Yuan3.0 Ultra: A Trillion-Parameter Enterprise-Oriented MoE LLM
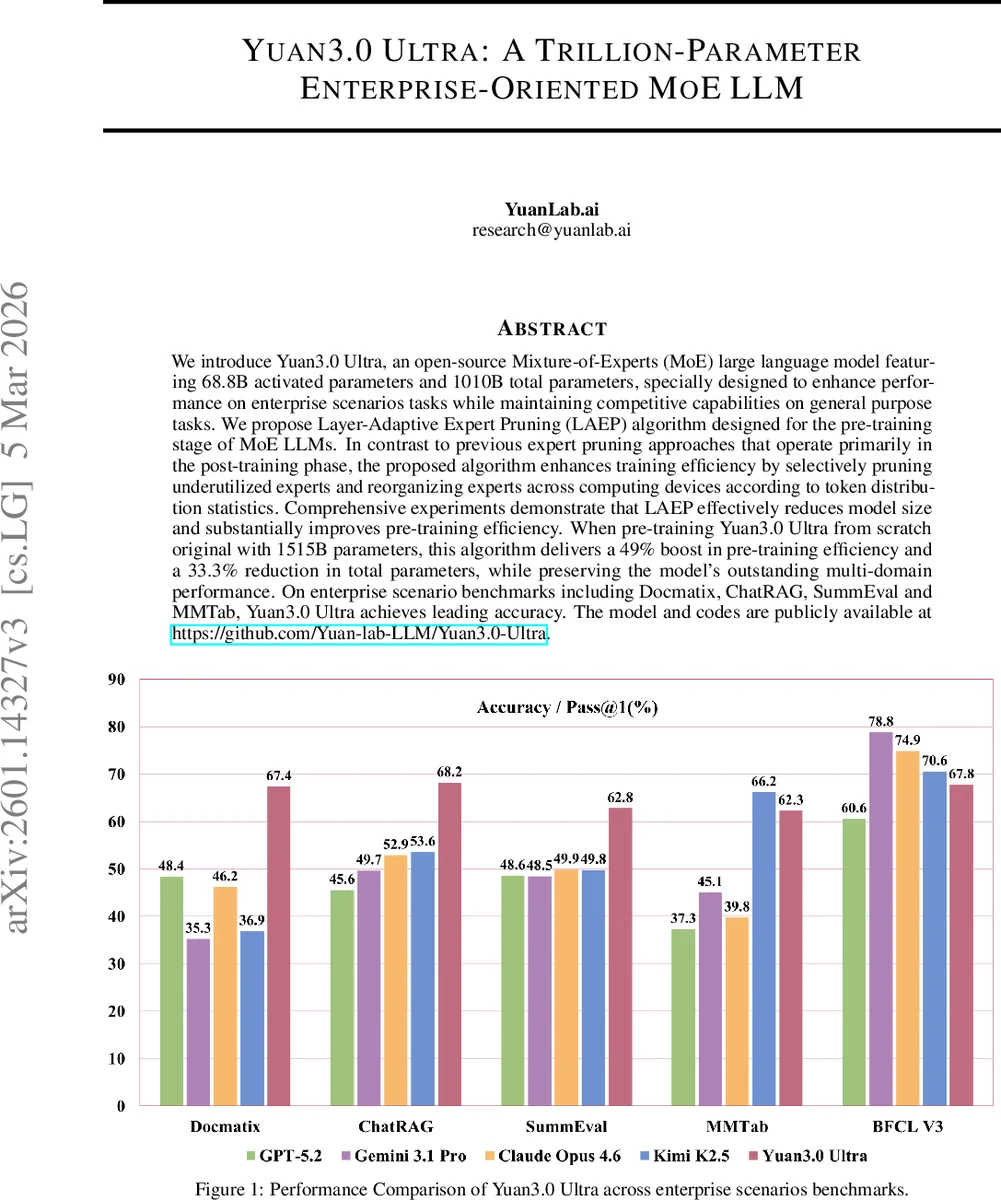
We introduce Yuan3.0 Ultra, an open-source Mixture-of-Experts (MoE) large language model featuring 68.8B activated parameters and 1010B total parameters, specially designed to enhance performance on enterprise scenarios tasks while maintaining competitive capabilities on general purpose tasks. We propose Layer-Adaptive Expert Pruning (LAEP) algorithm designed for the pre-training stage of MoE LLMs. In contrast to previous expert pruning approaches that operate primarily in the post-training phase, the proposed algorithm enhances training efficiency by selectively pruning underutilized experts and reorganizing experts across computing devices according to token distribution statistics. Comprehensive experiments demonstrate that LAEP effectively reduces model size and substantially improves pre-training efficiency. When pre-training Yuan3.0 Ultra from scratch original with 1515B parameters, this algorithm delivers a 49% boost in pre-training efficiency and a 33.3% reduction in total parameters, while preserving the model’s outstanding multi-domain performance. On enterprise scenario benchmarks including Docmatix, ChatRAG, SummEval and MMTab, Yuan3.0 Ultra achieves leading accuracy. The model and codes are publicly available at https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra.
💡 Research Summary
Yuan3.0 Ultra is an open‑source Mixture‑of‑Experts (MoE) large language model (LLM) that boasts 68.8 billion active parameters while maintaining a total of 1.01 trillion parameters. The paper addresses two persistent challenges in MoE LLMs: severe expert load imbalance during training and the reliance on post‑training pruning methods that do not improve training efficiency. To tackle these issues, the authors introduce Layer‑Adaptive Expert Pruning (LAEP), a novel algorithm that operates during the pre‑training phase.
Expert Load Characterization
Through a detailed analysis of a 20 B‑parameter MoE model trained from scratch, the authors observe that expert token loads evolve in two distinct phases. In the early “transition” phase (first few hundred iterations), token assignments fluctuate wildly due to random initialization. After processing roughly 80 B tokens, a “stable” phase emerges: the relative ranking of experts by token count becomes fixed, yet a small subset of “super‑experts” continues to dominate while many experts receive only a handful of tokens. This stable ranking provides a reliable signal for identifying persistently under‑utilized experts.
LAEP Design
LAEP leverages the stable token‑distribution statistics with two hyper‑parameters: α (individual load threshold) and β (cumulative load threshold).
- Candidate Selection (β) – Experts whose cumulative token count falls below a β‑fraction of the total tokens are flagged as pruning candidates.
- Final Pruning (α) – Among the candidates, any expert whose per‑token load is less than α times the average load is actually removed.
Mathematically, this corresponds to Equations (2) and (3) in the paper. By combining a global (β) and a local (α) criterion, LAEP avoids over‑pruning while eliminating truly redundant experts.
After pruning, the remaining experts are redistributed across compute devices (GPUs/TPUs) using a greedy rearrangement algorithm. Experts are sorted by token load and then placed alternately on devices to minimize the variance of token counts per device. This step eliminates the need for auxiliary load‑balancing losses (e.g., the Switch Transformer or Mixtral losses) and their delicate coefficient tuning.
Empirical Results
Applying LAEP to a 1.515 T‑parameter base model yields a 33.3 % reduction in total parameters and a 49 % improvement in pre‑training throughput, without sacrificing accuracy. Sensitivity studies show that moderate pruning (β ≈ 0.1, α ≤ 0.4) can even lower test loss compared to the unpruned baseline, suggesting a regularization effect. The method works consistently across different attention mechanisms (Localized Filtering Attention vs. standard self‑attention).
For downstream evaluation, a 20 B model trained with LAEP achieves lower loss on a suite of benchmarks (CMath, GSM8K, TRIVIAQA) and sets state‑of‑the‑art results on enterprise‑focused tasks such as Docmatix, ChatRAG, SummEval, and MMTab. Parameter counts can be trimmed by up to 26.5 % while maintaining or improving task performance.
Reinforcement Learning Enhancement
The authors also refine the Reflection Inhibition Reward Mechanism (RIRM) originally proposed in Yuan3.0 Flash, integrating it into a fast‑thinking reinforcement‑learning pipeline. This yields a 16.33 % gain in training accuracy and reduces generated token length by 14.38 %, further boosting inference efficiency.
Significance
Yuan3.0 Ultra demonstrates that expert pruning can be effectively performed during pre‑training, a first in the MoE literature. By coupling data‑driven pruning with device‑level expert rearrangement, the approach simultaneously improves parameter efficiency, training speed, and downstream performance without relying on auxiliary loss terms. The open‑source release (code and model) invites the community to reproduce and extend these techniques.
In summary, the paper presents a comprehensive solution—LAEP—that redefines how large‑scale MoE LLMs are built and trained, delivering a trillion‑parameter model that is both computationally tractable and highly performant on real‑world enterprise applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment