More Than Memory Savings: Zeroth-Order Optimization Mitigates Forgetting in Continual Learning
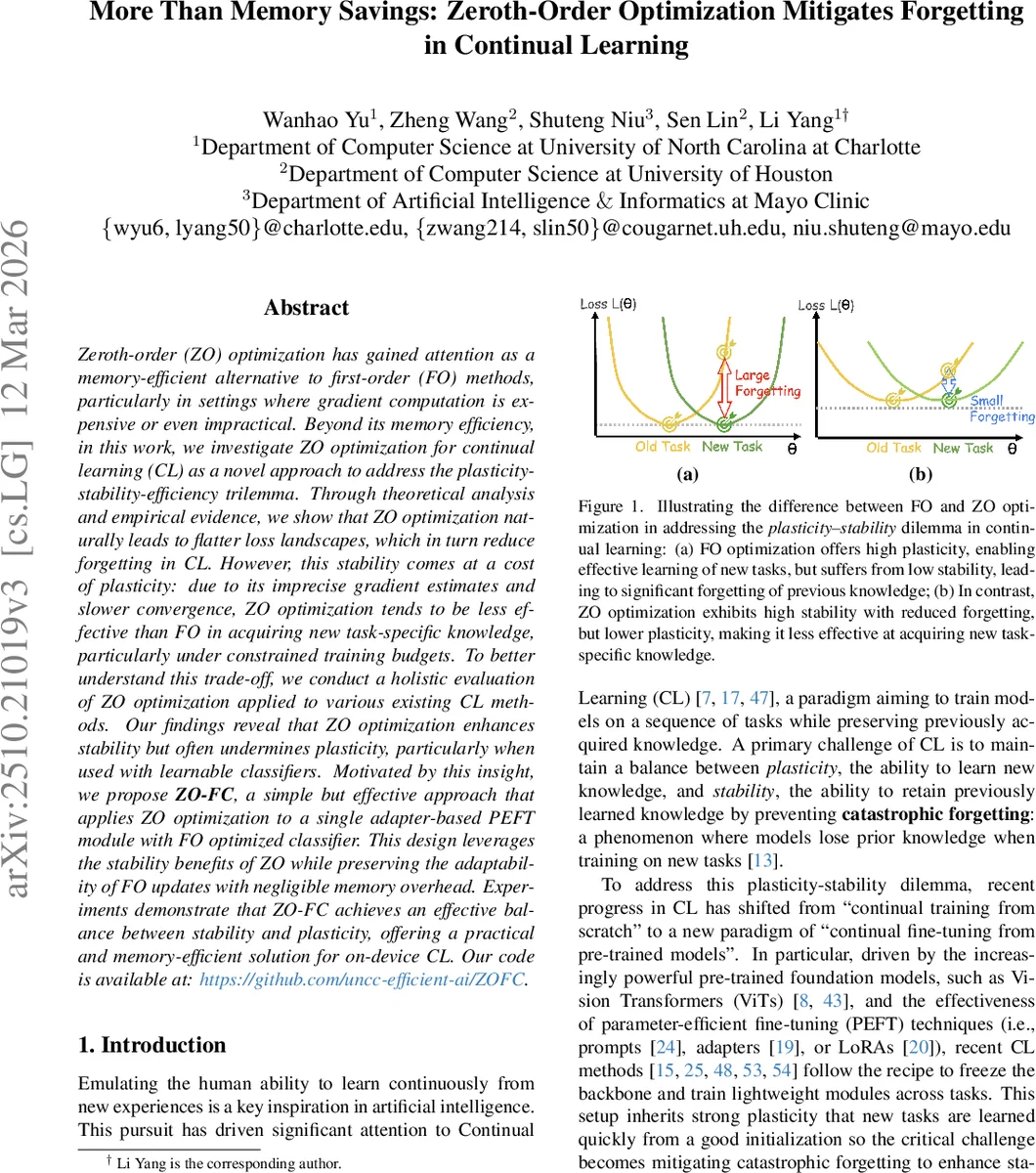
Zeroth-order (ZO) optimization has gained attention as a memory-efficient alternative to first-order (FO) methods, particularly in settings where gradient computation is expensive or even impractical. Beyond its memory efficiency, in this work, we investigate ZO optimization for continual learning (CL) as a novel approach to address the plasticity-stability-efficiency trilemma. Through theoretical analysis and empirical evidence, we show that ZO optimization naturally leads to flatter loss landscapes, which in turn reduce forgetting in CL. However, this stability comes at a cost of plasticity: due to its imprecise gradient estimates and slower convergence, ZO optimization tends to be less effective than FO in acquiring new task-specific knowledge, particularly under constrained training budgets. To better understand this trade-off, we conduct a holistic evaluation of ZO optimization applied to various existing CL methods. Our findings reveal that ZO optimization enhances stability but often undermines plasticity, particularly when used with learnable classifiers. Motivated by this insight, we propose ZO-FC, a simple but effective approach that applies ZO optimization to a single adapter-based PEFT module with FO optimized classifier. This design leverages the stability benefits of ZO while preserving the adaptability of FO updates with negligible memory overhead. Experiments demonstrate that ZO-FC achieves an effective balance between stability and plasticity, offering a practical and memory-efficient solution for on-device CL.
💡 Research Summary
Continual learning (CL) aims to train models on a sequence of tasks while preserving knowledge from earlier tasks, a challenge often framed as the plasticity‑stability‑efficiency trilemma. Recent CL research has shifted toward “continual fine‑tuning” of large pre‑trained foundation models, freezing the backbone and adapting lightweight parameter‑efficient fine‑tuning (PEFT) modules such as prompts, adapters, or LoRAs. This paradigm yields high plasticity because the frozen backbone already provides strong representations, but the reliance on first‑order (FO) gradient‑based optimization leads to sharp minima that are highly sensitive to subsequent parameter updates, thereby compromising stability and causing catastrophic forgetting.
The paper investigates zeroth‑order (ZO) optimization as an alternative that may naturally mitigate forgetting while offering substantial memory savings. ZO methods, exemplified by Simultaneous Perturbation Stochastic Approximation (SPSA), estimate gradients solely from function evaluations: a random perturbation Δ is added and subtracted from the current parameters θ, the loss difference is scaled by the perturbation magnitude ε, and the resulting estimate is used in a standard optimizer (e.g., SGD). Because ZO does not require back‑propagation, activation storage is avoided and training memory approaches inference‑time levels.
The authors first provide a theoretical link between ZO and the CL trilemma. They recall that forgetting after learning task t+1 can be expressed as the increase in the cumulative loss of previous tasks, F_t ≈ ½ Δθᵀ H_t Δθ, where H_t is the Hessian of the old‑task loss and λ_max(H_t) measures curvature (sharpness). Prior work shows that flatter minima (lower λ_max) reduce sensitivity to parameter changes and thus lower forgetting. ZO optimization, however, implicitly minimizes a smoothed objective L_ε(θ)=E_Δ
Comments & Academic Discussion
Loading comments...
Leave a Comment