MobileFetalCLIP: Selective Repulsive Knowledge Distillation for Mobile Fetal Ultrasound Analysis
Fetal ultrasound AI could transform prenatal care in low-resource settings, yet current foundation models exceed 300M visual parameters, precluding deployment on point-of-care devices. Standard knowledge distillation fails under such extreme capacity…
Authors: Numan Saeed, Fadillah Adamsyah Maani, Mohammad Yaqub
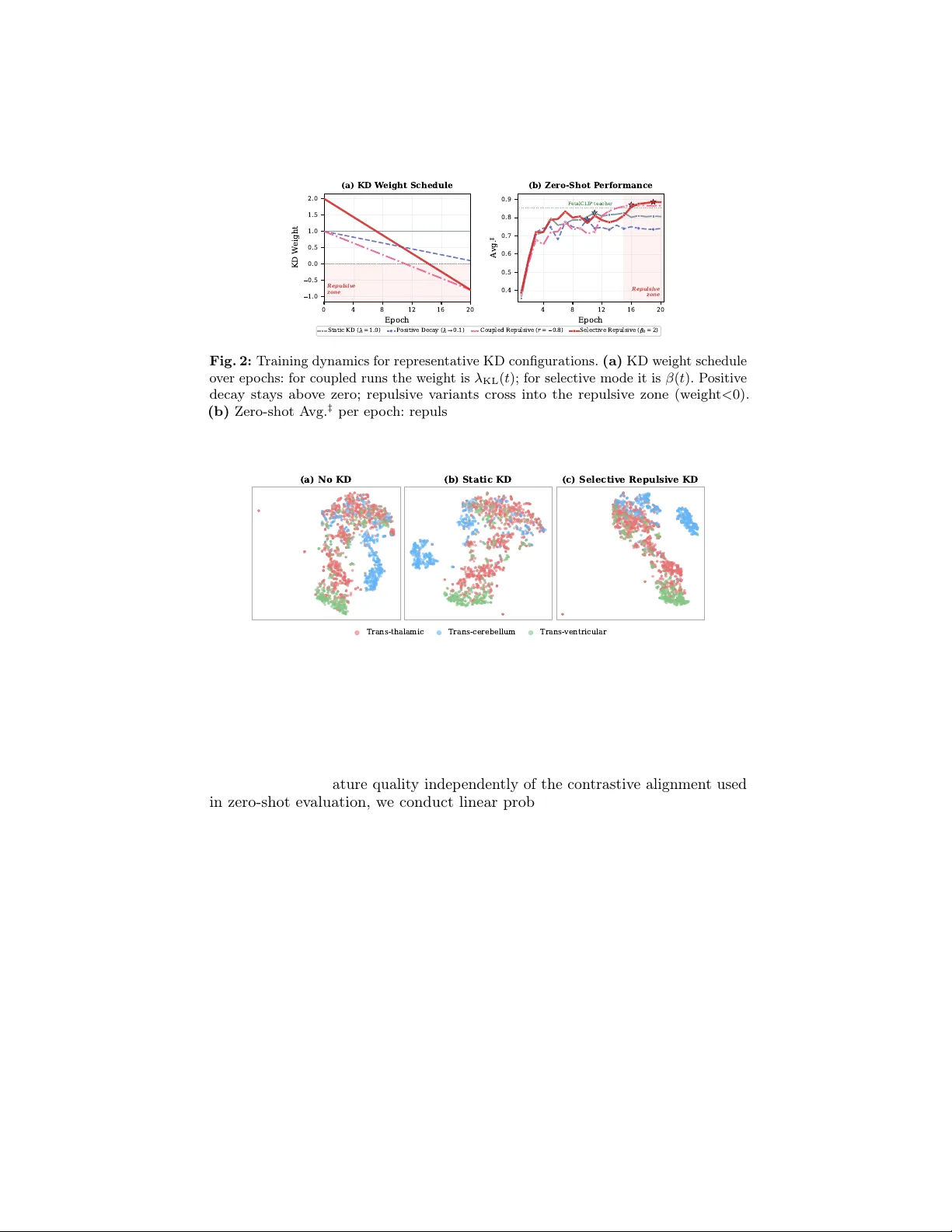
MobileF etalCLIP: Selectiv e Repulsiv e Kno wledge Distillation for Mobile F etal Ultrasound Analysis Numan Saeed 1 ⋆ , F adillah A damsyah Maani 1 , and Mohammad Y aqub 1 Computer Vision Departmen t, Mohamed bin Za yed Universit y of Artificial Intelligence, Abu Dhabi, UAE Abstract. F etal ultrasound AI could transform prenatal care in lo w- resource settings, y et current foundation models exceed 300M visual parameters, precluding deploymen t on point-of-care devices. Standard kno wledge di stillation fails under suc h extreme capacity gaps ( ≈ 26 × ), as compact students w aste capacit y mimicking arc hitectural artifacts of ov ersized teachers. W e in tro duce Selectiv e Repulsiv e Kno wledge Distillation , which decomp oses contrastiv e KD into diagonal and off- diagonal components: matched pair alignment is preserv ed while the off-diagonal weigh t deca ys in to negativ e v alues, rep elling the studen t from the teacher’s inter-class confusions and forcing discov ery of arc hi- tecturally native features. Our 11.4M parameter student surpasses the 304M-parameter F etalCLIP teacher on zero-shot HC18 biometry v alid- it y ( 88.6% vs. 83.5%) and brain sub-plane F1 ( 0.784 vs. 0.702), while running at 1.6 ms on iPhone 16 Pro, enabling real-time assistive AI on handheld ultrasound devices. Our co de and mo dels are publicly av ailable at https://github.com/numanai/MobileFetalCLIP . Keyw ords: Kno wledge distillation · F etal ultrasound · Vision-language mo dels · Mobile AI · Repulsive regularisation 1 In tro duction F etal ultrasound is the primary mo dalit y for monitoring fetal wellbeing, spanning standard plane classification [2, 4], biometric measurement [23], and congenital heart disease screening [1]. Deplo ying AI assistance at the p oin t of care is clinically impactful, particularly in lo w-resource settings where ultrasound exp ertise remains limited [25] and AI-driven mobile solutions are emerging to bridge the gap [ ? , 9]. Recen t vision-language foundation mo dels such as F etalCLIP [17] demonstrate comp elling zero-shot capabilities across these tasks by pretraining on large-scale clinical image-caption pairs. Ho wev er, F etalCLIP’s ViT-L/14 image enco der alone con tains ≈ 304M parameters (427M parameters for the full mo del), making it unsuitable for p oin t-of-care ultrasound (POCUS) devices such as handheld prob es and tablet-based platforms. Kno wledge distillation (KD) [11] provides a natural path wa y: train a compact studen t to mimic a large teacher. F or vision-language models, prior w ork such as ⋆ Corresp onding author: numan.saeed@mbzuai.ac.ae 2 N. Saeed et al. Tin yCLIP [33] and CLIP-KD [34] demonstrates that distilling CLIP-family mo dels preserv es zero-shot generalisation. How ev er, these approac hes target general- domain vision and assume mo derate teac her-student capacity gaps. When the gap is large, as in our setting where the teacher has ≈ 26 × more visual parameters, Cho and Hariharan [6] show that standard KD degrades, and Stan ton et al . [24] demonstrate that higher fidelity to the teac her do es not guarantee b etter student accuracy . W e argue that the core issue is ar chite ctur al inc ommensur ability : the teac her’s off-diagonal (non-target) similarity structure is shap ed in part by ViT- L’s global self-attention, whereas a con volution-atten tion h ybrid student suc h as F astViT m ust allo cate capacity to approximating patterns it cannot naturally represen t. In this work, we distil F etalCLIP into MobileF etalCLIP (Figure 1), a mobile mo del with a F astViT image enco der [7, 29, 30] (11.4M visual parameters, 26 × few er than the teac her). W e extend the distillation sc hedule to negativ e minimum ratios ( r < 0 ), at whic h p oin t the KD weigh t crosses zero and the ob jective inverts : instead of attracting the student tow ard the teacher’s inter-class similarity structure, it rep els the studen t a wa y from it, using th e teacher’s confusion patterns as a structured signal for where the student should build sharper b oundaries with its own architectural strengths. Building on the insigh t from Decoupled KD [37] that target-class and non-target-class kno wledge serv e different roles, w e decomp ose the contrastiv e KD loss in to diagonal (matched-pair) and off-diagonal (non-target) components, applying repulsion selectively to the off- diagonal comp onen ts while protecting matc hed-pair alignment. W e term this Selectiv e Repulsiv e KD ; the selectiv e repulsion forces the studen t to disco v er ar chite ctur al ly native features, i.e . compact discriminative cues suited to F astViT’s con volutional-atten tion hybrid design rather than replications of ViT-L’s global self-atten tion patterns (Secs. 4.6 and 5). Our key finding is that Selectiv e Repulsive KD outp erforms all standard KD baselines and surpasses the teac her on key zero-shot ev aluation axes. Compared to the standard logit KD baseline, Selectiv e Repulsive KD improv es HC18 biometry v alidit y from 79.4% to 88.6% ( + 9.2 pp) and zero-shot brain sub-plane F1 from 0.715 to 0.784 ( + 6.9 pp). With 26 × few er visual enco der parameters, MobileF etalCLIP surpasses the F etalCLIP teac her in zero-shot HC18 biometry v alidit y (88.6% vs. 83.5%, + 5.1 pp) and zero-shot brain sub-plane F1 (0.784 vs. 0.702, + 8.2 pp), while maintaining competitive 5-plane classification (0.946 vs. 0.973). Linear probing confirms that frozen MobileF etalCLIP features retain 97–98% of the teacher’s downstream p erformance (Sec. 4.7), indicating that the capacit y gap primarily limits raw feature information while Selective Repulsiv e KD reco vers and even improv es the relational structure that zero-shot ev aluation prob es. Analysis via embedding geometry and logit distributions (Sec. 4.6) reveals the mechanism: Selectiv e Repulsive KD pro duces structur e d de c orr elation , yielding w ell-separated, confident representations that are systematically different from the teac her’s. Selectiv e Repulsive KD connects to Decoupled KD [37], decorrelation-based learning [31, 35], and confidence regularisation [20], but o ccupies a distinct p osition MobileF etalCLIP: Selective Repulsive KD for F etal Ultrasound 3 among these paradigms; we formalise this relationship in Sec. 3.5 and v alidate it empirically in Sec. 4.4. Our main con tributions are: – W e prop ose Selectiv e Repulsive Kno wledge Distillation , an architecture- and domain-agnostic metho dology which decomp oses con trastive KD into diagonal (matc hed-pair) and off-diagonal (non-target) components. By ap- plying repulsion selectively to the off-diagonal while preserving matched-pair alignmen t, it provides a general framew ork for distilling ov er-parameterised foundation mo dels into highly compact studen ts. – W e introduce MobileF etalCLIP, a mobile-scale vision-language mo del for fetal ultrasound that surpasses the F etalCLIP teac her in zero-shot HC18 biometry v alidit y and brain sub-plane F1 at 26 × few er visual enco der parameters, while retaining 97–98% of linear probing p erformance (T abs. 1 and 5). – W e provide mec hanistic analysis via em b edding geometry , logit distributions, and con trolled ablations, demonstrating that Selectiv e Repulsive KD pro duces structured decorrelation and that the teacher’s logit geometry is essential as a directional signal (Secs. 3.5 and 4.6). 2 Related W ork Vision-Language Pretraining. CLIP [21] demonstrated that con trastive pretraining on image-text pairs yields transferable zero-shot represen tations. Sub- sequen t work refined the ob jectiv e (SigLIP [36]), scaling laws (Op enCLIP [5, 13]), and efficiency (MobileCLIP [7, 30]). Our studen t backbone extends MobileCLIP with multi-modal reinforced training, yielding strong accuracy-p er-parameter trade-offs via a F astViT image enco der [29]. Medical Vision-Language Mo dels. MedCLIP [32], BiomedCLIP [ ? ], and UniMed-CLIP [14] adapt CLIP to the medical domain using broad biomedical corp ora spanning m ultiple imaging mo dalities. CheXzero [28] demonstrates that mo dalit y-specific CLIP pretraining on c hest X-ra ys achiev es exp ert-lev el zero-shot pathology detection, confirming the imp ortance of domain sp ecificit y . None of these models transfer effectively to fetal ultrasound (T ab. 1). F etalCLIP [17] is the first VLM specialised for fetal ultrasound, achieving state-of-the-art across plane classification, biometry , and congenital heart disease detection. Ho wev er, it emplo ys a 304M-parameter ViT-Large mo del as its image encoder, limiting its suitabilit y for resource-constrained deplo yment scenarios such as POCUS and mobile devices. Kno wledge Distillation and the Capacity Gap. Hinton et al . [11] show ed that soft targets carry rich inter-class structure; FitNets [22] extended this to in termediate features; CRD [27] established contrastiv e ob jectives for distillation; RKD [19] distilled relational structure betw een samples. F or CLIP mo dels, CLIP- KD [34] studied logit, feature, and combined strategies; TinyCLIP [33] used weigh t inheritance, though this requires the studen t to b e a pruned v ersion of the teacher, 4 N. Saeed et al. whic h is inapplicable when teacher and studen t differ arc hitecturally . Zhao et al . [37] show ed in Decoupled KD that indep enden tly w eighting target-class and non-target-class comp onen ts impro ves distillation; w e adapt this decomp osition to the con trastive N × N setting and extend it to negativ e weigh ts. Crucially , distillation degrades with increasing capacity gap [6, 18, 24]: larger teac hers can pro duce worse students, and exact KL-matching destabilises un- der strong teac hers [12, 26]. Conv ersely , F urlanello et al . [8] show ed re-distilled studen ts can surpass their teacher. Prior approaches either bridge the gap via in termediate mo dels [18], relax the ob jectiv e [12, 26], or require arc hitectural corre- sp ondence [33]. Selective Repulsiv e KD tak es an orthogonal approach: w e exploit the teacher’s confusion structure as a directional signal, inv erting the off-diagonal ob jective to push the student to ward architecturally nativ e representations. Regularisation and Decorrelation. Barlo w T wins [35] sho wed that decorre- lating represen tation dimensions preven ts collapse and impro ves generalisation; W ang and Isola [31] formalised alignmen t and uniformit y as the tw o desiderata of con trastive learning. Building on these principles, we subsequently measure align- men t and uniformit y to c haracterise the decorrelation mec hanism of our repulsiv e ob jective (Sec. 4.6). Kim et al . [15] demonstrated that negative learning, where the mo del learns what a class is not , can b e more robust than p ositiv e learning, pro viding a conceptual parallel to our teacher-informed repulsion. Pereyra et al . [20] sho wed that penalising ov erconfident predictions impro ves generalisation. Our repulsive regime is sup erficially similar but fundamen tally differs in its use of the teacher’s logit geometry as a directional signal; w e formalise this distinction in Sec. 3.5. 3 Metho d 3.1 Preliminary: CLIP Contrastiv e Learning Giv en a batch of N image-text pairs { ( x i , c i ) } N i =1 , CLIP [21] trains image enco der f I and text enco der f T b y maximising the cosine similarity b et w een paired em b eddings and minimising it for non-paired ones: L CLIP = − 1 2 N N X i =1 " log e s ii /τ P N j =1 e s ij /τ + log e s ii /τ P N j =1 e s j i /τ # , (1) where s ij = f I ( x i ) ⊤ f T ( c j ) and τ is a learned temp erature (inv erse logit scale). 3.2 Logit Knowledge Distillation F ollo wing CLIP-KD [34], we align the N × N similarit y logit matrices of student and teac her. The teacher (F etalCLIP , ViT-L/14) is frozen; the studen t (F astViT) is trained. Given studen t logit matrix S S and teacher logit matrix S T , we soften MobileF etalCLIP: Selective Repulsive KD for F etal Ultrasound 5 Fig. 1: Ov erview of the MobileF etalCLIP framework. (A) Distillation setup: a frozen F etalCLIP teacher (ViT-L/14, 304M visual params) pro duces an N × N similarit y matrix; a ligh tw eight F astViT student (11.4M visual params) is trained via L CLIP and L KD . (B) Attraction-to-repulsion dynamics: the off-diagonal w eight β ( t ) decays from β 0 in to negativ e v alues; the diagonal weigh t L diag remains fixed, preserving matc hed- pair alignment throughout training. (C) Outcome: Selective Repulsiv e KD produces structured decorrelation, resulting in b etter cluster separation and a higher HC18 v alidit y rate and brain sub-plane F1 with 26 × fewer visual parameters. only the teac her with KD temp erature τ KD while k eeping the student at native scale: p T i = softmax S T i, : τ KD , q S i = softmax S S i, : , (2) where p T i and q S i denote the ro w-wise softmax distributions of teacher and student, resp ectiv ely . The symmetric logit KD loss a verages the image-to-text ( I → T x ) and text-to-image ( T x → I ) directions, where T x here denotes text (not teacher): L KD = 1 2 H ( p T , q S ) I → T x + H ( p T , q S ) T x → I , (3) where H ( p, q ) = − P j p j log q j is the cross-entrop y , equiv alen t to KL ( p T ∥ q S ) up to additive teacher-en tropy constants. W e apply temp erature only to the teacher (studen t unscaled, no T 2 correction); details are in supplemen tary § 1.3. 3.3 Linear Decay Sc hedule and Repulsive KD The total training ob jective is: L = L CLIP + λ KL ( t ) · L KD , (4) where λ KL ( t ) follo ws a linear schedule parameterised by initial w eight λ 0 , total training ep ochs S (distinct from temp erature τ ), and minimum ratio r : λ KL ( t ) = λ 0 · 1 − t S (1 − r ) . (5) 6 N. Saeed et al. F or r ≥ 0 , λ KL deca ys to a p ositiv e floor λ 0 r , corresp onding to standard KD that w eakens o ver time. When r < 0 , λ KL ev entually b ecomes negativ e. At this p oin t the gradient of λ KL ( t ) · L KD inverts : instead of minimising KL divergence from the teac her, the ob jectiv e maximises it, actively repelling the studen t’s similarit y distribution aw ay from the teac her’s. W e call this the Repulsiv e KD regime. The off-diagonal en tries of the teacher’s similarity matrix enco de in ter- class confusions that are partly architectural: patterns arising from ViT-L’s global self-atten tion rather than in trinsic visual ambiguit y alone (confirmed empirically in Sec. 4.6). A conv olutional student forced to replicate these patterns wastes capacit y on confusion structures it cannot naturally represent; repulsion frees it to resolve these confusions using its arc hitecturally native lo cal-texture and m ulti-scale features. The training pro cess pro ceeds through three phases (Figure 1B): 1. A ttractive phase ( λ KL > 0 ): Standard KD, where the student absorbs domain kno wledge from the teacher’s similarit y structure. 2. T ransition ( λ KL ≈ 0 ): Near the zero-crossing, the KD term contributes negligibly and the studen t is driven primarily b y L CLIP . 3. Repulsiv e phase ( λ KL < 0 ): The gradien t inv erts, pushing the studen t to resolv e inter-class confusions differently from the teacher. Combined with the alwa ys-p ositiv e L CLIP whic h main tains correct image-text alignment, this forces discov ery of architecturally native features suited to F astViT’s con volutional-atten tion design. 3.4 Selectiv e Repulsive KD: Diagonal-Protected Decomp osition Zhao et al . [37] sho wed that in classification KD, the non-target class comp onen t (NCKD) carries the ma jorit y of the “dark kno wledge” and benefits from inde- p enden t w eighting. W e adapt this decomp osition to the contrastiv e setting. In the N × N similarit y matrix, diagonal entries ( i = j ) represent matched image-text pairs (analogous to TCKD), while off-diagonal entries ( i = j ) capture non-target similarit y structure (analogous to NCKD). W e decomp ose the KD loss: L KD = L diag + β ( t ) · L off - diag , (6) where, for each row of the cross-entrop y H ( p T i , q S i ) = − P j p T ij log q S ij , w e partition the sum into its j = i term ( L diag ) and its j = i terms ( L off - diag ). The diagonal weigh t is fixed at 1.0 throughout training, preserving correct image-text alignment. The off-diagonal weigh t β ( t ) follows the same linear sc hedule as Eq. (5), parameterised b y initial v alue β 0 and minim um ratio r : β ( t ) = β 0 · 1 − t S (1 − r ) , (7) and is p ermitted to become negative when r < 0 . In coupled mo de (Eq. (4)), the same schedule applies uniformly to the en tire L KD via λ KL ( t ) ; in selective mode, only the off-diagonal comp onen t is sc heduled while the diagonal remains fixed. MobileF etalCLIP: Selective Repulsive KD for F etal Ultrasound 7 This diagonal protection ensures that ev en during the repulsiv e phase, the studen t maintains high-qualit y matched-pair represen tations. Only the non-target similarit y structure, i.e . how the studen t relates non-matching images and texts, is pushed a wa y from the teacher’s pattern. F ollo wing Zhao et al .’s finding that upw eighting NCKD improv es distilla- tion [37], w e allo w β 0 > 1 ( NCKD amplification ), which increases the emphasis on non-target structure during the attractive phase before the transition into repulsion. The sensitivit y to β 0 is analysed in Sec. 4.4. 3.5 P ositioning Among Regularisation P aradigms Selectiv e Repulsiv e KD relates to t wo confidence-mo dulating strategies, yet differs in directionality: (i) confidence p enalt y [20] pushes tow ard uniform distributions with no notion of which classes to separate; (ii) standard KD [11] attracts tow ard the te acher’s distribution, constraining under large capacity gaps; (iii) Selectiv e Repulsiv e KD repels from the teac her’s non-tar get structure while preserving matc hed-pair alignment. The teac her’s confusion patterns tell the student ex- actly which class pairs to separate; our ablation (Sec. 4.4) confirms that this directionalit y is essential, as undirected entrop y p erforms comparably to no KD. 3.6 T raining Setup Mo dels. The student uses a F astViT image enco der [7, 29, 30] (11.4M visual parameters, 256 × 256 input, 512-d embeddings) with a 4-lay er text T ransformer (75M total parameters). The teacher is F etalCLIP [17] with ViT-L/14 (304M visual parameters, 427M total), frozen throughout training. T raining data. W e use the F etalCLIP pretraining corpus [17]: 246,349 fetal ultrasound image-caption pairs comprising routine second-trimester clinical scans from a tertiary hospital with LLM-generated captions and exp ert-annotated textb ook image-caption pairs, served in W ebDataset format [3]. W e train for 20 ep ochs with effective batch size 1,024 and τ KD = 5 . 0 (following CLIP-KD [34]; the elev ated temperature amplifies the repulsiv e signal once λ KL crosses zero). With the linear schedule (Eq. (5)), the zero crossing occurs at ep och t ∗ = S / (1 − r ) ≈ 11 for r = − 0 . 8 . Augmen tation. In KD mo de, student and teac her views share the same sampled affine/jitter parameters (coupled augmentation), so compared logit matrices corresp ond to the same underlying view. F ull details. Complete h yp erparameters, optimiser/sc heduler settings, preci- sion/distributed setup, and data pip eline details are provided in supplemen- tary § 1. 4 Exp erimen ts 4.1 Ev aluation Setup Datasets. W e ev aluate zero-shot p erformance on t wo public b enc hmarks. 8 N. Saeed et al. Planes DB [4]: 12,400 fetal ultrasound images from 1,792 patien ts across t w o hospitals. W e use 8,187 images for 5-plane classification (abdomen, brain, femur, thorax, cervix; excluding the “Other” category) and 2,949 brain images for 3-class brain sub-plane classification (transthalamic, transcereb ellum, transv entricular). F ollo wing F etalCLIP [17], zero-shot ev aluation uses the full labelled set rather than in tro ducing an additional train/test partition. HC18 [10]: 999 head circumference images. W e filter to 814 with ph ysiologically plausible HC (100–342 mm, corresponding to 14–40 w eeks gestational age). F ollo wing F etalCLIP [17], w e rep ort validity r ate : gestational age (GA) is predicted via similarit y matc hing against GA-sp ecific text prompts, and a prediction is valid if the true HC falls within the 2.5th–97.5th p ercen tile range of the WHO fetal gro wth charts [16] for the predicted GA. Metrics. All metrics are zero-shot. W e rep ort the HC18 v alidity score, the macro-a verage F1 for 5-plane classification (F1-5Plane), and the macro-av erage F1 for 3-class brain sub-plane classification (F1-3Brain). W e also rep ort F1- all, the macro-av erage across all fetal-plane classes, computed as F1 - all = 5 × F1 - 5Plane + 3 × F1 - 3Brain 8 . F or hyperparameter selection across runs, w e use the a verage of F1 - all and the HC18 v alidit y rate (denoted A vg. ‡ in tables); this is not an ev aluation metric but a run-selection heuristic. Baselines. W e compare against CLIP (ViT-L/14) [21], BiomedCLIP [ ? ], UniMed- CLIP [14], SonoNet [2], and the F etalCLIP teacher [17]; baseline num b ers are from Maani et al . [17]. The primary distillation baseline is static logit KD ( λ KL = 1 . 0 ), implemen ting the CLIP-KD [34] symmetric cross-en tropy ob jective. Tin yCLIP-style w eight inheritance [33] is inapplicable as our student (F astViT) and teac her (ViT-L/14) share no architectural correspondence. 4.2 Main Results T able 1 reports zero-shot p erformance on both b enc hmarks. Without distilla- tion, the studen t achiev es HC18 v alidity of 71.3% and F1-5Plane of 0.889 from con trastive pretraining alone. Standard logit KD (the CLIP-KD [34] baseline) impro ves HC18 to 79.4% and F1-5Plane to 0.946, confirming that the teacher pro vides v aluable domain kno wledge. How ev er, HC18 v alidit y remains well b elo w the teac her’s 83.5%, consistent with the capacity-gap degradation predicted b y Cho and Hariharan [6]. Selectiv e Repulsive KD not only closes this gap but inv erts the degradation. With 26 × few er visual parameters, MobileF etalCLIP surpasses the F etalCLIP teac her on HC18 biometry v alidity (88.6% vs. 83.5%, + 5.1 pp) and brain sub- plane F1 (0.784 vs. 0.702, + 8.2 pp), while maintaining comp etitiv e 5-plane classification (0.946 vs. 0.973). The impro vemen t from CLIP-KD baseline to Selectiv e Repulsive KD is entirely attributable to the distillation strategy , as the arc hitecture and training data are identical. MobileF etalCLIP: Selective Repulsive KD for F etal Ultrasound 9 T able 1: Zero-shot comparison on fetal ultrasound b enc hmarks. Best student result in b old . Static Logit KD implements the CLIP-KD [34] ob jective (the standard distillation baseline for CLIP mo dels). A vg. ‡ : run-selection heuristic ( F1-all + HC18% / 100) / 2 . † : results from Maani et al . [17]. Model Params HC18 (%) F1-5Pl. F1-3Br. F1-all A vg. ‡ T eacher F etalCLIP (ViT-L/14) † 427M 83.5 0.973 0.702 0.871 0.853 Gener al VLMs (not fetal-spe cific) CLIP (ViT-L/14) † 427M 11.0 0.308 0.206 0.270 0.190 BiomedCLIP (ViT-B/16) † 150M 24.0 0.603 0.236 0.466 0.353 UniMed-CLIP (ViT-B/16) † 150M 9.0 0.679 0.187 0.495 0.293 Sup ervise d (not zero-shot) SonoNet-16 † 11M – 0.827 0.485 0.699 – MobileF etalCLIP (F astViT, 75M total) No KD (CLIP only) 75M 71.3 0.889 0.712 0.823 0.768 Static Logit KD (CLIP-KD baseline) 75M 79.4 0.946 0.715 0.859 0.826 Coupled Repulsive KD ( r = − 0 . 8 ) 75M 84.4 0.933 0.763 0.869 0.857 Selectiv e Repulsiv e KD ( β 0 =2 , r = − 0 . 8 ) 75M 88.6 0.946 0.784 0.886 0.886 T able 2: Inference efficiency: visual-encoder parameters, GMA Cs, and on-device en- co der latency (CoreML, fp16, batch 1). Measured on t wo iPhones to sho w generational consistency . iPhone Latency (ms) Model Vis. Params GMACs 16 Pro 17 Pro F etalCLIP (ViT-L/14) 304M 38.9 37.6 31.9 MobileF etalCLIP (F astViT) 11.4M (26 × ↓ ) 1.2 (32 × ↓ ) 1.6 (24 × ↓ ) 1.4 (23 × ↓ ) 4.3 Inference Efficiency T able 2 compares the visual enco der’s computational cost. The student requires 32 × few er multiply-accum ulate op erations and 26 × few er parameters than the teac her. On an iPhone 16 Pro the encoder runs in 1.6 ms (24 × faster than the teac her’s 37.6 ms), corresp onding to ov er 600 frames p er second, w ell b ey ond the 30–60 fps typical of diagnostic ultrasound. This throughput headro om means the enco der can b e embedded in an on-device assistiv e pip eline for real-time standard- plane iden tification without interfering with the clinical scanning w orkflow. 4.4 Ablation Study T able 3 presen ts the full ablation. The results reveal a clear progression: Standard KD helps, but has limits. Static KD ( λ KL = 1 . 0 ) impro ves F1- 5Plane from 0.889 to 0.946 and HC18 v alidit y from 71.3% to 79.4%. How ever, HC18 remains well b elo w the teacher’s 83.5%, and F1-3Brain barely mo ves (0.712 → 0.715). P ositive deca y and complete abandonmen t fail. Deca ying λ KL to 0.1 degrades HC18 to 74.6%. Complete teacher abandonment ( r = 0 . 0 ) is worst among 10 N. Saeed et al. deca y sc hedules (HC18 73.1%), confirming that the teac her pro vides essen tial regularisation. Confidence p enalt y is not the answ er. The confidence p enalt y ( ε = 0 . 1 , HC18 74.9%, F1-3Brain 0.680) p erforms comparably to no KD, confirming that undirected en tropy maximisation cannot substitute for structured teac her guidance. F eature KD consisten tly h urts. A dding CLIP-KD-style [34] feature alignment ( λ feat = 2000 ) to static KD degrades HC18 from 79.4% to 75.9% and F1-3Brain from 0.715 to 0.664, confirming that p oin twise embedding mimicry is counterpro- ductiv e under a 26 × gap. Coupled repulsive KD ov ercomes the gap. Allo wing λ KL to decay into negativ e v alues ( r = − 0 . 8 ) improv es HC18 to 84.4%, surpassing the teacher’s 83.5% (Figure 2b), and b oosts F1-3Brain from 0.715 to 0.763. Selectiv e Repulsive KD achiev es the b est results. Diagonal protection with NCKD amplification ( β 0 = 2 , r = − 0 . 8 ) surpasses the teac her on HC18 (88.6% vs. 83.5%) and F1-3Brain (0.784 vs. 0.702). Comparing selective against coupled isolates diagonal protection’s contribution: HC18 + 4.2 pp, F1-3Brain + 2.1 pp. The larger HC18 gain suggests that diagonal protection is particularly imp ortan t for retriev al-dependent tasks that rely on preserv ed image-text asso ciations, whereas classification b enefits more from the repulsive signal itself. Higher amplification ( β 0 ≥ 4 ) and w eaker repulsion ( r ≥− 0 . 5 ) b oth degrade performance, confirming that the decomp osition and repulsion strength jointly determine the result. Across three seeds (42, 123, 7), the b est selective configuration yields A vg. ‡ 0 . 867 ± 0 . 016 , with HC18 v alidity 87 . 1 ± 2 . 2 % and F1-3Brain exhibiting the highest v ariance ( 0 . 735 ± 0 . 069 ); all seeds surpass the static KD baseline (supplementary § 3.3). 4.5 T raining Dynamics Figure 2 visualises training b eha viour across KD configurations. Repulsive runs exhibit a characteristic “late surge” in zero-shot p erformance once the KD weigh t crosses zero ( ∼ ep och 11 for r = − 0 . 8 ), with Selective Repulsive KD ( β 0 = 2 , r = − 0 . 8 ) reac hing the highest A vg. ‡ (0.886), exceeding the teac her’s 0.853. The surge o ccurs b ecause the sign flip conv erts the KD ob jectiv e from minimising to maximising KL div ergence on non-target pairs: the inv erted gradient directly p enalises the studen t for preserving the teac her’s inter-class confusion structure, forcing rapid disco very of more discriminative features. Extended dynamics are in supplementary Figs. S4– S5. 4.6 F eature Space Analysis t-SNE Visualisation. Figure 3 shows t-SNE pro jections of brain sub-plane em- b eddings, the hardest subtask (three visually similar fetal head planes). Without KD, transthalamic and transven tricular o verlap substan tially; static KD provides marginal impro vemen t. Selective Repulsive KD pro duces dramatically tighter, w ell-separated clusters, consistent with the + 8.2 pp F1-3Brain gain o ver the teac her. MobileF etalCLIP: Selective Repulsive KD for F etal Ultrasound 11 T able 3: Unified ablation: KD strategies for MobileF etalCLIP (F astViT-MCI0, 11.4M visual enco der) distilled from F etalCLIP ViT-L/14 (304M). All runs: lr= 10 − 5 , τ KD = 5 . 0 , seed 42, 20 ep ochs. Best p er-column in b old . A vg. ‡ : run-selection heuristic ( F1-all + HC18% / 100) / 2 . Configuration F1-5Plane F1-3Brain F1-all HC18 (%) A vg. ‡ F etalCLIP T e acher (ViT-L/14) 0.973 0.702 0.871 83.5 0.853 No KD (CLIP only) 0.889 0.712 0.823 71.3 0.768 Static KD ( λ KL =1 . 0 ) 0.946 0.715 0.860 79.4 0.826 Static + F eat. KD ( λ feat =2000 ) 0.946 0.664 0.840 75.9 0.800 Pos. Decay ( λ KL : 1 → 0 . 1 ) 0.902 0.713 0.831 74.6 0.788 F ull Deca y ( λ KL → 0 ) 0.842 0.742 0.805 73.1 0.768 Conf. Penalt y ( ε =0 . 1 ) 0.854 0.680 0.789 74.9 0.769 Couple d R epulsive KD (uniform λ KL on ful l matrix) r = − 0 . 8 0.933 0.763 0.869 84.4 0.857 Sele ctive R epulsive KD (diag.-prote cted, off-diag. repulsion) Selective β 0 =2 , r = − 0 . 8 0.946 0.784 0.885 88.6 0.886 NCKD amplific ation ablation (selective, r = − 0 . 8 ): β 0 =4 0.950 0.709 0.860 85.4 0.857 β 0 =8 0.943 0.714 0.857 78.6 0.822 R epulsion str ength ablation (selective, β 0 =2 ): r = − 0 . 5 0.941 0.725 0.860 84.6 0.853 r = − 0 . 4 0.938 0.724 0.858 78.4 0.821 T able 4: Em b edding geometry on Planes DB (5-plane, 8,187 images). d eff : effectiv e dimensionalit y (participation ratio). Rank 95 : singular v alues for 95% v ariance. Method d eff Rank 95 Silh. ↑ In tra ↑ Inter ↓ Unif. ↓ Static KD ( λ KL =1 . 0 ) 8.0 77 0.375 0.712 0.445 − 1.662 Conf. p enalt y 9.0 84 0.406 0.693 0.389 − 1.811 Coupled r = − 0 . 8 6.4 50 0.509 0.645 0 . 010 − 2.231 Selective β 0 =2 10.0 74 0.525 0.623 0.076 − 2 . 308 Em b edding Geometry . W e p erform quan titative cluster and sp ectral anal- ysis on the Planes DB 5-plane ev aluation set (8,187 images). T able 4 reports silhouette score, in ter-class cosine similarit y , W ang and Isola’s uniformit y [31], and effective dimensionality d eff via the participation ratio of the embedding co v ariance sp ectrum. Repulsiv e KD dramatically impro ves cluster geometry: silhouette scores in- crease by + 40% ov er static KD (0.525 vs. 0.375), and inter-class cosine collapses from 0.445 to near zero. The confidence p enalt y pro vides only mo dest impro ve- men t (0.406), confirming that undirected en tropy cannot matc h teac her-informed repulsion. Coupled repulsion concen trates features into fewer dimensions ( d eff 6.4 vs. 8.0 for static KD), while Selectiv e Repulsiv e KD achiev es the highest d eff (10.0) and best uniformit y ( − 2 . 308 ), connecting to the Barlo w T wins [35] decorrelation principle. F ull sp ectral analysis is in supplementary § 2.6. P er-class F1 heatmaps and confusion matrices are in supplementary § 2.1. 12 N. Saeed et al. 0 4 8 12 16 20 Epoch 1.0 0.5 0.0 0.5 1.0 1.5 2.0 KD W eight Repulsive zone (a) KD W eight Schedule 4 8 12 16 20 Epoch 0.4 0.5 0.6 0.7 0.8 0.9 A v g . F etalCLIP teacher Repulsive zone (b) Zero-Shot P erformance S t a t i c K D ( = 1 . 0 ) P o s i t i v e D e c a y ( 0 . 1 ) C o u p l e d R e p u l s i v e ( r = 0 . 8 ) S e l e c t i v e R e p u l s i v e ( 0 = 2 ) Fig. 2: T raining dynamics for represen tative KD configurations. (a) KD weigh t schedule o ver epo c hs: for coupled runs the weigh t is λ KL ( t ) ; for selectiv e mo de it is β ( t ) . P ositive deca y stays ab o ve zero; repulsive v ariants cross into the repulsive zone (weigh t < 0 ). (b) Zero-shot A vg. ‡ p er ep och: repulsive runs exhibit a characteristic late surge once en tering the repulsive zone; Selective Repulsive KD ( β 0 = 2 , r = − 0 . 8 ) ac hieves the highest final score ( ⋆ ), exceeding the F etalCLIP teacher. (a) No KD (b) Static KD (c) Selective Repulsive KD Trans-thalamic Trans-cerebellum Trans-ventricular Fig. 3: t-SNE pro jections of brain sub-plane embeddings (transthalamic, transcere- b ellum, transven tricular). (a) No KD: ov erlapping clusters. (b) Static KD: marginal impro vemen t. (c) Selective Repulsive KD: w ell-separated, compact clusters. 4.7 Linear Probing Ev aluation T o assess frozen feature quality independently of the con trastive alignmen t used in zero-shot ev aluation, we conduct linear probing on three downstream tasks (T ab. 5). F or each task, we freeze the image enco der, extract L2-normalised features, and train a single linear la yer. Setup. 6-view plane classific ation and 3-class br ain sub-plane classific ation use Planes DB [4] with the original patient-lev el train/test split (7,129/5,271 for 6-view; 1,543/1,406 for brain). Congenital he art dise ase (CHD) dete ction uses 418 four-cham ber fetal heart ultrasound videos (161 normal, 257 abnormal) with patien t-stratified split (333/85); for eac h video, 16 frames are sampled, frame- wise features extracted and concatenated b efore classification. All experiments use 5-fold cross-v alidation with 5 seeds (25 runs); 95% confidence interv als are computed via Studen t’s t -distribution. Results. MobileF etalCLIP retains 97–98% of the F etalCLIP teacher’s linear probing p erformance across all three tasks, while substantially outp erforming MobileF etalCLIP: Selective Repulsive KD for F etal Ultrasound 13 T able 5: Linear probing ev aluation. F rozen enco der features + single linear lay er. 95% CIs from 5-fold × 5 seeds. MobileF etalCLIP retains 97–98% of the teacher’s p erformance at 26 × few er visual parameters. Model 6-View (F1) Brain (F1) CHD (AUR OC) CLIP (ViT-L/14) .867 (.866–.869) .634 (.632–.637) .679 (.650–.708) BiomedCLIP (ViT-B/16) .856 (.855–.858) .582 (.577–.588) .643 (.622–.665) UniMed-CLIP (ViT-B/16) .860 (.858–.861) .607 (.603–.610) .718 (.702–.734) F etalCLIP (ViT-L/14) .947 (.947–.948) .820 (.818–.822) .787 (.770–.804) MobileF etalCLIP (F astViT) .930 (.930–.931) .799 (.797–.800) .769 (.758–.779) R etention 98.2% 97.4% 97.7% all general-purp ose VLMs ( + 6–22 pp on 6-view, + 17–22 pp on brain sub-plane, + 5–13 pp on CHD). The gap is expected: linear probing measures frozen feature information con tent, b ounded by enco der capacity [24], whereas zero-shot ev alua- tion probes image-text alignment, whic h logit-based distillation transfers most effectiv ely [11, 19]. This explains wh y MobileF etalCLIP surpasses the teacher on zero-shot tasks while retaining near-teac her linear probing. 5 Discussion 5.1 When and How Do es Selectiv e Repulsiv e KD W ork? Selectiv e Repulsive KD outp erforms standard KD when the capacity gap is large enough that faithful mimicry wastes studen t capacity . In our 26 × setting, the con trolled ablation (coupled vs. selective, b oth r = − 0 . 8 ) confirms that diagonal protection accoun ts for + 4.2 pp in HC18 and + 2.1 pp in F1-3Brain (Sec. 4.4). The mechanism is structur e d de c orr elation : well-separated, confiden t student represen tations that are systematically different from the teac her’s. Three lines of evidence supp ort this: 1. Em b edding geometry (T ab. 4): silhouette + 40% ov er static KD, near- zero inter-class cosine, highest d eff (10.0) and best uniformit y ( − 2 . 308 ); see supplemen tary § 2.6 for sp ectral analysis. 2. Logit distributions (supplementar y § 2.2): classification entrop y drops from 1.248 to 0.167 (more confident), while teacher-studen t rank correlation remains high (0.822), indicating preserved relational structure with divergence in sp ecific decisions. 3. Per-class patterns (supplemen tary § 2.1): brain sub-plane F1 reaches 0.784 ( + 8.2 pp ov er teac her), confirming superior fine-grained discrimination when freed from the teac her’s non-target structure. Wh y can the student surpass the teacher? The teacher’s ViT-L/14 dis- tributes representational capacity across all inter-class relationships through global self-attention, including confusable pairs ( e.g . brain sub-planes sharing similar ultrasound textures). The compact F astViT studen t (11.4M visual pa- rameters) cannot afford such distributed representations; standard KD w astes capacit y forcing the student to appro ximate inter-class relationships it cannot 14 N. Saeed et al. faithfully repro duce. Selective Repulsive KD uses the teac her’s confusion patterns as a structured signal for wher e to build sharp er boundaries, allo wing the studen t to exploit its conv olutional-attention architecture for lo cal discriminativ e cues that the teac her’s global attention did not prioritise. 5.2 When Do es It F ail? Excessiv e repulsion causes collapse. An exploration-phase coupled run with r = − 1 . 6 collapsed after ep o c h 14; excessiv e NCKD amplification ( β 0 = 8 ) degrades HC18 to 78.6%. All successful repulsive schedules require an initial attractive phase to absorb dom ain knowledge b efore div erging. F eature KD ( λ feat = 2000 ) consisten tly degrades p erformance under our 26 × gap (HC18: 79.4% → 75.9%), as the teac her’s embedding space is to o differen t for p oin twise alignment. 5.3 Connections to Prior W ork Selectiv e Repulsive KD draws from the capacit y gap literature [6, 18, 24], Zhao et al .’s [37] decomp osition insight (our con trastive adaptation differs; supplemen- tary § 2.4), Barlo w T wins [35] decorrelation, and Born-Again Netw orks [8]; our confidence p enalt y ablation empirically distinguishes it from undirected en tropy regularisation [20]. 5.4 Limitations and F uture W ork While retrospective benchmarks establish strong zero-shot capabilities, clinical translation requires prosp ectiv e v alidation to assess robustness against diverse ultrasound hardw are and op erator v ariabilit y . Given MobileF etalCLIP’s 1.6 ms latency , our immediate focus is real-time ev aluation on p ortable p oin t-of-care (POCUS) devices, targeting liv e assistive feedbac k in low-resource settings. F ur- thermore, b ecause Selective Repulsiv e KD is architecture- and domain-agnostic, future work will extend this framew ork to other resource-constrained clinical applications, suc h as echocardiography and cross-mo dal retriev al in general radiology . 6 Conclusion MobileF etalCLIP applies Selectiv e Repulsive Kno wledge Distillation , de- comp osing contrastiv e KD in to diagonal and off-diagonal terms and selectively rep elling only the latter, to distill F etalCLIP into a mobile vision-language mo del for fetal ultrasound. With 26 × few er parameters and 32 × few er GMACs, Mobile- F etalCLIP surpasses the teac her on HC18 v alidit y ( + 5.1 pp) and brain sub-plane F1 ( + 8.2 pp) at 1.6 ms on iPhone 16 Pro (24 × faster). W e release MobileF etal- CLIP and the Selective Repulsive KD framew ork to supp ort mobile medical AI at https://github.com/numanai/MobileFetalCLIP . MobileF etalCLIP: Selective Repulsive KD for F etal Ultrasound 15 References 1. A thalye, C., v an Nisselrooij, A., Rizvi, S., Haak, M., Mo on-Grady , A.J., Arnaout, R.: Deep-learning mo del for prenatal congenital heart disease screening generalizes to communit y setting and outp erforms clinical detection. Ultrasound in Obstetrics & Gynecology 63 (1), 44–52 (2024). https://doi.org/10.1002/uog.27503 2. Baumgartner, C.F., Kamnitsas, K., Matthew, J., Fletcher, T.P ., Smith, S., K o c h, L.M., Kainz, B., Rueck ert, D.: SonoNet: Real-time detection and lo calisation of fetal standard scan planes in freehand ultrasound. IEEE T rans. Med. Imaging 36 (11), 2204–2215 (2017). https://doi.org/10.1109/TMI.2017.2712367 3. Breuel, T.M., et al.: W ebDataset (2021), https : / / github . com / webdataset / webdataset 4. Burgos-Artizzu, X.P ., Coronado-Gutiérrez, D., V alenzuela-Alcaraz, B., Bonet-Carné, E., Eixarch, E., Crispi, F., Gratacós, E.: Ev aluation of deep con volutional neural net works for automatic classification of common maternal fetal ultrasound planes. Scien tific Rep orts 10 (1), 10200 (2020). https:/ /doi.org /10.1038 /s41598- 020 - 67076- 5 5. Cherti, M., Beaumon t, R., Wightman, R., W ortsman, M., Ilharco, G., Gordon, C., Sc huhmann, C., Schmidt, L., Jitsev, J.: Repro ducible scaling la ws for contrastiv e language-image learning. In: CVPR (2023) 6. Cho, J.H., Hariharan, B.: On the efficacy of kno wledge distillation. In: ICCV (2019) 7. F aghri, F., V asu, P .K.A., Koc, C., Shank ar, V., T oshev, A., T uzel, O., Pouransari, H.: MobileCLIP2: Impro ving multi-modal reinforced training. T ransactions on Mac hine Learning Research (2025) 8. F urlanello, T., Lipton, Z.C., T sc hannen, M., Itti, L., Anandkumar, A.: Born again neural netw orks. In: ICML (2018) 9. Gomes, R.G., V walik a, B., Lee, C., Willis, A., Sieniek, M., Pri ce, J.T., Chen, C., Kasaro, M.P ., T aylor, J.A., Stringer, E.M., McKinney , S.M., Sindano, N., Dahl, G.E., Go odnight, W., Gilmer, J., Chi, B.H., Lau, C., Spitz, T., Saensuksopa, T., Liu, K., Tiyasiric hokc hai, T., W ong, J., Pilgrim, R., Uddin, A., Corrado, G., Peng, L., Chou, K., T se, D., Stringer, J.S., Shetty , S.: A mobile-optimized artificial intelligence system for gestational age and fetal malpresentation assessment. Communications Medicine 2 , 128 (2022). https://doi.org/10.1038/s43856- 022- 00194- 5 10. v an den Heuv el, T.L., de Bruijn, D., de Korte, C.L., v an Ginneken, B.: Automated measuremen t of fetal head circumference using 2d ultrasound images. PLOS ONE 13 (8), e0200412 (2018) 11. Hin ton, G., Vin yals, O., Dean, J.: Distilling the knowledge in a neural netw ork. arXiv preprint arXiv:1503.02531 (2015) 12. Huang, T., Y ou, S., W ang, F., Qian, C., Xu, C.: Knowledge distillation from a stronger teacher. In: NeurIPS (2022) 13. Ilharco, G., W ortsman, M., Wightman, R., Gordon, C., Carlini, N., T aori, R., Dav e, A., Shank ar, V., Namkoong, H., Miller, J., Ha jishirzi, H., F arhadi, A., Schmidt, L.: Op enCLIP (2021), https://doi.org/10.5281/zenodo.5143773 14. Khattak, M.U., Kunhimon, S., Naseer, M., Khan, S., Khan, F.S.: UniMed-CLIP: T ow ards a unified image-text pretraining paradigm for diverse medical imaging mo dalities. arXiv preprin t arXiv:2412.10372 (2024) 15. Kim, Y., Yim, J., Y un, J., Kim, J.: NLNL: Negativ e learning for noisy lab els. In: ICCV (2019) 16. Kiserud, T., Piaggio, G., Carroli, G., Widmer, M., Carv alho, J., Jensen, L.N., Giordano, D., Cecatti, J.G., Aleem, H.A., T alegawk ar, S.A., Benachi, A., Diemert, 16 N. Saeed et al. A., Kitoto, A.T., Thinkhamrop, J., Lum biganon, P ., T ab or, A., Kriplani, A., Perez, R.G., Hec her, K., Hanson, M.A., Gülmezoglu, A.M., Platt, L.D.: The W orld Health Organization fetal growth c harts: A multinational longitudinal study of ultrasound biometric measurements and estimated fetal w eight. PLoS Medicine 14 (1), e1002220 (2017). https://doi.org/10.1371/journal.pmed.1002220 17. Maani, F., Saeed, N., Saleem, T., F aroo q, Z., Alasmawi, H., Diehl, W., Moham- mad, A., W aring, G., V alappi, S., Brick er, L., Y aqub, M.: F etalCLIP: A visual- language foundation mo del for fetal ultrasound image analysis. arXiv preprint arXiv:2502.14807 (2025) 18. Mirzadeh, S.I., F ara jtabar, M., Li, A., Levine, N., Matsuk aw a, A., Ghasemzadeh, H.: Improv ed knowledge distillation via teac her assistan t. In: AAAI (2020) 19. P ark, W., Kim, D., Lu, Y., Cho, M.: Relational knowledge distillation. In: CVPR (2019) 20. P ereyra, G., T uck er, G., Chorowski, J., Kaiser, L., Hin ton, G.: Regularizing neural net works by p enalizing confident output distributions. In: International Conference on Learning Represen tations W orkshop (2017) 21. Radford, A., Kim, J.W., Hallacy , C., Ramesh, A., Goh, G., Agarwal, S., Sastry , G., Ask ell, A., Mishkin, P ., Clark, J., Krueger, G., Sutsk ever, I.: Learning transferable visual mo dels from natural language sup ervision. In: ICML (2021) 22. Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: FitNets: Hin ts for thin deep nets. In: ICLR (2015) 23. Slimani, S., Hounk a, S., Mahmoudi, A., Rehah, T., Laoudiyi, D., Saadi, H., Bouziy ane, A., Lamrissi, A., Jalal, M., Bouhy a, S., Akiki, M., Bouyakhf, Y., Badaoui, B., Radgui, A., Mhlanga, M., Bouyakhf, E.H.: F etal biometry and amniotic fluid v olume assessmen t end-to-end automation using deep learning. Nature Comm uni- cations 14 , 7047 (2023). https://doi.org/10.1038/s41467- 023- 42438- 5 24. Stan ton, S., Izmailov, P ., Kirichenk o, P ., Alemi, A.A., Wilson, A.G.: Does knowledge distillation really w ork? In: NeurIPS (2021) 25. Stew art, K.A., Na v arro, S.M., Kambala, S., T an, G., P o ondla, R., Lederman, S., Barb our, K., Lavy , C.: T rends in ultrasound use in lo w and middle income countries: A systematic review. In ternational Journal of MCH and AIDS 9 (1), 103–120 (2020). https://doi.org/10.21106/ijma.294 26. Sun, S., Ren, W., Li, J., W ang, R., Cao, X.: Logit standardization in kno wledge distillation. In: CVPR (2024) 27. Tian, Y., Krishnan, D., Isola, P .: Con trastive represen tation distillation. In: ICLR (2020) 28. Tiu, E., T alius, E., Patel, P ., Langlotz, C.P ., Ng, A.Y., Ra jpurk ar, P .: Expert-level detection of pathologies from unannotated chest X-ray images via self-sup ervised learning. Nature Biomedical Engineering 6 , 1399–1406 (2022) 29. V asu, P .K.A., Gabriel, J., Zhu, J., T uzel, O., Ranjan, A.: F astViT: A fast hybrid vision transformer using structural reparameterization. In: ICCV (2023) 30. V asu, P .K.A., Pouransari, H., F aghri, F., V emulapalli, R., T uzel, O.: MobileCLIP: F ast image-text mo dels through multi-modal reinforced training. In: CVPR (2024) 31. W ang, T., Isola, P .: Understanding contrastiv e represen tation learning through alignmen t and uniformity on the hypersphere. In: ICML (2020) 32. W ang, Z., W u, Z., Agarwal, D., Sun, J.: MedCLIP: Con trastive learning from unpaired medical images and text. In: EMNLP . pp. 3876–3887 (2022) 33. W u, K., Peng, H., Zhou, Z., Xiao, B., Liu, M., Y uan, L., Xuan, H., V alenzuela, M., Chen, X.S., W ang, X., Chao, H., Hu, H.: Tin yCLIP: CLIP distillation via affinity mimic king and weigh t inheritance. In: ICCV (2023) MobileF etalCLIP: Selective Repulsive KD for F etal Ultrasound 17 34. Y ang, C., An, Z., Huang, L., Bi, J., Y u, X., Y ang, H., Diao, B., Xu, Y.: CLIP-KD: An empirical study of CLIP model distillation. In: CVPR (2024) 35. Zb on tar, J., Jing, L., Misra, I., LeCun, Y., Deny , S.: Barlo w t wins: Self-supervised learning via redundancy reduction. In: ICML (2021) 36. Zhai, X., Mustafa, B., Kolesnik ov, A., Beyer, L.: Sigmoid loss for language image pre-training. In: ICCV (2023) 37. Zhao, B., Cui, Q., Song, R., Qiu, Y., Liang, J.: Decoupled knowledge distillation. In: CVPR (2022)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment