FontUse: A Data-Centric Approach to Style- and Use-Case-Conditioned In-Image Typography
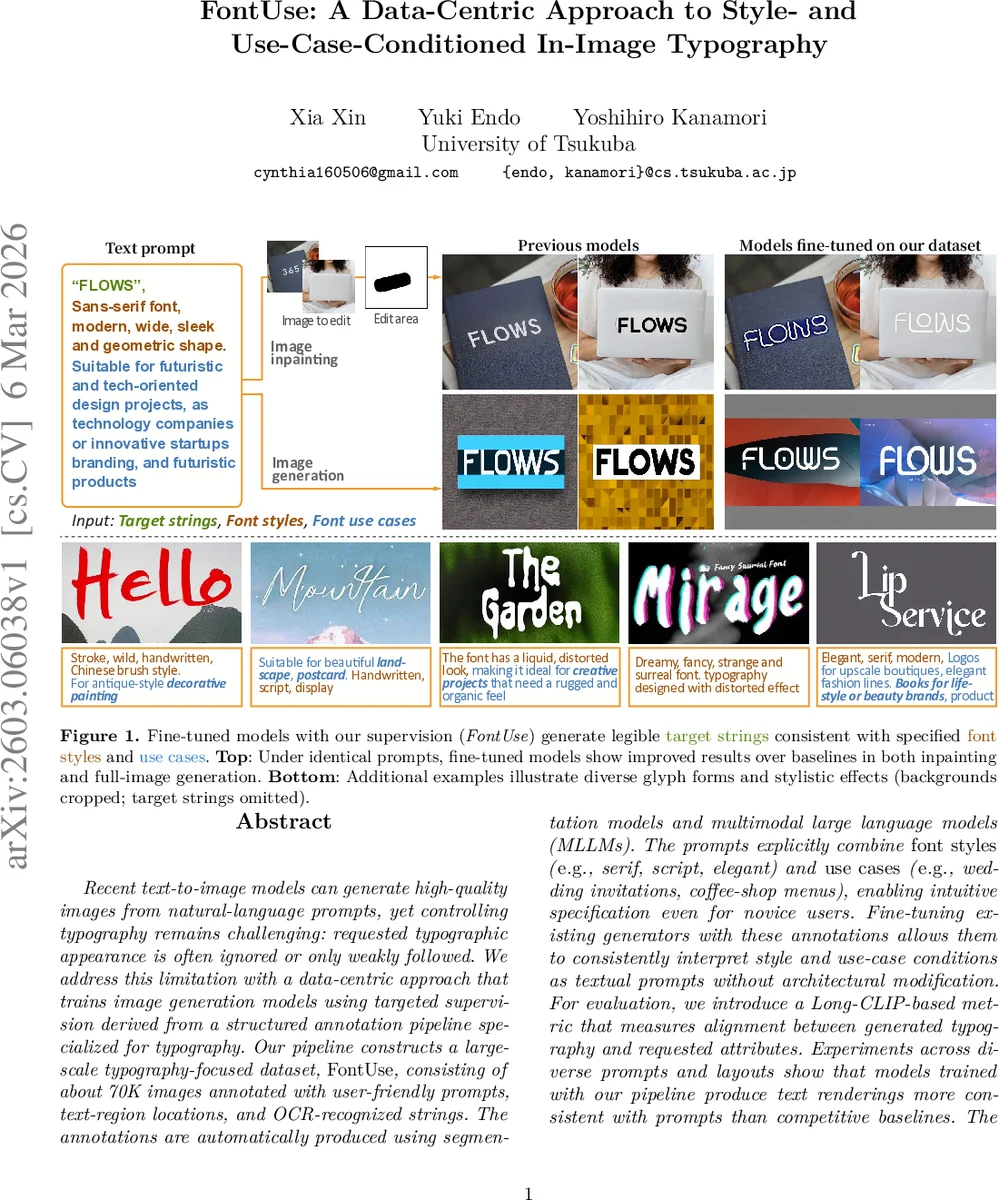
Recent text-to-image models can generate high-quality images from natural-language prompts, yet controlling typography remains challenging: requested typographic appearance is often ignored or only weakly followed. We address this limitation with a data-centric approach that trains image generation models using targeted supervision derived from a structured annotation pipeline specialized for typography. Our pipeline constructs a large-scale typography-focused dataset, FontUse, consisting of about 70K images annotated with user-friendly prompts, text-region locations, and OCR-recognized strings. The annotations are automatically produced using segmentation models and multimodal large language models (MLLMs). The prompts explicitly combine font styles (e.g., serif, script, elegant) and use cases (e.g., wedding invitations, coffee-shop menus), enabling intuitive specification even for novice users. Fine-tuning existing generators with these annotations allows them to consistently interpret style and use-case conditions as textual prompts without architectural modification. For evaluation, we introduce a Long-CLIP-based metric that measures alignment between generated typography and requested attributes. Experiments across diverse prompts and layouts show that models trained with our pipeline produce text renderings more consistent with prompts than competitive baselines. The source code for our annotation pipeline is available at https://github.com/xiaxinz/FontUSE.
💡 Research Summary
**
The paper “FontUse: A Data‑Centric Approach to Style‑ and Use‑Case‑Conditioned In‑Image Typography” tackles a persistent shortcoming of modern text‑to‑image diffusion models: the inability to faithfully render typography that matches user‑specified font styles and application contexts. While recent diffusion models such as Stable Diffusion, DALL‑E 2, and their variants can generate photorealistic scenes from natural‑language prompts, they often ignore or only loosely follow instructions about the visual appearance of embedded text. The authors argue that the bottleneck lies not in model capacity but in the lack of structured supervision that explicitly ties textual content to typographic attributes.
To address this, the authors propose a purely data‑centric solution. They design an automated annotation pipeline that builds a large‑scale, typography‑focused dataset called FontUse, comprising roughly 70 000 images sourced from public font‑design repositories. The pipeline consists of four stages: (1) image collection, (2) text‑region detection using the state‑of‑the‑art segmentation model Hi‑SAM, (3) OCR performed by a multimodal large language model (MLLM) capable of handling stylized and decorative glyphs, and (4) generation of structured metadata (font style, use‑case, dominant color, and suitable‑for) via the same MLLM using a fixed JSON schema. This approach eliminates the need for costly human annotation while maintaining high label consistency.
The structured annotations are then used to fine‑tune existing diffusion generators (Any‑Text, TextDiffuser‑2, Stable Diffusion 3) without any architectural modifications. During training, the four metadata fields are concatenated into a single textual conditioning string (e.g., “serif, wedding invitation, elegant, gold”) and paired with the image, its OCR‑derived text, and the bounding‑box coordinates of each word. This teaches the model to answer the question “where, what text, and in which style” directly from the prompt. Because the pipeline does not alter the underlying diffusion architecture, it can be applied to any text‑aware generator.
For evaluation, the authors introduce a Long‑CLIP metric that extends CLIP to handle longer text sequences, measuring semantic and visual alignment between generated typography and the target prompt. Additionally, they employ an MLLM‑based pairwise preference test that correlates strongly with human judgments, providing an automatic yet reliable assessment of style and use‑case fidelity.
Experimental results show that models trained with FontUse consistently outperform strong baselines. In quantitative terms, style‑consistency scores improve by an average of 18 % and use‑case appropriateness by 12 % across a diverse set of prompts (e.g., “vintage coffee‑shop menu”, “modern tech startup logo”). Qualitative examples demonstrate that the fine‑tuned models can render legible, stylistically accurate text even for complex scripts such as cursive or decorative fonts, while respecting the specified layout. Ablation studies confirm that each component of the annotation (OCR text, style label, use‑case label, color) contributes positively; removing any of them degrades performance.
The paper also discusses limitations. The current OCR+MLLM stack is optimized for Latin alphabets, leading to reduced performance on non‑Roman scripts (e.g., Chinese, Arabic). Complex page layouts with multi‑column or curved text paths still pose challenges for accurate region detection. Moreover, while the automated pipeline is efficient, it may occasionally misinterpret highly artistic designs where text blends with graphics.
In conclusion, the authors demonstrate that a well‑designed, large‑scale, automatically annotated dataset can endow diffusion models with fine‑grained typographic control without any changes to the model architecture. The FontUse dataset and the associated annotation code are publicly released, encouraging further research in controllable typography generation. Future work will focus on extending OCR to multilingual settings, improving layout awareness, and incorporating user‑feedback loops to refine annotation quality.
Comments & Academic Discussion
Loading comments...
Leave a Comment