Idiosyncrasies of Programmable Caching Engines
Programmable caching engines like CacheLib are widely used in production systems to support diverse workloads in multi-tenant environments. CacheLib's design focuses on performance, portability, and configurability, allowing applications to inherit c…
Authors: José Peixoto, Alexis Gonzalez, Janki Bhimani
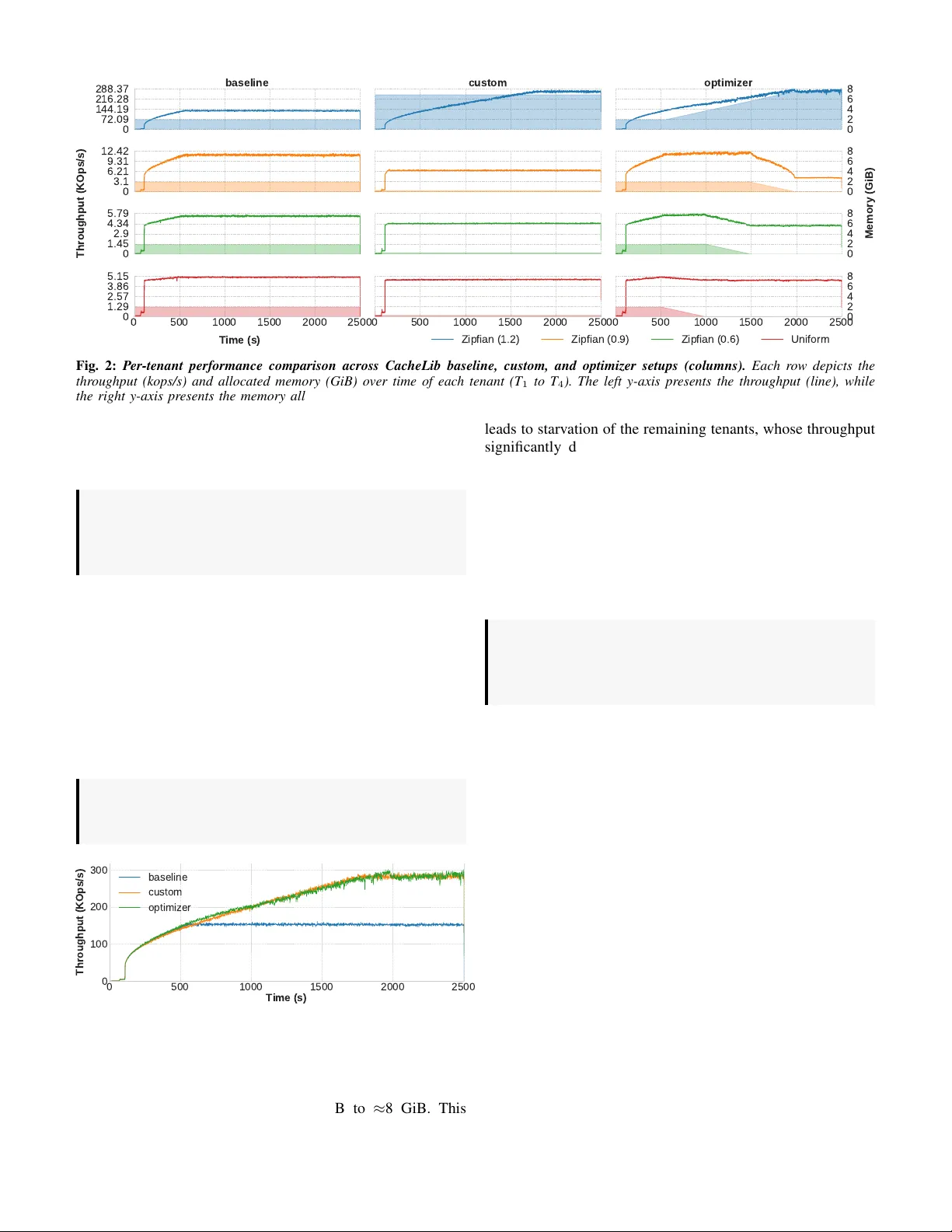
Idiosyncrasies of Programmable Caching Engines W orkshop Paper Jos ´ e Peixoto, Alexis Gonzalez * , Janki Bhimani * , Raju Rangaswami * , Cl ´ audia Brito, Jo ˜ ao Paulo, Ricardo Macedo INESC TEC & University of Minho * Florida International University Abstract —Programmable caching engines lik e CacheLib are widely used in production systems to support di verse workloads in multi-tenant en vir onments. CacheLib’ s design focuses on per- formance, portability , and configurability, allowing applications to inherit caching impro vements with minimal implementa- tion effort. Howev er , its behavior under dynamic and evolving workloads remains largely unexplored. This paper presents an empirical study of CacheLib with multi-tenant settings under dynamic and volatile envir onments. Our e valuation acr oss mul- tiple CacheLib configurations re veals sev eral limitations that hinder its effectiveness under such en vir onments, including rigid configurations, limited runtime adaptability , lack of quality-of- service support and coordination, which lead to suboptimal performance, inefficient memory usage, and tenant starvation. Based on these findings, we outline future resear ch directions to impro ve the adaptability , fairness, and programmability of future caching engines. Index T erms —Programmable caches, CacheLib, Multi- tenancy , Adaptability . I . I N T RO D U C T I O N Data-intensiv e systems, such as databases, key-v alue stores, content deliv ery networks (CDNs), and machine learning engines, hav e become a fundamental part of modern I/O infrastructures [1]. T o process large v olumes of data with high throughput and low latency , these systems rely on in- memory caching. T ypically , each system employs a cache optimized for its specific requirements, including read-write ratio, access distribution, I/O granularity (block, file, object), and concurrency model (e.g., single vs. multi-tenant) [2], [3]. Despite their differences, caching systems often share com- mon goals and face similar challenges ( e.g . , interf aces, e viction policies, memory allocation strategies). The lack of a unified cache abstraction leads to fragmented features, duplicated engineering ef forts, and significant maintenance overhead. T o address these limitations, Meta introduced CacheLib [2], a general-purpose, programmable caching engine that provides a common set of building blocks for designing high-performance caches. Through a flexible and extensible API covering cache indexing, thread-safe structures, eviction policies, memory management, and multi-tenancy isolation, CacheLib enables the design of caches fine-tuned for diverse data-intensi ve systems. Its success stems from configurability and perfor- mance portability , allo wing applications to inherit caching improv ements without major reimplementation. T oday , CacheLib po wers more than 70 Meta services ( e.g . , CDNs, ke y-value stores, recommendation engines, databases) [2], Pelikan.io, and sev eral research initiatives [4]. For ease of management and cost efficienc y , multiple services and applications are often co-located on the same compute node, each managing its o wn cache instance. Even a single application may employ multiple caches ( e.g. , with different eviction policies and sizes) to serve distinct workloads [2], [5]. While CacheLib provides a strong foundation, important questions remain in the context of shared, multi-tenant deploy- ments: i) how does CacheLib simplify memory management under multiple tenants? ii) how does it handle workloads with ev olving access patterns and dynamic resource demands? This paper presents the first empirical study of CacheLib’ s performance and adaptability in dynamic, multi-tenant en vi- ronments. Our study rev eals se veral limitations that open new research directions. Rigid configuration model. CacheLib’ s configuration model is too rigid for the dynamic nature of co-located workloads. Although it exposes man y tuning knobs ( i.e., eviction policies, memory allocation, and rebalancing schemes), these param- eters are typically set at initialization and do not adapt to changing workloads ( e.g., shifting access distributions, tenants joining or leaving), leading to suboptimal performance. Limited adaptability . CacheLib includes mechanisms such as the pool optimizer to adjust memory allocations at run- time. Howe v er , our study shows these mechanisms are often ineffecti v e under shifting workloads, resulting in performance variability and inef ficient memory use. Lack of quality-of-service (QoS) support. CacheLib’ s ag- gressiv e reallocation strategies prioritize global cache effi- ciency over indi vidual tenants. Without QoS guarantees, pri- oritization, or differentiation mechanisms, this behavior can lead to starvation, especially for latency-sensitiv e workloads that share resources with more aggressi ve tenants. Lack of inter -instance coordination. Multiple CacheLib instances can run on the same compute node but operate in isolation. This lack of coordination prev ents efficient resource utilization and holistic memory rebalancing, especially under ske wed workloads where some instances are underprovisioned while others are overpro visioned. In summary , our findings show that while CacheLib offers key b uilding blocks for multi-tenant en vironments, it f alls short in handling the complexities introduced by dynamic workloads and shared resources. T o bridge this gap, we identify several research directions to improve CacheLib’ s adaptability , inter- instance coordination, and QoS support, making it more ef- fectiv e and robust for modern data-intensiv e applications. Rebalance strategy Resize strategy Pool 1 slab slab Slab class 1 ... Slab class N slab Rebalance strategy Resize strategy Optimize strategy Pool N slab slab Slab class 1 ... slab slab Slab class N ... Pool rebalancer Pool resizer Pool optimizer CacheLib Instance Optimize strategy CacheLib Instance T 1 T 2 T 3 T 4 Application Compute Node Compute Node (a) CacheLib design overview . (c) Multiple CacheLib instances. (b) Single CacheLib instance. Storage backend Application CacheLib Instance 1 Application 1 CacheLib Instance 2 Application 2 CacheLib Instance N Application N Fig. 1: Cac heLib design overvie w (a) and typical applicability models in pr oduction (b-c). I I . B AC K G RO U N D This section provides background on the CacheLib engine, outlining its design, core functionalities, and applicability . A. CacheLib overview CacheLib [2] is an embeddable caching library developed by Meta, designed for high performance in concurrent en- vironments. Its architecture emphasizes memory efficiency , workload isolation, and runtime adaptability . It exposes a simple, thread-safe interface where users can store and retrieve items using a key-v alue pair abstraction. At its core, CacheLib comprises four main components, as depicted in Fig. 1 (a) . The memory pool , an isolated region with independent allocation strategies, eviction policies, and memory limits, stores and serves data items. The pool r ebalancer and pool resizer min- imize memory waste and fragmentation by moving memory within and across pools. The pool optimizer aims at improving ov erall memory usage by dynamically resizing each pool. Memory allocation and fragmentation management. CacheLib employs a slab-based memory allocation scheme to minimize external memory fragmentation. Rather than allo- cating variable-sized chunks, it partitions memory into fixed- size slabs, each associated with a (slab) class that stores items of similar size. Each slab class manages its o wn memory region, and a single memory pool may contain multiple slab classes. Once memory has been allocated across slab classes, the system enters a static state, which can lead to slab calcification . This phenomenon occurs when slabs are assigned to item sizes that are no longer accessed, leading to wasted memory and allocation failures for other slab classes. T o mitigate this, CacheLib inte grates a pool rebalancer , a background worker that 1) identifies imbalanced slab classes within a memory pool, 2) selects a victim class with surplus slabs, and 3) transfers slabs to a receiv er class with higher demand. Moreover , each pool employs a configurable rebal- ance strate gy to guide the slab distrib ution, such as minimizing allocation failures or maximizing per-item hit ratio. Multi-tenancy support. T o support multiple concurrent work- loads, CacheLib enables the creation of numerous memory pools, each isolating a specific workload or tenant, enabling flexible memory partitioning within the same CacheLib in- stance. By default, each pool is assigned a static memory limit. While users can adjust this limit at runtime, increasing a pool’ s allocation does not guarantee it will immediately receiv e more memory , as slabs may remain held by other pools until explicitly rebalanced. T o enforce these limits, CacheLib implements a pool resizer , a background worker that 1) identifies pools exceeding their configured memory limits, 2) selects slabs from pools exceeding their capacity , and 3) transfers them to underprovisioned ones. This process allows the system to better enforce memory limits, but does require manual interv ention to initiate resizing. Moreo ver , each memory pool implements a resize strate gy ( e.g ., maximize hit ratio, minimize allocation failures) to guide the resize process. Adaptive memory management. T o reduce manual config- uration ov erhead, CacheLib implements the pool optimizer , a background work er for automatic pool resizing [4]. It contin- uously monitors the workload, analyzes access patterns at the tail of the eviction queue to estimate workload pressure, and proposes new memory limits for each pool to enhance overall hit ratio. T o enforce these limits, the pool optimizer and resizer must operate together . B. CacheLib request workflow The request workflo w in CacheLib is divided into two parts: the for e gr ound flow , which handles read and write requests submitted by the application, and the bac kgr ound flow , which manages internal system operations. For egr ound flow . Applications interact with the cache by inserting and retrieving data objects through a key-v alue pair abstraction. On writes, the application first attempts to allocate memory for the object within the target pool. If the allocation succeeds, the application copies the data into the allocated region, and only then can the transaction be committed to the cache. It is the application’ s responsibility to ensure data persists in durable storage. On reads, given a key , CacheLib searches across all memory pools and returns the object if found, or if a cache miss occurs, otherwise, leaving the responsibility of retrieving data from persistent storage to the application. Background flow . The background flo w is responsible for maintaining the cache’ s internal structure and adapting to workload changes through background workers, including the pool r ebalancer , r esizer , and optimizer (§II-A). These opera- tions are ex ecuted periodically , asynchronously , and indepen- dently of the foreground flow , allowing CacheLib to adapt to workload changes without interrupting application service. C. Usage in pr oduction envir onments CacheLib supports a range of deployment scenarios, de- pending on the number of applications and tenants in v olved. This section highlights two common production setups, which serve as the foundation for the discussion in the following sections. Single instance, multiple tenants. As depicted in Fig. 1 (b) , a single application or service, such as CDNs, key-v alue stores, social-graph systems, and databases, can use just a single CacheLib instance to support multiple tenants [2]. T enants are typically represented by distinct threads, processes, or components with different request patterns and memory needs. Each tenant is assigned a dedicated memory pool, ensuring isolation and predictable performance. Multiple instances. As depicted in Fig. 1 (c) , multiple Cache- Lib instances are deployed on the same compute node, each serving a different application or service, which is common in complex data-intensive software stacks, such as those used by Uber, Amazon, and more [6]–[8]. Instances operate in iso- lation, with indi vidual configurations and allocation policies, configured with a fixed memory limit. I I I . U N D E R S TA N D I N G C AC H E L I B P E R F O R M A N C E T o understand the performance and adaptability of CacheLib under dynamic and heterogeneous en vironments, we seek to answer the following questions: • Ho w does CacheLib perform under varying workload re- quest popularity distributions? • Ho w does CacheLib perform under different memory parti- tioning? • Can CacheLib adapt to dynamic and e v olving workloads? Hardwar e and OS configurations. Experiments were con- ducted on compute nodes of the Deucalion supercomputer equipped with 2 × 64-core AMD EPYC 7742 processors, 256 GiB of memory , and a 480 GiB SSD, running RockyLinux 8. Software-wise, we used CacheLib v20231101. Methodology . The experimental testbed consists of three components: a benchmark that acts as the application and generates requests with varying access distributions, a Cache- Lib instance that caches the application’ s read requests, and RocksDB as the persistent storage backend. Write operations are always submitted to RocksDB, and to a void cache incoher- ence, the write operation is propagated to the cache if the item was previously cached. For reads, requests are first submitted to CacheLib – on a cache hit, it returns the corresponding item to the application; on a cache miss, the application fetches the item from persistent storage and inserts it in the corresponding CacheLib memory pool. Further , to isolate the performance benefits of CacheLib, both RocksDB’ s internal block cache and the page cache were disabled. As in pre vious studies ([9]–[11]), we ev aluated CacheLib’ s performance in a heterogeneous multi-tenant en vironment by conducting experiments with 4 tenants, each configured with different workload characteristics and memory limits. W orkloads. Experiments were conducted using read-only workloads, as it is common in ev aluating caching systems [2], [9], [12]. Each tenant is configured with a distinct workload distribution, emulating access patterns observed in production en vironments [13]. Specifically , tenants T 1 , T 2 , and T 3 were assigned with Zipfian distributions with skew factors of 1.2, 0.9, and 0.6, respecti vely , while tenant T 4 was configured with a uniform distribution. Further , each tenant operated on an exclusi ve key-space containing 20 million unique items, each 1 KiB in size, totaling approximately 20 GiB of data. Unless stated otherwise, all tenants execute their workloads concurrently o ver 2500 seconds. Additionally , before workload ex ecution, the 20 million unique key-v alue pairs of 1 KiB each are pre-loaded into the storage backend for each tenant, totaling approximately 80 GiB of data. As such, the size of the CacheLib instance was configured to store only up to 10% of the dataset, similarly to previous studies ([12], [14]), resulting in a total memory capacity of 8 GiB partitioned into four memory pools, each dedicated to a specific tenant. Setups. T o explore the impact of dif ferent memory manage- ment strategies, with three CacheLib configurations: baseline refers to the default CacheLib, where only the pool r ebalancer worker is enabled; custom extends the baseline setting by integrating a custom memory allocation policy which, in combination with the pool resizer , enforces dynamic memory limits defined by the user for each pool; and optimizer enables pool r esizer and pool optimizer workers. W orkers from both custom and optimizer execute e very second; the pool resizer was set with a resize strategy to maximize hit ratio, which best suits our needs. A. Memory partitioning under static workloads W e begin by e valuating the performance and adaptability of different CacheLib configurations in a static environment, where all tenants start and complete their workloads simultane- ously . W e use the follo wing configurations that apply distinct memory allocation policies: • Baseline : memory is allocated uniformly across all tenants, with each pool receiving 25% of the total cache capacity . • Custom : fav ors the tenant with the highest Zipfian skew , allocating 91% of the cache capacity to T 1 , while the re- maining space is evenly distrib uted across the other tenants. • Optimizer : initially adopts a uniform allocation b ut dynami- cally adjusts the memory distribution during execution based on the observed cache performance metrics, and is tuned to maximize ov erall throughput. Results. Fig. 2 and 3 illustrate, respectively , the per-tenant and global throughput and allocated memory under the three CacheLib configurations. As expected, throughput varies sig- nificantly across tenants due to their different data distribu- tions. In the baseline setup, after the initial cache warm-up, T 1 reaches ≈ 140 kops/s, outperforming T 2 , T 3 , and T 4 by 14 × , 25 × , and 28 × , respectively . These results highlight that uni- form memory allocation can lead to imbalanced performance when tenants exhibit heterogeneous access patterns. The custom configuration sho ws that fa voring highly ske wed workloads yields significant performance gains. As depicted in Fig. 3, the ov erall system throughput improves up to 1.8 × compared to the baseline, with T 1 experiencing a throughput of up to 280 kops/s. This is because the number of I/O requests to the backend grows in versely with the hit ratio, meaning that small increases in hit ratio lead to significant throughput improvements when the hit ratio is already high. In the case of T 1 , which follo ws a highly skewed distribution, fur- ther gains in hit ratio/throughput required a disproportionately baseline 0 72.09 144.19 216.28 288.37 custom optimizer 0 3.1 6.21 9.31 12.42 0 1.45 2.9 4.34 5.79 0 500 1000 1500 2000 2500 0 1.29 2.57 3.86 5.15 0 500 1000 1500 2000 2500 0 500 1000 1500 2000 2500 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 Throughput (KOps/s) Memory (GiB) T ime (s) Zipfian (1.2) Zipfian (0.9) Zipfian (0.6) Uniform Fig. 2: Per-tenant performance comparison across CacheLib baseline, custom, and optimizer setups (columns). Each row depicts the thr oughput (kops/s) and allocated memory (GiB) over time of each tenant (T 1 to T 4 ). The left y-axis presents the thr oughput (line), while the right y-axis presents the memory allocated (filled ar ea). larger share of memory , thus the 91% allocation. Ho we ver , if the goal was instead to maximize hit ratio across all tenants or to ensure fairness, this partitioning might not be optimal. Observation 1. Under heter ogeneous workloads, uniform memory allocation can lead to sever e performance imbal- ance. Fine-tuning cache partitioning according to work- load distrib ution can significantly impr ove thr oughput. As depicted in Fig. 2, the optimizer setup begins with the same uniform memory distribution as the baseline but gradually reallocates memory based on observed workload behavior . This process, howe ver , requires a warm-up period to collect enough statistics. Only after ≈ 500 seconds, the optimizer begins adjusting memory allocations effecti vely , con verging to ward an improved state. Despite this initial delay , as observed by Fig. 3, the ov erall throughput of optimizer is higher than the baseline configuration, reaching ≈ 290 kops/s, a 1.85 × improvement under the same memory capacity . Observation 2. Dynamically r eallocating memory based on workload char acteristics can outperform static config- urations, even under identical resour ce constraints. 0 500 1000 1500 2000 2500 T ime (s) 0 100 200 300 Throughput (KOps/s) baseline custom optimizer Fig. 3: Ov erall throughput under different allocation policies. W orkload-awar e memory allocation substantially outperforms uni- form policies. Interestingly , a closer inspection (Fig. 2) reveals that the optimizer reallocates nearly the entire cache capacity to T 1 , increasing its memory pool from 2 GiB to ≈ 8 GiB. This leads to starv ation of the remaining tenants, whose throughput significantly drops, ev en falling below the performance ob- served under the baseline setup. While such behavior might be suited for environments where maximizing the global through- put is the primary goal, it is incompatible with scenarios that require per-tenant quality-of-service (QoS) guarantees or enforce different priority levels. Under these scenarios, e ven if global throughput is improved, the optimizer ’ s aggressiv e reallocation strategy compromises the performance isolation expected between tenants. Observation 3. W ithout QoS or prioritization mecha- nisms, CacheLib’ s dynamic r eallocation strate gy can lead to starvation, compr omising the performance isolation acr oss tenants and resulting in unfair memory attribution. B. Memory partitioning under dynamic workloads Both baseline and custom configurations rely on static memory allocation, where the memory assigned to each tenant is fixed at setup time. While this approach can be effecti ve in stable scenarios, where workload characteristics and system settings remain constant ov er time, this may not hold for more volatile en vironments. W e no w ev aluate dif ferent CacheLib setups under such en vironments, where tenants enter and leav e the system at different points in time. Specifically , tenants are added to the system sequentially every 500 seconds, and after all tenants are activ e for 500 seconds, they leave the system in rev erse order of arriv al. The initial memory allocations across tenants follow the same setup as in §III-A. For the custom setup, the allocation polic y was adapted with the following rules: 1) at the start up time, no tenant is allocated with more memory than its expected demand, and 2) an y leftover memory capacity if a vailable is proportionally distributed among active tenants to prev ent underutilization of memory resources. Finally , the baseline configuration is omitted from this experiment, as it custom 0 79.22 158.44 237.66 316.88 optimizer 0 3.68 7.36 11.05 14.73 0 1.55 3.1 4.66 6.21 0 500 1000 1500 2000 2500 0 1.24 2.48 3.71 4.95 0 500 1000 1500 2000 2500 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 0 2 4 6 8 Throughput (K Ops/s) Memory (GiB) Time (s) Zipfian (1.2) Zipfian (0.9) Zipfian (0.6) Unifor m Fig. 4: P er-tenant performance comparison across CacheLib custom and optimizer setups under dynamic workloads. Each r ow depicts the throughput (kops/s) and allocated memory (GiB) over time of each tenant (T 1 to T 4 ). The left y-axis presents the thr oughput (line), while the right y-axis presents the memory allocated (filled ar ea). 0 500 1000 1500 2000 2500 Time (s) 0 50 100 150 200 250 300 Throughput (K Ops/s) custom optimizer Fig. 5: Overall throughput under dynamic workloads. W orkload- awar e reallocation outperforms static or delayed adaptation. is not capable of adapting to dynamic workloads, thus would exhibit the same behavior as in §III-A. Results. Fig. 4 depicts the throughput and memory allocation per tenant under the custom and optimizer setups. Contrary to the previous results (§III-A), the optimizer fails to reallocate memory dynamically and con verge to an improved state since tenants are active for too short a period, resulting in insuffi- cient data to trigger reallocation. Nevertheless, even if tenant interleaving periods were larger , the optimizer could still fail to con verge due to erroneous memory allocation decisions under the rapidly changing nature of the workloads. In any case, the optimizer fails to adapt and remains with a static memory allocation of 25% of the total cache capacity to each tenant, achieving a maximum throughput of ≈ 170 kops/s. On the other hand, as depicted in Fig. 5, the custom configuration achie ved a peak throughput of ≈ 315 kops/s, a 1.85 × improvement over the optimizer under the same memory constraints. This improvement stems from two key factors. First, the startup memory allocations of custom are better aligned with the expected workload characteristics, ensuring each tenant receiv es a memory share closer to its actual demand. Second, the custom policy reclaims and redis- tributes unused memory proportionally among activ e tenants, improving ov erall resource usage and throughput. For instance, during the first 500 seconds of the experiment, when only T 1 is active, while the optimizer limits T 1 to 25% of the cache, the custom setup allocates the full cache capacity , maximizing its performance. As additional tenants join, the custom policy continues to dynamically adjust memory allocations propor- tionally , ensuring effecti ve cache usage. Observation 4. T o maximize cac he effectiveness in dynamic en vironments, it is fundamental to combine workload-awar e memory allocation primitives with pr o- portional r edistribution of unused memory r esources. I V . D I S C U S S I O N CacheLib made significant contributions to the design of programmable caching engines, particularly for multi-tenant en vironments. Despite offering a pool optimizer for better resource management, our study highlights that CacheLib still faces challenges in handling dynamic workloads on multi- tenant deployments, which opens up the path for new research. Handling dynamic workloads. Our study sho ws that the pool optimizer cannot properly handle dynamic tenants, leading to inefficient memory allocation and underutilization of available resources. In particular , when tenants frequently join or leav e the system, such as in applications with background jobs ( e.g ., RocksDB compactions) or social networks with services experiencing idle periods follo wed by bursts of activity ( e.g., T witter [13]), the pool optimizer fails to react promptly and adequately . T o address this, the prediction mechanism could be improv ed using techniques such as Miss-Ratio Curves (MRCs) to describe how hit-ratio, throughput, or latency varies with distinct pool sizes [15], [16]. Handling multiple instances. CacheLib instances operate in isolation, leading to the absence of global coordination. Han- dling dynamic workloads across multiple instances becomes more challenging, as the pool optimizer only manages pools within the same instance, pre venting memory from being reallocated across instances and limiting o verall resource effi- ciency . This isolation also hinders the ability to enforce QoS guarantees to prioritize critical tenants over less critical ones. Solving this challenge will require a coordinated resource management layer across instances, with QoS-aware policies and, potentially , through a centralized controller capable of monitoring cache usage and enforcing tenant-specific perfor- mance tar gets across the entire infrastructure [17], [18]. Related work and study generalizability . This paper focuses on CacheLib, gi ven its widespread adoption. Nonetheless, sev eral other caching solutions have been proposed to address multi-tenant workloads. Dynacache [19], Cliffhanger [20], AdaptSize [21], zExpander [14], FrozenHot [12], LAMA [22], AdaptCache [11], and SegCache [10] focus on general cache optimizations, such as reducing latency , increasing throughput, improving hit ratios, or balancing memory usage, by em- ploying different strategies, including workload monitoring, adaptiv e resizing, and probabilistic policies. Ho wev er, these approaches are tenant-oblivious, as they aim to maximize cache performance rather than providing tenant fairness and isolation, crucial for multi-tenant environments such as those supported by CacheLib . This limitation often leads to ag- gressiv e tenants monopolizing cache resources, inadvertently evicting other tenants’ working sets, leading to performance degradation and QoS violations [9], [13]. As for systems that e xplicitly address QoS, Moirai [3], Pisces [9], Centaur [15], and RobinHood [5] implement tenant- aware management techniques to meet specific performance objectiv es. For instance, Centaur employs optimization algo- rithms, such as Simulated Annealing (SA) combined with Miss-Ratio Curves (MRCs), to optimize the cache partitioning and allocation of resources across multiple tenants to meet the specified performance constraints [15]. Ho wev er, these systems are typically fine-tuned for specific workloads and storage scenarios, such as hypervisors and key-v alue stores, limiting their generalizability to broader multi-tenant caching en vironments like those targeted by CacheLib. For example, a prediction model designed for block caches assumes uniform item sizes, whose assumption breaks down in key-v alue stores, which handle variable-sized items, leading to inaccurate per- formance estimations [15], [16]. A C K N O W L E D G E M E N T S This work was co-funded by the European Regional De- velopment Fund (ERDF) through the NOR TE 2030 Regional Programme under Portugal 2030, within the scope of the project BCD.S+M, reference 14436 (NOR TE2030-FEDER- 00584600), by national funds through FCT - Fundac ¸ ˜ ao para a Ci ˆ encia e a T ecnologia, I.P ., under the support UID/50014/2023 (https://doi.org/10.54499/UID/50014/2023), and by FCCN within the scope of the project Deucalion, with reference 2024.00014.TEST .DEUCALION. This work was also supported by funding from NSF (grants CNS-1956229, CSR-2402328, CAREER-2338457, and CSR-2323100), as well as generous donations from NetApp and Seagate. R E F E R E N C E S [1] Y . Feng, Z. Liu, Y . Zhao, T . Jin, Y . W u, Y . Zhang, J. Cheng, C. Li, and T . Guan, “Scaling Large Production Clusters with Partitioned Synchronization, ” in 2021 USENIX Annual T echnical Conference , 2021. [2] B. Berg, D. S. Berger, S. McAllister et al. , “The CacheLib Caching Engine: Design and Experiences at Scale, ” in 14th USENIX Symposium on Operating Systems Design and Implementation , 2020. [3] I. A. Stefanovici, E. Thereska, G. O’Shea, B. Schroeder, H. Ballani, T . Karagiannis, A. I. T . Rowstron, and T . T alpey , “Software-defined caching: managing caches in multi-tenant data centers, ” in Pr oceedings of the Sixth ACM Symposium on Cloud Computing , 2015. [4] (2021) CacheLib: Facebook’ s open source caching engine. [Online]. A vailable: https://engineering.fb.com/2021/09/02/open- source/cachelib/ [5] D. S. Berger , B. Berg, T . Zhu, S. Sen, and M. Harchol-Balter , “Robin- Hood: T ail Latency A ware Caching - Dynamic Reallocation from Cache- Rich to Cache-Poor, ” in 13th USENIX Symposium on Operating Systems Design and Implementation , 2018. [6] Y . Fu and C. Soman, “Real-time Data Infrastructure at Uber, ” in 2021 International Conference on Management of Data , 2021. [7] N. Armenatzoglou et al. , “ Amazon Redshift Re-in vented, ” in 2022 International Conference on Management of Data , 2022. [8] T . B ¨ ottger et al. , “Open Connect Everywhere: A Glimpse at the Internet Ecosystem through the Lens of the Netflix CDN, ” ACM SIGCOMM Computer Communication Review , 2018. [9] D. Shue, M. J. Freedman, and A. Shaikh, “Performance Isolation and Fairness for Multi-T enant Cloud Storage, ” in 10th USENIX Symposium on Operating Systems Design and Implementation , 2012. [10] J. Y ang, Y . Y ue, and R. V inayak, “Segcache: a memory-efficient and scalable in-memory key-v alue cache for small objects, ” in 18th USENIX Symposium on Networked Systems Design and Implementation , 2021. [11] O. Asad and B. Kemme, “AdaptCache: Adaptiv e Data Partitioning and Migration for Distributed Object Caches, ” in Proceedings of the 17th International Middleware Confer ence , 2016. [12] Z. Qiu, J. Y ang, J. Zhang, C. Li, X. Ma, Q. Chen, M. Y ang, and Y . Xu, “FrozenHot Cache: Rethinking Cache Management for Modern Hardware, ” in 18th European Confer ence on Computer Systems , 2023. [13] J. Y ang, Y . Y ue, and K. V . Rashmi, “A lar ge scale analysis of hundreds of in-memory cache clusters at T witter, ” in 14th USENIX Symposium on Operating Systems Design and Implementation , 2020. [14] X. Wu, L. Zhang, Y . W ang, Y . Ren, M. Hack, and S. Jiang, “zExpander: a ke y-value cache with both high performance and fe wer misses, ” in 11th Eur opean Conference on Computer Systems , 2016. [15] R. K oller , A. J. Mashtizadeh, and R. Rangaswami, “Centaur: Host- Side SSD Caching for Storage Performance Control, ” in 2015 IEEE International Conference on Autonomic Computing , 2015. [16] C. A. W aldspurger , N. Park, A. T . Garthwaite, and I. Ahmad, “Efficient MRC construction with SHARDS, ” in 13th USENIX Confer ence on F ile and Storage T echnologies , 2015. [17] R. Macedo, M. Miranda, Y . T animura, J. Haga, A. Ruhela, S. L. Harrell, R. T . Evans, J. Pereira, and J. Paulo, “T aming Metadata-intensive HPC Jobs Through Dynamic, Application-agnostic QoS Control, ” in 23rd IEEE/ACM International Symposium on Cluster , Cloud and Internet Computing . IEEE, 2023. [18] M. Miranda, Y . T animura, J. Haga, A. Ruhela, S. L. Harrell, J. Cazes, R. Macedo, J. Pereira, and J. Paulo, “Can Current SDS Controllers Scale T o Modern HPC Infrastructures?” in W orkshops of the International Confer ence for High P erformance Computing, Networking, Stora ge and Analysis . IEEE, 2024. [19] A. Cidon, A. Eisenman, M. Alizadeh, and S. Katti, “Dynacache: Dynamic Cloud Caching, ” in 7th USENIX W orkshop on Hot T opics in Cloud Computing , 2015. [20] ——, “Cliffhanger: Scaling Performance Cliffs in W eb Memory Caches, ” in 13th USENIX Symposium on Networked Systems Design and Implementation , 2016. [21] D. S. Berger , R. K. Sitaraman, and M. Harchol-Balter , “ AdaptSize: Orchestrating the Hot Object Memory Cache in a Content Delivery Network, ” in 14th USENIX Symposium on Networked Systems Design and Implementation , 2017. [22] X. Hu, X. W ang, Y . Li, L. Zhou, Y . Luo, C. Ding, S. Jiang, and Z. W ang, “LAMA: Optimized Locality-aware Memory Allocation for Key-v alue Cache , ” in 2015 USENIX Annual T echnical Conference , 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment