Music Source Restoration with Ensemble Separation and Targeted Reconstruction
The Inaugural Music Source Restoration (MSR) Challenge targets the recovery of original, unprocessed stems from fully mixed and mastered music. Unlike conventional music source separation, MSR requires reversing complex production processes such as e…
Authors: Xinlong Deng, Yu Xia, Jie Jiang
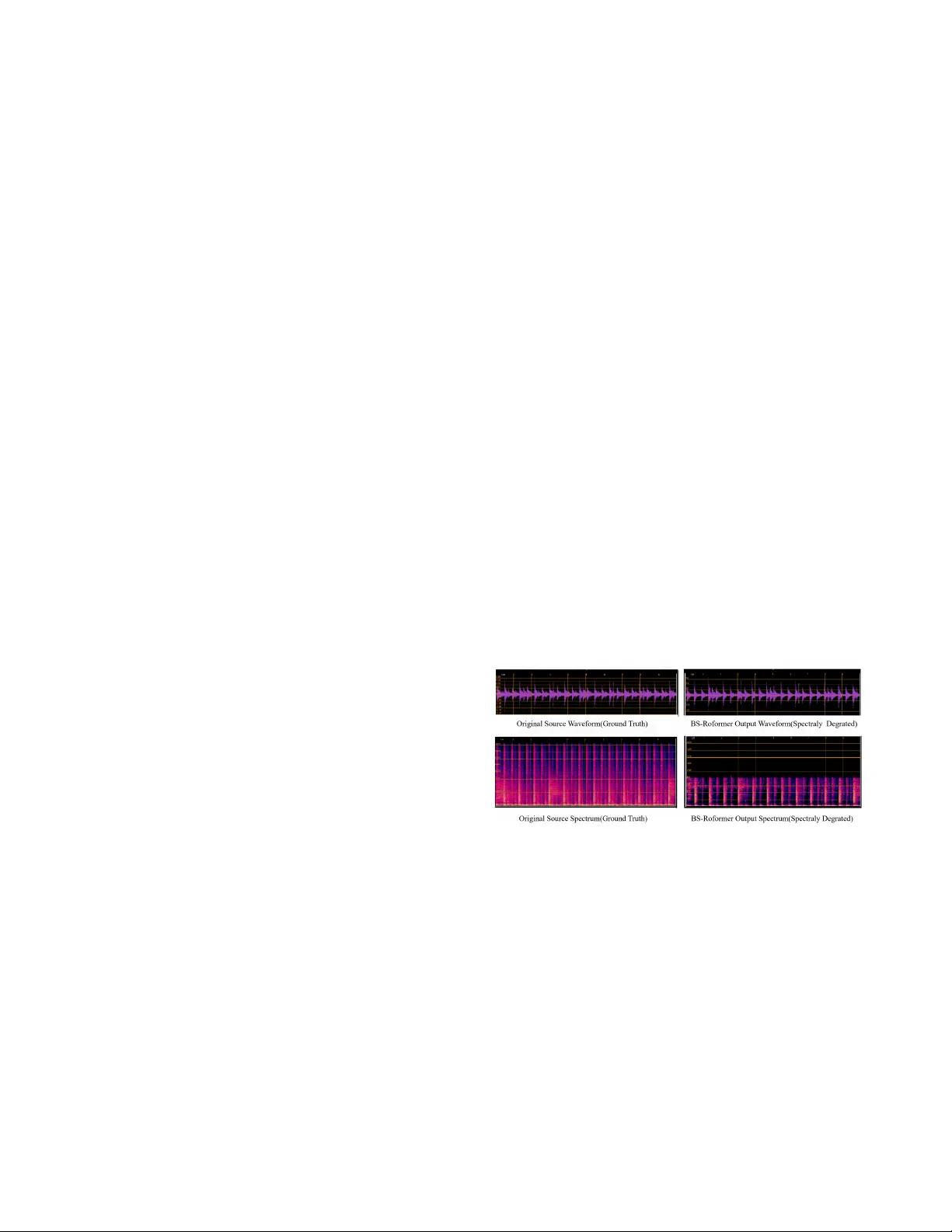
MUSIC SOURCE RESTORA TION WITH ENSEMBLE SEP ARA TION AND T ARGETED RECONSTR UCTION Xinlong Deng , Y u Xia , Jie Jiang College of Artificial Intelligence, China Uni versity of Petroleum, Beijing { 2022012257, 2023011703 } @student.cup.edu.cn, jiangjie@cup.edu.cn ABSTRA CT The Inaugural Music Source Restoration (MSR) Challenge targets the reco very of original, unprocessed stems from fully mixed and mastered music. Unlike con ventional music source separation, MSR requires re versing comple x production pro- cesses such as equalization, compression, reverberation, and other real-world degradations. T o address MSR, we propose a two-stage system. First, an ensemble of pre-trained sepa- ration models produces preliminary source estimates. Then a set of pre-trained BSRNN-based restoration models per - forms targeted reconstruction to refine these estimates. On the official MSR benchmark, our system surpasses the base- lines on all metrics, ranking second among all submissions. The code is available at https://github.com/xinghour/Music- source-restoration-CUP AudioGroup Index T erms — Music Source Restoration, Music Source Separation, Ensemble, Generation 1. INTRODUCTION The Music Source Restoration (MSR) task, introduced in the ICASSP 2026 Signal Processing Grand Challenge, aims to recov er original, unprocessed instrument stems from fully mixed and mastered music by effecti vely inv erting produc- tion ef fects such as equalization, dynamic range compression, rev erberation, and codec artifacts. While pre vious w orks tar - get separation or restoration independently , MSR requires a unified approach. Music source separation (MSS) methods like BS-RoFormer [1] assume linearly mixed clean sources, whereas restoration models like Apollo [2] and SonicMaster [3] suppress degradations without explicitly reco vering indi- vidual stems. MSR is more challenging than either task, as it demands the joint reco very of indi vidual instruments from mixtures subjected to div erse, unknown, and often non-linear production chains. In this paper , we propose a two-stage system for MSR. Our approach first le verages an ensemble of pre-trained MSS models to generate initial source estimates for each instrument. These estimates are subsequently processed by a BSRNN-based restoration module [4] for joint separation re- finement and tar geted restoration. Experimental results on the official MSR benchmark demonstrate that our system outper- forms the of ficial baselines across all three objecti ve tracks, ranking second on the ICASSP 2026 MSR leaderboard. 2. METHODOLOGY 2.1. Ensembled Music Source Separation Although MSS models are not explicitly designed to recover clean sources from degraded mixtures, our experiments in- dicate that training with mask target enables them to learn instrument-specific spectral and structural priors. As shown in Figure 1, the separators trained on clean mixtures retain the ability to localize and extract residual instrument compo- nents from degraded mixtures, provided their discriminative structures remain partially intact despite the degradation. Fig. 1 . W av eform and spectrogram of the original audio and the BS-RoFormer separated output for drums. Motiv ated by this observation, we implement a cascaded ensemble to cover eight instrument classes. W e first utilize BS-RoFormer [1] to generate initial estimates for vocals, bass, drums and an aggregate other stem. Given that percus- sion is often entangled with drums, we then employ MDX23C [5], a specialized drum separation model, to refine the drum track and isolate percussion. Any remaining instrumental content is then categorized under the other stem. Howe ver , as MSS models are generally trained on clean mixtures, they face a domain gap when applied to mastered music. Consequently , their outputs often fail to account for complex production effects, resulting in incomplete source T able 1 . Results of different MSR systems per instrument class. Model Metric V ocals Gtr . Ke y . Synth Bass Drums Perc. Orch. BSRNN (baseline) MMSNR 1.3365 0.2722 0.0588 0.0223 0.6303 0.8569 0.0000 0.0388 F AD 0.3476 0.4085 1.0690 0.9027 0.7334 0.6393 1.1880 0.7472 EnsembleSep MMSNR 1.3047 0.5836 0.2578 0.0693 1.4700 1.6712 0.6846 0.1348 F AD 0.2607 0.4832 0.7842 0.8156 0.4387 0.4540 0.7412 0.7460 EnsembleSep+BSRNN MMSNR 1.3298 0.6274 0.4077 0.0596 1.3800 1.9461 0.0000 0.1570 F AD 0.2680 0.2802 0.6662 0.7525 0.4045 0.3236 0.8461 0.5981 disentanglement and persistent audio degradations. This ne- cessitates a dedicated second stage designed specifically for joint separation refinement and restoration. 2.2. T argeted Source Restoration Con ventional audio restoration models typically assume that the input signal is already isolated [2, 3]. Consequently , these models cannot be directly applied to the outputs of our sys- tem’ s first stage due to a fundamental domain mismatch be- tween the degradation patterns in isolated sources and the ar- tifacts present in the separation estimates. T o bridge this gap, we require a framew ork capable of treating these imperfect estimates as informativ e priors. This allows for joint separa- tion refinement and restoration, aimed at recovering the orig- inal, unprocessed instrument stems. In the absence of existing specialized models for this task, we adopt the baseline system pro vided by the MSR Chal- lenge: a suite of pre-trained BSRNN-based MSR models [4]. These models are specifically designed and trained to map degraded mixtures to unprocessed stem targets by performing simultaneous separation and restoration. In our pipeline, we utilize these models for targeted refinement, i.e., the separa- tion estimates from the first stage are fed into their respectiv e instrument-specific BSRNN models. This allows the system to lev erage the initial estimates as informed starting points to further suppress residual artifacts and achieve better restora- tion of each instrument stem. 3. RESUL TS T able 1 summarizes the performance of the baseline sys- tem, the ensembled MSS (EnsembleSep), and the proposed two-stage MSR system (EnsembleSep+BSRNN) on the MSRBench validation set. Evaluation is conducted using Multi-Mel Spectrogram Signal-to-Noise Ratio (MMSNR) and Fr ´ echet Audio Distance with CLAP (F AD-CLAP) [6] to assess time-frequency accuracy and semantic restoration respectiv ely . In general, EnsembleSep+BSRNN achieves su- perior performance across most instrument classes. Howe ver , for Percussion, the MMSNR for both the baseline and our system approached zero. This is due to a significant distribu- tion shift and data scarcity between the training and validation sets. Consequently , the BSRNN stage was bypassed for this specific instrument class during ev aluation on the test set. Our proposed system further demonstrated its efficac y by outperforming the baseline on the Challenge test set. Specifi- cally , it achiev ed scores of 2.3405 (MMSNR), 0.2253 (F AD), and 0.0164 (Zimt) [7], alongside an av erage MOS of 3.2262. 4. CONCLUSION W e propose a two-stage system for MSR that integrates en- semble separation with targeted reconstruction. Experimental results validate the efficac y of this system. Furthermore, our analysis rev eals that data scarcity remains a significant bottle- neck; we posit that scaling with higher-quality , diverse train- ing data will be essential to further advancing the performance of separation and restoration modules. 5. REFERENCES [1] W ei-Tsung Lu, Ju-Chiang W ang, Qiuqiang Kong, and Y un-Ning Hung, “Music source separation with band-split rope transformer, ” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2024, pp. 481–485. [2] Kai Li and Yi Luo, “ Apollo: Band-sequence modeling for high-quality audio restoration, ” in ICASSP 2025-2025 IEEE International Confer- ence on Acoustics, Speec h and Signal Pr ocessing (ICASSP) . IEEE, 2025, pp. 1–5. [3] Jan Melechovsky , Ambuj Mehrish, Abhinaba Roy , and Dorien Herre- mans, “Sonicmaster: T owards controllable all-in-one music restoration and mastering, ” arXiv pr eprint arXiv:2508.03448 , 2025. [4] Y ongyi Zang, Jiarui Hai, W anying Ge, Qiuqiang Kong, Zheqi Dai, Helin W ang, Y uki Mitsufuji, and Mark D Plumbley , “Msrbench: A benchmarking dataset for music source restoration, ” arXiv preprint arXiv:2510.10995 , 2025. [5] Alessandro Ilic Mezza, Riccardo Giampiccolo, Alberto Bernardini, and Augusto Sarti, “Benchmarking music demixing models for deep drum source separation, ” in 2024 IEEE 5th International Symposium on the Internet of Sounds (IS2) . IEEE, 2024, pp. 1–6. [6] K evin Kilgour , Mauricio Zuluaga, Dominik Roblek, and Matthew Shar- ifi, “Fr ´ echet audio distance: A metric for e valuating music enhancement algorithms, ” arXiv pr eprint arXiv:1812.08466 , 2018. [7] Jyrki Alakuijala, Martin Bruse, Sami Boukortt, Jozef Marus Coldenhof f, and Milos Cernak, “Zimtohrli: An efficient psychoacoustic audio simi- larity metric, ” 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment