Early Failure Detection and Intervention in Video Diffusion Models
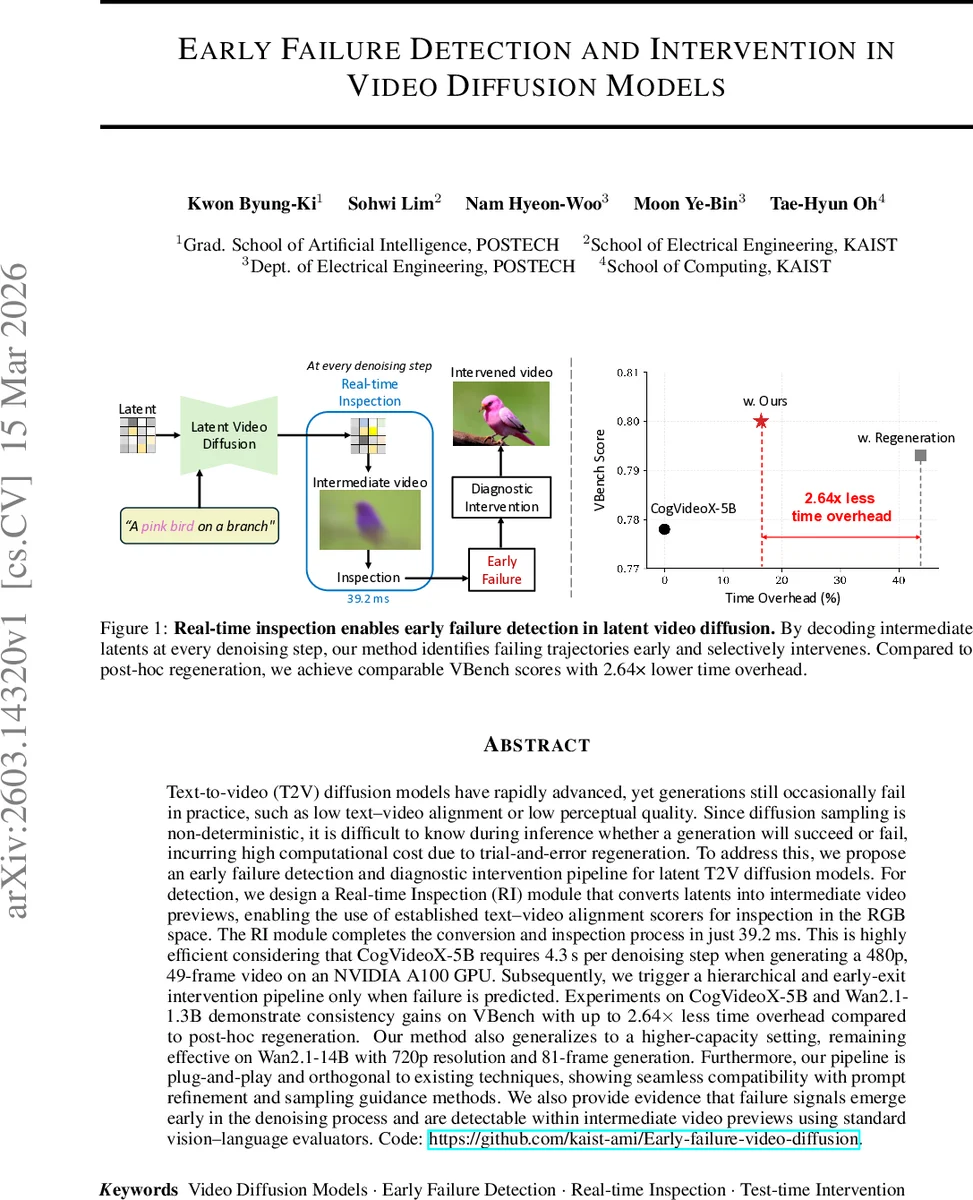
Text-to-video (T2V) diffusion models have rapidly advanced, yet generations still occasionally fail in practice, such as low text-video alignment or low perceptual quality. Since diffusion sampling is non-deterministic, it is difficult to know during inference whether a generation will succeed or fail, incurring high computational cost due to trial-and-error regeneration. To address this, we propose an early failure detection and diagnostic intervention pipeline for latent T2V diffusion models. For detection, we design a Real-time Inspection (RI) module that converts latents into intermediate video previews, enabling the use of established text-video alignment scorers for inspection in the RGB space. The RI module completes the conversion and inspection process in just 39.2ms. This is highly efficient considering that CogVideoX-5B requires 4.3s per denoising step when generating a 480p, 49-frame video on an NVIDIA A100 GPU. Subsequently, we trigger a hierarchical and early-exit intervention pipeline only when failure is predicted. Experiments on CogVideoX-5B and Wan2.1-1.3B demonstrate consistency gains on VBench with up to 2.64 times less time overhead compared to post-hoc regeneration. Our method also generalizes to a higher-capacity setting, remaining effective on Wan2.1-14B with 720p resolution and 81-frame generation. Furthermore, our pipeline is plug-and-play and orthogonal to existing techniques, showing seamless compatibility with prompt refinement and sampling guidance methods. We also provide evidence that failure signals emerge early in the denoising process and are detectable within intermediate video previews using standard vision-language evaluators.
💡 Research Summary
The paper tackles a practical problem in text‑to‑video (T2V) diffusion models: generations often fail due to poor text‑video alignment, temporal inconsistency, or low perceptual quality, and because diffusion sampling is stochastic it is impossible to know in advance whether a particular run will succeed. The naïve solution—generate, evaluate, and if the result is unsatisfactory, regenerate—incurs huge computational waste.
To address this, the authors propose an early‑failure detection and diagnostic intervention pipeline that works directly on latent‑space video diffusion models. The pipeline consists of two main components:
-
Real‑time Inspection (RI) module – a lightweight Latent‑to‑RGB (L2R) converter that can decode intermediate latent tensors into a full‑resolution RGB preview in only 19.7 ms (0.059 M parameters, 0.138 MB memory). This is more than 200× faster than the native decoder of CogVideoX‑5B (≈4 s). The preview is then fed to a ViCLIP‑based alignment scorer, which computes a text‑video semantic similarity score in an additional 19.5 ms. The total latency per inspection step is 39.2 ms, allowing the system to monitor every denoising step in real time.
-
Dynamic failure detector and hierarchical intervention framework – a small predictor aggregates a short history of intermediate alignment scores {sₖ} to estimate the final alignment score Ŝ₀. If Ŝ₀ is above a threshold τ (set to 0.22) the generation proceeds unchanged (Trial 0). Otherwise, the system triggers a cascade of increasingly costly corrective actions:
- Trial 1 – Single‑frame semantic injection: The model generates a single‑image preview for the same prompt. If its alignment score Ŝ_img exceeds the current video score by a margin δ (0.05), the latent of that image is injected back into the video generation at the very first 1–2 denoising steps, effectively anchoring the semantic content while leaving temporal dynamics to be refined. This step is cheap because it only involves a single frame.
- Trial 2 – Observation‑driven prompt refinement: If the single‑frame injection does not improve alignment, a visual‑language model (VLM) analyses the failed preview and produces an intent‑preserving refined prompt that addresses visual artifacts. Generation restarts with the new prompt; if it still fails, Trial 1 is attempted once more with the refined prompt.
Even in the worst case where all three trials are executed, the total extra compute is only about 56 % of a full regeneration, yielding a 2.64× reduction in time overhead compared with naïve post‑hoc regeneration.
Experiments were conducted on three state‑of‑the‑art video diffusion models: CogVideoX‑5B, Wan2.1‑1.3B, and the larger Wan2.1‑14B (720p, 81 frames). Using the VBench benchmark, the authors show consistent improvements in text‑video alignment, temporal consistency, and overall perceptual quality. The early‑failure signals were found to emerge as early as step T‑10, confirming that intermediate previews are sufficient for reliable prediction. Moreover, the pipeline is plug‑and‑play: it works alongside existing techniques such as classifier‑free guidance, prompt refinement, and other sampling‑time interventions without any modification to the underlying diffusion model.
Key insights and contributions:
- Demonstrates that a tiny, fast latent‑to‑RGB decoder can provide a usable RGB preview for real‑time quality inspection, overcoming the bottleneck of full decoding.
- Shows that standard vision‑language alignment scores (ViCLIP) are effective early indicators of final video quality when applied to intermediate previews.
- Introduces a dynamic, sample‑adaptive failure detector that predicts final success/failure from a short sequence of scores, enabling selective intervention rather than blanket regeneration.
- Proposes a hierarchical intervention strategy that first exploits the model’s inherent semantic knowledge (single‑frame anchor) before resorting to higher‑level prompt engineering, thereby keeping additional compute minimal.
Limitations include reliance on ViCLIP for alignment scoring (which may be weak for certain domains), the L2R decoder being optimized for 480p‑scale videos (higher resolutions may need more sophisticated up‑sampling), and the need to tune τ and δ for different datasets or model sizes.
In summary, the paper presents a practical, efficient framework that brings “monitor‑and‑repair” capabilities to video diffusion models, substantially reducing wasted computation while improving generation quality, and it does so in a way that can be readily combined with existing generation‑enhancement methods.
Comments & Academic Discussion
Loading comments...
Leave a Comment