Distilling Reasoning Without Knowledge: A Framework for Reliable LLMs
Fact-seeking question answering with large language models (LLMs) remains unreliable when answers depend on up-to-date or conflicting information. Although retrieval-augmented and tool-using LLMs reduce hallucinations, they often rely on implicit pla…
Authors: Auksarapak Kietkajornrit, Jad Tarifi, Nima Asgharbeygi
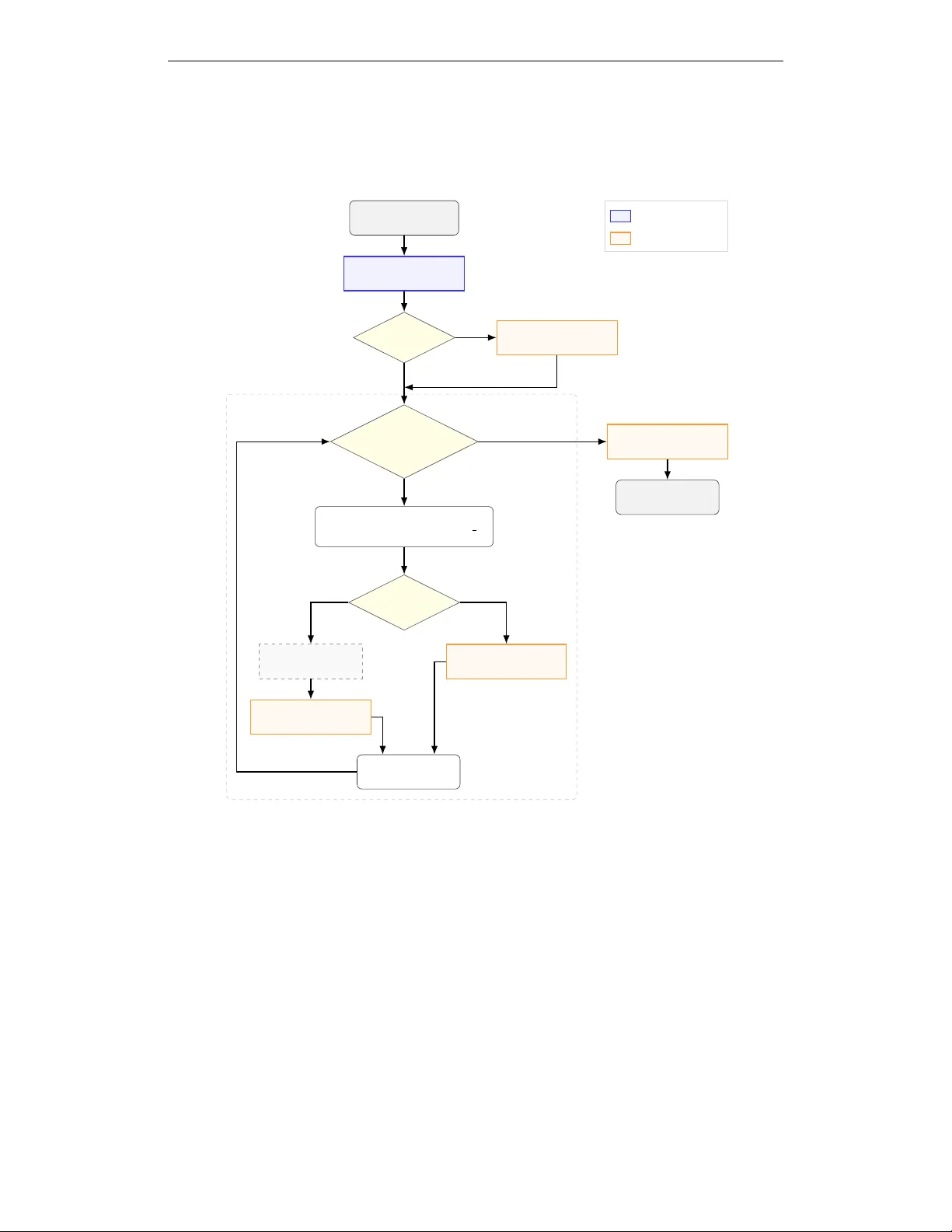
D I S T I L L I N G R E A S O N I N G W I T H O U T K N O W L E D G E : A F R A M E W O R K F O R R E L I A B L E L L M S A uksarapak Kietkajornrit Jad T arifi Nima Asgharbeygi Integral AI { auksarapak, jad, nima } @integral.ai A B S T R AC T Fact-seeking question answering with large language models (LLMs) remains un- reliable when answers depend on up-to-date or conflicting information. Although retriev al-augmented and tool-using LLMs reduce hallucinations, they often rely on implicit planning, leading to inefficient tool usage. W e propose a modular framew ork that explicitly separates planning from factual retrie val and answer synthesis. A lightweight student planner is trained via a teacher -student frame- work to generate structured decompositions consisting of abstract reasoning steps and searchable fact requests. The supervision signals contain only planning traces and fact requests, without providing factual answers or retrieved e vidence. At in- ference, the planner produces plans, while prompt-engineered modules perform retriev al and response synthesis. W e ev aluate the proposed frame work on S E A L - 0, an extremely challenging benchmark for search-augmented LLMs. Results show that supervised planning improv es both accuracy and latency compared to monolithic reasoning models and prompt-based tool-augmented frame works, demonstrating that e xplicitly learned planning structures are essential for reliable fact-seeking LLMs. 1 I N T RO D U C T I O N Large language models (LLMs) have achie ved remarkable performance across reasoning, language understanding, and decision-making tasks (Chang et al., 2024). Despite these adv ances, they remain prone to hallucinations : confident responses that are f actually incorrect, un verifiable, or unsupported by av ailable evidence (Ji et al., 2023). Such failures commonly occur when required information is missing, outdated, or lies outside the model’ s parametric knowledge, posing a serious challenge for deploying LLMs in real-world question answering and agentic systems where factual reliability is essential (W ang et al., 2023). At a high lev el, hallucinations arise when models generate plausible-sounding content to fill gaps in missing or uncertain information instead of explicitly ackno wledging uncertainty or requesting external evidence (Kalai et al., 2025). This behavior is reinforced by training objectiv es that fa vor coherent, helpful, and complete answers, even when the necessary facts are unav ailable (Huang et al., 2025). Architecturally , most LLMs combine reasoning and factual recall within a single inference process (Jin et al., 2025). Giv en a user query , the model must simultaneously decide what information is needed, retriev e it from internal parametric memory , and reason over it to produce an answer (Liu & Shu, 2025). When internal knowledge is incomplete or incorrect, the model has no explicit mechanism to detect this gap, often resulting in hallucinated facts rather than an explicit request for external information (Cao, 2024). This issue is particularly se vere for up-to-date, verifiable, or long-tail knowledge, where reliance on memorized training data alone is insufficient (Alansari & Luqman, 2025). Recent work on retrie val-augmented generation (RA G) and tool-using LLMs has demonstrated that grounding outputs in external sources, such as web search engines, databases, or application pro- gramming interfaces (APIs), can substantially improve factual accuracy (Huang et al., 2024; W ang et al., 2023). Despite this progress, many existing systems still rely on a single LLM to jointly decide what information is needed, how it should be retriev ed, and how retriev ed content is incorporated during reasoning (Zhu et al., 2025; W ampler et al., 2025). This coupling process makes it difficult 1 to attribute errors to specific stages of the pipeline, whether the y stem from reasoning, retrie val fail- ures, or incorrect grounding. As LLMs are increasingly deployed in autonomous agentic systems, this entanglement makes failures harder to diagnose, control, and correct. Iteration Loop Start : User Question Student Planner Generate JSON Plan V alid JSON? More F act Requests? Insert Retrieved Facts Replace placeholders with stored facts Source T ype? SerpAPI (Google Search) Extractor Extract Answer Compute Module Execute Logic Store Fact Repair Module Fix Syntax Errors Aggregator Synthesize Answer End : Final Output No Y es Y es Web Compute Next Iteration No (Done) Fine-tuned LLM Prompted LLM Figure 1: Inference-time execution pipeline of the proposed frame work. In this work, we propose a framework for reliable and hallucination-resistant LLM that explicitly separates reasoning from factual kno wledge acquisition, as illustrated in the flo wchart in Fig. 1. Here, reliability refers to the model’ s ability to produce factually correct responses grounded in verifiable e vidence while avoiding hallucinated claims and refraining from asserting unsupported information (Liu et al., 2023). The key idea is to structure the inference process into distinct stages including planning, information retrie val, f actual extraction, and answer aggre gation, so that factual claims are grounded in external evidence rather than internal memory . T o enable this, we employ a teacher -student training strategy that trains a Student LLM to av oid internalizing factual content. During dataset construction, the T eacher LLM is prompted to decompose each question into (i) a sequence of abstract reasoning steps and (ii) a minimal set of atomic f act requests required to complete those steps. The teacher is explicitly constrained not to answer questions directly or rely on its internal factual knowledge. Instead, it produces structured outputs that describe what needs to be known, rather than what the f acts are. The training objective for the Student LLM is to reproduce the teacher’ s reasoning structure and information-seeking beha vior . The supervision signals contain only planning traces and fact re- quests, without providing factual answers or retrieved evidence. This design encourages the model 2 to learn planning and retriev al strategies rather than internalizing additional factual content. At infer- ence time, as summarized in Fig. 1, the student operates independently of the teacher and produces a structured plan consisting of reasoning steps and atomic fact requests. A separate retriev al compo- nent executes these requests using external tools. An LLM extractor then con verts ra w e vidence into atomic facts and an LLM aggregator synthesizes the final answer grounded in the retriev ed e vidence. By shifting factual responsibility to external and verifiable sources, the framework substantially re- duces hallucinated content. Moreover , because the student learns structured reasoning rather than factual knowledge, it can be significantly smaller and faster than frontier models, enabling efficient and reliable deployment. W e ev aluate our framew ork on S E A L Q A, a challenge benchmark for search-augmented language models that tar gets fact-seeking questions with noisy , conflicting, or unhelpful web evidence (Pham et al., 2025). In this work, we focus on S E A L - 0 , the primary split of S E A L Q A, which consists of difficult questions for which ev en strong chat models typically achie ve near-zero accuracy . Exper - imental results show that the framew ork achie ves near state-of-the-art performance, outperforming most open-source models while remaining competitiv e with the strongest reported agentic mod- els. These findings suggest that reasoning-focused distillation, rather than knowledge distillation, provides a promising direction for b uilding more reliable and controllable agentic LLM systems. 2 R E L I A B L E L L M F R A M E W O R K W e propose a modular framework for reliable and hallucination-resistant language model inference that explicitly separates reasoning from factual kno wledge acquisition. The core design principle is to structure the inference process into distinct stages including planning, information retriev al, factual extraction, and answer aggregation, so that factual claims are grounded in external evidence rather than internal parametric memory . A central component of the frame work is a teac her-student training strategy used to learn a high-quality planner . Our framework trains a dedicated planner to generate structured reasoning plans and precise information requests, while delegating f actual content acquisition entirely to external tools. 2 . 1 P R O B L E M F O R M U L AT I O N A N D O V E R A L L F R A M E W O R K Giv en a natural language question q , the goal is to produce an answer a that is both logically consis- tent and f actually grounded. W e assume access to external tools that can return up-to-date, verifiable information. W e model inference as a modular pipeline with four stages: (i) planning, (ii) retriev al, (iii) factual extraction, and (i v) answer aggregation. First, a planner generates a structured plan P ( q ) = ( R, F ) , (1) where R = { r 1 , r 2 , . . . , r K } is a sequence of K abstract steps describing how to solve the problem, and F = { f 1 , f 2 , . . . , f M } is a set of M atomic fact requests specifying what information must be obtained externally . Next, each fact request f m is ex ecuted by a retriev al tool to obtain raw evidence E m = Retriev e( f m ) . Since retriev ed evidence may be noisy or verbose, an extractor maps each E m to a concise atomic fact ˆ x m = Extract( f m , E m ) . Finally , an aggregator produces the final answer using the plan and extracted facts: a = Aggregate q , R , { f m , ˆ x m } M m =1 . (2) Crucially , the planner is discouraged from answering q directly using internal factual kno wledge. Instead, it is trained to externalize missing information into F , so that factual claims are supported by retriev ed evidence rather than parametric memory . 2 . 2 P L A N N E R T R A I N I N G V I A A T E A C H E R - S T U D E N T F R A M E W O R K The quality of tool usage and factual grounding critically depends on the planner’ s ability to decom- pose a question and to formulate relev ant, precise, and search-ready information requests suitable for external retriev al systems. T eacher -student learning is used here solely as a mechanism for su- pervising planning behavior , not for transferring factual kno wledge or answers. 3 2 . 2 . 1 T E A C H E R - G U I D E D D A T A S E T C O N S T R U C T I O N During dataset construction, we use G P T- 5 . 2 1 as a T eacher LLM to generate structured planning supervision. The teacher system prompt that enforces a strict decomposition behavior can be found in Appendix A. Giv en a natural language question q , the teacher outputs: (i) a sequence of abstract reasoning steps describing how the problem should be solved, and (ii) a set of atomic fact requests specifying what external information is required to ex ecute those steps. W e construct a dataset of 1,596 questions drawn from three complementary sources. First, we generate 900 synthetic fact-seeking questions using G P T - 5 . 1 2 . These questions span nine topi- cal categories including economics, technology , geography , companies and market data, finance, en vironment, sports, medicine, and cross-mixed categories, and cov er div erse comparison and decision-making formats with balanced representation across question types. Second, we include 100 personal-entity questions sampled from the hard split of HotpotQA (Y ang et al., 2018), which emphasizes multi-document reasoning. This subset is intentionally added because G P T-based gen- erators tend to av oid producing questions about real-world named individuals due to safety align- ment constraints. Third, we incorporate 596 questions from the FreshQA benchmark (V u et al., 2023), which ev aluates LLMs on fact-seeking queries that require up-to-date information beyond pretraining. FreshQA focuses on recent events and continuously ev olving facts and is regularly updated. The version used in our experiments covers information up to November 24, 2025. W e explicitly ensure that none of the selected questions for dataset construction overlap with S E A L Q A, which is used for ev aluation in this work. For each question q , the teacher produces a structured planning trace, yielding paired supervision examples of the form ( q , { R, F } ) . An example teacher output in JSON format for the question “How long has Elon Musk been X Corp. ’ s CEO?” is shown belo w . "required_information": [ { "query": "CEO of X Corp (company)", "source": "web", "dependent": false }, { "query": "Is equal to \"Elon Musk\"?", "source": "compute", "dependent": true }, { "query": "date Elon Musk became CEO of X Corp", "source": "web", "dependent": false }, { "query": "today’s date", "source": "web", "dependent": false }, { "query": "time difference between and (duration in days, and in years-months-days)", "source": "compute", "dependent": true }], "reasoning_steps": [ "Use the retrieved CEO name and the equality check result to determine whether the premise that Elon Musk is X Corp.’s CEO is supported.", "If supported, report the computed tenure duration from the retrieved CEO start date to today’s date; otherwise, report that the requested duration is not applicable."] Here, each entry in required information specifies a single atomic operation. The source field indicates whether the query is executed via an external web lookup ( web ) or an analytical reasoning ( compute ). The dependent flag denotes whether a query depends on the output of earlier queries, referenced through index ed placeholders such as . This structure en- forces explicit information dependencies and prevents the planner from implicitly reasoning over unstated facts. In the example, the teacher-generated plan does not assume the premise is correct. Instead, it first issues a web query to verify the current CEO of X Corp., follo wed by a compute query to check whether the retriev ed name matches the presupposed entity . Only if this premise is supported does the plan request the CEO start date. T o avoid relying on implicit temporal assump- tions, the plan also retrieves the current date explicitly , and finally in vokes a compute operation to 1 https://openai.com/index/gpt-5-system-card-update-gpt-5-2/ 2 https://openai.com/index/gpt-5-system-card-addendum-gpt-5-1/ 4 calculate the tenure duration. These teacher-generated planning traces constitute only supervision used to train the student planner . W e additionally performed manual verification of the generated traces to confirm that no factual answers or retrie ved evidence were included in the dataset. 2 . 2 . 2 S T U D E N T P L A N N E R T R A I N I N G W e fine-tune a lightweight open-weight model, Q W E N 3 - 8 B (Qwen, 2025), to serve as the student planner . The student is trained to imitate the teacher’ s planning behavior using the constructed dataset: given an input question q , it generates the structured decomposition ( R, F ) produced by the teacher . Crucially , the student is not supervised with factual answers, retriev ed evidence, or final task outputs. Instead, supervision is restricted to planning structure and sear chable information requests, i.e., short and well-scoped queries that a standard web search engine or a deterministic compute tool can ex ecute directly . This training objecti ve teaches the planner to (i) decompose questions into abstract steps and (ii) produce relev ant fact requests that can be satisfied by downstream tools. By restricting supervision to planning structure and information-seeking beha vior , the student learns to produce high-quality and reusable plans. Factual correctness is handled entirely by downstream retriev al, extraction, and aggre gation components at inference time. 2 . 3 I N F E R E N C E - T I M E E X E C U T I O N P I P E L I N E Fig. 1 summarizes the inference-time pipeline used in our framew ork. Giv en a user question q , the fine-tuned student planner generates a structured JSON plan ( R, F ) . All remaining components are pr ompt-engineered modules executed using the base Q W E N 3 - 8 B model together with external tools, with internal reasoning explicitly disabled. Their full prompts are provided in Appendix B. Plan Parsing and JSON Repair . In practice, the planner may occasionally produce outputs that are not valid JSON. Follo wing the flowchart, we first attempt to parse the planner out- put directly . If parsing f ails, we in vok e a prompt-engineered JSON repair module that remov es any extraneous text and rewrites the output into a v alid JSON object with the required ke ys ( required information and reasoning steps ). This repair step is only applied when necessary , and allows do wnstream components to utilize a consistent structured plan. Iterative Retrieval with Dependency Resolution. W e e xecute the f act requests in F sequentially , as illustrated in iteration loop in Fig. 1. Each request f m specifies a source ( web or compute ) and a dependent flag. Before execution, we resolve dependencies by substituting placeholders with pre viously stored outputs, producing an ef fective query ˜ f m which is e xecutable. If source is web , we retrie ve raw search results from Google Search via SerpAPI 3 , which provides real-time, structured access to the search engine results page (SERP). If source is compute , we prompt the base Q W E N 3 - 8 B model to perform analytical reasoning over previously retrie ved results. This step handles operations such as numerical comparisons, arithmetic aggregation, and date calculations, ensuring the process relies solely on the provided context without introducing new external information. Each ex ecuted step yields a stored fact ˆ x m , which is appended to the f act list and becomes av ailable for later dependent requests. Factual Extraction from W eb Evidence. W eb search results are returned as raw SerpAPI JSON and often contain noisy content. For each web request, we apply a prompt-engineered extraction module that reads only the SerpAPI JSON and outputs a concise answer . The extractor is explicitly constrained not to rely on external knowledge beyond the provided JSON and to avoid guessing. When the retrieved evidence contradicts the request premise, it is instructed to state that directly . This step produces the factual v alue used by subsequent dependent queries and the final aggregator . Answer Aggregation. After all required items are processed, an aggregator synthesizes the final answer . The aggregator receives the original question q , the planner -provided reasoning steps R , and the full list of retrieved facts (query-answer pairs { f m , ˆ x m } ). It is prompt-engineered to use only these retriev ed facts to generate the final response, and to explicitly indicate the answer is unknown or cannot be determined if the av ailable evidence is insufficient. This design ensures that factual claims in the final answer are grounded in the retriev ed evidence rather than parametric memory . 3 https://serpapi.com/search-api 5 3 E X P E R I M E N T S 3 . 1 E X P E R I M E N T A L S E T U P T raining Setup. Fine-tuning is performed via supervised instruction tuning with label masking using an effecti ve batch size of 16 via gradient accumulation, a learning rate of 5 × 10 − 5 with a cosine schedule, and training proceeds until validation loss con verges on a single NVIDIA L40S GPU with 48GB of VRAM. T o reduce training cost, we adopt parameter-efficient fine-tuning with QLoRA on top of a 4-bit quantized base model (Dettmers et al., 2023). Inference Configuration and Implementation Details. At inference time, the planner generates a structured JSON plan consisting of reasoning steps and atomic fact requests. All subsequent components, including retrie val, factual e xtraction, computation, JSON repair , and answer aggrega- tion, are prompt-engineered and use a frozen base Q W E N 3 - 8 B model. W eb retriev al is performed using the Google Search Engine Results API via SerpAPI, while analytical reasoning for computa- tion tasks is executed using prompted compute agents. All experiments are conducted on a single NVIDIA L40S GPU with 48 GB of VRAM. T o ensure reproducibility and to isolate planning and retriev al behavior , all language model generations during inference are performed with determin- istic decoding. This setting prevents stochastic variation in planner outputs, tool queries, and final answers, allowing consistent e valuation across runs. Baselines. W e compare the following systems: (i) Monolithic Base LLM (Reasoning Enabled). The base Q W E N 3 - 8 B model is queried directly to answer each question, without access to external tools, with its nati ve reasoning capability enabled. (ii) Our F ramework without F ine-T uned Plan- ner (Pr ompted). The same base Q W E N 3 - 8 B model is integrated into our modular framew ork via prompting to replace the student planner, enabling external search. The planner is prompted using the same system prompt as the teacher planner shown in Appendix A. W e e valuate two planner prompt variants: one that allows internal reasoning and one that explicitly suppresses reasoning, to isolate the effect of reasoning under identical tool access. (iii) Our F rame work with Student Planner . A fine-tuned Q W E N 3 - 8 B student model is trained to generate structured plans. The student is not trained on reasoning traces and therefore does not rely on internal reasoning. Evaluation Benchmarks. All e xperiments are conducted on the S E A L - 0 split of S E A L Q A, a small but exceptionally challenging benchmark designed to ev aluate search-augmented LLMs on fact-seeking questions. W e use the S E A L - 0 (v260105) release throughout our experiments. S E A L - 0 consists of 111 carefully curated questions for which e ven frontier models with browsing capabil- ities consistently fail. Each question is iterativ ely refined until multiple strong models achiev e zero accuracy across repeated attempts, hence the “0” in the name (Pham et al., 2025). T o illustrate the difficulty , example questions include: • How many of the top 50 most-followed Instagram accounts belong to individuals or entities based in the United States? • How many NB A players have scor ed 60 or more points in a r e gular season game since 2023? Metrics. W e report answer accuracy and av erage latency per question. Answer accuracy is ev al- uated based on whether the model produces the correct factual answer, following the same grading protocol and ev aluation template used in the S E A L Q A benchmark to ensure direct comparability with prior results in Pham et al. (2025). A verage latency is measured end-to-end per question and also broken do wn into planner, retrie val, and aggre gation components where relev ant. 3 . 2 E X P E R I M E N T A L R E S U LT S T able 1 reports the performance of different system configurations on the S E A L - 0 benchmark in terms of accuracy and a verage latenc y . The ev aluated configurations differ in both ho w the base lan- guage model is used (monolithic versus tool-augmented) and ho w planning is performed (prompted versus fine-tuned). W e analyze the results with respect to these metrics and relate our findings to previously reported results on S E A L - 0 (Pham et al., 2025). Example question and outputs produced by each configuration are provided in Appendix C. 6 T able 1: Performance comparison of system configurations on the S E A L - 0 benchmark. Configuration T ype Accuracy A vg latency per question Q W E N 3 - 8 B W ithout search Reasoning 1.8% 159.9 s Our framew ork (Prompted planner) W ith search No reasoning 6.3% 41.1 s W ith search Reasoning 3.6% 107.9 s Our framew ork (Student planner) W ith search No reasoning 10.8% 27.8 s Accuracy . As reported in the S E A L Q A benchmark study , models such as G P T - 4 . 1 and G P T- 4 O consistently obtain 0% accuracy on this split despite access to built-in search. Consistent with these findings, the monolithic Q W E N 3 - 8 B baseline achiev es only 1 . 8% accuracy when answering questions directly using parametric reasoning. Qualitative examples rev eal the cause of this f ail- ure. Without external tools, the base model either hallucinates facts or becomes trapped in repet- itiv e reasoning loops until reaching the generation limit (Appendix C-1). Using our frame work with prompted planning and external search improv es accuracy to 6 . 3% , highlighting the benefit of tool-oriented ex ecution (Appendix C-2). Howev er , enabling internal reasoning within the prompted planner reduces accuracy to 3 . 6% , as the model often produces malformed or ambiguous plans and then becomes trapped in reasoning loops (Appendix C-3). Our proposed framework with the student planner achieves the highest accuracy among our ev al- uated system configurations at 10 . 8% . This performance gain stems from the student’ s ability to generate robust multi-step decompositions (Appendix C-4). Although absolute accuracy remains low due to the extreme difficulty of S E A L - 0 , our result compares fa vorably with pre viously re- ported performance in Pham et al. (2025). In that study , most closed-source and open-weight models achiev ed between 0% and 5 . 4% accuracy on this split, e ven when equipped with browsing capabili- ties. The only notably higher reported score ( 17 . 1% ) is obtained by O 3 - M E D I U M using ChatGPT’ s built-in search. Thus, our framework highlights the critical benefit of e xplicitly supervising planning structure beyond simple search augmentation. Latency . Latency varies substantially across configurations. The monolithic baseline is the slow- est (159.9 s), reflecting long internal reasoning traces. The prompted framew ork reduces latenc y when reasoning is disabled (41.1 s), but incurs significant ov erhead when reasoning is enabled (107.9 s), due to increased generation length, repeated planning attempts, and frequent inv ocation of the JSON repair module. The proposed student planner achiev es the lowest latency (27.8 s), in- dicating more ef ficient inference. In addition to producing concise, well-scoped fact requests and av oiding unnecessary internal reasoning, the student planner outputs valid structured plans, elimi- nating the need for costly JSON repair steps and further reducing end-to-end ex ecution time. 4 R E L A T E D W O R K T eacher-Student Learning Frameworks. T eacher -student learning, often formalized as kno wl- edge distillation (KD), was established as a paradigm for transferring knowledge from a large, high- capacity teacher model to a smaller student model (Hinton et al., 2015). Recent research has adapted the framew ork for specific capabilities such as factual consistency and hallucination mitigation. Gekhman et al. (2023) utilized a teacher model to label model-generated summaries for factual consistency , creating synthetic datasets to train a student. Unlike conv entional KD, this approach focused on consistency rather than directly transferring answers or reasoning traces. Building on the idea of refining supervision, McDonald et al. (2024) demonstrated that distilling softened or structured supervision from a teacher can effecti vely reduce erroneous or ov erconfident outputs in student models, while maintaining computational efficienc y . 7 More recently , Xia et al. (2025) proposed a framework where the teacher first produces candidate annotations reflecting uncertainty , and the student is trained to distill these candidates into a sin- gle prediction. Their findings suggest that distilling structured outputs improv es robustness com- pared to using single annotations. Similarly addressing robustness, Nguyen et al. (2025) introduced smoothed KD, where the teacher provides soft token-le vel supervision to reduce ov erconfidence from hard labels. This approach improv es output calibration and reduces hallucinations in summa- rization tasks while implicitly transferring factual content. While these approaches and other distillation-based frameworks (T onmoy et al., 2024; Y ang et al., 2024) primarily aim to transfer factual kno wledge, supervision signals, or compress the teacher’ s knowledge, our work adopts a fundamentally different strategy . Rather than distilling answers, labels, or probability distrib utions, we use the teacher e xclusively during dataset construction to generate structured problem decompositions. The student is trained to reproduce reasoning structur e and information-seeking behavior , with factual content explicitly e xcluded from training. Modular Planning and T ool-Using Frameworks. LLM-based agents that combine task planning with external tool usage have been widely studied to mitigate limitations such as outdated knowledge and hallucinations (Gao et al., 2023). T o assess these capabilities, Ruan et al. (2023) proposed a structured framework for ev aluating T ask Planning and T ool Usage in both one-step and sequential workflo ws. Their analysis highlighted persistent weaknesses in agentic behaviors, such as failing to follow formats, ov er-utilizing single tools, and weak summarization, moti vating the need for improv ed planning and query formulation. Subsequent work argued that addressing these weaknesses requires mo ving beyond monolithic mod- els. Kambhampati et al. (2024) emphasized that robust planning requires e xplicit structure, advocat- ing for interaction patterns where candidate solutions are generated and iterativ ely refined through verification loops. This shift is evident in recent systems, as Li (2025) revie wed architectures that formally separate planning, query generation, e vidence retrie val, and verification. In specialized domains like mathematics, Luo et al. (2025) demonstrated that decomposing inference into action selection and tool execution substantially improves reliability . Similarly , Trinh et al. (2025) ap- plied multi-agent frame works to fact-checking, relying on planners to generate search queries or sub-questions at inference time. Our w ork builds on these modular directions but tar gets a specific bottleneck they exposed: the planner’ s ability to ask the right questions . While framew orks like Trinh et al. (2025) often relied on untrained or monolithic planners to guide information seeking, we train a dedicated planner to produce structured decompositions consisting of abstract reasoning steps and atomic fact requests. This design focuses explicitly on generating rele vant and high-quality queries, strengthening the planning component that upstreams the entire tool-using pipeline. 5 C O N C L U S I O N This work presented a framew ork for reliable fact-seeking question answering that separates plan- ning from factual retriev al. By training a lightweight student planner on a teacher -guided dataset, we enable the generation of structured, searchable information requests without exposure to factual answers. Ev aluations on the S E A L - 0 benchmark demonstrate that supervised planning approach improv es both accuracy and ef ficiency compared to monolithic reasoning models and prompt-based tool-augmented baselines. Despite the difficulty of the benchmark, the proposed framework achiev es competitiv e performance relative to models previously reported on the S E A L - 0 benchmark, while maintaining lo w inference latency through more ef ficient tool usage. These results demonstrate that explicitly learned planning structure, rather than internal reasoning or search access alone, is crit- ical for reliable search-augmented language models. Howev er , the proposed framework remains bounded by the quality and availability of external search results, and retriev al failures can directly propagate to the final answer . Although the student planner reduces unnecessary tool calls, inference latency is still dominated by e xternal search and e xtraction, which may limit scalability in high- throughput or real-time settings. In addition, while our ev aluation focuses on S E A L - 0 benchmark, further experiments on easier yet time-sensitive factual benchmarks would help better characterize the framew ork’ s performance across a broader range of real-world scenarios. 8 R E F E R E N C E S Aisha Alansari and Hamzah Luqman. Large language models hallucination: A comprehensiv e surve y . arXiv pr eprint arXiv:2510.06265 , 2025. Lang Cao. Learn to refuse: Making large language models more controllable and reliable through knowledge scope limitation and refusal mechanism. In Pr oceedings of the 2024 Confer ence on Empirical Methods in Natural Languag e Pr ocessing , pp. 3628–3646, 2024. Y upeng Chang, Xu W ang, Jindong W ang, Y uan W u, Linyi Y ang, Kaijie Zhu, Hao Chen, Xiaoyuan Y i, Cunxiang W ang, Y idong W ang, et al. A survey on ev aluation of lar ge language models. ACM transactions on intelligent systems and tec hnology , 15(3):1–45, 2024. T im Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer . Qlora: Efficient finetuning of quantized llms, 2023. URL . Y unfan Gao, Y un Xiong, Xin yu Gao, Kangxiang Jia, Jinliu Pan, Y uxi Bi, Y ixin Dai, Jia wei Sun, Haofen W ang, and Haofen W ang. Retriev al-augmented generation for large language models: A surve y . arXiv pr eprint arXiv:2312.10997 , 2(1), 2023. Zorik Gekhman, Jonathan Herzig, Roee Aharoni, Chen Elkind, and Idan Szpektor . T rueteacher: Learning f actual consistency ev aluation with large language models. arXiv pr eprint arXiv:2305.11171 , 2023. Geoffre y Hinton, Oriol V inyals, and Jef f Dean. Distilling the kno wledge in a neural network, 2015. URL . Lei Huang, W eijiang Y u, W eitao Ma, W eihong Zhong, Zhangyin Feng, Haotian W ang, Qianglong Chen, W eihua Peng, Xiaocheng Feng, Bing Qin, and T ing Liu. A surv ey on hallucination in large language models: Principles, taxonomy , challenges, and open questions. ACM T rans. Inf. Syst. , 43(2), January 2025. ISSN 1046-8188. doi: 10.1145/3703155. URL https://doi.org/ 10.1145/3703155 . Zhongzhen Huang, Kui Xue, Y ongqi Fan, Linjie Mu, Ruoyu Liu, T ong Ruan, Shaoting Zhang, and Xiaofan Zhang. T ool calling: Enhancing medication consultation via retriev al-augmented large language models. arXiv preprint , 2024. Ziwei Ji, Nayeon Lee, Rita Frieske, T iezheng Y u, Dan Su, Y an Xu, Etsuko Ishii, Y e Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys , 55(12):1–38, March 2023. ISSN 1557-7341. doi: 10.1145/3571730. URL http://dx.doi.org/10.1145/3571730 . Mingyu Jin, W eidi Luo, Sitao Cheng, Xinyi W ang, W enyue Hua, Ruixiang T ang, W illiam Y ang W ang, and Y ongfeng Zhang. Disentangling memory and reasoning ability in lar ge language mod- els. In Proceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 1681–1701, 2025. Adam T auman Kalai, Ofir Nachum, Santosh S V empala, and Edwin Zhang. Why language models hallucinate. arXiv preprint , 2025. Subbarao Kambhampati, Karthik V almeekam, Lin Guan, Mudit V erma, Kaya Stechly , Siddhant Bhambri, Lucas Paul Saldyt, and Anil B Murthy . Position: LLMs can’t plan, b ut can help planning in LLM-modulo frame works. In F orty-first International Confer ence on Machine Learning , 2024. URL https://openreview.net/forum?id=Th8JPEmH4z . Xinzhe Li. A revie w of prominent paradigms for LLM-based agents: T ool use, planning (includ- ing RA G), and feedback learning. In Owen Rambow , Leo W anner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Stev en Schockaert (eds.), Proceedings of the 31st Interna- tional Conference on Computational Linguistics , pp. 9760–9779, Abu Dhabi, U AE, January 2025. Association for Computational Linguistics. URL https://aclanthology.org/2025. coling- main.652/ . Lihui Liu and Kai Shu. Unifying knowledge in agentic llms: Concepts, methods, and recent ad- vancements. A CM SIGKDD Explorations Newsletter , 27(2):88–96, 2025. 9 Y ang Liu, Y uanshun Y ao, Jean-Francois T on, Xiaoying Zhang, Ruocheng Guo, Hao Cheng, Y egor Klochkov , Muhammad Faaiz T aufiq, and Hang Li. Trustworth y llms: a survey and guideline for ev aluating large language models’ alignment. arXiv pr eprint arXiv:2308.05374 , 2023. Haipeng Luo, Hua wen Feng, Qingfeng Sun, Can Xu, Kai Zheng, Y ufei W ang, T ao Y ang, Han Hu, Y ansong T ang, and Di W ang. Agentmath: Empowering mathematical reasoning for lar ge language models via tool-augmented agent. arXiv preprint , 2025. Daniel McDonald, Rachael Papadopoulos, and Leslie Benningfield. Reducing llm hallucination using knowledge distillation: A case study with mistral large and mmlu benchmark. Author ea Pr eprints , 2024. Hieu Nguyen, Zihao He, Shoumik Atul Gandre, Ujjwal Pasupulety , Sharanya Kumari Shiv akumar, and Kristina Lerman. Smoothing out hallucinations: Mitigating llm hallucination with smoothed knowledge distillation, 2025. URL . Thinh Pham, Nguyen Nguyen, Pratibha Zunjare, W eiyuan Chen, Y u-Min Tseng, and T u V u. Sealqa: Raising the bar for reasoning in search-augmented language models, 2025. URL https:// arxiv.org/abs/2506.01062 . Qwen. Qwen3 technical report, 2025. URL . Jingqing Ruan, Y ihong Chen, Bin Zhang, Zhiwei Xu, T ianpeng Bao, Hangyu Mao, Ziyue Li, Xingyu Zeng, Rui Zhao, et al. Tptu: T ask planning and tool usage of large language model-based ai agents. In NeurIPS 2023 F oundation Models for Decision Making W orkshop , 2023. SMTI T onmoy , SM Zaman, V inija Jain, Anku Rani, V ipula Rawte, Aman Chadha, and Amitav a Das. A comprehensiv e survey of hallucination mitigation techniques in large language models. arXiv pr eprint arXiv:2401.01313 , 6, 2024. T am Trinh, Manh Nguyen, and T ruong-Son Hy . T owards robust fact-checking: A multi-agent system with advanced e vidence retriev al, 2025. URL . T u V u, Mohit Iyyer, Xuezhi W ang, Noah Constant, Jerry W ei, Jason W ei, Chris T ar, Y un-Hsuan Sung, Denny Zhou, Quoc Le, and Thang Luong. Freshllms: Refreshing large language models with search engine augmentation, 2023. URL . Dean W ampler , Dav e Nielson, and Alireza Seddighi. Engineering the rag stack: A comprehensiv e revie w of the architecture and trust frameworks for retriev al-augmented generation systems. arXiv pr eprint arXiv:2601.05264 , 2025. Cunxiang W ang, Xiaoze Liu, Y uanhao Y ue, Xiangru T ang, T ianhang Zhang, Cheng Jiayang, Y unzhi Y ao, W enyang Gao, Xuming Hu, Zehan Qi, et al. Surve y on factuality in large language models: Knowledge, retrie val and domain-specificity . arXiv pr eprint arXiv:2310.07521 , 2023. Mingxuan Xia, Haobo W ang, Y ixuan Li, Ze wei Y u, Jindong W ang, Junbo Zhao, and Runze W u. Prompt candidates, then distill: A teacher-student frame work for llm-dri ven data annotation, 2025. URL . Ling Y ang, Zhaochen Y u, Tianjun Zhang, Minkai Xu, Joseph E Gonzalez, Bin Cui, and Shuicheng Y an. Supercorrect: Advancing small llm reasoning with thought template distillation and self- correction. arXiv preprint , 2024. Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengio, William W . Cohen, Ruslan Salakhutdinov , and Christopher D. Manning. Hotpotqa: A dataset for div erse, explainable multi-hop question answering, 2018. URL . Y utao Zhu, Huaying Y uan, Shuting W ang, Jiongnan Liu, W enhan Liu, Chenlong Deng, Haonan Chen, Zheng Liu, Zhicheng Dou, and Ji-Rong W en. Large language models for information retriev al: A survey . A CM T ransactions on Information Systems , 44(1):1–54, 2025. 10 A T E A C H E R S Y S T E M P R O M P T F O R P L A N N E R S U P E RV I S I O N T eacher System Prompt (Planner Supervision) Y ou are a decomposition-only reasoning planner . Y our role is to break down e ver y user question into: • shor t, realistic, atomic factual quer ies that a standard web search engine or a simple compute tool could e xecute directly , and • abstract reasoning steps that describe how to combine only those retr ie ved f acts. Y ou must never ans wer the question directly . Critical Design Principles (Most Important) A. Realistic Search Principle Each f actual query must be something that a real user could reasonably type into a web search engine and e xpect a direct factual ans wer from the top results. B. Minimality Principle If a question can be answered by one w ell-phrased factual query , you must not decompose it fur ther . C. No-Conceptual-Reasoning Principle Y ou must not ask definitional, philosophical, or y es/no questions. Conceptual reasoning must be av oided entirely; only concrete facts ma y be retriev ed. When to Decompose Y ou must decompose only when the question requires: • comparison of two or more f actual values • date arithmetic or age calculation • counting or aggregation • combining f acts from multiple sources • resolving relativ e time expressions (e.g., toda y , latest ) Y ou must not decompose when: • a single f actual entity or fact can be directly retriev ed • decomposition would introduce definitions or logic shortcuts Y our T ask • Analyze the user question. • Identify the minimum set of external facts required. • Express each required f act as a shor t, concrete, independently e xecutable query . • A void unnecessary inter mediate reasoning or conceptual checks . Output Format (Strict) Y ou must output exactly one JSON object with the f ollowing structure: { "required_information": [ { "query": "", "source": "web or compute", "dependent": false }, { "query": ">", "source": "web or compute", "dependent": true } ], "reasoning_steps": [ "", "" ] } 11 Rules for required information 1. Atomicity (Mandatory) • Each query must retr ie ve or compute e xactly one factual result. • Do not request lists, tab les, or enumerations . • Do not include reasoning or comparisons inside queries. • Do not combine multiple f acts in one quer y . 2. W eb Queries • Use only f or direct real-world factual lookups. • Queries must be shor t, concrete, and directly searchab le. • Queries must not be yes/no questions or request e xplanations. 3. Compute Queries • Use only for deter ministic operations such as comparison, counting, or date ar ith- metic. • Compute queries must depend on pre viously retr ie ved results. • Inputs must be ref erenced via placeholders such as . 4. Dependent Queries • If a query is dependent, it must e xplicitly ref erence prior results using index ed place- holders. • The query must become ex ecutable after placeholder substitution. 5. Time Handling • Relativ e expressions such as toda y or latest require first retrieving the current date . • The current date must ne ver be assumed. 6. Plan Completeness • The required inf or mation must be sufficient to resolv e the user question. • Requested entities or v alues must be explicitly retrie ved if they e xist. 7. In valid Premises • If a presupposed entity ma y not exist, e xistence must be verified first. • If it does not e xist, the reasoning steps must conclude non-existence . Rules for reasoning steps • Use only f acts retr ie ved in required information . • Describe logical operations abstractly . • Do not include f actual values or final ans wers. Global Rules • Output only v alid JSON. • No e xplanations, notes, or markdown. • No trailing commas . 12 B I N F E R E N C E - T I M E S Y S T E M P R O M P T S Extractor System Prompt Y ou are a precise extraction agent. Y ou will be given: 1. A factual sub-question. 2. Raw web search results returned by an e xter nal search engine in JSON f or mat. Y our task: - Use ONL Y the information contained in the provided JSON. - If the JSON clearly contains the answer , extract it v erbatim. - If the JSON indicates that the premise of the sub-question is f alse, state this explicitly . Rules: - Do NO T use any e xter nal knowledge be yond the given JSON. - Do NO T guess, inf er, or in vent missing inf or mation. - Output ONL Y the final extracted ans wer as plain te xt. Compute System Prompt Y ou are a deter ministic computation agent. Y ou will be given: 1. A compute-style instruction that may ref erence previously retrie ved results. Y our task: - P erform only logical, mathematical, or date-based operations e xplicitly requested. - Use ONL Y the provided inputs. - Do NO T retr ie ve ne w information or assume external facts . Output: - Retur n ONL Y the final computed value or a concise phr ase representing the result. Aggregator System Pr ompt Y ou are a careful and faithful ans wer synthesis agent. Y ou will be given: 1. The original user question. 2. A sequence of planner-generated reasoning steps. 3. A list of retriev ed atomic facts, each paired with its originating query . Y our task: - Ans wer the or iginal question using ONL Y the provided f acts. - Do NO T introduce new inf or mation or rely on prior knowledge. - If the f acts are insufficient to answ er the question, explicitly state what inf or mation is missing. Output: - Produce a clear , concise natural-language ans wer grounded in the retriev ed facts . JSON Repair System Prompt Y ou are a JSON repair assistant. Y ou will be given raw text output that is intended to represent a single JSON object with the f ollowing ke ys: - required information - reasoning steps Y our task: - Remov e any internal reasoning traces or mar kup if present. - Repair syntax errors so that the output becomes valid JSON. - Ensure the output contains e xactly one JSON object with the required keys . Rules: - Output ONL Y valid JSON. - Do NO T add explanations , comments, or formatting. 13 C E X A M P L E Q U E S T I O N A N D O U T P U T S A C R O S S C O N FI G U R A T I O N S T est Question (T ested on Jan 7, 2026) Q: What is the current age of the youngest gr andmaster of chess? Expected Answer: 16 years old 1 . Q W E N 3 - 8 B ( B A S E M O D E L ) Internal Reasoning T race (T runcated) Okay , so I need to find out the current age of the youngest grandmaster in chess ... I remember that there have been some young play ers... Sergey Karjakin. W ait, w asn’t he a child prodigy? ... Another name is Hikar u Nakamura... W ait, there was a player named Magnus Carlsen... ...W ait, let me chec k. Magnus Car lsen was born in 1990... W ait, no, I think Karjakin was bor n in 1990... So Karjakin is younger . But then there’ s another pla yer ... Abhimanyu Khatri... Wait, b ut I’m not sure if that’ s accurate... ...So , let’s list the kno wn youngest grandmasters: 1. Magnus Carlsen... 2. Sergey Karjakin... 6. Others... W ait, but Karjakin was born in 1990... Wait, this is confusing. ...Alternatively , maybe the youngest grandmaster is the one who became a gr andmas- ter at the earliest age... But I need to check if there are any pla yers who became grandmasters at the same age as Karjakin but were born later ... W ait, but the youngest grandmaster in terms of current age would be the one who became a grandmaster at... (The full output e xceeds sev eral hundred lines and is omitted here for bre vity .) T otal Latency: 255.2 s (Generation Limit Reached) Final Answer: (None pr oduced) 2 . O U R F R A M E W O R K ( P RO M P T E D P L A N N E R - N O R E A S O N I N G ) Prompted Planner (No Reasoning) Output Reasoning Steps: 1. Identify the youngest chess g randmaster ev er . 2. Retriev e the date of bir th of the identified grandmaster . 3. Retriev e today’ s date. 4. Calculate the age in full years betw een the two dates. Plan Generated: 1. S E AR C H : ”youngest chess grandmaster e ver” 2. S E AR C H : ”date of bir th of < RESUL T 1 > ” 3. S E AR C H : ”today’ s date” 4. C O M P U T E : ”age in full years between < RESUL T 2 > and < RESUL T 3 > ” Execution T race: • Fact 1 (Web): ”Abhimanyu Mishra” • Fact 2 (Web): ”F ebr uary 5, 2009” 14 • Fact 3 (Web): ”Jan uar y 7, 2026” • Fact 4 (Compute): ”16 years old” Latency Breakdown: Planning (11.6s) + Execution (21.3s) + Aggregation (1.8s) = 34.6s Final Answer: The current age of the youngest grandmaster of chess, Abhiman yu Mishra, is 16 years old. (Correct) 3 . O U R F R A M E W O R K ( P RO M P T E D P L A N N E R - R E A S O N I N G ) Prompted Planner (Reasoning) Output Reasoning Steps: 1. Retriev e bir th date of the youngest chess gr andmaster . 2. Retriev e current date to calculate age. 3. Compute age diff erence between current date and bir th date. Plan Generated: 1. S E AR C H : ”youngest chess grandmaster’ s date of bir th” 2. S E AR C H : ”today’ s date” 3. C O M P U T E : ”age in full years between < RESUL T 1 > and < RESUL T 2 > ” Execution T race: • Fact 1 (Web): ”29 Ma y 2006” (Incorrect Entity Fetched) • Fact 2 (Web): ”Jan uar y 7, 2026” • Fact 3 (Compute): ”19 years old” Latency Breakdown: Planning (12.8s) + Execution (19.4s) + Aggregation (0.9s) = 33.1s Final Answer: The current age of the youngest grandmaster of chess is 19 years old. (Incorrect) 4 . O U R F R A M E W O R K ( S T U D E N T P L A N N E R ) Student Planner Output Reasoning Steps: 1. Use the retriev ed name of the youngest current chess gr andmaster. 2. Retriev e the bir th date of that individual. 3. Retriev e today’ s date. 4. Compute the age in full years as of toda y’ s date for the birth date retr ie ved. Plan Generated: 1. S E AR C H : ”youngest grandmaster of chess” 2. S E AR C H : ”date of bir th of < RESUL T 1 > ” 3. S E AR C H : ”today’ s date” 4. C O M P U T E : ”age in full y ears on < RESUL T 3 > for someone bor n on < RESUL T 2 > ” 15 Execution T race: • Fact 1 (Web): ”Abhimanyu Mishra” • Fact 2 (Web): ”F ebr uary 5, 2009” • Fact 3 (Web): ”W ednesday , January 7, 2026” • Fact 4 (Compute): ”16” Latency Breakdown: Planning (8.9s) + Execution (20.6s) + Aggregation (1.3s) = 30.8s Final Answer: The current age of the youngest grandmaster of chess, Abhiman yu Mishra, is 16 years old. (Correct) 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment