Efficient Point Cloud Processing with High-Dimensional Positional Encoding and Non-Local MLPs
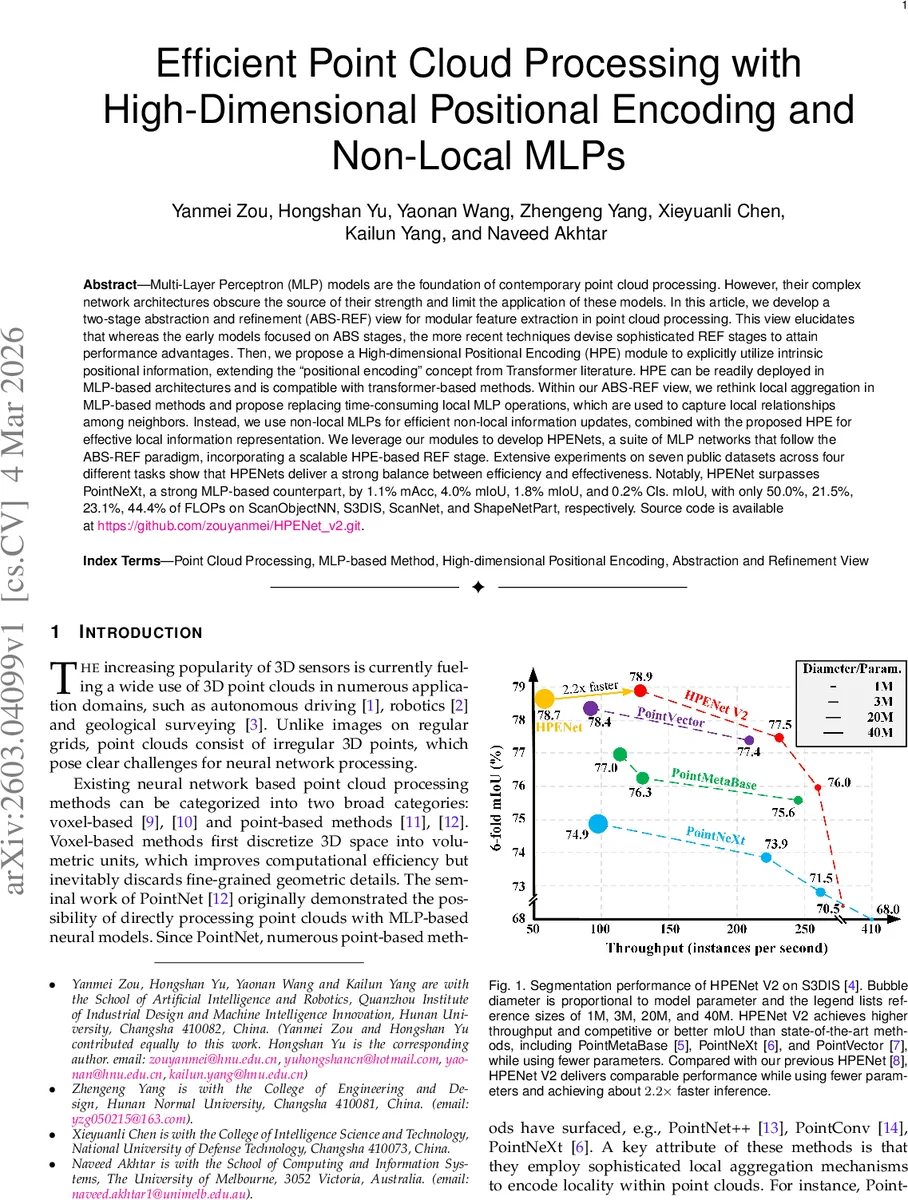
Multi-Layer Perceptron (MLP) models are the foundation of contemporary point cloud processing. However, their complex network architectures obscure the source of their strength and limit the application of these models. In this article, we develop a two-stage abstraction and refinement (ABS-REF) view for modular feature extraction in point cloud processing. This view elucidates that whereas the early models focused on ABS stages, the more recent techniques devise sophisticated REF stages to attain performance advantages. Then, we propose a High-dimensional Positional Encoding (HPE) module to explicitly utilize intrinsic positional information, extending the ``positional encoding’’ concept from Transformer literature. HPE can be readily deployed in MLP-based architectures and is compatible with transformer-based methods. Within our ABS-REF view, we rethink local aggregation in MLP-based methods and propose replacing time-consuming local MLP operations, which are used to capture local relationships among neighbors. Instead, we use non-local MLPs for efficient non-local information updates, combined with the proposed HPE for effective local information representation. We leverage our modules to develop HPENets, a suite of MLP networks that follow the ABS-REF paradigm, incorporating a scalable HPE-based REF stage. Extensive experiments on seven public datasets across four different tasks show that HPENets deliver a strong balance between efficiency and effectiveness. Notably, HPENet surpasses PointNeXt, a strong MLP-based counterpart, by 1.1% mAcc, 4.0% mIoU, 1.8% mIoU, and 0.2% Cls. mIoU, with only 50.0%, 21.5%, 23.1%, 44.4% of FLOPs on ScanObjectNN, S3DIS, ScanNet, and ShapeNetPart, respectively. Source code is available at https://github.com/zouyanmei/HPENet_v2.git.
💡 Research Summary
This paper addresses the growing complexity of modern point‑cloud networks built on multi‑layer perceptrons (MLPs). The authors first introduce a unified “abstraction‑refinement” (ABS‑REF) perspective that separates any point‑cloud backbone into two logical stages. In the ABS stage, the network reduces spatial resolution while extracting coarse features; in the REF stage, the same resolution is retained and the features are refined, typically by expanding the receptive field and incorporating more context. By mapping existing methods onto this view, the authors show that early works (e.g., PointNet++, PointConv) focused almost exclusively on sophisticated local aggregation in the ABS stage, whereas recent high‑performing models (including transformer‑based ones) achieve their gains largely through a dedicated REF stage.
Guided by this insight, the paper proposes three lightweight modules that can be plugged into either stage:
-
High‑dimensional Positional Encoding (HPE).
Traditional MLP‑based point‑cloud models treat coordinates as an auxiliary channel, simply concatenating relative positions with learned features. HPE instead projects the relative coordinates into a high‑dimensional space (e.g., 64‑256 dimensions) using a linear or sinusoidal mapping, then passes the result through a small MLP to align it with the feature space. This makes the encoding translation‑invariant and gives the network a richer geometric signal. HPE can be inserted in both ABS and REF stages and is also compatible with transformer backbones. -
Non‑local MLPs.
Conventional local MLPs operate on a fixed neighbourhood (k‑nearest points) and thus incur O(N·k·C) complexity. The authors replace these with “non‑local” MLPs that process a broader set of points before the grouping operation, effectively delivering a global context update with far fewer FLOPs. In the ABS stage, non‑local MLPs dramatically reduce computation while still providing enough information for subsequent refinement. In the REF stage, the combination of non‑local updates and HPE restores fine‑grained local detail. -
Backward Fusion Module (BFM).
In many encoder‑decoder designs, high‑resolution features are only used unilaterally in the decoder, limiting the flow of contextual information. BFM extracts simple statistics (max‑pool and mean‑pool) from high‑resolution feature maps, embeds them via inverted‑residual MLP blocks, and injects the resulting context into lower‑resolution features. This creates a bidirectional interaction between multi‑scale representations, improving the handling of small objects and boundary regions without adding significant parameters.
Using these components, the authors build HPENet and its more efficient successor HPENet V2. The architecture explicitly separates ABS and REF stages, employs non‑local MLPs in the former, and integrates HPE and BFM in the latter. Compared with the strong MLP‑based baseline PointNeXt, HPENet V2 achieves:
- ScanObjectNN: +1.1 % mAcc with only 50 % of the FLOPs.
- S3DIS: +4.0 % mIoU with 21.5 % FLOPs.
- ScanNet: +1.8 % mIoU with 23.1 % FLOPs.
- ShapeNetPart: +0.2 % class‑wise mIoU with 44.4 % FLOPs.
The paper also validates the generality of HPE and BFM by inserting them into two transformer‑based backbones—Point Transformer and Stratified Transformer. The modifications yield +2.5 % and +1.3 % mIoU improvements respectively, demonstrating that the proposed modules are not tied to MLP‑only designs.
Experiments span seven public datasets and four tasks (object classification, scene semantic segmentation, part segmentation, and object detection). Across all benchmarks, HPENet family models consistently rank at or near the state‑of‑the‑art while requiring substantially fewer parameters and less compute, making them attractive for real‑time or edge deployments.
The authors acknowledge some limitations: HPE’s high‑dimensional projection can increase memory usage, non‑local MLPs may need careful batching for very large point clouds, and BFM’s reliance on simple statistics may not capture highly complex local geometry. Nevertheless, the work provides a clear, modular framework for designing efficient point‑cloud networks and opens avenues for hybrid MLP‑transformer architectures that leverage explicit positional encoding and bidirectional multi‑scale fusion.
Comments & Academic Discussion
Loading comments...
Leave a Comment