Post Training Quantization for Efficient Dataset Condensation
Dataset Condensation (DC) distills knowledge from large datasets into smaller ones, accelerating training and reducing storage requirements. However, despite notable progress, prior methods have largely overlooked the potential of quantization for fu…
Authors: Linh-Tam Tran, Sung-Ho Bae
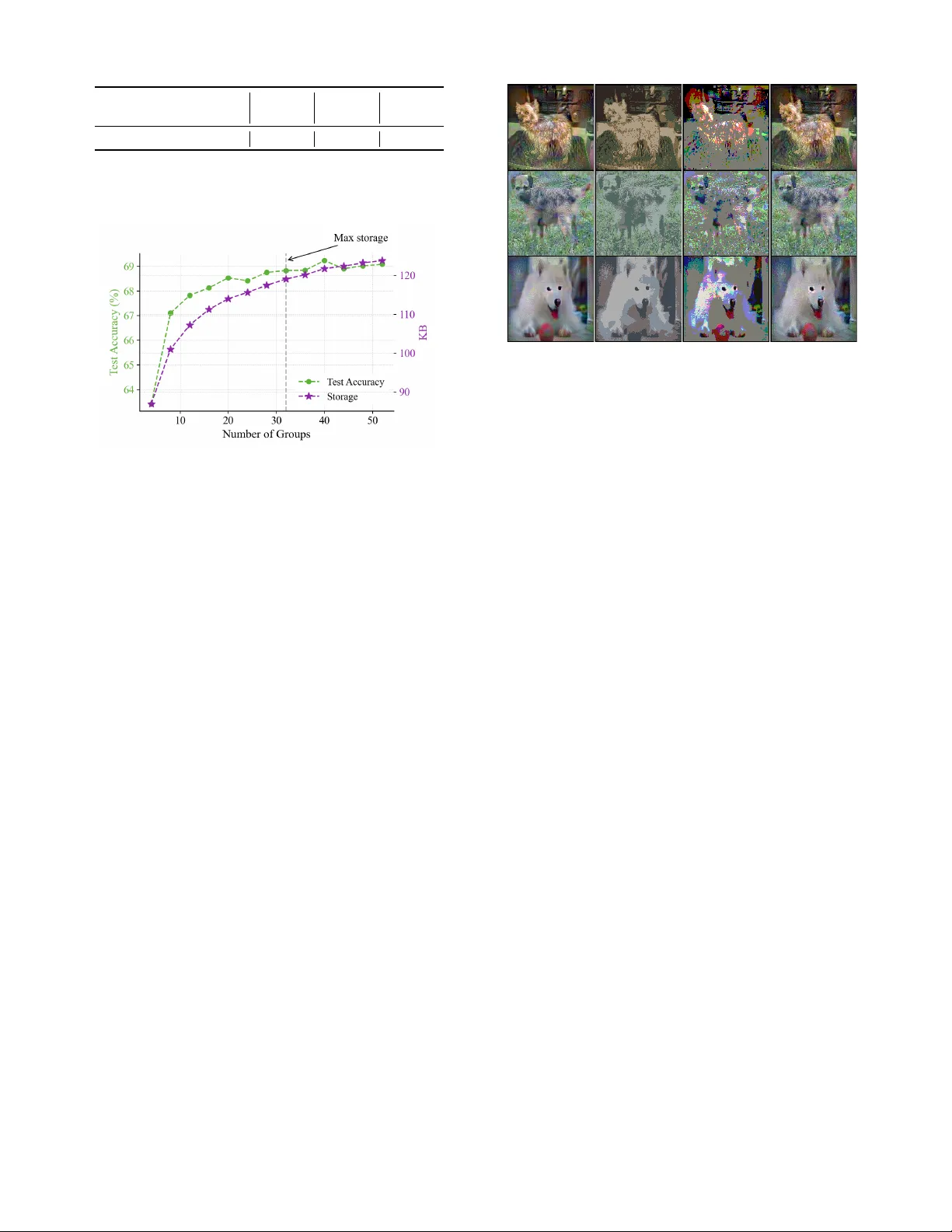
P ost T raining Quantization f or Efficient Dataset Condensation Linh-T am T ran, and Sung-Ho Bae * Kyung Hee Uni v ersity , Republic of K orea { tamlt,shbae } @khu.ac.kr Abstract Dataset Condensation (DC) distills knowledge from lar ge datasets into smaller ones, accelerating training and reduc- ing storage requirements. Howe ver , despite notable progress, prior methods hav e largely overlooked the potential of quan- tization for further reducing storage costs. In this paper , we take the first step to explore post-training quantization in dataset condensation, demonstrating its effecti veness in re- ducing storage size while maintaining representation qual- ity without requiring expensi ve training cost. Ho wev er , we find that at extremely low bit-widths (e.g., 2-bit), con ven- tional quantization leads to substantial degradation in repre- sentation quality , ne gati vely impacting the networks trained on these data. T o address this, we propose a nov el patch- based post-training quantization approach that ensures local- ized quantization with minimal loss of information. T o reduce the overhead of quantization parameters, especially for small patch sizes, we employ quantization-aware clustering to iden- tify similar patches and subsequently aggre gate them for ef- ficient quantization. Furthermore, we introduce a refinement module to align the distribution between original images and their dequantized counterparts, compensating for quantiza- tion errors. Our method is a plug-and-play framew ork that can be applied to synthetic images generated by various DC methods. Extensive experiments across di verse benchmarks including CIF AR-10/100, Tin y ImageNet, and ImageNet sub- sets demonstrate that our method consistently outperforms prior works under the same storage constraints. Notably , our method nearly doubles the test accuracy of existing meth- ods at extreme compression regimes (e.g., 26.0% → 54.1% for DM at IPC=1), while operating directly on 2-bit images without additional distillation. Introduction Deep Neural Networks (DNNs) ha ve become a primary so- lution in many computer vision tasks (He et al. 2015; Red- mon et al. 2016). Howe v er , training these networks effec- tiv ely requires vast amounts of data and significant compu- tational resources (Simonyan and Zisserman 2015; He et al. 2015; Redmon et al. 2016). T o address this, Dataset Con- densation (DC) (W ang et al. 2018; Zhao, Mopuri, and Bilen 2021) techniques hav e been developed to create smaller , * Corresponding Author Copyright © 2026, Association for the Adv ancement of Artificial Intelligence (www .aaai.org). All rights reserved. IPC=1 IPC=10 IPC=50 40 60 80 28.8 52.1 60.6 55.3 58.3 73.4 DSA DSA+Ours IPC=1 IPC=10 IPC=50 26.0 48.9 63.0 54.1 68.2 77.1 DM DM+Ours IPC=1 IPC=10 IPC=50 68.9 79.0 83.8 46.9 66.8 76.1 DA TM+Ours DA TM T est Accuracy (%) Figure 1: Performance comparison when applying our framew ork to DSA (Zhao and Bilen 2021), DM (Zhao and Bilen 2022), and D A TM (Guo et al. 2024). Notably , our framew ork doubles the perf ormance for DSA and DM at a budget of 1 Image Per Class (IPC), demonstrating its ef fec- tiv eness in e xtremely low-storage scenarios. condensed datasets that preserve the performance of the original, larger dataset. Due to its effecti v eness, DC is an activ e research topic (Zhao, Mopuri, and Bilen 2021; Cazenav ette et al. 2022; W ang et al. 2022; Y uan et al. 2024a) with numerous applications, including neural architecture search (Zhao, Mopuri, and Bilen 2021), continual learning (Y ang et al. 2023; Gu et al. 2024), super -resolution (Zhang et al. 2024), and pri v ac y preserving (Dong, Zhao, and L yu 2022; Chai et al. 2024). Approaches such as gradient matching (Zhao, Mopuri, and Bilen 2021), distribution matching (Zhao and Bilen 2022), and trajectory matching (Cazenavette et al. 2022) hav e demonstrated strong performance in producing high- quality condensed datasets. Ho we v er , these methods primar- ily focus on impro ving dataset quality while ne glecting stor - age efficiency , as each synthetic sample still requires full- resolution storage. T o overcome such storage bottlenecks, Parameterization- based Dataset Condensation (PDC) methods encode syn- thetic data as compact latent representations instead of raw pixels (Y uan et al. 2024a). These include frequency-space learning (Shin, Shin, and Moon 2023), sample factorization (Liu et al. 2022), and color space optimization (Y uan et al. 2024a). By reconstructing images at inference time, PDC methods achieve higher compression while retaining task- relev ant information, often surpassing conv entional DC in efficienc y and scalability . Howe ver , to the best of our kno wledge, no prior work has explored post-training quantization (PTQ) to compress syn- thetic images for dataset condensation, despite its potential to significantly reduce storage costs with minimal ov erhead. This moti vates our work, which aims to integrate PTQ into DC, reducing the bit-width of stored synthetic images with- out requiring expensi v e retraining or decoder networks. T o this end, we propose a novel framework that stores synthetic images in extremely lo w bit-widths ( e.g. , 2-bit). A nai ve application of global quantization—using a single set of quantization parameters for an entire image—suffers from severe degradation of task-relev ant information due to spatially varying textures and details being quantized with insufficient precision. This results in a dramatic drop in the network’ s performance when trained on the dequantized im- ages. T o address this, we propose a patch-based asymmetric quantization scheme that applies quantization locally to each image patch, ef fectiv ely preserving spatial variations. T o fur- ther reduce the overhead of quantization parameters, we in- troduce a quantization-aware grouping strategy that clusters similar patches and applies shared quantization within each group. Finally , we present a refinement module that fine- tunes the synthetic images to align their feature distrib utions with those of the original images, mitigating the ef fects of quantization noise. By applying our method to various synthetic images gen- erated from existing DC techniques, we observe up to 2 × accuracy improvement at IPC=1 (see Figure 1) under ex- treme storage constraints, while operating entirely with 2-bit images. Our contributions are summarized as follo ws: • W e introduce a patch-based quantization method that sig- nificantly improves task performance at extremely low bit-widths by preserving spatial and structural details. • W e propose a clustering-based grouping strategy to share quantization parameters among similar patches, reducing storage ov erhead. • W e present a quantization-a ware refinement module that aligns the distributions of dequantized and original syn- thetic images to improv e downstream model perfor- mance. • W e validate our method through extensi ve experiments on diverse datasets, consistently achieving state-of-the- art performance under constrained storage budgets. Related W orks Dataset Condensation and Redundancy Dataset Condensation (DC) aims to distill a large dataset into a compact synthetic set such that a model trained on it performs comparably to one trained on the full dataset (W ang et al. 2018; Zhao, Mopuri, and Bilen 2021). Early approaches address this by surrogate optimization, such as matching the gradients (Zhao, Mopuri, and Bilen 2021; Kim et al. 2022; Zhao and Bilen 2021), network parame- ters (Cazena v ette et al. 2022; Cui et al. 2023; Du et al. 2023; Guo et al. 2024), or intermediate feature distributions (Zhao Method Redundancy Strategy Bit Cost IDC Spatial Spatial Downsample 32 Med. AutoPalette Color Palette Reduction 32 High DDiF Feature Neural Field 32 High Ours Bit-lev el Patch Quantization 2 Low T able 1: Comparison of redundancy reduction strategies in PDC. and Bilen 2022; Zhao et al. 2023; W ang et al. 2022; Sajedi et al. 2023) between real and synthetic data. While these methods successfully preserve task perfor- mance, they are inef ficient in storage since the synthesized images are stored at full resolution and precision. T o o ver - come this, PDC explores compact representations by reduc- ing various forms of redundanc y: • IDC reduces spatial redundancy by storing data in low- dimensional latent spaces and reconstructing them via upsampling (Kim et al. 2022). • A utoPalette targets color r edundancy using a learned palette encoder (Y uan et al. 2024a). • DDiF compresses featur e r edundancy by encoding data into neural fields that generate images on demand (Shin et al. 2025). Although these methods improve storage efficienc y , they still rely on 32 -bit representations and incur high computa- tional cost due to decoder networks. In contrast, our method uniquely targets bit-level r edundancy through PTQ, enabling extremely low-bit ( e.g. , 2 -bit) storage. T able 1 summarizes recent PDC methods in terms of their redundancy type, com- pression strategy , approximate compression ratio (vs. 32 - bit baseline), storage bitwidth, and computational ov erhead. Our method achieves the highest ratio via bit-le v el quantiza- tion while maintaining the lowest o v erhead. Post-T raining Quantization Quantization reduces storage and computation by repre- senting model weights or activ ations with fe wer bits (Han, Mao, and Dally 2016; Esser et al. 2020). PTQ, in particu- lar , is a widely adopted technique for ef ficient deplo yment on resource-constrained de vices, since it av oids retraining (Zhang, Zhou, and Saab 2022; Y uan et al. 2024b; Cai et al. 2020; Y ao et al. 2023). While PTQ has been extensiv ely explored for compress- ing models, its application to dataset condensation has re- mained largely unexplored. T o the best of our knowledge, this is the first work that applies post-training quantization to synthetic datasets in dataset condensation. Our method in- troduces a patch-based quantization framew ork with group- ing and refinement, operating directly on 2-bit tensors with- out additional training or decoder models. This enables highly compressed, efficient, and distillation-free dataset storage and deployment. Method Figure 2 provides the overvie w of our proposed framework. In this section, we first provide background on DC and quan- I I . P a tch G r o u p i n g 6 3 5 6 3 3 3 7 5 4 4 1 6 3 5 6 2 2 4 4 1 4 1 3 G r ou p I nd e x m s am pl e 𝑸 : Q u a n t i z a t i o n 𝑬𝑪 : E n t r o p y C o d i n g F r o z e n 𝜽 : Q u a n t i z a t i o n P a r a me t e r F o r w a r d p a s s B a c k w a r d p a s s m s a m p l e F i ne t u ne d i m a g e s 𝑸 𝑸 Q u ant i z e d i m a ge s 𝑬𝑪 I I I . Co m p r e s s i o n S ynt he t i c i m a ge s M at c hi n g Lo s s D 𝑸 S ynt he t i c i m a ge s m s a m p l e I . R e f i n e m e n t Ind e x P a t c h i fy P a t c h - b a s e d q u a n t i z a t i o n G r o u p q u a n t i z a t i o n W i d t h N C h a n n e l s C o nd e ns e d da t a 𝑸 𝑸 : De - q u a n t i z a t i o n 𝜽 𝜽 𝜽 G r ou p 1 G r ou p 2 C l u s t e r i n g G r ou p g Figure 2: Overvie w of the proposed patch-based quantization frame work for dataset condensation. (I) Synthetic images are first refined using a quantization-aw are loss. (II) Patches are grouped based on quantization parameters via k -means clustering. (III) Each group is quantized with shared parameters, and the result is entropy encoded to produce the final compressed dataset. tization. Then, we introduce our patch-based quantization. Next, we present our quantization grouping. Lastly , we de- scribe the refinement module. Preliminaries Dataset Condensation. DC aims to generate a compact synthetic dataset S = { ( x i , y i ) | i = 0 , 1 , . . . , |S | − 1 } from a larger dataset T = { ( x i , y i ) | i = 0 , 1 , . . . , |T | − 1 } , such that training a model on S yields performance comparable to training on T . Let D denote a distance metric (e.g., Mean Squared Error), and Φ denote a matching objecti v e function. The condensation problem is formulated as the following optimization: S ∗ = arg min S D (Φ( S ) , Φ( T )) , (1) where S ∗ is the optimal condensed set minimizing the dis- crepancy between the two objecti ve functions. Quantization. Quantization reduces the precision of model parameters by representing them with lower bit-width integers. A widely used method is asymmetric quantization (A Q) (Nagel et al. 2021), which employs two parameters: the scale and the zer o-point . These enable the mapping of floating-point values to discrete integers. Let x ∈ R H × W × C be an input tensor , and let Q min = 0 and Q max = 2 b − 1 denote the quantization bounds for a bit-width b . The scale factor α is computed as: α = max( x ) − min( x ) Q max − Q min (2) The zero-point z aligns the minimum value to the quan- tized range: z = Q min − min( x ) α (3) where ⌊·⌉ denotes rounding to the nearest integer . Gi ven α and z , quantization and dequantization are defined as: x q = j x α + z m , x deq = ( x q − z ) · α. (4) Analysis of Whole-Image Quantization Whole-image quantization applies a single set of parameters (scale and zero-point) to the entire image. While simple and storage-efficient, this global approach suffers at extremely low bit-widths due to its inability to preserve fine-grained features. As a result, do wnstream performance de grades sig- nificantly . W e analyze this issue using tw o methods: (1) asymmetric quantization, and (2) Median Cut (Heckbert 1982), which partitions color space recursi v ely along high-variance chan- nels. W e apply each method to synthetic images generated by DM (Zhao and Bilen 2022), then dequantize and train a 3-layer CNN for ev aluation. As sho wn in Fig. 3 (b,c), both whole-image quantization methods result in noticeable visual distortion and accuracy degradation compared to the original images (a). T o quantify this, we measure the Mean Squared Error (MSE) between the feature embeddings of original and dequantized images. The results in Fig. 3 (e) confirm that representational dis- tortion increases as bit-width decreases. These findings sug- gest that whole-image quantization fails to maintain essen- tial information needed for learning under aggressiv e com- pression. Patch-based Quantization T o address the limitations of whole-image quantization and better align with the goals of dataset condensation, we intro- duce patch-based asymmetric quantization (P A Q). Unlike traditional approaches that apply a single global quantization (a) (b) (c) (e) T e s t A c c . 39.2% T e s t A c c . 41.2% T e s t A c c . 47.5% T e s t A c c . 48.9% (d) Bit -width: 32 Bit -width: 2 Bit -width: 2 Bit -width: 2 T est Acc. 48.9% T est Acc. 39.2% T est Acc. 41.2% T est Acc. 47.5% Figure 3: V isualization comparison of quantization strategies on synthetic images: (a) original images, (b) Median Cut (Heck- bert 1982), (c) asymmetric quantization, and (d) our patch-based quantization. All quantized images use 2-bit precision. (e) shows distortion (MSE) v ersus bit-width across methods. Images are generated by DM (Zhao and Bilen 2022) on CIF AR-10. to the entire image, P A Q operates at the patch lev el, enabling localized control of quantization and better preserv ation of fine-grained details. Formally , given an image x , we divide it into P non- ov erlapping patches { x i } P i =1 , where each x i ∈ R h × w × C represents a spatial region. W e then perform per -patch quan- tization: x q i = Q ( x i , θ i ) , (5) where Q ( · , θ i ) is the quantization function and θ i = ( α i , z i ) includes the scale and zero-point for patch i . This localized formulation allows each patch to adapt to its o wn distribu- tion, minimizing information loss. As shown in Fig. 3 (e), P A Q significantly reduces quantization-induced distortion across bit-widths compared to whole-image quantization. Notably , ev en at 2-bit preci- sion, P A Q achie v es competiti ve accurac y (47.5%) relati v e to full-precision data (48.9%), demonstrating its ef fecti v eness in preserving task-rele v ant features under extreme compres- sion. Quantization-A ware Patch Gr ouping While P A Q improves fidelity by assigning independent quantization parameters to each patch, it also increases stor - age cost due to the need to store θ i for all patches. T o mit- igate this, we propose group-awar e quantization (GA Q), which clusters similar patches to share quantization param- eters. W e apply k -means clustering in the quantization parame- ter space to group patches with similar quantization behav- ior . Specifically , each patch x i has an associated quantiza- tion parameter θ i = ( α i , z i ) , where α i and z i denote the scale and zero-point, respectiv ely . Let C g denote the set of patches assigned to group g , and G be the total number of groups. Our objecti ve is to minimize the intra-group vari- ance of quantization parameters, encouraging patches within each group to share a common parameter: {C ∗ g , θ ∗ g } G g =1 = arg min {C g } , { θ g } G X g =1 X θ i ∈C g θ i − ˆ θ g 2 , (6) where ˆ θ g = 1 |C g | X θ i ∈C g θ i . where ˆ θ g represents the centroid (mean) of the quantiza- tion parameters in group g . This clustering step enables all patches in the same group to share a single quantization pa- rameter θ g , significantly reducing storage overhead while maintaining quantization fidelity . Intra-group Recalibration. Rather than directly using the cluster centroids ˆ θ g as quantization parameters, we re- calibrate θ g based on the actual data distrib ution of patches within each group C g . Specifically , for each group g , we first concatenate all patches, x g = concat ( { x i } i ∈C g ) , and then reshape the result into a one-dimensional tensor , x flat g = reshape ( x g ) . W e compute the group-specific quantization parameter θ g by calibrating over x flat g , and quantize the group as: x q g = Q ( x flat g , θ g ) , (7) where Q ( · , θ g ) is the quantization function. All patches in C g are quantized using this shared parameter θ g . This recalibra- tion ensures that the shared quantization parameters accu- rately reflect the underlying patch distributions, thereby re- ducing quantization error and enhancing downstream model performance. Refinement f or Synthetic Images Our goal is to refine synthetic images to mitigate the feature-space distortion caused by quantization. Prior stud- ies have shown that quantization noise in inputs can sig- nificantly degrade the quality of extracted features (Sun et al. 2018; Zheng et al. 2016; V asilje vic, Chakrabarti, and Shakhnarovich 2016). Giv en a target bit-width b , we optimize a finetuned im- age x ft such that its feature representation remains close to that of the original synthetic image, e ven after undergoing quantization and dequantization. Formally , we define: ( x ft ) deq = ˆ Q ( Q ( x ft , θ ) , θ ) , (8) where Q ( · , θ ) and ˆ Q ( · , θ ) denote the quantization and de- quantization functions parameterized by θ , respecti vely . W e extract features from both the original and the dequan- tized versions using a neural network f ( · ) : f = f ( x ) , ˜ f = f (( x ft ) deq ) . (9) Dataset CIF AR-10 CIF AR-100 T iny ImageNet IPC 1 10 50 1 10 50 1 10 Distillation DD – 36.8 ± 1.2 – – – – – – DM 26.0 ± 0.8 48.9 ± 0.6 63.0 ± 0.4 11.4 ± 0.3 29.7 ± 0.3 43.6 ± 0.4 3.9 ± 0.2 12.9 ± 0.4 DSA 28.8 ± 0.7 52.1 ± 0.5 60.6 ± 0.5 13.9 ± 0.3 32.3 ± 0.3 42.8 ± 0.4 – – MTT 46.3 ± 0.8 65.3 ± 0.7 71.6 ± 0.2 24.3 ± 0.3 40.1 ± 0.4 47.7 ± 0.2 8.8 ± 0.3 23.2 ± 0.2 D A TM 46.9 ± 0.5 66.8 ± 0.2 76.1 ± 0.3 27.9 ± 0.2 47.2 ± 0.4 55.0 ± 0.2 17.1 ± 0.3 31.1 ± 0.3 Parameterization IDC 55.0 ± 0.4 67.5 ± 0.5 74.5 ± 0.1 – – – – – HaBa 48.3 ± 0.8 69.9 ± 0.4 74.0 ± 0.2 33.4 ± 0.4 40.2 ± 0.2 47.0 ± 0.2 – – SPEED 63.2 ± 0.1 73.5 ± 0.2 77.7 ± 0.4 40.0 ± 0.4 45.9 ± 0.3 49.1 ± 0.2 26.9 ± 0.3 28.8 ± 0.2 FreD 60.6 ± 0.8 70.3 ± 0.3 75.8 ± 0.1 34.6 ± 0.4 42.7 ± 0.2 47.8 ± 0.1 19.2 ± 0.4 24.2 ± 0.4 Spectral 68.5 ± 0.8 73.4 ± 0.2 75.2 ± 0.6 36.5 ± 0.3 46.1 ± 0.2 – 21.3 ± 0.2 – AutoPalette 58.6 ± 1.1 74.3 ± 0.2 79.4 ± 0.2 38.0 ± 0.1 52.6 ± 0.3 53.3 ± 0.8 – – Quantization DSA+Ours 55.3 ± 0.4 58.3 ± 0.5 73.4 ± 0.4 34.7 ± 0.3 41.1 ± 0.5 – – – DM+Ours 54.1 ± 0.5 68.2 ± 0.4 77.1 ± 0.3 34.0 ± 0.3 51.2 ± 0.3 – 14.8 ± 0.5 30.6 ± 0.3 D A TM+Ours 68.9 ± 0.4 79.0 ± 0.3 83.8 ± 0.2 48.0 ± 0.3 56.5 ± 0.2 – 27.3 ± 0.5 39.4 ± 0.4 Whole T 84.8 ± 0.1 56.2 ± 0.2 37.6 ± 0.4 T able 2: T est accuracy (%) comparison on CIF AR-10, CIF AR-100, and T iny ImageNet. Results are reported in mean ± std format. Experiments on CIF AR-100 with IPC=50 are omitted, as this would require 1,000 images per class under a compression rate of 20, which exceeds the original 500 images per class. T o ensure that quantization does not introduce harmful fea- ture drift, we minimize MSE between these feature repre- sentations: L quant = E x ∼S f − ˜ f 2 2 , (10) where S denotes the set of synthetic images. The finetuned image x ft is optimized to minimize this loss, thereby align- ing its quantized feature representation with that of the orig- inal. In practice, we explore three refinement strategies in our framew ork: (1) applying refinement only before group quan- tization, (2) only after group quantization, and (3) both be- fore and after . W e analyze the quantitativ e effects of each strategy in our ablation study and provide qualitati ve exam- ples in the final part of the experimental section through vi- sualization. Storage Measurement Under a fix ed storage b udget, our objective is to maxi- mize the number of synthetic images per class. Starting from a baseline setting with IPC= m , we apply our compres- sion framework to reduce the per-class footprint to IPC= n , thereby enabling a denser representation under the same storage constraint. The total storage required to represent the synthetic data comprises three components: (i) Gr oup Indices G = { g i } P × m i =1 , which indicate the group assignment for each patch, (ii) Quantization Parameters Q = { θ g } G g =1 , shared across patches within each group, and (iii) Quantized Im- ages X q = { x flat g } G g =1 , representing the flattened and quan- tized pixel values of each group. T o further reduce the foot- print of X q , we apply Entropy Coding (EC), which lev er- ages the statistical redundanc y in quantized values for addi- tional compression. Giv en a target storage budget corresponding to IPC= n , we ensure that the total compressed size does not exceed this constraint: siz e ( G ) + size ( Q ) + siz e ( EC ( X q )) ≤ siz e ( IPC ) . (11) This formulation allows us to fit more quantized synthetic samples within the same memory budget, thereby improving the representational density of the condensed dataset. Experiment In this section, we ev aluate the effecti veness of our pro- posed method in compressing synthetic images generated by various distillation techniques. W e also conduct an ablation study to analyze the contribution of each component includ- ing group quantization, refinement, and entropy coding, to the ov erall performance. Experimental Setting W e ev aluate our method across diverse datasets, ranging from toy datasets lik e CIF AR (Krizhevsk y and Hinton 2009) to large-scale, real-world datasets such as ImageNet sub- sets (Cazena vette et al. 2022), CC3M (Sharma et al. 2018), and Places365 (Zhou et al. 2017). As a plug-and-play frame- work, our method is applied to synthetic images generated by various distillation approaches, including DM (Zhao and Bilen 2022), DSA (Zhao and Bilen 2021), and D A TM (Guo et al. 2024). Giv en a storage budget of IPC= m , we first gen- erate synthetic images using existing methods, then com- press them to IPC= n using our frame work. By default, we apply 2-bit quantization using non- ov erlapping patches of size 5 × 5 . W e perform a grid search to determine the maximum number of groups that satisfy the storage constraint. Prior to group quantization, synthetic images are refined for 500 iterations on CIF AR-10/100 and Dataset I-Nette I-W oof I-Fruit I-Meow I-Squawk I-Y ellow MTT 63.0 ± 1.3 35.8 ± 1.8 40.3 ± 1.3 40.4 ± 2.2 52.3 ± 1.0 60.0 ± 1.5 D A TM 65.8 ± 2.0 38.8 ± 1.6 41.2 ± 1.4 45.7 ± 1.8 56.3 ± 1.5 61.1 ± 1.8 HaBa 64.7 ± 1.6 38.6 ± 1.3 42.5 ± 1.5 42.9 ± 0.9 56.8 ± 1.0 63.0 ± 1.6 SPEED 72.9 ± 1.5 44.1 ± 1.4 50.0 ± 0.8 52.0 ± 1.3 71.8 ± 1.3 70.5 ± 1.5 FreD 72.0 ± 0.8 41.3 ± 1.2 47.0 ± 1.1 48.6 ± 0.4 67.3 ± 0.8 69.2 ± 0.6 AutoPalette 73.2 ± 0.6 44.3 ± 0.9 48.4 ± 1.8 53.6 ± 0.7 68.0 ± 1.4 72.0 ± 1.6 D A TM+Ours 81.1 ± 1.2 53.0 ± 0.8 56.6 ± 0.9 61.2 ± 0.9 80.6 ± 0.7 78.9 ± 0.9 T able 3: Performance comparison on ImageNet Subsets (I- subset ). Dataset CC3M Places365 Standard IPC 1 10 1 10 Random 2.9 ± 0.1 7.0 ± 0.1 0.9 ± 0.1 3.9 ± 0.1 DM 5.9 ± 0.2 8.7 ± 0.1 2.6 ± 0.1 5.8 ± 0.1 IDC 8.2 ± 0.3 12.1 ± 0.2 4.0 ± 0.1 9.8 ± 0.1 DM+Ours 9.9 ± 0.2 17.4 ± 0.1 7.7 ± 0.1 19.2 ± 0.1 Whole T 46.7 ± 0.1 40.4 ± 0.1 T able 4: Performance comparison on real-world datasets. Method IPC=10 IPC=20 Random 42.6 57.0 Herding 56.2 72.9 DM 69.1 77.2 IDC 82.9 86.6 DDiF 90.5 92.7 DM+Ours 93.1 95.0 Whole T 93.4 T able 5: Performance comparison on Audio domain. L Method MNet SNet DC IDC 78.7 79.9 DDiF 87.1 89.6 Ours 93.7 91.1 DM IDC 85.6 85.3 DDiF 88.4 93.1 Ours 93.9 93.1 Whole T 91.6 98.3 T able 6: Performance compar- ison on 3D voxel domain at IPC=1. 2000 iterations on ImageNet subsets. F or e valuation, models are trained on the compressed synthetic datasets and tested on the original test sets. Experimental Results Results on small-scale datasets. W e compare our quantization-based parameterization method against v arious PDC baselines, including Factorization (Liu et al. 2022) (HaBa), Coding Matrices (W ei et al. 2023) (SPEED), Fre- quency Domain (Shin, Shin, and Moon 2023) (FreD), Spec- tral Domain (Y ang et al. 2025) (Spectral), and Color Redun- dancy Reduction (Y uan et al. 2024a) (AutoP alette). As shown in T able 2, our framework significantly im- prov es the performance of DM and DSA. F or instance, at IPC=1, DM achie v es 26% accuracy , whereas DM+Ours achiev es 54.1%, a relativ e gain of over 100%. A similar trend is observed for DSA. When applied to the latest dis- tillation method D A TM, our framework achie ves state-of- the-art performance across all IPC levels. Although Au- toPalette (Y uan et al. 2024a) reduces color redundancy via an additional netw ork, it incurs higher computational cost. Despite sharing the same distillation base (D A TM), our method consistently outperforms AutoPalette, demonstrat- ing both higher efficienc y and accurac y . Results on mid- and large-scale datasets. Follow- ing (Cazenav ette et al. 2022), we ev aluate our method on high-resolution ImageNet subsets. As sho wn in T able 3, in- tegrating our framew ork into D A TM consistently yields the best performance across all subsets, with gains ranging from 6.9% (I-Y ellow) to 12.6% (I-Squawk). Furthermore, when Method Network Con vNet AlexNet VGG11 ResNet18 DC 44.9 ± 0.5 22.4 ± 1.4 35.9 ± 0.7 18.4 ± 0.4 MTT 65.3 ± 0.7 34.2 ± 0.6 50.3 ± 0.8 46.6 ± 0.6 D A TM 66.8 ± 0.2 32.7 ± 3.8 38.8 ± 2.1 51.4 ± 1.7 FRePo 65.5 ± 0.4 61.9 ± 0.7 59.4 ± 0.7 58.1 ± 0.6 Spectral 73.4 ± 0.2 71.4 ± 0.3 67.8 ± 0.2 64.9 ± 1.3 D A TM+Ours 79.0 ± 0.3 74.7 ± 0.5 74.7 ± 0.3 77.5 ± 0.3 T able 7: Cross-architecture performance comparison be- tween our framew ork and other methods at IPC=10. ev aluating our method on CC3M and Places365, we observe the highest test accuracy in all cases (see T able 4). These re- sults demonstrate the scalability of our framework to more complex domains. Generalization to other modalities. T o demonstrate ver - satility , we apply our frame work to audio and 3D data do- mains follo wing the experiment setup in (Shin et al. 2025). As shown in T able 5 and T able 6, our method outperforms recent approaches such as DDiF (Shin et al. 2025), high- lighting its cross-modal robustness. Cross-ar chitectur e validation. W e further assess gen- eralization across architectures. Using synthetic images generated by DA TM, we apply our method and ev alu- ate on AlexNet (Krizhe vsk y , Sutske ver , and Hinton 2012), VGG (Simonyan and Zisserman 2015), and ResNet (He et al. 2015). As sho wn in T able 7, our method demonstrates superior generalization performance compared to previous approaches. GA Q Refinement EC CIF AR-10 I-Nette ✗ ✗ ✗ 71.8 ± 0.3 75.2 ± 0.8 ✓ ✗ ✗ 76.1 ± 0.3 76.5 ± 1.1 ✓ ✓ ✗ 77.2 ± 0.3 77.2 ± 1.0 ✓ ✓ ✓ 79.0 ± 0.3 81.1 ± 1.2 T able 8: Effect of each component on final performance. The first ro w shows the baseline using global asymmetric quan- tization. IPC is set to 10 for both CIF AR-10 and I-Nette. Refinement before GA Q ✓ ✗ ✓ Refinement after GA Q ✗ ✓ ✓ T est Accuracy (%) 68.9 ± 0.4 68.7 ± 0.5 68.9 ± 0.3 T able 9: T est accurac y on CIF AR-10 at IPC=1 with refine- ment applied at different stages. Figure 4: Measured test accuracy (%) and storage across dif- ferent numbers of groups. The v ertical dotted line marks the maximum allow able storage under the gi ven b udget. Ablation Study W e conduct an ablation study to analyze the ef fect of each component in our framework on the final performance, as well as the impact of the number of groups. By default, we adopt D A TM to generate synthetic images. Effect of Each Component. As shown in T able 8, ap- plying asymmetric quantization (A Q) alone achieves 71.8% test accurac y on CIF AR-10, outperforming the base D A TM method (66.8%) at IPC=10. Adding group-aware quantiza- tion (GA Q) further improv es accuracy to 76.1%, and incor- porating the refinement module increases it to 77.2%. Fi- nally , applying entropy coding allows more samples to be stored within the same budget, leading to a final performance of 79%. Ablation on Refinement Timing. As shown in T able 9, applying refinement before group quantization yields better performance than applying it afterward. This is likely be- cause group quantization assigns patches to groups based on their quantization parameters, which are more accurately es- timated when the image is refined beforehand. In contrast, applying group quantization first may lead to suboptimal grouping due to uncorrected quantization noise. Notably , performing refinement both before and after group quanti- zation does not lead to further improvement, suggesting di- minishing returns from post-group refinement. Ablation on the Number of Gr oups. Figure 4 shows how the number of groups ( G in Eq. (6)) affects performance. W e observe that increasing the number of groups consistently improv es test accuracy , while staying within the storage bud- get. Based on this trend, we choose the maximum number of (a) (b) (c) (d) Figure 5: V isualization of (a) original synthetic images and their quantized versions using (b) Median Cut, (c) Asym- metric Quantization (A Q), and (d) Group-A ware Quantiza- tion (GA Q). While Median Cut preserves texture but distorts color , and A Q preserves color but loses fine details, GA Q achiev es a better balance between te xture and color fidelity . groups that satisfies the storage constraint. V isualization of Synthetic Images. W e visualize quan- tized synthetic images generated by MTT (Cazenav ette et al. 2022) on I-W oof. As shown in Figure 5, the Median Cut method retains texture but alters color severely , while A Q preserves color at the cost of heavy texture distortion. In contrast, our group-based quantization strikes a better bal- ance, maintaining both texture and color fidelity . Additional examples are pro vided in the supplementary material. Conclusion W e propose a nov el quantization frame work for dataset con- densation that achie ves substantial storage reduction while preserving do wnstream performance. Unlike prior work that focuses solely on synthetic image generation, our method explicitly tar gets bit-le v el redundancy through patch-based quantization, group-wise parameter sharing, and lightweight feature refinement. This combination enables ef fective com- pression ev en at extremely low bit-widths. Extensive exper - iments across diverse distillation methods and datasets v ali- date that our approach consistently outperforms e xisting pa- rameterized condensation baselines under tight storage con- straints. Limitation and Future W ork. Our frame work is cur - rently designed for condensation pipelines that focus on visual data and hard labels. It does not yet support meth- ods that utilize soft labels. Future work may e xplore label- aware quantization. In addition, our method is tailored for CNN-based architectures operating on spatial patches, and has not been extended to transformers. Designing quantiza- tion strategies that operate on token embeddings presents a promising direction for transformer-based models. Acknowledgments This work was supported by the National Research Foun- dation of K orea (NRF) grant funded by the K orea gov- ernment (MSIT) (No. RS-2025-24534076) and (No. RS- 2025-02216217), and by the IITP (Institute of Informa- tion & Communications T echnology Planning & Evalua- tion) - ITRC (Information T echnology Research Center) grant funded by the K orea gov ernment (Ministry of Science and ICT) (IITP-2025-RS-2024-00438239) References Cai, Y .; Y ao, Z.; Dong, Z.; Gholami, A.; Mahoney , M. W .; and Keutzer , K. 2020. Zeroq: A no v el zero shot quantization framew ork. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , 13169–13178. Cazenav ette, G.; W ang, T .; T orralba, A.; Efros, A. A.; and Zhu, J.-Y . 2022. Dataset Distillation by Matching T raining T rajectories. In CVPR . Chai, Z.; Gao, Z.; Lin, Y .; Zhao, C.; Y u, X.; and Xie, Z. 2024. Adaptiv e Backdoor Attacks Against Dataset Distillation for Federated Learning. In ICC , 4614–4619. Cui, J.; W ang, R.; Si, S.; and Hsieh, C.-J. 2023. Scaling up dataset distillation to imagenet-1k with constant memory . In International Confer ence on Machine Learning , 6565– 6590. PMLR. Dong, T .; Zhao, B.; and L yu, L. 2022. Priv ac y for Free: How does Dataset Condensation Help Priv acy? In ICML , v olume 162, 5378–5396. PMLR. Du, J.; Jiang, Y .; T an, V . Y . F .; Zhou, J. T .; and Li, H. 2023. Minimizing the Accumulated T rajectory Error T o Im- prov e Dataset Distillation. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 3749–3758. Esser , S. K.; McKinstry , J. L.; Bablani, D.; Appuswamy , R.; and Modha, D. S. 2020. LEARNED STEP SIZE QU ANTI- ZA TION. In International Confer ence on Learning Repr e- sentations . Gu, J.; W ang, K.; Jiang, W .; and Y ou, Y . 2024. Summariz- ing Stream Data for Memory-Constrained Online Continual Learning. Guo, Z.; W ang, K.; Cazenavette, G.; LI, H.; Zhang, K.; and Y ou, Y . 2024. T ow ards Lossless Dataset Distillation via Difficulty-Aligned T rajectory Matching. In The T welfth In- ternational Confer ence on Learning Representations . Han, S.; Mao, H.; and Dally , W . J. 2016. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. International Confer- ence on Learning Repr esentations (ICLR) . He, K.; Zhang, X.; Ren, S.; and Sun, J. 2015. Deep Residual Learning for Image Recognition. CoRR , abs/1512.03385. Heckbert, P . 1982. Color image quantization for frame buf fer display . In ACM . Kim, J.-H.; Kim, J.; Oh, S. J.; Y un, S.; Song, H.; Jeong, J.; Ha, J.-W .; and Song, H. O. 2022. Dataset Condensation via Efficient Synthetic-Data Parameterization. In ICML , v olume 162, 11102–11118. PMLR. Krizhevsk y , A.; and Hinton, G. 2009. Learning multiple lay- ers of features from tiny images. Krizhevsk y , A.; Sutskev er , I.; and Hinton, G. E. 2012. Ima- geNet Classification with Deep Con volutional Neural Net- works. In Pereira, F .; Burges, C.; Bottou, L.; and W ein- berger , K., eds., Advances in Neural Information Pr ocessing Systems , volume 25. Curran Associates, Inc. Liu, S.; W ang, K.; Y ang, X.; Y e, J.; and W ang, X. 2022. Dataset Distillation via Factorization. In NeurIPS . Nagel, M.; Fournarakis, M.; Amjad, R. A.; Bondarenko, Y .; van Baalen, M.; and Blankev oort, T . 2021. A White Paper on Neural Network Quantization. CoRR , abs/2106.08295. Redmon, J.; Divv ala, S.; Girshick, R.; and F arhadi, A. 2016. Y ou Only Look Once: Unified, Real-Time Object Detection. In CVPR . Sajedi, A.; Khaki, S.; Amjadian, E.; Liu, L. Z.; Lawryshyn, Y . A.; and Plataniotis, K. N. 2023. DataD AM: Efficient Dataset Distillation with Attention Matching. In ICCV , 17097–17107. Sharma, P .; Ding, N.; Goodman, S.; and Soricut, R. 2018. Conceptual Captions: A Cleaned, Hypernymed, Image Alt- text Dataset For Automatic Image Captioning. In Pr oceed- ings of A CL . Shin, D.; Bae, H.; Sim, G.; Kang, W .; and chul Moon, I. 2025. Distilling Dataset into Neural Field. In The Thirteenth International Confer ence on Learning Representations . Shin, D.; Shin, S.; and Moon, I.-C. 2023. Frequency Domain-Based Dataset Distillation. In NeurIPS . Simonyan, K.; and Zisserman, A. 2015. V ery Deep Con- volutional Networks for Large-Scale Image Recognition. Sun, Z.; Ozay , M.; Zhang, Y .; Liu, X.; and Okatani, T . 2018. Feature Quantization for Defending Against Distortion of Images. In 2018 IEEE/CVF Conference on Computer V ision and P attern Recognition , 7957–7966. V asiljevic, I.; Chakrabarti, A.; and Shakhnarovich, G. 2016. Examining the Impact of Blur on Recognition by Con volu- tional Networks. CoRR , abs/1611.05760. W ang, K.; Zhao, B.; Peng, X.; Zhu, Z.; Y ang, S.; W ang, S.; Huang, G.; Bilen, H.; W ang, X.; and Y ou, Y . 2022. CAFE: Learning to Condense Dataset by Aligning Features. In CVPR , 12186–12195. W ang, T .; Zhu, J.; T orralba, A.; and Efros, A. A. 2018. Dataset Distillation. CoRR , abs/1811.10959. W ei, X.; Cao, A.; Y ang, F .; and Ma, Z. 2023. Sparse Pa- rameterization for Epitomic Dataset Distillation. In Thirty- seventh Conference on Neur al Information Pr ocessing Sys- tems . Y ang, E.; Shen, L.; W ang, Z.; Liu, T .; and Guo, G. 2023. An Efficient Dataset Condensation Plugin and Its Application to Continual Learning. In NeurIPS . Y ang, S.; Cheng, S.; Hong, M.; Fan, H.; W ei, X.; and Liu, S. 2025. Neural Spectral Decomposition for Dataset Distil- lation. In Leonardis, A.; Ricci, E.; Roth, S.; Russakovsky , O.; Sattler , T .; and V arol, G., eds., Computer V ision – ECCV 2024 , 275–290. Cham: Springer Nature Switzerland. Y ao, Z.; W u, X.; Li, C.; Y oun, S.; and He, Y . 2023. ZeroQuant-V2: Exploring Post-training Quantization in LLMs from Comprehensive Study to Low Rank Compen- sation. Y uan, B.; W ang, Z.; Baktashmotlagh, M.; Luo, Y .; and Huang, Z. 2024a. Color-Oriented Redundancy Reduction in Dataset Distillation. In NeurIPS . Y uan, Z.; Xue, C.; Chen, Y .; W u, Q.; and Sun, G. 2024b. PTQ4V iT : Post-training quantization for vision transformers with twin uniform quantization. Zhang, H.; Su, S.; Zhu, Y .; Sun, J.; and Zhang, Y . 2024. GSDD: Generativ e Space Dataset Distillation for Image Super-resolution. In AAAI , 7069–7077. Zhang, J.; Zhou, Y .; and Saab, R. 2022. Post-training Quantization for Neural Networks with Provable Guaran- tees. CoRR , abs/2201.11113. Zhao, B.; and Bilen, H. 2021. Dataset Condensation with Differentiable Siamese Augmentation. In ICML , volume 139, 12674–12685. PMLR. Zhao, B.; and Bilen, H. 2022. Dataset Condensation with Distribution Matching. arXi v:2110.04181. Zhao, B.; Mopuri, K. R.; and Bilen, H. 2021. Dataset Con- densation with Gradient Matching. In ICLR . Zhao, G.; Li, G.; Qin, Y .; and Y u, Y . 2023. Impro ved Distri- bution Matching for Dataset Condensation. In CVPR , 7856– 7865. Zheng, S.; Song, Y .; Leung, T .; and Goodfellow , I. 2016. Improving the Robustness of Deep Neural Networks via Sta- bility T raining. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) . Zhou, B.; Lapedriza, A.; Khosla, A.; Oli v a, A.; and T orralba, A. 2017. Places: A 10 million Image Database for Scene Recognition. IEEE T ransactions on P attern Analysis and Machine Intellig ence .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment