Leveraging Large Vision Model for Multi-UAV Co-perception in Low-Altitude Wireless Networks
Multi-uncrewed aerial vehicle (UAV) cooperative perception has emerged as a promising paradigm for diverse low-altitude economy applications, where complementary multi-view observations are leveraged to enhance perception performance via wireless com…
Authors: Yunting Xu, Jiacheng Wang, Ruichen Zhang
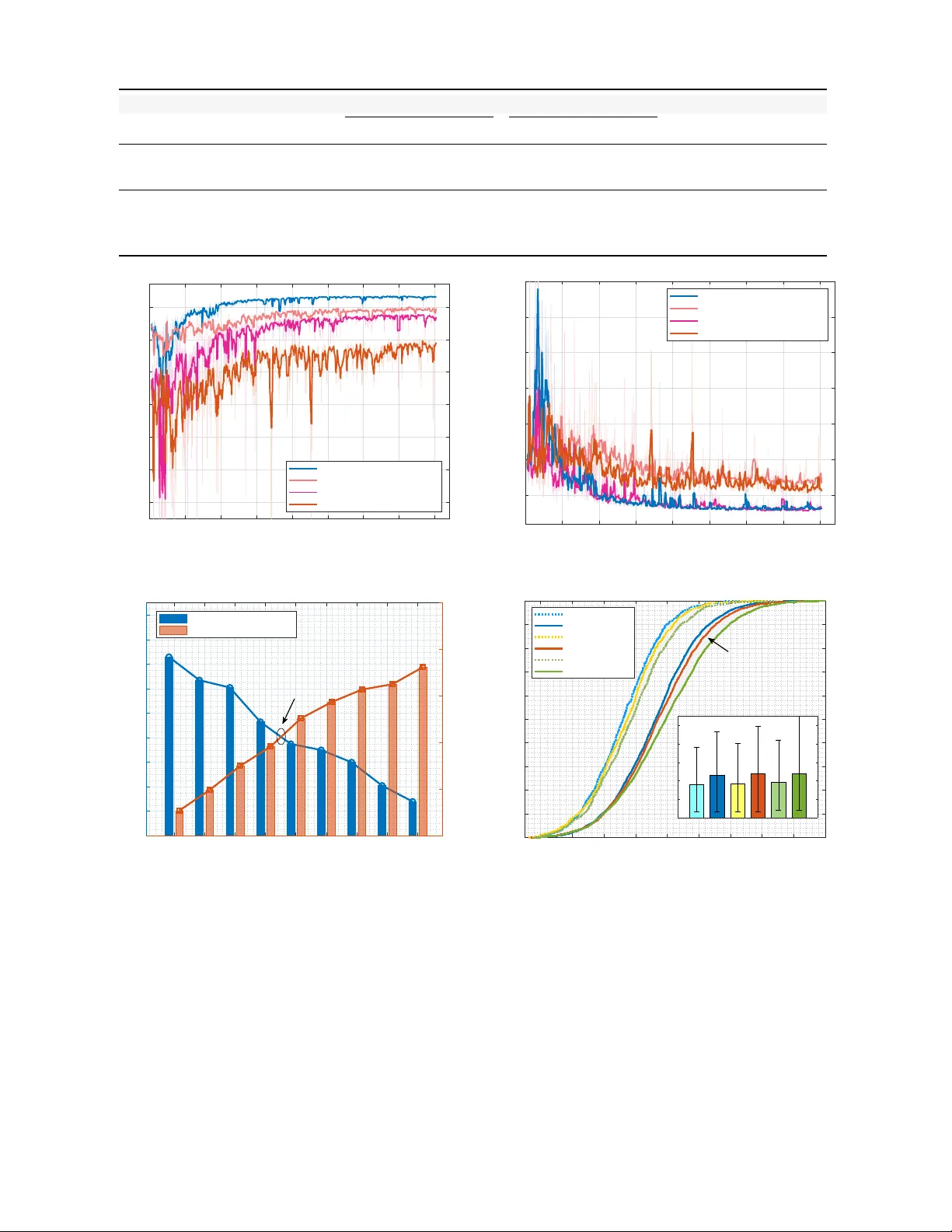
1 Le v eraging Lar ge V ision Model for Multi-U A V Co-perception in Lo w-Altitude W ireless Networks Y unting Xu, Jiacheng W ang, Ruichen Zhang, Changyuan Zhao, Y inqiu Liu, Dusit Niyato, F ellow , IEEE , Liang Y u, Haibo Zhou, F ellow , IEEE , and Dong In Kim, Life F ellow , IEEE Abstract —Multi-uncrewed aerial vehicle (U A V) cooperative perception has emerged as a promising paradigm for diverse low- altitude economy applications, where complementary multi-view observations are leveraged to enhance perception perf ormance via wireless communications. Ho wever , the massive visual data generated by multiple U A Vs poses significant challenges in terms of communication latency and resour ce efficiency . T o address these challenges, this paper pr oposes a communication-efficient cooperative per ception framework, termed Base-Station-Helped U A V (BHU), which reduces communication o verhead while en- hancing perception perf ormance. Specifically , we employ a T op-K selection mechanism to identify the most informative pixels from U A V -captured RGB images, enabling sparsified visual transmis- sion with reduced data volume and latency . The sparsified images are transmitted to a gr ound server via multi-user MIMO (MU- MIMO), where a Swin-large-based MaskDINO encoder extracts bird’ s-eye-view (BEV) features and performs cooperative feature fusion for ground vehicle perception. Furthermore, we develop a diffusion model–based deep reinfor cement learning (DRL) algo- rithm to jointly select cooperative U A Vs, sparsification ratios, and precoding matrices, achieving a balance between communication efficiency and perception utility . Simulation r esults on the Air- Co-Pred dataset demonstrate that, compared with traditional CNN-based BEV fusion baselines, the proposed BHU framework impro ves per ception performance by over 5% while r educing communication overhead by 85%, providing an effective solution for multi-U A V cooperativ e per ception under r esource-constrained wireless envir onments. Index T erms —Multi-U A V perception, BEV , MU-MIMO, large vision model, low-altitude economy networks I . I N T R O D U C T I O N Multi-unmanned aerial v ehicle (U A V) cooperativ e percep- tion has recently emerged as a promising technology for a v ariety of lo w-altitude economy applications, such as in- telligent transportation, urban surveillance, and autonomous inspection [1]–[3]. By exploiting the complementary multi- view observations from spatially distrib uted U A Vs, cooperativ e perception systems can substantially enhance perception accu- racy and robustness compared with single-UA V solutions [4], [5]. Ho wever , realizing such performance gains in practical Y . Xu, J. W ang, R. Zhang, C. Zhao, Y . Liu, and D. Niyato are with the Col- lege of Computing and Data Science, Nanyang T echnological University , Sin- gapore, 639798 (e-mail: yunting.xu@ntu.edu.sg, jiacheng.wang@ntu.edu.sg, ruichen.zhang@ntu.edu.sg, zhao0441@e.ntu.edu.sg, yinqiu001@e.ntu.edu.sg, dniyato@ntu.edu.sg). L. Y u is with the Alibaba Cloud, Hangzhou, China, 311121 (e-mail: liangyu.yl@alibaba-inc.com). H. Zhou is with the School of Electronic Science and Engineering, Nanjing Univ ersity , Nanjing, China, 210023 (e-mail: haibozhou@nju.edu.cn). D. I. Kim is with the Department of Electrical and Computer Engineer- ing, Sungkyunkwan University , Suwon 16419, South Korea (email: don- gin@skku.edu). wireless environments remains challenging due to the mas- siv e volume of visual data generated by multiple UA Vs [6], [7]. Additionally , the heterogeneous and time-varying channel conditions between U A Vs and base stations (BSs), together with the limited wireless time–frequency resources, make it difficult to satisfy the stringent latency requirements for real- time UA V communications, thereby hindering the ef ficient data transmission for cooperative multi-UA V perception [8]. T o reduce communication ov erhead between the cooperativ e U A Vs, instead of transmitting raw U A V images or dense visual features, recent studies hav e explored feature-le vel compres- sion or sparsification to alleviate communication bottlenecks [9], [10]. By dynamically adjusting the transmission data size of visual images, these approaches can scale ef fecti vely in bandwidth-limited and latency-sensiti ve scenarios [11], [12]. Nev ertheless, since U A Vs operate as resource-constrained edge devices with limited ener gy and computational capacity , they are typically equipped with lightweight network modules for onboard image processing [13]. As a result, compression or sparsification approaches often suf fer from limited reconstruc- tion and feature extraction capabilities, which significantly degrades the quality of perception. Therefore, effecti vely bal- ancing perception performance and communication efficienc y remains a challenging problem, particularly for multi-UA V cooperativ e perception tasks. Recent dev elopment of large vision models (L VMs), such as V ision T ransformers (V iT) [14] and Self-distillation with No Label (DINO) [15], hav e demonstrated adv anced representa- tion and generalization capabilities compared with traditional Con volutional Neural Networks (CNNs). Based on the self- attention mechanism, L VMs can ef fecti vely capture long-range dependencies and semantic relationships to extract rich visual information, thus achie ving state-of-the-art performance across div erse image tasks such as object classification, instance detection, and semantic segmentation [16]. As a consequence, L VMs ha ve shown substantial potential for enhancing multi- U A V cooperative perception, enabling more accurate image reconstruction, feature extraction, and scene understanding from information-reduced visual data [17]. Ne vertheless, while L VMs are capable of achieving high perception performance, their large-scale model parameters and substantial computa- tional ov erhead pose significant challenges to the practical implementation in real-world U A V applications. Motiv ated by the growing demand to fully exploit the poten- tial of L VMs, this paper proposes a communication-efficient multi-U A V perception frame work, named Base-Station-Helped U A V (BHU), aiming to reduce the communication overhead 2 while enhancing perception performance. The core idea of the BHU frame work is to transmit sparsified U A V images to a ground server via wireless communication, where an L VM–based encoder extracts bird’ s-eye-view (BEV) features from the aerial images and performs cooperati ve feature fu- sion for downstream perception tasks. Specifically , we model the communication between cooperative U A Vs and the BS as a multi-user multiple-input multiple-output (MU-MIMO) system. T o further achieve an effecti ve trade-off between perception utility and communication efficienc y , we adaptiv ely select the cooperativ e UA Vs, image sparsification ratios, pre- coding strategies for each UA V based on the channel state information, establishing a communication-aw are multi-UA V cooperativ e perception mechanism for lo w-altitude economy scenarios. The main contrib utions are summarized as follo ws: • W e introduce an importance score–based T op-K mecha- nism for sparsified visual transmission, which selects the most informativ e pixels from U A V -captured images and substantially reduces both transmission data volume and communication latency . • W e lev erage a Swin-large-based MaskDINO encoder [18] to extract BEV features and perform cooperative feature fusion for vehicle instance and motion-aware perception, thereby significantly enhancing perception performance through the strong representation capability of L VMs. • W e propose a dif fusion model–based deep reinforcement learning (DRL) framework to jointly optimize cooperative U A V selection, T op-K sparsification ratios, and precoding matrices. A denoising diffusion implicit model (DDIM) is integrated to improv e the training stability and efficienc y of the DRL framework. • Extensive simulations conducted on Air-Co-Pred dataset [19] demonstrate that the proposed BHU framew ork enhances perception utility by ov er 5% and reduces com- munication overhead by 85%, offering a communication- efficient solution for multi-UA V cooperativ e perception in resource-constrained wireless environment. The remainder of this paper is organized as follows. Section II re vie ws the related work. Section III introduces the system model of multi-U A V cooperativ e perception. Section IV de- scribes the proposed BHU frame work. Section V presents the DDIM-based DRL solution. Simulation results are provided in Section VI. Finally , Section VII concludes this paper . I I . R E L A T E D W O R K A. V isual Data Reduction and UA V W ireless T ransmission The transmission of high-resolution visual data from U A Vs to ground infrastructure poses a major challenge due to stringent bandwidth and latency constraints [20], [21]. T o mitigate communication ov erhead, extensi ve research has in- vestigated image and feature compression techniques for ef- ficient transmission [22]. For example, Giordano et al. [23] dev eloped an onboard re gion-of-interest (RoI)-based com- pression framew ork for remote sensing images, combining RoI identification with differential compression schemes to reduce transmission volume while preserving target quality . Additionally , sparsification methods adopt token selection mechanisms to transmit only informative content, such as the spatial confidence–guided sparse messaging scheme proposed in Wher e2comm [9] and the codebook-based discrete message representation employed by CodeF illing [12], thereby enabling communication-efficient collaborative perception. Except for image processing, advanced wireless technolo- gies have been widely adopted to enhance transmission per- formance in U A V communications [24]–[26]. For instance, Geraci et al. [27] ev aluated the achiev able throughput of U A V cellular communications within massive MIMO systems, demonstrating that the adoption of massiv e MIMO technology enables approximately a 50% increase in the number of U A Vs that meet the minimum SINR threshold compared with con ventional cellular deployments. In the context of multi- U A V scenarios, Zeng et al. [28] inv estigated the optimization of MU-MIMO beamforming matrices based on the weighted minimum mean square error (WMMSE) method. Simulation results validated that the proposed MU-MIMO beamforming optimization scheme can ef fectively increase the sum rate of all UA V users by approximately 30%. Furthermore, Elwekeil et al. [29] introduced cell-free massiv e MIMO into U A V communications, where ef fecti ve interference management is achiev ed through power control mechanism. By transforming the inter-U A V interferences into useful signal components, cell-free mechanism significantly enhances spectral efficienc y and improves the per-user communication rate performance compared to traditional multi-cell network deployment [30]. B. Cooperative P erception for Multi-U A V Systems Cooperativ e perception aggregates complementary obser- vations from multiple U A Vs to enhance detection perfor- mance, yet it ine vitably incurs additional coordination and communication overhead [31]. Existing cooperativ e percep- tion framew orks can be broadly categorized into U A V -centric and infrastructure-assisted approaches. In UA V -centric coop- eration, U A Vs exchange perception features or intermediate results directly with neighboring U A Vs, enabling distributed collaboration without relying on ground infrastructures [32]. For instance, Liu et al. presented When2com [33], where one U A V agent is required to perform a perception task and share information with other agents. Based on communication group construction, When2com significantly reduces commu- nication bandwidth while maintaining superior performance. In infrastructure-assisted cooperation, a ground station or edge server aggregates information from multiple UA Vs for centralized processing. A representati ve multi-drone collabo- rativ e framework is U A V -CodeAgents [34], which employs an Airspace Management Agent to provide centralized reasoning capabilities for coordinating UA V agents. Simulation demon- strates that the proposed system can effecti vely enhance the reliability in coordinating U A V operations, achie ving a 93% success rate in a cooperati ve fire detection task. C. L VMs for U A V -based V isual P er ception Recent advances in L VMs, such as V iT , Swin Transformer [35], self-supervised DINO [15], and unified detection and 3 segmentation framew orks hav e demonstrated remarkable rep- resentation capability and generalization performance [36], [37]. Specifically , the V iTs pioneered the patch-based Trans- former backbones in visual recognition, exhibiting remarkable scalability under large-scale pretraining. Hierarchical Trans- former backbones such as Swin T ransformer improv e effi- ciency via shifted-window attention while retaining strong dense-prediction performance. DINO employs knowledge dis- tillation and contrastive learning techniques to acquire high- quality representations without human annotations, rev eal- ing rich semantic structures in the learned representations. Building upon end-to-end Detection Transformer (DETR) [38] paradigms, MaskDINO [18], extending DINO with a mask prediction branch to support instance, panoptic, and semantic segmentation in a unified Transformer -based framework. Motiv ated by these advanced capabilities, recent research has explored le veraging L VMs for a variety of U A V perception tasks. For aerial object detection, Zhang et al. proposed U A V - DETR [39], which introduced a multi-scale feature fusion mechanism to capture both spatial and frequency information, thereby significantly enhancing the detection performance. In the remote sensing tasks, W ang et al. [40] adopted Swin T ransformer as the backbone and designed a densely con- nected feature aggregation decoder for fine-resolution semantic segmentation. Beyond task-specific applications, Shan et al. [41] built R OS-SAM, a redesigned data processing pipeline based on the Se gment Anything Model (SAM) [42] and a mask decoder to obtain high-quality interactiv e segmentation for remote sensing moving objects. Nonetheless, existing L VM- based UA V perception studies primarily focus on perception accuracy or inference efficiency , while the joint optimization among transmission ef ficiency collaboration policies, and per- ception utility in multi-UA V settings remains explored. I I I . S Y S T E M M O D E L A. 3D Geometry-Based W ideband Channel In this paper, we consider a multi-UA V cooperative percep- tion scenario as illustrated in Fig. 1. Define the set of U A V as U = { 1 , . . . , U } and the set of BS as B = { 1 , . . . , B } . For a MIMO transmission system, the U A V and the ground BS are equipped with t x transmit antennas and r x receiv e antennas, respectiv ely . For the propagation channel between the u -th U A V user and the b -th BS, the ℓ -th path component H ℓ u,b ∈ C r x × t x is characterized by the following geometry- based 3D wideband model [43] H ℓ u,b ( t, f ) = ρ u,b,ℓ e j 2 π ν u,b,ℓ t e − j 2 π f τ u,b,ℓ a r θ az u,b,ℓ , θ el u,b,ℓ · a t ϕ az u,b,ℓ , ϕ el u,b,ℓ H , ∀ u ∈ U , ∀ b ∈ B , (1) where t and f denote the continuous variables in the time and frequency domains. For the ℓ -th channel path, ρ u,b,ℓ and τ u,b,ℓ are the complex path gain and propagation delay , respectively , while ν u,b,ℓ denotes the Doppler shift. a r ( θ az u,b,ℓ , θ el u,b,ℓ ) and a t ( ϕ az u,b,ℓ , ϕ el u,b,ℓ ) represent the 3D array response vectors at the b -th BS and the u -th U A V , parameterized by the azimuth and elev ation angles of arriv al (AoA) θ az /el u,b,ℓ and the angles of departure (AoD) ϕ az /el u,b,ℓ , respectively . Assume the BS uses a z x U AV G r o u n d D ev i c es y V i s ua l P e r ce pt i on U A V agent 1 U A V agent 2 M u l t i - UA V Ag e n t S y stem z x G r ound D ev ic es y z x Cl o u d S erver V i s ua l P e r ce pt i on UA V V i e w 1 UA V V i e w 2 M u l t i - UA V Us e r S y stem z x U AV G r o u n d D ev i c es y V i s ua l P e r ce pt i on U A V agent 1 U A V agent 2 M u l t i - UA V Ag e n t S y stem y U AV 3 U AV 2 U AV 1 Fig. 1: Illustration of multi-U A V cooperative perception scenario. The U A V -captured aerial images are transmitted to a ground serv er via MU-MIMO communication, where multi-view information is fused to enable cooperative feature learning for vehicle instance and motion detection in low-altitude economy scenarios. uniform planar array (UP A) with ( N x × N y ) antenna elements, the antenna array response can be expressed as: a r ( θ az u,b,ℓ , θ el u,b,ℓ ) = a x ( θ az u,b,ℓ , θ el u,b,ℓ ) ⊗ a y ( θ az u,b,ℓ , θ el u,b,ℓ ) , (2) where a x ( · ) and a y ( · ) are the impulse response vectors of the horizontal and v ertical antenna arrays, and ⊗ represents the Kronecker product operation. Denote the inter -element spacing as d and the carrier wav elength as λ c , a x ( · ) and a y ( · ) can be formulated as: a x ( θ az u,b,ℓ ,θ el u,b,ℓ ) = 1 √ N x h 1 , e j 2 π d λ c sin ( θ el u,b,ℓ ) cos ( θ az u,b,ℓ ) , · · · , e j 2 π d λ c ( N 1 − 1) sin ( θ el u,b,ℓ ) cos ( θ az u,b,ℓ ) i T , (3) a y ( θ az u,b,ℓ ,θ el u,b,ℓ ) = 1 p N y h 1 , e j 2 π d λ c sin ( θ el u,b,ℓ ) sin ( θ az u,b,ℓ ) , · · · , e j 2 π d λ c ( N 2 − 1) sin ( θ el u,b,ℓ ) sin ( θ az u,b,ℓ ) i T . (4) Similarly , the U A V transmit array response a t ( ϕ az u,b,ℓ , ϕ el u,b,ℓ ) is obtained following the same procedure as a r ( · ) . T o explic- itly model the LoS component in aerial communication links, Rician channel model is employed to characterize the relativ e contributions of the LoS and NLoS components, given by H u,b ( t, f ) = r k r k r + 1 H LoS u,b ( t, f ) + r 1 k r + 1 L X ℓ =1 H ℓ u,b ( t, f ) , (5) 4 where k r denotes the Rician K-factor . H LoS u,b represents the sin- gle dominant LoS path, while the N LoS channel component is formed by L scattered paths with corresponding AoA/AoD and propagation delays. B. Multi-User MIMO T ransmission For the scenario of multi-U A V users and ground BS commu- nications, we consider an uplink MU-MIMO OFDM transmis- sion where U U A V users simultaneously transmit signals to a multi-antenna BS ov er the same time–frequency resources. A binary variable a u,b is adopted to indicate the user association between U A V u and BS b , which is expressed as: a u,b = ( 1 if U A V u accesses BS b, 0 otherwise. (6) Consequently , the signal receiv ed at BS b is given by y b [ k ][ s ] = U X u =1 a u,b H u,b [ k ][ s ] W u √ p u x u [ k ][ s ] + n b , (7) where k ∈ K = { 1 , · · · , K } and s ∈ S = { 1 , · · · , S } denote the indexes of the subcarrier and the OFDM symbol, respec- tiv ely . p u is the transmit power of UA V u , while W u ∈ C t x × 1 denotes the precoding vector for single-stream transmission. x u [ k ][ s ] is the transmitted symbol with E {| x u [ k ][ s ] | 2 } = 1 and H u,b [ k ][ s ] ∈ C r x × t x represents the discrete frequency- domain MIMO channel. n b ∈ C r x × 1 ∼ C N 0 , σ 2 I r x is the additiv e white Gaussian noise with the noise v ariance σ 2 . Considering the perception-oriented task where the ho vering U A Vs maintain low mobility , the Doppler spread is assumed to be sufficiently small such that the inter-carrier interference is negligible. Let A u,b = a u,b I r x , ∀ u ∈ U , b ∈ B , (8) and omit the indexes k and s for simplicity of expression, Eq. (7) can be transformed into y b = [ A 1 ,b H 1 ,b , · · · , A U,b H U,b ] | {z } ∈ C r x × ( U · t x ) W 1 √ p 1 x 1 . . . W U √ p U x U | {z } ∈ C ( U · t x ) × 1 + n b . (9) Let the aggregated matrices W b ∈ C ( U · t x ) × U , H b ∈ C ( U · r x ) × ( U · t x ) , and A b ∈ { 0 , 1 } r x × ( U · r x ) be defined as W b = diag ( √ p 1 W 1 , · · · , √ p U W U ) , (10) H b = diag ( H 1 ,b , · · · , H U,b ) , (11) A b = [ A 1 ,b , · · · , A U,b ] . (12) Eq. (9) can be reformulated as y b = A b H b W b | {z } H eff ∈ C r x × U x b + n b , (13) where x b = [ x 1 ,b , · · · , x U,b ] T ∈ C U × 1 denotes the aggre- gated vector of the transmit signals. Define A b H b W b as the effecti ve channel matrix H eff . Then, the received signal can be processed by a minimum mean square error (MMSE) equalizer to mitigate channel distortion [44], e xpressed as G MMSE = H H eff H eff + σ 2 I − 1 H H eff . (14) Consequently , denote the MMSE equalizer employed at BS b as G b ∈ C U × r x , which is given by G b = ( A b H b W b ) H ( A b H b W b ) + σ 2 I − 1 ( A b H b W b ) H . (15) W e can obtain the linear estimation of the transmitted symbol vector e x b ∈ C U × 1 as e x b = G b y b = G b ( A b H b W b x b + n b ) = G b A b H b W b | {z } G b H eff ∈ C U × U x b + G b n b | {z } ∈ C U × 1 . (16) Let g H u denote the u -th ro w of G b and h u denote the u -th column of H eff . Then, the estimated symbol ˆ x u corresponding to the u -th UA V user is obtained by ˆ x u = g H u h u x u | {z } Expected Signal + X u ′ = u g H u h u ′ x u ′ | {z } Interference + g H u n b | {z } Noise . (17) Accordingly , the post-equalization SINR for the u -th UA V is calculated as SINR u = g H u h u 2 P u ′ = u | g H u h u ′ | 2 + σ 2 ∥ g u ∥ 2 . (18) Based on Shannon capacity theory , the av erage achie v able rate for the u -th UA V ov er all OFDM symbols and subcarriers can be expressed as R u = 1 K S K X k =1 S X s =1 log 2 (1 + SINR u [ k ][ s ] ( W u , a u,b )) . (19) C. Pr oblem F ormulation In multi-UA V cooperativ e perception tasks, each U A V cap- tures different aerial vie ws using onboard cameras. Instead of transmitting raw images to the ground server , these images are sparsified via T op-K pixel selection to enable efficient wireless transmission. The sparsified images are then encoded at the ground server , where multi-UA V feature fusion is performed to support downstream perception tasks, including semantic segmentation and instance segmentation. The overall objec- tiv e is to maximize the perception utility while minimizing the transmission latency , thereby maintaining high task-level accuracy under stringent communication resource constraints. T o ev aluate the utility of semantic segmentation, the com- monly used Intersection-ov er-Union (IoU) [11] metric is adopted to measure the pixel-le vel ov erlap between the pre- dicted se gmentation and the ground-truth labels. Specifically , for the pixel region of the vehicle class, the IoU is computed 5 as IoU ˆ ℓ veh , ℓ veh = 1 T F − 1 X t =0 P h,w ˆ ℓ veh t · ℓ veh t P h,w ˆ ℓ veh t + ℓ veh t − ˆ ℓ veh t · ℓ veh t , (20) where t ∈ { 0 , . . . , F − 1 } denotes the frame index, and F is the total number of frames in the perception and future prediction horizons. ˆ ℓ veh t is the pixel of the predicted vehicle segmentation, and ℓ veh t represents the pixel of the correspond- ing ground-truth label. h and w denote the height and width indices of the BEV image, respecti vely . For the instance segmentation task, we adopt the panoptic quality (PQ) [45] metric to jointly ev aluate segmentation accu- racy and instance recognition performance, which is calculated by the product of se gmentation quality (SQ) and recognition quality (RQ). Specifically , SQ measures the a verage IoU over matched prediction–ground-truth instance pairs ( p, g ) , while RQ reflects the detection accuracy of the instance matching. The PQ metric is computed as follows: P Q = P ( p,g ) ∈ TP IoU ( p, g ) | TP | | {z } SQ × | TP | | TP | + 1 2 | FP | + 1 2 | FN | | {z } RQ , (21) where TP , FP , and FN represent the set of true positiv es (matched instances), false positi ves (unmatched predictions), and false negati ves (missed ground truths), respectiv ely . Con- sequently , the utility of PQ across the F detection frames can be expressed as P Q = F − 1 X t =1 P ( p t ,g t ) ∈ TP t IoU ( p t , g t ) | TP t | + 1 2 | FP t | + 1 2 | FN t | . (22) Subsequently , to reduce the transmission latency and com- munication overhead of U A V image data, the T op-K strategy that transmits only a fraction κ u of the most informativ e pixels is adopted. Accordingly , the transmission data size D u for U A V u can be calculated as D u = T op K ( u ) = κ u · X Y · C · M , (23) where X × Y denotes the image resolution, C is the number of channels, and M represents the quantization bits per pixel. Based on the achiev able rate given in (19), the communication latency of U A V u at frame t can be computed as L u ( t ) = D u ( t ) R u ( t ) . (24) For the cooperative perception task, images from all U A Vs are required to be receiv ed before joint processing. Conse- quently , we define the following objectiv e function to balance the trade-off between weighted utility and maximum commu- nication latency , expressed as α U PQ ( t ) + (1 − α ) U IoU ( t ) | {z } W eighted U til ity − λ · max u ∈U a u,b D u ( t ) R u ( t ) | {z } C omm. lantency L , (25) where α ∈ [0 , 1] is the weighting factor between the PQ-based and IoU-based utilities, and λ > 0 is the penalty coefficient of the maximum latency . For the total F frames, we formulate the multi-U A V cooperative perception problem as max W u ,κ u ,a u,b 1 F F X t =1 α U PQ ( t ) + (1 − α ) U IoU ( t ) − λL ( t ) s.t. 1 ≤ T op-K ( u ) ≤ X Y · C · M , ∀ u ∈ U , (26a) W u ∈ P t x , ∀ u ∈ U , (26b) ∥ W u ∥ F = 1 , ∀ u ∈ U , (26c) a u,b ∈ { 0 , 1 } , ∀ u ∈ U , (26d) where constraint (26a) limits the data size of transmitted U A V images after T op-K selection. Constraint (26b) selects W u from a predefined precoder set P t x designed for single- stream data transmission with t x antennas and Constraint (26c) normalizes W u into a unit-power matrix, where || · || F denotes the Frobenius norm. Constraint (26d) indicates the U A V -BS association decisions for implementing the multi- U A V perception task. The optimization problem in (26) jointly determines the T op-K ratios, precoding matrices, and associ- ation indicators to maximize the weighted perception utility while minimizing the maximum communication latency . I V . P E R C E P T I O N F R A M E W O R K This section presents the proposed BHU framework for multi-U A V cooperativ e perception. As illustrated in Fig. 2, the framew ork consists of (i) a sliding-window T op-K selection scheme, (ii) a MaskDINO-based feature extractor , (iii) a BEV feature fusion module, and (iv) a U-Net predictor that outputs semantic and instance segmentation results. A. T op-K Selection Sc heme For an RGB image I u ∈ R C × X × Y captured by U A V u , a lightweight neural network deployed onboard is employed to compress the image into a single-channel importance map, giv en by S u = ϕ RGB ( I u ) ∈ R 1 × X × Y . Subsequently , for each pixel I u ( i, j ) in the original image, a (3 × 3) sliding window , implemented as an averaging kernel with the center excluded, is applied to compute the av erage importance score of its eight neighboring pixels [9]. The score for ( i, j ) is calculated as follows: Score u ( i, j ) = 1 |N i,j | X ( i ′ ,j ′ ) ∈N i,j S u ( i ′ , j ′ ) − S u ( i, j ) , (27) where N i,j denotes the set of scores within the 3 × 3 neigh- borhood centered at ( i, j ) . Gi ven a T op-K ratio κ u ∈ (0 , 1] of U A V u , the ⌊ κ u X Y ⌋ pixels with the largest importance scores are selected for transmission, which can be expressed as ˜ I u ( i, j ) = I Score u ( i, j ) ≥ S T op-K u ⊙ I u ( i, j ) , (28) where S T op-K u denotes the ⌊ κ u X Y ⌋ -th largest importance score, I ( · ) is the indicator function, and ⊙ denotes the element- wise product operation. The sparsified image ˜ I u ( i, j ) is then transmitted to a ground server via wireless links and is recon- 6 Po si ti o n al Em b e d d ing Ae ri al Images Ma sk DI NO - b as ed En co d er Sliding Windo ws UA V 1 UA V 2 V i e w 2 Deformable Attention Ad ap t M LP M u l t i - H ea d A tt e n ti o n La ye r No r m 𝑁 × M L P Up R eL U L a y e r N o r m D o w n S F ro z en T r a i n a b l e S c a li n g Factor S Multi - scal e Feature Maps … L a ye rN o rm 4 × … … … … W ireless L inks 1/8 1 / 1 6 1/4 1 / 3 2 Unflatten Pix el embedding map 1/4 BE V F ea tu re F u si on V iew 1 Fe ature V iew 2 Fe ature S eg me n t a n d F lo w P red ic ti o n Fuse d BEV Represe ntation 2D Project t 0 t 1 t 2 t 2 U - Net Predictor Sem antic & ins tanc e Segm enta tion Ground Server V i e w 1 T op - k Fig. 2: Illustration of the proposed BHU framew ork for multi-UA V cooperati ve perception. The aerial images are first sparsified via a T op-K selection mechanism and transmitted to the ground server through wireless links. A MaskDINO-based encoder extracts multi-scale features, which are projected into BEV representations and cooperatively fused across multi-U A Vs. The fused BEV features are employed for downstream perception tasks, including vehicle instance segmentation and motion flow prediction. structed into a complete image through a learnable Gaussian interpolation module, which is computed by ˆ I u ( i, j ) = P ( i ′ ,j ′ ) ∈N i,j exp − ∥ ( i,j ) − ( i ′ ,j ′ ) ∥ 2 2 2 σ 2 u ˜ I u ( i ′ , j ′ ) P ( i ′ ,j ′ ) ∈N i,j exp − ∥ ( i,j ) − ( i ′ ,j ′ ) ∥ 2 2 2 σ 2 u , (29) where ˆ I u ∈ R C × X × Y and σ 2 u is a distance-weighting factor . B. MaskDINO-based F eatur e Extr actor Giv en the reconstructed image ˆ I u , a MaskDINO-based vi- sual encoder is employed to extract pixel-wise embeddings and multi-scale features for subsequent BEV projection. Specifi- cally , a Swin-large Transformer [35] backbone first produces a pyramid of multi-scale feature maps as n Z ( l ) u o L l =1 = ϕ Swin-L ˆ I u , Z ( l ) u ∈ R C l × X d l × Y d l , (30) where L denotes the number of pyramid levels, and d l is the downsampling factor at lev el l . Subsequently , a deformable attention module is adopted to ef ficiently aggregate multi-scale features by sampling a sparse set of reference points p across feature lev els, expressed as follo ws: b Z u = DeformAttn n Z ( l ) u o L l =1 , p , (31) where the DeformAttn ( · ) for the q -th query z q of { Z ( l ) u } L l =1 can be calculated by DeformAttn ( z q , p q ) = L X l =1 N ref X n =1 A q ,l,n ϕ v Z ( l ) u ( p q + ∆ p q ,l,n ) , (32) where N ref denotes the number of sampling points per lev el, A q ,l,n is the attention weight that satisfies P l,n A q ,l,n = 1 . ∆ p q ,l,n is the learned offset, and ϕ v is a linear projection applied to the sampled feature. Finally , the output feature maps in b Z u are unflatten and concatenated into a dense pixel embedding map b Z e u ∈ R C e × X ′ × Y ′ , serving as the input to the BEV projection and cross-UA V feature fusion module. C. BEV F eatur e Fusion Follo wing the Lift-Splat-Shoot (LSS) [46] paradigm, the pixels ( i, j ) ∈ { 0 , . . . , X ′ − 1 } × { 0 , . . . , Y ′ − 1 } in the embed- ding map b Z e u are projected into a unified LiD AR coordinate system where the BEV features across UA Vs are fused. Given the camera intrinsic matrix, K = f x 0 i c 0 f y j c 0 0 1 ∈ R 3 × 3 , (33) where f x and f y denote the focal length and i c , j c represents the principal point of the feature map, ( i, j ) can be transformed into a corresponding 3D ray [ X c / Z c , Y c / Z c , 1] T in the camera coordinate system as follows: 1 f x 0 − i c f x 0 1 f y − j c f y 0 0 1 | {z } K − 1 · i j 1 = i − i c f x j − j c f y 1 = X c / Z c Y c / Z c 1 , (34) where [ X c , Y c , Z c ] T represents the 3D camera coordinates. Let the extrinsic matrix from the camera coordinate to the LiD AR coordinate be E ∈ R 4 × 4 , the corresponding 3D point 7 in the LiD AR coordinate system is gi ven by X lidar Y lidar Z lidar 1 = R E T E 0 T 1 | {z } E ∈ R 4 × 4 · X c Y c Z c 1 , (35) where R E ∈ R 3 × 3 and T E ∈ R 3 × 1 denote the rotation matrix and the translation vector , respecti vely . Defining a 2D BEV plane on the LiDAR coordinate system with a predefined spatial range [ h min , h max ] × [ w min , w max ] and resolution ∆ h , ∆ w , we can obtain the BEV length and width as follows: W bev = w max − w min ∆ w , H bev = h max − h min ∆ h , (36) Accordingly , each 3D point ( X lidar , Y lidar , Z lidar ) can be assigned and projected to a 2D BEV grid ( w , h ) by w = X lidar − w min ∆ w , h = Y lidar − h min ∆ h . (37) Consequently , follo wing the geometric relationship defined by the camera intrinsic and extrinsic, the pixel embedding map b Z e u ∈ R C e × X ′ × Y ′ of the MaskDINO encoder are transformed into a BEV domain representation BEV u ∈ R C e × W bev × H bev . For the perception frame t , the BEV feature maps from all participating U A Vs are aggregated by performing element- wise summation at each spatial location ( h, w ) , constructing a fused BEV representation as BEV t = P U u =1 BEV u ( t ) . D. Multi-T ask Prediction T o jointly perform the semantic segmentation and instance segmentation tasks in multi-frame perception, two parallel pre- diction heads are appended to a shared U-Net-based decoder, which reconstructs segmentation and motion representations from the fused BEV feature maps { BEV t } F t =0 . For semantic segmentation, the decoder produces pixel-lev el class predic- tions for vehicle and background re gions in the BEV plane. The task is modeled as a pixel-wise classification problem [19] and optimized using the cross-entropy loss function: L seg ( ˆ ℓ veh t , ℓ veh t ) = 1 2 σ 2 seg L C E ( ˆ ℓ veh t , ℓ veh t ) + 1 2 log σ 2 seg , (38) where log σ 2 seg is a learnable uncertainty parameter that can adaptiv ely adjust the loss weight for multi-task optimization. For instance se gmentation, let ˆ ℓ flow t be the predicted instance flow in the BEV plane at frame t , and ℓ flow t be the correspond- ing instance ground truth. W e adopt the L 1 regression with a similar learnable parameter log σ 2 flow as the loss function giv en by L l 1 ( ˆ ℓ flow t , ℓ flow t ) = 1 2 σ 2 flow ˆ ℓ flow t − ℓ flow t 1 + 1 2 log σ 2 flow . (39) For the total F frames, the overall loss function is defined as the weighted summation of the semantic segmentation and instance flow losses o ver all frames as L = 1 F F X t =0 γ t λ seg L seg ( ˆ ℓ veh t , ℓ veh t ) + λ flow L l 1 ( ˆ ℓ flow t , ℓ flow t ) , (40) where γ t is a temporal factor that discounts the contribution of long-horizon future frames, and λ seg and λ flow are coef ficients that balance the relativ e importance of semantic segmentation and instance flow regression. V . P R O P O S E D S O L U T I O N After training the BHU framework, cooperative U A Vs can perform real-time inference by transmitting T op-K sparsified images to the ground server , where the corresponding percep- tion performance of IoU and PQ metrics can be ev aluated for the objecti ve in (26). T o solve the perception utility and latenc y trade-off problem formulated in (26), this section proposes a DDIM-based DRL algorithm to jointly optimize the T op-K selection ratio, U A V association, and precoding strategy . A. Deep Reinfor cement Learning F rame work Owing to the stochastic wireless channel dynamics during U A V image transmission and the inv olvement of binary UA V - BS association variables in the numerator and denominator of the SINR e xpressions, the problem (26) constitutes a stochastic mixed-inte ger programming problem. Such an optimization problem has been demonstrated to be non-con ve x and NP- hard, making it difficult to obtain an optimal solution [47]. Therefore, we adopt a DRL framework to independently out- put the U A V -BS association, the top-K ratio, and the precoding schemes, thus providing a feasible solution for the formulated problem in (26). The state, action, and reward function of the DRL framew ork are defined as follo ws. 1) State: In the multi-U A V cooperative perception sce- nario, the trade-off between perception utility and transmission latency depends on both the wireless channel states and the images captured by the U A Vs at the current frame t . Accordingly , the wireless channels H u,b between all U A Vs and the BS, together with the images I u captured by each U A V , are incorporated as the state information of the DRL framew ork, expressed as S t = { H u,b ( t ) } U u =1 , { I u ( t ) } U u =1 . (41) 2) Action: The action to solve the problem (26) includes the selection of cooperativ e UA Vs a u,b , T op-K ratios κ u , and the precoding matrix W u for each UA V . Denote the DRL action associated with the U A V selection as A U , which can be obtained using the binomial coef ficient U N uav that selects N uav U A Vs from a total of U U A Vs. Consequently , by summing all the binomial coefficients with N uav = { 1 , . . . , U } , the action space corresponding to the U A V -BS association scheme can be expressed as |A U | = U X N uav =1 U N uav = U X N uav =1 U ! N uav !( U − N uav )! . (42) 8 For the action of selecting the T op-K transmission ratio, we discretize the ratio into a finite set K = { κ min + ( n − 1)∆ κ } N κ n =1 that consists of N κ candidate v alues, where ∆ κ denotes the interval between adjacent ratios. Each ratio in K lies within the range [0 , 1] to satisfy constraint (26a). Accordingly , the action A κ for the T op-K ratio selection is defined as follows: A κ = { κ u ∈ K , ∀ u ∈ { 1 , . . . , U }} . (43) W ith the total number of U U A Vs, the action space for the T op-K ratio selection is gi ven by |A κ | = N U κ . For the action of precoding matrix selection A W , the prede- fined precoder set P t x in constraint (26b) is constructed based on the T ype-I codebook specified in the 3GPP standard [48]. Each precoding matrix in the T ype-I codebook is composed of discrete Fourier transform (DFT) beamforming vectors with unit po wer, thereby satisfying the unit norm constraint in (26c). The composition of T ype-I codebook is provided as follows. Remark 1: F or a uniform planar array with ( N x × N y ) antenna elements, let O x and O y denote the o versampling factors in the horizontal and vertical dimension, the corresponding discrete DFT beamforming vectors can be expressed as C n x = h 1 e j 2 π n x · 1 N x O x · · · e j 2 π n x · ( N x − 1) N x O x i T , ∀ n x ∈ { 0 , · · · , O x N x − 1 } , (44) C n y = 1 e j 2 π n y · 1 N y O y · · · e j 2 π n y · ( N y − 1) N y O y T , ∀ n y ∈ { 0 , · · · , O y N y − 1 } . (45) Subsequently , the precoding matrix for U A V u is calculated by W u = C n x ⊗ C n y 0 0 C n x ⊗ C n y W adj , (46) where W adj is an adjustment matrix with narrow-band prop- erties. For the precoding matrix designed for single-stream transmission, W adj is formulated as W adj = 1 p 2 N x N y e ψ m e T . (47) Specifically , ψ m is a co-phasing factor and is obtained by ψ m = e j π m 2 , m = { 0 , 1 , 2 , 3 } , (48) where the v alues of m index four discrete co-phasing candi- dates ψ m ∈ { 1 , j, − 1 , − j } . Let M n x ,n y be the Kronecker product of the DFT vectors: M n x ,n y = C n x ⊗ C n y ∈ C N x N y × 1 , (49) the candidate precoding matrix in P t x can be expressed as W u ( n x , n y , m ) = 1 p 2 N x N y M n x ,n y ψ n 3 M n x ,n y . (50) Therefore, for the total number of U U A Vs, the action space for the precoding selection is calculated by |A W | = |P t x | U . 3) Rewar d function: Gi ven the state S t at frame t , after selecting the cooperati ve UA Vs, T op-K ratios, and precoding P r e c oding I t e r a t e T ype - I C od e bo ok L os s O bt a i n U E s t a t e O bt a i n U E s t a t e O ut put a U B S s e t O bt a i n U E s t a t e Evaluate network Evaluate network O ut pu t a U B S s e t Evaluate network O ut pu t a U B S s e t B S 2 B S U F r o n t h a u l L i n ks … I m a g e a n d C h a n n e l f o r D R L S t a t e BS C o o p e r a t i ve B S se t BS C o o p e r a t i ve B S se t T o p - K ra t i o 3 D G e o m e t r y - B a se d M o d e l S ub c a r r i e r k y z N 1 N 2 dua l pol a r i z e d a nt e nna L O S P a th S c a t t e r 1 S c a t t e r 2 S ub - pa t h 2 NL OS C l us t e r 1 N L O S C l us t e r 2 S ub - pa t h 1 S ub - pa th 3 S ub c a r r i e r k y z N 1 N 2 dua l pol a r i z e d a nt e nna L O S P a th S c a t t e r 1 S c a t t e r 2 S ub - pa t h 2 NL OS C l us t e r 1 N L O S C l us t e r 2 S ub - pa t h 1 S ub - pa th 3 S ub c a r r i e r k y z N 1 N 2 dua l pol a r i z e d a nt e nna L O S P a th S c a t t e r 1 S c a t t e r 2 S ub - pa t h 2 NL OS C l us t e r 1 N L O S C l us t e r 2 S ub - pa t h 1 S ub - pa th 3 Ed g e C l o u d Ex p e rt 1 L O S P a t h S c a t t e r 1 S c a t t e r 2 S ub - pa t h 2 N L O S C l us t e r 2 S ub - pa t h 1 S ub - pa t h 3 L O S P a t h S c a t t e r 1 S c a t t e r 2 S ub - pa t h 2 N L O S C l us t e r 2 S ub - pa t h 1 S ub - pa t h 3 y z N 1 N 2 y z N 1 N 2 y z N 1 N 2 L O S P a t h S c a t t e r 1 S c a t t e r 2 S ub - pa t h 2 N L O S C l us t e r 2 S ub - pa t h 1 S ub - pa t h 3 y z N 1 N 2 ML P N e t w o rk ML P N e t w o rk ML P N e t w o rk ML P N e t w o rk S ub c a r r i e r k S ub c a r r i e r k MU - M I M O S ys t e m MU - M I M O S ys t e m U A V 2 U A V 1 C h a n n e l b e t w e e n U A V a n d b a se st a t i o n O u t p u t a co m b i n a t i o n o f a va i l a b l e BSs aa L VM T o p - K P i x e l S e l e c t i o n Wi r e l e s s T r a n s m i s s i o n P r o c e s s e d b y g r o u n d s e r v e r B E V V i e w 1 V i e w 2 V i e w 3 C a l cu l a t e w e i g h t e d u t i l i t y o f PQ a n d I o U C h a n n e l M a t r i x R G B I m a g e s D i f f u si o n N e t w o rk D i f f u si o n N e t w o rk U AV Se l e ct i o n U AV se l e ct i o n 4 Pre co d i n g Ma t ri x U E 1 … … A n t e n n a 1 U A V 1 U A V 2 U A V U … … … B a se S t a t i o n T r a n sm i t t e r A n t e n n a 2 R e ce i ve r U E 1 … … A n t e n n a 1 U A V 1 U A V 2 U A V U … … … B a se S t a t i o n T r a n sm i t t e r A n t e n n a 2 R e ce i ve r G e n a r a t e d C h a n n e l R e ve r se P r o ce ss o f D i f f u si o n D e n o i si n g G a u ssi a n N o i se () T hk () t hk 1 () t hk − 1 () hk 0 () r hk G e n a r a t e d C h a n n e l R e ve r se P r o ce ss o f D i f f u si o n D e n o i si n g G a u ssi a n N o i se () T hk () t hk 1 () t hk − 1 () hk 0 () r hk P r e co d i n g M a t r i x G a u ssi a n N o i se P r e co d i n g M a t r i x G a u ssi a n N o i se P r e c o d i n g V e c t o r S a m p l e d T i m e S t e p R e v e r s e D e n o i s i n g P r o c e s s o f D D I M N e t w o r k u p d a t e s w i t h a n d C a l cu l a t e S I N R T o p - K R a t i o Pr e co d i n g Ma t r i x Fig. 3: Illustration of the proposed DDIM-based DRL framework. An MLP network is employed to determine the cooperati ve U A Vs and T op-K sparsification ratios, while a DDIM module is employed to generate precoding actions by modeling the conditional distribution of optimal precoding vectors through a reverse denoising process. matrices, the rew ard is calculated as the difference between weighted utility and maximum transmission latency , gi ven by R ( S t , A t U , A t κ , A t W ) = α U PQ ( t ) + (1 − α ) U IoU ( t ) − λ · max u ∈U a u,b D u ( t ) R u ( t ) . (51) Consequently , maximizing the reward function is equiv alent to optimizing the objectiv e in problem (26), thereby enhancing the performance of perception tasks while reducing the UA V image transmission latency . B. DDIM-based Algorithm Once the number of cooperati ve U A Vs is determined, the action spaces associated with the T op-K ratio ( |A κ | = N U κ ) and the precoding matrix ( |A W | = |P t x | U ) grow exponen- tially with the number of UA Vs. As a result, directly allowing the DRL to output a policy over the joint action space would incur prohibitiv e dimensionality and computational complex- ity . T o address this issue, we first employ a neural network to determine the T op-K transmission ratio for each selected U A V . Based on the actions of selected U A Vs A U and T op-K ratios A κ , we can exhaustiv ely search the precoding codebook for each UA V to obtain the optimal precoding matrices { W o u } U u =1 for A W . Subsequently , we employ a dif fusion model to model the distribution of optimal precoding decisions, thereby enabling the generation of precoding actions. The overall DRL frame work is depicted in Fig. 3. Although diffusion models hav e demonstrated strong capabilities in de- cision modeling and generation, con ventional diffusion-based approaches typically require a large number of iterative de- noising steps, which significantly increases training overhead 9 and degrades training efficienc y . Consequently , we incorporate the DDIM mechanism [49], which approximates the denoising process of dif fusion models by sampling a subsequence of time steps, thereby substantially improving the training efficienc y of the proposed DRL frame work. Let w 0 denote the flattened and concatenated vector of the optimal precoding matrices { W o u } U u =1 . The function of DDIM is to model the conditional distribution of w 0 giv en the UA V selection actions A U and the sparsification ratios A κ , and then to generate the corresponding precoding vectors ¯ w 0 for action A W . In the forward noising process of DDIM, following the same procedure as the DDPM, Gaussian noise is progressively injected into the w 0 vector ov er T time steps, where the noise added at time step τ has fixed variance β τ . For the denoising process, a subsequence { τ i } D i =1 is sampled from the original diffusion timeline of length T , where D ≪ T denotes the total number of DDIM denoising steps. Consequently , let c be the flattened and concatenated conditional vector of A U and A κ , the forward noising adding process of DDIM is described as q ( w τ | w τ − 1 , c ) = N w τ ; p 1 − β τ w τ − 1 , β τ I . (52) Subsequently , the distribution of the τ -th noised precoding vector is calculated as q ( w τ | w 0 , c ) = τ Y t =1 N w τ ; p 1 − β τ w τ − 1 , β τ I (1) = N w τ ; √ ¯ α τ w 0 , (1 − ¯ α τ ) I , (53) where (1) = is obtained by letting α τ = 1 − β τ and ¯ α τ = Q τ 1 α τ . As a result, for an arbitrary time step τ , the noised precoding vector w τ can be directly computed as w τ = √ ¯ α τ w 0 + p (1 − ¯ α τ ) ϵ τ , ϵ τ ∼ N ( 0 , I ) . (54) In the denoising process of the dif fusion model, gi ven the original precoding vector w 0 and the conditioning v ariable c , the posterior distribution of the previous time step τ − 1 can be deriv ed from Bayes’ rule as q ( w τ − 1 | w τ , w 0 , c ) = q ( w τ | w τ − 1 , c ) q ( w τ − 1 | w 0 , c ) q ( w τ | w 0 , c ) = N w τ − 1 ; µ τ ( w τ , w 0 , c ) , σ 2 τ I , (55) where the mean µ τ and the variance σ 2 τ are giv en by µ τ = √ ¯ α τ − 1 β τ 1 − ¯ α τ w 0 + √ α τ (1 − ¯ α τ − 1 ) 1 − ¯ α τ w τ , (56) σ 2 τ = 1 − ¯ α τ − 1 1 − ¯ α τ β τ . (57) Howe ver , w 0 is not av ailable during the practical reverse process. Therefore, a neural network θ d is employed to esti- mate w 0 with ˆ w 0 ( w τ , τ , c ; θ d ) . Accordingly , we can obtain a mean ˜ µ τ ( θ d ) by substituting ˆ w 0 into Eq. (56), and the resulting posterior distribution can be written as p θ d ( w τ − 1 | w τ , c ) = N w τ − 1 ; ˜ µ τ ( θ d ) , σ 2 τ I . (58) Subsequently , θ d is optimized by minimizing the Kullback- Leibler (KL) di ver gence between q ( w τ − 1 | w τ , w 0 , c ) and Algorithm 1: DDIM-based DRL Algorithm. 1 Input: The channel matrix and RGB images. 2 Ouput: The UA V -BS association, T op-K ratios, and precoding scheme. 3 repeat 4 Input the state S t = ( { H u,b ( t ) } U u =1 , { I u ( t ) } U u =1 ) ; 5 Select an action for U A V association A i U and T op-K ratios A κ based on the output Q -v alues; 6 Exhaustiv ely search the codebook P t x | to obtain the precoding vector w 0 ; 7 Sample τ ∼ Uniform( { 1 , . . . , T } ) ; 8 Calculate the noised the precoding vector w τ = √ ¯ α τ w 0 + p (1 − ¯ α τ ) ϵ τ , ϵ τ ∼ N ( 0 , I ) ; 9 Update diffusion network θ d based on ∇ θ d E w τ ,τ , c h ∥ ˆ w 0 ( w τ , τ , c ) − w 0 ∥ 2 i ; 10 for DDIM denoising step τ i = τ D , τ D − 1 , · · · , 1 do 11 Obtain w τ i − 1 = √ ¯ α τ i − 1 ˆ w 0 ( w τ i , τ i , c ) + p 1 − ¯ α τ i − 1 ˆ ϵ ; 12 end 13 Generate ¯ w 0 for precoding action A W ; 14 Obtain rew ard R ( S t , A t U , A t κ , A t W ) using Eq. (51); 15 Update network θ Q based on L ( θ Q ) = 1 2 ∥Q ( S t , A t U , A t κ ) − R ( S t , A t U , A t κ , A t W ) ∥ 2 ; 16 until The networks θ d and θ Q con verg es ; p θ d ( w τ − 1 | w τ , c ) , i.e., arg min θ d D KL ( q ( w τ − 1 | w τ , w 0 , c ) ∥ p θ d ( w τ − 1 | w τ , c )) = N w τ − 1 ; µ τ , σ 2 τ I ∥N w τ − 1 ; ˜ µ τ ( θ d ) , σ 2 τ I = 1 2 ( ˜ µ τ ( θ d ) − µ τ ) T ( σ 2 τ ) − 1 ( ˜ µ τ ( θ d ) − µ τ ) = 1 2 ˜ σ 2 τ ∥ ˜ µ τ ( θ d ) − µ τ ∥ 2 , = 1 2 ˜ σ 2 τ ¯ α τ − 1 β 2 τ (1 − ¯ α τ ) 2 ∥ ˆ w 0 ( w τ , τ , c ) − w 0 ∥ 2 . (59) In this paper , we use the following simplified expression as the training loss function of the diffusion model: L ( θ d ) = ∇ θ d E w τ ,τ , c h ∥ ˆ w 0 ( w τ , τ , c ) − w 0 ∥ 2 i . (60) For the DDIM denoising process, we denote the sampled time-step sequence as { τ i } D i =1 = { τ D > τ D − 1 > · · · > τ 1 } . (61) At each step τ i , the denoising trajectory is updated to the previous time step τ i − 1 by w τ i − 1 = p ¯ α τ i − 1 ˆ w 0 ( w τ i , τ i , c ) + p 1 − ¯ α τ i − 1 ˆ ϵ , (62) where ˆ ϵ is computed based on Eq. (54) using ˆ w 0 ( w τ i , τ i , c ) , and is expressed as ˆ ϵ = w τ i − √ ¯ α τ i ˆ w 0 ( w τ i , τ , c ) p (1 − ¯ α τ i ) . (63) 10 UA V_1 UA V_2 UA V_3 UA V_4 Senario 1 Senario 2 Ground Truth Prediction V ehicle Instance in BEV Ground Truth Prediction Fig. 4: V isualization of 3D object detection results in the BEV representation. 0 1 2 3 4 5 6 Training Step # 10 4 0 5 10 15 20 25 30 35 40 Loss of Segmentation MaskDINO 1e-4 MaskDINO 3e-4 0 1 2 3 4 5 # 10 4 0.5 1 1.5 Loss of Instance Flow Fig. 5: The training loss of segmentation and predicted instance flow . w/o Fusion 2 UAVs 4 UAVs Different UAV Fusion Numbers 25 30 35 40 45 50 55 60 65 70 Mean IoU (%) EfficientNet (25 # 25) BEV Short (50 # 50) MaskDINO (ResNet50) MaskDINO (SwinL) 4.94% 4.82% 4.26% Fig. 6: Mean IoU of dif ferent perception backbones under varying U A V numbers. 0 2 4 6 8 10 12 14 16 18 Top-K Ratio (%) 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6 Mean IoU (%) EfficientNet (BEV Short) ResNet-50 (BEV Short) Swin-L (BEV Short) EfficientNet (BEV Long) ResNet-50 (BEV Long) Swin-L (BEV Long) 6.3% IoU improvement 5.67% IoU improvement Fig. 7: Mean IoU versus T op-K ratios under BEV -Short and BEV -Long settings. When the rev erse denoising process of DDIM reaches the final time step, the output of the dif fusion model is denoted by ¯ w 0 , which will be unflattened into precoding matrices and serves as the action for A W . A W together with the U A V selection action A U and the T op-K ratio action A κ will jointly determine the reward in Eq. (51). Specifically , A U and A κ are determined by a Q -network θ Q , which outputs the action- value Q ( · ) for all candidate actions. The parameters of the network θ Q are updated by minimizing the mean-squared error (MSE) loss, giv en by L ( θ Q ) = 1 2 Q ( S t , A t U , A t κ ) − R ( S t , A t U , A t κ , A t W ) 2 . (64) The detailed procedures for the propsoed DDIM-based DRL algorithm are presented in Algorithm 1. Compared with the con ventional diffusion model, the computational complexity of DDIM is reduced from O ( N e T ) to O ( N e ∆ τ ) , where ∆ τ = T /D denotes the sampling interv al of the denoising process and N e is the number of DRL training epochs. The adoption of DDIM significantly improv es computational efficienc y while maintaining high-quality precoding performance. V I . S I M U L A T I O N R E S U LT S This section ev aluates the proposed BHU framew ork and DDIM-based DRL algorithm on the Air-Co-Pred [19] dataset. In Air-Co-Pred, 4 U A Vs hovering at an altitude of 50 m moni- tor ground traffic flows from different viewpoints, covering an area of approximately 100 m × 100 m. The dataset is generated using the CARLA simulator [50], providing 200 realistic urban traffic scenes with a total of 32,000 synchronized images col- lected at a sampling rate of 2 Hz. Each image has a resolution of 1600 × 900 pixels, and the dataset supports multi-frame temporal prediction tasks. Based on this dataset, we construct 5,780 training sequences and 1,020 testing sequences, where each sequence contains sev en consecutiv e frames. Specifically , the first three frames are used as inputs, and the remaining four frames are used for prediction. For the wireless communication links between the UA Vs and the BS, the 3D channel model with a carrier frequency of 3.5 GHz is employed based on the 3GPP 38.901 [43] standard. Each U A V is equipped with a 2 × 1 dual-polarized antenna array with 4 antenna elements, while the BS employs a 2 × 2 dual-polarized antenna array with 8 antenna elements. All selected U A Vs share the same time–frequenc y resources and transmit data to the BS using OFDM symbols, which consists of 72 subcarriers with a subcarrier spacing of 15 kHz. A. V isualization and P erformance of the BHU Sc heme Fig. 4 presents two representati ve scenarios with 3D object detection visualizations, demonstrating vehicle instance anno- tations from different viewpoints of four UA Vs. The rightmost 11 T ABLE I: Performance comparison of EfficientNet- and MaskDINO-based networks with/without BEV fusion. Method IoU (%) ↑ PQ (%) ↑ Comm. Cost (Bps) ↓ DHD [19] Short Long A vg. Short Long A vg. T op-k (25%) Ef ficientNet (4 U A Vs) 60.58 53.14 56.86 51.80 45.89 48.85 6 . 14 × 10 7 Ef ficientNet (2 U A Vs) 50.59 40.82 45.71 43.43 35.37 39.40 2 . 05 × 10 7 Ef ficientNet w/o Fusion 41.31 33.11 37.21 35.07 28.29 31.68 0 MaskDINO (ResNet50) 63.99 55.97 59.98 54.24 48.23 51.24 6 . 14 × 10 7 MaskDINO (SwinL) 65.52 57.66 61.59 54.10 50.63 52.37 6 . 14 × 10 7 MaskDINO (SwinL) w/o Fusion 45.57 34.30 39.94 39.50 30.26 34.88 0 T ABLE II: Results of backbone networks and LoRA fine-tuning. Method Metrics (%) ↑ Parameters ↓ SwinL (Backbone) IoU Prec. T otal T raining EfficientNet Baseline 52.89 70.15 39.5 M 39.5 M BHU w pretrained 57.81 77.57 0.3 B 0.3 B BHU w/o pretrained 53.27 72.22 0.3 B 0.3 B DHD + LoRA 55.24 73.40 ∼ 0.3 B 37.4 M BHU + LoRA 55.86 74.38 ∼ 0.3 B 37.4 M column compares the predicted instances (shown in blue) with the ground-truth annotations (shown in gold) in the BEV plane. The substantial overlap between the predicted and ground-truth bounding boxes indicates the ef fectiveness and high accuracy of the proposed BHU method, even in challenging scenes with scattered or partially occluded v ehicles. Fig. 5 illustrates the training dynamics of MaskDINO under the learning rate settings of 1 × 10 − 4 and 3 × 10 − 4 for both the segmentation loss and the instance flo w loss. The configuration with a learning rate of 3 × 10 − 4 exhibits significantly faster con vergence in the early training stage, whereas the learning rate of 1 × 10 − 4 yields smoother training trajectories while achieving comparable final conv ergence performance. These results indicate that MaskDINO can be trained reliably to con- ver gence in different learning rate settings, and that selecting a learning rate of 3 × 10 − 4 provides a reasonable trade-off between con ver gence speed and training stability . T o ev aluate the performance of the proposed BHU scheme under different network backbones and varying numbers of U A Vs, Fig. 6 compares the mean IoU in a long BEV setting of 50 × 50 and a short setting of 25 × 25 . The ev aluated back- bones include a CNN-based EfficientNet, a ResNet-50-based lightweight MaskDINO, and a Swin-large-based MaskDINO. The simulation results show that increasing the number of cooperativ e U A Vs consistently improves the mean IoU across all considered backbones and BEV configurations, indicating that multi-view observ ations provide complementary visual information that effecti vely enhances perception accuracy . In particular , the L VM-based backbone yields significant perfor- mance gains for all 1, 2, and 4 UA V configurations, achieving relativ e improvements ranging from 4.26% to 4.94% compared to the EfficientNet-based baseline. Fig. 7 depicts the mean IoU performance versus different T op-K transmission ratio under both the long BEV and short 0 2 4 6 8 10 12 14 16 18 20 22 Top-K Ratio (%) 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6 Mean IoU (%) BHV (SwinL) BHV (SwinL) + LoRA DHD (SwinL) + LoRA BHV (SwinL) w/o Pretrained EfficientNet LoRA SwinL 0 100 200 300 Trainable Params Less than 2% degradation 15.17% 14.36% Fig. 8: IoU versus T op-K ratios under SwinL and LoRA settings. BEV settings. For all ev aluated backbones, increasing the T op- K ratio leads to improved perception accuracy , indicating that re3etaining a lar ger portion of images helps preserv e geometric feature information. Howe ver , the IoU improvement gradually saturates when the sparsification ratio exceeds approximately 15%, which is attributed to the f act that the perception task focuses on vehicle detection and a substantial portion of background information can be discarded. Moreover , as highlighted in Fig. 7, the Swin-large achiev es 5.67% and 6.3% larger relati ve IoU gains compared to the EfficientNet under the BEV -short and BEV -long settings, respectively . The simu- lation results demonstrate the enhanced model generalization and representation capacity of L VMs due to their increased network depth advanced architectural designs. B. Comparison with the DHD Baseline W e further conduct benchmark comparisons in terms of collaborativ e perception utility and communication overhead with a representati ve Drone-Help-Drone (DHD) scheme [19]. In DHD, a lightweight EfficientNet is deployed onboard to ex- tract BEV features, and sparse BEV features from neighboring U A Vs will be collected and fused for cooperativ e perception. As reported in T able I, similar to the BHU scheme, increas- ing the number of cooperativ e U A Vs consistently improves both IoU and PQ performance under all BEV configurations. On the other hand, inv olving more U A Vs in cooperation 12 T ABLE III: Comparison of the proposed BHU scheme and baselines in terms of utility and communication cost. Method IoU (%) ↑ PQ (%) ↑ Comm. Cost (Bps) ↓ BHU (Proposed) Short Long A vg. Short Long A vg. T op-k (25%) DHD (EfficientNet) Baseline 60.58 53.14 56.86 51.80 45.89 48.85 6.14 × 10 7 BHU (EfficientNet) 57.39 52.89 55.14 47.23 45.68 46.46 9.22 × 10 6 MaskDINO (ResNet50) 64.00 56.32 60.16 56.05 49.40 52.73 9.22 × 10 6 MaskDINO (SwinL) 65.71 57.81 61.76 54.64 51.26 52.95 9.22 × 10 6 MaskDINO (SwinL) + LoRA 63.51 55.86 59.69 53.74 48.58 51.16 9.22 × 10 6 0 0.5 1 1.5 2 2.5 3 3.5 4 Training Step # 10 4 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 Reward Function DDIM-based DRL ( 6 = 0.1) w/o Precoding Label ( 6 = 0.1) DDIM-based DRL ( 6 = 0.3) w/o Precoding Label ( 6 = 0.3) Fig. 9: Training reward comparison with and without search-based precoding labels. 0 0.5 1 1.5 2 2.5 3 3.5 4 Training Step # 10 4 1 2 3 4 5 6 7 Mean Maximum Delay (s) DDIM-based DRL ( 6 = 0.1) w/o Precoding Label ( 6 = 0.1) DDIM-based DRL ( 6 = 0.3) w/o Precoding Label ( 6 = 0.3) Fig. 10: Training latency comparison with and without search-based precoding labels. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Weighted Factor 6 0.51 0.512 0.514 0.516 0.518 0.52 0.522 0.524 0.526 0.528 15.5 16 16.5 17 17.5 18 Mean Weighted Utility (%) Mean SINR (dB) Trade-off point between SINR and Utility Fig. 11: Trade-of f between utility and SINR under different weighted factors λ . 1 2 3 4 5 6 7 8 9 10 Communication Rates (bit/s) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 CDF Min Rate ( 6 = 0.1) Rates ( 6 = 0.1) Min Rate ( 6 = 0.3) Rates ( 6 = 0.3) Min Rate ( 6 = 0.9) Rates ( 6 = 0.9) Mean Rate 0 2 4 6 8 10 Rate gain achieved with larger 6 factor Fig. 12: Communication rates of U A Vs under different weighted λ factors. inevitably incurs additional communication overhead. Specif- ically , for the DHD scheme without feature fusion, no visual data are exchanged and hence the communication ov erhead is zero. When 2 or 4 U A Vs participate in cooperative perception, assuming a T op-k ratio of 25% and a payload of 2 bytes per pixel, the communication overhead of transmitted BEV features (64 × 200 × 200) increases to 2 . 05 × 10 7 and 2 . 05 × 10 7 Bps, respectively . Additionally , when the backbone of Effi- cientNet is replaced with a Swin-large-based MaskDINO, the av erage IoU and PQ are improv ed from 56.86% and 48.85% to 61.59% and 52.37%, which exhibits the enhanced capability of L VMs under the same communication o verhead. T able II further summarizes the scale impact of the network backbone on perception performance. Compared to Efficient- Net, the Swin-large model, which contains approximately 0.3 B parameters (about 7.6 × more than Ef ficientNet), achiev es improv ements of 4.92% in mean IoU and 7.42% in prediction accuracy . Howe ver , retraining Swin-large without pretrained weights yields only marginal performance gains and incurs significant training o verhead. Additionally , we in vestigate the application of low-rank adaptation (LoRA) fine-tuning, which introduces only 37.4 M (14.36%) trainable parameters to the Swin-large backbone. As illustrated in Fig. 8, the Swin-large with LoRA setting exhibits less than a 2% degradation in IoU 13 compared to the full training with pretrained weights, requiring ev en fe wer trainable parameters than EfficientNet (15.17%). Unlike the DHD scheme, the proposed BHU frame work transmits T op-K RGB images and performs BEV fusion using the Swin-large backbone at a ground server . As presented in T able III, the communication overhead of BHU is measured at 9 . 22 × 10 6 bps when the input image resolution is resized to 224 × 480 and the T op-K ratio is set to 25%, which accounts for only 15% of the ov erhead required by the DHD bench- mark. Moreov er , by lev eraging the representation capability of L VMs, BHU achie ves average IoU and PQ gains of 4.90% and 4.10% ov er DHD. Under the LoRA fine-tuning setting, the av erage IoU and PQ are still improved by 2.83% and 2.31%, respectiv ely . These results demonstrate that BHU provides an effecti ve solution to reduce communication overhead while enhancing cooperativ e perception performance among UA Vs. C. P erformance of DDIM-based DRL Algorithm Based on the BHU performance under different numbers of cooperativ e UA Vs and T op-K ratios, we ev aluate the effecti ve- ness of the proposed DDIM-based DRL algorithm in jointly optimizing communication rates and perception utility . Fig. 9 illustrates the training reward of the proposed DRL approach under latenc y weight factors λ = 0 . 1 and λ = 0 . 3 . A higher reward indicates that the DRL policy achiev es better perception performance in terms of IoU and PQ, as well as higher wireless transmission efficienc y . It can be observed that, for both λ settings, the incorporation of DDIM module for modeling the distribution of optimal precoding labels (obtained through exhausti ve codebook search) leads to faster and more stable conv ergence. In contrast, the scheme without optimal precoding labels exhibits lar ger fluctuations in the training reward and con verges to a relativ ely lo wer reward value, demonstrating the ef fecti veness of DDIM in generating precoding actions for the DRL training process. In addition, since the rew ard function is formulated as the difference between the perception utility and the commu- nication latenc y penalty , a larger latenc y weight ( λ = 0.3) places greater emphasis on the communication penalty . As a result, the overall rew ard value is lower than that obtained under the setting of λ = 0.1. Fig. 10 illustrates the reduction and con ver gence behavior of U A V communication latency during the DRL training process, validating the efficac y of the designed rew ard function in improving transmission efficienc y . Specifically , for λ = 0.1, the DDIM-based approach achieves a lower latency than the scheme without optimal precoding labels, even when compared with the latter under a higher latency weight of λ = 0.3. These simulation results further ver - ify the advantage of DDIM-generated precoding in enhancing communication performance for multi-UA V scenarios. Subsequently , Fig. 11 illustrates the variation curves of the weighted perception utility and the average signal-to-noise ratio (SNR) as the latency weight factor λ increases from 0.1 to 0.9. It can be observed that the av erage SNR of cooperativ e U A Vs increases as the latency weight factor λ increases, whereas the av erage perception utility gradually decreases. This behavior is attributed to the role of λ in regulating the trade-off between perception utility and communication latency , which can adjust the penalty imposed on latency during the DRL training process. In addition, Fig. 11 rev eals a turning point characterized by the intersection of the percep- tion utility and SNR curves, which provides practical guidance for selecting an appropriate weighting factor to balance the perception and communication performance. Fig. 12 presents the cumulativ e distribution function (CDF) of the minimum and total communication rates of the coop- erativ e U A Vs under dif ferent λ settings. The inset illustrates the average communication rate along with the corresponding standard deviation. Similar to the SNR performance in Fig. 11, both the minimum and total communication rates increase with the value of λ . Consequently , under a higher λ setting, the DDIM-based DRL algorithm tends to select U A Vs with more fa vorable channel conditions, along with more optimized T op- K transmission and precoding strategies, thereby providing a communication-efficient strategy under resource-constrained wireless en vironments. V I I . C O N C L U S I O N In this paper, we ha ve in vestig ated a communication-aware cooperativ e perception framework for multi-U A V systems in low-altitude economy scenarios, aiming to address the critical challenges of excessi ve visual data transmission and stringent latency constraints. Specifically , we have proposed a T op- K sparsification mechanism to enable efficient visual trans- mission by selecting the most informati ve pixels from U A V - captured images. An L VM–based perception pipeline deplo yed at the ground server has been established to perform BEV feature extraction and feature fusion based on the sparsified visual data. Furthermore, a DDIM-based DRL algorithm was dev eloped to jointly optimize cooperativ e U A V selection, spar- sification ratios, and precoding matrices, achie ving an ef fecti ve trade-off between perception utility and communication effi- ciency . In future work, we will extend the proposed framework to more dynamic U A V mobility scenarios and integrate the advanced reasoning capabilities of lar ge foundation models into intelligent applications in low-altitude economy networks. R E F E R E N C E S [1] X.-W . T ang, Y . Huang, Y . Shi, and Q. Wu, “Mul-vr: Multi-uav collab- orativ e layered visual perception and transmission for virtual reality , ” IEEE T rans. W ireless Commun. , vol. 24, no. 4, pp. 2734–2749, 2025. [2] Y . W ang, Z. Su, Q. Xu, R. Li, T . H. Luan, and P . W ang, “ A secure and intelligent data sharing scheme for ua v-assisted disaster rescue, ” IEEE/ACM T rans. Netw . , vol. 31, no. 6, pp. 2422–2438, 2023. [3] Y . Xu, H. Zhou, T . Ma, J. Zhao, B. Qian, and X. Shen, “Leveraging multiagent learning for automated vehicles scheduling at nonsignalized intersections, ” IEEE Internet Things J. , v ol. 8, no. 14, pp. 11 427–11 439, 2021. [4] W . Xu, Y . Sun, R. Zou, W . Liang, Q. Xia, F . Shan, T . W ang, X. Jia, and Z. Li, “Throughput maximization of uav networks, ” IEEE/A CM T ransactions on Networking , vol. 30, no. 2, pp. 881–895, 2021. [5] H. Zhou, Y . Xu, T . Zhang, X. Zhang, J. Chen, and X. Shen, “Leveraging generativ e artificial intelligence for uplink feedback-free transmission in 6g fd-ran, ” IEEE T ransactions on Mobile Computing , pp. 1–15, 2025. [6] X. Kang, B. Song, J. Guo, Z. Qin, and F . R. Y u, “T ask-oriented image transmission for scene classification in unmanned aerial systems, ” IEEE T ransactions on Communications , vol. 70, no. 8, pp. 5181–5192, 2022. 14 [7] J. Xue, K. Y u, T . Zhang, H. Zhou, L. Zhao, and X. Shen, “Cooperative deep reinforcement learning enabled power allocation for packet duplica- tion urllc in multi-connectivity vehicular networks, ” IEEE T ransactions on Mobile Computing , vol. 23, no. 8, pp. 8143–8157, 2024. [8] J. W ang, M. Dong, B. Liang, G. Boudreau, and A. Afana, “Exploring temporal similarity for joint computation and communication in online distributed optimization, ” IEEE T ransactions on Networking , vol. 33, no. 3, pp. 1309–1325, 2025. [9] Y . Hu, S. Fang, Z. Lei, Y . Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confidence maps, ” Advances in neural information processing systems , vol. 35, pp. 4874–4886, 2022. [10] J. Zhao, P . Zhu, Z. W en, F . T ang, B. Zheng, R. Zhu, H. Qian et al. , “ Adaptive transparent cloaking tunnel enabled by meta-reinforcement- learning metasurfaces, ” PhotoniX , vol. 7, no. 1, p. 2, 2026. [11] T .-H. W ang, S. Maniv asagam, M. Liang, B. Y ang, W . Zeng, and R. Ur- tasun, “V2vnet: V ehicle-to-vehicle communication for joint perception and prediction, ” in in Pr oc. ECCV . Springer , 2020, pp. 605–621. [12] Y . Hu, J. Peng, S. Liu, J. Ge, S. Liu, and S. Chen, “Communication- efficient collaborativ e perception via information filling with codebook, ” in Proc. IEEE/CVF Conf. Comput. V is. P attern Recognit. (CVPR) , 2024, pp. 15 481–15 490. [13] A. K. Singh and K. K. Nguyen, “Communication efficient compressed and accelerated federated learning in open ran intelligent controllers, ” IEEE/ACM T rans. Netw . , vol. 32, no. 4, pp. 3361–3375, 2024. [14] A. Doso vitskiy , “ An image is worth 16x16 words: T ransformers for image recognition at scale, ” arXiv preprint , 2020. [15] M. Caron, H. T ouvron, I. Misra, H. J ´ egou, J. Mairal, P . Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers, ” in Pr oc. IEEE/CVF ICCV , 2021, pp. 9650–9660. [16] Y . Xu, J. W ang, R. Zhang, G. Liu, C. Zhao, G. Sun, D. Niyato, L. Y u, H. Zhou, A. Jamalipour et al. , “Integrating large vision models into agentic ai communications and networking: A survey , ” Author ea Pr eprints , 2025. [17] O. Sim ´ eoni, H. V . V o, M. Seitzer, F . Baldassarre, M. Oquab, C. Jose, V . Khalidov , M. Szafraniec, S. Y i, M. Ramamonjisoa et al. , “Dinov3, ” arXiv pr eprint arXiv:2508.10104 , 2025. [18] F . Li, H. Zhang, H. Xu, S. Liu, L. Zhang, L. M. Ni, and H.-Y . Shum, “Mask dino: T ow ards a unified transformer-based framework for object detection and segmentation, ” in Proc. IEEE/CVF Conf. Comput. V is. P attern Recognit. (CVPR) , 2023, pp. 3041–3050. [19] Z. W ang, P . Cheng, M. Chen, P . Tian, Z. W ang, X. Li, X. Y ang, and X. Sun, “Drones help drones: A collaborati ve framework for multi- drone object trajectory prediction and beyond, ” Advances in Neural Information Pr ocessing Systems , vol. 37, pp. 64 604–64 628, 2024. [20] X. Zhang, X. Qin, Y . W ang, Y . Xu, H. Zhou, and W . Zhuang, “Robust downlink data transmission in leo satellite-terrestrial networks: A rate- splitting multiple access approach, ” IEEE Internet Things J. , 2025. [21] J. Zhao, Q. Y u, B. Qian, K. Y u, Y . Xu, H. Zhou, and X. Shen, “Fully-decoupled radio access networks: A resilient uplink base stations cooperativ e reception frame work, ” IEEE T rans. W ir eless Commun. , vol. 22, no. 8, pp. 5096–5110, 2023. [22] J. Xue, Y . Xu, W . W u, T . Zhang, Q. Shen, H. Zhou, and W . Zhuang, “Sparse mobile crowdsensing for cost-effectiv e traffic state estimation with spatio–temporal transformer graph neural network, ” IEEE Internet Things J. , vol. 11, no. 9, pp. 16 227–16 242, 2024. [23] R. Giordano and P . Guccione, “Roi-based on-board compression for hyperspectral remote sensing images on gpu, ” Sensors , vol. 17, no. 5, p. 1160, 2017. [24] Y . Xu, B. Qian, K. Y u, T . Ma, L. Zhao, and H. Zhou, “Federated learning ov er fully-decoupled ran architecture for two-tier computing acceleration, ” IEEE Journal on Selected Ar eas in Communications , vol. 41, no. 3, pp. 789–801, 2023. [25] X. Zhang, X. Qin, Z. Zhang, L. X. Cai, H. Zhou, and W . Zhuang, “Ris- aided mimo downlink transmission for ultra-dense leo satellite-terrestrial networks, ” IEEE Internet Things J. , 2025. [26] J. Xue, H. Zhou, H. Huang, G. W en, Y . Xu, X. Huang, and X. Shen, “Fd- ran empowered multiple base stations cooperative isac for low-altitude networks, ” IEEE T rans. Netw . Sci. Eng. , pp. 1–18, 2026. [27] G. Geraci, A. Garcia-Rodriguez, L. Galati Giordano, D. L ´ opez-P ´ erez, and E. Bj ¨ ornson, “Understanding uav cellular communications: From existing networks to massive mimo, ” IEEE Access , vol. 6, pp. 67 853– 67 865, 2018. [28] C. Zeng, J.-B. W ang, M. Xiao, Y . Pan, Y . Chen, H. Y u, and J. W ang, “Generalized optimization method of placement and beamforming de- sign for multiuser mimo uav communications, ” IEEE Wir eless Commu- nications Letters , vol. 13, no. 2, pp. 402–406, 2024. [29] M. Elwekeil, A. Zappone, and S. Buzzi, “Power control in cell-free massiv e mimo networks for uavs urllc under the finite blocklength regime, ” IEEE Tr ans. Commun. , vol. 71, no. 2, pp. 1126–1140, 2023. [30] K. Y u, Q. Y u, Z. T ang, J. Zhao, B. Qian, Y . Xu, H. Zhou, and X. Shen, “Fully-decoupled radio access networks: A flexible downlink multi- connectivity and dynamic resource cooperation frame work, ” IEEE T rans. W ireless Commun. , vol. 22, no. 6, pp. 4202–4214, 2023. [31] Y . Xu, J. W ang, R. Zhang, C. Zhao, D. Niyato, J. Kang, Z. Xiong, B. Qian, H. Zhou, S. Mao et al. , “Mixture of experts for decentralized generativ e ai and reinforcement learning in wireless networks: A com- prehensiv e survey , ” IEEE Communications Surveys & T utorials , 2025. [32] T . Feng, X. W ang, F . Han, L. Zhang, and W . Zhu, “U2udata: A large-scale cooperative perception dataset for swarm uavs autonomous flight, ” in Pr oceedings of the 32nd ACM International Confer ence on Multimedia , 2024, pp. 7600–7608. [33] Y .-C. Liu, J. T ian, N. Glaser , and Z. Kira, “When2com: Multi-agent perception via communication graph grouping, ” in Pr oc. IEEE/CVF Conf. Comput. V is. P attern Recognit. (CVPR) , 2020, pp. 4106–4115. [34] O. Sautenkov , Y . Y aqoot, M. A. Mustafa, F . Batool, J. Sam, A. L yko v , C.-Y . W en, and D. Tsetserukou, “Uav-codeagents: Scalable uav mission planning via multi-agent react and vision-language reasoning, ” arXiv pr eprint arXiv:2505.07236 , 2025. [35] Z. Liu et al. , “Swin transformer: Hierarchical vision transformer using shifted windows, ” in Proc. IEEE/CVF ICCV , 2021, pp. 10 012–10 022. [36] Y . Xu, J. W ang, R. Zhang, D. Niyato, D. Rajan, L. Y u, H. Zhou, A. Jamalipour , and X. W ang, “Enhancing wireless networks for iot with large vision models: Foundations and applications, ” arXiv preprint arXiv:2508.00583 , 2025. [37] Z. Liu, H. Du, J. Lin, Z. Gao, L. Huang, S. Hosseinalipour , and D. Niyato, “Dnn partitioning, task offloading, and resource allocation in dynamic vehicular networks: A lyapunov-guided dif fusion-based rein- forcement learning approach, ” IEEE T ransactions on Mobile Computing , vol. 24, no. 3, pp. 1945–1962, 2025. [38] N. Carion, F . Massa, G. Synnaeve, N. Usunier, A. Kirillov , and S. Zagoruyko, “End-to-end object detection with transformers, ” in Proc. Eur opean Confer ence on Computer V ision (ECCV) . Springer , 2020, pp. 213–229. [39] H. Zhang, H. Zhang, K. Liu, Z. Gan, and G.-N. Zhu, “Uav-detr: efficient end-to-end object detection for unmanned aerial vehicle imagery , ” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IR OS) . IEEE, 2025, pp. 15 143–15 149. [40] L. W ang, R. Li, C. Duan, C. Zhang, X. Meng, and S. Fang, “ A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images, ” IEEE Geoscience and Remote Sensing Letters , vol. 19, pp. 1–5, 2022. [41] Z. Shan, Y . Liu, L. Zhou, C. Y an, H. W ang, and X. Xie, “Ros-sam: High- quality interactiv e segmentation for remote sensing moving object, ” in Pr oc. IEEE/CVF Conf. Comput. V is. P attern Recognit. (CVPR) , 2025, pp. 3625–3635. [42] A. Kirillov et al. , “Segment anything, ” in Pr oc. IEEE/CVF Int. Conf. Comput. V is. (ICCV) , 2023, pp. 4015–4026. [43] 3GPP , “Study on channel model for frequencies from 0.5 to 100 GHz, ” 3rd Generation Partnership Project (3GPP), T echnical report (TR) 38.901, Apr . 2024, version 18.0.0. [44] K. Y u, H. Zhou, Y . Xu, Z. Liu, H. Du, and X. Shen, “Large sequence model for mimo equalization in fully decoupled radio access network, ” IEEE Open Journal of the Communications Society , vol. 6, pp. 4491– 4504, 2025. [45] A. Kirillov , K. He, R. Girshick, C. Rother, and P . Doll ´ ar , “Panoptic segmentation, ” in Proc. IEEE/CVF Conf. Comput. V is. P attern Recognit. (CVPR) , 2019, pp. 9404–9413. [46] D. Chen, H. Zheng, Y . Zhou, X. Li, W . Liao, T . He, P . Peng, and J. Shen, “Semantic causality-aware vision-based 3d occupancy prediction, ” in Pr oc. IEEE/CVF Int. Conf. Comput. V is. , 2025, pp. 24 878–24 888. [47] Y . Xu, Z. Liu, B. Qian, H. Du, J. Chen, J. Kang, H. Zhou, and D. Niyato, “Fully-decoupled ran for feedback-free multi-base station transmission in mimo-ofdm system, ” IEEE Journal on Selected Ar eas in Communications , vol. 43, no. 3, pp. 780–794, 2025. [48] 3GPP , “NR; Physical layer procedures for data, ” 3rd Generation Part- nership Project (3GPP), T echnical specification (TS) 38.214, Jan. 2024, version 18.1.0. [49] J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models, ” arXiv pr eprint arXiv:2010.02502 , 2020. [50] A. Dosovitskiy , G. Ros, F . Codevilla, A. Lopez, and V . Koltun, “Carla: An open urban dri ving simulator , ” in Confer ence on r obot learning . PMLR, 2017, pp. 1–16.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment