Two-Stage Heterogeneous Graph Neural Network for RIS-Aided Physical-Layer Security
This paper investigates physical-layer security (PLS) enabled by graph neural networks (GNNs). We propose a two-stage heterogeneous GNN (HGNN) to maximize the secrecy energy efficiency (SEE) of a reconfigurable intelligent surface (RIS)-assisted mult…
Authors: Zihan Song, Yang Lu, Wei Chen
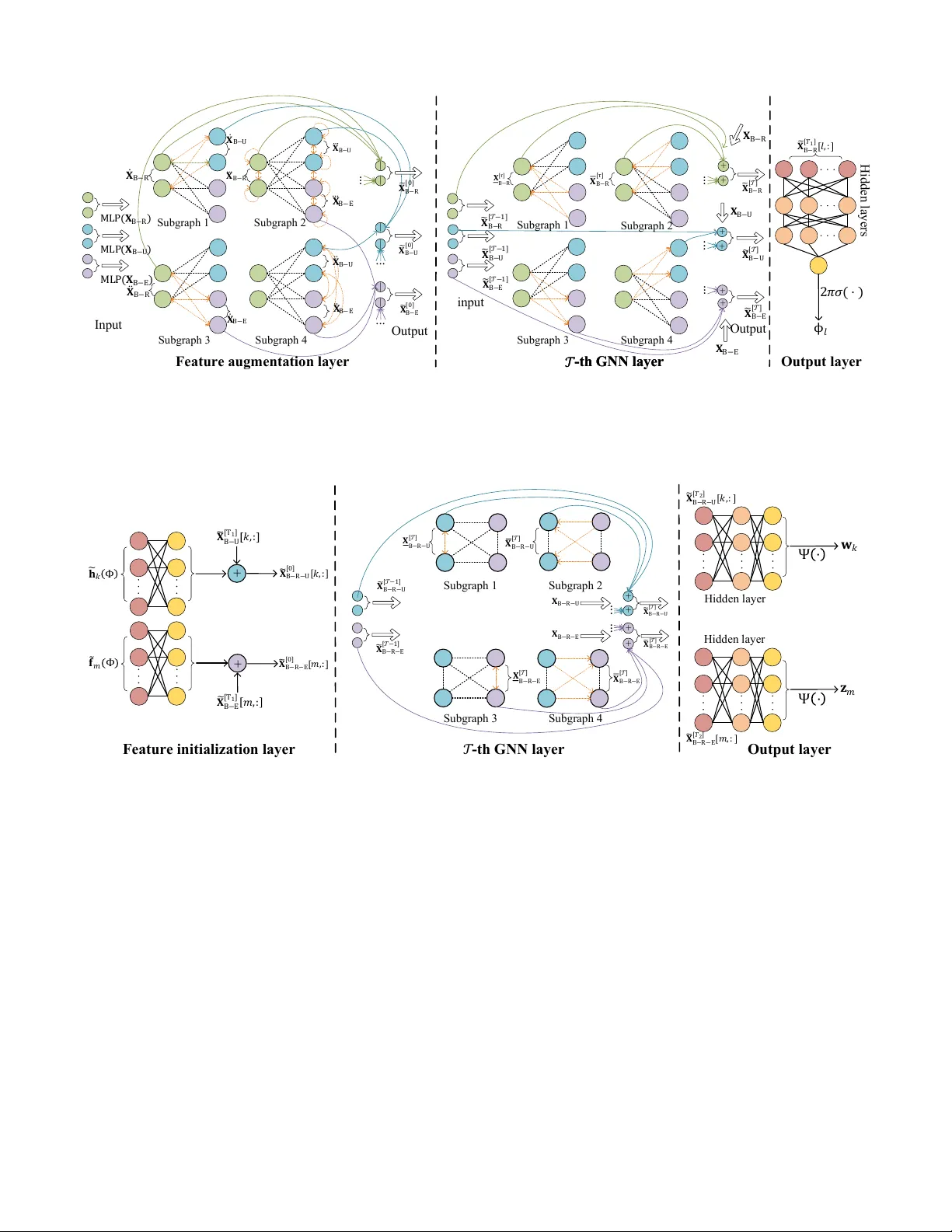
1 T wo-Stage Heterogeneous Graph Neural Network for RIS-Aided Physical-Layer Security Zihan Song, Y ang Lu, Senior Member , IEEE , W ei Chen, Senior Member , IEEE , Bo Ai, F ellow , IEEE , Zhiguo Ding, F ellow , IEEE , and Arumugam Nallanathan, F ellow , IEEE Abstract —This paper inv estigates physical-layer security (PLS) enabled by graph neural networks (GNNs). W e propose a two-stage heterogeneous GNN (HGNN) to maximize the se- crecy energy efficiency (SEE) of a reconfigurable intelligent surface (RIS)-assisted multi-input-single-output (MISO) system that serves multiple legitimate users (LUs) and eavesdr oppers (Eves). The first stage formulates the system as a bipartite graph in volving three types of nodes—RIS reflecting elements, LUs, and Eves—with the goal of generating the RIS phase shift matrix. The second stage models the system as a fully connected graph with two types of nodes (LUs and Eves), aiming to pr oduce beamforming and artificial noise (AN) vectors. Both stages adopt an HGNN integrated with a multi-head attention mechanism, and the second stage incorporates two output methods: beam-direct and model-based approaches. The two-stage HGNN is trained in an unsupervised manner and designed to scale with the number of RIS r eflecting elements, LUs, and Eves. Numerical results demonstrate that the proposed two-stage HGNN outperforms state-of-the-art GNNs in RIS-aided PLS scenarios. Compared with con vex optimization algorithms, it r educes the a verage running time by three orders of magnitude with a performance loss of less than 4% . Additionally , the scalability of the two-stage HGNN is validated through extensive simulations. Index T erms —PLS, two-stage, HGNN, RIS. I . I N T RO D U C T I O N A. Backgr ound RIS has been widely regarded as a key wireless cov erage enabler for next-generation mobile communication systems [1]. Specifically , RIS can intelligently adjust the phase of incident electromagnetic wav es without additional radio fre- quency chains, thus effecti vely improving wireless channel quality , extending coverage, and mitigating signal interference [2]. Its passiv e operation enables energy-ef ficient deployment, which aligns well with the requirements of green communi- cations. The channel reconfigurability of RIS can enlarge the channel div ersity among receiv ers, which can be lev eraged to enhance PLS [3]. As demonstrated in [4], RIS-aided PLS can significantly improve the system SEE and secrecy sum rate Zihan Song and Y ang Lu are with the School of Computer and Information T echnology , Beijing Jiaotong University , Beijing 100044, China (e-mail: 23120405@bjtu.edu.cn, yanglu@bjtu.edu.cn). W ei Chen and Bo Ai are with the School of Electronics and Information Engineering, Beijing Jiaotong University , Beijing 100044, China (e-mail: weich@bjtu.edu.cn, boai@bjtu.edu.cn). Zhiguo Ding is with the School of Electrical and Electronic En- gineering (EEE), Nanyang T echnological University , Singapore 639798 (Zhiguo.ding@ntu.edu.sg). Arumugam Nallanathan is with the School of Electronic Engineering and Computer Science, Queen Mary University of London, London and also with the Department of Electronic Engineering, K yung Hee Univ ersity , Y ongin-si, Gyeonggi-do 17104, South Korea (e-mail: a.nallanathan@qmul.ac.uk). (SSR) even when there are no direct communication links, and the performance gain increases with the number of reflecting elements. Despite the adv antages of RIS, efficiently optimizing RIS-assisted communication systems is non-tri vial due to the deeply coupled BS-related and RIS-related parameters. Existing optimization approaches for RIS can be cate go- rized into three categories: 1) con v ex optimization (CVXopt)- based approach, 2) deep reinforcement learning (DRL)-based approach, and 3) learn-to-optimize approach. For example, the authors in [5], [6] and [7] inv estigated multi-user MISO sys- tems assisted by RIS, employing CVXopt-based approaches to maximize the system SEE and sum rate, respectiv ely . Howe ver , as revie wed in [8], most existing CVXopt-based methods mainly rely on alternating optimization (A O) or block coordinate descent (BCD) to tackle the deeply coupled variables, leading to high computational ov erhead and separate optimization losses. In contrast, DRL-based approaches have emerged as a promising joint-optimization solver for RIS- assisted systems. They have been validated to enable energy- efficient designs in RIS-assisted MISO [9], simultaneous wire- less information and power transfer [10], and unmanned aerial vehicle mobile edge computing systems [11]. Nevertheless, DRL-based approaches learn from interactions in partially controllable wireless en vironments, thus suffering from limited generalization capability . This paper focuses on the data-driv en learn-to-optimize approach, which has been widely adopted as an efficient opti- mization solver for various wireless systems [12]. Specifically , existing studies have adopted multi-layer perceptrons (MLPs) [13], [14] and conv olutional neural network (CNNs) [15], [16], respectiv ely , to realize joint optimization for RIS-assisted systems. Howe ver , MLPs and CNNs are inherently limited by their fixed input and output dimensions, thus failing to pro- vide satisfactory generalization performance in dynamic RIS- assisted systems. By contrast, GNNs can effecti v ely overcome the limitation [17], [18]. As analyzed in [19], GNNs are well matched to the topology of wireless networks, thereby not only outperforming other models but also achieving strong adaptability to wireless dynamics. For example, GNNs hav e been sho wn to enable real-time, near-optimal and scalable inference for MISO systems, aiming to maximize the sum rate (SR) [20], energy efficienc y (EE) [21] and SEE [22], respec- tiv ely . Compared with non-RIS and non-PLS systems, RIS- aided PLS inv olv es complicated heterogeneity among distinct entities, such as the BS, RIS, LUs, and Eves. Therefore, it is of great importance to align the deep learning (DL) model with both the system and the task. Existing works handle 2 the “heterogeneity” via two perspectives, i.e., frame work and neural architecture. For the framework, the authors in [23], [24] developed a multi-stage GNN to sequentially generate the phase shift matrix and beamforming vectors. This framework inherits the algorithmic structure of con ventional CVXopt- based approaches and enhances the model’ s interpretability . For the neural architecture, the authors in [25]–[28] exploited HGNNs to capture the heterogeneity within RIS-assisted sys- tems. These HGNNs exhibit superior scalability with respect to the system entities. B. Contribution Existing works have demonstrated that the model’ s expres- siv e capability can be enhanced from the perspectiv es of both framew ork and neural architecture. Howe ver , no existing work has yet integrated the advantages of these two aspects. T o fill this gap, this paper proposes to utilize the tw o-stage frame w ork and HGNNs for RIS-aided physical-layer security , which in v olves heterogeneous system entities (i.e., BS, RIS, LUs, and Eves) as well as dual-functional services. The contributions of this paper are summarized as follo ws. • W e consider a typical RIS-aided PLS system, in which a multi-antenna BS serves multiple LUs in the presence of Eves via both direct and cascaded links. The transmitted signals consist of both information-bearing signals for LUs and AN to disrupt Eves. W e formulate an SEE maxi- mization problem by jointly optimizing the beamforming and AN vectors, as well as the RIS phase shift matrix. • W e propose a two-stage HGNN to solve the formulated problem. Specifically , the first stage models the consid- ered system as a bipartite graph and employs both edge- based and edge-free graph attention operators to map channel state information (CSI) to the phase shift matrix. The second stage models the system as a fully-connected graph with heterogeneous node types and adopts an edge- free graph attention operator and a semantic attention mechanism to map augmented effecti v e CSI to the beam- forming and AN vectors. The outputs of both stages are fed into an unsupervised loss function for end-to-end joint training. • Analysis results are presented to validate that the pro- posed two-stage HGNN is scalable with respect to the number of RIS reflecting elements, LUs, and Eves. Nu- merical results are provided to corroborate the analytical findings. Furthermore, the superiority of the proposed two-stage HGNN is demonstrated through comparisons with the state-of-the-art GNNs. Additionally , ablation experiments are conducted to validate the effecti veness of the ke y components of the proposed model. The rest of this paper is organized as follows. Section II revie ws emerging AI-based RIS-aided wireless communication technologies. Section III introduces the system model and problem formulation. Section IV presents two heterogeneous graph representation methods for the system. Section V details the proposed two-stage HGNN, followed by a scalability anal- ysis. Section VI presents numerical results and ev aluations. Section VII concludes the paper . Notation : The following mathematical notations and sym- bols are used throughout this paper . Bold lowercase letters (e.g., a ) denote column vectors, and bold uppercase letters (e.g., A ) denote matrices or higher-dimensional tensors. The set of real numbers is denoted by R , and the set of n × m real matrices by R n × m . Similarly , C n and C n × m denote the sets of n -dimensional complex column vectors and n × m complex matrices, respecti vely . F or a comple x number a , | a | denotes its modulus, and ℜ ( a ) and ℑ ( a ) denote its real and imaginary parts, respectively . For a vector a , ∥ a ∥ denotes its Euclidean norm. For a matrix A , A T , A H , ∥ A ∥ , and Trace ( A ) represent its transpose, conjugate transpose, Frobenius norm, and trace (i.e., the sum of its diagonal elements), respectively . The notation a [ i ] denotes the i -th entry of vector a ; A [ i, j ] denotes the element in the i -th row and j -th column of matrix A ; and A [ i, :] denotes the entire i -th row of A . The operator Concat ( · ) denotes the concatenation of its inputs. The operator LeakyReLU ( · ) denotes the leaky rectified linear unit (ReLU) with a small negati v e slope for negativ e inputs. I I . R E L A T E D W O R K S This section summarizes the related works on GNN-enabled RIS-assisted systems. T o clearly highlight the nov elty of this paper , we compare the proposed tw o-stage HGNN and existing GNN-based models in T able I. A. GNN-Enabled RIS T ransmission V arious GNNs have been leveraged to jointly optimize RIS- assisted systems. The authors in [23] modeled an RIS-assisted MISO system as a homogeneous graph and proposed a two- stage frame work to solve a sum-rate maximization problem, where the first stage employed a graph attention network (GA T) to predict the phase shift matrix and the second stage utilized an MLP to generate beamforming vectors. The authors in [24] considered an RIS-assisted downlink pinching-antenna system, with the objectiv e of optimizing both the sum rate (SR) and energy ef ficiency (EE). They proposed a three- stage GNN, where each stage modeled the system as a fully connected graph and adopted either a graph con v olutional network (GCN) [29] or a GA T [30] to deriv e the transmit parameters. In addition to the homogeneous graph, the heterogeneous graphs may be more suitable for RIS-assisted systems and enable the problem to be solved within a single-stage frame- work. The authors in [25] formulated an RIS-assisted MISO mmW a ve system into a heterogeneous graph with an RIS node and multiple user nodes, and proposed a modified GA T to map angular cascaded channels to beamforming vectors and reflection coefficients for sum-rate maximization. Besides, they adopted transfer learning in the model to adapt to vari- ations in user counts. The authors in [26] formulated a sum- rate maximization problem for a system utilizing collaboration of an RIS and a relay , which includes two phases, i.e., BS-RIS-user phase and relay-RIS-user phase. Regarding the first phase, they modeled the system as a fully-connected heterogeneous graph with one RIS node and multiple user nodes, and adopted an HGNN to yield phase shift matrix 3 T ABLE I C O M P A RI S O N W I T H E X I ST I N G W O R K S O N G N N - E NA B L E D R I S - A S SI S T E D S Y S T EM S . Ref. Architectur e Objective Multi-Stage Heterogeneous Residual Attention Generalization LU RIS Eve [23] GA T+MLP SR ✓ × × ✓ × × – [24] GA T+GCN SR/EE ✓ × ✓ ✓ ✓ ✓ – [25] GCN+GA T SR × ✓ × ✓ × × – [26] HGNN SR × ✓ ✓ × ✓ × – [27] HGNN EE × ✓ ✓ × ✓ × – [28] HGNN WSR × ✓ ✓ × × ✓ – [31] HGNN Max-Min × ✓ × × ✓ ✓ – [32] HGNN SR × ✓ × × ✓ ✓ – [33] GNN SSR × ✓ ✓ × ✓ × × [34] CO-GNN SSR × ✓ × ✓ ✓ × ✓ Our work HGNN SSE ✓ ✓ ✓ ✓ ✓ ✓ ✓ and beamforming vectors via different message aggregation methods. The authors in [27] considered an RIS-assisted MISO system covering both single-cell and cell-free scenarios and formulated an EE maximization problem. The system was represented as a heterogeneous graph with one RIS node and multiple user nodes, which w as fed into a GNN with two distinct feature initialization strategies to jointly optimize and the phase shift matrices and beamforming vectors. The authors in [28] considered a multi-RIS-assisted system and formulated a sum-rate maximization problem. The system is represented by a fully-connected heterogeneous graph with a BS node, multiple RIS nodes and user nodes, and fed into an HGNN to jointly obtain the phase shift matrix, beamforming vectors and the RIS association matrix. Howe ver , since all reflecting elements are represented by a single RIS node, the models in [25]–[28] are not scalable with respect to the number of reflecting elements. The authors in [31] considered an RIS-assisted cell-free system under imperfect CSI assumption and formulated a max-min uplink rate maximization problem. The system is represented by a heterogeneous graph comprising access point nodes, RIS reflecting element nodes, and user nodes. The y proposed an advanced HGNN to jointly solv e the problem. The authors in [32] considered a simultaneous transmitting and reflecting (ST AR)-RIS-assisted MISO system and formulated a sum- rate maximization problem. They modeled the system using a bipartite graph and solved the problem with a beamforming HGNN based on a heterogeneous graph message-passing protocol, with guaranteed permutation equiv ariance and scal- ability . B. GNN-Enabled RIS-Aided PLS There are a limited number of works focusing on GNN- enabled RIS-aided PLS. The authors in [33] presented an RIS-assisted integrated sensing and communication (ISA C) system as a heterogeneous graph, which models LUs and an Eve as receiv er nodes, and the RIS as an additional node. They utilized an HGNN to maximize the minimum secrecy rate. The authors in [34] considered an RIS-assisted non- orthogonal multiple access (NOMA) system encompassing ... ... m - t h E v e m' - t h E v e RIS BS H h B, k h R, k k - t h u s e r k' - t h u s e r f R, m f B, m' f B, m f R, m' h R, k' h B, k Fig. 1. An RIS-aided MISO PLS system, where a BS serves multiple LUs in the presence of multiple Eves. downlink, uplink, and eav esdropping links. They modeled the system as a heterogeneous graph in v olving a BS node, a RIS node, and multiple LU nodes and Eve nodes. They proposed a combinatorial optimization GNN (CO-GNN) to maximize sum secrecy rate. Howe v er , the models proposed in [33] and [34] rely on a single-stage framework and lack scalability with respect to the number of reflecting elements. From the related works, we deri ve the following obser- vations for designing GNN-enabled RIS-assisted systems: 1) both the multi-stage framework and heterogeneous graph representation can enhance the model’ s expressi ve power; 2) sophisticated graph modeling enables strong scalability . Furthermore, the design of GNN architecture should be well aligned with the adopted framew ork and graph representation, which is crucial to the model performance. Moti v ated by the abov e insights, we dev elop a two-stage HGNN for efficient and scalable design in RIS-aided PLS systems. I I I . S Y S T E M M O D E L A N D P R O B L E M F O R M U L A T I O N A. Signal T ransmission Consider a passi ve RIS-assisted communication system as shown in Fig. 1 where an N T -antenna BS serves K single- antenna LUs with the assistance of an RIS equipped with L 4 R k ( { w k ′ , z m ′ } , Φ ) = log 2 1 + e h H k ( Φ ) w k 2 P k ′ ∈ K / { k } e h H k ( Φ ) w k ′ 2 + P m ′ ∈ M e h H k ( Φ ) z m ′ 2 + σ 2 k (3) R E ,m,k ( { w k ′ , z m ′ } , Φ ) = log 2 1 + e f H m ( Φ ) w k 2 P k ′ ∈ K / { k } e f H m ( Φ ) w k ′ 2 + P m ′ ∈ M e f H m ( Φ ) z m ′ 2 + σ 2 E ,m (5) reflecting elements. M single-antenna Eves intend to intercept information from the BS to LUs. For clarity , we use k ∈ K = { 1 , 2 , ..., K } to denote the k -th LU, l ∈ L = { 1 , 2 , ..., L } to denote the l -th reflecting element and m ∈ M = { 1 , 2 , ..., M } to denote the m -th Eve. In each time slot, the transmit signal of the BS is gi ven by x = X k ∈ K w k s k + X m ∈ M z m s 0 , (1) where s k and w k ∈ C N T denote the information-bearing sig- nal and the beamforming vector for the k -th LU, respectively , and s 0 ∈ C and z m ∈ C N T denote the AN signal and the AN vector for the m -th Eve, respecti vely . W ithout loss of generality , it is assumed that E {| s k | 2 } = 1 and E {| s 0 | 2 } = 1 . The recei ved signal at the k -th LU is gi ven by y k = h H B ,k + h H R ,k ΦH | {z } ≜ e h H k ( Φ ) ∈ C N T X k ′ ∈ K w k ′ s k ′ + X m ′ ∈ M z m ′ s 0 ! + n k , (2) where h B ,k ∈ C N T , h R ,k ∈ C L , and H ∈ C L × N T respectiv ely denote the direct CSI between the BS and the k -th LU, the CSI between the RIS and the k -th LU and the CSI between the BS and the RIS. Φ = diag { [ e j ϕ 1 , e j ϕ 2 , ..., e j ϕ L ] } denotes the phase shift matrix, where ϕ l ∈ [0 , 2 π ) denotes the phase shift of the l -th reflecting element. n k ∼ CN (0 , σ 2 k ) denotes the additiv e white Gaussian noise (A WGN) at the k -th LU. The recei ved information rate at the k -th LU is gi ven by (3). Similarly , the receiv ed signal at the m -th Eve is giv en by y E ,m = (4) f H B ,m + f H R ,m ΦH | {z } ≜ e f H m ( Φ ) ∈ C N T X k ′ ∈ K w k ′ s k ′ + X m ′ ∈ M z m ′ s 0 ! + n E ,m , where f B ,m ∈ C N T and f R ,m ∈ C L respectiv ely denote the direct CSI from the BS and the RIS to the m -th Ev e, and n E ,m ∼ CN (0 , σ 2 E ,m ) denotes the A WGN at the m -th Eve. If the m -th Eve intends to intercept the k -th LU, the information leakage data rate is expressed as (5). The secrecy rate of the k -th LU is expressed as R Sec ,k ( { w k ′ , z l ′ } , Φ ) = (6) h R k ( { w k ′ , z m ′ } , Φ ) − max m { R E ,m,k ( { w k ′ , z m ′ } , Φ ) } i + . B. Pr oblem F ormulation Our goal is to jointly optimize { w k ′ , z m ′ , Φ } to maximize the system SEE under the constraint of the po wer b udget denoted by P max . Mathematically , this problem is formulated as max { w k ′ , z m ′ } , Φ P k ∈ K R Sec ,k ( { w k ′ , z m ′ } , Φ ) P k ∈ K ∥ w k ∥ 2 + P m ∈ M ∥ z m ∥ 2 + P C (7a) s . t . X k ∈ K ∥ w k ∥ 2 + X m ∈ M ∥ z m ∥ 2 ≤ P max , (7b) ϕ l ∈ [0 , 2 π ) , l ∈ L , (7c) where P C denotes the constant po wer consumption. T o solve Problem (7), we leverage the learning-to-optimize approach and propose a two-stage HGNN to map CSI to { w k ′ , z m ′ , Φ } . I V . G R A P H R E P R E S E N TA T I O N Graph representation is utilized to organize system param- eters into graph-structured data and to define readout oper- ations. The proposed model adopts a two-stage framework, where the two stages employ different heterogeneous graph representation methods to represent the considered system. Notably , compared with existing graphs designed for non-RIS and non-PLS systems [20], [21], the proposed graph captures the heterogeneity among different system entities, including the RIS, LUs, and Eves. Compared with most existing graphs representing RIS-assisted PLS systems [33], [34], the proposed graph identifies distinct RIS reflecting elements rather than regarding all elements as a single node. Mathematically , we define a heterogeneous graph as G = { V 1 , . . . , V N , E 1 , . . . , E E } , (8) where N and E denote the number of node types and edge types, respectiv ely , and V n ( n ∈ { 1 , 2 , . . . , N } ) and E e ( e ∈ { 1 , 2 , . . . , E } ) represent the node set of the n -th type and the edge set of the e -th type. Furthermore, the node feature matrix and edge feature matrix for all nodes in V n and all edges in E e are defined by X n and Y e , respecti vely . A. Stage 1: Bipartite Graph Representation The graph in Stage 1 is defined as G (1) = n V (1) 1 , V (1) 2 , V (1) 3 , E (1) 1 , E (1) 2 o , (9) 5 S ta g e 1 S ta g e 2 R , [ ] R , [ ' ] R , ' [ ' ] R , ' [ ] R , ' [ ] R , [ ' ] R , [ ] B , B , [ , : ] [ , : ] [ ' , : ] [ ' , : ] B , B , B , B , B , B , R , ' [ ' ] BS - R I S l i n k BS - LU l i n k BS - Ev e l i n k BS - R I S - LU l i n k BS - R I S - Ev e l i n k ( ) ' ( ) ' ( ) ( ) Fig. 2. Heterogeneous graph presentation and key node feature components: 1) Stage 1 constructs a bipartite graph consisting of three types of nodes corresponding to the BS-LU links, the BS-Eves links, and the BS-RIS links; 2) Stage 2 constructs a fully-connected graph consisting of two types of nodes corresponding to the BS-RIS-LU links and BS-RIS-Eve links. S ta g e 1 G N N l a y e r s F ea t u r e a u g men t a t i o n l a y er S ta g e 2 G N N l a y e r s F ea t u r e i n i t i a l i z a t i o n l a y er O u t p u t l a y er O u t p u t l a y er B E [ 1 ] B U [ 1 ] B R B U B E Fig. 3. Neural architecture of the two-stage HGNN: 1) Stage 1 comprises a feature augmentation layer , T 1 GNN layers, and an output layer . It maps { X B - R , X B - U , X B - E } to { Φ , e X [ T 1 ] B - U , e X [ T 1 ] B - E } . 2) Stage 2 consists of a feature initialization layer, T 2 GNN layers, and an output layer . It takes { e h k ( Φ ) , e f m ( Φ ) } and { e X [ T 1 ] B - U , e X [ T 1 ] B - E } as inputs and outputs { w k , z m } . which is a bipartite and undirected graph with 3 node types and 2 edge types. The structure of G (1) is illustrated in Fig. 2. The node definition, edge definition, and readout operation are detailed as follo ws. • Node Definition : In G (1) , there are 3 node types: 1) | V (1) 1 | = L BS-RIS link nodes, with the l -th node feature being H [ l, :] ∈ C N T ; 2) | V (1) 2 | = K BS-LU link nodes, with the k -th node feature being h B ,k ; 3) | V (1) 3 | = M BS- Eve link nodes, with the m -th node feature being f B ,m . In summary , the node feature matrices corresponding to the three node types are defined as follows, respectively: X B - R = H ′ ∈ R M × 2 N T , (10) X B - U = h ′ B , 1 , h ′ B , 2 ; . . . ; h ′ B ,K T ∈ R K × 2 N T , (11) X B - E = f ′ B , 1 , f ′ B , 2 ; . . . ; f ′ B ,M T ∈ R L × 2 N T , (12) where H ′ = Concat (real ( H ) , imag ( H )) ∈ R M × 2 N T , (13) h ′ B ,i = Concat (real ( h B , i ) , imag ( h B , i )) ∈ R 2 N T , (14) f ′ B ,i = Concat (real ( f B , i ) , imag ( f B , i )) ∈ R 2 N T . (15) • Edge Definition : In G (1) , there are 2 undirected edge types: 1) | E (1) 1 | = L × K edges, each connecting one BS-RIS link node and one BS-LU link node, with the ⟨ l, k ⟩ -th edge feature being h R ,k [ l ] ; 2) | E (1) 2 | = L × M edges, each connecting one BS-RIS link node and one BS-Eve link node, with the ⟨ l, m ⟩ -th edge feature being f R ,m [ l ] . • Readout Operation : The HGNN in Stage 1 updates the features of ( L + K + M ) nodes. The updated feature of L BS-RIS link nodes are readout as Φ , which is fed into both Stage 2 (cf. (42)) and the loss function (cf. (58)). The updated features of each BS-LU link node and each BS-Eve link node are used as augmented features (cf. (42) and (43)) for beamforming learning and AN learning, respectiv ely , in Stage 2. B. Stage 2: Fully-Connected Graph Representation The graph in Stage 2 is defined as G (2) = n V (2) 1 , V (2) 2 , E (2) 1 , E (2) 2 , E (2) 3 o , (16) which is a fully-connected and undirected graph. The structure of G (2) is illustrated in Fig. 2. The node definition, edge definition, and readout operation are detailed as follo ws. • Node Definition : In G (2) , there are 2 node types: 1) | V (2) 1 | = K BS-RIS-LU link nodes, where the k -th node feature (cf. (42)) consists of e h k ( Φ ) and the augmented feature of the k -th BS-LU node yielded by Stage 1; 2) | V (2) 2 | = M BS-RIS-Eve link nodes, where the m -th node feature consists of e f m ( Φ ) and the augmented feature (cf. (43)) of the m -th BS-Eve node yielded by Stage 1. Here, Φ is deri ved from Stage 1. • Edge Definition : In G (2) , there are three types of edges which connect two BS-RIS-LU link nodes, one BS-RIS- LU link node and one BS-RIS-Eve link node, and two BS-RIS-Eve link nodes, respectiv ely . But all edges are non-feature. • Readout Operation : The HGNN in Stage 2 updates the features of ( K + M ) nodes. The updated features of the k -th BS-RIS-LU link node and the m -th BS-RIS-Eve link node are used to readout relev ant parameters for the k -th beamforming vector and m -th AN vector , respectiv ely . V . T W O - S TAG E H G N N The overall computational process of the two-stage HGNN is illustrated in Fig. 3, and the models of the two stages incorporate some similar operations based on the meta-paths [35]. For clarity , we first define the common operations and then introduce the architectures of the models in the two stages, respecti vely . A. Common Operations 1) Subgraph Extraction Operations: T o flexibly extract the intra-graph features, two types of subgraph extraction operations are defined ov er a given graph G . • Unidirectional bipartite graph extraction operation: e G D − BG = ψ Uni ( V n , V n ′ ) , (17) 6 H i d d e n l a y e r s I n p u t O u t p u t B U [ 0 ] B E [ 0 ] B R [ 0 ] | | | | | | i n p u t B R B U B E B E B U B R B R B U B E B R [ 1] B U [ 1] B E [ 1] + + + + B U [ ] + + B R [ ] B E [ ] O u t p u t B E B U B R B R [ 1 ] [ , : ] 2 ( ) B R [ ] B R [ ] Fea tu r e a u g m e n ta tio n la y e r O u tp u t la y e r M L P ( B R ) M L P ( B U ) M L P ( B E ) - th G N N l a y e r - th G N N l a y e r . . . . . . . . . S u bgr a ph 1 S u bgr a ph 2 S u bgr a ph 4 S u bgr a ph 3 S u bgr a ph 1 S u bg r aph 2 S u bgr a ph 4 S u bgr a ph 3 . . . . . . .. . Fig. 4. Illustration of key processes in Stage 1: 1) The feature augmentation layer maps { X B - R , X B - U , X B - E } to { e X [0] B - R , e X [0] B - U , e X [0] B - E } via GA T on four subgraphs. 2) The τ -th GNN layer maps { e X [ τ − 1] B - R , e X [ τ − 1] B - U , e X [ τ − 1] B - E } combined with the residual terms { e X [ τ − 1] B - R , e X [ τ − 1] B - U , e X [ τ − 1] B - E , X B - R , X B - U , X B - E } to { e X [ τ ] B - R , e X [ τ ] B - U , e X [ τ ] B - E } via GA T on four subgraphs. 3) The output layer maps { e X [ T 1 ] B - R [ l, :] } to { ϕ l } using an MLP . + + B E [ T 1 ] ,: B U [ T 1 ] ,: B R U [ 0 ] ,: B R E [ 0 ] ,: B R E [ 1 ] B R U [ 1 ] + B R E [ ] B R U [ ] B R U [ ] B R E [ ] B R E [ ] B R U [ ] B R U B R E H i dd e n l a y e r Hidd e n l a y e r B R U [ 2 ] [ , : ] B R E [ 2 ] [ , : ] Fe a tu r e i ni tia lizati o n la y e r - th G NN la y e r O u tp u t la y e r S u bgr a ph 1 S u bgr a ph 2 S u bgr a ph 4 S u bgr a ph 3 + + + . . . . . . Fig. 5. Illustration of key processes in Stage 2: 1) The feature initialization layer employs two separate MLPs to map { e h k , e f m } to intermediate values, respectively . These values are then summed with { e X [ T 1 ] B - U [ k, :] , e X [ T 1 ] B - E [ m, :] } to obtain { e X [0] B - R - U [ k, :] , e X [0] B - R - E [ m, :] } . 2) The τ -th GNN layer maps { e X [ τ − 1] B - R - U , e X [ τ − 1] B - R - E } combined with the residual terms { e X [ τ − 1] B - R - U , e X [ τ − 1] B - R - E , X B - R - U , X B - R - E } to { e X [ τ ] B - R - U , e X [ τ ] B - R - E } via GA T on four subgraphs. 3) The output layer uses two separate MLPs to map { e X [ T 2 ] B - R - U [ k, :] , e X [ T 2 ] B - R - E [ m, :] } to { w k , z m } , respectively . where V n and V n ′ denote two node sets of distinct types, and e G D − BG is a subgraph of G that forms a directed bipartite graph. The extracted subgraph e G D − BG consists of two node sets, i.e., V n and V n ′ , along with directed 1 edges from each node in V n to each node in V n ′ . The nodes and edges in e G D − BG hav e consistent features with those in G . • Bidirectional bipartite graph extraction operation: e G UD − BG = ψ Bi ( V n , V n ′ ) , (18) where e G UD − BG is a subgraph of G that forms an 1 Even for an undirected G , a directed subgraph can be constructed, since an undirected edge can be treated as bidirectional edges sharing the identical features. undirected bipartite graph. The only difference between e G UD − BG and e G D − BG is that the edges in e G UD − BG are undirected. 2) Fully-Connected Graph Construction Operation: T o ex- ploit the similarity among nodes with the same type, the fully- connected graph construction operation is defined by e G UD − FC = ψ FC ( V n ) , (19) where e G UD − FC is a fully-connected and undirected graph consisting of nodes in V n with undirected and feature-free edges connecting these nodes. The nodes inherit the features from their original G . 3) Graph Attention Operator s: T o distinguish the interac- tions between nodes, tw o types of graph attention operators are 7 defined, which adapt to dif ferent graph-structured features. The output dimensions of the both operators are uniformly set to D × B , where D and B denote the number of attention heads and the projection dimension of a single head, respecti vely . • Edge-based graph attention operator: { X n } n ∈{ 1 , 2 ,...,N ′ } := υ EAtt ( G , { X n } ) , (20) where N ′ ≤ N denotes the number of target node types. • Edge-free graph attention operator: { X n } n ∈{ 1 , 2 ,...,N ′ } := υ Att ( G , { X n } ) . (21) The detailed processes of the two attention operators are detailed in the Appendix A and B. Notably , the learnable parameters and output dimensions of both operators are as- sociated with the input graph. B. Stage 1: Phase Shift Matrix Learning over G (1) In Stage 1, we utilize an HGNN to learn the phase shift matrix ov er G (1) through three sequential modules: 1) the feature augmentation layer; 2) T 1 GNN layers; and 3) the phase shift output layer . The detailed computational process of the HGNN is illustrated in Fig. 4. 1) F eatur e Augmentation Layer: This module is designed to enhance the initial input features, yielding the inputs for the first GNN layer , which are defined by e X [0] B - U , e X [0] B - E , and e X [0] B - R . W e first apply a single-layer MLP to enhance the initial dimension, which expands the feature space and improves the model’ s expressi ve capacity before subsequent feature processing. X ′ B - R [ l, :] = LeakyReLU ( W 1 X B - R [ l, :]) , (22) X ′ B - U [ k , :] = LeakyReLU ( W 1 X B - U [ k , :]) , (23) X ′ B - E [ m, :] = LeakyReLU ( W 1 X B - E [ m, :]) , (24) where W 1 is a learnable weight matrix. W e employ graph attention operations to obtain n ˙ X B - R , ˙ X B - U o = υ EAtt ψ Bi V (1) 1 , V (1) 2 , X ′ B - R , X ′ B - U , (25) n ¨ X B - R , ˙ X B - E o = υ EAtt ψ Bi V (1) 1 , V (1) 3 , X ′ B - R , X B - E ′ , (26) n ¨ X B - U , ¨ X B - E o = υ Att ψ FC V (1) 2 , V (1) 3 , X ′ B - U , X ′ B - E , (27) ... X B - R , ... X B - U , ... X B - E = υ Att ψ FC V (1) 1 ∪ ψ FC V (1) 2 ∪ ψ FC V (1) 3 , X ′ B - R , X ′ B - U , X ′ B - E , (28) and then, construct e X [0] B - U = Concat ˙ X B - U , ¨ X B - U , ... X B - U , (29) e X [0] B - E = Concat ˙ X B - E , ¨ X B - E , ... X B - E , (30) e X [0] B - R = Concat ˙ X B - R , ¨ X B - R , ... X B - R . (31) 2) GNN Layers: T 1 GNN layers update the node feature matrix for each node type using graph attention operators and residual connections. At the τ -th layer , the node feature matrices are first com- puted as e X [ τ ] B - U = υ EAtt ψ Uni V (1) 1 , V (1) 2 , e X [ τ − 1] B - R , e X [ τ − 1] B - U , (32) e X [ τ ] B - E = υ EAtt ψ Uni V (1) 1 , V (1) 3 , e X [ τ − 1] B - R , e X [ τ − 1] B - E , (33) e X [ τ ] B - R = X [ τ ] B - R + X [ τ ] B - R , (34) where X [ τ ] B - R = υ EAtt ψ Uni V (1) 2 , V (1) 1 , e X [ τ − 1] B - U , e X [ τ − 1] B - R , (35) X [ τ ] B - R = υ EAtt ψ Uni V (1) 3 , V (1) 1 , e X [ τ − 1] B - E , e X [ τ − 1] B - R . (36) Then, these node feature matrices undergo residual connec- tions [36] to mitigate the gradient v anishing problem caused by layer stacking: e X [ τ ] B - U := e X [ τ ] B - U + P ( X B - U ) + P e X [ τ − 1] B - U , (37) e X [ τ ] B - E := e X [ τ ] B - E + P ( X B - E ) + P e X [ τ − 1] B - E , (38) e X [ τ ] B - R := e X [ τ ] B - R + P ( X B - R ) + P e X [ τ − 1] B - R , (39) where P ( · ) is the zero-padding operation, aiming to align the dimensions of the matrices in a lightweight manner . 3) Phase Shift Output Layer: For the l -th reflecting ele- ment, its phase shift is obtained by ϕ l =2 π × sigmoid ( c 1 LeakyReLU ( W 2 LeakyReLU W 3 e X [ T 1 ] B - R [ l, :] , (40) where c 1 , W 2 , and W 3 are learnable parameters. Then, the phase shift matrix is output as Φ = diag e j ϕ 1 , e j ϕ 2 , ..., e j ϕ L . (41) C. Stage 2: Beamforming and AN Learning over G (2) In Stage 2, we utilize an HGNN to learn the beamforming vectors and AN v ectors ov er G (2) through three sequential modules: 1) the feature initialization layer; 2) T 2 GNN layers; and 3) the beamforming and AN output layer . The detailed computational process of the HGNN is illustrated in Fig. 5. 1) F eatur e Initialization Layer: W ith the obtained Φ , the effecti ve CSI for the k -th LU and the m -th Eve are deri ved as e h k ( Φ ) and e f k ( Φ ) . The node feature matrices for the two node types in G (2) are initialized by fusing the effecti ve CSI and the outputs of Stage 1, which are gi ven respectiv ely by e X [0] B - R - U [ k , :] = LeakyReLU W 4 e h k ( Φ ) + e X [ T 1 ] B - U [ k , :] , (42) e X [0] B - R - E [ m, :] = LeakyReLU W 5 e f m ( Φ ) + e X [ T 1 ] B - E [ m, :] , (43) where W 4 and W 5 are learnable weight matrices to align the dimensions of the matrices. 8 2) T 2 GNN Layers: T 2 GNN layers update the node feature matrix for each node type using graph attention operators and residual connections. At the τ -th layer , the node feature matrices are first com- puted as e X [ τ ] B - R - U = X [ τ ] B - R - U + X [ τ ] B - R - U , (44) e X [ τ ] B - R - E = X [ τ ] B - R - E + X [ τ ] B - R - E , (45) where X [ τ ] B - R - U = υ Att ψ Uni V (2) 1 , V (2) 2 , e X [ τ − 1] B - R - U , e X [ τ − 1] B - R - E , (46) X [ τ ] B - R - E = υ Att ψ Uni V (2) 2 , V (2) 1 , e X [ τ − 1] B - R - E , e X [ τ − 1] R - R - U , (47) X [ τ ] B - R - U = υ Att ψ FC V (2) 1 , e X [ τ − 1] B - R - U , (48) X [ τ ] B - U - E = υ Att ψ FC V (2) 2 , e X [ τ − 1] B - R - E . (49) The residual connections are introduced to alleviate the gradient vanishing problem, and the final output of each layer is e X [ τ ] B - R - U := e X [ τ ] B - R - U + P ( X B - R - U ) + P e X [ τ − 1] B - R - U , (50) e X [ τ ] B - R - E := e X [ τ ] B - R - E + P ( X B - R - E ) + P e X [ τ − 1] B - R - E , (51) where X B - R - U ≜ h e h 1 ( Φ ) , e h 2 ( Φ ) ; . . . ; e h K ( Φ ) i , (52) X B - R - E ≜ h e f 1 ( Φ ) , e f 2 ( Φ ) ; . . . ; e f M ( Φ ) i . (53) 3) Beamforming and AN Output Layer: W e consider two output methods, i.e., beam-direct and model-based. The beam-direct output enables ( K + L ) nodes to share two fully-connected layers and one activ ation function to directly map the final node embeddings e X [ T 2 ] B - R - U and e X [ T 2 ] B - R - E to the unconstrained beamforming vector and AN vector: e w k = f 2 W 6 LeakyReLU W 7 e X [ T 2 ] B - R - U [ k , :] + η 1 + η 2 , (54) e z m = f 2 W 8 LeakyReLU W 9 e X [ T 2 ] B - R - E [ m, :] + η 3 + η 4 , (55) where W 6 , W 7 , W 8 , W 9 , η 1 , η 2 , η 3 , and η 4 are learnable weights, and f 2 ( · ) : R 2 N T → C N T is a dimension reshap- ing function. Then, { e w k } and { e z m } undergo the following operation to meet the total po wer budget constraint: Ψ ( v i ) = v u u t P max max P max , P i ′ ∈ K ∪ M ∥ v i ′ ∥ 2 v i , (56) where v n ∈ { w k , z m } k ∈ K ,m ∈ M . The model-based output utilizes the hybrid zero forcing (ZF) and maximum ratio transmission (MR T) method [37], which defines ( α k , p k ) and ( β m , p m ) in the Appendix C, where α k and β m represent the direction-related parameters, and p k and p m represents the power -related parameters. The model-based output employs two fully-connected layers along with one activ ation function to yield ( α k , p k ) for the k -th LU and ( β m , p m ) for the m -th Eve. Specifically , to meet the constraints, α k and β m are activ ated via the Sigmoid function, while p k and p m undergo the ReLU function along with e Ψ ( p i ) = s P max max P max , P i ′ ∈ K ∪ M p i ′ p i , (57) where p i ∈ { p k , p m } k ∈ K ,m ∈ M . D. Loss Function W e adopt unsupervised learning to train the proposed model, and the loss function is gi ven by L = − P k ∈ K e R Sec ,k ( { w k ′ , z m ′ } , Φ ) P k ∈ K ∥ w k ∥ 2 + P m ∈ M ∥ z m ∥ 2 + P C , (58) where e R Sec ,k ( { w k ′ , z m ′ } , Φ ) is given by e R Sec ,k ( { w k ′ , z l ′ } , Φ ) = (59) R k ( { w k ′ , z m ′ } , Φ ) − γ max m { R E ,m,k ( { w k ′ , z m ′ } , Φ ) } , where γ is a hyperparameter, which is usually set to 0 . 1 . E. Scalability Analysis Notably , all learnable parameters in the proposed two-stage HGNN are independent of the number of reflecting elements L , LUs K , and Eves M . This property stems from the permutation equiv ariance inherent in the graph representations and graph operations employed in the model. 1) P ermutation-Equivariant Graph Repr esentation: The graph in Stage 1 incorporates three types of nodes corre- sponding to reflecting elements, LUs, and Eves, where both LU nodes and Eve nodes are connected to reflecting element nodes. The graph in Stage 2 is fully-connected, which consists of two types of nodes corresponding to LUs and Eves, where the features of both node types in v olve the phase shift matrix. The graphs utilized in both stages satisfy permutation equiv ariance, i.e., permuting the input order of the same node type does not alter the model’ s output or optimization results. Such a property renders the model inherently adaptable to dynamic numbers of reflecting elements, LUs, and Eves. In particular , this can be achieved simply by adding or removing corresponding nodes in the graph, while the core message- passing mechanism remains unchanged and no retraining is necessitated. 2) P ermutation-Equivariant Graph Operation: The key op- erator employed in both stages relies on the multi-head atten- tion mechanism from GA T . Such a mechanism is inherently permutation-equiv ariant. That is, arbitrary permutations of the input node set, including the rearrangement of node indices and their associated features, yield identical permutations of the output node representations, without altering the model’ s core computational logic or the relati ve relationships among the learned node embeddings. When ne w nodes are added to the graph, the model automatically integrates them into the message-passing procedure by computing attention weights between the newly introduced nodes and existing ones ac- cording to their feature similarities, without any modification 9 T ABLE II T H E S T RU C TU R E O F T H E T W O - S T AG E H G N N . Stage T ype IFs HNs OFs AHs 1 FIL 2 N T 640 32 5 GL 1 480 × 64 10 2 640 × 64 10 OL 640 320, 128 1 × 2 F AL 2 N T × 640 × GL 1 640 × 128 10 2 1280 × 256 10 OL 2560 640 2 N T × GL/F AL/FIL/OL: GNN layer/Feature augmentation layer/Feature initial- ization layer/Output layer . IFs/OFs/HNs/AHs: Input features/Output features/Number of neurons in hidden layer/Number of attention heads. T ABLE III T R A IN I N G A N D T E S T S E T C O N FI G U RAT IO N S . T raining set T est set ( L T r , K T r , M T r ) ( L T e , K T e , M T e ) (8 , 3 , 4) (8 , 3 , 4) (8 , 2 , 4) (8 , 4 , 4) (7 , 3 , 4) (9 , 3 , 4) (8 , 3 , 3) (8 , 3 , 5) #Sample 9 . 6 × 10 5 #Sample 1000 per set to the pre-trained model parameters. Similarly , when nodes are remov ed, the model simply excludes the corresponding nodes from the message aggregation and attention computation steps, while the underlying message-passing mechanism remains unchanged. V I . N U M E R I C A L R E S U LT S This section ev aluates the proposed model. The structures of the proposed model are displayed in T able II. A. Experimental Setting 1) Simulation Scenario: The BS is deployed at (0 , 0) m, while the RIS is placed at (10 , 0) m close to the BS to mitigate cascaded fading. The LUs are randomly distributed within a circular area centered at (50 , 50) m with a radius of 10 m, and the Eves are randomly distributed within a circular area centered at (25 , 25) m with a radius of 10 m. Notably , Eves are closer to the BS than LUs. The transmit antennas at BS are set as N T = 8 . 2) Channel Model: The path loss of direct link (including h B ,k and f B ,m ) is modeled as p ρd − α where d and ρ denote the corresponding Euclidean distance and the path loss per meter distance, respecti vely , and α denotes the fading exponent. The small-scale fading is modeled as Rayleigh fading. The RIS-related CSI contains one LoS path and a large number of NLoS paths. Specifically , the CSI between the RIS T ABLE IV S I M UL ATI O N P A R AM E T E R S . Notation V alues BS location (0 , 0) RIS location (10 , 0) LU location center (50 , 50) radius 10 Eve location center (25 , 25) radius 10 Number of antennas N T = 8 Central frequency f c = 1 . 8 GHz Constant po wer P C = 0 . 5 W Antenna separation ∆ = λ/ 2 W a velength λ = c/f c Rician factor β = 3 dB Fading exponent α = 2 . 8 Power budget P max = 30 dBm Path loss per meter ρ = − 20 dB Noise po wer σ 2 = − 80 dBm and a receiver (either an LU or an Eve), or between the BS and the RIS, is modeled using Rician fading, which is gi ven by h = p ρd − α s β 1 + β h LoS ( ϕ ) + r 1 β + 1 h NL ! , (60) H = p ρd − α s β 1 + β H LoS ( ϕ ) + r 1 β + 1 H NL ! , (61) where β denotes the Rician factor , and the entries of h NL / H NL are independently drawn from the complex Gaus- sian distribution with zero mean and unit variance, i.e., CN (0 , 1) . The LoS components are expressed by the responses of the ULA. For an N -element ULA, the response is given by a N ( ϕ ) = h 1 , e − j 2 π λ ∆ sin( ϕ ) , ..., e − j 2 π λ ( N − 1)∆ sin( ϕ ) i T , (62) where ∆ and λ denote antenna separation and wa velength, respectiv ely , and ϕ denotes the angle of departure (AoD) or angle of arri v al (AoA) of a signal. Then, h LoS and H LoS are respectiv ely giv en by h LoS = a L ( ϕ AoD ) , (63) H LoS = a L ( ϕ AoA ) a H N T ( ϕ AoD ) . (64) All default parameters are summarized in T able IV. 3) Dataset and Metric: W e prepare one training set with 9 . 6 × 10 5 samples and seven test sets with 1000 samples each. The training set adopts the setting of ( L T r , K T r , M T r ) = (8 , 3 , 4) , while the configurations of the test sets are provided in T able III. All samples in both the training set and test sets are gener- ated independently according to the channel model. Moreover , for each test sample, we employ the BCD method to obtain its optimal SEE as the label. During the test, we use the ratio of the SEE yielded by the DL model to the SEE label as the ev aluation metric. 10 T ABLE V P E R FO R M A N C E C O M PAR I S O N . N T T raining Setting T est Setting Baselines T wo-stage HGNN Note ( L T r , K T r , M T r ) ( L T e , K T e , M T e ) MLP CO-GNN BHGNN Beam-direct Model-based 8 (8 , 3 , 4) (8 , 3 , 4) 23.57% 61.61% 34.87% 90.76% 96.60% (8 , 2 , 4) 28.31% 50.28% 49.59% 82.01% 96.80% Scale to (8 , 4 , 4) – 25.35% 2.01% 45.20% 96.99% L (7 , 3 , 4) – – 23.98% 89.54% 96.46% Scale to (9 , 3 , 4) – – 25.26% 89.73% 96.43% K (8 , 3 , 3) 25.72% 63.03% 37.30% 91.56% 97.27% Scale to (8 , 3 , 5) – 61.06% 34.14% 79.39% 95.93% M Inference time 0 . 73 ms 0 . 99 ms 2 . 3 ms 11 . 53 ms 11 . 64 ms 82 . 74 s by CVXopt 4) Implementation Details: The learning rate is initialized as 1 × 10 − 4 . The adapti ve moment estimation is adopted as the optimizer during the training phase. The batch size is set to 256 for 100 epochs of training, and the learnable weights with the best performance are used as the training result. Our implementation is de veloped using Python 3.11.5 with PyT orch 2.1.0 on a computer with Intel(R) Core(TM) Ultra 9 275HX CPU and one NVIDIA GeForce R TX 5070 Ti Laptop GPU (12 GB of memory). 5) Baselines: The baselines employed to e v aluate the ef- fectiv eness of the proposed two-stage HGNN are listed as follows: • MLP: A basic feed-forward neural network with a three- branch output architecture. • CO-GNN: A GNN model with one RIS node and mul- tiple LU nodes, which adopts a custom message-passing mechanism integrating mean-pooling, max-pooling, and MLP-based node feature update, similar to [34]. • BHGNN: A GNN model with multiple RIS nodes, multi- ple LU nodes, and edge feature integration, which adopts a custom message-passing mechanism integrating sum- pooling, MLP-based node feature update, and iterativ e optimization update, similar to [32]. B. Effectiveness T able V compares the proposed two-stage HGNN with the baselines. For identical training and test settings, i.e., ( L T r , K T r , M T r ) = ( L T e , K T e , M T e ) , the proposed two-stage HGNN achie ves a higher SEE using both the beam-direct and model-based output methods, where the model-based one can attain near-optimal performance. Howe v er , the existing baselines fail to yield satisfactory performance. Especially , the MLP achiev es a performance near 20% , highlighting the necessity of de veloping task-suitable neural architectures. The two-stage HGNN, COGNN and BHGNN are scalable with respect to the number of reflecting elements and Eves. As observed, only the two-stage HGNN with the model- based output method can maintain a good performance. In contrast, the two-stage HGNN with the beam-direct output method suf fers from a notable performance degradation when encountering a larger L or M . Furthermore, the baselines Fig. 6. CDF of SEE for DL-based and CVXopt-based approaches. exhibit even poorer performance. The two-stage HGNN and BHGNN are scalable with respect to the number of LUs K . In this scenario, both the beam-direct and model-based output methods maintain limited performance loss, whereas BHGNN does not scale well. Moreover , the two-stage HGNN requires longer inference time for the transmit design than the baselines, since it in v olv es more sophisticated designs in both framework and architecture. Nev ertheless, it still maintains millisecond-le vel efficiency , which is considerably faster than the CVXopt-based approach. In summary , the two- stage HGNN yields near-optimal performance, with a notable performance improvement o ver the baselines. Moreover , the two-stage HGNN, especially with the model-based output method, scales well with respect to the number of reflecting elements, LUs, and Eves, demonstrating its adaptability to dynamic wireless en vironments. Fig. 6 plots the cumulativ e distribution function (CDF) of the achiev able SEE for the proposed model and baselines as well as the CVXopt-based approach ov er 1000 test samples, with ( L T r , K T r , M T r ) = ( L T e , K T e , M T e ) = (8 , 3 , 4) . Com- pared with the baselines, the two-stage HGNN yields more 11 Fig. 7. SEE versus power budget by the two-stage HGNN trained with P max = 1 W . stable SEE performance and significantly reduces the proba- bility of low SEE. Particularly , the model-based method allows the two-stage HGNN to achie ve performance comparable to that of the CVXopt-based approach for all test samples, while requiring much less inference time. Fig. 7 illustrates the achie v able SEE by the proposed two- stage HGNN trained with P max = 30 dBm over the po wer budget range [0 , 33] dBm. Results for both the beam-direct and model-based output methods are provided. It can be observed that the SEE first increases and then remains unchanged with the po wer b udget, which is consistent with the theoretical results [38]. That is, the two-stage HGNN can learn the key characteristics of the SEE function, enabling it to adapt to various power budgets. Such a capability is deri ved by the parameter-free scaling operation (56) and (57). Moreover , the model-based output method behav es comparably to the beam- direct one at low power budgets, while achieving superior performance at high po wer budgets. Fig. 8 illustrates the scalability of the two-stage HGNN with respect to the number of LUs K or Eves M over a range [2 , 7] . During the training phase, K and M are set to 3 and 4 , respectiv ely , and the model-based output method is emplo yed. It can be observ ed that the two-stage HGNN accurately captures the trend that the achiev able SEE increases with K , which is consistent with the simulation results in [6]. Moreov er , as M increases, the SEE achiev ed by the two-stage HGNN degrades, since it becomes increasingly challenging to pre vent information leakage, which is consistent with the simulation results in [39]. Notably , such scalability is obtained without retraining, making it highly crucial for adapting to the dynamics of wireless networks. Fig. 8. Generalization performance of the two-stage GNN with the model- based output method with K T r = 3 and M T r = 4 . C. Ablation Experiment T able VI presents the ablation study 2 to validate the effec- tiv eness of three key components, i.e., the residual connection, the two-stage framework, and the model-based output method. As observed, all components contrib ute to the performance improv ement. For clarity , we report the av erage gain compared with the model without the three components. Specifically , the residual connection and the two-stage framework improve the achiev able SEE by 1 . 54% and 19 . 07% , respecti v ely , and their combination yields a 27 . 67% performance gain. This result demonstrates that the basic GNN model for RIS- assisted systems can be effecti v ely built upon the two-stage framew ork with residual connections. The model-based output method contributes to an av erage gain of 43 . 56% , which mainly benefits from its stable performance when scaling to different system configurations. Thus, it is essential to inte grate theoretical results into the neural network architecture. V I I . C O N C L U S I O N This paper focused on dev eloping a GNN-based learning- to-optimize approach for RIS-aided PLS systems. W e pro- posed to jointly exploit the multi-stage frame work and the heterogeneous graph representation to tackle the deeply cou- pled optimization variables and inherent system heterogeneity . Specifically , a two-stage HGNN is de veloped to maximize the system SEE. The tw o-stage HGNN follo ws a stage-wise graph modeling strategy: the first stage constructs a bipartite graph to learn the optimal RIS phase shift matrix, while the second stage employs a fully-connected heterogeneous graph to generate beamforming and AN vectors. Multi-head attention mechanisms and residual connections are integrated into both stages to enhance feature learning and model stability . Trained in an unsupervised manner , the two-stage HGNN av oids the 2 The ablation study on HGNN is intractable, since the considered system deviates significantly from the homogeneous graph representation. 12 T ABLE VI A B L A T I O N E X P E R IM E N T W I T H ( L r , K T r , M T r ) = (8 , 3 , 4) . Res T wo-Stage Model-based ( L T e , K T e , M T e ) A verage (8 , 3 , 4) (8 , 2 , 4) (8 , 4 , 4) (7 , 3 , 4) (9 , 3 , 4) (8 , 3 , 3) (8 , 3 , 5) Gain × × × 58.70% 63.99% 36.00% 45.54% 51.20% 58.93% 57.14% – ✓ × × 60.35% 55.87% 34.69% 54.80% 56.73% 60.77% 59.10% 1.54% × ✓ × 87.12% 65.54% 38.04% 86.07% 86.21% 88.09% 53.97% 19.07% ✓ ✓ × 90.76% 82.01% 42.20% 89.54% 89.73% 91.56% 79.39% 27.67% ✓ ✓ ✓ 96.60% 96.80% 96.99% 96.46% 96.43% 97.27% 95.93% 43.56% α ( i,j ) d = exp a T d LeakyReLU W ( S ) d X i + W ( N ) d x j + W ( E ) d y i,j P i ′ ∈ N ( i ) exp a T d LeakyReLU W ( S ) d x i + W ( N ) d x i ′ + W ( E ) d y i,i ′ (65) dependence on lar ge labeled datasets and reduces the computa- tional burden. Its scalable structure enables flexible adaptation to dynamic numbers of RIS elements, LUs, and Eves. Numer- ical results confirmed the superiority of the proposed HGNN ov er state-of-the-art GNNs in RIS-aided PLS scenarios. Com- pared with CVXopt-based algorithms, it drastically reduces the inference time while limiting the performance degradation to below 4% . Furthermore, its scalability under various system configurations is verified. A P P E N D I X A. Edge-Based Graph Attention Operator Giv en a graph G and the corresponding node feature matri- ces { X n } , the edge-based graph attention operator is detailed as follo ws to update the node feature matrices. For clarity , we define the x i (deriv ed from { X n } ) by the node feature of the i -th node, N ( i ) by the neighboring source node set of the i -th node, and y i,i ′ by the directed edge feature from the i ′ -th ( i ′ ∈ N ( i ) ) node to the i -th node, which keeps unchanged. The i -th target node assigns an attention coefficient as- sociated with the d -th ( d ∈ { 1 , 2 , . . . , D } ) head to its j -th ( j ∈ N ( i ) ) source node, which is calculated by (65), where a d denotes the learnable attention weight vector , and W (S) d , W (N) d , and W (E) d denote the learnable projection matrices for target node, source node, and edge features, respectiv ely . Then, the i -th node aggregates the node features of itself and its neighboring target nodes based on the d -th attention head to obtain β ( i ) d = W ( S ) d x i + X i ′ ∈ N ( i ) α ( i,i ′ ) d W ( N ) d x i ′ + W ( E ) d y i,i ′ , (66) By concatenating the D aggregated features, the feature of the i -th node is updated to e x i , which is gi ven by e x i = Concat n β ( i ) d o . (67) B. Edge-F ree Graph Attention Operator Similarly , the edge-free graph attention operator updates node features of a given graph G without in v olving the edge features. W e reuse the symbols defined for simplicity . The d -th attention coefficient assigned by the i -th target node to the j -th source node is giv en by α ( i,j ) d = (68) exp a T d LeakyReLU W ( S ) d X i + W ( N ) d x j P i ′ ∈ N ( i ) exp a T d LeakyReLU W ( S ) d x i + W ( N ) d x i ′ . Then, the node feature of the i -th node is updated by e x i = Concat X i ′ ∈ N ( i ) α ( i,i ′ ) d W ( N ) d x i ′ . (69) C. Hybrid ZF and MRT method W e represent w k and z m as w k = √ p k w k ( α k ) , ∥ w k ( α k ) ∥ = 1 , (70) z m = √ p m z m ( β m ) , ∥ z m ( β m ) ∥ = 1 . (71) For w k , the hybrid ZF and MR T scheme is adopted to design its direction, which is gi ven by w k ( α k ) = α k v k ∥ v k ∥ + (1 − α k ) e h k ( Φ ) ∥ e h k ( Φ ) ∥ α k v k ∥ v k ∥ + (1 − α k ) e h k ( Φ ) ∥ e h k ( Φ ) ∥ , (72) where α k ∈ [0 , 1] is a learnable parameter, and v k is the k -th column of V ≜ G H GG H − 1 , (73) where G ≜ [ e h 1 ( Φ ) , e h 2 ( Φ ) , . . . , e h K ( Φ )] . For z m , its direction is gi ven by z m ( β m ) = β m v Eve ,m ∥ v Eve ,m ∥ + (1 − β m ) e f m ( Φ ) ∥ e f m ( Φ ) ∥ β m v Eve ,m ∥ v Eve ,m ∥ + (1 − β m ) e f m ( Φ ) ∥ e f m ( Φ ) ∥ , (74) 13 where β m ∈ [0 , 1] is a learnable parameter, and v Eve ,m is the ( k + 1) -th column of V Eve ,m ≜ G H Eve ,m G Eve ,m G H Eve ,m − 1 , (75) where G Eve ,m ≜ [ e h 1 ( Φ ) , e h 2 ( Φ ) , . . . , e h K ( Φ ) , e f m ( Φ )] . R E F E R E N C E S [1] Q. W u and R. Zhang, “T owards smart and reconfigurable environment: Intelligent reflecting surface aided wireless network, ” IEEE Commun. Mag. , vol. 58, no. 1, pp. 106–112, Jan. 2020. [2] M. A. ElMossallamy , H. Zhang, L. Song, K. G. Seddik, Z. Han, and G. Y . Li, “Reconfigurable intelligent surfaces for wireless communica- tions: Principles, challenges, and opportunities, ” IEEE Tr ans. Cognit. Commun. Networking , vol. 6, no. 3, pp. 990–1002, Sept. 2020. [3] Y . Liu, X. Liu, X. Mu, T . Hou, J. Xu, M. Di Renzo, and N. Al-Dhahir, “Reconfigurable intelligent surfaces: Principles and opportunities, ” IEEE Commun. Surv . T utorials , vol. 23, no. 3, pp. 1546–1577, 2021. [4] S. Hong, C. P an, H. Ren, K. W ang, and A. Nallanathan, “ Artificial-noise- aided secure MIMO wireless communications via intelligent reflecting surface, ” IEEE T rans. Commun. , vol. 68, no. 12, pp. 7851–7866, Dec. 2020. [5] H. Amiriara, F . Ashtiani, M. Mirmohseni, and M. Nasiri-Kenari, “IRS- user association in IRS-aided MISO wireless networks: Conv ex opti- mization and machine learning approaches, ” IEEE Tr ans. V eh. T echnol. , vol. 72, no. 11, pp. 14 305–14 316, Nov . 2023. [6] Y . Lu, “Secrecy energy efficienc y in RIS-assisted networks, ” IEEE T r ans. V eh. T echnol. , vol. 72, no. 9, pp. 12 419–12 424, Sept. 2023. [7] H. Guo, Y .-C. Liang, J. Chen, and E. G. Larsson, “W eighted sum- rate maximization for reconfigurable intelligent surface aided wireless networks, ” IEEE Tr ans. W ir eless Commun. , vol. 19, no. 5, pp. 3064– 3076, May 2020. [8] C. Pan, G. Zhou, K. Zhi, S. Hong, T . Wu, Y . Pan, H. Ren, M. D. Renzo, A. Lee Swindlehurst, R. Zhang, and A. Y . Zhang, “ An overview of signal processing techniques for RIS/IRS-aided wireless systems, ” IEEE J. Sel. T op. Signal Pr ocess. , vol. 16, no. 5, pp. 883–917, Aug. 2022. [9] C. Huang, R. Mo, and C. Y uen, “Reconfigurable intelligent surface as- sisted multiuser MISO systems exploiting deep reinforcement learning, ” IEEE J. Sel. Ar eas Commun. , vol. 38, no. 8, pp. 1839–1850, Aug. 2020. [10] R. Zhang, K. Xiong, Y . Lu, P . Fan, D. W . K. Ng, and K. B. Letaief, “Energy efficiency maximization in RIS-assisted SWIPT networks with RSMA: A PPO-based approach, ” IEEE J . Sel. Areas Commun. , v ol. 41, no. 5, pp. 1413–1430, May 2023. [11] A. S. Abdalla and V . Marojevic, “Enhancing secrecy energy efficiency in RIS-aided aerial mobile edge computing networks: A deep reinforce- ment learning approach, ” in Proc. ICC , 2025, pp. 6585–6590. [12] H. Sun, X. Chen, Q. Shi, M. Hong, X. Fu, and N. D. Sidiropoulos, “Learning to optimize: Training deep neural networks for interference management, ” IEEE T rans. Signal Pr ocess. , vol. 66, no. 20, pp. 5438– 5453, Oct. 2018. [13] P . Saikia, K. Singh, S. K. Singh, W .-J. Huang, C.-P . Li, and S. Biswas, “Beamforming design in vehicular communication systems with multiple reconfigurable intelligent surfaces: A deep learning approach, ” IEEE Access , vol. 11, pp. 100 832–100 844, 2023. [14] J. Gao, C. Zhong, X. Chen, H. Lin, and Z. Zhang, “Unsupervised learning for passive beamforming, ” IEEE Commun. Lett. , vol. 24, no. 5, pp. 1052–1056, May 2020. [15] Y . Ma, X. Zhou, X. Li, L. Liang, and S. Jin, “Unsupervised learning- based joint resource allocation and beamforming design for RIS-assisted MISO-OFDMA systems, ” IEEE T r ans. Cognit. Commun. Networking , vol. 12, pp. 2251–2264, 2026. [16] H. Zhang, Q. Jia, M. Li, J. W ang, and Y . Song, “Passiv e Beamforming Design of IRS-Assisted MIMO Systems Based on Deep Learning, ” Sensors , vol. 23, no. 16, p. 7164, Aug. 2023. [17] Y . Lu, S. Zhang, C. Liu, R. Zhang, B. Ai, D. Niyato, W . Ni, X. W ang, and A. Jamalipour , “ Agentic graph neural networks for wireless commu- nications and networking toward edge general intelligence: A survey , ” IEEE Commun. Surv . T utorials , vol. 28, pp. 4519–4554, 2026. [18] Y . Lu, Y . Li, R. Zhang, W . Chen, B. Ai, and D. Niyato, “Graph neural networks for wireless networks: Graph representation, architecture and ev aluation, ” IEEE W ir eless Commun. , vol. 32, no. 1, pp. 150–156, Feb. 2025. [19] Y . Shen, J. Zhang, S. H. Song, and K. B. Letaief, “Graph neural netw orks for wireless communications: From theory to practice, ” IEEE Tr ans. W ir eless Commun. , vol. 22, no. 5, pp. 3554–3569, May 2023. [20] Y . Li, Y . Lu, B. Ai, O. A. Dobre, Z. Ding, and D. Niyato, “GNN-based beamforming for sum-rate maximization in MU-MISO networks, ” IEEE T r ans. W ir eless Commun. , vol. 23, no. 8, pp. 9251–9264, Aug. 2024. [21] C. He, Y . Lu, B. Ai, O. A. Dobre, Z. Ding, and D. Niyato, “ICGNN: Graph neural network enabled scalable beamforming for MISO interfer- ence channels, ” IEEE T rans. Mob. Comput. , vol. 24, no. 10, pp. 10 778– 10 791, Oct. 2025. [22] Z. Song, Y . Lu, X. Chen, B. Ai, Z. Zhong, and D. Niyato, “ A deep learning frame work for physical-layer secure beamforming, ” IEEE T r ans. V eh. T echnol. , vol. 73, no. 12, pp. 19 844–19 849, Dec. 2024. [23] J. Y ang, J. Xu, Y . Zhang, H. Zheng, and T . Zhang, “Graph attention network-based precoding for reconfigurable intelligent surfaces aided wireless communication systems, ” IEEE T rans. V eh. T echnol. , vol. 73, no. 6, pp. 9098–9102, June 2024. [24] C. He, Y . Lu, Y . Xu, C.-Y . Chi, B. Ai, and A. Nallanathan, “RIS- assisted downlink pinching-antenna systems: GNN-enabled optimization approaches, ” arXiv preprint , Nov . 2025. [Online]. A vailable: https://arxiv .org/abs/2511.20305 [25] T .-J. Y eh, W .-C. Tsai, C.-W . Chen, and A.-Y . W u, “Enhanced-GNN with angular csi for beamforming design in IRS-assisted mmW av e communication systems, ” IEEE Commun. Lett. , vol. 28, no. 4, pp. 827– 831, April 2024. [26] H. T ang, J. Zhang, Z. Zhao, H. W u, H. Sun, and P . Jiao, “Joint optimization based on two-phase GNN in RIS- and DF-assisted MISO systems with fine-grained rate demands, ” IEEE T rans. W ir eless Com- mun. , vol. 24, no. 12, pp. 9989–10 002, Dec. 2025. [27] B. Y in, J. Schampheleer, W . Joseph, and M. Deruyck, “Graph neural network-based energy-efficient optimization for RIS-assisted wireless networks, ” IEEE T rans. W ir eless Commun. , vol. 25, pp. 664–680, 2026. [28] M. Liu, C. Huang, A. Alhammadi, M. Di Renzo, M. Debbah, and C. Y uen, “Beamforming design and association scheme for multi-RIS multi-user mmW ave systems through graph neural networks, ” IEEE T r ans. W ir eless Commun. , vol. 24, no. 9, pp. 7940–7954, Sept. 2025. [29] T . N. Kipf and M. W elling, “Semi-supervised classification with graph con volutional networks, ” in Pr oc. ICLR , Apr. 2017. [30] P . V eli ˇ ckovi ´ c, G. Cucurull, A. Casanova, A. Romero, P . Li ` o, and Y . Bengio, “Graph attention networks, ” in Proc. ICLR , Apr . 2018. [31] Q.-S. Nguyen, X.-T . Dang, and O.-S. Shin, “Optimization of RIS- assisted cell-free massive MIMO systems with heterogeneous graph neural networks under imperfect channel estimation, ” IEEE T rans. V eh. T echnol. , pp. 1–16, 2025. [32] H. A. Le, T . V an Chien, and W . Choi, “Graph neural network-based ac- tiv e and passiv e beamforming for distributed ST AR-RIS-assisted multi- user MISO systems, ” IEEE Tr ans. Commun. , vol. 73, no. 10, pp. 9299– 9312, Oct. 2025. [33] J. Zhang, H. T ang, P . Jiao, H. W u, Z. Zhao, and R. Li, “Secrecy rate optimization based on GNN for RIS-assisted ISAC system, ” IEEE Internet Things J. , pp. 1–1, 2026. [34] L. Liang, Z. Tian, H. Huang, X. Li, Z. Y in, D. Zhang, N. Zhang, and W . Zhai, “Heterogeneous secure transmissions in IRS-assisted NOMA communications: CO-GNN approach, ” IEEE Internet Things J. , vol. 12, no. 16, pp. 34 113–34 125, Aug. 2025. [35] X. W ang, H. Ji, C. Shi, B. W ang, Y . Y e, P . Cui, and P . S. Y u, “Heterogeneous graph attention network, ” in Pr oc. W orld W ide W eb Conf. (WWW) , May 2019, pp. 2022–2032. [36] X. Zheng, Z. Liu, J. Liang, Y . Wu, Y . Chen, and Q. Zhang, “Residual learning and multi-path feature fusion-based channel estimation for millimeter-wa ve massive MIMO system, ” Entropy , vol. 24, no. 2, p. 292, Feb. 2022. [37] R. Zhang, Y . Lu, W . Chen, B. Ai, and Z. Ding, “Model-based GNN en- abled energy-ef ficient beamforming for ultra-dense wireless networks, ” IEEE T rans. W ir eless Commun. , vol. 24, no. 4, pp. 3333–3345, 2025. [38] Y . Li, M. Sheng, C. Y ang, and X. W ang, “Energy efficienc y and spectral efficiency tradeoff in interference-limited wireless networks, ” IEEE Commun. Lett. , vol. 17, no. 10, pp. 1924–1927, Oct. 2013. [39] W . Hao, J. Li, G. Sun, C. Huang, M. Zeng, O. A. Dobre, and C. Y uen, “Robust security energy efficiency optimization for RIS-aided cell-free networks with multiple eavesdroppers, ” IEEE T rans. Commun. , vol. 72, no. 12, pp. 7401–7416, Dec. 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment