IAML: Illumination-Aware Mirror Loss for Progressive Learning in Low-Light Image Enhancement Auto-encoders
This letter presents a novel training approach and loss function for learning low-light image enhancement auto-encoders. Our approach revolves around the use of a teacher-student auto-encoder setup coupled to a progressive learning approach where mul…
Authors: Farida Mohsen, Tala Zaim, Ali Al-Zawqari
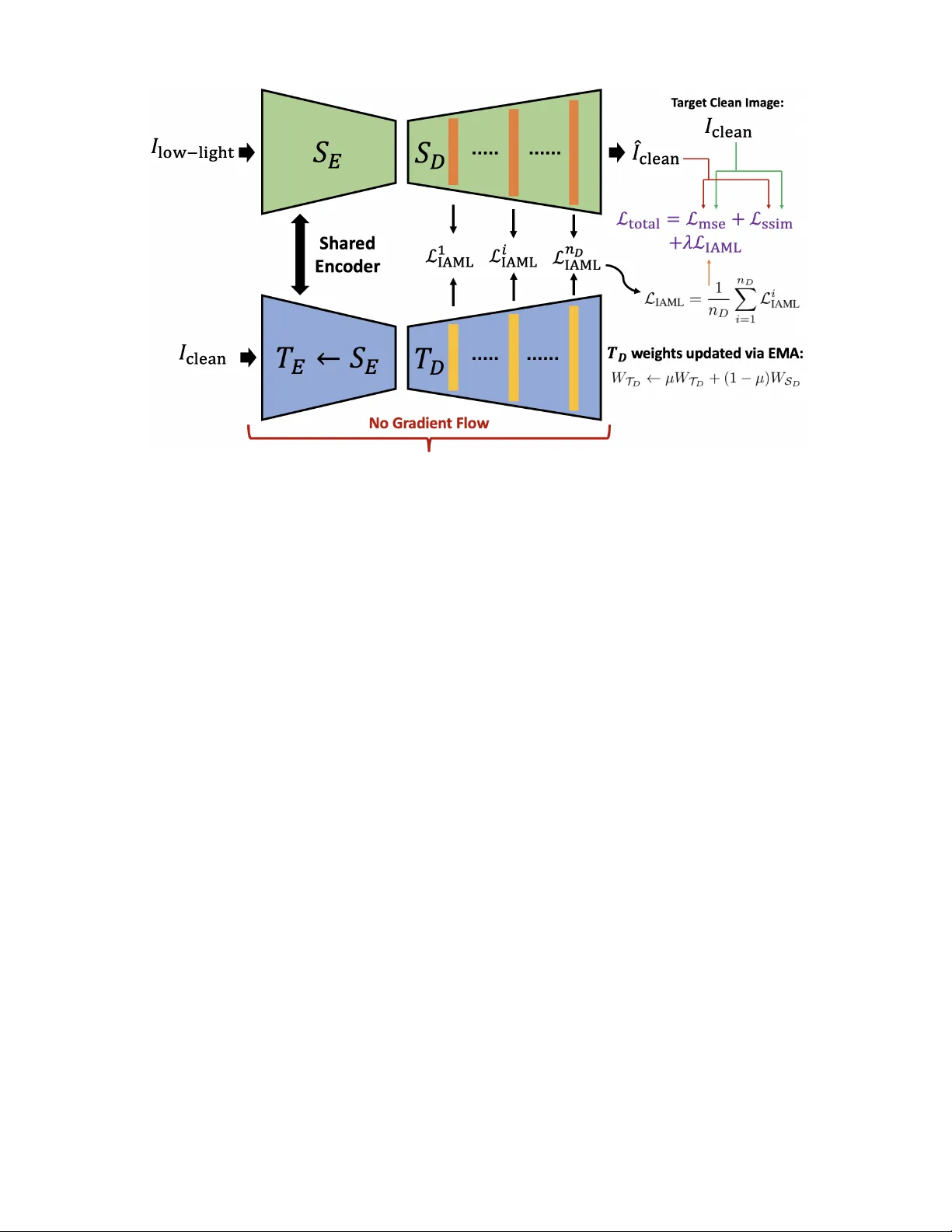
JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 1 IAML: Illumination-A ware Mirror Loss for Progressi v e Learning in Lo w-Light Image Enhancement Auto-encoders Farida Mohsen, T ala Zaim, Ali Al-Zawqari, Ali Safa, Member , IEEE, and Samir Belhaouari, Senior Member , IEEE Abstract —This letter presents a novel training approach and loss function for lear ning low-light image enhancement auto- encoders. Our approach r evolves around the use of a teacher - student auto-encoder setup coupled to a progr essive learning ap- proach where multi-scale information from clean image decoder feature maps is distilled into each layer of the student decoder in a mirrored fashion using a newly-proposed loss function termed Illumination-A war e Mirror Loss (IAML). IAML helps aligning the feature maps within the student decoder network with clean feature maps originating from the teacher side while taking into account the effect of lighting variations within the input images. Extensive benchmarking of our proposed appr oach on thr ee popular low-light image enhancement datasets demonstrate that our model achieves state-of-the-art performance in terms of av- erage SSIM, PSNR and LPIPS reconstruction accuracy metrics. Finally , ablation studies are performed to clearly demonstrate the effect of IAML on the image reconstruction accuracy . Index T erms —Low-light image enhancement, auto-encoders, loss function design. I . I N T RO D U C T I O N I N the past decade, lo w-light image enhancement using modern deep learning (DL) techniques has been an ac- tiv e area of research, with applications to nighttime vision for autonomous car navigation, remote sensing, photography enhancement and so on [1], [2], [3], [4], [5]. The use of DL models over traditional luminosity and exposure amplification has constituted a major leap forward within the field, enabling much higher fidelity image recovery ev en within extreme low- light conditions where con ventional luminosity and exposure manipulation fails [6], [7], [8], [9]. W ithin this context, the use of con volutional auto-encoder architectures has been widely adopted as one of the models of choice for lo w-light image enhancement [6]. Certainly , auto- encoders constitute a natural choice for this application follo w- ing their ability at reconstructing output images of the same type and dimension as their input image [10]. Furthermore, the use of skip connections [11], where the original input image is added as an additional input to subsequent layers, has also been prov en to be critical for achieving high-accuracy image F . Mohsen, T . Zaim, A. Safa and S. Belhaouari are with the College of Science and Engineering, Hamad Bin Khalifa University , Doha, Qatar. emails: { fmohsen, taza89388, asafa, sbelhaouari } @hbku.edu.qa; A. Al-Zawqari is with the ELEC department, Vrije Univ ersiteit Brussel, Brussels, Belgium. emails: ali.mohammed.mohammed.al-zawqari@vub .be; F . Mohsen developed the methods and performed the experiments. T . Zaim and A. Al-Zawqari contributed to the analysis of the results. A. Safa and S. Belhaouari supervised the project as Principal Inv estigators. All authors contributed to the writing of the manuscript. reconstruction. Popular models such as the U-Net architecture hav e therefore been utilized in man y works related to image restoration, as a well-suited auto-encoder backbone equipped with skip connections and moderate compute complexity [12]. In addition to DL architectural choices, the choice of the loss function used during training has been prov en to be of crucial importance [13]. Indeed, prior works hav e explored how the design of the loss function impacts the performance of low-light image enhancement models [13], in terms of standard benchmark metrics such as Structural Similarity Index Measur e (SSIM), P eak Signal-to-Noise Ratio (PSNR) and Learned P er ceptual Image P atc h Similarity (LPIPS) [14], [15]. Follo wing these realizations within the field, this paper focuses on the design of a nov el loss function termed Illumination-A ware Mirr or Loss (IAML) for learning low-light enhancement auto-encoder models. Inspired by the growing use of teacher-student setups [16], our proposed IAML loss is used alongside a custom teacher-student auto-encoder setup that distills information from clean image representations into each layer of the student’ s decoder sub-network, better guiding model learning during the training procedure. The contributions of this paper are the follo wing: 1) W e introduce a teacher-student paradigm for low-light image enhancement where the teacher processes clean images while the student enhances degraded ones, en- abling implicit learning of clean image priors. 2) W e propose a novel IAML loss that aligns student decoder feature maps with clean teacher decoder ones across all layers, facilitating multi-scale feature learning and distillation. 3) W e perform extensi ve benchmarking and ablation stud- ies to clearly demonstrating the usefulness of IAML and we show that our proposed approach outperforms more than a dozen prior techniques on three popular benchmark datasets. This paper is organized as follows. The proposed meth- ods are introduced in Section II. Experimental studies are presented in Section III. Finally , conclusions are provided in Section IV. I I . P RO P O S E D M E T H O D This section describes our proposed method for low-light image enhancement, based on the formulation of a multi-lev el mirror learning scheme between a teacher encoder network JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 2 Fig. 1. Proposed teacher -student auto-encoder setup for lo w-light image enhancement. The student network S receives as input the de graded lo w-light images I low-light and seeks to recover the clean images ˆ I clean . The teacher network T shares the same encoder as S (updated as T E ← − S E during the training iterations) and updates its decoder T D via an exponential moving av erage using the weights of the student decoder S D (no gradient-based learning in T ). The teacher takes as input the clean target images I clean , leading to clean multi-scale feature maps at each layer of T D . These clean feature maps are then used to guide the learning of the layers within S D in a mirrored fashion using the proposed Illumination-A ware Mirror Loss (IAML). and a student auto-encoder which learns to output the en- hanced image from the degraded low-light input image. A. T eac her-student auto-encoder setup Our proposed neural network setup is composed of both a teacher and a student auto-encoder , as shown in Fig. 1. First, we set up a student auto-encoder S which al ways tak es as input the degraded low-light images I low-light and aims to reconstruct the corresponding target clean images I clean . min || ˆ I clean − I clean || 2 giv en ˆ I clean = S ( I low-light ) (1) W e respecti vely denote by S E and S D the encoder and decoder parts of S . Then, in addition to the student auto- encoder , we set up a teacher auto-encoder T which strictly takes as input the tar get clean images I clean and seeks to re- produce them as its output. Crucially , the encoder part of T noted T E is an e xact copy of the student encoder S E (shared encoder), with the difference that the backpropagation of gradients is disabled so that the clean images given as input to the teacher encoder T E nev er impact the learning of this shared encoder block: T E ← − S E (2) Now , regarding the teacher decoder T D , both the student and teacher encoders are initialized with the same random weights at the beginning of the training process: T 0 D , S 0 D ← − random init (3) Then, during the learning process, gradients are allowed to flow within the student decoder while being blocked for the teacher decoder once again. Instead, at each learning iteration, the teacher decoder T D is updated following an exponential moving averag e (EMA) scheme as follo ws [17]: W T D ← − µW T D + (1 − µ ) W S D (4) where µ is the EMA coefficient, W T D denotes the teacher decoder weights and W S D denotes the student decoder weights (where gradient-based update occurs). During training, the multi-scale feature representations within S D will undergo an alignment process with regard to the representations within T D , corresponding to feature maps associated with the clean target images I clean that the student need to produce. This is done through the formulation of a nov el loss function strategy , which will be explained in Section II-B. The combination of the shared encoder S E = T E processing both the degraded low-light and clean inputs, together with the EMA-dri ven teacher decoder T D creates a self-distillation loop : the teacher receiv es as input images in the clean do- main and gradually con ver ges to produce ideal intermediate representations, which the student processing within the de- graded domain is trained to mirror . The EMA-based update of T D ensures smooth, non-collapsing targets. Gradient stopping prev ents the teacher from being directly optimized, preserving the asymmetric role of the two branches. B. Illumination-awar e mirror loss The goal of our proposed IAML is to force each feature map produced within S D to align itself with the corresponding feature map of T D which processes the tar get clean images. Doing so, layer-wise and multi-scale information about the feature representations of clean images are injected at each scale lev el of S D , better guiding it during learning tow ards JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 3 the generation of clean images from its degraded low-light inputs. Crucially , our proposed mirror loss is made illumination- awar e . Indeed, because the student and teacher model decode features from two dif ferent illumination domains, their inter- mediate acti v ations occupy different dynamic ranges. Hence, a nai ve ℓ 1 or ℓ 2 matching between corresponding student and teacher feature maps would be dominated by domain-le vel magnitude differences rather than structural discrepancies. T o alleviate this, we adopt a weighted loss approach taking into account the luminance of each pixel in the input images as follo ws. Gi ven the low-light input I low-light , we compute a luminance map L p per pixel p via the standard RGB-to- luminance coefficients [18]: L p = 0 . 299 I R low-light , p + 0 . 587 I G low-light , p + 0 . 114 I B low-light , p (5) Then, L p is min-max normalized to ˜ L p ∈ [0 , 1] , and con verted to an emphasis weight matrix : W p = 1 + β (1 − ˜ L p ) , β = 0 . 6 , (6) so that darker regions receive weight up to 1 + β = 1 . 6 while well-lit regions receiv e the base weight of 1 . 0 . Later on, upon feeding an input sample, its corresponding W p can be resized to match the size of each feature scale i , noted as W i . In addition, we first apply standar d normalization to the flattened student and teacher feature maps f i S , f i T for all decoder scale lev els i as follo ws: ˜ f i S,T ← − ˜ f i S,T − µ ( ˜ f i S,T ) σ ( ˜ f i S,T + ϵ ) , ϵ = 10 − 6 , (7) where µ and σ respecti vely denote the mean and standard deviation operators (and ϵ av oids di vision by zero). Doing so, the proposed IAML at decoder layer lev el i is then defined as: L i IAML = D W i ⊙ ˜ f i S − sg( ˜ f i T ) E , (8) where ⟨·⟩ denotes spatial averaging, ⊙ is the element-wise multiplication with broadcasting ov er the channel dimension and sg ( · ) denotes the blocking of the gradient flow associated with the teacher data. Finally , the total IAML is computed as the average across all decoder le vels i = 1 , ..., n D : L IAML = 1 n D n D X i =1 L i IAML . (9) C. Global loss function During training, the final loss is computed as a combination of a per-pix el reconstruction loss and the proposed IAML: L total = L mse + L ssim | {z } per-pixel reconstruction + λ L IAML | {z } feature map distillation (10) where L mse is the standard mean square error between the student decoder output ˆ I clean and the target clean image I clean , L ssim = 1 − SSIM ( ˆ I clean , I clean ) is the structural similarity loss [13] and λ is a hyper-parameter defining the strength of the proposed IAML contribution. T ABLE I Q UA N TI TA T I V E C O M P A R IS O N O F ME T H O DS O N T HE L OL - V 1 D A TA S ET . B E ST S CO R E S A R E I N B O L D . Method SSIM ↑ PSNR ↑ LPIPS ↓ LIME [19] 0.564 16.74 0.350 SRIE [20] 15.12 0.569 0.340 BVIF [21] 0.561 16.61 0.286 BIMEF [22] 0.566 14.80 0.326 ZeroDCE++ [23] 0.595 16.72 0.335 EnlightenGAN [24] 0.650 17.48 0.322 RetinexNet [25] 0.560 16.77 0.474 KinD [26] 0.790 20.86 0.207 MIRNet [27] 0.830 24.14 0.131 UFormer [28] 0.771 16.36 0.321 Restormer [29] 0.823 22.43 0.141 LANet [30] 0.810 21.71 0.101 SurroundNet [1] 0.853 23.84 0.113 Retinexformer [2] 0.816 23.69 0.140 SCFR-WLMB [31] 0.811 23.270 – LightenDiffusion [32] 0.811 19.977 0.178 IAML (ours) 0.876 23.84 0.0848 I I I . E X P E R I M E N TA L S E T U P A. Model arc hitectur e and training procedur e As auto-encoder backbone, we use the popular U-Net ar- chitecture with CB AM attention [33] used at each scale. As detailed in Section II-A, both the student and teacher networks share this same architecture. During training, images are ran- domly cropped to 256 × 256 patches with horizontal and v ertical flipping augmentation. W e use the Adam optimizer with an initial learning rate of 2 × 10 − 4 , β 1 = 0 . 9 , β 2 = 0 . 999 , and a cosine-annealing schedule ov er 500 epochs with batch size 8. The EMA momentum in (4) is fixed at µ = 0 . 999 throughout training. In addition, grid search has been performed on the hyper-parameter λ in (10) and the best results corresponding to λ = 0 . 8 are reported. All experiments are carried using an NVIDIA R TX 4090 GPU. B. Benchmark Datasets W e ev aluate our proposed approach on three widely adopted low-light benchmarks: LOL-v1 , LOL-v2-Real and LOL-v2-Synthetic . First, LOL-v1 [25] contains 485 training and 15 test image pairs captured under real lo w-light conditions. Then, LOL-v2-Real [34] extends the LOL-v1 protocol with 689 training and 100 test pairs captured in real- world settings. Finally , LOL-v2-Synthetic [34] provides 900 training and 100 test pairs generated via synthetic degra- dation pipelines. All three datasets supply spatially aligned low-light / normal-light pairs enabling supervised training and reliable quantitative e valuation. C. Benchmark r esults During the benchmarking process, we use three widely used and standard similarity measurement scores: SSIM (the higher the better), PSNR (the higher the better) and LPIPS (the lower the better) [14], [15]. On LOL-v1 , our method achie ves state-of-the-art percep- tual quality , with the highest SSIM and lowest LPIPS metrics JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 4 T ABLE II Q UA N TI TA T I V E C O M P A R IS O N O F ME T H O DS O N T HE L OL - V 2 - R E A L A N D L O L - V 2 - S YN T H E TI C D A TAS E T S . B ES T SC O R E S A R E I N B O LD . Method LOL-v2-real LOL-v2-synthetic SSIM ↑ PSNR ↑ LPIPS ↓ SSIM ↑ PSNR ↑ LPIPS ↓ LIME [19] 0.469 15.19 0.415 0.776 16.85 0.675 SRIE [20] 0.556 16.12 0.332 0.617 14.51 0.196 BVIF [21] 0.546 16.43 0.317 0.717 17.24 0.198 BIMEF [22] 0.613 16.51 0.307 0.616 14.09 0.193 ZeroDCE++ [23] 0.571 18.75 0.313 0.829 18.04 0.168 EnlightenGAN [24] 0.617 18.23 0.309 0.734 16.57 0.212 RetinexNet [25] 0.567 15.47 0.365 0.798 17.13 0.754 KinD [26] 0.641 14.74 0.375 0.578 13.29 0.435 MIRNet [27] 0.820 20.02 0.317 0.876 21.94 0.112 UFormer [28] 0.771 18.82 0.347 0.871 19.66 0.107 Restormer [29] 0.827 19.94 0.191 0.830 21.41 0.066 LANet [30] 0.780 19.21 0.178 0.882 22.54 0.069 SurroundNet [1] 0.807 20.18 0.144 0.900 23.88 0.068 Retinexformer [2] 0.814 21.43 0.184 0.930 24.16 0.061 URetinex-Net++ [3] 0.811 20.55 0.143 0.899 24.02 0.067 SCFR-WLMB [31] 0.834 21.430 – 0.917 25.830 – LightenDiffusion [32] 0.853 22.831 0.167 0.867 21.523 0.157 IAML (ours) 0.855 21.45 0.15 0.932 24.82 0.058 among all compared methods, while reaching second-best position on the PSNR metric (see T able I). Furthermore, T able II reports benchmark metrics on LOL-v2-Real and LOL-v2-Synthetic , clearly showing once again that our method achie ves state-of-the-art performance in terms of SSIM and LPIPS, while systematically reaching second-best perfor- mance in terms of PSNR. Overall, when e valuating the av erage SSIM, PSNR and LPIPS across all datasets, T able III clearly sho ws that our method outperforms prior approaches by reaching the highest av erage SSIM, PSNR and LPIPS measures. T ABLE III A V E R AG E B E NC H M A RK M ET R I C S AC RO S S LOL- V 1 , LOL- V 2-R E A L A N D LOL- V 2-S Y N T H E T I C . Method SSIM ↑ PSNR ↑ LPIPS ↓ LIME [19] 0.603 16.26 0.480 SRIE [20] 5.431 10.40 0.289 BVIF [21] 0.608 16.76 0.267 BIMEF [22] 0.598 15.13 0.275 ZeroDCE++ [23] 0.665 17.84 0.272 EnlightenGAN [24] 0.667 17.43 0.281 RetinexNet [25] 0.642 16.46 0.531 KinD [26] 0.670 16.30 0.339 MIRNet [27] 0.842 22.03 0.187 UFormer [28] 0.804 18.28 0.258 Restormer [29] 0.827 21.26 0.133 LANet [30] 0.824 21.15 0.116 SurroundNet [1] 0.853 22.62 0.098 Retinexformer [2] 0.853 23.09 0.128 SCFR-WLMB [31] 0.854 23.51 – LightenDiffusion [32] 0.844 21.44 0.167 IAML (ours) 0.888 23.37 0.098 D. Ablation studies Importantly , in order to explore the impact of our proposed IAML approach, we perform ablation studies on the mirror loss formulation in (8) and on the total loss formulated in T ABLE IV A B LAT IO N S T U DY O N T H E E FF E C T O F T H E L O SS F OR M U L A T I O N O N T H E A V ER A GE S SI M , P S N R A N D L P IP S . B E S T R E S ULT S A R E S H OW N I N B O LD , AN D SE C O ND - B E ST R ES U LTS A RE U ND E R L IN E D . Loss Configuration SSIM ↑ PSNR ↑ LPIPS ↓ 1) MSE only 0.8545 23.3342 0.0935 2) MSE + SSIM 0.8722 23.1278 0.0897 3) MSE + SSIM + Cos. Sim. 0.8606 23.3549 0.0989 4) MSE + SSIM + Std. ℓ 1 0.8737 23.801 0.0882 5) MSE + SSIM + IAML 0.888 23.37 0.098 (10). T able IV reports the SSIM, PSNR and LPIPS metrics for five different ablation cases on our loss formulation. In T able IV, entry 3) replaces the IAML with cosine similarity losses between student and teacher decoder feature maps. Fur- thermore, entry 4) replaces the IAML with an ℓ 1 loss between standardized student and teacher decoder feature maps (7). Finally , entry 5) denotes our full IAML approach. T able IV clearly demonstrates that our custom IAML formulation (entry 5) leads to thee best performance, sho wing the crucial effect of illumination-aware feature map distillation during training. I V . C O N C L U S I O N This paper has presented a novel method for the training of low-light image enhancement auto-encoders. The proposed IAML framework relies on a teacher-student pair of auto- encoder network where information from teacher feature maps corresponding to clean input image representations are used to guide the training of the student model, by aligning the stu- dent decoder’ s internal representations with the teacher ones. Extensiv e benchmarking and ablation studies have clearly demonstrated the usefulness of our approach, outperforming more than a dozen prior methods in terms of average SSIM, PSNR and LPIPS across three datasets. As future work, we plan to apply our approach to other image restoration tasks in order to study its validity across various application domains. JOURNAL OF L A T E X CLASS FILES, VOL. 14, NO. 8, A UGUST 2015 5 R E F E R E N C E S [1] F . Zhou, X. Sun, J. Dong, and X. Zhu, “Surroundnet: T o wards ef fective low-light image enhancement, ” P attern Recognition , v ol. 141, p. 109602, 2023. [2] Y . Cai, H. Bian, J. Lin, H. W ang, R. T imofte, and Y . Zhang, “Retinex- former: One-stage retinex-based transformer for lo w-light image en- hancement, ” in ICCV , 2023, pp. 12 504–12 513. [3] W . Wu, J. W eng, P . Zhang, X. W ang, W . Y ang, and J. Jiang, “Inter- pretable optimization-inspired unfolding network for low-light image enhancement, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , 2025. [4] Q. Xiao, H. Jin, H. Su, and R. Y an, “Sell:a method for lo w-light image enhancement by predicting semantic priors, ” IEEE Signal Processing Letters , vol. 32, pp. 1785–1789, 2025. [5] J. He, S. Palaiahnakote, A. Ning, and M. Xue, “Zero-shot low-light image enhancement via joint frequency domain priors guided diffusion, ” IEEE Signal Processing Letters , vol. 32, pp. 1091–1095, 2025. [6] C. Li, C. Guo, L. Han, J. Jiang, M.-M. Cheng, J. Gu, and C. C. Loy , “Low-light image and video enhancement using deep learning: A sur- vey , ” IEEE T ransactions on P attern Analysis and Mac hine Intelligence , vol. 44, no. 12, pp. 9396–9416, 2022. [7] Z.-M. Du, H.-A. Li, and F .-l. Han, “Dynamic fusion for generating high- quality labels in low-light image enhancement, ” IEEE Signal Processing Letters , vol. 32, pp. 2324–2328, 2025. [8] H. Lee, K. Sohn, and D. Min, “Unsupervised low-light image en- hancement using bright channel prior , ” IEEE Signal Processing Letters , vol. 27, pp. 251–255, 2020. [9] J. Kim, G.-H. Park, J. Bae, and S.-W . Jung, “Intrinsic decomposition- based curriculum learning for low-light image enhancement, ” IEEE Signal Pr ocessing Letters , vol. 32, pp. 4019–4023, 2025. [10] A. Safa, T . V erbelen, O. C ¸ atal, T . V an de Maele, M. Hartmann, B. Dhoedt, and A. Bourdoux, “Fmcw radar sensing for indoor drones using variational auto-encoders, ” in 2023 IEEE Radar Conference (RadarConf23) , 2023, pp. 1–6. [11] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in 2016 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , 2016, pp. 770–778. [12] O. Ronneberger , P . Fischer , and T . Brox, “U-net: Conv olutional networks for biomedical image segmentation, ” in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015 , N. Navab, J. Horneg- ger , W . M. W ells, and A. F . Frangi, Eds. Cham: Springer International Publishing, 2015, pp. 234–241. [13] H. Zhao, O. Gallo, I. Frosio, and J. Kautz, “Loss functions for image restoration with neural networks, ” IEEE Tr ansactions on Computational Imaging , vol. 3, no. 1, pp. 47–57, 2017. [14] A. Hor ´ e and D. Ziou, “Image quality metrics: Psnr vs. ssim, ” in 2010 20th International Confer ence on P attern Recognition , 2010, pp. 2366– 2369. [15] R. Zhang, P . Isola, A. A. Efros, E. Shechtman, and O. W ang, “The unreasonable effecti veness of deep features as a perceptual metric, ” in 2018 IEEE/CVF Conference on Computer V ision and P attern Recogni- tion , 2018, pp. 586–595. [16] C. Zhang and D. Lee, “ Advancing nighttime object detection through image enhancement and domain adaptation, ” Applied Sciences , vol. 14, no. 18, 2024. [Online]. A vailable: https://www .mdpi.com/2076- 3417/14/18/8109 [17] Y . Y u, F . Chen, J. Y u, and Z. Kan, “Lmt-gp: Combined latent mean- teacher and gaussian process for semi-supervised low-light image en- hancement, ” in Computer V ision – ECCV 2024 , A. Leonardis, E. Ricci, S. Roth, O. Russakovsky , T . Sattler, and G. V arol, Eds. Cham: Springer Nature Switzerland, 2025, pp. 261–279. [18] R. M. H. Nguyen and M. S. Brown, “Why you should forget luminance con version and do something better, ” in 2017 IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2017, pp. 5920– 5928. [19] X. Guo, Y . Li, and H. Ling, “Lime: Low-light image enhancement via illumination map estimation, ” IEEE T ransactions on Image Pr ocessing , vol. 26, no. 2, pp. 982–993, 2016. [20] X. Fu, D. Zeng, Y . Huang, X. Ding, and Y .-P . Zhang, “ A weighted v ari- ational model for simultaneous reflectance and illumination estimation, ” in Pr oceedings of the IEEE Conference on Computer V ision and P attern Recognition , 2016. [21] K.-F . Y ang, X.-S. Zhang, and Y .-J. Li, “ A biological vision inspired framew ork for image enhancement in poor visibility conditions, ” IEEE T ransactions on Image Pr ocessing , vol. 29, pp. 1493–1506, 2020. [22] Z. Y ing, G. Li, and W . Gao, “ A bio-inspired multi-exposure fu- sion framework for low-light image enhancement, ” arXiv preprint arXiv:1711.00591 , 2017. [23] C. W . Li, C. Li, and C. C. Loy , “Learning to enhance low-light image via zero-reference deep curve estimation, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 44, no. 8, pp. 4225–4238, 2021. [24] Y . Jiang, X. Gong, D. Liu, Y . Cheng, C. Fang, X. Shen, J. Y ang, P . Zhou, and Z. W ang, “Enlightengan: Deep light enhancement without paired supervision, ” IEEE T ransactions on Image Pr ocessing , vol. 30, pp. 2340–2349, 2021. [25] C. W ei, W . Ren, W . Y ang, and J. Liu, “Deep retinex decomposition for low-light enhancement, ” arXiv pr eprint arXiv:1808.04560 , 2018. [26] Y . Zhang, J. Zhang, C. Xu, and X. Guo, “Kindling the darkness: A practical low-light image enhancer, ” in ACM International Conference on Multimedia , 2019, pp. 1632–1640. [27] S. W . Zamir, A. Arora, S. Khan, M. Hayat, F . S. Khan, and M.- H. Y ang, “Learning enriched features for real image restoration and enhancement, ” in European Confer ence on Computer V ision , 2020, pp. 492–511. [28] Z. W ang, X. Cun, J. Bao, W . Zhou, D. Chen, and F . W en, “Uformer: A general u-shaped transformer for image restoration, ” in CVPR , 2022, pp. 17 683–17 693. [29] S. W . Z. et al., “Restormer: Ef ficient transformer for high-resolution image restoration, ” in CVPR , 2022, pp. 5728–5739. [30] K.-F . Y ang, C. Cheng, S.-X. Zhao, H.-M. Y an, X.-S. Zhang, and Y .-J. Li, “Learning to adapt to light, ” International Journal of Computer V ision , vol. 131, no. 4, pp. 1022–1041, 2023. [31] X. Lv , X. Dong, J. Y ang, L. Zhao, B. Pu, Z. Jin, and Y . Zhang, “Low- light image enhancement with luminance duality , ” Knowledge-Based Systems , p. 114420, 2025. [32] H. Jiang, A. Luo, X. Liu, S. Han, and S. Liu, “Lightendif fusion: Unsupervised low-light image enhancement with latent-retinex diffusion models, ” in Eur opean Conference on Computer V ision . Springer , 2024, pp. 161–179. [33] S. W oo, J. Park, J.-Y . Lee, and I. S. Kweon, “Cbam: Conv olutional block attention module, ” in Computer V ision – ECCV 2018: 15th European Confer ence, Munich, Germany , September 8–14, 2018, Proceedings, P art VII . Berlin, Heidelber g: Springer-V erlag, 2018, p. 3–19. [34] W . Y ang, W . W ang, H. Huang, S. W ang, and J. Liu, “Sparse gradient reg- ularized deep retinex network for robust low-light image enhancement, ” IEEE Tr ansactions on Image Processing , vol. 30, pp. 2072–2086, 2021.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment