Temporal Straightening for Latent Planning
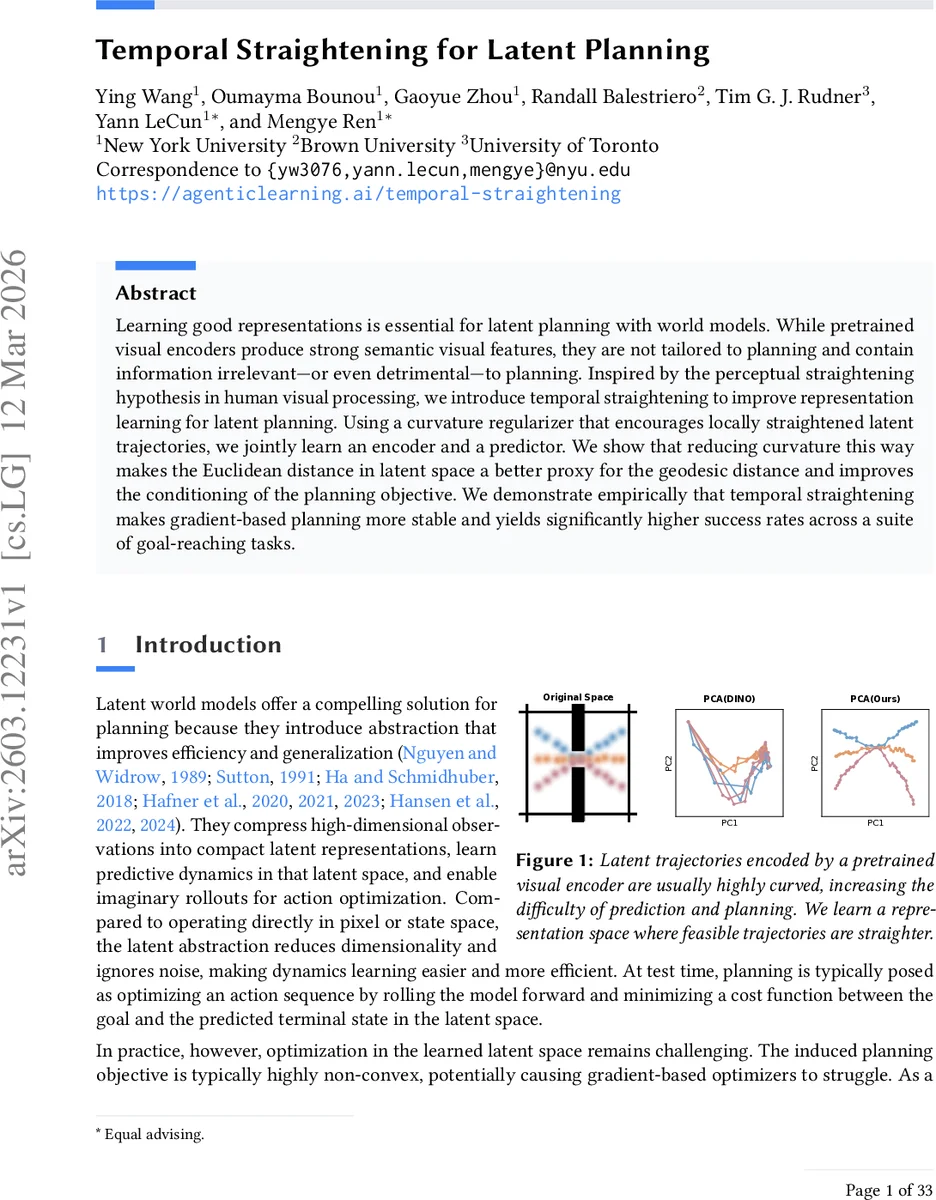
Learning good representations is essential for latent planning with world models. While pretrained visual encoders produce strong semantic visual features, they are not tailored to planning and contain information irrelevant – or even detrimental – to planning. Inspired by the perceptual straightening hypothesis in human visual processing, we introduce temporal straightening to improve representation learning for latent planning. Using a curvature regularizer that encourages locally straightened latent trajectories, we jointly learn an encoder and a predictor. We show that reducing curvature this way makes the Euclidean distance in latent space a better proxy for the geodesic distance and improves the conditioning of the planning objective. We demonstrate empirically that temporal straightening makes gradient-based planning more stable and yields significantly higher success rates across a suite of goal-reaching tasks.
💡 Research Summary
The paper addresses a fundamental mismatch between high‑quality visual features produced by large‑scale pretrained encoders and the needs of latent‑space planning. While such encoders (e.g., DINOv2) capture rich semantic information, they also retain low‑level details irrelevant to dynamics, leading to highly curved latent trajectories. Curved trajectories make Euclidean distances in latent space a poor proxy for the true geodesic distance along feasible transitions, which in turn yields ill‑conditioned planning objectives and unstable gradient‑based optimization.
Inspired by the perceptual straightening hypothesis in human vision, the authors propose “temporal straightening”: a curvature regularizer that penalizes the angle between consecutive latent velocity vectors. Concretely, for three successive latent embeddings (z_t, z_{t+1}, z_{t+2}) they define velocities (v_t = z_{t+1} - z_t) and (v_{t+1} = z_{t+2} - z_{t+1}) and maximize their cosine similarity (C = \frac{v_t \cdot v_{t+1}}{|v_t||v_{t+1}|}). The straightening loss (L_{\text{curv}} = 1 - C) is added to the standard prediction MSE loss, yielding a total objective (L_{\text{total}} = L_{\text{pred}} + \lambda L_{\text{curv}}). A stop‑gradient on the target latent prevents collapse, and the method requires no negative samples or extra hyper‑parameters beyond the weighting (\lambda).
The authors provide a rigorous theoretical analysis for linear latent dynamics (z_{t+1}=Az_t+Ba_t). They define an (\epsilon)-straight transition as one where (|A-I|2 \le \epsilon). Under this assumption, they derive an upper bound on the effective condition number of the planning Hessian: (\kappa{\text{eff}}(H) \le \kappa(B)^2 \frac{1+\epsilon}{1-\epsilon} 2^{K-1}), which for (\epsilon \le 0.5) simplifies to (\kappa_{\text{eff}}(H) \le \kappa(B)^2 e^{6\epsilon K}). Hence, as the dynamics become “straighter” (smaller (\epsilon)), the Hessian remains well‑conditioned even for long horizons, guaranteeing faster and more stable convergence of gradient‑based planners. For nonlinear predictors, the authors argue that controlling state‑dependent Jacobians would yield analogous benefits, leaving a promising direction for future work.
Empirically, the method is evaluated on four benchmark goal‑reaching environments: Wall, PointMaze (UMaze and a medium‑size maze), and PushT. The baseline is DINO‑WM, which uses frozen DINOv2 features directly for planning. Two encoder configurations are tested: (1) a frozen DINOv2 backbone with a lightweight trainable projector, and (2) a fully trainable CNN encoder. In all settings, adding the curvature regularizer dramatically straightens latent trajectories (visualized in Figure 2), aligns Euclidean distances with true progress, and produces smoother loss landscapes (Figure 4). Quantitatively, open‑loop gradient planners achieve 20–60 % higher success rates, while model‑predictive control (MPC) gains 20–30 % over the baseline.
The paper also discusses practical considerations such as collapse prevention via stop‑gradient, the simplicity of the regularizer compared to contrastive or reconstruction losses, and the fact that no expert trajectories are required. Limitations include the local nature of the curvature term (only three‑frame windows) and the lack of a full theoretical treatment for highly nonlinear dynamics.
In summary, temporal straightening offers a lightweight yet powerful way to reshape latent representations for planning. By explicitly encouraging locally straight latent paths, it makes Euclidean distances more meaningful, improves the conditioning of the planning objective, and leads to substantially better performance across diverse tasks without sacrificing the expressive power of large‑scale pretrained visual encoders. This work opens a clear avenue for integrating geometric regularization into future latent‑space model‑based reinforcement learning and robotics pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment