Outcome-Aware Tool Selection for Semantic Routers: Latency-Constrained Learning Without LLM Inference
Semantic routers in LLM inference gateways select tools in the critical request path, where every millisecond of added latency compounds across millions of requests. We propose Outcome-Aware Tool Selection (OATS), which interpolates tool embeddings t…
Authors: Huamin Chen, Xunzhuo Liu, Junchen Jiang
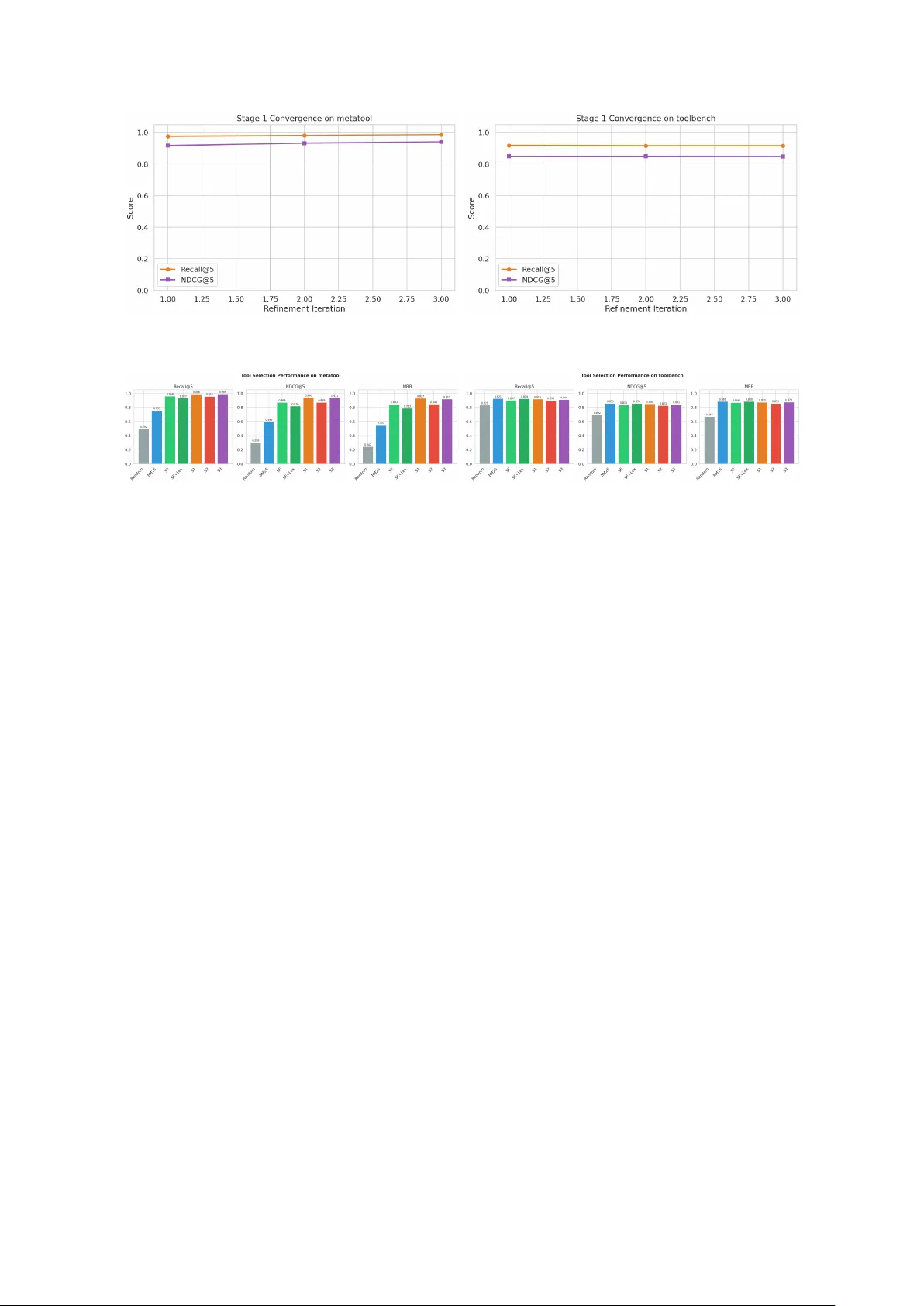
Outcome-A w are T o ol Selection for Seman tic Routers: Latency-Constrained Learning Without LLM Inference Huamin Chen 1 Xunzh uo Liu 1 Junc hen Jiang 2 Bo wei He 3 Xue Liu 3 1 vLLM Seman tic Router Pro ject 2 T ensormesh Inc / UChicago 3 MBZUAI / McGill Univ ersity Abstract Seman tic routers in LLM inference gatew ays select tools in the critical request path, where ev ery millisecond of added latency comp ounds across millions of requests. W e prop ose Outcome-A w are T o ol Selection (O A TS) , whic h interpolates tool em b eddings tow ard the cen troid of queries where they historically succeed—an offline process that adds no parameters, latency , or GPU cost at serving time. On MetaT o ol (199 to ols, 4,287 queries), this improv es NDCG@5 from 0.869 to 0.940; on T o olBench (2,413 APIs), from 0.834 to 0.848. W e also ev aluate tw o learned extensions: a 2,625-parameter MLP re-rank er and a 197K-parameter con trastive adapter. The MLP re-rank er hurts or matches baseline when outcome data is sparse relativ e to the to ol set; the contrastiv e adapter pro vides comparable gains on MetaT o ol (NDCG@5: 0.931). All metho ds are ev aluated on the same held-out 30% test split. The practical takea wa y is to start with the zero-cost refinemen t and add learned comp onen ts only when data densit y w arrants it. All mechanisms run within single-digit millisecond CPU budgets. 1 In tro duction LLM serving infrastructure increasingly uses semantic r outers —ligh tw eigh t pro xies that insp ect requests and mak e routing decisions b efore forw arding them to back end mo del po ols. These routers sit in the critical path: added latency compounds across millions of daily requests. Among their functions—model selection, prompt-length-based p ool assignmen t, rate limiting— one of the most consequential for agen tic applications is to ol sele ction : c ho osing whic h tools to attac h to a request b efore it reaches the LLM. 1.1 The Latency–Accuracy T radeoff T o ol selection in a router m ust satisfy a hard constrain t: Complete within single-digit mil lise c onds, without GPU r esour c es or LLM infer enc e. A t 10,000 requests/second with a 5 ms budget, to ol selection alone consumes 50 CPU-seconds p er second. Any metho d requiring LLM inference—even on a small mo del—exceeds this budget b y orders of magnitude. T able 1 shows that all OA TS metho ds stay within this budget on CPU. Figure 1 illustrates the arc hitecture difference. In the LLM-based approach, a dedicated orc hestrator runs full inference on every request—requiring GPU resources and adding hundreds of milliseconds. In the semantic router approac h, selection is a light weigh t CPU op eration, but it relies on static similarity with no learning. O A TS preserves the fast path while incorp orating outcome feedback through offline lo ops. 1 T able 1: Cost of to ol selection mec hanisms. Latency is p er-request p50 on 2,413 to ols (T o ol- Benc h). All metho ds run on CPU. Metho d Latency P arameters GPU Viable at (ms) Required 10K rps? BM25 (lexical) ∼ 7 0 No ✓ Static embedding ∼ 5 22M † No ∗ ✓ O A TS-S1 (offline) ∼ 4 22M † No ∗ ✓ O A TS-S2 (+ MLP) ∼ 5 22M + 2.6K No ∗ ✓ O A TS-S3 (+ adapter) ∼ 5 22M + 197K No ∗ ✓ † Em b edding mo del (all-MiniLM-L6-v2); runs on CPU at batch throughput. ∗ CPU inference; GPU optional for higher throughput but not required. (a) LLM-based to ol selection User Router (proxy) LLM Orchestrator 8B–70B params LLM Serving Resp onse + to ols 500–2000 ms, GPU 200–2000 ms 700–10,000 ms (b) OA TS seman tic router (ours) User Seman tic Router (CPU) embed → sim → re-rank → top- K LLM Serving Resp onse query + to ols 3–7 ms, CPU only 200–2000 ms Offline Learning Stages 1–3 Outcome Logs outcomes updates Figure 1: (a) LLM-based to ol selection requires a GPU-b ound orchestrator in the request path (500–2,000 ms). (b) O A TS p erforms selection on CPU in the router (3–7 ms), with all learning offline. LLM serving latency is the same in b oth cases. 1.2 Limitations of Static Embedding Similarit y The standard approach in pro duction routers is static emb e dding similarity : em b ed each tool’s description once, compute dot pro ducts against the query em b edding at request time, and return the top- K . This satisfies the latency constrain t but has clear accuracy limitations: 1. Description qualit y b ottlenec k. T o ol descriptions are written by dev elop ers once and nev er up dated. A po orly worded description p ermanen tly under-selects an otherwise useful to ol. 2. No outcome feedback. The system cannot learn that T o ol A consistently pro duces b etter outcomes than T o ol B for a given query class, ev en after pro cessing millions of requests. 3. Single-p oin t representation. Each to ol is a single em b edding vector, which cannot capture to ols that serve multiple distinct use cases in differen t regions of the em b edding space. 4. Lexical bias. Embedding similarity rewards surface-lev el textual similarit y b et w een prompts 2 and descriptions rather than functional relev ance. Our exp erimen ts confirm this: on T o ol- Benc h, BM25 (pure lexical) achiev es NDCG@5 of 0.853, exc e e ding dense embedding retriev al at 0.834. These limitations leav e ro om to improv e accuracy within the existing latency budget. RL- based to ol orchestration [Jin et al., 2025, Li et al., 2025, Qian et al., 2025, W ang et al., 2025, Su et al., 2025] has sho wn that outcome-a w are selection outperforms static methods—but it relies on LLM inference and m ulti-turn rollouts, whic h are incompatible with router-level latency constrain ts. 1.3 Our Approach W e propose Outcome-A ware T o ol Selection (O A TS) . The core idea is straigh tforward: interp olate to ol emb e ddings offline towar d the c entr oid of queries wher e they suc c e e d . This tak es the same idea as RL-based orc hestration—learning from outcomes—but implements it as an em b edding transformation that adds no parameters, latency , or LLM inference at serving time. Core mechanism: Em b edding-Space Outcome Refinement. F or each tool, OA TS col- lects queries where it was selected and succeeded vs. failed, then mov es the tool’s em b edding to ward the p ositiv e-outcome centroid and aw ay from the negative-outcome centroid. The refined em b eddings replace the originals in the to ol database as a p erio dic batch job. A t serving time, the path is unchanged: embed the query , compute similarities, return top- K . On MetaT o ol (199 to ols), this improv es NDCG@5 from 0.869 to 0.940 with no added serving cost. App endix A w alks through real examples where the refinemen t corrects specific selection errors. Ablations: learned components. W e also ev aluate t w o extensions to understand when added complexity pays off: 1. Learned Re-Ranking (2,625 parameters). A small MLP re-scores candidates using outcome-deriv ed features. A dds < 0.5 ms. 2. Con trastive Embedding Adaptation (197K parameters). Reshap es the em b edding space via hard-negativ e contrastiv e learning. Deplo yed as a drop-in mo del replacement. The MLP re-ranker can actually h urt p erformance when outcome data is sparse—a result that has direct implications for deplo yment (Section 6). 1.4 Con tributions • An outcome feedback mec hanism (Section 4.1) that improv es to ol selection without adding parameters, latency , or GPU cost at serving time. • A cost-a ware framew ork (Section 3) that separates the learning and serving concerns, formal- izing the latency–accuracy tradeoff. • Exp erimen ts on T oolBench (2,413 APIs) and MetaT o ol (Section 6) showing when refinement suffices and when learned comp onen ts add v alue, including a data-to-to ol ratio threshold b elow whic h learned re-ranking hurts. 2 Related W ork T o ol-Use in LLMs. T o ol learning has b ecome a standard w a y to extend LLM capabilities. T o olformer [Schic k et al., 2023] sho wed that mo dels can learn to ol use in a self-sup ervised manner. 3 T o olLLM [Qin et al., 2024] scaled to 16,000+ real-world APIs and introduced the T o olBenc h b enc hmark. MetaT o ol [Huang et al., 2024] b enc hmarks the sele ction decision—whether to use to ols and which to use—and finds that most LLMs still struggle with it. T o ol Retriev al and Reranking. As to ol sets grow, retriev al b ecomes necessary b efore selec- tion. CRAFT [Y uan et al., 2024] creates task-specific co de toolsets and retriev es from them at inference time. T oolRerank [Zheng et al., 2024] in tro duces hierarc hy-a ware reranking that dis- tinguishes b et ween seen and unseen to ols and adapts diversit y for single- vs. multi-tool queries. Our w ork shares the retriev al p erspective but fo cuses on refining the embedding space using outcome data rather than post-retriev al reranking. RL for T o ol Orc hestration. Recen t w ork frames tool use as sequential decision-making. Searc h-R1 [Jin et al., 2025] trains LLMs to reason ov er search results. T oRL [Li et al., 2025] scales to ol-in tegrated RL; T o olRL [Qian et al., 2025] shows that reward shaping alone can driv e to ol learning. OTC [W ang et al., 2025] p enalizes excessiv e tool calls while preserving accuracy , and several studies explore multi-ob jective rew ards balancing correctness, cost, and user preference [Su et al., 2025, Qian et al., 2025]. Con trastive Learning for Retriev al. The InfoNCE ob jective [v an den Oord et al., 2018] is the basis for most con trastiv e represen tation learning. Dense P assage Retriev al [Karpukhin et al., 2020] applied contrastiv e training to retriev al, and Sentence-BER T [Reimers & Gurevyc h, 2019] enabled efficient seman tic similarit y via siamese BER T net works—the backbone w e use. R3 [Zhou & Chen, 2025] applies reinforced con trastive learning to RAG retriev al, generating con trastive signals from en vironment in teractions, whic h is closely related to our Stage 3. Seman tic Routing. Pro duction LLM gatewa ys use seman tic routing for mo del selection, load balancing, and tool attachmen t. T o our knowledge, no prior work has studied outcome-a w are to ol selection in the context of high-throughput routing proxies, where latency constrain ts rule out LLM inference for selection. Existing RL-based metho ds assume the selector and executor share a mo del or that the selector has its o wn GPU—neither holds in pro duction routers, whic h are stateless CPU-bound pro xies handling thousands of concurren t requests. 3 F ramew ork: F rom Static Matc hing to Learned Orc hestration 3.1 Problem F orm ulation Let T = { t 1 , t 2 , . . . , t n } b e a set of a v ailable to ols, each with a description d i ∈ D . Given a user query q , the to ol selection problem is to c ho ose a subset S ⊆ T of size at most K that maximizes the exp ected quality of the do wnstream LLM resp onse, sub ject to a latency budget L max and a r esour c e c onstr aint R : max S ⊆T , | S |≤ K E [ qualit y ( q , S )] s.t. latency ( S ) ≤ L max , resources ( S ) ⊆ R (1) In pro duction routers, L max is typically 5–10 ms and R excludes GPU allo cation (which is reserv ed for mo del serving). These constrain ts eliminate any metho d requiring LLM inference for selection. Definition 1 (T o ol Selection as Retriev al) . Static to ol sele ction c omputes: S static ( q ) = top - K t i ∈T sim e ( q ) , e ( d i ) (2) wher e e ( · ) is an emb e dding function and sim ( · , · ) is c osine similarity or dot pr o duct. 4 Definition 2 (T o ol Selection as Decision-Making) . RL-b ase d appr o aches [Jin et al., 2025, Li et al., 2025, Su et al., 2025] formulate to ol sele ction as an MDP M = ( U , S , A , O , T , Z , r, ρ, γ ) wher e an or chestr ator p olicy π θ ( a k | h k ) sele cts to ols se quential ly with a multi-obje ctive r ewar d: R ( τ ) = M τ normalize d · P (3) wher e M τ enc o des to ol usage c ounts, outc ome, c ost, and latency, and P is a user pr efer enc e ve ctor. 3.2 Bridging the Gap: Offline Learning, Online Retriev al O A TS approximates the outcome-a ware b eha vior of Equation 3 within the constraints of Equa- tions 2 and 1. The design principle is to separate learning from serving: all outcome-a ware optimization happ ens offline from logged data, while the serving path remains a fast em b edding lo okup. W e write the resulting scoring function as: S OA TS ( q ) = top - K t i ∈T f ϕ e ψ ( q ) , e ψ ( d i ) , m i , h i ( q ) (4) where f ϕ is a learned scoring function, e ψ are (p otentially fine-tuned) embeddings, m i is to ol metadata, and h i ( q ) enco des historical outcome statistics for to ol t i on queries similar to q . The three OA TS stages correspond to optimizing differen t components of Equation 4: • Stage 1 replaces e ( d i ) (the stored to ol embeddings) via offline centroid interpolation, keeping f and h fixed. • Stage 2 learns f ϕ while keeping e and d i fixed. • Stage 3 jointly optimizes e ψ via contrastiv e learning. 3.3 Connection to RL Reward Normalization P olicy-gradient metho ds such as GRPO [Shao et al., 2024] compute a normalized adv antage o ver a batch of rollouts: A ( τ ) = R ( τ ) − mean τ ∈ T R ( τ ) std τ ∈ T R ( τ ) (5) This creates a contrastiv e signal: tra jectories with b etter to ol selections receive p ositive adv an- tage relative to the batc h. Our Stage 3 con trastive loss implemen ts the same idea in embedding space: L contrastiv e = − log exp( sim ( e ( q ) , e ( d + )) /τ ) P d − ∈N ( q ) exp( sim ( e ( q ) , e ( d − )) /τ ) (6) where d + is a to ol description that led to a p ositiv e outcome for query q , and N ( q ) contains descriptions of to ols that led to negative outcomes. This mirrors p olicy-gradien t adv an tage computation but op erates in em b edding space rather than ov er p olicy parameters, without the cost of tra jectory rollouts. 4 Metho d W e first describ e the core O A TS mec hanism—embedding-space outcome refinement—and then t wo learned extensions (re-ranking and contrastiv e adaptation) ev aluated as ablations. Figure 2 giv es an ov erview. 4.1 Core Mechanism: Outcome-Guided Embedding Refinemen t Resource profile. No inference cost, no additional parameters at serving time. The only requiremen t is a p erio dic offline batc h job (hourly or daily). 5 Online Serving Path (p er request, CPU, 3–7 ms) Query q Embed T ool DB Similarity Re-Rank T op- K Outcome Logs ( q, t, o ) triples Offline Learning (perio dic batch) Stage 1 Description Refinement 0 params, 0 ms Stage 2 Learned Re-Ranker 2.6K params → Re-Rank Stage 3 Contrastiv e Adapter 197K params → Embed refine embs outcomes Figure 2: The O A TS pip eline. T op: the online serving path runs on CPU in 3–7 ms. Bottom: offline learning from outcome logs. The core mechanism (Stage 1, dashed arrow) refines to ol em b eddings in the T o ol DB at zero serving cost. Stages 2 and 3 are ablation mec hanisms that optionally up date the Re-Rank and Em b ed comp onen ts respectively . What it do es and do es not change. O A TS-S1 do es not rewrite or mo dify to ol descriptions. The text stays the same. What changes is the emb e dding ve ctor stored in the to ol database: the original v ector e ( d i ) —computed from the description—is replaced by a refined vector that b etter reflects the to ol’s actual usage, as learned from outcome data. At serving time, the selection path is iden tical to the static baseline (embed query , compute similarities, return top- K ); only the stored tool v ectors differ. Motiv ating example. Consider a to ol called buildbetter whose description reads: “Chat with the knowledge of all your calls in BuildBetter (Zo om, GMeet, W eb ex). Start for free @ BuildBetter.ai.” This is a meeting-transcript to ol, but the description is a marketing tagline. When a user asks “ pr ovide the c omplete tr anscript of the str ate gy c al l with the exe cutives ,” a static em b edding mo del ranks the financial-data to ol QuiverQuantitative first (cosine simi- larit y 0.337) and the correct to ol second (0.276), b ecause “strategy . . . executiv es” is closer to “congressional. . . lobb ying. . . legislation” in em b edding space than to “BuildBetter.ai.” After S1 refinemen t, the buildbetter em b edding has b een pulled to ward the centroid of queries lik e “ r etrieve the tr anscript of the customer supp ort c al l ” and “ what wer e the key p oints fr om last we ek’s me eting ”—queries where it w as the correct to ol in the training set. Its similarity to the test query jumps from 0.276 to 0.440, while QuiverQuantitative barely mo ves (0.337 → 0.343). The description text is unchanged; only the vector in the database differs. Figure 3 illustrates the geometry; App endix A giv es the full walkthrough. Algorithm. The procedure is in Algorithm 1. W e explain each step b elow. Step 1–2: Outcome collection and partitioning. F rom pro duction logs (or ground-truth lab els in b enc hmarks), w e collect tuples ( q j , t i , o j ) where q j is a query , t i a retrieved to ol, and o j ∈ { 0 , 1 } indicates whether t i w as relev an t. F or eac h to ol t i , this gives a p ositive set Q + i (queries where t i w as correct) and a negativ e set Q − i (queries where t i w as retriev ed but wrong—hard negativ es). Because Q − i con tains only high-similarit y negatives rather than random ones, the repulsion signal is targeted: the to ol is pushed aw ay sp ecifically from the queries that currently cause false matc hes. 6 SaaS / productivity meeting transcripts / calls call management (CLINQ) “transcript of call” “key points from meeting” ¯ e + “create call reminder on CLINQ” ¯ e − buildbetter original e ( d i ) buildbetter refined ˆ e i test query QuiverQuant. + α · ¯ e + − β · ¯ e − Q + queries Q − queries test query pos. centroid neg. centroid / orig. / refined Figure 3: Geometry of O A TS-S1 for the buildbetter example. The original embedding (blue circle) sits in a generic “SaaS” region, far from the test query (star). Positiv e training queries Q + (teal dots) cluster around “meeting transcripts”; negativ e queries Q − (red dots) cluster around “call management.” The refinemen t pulls the to ol embedding to w ard ¯ e + and aw a y from ¯ e − , placing the refined em b edding (teal circle) closer to the test query . The description text nev er c hanges. Step 3: Cen troid in terp olation. Each to ol em b edding is mov ed tow ard its p ositiv e centroid and aw a y from its negativ e cen troid: ˆ e i = (1 − α ) · e ( d i ) + α · ¯ e ( Q + i ) − β · ¯ e ( Q − i ) (7) where ¯ e ( Q + i ) = 1 | Q + i | P q ∈ Q + i e ( q ) is the positive cen troid, ¯ e ( Q − i ) is the negativ e centroid, α = 0 . 3 con trols the attraction strength, and β = 0 . 1 controls the repulsion strength ( β < α b ecause false negativ es in Q − i are more common than false p ositiv es in Q + i ). The result is re-normalized to unit length. Step 4: Iterative refinemen t with momentum. A single pass ma y not fully correct em- b eddings, b ecause the outcome logs dep end on the current rankings. After iteration 1, the top- K retriev als change, exp osing new hard negatives. W e iterate N = 3 times, re-computing outcomes against up dated em b eddings at eac h step. T o preven t oscillation, eac h iteration blends with the previous estimate via momentum µ = 0 . 5 : e ( n ) = µ · e ( n − 1) + (1 − µ ) · ˆ e . Step 5: V alidation gate. The refined embeddings are accepted only if they improv e Recall@ K on a held-out v alidation set. This prev en ts drift from noisy outcomes—the system cannot de- grade b elow the static baseline. In our experiments (Section 6), the gate alw ays accepts. Wh y it w orks. App endix A giv es four work ed examples with real similarity scores. The refinemen t helps with three failure mo des of static embeddings: (1) semantic deco ys—to ols with sup erficially similar descriptions but different functions; (2) opaque descriptions—branded or generic names that do not embed well; and (3) lo w-similarit y regimes—when candidates score similarly and small interpolations flip rankings. 7 4.2 Ablation Mechanism A: Learned Re-Ranking W e next ask whether a learned comp onen t on top of refined embeddings impro v es selection, ev aluating a ligh tw eigh t MLP re-ranker as the simplest learned interv ention. Resource profile. 2,625 trainable parameters (architecture: [7 , 64 , 32 , 1] ). A dds < 0.5 ms p50 latency . Runs entirel y on CPU. The mo del binary is ∼ 11 KB. Arc hitecture. W e train a ligh tw eigh t MLP f ϕ : R d feat → [0 , 1] on features deriv ed from the candidate set: features ( q , t i ) = sim ( e ( q ) , e ( d i )) , ∆ sim , cat ( t i ) , sr i ( q ) , freq i , len ( q ) (8) where ∆ sim is the similarity gap to the next candidate, cat ( t i ) is a category indicator, sr i ( q ) is the historical success rate of to ol t i on queries in the same cluster as q , freq i is to ol usage frequency , and len ( q ) is the query length. The re-ranker is trained with binary cross-en trop y: L rerank = − 1 N N X j =1 o j log f ϕ ( features ( q j , t j )) + (1 − o j ) log(1 − f ϕ ( features ( q j , t j ))) (9) A t inference time, we retriev e C = αK candidates via static similarit y ( α = 5 ), then re- rank with f ϕ and return the top- K . The re-rank er needs enough training data p er to ol to b e useful—roughly 10 outcome examples per tool as a minimum (Section 6). 4.3 Ablation Mechanism B: Contrastiv e Em b edding A daptation The second ablation reshap es the embedding space directly via contrastiv e learning, rather than adding a p ost-ho c re-rank er. This ma y scale b etter to large to ol sets where per-to ol feature learning is data-starv ed. Resource profile. 197K adapter parameters (t wo-la y er pro jection head). At serving time, the adapter runs a single matrix m ultiply on the 384-dimensional embedding, adding < 0.1 ms. The adapter can b e fused into the em b edding mo del weigh ts for zero o verhead. T otal mo del size increase: < 1 MB. T riplet mining. F rom outcome logs, we mine triplets ( q , d + , d − ) where d + is the description of a to ol that pro duced a p ositiv e outcome for q , and d − is a har d ne gative —a tool with high em b edding similarit y to q but p o or outcomes. Hard negativ es are critical for learning the functional b oundaries that static embeddings miss. T raining ob jectiv e. W e train the adapter with InfoNCE loss [v an den Oord et al., 2018] (Equation 6), com bining in-batc h negativ es with mined hard negativ es. W e use a small learning rate ( 10 − 5 ) and early stopping on v alidation NDCG to av oid degrading general em b edding qualit y . W e train an adapter head rather than fine-tuning the full mo del, which reduces training cost, preserves base model qualit y , and allo ws instan t rollbac k b y disabling the adapter. Deplo yment. The adapter is placed alongside the embedding mo del at the router level. Since the output dimension is unc hanged, it is a drop-in replacemen t— ToolsDatabase , similarit y computation, and FilterAndRankTools all remain the same. T o ol embeddings are recomputed once after deplo ymen t ( < 2 seconds for 2,413 to ols). 8 5 Exp erimen tal Setup 5.1 Datasets T o olBenc h [Qin et al., 2024]. W e use the b enc hmark split from the T o olBenc h dataset, ex- tracting 2,413 unique APIs across 46 categories and 600 queries across three ev aluation settings of increasing difficulty: G1-Instruction (single-to ol, 200 queries), G1-Category (in tra-category , 200 queries), and G2-Instruction (multi-tool, 200 queries). W e treat the annotated relevant_apis as ground truth for tool selection ev aluation. MetaT o ol [Huang et al., 2024]. W e use the T ask 2 (to ol selection) data from the official MetaT o ol repository , whic h contains 4,287 queries across 199 to ols with four subtask t yp es: similar c hoices (995 queries), sp ecific scenarios (1,800 queries), reliability issues (995 queries), and multi-tool selection (497 queries). Eac h query includes ∼ 10 candidate to ols and h uman- annotated ground-truth tool(s). 5.2 Ev aluation Metrics W e report standard retriev al metrics: • Recall@ K : F raction of ground-truth to ols present in the top- K selected tools. • Precision@ K : F raction of selected to ols that are ground-truth relev ant. • NDCG@ K : Normalized Discoun ted Cum ulativ e Gain measuring ranking qualit y . • MRR : Mean Recipro cal Rank of the first relev ant to ol. W e report results for K ∈ { 1 , 3 , 5 } to capture differen t operational settings. 5.3 Baselines 1. BM25 : Sparse lexical retriev al o ver to ol descriptions. 2. Static Em b edding (SE) : Dense retriev al using sen tence-transformers with original to ol descriptions (analogous to the curren t seman tic router). 3. SE + Lexical : Static em b edding with the lexical/tag/name/category weigh ted combination from the seman tic router’s FilterAndRankTools . 4. Random : Random tool selection (low er b ound). 5.4 O A TS Configurations 1. O A TS-S1 : Core mec hanism only (em b edding refinemen t via outcome-guided centroid inter- p olation). 2. O A TS-S2 : Core + ablation A (embedding refinemen t + MLP re-ranker). 3. O A TS-S3 : Core + ablation A + ablation B (em b edding refinemen t + MLP re-ranker + con trastive adapter). 5.5 Implemen tation Details The base em b edding mo del is all-MiniLM-L6-v2 [Reimers & Gurevych, 2019] (22M parameters, 384 dimensions), represen tative of models deploy ed in pro duction routers. The re-ranker MLP is [7 , 64 , 32 , 1] (2,625 parameters, ReLU, drop out 0.1). The contrastiv e adapter is [384 , 256 , 384] (197K parameters), trained with learning rate 10 − 5 , temp erature τ = 0 . 07 , up to 5 ep ochs with early stopping. All exp erimen ts use α = 5 for the re-ranking candidate p ool. 9 Outcome lab els. Both b enc hmarks provide h uman-annotated to ol relev ance p er query . W e use these as outcome lab els: o j = 1 if tool t j is in the annotated relev ant set for q j , and o j = 0 otherwise. In pro duction, o j w ould come from downstream signals (task completion, user satisfaction); the framew ork is agnostic to the source. T rain/test proto col. All metho ds are ev aluated on the same held-out 30% test split (fixed 70/30 split, deterministic seed). OA TS stages use the 70% training p ortion for learning; Stage 2 further sub-splits training into 85/15 train/v alidation. Latency measuremen t. All latencies are measured on a single CPU core (no GPU), cov ering em b edding computation, similarity search, and an y re-ranking o verhead. W e rep ort p50 and p99. 6 Results W e ev aluate eac h metho d on selection accuracy and serving cost. 6.1 Core Result: Zero-Cost Refinemen t MetaT o ol (199 to ols, 1,287 test queries). This b enc hmark cov ers four subtask t yp es in- cluding adversarially similar to ol choices and multi-tool selection. Static em b edding achiev es Recall@1 = 0.716 and NDCG@5 = 0.869. OA TS em b edding refinemen t improv es this to Re- call@1 = 0.830 and NDCG@5 = 0.940, with no added serving cost (p50: 3.53 ms vs. 3.66 ms). App endix A shows concrete before/after examples. T o olBenc h (2,413 to ols, 180 test queries). With a larger to ol set, all metho ds are stressed. BM25 (pure lexical) achiev es NDCG@5 of 0.853, exceeding static embedding at 0.834—suggesting that T o olBenc h queries hav e enough lexical ov erlap with API descriptions for sparse retriev al to work w ell. OA TS em b edding refinement reac hes NDCG@5 of 0.848 (+1.7% o ver dense em- b edding) at sligh tly lo wer latency (p50: 4.42 ms vs. 4.59 ms). The more mo dest gain compared to MetaT o ol is expected: with 2,413 to ols, the em b edding space is densely pac ked and centroid in terp olation has less ro om to separate to ols without affecting neigh b ors. 6.2 Ablation: Do Learned Comp onents Help F urther? T able 5 summarizes the incremental con tribution and cost of eac h learned component on top of refined embeddings. MLP re-rank er (2.6K parameters). The re-rank er h urts on T o olBench (NDCG@5: 0.823 vs. 0.834 baseline) and is flat on MetaT o ol (0.869 vs. 0.869). On T o olBench, 357 training queries spread across 2,413 to ols giv es < 0 . 15 positive examples p er to ol. Ev en on MetaT o ol ( ∼ 13 examples/to ol), the MLP adds nothing. Either the feature set (similarity gap, category indicator, etc.) lacks discriminativ e p o wer for this task, or the MLP cannot generalize from sparse p er-to ol statistics. In short, a learned re-rank er is not guaran teed to help and should be v alidated before deplo ymen t. Con trastive adapter (197K parameters). The adapter reaches NDCG@5 of 0.842 on T o ol- Benc h (+0.008 ov er baseline) and 0.931 on MetaT o ol (+0.062). On MetaT o ol the adapter p er- forms comparably to em b edding refinemen t (0.931 vs. 0.940), suggesting b oth capture similar outcome signals at this scale. Unlike the MLP , the adapter reshapes the full em b edding space via hard-negative contrastiv e learning rather than learning p er-to ol features. 10 6.3 Latency and Resource Analysis T able 6 shows that all OA TS stages stay within single-digit millisecond p50 latency on both b enc hmarks; Stage 1 is comparable to or faster than the baseline. Cost-efficiency metric. W e define accuracy gain p er millisecond (AG/ms) as ∆ NDCG@5 / ∆ latency. When accuracy impro v es with no latency increase, we assign ∞ . T able 2 summarizes. T able 2: Cost efficiency: NDCG@5 gain p er additional millisecond of p50 latency vs. SE baseline. ∞ means accuracy improv ed with no latency increase. MetaT o ol T o olBenc h Metho d ∆ NDCG@5 AG/ms ∆ NDCG@5 A G/ms SE (baseline) — — — — Em b. refinemen t (core) +0.071 ∞ +0.014 ∞ + Contrastiv e (ablation B) +0.062 ∞ +0.008 ∞ SE + Lexical -0.053 — +0.020 ∞ Em b edding refinemen t improv es accuracy at no latency cost on b oth b enc hmarks. On T o ol- Benc h, SE + Lexical ac hieves the best accuracy (0.854), but O A TS refinemen t is close (0.848) without lexical features. 6.4 Key Findings F our findings for practitioners: 1. Start with embedding refinement. It is free at inference time, needs no co de changes, and giv es the largest gains on MetaT o ol (NDCG@5 0.869 → 0.940) with meaningful improv emen t on T o olBenc h (0.834 → 0.848). 2. An MLP re-rank er do es not reliably help. It fails to impro ve on either b enc hmark and h urts on T o olBenc h. Do not assume a learned re-ranker will help without v alidation on your data. 3. Con trastive adaptation is an alternativ e. On MetaT o ol it reac hes NDCG@5 0.931 vs. 0.940 for refinement. Useful for teams that cannot mo dify embedding tables but can sw ap mo dels. 4. Lexical features remain strong on T o olBenc h. BM25 b eats dense em b eddings, and SE + Lexical gets the b est NDCG@5 (0.854). Refinement should be ev aluated on top of lexical features in production. 6.5 Comparison with LLM-Based T o ol Selection T able 3 compiles published LLM-based results on MetaT o ol [Huang et al., 2024] alongside OA TS. On the “similar choices” subtask—the hardest split where to ols share ov erlapping functionalit y— O A TS-S1 reac hes 83.4%, roughly 10 p oin ts ab o ve Vicuna-7b (73.5%) and 14 p oin ts ab o ve Chat- GPT (69.1%), while running ∼ 1,000 × faster on CPU without an y language-model inference. Ca veats apply: (1) MetaT o ol rep orts CSR (correct selection rate) while we rep ort Recall@1— these coincide for single-to ol queries but may differ for m ulti-to ol ones; (2) LLM-based selection uses full query text with in-context descriptions, while retriev al compresses tools in to fixed em b eddings; (3) LLMs can handle nov el tools zero-shot, whereas O A TS needs outcome data to impro ve past the static baseline. 11 T able 3: Comparison with LLM-based tool selection on the MetaT o ol “similar c hoices” subtask (295 test queries). LLM results rep ort Correct Selection Rate (CSR) from Huang et al. [2024]; retriev al-based results rep ort Recall@1 on the same subtask and split. Both metrics measure whether the top-selected to ol is correct. Metho d A ccuracy Latency Hardw are LLM-b ase d (fr om publishe d b enchmarks) ChatGPT (GPT-3.5) † 69.1% ∼ 1–3 s API / GPU Vicuna-7b † 73.5% ∼ 2–5 s GPU Vicuna-13b † 58.2% ∼ 3–8 s GPU LLaMA2-13b † 44.1% ∼ 2–5 s GPU A verage (9 LLMs) † ∼ 57% — GPU R etrieval-b ase d (ours, same subtask, CPU-only) BM25 42.7% 0.4 ms CPU Static Embedding (SE) 66.4% 3.7 ms CPU O A TS-S1 (em b. refine) 83.4% 3.5 ms CPU † CSR on “to ol selection with similar choices” subtask [Huang et al., 2024]. LLM latencies are approximate wall-clock times for full inference. Other benchmarks tell a similar story: AppSelectBench [Chen et al., 2025] rep orts GPT-5 at 63.3% on 100+ desktop tools, and GT A [W ang et al., 2024] found GPT-4 completing few er than 50% of real-world to ol-use tasks. LLM-based to ol selection is b oth slo w and unreliable; ligh tw eigh t retriev al with outcome refinemen t offers a b etter cost–accuracy tradeoff for routing. T able 4: Selection p erformance on T o olBench (2,413 to ols, 180 test queries) and MetaT o ol (199 to ols, 1,287 test queries). Same 30% test split for all metho ds. Best in b old , second underlined. T o olBenc h MetaT o ol Metho d R@1 R@3 R@5 NDCG@5 R@1 R@3 R@5 NDCG@5 Random 0.238 0.656 0.829 0.692 0.096 0.308 0.492 0.298 BM25 0.392 0.772 0.921 0.853 0.397 0.617 0.753 0.595 SE 0.382 0.765 0.897 0.834 0.716 0.904 0.958 0.869 SE + Lexical 0.388 0.783 0.919 0.854 0.640 0.860 0.927 0.816 O A TS-S1 0.381 0.793 0.915 0.848 0.830 0.964 0.986 0.940 O A TS-S2 0.372 0.774 0.896 0.823 0.716 0.909 0.954 0.869 O A TS-S3 0.387 0.778 0.906 0.841 0.810 0.956 0.988 0.931 7 Discussion 7.1 Wh y Not Use an LLM for Selection? One might ask whether the LLM itself could select its o wn to ols. There are three problems with this: 1. Circular dep endency . T o ols must b e attac hed b efor e inference begins, so the LLM w ould need a separate pre-flight call, doubling latency and cost. 2. Resource con tention. GPU capacity is the b ottlenec k in LLM serving. At 10K rps, an 8B selection mo del would consume 5–10 GPUs just for routing. 12 T able 5: Ablation: incremental cost and con tribution of each OA TS comp onen t. Same 30% test split. Em b edding refinement adds zero cost; the MLP re-rank er degrades T o olBench due to data sparsit y ( < 0.15 examples/to ol). Serving Added T o olBenc h MetaT o ol params latency NDCG@5 ∆ NDCG@5 ∆ SE (baseline) 0 — 0.834 – 0.869 – + Emb. refinement (core) 0 0 ms 0.848 +0.014 0.940 +0.071 + MLP re-rank er (ablation A) 2.6K < 0.5 ms 0.823 -0.011 0.869 +0.000 + Contrastiv e (ablation B) 197K < 0.1 ms 0.841 +0.007 0.931 +0.062 T able 6: Inference latency p er request (CPU-only). All metho ds sta y within single-digit mil- lisecond p50. MetaT o ol T o olBenc h Metho d p50 (ms) p99 (ms) p50 (ms) p99 (ms) GPU SE (baseline) 3.66 6.47 4.59 9.83 No O A TS-S1 3.53 5.99 4.42 6.19 No O A TS-S2 3.92 6.91 5.04 16.38 No O A TS-S3 3.87 7.25 4.95 11.11 No 3. Latency . T o ol selection happ ens b efore the request reaches any mo del p o ol. Adding 500 ms of LLM inference on top of 200–2,000 ms mo del inference increases total latency b y 25–250%, directly degrading time-to-first-tok en. O A TS a voids all three by learning offline and deplo ying only a refined embedding table on CPU. 7.2 Deplo ymen t Arc hitecture O A TS in tegrates in to existing router infrastructure with minimal c hanges: • Em b edding refinemen t runs as a cron job: read outcome logs, compute centroid up dates, v alidate, and sw ap the embedding table. No co de changes to the serving path. • MLP re-rank er (optional) adds a re-scoring call after FindSimilarTools . Gate behind a data-densit y c hec k ( ≥ 10 examples/to ol). • Con trastive adapter (optional) replaces the em b edding model in ToolsDatabase . Output dimension is unc hanged, so no downstream c hanges. Rollbac k is instan taneous. 7.3 When to A dd Complexit y Beyond Refinemen t Based on our results: • |T | < 200 : Embedding refinemen t alone. Our MetaT o ol results (199 to ols, +8.3% NDCG) confirm this. • |T | = 50–500, > 5K logs: Refinement + MLP re-rank er, but only if the data-to-tool ratio exceeds ∼ 10:1. Belo w that, it hurts. • |T | > 500 , > 10K logs: Refinement + contrastiv e adapter. Con trastive learning scales b etter than point wise re-ranking for large to ol sets. Skip the MLP unless data is abundant ( > 50 examples/to ol). 13 Figure 4: Stage 1 con v ergence o v er iterations. Left: MetaT o ol. Righ t: T o olBenc h. Figure 5: Selection p erformance across all metho ds. Left: MetaT o ol. Right: T o olBenc h. 7.4 Limitations Outcome signal qualit y . Our exp eriments use a binary proxy (match/no-matc h with ground truth). Pro duction outcomes are richer—a to ol migh t b e selected but un used, used but erroring, or used but sub optimal. The framework accepts an y scalar signal; ric her signals should yield stronger improv emen ts. Cold start. New to ols ha ve no outcome history and fall back to static similarity . They warm up as data accumulates. Em b edding mo del ceiling. All stages are b ounded b y the base mo del’s capacit y . If all-MiniLM-L6-v2 cannot distinguish t wo tools’ semantic domains, refinemen t will not help. A larger base mo del w ould pro vide orthogonal gains. Ev aluation scope. W e measure selection quality , not end-to-end task completion. Goo d selection do es not guaran tee the LLM uses to ols correctly , but it is a prerequisite: the righ t to ol m ust be in the con text windo w. 8 Conclusion W e presented O A TS, which incorporates outcome feedbac k into tool selection by in terp olating to ol em b eddings offline to ward the centroid of queries where they succeed. This adds no pa- rameters, latency , or GPU cost at serving time, yet improv es NDCG@5 from 0.869 to 0.940 on MetaT o ol and from 0.834 to 0.848 on T oolBench, within single-digit millisecond CPU budgets. The ablation study shows that learned comp onen ts do not alwa ys help. The MLP re-rank er degrades accuracy when outcome data is sparse (b elo w a ∼ 10:1 data-to-to ol ratio), while the con trastive adapter provides mo dest but consisten t gains for larger tool sets. F or pro duction LLM routing, to ol selection should b e treated as a learned retriev al problem, but the first step should b e the simplest one. A zero-cost em b edding refinemen t, informed 14 b y pro duction outcomes, captures most of the av ailable gains. More complex comp onents or LLM-based selection rarely justify their cost at the routing la yer. References Timo Schic k, Jane Dwivedi-Y u, Rob erto Dessì, et al. T o olformer: Language mo dels can teach themselv es to use to ols. In NeurIPS , 2023. Y ujia Qin, Shihao Liang, Yining Y e, et al. T o olLLM: F acilitating large language mo dels to master 16000+ real-w orld APIs. In ICLR , 2024. Y ue Huang, Jia wen Shi, Y uan Li, et al. MetaT o ol b enc hmark for large language mo dels: Deciding whether to use to ols and whic h to use. In ICLR , 2024. Vladimir Karpukhin, Barlas Oguz, Sew on Min, et al. Dense passage retriev al for op en-domain question answering. In EMNLP , 2020. Bo wen Jin, Hansi Zeng, Zhenrui Y ue, et al. Searc h-R1: T raining LLMs to reason and lev erage searc h engines with reinforcement learning. arXiv pr eprint arXiv:2503.09516 , 2025. Xuefeng Li, Haoy ang Zou, and Pengfei Liu. T oRL: Scaling to ol-in tegrated RL. arXiv pr eprint arXiv:2503.23383 , 2025. Cheng Qian, Emre Can A cikgoz, Qi He, et al. T o olRL: Reward is all tool learning needs. arXiv pr eprint arXiv:2504.13958 , 2025. Hongru W ang, Cheng Qian, W anjun Zhong, et al. Acting less is reasoning more! T eaching mo del to act efficien tly . arXiv pr eprint arXiv:2504.14870 , 2025. Hong jin Su, Shizhe Diao, Ximing Lu, et al. T o olOrc hestra: Elev ating in telligence via efficient mo del and to ol orc hestration. arXiv pr eprint arXiv:2511.21689 , 2025. Zhihong Shao, Peiyi W ang, Qihao Zh u, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language mo dels. arXiv pr eprint arXiv:2402.03300 , 2024. Jia wei Zhou and Lei Chen. Optimizing retriev al for RA G via reinforced contrastiv e learning. arXiv pr eprint arXiv:2510.24652 , 2025. Tian yi Chen, Michael Solo dk o, Sen W ang, et al. AppSelectBench: Application-level to ol selection b enc hmark. arXiv pr eprint arXiv:2511.19957 , 2025. Jize W ang, Zerun Ma, Yining Li, et al. GT A: A benchmark for general to ol agents. In NeurIPS Datasets and Benchmarks T r ack , 2024. Nils Reimers and Iryna Gurevyc h. Sen tence-BER T: Sen tence embeddings using Siamese BER T- net works. In EMNLP , 2019. Aaron v an den Oord, Y azhe Li, and Oriol Viny als. Represen tation learning with con trastive predictiv e coding. arXiv pr eprint arXiv:1807.03748 , 2018. Lifan Y uan, Y angyi Chen, Xingyao W ang, et al. CRAFT: Customizing LLMs b y creating and retrieving from specialized toolsets. In ICLR , 2024. Y uanhang Zheng, Peng Li, W ei Liu, et al. T o olRerank: Adaptiv e and hierarch y-aw are reranking for to ol retriev al. In LREC-COLING , 2024. 15 A O A TS-S1: Step-b y-Step W alkthrough W e trace Algorithm 1 on a real MetaT o ol test query . All n umbers are from the 70/30 train/test split with all-MiniLM-L6-v2 embeddings. A.1 Setup: The Query and Candidate T o ols T est query: “Could y ou please searc h for and provide the complete and v erbatim transcript of the strategy call that took place last week b et ween ourselv es and the executiv es?” The MetaT o ol b enc hmark pro vides 11 candidate to ols for this query . The ground-truth answ er is buildbetter , a meeting-transcript tool. T able 7 lists all candidates with their descriptions. T able 7: Candidate to ols for the example query , with original descriptions from MetaT o ol. T o ol Description buildbetter ⋆ Chat with the knowledge of all your calls in BuildBetter (Zo om, GMeet, W eb ex). Start for free @ BuildBetter.ai QuiverQuantitative Access data on congressional sto c k trading, lobb ying, insider trading, and prop osed legislation. MixerBox_WebSearch Search and summarize the web with our customized searc h engine pow ered b y Go ogle Search API! brandfetch Retrieve company and brand data including logos, col- ors, fonts, and other brand information. C3_Glide Get live aviation data for pilots. Ask questions ab out MET ARs, T AF s, NOT AMs. . . locator Displa ying the current co ordinates of the ISS and the names of the curren t crew. speechki_tts The easiest wa y to conv ert texts to ready-to-use audio. MemoryTool A learning application with spaced rep etition function- alit y . CTCP Analyze eligibility criteria in ClinicalT rials.gov. StrologyTool Pro vides astrology services for you. ExchangeTool Seamlessly conv ert currencies with our integrated cur- rency conv ersion to ol. ⋆ Ground-truth to ol. The correct tool’s description says “BuildBetter.ai”—a branded name that tells an embedding mo del nothing ab out meeting transcripts. The query men tions “executiv es” and “strategy call,” whic h ha v e lexical affinity to business/finance tools. A.2 Step 1: Static Retriev al (Before Refinement) W e enco de the query and all 11 candidate descriptions with the base embedding mo del, then rank by cosine similarit y: Rank T o ol Cosine sim 1 QuiverQuantitative 0.337 2 buildbetter ⋆ 0.276 3 MixerBox_WebSearch 0.254 4 brandfetch 0.228 5 C3_Glide 0.200 (6 mor e c andidates b elow 0.18) 16 Static embedding puts the correct to ol at rank 2. QuiverQuantitative wins b ecause “congres- sional. . . lobb ying. . . legislation” sits in a similar embedding region as “strategy call. . . executiv es.” The margin is 0 . 337 − 0 . 276 = 0 . 061 . A.3 Step 2: Collecting Outcome Data (Algorithm 1, Steps 1–2) F rom the 70% training split, w e collect the queries where buildbetter appears in the ground- truth relev an t tools ( Q + ) and queries where it w as retriev ed in the top- K but was not relev ant ( Q − ): P ositive queries Q + (4 unique training queries): + 1 . “Retriev e the complete and unedited transcript of the customer supp ort call I had with John Do e. . . ” + 2 . “I am unable to lo cate the complete and accurate transcript of yesterda y’s standup meet- ing. . . ” + 3 . “Can y ou find the complete and accurate transcript of the last sales call I had, specifically with Acme Corp. . . ” + 4 . “I had a strategy meeting last week, what w ere the key p oin ts we discussed?” Hard-negativ e queries Q − (7 training queries where buildbetter was retrieved but wrong): − 1 . “Can the CLINQ plugin displa y the detailed information of the total duration for all y our calls. . . ” − 2 . “Can you help me add a new page to m y Notion workspace?” − 3 . “Can you create a recurring call reminder for m y w eekly team meetings on CLINQ?” The positive queries cluster around “retrieving transcripts from meetings and calls.” The nega- tiv es men tion “calls” but are about call managemen t (CLINQ) or unrelated to ols—cases where buildbetter was a false p ositiv e. A.4 Step 3: Computing the Refined Em b edding (Algorithm 1, Step 3) W e enco de all Q + queries, compute their cen troid ¯ e + , and do the same for Q − . Then w e apply the up date rule from Equation 7: ˆ e buildbetter = 0 . 7 · e ( buildbetter ) | {z } retain original + 0 . 3 · ¯ e ( Q + ) | {z } attract to ward transcripts − 0 . 1 · ¯ e ( Q − ) | {z } repel from call-management Geometric interpretation. The original em b edding sits in a generic “productivity SaaS” region. The p ositiv e cen troid ¯ e ( Q + ) sits in a “meeting transcripts” region. The interpolation pulls the to ol to ward transcripts and pushes it a wa y from call managemen t. After re-normalization, the to ol lives where transcript-retriev al queries concentrate. A.5 Step 4: Re-Ranking After Refinemen t With the refined buildbetter embedding (and refined embeddings for all other tools that had training data), w e re-rank the same 11 candidates: 17 Rank T o ol New sim ∆ 1 buildbetter ⋆ 0.440 +0.164 2 QuiverQuantitative 0.343 +0.005 3 MixerBox_WebSearch 0.283 +0.029 4 brandfetch 0.253 +0.026 5 C3_Glide 0.243 +0.043 (6 mor e c andidates b elow 0.16) The correct to ol mo ves from rank 2 to rank 1, gaining +0 . 164 in similarit y . QuiverQuantitative barely mov es ( +0 . 005 ) b ecause its training signal (congressional trading queries) is unrelated to transcripts. The margin reverses from − 0 . 061 to +0 . 097 . Wh y the correction is large. buildbetter had only 4 p ositiv e and 7 negativ e training queries. But the positives cluster tigh tly around “call transcript retriev al,” giving a directional cen troid. The original em b edding was far from this cluster b ecause the description (“BuildBet- ter.ai”) is opaque. This is where refinemen t helps most: when the description fails to comm uni- cate function, outcome data fills the gap. A.6 A dditional Examples T able 8 summarizes three additional cases where O A TS-S1 corrects a static embedding failure, spanning different MetaT o ol subtask t yp es. T able 8: A dditional O A TS-S1 corrections on MetaT o ol test queries. “SE sim” and “S1 sim” are cosine similarities to the c orr e ct tool b efore and after refinement. “SE top-1” is the wrong to ol selected by static em b edding. Query (truncated) Correct SE top-1 SE S1 “Sho w me div erse and am using memes. . . ” lsongai PolishTool 0.287 0.450 “Discoun t co des for b o oking hotels or flights?” Discount TripTool 0.585 0.691 “Meaning of arigatou in Japanese?” speak ResearchFinder 0.077 0.149 Memes query . PolishTool (“creative inspiration”) outscores lsongai (“AI-p o w ered con tent. . . memes”) b y +0 . 066 under SE. After refinement, lsongai gains +0 . 163 from enterta inment-related train- ing queries. F ailure mo de: seman tic decoy—similar descriptions, differen t function. Discoun t co des query . TripTool mentions “discoun ted hotel,” creating lexical ov erlap ( +0 . 057 margin). Outcome data pulls Discount tow ard coup on/promo queries, flipping the margin to +0 . 015 . F ailure mo de: lexical o verlap masking functional in tent. Japanese translation query . All candidates score b elo w 0 . 15 —near random. “sp eak” do es not em b ed w ell for translation queries. T raining queries ab out language learning nearly double its similarity ( +0 . 072 ). F ailure mo de: opaque name in a lo w-similarity regime. A.7 Summary of F ailure P atterns Three recurring patterns emerge: 18 1. Seman tic deco ys : Similar descriptions, differen t function. The positive centroid separates them by pulling eac h tool to ward its actual use cases. 2. Opaque descriptions : Generic or branded names (“BuildBetter.ai,” “Sp eak”) that em b ed- dings cannot in terpret. Outcome data comp ensates. 3. Lo w-similarity regimes : When all candidates score similarly , small centroid interpolations flip rankings. 19 Algorithm 1 OA TS-S1: Iterative Outcome-Guided Embedding Refinemen t Require: T o ol set T with embeddings { e ( d i ) } , training queries with ground-truth labels, iter- ations N , step sizes α , β , momentum µ = 0 . 5 Ensure: Refined embeddings { e ′ ( d i ) } for eac h to ol 1: Initialize e (0) ( d i ) ← e ( d i ) for all t i ∈ T 2: for n = 1 to N do 3: // Step 1: Build outcome logs using curren t em b eddings 4: for eac h training query q j do 5: Retriev e top- K to ols by sim ( e ( q j ) , e ( n − 1) ( d i )) 6: Label eac h retriev ed tool: o = 1 if t i ∈ ground_truth ( q j ) , else o = 0 7: end for 8: // Step 2: P artition queries b y tool and outcome 9: for eac h tool t i do 10: Q + i ← { q j : t i retriev ed for q j and o j = 1 } 11: Q − i ← { q j : t i retriev ed for q j and o j = 0 } 12: end for 13: // Step 3: Compute refined embedding p er tool 14: for eac h tool t i with | Q + i | ≥ 1 do 15: ¯ e + ← 1 | Q + i | P q ∈ Q + i e ( q ) (p ositiv e centroid) 16: ˆ e i ← (1 − α ) e ( n − 1) ( d i ) + α ¯ e + 17: if | Q − i | ≥ 1 then 18: ¯ e − ← 1 | Q − i | P q ∈ Q − i e ( q ) (negativ e cen troid) 19: ˆ e i ← ˆ e i − β ¯ e − (rep el from failures) 20: end if 21: ˆ e i ← ˆ e i / ∥ ˆ e i ∥ (re-normalize) 22: // Step 4: Momen tum blend with previous iteration 23: if n > 1 then 24: e ( n ) ( d i ) ← µ e ( n − 1) ( d i ) + (1 − µ ) ˆ e i 25: e ( n ) ( d i ) ← e ( n ) ( d i ) / ∥ e ( n ) ( d i ) ∥ 26: else 27: e ( n ) ( d i ) ← ˆ e i 28: end if 29: end for 30: end for 31: // Step 5: V alidation gate 32: Ev aluate { e ( N ) ( d i ) } on held-out v alidation set 33: A ccept e ′ ( d i ) ← e ( N ) ( d i ) only if Recall@ K improv es ov er e ( d i ) 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment