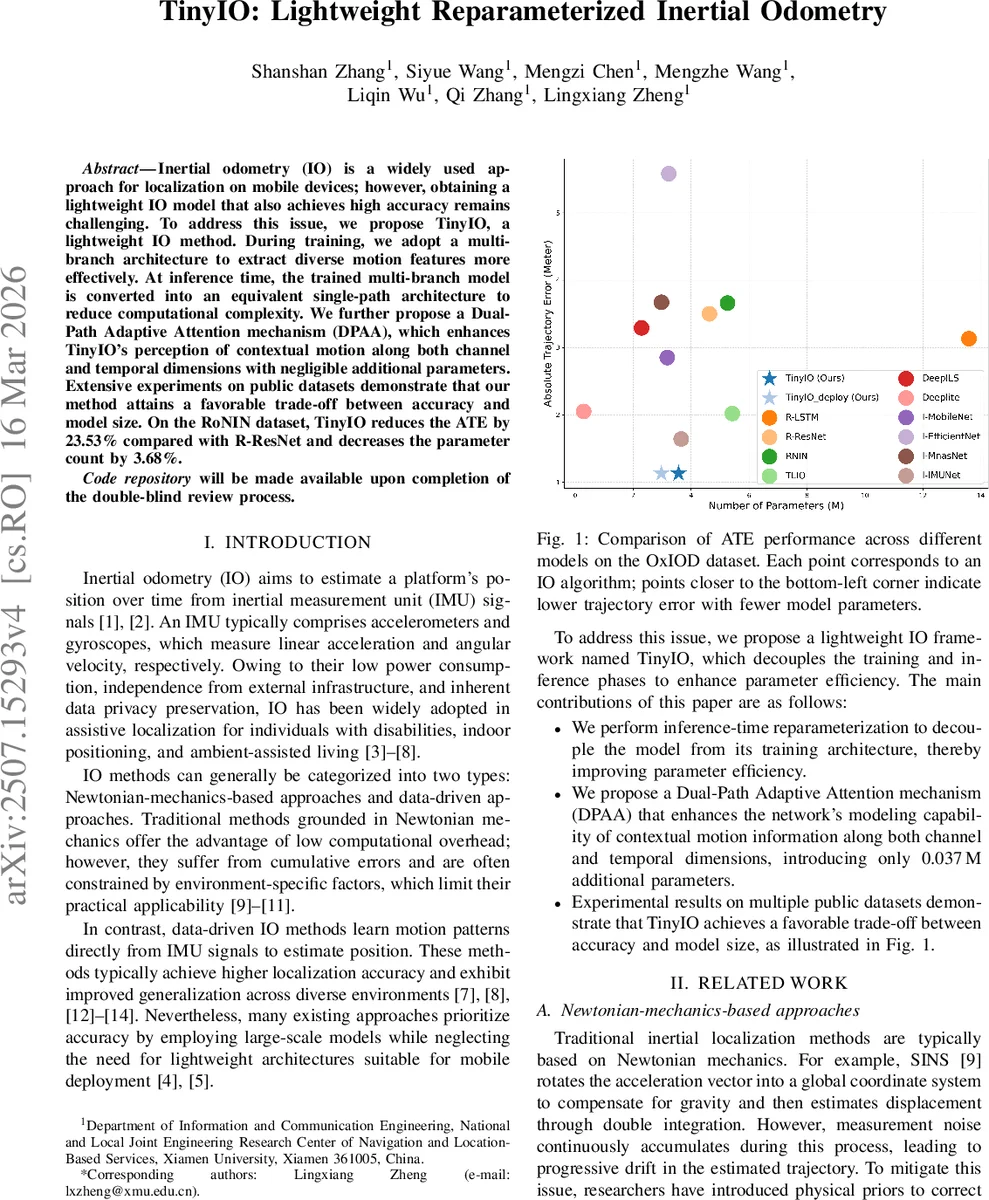
Inertial odometry (IO) is a widely used approach for localization on mobile devices; however, obtaining a lightweight IO model that also achieves high accuracy remains challenging. To address this issue, we propose TinyIO, a lightweight IO method. During training, we adopt a multi-branch architecture to extract diverse motion features more effectively. At inference time, the trained multi-branch model is converted into an equivalent single-path architecture to reduce computational complexity. We further propose a Dual-Path Adaptive Attention mechanism (DPAA), which enhances TinyIO’s perception of contextual motion along both channel and temporal dimensions with negligible additional parameters. Extensive experiments on public datasets demonstrate that our method attains a favorable trade-off between accuracy and model size. On the RoNIN dataset, TinyIO reduces the ATE by 23.53% compared with R-ResNet and decreases the parameter count by 3.68%.
💡 Research Summary
The paper introduces TinyIO, a lightweight inertial odometry (IO) framework designed for mobile devices where computational resources and power are limited. The authors address the long‑standing trade‑off between model size and localization accuracy by decoupling the training and inference architectures through a reparameterization technique and by adding a highly efficient attention module. During training, each Lightweight Inertial Odometry Block (LIOB) contains a multi‑branch Reparameterization Block (RepBlock) that consists of a 3‑tap 1‑D convolution, a 1‑tap 1‑D convolution, and an identity shortcut, reminiscent of the multi‑branch design of ResNet. This structure enables the network to capture motion patterns at multiple receptive‑field scales and to learn richer representations from raw six‑channel IMU data (three‑axis accelerometer and gyroscope). At inference time, the three branches are mathematically merged into a single 3‑tap convolution, preserving the learned function while dramatically reducing the number of parameters and FLOPs. This inference‑time reparameterization is the core of the “lightweight” claim.
To compensate for the limited contextual modeling capacity of a purely convolutional block, the authors propose a Dual‑Path Adaptive Attention (DPAA) mechanism. DPAA contains two parallel attention branches: (1) a channel‑attention branch that applies adaptive average‑ and max‑pooling across the temporal dimension, feeds the pooled statistics through shared 1‑D convolutions (instead of fully‑connected layers) and generates a sigmoid‑scaled channel weight vector; (2) a temporal‑attention branch that aggregates per‑channel statistics (mean and max across channels), concatenates them, and passes them through another shared 1‑D convolution to produce a time‑wise weight vector. The two weighted feature maps are then fused with learnable scalar coefficients α and β (α+β=1). The entire DPAA adds only 0.037 M parameters, far less than conventional self‑attention or Transformer blocks, yet it effectively highlights informative channels and critical time steps, improving the network’s ability to model long‑range dependencies in the IMU signal.
The overall TinyIO architecture stacks four LIOBs with channel dimensions
Comments & Academic Discussion
Loading comments...
Leave a Comment