YOLO-NAS-Bench: A Surrogate Benchmark with Self-Evolving Predictors for YOLO Architecture Search
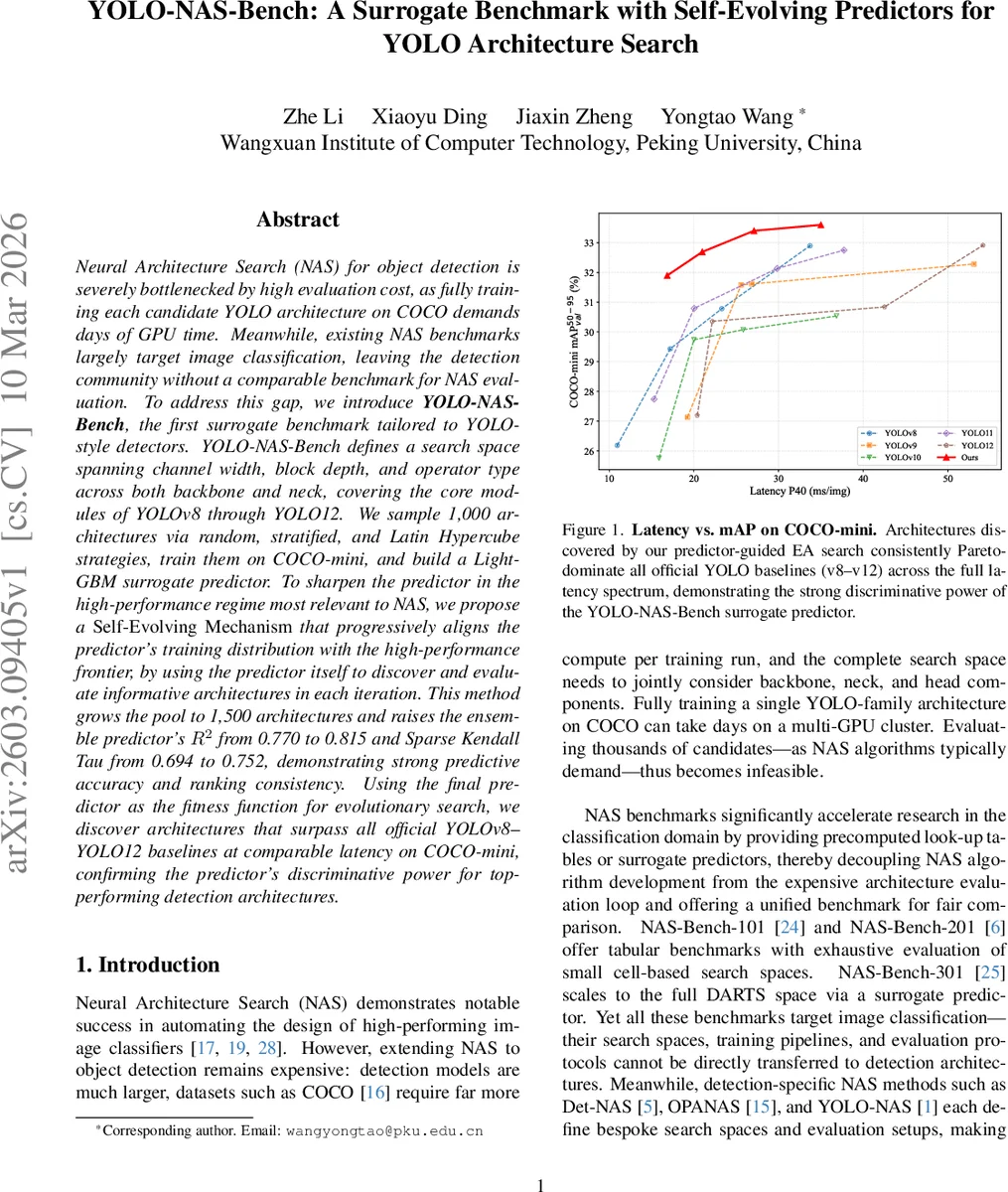
Neural Architecture Search (NAS) for object detection is severely bottlenecked by high evaluation cost, as fully training each candidate YOLO architecture on COCO demands days of GPU time. Meanwhile, existing NAS benchmarks largely target image classification, leaving the detection community without a comparable benchmark for NAS evaluation. To address this gap, we introduce YOLO-NAS-Bench, the first surrogate benchmark tailored to YOLO-style detectors. YOLO-NAS-Bench defines a search space spanning channel width, block depth, and operator type across both backbone and neck, covering the core modules of YOLOv8 through YOLO12. We sample 1,000 architectures via random, stratified, and Latin Hypercube strategies, train them on COCO-mini, and build a LightGBM surrogate predictor. To sharpen the predictor in the high-performance regime most relevant to NAS, we propose a Self-Evolving Mechanism that progressively aligns the predictor’s training distribution with the high-performance frontier, by using the predictor itself to discover and evaluate informative architectures in each iteration. This method grows the pool to 1,500 architectures and raises the ensemble predictor’s R2 from 0.770 to 0.815 and Sparse Kendall Tau from 0.694 to 0.752, demonstrating strong predictive accuracy and ranking consistency. Using the final predictor as the fitness function for evolutionary search, we discover architectures that surpass all official YOLOv8-YOLO12 baselines at comparable latency on COCO-mini, confirming the predictor’s discriminative power for top-performing detection architectures.
💡 Research Summary
The paper introduces YOLO‑NAS‑Bench, the first surrogate benchmark specifically designed for YOLO‑style object detectors, addressing the lack of a unified evaluation platform for detection‑oriented neural architecture search (NAS). The authors first define a comprehensive search space that spans the backbone and neck of YOLO models, covering three key dimensions: channel width, block depth, and operator type. The channel choices grow with stage depth (P2‑P5), depths range from 1 to 4 blocks per stage, and operators include the modern modules C2f, C3k2, C2fCIB, and C2PSA for feature extraction, as well as Conv and SCDown for down‑sampling. This design yields a combinatorial space of several million configurations while keeping the head fixed for tractability.
To populate the benchmark, three complementary sampling strategies are employed: random sampling (200 architectures), stratified sampling based on parameter count (400), and Latin Hypercube Sampling (400). All 1,000 sampled architectures are trained from scratch on a reduced COCO‑mini dataset (10 % of COCO, preserving class and size distribution) using a unified training protocol (120 epochs, batch size 128, Mosaic, MixUp, Copy‑Paste, etc.). Each model’s performance is recorded as mAP₅₀₋₉₅.
Each architecture is encoded into a 24‑dimensional feature vector (scalar channel and depth values plus one‑hot operator encodings). A LightGBM gradient‑boosted decision tree regressor is trained to predict mAP from this encoding. The initial surrogate achieves a coefficient of determination R² = 0.770 and Sparse Kendall‑Tau (sKT) = 0.694, indicating reasonable regression accuracy but limited ranking fidelity in the high‑performance region.
To overcome the distribution mismatch between uniformly sampled training data and the high‑performance frontier crucial for NAS, the authors propose a Self‑Evolving Predictor. The overall latency range of the initial pool is divided into ten equal buckets. Within each bucket, a target latency is sampled and an evolutionary algorithm (EA) runs with predicted mAP as the fitness function while respecting the real latency constraint. The EA uses a population of 50, 100 generations, 25 % elite selection, uniform crossover (50 %) and mutation (50 % with probability 0.2). The top five architectures per bucket (50 per round) are fully trained on COCO‑mini, added to the pool, and the LightGBM model is retrained. This loop repeats for ten rounds, expanding the dataset to 1,500 architectures. After the final round, an ensemble of ten LightGBM models (different random seeds) is used, raising R² to 0.815 and sKT to 0.752, demonstrating significantly improved predictive and ranking performance, especially near the Pareto front.
The refined surrogate is then employed as the fitness function for a fresh EA search. The resulting architectures consistently dominate official YOLOv8‑v12 baselines across the entire latency spectrum on COCO‑mini, confirming that the surrogate can reliably guide NAS toward top‑performing detectors.
Key contributions are: (1) a YOLO‑specific, high‑dimensional search space covering backbone and neck; (2) a diverse, 1,000‑model ground‑truth database built with three sampling strategies; (3) a Self‑Evolving mechanism that iteratively enriches the training set with high‑value candidates, closing the gap between training distribution and NAS search distribution; (4) a publicly usable surrogate benchmark that enables near‑zero‑cost evaluation of any detection‑focused NAS algorithm. Limitations include reliance on the COCO‑mini subset (potentially affecting absolute performance transfer) and a fixed detection head, which may restrict exploration of head‑level innovations. Future work could extend the benchmark to full COCO, incorporate head design into the search space, and explore alternative surrogate models such as neural networks or graph‑based predictors.
Comments & Academic Discussion
Loading comments...
Leave a Comment