A Bipartite Graph Approach to U.S.-China Cross-Market Return Forecasting
This paper studies cross-market return predictability through a machine learning framework that preserves economic structure. Exploiting the non-overlapping trading hours of the U.S. and Chinese equity markets, we construct a directed bipartite graph…
Authors: Jing Liu, Maria Grith, Xiaowen Dong
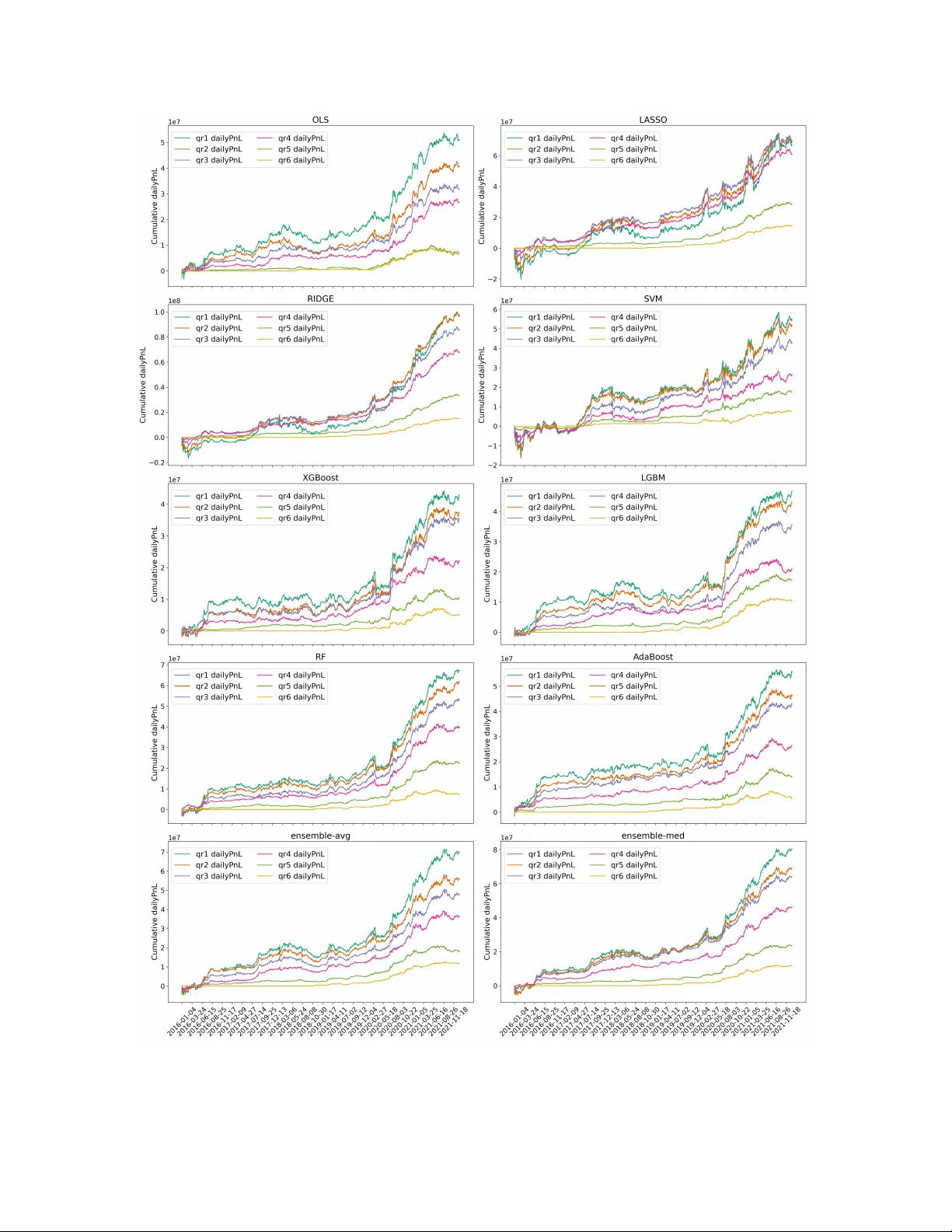
A Bipartite Graph Approac h to U.S.-China Cross-Mark et Return F orecasting Jing Liu ∗ 1 , Maria Grith 2 , Xiao wen Dong 3 , and Mihai Cucuringu 4,1,5 1 Departmen t of Statistics, Universit y of Oxford, UK 2 Finance Departmen t, Neoma Business School, F rance 3 Departmen t of Engineering Science, Universit y of Oxford, UK 4 Departmen t of Mathematics, Universit y of California Los Angeles, US 5 Oxford-Man Institute of Quan titative Finance, Univ ersity of Oxford, UK Abstract This pap er studies cross-mark et return predictability through a mac hine learning framework that preserv es economic structure. Exploiting the non-ov erlapping trading hours of the U.S. and Chinese equit y markets, w e construct a directed bipartite graph that captures time-ordered pre- dictiv e link ages b et w een sto c ks across markets. Edges are selected via rolling-window h yp othesis testing, and the resulting graph serv es as a sparse, economically in terpretable feature-selection la y e r for do wnstream mac hine learning models. W e apply a range of regularized and ensem- ble metho ds to forecast op en-to-close returns using lagged foreign-market information. Our results rev eal a pronounced directional asymmetry: U.S. previous-close-to-close returns contain substan tial predictive information for Chinese in trada y returns, whereas the reverse effect is limited. This informational asymmetry translates into economically meaningful p erformance differences and highligh ts ho w structured mac hine learning framew orks can unco ver cross-market dep endencies while maintaining interpretabilit y . ∗ Corresp o nding author; Email: jing.liu@exeter.ox.ac.uk 1 Keyw ords: Return prediction, cross-market analysis, machine learning, bipartite graphs JEL Classification: G17, G15, C58 1 In tro duction Return prediction remains a cen tral problem in empirical asset pricing and portfolio managemen t, yet its statistical difficult y is amplified by noise, non-stationarity , and nonlinear dep endence structures in financial markets. While machine learning metho ds hav e b ecome increasingly prev alen t in single- mark et forecasting applications ( Chen et al. , 2015 ; W ang , 2024 ; Y ang and He , 2026 ), comparativ ely little atten tion has b een paid to sto c k-lev el cross-mark et return prediction under realistic trading- session timing constrain ts. Most existing studies on return forecasting fo cus on predicting within a single mark et. F or example, Chen et al. ( 2015 ) apply a Long Short-T erm Memory (LSTM) mo del to predict sto c k returns in the Chinese mark et, while W ang ( 2024 ) studies U.S. sto c k return prediction using neural net work mo dels. Similarly , Y ang and He ( 2026 ) prop ose an in traday volume-based uncertaint y pro xy to predict return direction in the Chinese market. These studies demonstrate the growing use of machine learning metho ds in single-mark et settings. By contrast, researc h on cross-market in teractions has largely emphasized con temp oraneous co-mo v emen t, spillov ers, or causal transmission rather than explicit sto c k-level return prediction. F or instance, Eun and Shim ( 1989 ) analyze the in ternational transmission of sto c k market mov ements using vector autoregression, Baur and Jung ( 2006 ) ev aluate contemporaneous return correlations using GAR CH mo dels, and Rapach et al. ( 2013 ) do cumen t the leading role of the U.S. market through causalit y tests. Sarw ar ( 2014 ) examine the relationship b et ween U.S. mark et uncertaint y and Europ ean equity returns during crisis p eriods, while Jung et al. ( 2024 ) study in terdep endency patterns b et w een the U.S. and Chinese markets using threshold o vernigh t co-mov ement pro cesses. Only a limited num b er of studies hav e attempted explicit cross-market predictive analysis using mac hine learning mo dels. F or example, Lee and Y o o ( 2020 ) apply a deep neural net w ork to fuse information from the U.S. and South Korean mark ets for index-lev el return prediction, and Kumar et al. ( 2024 ) prop ose a graph neural netw ork to mo del volatilit y spillov ers across markets. How ever, 2 most existing work op erates at the index lev el, and to our knowledge no prior study has examined sto c k-lev el cross-market return prediction b et ween the U.S. and Chinese markets under realistic trading-session timing. Our study fills this gap by dev eloping a directed bipartite graph framew ork for sto c k-lev el cross-mark et return forecasting b et ween the U.S. and Chinese equit y markets. W e construct a time-ordered bipartite graph that selects cross-market predictors based on rolling-window screening, thereb y capturing directed predictive links across non-ov erlapping trading sessions. The selected predictors are then embedded into a suite of ten mac hine learning mo dels to forecast next-session op en-to-close (OPCL) returns in each mark et. Empirically , we demonstrate a pronounced directional asymmetry: U.S. mark et information is substantially more informativ e for predicting Chinese sto c k returns than vice versa. Sharp e Ratios (SRs) obtained when forecasting Chinese sto c ks using U.S. predictors consistently exceed those in the reverse direction. W e further sho w that b oth the graph-based selection mec hanism and cross-mark et information contribute materially to predictive p erformance. Sector-lev el patterns in the estimated graph rev eal economically in terpretable transmission c hannels across markets. F or instance, sector-level aggregation of the bipartite graph rev eals meaningful cross-sector transmission patterns rather than a blo c k-diagonal structure. Our fo cus is on do cumen ting directional cross-market predictability and the structure of the asso ciated dep endency graph rather than designing a fully implementable trading strategy . Accordingly , p erformance metrics are rep orted pre-transaction-cost and without liquidity-optimized weigh ting, and should b e interpreted as evidence of predictiv e asymmetry rather than deploy able alpha. Our setting is economically and statistically distinctive b ecause the U.S. and Chinese equit y sessions do not o v erlap. This implies that U.S. previous-close-to-close (p vCLCL) information is fully observ ed b efore the subsequent Chinese OPCL window b egins, yielding a clean timing structure for cross-mark et prediction. The directed bipartite graph can therefore b e interpreted as a time-ordered map of p oten tial information transmission c hannels across markets, rather than a contemporaneous correlation net work. The structure of the pap er is arranged as follows. Section 2 pro vides a detailed review of related w ork. Section 3 describ es the data we use and the definitions of financial terms inv olved. Section 4 in tro duces the graph-based metho dology for feature selection and prediction. Section 5 presents the 3 ev aluation metrics and exp erimen tal results. Finally , Section 6 summarizes the study and discusses future researc h directions. 2 Related Literature 2.1 Cross-Mark et Analysis and Prediction Global financial markets hav e b ecome increasingly interconnected with the in tensification of inter- national economic and financial integration. As a result, sho c ks, volatilit y , and information can propagate rapidly across countries through multiple transmission channels. A substantial b ody of researc h therefore examines cross-market link ages, including price discov ery , return co-mov ement, v olatility spillov ers, and broader measures of financial interconnectedness, typically within economet- ric framew orks. Such interconnectedness has motiv ated studies of directional information flow and mark et leadership across countries. F or example, Liu and An ( 2011 ) examine information transmis- sion and price discov ery b et ween the U.S. and Chinese mark ets. Asgharian et al. ( 2013 ) study ho w economic and geographical relationships across coun tries affect sto c k market returns. Mohammadi and T an ( 2015 ) analyze daily returns and volatilit y dynamics in the U.S. and Chinese markets. Clemen ts et al. ( 2015 ) inv estigate global transmission of news and v olatilit y across financial markets, while Ahmad et al. ( 2018 ) explore mark et interconnectedness through return and volatilit y spillov ers. Huang and Liu ( 2023 ) construct a financial net work to c haracterize cross-market risk spillo vers and interaction top ology . These studies primarily emphasize contemporaneous relationships and transmission mec hanisms rather than explicit sto c k-level return prediction. Bey ond studying cross-mark et information propagation, a gro wing strand of researc h incorp orates signals from m ultiple markets into forecasting models to improv e predictive p erformance. Suc h in tegration t ypically relies on feature engineering that embeds external market indicators, deep learning architectures that fuse multi-mark et inputs, or graph-based mo dels designed to capture in ter-market dep endencies. F or example, Thenmozhi and Sarath Chand ( 2016 ) use foreign index information to enhance index prediction, Lee and Y o o ( 2020 ) develop m ultimo dal deep learning mo dels for cross-market index forecasting, and Lin et al. ( 2025 ) leverage external futures mark et data to predict mov ements of the China Securities Index. Gong et al. ( 2025 ) prop ose a cross-market v olatility forecasting framework exploiting risk transmission across markets. 4 Ho wev er, muc h of this literature fo cuses on aggregate indices or volatilit y measures rather than sto c k-lev el return prediction. Moreov er, netw ork structures are often emplo y ed to characterize spillo vers and interconnectedness rather than as predictive screening devices for individual sto c ks. Explicit sto c k-lev el cross-market return forecasting under time-ordered, non-ov erlapping trading sessions remains largely unexplored. Applying our metho dology in this setting is therefore nov el. Empirically , the directed bipartite structure reveals pronounced asymmetry in cross-mark et pre- dictabilit y , with U.S. sto c ks exerting substan tially stronger predictive influence on Chinese sto c ks than vice v ersa. These findings align with the literature do cumen ting asymmetric cross-mark et return predictability with a leading role for the U.S.. Rapach et al. ( 2013 ) show that lagged U.S. mark et returns p ossess substantial predictive p o wer for foreign equity mark ets, while the rev erse predictabilit y is considerably w eaker, highligh ting the cen tral role of the U.S. in global price disco very . Similarly , Siliversto vs ( 2017 ) finds that the predictive influence of the U.S. is particularly pronounced during market down turns, reinforcing the view that U.S. information dominates international return dynamics. F ocusing sp ecifically on China-related mark ets, Mohammadi and T an ( 2015 ) do cumen t significan t return and volatilit y spillo vers from the U.S. to China mainland and Hong Kong, with w eaker effects in the opp osite direction. 2.2 Graph Metho ds in Finance Graph metho ds provide a w a y to represent relationships among financial entities, rather than treating each entit y in isolation. The use of graphs aligns with the view that financial systems are in terconnected ( Bardoscia et al. , 2021 ), and that mo deling these interconnections can improv e forecasting and risk-managemen t ( Chen and F an , 2025 ). Many financial phenomena, such as asset co-mo vemen ts, spillov ers and supply-chain link ages, are naturally represented as graphs. Bipartite graphs, which originate in graph theory and net work science as representations of relationships b et ween tw o distinct sets of no des ( Guillaume and Latapy , 2006 ; Newman , 2018 ), pro vide a natural framew ork for mo deling interactions across disjoint groups. In economics and finance, bipartite structures arise in contexts suc h as credit netw orks, pro duction netw orks, and supply-c hain relationships, where connections form b et ween t w o heterogeneous sets of en tities rather than within a single homogeneous mark et. F or instance, Kley et al. ( 2020 ) study extremal dep endence for op erational risk by a bipartite graph. W ang and Chen ( 2020 ) design a bipartite- 5 graph-based recommender for cro wdfunding with sparse data. In econometrics, W u et al. ( 2024 ) prop ose a quasi-maximum lik eliho od approach to estimate a bipartite netw ork influence mo del. A growing literature applies graph neural netw orks (GNNs) and related architectures to financial forecasting tasks. W ang et al. ( 2021 ) provide a survey of GNN metho ds in financial applications, including sto c k mov ement prediction, loan default risk assessment, recommender systems, fraud detection, and other financial even ts. Chen et al. ( 2018 ) apply a Graph Conv olutional Netw ork (GCN) to integrate information from related companies and improv e sto c k price prediction. Li et al. ( 2021 ) prop ose an LSTM-relational GCN that captures inter-stock relationships through correlation matrices to predict ov ernight mov ements. Capp oni et al. ( 2024 ) dev elop a GNN framew ork for asset pricing using supply-chain data. Zhang et al. ( 2025 ) incorp orate cross-sto c k spillov er effects to forecast multiv ariate realized volatilities, and Luo et al. ( 2025 ) construct a semantic company relationship graph to enhance sto c k price forecasting. Some recent empirical work extends graph-based forecasting to richer and more dynamic arc hitectures. F or example, Cheng and Li ( 2021 ) employ a Graph Atten tion Netw ork (GA T) to mo del momentum spillov ers in sto c k returns, while Kumar et al. ( 2024 ) introduce a temp oral GA T that com bines graph conv olution and attention mec hanisms to capture structural and temp oral dep endencies across global market indices. Lee et al. ( 2025 ) sho w that GCN- and GA T-based mo dels can outp erform conv entional machine learning baselines by exploiting symmetric interdependencies among financial indices. Related research also incorp orates m ultimo dal information in to graph construction. Cheng et al. ( 2022 ) integrate financial ev en ts and news in to a multimodal GNN framew ork for price prediction, and Liu et al. ( 2024 ) develop a m ultiscale dynamic GCN that com bines textual and numerical inputs to forecast sto c k mov ements. Despite these adv ances, most graph-based forecasting mo dels construct within-market netw orks, where edges are defined through contemporaneous similarit y , correlation, or learned attention mec hanisms. Suc h graphs typically capture symmetric interdependencies among assets within a single mark et and are primarily used to enhance predictiv e performance through ric her represen tation learning. In con trast, our framew ork constructs a directed bipartite graph across tw o distinct mark ets, where edges are formed through time-ordered predictiv e screening rather than contemporaneous asso ciation. The resulting graph serves as a feature-selection mechanism for sto c k-level cross-m ar k et return prediction, explicitly exploiting the non-ov erlapping trading sessions b et ween the U.S. and 6 Chinese mark ets. 2.3 Mac hine Learning in Finance Driv en b y increasing data a v ailability and computational pow er, the application of mac hine learning in finance has expanded substan tially in recent years. Compared to c l assical time-series and econometric mo dels, suc h as ARIMA and GARCH, mac hine learning approaches are often considered b etter suited to high-dimensional and nonlinear settings. A surv ey b y Rundo et al. ( 2019 ) do cumen ts that mac hine-learning-based systems demonstrate sup erior ov erall p erformance compared to traditional approac hes. Another survey by Kelly et al. ( 2023 ) highlights how machine learning metho ds ha v e b ecome established in empirical financial researc h. Key applications include forecasting asset returns, v olatility estimation, fraud detection, and algorithmic trading. F orecasting asset returns remains inheren tly difficult due to low signal-to-noise ratios, structural instability , and nonlinear dep endence patterns. Moreov er, evidence of predictiv e gains is often sensitive to mo del sp ecification and feature construction. These challenges partly motiv ate the adoption of flexible machine learning metho ds and the incorp oration of richer information sets. Given recen t developmen ts in mac hine learning, its applications in finance can b e group ed into sev eral ma jor categories: traditional machine learning metho ds, deep learning metho ds, and large-language-mo del-based metho ds. F or traditional machine learning metho ds, Huang et al. ( 2005 ) employ supp ort v ector mac hines (SVM) to predict the direction of weekly price mov ements. Kumar and Thenmoz h i ( 2006 ) inv estigate the application of SVM and Random F orests (RF) in predicting the direction of a mark et index. Cakra and T risedya ( 2015 ) incorp orate sentimen t information and use a basic linear regression mo del for sto c k price prediction. Thenmozhi and Sarath Chand ( 2016 ) predict sto c k prices of sev eral ma jor indices using supp ort vector regression. Y ang and He ( 2026 ) prop ose a no vel proxy and apply Extreme Gradien t Bo osting (X GBo ost) to predict return directions in the Chinese mark et. F or deep learning metho ds, Chen et al. ( 2015 ) use an LSTM mo del for sequence learning and Chinese sto c k return forecasting. W ang ( 2024 ) inv estigates the p erformance of neural netw ork mo dels in predicting sto c k returns. A survey b y Gao et al. ( 2024 ) highlights the expanding use of deep neural netw orks, conv olutional neural netw orks, recurrent neural net works, and other adv anced arc hitectures in financial contexts. F or large-language-mo del-based metho ds, Nie et al. ( 2024 ) review how Large Language Mo dels 7 (LLMs) are applied in finance. Ding et al. ( 2023 ) demonstrate the effectiv eness of LLMs in forecasting sto c k returns. Chen et al. ( 2023 ) propose a framework that in tegrates ChatGPT and GNN to forecast sto c k mov ements. Chen et al. ( 2024 ) inv estigate the abilit y of ChatGPT for sto c k return forecasting. Despite these adv ances, most existing studies fo cus on single-mark et return prediction and rely primarily on information dra wn from within the same market. Additional information is often shown to improv e predictive p erformance, y et it is typically incorp orated in contemporaneous or symmetric settings. V ery few studies employ mac hine learning metho ds in sto c k-lev el cross-market forecasting en vironments c haracterized by async hronous trading sessions and explicitly time-ordered information flo ws. Differing from existing studies, our framework combines directed bipartite screening with a second-stage machine learning prediction step, enabling systematic exploitation of cross-mark et dep endencies, temp oral ordering, and asymmetric predictive structure. 3 Data The stock data used in this study co ver several of the world’s largest mark ets b y mark et capitalization, including the New Y ork Sto c k Exc hange (NYSE), Nasdaq, the Shanghai Sto c k Exchange (SSE), and the Shenzhen Sto c k Exchange (SZSE). Daily U.S. sto c k data are sourced from the Cen ter for Researc h in Security Prices 1 (CRSP), while daily Chinese sto c k data are sourced from the Wind Database 2 . The data span the p erio d from 2014 through 2021. This selection of data enables us to in vestigate the transferability of signals across the world’s largest and most liquid equity markets op erating under non-ov erlapping trading sessions. In this pap er, we rely on the market excess return of a sto c k, defined as the difference b et ween the raw return of its price and the return of an exc hange-traded fund (ETF) represen ting ov erall sto c k mark et p erformance. W e use both p vCLCL returns and OPCL returns in one mark et to forecast OPCL returns in the other market (see Section 4.2 for a more detailed justification of this setting). The p vCLCL logarithmic ra w return for sto c k i on day t can b e calculated b y: R ( t ) i, pvCLCL = log p ( t ) i, cl p ( t − 1) i, cl , (1) 1 h ttps://www.crsp.org/ 2 h ttps://www.wind.com.cn/ 8 while the OPCL logarithmic ra w return for sto c k i on day t can b e calculated b y: R ( t ) i, OPCL = log p ( t ) i, cl p ( t ) i, op . (2) Here p ( t ) i, cl and p ( t ) i, op denote the closing and op ening price of sto c k i on da y t resp ectiv ely . Then the mark et excess return of sto c k i on day t can b e defined as: r ( t ) i = R ( t ) i, pvCLCL − R ( t ) ETF , pvCLCL (3) for p vCLCL returns, or r ( t ) i = R ( t ) i, OPCL − R ( t ) ETF , OPCL (4) for OPCL returns. W e use SPY as the market ETF in the U.S. and 513500.SH in China. W e select 500 sto c ks with the highest av erage market capitalizations o ver the years cov ered in the dataset from each country . 3 Unless otherwise sp ecified, all returns mentioned in the follo wing con tents refer to market excess returns. T o mitigate the influence of extreme v alues and p oten tial outliers, we apply winsorization to the training-sample returns of eac h sto c k, replacing observ ations b elo w the 0.5th p ercen tile with the 0.5th p ercen tile v alue and those ab o v e the 99.5th p ercen tile with the 99.5th p ercen tile v alue. 4 Metho dology This study aims to predict individual sto c k returns using a cross-market directed bipartite graph. The prediction framework consists of t wo main stages. First, w e build a directed bipartite graph using return data from tw o mark ets within a lo ok-bac k training windo w. This graph identifies cross-mark et predictive links: if a directed edge connects t wo sto c ks, the sto c k at the source of the edge is treated as a predictor for forecasting the returns of the sto c k at the destination. In the 3 This universe selection relies on full-sample information (av erage market capitalization ov er 2014–2021) and therefore in tro duces a mechanical look-ahead comp onen t. W e adopt it as a pragmatic wa y to fo cus on contin uously traded, highly liquid sto c ks and reduce missing observ ations. How ever, we caution that a fully inv estable design w ould require time- t reconstitution based solely on lagged market capitalization information. Imp ortan tly , our main qualitativ e finding is directional asymmetry (the influence of the U.S. market on the Chinese market b eing stronger than the reverse effect), which is unlikely to b e driven solely by this selection pro cedure. Nonetheless, we consider time-lo cal univ erse formation as a v aluable extension. 9 second stage, w e apply v arious mac hine learning metho ds to forecast returns based on the identified relationships. 4.1 Directed Bipartite Graph A graph can b e defined as G = ( V , E ), where V represen ts the v ertex set and E represen ts the edge set. G is called bipartite if V can b e divided into tw o disjoin t sets X and Y suc h that all edges ha v e one endp oint in X and another in Y . W e denote a directed edge from v i to v j as e ij with asso ciated w eight w ij . F or a bipartite graph G , the biadjacency matrix B is defined where rows corresp ond to no des in X , columns corresp ond to no des in Y , and each entry b ij con tains the weigh t w ij of edge e ij . W e represent t w o different markets, the source market X and target market Y , as tw o v ertex sets, where sto cks in each market are interpreted as no des. Edges originate from no des in X and p oin t to no des in Y . F or a sp ecific p erio d of time w , whic h is the lo ok-back training window in the exp erimen t, the daily return v ector of the j th sto c k in market X is x = [ r ( t − l − w ) X j , r ( t − l − w +1) X j , ..., r ( t − l − 1) X j ] ⊺ , where r ( t ) X j is the return of the j th sto c k on da y t . The daily return v ector of the i th sto c k in mark et Y is y = [ r ( t − w ) Y i , r ( t − w +1) Y i , ..., r ( t − 1) Y i ] ⊺ . The lag parameter l captures the temp oral ordering induced b y non-ov erlapping trading sessions, ensuring that returns in the source market precede those in the target mark et. Note that in our study the calculation with t uses the trading calendar rather than the natural calendar. This time-ordered screening pro cedure induces a directed bipartite graph, where no des in the source mark et X are c onnected to no des in the target market Y whenev er statistically significant predictiv e links are detected within the rolling training window. Figure 1 pro vides a schematic illustration of this bipartite structure. F or each ordered pair ( X j , Y i ), we estimate a univ ariate linear regression of y on x within the 10 Figure 1: Sc hematic illustration of the directed bipartite graph linking source-market sto c ks to target-mark et sto c ks based on significan t predictive relationships. lo ok-bac k windo w. W e quantify such relationship using the t-statistic from regression, defined as t β = β s e / p P w i =1 ( x i − ¯ x ) 2 . (5) Here, β is the slop e co efficien t of the simple linear regression, given b y β = co v ( x , y ) v ar( x ) and s e denotes the standard error of the regression s e = r SSE w − 2 . SSE denotes the sum of squared residuals, SSE = w X i =1 ( y i − ˆ y i ) 2 , where ˆ y = β x + α , and α = ¯ y − β ¯ x . Here, ˆ y i is the fitted v alue of y i , and α is the in tercept of the regression line. The use of pairwise univ ariate screening serves primarily as a computationally tractable sparsifi- cation device rather than as a formal structural inference pro cedure. Similar marginal screening approac hes are common in high-dimensional predictive settings where the ob jective is feature selection rather than causal identification (see, e.g., F an and Lv ( 2008 ); Hastie et al. ( 2009 )). W e recognize that testing across a large num b er of sto ck pairs raises multiple-testing considerations and ma y in tro duce spurious edges in finite samples (cf. Harv ey et al. ( 2015 )). In principle, false disco very rate or m ultiple-comparison corrections could b e applied. How ev er, our primary goal is to construct a predictive graph that enhances out-of-sample forecasting p erformance rather than to perform statistical inference on individual edges. W e therefore treat the screening step as a mo del-selection heuristic and assess its v alidity through out-of-sample forecasting p erformance and 11 robustness analyses. Figure 2 shows the return time series for an example pair of U.S. and Chinese technology sto c ks, CDNS (pvCLCL returns) and 002410.XSHE (OPCL returns), smo othed with a three-day moving a verage for visualization purp oses. Here l = 1 and w = 250. The t-statistic from the regression of 002410.XSHE on CDNS is high during the p erio d sho wn, illustrating a statistically significant cross-mark et predictiv e relation within the training window under the linear screening sp ecification. Figure 2: Example time series of U.S. pvCLCL returns for CDNS and Chinese OPCL returns for 002410.XSHE ov er the rolling training window. The series are sho wn for illustrative purp oses to highligh t cross-market co-mov ement underlying the detected predictive link. In our setting, either the U.S. or the Chinese market can b e treated as the source market X , with the target market of prediction serving as mark et Y . After p erforming the regression t-test ab ov e for all ordered sto ck pairs in market X and Y , w e set a threshold to filter the resulting t-statistics by magnitude. W e introduce an explicit threshold parameter, denoted by τ , to facilitate later reference. In our exp eriments, we set τ = 2, and select edges whenever | t β | > τ , corresp onding approximately to conv entional significance levels under standard asymptotic approximations. If the magnitude of the t-statistics for x and y is larger than τ , we select the return of X j on day t − l to predict the return of Y i on day t . This selection forms a directed edge in the graph p ointing from X j to Y i . Note that the thresholding step is used purely as a sparsification mechanism, aimed at denoising the signal and improvi ng computational tractability rather than constituting a formal multiple-testing correction. A sample directed bipartite graph is shown in Figure 1 , where X j and X k on da y t − l are selected to predict Y i on da y t . This construction yields a time-lagged cross-mark et predictiv e 12 net work that can b e naturally interpreted as a directed bipartite graph. Figure 3 presents a section of the heatmap corresp onding to the biadjacency matrix of the U.S.–Chinese sto ck netw ork on 21 Octob er 2021. T o illustrate the structure more clearly , we select 25 representativ e sto cks from each sector. F or sectors containing fewer than 25 sto cks in the original dataset, all a v ailable sto cks are included, resulting in 254 U.S. sto cks and 235 Chinese sto cks in this visualization. Each row corresp onds to a Chinese sto ck, while each column represents a U.S. sto c k. The colour intensit y represen ts the v alue of the t-statistic, and black grid lines delineate sectoral b oundaries. This visualization shows that cross-market predictive connectivity is not restricted to within-sector interactions (which would lead to a blo c k-diagonal structure), thereby motiv ating a flexible cross-mark et predictive framework. Figure 3: Heatmap of the directed biadjacency matrix for a representativ e trading day . Ro ws corresp ond to Chinese sto c ks and columns to U.S. sto cks, group ed by sector. Each entry represents the t-statistic from the rolling-window regression of Chinese returns on lagged U.S. returns. Colour in tensity reflects the magnitude and sign of the predictive relationship. T o summarize cross-market structure o ver time, we av erage the daily biadjacency matrices across the full sample p erio d, obtaining an aggregate representation of predictive link ages. W e 13 then compute, for this time-av eraged matrix, the median of absolute t-statistics within each sector- b y-sector blo ck of the corres p onding heatmap (Figure 4 ). This aggregation highlights systematic sectoral dep endencies rather than sto c k-sp ecific effects. F or example, the financial services sector in the Chinese mark et exhibits strong predictive links with the utilities sector in the U.S. market. Figure 4: Sector-lev el heatmap of the absolute median t-statistic in the time-a veraged biadjacency matrix of the directed cross-market graph. Rows corresp ond to Chinese sectors and columns to U.S. sectors. Each en try rep orts the median absolute predictiv e strength across all sto c k pairs within the corresp onding sector-b y-sector blo ck. W e also examine the cross-market relations ov er time. Figure 5 shows how the in-degree of all no des in set Y ev olves ov er time. F or each da y , the 25th, 50th, and 75th p ercentiles of the in-degree distribution are computed across all target no des. The blue curves represent the num b er of U.S. p vCLCL no des selected to predict Chinese OPCL returns, while the red curves corresp ond to the n umber of Chinese p vCLCL no des selected to predict U.S. OPCL returns. As time progresses, the in-degree in b oth directions increases, suggesting strengthening cross-market predictive connectivity o ver the sample p erio d. 4.2 Predictiv e Analysis with Machine Learning In order to predict the return of sto c k Y i on day t , we use training data from da y t − w to day t − 1 for mark et Y and from da y t − l − w to da y t − l − 1 for mark et X . Since we wish to predict 14 Figure 5: The figure shows the 25th, 50th, and 75th p ercen tiles of the in-degree distribution of target no des by day . US-CN represents the num b er of U.S. pvCLCL nodes selected to predict Chinese OPCL returns, while CN-US represen ts the n umber of Chinese pvCLCL no des selected to predict U.S. OPCL returns. r ( t ) Y i b y using information from mark et X , we select n sto c ks, i.e., X 1 , X 2 , ..., X n from mark et X , corresp onding to those sto cks that exhibit the strongest cross-market predictive asso ciations with Y i according to the t-statistic defined ab ov e. Their daily returns on day t − l are r ( t − l ) X 1 , r ( t − l ) X 2 , ..., r ( t − l ) X n . The data used for training and prediction are illustrated in Figure 6 . All predictor selection is p erformed within the rolling training windo w to a void lo ok-ahead bias. The U.S. market is op en from 9:30am to 4:00pm U.S. Eastern Time (ET), while the Chinese mark et is op en from 9:30am to 11:30am, and 1:00pm to 3:00pm China Standard Time (UTC+8). There is no ov erlap b etw een the t wo trading p erio ds, as sho wn in the time zone diagram in Figure 7 , under the standard time difference. Note that adjusting for dayligh t saving time do es not result in an y ov erlap b etw een the trading sessions. W e predict OPCL returns for b oth countries. W e set l = 1 when predicting Chinese sto cks using the latest information from the U.S. market, and l = 0 in the rev erse direction. This timing structure ensures that predictor information from the source mark et is fully observ able prior to the op ening of the target market. W e build the forecasting mo del as follo ws: r ( t ) Y i = F i ( r ( t − l ) X 1 , r ( t − l ) X 2 , ..., r ( t − l ) X n ; θ ) + ϵ ( t ) i . (6) 15 Figure 6: Schematic illustration of the rolling training and prediction framework. F or each target sto c k Y i , returns ov er the lo ok-back windo w [ t − w , t − 1] are regressed on lagged source-mark e t returns ov er [ t − l − w , t − l − 1]. The b ottom row represen ts the out-of-sample prediction of r ( t ) Y i using source returns observ ed at t − l , thereb y preserving temp oral ordering and eliminating lo ok-ahead bias. Figure 7: Timeline of op ening and closing times for the U.S. and Chinese sto c k markets. The non-o verlapping trading sessions induce a natural temp oral ordering of information, with U.S. day t − 1 close preceding Chinese day t trading, and Chinese day t close preceding U.S. da y t trading. 16 Here, the function F i represen ts the differen t mac hine learning metho ds we use, and θ refers to the parameters that are estimated for each mac hine learning mo del. The aim is to identify a mo del that can generate accurate out-of-sample predictions of r ( t ) Y i so that a high SR can b e ac hiev ed. W e applied a total of ten machine learning mo dels to forecast returns. They include: Ordinary Least Squares (OLS), Least Absolute Shrink age and Selection Op erator (LASSO), Ridge Regression (RIDGE), Supp ort V ector Machine (SVM), Extreme Gradien t Bo osting (XGBoost), Light Gradient Bo osting Mac hine (LGBM), Random F orests (RF), Adaptive Bo osting (AdaBo ost), ensemble by results a verage (ensem ble-avg) and ensemble by results median (ensemble-med). This range of mo dels spans linear, regularized, kernel-based, tree-based, and ensem ble approac hes, allo wing us to assess whether cross-market predictive gains depend on model class or are robust across specifications. W e describe each model in detail b elow. All mo dels are estimated within each rolling training windo w and ev aluated out-of-sample to ensure temp oral v alidity . • Ordinary Least Squares (OLS) : The main idea of OLS is to estimate regression co efficien ts b y choosing parameter v alues that minimize the sum of squared residuals b etw een observed and predicted v alues. Sp ecifically , the mo del is defined as: r ( t ) Y i = α i + n X j =1 β ij r ( t − l ) X j + ϵ ( t ) i . (7) The linear mo del is fit with an ob jective of minimizing the residual sum of squares (RSS): min α i , w ∥ y − α i 1 − X w ∥ 2 2 . (8) y ∈ R d is the vector of returns corresp onding to r ( t ) Y i , X ∈ R d × n is the matrix of predictors where each row is [ r ( t − l ) X 1 , . . . , r ( t − l ) X n ], and w = [ β i 1 , . . . , β in ] ⊤ is the asso ciated co efficient v ector. Here d = w , which is the length of training window, i.e., the num b er of time p oints. • Least Absolute Shrink age and Selection Op erator (LASSO) : The OLS metho d often leads to low bias but high v ariance ( Hastie et al. , 2009 ). Shrink age me tho ds are introduced to mitigate this problem, and LASSO is one of them. It uses ℓ 1 -norm regularization to imp ose a p enalt y on the size of regression co efficients ( Hastie et al. , 2009 ). The ob jective function is giv en by: 17 min α i , w 1 2 d ∥ y − α i 1 − X w ∥ 2 2 + λ ∥ w ∥ 1 . (9) Here λ is the regularization parameter. • Ridge Regression (RIDGE) : RIDGE is another type of shrink age metho d. It adds ℓ 2 -norm regularization to the linear least squares loss function. The ob jective function is given b y: min α i , w ∥ y − α i 1 − X w ∥ 2 2 + λ ∥ w ∥ 2 2 . (10) • Supp ort V ector Mac hine (SVM) : SVMs can tackle complex learning problems while retaining the analytical simplicity of linear mo dels. With kernel functions, this metho d a v oids direct computation in high-dimensional spaces, enabling nonlinear learning using a linear algorithm in the feature space ( Hearst et al. , 1998 ). W e use the radial basis function kernel throughout our exp eriment. The goal is to minimize the following dual optimization problem with resp ect to the Lagrange m ultipliers: min α 1 2 n X j =1 n X k =1 α j α k y j y k K ( x j , x k ) − n X j =1 α j s.t. n X j =1 α j y j = 0 0 ≤ α j ≤ C, j = 1 , 2 , . . . , n. (11) Here α j is the Lagrange multiplier, C is a hyperparameter that con trols the trade-off b etw een the flatness of the function and the amount by which deviations larger than ϵ are tolerated, K ( x j , x k ) is the kernel function, y j is r ( t − w + j − 1) Y i in the training window, and x j is its corresp onding v ector of predictors [ r ( t − w + j − 1 − l ) X 1 , . . . , r ( t − w + j − 1 − l ) X n ] ⊺ . • Extreme Gradient Bo osting (X GBo ost) : XGBoost is a scalable end-to-end tree b o osting metho d ( Chen and Guestrin , 2016 ). It implemen ts parallel and distributed computing to accelerate training. The mo del is defined by the follo wing equation: ˆ y j = ϕ ( x j ) = X k f k ( x j ) , f k ∈ F , (12) 18 where F is the space of regression trees, and f k is one indep enden t tree. The ob jective function is giv en by: min X j l ( ˆ y j , y j ) + X k Ω( f k ) , (13) where Ω( f ) = γ M + 1 2 λ ∥ w ∥ 2 . (14) Here l is a differen tiable con v ex loss function, Ω( f ) is the regularization term, M is the n umber of lea ves, w is the leaf weigh t, and γ and λ are the corresp onding regularization parameters. • Ligh t Gradient Bo osting Mac hine (LGBM) : LGBM is another gradien t b o osting metho d that improv es computational efficiency compared with standard gradient b o osting tree al- gorithms ( Ke et al. , 2017 ). Two k ey techniques emplo yed b y LGBM are Gradient-Based One-Side Sampling and Exclusive F eature Bundling. The former retains instances with large gradien ts and randomly samples those with small gradien ts. The latter com bines mutually exclusiv e sparse features, which never take nonzero v alues at the same time, in to a single com bined feature, effectively reducing computational complexity ( Ke et al. , 2017 ). • Random F orests (RF) : Random forests consist of an ensemble of decision trees. At eac h no de of each tree, the algorithm randomly selects a subset of features to consider for splitting. Eac h tree is grown using b o otstrap sampling of the data ( Breiman , 2001 ). By combining these de-correlated trees, the final prediction is obtained b y a veraging their outputs ( Hastie et al. , 2009 ). • Adaptiv e Bo osting (AdaBo ost) : AdaBo ost combines multiple weak learners to form a strong learner. Each weak er learner is trained to correct the errors made b y the previous learners. The algorithm iterativ ely rew eights training observ ations based on their absolute prediction errors, so that more emphasis is giv en to instances with larger errors from earlier learners. The final prediction is obtained by aggregating the weak learners, summing their probabilistic predictions ( F reund and Sc hapire , 1997 ). W e c ho ose a decision tree regressor as the base learner in our exp erimen t. • Ensem ble by results a v erage (ensemble-a vg) : F or each sto ck and each da y , we take the 19 a verage of the prediction results from the eight metho ds ab o ve as the final output. • Ensem ble by results median (ensemble-med) : Similar to ensemble-a vg, w e take the median of the prediction results from the eight metho ds as the final output for eac h sto ck on eac h day . 5 Exp erimen ts In this section, we conduct an extensiv e set of exp eriments to ev aluate the cross-mark et predictability of individual sto ck returns and examine the economic relev ance of the prop osed graph-based framew ork. All results are obtained using a rolling-window estimation scheme and ev aluated strictly out-of-sample. 5.1 Ev aluation Metrics W e use Profit and Loss (PnL) and Sharp e Ratio (SR) to ev aluate the p erformance of forecasting metho ds. W e abstract from liquidity-optimized p ortfolio construction and explicit transaction cost mo deling, and therefore interpret rep orted SRs as pre-cost measures of predictive strength rather than implemen table p erformance. • Profit and Loss (PnL) : The PnL on day t is calculated with the following equation: P nL ( t ) = X i sign( s ( t ) i ) · r ( t ) i · b ( t ) i . (15) Here s ( t ) i denotes the predicted return of sto c k i on da y t , and r ( t ) i denotes the actual return of sto ck i on day t . b ( t ) i = min (0 . 001 × mdv (21) i , L ) is the amount of capital deplo y ed on sto ck i , where mdv (21) i denotes the median daily traded volume of sto ck i o ver the 21-day interv al preceding day t , and L is the maximum limit to the bid. The parameter L con trols the maxim um p osition size. This p osition-sizing rule serv es as a coarse liquidit y proxy , limiting exp osure in less actively traded names. Throughout our exp eriment, L is set to 100,000 USD for the U.S. mark et prediction and 1,500,000 CNY for the Chinese market prediction. • Sharp e Ratio (SR) : After computing daily PnLs of all sto cks, we calculate the mean and 20 standard deviation of the daily PnL vector with length T , denoted as µ ( T ) P nL and σ ( T ) P nL , where T is the length of predicting p erio d in our exp eriment. The annualized SR is given by: S R = µ ( T ) P nL σ ( T ) P nL · √ 252 . (16) Here the scaling accoun ts for the fact that there are 252 trading days in a calendar year and ann ualizes daily PnL v ariability . Sev eral practical limitations should b e noted. First, the graph is obtained via large-scale pairwise screening and therefore may include spurious edges in the presence of multiple testing. Second, our economic ev aluation abstracts from transaction costs, market impact, short-sale constraints, and other trading frictions, so rep orted SRs reflect pre-cost predictive p erformance. Third, w e do not implemen t liquidity-w eighted p ortfolio construction or dynamic capacity con trols; p osition sizes are capp ed but not optimized with resp ect to mark et depth. Consequently , the trading design is st ylized rather than fully implementable. As emphasized by Cartea et al. ( 2025 ), ignoring sto ck-lev el capacit y constrain ts can substantially ov erstate the implementable v alue of predictiv e strategies. Our ob jective is to isolate and quantify directional cross-market predictive asymmetries rather than to construct a pro duction-ready trading strategy . 5.2 Exp erimen tal Setup W e use a 250-da y training windo w and up date b oth the graphs and the predictive mo dels every 10 da ys. Prediction b egins on the first trading da y of 2016 and ends on the last trading day of 2021. All mo dels are re-estimated using a rolling-windo w scheme to ensure strict out-of-sample ev aluation and a void lo ok-ahead bias. 5.2.1 Graph-Based Cross-Mark et Prediction. • Predicting the Chinese Market with the U.S. mark et : W e let market X denote the U.S. market, and market Y denote the Chinese market. W e use the most recent a v ailable U.S. returns as predictors to forecast Chinese returns, i.e., l = 1, reflecting the non-ov erlapping trading sessions and the temp oral ordering of information flo w. 21 • Predicting the U.S. Mark et with the Chinese market : W e let mark et X denote the Chinese market, and market Y denote the U.S. market. W e also use the most recen t a v ailable returns for forecasting, i.e., l = 0, since Chinese trading concludes b efore the U.S. mark et op ens on the same calendar da y . 5.2.2 Baseline. • Non-Graph-Based Same-Mark et Baseline : F or eac h target sto ck, the previous 25 da ys of daily return data are used as predictive features. The training windo w remains 250 days and mo dels are up dated ev ery 10 da ys to ensure comparability with the graph-based sp ecifications. This baseline mo del can b e describ ed with the following equation: r ( t ) Y i = F i ( r ( t − 25) Y i , r ( t − 24) Y i , ..., r ( t − 1) Y i ; θ ) + ϵ ( t ) i . (17) Note that the predictive features r ( t − 25) Y i , r ( t − 24) Y i , ..., r ( t − 1) Y i can b e either all pvCLCL returns or all OPCL returns, while r ( t ) Y i is an OPCL return. • Graph-Based Same-Market Baseline : Based on the metho dology describ ed in Section 4.1 , this baseline sets markets X and Y iden tical, so that for each sto ck its predictors are dra wn from the same market. The return v alues of predictors are one-day ahead of the resp onse v alues, i.e., l = 1. This sp ecification isolates the incremen tal con tribution of cross-market information relativ e to graph-based mo deling p er se. 5.3 Main Results W e b egin by ev aluating the economic p erformance of the cross-market forecasting framew ork. P ortfolio sorts based on mo del-implied signals are standard in the return predictability literature. F or each day t , sto c ks are rank ed by the absolute v alue of their predicted returns, | ˆ r ( t ) i | . T o examine ho w p erformance v aries with signal strength, we construct six nested quantile p ortfolios: • quantile 1 (qr1): all sto cks; • quantile 2 (qr2): top 80% of sto cks ranked by | ˆ r ( t ) i | ; • quantile 3 (qr3): top 60%; 22 • quantile 4 (qr4): top 40%; • quantile 5 (qr5): top 20%; • quantile 6 (qr6): top 10%. These p ortfolios are nested, so that qr6 ⊂ qr5 ⊂ qr4 ⊂ qr3 ⊂ qr2 ⊂ qr1 . This construction allows us to assess whether stronger mo del signals translate into impro ved risk-adjusted p erformance. Imp ortan tly , the ranking at da y t is based solely on mo del predictions av ailable at that date and do es not use realized returns, thereby av oiding lo ok-ahead bias in p ortfolio formation. W e first do cument that cross-market information and graph-based mo deling contribute to improv ed forecasting p erformance. (a) Predictors: U.S. p vCLCL returns. (b) Predictors: U.S. OPCL returns. Figure 8: Sharp e Ratios for forecasting Chinese OPCL returns using U.S. pvCLCL and OPCL returns as predictors. Figure 8 and Figure 9 displa y the results of forecasting in tw o differen t directions. According to Figure 8 , when predicting Chinese sto cks with U.S. sto cks, RIDGE, LGBM, ensemble-a vg and ensem ble-med yield strong p erformance. SVM app ears less effectiv e for this task, since its SRs are mostly lo wer than one. F or other forecasting metho ds and most quantiles, SRs exceed one, with some approaching t w o. Notably , the ensemble-a verage and ensemble-median metho ds maintain robust and stable p erformance, often comparable to the b est individual mo dels, highligh ting the b enefit of mo del diversification. Using U.S. pvCLCL returns as features p erforms b etter than using the U.S. OPCL returns to predict Chinese OPCL returns. The cumulativ e PnL plots of each metho d for the former are shown in Figure 10 , where the upw ard-sloping tra jectories indicate economically 23 meaningful profitabilit y . In contrast, as sho wn in Figure 9 , when predicting the U.S. sto cks with Chinese sto cks, SRs are substan tially low er across metho ds and quantiles. Therefore the Chinese market exerts weak er predictiv e influence than the U.S. market in cross-market return prediction. Since the p erformance is stronger when predicting Chinese sto c ks using U.S. p vCLCL returns, we fo cus on this setting in subsequen t exp erimen ts and analyses. (a) Predictors: Chinese p vCLCL returns. (b) Predictors: Chinese OPCL returns. Figure 9: Sharp e Ratios for forecasting U.S. OPCL returns using Chinese returns as predictors. Figure 11 sho ws the results of predicting Chinese sto cks with Chinese sto c ks based on graph structures. Figure 12 summarizes SRs across sp ec ifications, comparing graph-based cross-market approac hes, graph-based single-market approaches, and the non-graph-based baseline, with pvCLCL returns used as predictors. Figure 13 rep orts the corresp onding p erformance differen tials (deltas), computed as SRs of graph-based approaches minus those of the non-graph-based baseline. The results indicate that graph-based same-market approac hes outp erform non-graph-based same-market approac hes for most machine learning mo dels under most quantiles, esp ecially for OLS, LGBM, and qr5. T urning to the incremental v alue of cross-market information, combining cross-mark et information with graph information yields the strongest ov erall p erformance, outp erforming approaches that use graph structures with same-market information only , as w ell as the non-graph-based baseline relying solely on same-mark et information. 24 Figure 10: Cum ulative daily Profit and Loss (PnL) from forecasting Chinese OPCL returns using U.S. p vCLCL returns as predictors. Each panel corresp onds to a different machine learning mo del, and coloured curv es represent nested quantile p ortfolios ranked by the absolute v alue of predicted returns. 25 (a) Predictors: Chinese p vCLCL returns. (b) Predictors: Chinese OPCL returns. Figure 11: Sharp e Ratios for forecasting Chinese OPCL returns using Chinese returns as predictors. Figure 12: Comparison of Sharp e Ratios across graph-based cross-market, graph-based same- mark et, and non-graph-based baseline sp ecifications, using pvCLCL returns as predictors. CN-CN denotes using Chinese sto cks to forecast Chinese sto cks, while US-CN denotes using U.S. sto cks to forecast Chinese sto c ks. 26 Figure 13: Performance differen tials (Sharp e Ratio deltas) relativ e to the non-graph-based baseline, using p vCLCL returns as predictors. US-CN denotes using U.S. sto cks to forecast Chinese sto cks, while CN-CN denotes using Chinese sto c ks to forecast Chinese sto c ks. 5.4 Sensitivit y Analysis W e next ev aluate the robustness of predictive p erformance to p erturbations in graph structure and temp oral alignment when forecasting Chinese returns using U.S. pvCLCL returns. W e first conduct a feature-replacemen t test, where selected informative sto cks are randomly substituted with other sto c ks. Additionally , we assess temp oral sensitivit y by v arying the recency of input data, using features from earlier da ys (e.g., t − 2, t − 3, etc.) instead of the most recent day t − 1. First, we conduct a feature-replacement exp eriment. Based on graphs built for predicting returns on day t in the Chinese market using returns on day t − 1 in the U.S. mark et, we maintain the same in-degree of each target no de to preserve graph sparsity while randomly changing some of their connections. Only previously unconnected no des are considered as replacemen ts for the original connections. W e randomly replace 20%, 40%, 60%, 80% and all of the edges. F or each quan tile lev el, we obtain the median of the results from all the 10 metho ds. As sho wn in Figure 14a , SRs generally decline as a larger fraction of edges is replaced, indicating that predictive gains dep end critically on the economically meaningful structure captured b y the graph rather than on generic div ersification effects. The deterioration is strongest in lo w er and in termediate quan tiles, whereas the highest quantile (qr6) exhibits comparatively greater resilience. 27 Second, we assess temp oral sensitivit y by v arying the recency of input data. Still based on graphs built for predicting returns on day t in the Chinese mark et using returns on day t − 1 in the U.S. market, we lo ok into forecasting p erformance as the temp oral gap increases (e.g., t w o-day , three-da y , or longer gaps) b et w een the predictor windo w and the target return window. As defined in Section 4.2 , when we forecast r ( t ) Y i , the predictors are given by [ r ( t − l ) X 1 , r ( t − l ) X 2 , ..., r ( t − l ) X n ]. Here w e set l = 2 , 3 , ... when predicting Chinese sto cks. F or each quantile lev el, we also obtain the median of the results from all the 10 metho ds. Figure 14b sho w s that SRs generally decline as l increases, consisten t with the h yp othesis that cross-mark et predictiv e con tent decays with time. The decline is again less pronounced for qr6, suggesting that large-magnitude signals may capture more p ersistent cross-market effects. A mild stabilization b ey ond Lag 4 lik ely reflects weekly trading-cycle effects. T ak en together, these exp eriments confirm that predictive p erformance dep ends critically on b oth the structural accuracy of the graph and the recency of cross-mark et information. (a) Effect of graph randomization (fraction of edges replaced). (b) Effect of increasing temp oral lag l . Figure 14: Median forecasting p erformance under graph randomization (a) and increasing temporal lag (b). Panel (a) rep orts Sharp e Ratios as a function of the fraction of replaced edges while preserving in-degree. Panel (b) rep orts Sharp e Ratios as the lag parameter l increases, measuring the effect of input recency . 6 Conclusion and F uture Researc h This pap er inv estigates cross-mark et return forecasting at the individual sto ck lev el. W e develop a graph-based arc hitecture that enables structured information transmission across markets and use 28 it to construct cross-market predictive features. Building on this framew ork, w e implemen t a range of mac hine learning mo dels to forecast OPCL returns for eac h sto c k. Empirically , we find that combining cross-mark et information with graph-based feature selection deliv ers sup erior p erformance relativ e to b oth graph-based same-mark et approac hes and non-graph- based baselines. The predictive relationship is asymmetric: U.S. sto cks are substan tially more informativ e for forecasting Chinese returns than the reverse. In particular, U.S. p vCLCL returns exhibit stronger predictive p ow er for Chinese OPCL returns than U.S. OPCL returns, highlighting the imp ortance of ov ernigh t information transmission. Sensitivity analyses confirm that preserving the economically meaningful bipartite graph structure is crucial for ac hieving strong risk-adjusted p erformance. Moreov er, forecasting p erformance deteriorates as the temp oral gap b etw een predictor and target returns widens, emphasizing the v alue of recency . Sev eral directions for future researc h emerge. First, extending the analysis to additional regions, including Europ ean and other Asian mark ets, w ould help assess the generalizability of cross-market predictiv e link ages. Second, GNNs could be applied directly to the constructed bipartite graph to learn nonlinear cross-market dep endencies. Finally , recent adv ances in time-series-sp ecialized large language mo dels ma y offer an alternative framework for mo deling structured cross-mark et in teractions. Conflicts of In terest The authors declare that they ha ve no comp eting interests. References Ahmad, W., Mishra, A. V., and Daly , K. J. (2018). Financial connectedness of brics and global so vereign b ond mark ets. Emer ging Markets R eview , 37:1–16. Asgharian, H., Hess, W., and Liu, L. (2013). A spatial analysis of international sto ck mark et link ages. Journal of Banking & Financ e , 37(12):4738–4754. Bardoscia, M., Barucca, P ., Battiston, S., Caccioli, F., Cimini, G., Garlaschelli, D., Saracco, F., 29 Squartini, T., and Caldarelli, G. (2021). The physics of financial net w orks. Natur e R eviews Physics , 3(7):490–507. Baur, D. and Jung, R. C. (2006). Return and volatilit y link ages b et ween the us and the german sto c k mark et. Journal of International Money and Financ e , 25(4):598–613. Breiman, L. (2001). Random forests. Machine le arning , 45(1):5–32. Cakra, Y. E. and T risedya, B. D. (2015). Sto c k price prediction using linear regression based on sen timen t analysis. In 2015 international c onfer enc e on advanc e d c omputer scienc e and information systems (ICA CSIS) , pages 147–154. IEEE. Capp oni, A., Sidaoui, J. A., and Zou, J. (2024). Graph machine learning for asset pricing: T ra v ersing the supply c hain and factor zo o. A vailable at SSRN 5031617 . Cartea, ´ A., Cucuringu, M., Jin, Q., and Zhu, J. (2025). Liquidity constraints and the illusion of anomaly profitabilit y . Available at SSRN 5797502 . Chen, K., Zhou, Y., and Dai, F. (2015). A lstm-based metho d for sto c k returns prediction: A case study of ch ina sto ck market. In 2015 IEEE international c onfer enc e on big data (big data) , pages 2823–2824. IEEE. Chen, L. and F an, X. (2025). Financial risk forecasting with rgct-prerisk: a relational graph and cross-temp oral con trastive pretraining framework. Journal of King Saud University Computer and Information Scienc es , 37(6):143. Chen, S., Green, T. C., Gulen, H., and Zhou, D. (2024). What do es chatgpt make of historical sto c k returns? extrap olation and miscalibration in llm sto ck return forecasts. arXiv pr eprint arXiv:2409.11540 . Chen, T. and Guestrin, C. (2016). Xgb o ost: A scalable tree b o osting system. In Pr o c e e dings of the 22nd acm sigkdd international c onfer enc e on know le dge disc overy and data mining , pages 785–794. Chen, Y., W ei, Z., and Huang, X. (2018). Incorp orating corp oration relationship via graph 30 con volutional neural netw orks for sto c k price prediction. In Pr o c e e dings of the 27th ACM international c onfer enc e on information and know le dge management , pages 1655–1658. Chen, Z., Zheng, L. N., Lu, C., Y uan, J., and Zhu, D. (2023). Chatgpt informed graph neural net work for sto c k mov ement prediction. arXiv pr eprint arXiv:2306.03763 . Cheng, D., Y ang, F., Xiang, S., and Liu, J. (2022). Financial time series forecasting with multi- mo dalit y graph neural net work. Pattern R e c o gnition , 121:108218. Cheng, R. and Li, Q. (2021). Mo deling the momen tum spillo v er effect for sto ck prediction via attribute-driv en graph attention net w orks. In Pr o c e e dings of the AAAI c onfer enc e on artificial intel ligenc e , v olume 35, pages 55–62. Clemen ts, A. E., Hurn, A. S., and V olko v, V. V. (2015). V olatility transmission in global financial mark ets. Journal of Empiric al Financ e , 32:3–18. Ding, Y., Jia, S., Ma, T., Mao, B., Zhou, X., Li, L., and Han, D. (2023). In tegrating sto ck features and global information via large language mo dels for enhanced sto ck return prediction. arXiv pr eprint arXiv:2310.05627 . Eun, C. S. and Shim, S. (1989). International transmission of sto ck mark et mo vemen ts. Journal of financial and quantitative A nalysis , 24(2):241–256. F an, J. and Lv, J. (2008). Sure indep endence screening for ultrahigh dimensional feature space. Journal of the R oyal Statistic al So ciety: Series B (Statistic al Metho dolo gy) , 70(5):849–911. F reund, Y. and Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to b o osting. Journal of c omputer and system scienc es , 55(1):119–139. Gao, H., Kou, G., Liang, H., Zhang, H., Chao, X., Li, C.-C., and Dong, Y. (2024). Machine learning in business and finance: a literature review and research opp ortunities. Financial Innovation , 10(1):86. Gong, J., W ang, G.-J., Zhou, Y., and Xie, C. (2025). Cross-market v olatility forecasting with atten tion-based spatial-temp oral graph con v olutional netw orks. Journal of Empiric al Financ e , page 101639. 31 Guillaume, J.-L. and Latap y , M. (2006). Bipartite graphs as mo dels of complex netw orks. Physic a A: Statistic al Me chanics and its Applic ations , 371(2):795–813. Harv ey , C. R., Liu, Y., and Zhu, H. (2015). . . . and the cross-section of exp ected returns. The R eview of Financial Studies , 29(1):5–68. Hastie, T., Tibshirani, R., F riedman, J. H., and F riedman, J. H. (2009). The elements of statistic al le arning: data mining, infer enc e, and pr e diction , volume 2. Springer. Hearst, M. A., Dumais, S. T., Osuna, E., Platt, J., and Scholk opf, B. (1998). Support vector mac hines. IEEE Intel ligent Systems and their applic ations , 13(4):18–28. Huang, W., Nak amori, Y., and W ang, S.-Y. (2005). F orecasting sto ck market mo v ement direction with supp ort v ector mac hine. Computers & op er ations r ese ar ch , 32(10):2513–2522. Huang, W.-Q. and Liu, P . (2023). Cross-mark et risk spillov ers among sov ereign cds, sto ck, foreign exc hange and commo dity markets: An interacting netw ork p ersp ective. International R eview of Financial A nalysis , 90:102875. Jung, J., Lee, K., and Leung, T. (2024). Threshold o v ernight comov ement analysis of intrada y and o vernigh t returns. Available at SSRN 4946188 . Ke, G., Meng, Q., Finley , T., W ang, T., Chen, W., Ma, W., Y e, Q., and Liu, T.-Y. (2017). Lightgbm: A highly efficient gradient b o osting decision tree. A dvanc es in neur al information pr o c essing systems , 30. Kelly , B., Xiu, D., et al. (2023). Financial mac hine learning. F oundations and T r ends ® in Financ e , 13(3-4):205–363. Kley , O., Kl ¨ upp elb erg, C., and P aterlini, S. (2020). Mo delling extremal dep endence for op erational risk b y a bipartite graph. Journal of Banking & Financ e , 117:105855. Kumar, M. and Thenmozhi, M. (2006). F orecasting sto c k index mo vemen t: A comparison of supp ort v ector machines and random forest. In Indian institute of c apital markets 9th c apital markets c onfer enc e p ap er . 32 Kumar, P . N., Umeorah, N., and Alo c h ukwu, A. (2024). Dynamic graph neural net works for enhanced v olatility prediction in financial markets. arXiv pr eprint arXiv:2410.16858 . Lee, S. I. and Y o o, S. J. (2020). Multimo dal deep learning for finance: in tegrating and forecasting in ternational sto c k mark ets. The Journal of Sup er c omputing , 76(10):8294–8312. Lee, T. K., Choi, I., and Kim, W. C. (2025). Symmetry-a ware graph neural approac hes for data-efficien t return prediction in international financial market indices. Symmetry , 17(9):1372. Li, W., Bao, R., Harimoto, K., Chen, D., Xu, J., and Su, Q. (2021). Mo deling the sto ck relation with graph netw ork for o vernigh t sto c k mov emen t prediction. In Pr o c e e dings of the twenty- ninth international c onfer enc e on international joint c onfer enc es on artificial intel ligenc e , pages 4541–4547. Lin, S., Chen, Y., Qi, Y., Ma, C., Cao, B., Zhang, Y., Liu, X., and Guo, J. (2025). Cspo: Cross- mark et synergistic sto c k price mov ement forecasting with pseudo-volatilit y optimization. In Comp anion Pr o c e e dings of the ACM on Web Confer enc e 2025 , pages 354–363. Liu, Q. and An, Y. (2011). Information transmission in informationally linked markets: Evidence from us and chinese commo dity futures mark ets. Journal of International Money and Financ e , 30(5):778–795. Liu, R., Liu, H., Huang, H., Song, B., and W u, Q. (2024). Multimo dal multiscale dynamic graph con volution netw orks for sto ck price prediction. Pattern R e c o gnition , 149:110211. Luo, C., He, H., Cucuringu, M., and Ma, T. (2025). Spatial-temp oral sto ck mov emen t prediction and p ortfolio selection based on the semantic company relationship graph. Quantitative Financ e , pages 1–19. Mohammadi, H. and T an, Y. (2015). Return and v olatility spillo vers across equit y markets in mainland c hina, hong kong and the united states. Ec onometrics , 3(2):215–232. Newman, M. (2018). Networks . Oxford univ ersit y press. Nie, Y., Kong, Y., Dong, X., Mulvey , J. M., P o or, H. V., W en, Q., and Zohren, S. (2024). A surv ey 33 of large language mo dels for financial applications: Progress, prosp ects and challenges. arXiv pr eprint arXiv:2406.11903 . Rapac h, D. E., Strauss, J. K., and Zhou, G. (2013). In ternational sto ck return predictability: what is the role of the united states? The Journal of Financ e , 68(4):1633–1662. Rundo, F., T renta, F., Di Stallo, A. L., and Battiato, S. (2019). Machine learning for quantitativ e finance applications: A surv ey . Applie d Scienc es , 9(24):5574. Sarw ar, G. (2014). Us sto ck mark et uncertain ty and cross-mark et europ ean sto ck returns. Journal of Multinational Financial Management , 28:1–14. Siliv erstovs, B. (2017). In ternational sto ck return predictability: on the role of the united states in bad and go o d times. Applie d Ec onomics L etters , 24(11):771–773. Thenmozhi, M. and Sarath Chand, G. (2016). F orecasting sto ck returns based on information transmission across global mark ets using supp ort vector machines. Neur al Computing and Applic ations , 27(4):805–824. W ang, C. (2024). Sto ck return prediction with m ultiple measures using neural netw ork mo dels. Financial Innovation , 10(1):72. W ang, H. and Chen, S. (2020). A bipartite graph-based recommender for crowdfunding. Banking and financ e , page 197. W ang, J., Zhang, S., Xiao, Y., and Song, R. (2021). A review on graph neural netw ork metho ds in financial applications. arXiv pr eprint arXiv:2111.15367 . W u, Y., Lan, W., F an, X., and F ang, K. (2024). Bipartite net w ork influence analysis of a t w o-mo de net work. Journal of Ec onometrics , 239(2):105562. Y ang, D. and He, Q. (2026). Enhancing intrada y momen tum prediction: The role of volume-based information uncertain t y in the c hinese sto ck market. International Journal of Financial Studies , 14(2):47. 34 Zhang, C., Pu, X., Cucuringu, M., and Dong, X. (2025). F orecasting realized volatilit y with spillo ver effects: Perspectives from graph neural netw orks. International Journal of F or e c asting , 41(1):377–397. App endix A Hyp erparameter Settings The OLS metho d do es not in volv e any hyperparameters. T able A.1 rep orts the p erformance of the remaining seven machine learning mo dels under alternative h yp erparameter configurations. The SVM mo del app ears relatively insensitive to v ariations in h yp erparameter v alues, and its SRs remain generally b elow one across sp ecifications, suggesting limited suitability for this particular forecasting setting. F or the other mo dels, SRs exceed one across most quan tiles and hyperparameter choices, indicating that the cross-market forecasting framework delivers robust risk-adjusted p erformance and is not o verly sensitive to sp ecific tuning parameters. App endix B Comparison with Baselines when Predicting with OPCL Returns Similar to Figure 12 and Figure 13 , Figure B.1 and Figure B.2 rep ort the p erformance comparison among the graph-based cross-market approac h, the graph-based same-market baseline, and the non-graph-based baseline when OPCL returns are used as predictors. The results indicate that incorp orating graph structure generally improv es forecasting p erfor- mance across most quantiles and machine learning mo dels. How ever, in contrast to the p vCLCL setting, the incremen tal contribution of cross-market information is substantially weak er when OPCL returns are used as predictors. App endix C Cross-Mark et Spillo v ers under U.S. Mark et Sho c ks T o inv estigate whether cross-market predictability strengthens during p erio ds of heightened U.S. mark et activit y and volatilit y , we condition the analysis on large mov ements in the U.S. mark et. Sp ecifically , we identify days on which the S&P 500 ETF (SPY) exhibits large absolute p vCLCL 35 T able A.1: Summary of SR results across different hyperparameter settings (using the most recent U.S. pvCLCL returns to predict Chinese OPCL returns). V alues are rep orted as mean ± standard deviation. Metho ds P arameters qr1 qr2 qr3 qr4 qr5 qr6 LASSO λ = { 1e-4, 1e-3, 1e-2, 1e-1, 1, 10, 100, 1000 } 0 . 848 ± 0 . 222 0 . 969 ± 0 . 247 1 . 238 ± 0 . 31 1 . 65 ± 0 . 398 1 . 821 ± 0 . 433 1 . 777 ± 0 . 424 RIDGE λ = { 1e-4, 1e-3, 1e-2, 1e-1, 1, 10, 100, 1000 } 1 . 238 ± 0 . 429 1 . 293 ± 0 . 43 1 . 437 ± 0 . 449 1 . 715 ± 0 . 51 1 . 668 ± 0 . 619 1 . 55 ± 0 . 461 SVM C = { 0.1, 1, 10, 100, 1000 } 0 . 743 ± 0 . 194 0 . 751 ± 0 . 196 0 . 782 ± 0 . 204 0 . 719 ± 0 . 188 1 . 02 ± 0 . 267 0 . 836 ± 0 . 218 X GBo ost max depth = { 3,6,9 } learning rate = { 0.01, 0.1, 0.2 } n estimators = { 50, 100, 300 } 1 . 445 ± 0 . 224 1 . 48 ± 0 . 247 1 . 587 ± 0 . 214 1 . 539 ± 0 . 309 1 . 381 ± 0 . 401 0 . 964 ± 0 . 233 LGBM n um lea ves = { 10, 31, 90 } learning rate = { 0.01, 0.1, 0.2 } n estimators = { 50, 100, 300 } 1 . 32 ± 0 . 348 1 . 457 ± 0 . 388 1 . 541 ± 0 . 422 1 . 44 ± 0 . 485 1 . 652 ± 0 . 466 1 . 424 ± 0 . 407 RF n estimators = { 50, 100, 300 } max depth = { 5, 10, 50 } 1 . 481 ± 0 . 41 1 . 558 ± 0 . 422 1 . 639 ± 0 . 447 1 . 799 ± 0 . 486 1 . 747 ± 0 . 474 1 . 09 ± 0 . 351 AdaBo ost max depth = { 1, 5, 10 } n estimators = { 50, 100, 300 } learning rate = { 0.01, 0.1, 0.2 } 1 . 389 ± 0 . 358 1 . 405 ± 0 . 385 1 . 549 ± 0 . 436 1 . 548 ± 0 . 419 1 . 1 ± 0 . 305 0 . 667 ± 0 . 187 Note: max depth is the maximum depth of a tree. learning rate is the learning rate. n estimators is the maximum num b er of estimators at whic h b o osting is terminated. num leav es is maxim um tree leav es for base learners in an LGBM mo del. 36 Figure B.1: Comparison of Sharp e Ratios across graph-based cross-market, graph-based same- mark et, and non-graph-based baseline sp ecifications, using OPCL returns as predictors. US-CN denotes using U.S. sto cks to forecast Chinese sto c ks, while CN-CN denotes using Chinese sto cks to forecast Chinese sto c ks. Figure B.2: P erformance differentials (Sharp e Ratio deltas) relative to the non-graph-based baseline, using OPCL returns as predictors. US-CN denotes using U.S. sto cks to forecast Chinese sto c ks, while CN-CN denotes using Chinese sto c ks to forecast Chinese sto c ks. 37 returns. W e divide the SPY absolute p vCLCL returns into nested quantiles (qr1–qr6), consistent with the earlier quantile construction. F or example, qr2 contains the top 80% of days rank ed b y absolute SPY returns. F or each identified SPY sho c k date t i , we extract the mo del’s OPCL return forecast for the next trading day t i + 1 in the Chinese market. W e then compute SRs restricted to these subsets of dates. This conditional ev aluation allows us to assess whether predictiv e p erformance impro v es during p erio ds of elev ated U.S. market volatilit y , when cross-mark et information transmission is lik ely to b e stronger. The results are sho wn in Figure C.1 . Nonlinear ensemble mo dels such as XGBoost, LGBM, RF, and AdaBo ost achiev e consistently high SRs across quantiles, esp ecially in the upp er ranges (qr4–qr6), suggesting that nonlinear mo dels capture state-dep endent spillov er effects more effectively . OLS also p erforms well, achieving its highest SR in qr6. In con trast, LASSO and SVM exhibit w eaker performance, with SRs turning negativ e in some quan tiles, while RIDGE shows comparatively unstable p erformance. Figure C.1: Sharp e Ratios of forecasting mo dels conditional on SPY absolute pvCLCL return nested quan tiles, measuring predictive p erformance following different magnitudes of U.S. market sho c ks. App endix D Comparison of Sharp e Ratio Results across Sectors W e con tin ue to fo cus on the setting in whic h U.S. pvCLCL returns are used to forecast Chinese OPCL returns. The sector-lev el SR results are rep orted in Figure D.1 . Because the num b er of sto c ks 38 Figure D.1: Sector-level Sharp e Ratios for cross-market forecasting (using U.S. pvCLCL returns to forecast Chinese OPCL returns). v aries across sectors, these results should b e interpreted with caution. Ov erall, the technology and consumer defensive sectors exhibit relativ ely higher SRs compared with other sectors, indicating stronger cross-mark et predictive effects in these segments. App endix E Predicting Chinese Sto c ks Using Both U.S. and Chi- nese Sto c ks W e extend the analysis by allowing the predictor set X to include all sto c ks from b oth the U.S. and Chinese markets, while the target set Y con tinues to consist of Chinese stocks only . The graph construction phase follo ws the pro cedure in tro duced in Section 4.1 . The results are presented in Figure E.1 . In several sp ecifications, the resulting SRs exceed those obtained when using only U.S. returns as predictors (Figure 8 ), suggesting that combining domestic and cross-market information can further enhance predictiv e p erformance. 39 (a) U.S. pvCLCL + Chinese p vCLCL returns. (b) U.S. pvCLCL + Chinese OPCL returns. (c) U.S. OPCL + Chinese pvCLCL returns. (d) U.S. OPCL + Chinese OPCL returns. Figure E.1: Sharp e Ratios for forecasting Chinese OPCL returns when the predictor set includes b oth U.S. and Chinese sto cks. Panels v ary the combination of pvCLCL and OPCL features across the t wo markets. 40
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment