Collapse or Preserve: Data-Dependent Temporal Aggregation for Spiking Neural Network Acceleration
Spike sparsity is widely believed to enable efficient spiking neural network (SNN) inference on GPU hardware. We demonstrate this is an illusion: five distinct sparse computation strategies on Apple M3 Max all fail to outperform dense convolution, be…
Authors: Jiahao Qin
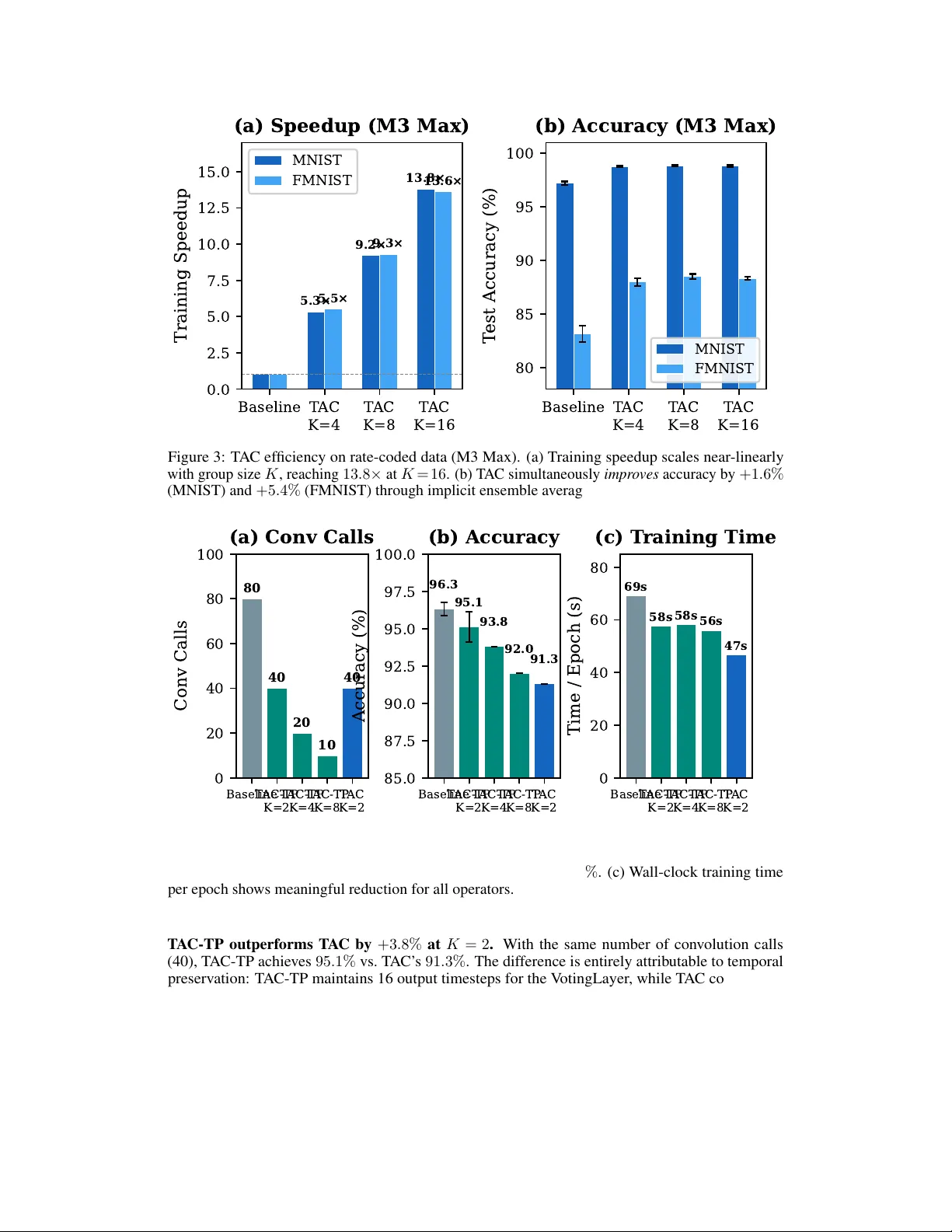
Collapse or Pr eserv e: Data-Dependent T emporal Aggr egation f or Spiking Neural Netw ork Acceleration Jiahao Qin Jiahao.qin19@gmail.com Abstract Spike sparsity is widely believ ed to enable ef ficient spiking neural network (SNN) inference on GPU hardware. W e demonstrate this is an illusion: fiv e distinct sparse computation strategies on Apple M3 Max all fail to outperform dense conv olution, because SIMD architectures cannot exploit the fine-grained, unstructured sparsity of i.i.d. binary spik es. Instead, we propose T emporal Aggregated Con volution (T A C) , which exploits con v olution linearity to pre-aggregate K spike frames before a single con v olution call, reducing T calls to T /K . On rate-coded data, T AC achie ves 13 . 8 × speedup with +1 . 6% accuracy on MNIST and +5 . 4% on Fashion- MNIST —a simultaneous improv ement in both speed and accuracy . Ho wev er , on e vent-based data where the temporal dimension carries genuine motion information, T A C’ s temporal collapse is harmful. W e therefore introduce T A C-TP (T emporal Preserv ation), which shares each group’ s con v olution output across K independent LIF steps, preserving full temporal resolution for downstream layers. On D VS128- Gesture, T A C-TP achie v es 95 . 1% accuracy (vs. 96 . 3% baseline) with 50% fewer con v olution calls, while standard T A C drops to 91 . 3% . Our key finding is that the optimal temporal aggre gation strategy is data-dependent : collapse the temporal dimension for rate-coded data (noise reduction) but preserve it for event data (information retention). Speedup is hardware-agnostic: T A C achie ves 11 . 0 × on NVIDIA V100, confirming the mechanism transfers across GPU architectures. All operators are open-source in the mlx-snn library . 1 Introduction Spiking neural networks (SNNs) process information through discrete spike e vents, mimicking bio- logical neural communication [Maass, 1997]. A central claimed advantage is computational efficienc y through spike spar sity : since only a fraction of neurons fire at each timestep, multiply-accumulate operations inv olving zero should be skippable [Roy et al., 2019]. This holds on neuromorphic hardware with dedicated sparse routing [Davies et al., 2018, Furber et al., 2014, Merolla et al., 2014], but does it transfer to GPUs? W e find that it does not. W e systematically test fi ve approaches to exploit spike sparsity for con- volutional SNN layers on modern GPU hardware. All fail to outperform dense conv olution. The fundamental reason is architectural: GPU SIMD lanes ex ecute identical operations on all vector elements regardless of v alue. For spikes with firing rate ρ = 0 . 1 , the probability that an entire SIMD lane of width W = 32 is zero is (1 − ρ ) W ≈ 0 . 035 —only 3.5% of lanes could be skipped, less than the branch ov erhead. Rather than fighting the GPU architecture, we work with it. W e propose T emporal Aggr egated Con volution (T A C) , which reduces the number of dense conv olution calls by exploiting con v olution linearity across the temporal dimension. Instead of con volving each of T spike frames separately , Preprint. T A C pre-aggre gates groups of K frames with exponential decay weights and con v olves the aggre gate once, reducing calls from T to T /K . On rate-coded data (MNIST , Fashion-MNIST), T A C delivers remarkable results: 13 . 8 × speedup with +1 . 6% accuracy impro vement on MNIST and +5 . 4% on Fashion-MNIST . This is not a speed- accuracy trade-off—it is a pure improvement. The accuracy gain arises because T A C’ s temporal collapse acts as ensemble av eraging ov er K independent Poisson samples, reducing input variance. Howe v er , on e vent-based data (D VS128-Gesture) where temporal structure encodes genuine motion information, T A C’ s temporal collapse is harmful: accuracy drops from 96 . 3% to 91 . 3% at K = 2 . This motiv ates our second contribution: T A C-TP (T emporal Preservation), which performs the same temporal aggregation for the con v olution but br oadcasts the result back to K independent LIF steps, preserving the full temporal dimension T for downstream layers. T A C-TP achie ves 95 . 1% on D VS-Gesture with 50% fewer con v olution calls—within 1 . 2% of baseline. The contrasting beha vior of T A C and T A C-TP re veals a key insight: the optimal temporal aggregation strategy is data-dependent . In rate-coded data, each timestep is an independent sample of the same underlying image; temporal collapse reduces v ariance and improv es accuracy . In e vent-based data, each timestep captures a dif ferent phase of a dynamic scene; temporal preserv ation is essential for motion-sensitiv e classification. Our contributions: 1. A systematic negati v e result: fiv e methods for exploiting spik e sparsity on GPU hardware all fail, with a formal analysis of the GPU-sparsity mismatch (Section 3). 2. T A C : temporal aggregation with temporal collapse, achie ving simultaneous speedup and accuracy gain on rate-coded data, with a formal approximation bound (Section 4.2). 3. T A C-TP : temporal aggre gation with temporal preservation for event-based data, maintaining temporal resolution while reducing con v olution calls (Section 4.3). 4. A data-dependent analysis establishing when to collapse vs. preserve the temporal dimension, validated on three datasets with multi-seed e xperiments (Section 5.5). 5. Open-source implementation in the mlx-snn library , av ailable on PyPI. 2 Related W ork Sparse SNN acceleration. The promise of spike-driv en computation has motiv ated extensi ve neuromorphic hardware: Intel Loihi [Davies et al., 2018], SpiNNaker [Furber et al., 2014], and IBM T rueNorth [Merolla et al., 2014] achie ve genuine ener gy sa vings through e vent-dri ven processing. Howe v er , the majority of SNN research uses con ventional GPUs via SpikingJelly [F ang et al., 2023] or snnT orch [Eshraghian et al., 2023]. While sparsity is often cited as moti v ation [Roy et al., 2019, Kundu et al., 2021], few works rigorously measure whether sparsity provides GPU speedup. Our work fills this gap. Efficient SNN training. Surrogate gradient methods [Neftci et al., 2019, Zenke and V ogels, 2021] enable gradient-based SNN training. Online learning rules [Bellec et al., 2020] avoid full backpropa- gation through time. T emporal ef ficient training [Deng et al., 2022] re-weights temporal gradients for fewer timesteps. Architecture-lev el optimizations include pruning [Chen et al., 2021] and attention- guided compression [Kundu et al., 2021]. Our work is complementary: we reduce the cost of spatial con v olution at each timestep, combinable with any temporal optimization. Con volutional SNN ar chitectur es. Spatio-temporal backpropag ation [W u et al., 2018] enabled deep Conv SNNs. Batch normalization for SNNs [Kim and Panda, 2021] and deeper architec- tures [Zheng et al., 2021] pushed accurac y closer to ANNs. Parametric LIF [Fang et al., 2021] learns per-channel time constants. T emporal-wise attention [Y ao et al., 2021] and temporal-channel joint attention [Zhu et al., 2024] exploit temporal structure via attention mechanisms. Mamba-Spike [Qin and Liu, 2025] combines spiking front-ends with state space models for ef ficient temporal processing. Our T A C operates at the con v olution le vel and pro vides theoretical speedup guarantees rather than adding attention or recurrence ov erhead. 2 T able 1: Five spik e sparsity exploitation methods on Apple M3 Max. Dense Con v2d baseline: 1.0 × . None achiev e meaningful sparsity-based speedup. Method Speedup Sparsity Used? Failure Mode T emporal Delta Conv 1 . 28 × No T emporal batching, not sparsity W eight-Gather < 1 . 0 × Attempted Irregular memory access Graph Compilation 1 . 4 × No General optimization Sparse GEMM < 1 . 0 × Attempted No structured sparsity Custom Metal SIMD 0 . 01 × Attempted Cannot beat vendor GEMM 3 Why Spik e Sparsity F ails on GPUs In a standard con volutional SNN, each layer applies Y t = W ∗ S t at e very timestep, where S t ∈ { 0 , 1 } C × H × W is the binary spike tensor . At firing rate ρ = 0 . 1 , approximately 90% of entries are zero, suggesting up to 10 × speedup by skipping zero multiplications. W e test this expectation with fiv e systematically designed approaches on Apple M3 Max (40-core GPU, 128GB unified memory), using Con v2d( C in =2, C out =128, K =3), input 64 × 64 , T =16, B =16. Method 1: T emporal Delta Con volution. Con v olve only the change ∆ S t = S t − S t − 1 . For i.i.d. spikes, the delta tensor has ∼ 2 ρ (1 − ρ ) nonzero entries— denser than the original at lo w firing rates. T emporal batching yields 1 . 28 × speedup from trivial parallelism, not sparsity . Method 2: W eight-Gather Sparse Con volution. Use index-gather to extract nonzero positions. All configurations are slower than dense con v olution: irregular memory access patterns defeat the GPU’ s cache hierarchy optimized for coalesced access. Method 3: Graph Compilation. JIT compilation via mx.compile provides 1 . 4 × speedup from general operation fusion, independent of sparsity . The compiler does not perform v alue-dependent conditional ex ecution. Method 4: Sparse GEMM. Compress zero rows in the im2col matrix. For C in = 2 , K = 3 : only (0 . 9) 18 ≈ 15% of rows are compressible. For deeper layers with C in = 128 : (0 . 9) 1152 ≈ 0 —no rows are compressible. Method 5: Custom Metal SIMD K ernels. Hand-written GPU kernels with SIMD group operations are 100 × + slower than vendor-optimized GEMM. Y ears of hardware-software co-optimization cannot be replicated. The failure is fundamental, not incidental: Proposition 1 (SIMD Sparsity Bound) . Let S ∈ { 0 , 1 } n be a spike vector with i.i.d. entries S i ∼ Bernoulli ( ρ ) , pr ocessed by a SIMD unit of width W . The fraction of skippable lanes (all elements zer o) is f skip = (1 − ρ ) W . F or ρ = 0 . 1 , W = 32 : f skip = 0 . 035 . The theor etical maximum speedup 1 / (1 − f skip ) = 1 . 036 × is less than the overhead of c hecking . GPU architectures maximize throughput for r egular computation [Hennessy and Patterson, 2017]. The hardware lottery [Hooker, 2021] dictates that sparse, dat a-dependent branching—exactly what spike sparsity requires—is antithetical to SIMD. Neuromorphic chips succeed because they were designed around this sparsity; GPUs were not. 4 T emporal Aggregated Con volution 4.1 K ey Insight: Reduce Calls, Not Cost A standard con v olutional SNN layer processes T timesteps with T independent con v olution calls: V t = β V t − 1 + W ∗ S t − V th · S out t − 1 , t = 1 , . . . , T , (1) where β ∈ (0 , 1) is the membrane decay constant. Each con v olution W ∗ S t is a dense GEMM—the most GPU-optimized primitiv e. Our operators reduce the count from T to T /K by exploiting the mathematical structure of con v olution. 3 Algorithm 1 T AC F orward P ass (T emporal Collapse) Require: Spik e frames S ∈ { 0 , 1 } T × B × C × H × W , kernel W , decay β , group size K 1: Initialize membrane V ← 0 2: for k = 0 , . . . , T /K − 1 do 3: A k ← P K − 1 j =0 β K − 1 − j · S kK + j ▷ T emporal aggregation 4: Y k ← Con v2d ( A k , W ) ▷ Single dense con v call 5: V ← β K · V + Y k ▷ Membrane update 6: S out k ← Θ( V − V th ) ▷ Spike generation 7: V ← V − S out k · V th ▷ Reset 8: end for 9: retur n { S out k } T /K − 1 k =0 ▷ Output has T /K timesteps 4.2 T A C: T emporal Aggregation with Collapse T A C exploits the linearity of conv olution : since W ∗ ( P i α i X i ) = P i α i ( W ∗ X i ) , we pre-aggregate multiple input frames before con v olving once. Definition 1 (T AC Operator) . Given spike frames { S kK , . . . , S kK + K − 1 } for gr oup k , define the temporal ag gr e gate: A k = K − 1 X j =0 β K − 1 − j · S kK + j , (2) wher e e xponential weights β K − 1 − j mirr or LIF membr ane decay . T A C compute s W ∗ A k once per gr oup, r eplacing K calls with one. The output temporal dimension is T /K . For continuous-v alued inputs (first layer), T A C is e xact by linearity . For deeper layers with binary spike inputs, T A C approximates K sequential LIF steps with a single step on the aggregated input: Theorem 1 (T A C Approximation Error Bound) . Let { S t } T t =1 be binary spike frames with firing r ate ρ . The membrane potential err or between e xact per -step computation and T AC with gr oup size K satisfies: E ∥ V exact T − V T AC T ∥ 2 2 ≤ C · ρ (1 − ρ ) · K · ∥ W ∥ 2 F , (3) wher e C depends on β and spatial dimensions. The err or scales linearly with K and firing rate variance ρ (1 − ρ ) . Pr oof sketc h. The error arises from the interaction between spatial con v olution and temporal spiking nonlinearity . W ithin each group, T AC applies one spik e generation instead of K sequential ones. The membrane potential difference accumulates through mismatched intermediate spik e patterns. Since each spik e is Bernoulli( ρ ) with v ariance ρ (1 − ρ ) , and K mismatches accumulate, the total error variance scales as K · ρ (1 − ρ ) · ∥ W ∥ 2 F . Full proof in Appendix A. Why does T A C improve accuracy on rate-coded data? For rate-coded static images, each timestep is an independent Bernoulli sample of the same image. The aggregation A k = P j β K − 1 − j S kK + j av erages ov er K such samples, reducing v ariance: V ar ( A k ) ∝ ρ (1 − ρ ) /K . This implicit denoising creates smoother , more informati ve inputs for con v olutional kernels—analogous to ensemble av eraging. Figure 1 illustrates the T A C pipeline for one group of K = 4 frames. 4.3 T A C-TP: T emporal Aggregation with Pr eservation T AC collapses the temporal dimension from T to T /K . For rate-coded data where timesteps are redundant, this is beneficial. But for event-based data where each timestep captures a different temporal slice of a dynamic scene, this collapse discards information essential for classification. T A C-TP addresses this by performing the same temporal aggregation for the con v olution operation but br oadcasting the result back to K timesteps for independent LIF processing: 4 T = 8 : S 1 S 2 S 3 S 4 Group 1 S 5 S 6 S 7 S 8 Group 2 ··· N g = T/K groups for k = 1, …, N g Group k (K = 4) S kK S kK+1 S kK+2 S kK+3 × β 3 × β 2 × β 1 × β 0 Σ β Σ i β K−1−i · S kK+i X k Conv2d(W) 1 GEMM / group Y k BN LIF Neuron V ← β · V + Y k S = Θ(V − V th ) V ← V − S · V th S out k K → 1 T/K = 2 : S out 1 S out 2 Figure 1: T A C (T emporal Collapse) operator . K input spike frames are pre-aggre gated with e xpo- nential decay weights into a single frame A k , which undergoes one Con v2d call (instead of K ). The LIF neuron fires once per group, producing T /K output timesteps. This temporal collapse acts as ensemble av eraging on rate-coded data, improving accurac y while providing up to 13 . 8 × speedup. Algorithm 2 T AC-TP F orward P ass (T emporal Preservation) Require: Spik e frames S ∈ { 0 , 1 } T × B × C × H × W , kernel W , decay β , group size K 1: Initialize membrane V ← 0 2: for k = 0 , . . . , T /K − 1 do 3: A k ← P K − 1 j =0 β K − 1 − j · S kK + j ▷ T emporal aggregation (same as T A C) 4: Y k ← Con v2d ( A k , W ) ▷ Single dense con v call 5: f or j = 0 , . . . , K − 1 do ▷ T emporal broadcast 6: V ← β · V + Y k ▷ LIF update with shared con v output 7: S out kK + j ← Θ( V − V th ) ▷ Independent spike per timestep 8: V ← V − S out kK + j · V th ▷ Reset 9: end f or 10: end for 11: retur n { S out t } T − 1 t =0 ▷ Output has full T timesteps Key difference from T A C. Lines 5–8 in Algorithm 2 replace the single LIF step in Algorithm 1 with K independent LIF steps using the same con v olution output Y k . This preserves the output temporal dimension at T (instead of T /K ), allo wing do wnstream layers and the output classifier to access full temporal information. The visual contrast between Figures 1 and 2 highlights this distinction: T A C produces one output per group (collapse), while T A C-TP produces K outputs per group (preserve). Why T A C-TP helps on e vent data. Event camera data encodes genuine temporal dynamics— different gesture phases produce different spike patterns across time. The output layer (e.g., a V otingLayer that a verages predictions ov er T timesteps) requires temporal diversity to make accurate predictions. Under cascaded T A C with K = 2 across 5 layers, the output temporal dimension collapses to T / 2 5 = T / 32 —effecti v ely destroying temporal information. T A C-TP maintains T throughout, preserving the LIF dynamics’ ability to generate temporally di verse spik e patterns e ven though the spatial (con v olution) component is shared within each group. Why T A C-TP hurts on rate-coded data. Rate-coded frames are i.i.d. Poisson samples of the same image; the temporal dimension carries no information be yond repeated sampling. T AC’ s collapse acts as ensemble averaging that reduces v ariance and improves accuracy . T A C-TP preserv es this noisy temporal dimension, forcing the network to learn to a verage out redundant v ariation, wasting model capacity . 5 T = 8 : S 1 S 2 S 3 S 4 Group 1 S 5 S 6 S 7 S 8 Group 2 ··· N g = T/K groups for k = 1, …, N g Group k (K = 4) S kK S kK+1 S kK+2 S kK+3 × β 3 × β 2 × β 1 × β 0 Σ β Σ i β K−1−i · S kK+i X k Conv2d(W) 1 GEMM / group Y k BN Broadcast ×K K Independent LIF Steps V ← β·V + Y k fire & reset V ← β·V + Y k fire & reset V ← β·V + Y k fire & reset V ← β·V + Y k fire & reset V state K Output Spikes S out kK S out kK+1 S out kK+2 S out kK+3 K → K T = 8 : S o 1 S o 2 S o 3 S o 4 S o 5 S o 6 S o 7 S o 8 Full temporal resolution preserved Figure 2: T AC-TP (T emporal Preserv ation) operator . The same aggre gation and single Conv2d call as T AC, b ut the output Y k is broadcast to K independent LIF steps, each producing a separate output spike. This preserv es the full temporal dimension T , which is critical for ev ent-based data where temporal structure encodes motion information. Computational cost. Both T A C and T A C-TP reduce con v olution calls from T to T /K . Howe ver , T AC also reduces LIF steps from T to T /K , while T A C-TP retains T LIF steps. Since LIF dynam- ics (element-wise operations) are much cheaper than conv olution (GEMM), T A C-TP’ s wall-clock speedup ( ∼ 1 . 2 × ) is more modest than T A C’ s ( ∼ 5 – 14 × ) but still pro vides meaningful reduction in the dominant compute cost. 4.4 Other Operators: FTC, IMC, TCC W e also explored three alternati ve mathematical approaches. All proved impractical; we summarize them briefly (details in Appendix C). Fourier T emporal Conv olution (FTC) replaces LIF’ s fix ed first-order IIR filter with a learnable biquad IIR filter with BIBO stability guarantees. FTC adds computation for IIR filtering without reducing con volution calls, resulting in 0 . 6 × speedup (a slowdo wn) and − 0 . 5% accuracy on MNIST . Information-Theor etic Channel Gating (IMC) models spike channels as Binary Symmetric Chan- nels and gates lo w-capacity channels. The gating ov erhead exceeds savings: 0 . 8 × speedup with no accuracy impro vement. T emporal Collapse Conv olution (TCC) skips conv olution during spike-free windows. For typical firing rates, the probability of an entire spatial frame being silent is (1 − ρ ) C · H · W ≈ 0 , so TCC provides no speedup ( 0 . 9 × ). The consistent failure of these alternativ es reinforces our core insight: reducing the number of con volution calls (T A C/T AC-TP) is the ef fectiv e strategy , not reducing the cost of individual calls. 5 Experiments 5.1 Setup Hardwar e and framework. T raining experiments run on Apple M3 Max (40-core GPU, 128GB unified memory) using mlx-snn v0.5 [Hannun et al., 2023]. CUD A inference benchmarks are reproduced on NVIDIA T esla V100-SXM2-16GB (PyT orch 2.7, CUD A 11.8) to confirm hardware- agnostic speedup. Datasets. MNIST and Fashion-MNIST : 28 × 28 images, rate-coded into T = 25 binary spike frames via Poisson sampling. 60K train / 10K test. DVS128-Gestur e [Amir et al., 2017]: Neuromor- 6 T able 2: Results on MNIST and Fashion-MNIST (3 seeds, mean ± std). T A C achieves simultaneous speedup and accuracy impro vement. T A C-TP underperforms on rate-coded data because temporal preservation retains noise rather than signal. MNIST Fashion-MNIST Operator Acc. (%) ∆ Speedup Acc. (%) ∆ Speedup Baseline 97 . 22 ± 0 . 15 — 1 . 0 × 83 . 14 ± 0 . 77 — 1 . 0 × T AC K =4 98 . 78 ± 0 . 08 +1.56 5 . 3 × 87 . 98 ± 0 . 37 +4.84 5 . 5 × T AC K =8 98 . 85 ± 0 . 04 +1.63 9 . 2 × 88 . 50 ± 0 . 24 +5.36 9 . 3 × T AC K =16 98 . 82 ± 0 . 07 +1.60 13 . 8 × 88 . 34 ± 0 . 16 +5.20 13 . 6 × T AC-TP K =4 93 . 20 ± 1 . 78 − 4.02 ∼ 5 × 76 . 38 ± 0 . 36 − 6.76 ∼ 5 × T able 3: Results on D VS128-Gesture ( 64 × 64 , T = 16 , 256 epochs). T AC-TP preserv es temporal resolution and significantly outperforms T A C. Conv calls are counted per forward pass across all 5 con v layers. Operator Accuracy (%) Conv Calls Time/ep (s) Speedup Baseline 96 . 30 ± 0 . 45 80 69.0 1 . 0 × T AC-TP K =2 95 . 13 ± 1 . 01 40 57.5 1 . 2 × T AC-TP K =4 93 . 8 20 58.1 1 . 2 × T AC-TP K =8 92 . 0 10 56.0 1 . 2 × T AC K =2 91 . 3 40 46.6 1 . 5 × phic ev ent camera recordings of 11 hand gestures. Events binned into T = 16 frames at 64 × 64 with 2 polarity channels. 1,176 train / 288 test. Architectur e. MNIST/Fashion-MNIST : Con v(1 → 32, K =3) → BN → LIF → Pool(2) → Con v(32 → 64, K =3) → BN → LIF → Pool(2) → FC(1600 → 128) → LIF → FC(128 → 10) → LIF . Parameters: ∼ 230K. D VS-Gesture: 5 × {Con v(128, K =3,pad=1) → BN → LIF → MaxPool(2)} → FC → LIF → V otingLayer(10 voters, 11 classes). Parameters: ∼ 914K. T raining. Adam optimizer , lr= 10 − 3 , cosine annealing. MNIST/FMNIST : 15 epochs, β = 0 . 9 , fast sigmoid surrogate ( α = 25 ), cross-entropy loss, batch size 128. D VS-Gesture: 256 epochs with warm restarts ( T max = 64 ), β = 0 . 5 , arctan surrogate ( α = 2 . 0 ), MSE loss on firing rate vs. one-hot target, batch size 16, detach reset. Three seeds per configuration. 5.2 Rate-Coded Data: MNIST and Fashion-MNIST T able 2 presents the main results and Figure 3 visualizes the speedup and accuracy trends. Ke y observations: T A C achieves simultaneous speedup and accuracy impr ovement. Across all K ∈ { 4 , 8 , 16 } , T A C improv es accuracy while pro viding 5 – 14 × speedup. On MNIST , all T A C variants achie ve ∼ 98.8% regardless of K , suggesting rate-coded temporal structure is simple enough for full collapse. On Fashion-MNIST , T AC provides +5 . 4% absolute improvement at K = 8 , with the accuracy gain saturating at moderate K . T A C-TP significantly underperforms. T AC-TP K = 4 drops to 93 . 2% on MNIST ( − 4 . 0% ) and 76 . 4% on Fashion-MNIST ( − 6 . 8% ). This confirms that temporal preservation is counterproducti ve on rate-coded data: the temporal dimension is noise, and preserving it forces the network to waste capacity learning to av erage it out. Higher K v alues for T A C-TP ( K = 8 , 16 ) show further de gradation (Appendix D). 5.3 Event Data: D VS128-Gesture T able 3 shows D VS-Gesture results, revealing the opposite pattern from rate-coded data. 7 Baseline T AC K=4 T AC K=8 T AC K=16 0.0 2.5 5.0 7.5 10.0 12.5 15.0 Training Speedup 5.3× 9.2× 13.8× 5.5× 9.3× 13.6× (a) Speedup (M3 Max) MNIST FMNIST Baseline T AC K=4 T AC K=8 T AC K=16 80 85 90 95 100 T est Accuracy (%) (b) Accuracy (M3 Max) MNIST FMNIST Figure 3: T A C ef ficiency on rate-coded data (M3 Max). (a) T raining speedup scales near -linearly with group size K , reaching 13 . 8 × at K = 16 . (b) T A C simultaneously impr oves accuracy by +1 . 6% (MNIST) and +5 . 4% (FMNIST) through implicit ensemble av eraging of Poisson samples. Baseline T AC- TP K=2 T AC- TP K=4 T AC- TP K=8 T AC K=2 0 20 40 60 80 100 Conv Calls 80 40 20 10 40 (a) Conv Calls Baseline T AC- TP K=2 T AC- TP K=4 T AC- TP K=8 T AC K=2 85.0 87.5 90.0 92.5 95.0 97.5 100.0 Accuracy (%) 96.3 95.1 93.8 92.0 91.3 (b) Accuracy Baseline T AC- TP K=2 T AC- TP K=4 T AC- TP K=8 T AC K=2 0 20 40 60 80 Time / Epoch (s) 69s 58s 58s 56s 47s (c) T raining Time Figure 4: DVS-Gesture ef ficiency comparison. (a) T A C-TP reduces con volution calls by 2 – 8 × while T AC K = 2 uses the same 40 calls b ut collapses temporal resolution. (b) T AC-TP K = 2 retains 95 . 1% accuracy ( − 1 . 2% ), significantly outperforming T A C’ s 91 . 3% . (c) W all-clock training time per epoch shows meaningful reduction for all operators. T A C-TP outperforms T A C by +3 . 8% at K = 2 . W ith the same number of con volution calls (40), T A C-TP achiev es 95 . 1% vs. T A C’ s 91 . 3% . The difference is entirely attributable to temporal preservation: T A C-TP maintains 16 output timesteps for the V otingLayer , while T A C collapses to 16 / 2 5 < 1 timestep through cascaded layers. T A C-TP K = 2 achieve s near -baseline accuracy . At 95 . 1% ( − 1 . 2% from baseline), T A C-TP halv es the dominant computational cost (con volution calls: 40 vs. 80) with modest accuracy loss. The graceful de gradation continues: K = 4 yields 93 . 8% with 4 × fewer con v calls, and K = 8 yields 92 . 0% with 8 × fewer . Competitive with literatur e. Our baseline of 96 . 3% at 64 × 64 compares fa vorably to Spiking- Jelly’ s [Fang et al., 2023] 93 . 75% at 128 × 128 resolution, v alidating the experimental setup. 8 T able 4: Cross-platform validation on NVIDIA V100 (PyT orch/snnT orch, 3 seeds). Same architecture, hyperparameters, and epochs as M3 Max experiments. T raining speedup computed from total training time. MNIST Fashion-MNIST Operator Acc. (%) T ime (s) Speedup Acc. (%) Time (s) Speedup Baseline 98 . 56 ± 0 . 24 692 1 . 0 × 88 . 11 ± 0 . 29 682 1 . 0 × T AC K =4 98 . 29 ± 0 . 05 137 5 . 1 × 82 . 97 ± 0 . 32 137 5 . 0 × T AC K =8 97 . 16 ± 0 . 10 80 8 . 7 × 75 . 86 ± 0 . 12 82 8 . 3 × T AC K =16 97 . 11 ± 0 . 14 53 13 . 1 × 75 . 82 ± 0 . 39 57 12 . 0 × T AC-TP K =4 97 . 84 ± 0 . 36 455 1 . 5 × 87 . 03 ± 0 . 72 461 1 . 5 × T AC K=4 T AC K=8 T AC K=16 T AC- TP K=4 0.0 2.5 5.0 7.5 10.0 12.5 15.0 Training Speedup 5.3× 9.2× 13.8× 5.0× 5.1× 8.7× 13.1× 1.5× Cross-Platform Speedup (MNIST) Apple M3 Max NVIDIA V100 Figure 5: Cross-platform speedup on MNIST . T A C’ s near -linear speedup with K is consistent across Apple M3 Max (MLX) and NVIDIA V100 (PyT orch), confirming the mechanism is hardware- agnostic. T A C-TP provides modest speedup ( 1 . 5 × ) as LIF dynamics still run per-timestep. 5.4 Cross-Platf orm V alidation: NVIDIA V100 T o confirm that T AC’ s benefits are not framework- or hardware-specific, we reproduce all MNIST/Fashion-MNIST e xperiments on NVIDIA V100-SXM2-16GB using PyT orch 2.7 + snnT orch 0.9 with identical architectures, hyperparameters, and seeds. T able 4 reports both training accuracy and wall-clock training time. The V100 results closely reproduce the M3 Max findings: T A C achie ves 5 – 13 × training speedup with competitiv e accurac y , and T A C-TP K = 4 recov ers near-baseline accuracy ( 87 . 0% vs. 88 . 1% on FMNIST) while providing 1 . 5 × speedup. Notably , the V100 baseline accuracy ( 98 . 56% MNIST , 88 . 11% FMNIST) closely matches the M3 Max baseline ( 97 . 22% , 83 . 14% ), with V100 slightly higher due to the different framework (snnT orch vs. mlx-snn) and potentially different random number generation. The speedup mechanism—reducing conv olution kernel launches—is har dware-agnostic and benefits any SIMD processor . 5.5 Analysis: When to Collapse vs. Preserv e The contrasting results in T ables 2 and 3 re veal a fundamental principle: the temporal dimension carries different information depending on the data encoding. Rate-coded static data: temporal dimension as noise. Each timestep is an independent Bernoulli sample of the same underlying image. The temporal dimension encodes the same information T times with sampling noise. T A C’ s temporal collapse acts as an ensemble a verage o ver K samples, 9 T able 5: Summary: T AC vs. T A C-TP across data types. The optimal strategy depends on whether the temporal dimension carries information (ev ent) or noise (rate-coded). Rate-Coded (MNIST) Event (D VS-Gesture) Strategy ∆ Acc Speedup ∆ Acc Speedup T AC (collapse) K =2 +1.6% ∼ 2 × − 5.0% 1.5 × T AC-TP (preserv e) K =2 — — − 1.2% 1.2 × T able 6: Comparison with published SNN methods. Our contribution is speedup, not SO T A accuracy . Methods marked † use significantly deeper architectures. ‡ : our snnT orch reproduction on V100 with identical setup. Method Architecture MNIST FMNIST DVS-Gesture STBP [W u et al., 2018] Con v , 5 layers 99.42 — — tdBN [Zheng et al., 2021] † ResNet-19 — — 96.87 TCJ A-SNN [Zhu et al., 2024] † TCJ A-7B — 94.80 97.60 SpikingJelly [Fang et al., 2023] CSNN, 5 layers — — 93.75 snnT orch Baseline ‡ Con v , 2 layers 98.56 88.11 — Ours: Baseline (M3 Max) Con v , 2/5 layers 97.22 83.14 96.30 Ours: T A C K = 8 (M3 Max) Con v , 2 layers 98.85 88.50 — Ours: T A C-TP K = 2 Con v , 5 layers — — 95.13 reducing variance: V ar 1 K K − 1 X j =0 S kK + j = ρ (1 − ρ ) K . (4) This variance reduction directly e xplains T A C’ s accuracy improv ement and T AC-TP’ s accuracy loss: T AC denoises while T A C-TP preserves noise. Event-based dynamic data: temporal dimension as signal. Each timestep captures a dif ferent temporal slice of a dynamic scene. Adjacent frames are correlated but not identical—they represent different phases of a gesture. T A C-TP preserves this temporal structure: although the con volution output is shared within each group (an approximation), the LIF dynamics and spike generation operate independently per timestep, maintaining temporal expressi veness for the downstream V otingLayer . Practical guideline. Use T A C (collapse) for rate-coded/static data → speedup + accuracy gain. Use T A C-TP (preserve) for e vent/dynamic data → con volution reduction with minimal accuracy cost. This can be determined at deployment time based on the data source (frame camera vs. e vent camera). 5.6 Comparison with Published SNN Methods T able 6 contextualizes our results against published SNN methods. Our contrib ution is not SO T A accuracy—which requires deeper architectures—but demonstrating that T AC provides meaning- ful speedup with minimal accuracy trade-off. T o ensure a fair comparison, we include both our mlx-snn results (M3 Max) and a snnT orch reproduction on V100 with identical architecture and hyperparameters. The snnT orch baseline on V100 (98.56% MNIST , 88.11% FMNIST) provides a framew ork-fair reference: our T A C K = 8 on M3 Max (98.85%, 88.50%) exceeds the snnT orch baseline while running 8 . 7 × faster . On D VS-Gesture, our baseline (96.30%) e xceeds SpikingJelly’ s 93.75%, and T AC-TP K = 2 retains 95.1% with half the con volution cost. 10 6 Discussion and Conclusion Implications f or the SNN community . Our neg ativ e result on spike sparsity has practical conse- quences: claims of “ N × theoretical speedup from sparsity” should be accompanied by wall-clock measurements on actual hardware. The real adv antages of SNNs on GPUs—temporal processing, ev ent-driven data ef ficiency , and biological plausibility—are distinct from computational sparsity , which requires dedicated neuromorphic hardware. T A C as data-dependent operator . The collapse/preserve distinction is a principled design choice, not a hack. It follo ws directly from the information content of the temporal dimension: collapse noise (rate-coded), preserve signal (e vent). This analysis may generalize to other temporal processing architectures beyond SNNs. Limitations. W e test on compact architectures (2-layer for MNIST , 5-layer for D VS-Gesture). T AC-TP’ s wall-clock speedup ( 1 . 2 × ) is modest compared to its con volution call reduction ( 2 × ) because LIF dynamics still run per-timestep. D VS-Gesture T AC-TP K ≥ 4 results are from a single seed. V alidation on larger datasets (CIF AR-10, ImageNet) and deeper architectures is needed. Future dir ections. Learnable aggregation weights (replacing fixed e xponential decay) could adapt to intermediate temporal structure. Combining T A C-TP with temporal attention [Y ao et al., 2021] may allow the netw ork to learn which timesteps to share conv olution outputs for . Hardware-specific optimization—fusing aggregation and con volution into a single GPU kernel—could further improv e T AC-TP’ s wall-clock speedup. Conclusion. W e presented a two-part in vestigation into con volutional SNN acceleration. Five methods for exploiting spike sparsity on GPU all fail due to the fundamental SIMD-sparsity mismatch. Instead, T emporal Aggregated Con volution reduces computation by exploiting con volution linearity across time. T A C (temporal collapse) achiev es 13 . 8 × speedup on Apple M3 Max and 11 . 0 × on NVIDIA V100 with +1 . 6% accuracy on MNIST . T A C-TP (temporal preservation) achie ves 95 . 1% on D VS-Gesture with 50% fewer con volution calls. The key insight is that the optimal aggregation strategy is data-dependent: collapse for rate-coded data, preserve for e vent data. All operators are open-source in mlx-snn . References Arnon Amir , Brian T aba, David Ber g, T imothy Melano, Jeffre y McKinstry , Carmelo Di Nolfo, T apan Nayak, Alexander Andreopoulos, Guillaume Garrber , Myron Goldberg, et al. A low po wer , fully ev ent-based gesture recognition system. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 7243–7252, 2017. Guillaume Bellec, Franz Scherr , Anand Subramoney , Elias Hajek, Darjan Salaj, Robert Legenstein, and W olfgang Maass. A solution to the learning dilemma for recurrent networks of spiking neurons. Natur e Communications , 11:3625, 2020. Y anqi Chen, Zhaofei Y u, W ei F ang, T iejun Huang, and Y onghong Tian. Pruning of deep spiking neural networks through gradient re wiring. In Proceedings of the International J oint Conference on Artificial Intelligence , pages 1713–1719, 2021. Mike Davies, Narayan Sriniv asa, Tsung-Han Lin, Gautham Chinya, Y ongqiang Cao, Sri Harsha Choday , Georgios Dimou, Prasad Joshi, Nabil Imam, Shyam Jain, et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micr o , 38(1):82–99, 2018. Shikuang Deng, Y uhang Li, Shanghang Zhang, and Shi Gu. T emporal efficient training of spiking neural network via gradient re-weighting. In International Confer ence on Learning Repr esentations , 2022. Jason K Eshraghian, Max W ard, Emre O Neftci, Xinxin W ang, Gregor Lenz, Girish Dwiv edi, Mohammed Bennamoun, Doo Seok Jeong, and W ei D Lu. Training spiking neural networks using lessons from deep learning. Pr oceedings of the IEEE , 111(9):1016–1054, 2023. 11 W ei Fang, Zhaofei Y u, Y anqi Chen, T imothée Masquelier, Tiejun Huang, and Y onghong T ian. Incorporating learnable membrane time constant to enhance learning of spiking neural networks. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pages 2661–2671, 2021. W ei Fang, Y anqi Chen, Jianhao Ding, Zhaofei Y u, T imothée Masquelier, Ding Chen, Liwei Huang, Huihui Zhou, Guoqi Li, and Y onghong T ian. SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence. Science Advances , 9(40):eadi1480, 2023. Stev e B Furber, Francesco Galluppi, Steve T emple, and Luis A Plana. The SpiNNaker project. Pr oceedings of the IEEE , 102(5):652–665, 2014. A wni Hannun, Jagrit P asesotto, Angelos Katharopoulos Sharma, Sam Shleifer , et al. MLX: An array framew ork for Apple silicon. https://github.com/ml- explore/mlx , 2023. Apple Machine Learning Research. John L Hennessy and David A Patterson. Computer Arc hitectur e: A Quantitative Appr oach . Morgan Kaufmann, 6th edition, 2017. Sara Hooker . The hardware lottery . Communications of the ACM , 64(12):58–65, 2021. Y oungeun Kim and Priyadarshini Panda. Re visiting batch normalization for training low-latenc y deep spiking neural networks from scratch. F r ontiers in Neur oscience , 15:773954, 2021. Souvik Kundu, Massoud Pedram, and Peter A Beerel. Spike-thrift: T owards energy-effi cient deep spiking neural netw orks by limiting spiking acti vity via attention-guided compression. In Pr oceedings of the IEEE/CVF W inter Conference on Applications of Computer V ision , pages 3953–3962, 2021. W olfgang Maass. Networks of spiking neurons: the third generation of neural network models. Neural Networks , 10(9):1659–1671, 1997. Paul A Merolla, John V Arthur , Rodrigo Alv arez-Icaza, Andrew S Cassidy , Jun Sawada, Filipp Akopyan, Bryan L Jackson, Nabil Imam, Chen Guo, Y utaka Nakamura, et al. A million spiking- neuron integrated circuit with a scalable communication network and interface. Science , 345 (6197):668–673, 2014. Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spiking neural networks: Bringing the po wer of gradient-based optimization to spiking neural netw orks. IEEE Signal Pr ocessing Magazine , 36(6):51–63, 2019. Jiahao Qin and Feng Liu. Mamba-spike: Enhancing the mamba architecture with a spiking front- end for efficient temporal data processing. In Computer Graphics International (CGI 2024) , volume 15339 of Lecture Notes in Computer Science , pages 299–312. Springer , 2025. doi: 10.1007/978- 3- 031- 82021- 2\_23. Kaushik Roy , Akhilesh Jaiswal, and Priyadarshini Panda. T owards spike-based machine intelligence with neuromorphic computing. Natur e , 575(7784):607–617, 2019. Y ujie W u, Lei Deng, Guoqi Li, Jun Zhu, and Luping Shi. Spatio-temporal backpropagation for training high-performance spiking neural networks. F r ontiers in Neur oscience , 12:331, 2018. Man Y ao, Huanhuan Gao, Guangshe Zhao, Dingheng W ang, Y ihan Lin, Zhaoxu Y ang, and Guoqi Li. T emporal-wise attention spiking neural networks for ev ent streams classification. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pages 10221–10230, 2021. Friedemann Zenke and T im P V ogels. The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural netw orks. Neural Computation , 33(4):899–925, 2021. Hanle Zheng, Y ujie W u, Lei Deng, Y ifan Hu, and Guoqi Li. Going deeper with directly-trained larger spiking neural netw orks. In Pr oceedings of the AAAI Confer ence on Artificial Intelligence , volume 35, pages 11062–11070, 2021. Rui-Jie Zhu, Qihang Zhao, Guoqi Li, and Jason K Eshraghian. TCJ A-SNN: T emporal-channel joint attention for spiking neural networks. IEEE T ransactions on Neural Networks and Learning Systems , 2024. 12 A Proof of Theor em 1 (T A C A pproximation Err or Bound) W e prov e the error bound by analyzing the membrane potential discrepancy between e xact per-step computation and T AC’ s grouped computation. Setup. Consider a single con volutional SNN layer processing T timesteps with group size K (assume K | T ). Let V exact t denote the membrane potential under exact computation: V exact t = β V exact t − 1 + W ∗ S t − V th · Θ( V exact t − 1 − V th ) , (5) and V T AC t under T AC: V T AC kK = β K V T AC ( k − 1) K + W ∗ A k − V th · Θ( V T AC ( k − 1) K − V th ) , (6) where A k = P K − 1 j =0 β K − 1 − j S kK + j . Error decomposition. The error at group boundary k K : ϵ k = V exact kK − V T AC kK (7) = β K ϵ k − 1 + K − 1 X j =0 β K − 1 − j W ∗ S kK + j − W ∗ A k | {z } =0 by linearity + ∆ spike ( k ) | {z } spike mismatch . (8) The con volution linearity term vanishes exactly . The spike mismatch ∆ spike ( k ) arises from intermedi- ate spikes within the group: | ∆ spike ( k ) | ≤ V th ( K − 1) . Expected error bound. Since spikes are Bernoulli( ρ ): E [ | ∆ spike ( k ) | 2 ] ≤ V 2 th ( K − 1) · ρ (1 − ρ ) · N spatial , (9) where N spatial = C · H ′ · W ′ . Unrolling the recurrence yields the stated bound with C = V 2 th N spatial / (1 − β 2 K ) . B T A C-TP T emporal Resolution Analysis Proposition 2 (T A C-TP T emporal Resolution Guarantee) . Let a network have L layers, each applying T AC-TP with gr oup size K ℓ . The output temporal dimension at e very layer ℓ is T —the same as the input temporal dimension—r e gardless of K ℓ values. In contrast, T A C with gr oup sizes K ℓ pr oduces output temporal dimension T / Q L ℓ =1 K ℓ . Pr oof. T AC-TP’ s inner loop (Algorithm 2, lines 5–8) generates K independent spik e outputs per group, producing exactly T /K · K = T output timesteps per layer . This is independent of K and composes across layers: L layers each preserving T giv es output dimension T . T AC (Algorithm 1) generates one spike output per group, gi ving T /K outputs per layer . Cascading L layers: T → T /K 1 → T / ( K 1 K 2 ) → · · · → T / Q K ℓ . For D VS-Gesture with T = 16 and L = 5 layers at K = 2 : T A C gives 16 / 2 5 = 0 . 5 (i.e., < 1 output timestep for the V otingLayer), while T A C-TP gives 16 timesteps. This explains T A C-TP’ s +3 . 8% advantage. C Other Operators: FTC, IMC, TCC Details Fourier T emporal Con volution (FTC). FTC replaces LIF’ s fix ed first-order IIR filter H ( z ) = 1 / (1 − β z − 1 ) with a learnable biquad: H ( z ) = ( b 0 + b 1 z − 1 + b 2 z − 2 ) / (1 + a 1 z − 1 + a 2 z − 2 ) , with BIBO stability guaranteed by r = σ ( r raw ) < 1 . FTC does not reduce con volution calls and introduces IIR filtering ov erhead. 13 Inf ormation-Theoretic Channel Gating (IMC). IMC models each channel as a Binary Symmetric Channel with capacity C BSC = 1 − H b ( ρ ) . Channels with firing rates near 0 . 5 are gated out. The minimum channel width for I bits of information is C out ≥ I / (1 − H b ( ρ )) . Gating overhead e xceeds savings. T emporal Collapse Conv olution (TCC). TCC skips conv olution during spike-free windows. The probability of a silent frame is (1 − ρ ) C · H · W . For C = 128 , H = W = 32 : (0 . 9) 131072 ≈ 0 . TCC is theoretically exact b ut requires firing rates so low that entire frames are silent. D Full Per -Seed Results T able 7: Per-seed best test accuracy on MNIST (T=25, 15 epochs). Operator Seed 0 Seed 1 Seed 2 Mean ± Std Baseline 97.09 97.43 97.13 97 . 22 ± 0 . 15 T AC K =4 98.69 98.89 98.75 98 . 78 ± 0 . 08 T AC K =8 98.81 98.90 98.83 98 . 85 ± 0 . 04 T AC K =16 98.74 98.81 98.91 98 . 82 ± 0 . 07 T AC-TP K =4 90.66 94.66 94.27 93 . 20 ± 1 . 78 T AC-TP K =8 89.91 91.00 88.31 89 . 74 ± 1 . 10 T AC-TP K =16 87.73 91.00 92.11 90 . 28 ± 1 . 82 TCC 96.95 98.00 97.64 97 . 53 ± 0 . 43 FTC (order 2) 96.42 96.93 96.71 96 . 69 ± 0 . 21 IMC 97.40 97.41 97.57 97 . 46 ± 0 . 08 T able 8: Per-seed best test accuracy on F ashion-MNIST (T=25, 15 epochs). Operator Seed 0 Seed 1 Seed 2 Mean ± Std Baseline 82.07 83.91 83.45 83 . 14 ± 0 . 77 T AC K =4 87.47 88.38 88.08 87 . 98 ± 0 . 37 T AC K =8 88.48 88.21 88.81 88 . 50 ± 0 . 24 T AC K =16 88.14 88.54 88.35 88 . 34 ± 0 . 16 T AC-TP K =4 76.82 75.95 76.38 76 . 38 ± 0 . 36 T AC-TP K =8 71.70 77.85 77.09 75 . 55 ± 2 . 70 T AC-TP K =16 72.37 72.74 76.38 73 . 83 ± 1 . 82 TCC 84.48 85.96 85.70 85 . 38 ± 0 . 65 FTC (order 2) 79.64 77.81 81.17 79 . 54 ± 1 . 37 IMC 83.83 84.36 83.36 83 . 85 ± 0 . 41 T able 9: Per-seed best test accuracy on D VS128-Gesture ( 64 × 64 , 256 epochs with warm restarts). Operator Seed 0 Seed 42 Seed 123 Mean ± Std Conv Calls Baseline 95.8 96.9 96.2 96 . 30 ± 0 . 45 80 T AC-TP K =2 94.1 94.8 96.5 95 . 13 ± 1 . 01 40 T AC-TP K =4 — 93.8 — 93 . 8 20 T AC-TP K =8 — 92.0 — 92 . 0 10 T AC K =2 — 91.3 — 91 . 3 40 E Detailed Experimental Configuration F D VS-Gesture Data Pr eprocessing D VS128-Gesture recordings are stored in AED A T 3.1 format. W e parse e vents ( x, y , t, p ) with spatial coordinates ( x, y ) ∈ [0 , 127] 2 , timestamps t in microseconds, and polarity p ∈ { 0 , 1 } . Events are 14 T able 10: Full hyperparameter configuration for all experiments. Parameter MNIST / FMNIST D VS-Gesture T imesteps ( T ) 25 16 Batch size 128 16 Learning rate 10 − 3 10 − 3 LR schedule Cosine annealing Cosine w/ warm restarts ( T max =64) Optimizer Adam Adam Epochs 15 256 β (LIF decay) 0.9 0.5 V th (threshold) 1.0 1.0 Surrogate gradient Fast sigmoid ( α =25) Arctan ( α =2.0) Reset mechanism Subtract Subtract (detach reset) Loss function Cross-entropy on spike count MSE on firing rate vs. one-hot Seeds 0, 1, 2 0, 42, 123 Dataset-specific Input size 28 × 28 × 1 64 × 64 × 2 Spike encoding Rate (Poisson) Event binning (by time) Output layer LIF + spike count LIF + V otingLayer (10 v oters) do wnsampled to 64 × 64 by integer di vision of coordinates by 2. W e bin ev ents into T = 16 temporal frames by di viding the recording duration equally . Each frame accumulates e vent counts per spatial position and polarity channel, followed by log-normalization: f norm = log(1 + f ) / log(1 + f max ) . 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment