One Operator to Rule Them All? On Boundary-Indexed Operator Families in Neural PDE Solvers
Neural PDE solvers are often described as learning solution operators that map problem data to PDE solutions. In this work, we argue that this interpretation is generally incorrect when boundary conditions vary. We show that standard neural operator …
Authors: Lennon J. Shikhman
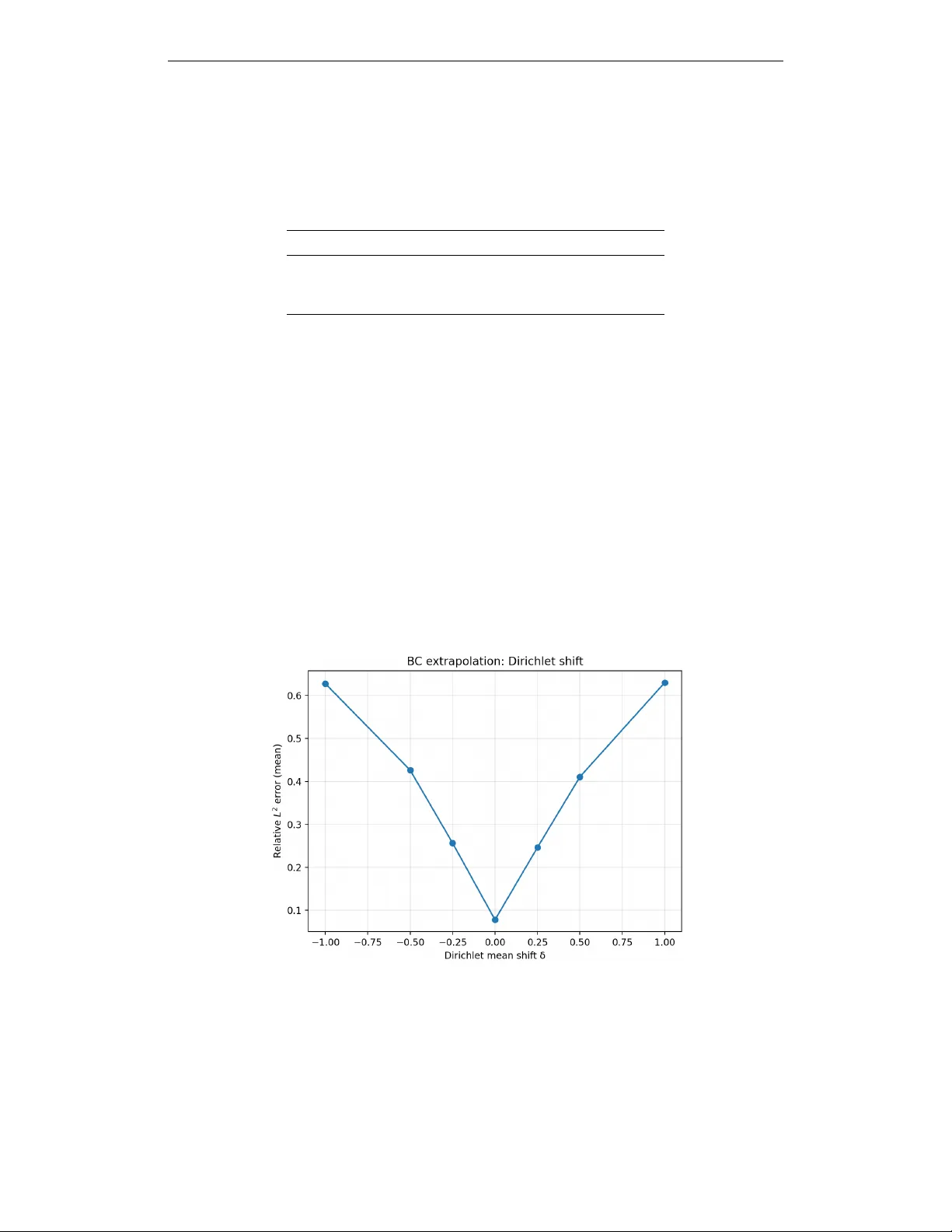
Published as a conference paper at ICLR 2026 O N E O P E R A T O R T O R U L E T H E M A L L ? O N B O U N D A RY - I N D E X E D O P E R A T O R F A M I L I E S I N N E U R A L P D E S O L V E R S Lennon J. Shikhman College of Computing, Geor gia Institute of T echnology Department of Mathematics and Systems Engineering, Florida Institute of T echnology lshikhman3@gatech.edu A B S T R AC T Neural PDE solvers are often described as learning solution operators that map problem data to PDE solutions. In this work, we argue that this interpretation is generally incorrect when boundary conditions vary . W e sho w that standard neural operator training implicitly learns a boundary-inde xed f amily of operators, rather than a single boundary-agnostic operator, with the learned mapping fundamentally conditioned on the boundary-condition distribution seen during training. W e formalize this perspecti ve by framing operator learning as conditional risk minimization ov er boundary conditions, which leads to a non-identifiability result outside the support of the training boundary distrib ution. As a consequence, generalization in forcing terms or resolution does not imply generalization across boundary conditions. W e support our theoretical analysis with controlled experiments on the Poisson equation, demonstrating sharp degradation under boundary-condition shifts, cross-distribution failures between distinct boundary ensembles, and con vergence to conditional expectations when boundary information is remov ed. Our results clarify a core limitation of current neural PDE solvers and highlight the need for explicit boundary-a ware modeling in the pursuit of foundation models for PDEs. 1 I N T RO D U C T I O N Recent progress in neural methods for partial differential equations (PDEs) has led to models that aim to directly approximate mappings from problem specifications to PDE solutions. Neural operators, physics-informed networks, and related architectures are frequently described as learning solution operators for entire PDE families, enabling rapid e valuation across varying inputs such as forcing functions, coefficients, or discretizations. This viewpoint has fueled growing interest in dev eloping scalable, reusable neural PDE solvers as potential foundation models for scientific computing. From the perspectiv e of classical PDE theory , howe ver , a solution operator is not defined by the differential equation alone. Boundary conditions are essential to well-posedness and fundamentally determine the mapping from problem data to solutions. In many learning-based approaches, boundary conditions v ary across training instances b ut are incorporated implicitly , for example through boundary padding, auxiliary input channels, or fixed encodings. This raises a basic but unresolved question: when boundary conditions are not fixed, what object is a neural PDE solver actually approximating? In this paper , we contend that standard neural PDE solvers do not learn a single operator that is in variant to boundary conditions. Rather , they learn a family of operators index ed by boundary conditions, with the learned mapping intrinsically tied to the boundary-condition distribution present in the training data. This interpretation exposes a structural limitation of current training paradigms. Because learning is driven by empirical risk minimization, the model is only constrained on the subset of boundary conditions it observes, leaving its beha vior under boundary shifts or extrapolation ef fectively unconstrained. 1 Published as a conference paper at ICLR 2026 W e dev elop this argument by explicitly casting neural operator learning as conditional risk minimization with respect to boundary conditions. W ithin this framework, breakdowns in boundary-condition generalization arise naturally and do not depend on architectural deficiencies or optimization f ailures. In particular, robustness to changes in forcing terms or spatial resolution does not guarantee robustness to changes in boundary conditions, e ven when the underlying PDE operator is unchanged. Furthermore, when boundary information is omitted or weakly represented, learned models tend to approximate conditional av erages rather than well-defined PDE solution maps. W e illustrate these phenomena through a series of controlled numerical e xperiments on the Poisson equation with mixed boundary conditions. The experiments reveal pronounced performance degradation under boundary-condition shifts, systematic failures when training and testing boundary distributions differ , and con vergence toward conditional expectations when boundary inputs are remov ed. T ogether , these results provide empirical support for the theoretical characterization. Sev eral prior works hav e documented sensiti vity to boundary-condition v ariability and proposed boundary-aware architectures or constraints to mitigate such effects. Our contrib ution is not to introduce a new architecture, but to provide a learning-theoretic framing that interprets these empirical beha viors through conditional risk minimization and non-identifiability under boundary distribution shift. This perspectiv e clarifies what object is being learned when boundary conditions vary and sharpens the interpretation of operator -lev el generalization claims. Contributions. This work makes the follo wing contributions: • W e introduce a conceptual framework that interprets neural PDE solvers as learning boundary-index ed operator families rather than boundary-in variant solution operators. • W e identify a non-identifiability phenomenon induced by empirical risk minimization, showing that operator behavior outside the training boundary distribution is not determined. • W e v alidate the theoretical predictions with controlled e xperiments that isolate the effects of boundary-condition variation. 2 P RO B L E M S E T U P A N D N OTA T I O N W e inv estigate learning-based approximations of solution mappings for elliptic partial dif ferential equations under varying boundary conditions. T o isolate the role of boundary conditions in a controlled setting, we focus on a single canonical problem where the underlying dif ferential operator is fixed while boundary specifications v ary across samples. Differential equation and domain. Let Ω = [0 , 1] 2 ⊂ R 2 denote a bounded rectangular domain. For a gi ven forcing field f : Ω → R , we consider the Poisson equation − ∆ u ( x, y ) = f ( x, y ) , ( x, y ) ∈ Ω , (1) supplemented by mixed boundary conditions imposed on the boundary ∂ Ω . Boundary specification. Boundary conditions are prescribed independently on each edge of the domain. Specifically , we impose Dirichlet conditions on the left and bottom boundaries and Neumann conditions on the right and top boundaries: u (0 , y ) = g L ( y ) , y ∈ [0 , 1] , (2) u ( x, 0) = g B ( x ) , x ∈ [0 , 1] , (3) ∂ x u (1 , y ) = h R ( y ) , y ∈ [0 , 1] , (4) ∂ y u ( x, 1) = h T ( x ) , x ∈ [0 , 1] . (5) The tuple B = ( g L , g B , h R , h T ) collects all boundary data required to define a single well-posed problem instance. In our experiments, the boundary functions are drawn from parameterized families of smooth functions generated via truncated Fourier expansions. By adjusting parameters such as bandwidth, 2 Published as a conference paper at ICLR 2026 amplitude, and mean of fset, we construct distinct boundary-condition distrib utions while leaving the interior forcing distribution unchanged. Solution mappings. When the boundary data B are held fix ed, the Poisson problem induces a deterministic solution operator S B : f 7→ u. (6) When boundary conditions vary across samples, it is more appropriate to view the problem in terms of the joint mapping S : ( f , B ) 7→ u, (7) which assigns a solution to each combination of forcing and boundary specification. Learning-based PDE solvers seek to approximate this joint map from finite data. Data generation. T raining and ev aluation data are generated synthetically . For each sample, a forcing function f i is sampled from a fixed distribution of smooth functions on Ω . Boundary data B i are sampled independently from a boundary-condition distribution µ B . The corresponding solution u i is computed numerically using a finite-difference discretization combined with an iterative Jacobi solver applied on a uniform grid. W e consider multiple choices of µ B that dif fer only in the statistical properties of the boundary functions, such as shifts in mean value or changes in smoothness, while keeping the differential operator and forcing distribution fix ed. This design enables a direct examination of ho w learned solution mappings depend on the boundary-condition distribution observ ed during training. Neural solver inputs. Neural PDE solv ers operate on discretized fields defined on a regular grid. Model inputs consist of the discretized forcing field and spatial coordinate channels. When boundary information is pro vided, additional channels encode boundary v alues along with binary masks identifying boundary locations. For comparison, we also consider boundary-ablated models that receiv e only the forcing and coordinate information, thereby excluding explicit access to boundary conditions. 3 W H A T I S A C T UA L LY B E I N G L E A R N E D Neural PDE solvers are often interpreted as approximating solution operators associated with a fixed differential equation. This interpretation becomes ambiguous when boundary conditions vary across training samples, since the PDE no longer defines a single mapping from problem data to solutions. Learning as conditional pr ediction. In our setting, training data consist of samples ( f i , B i , u i ) drawn from a joint distribution ov er forcing functions and boundary conditions. Standard training minimizes empirical risk of the form min θ E ( f , B ) ∼ µ h ℓ ˆ S θ ( f , B ) , S ( f , B ) i , (8) which corresponds to learning a conditional predictor of u given ( f , B ) . As a result, the learned model should be vie wed as approximating a collection of solution maps indexed by boundary conditions, rather than a boundary-in variant operator . Dependence on the boundary distribution. Because empirical risk minimization constrains the model only on the support of the training distribution, the learned mapping is well-defined only for boundary conditions drawn from the training boundary distribution µ B . For boundary conditions outside this support, the training objective imposes no constraints, and multiple extensions of the learned mapping are equally v alid. Consequently , two models trained under different boundary-condition distrib utions may conv erge to different solution mappings, ev en when the underlying PDE and forcing distribution are identical. ERM interpretation. Under squared loss, empirical risk minimization yields the conditional expectation of the tar get giv en the observed inputs. Our contribution is to interpret this standard result in the operator-learning setting where boundary variability may be unobserved or weakly 3 Published as a conference paper at ICLR 2026 encoded. W ithin the class of ERM-trained Fourier Neural Operator models studied here, this behavior is therefore not attributable to insuf ficient capacity or optimization instability . When boundary information is removed or poorly represented, ERM fav ors predictors that approximate conditional av erages over the unobserv ed boundary variables, ˆ u ( f ) ≈ E B∼ µ B [ S ( f , B ) | f ] , (9) which generally does not correspond to the solution operator for any fix ed boundary condition. This perspecti ve clarifies why rob ustness along one axis of v ariability does not necessarily imply robustness along another , and motiv ates vie wing neural PDE solvers as learning families of operators parameterized by boundary conditions. 4 N O N - I D E N T I FI A B I L I T Y I N D U C E D B Y B O U N DA RY D I S T R I B U T I O N S H I F T When boundary conditions vary across training samples, the solution map associated with a fix ed differential operator is no longer uniquely determined by the training objecti ve alone. In this setting, learning-based PDE solv ers are tasked with approximating a mapping that is only partially observed, with key degrees of freedom controlled by the boundary-condition distrib ution encountered during training. W e use the term non-identifiability to describe this phenomenon. Informally , a learned solution map is non-identifiable if multiple distinct mappings achiev e the same empirical risk under the training distribution b ut behave dif ferently under boundary conditions not observed during training. This notion is distinct from approximation error: ev en in the limit of infinite model capacity and perfect optimization, the training objectiv e does not select a unique extension of the learned mapping beyond the support of the boundary-condition distribution. This behavior follows directly from the structure of empirical risk minimization. During training, errors are penalized only on samples drawn from the joint distribution over forcings and boundary conditions. F or boundary conditions that occur with nonzero probability under this distribution, the learned model is constrained to approximate the corresponding solutions accurately . For boundary conditions outside this support, howe ver , the objective provides no information, and the learned mapping may vary arbitrarily without af fecting training loss. From this perspectiv e, boundary-condition generalization is fundamentally dif ferent from generalization in forcing terms or spatial resolution. V ariations in forcing are explicitly represented in the input and are typically sampled densely during training, whereas boundary conditions may occupy a low-dimensional or sparsely sampled subspace. As a result, robustness to unseen forcing functions does not imply robustness to unseen boundary specifications, ev en when the underlying PDE remains unchanged. The implications of this non-identifiability are directly reflected in our empirical results. Models trained under one boundary-condition distribution exhibit sharp performance degradation when ev aluated under a shifted boundary distrib ution, despite unchanged forcing statistics and identical differential operators. W ithin the class of ERM-trained Fourier Neural Operator models studied here, this failure is not attributable to insuf ficient capacity or optimization instability , as the same architecture performs well in-distribution. Finally , non-identifiability also explains the behavior observed when boundary information is remov ed or weakly encoded. In this case, the learning objectiv e cannot condition on boundary conditions at all, and empirical risk minimization instead fav ors predictors that a verage over the unobserved boundary v ariability . The resulting mapping corresponds to a conditional e xpectation ov er boundary conditions rather than a valid solution operator for any fix ed boundary specification. T aken together , these considerations show that non-identifiability under boundary distrib ution shift arises naturally under empirical risk minimization in the class of Fourier Neural Operator models studied here, rather than from insufficient capacity or optimization instability . 4 Published as a conference paper at ICLR 2026 5 I M P L I C AT I O N S F O R G E N E R A L I Z A T I O N The perspectiv e dev eloped above has se veral immediate implications for ho w generalization in neural PDE solvers should be interpreted and e valuated. In particular, it clarifies why success along certain axes of v ariation does not translate to rob ustness under boundary-condition shift, and why common ev aluation protocols may substantially overestimate operator -level generalization. For cing generalization versus boundary generalization. Generalization in forcing terms is often taken as evidence that a neural PDE solver has learned the underlying solution operator . Ho wever , forcing functions are typically sampled densely during training and enter the problem as interior data. By contrast, boundary conditions define constraints on the solution space and may vary over a much lower -dimensional and sparsely sampled space. As a result, robustness along one axis of variability does not necessarily imply robustness along another . While we do not explicitly ev aluate forcing-distribution shift in this work, boundary variability occupies a distinct structural role under empirical risk minimization, and therefore generalization across forcing and boundary conditions need not coincide. Resolution rob ustness does not imply boundary robustness. Similarly , robustness to changes in spatial resolution is often cited as a hallmark of operator learning. While resolution generalization reflects stability with respect to discretization, it does not address v ariability in the boundary specification. A model that performs consistently across grids may still fail catastrophically when boundary conditions shift, e ven if the continuous PDE and forcing distribution remain unchanged. Resolution robustness therefore probes numerical consistency rather than inv ariance to problem-defining constraints. Reinterpr eting prior empirical results. These observations suggest a reinterpretation of prior empirical successes reported for neural PDE solvers. In many benchmark settings, boundary conditions are fixed or vary within a narrow distribution, implicitly collapsing the problem to learning a single operator or a small family thereof. Under such conditions, strong empirical performance is expected and does not contradict the limitations identified here. Conv ersely , failures under boundary-condition shift should not be vie wed as anomalous b ut as predictable consequences of the learning objectiv e and data distribution. Implications for model design and e valuation. T aken together , these considerations indicate that meaningful claims of operator generalization require explicit treatment of boundary-condition variability . W ithout boundary-aware representations or in variance mechanisms, scaling model capacity or training data alone is insuf ficient to ensure robustness beyond the training boundary distribution. Evaluations that do not probe boundary-condition shift risk conflating in-distribution interpolation with genuine operator-le vel generalization. This analysis moti vates treating boundary conditions as first-class objects in the design and assessment of neural PDE solvers, particularly in the context of de veloping reusable or foundation-lev el models for scientific computing. 6 E X P E R I M E N TA L V E R I FI C A T I O N W e empirically v alidate the theoretical perspecti ve de veloped above through controlled e xperiments on the two-dimensional Poisson equation. The experiments are specifically designed to isolate the effect of boundary-condition variability by holding the differential operator , forcing distribution, discretization, and resolution fixed, while varying only the boundary-condition distribution. W e ev aluate both boundary-aw are and boundary-ablated Fourier Neural Operator models under in-distribution, cross-distribution, and extrapolation settings to directly test the claims about boundary-index ed learning and non-identifiability . 6 . 1 E X P E R I M E N TA L S E T U P PDE and discretization. All e xperiments consider the tw o-dimensional Poisson equation on the unit square Ω = [0 , 1] 2 with mixed boundary conditions. The equation is discretized on a 5 Published as a conference paper at ICLR 2026 uniform 64 × 64 grid using a standard fi ve-point finite-dif ference stencil. Ground-truth solutions are computed using a batched Jacobi iterativ e solver with a fixed number of iterations. Boundary-condition distributions. Boundary conditions are parameterized by smooth functions sampled from truncated Fourier series. For both distrib utions, Dirichlet and Neumann boundary functions are generated with Fourier bandwidth K = 6 . In µ B 0 , Dirichlet boundary functions ha ve amplitude 1 . 0 with zero mean shift, while Neumann boundary functions hav e amplitude 0 . 5 with zero mean shift. In µ B 1 , the Dirichlet amplitude remains 1 . 0 but includes a mean shift of 0 . 6 , while Neumann boundary functions ha ve amplitude 0 . 8 with a mean shift of 0 . 2 . The functional form and bandwidth are otherwise identical across distributions. Forcing functions are sampled independently from a truncated Fourier expansion with bandwidth K = 6 and amplitude 3 . 0 , and this forcing distrib ution is held fixed across all experiments. Figure 1: T raining dynamics for boundary-aware Fourier Neural Operators trained on µ B 0 (left) and µ B 1 (right). Relati ve L 2 error decreases smoothly and stabilizes in both cases, indicating that subsequent generalization failures are not due to optimization instability or lack of con vergence. Models and training . W e e valuate a Fourier Neural Operator (FNO) architecture trained under three settings: (i) an FNO trained on µ B 0 with explicit boundary-condition channels, (ii) an FNO trained on µ B 1 with e xplicit boundary-condition channels, and (iii) a boundary-ablated FNO trained on µ B 0 that receiv es only the forcing field and spatial coordinates. All models are trained using the Adam optimizer with learning rate 8 × 10 − 4 and mean-squared error loss for 2500 gradient steps with batch size 12 . Experiments are conducted on a 64 × 64 grid. T raining data are generated using 220 Jacobi iterations per sample, while e valuation data use 320 iterations. The random seed is fix ed to 7 for reproducibility . V ariability across random initializations is not explored in this study and remains future work. Error metric. Relative L 2 error is computed as q 1 H W P i,j ( u pred ( i, j ) − u ( i, j )) 2 q 1 H W P i,j u ( i, j ) 2 , corresponding to the ratio of root-mean-square error to root-mean-square ground-truth magnitude ov er the spatial grid. 6 . 2 C RO S S - D I S T R I B U T I O N G E N E R A L I Z A T I O N W e first examine generalization under pure boundary-condition distribution shift. Each boundary-aware model is ev aluated both in-distrib ution and on the alternate boundary distribution, while keeping the PDE, forcing distrib ution, and resolution unchanged. In-distribution results are 6 Published as a conference paper at ICLR 2026 computed on independently sampled e valuation batches drawn from the same boundary distrib ution as training. T able 1: Cross-distribution generalization under boundary-condition shift. Relativ e L 2 errors are reported as mean ± standard de viation over e valuation batches. Model T est on µ B 0 T est on µ B 1 FNO trained on µ B 0 0 . 078 ± 0 . 005 0 . 489 ± 0 . 022 FNO trained on µ B 1 0 . 601 ± 0 . 036 0 . 102 ± 0 . 003 FNO (no BC channels) 0 . 999 ± 0 . 001 1 . 001 ± 0 . 001 As shown in T able 1, each boundary-aware model performs well only on the boundary distrib ution it was trained on, while exhibiting sev ere degradation under boundary-condition shift. In contrast, the boundary-ablated model fails uniformly across both distrib utions. These results demonstrate that the learned solution mappings are strongly indexed by the training boundary-condition distrib ution, rather than determined solely by the underlying PDE. 6 . 3 B O U N DA RY E X T R A P O L A T I O N W e next ev aluate robustness to boundary e xtrapolation by modifying boundary conditions be yond the support of the training distribution while k eeping all other factors fixed. Dirichlet mean shift. W e apply additive shifts to the Dirichlet boundary v alues at test time and measure performance as a function of the shift magnitude. Error increases smoothly and symmetrically as boundary conditions move aw ay from the training distrib ution, indicating continuous degradation rather than abrupt failure. W e sweep mean shifts δ ∈ {− 1 . 0 , − 0 . 5 , − 0 . 25 , 0 , 0 . 25 , 0 . 5 , 1 . 0 } applied to the Dirichlet boundary mean relati ve to the training distribution. Figure 2: Boundary extrapolation via Dirichlet mean shifts. Relative L 2 error increases smoothly and symmetrically as boundary conditions move away from the training distribution, despite unchanged forcing distribution, resolution, and PDE operator . Frequency extrapolation. W e also increase the Fourier bandwidth of the Dirichlet boundary functions beyond the training range. Performance degrades monotonically as higher -frequency boundary components are introduced, despite unchanged forcing statistics and resolution. W e increase the Dirichlet bandwidth from the training value K = 6 to K ∈ { 6 , 8 , 10 , 12 } . 7 Published as a conference paper at ICLR 2026 T ogether , these results sho w that ev en modest e xtrapolation in boundary-condition space leads to substantial error growth, reinforcing the vie w that learned operators are constrained to the support of the training boundary distribution. Figure 3: Boundary extrapolation via increased Dirichlet bandwidth. Performance degrades monotonically as higher-frequency boundary components are introduced beyond the training support. 6 . 4 B O U N DA RY A B L A T I O N A N D C O N D I T I O N A L E X P E C TA T I O N Finally , we analyze the behavior of models that do not recei ve explicit boundary-condition information. The boundary-ablated FNO fails to learn a meaningful solution mapping, achieving relativ e L 2 error close to one regardless of the boundary distrib ution. T o further interpret this behavior , we fix a single forcing function and compare the model output to the empirical average of solutions obtained by sampling boundary conditions from µ B 0 . The boundary-ablated model closely matches this conditional average, indicating that empirical risk minimization dri ves the model toward a conditional expectation ov er boundary conditions when boundary information is unav ailable. This experiment provides direct empirical evidence for the learning-theoretic interpretation dev eloped in Sections 3 and 4, and confirms that boundary ablation leads to averaging behavior rather than recov ery of a valid solution operator . 7 D I S C U S S I O N A N D I M P L I C A T I O N S F O R F O U N D A T I O N M O D E L S The results of this study have direct implications for ho w neural PDE solvers should be interpreted, scaled, and ev aluated in the context of foundation models for scientific computing. In particular , the y clarify which aspects of generalization are structurally achie vable under standard training objecti ves and which are not. Boundary awareness as a structural requirement. Our findings indicate that boundary conditions cannot be treated as incidental inputs when learning solution operators. Instead, they define essential constraints that index distinct solution maps. Models trained without explicit mechanisms to represent or reason ov er boundary variability ine vitably learn mappings that are tied to the boundary-condition distribution observed during training. From this perspective, boundary awareness is not an architectural enhancement but a structural requirement for operator-lev el generalization. 8 Published as a conference paper at ICLR 2026 Figure 4: Conditional expectation beha vior under boundary ablation. For a fixed forcing f ∗ , the boundary-ablated model output (left) closely matches the Monte Carlo estimate of E [ u | f ∗ ] (center), with the absolute dif ference shown on the right. This provides empirical e vidence that training via empirical risk minimization leads to conditional a veraging when boundary information is unav ailable. Limits of scaling under empirical risk minimization. The observed failures under boundary-condition shift are not attributable to insufficient data, model capacity , or optimization instability . Rather , they arise from the interaction between empirical risk minimization and variability in boundary conditions. Scaling model size or dataset volume within a fixed boundary distribution improves in-distribution performance b ut does not resolve non-identifiability outside the support of that distribution. Consequently , scaling alone is insufficient to produce boundary-agnostic solution operators. Implications for PDE f oundation models. For foundation models aimed at learning reusable PDE solv ers across domains and boundary regimes, these results highlight a critical challenge. W ithout explicit treatment of boundary conditions, such as in variant representations, conditional operator decompositions, or structured boundary encodings, learned models should be expected to generalize only within the boundary distributions they are trained on. Evaluation protocols that fix or narro wly vary boundary conditions therefore risk o verstating the scope of learned operator generalization. These considerations complement recent studies of scaling and transfer behavior in scientific foundation models (e.g., Subramanian et al., 2023), which emphasize the importance of distributional co verage across physical parameters during pre-training and transfer . T aken together , our analysis suggests that progress to ward genuine foundation models for PDEs will require training objectives and representations that address boundary-condition variability as a first-class modeling concern, rather than relying on scale or architectural expressi veness alone. 8 L I M I T A T I O N S A N D F U T U R E W O R K This work is intentionally scoped to isolate the ef fects of boundary-condition variability in a controlled setting. As such, sev eral limitations point to natural directions for future research. PDE classes. Our experiments focus on a single elliptic PDE with smooth solutions and mixed boundary conditions. While the conceptual arguments are not specific to the Poisson equation, extending the empirical analysis to other PDE classes—such as parabolic, hyperbolic, or nonlinear systems—would further clarify how boundary-induced non-identifiability manifests across dif ferent dynamical regimes. Time-dependent systems. W e restrict attention to steady-state problems. In time-dependent PDEs, boundary conditions may interact with temporal ev olution and initial conditions in more complex w ays. In vestigating whether analogous boundary-index ed behavior arises in neural solvers for ev olutionary systems remains an important direction. Theoretical extensions. Our analysis adopts a learning-theoretic perspective rather than pro viding formal guarantees. Developing more e xplicit theoretical characterizations of identifiability under 9 Published as a conference paper at ICLR 2026 boundary variability , as well as designing training objectiv es or representations that mitigate these effects, are promising a venues for future work. Overall, these limitations reflect deliberate design choices rather than deficiencies of the proposed analysis, and highlight opportunities for extending the frame work de veloped here. A C K N O W L E D G M E N T S Computational Resources. The author gratefully acknowledges Dell T echnologies, and in particular the Dell Pro Precision division, for pro viding computational resources that supported the experiments in this work. All experiments were conducted on a Dell Pro Max T2 workstation equipped with an Intel Core Ultra 9 285K processor , 128 GB of DDR5 ECC memory , and an NVIDIA R TX PR O 6000 Blackwell GPU. The vie ws and conclusions expressed herein are those of the author and do not necessarily reflect the views of Dell T echnologies. Reproducibility . For reproducibility , the full experimental code, data-generation scripts, and training configurations used in this study are publicly av ailable at https://github.com/ lennonshikhman/boundary- indexed- neural- pde . R E F E R E N C E S Lawrence C. Evans. P artial differ ential equations . American Mathematical Society , Providence, R.I., 2010. ISBN 9780821849743 0821849743. Nikola Ko vachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar . Neural operator: Learning maps between function spaces with applications to pdes. Journal of Machine Learning Researc h , 24(89):1–97, 2023. URL http://jmlr.org/papers/v24/21- 1524.html . Nikola B. Ko vachki, Samuel Lanthaler , and Andre w M. Stuart. Operator learning: Algorithms and analysis, 2024. URL . Zongyi Li, Nikola K ov achki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar . Neural operator: Graph kernel network for partial differential equations, 2020. URL . Zongyi Li, Nikola K ov achki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar . F ourier neural operator for parametric partial differential equations, 2021. URL . Zongyi Li, Hongkai Zheng, Nikola K ov achki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar . Physics-informed neural operator for learning partial differential equations, 2023. URL . Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the uni versal approximation theorem of operators. Natur e Machine Intelligence , 3(3):218–229, March 2021. ISSN 2522-5839. doi: 10.1038/ s42256- 021- 00302- 5. URL http://dx.doi.org/10.1038/s42256- 021- 00302- 5 . Shashank Subramanian, Peter Harrington, K urt Keutzer , W ahid Bhimji, Dmitriy Morozov , Michael Mahoney , and Amir Gholami. T o wards foundation models for scientific machine learning: Characterizing scaling and transfer behavior , 2023. URL 00258 . 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment