ZACH-ViT: Regime-Dependent Inductive Bias in Compact Vision Transformers for Medical Imaging
Vision Transformers rely on positional embeddings and class tokens encoding fixed spatial priors. While effective for natural images, these priors may be suboptimal when spatial layout is weakly informative, a frequent condition in medical imaging. W…
Authors: Athanasios Angelakis
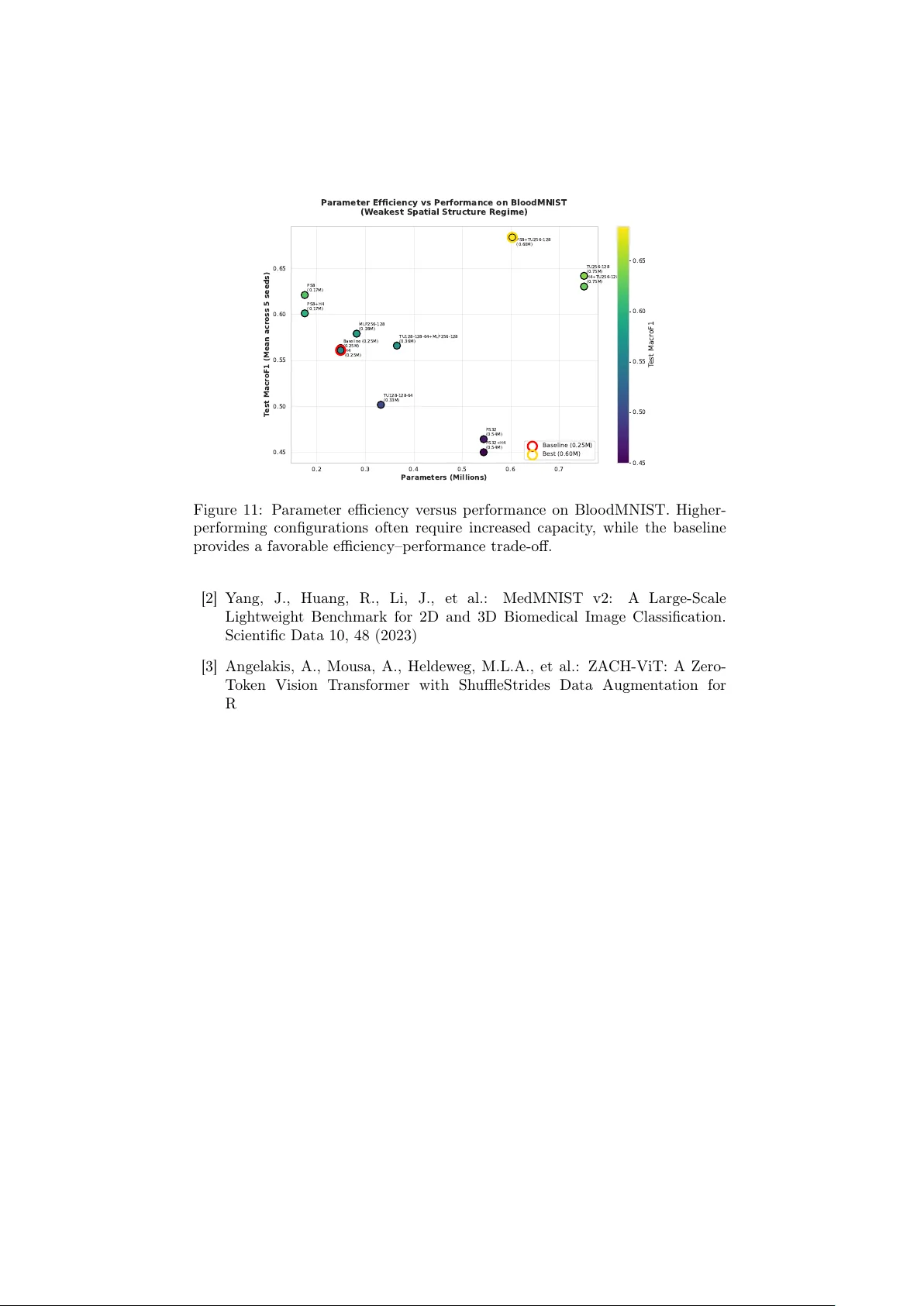
ZA CH-ViT: Regime-Dep enden t Inductiv e Bias in Compact Vision T ransformers for Medical Imaging A thanasios Angelakis athanasios.angelakis@unib w.de OR CID: 0000-0003-1226-9560 1 BioML Lab, RI CODE, UniBW, Munich, Germany 2 EDS, Amsterdam UMC, Amsterdam, Netherlands Abstract Vision T ransformers rely on positional em b eddings and class tok ens that enco de fixed spatial priors. While effective for natural images, these priors ma y hinder generalization when spatial lay out is weakly informativ e or inconsisten t, a frequen t condition in medical imaging and edge-deploy ed clinical systems. W e in tro duce ZACH-ViT (Zero-token Adaptiv e Compact Hierarc hical Vision T ransformer), a compact Vision T ransformer that re- mo ves b oth p ositional embeddings and the [CLS] token, ac hieving p erm u- tation inv ariance through global av erage p ooling ov er patc h representa- tions. The term “Zero-token” refers specifically to the remov al of the ded- icated [CLS] aggregation token and p ositional embeddings; patc h tokens are still present and pro cessed normally . A daptive residual pro jections preserv e training stabilit y in compact configurations while main taining a strict parameter budget. Ev aluation is p erformed across seven MedMNIST datasets spanning binary and m ulti-class tasks under a strict few-shot proto col (50 samples p er class, fixed hyperparameters, and fiv e random seeds). The empirical analysis reveals a clear regime-dep enden t b eha vior: ZA CH-ViT (0.25M parameters, trained from scratc h) ac hieves its strongest adv antage on Blo odMNIST and remains comp etitiv e with T ransMIL on PathMNIST, while its relative adv an tage decreases on datasets with strong anatom- ical priors (OCTMNIST, OrganAMNIST), consisten t with the architec- tural hypothesis. These results supp ort the view that architectural align- men t with data structure can b e more imp ortan t than pursuing univ ersal b enc hmark dominance. Despite its minimal size and lack of pretrain- ing, ZACH-ViT achiev es comp etitiv e p erformance while maintaining sub- second inference times, supp orting deplo yment in resource-constrained clinical environmen ts. Co de and mo dels are av ailable at https://github. com/Bluesman79/ZACH- ViT . Keyw ords: Vision T ransformers, F ew-shot learning, Perm utation inv ariance, P arameter efficiency , Edge AI, Medical imaging, Spatial structure 1 1 In tro duction Vision T ransformers (ViT s) hav e reshap ed computer vision through strong p er- formance and scalability on large-scale b enc hmarks such as ImageNet [1]. Their arc hitecture typically relies on p ositional embeddings and a [CLS] tok en, whic h in tro duce an implicit bias tow ard spatially structured representations. While appropriate for natural images, this assumption do es not universally hold. In man y real-world scenarios, image patches lack intrinsic ordering or spatial rela- tionships carry limited discriminative v alue. Sev eral medical imaging modalities illustrate this mismatc h. Blo od cells app ear randomly distributed within microscopy fields; histopathology patches often b ehav e as unordered collections where diagnosis depends on cellular com- p osition rather than spatial arrangement; lung ultrasound frames v ary substan- tially with probe positioning. In suc h settings, p ositional priors may introduce unin tended bias, encouraging mo dels to exploit spurious spatial correlations in- stead of inv ariant visual c haracteristics. T o address this mismatch b et w een arc hitectural priors and data structure, w e introduce ZA CH-ViT (Zero-token A daptive Compact Hierarc hical Vision T ransformer), a compact arc hitecture designed around p erm utation-in v ariant patc h pro cessing: • Zero-tok en : Positional embeddings are remov ed and the [CLS] aggrega- tion token is replaced with global av erage po oling, allowing patch tokens to b e treated as an unordered set. • A daptive : Residual pro jections preserv e gradient stability when feature dimensionalit y changes across transformer lay ers. • Compact : The architecture op erates with 0.25M parameters by av oiding comp onen ts dedicated to modeling p oten tially weakly informative spatial structure. • Hierarc hical : Multiple transformer lay ers capture comp ositional features without introducing p ositional bias. • End-to-end : Unlike MIL-based transformers designed primarily for bag- lev el aggregation, ZA CH-ViT functions as a standalone compact vision bac kb one with direct patch-lev el representation learning. The resulting mo del is p erm utation-inv ariant by construction while remain- ing parameter-efficien t (0.25M parameters) and computationally ligh t weigh t. W e ev aluate ZACH-ViT across seven representativ e MedMNIST datasets [2], co vering binary classification (BreastMNIST, PneumoniaMNIST) and m ulti- class tasks (Blo o dMNIST, DermaMNIST, OCTMNIST, PathMNIST, OrganAM- NIST). These datasets span a sp ectrum of spatial structure strength, ranging from weakly structured blo o d microscopy images to anatomically constrained ab dominal and retinal scans. Rather than claiming universal sup eriorit y , our results reveal a regime-dep endent b eha vior: ZACH-ViT p erforms strongest when spatial order is weakly informa- tiv e (Blo odMNIST, P athMNIST) and remains competitive when anatomical structure imp oses fixed spatial relationships (OCTMNIST, Orga nAMNIST). This supp orts the broader h yp othesis that architectural inductive biases should 2 align with the spatial c haracteristics of the target data instead of assuming uniform spatial relev ance. This p ersp ectiv e is particularly relev ant for edge AI deploymen t in medical imaging, where inference increasingly o ccurs on scanners, pathology worksta- tions, and hospital-side systems under strict latency , memory , and connectivit y constrain ts. In suc h environmen ts, mo dels m ust balance structural robustness with computational efficiency . Our contributions can be summarized as follows: • W e in tro duce ZACH-ViT, a compact p ermutation-in v ariant Vision T rans- former that remov es p ositional em b eddings and token-based aggregation, enabling efficient end-to-end patch pro cessing without reliance on spatial priors. • W e provide a systematic regime-spectrum analysis linking transformer in- ductiv e bias to spatial structure strength, demonstrating when p erm uta- tion in v ariance b ecomes adv antageous under con trolled few-shot medical imaging conditions. • Through a comprehensive b enc hmark across fiftee n architectures and seven MedMNIST datasets under identical proto cols, we show that arc hitectural alignmen t with data structure can b e more influen tial than absolute mo del scale or pretraining. Ov erall, the main con tribution of this w ork extends b ey ond the arc hitec- ture itself: we establish a repro ducible ev aluation framew ork for studying when p erm utation-in v ariant transformers are appropriate in medical imaging, shifting the fo cus from absolute b enc hmark dominance to ward principled inductive-bias alignmen t. 2 Related W ork 2.1 P erm utation-Inv arian t Vision Arc hitectures A preliminary arXiv preprin t introduced the ZACH-ViT architecture on a clin- ical lung ultrasound dataset [3]. Subsequen t analysis rev ealed annotation issues in that dataset, preven ting reliable clinical conclusions. The present work there- fore provides a structured and controlled ev aluation across seven MedMNIST datasets, enabling a systematic analysis of how p erm utation-inv ariant architec- tures b eha ve under v arying spatial-structure regimes. The presen t work pro vides a structured empirical v alidation of ZA CH-ViT across seven MedMNIST datasets spanning weak to strong spatial structure un- der consisten t few-shot proto cols. The analysis rev eals a clear regime-dep endent b eha vior, consis ten t with the architectural hypothesis: removing p ositional pri- ors is not universally b eneficial, but b ecomes adv antageous when spatial lay out is weakly informative. This broader v alidation was not p ossible in the earlier clinical study due to data limitations and narro w task scop e. 2.2 Distinction from MIL-based T ransformers. T ransMIL [4] also operates on unordered sets of patch representations within a m ultiple-instance learning (MIL) framework, resulting in p erm utation-inv ariant 3 aggregation at the bag level. How ever, the design ob jectives differ substan tially from ZACH-ViT. T ransMIL is primarily developed for whole-slide imaging, where transformers are used as an aggregation mec hanism ov er pre-extracted instances within a MIL pip eline. In contrast, ZACH-ViT is a compact trans- former bac kb one explicitly designed for end-to-end few-shot learning under strict parameter and edge-deplo yment constraints. The contribution of ZACH-ViT therefore lies not in introducing p ermutation in v ariance itself, but in demon- strating ho w removing p ositional priors within a minimal transformer architec- ture interacts with spatial-structure regimes across datasets. This distinction is supp orted by the regime-sp ectrum analysis, which reveals when p erm utation- in v ariant design is adv an tageous and when p ositional structure becomes b ene- ficial. Importantly , T ransMIL op erates on pre-extracted instance em b eddings within a multiple-instance learning (MIL) pip eline and applies transformer la y- ers as a bag-lev el aggregator. In its original form ulation, spatial relation- ships b et ween instances are modeled through relative p ositional cues derived from instance co ordinates, while the transformer itself is not designed as a compact end-to-end vision bac kb one. In contrast, ZACH-ViT performs direct patc h-level representation learning from images without an MIL preprocessing stage, remov es p ositional enco dings entirely , and enforces p ermutation inv ari- ance through global av erage p ooling. Th us, although b oth metho ds may pro cess unordered sets, they differ fundamentally in ob jectiv e, architectural role, and deplo yment constrain ts. 2.3 P ositional Em b edding Remo v al A cross Domains The idea that positional encodings ma y act as unnecessary or even harmful inductiv e biases has recen tly emerged in multiple domains. In language mo d- eling, Gelb erg et al. [5] sho wed that remo ving rotary p ositional embeddings af- ter pretraining (DroPE) enables impro ved con text-length extrap olation in large language mo dels. Although developed in a differen t setting, this observ ation is conceptually aligned with our w ork in questioning whether p ositional informa- tion should alwa ys b e em b edded as a p ermanen t architectural prior. Despite this conceptual o v erlap, the underlying challenges differ substan- tially . DroPE addresses sequence extrap olation in language mo dels where p osi- tional information is intrinsic but b ecomes out-of-distribution at longer con text lengths. In con trast, ZACH-ViT targets medical imaging scenarios in which spa- tial information is frequently weakly informative or non-diagnostic by design. T ak en together, these directions suggest a broader principle: architectural com- p onen ts enco ding spatial or temp oral priors should b e matched to the structural prop erties of the data rather than applied universally . Our regime-sp ectrum analysis (Figure 1) provides empirical evidence for this principle within medical vision tasks, clarifying when p ermutation-in v ariant mo deling is most effectiv e. 4 3 Metho d: ZA CH-ViT 3.1 Arc hitecture Ov erview Giv en an input image X ∈ R H × W × C , ZA CH-ViT extracts non-o verlapping patc hes and pro jects them in to a latent space: Z 0 = Linear ( Patc hify ( X )) ∈ R N × d , where N denotes the num b er of patc hes and d the embedding dimension. Unlike standard ViT s, no p ositional embeddings are added, preserving inv ariance to patc h p erm utations. A stac k of transformer blo c ks processes Z 0 , and the final represen tation is obtained via global a verage p o oling: h = 1 N N X i =1 Z ( i ) L A linear classifier maps h to output logits. By removing p ositional enco ding and replacing the [CLS] token with global p ooling, p erm utation inv ariance is ac hieved by construction while av oiding parameters dedicated to modeling po- ten tially non-informative spatial relationships. 3.2 A daptiv e Residual Pro jections Compact transformer architectures ma y exhibit unstable optimization when fea- ture dimensionality changes across lay ers, particularly under strict parameter constrain ts. ZA CH-ViT addresses this issue through adaptive residual pro jec- tions. Let x denote the input to a transformer blo c k and y its transformed output. Residual summation is defined as x ← ( W pro j x + y , if dim( x ) = dim( y ) , x + y , otherwise , where W pro j is a learnable linear pro jection initialized to zero. This mec hanism preserv es gradient flow across dimensional transitions while introducing mini- mal additional parameters, enabling stable training within the 0.25M-parameter regime. In preliminary exp erimen ts without adaptive pro jections, compact v ari- an ts with changing feature dimensionality show ed o ccasional optimization in- stabilit y (training divergence or increased v ariance across seeds), motiv ating the inclusion of this light weigh t pro jection mechanism. 4 Exp erimen tal Proto col 4.1 F ew-Shot Setting All exp erimen ts follow a unified proto col to ensure consisten t comparison: • 50 training samples p er class (randomly sampled from the official training split) • V alidation and test splits kept unc hanged 5 • Batc h size: 16 • Learning rate: 1 × 10 − 4 (A dam W optimizer) • Epo chs: 23 • Random seeds: { 3 , 5 , 7 , 11 , 13 } (reported as mean ± standard deviation) This setup inten tionally stresses models under data-scarce conditions repre- sen tative of real-w orld medical imaging scenarios. 4.2 Spatial Structure Sp ectrum and Dataset Selection W e ev aluate sev en datasets from the MedMNIST v2 suite [2], selected to span a broad sp ectrum of spatial structure while maintaining task compatibility: • V ery weak (1): Blo o dMNIST — blo od cells app ear randomly distributed in microscopy fields. • W eak (2): PathMNIST — histopathology patc hes behav e as unordered diagnostic collections. • Mo derate (3): BreastMNIST (v ariable ultrasound prob e position), Pneu- moniaMNIST (inconsistent X-ray framing). • Strong (4–5): DermaMNIST (lesion-cen tered but v ariable), OCTM- NIST (fixed retinal la y er structure), OrganAMNIST (stable abdominal anatom y). Three datasets from MedMNIST w ere excluded for metho dological reasons: • ChestMNIST: multi-label classification task, incompatible with the uni- fied binary/multi-class ev aluation proto col. • RetinaMNIST: ordinal regression task requiring sp ecialized ev aluation metrics. • TissueMNIST: histopathology mo dalit y with visual characteristics highly o verlapping P athMNIST, adding limited additional structural div ersit y . This selection preserves consistent ev aluation metrics while co vering the in- tended spatial-structure sp ectrum. 4.3 Mo del F amilies and Benc hmarking W e ev aluate fifteen mo dels spanning four arc hitectural families, co vering differ- en t parameter scales, initialization regimes, and inductiv e biases. Rather than rep orting only selected baselines, all trained mo dels are included in the analysis. This enables comparison from ultra-compact scratc h-trained arc hitectures (0.09M parameters) to large pretrained T ransformers (85.8M pa- rameters). T able 1 summarizes the ev aluated mo dels. Subset-sp ecific comparisons (e.g., scratch-only analyses to isolate inductiv e bias or reduced plots for readability) are explicitly indicated and do not reflect selectiv e rep orting. 6 T able 1: Complete list of ev aluated mo dels trained under the identical few-shot proto col. Initialization indicates whether ImageNet-pretrained weigh ts w ere used. P arameter coun ts are exact. Disk footprint reports sa ved w eight file size measured on BreastMNIST (seed=7, 50-shot, batc h size 16, 23 epo c hs) to appro ximate deploymen t-orien ted storage cost. Citations corresp ond to original arc hitecture publications. F amily Model Params (M) Initialization W eights (MB) Scratch Models ABMIL [6] 0.09 Random 1.082 ZACH-ViT (Ours) [3] 0.25 Random 2.949 T ransMIL [4] 0.26 Random 3.051 Minimal-ViT [1] 0.62 Random 7.458 CNN-ABMIL [6, 7] 1.12 Random 103.205 CNN (ImageNet) MobileNetV2 [8] 2.39 ImageNet 27.959 EfficientNetB0 [9] 4.17 ImageNet 48.611 DenseNet121 [10] 7.09 ImageNet 82.666 Inception V3 [11] 22.03 ImageNet 253.120 ResNet50 [7] 23.80 ImageNet 273.133 T ransformers (ImageNet) DeiT-Small [12] 21.67 ImageNet 82.722 Swin-Tiny [13] 27.52 ImageNet 105.058 ViT-B/16 [1] 85.80 ImageNet 327.365 Hybrid / Mo dern Backbones (ImageNet) MambaOut-Tin y [14] 24.24 ImageNet 92.555 ConvNeXt-Tin y [15] 27.92 ImageNet 319.985 Disk fo otprint complements parameter coun t b y measuring serialized mo del size under a fixed training configuration, reflecting practical storage and distri- bution cost relev an t to edge deploymen t and reproducibility . 4.4 Implemen tation and Exp erimen tal En vironmen t All exp eriments w ere executed in a controlled Linux environmen t using Python 3.10.12. ZA CH-ViT and all ablation studies were implemen ted in T ensorFlow 2.14.0. Certain baseline architectures whose official or stable implementations are a v ailable only in PyT orch w ere ev aluated using their original implementations (PyT orc h 2.2.2, timm 1.0.24). These mo dels w ere executed under iden tical dataset splits, training proto cols, and hardware settings to ensure comparability . Exp erimen ts w ere run on a w orkstation equipped with an NVIDIA R TX A5000 GPU (24 GB VRAM), CUDA 12.8, and 128 CPU cores. The softw are stac k included library_zViT (version 2026001011), MedMNIST 3.0.2, NumPy 1.24.3, Pandas 1.5.3, Matplotlib 3.10.8, and Scikit-learn 1.2.0. Random seeds were fixed across runs, and all mo dels used identical prepro- cessing and data splits to maximize repro ducibility . 4.5 Ev aluation Metrics Primary ev aluation metrics dep end on dataset type: • Binary datasets (BreastMNIST, PneumoniaMNIST): T est A UC@0.5 (threshold fixed at 0.5). • Multi-class datasets: T est MacroF1 to mitigate class imbalance effects. W e additionally report generalization gap (T rain − T est) to quantify ov er- fitting and inference time to assess suitability for edge deploymen t. 7 Figure 1: Regime sp ectrum analysis. Each p oin t shows ZACH-ViT’s adv an- tage ov er the mean p erformance of other scratc h-trained baselines on a dataset. Datasets are ordered b y an ordinal spatial-structure strength index (1 = very w eak, 5 = strong). The trend suggests that ZA CH-ViT’s relativ e adv antage is larger when spatial la yout is weakly informativ e and smaller when anatomical structure is fixed. 5 Results on Medical Imaging Benchmarks Unless stated otherwise, all results in this section are rep orted for the full set of fifteen mo dels summarized in T able 1. 5.1 Regime Sp ectrum V alidation: When Perm utation In- v ariance Matters Our architectural h yp othesis predicts that p erm utation inv ariance is most b ene- ficial when spatial la yout is weakly informative. Figure 1 ev aluates this relation- ship across seven MedMNIST datasets ordered by spatial structure strength. ZA CH-ViT ac hieves the strongest p erformance among sub-1M mo dels on Blo odMNIST (MacroF1 0 . 600 ± 0 . 071 ) and PathMNIST ( 0 . 578 ± 0 . 037 ), datasets where spatial arrangement is weakly informativ e. In these settings, p ermutation- in v ariant pro cessing aligns with the data c haracteristics, yielding a +0.051 MacroF1 gain o ver T ransMIL on Bloo dMNIST, while achieving comparable (sligh tly low er) p erformance on PathMNIST (-0.019 MacroF1). P erformance differences decrease on OCTMNIST and OrganAMNIST, where anatomical structure imposes strong spatial organization ( 0 . 247 ± 0 . 052 and 0 . 436 ± 0 . 036 MacroF1). This trend supp orts the hypothesis: p ositional in- formation con tributes positively whe n spatial relationships are diagnostically relev an t. In suc h cases, remo ving positional priors ma y limit mo deling of fine- grained structural patterns (e.g., retinal lay er organization). Ov erall, these re- sults clarify the regimes in whic h p erm utation inv ariance is adv antageous. 8 Figure 2: Global parameter efficiency across all ev aluated mo dels. ZACH- ViT comp etes with substan tially larger pretrained arc hitectures despite scratch training. 5.2 P arameter Efficiency Without Pretraining Medical edge deploymen t often constrains model size and limits reliance on large pretrained netw orks. Figure 2 sho ws that ZA CH-ViT achiev es comp etitiv e p erformance with only 0.25M parameters. On BreastMNIST, p erformance is comparable to MobileNetV2 (2.39M parameters) despite a substantially smaller parameter budget and no pretraining. On PathMNIST, ZACH-ViT outp erforms all sub-10M mo dels except DenseNet121. T o b etter understand ho w parameter efficiency v aries across spatial-structure regimes, Figure 3 prov ides a p er-dataset decomposition. Each subplot reports mo del p erformance versus parameter coun t within a specific MedMNIST dataset, illustrating how the efficiency–p erformance trade-off changes dep ending on spa- tial structure strength. The star mark er highligh ts ZA CH-ViT. The visual- ization shows that ZA CH-ViT remains consisten tly comp etitiv e among scratc h- trained mo dels across datasets, with strongest relative efficiency in weak-structure regimes (Blo odMNIST, PathMNIST), while pretrained mo dels tend to dominate regimes with stronger anatomical priors (OCTMNIST, OrganAMNIST). This decomp osition reveals that parameter efficiency is not a global prop ert y but a regime-dep enden t one: the same compact arc hitecture o ccupies differen t p ositions on the efficiency–p erformance frontier dep ending on spatial structure strength. Consequently , ev aluating edge-oriented architectures solely through aggregated p erformance can obscure where architectural inductive biases are most b eneficial. Imp ortan tly , although b oth ZACH-ViT and T ransMIL exhibit p erm utation- in v ariant b ehavior, their architectural roles differ. T ransMIL is primarily de- signed as a transformer-based multiple-instance learning aggregation framework op erating at the bag level, whereas ZA CH-ViT functions as a compact end-to- end vision backbone with direct patch-lev el feature learning and adaptiv e resid- ual pro jections. This distinction helps explain why b oth models achiev e com- 9 Figure 3: Parameter efficiency across individual MedMNIST datasets. Each subplot reports model performance versus parameter count within a sp ecific spatial-structure regime. The star indicates ZACH-ViT. Results illustrate regime-dep enden t efficiency: ZACH-ViT sho ws strong comp etitiv eness in weak- structure datasets, while pretrained models generally achiev e higher p erfor- mance in strongly structured anatomical regimes. T able 2: T est MacroF1/AUC@0.5 (mean ± std) for scratch mo dels across MedMNIST7. Bold indicates best p erformer p er dataset. Dataset Spatial Strength ZA CH-ViT ABMIL CNN-ABMIL Minimal-ViT T ransMIL Bloo dMNIST 1 (w eakest) 0.600 ± 0.071 0.211 ± 0.050 0.125 ± 0.067 0.515 ± 0.086 0.538 ± 0.065 PathMNIST 2 0.578 ± 0.041 0.291 ± 0.084 0.239 ± 0.028 0.443 ± 0.061 0.577 ± 0.048 BreastMNIST 3 0.577 ± 0.018 0.526 ± 0.058 0.532 ± 0.072 0.572 ± 0.014 0.599 ± 0.027 PneumoniaMNIST 3 0.707 ± 0.017 0.688 ± 0.026 0.711 ± 0.042 0.607 ± 0.027 0.674 ± 0.019 DermaMNIST 4 0.293 ± 0.029 0.216 ± 0.023 0.062 ± 0.058 0.241 ± 0.033 0.283 ± 0.024 OCTMNIST 5 (strongest) 0.239 ± 0.056 0.192 ± 0.059 0.179 ± 0.016 0.196 ± 0.069 0.258 ± 0.053 OrganAMNIST 5 0.416 ± 0.037 0.262 ± 0.023 0.183 ± 0.055 0.455 ± 0.029 0.470 ± 0.057 parable global ranking while exhibiting differen t b eha vior across spatial regimes and parameter-efficiency trade-offs. This efficiency follo ws from remo ving explicit spatial enco ding components and allocating capacit y to ward feature represen tation rather than positional mo deling. T able 2 summarizes performance across all sev en datasets, showing strong results in weak-structure regimes and comp etitiv e p erformance elsewhere. 5.3 Generalization and Edge Deploymen t Suitabilit y Robust deplo yment requires b oth generalization stabilit y and low inference cost. Figure 4 sho ws that ZACH-ViT main tains small train–test gaps across datasets, indicating limited ov erfitting under few-shot conditions. Figure 5 further shows that ZACH-ViT ac hieves lo w inference time relativ e to larger transformer mo dels while maintaining comp etitiv e p erformance. Com- bined with its 0.25M parameter count and 2.95MB serialized fo otprint (T able 1), this supp orts deplo yment in resource-constrained medical environmen ts. 10 Figure 4: Generalization gap (T rain–T est) for scratch models. ZACH-ViT ex- hibits consistently small gaps across datasets. 5.4 Global Ranking Analysis and Statistical Comparison T o obtain a dataset-agnostic comparison, mo dels were rank ed p er dataset using A UC@0.5 (binary tasks) or MacroF1 (multi-class tasks). Mean ranks were then computed across all seven datasets. Statistical differences were assessed using the F riedman test follow ed by the Nemen yi post-ho c pro cedure [16]. The F riedman test rejected the n ull hypoth- esis of equal p erformance ( p < 0 . 05 ), motiv ating p ost-hoc comparison. Figure 6 shows mean ranks across all mo dels. Pretrained architectures dominate aggregate ranking, with Mam baOut-Tiny achieving the best mean rank (1.29), follow ed b y DeiT-Small (2.43) and Swin-Tiny (3.14). DenseNet121 w as the strongest CNN baseline (3.86). Although ZACH-ViT and T ransMIL obtain identical mean ranks (10.00), indicating comparable aggregate p erfor- mance across heterogeneous datasets. Despite similar aggregate ranks, the t wo architectures differ substantially in design philosophy: T ransMIL acts as a transformer-based MIL aggregator, whereas ZA CH-ViT is a compact end-to- end backbone explicitly optimized for p erm utation-inv ariant few-shot learning under strict parameter constraints. The corresp onding Critical Difference diagram (Figure 7) shows that only large rank differences reach significance due to the relatively large num ber of mo dels ( k = 15 ) compared against seven datasets. T o isolate inductiv e-bias effects indep endent of pretraining, rankings w ere re- computed for scratch-trained mo dels only (Figure 8). T ransMIL and ZA CH-ViT form the top group, outp erforming Minimal-ViT, ABMIL, and CNN-ABMIL. The asso ciated CD diagram (Figure 9) indicates that T ransMIL and ZACH-ViT are statistically indistinguishable under this setting. These ranking results complement the regime-sp ectrum analysis: pretrained mo dels dominate aggregate rankings, whereas p erm utation-inv ariant architec- tures show clear adv antages in w eak spatial-structure regimes. 11 Figure 5: Inference time versus performance. ZACH-ViT occupies an efficient region of the accuracy–latency trade-off. 5.5 Limitations and Honest Assessment ZA CH-ViT does not univ ersally outperform all baselines. On datasets with strong anatomical structure (e.g., OCTMNIST and OrganAMNIST), models retaining p ositional priors o ccasionally achiev e higher performance. This b e- ha vior is consisten t with the trade-off introduced by removing explicit spatial enco ding. Overall, the results supp ort a regime-dep enden t interpretation: ar- c hitectural inductiv e bias should be matched to data structure rather than op- timized for universal dominance. 6 Hyp erparameter Sensitivity Analysis T o assess whe ther p erformance differences arise from architectural design rather than fav orable hyperparameter c hoices, we conduct a sensitivity analysis across t welv e arc hitectural v arian ts on Blo odMNIST, representing the w eakest spatial- structure regime in our sp ectrum. All v ariants follow the same training proto- col (50 samples p er class, five seeds { 3 , 5 , 7 , 11 , 13 } , batc h size 16, 23 ep ochs), while v arying only patch size, num b er of attention heads, transformer unit depth/width, and MLP configuration (T able 3). This setup isolates architec- tural effects while controlling for initialization v ariabilit y . Three observ ations emerge from this analysis (Figures 10–11): P atch size strongly influences performance. Reducing patch size from 16 × 16 to 8 × 8 impro ves MacroF1 (+0.048 o v er baseline, p = 0 . 008 ), whereas increasing patc h size to 32 × 32 decreases p erformance ( − 0 . 104 , p < 0 . 001 ). This trend suggests that fine-grained patc h decomposition better preserv es discrim- inativ e local features in weak-structure data such as blo o d microscop y . P erfor- mance improv ements are consisten t across seeds (Figure 10), indicating robust- ness to initialization. Capacit y scaling improv es absolute p erformance but reduces effi- 12 Figure 6: Mean rank across all fifteen mo dels ov er seven MedMNIST datasets. Lo wer rank indicates b etter a verage performance. ciency . The PS=8 + wider transformer unit configuration achiev es the highest MacroF1 ( 0 . 684 ± 0 . 088 ) but requires substantially more parameters (0.60M vs. 0.25M baseline). In contrast, the PS=8 configuration with reduced parameter coun t (0.17M) already impro ves p erformance relativ e to baseline, suggesting that architectural alignment con tributes more strongly than ra w capacit y . Fig- ure 11 illustrates this trade-off betw een accuracy and parameter efficiency . T raining remains stable across configurations. Most v ariants show low v ariance across seeds, indicating stable optimization. Increased depth (TU=[128,128,64]) leads to higher v ariabilit y without consistent p erformance gains, suggesting lim- ited b enefit from additional hierarch y under weak spatial structure. Ov erall, this analysis indicates that p erformance differences are primarily as- so ciated with architectural choices—particularly patch granularit y—rather than random initialization or isolated h yp erparameter effects. The results further supp ort the regime-dep enden t in terpretation observed in the main exp erimen ts: p erm utation-in v ariant modeling b enefits from configurations that preserve fine- grained lo cal information when spatial lay out is weakly informativ e. 7 Discussion Our comprehensive v alidation—spanning seven medical datasets and rigorous h yp erparameter sensitivity analysis—pro vides empirical supp ort for the archi- tectural hypothesis underlying ZACH-ViT. Rather than pursuing universal b enc h- mark dominance, the results reveal a consisten t relationship b etw een arc hi- tectural behavior and data structure. The regime sp ectrum analysis (Fig- ure 1) shows that ZA CH-ViT’s p erformance is systematically link ed to spatial- structure strength, shifting the focus from absolute accuracy tow ard structural alignmen t with data prop erties and clarifying when and why the architecture succeeds. T ak en together, these results suggest that architectural ev aluation should explicitly accoun t for spatial-structure heterogeneity rather than relying 13 Figure 7: Critical Difference diagram (Nemenyi test, α = 0 . 05 ) for all models. Connected groups indicate non-significant differences. Figure 8: Mean rank restricted to scratch-trained mo dels. solely on aggregate b enc hmark p erformance. Arc hitectural alignmen t outw eighs scale under data scarcit y . While pretrained mo dels generally outperform scratc h-trained ones in lo w-data set- tings, ZACH-ViT closes this gap significantly within its parameter regime (0.25M vs. 2–85M). On Blo o dMNIST and P athMNIST—where spatial order is w eakly informativ e—it ev en surpasses larger pretrained mo dels in parameter efficiency . This suggests that for low-data regimes common in medical imaging under edge- deplo yment constrain ts, architectural parsimon y aligned with data structure matters more than brute-force scaling. P ermutation inv ariance enables robust generalization. The mini- mal generalization gaps across all sev en datasets (Figure 4) are consistent with the hypothesis that remo ving p ositional priors can reduce ov erfitting. Without spatial assumptions to latc h onto, ZACH-ViT fo cuses on inv ariant visual fea- tures that generalize across acquisition proto cols—a critical prop ert y for clinical deplo yment where imaging conditions v ary widely . Edge deploymen t ma y require reconsidering arc hitectural priors. Most ViT v arian ts assume spatial structure is diagnostic—an assumption that 14 Figure 9: Critical Difference diagram (Nemen yi test, α = 0 . 05 ) for scratc h- trained mo dels. T able 3: Hyp erparameter sensitivity analysis on Blo odMNIST. T est MacroF1 and accuracy are reported as mean ± std across fiv e seeds. Bold indicates statistically significant after correction for multiple comparisons o v er the base- line (tw o-tailed paired t-test, p < 0.01, Bonferroni correction applied across all 11 v arian t-vs-baseline comparisons). The baseline configuration (PS=16, H=8, TU=[128,64]) represen ts the primary parameter-efficient setting at 0.25M pa- rameters. All v alues corresp ond to the final experimental proto col (23 ep ochs, fiv e seeds) and replace preliminary exploratory runs used during early develop- men t. V ariant Patc h Heads TU MLP Params (M) T est MacroF1 T est A cc T rain Time (s) Inf Time (ms) Baseline 16 8 128-64 128-64 0.25 0.561 ± 0.051 0.609 ± 0.054 250.1 ± 3.1 11.6 ± 0.1 PS=8 8 8 128-64 128-64 0.17 0.609 ± 0.038 0.640 ± 0.035 310.3 ± 3.6 13.1 ± 0.2 PS=32 32 8 128-64 128-64 0.54 0.457 ± 0.034 0.450 ± 0.037 252.9 ± 5.8 11.4 ± 0.2 H=4 16 4 128-64 128-64 0.25 0.579 ± 0.039 0.609 ± 0.041 253.5 ± 6.2 12.0 ± 0.5 Deeper TU 16 8 128-128-64 128-64 0.33 0.497 ± 0.095 0.516 ± 0.102 263.5 ± 1.9 12.2 ± 0.4 Wider TU 16 8 256-128 128-64 0.75 0.638 ± 0.036 0.673 ± 0.038 256.9 ± 3.8 11.5 ± 0.2 Wider MLP 16 8 128-64 256-128 0.28 0.599 ± 0.036 0.626 ± 0.038 255.4 ± 4.4 11.6 ± 0.2 PS=8 + H=4 8 4 128-64 128-64 0.17 0.599 ± 0.031 0.625 ± 0.033 281.3 ± 4.2 12.3 ± 0.3 PS=32 + H=4 32 4 128-64 128-64 0.54 0.435 ± 0.026 0.438 ± 0.028 250.8 ± 3.5 11.5 ± 0.1 Deeper+Wider 16 8 128-128-64 256-128 0.37 0.552 ± 0.036 0.575 ± 0.038 262.8 ± 2.6 11.7 ± 0.2 PS=8 + Wider TU 8 8 256-128 128-64 0.60 0.684 ± 0.088 0.713 ± 0.092 322.0 ± 3.3 13.7 ± 0.3 Wider TU + H=4 16 4 256-128 128-64 0.75 0.630 ± 0.048 0.662 ± 0.050 249.6 ± 1.4 12.4 ± 0.3 often breaks down in medical imaging scenarios where texture or lo cal statistics dominate. ZA CH-ViT’s success suggests that edge-deplo yed medical imaging systems b enefit from architectures whose inductiv e biases match deploymen t constrain ts: minimal parameters, no pretraining dep endency , and robustness to spatial v ariation. This ma y partially explain why many computational pathol- ogy pip elines remain confined to research environmen ts despite strong algorith- mic performance. In this sense, ZACH-ViT should be in terpreted less as a ligh tw eight alternativ e to existing ViT s and more as an example of architecture design driven by deplo yment constrain ts rather than benchmark con ven tions. F uture directions. While our hyperparameter sensitivity analysis supp orts arc hitectural alignmen t as a cen tral factor in ZA CH-ViT’s p erformance, future w ork could isolate c omponent contributions through targeted ablations (e.g., p ositional embeddings, p ooling op erators) across the spatial-structure sp ectrum. Suc h studies w ould provide deeper mec hanistic insight in to when permutation- in v ariant mo deling is most b eneficial in medical imaging. 15 PS8+TU256-128 TU256-128 H4+TU256-128 PS8 PS8+H4 MLP256-128 TU128-128-64+MLP256-128 H4 Baseline (0.25M) TU128-128-64 PS32 PS32+H4 Ar chitectural V ariant 0.40 0.45 0.50 0.55 0.60 0.65 0.70 0.75 T est Macr oF1 Hyperparameter Sensitivity on BloodMNIST (T est MacroF1 across 5 seeds) Baseline mean (0.25M params) Figure 10: Hyperparameter sensitivit y on Bloo dMNIST showing test MacroF1 distributions across five random seeds. Smaller patch sizes generally yield higher p erformance. 8 Conclusion W e introduced ZA CH-ViT, a zero-token Vision T ransformer that remo ves p osi- tional embeddings and the class token, relying instead on p erm utation-in v ariant patc h processing and global po oling. Ev aluation across seven represen tative MedMNIST datasets sho ws that ZACH-ViT ac hieves comp etitiv e performance with minimal parameters (0.25M) and no pretraining, while remaining stable under few-shot conditions where larger mo dels often degrade. Imp ortan tly , its adv an tage is regime-dependent: strongest when spatial order is weakly informa- tiv e (Blo odMNIST, PathMNIST) and reduced when anatomical structure im- p oses fixed lay outs (OCTMNIST, OrganAMNIST). These results supp ort the view that arc hitectural alignment with data structure ma y outw eigh pursuing univ ersal b enchmark dominance. F or edge-deplo yed medical imaging scenarios where spatial lay out is incon- sisten t or w eakly informative, ZA CH-ViT pro vides an alternative design strat- egy to conv entional ViT s. Its parameter efficiency , robust generalization, and lo w-latency inference support deplo yment in resource-constrained clinical en vi- ronmen ts. More broadly , our results suggest that, under edge-deplo yment con- strain ts, architectural priors should b e treated as data-dep endent design choices rather than default comp onen ts. References [1] Doso vitskiy , A., Beyer, L., K olesniko v, A., et al.: An Image is W orth 16x16 W ords: T ransformers for Image Recognition at Scale. In: International Conference on Learning Representations (ICLR) (2021) 16 0.2 0.3 0.4 0.5 0.6 0.7 P arameters (Millions) 0.45 0.50 0.55 0.60 0.65 T est MacroF1 (Mean across 5 seeds) H4 (0.25M) H4+TU256-128 (0.75M) TU128-128-64 (0.33M) TU128-128-64+MLP256-128 (0.36M) Baseline (0.25M) (0.25M) MLP256-128 (0.28M) TU256-128 (0.75M) PS32+H4 (0.54M) PS32 (0.54M) PS8+H4 (0.17M) PS8 (0.17M) PS8+TU256-128 (0.60M) P arameter Efficiency vs Performance on BloodMNIST (W eak est Spatial Structure Regime) Baseline (0.25M) Best (0.60M) 0.45 0.50 0.55 0.60 0.65 T est Macr oF1 Figure 11: Parameter efficiency versus p erformance on Blo odMNIST. Higher- p erforming configurations often require increased capacit y , while the baseline pro vides a fa v orable efficiency–p erformance trade-off. [2] Y ang, J., Huang, R., Li, J., et al.: MedMNIST v2: A Large-Scale Ligh tw eight Benchmark for 2D and 3D Biomedical Image Classification. Scien tific Data 10, 48 (2023) [3] Angelakis, A., Mousa, A., Heldeweg, M.L.A., et al.: ZACH-ViT: A Zero- T ok en Vision T ransformer with ShuffleStrides Data Augmentation for Robust Lung Ultrasound Classification. arXiv preprin t (2025) [4] Shao, R., Lu, M., W ang, L., et al.: T ransMIL: T ransformer-based Multiple Instance Learning for Whole Slide Image Classification. A dv ances in Neural Information Pro cessing Systems (NeurIPS) 34, 21083–21096 (2021) [5] Gelb erg, Y., Eguc hi, K., Akiba, T., Cetin, E.: Extending the Con text of Pretrained LLMs by Dropping Their P ositional Embeddings. arXiv preprin t arXiv:2512.12167 (2025) [6] Ilse, M., T omczak, J., W elling, M.: Atten tion-based Deep Multiple Instance Learning. In: In ternational Conference on Mac hine Learning (ICML), pp. 2127–2136 (2018) [7] He, K., Zhang, X., Ren, S., Sun, J.: Deep Residual Learning for Image Recognition. In: IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), pp. 770–778 (2016) [8] Sandler, M., How ard, A., Zh u, M., Zhmoginov, A., Chen, L.C.: Mo- bileNetV2: In v erted Residuals and Linear Bottlenecks. In: IEEE/CVF Conference on Computer Vision and P attern Recognition (CVPR), pp. 4510–4520 (2018) 17 [9] T an, M., Le, Q.V.: Efficien tNet: Rethinking Mo del Scaling for Con volu- tional Neural Net works. In: International Conference on Machine Learning (ICML), pp. 6105–6114 (2019) [10] Huang, G., Liu, Z., V an Der Maaten, L., W ein b erger, K.Q.: Densely Con- nected Conv olutional Net works. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4700–4708 (2017) [11] Szegedy , C., V anhouc k e, V., Ioffe, S., Shlens, J., W o jna, Z.: Rethinking the Inception Arc hitecture for Computer Vision. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2818–2826 (2016) [12] T ouvron, H., Cord, M., Douze, M., et al.: T raining Data-efficient Image T ransformers & Distillation through Atten tion. In: International Confer- ence on Machine Learning (ICML), pp. 10347–10357 (2021) [13] Liu, Z., Lin, Y., Cao, Y., et al.: Swin T ransformer: Hierarchical Vision T ransformer us ing Shifted Windo ws. In: IEEE/CVF International Confer- ence on Computer Vision (ICCV), pp. 10012–10022 (2021) [14] Zhang, Z., Li, Y., W ang, Y., et al.: MambaOut: Do W e Really Need Mam ba for Vision? arXiv preprin t arXiv:2405.15154 (2024) [15] Liu, Z., Mao, H., W u, C.Y., et al.: A ConvNet for the 2020s. In: IEEE/CVF Conference on Computer Vision and P attern Recognition (CVPR), pp. 11976–11986 (2022) [16] Demsar, J.: Statistical comparisons of classifiers ov er multiple data sets. Journal of Machine Learning Researc h 7, 1–30 (2006) 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment