Rubric-Guided Fine-tuning of SpeechLLMs for Multi-Aspect, Multi-Rater L2 Reading-Speech Assessment
Reliable and interpretable automated assessment of second-language (L2) speech remains a central challenge, as large speech-language models (SpeechLLMs) often struggle to align with the nuanced variability of human raters. To address this, we introdu…
Authors: Aditya Kamlesh Parikh, Cristian Tejedor-Garcia, Catia Cucchiarini
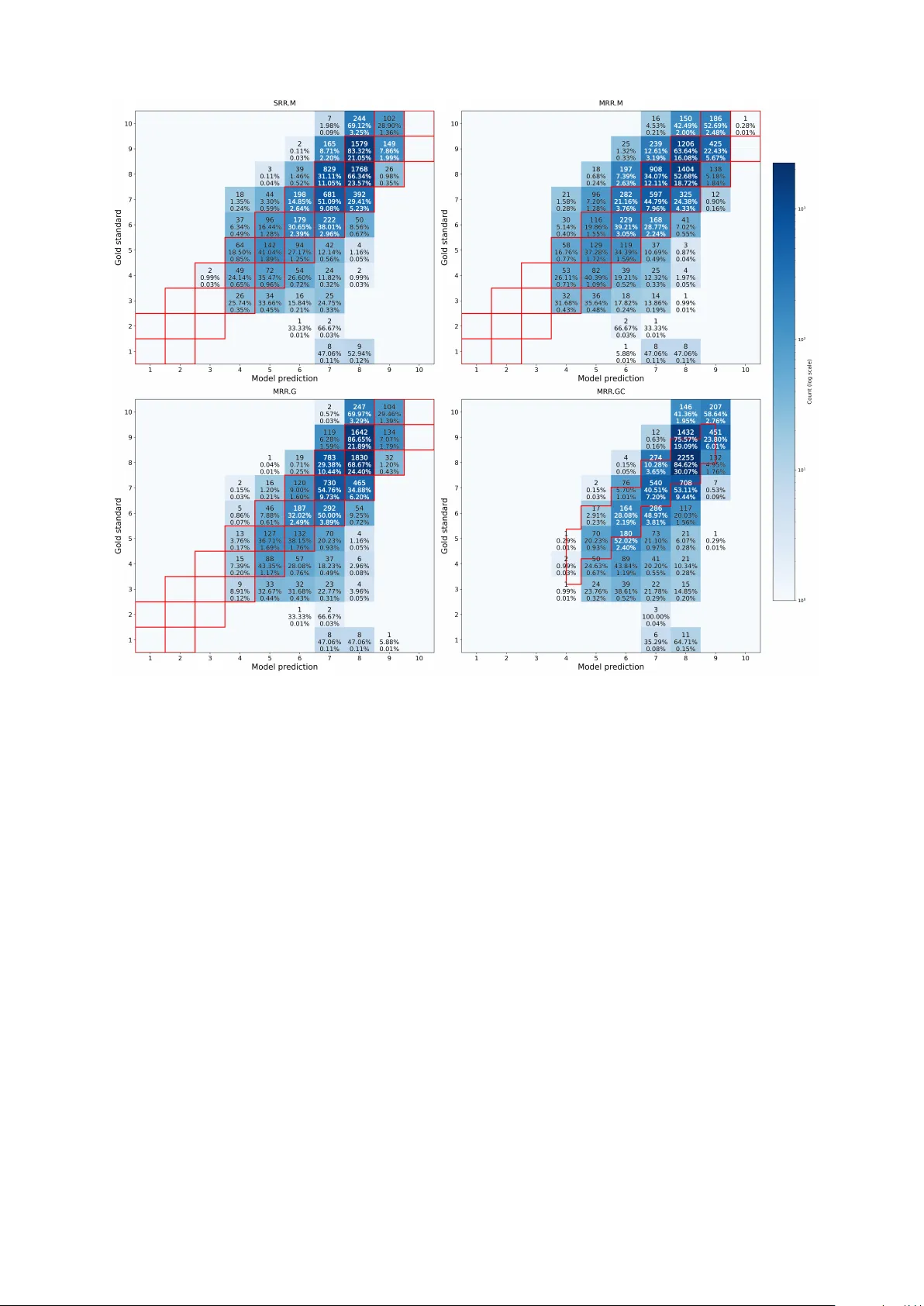
Rubric-Guided Fine-tuning of SpeechLLMs for Multi-Aspect, Multi-Rater L2 Reading-Speech Assessment Adity a Kamlesh Parikh, Cristian T ejedor -Garcia, Catia Cucchiarini, Helmer Strik Centre for Language Studies, Radboud University , The Netherlands {aditya.parikh, cristian.t ejedorgarcia, catia.cucchiarini, helmer .s trik}@ru.nl Abstract Reliable and interpretable automat ed assessment of second-language (L2) speech remains a central challenge, as large speech-language models (SpeechLLMs) of ten struggle to align with the nuanced variability of human raters. T o address this, we introduce a rubric-guided reasoning framework that explicitly encodes multi-aspect human assessment criteria: accuracy , fluency , and prosody , while calibrating model uncer tainty to capture natural rating variability . W e fine-tune the Qwen2-Audio-7B-Instruct model using multi-rater human judgments and develop an uncer tainty-calibr ated regression approach suppor ted by conformal calibration for interpretable confidence intervals. Our Gaussian uncertainty modeling and conformal calibration appr oach achiev es the strongest alignment with human ratings, outper forming regression and classification baselines. The model reliably assesses fluency and prosody while highlighting the inherent difficulty of assessing accuracy . T oge ther , these results demonstrate that rubric-guided, uncer tainty-calibr ated reasoning offers a principled path toward trustwor th y and explainable SpeechLLM-based speech assessment. Ke ywords: SpeechLLM, L2 Reading Speech, Multi-Aspect Assessment, SpeechLLM Fine-tuning, Uncer - tainty Modeling 1. Introduction Reading is a foundational skill for learning, com- munication, and par ticipation in society . It includes multiple aspects: readers must pronounce words accurately ( Newell et al. , 2020 ), maintain a natural temporal flow to ensure fluency ( Kuhn and Stahl , 2003 ), and conv ey appropriate phrasing and em- phasis to reflect prosody ( Schwanenflugel et al. , 2004 ). These dimensions interact in complex way s. For instance, prosodic phrasing can mask or am- plify word-lev el inaccuracies ( Zechner et al. , 2015 ). Many readers, including children dev eloping ba- sic reading skills ( Schwanenflugel et al. , 2004 ), L2 learners acquiring phonological and rhyt hmic competence ( Sleeman et al. , 2022 ), and adults encountering unfamiliar vocabulary or or thogra- phies ( Chang et al. , 2020 ), struggle to achieve fluent, accurate, and prosodically natural reading. Early , high-quality feedback is essential for en- abling teachers and clinicians to identify learners’ needs and adjust instruction ( Grønli et al. , 2024 ). Nev er theless, expert assessment and feedback are costly , time-consuming, often inconsistent across raters ( Smith and P aige , 2019 ), and suf- fer from variability in severity and scale usage (le- niency , harshness, central tendency , and halo ef- fects) and from drift ov er time due to fatigue or anchoring ( Neittaanmäki and Lamprianou , 2024 ). Ensuring inter - and intra-rater reliability across raters and sessions remains challenging, espe- cially for child and L2 speech, where accent varia- tion and atypical prosody fur ther reduce agreement ( Ishikaw a , 2023 ). In par ticular , raters tend to agree more on pronunciation accuracy than on fluency or prosody ( van der V elde et al. , 2024 ). Diverse modeling approaches hav e been ex- plored to develop automatic syst ems for speak - ing and reading assessment. Early work in the 1990s relied on statistical models such as Hid- den Marko v Models (HMMs) and Gaussian Mix- ture Models (GMMs), which primarily assessed pronunciation in reading speech using post erior probabilities or Goodness of Pronunciation (GOP) scores ( Kim et al. , 1997 ; Witt and Y oung , 2000 ; Witt , 2000 ). Subsequent studies broadened the scope to fluency and prosody , introducing timing- and pitch-based features ( W ang et al. , 2024 ). With the advent of deep neural networks, pro- nunciation assessment research began empha- sizing calibration to ensure that a model’s pre- dicted confidence aligns with the reliability of its assessments ( Evanini et al. , 2018 ). Later , text- based Language Models (LMs) such as BERT ( De- vlin et al. , 2019 ) and RoBER T a ( Liu et al. , 2019 ) were applied to automated scoring using Automatic Speech Recognition (ASR) transcripts; howe ver , their dependence on te xtual transcriptions and lack of acoustic aw areness limited their ability to capture fluency and prosody effectively . The emergence of pretrained acoustic models such as wav2v ec 2.0 ( Baevski et al. , 2020 ) addressed this gap, im- pro ving performance on task s lik e mispronunciation detection and diagnosis ( Cao et al. , 2024 ; Parikh et al. , 2025a , b ; Phan et al. , 2025 ). In parallel, the rise of multimodal Large Language Models (LLMs) has ext ended natural language processing bey ond te xt and inspired similar progress in the speech domain. For instance, models such as Speech- LLaMA ( Wu et al. , 2023 ), SALMONN ( T ang et al. , 2023 ), V OIL A ( W ang et al. , 2023 ), and Qwen-Audio ( Chu et al. , 2023 ) expanded t ext-based architec- tures by integr ating acoustic and linguistic represen- tations. These SpeechLLMs demonstrated strong per formance on general audio understanding tasks such as speech recognition, translation, audio cap- tioning, and spoken q uestion answering, ye t they still lacked the capability to follow detailed natural- language instructions. A newer generation of instruction-tuned Speech- LLMs has recently emerged, including Qwen2- Audio-Instruct ( Chu et al. , 2024 ), GAMA ( Ghosh et al. , 2024 ), and Audio Flamingo 2 ( Ghosh et al. , 2025 ). These models combine large-scale au- dio–te xt pretraining with instruction tuning, allow- ing them to reason ov er spoken input and gener - ate structured responses directly from raw speech. While such instruction-tuned models hold signif- icant potential for rubric-guided and explainable assessment of L2 speech proficiency , they remain undere xplored in the literature. Recent work has begun to highlight both their promise and limita- tions. For instance, P arikh et al. ( 2025c ) and Ma et al. ( 2025 ) inv estigated the Qwen2-Audio- Instruct model under distinct settings. P arikh et al. ( 2025c ) obser ved that rubric-based SpeechLLMs tend to pr oduce ov erly generous scores in zero-sho t conditions, reflecting a “niceness bias” inherited from instruction tuning that discourages low ratings ev en for poor -quality speech. Their study also in- troduced a multi-aspect assessment framework, allowing simultaneous scoring of complementar y proficiency dimensions such as accuracy , fluency , prosody , and sentence completeness. In contrast, Ma et al. ( 2025 ) demonstrated that super vised fine- tuning can effectivel y mitigate this bias, yielding more consistent and reliable proficiency predictions. Nonetheless, their framework was limited to single- score regression and classification setups and did not account for inter -rater variability or predictiv e uncer tainty , two critical factors for ensuring fairness and reliability in automated assessment. Building upon t hese findings, we adopt the Qwen2-Audio-Ins truct model as the foundation of our study , utilizing its instruction-f ollowing capac- ity with paired audio in puts and descriptive textual rubrics for assessment. The model is fine-tuned in a multi-aspect manner to infer holistic scores along three complementar y dimensions: accuracy (degree of mispronunciation), fluency (smoothness and coherence of delivery), and prosody (intona- tion, rhythm, and stress). We will share our code repository upon acceptance. T o systematically ex amine whether incorporating additional configurations can improv e robustness and alignment with human judgments, we design five state-of-the-art (SO T A) modeling strategies of increasing com ple xity based on the related litera- ture. (1) Discret e Classification ( DiCl ) treats profi- ciency scoring as a categorical prediction task ( Xi et al. , 2012 ). Howev er , this uniform treatment of er - rors disregards the ordinal relationship between cat- egories, which is crucial in assessment tasks where the sev erity of misclassification depends on the dis- tance between true and predicted proficiency le vels; (2) Single-Rubric Regression ( SRR.M ) formulates the scoring as continuous prediction using mean squared error (MSE) ( Chen et al. , 2018 ), aligning bett er with human rating scales and capturing finer performance differences; (3) Multi-Rubric Regres- sion ( MRR.M ) jointly predicts multiple rubrics si- multaneously with MSE ( Do et al. , 2023 ), enabling shared representation learning in multiple aspects such as accuracy , fluency , and prosody; (4) Multi- Rubric Regression with Gaussian Negative Log- Likelihood (GNLL), with the acronym MRR.G , re- places MSE with GNLL to model prediction un- cer tainty ( Kendall and Gal , 2017 ); and (5) Multi- Rubric Multi-Rat er Regression with GNLL and Con- formal Prediction ( MRR.GC ) incorporates multiple human ratings and applies Conformal Prediction ( Angelopoulos and Bates , 2021 ; Braun et al. , 2025 ) to generate calibrated confidence inter v als. Among these, the last two configurations (MRR.G and MRR.GC) represent nov el contributions to the field of automated L2 speech assessment. T o the best of our knowledge, this is the first study to integrate Gaussian uncer tainty modeling and conformal cali- bration within a multi-rater super vision framework for multi-aspect assessment using a rubric-guided fine-tuned SpeechLLM. This design advances the SO T A by jointly addressing score reliability , fair - ness, and explainability , three critical yet previously undere xplored dimensions in SpeechLLM-based proficiency assessment. This leads us to our research q uestion (RQ): T o what e xtent can a SpeechLLM appro ximate hu- man ratings in multi-aspect (accuracy , fluency , and prosody) per for mance assessment of L2 reading speech? 2. Methodology In this section, we describe the experimental setup for our sentence-le vel speech assessment frame- work, which leverages a multimodal (speech and te xt) SpeechLLM fine-tuned to predict rubric-based scores for multi-aspect (accur acy , fluency , and prosody) assessment. The task was framed either as classification (five discret e lev els: V ery Poor to Excellent) or as regression (continuous scores on a 1–10 scale). While classification provides interpretable, rubric-aligned decisions, regression enables finer granularity and captures subtle vari- ations in human ratings ( Xi et al. , 2012 ). We fine- tuned the Qwen2-Audio-7B-Instruct 1 model using Low-Rank Adaptation (LoRA) ( Hu et al. , 2022 ) for paramet er -efficient adaptation while preser ving the model’s pre-trained capabilities. The following sub- sections describe the model architecture, dataset, training setup, optimization loss functions, and the assessment protocol. 2.1. Model Architecture W e built upon the Qwen2-Audio-7B-Instruct model, a 7B-parame ter multimodal transformer -based SpeechLLM pre-trained on large-scale audio–text pairs for conditional generation tasks. The model integrat es an audio encoder with a text decoder , enabling it to process interlea ved audio and textual instructions. For speech assessment, a lightweight scoring head was added to project the hidden repre- sentations from the final transformer lay er to output predictions. We explored two v ariants: (i) a clas- sification head trained with cross-entropy loss for discret e 5-level scoring, and (ii) a regression head trained with MSE or GNLL loss to predict continu- ous scores. T o enable parameter -efficient fine-tuning, LoRA was applied to all linear lay ers of the base model. The ke y hyperparameters were a rank of r = 32 , a scaling factor of α = 32 , and a dropout rate of 0 . 1 , with rank -stabilized LoRA (rsLoRA) enabled. This configuration resulted in approximat ely 10 million trainable parameters ( ≈ 1 . 2% of the total), focusing the optimization on low-rank update matrices while keeping the original model weights frozen. 2.2. Dataset W e used the publicly available dataset Spee- chOcean762 ( Zhang et al. , 2021 ), a widely adopted benchmark for automatic pronunciation and speak - ing assessment for research. It contains 5000 En- glish read-speech utter ances, divided into 2500 for training and 2500 for testing. We fine-tuned our model on the training split and assessed the test split. The corpus includes recordings from both child and adult speakers whose native lan- guage is Mandarin Chinese (L1), reading English (L2). Each utterance was independently evalu- ated by five expert raters along sentence, word, and phoneme level aspects. Scores w ere as- signed on a 1–10 scale following the official an- notation protocol defined in the original dataset publication. This dataset is par ticularly suited for our study as it provides multi-rater , multi-aspect annotations, enabling analysis of both inter -rater variability and multi-dimensional scoring behavior . 1 https://huggingface.co/Qwen/ Qwen2- Audio- 7B- Instruct In this work, we focus on sentence-lev el scoring (accuracy/fluency/prosody) to study rubric-guided utterance-le vel assessment under multi-rater su- per vision. We e xclude Completeness due to an unclear rubric definition for our setup. Scores are ske wed tow ard mid- to high ratings, potentially bi- asing predictions toward the central range. In a multi-aspect assessment of speech, accu- racy is measured as the pronunciation correctness of the spoken sentence. A score of 10 corresponds to ex cellent pronunciation with no noticeable mis- pronunciations (near -native ar ticulation), whereas 1 indicates completely unintelligible speech or ab- sence of voice. Fluency ev aluates the temporal smoothness and coherence of speech, focusing on pauses, repetitions, and stammering. A score of 10 reflects coherent, uninterrupt ed deliver y with natural pacing, while 1 denotes inability to read the sentence as a whole or no voice. Finally , Prosody measures the intonation, rhythm, and speaking rate, capturing the naturalness and expressiv eness of speech. A score of 10 represents correct in- tonation with stable rhythm and speed, sounding natural and engaging, and 1 indicates speech too stammered to evaluat e or the absence of voice. The scoring rubrics for all three aspects follow the definitions provided in the SpeechOcean762 paper (( Zhang et al. , 2021 ), page 3). 2.3. T raining Procedure Fine-tuning of the Qwen model was conducted us- ing the Hugging Face T ransformers librar y with a custom data collator and trainer ( Wolf et al. , 2020 ) as it provides fle xibility in handling paired audio–te xt inputs and rubric-based labels. Each utterance was resampled to 16 kHz, converted to mono audio, and paired with a te xtual task prompt containing only rubric instructions (no target transcript), so the model assesses directly from audio rather than transcript comparison. The input was formatt ed as a conversational prompt following the model’s chat template, con- sisting of a user message that included the au- dio segment and a rubric-based instruction (e.g., “Score sentence-lev el accuracy on a scale from 1 to 10, ” accompanied by detailed rubric descriptions). Since the objectives included both regression and classification, no generation prompt was added, as the model was trained to produce direct scalar or categorical predictions rather than generated te xt. For optimization, the AdamW optimizer was used with a learning rate of 2 × 10 − 5 , a weight decay of 0 . 01 , and a constant learning rate schedule (no warm-up). The per -device batch size was set to 1 , with gradient accumulation steps of 1 . T raining was performed on a single GPU (NVIDIA A5000), with TF32 acceleration enabled for CUDA operations. 2.4. Optimization Loss Functions T o fine-tune the SpeechLLM for rubric-based speech assessment, five modeling strategies of increasing com ple xity were explored depending on how the task was formulated. Each formulation defines a distinct mapping between the model out- put and the target scores, influencing both learning behavior and interpretability . In what follows, we de- scribe the loss functions used for the classification and regression variants of our experiments. 2.4.1. Discrete Classification (DiCl) This method ser v ed as our baseline for sentence- lev el assessment. Each speech rubric was formu- lated as a five-class classification task, where ev er y utterance was assigned one of five categorical lev- els: V er y Poor , Poor , F air , Good, or V ery Good. T o obtain these labels, we discretize the original 1– 10 human rater scores into five ordinal categories using the rubric defined by Zhang et al. ( 2021 ). Scores of 1–2 were mapped to V er y Poor , 3–4 to Poor , 5–6 to Fair , 7–8 to Good, and 9–10 to V ery Good. A sof tmax output lay er produced the proba- bility distribution ov er the five classes. The model was optimized using the standard cross-entropy loss: L DiCl = 1 N N X i =1 " − C X c =1 y i,c log( ˆ y i,c ) # where N is the number of utterances in the dataset, i inde xes each utterance, C denot es the number of classes, y i,c is the one-hot ground-truth label, and ˆ y i,c is the predicted probability for class c . This loss treats all classes as independent and penalizes all misclassifications equally . For in- stance, predicting V er y Good when the true label is V er y P oor incur s the same penalty as predicting Good instead of Fair . 2.4.2. Single Rubric Regr ession with Mean Squared Error (SRR.M) In this setting, the sentence-lev el assessment was formulated as a regression task, where the model predicts a continuous score within the range [1, 10] for each rubric independently . Compared to the classification approach, regression provides finer granularity , as the MSE loss penalizes predictions in propor tion to their numerical deviation from the true score. For ex ample, predicting 7.5 for a true score of 8 incurs a smaller penalty than predicting 5 for 8, thereby preser ving ordinal relationships and av oiding discretization ar tifacts. A separate regression head was used to predict a single continuous value for each aspect (accuracy , fluency , or prosody). The model was trained to minimize the MSE loss: L SRR.M = 1 N N X i =1 ( y i − ˆ y i ) 2 where N is the total number of utterances, i inde xes each utterance, y i is the gold mean score per as- pect (av eraged over the five human raters), and ˆ y i is the model-predicted score for the same sample. 2.4.3. Multi Rubric Regr ession with Mean Squared Error (MRR.M) In this configuration, the assessment task w as ext ended t o a multi-output regr ession problem, where the model simultaneously predicts continu- ous scores for all three rubrics. This was achieved using a shared encoder followed by three paral- lel regr ession heads, each producing one scalar output per aspect. It also improves computational efficiency , as a single model produces a structured ev aluation vector [ ˆ y acc , ˆ y flu , ˆ y pro ] without requiring separate fine-tuning for each rubric. The training objective minimizes the av erage MSE across all three rubrics: L MRR.M = 1 3 X aspect 1 N N X i =1 ( y i, aspect − ˆ y i, aspect ) 2 where N is the total number of utterances, i inde xes each utterance, and y i, aspect and ˆ y i, aspect denote the gold and predicted mean scores, respectiv ely , for each rubric. 2.4.4. Multi Rubric Regr ession with Gaussian Negative Log-likelihood (MRR.G) Building upon the multi-head regression framework, this variant introduces uncer tainty estimation by al- lowing each output head to predict not only the mean score µ i but also the corresponding variance σ 2 i for ev er y rubric, accuracy , fluency , and prosody . This formulation enables the model to expr ess both its prediction and its confidence for each utterance. Fine-tuning employ ed the GNLL loss, which penal- izes large prediction errors while accounting for the predicted uncer tainty . For each utterance, the mean of the five rat er scores was used as the gold standard, making this a single-target regression task that reflects the central human consensus. The GNLL loss for each aspect was defined as: L MRR.G ( i ) = ( ¯ y i − µ i ) 2 2 σ 2 i + 1 2 log σ 2 i where ¯ y i denotes the aver aged human rating, and ( µ i , σ 2 i ) are the predict ed mean and variance, re- spectively . The total loss was computed as the mean across the three rubrics: L total = 1 3 X aspect 1 N N X i =1 L MRR.G ( i ) This formulation enables the model to capture aleatoric uncer tainty by adjusting its predicted vari- ance σ 2 i according to sample difficulty . 2.4.5. Multi Rubric Multi Rater Regression with Gaussian N egative Log-likelihood and Conformer Prediction (MRR.GC) This configuration extends the uncer tainty-a ware regression framework by directly modeling all five human rater scores per utterance, rather than rely- ing solely on their mean. For each rubric, accuracy , fluency , and prosody , the model predicts both a mean score µ i and a variance σ 2 i , jointly capturing the central tendency and spread of human judg- ments. Fine-tuning again em plo yed the GNLL loss, which in this case integrates the inter -rater variance term s 2 i to account for disagreement among raters: L MRR.GC = 1 3 N X aspect N X i =1 ( ¯ y i − µ i ) 2 + s 2 i 2 σ 2 i + 1 2 log σ 2 i where N is the total number of utterances, ¯ y i = 1 R P R r =1 y i,r is the mean rater score, R = 5 is the number of raters, and s 2 i = 1 R R X r =1 ( y i,r − ¯ y i ) 2 represents the inter -rater variance for each utt er - ance i . This formulation explicitly incor porates rater disagreement into the loss, enabling the model to reflect both prediction uncer tainty and obser ved human variability . After fine-tuning, conformal calibration was ap- plied using a 5-fold split of the test set to empir - ically calibrate the predictiv e inter vals. Normal- ized residuals | y i − µ i | /σ i were computed on the calibration folds to estimate aspect-wise quantiles ( q aspect ) corresponding to a target coverage of 90%. Final prediction inter vals were then obtained as [ µ i − q aspect σ i , µ i + q aspect σ i ] . This combination of multi-rater super vision and conformal prediction allows the model to capture both inter -rater v ariability and prediction uncer - tainty in a statistically interpretable manner . Con- formal calibration fur ther ensures empirical cov er - age, guaranteeing that a defined propor tion of true scores fall within the predicted confidence inter v als. 2.5. Evaluation Metrics The model performance was assessed using a com- prehensiv e set of metrics reflecting both categori- cal decision q uality and numerical agreement with human ratings. F or the DiCl baseline setup, perfor - mance was assessed using the W eighted F1-score and the Matthe ws Correlation Coefficient (MCC). W eighted F1 accounts for class imbalance by com- puting the F1-score per class and av eraging it by class frequency , while MCC quantifies the ov er - all correlation between predicted and true labels, providing a balanced measure even under uneven label distributions. For all four regression-based methods (SRR.M, MRR.M, MRR.G, and MRR.GC), we repor t five complementar y metrics: Weight ed F1, MCC, Pear - son Correlation Coefficient (PCC), Root MSE (RMSE), and Quadratic W eighted Kappa (QWK). T ogether , these capture both categorical agreement and continuous correlation with human ratings. The predicted continuous scores were rounded to the nearest integer on the 1–10 scale for computing W eighted F1 and MCC, ensuring com parability with discret e human ratings. PCC measures the linear association between predicted and gold scores, and RMSE quantifies the av erage prediction er- ror . Quadratic Weighted Kappa (QWK) measures the agreement between two ratings on an ordinal scale, accounting for chance agreement and the distance between rating categories. It ranges from -1 (worse than chance) to 1 (per fect agreement), with 0 indicating random agreement. QWK penal- izes larger score discrepancies more heavily than smaller ones, making it well-suited for ordinal rating tasks. For QWK (M–R), the agreement is com put ed between the model and each of the fiv e human raters individually and reported as mean ± stan- dard deviation across raters. The regression results were analyzed under two assessment conditions: (1) a strict, e xact-match setting without tolerance, and (2) a relax ed set- ting that allows a ± 1 score tolerance to account for natural rater variability . In practice, small differ - ences, such as one rater giving a 7 and another an 8, are not considered true disagreements but normal variations in human judgment. Prior work in speaking and writing assessment (e.g., TOEFL, SpeechRat er) repor ts inter -rater standard devia- tions of roughly 0.5–1.0 on a 10-point scale, sup- por ting this tolerance as a realistic estimate of hu- man rating variability . For the MRR.GC configu- ration, we also calculated the percentage of hu- man scores falling within the model’s predict ed High–Low confidence range for each aspect. This cov erage metric reflects how well the model’s pre- dictive inter v als capture real human variability , ser v- ing as a direct indicator of calibration q uality . Be- cause QWK depends on exact ordinal matches, it is computed only under the strict setting, not with the ± 1 tolerance. 3. Results 3.1. Inter -Rater Reliability QWK (R -R) Before presenting the results of the five models, we first repor t the inter -rater reliability (QWK, R–R) in T able 1 . The shown mean QWK values are av er - aged across all ten possible rater pair s, indicating ov erall moderate agreement among raters. Accuracy Fluency Prosody QWK (R–R) 0.5585 ± 0.0671 0.5019 ± 0.1353 0.5021 ± 0.1153 T able 1: QWK (mean ± SD) across human raters. 3.2. Classification-Based Assessment T able 2 summarizes the baseline classification performance (DiCl) across the three assessment rubrics: accuracy , fluency , and prosody . Ov erall, DiCl results demonstrate moderate discriminative ability across rubrics, providing a reference point for subsequent regression-based approaches that aim to capture finer score variations. Rubrics ↑ F1 ↑ MCC Accuracy 0.558 0.341 Fluency 0.642 0.452 Prosody 0.670 0.468 T able 2: Classification per formance across rubrics for DiCl. Arrows indicate that higher is better . Figure 1 shows the aggregated confusion matrix across all rubrics for DiCl. Predictions are largely concentrated along the main diagonal, indicating good alignment between the model’s output and hu- man ratings. The Good category dominates the pre- dictions. Misclassification mainly occurs between adjacent levels (see Figure 1 ). 3.3. Regression-Based Assessment In this section, we compare four regression- based fine-tuning configurations: SRR.M, MRR.M, MRR.G, and MRR.GC. Performance is repor ted for each rubric (accuracy , fluency , and prosody) un- der both strict (ex act-match) and lenient ev aluation settings ( ± 1 tolerance or High–Low calibration). 3.3.1. Exact-Match Regression Results (without tolerance) T able 3 presents the regression-based results un- der e xact-match ev aluation. Performance is re- por ted separately for the three rubrics: accuracy , fluency , and prosody , to analyze aspect-specific trends before summarizing overall behavior across model variants. Figure 1: Aggr egated confusion matrix across all rubrics for DiCl. Ro ws show human (gold-standard) ratings. Columns show model predictions. Each cell displays the count (top), percentage within the true class (middle), and percentage across all sam- ples (bottom). Rubrics ↑ F1 ↑ MCC ↑ PCC ↓ RMSE ↑ QWK (M–R) SRR.M Accuracy 0 . 2479 0 . 0843 0 . 7390 1 . 1854 0 . 432 ± 0 . 046 ± 1 0 . 7966 0 . 7543 0 . 9417 0 . 5456 Fluency 0 . 3717 0 . 2416 0 . 7956 0 . 9326 0 . 445 ± 0 . 081 ± 1 0 . 9137 0 . 9000 0 . 9571 0 . 4218 Prosody 0 . 4073 0 . 2838 0 . 7728 0 . 9163 0 . 468 ± 0 . 093 ± 1 0 . 9216 0 . 9117 0 . 9558 0 . 4357 MRR.M Accuracy 0 . 2424 0 . 0710 0 . 6969 1 . 2894 0 . 497 ± 0 . 051 ± 1 0 . 7561 0 . 6830 0 . 7454 0 . 6221 Fluency 0 . 4571 0 . 3161 0 . 7522 0 . 8910 0 . 501 ± 0 . 078 ± 1 0 . 9378 0 . 9286 0 . 8890 0 . 4462 Prosody 0 . 3435 0 . 1918 0 . 7463 1 . 0342 0 . 527 ± 0 . 052 ± 1 0 . 8809 0 . 8536 0 . 8457 0 . 4553 MRR.G Accuracy 0 . 2285 0 . 0705 0 . 7352 1 . 1762 0 . 464 ± 0 . 049 ± 1 0 . 7785 0 . 7428 0 . 8444 0 . 5402 Fluency 0 . 3931 0 . 2657 0 . 8003 0 . 9237 0 . 463 ± 0 . 054 ± 1 0 . 9179 0 . 9078 0 . 8489 0 . 4308 Prosody 0 . 4095 0 . 2821 0 . 7933 0 . 9082 0 . 494 ± 0 . 079 ± 1 0 . 9226 0 . 9133 0 . 8526 0 . 4185 MRR.GC Accuracy 0 . 4014 0 . 2654 0 . 7649 1 . 0159 0 . 505 ± 0 . 039 High–Low Cal 0 . 8707 0 . 8539 0 . 8716 0 . 5467 Fluency 0 . 4589 0 . 3397 0 . 8521 0 . 7768 0 . 521 ± 0 . 022 High–Low Cal 0 . 9276 0 . 9176 0 . 9164 0 . 4212 Prosody 0 . 4767 0 . 3458 0 . 8361 0 . 7903 0 . 496 ± 0 . 085 High–Low Cal 0 . 9319 0 . 9222 0 . 9119 0 . 3952 T able 3: Regression-based results across all model families. Arrows indicate the direction of improv e- ment. T olerance ( ± 1 ) and High–Low Calibration indicate lenient evaluation settings where predic- tions within the tolerance or predicted uncer tainty range are considered acceptable. Across all three rubrics, T able 3 results indicate consistent improv ements with increasing model complexity (i.e. from top to bottom). The multi-head models (MRR.M, MRR.G, MRR.GC) generally out- perform single-head regression (SRR.M), showing the benefit of shared representation learning across rubrics. Introducing the GNLL objective (MRR.G) fur ther im pro ves robustness by jointly modeling prediction uncer tainty , and the full MRR.GC config- uration achiev es the strongest ov erall per formance and highest alignment with human ratings across all evaluation metrics. Figure 2 presents the confusion matrices for all regression configurations. Overall, all models show tight clustering around mid-level utterances but lim- ited separability at the lowest and highest scores. Predictions across models are concentrated in the mid-range (scores 5–8), while the extr emes (1–2 and 10) are rarely or never predicted. 3.3.2. Regression Results with T olerance and Calibration T able 3 also summarizes the regression-based re- sults evaluat ed under a relax ed setting that allows a tolerance of ± 1 score point and, in the final config- uration, incorporates conformal calibration. Under this ev aluation, predictions within one score point of the human rating are considered acceptable, reflecting natural variability among human raters. When lenient settings are applied, the overall per - formance increases across all rubrics. The ± 1 tol- erance evaluation substantially boosts F1, MCC, and PCC scores, reflecting stable prediction behav- ior within one rating lev el of the human mean. In the uncer tainty-a ware MRR.GC model, conformal calibration achieves a com parable improvement by explicitl y modeling confidence intervals instead of tolerance bands. Figure 2 also illustrates the confusion matrices under lenient evaluation. In the first three pan- els (SRR.M, MRR.M, and MRR.G), the red box es mark the ± 1 tolerance region around the diagonal, highlighting predictions within one score point of the human gold standard. The bottom-right panel (MRR.GC) shows calibrated boundaries from con- formal prediction, with red contours marking the median empirical high–low range per score bin. 3.3.3. Cov erage Analysis under Conformal Calibration T o e valuat e how well the calibrated prediction in- tervals align with the em pirical variability among human ratings, we present in T able 4 the percent- age of utterances for which a given number of hu- man raters ( 0 – 5 ) fall within the model’s predicted high–low interval, obtained from conformal calibra- tion in the MRR.GC configuration. 4. Discussion In this section, we first discuss the main findings and then provide an answer to our RQ. T o ad- dress the RQ, we fine-tuned the Qwen2-Audio-7B- Instruct SpeechLLM using rubric-guided data for ≤ N raters Accuracy (%) Fluency (%) Prosody (%) 5 6.68 0.96 1.92 4 25.92 8.60 12.72 3 60.04 34.24 44.16 2 83.92 67.20 77.56 1 93.84 91.52 94.68 T able 4: Cumulative percentage with at most N raters within the model’s prediction inter v al (mono- tonic increasing with N ). multi-aspect assessment of L2 read speech under five differ ent configurations. We observe that perfor - mance gradually im pro ves from SRR.M to MRR.M, MRR.G, and MRR.GC (T able 3 ). Multi-rubric re- gression im pro ves stability and cap tures cross- rubric dependencies. Incorporating the GNLL ob- jective in MRR.G fur ther improv es calibration by modeling variability in human ratings, in line with computer vision research ( Kendall and Gal , 2017 ). The final MRR.GC, achieves the best overall align- ment with human judgments by combining multi- rater super vision and conformal calibration, as pro ven in other research fields ( Braun et al. , 2025 ), which produces adaptive confidence inter v als that reflect empirical rater disagreement. Allowing a tolerance of ± 1 score point improv es F1, MCC, and PCC, indicating that minor discrep- ancies fall within normal perceptual variability (T a- ble 3 , red box es in Fig. 2 ). Ho wev er , this margin spans 20% of the 10-point scale, so part of the gain stems from more lenient ev aluation. In con- trast, conformal calibration in MRR.GC provides a principled wa y for quantifying uncer tainty : inter v al widths adapt to local variability , yielding statistically valid confidence bounds consistent with human rating behavior . As shown in T able 4 , higher cov- erage for accuracy suggests closer human–model agreement, while narrower inter vals for fluency and prosody indicate more consistent rater behavior and tighter calibration around consensus scores. Human raters show moderate agreement among themselves (T able 1 ). F ur thermore, we obser ved higher inter -rater reliability for accuracy compared to fluency and prosody (T able 1 ) and the percent- ages of human ratings that fall within the model’s predict ed high–low intervals (T able 4 ). On the other hand, T able 3 shows that the regression-based re- sults are bett er for fluency and prosody than for accuracy . Possible explanations for these differ - ences might lie in (a) the definitions of the three aspects of accuracy , fluency , and prosody and (b) the operationalization of these three constructs. As to (a), while the definition of accuracy seems rather straightforward, the correctness of pronunciation, the definitions of fluency and prosody are some- what confusing. As a matter of fact, they seem to mix sev eral features. For ex ample, speaking Figure 2: Aggregated confusion matrices across regression methods (SRR.M, MRR.M, MRR.G, MRR.GC). Red box es in the fir st three panels indicate the ± 1 tolerance region, while in the bottom-right panel, red contours denote the median calibrated range from conformal prediction. Each cell shows the total count (top), the percentage within the true class (middle), and the percentage relative to all samples (bottom). rate could just as well be par t of fluency inst ead of prosody , based on the definition of fluency as temporal smoothness. As to (b), the instructions for fluency and prosody ma y be easier to opera- tionalize for LLMs than those for accuracy . T empo- ral aspects have long been recognized as easier to com pute automatically than featur es related to segmental quality that may involv e multiple dimen- sions. Previous research on automatic assessment of non-native speech rev ealed that ASR systems are better at capturing temporal-relat ed aspects of non-native speech than those related to segmental quality ( Cucchiarini et al. , 2000b , a , 2002 ). The main limitations of our work concern data imbalance and generalization. Model predictions tend to cluster around scores 6 to 8, reflecting the ske wed distribution of human ratings and reduc- ing sensitivity to extr eme proficiency levels. This mid-range bias inflates global performance metrics and constrains the model’s ability to generalize to underrepresent ed proficiency extremes. Finally , in response to our RQ, the results pre- sented in the current paper demonstrate that the proposed models align closely with human judg- ments across all rubrics, indicating that a well- designed SpeechLLM can effectively suppor t multi- aspect automatic assessment. Among them, the MRR.GC model per forms best, offering the addi- tional advantage of capturing not only mean human ratings but also their variability . 5. Conclusion This study inv estigated whether a rubric-guided SpeechLLM can appro ximate human judgments in the assessment of L2 reading speech. T o sys- tematically e xamine whether incorporating addi- tional configurations can im pro ve robustness and alignment with human judgments, we developed five SO T A modeling strategies of increasing com- ple xity for fine-tuning the Qwen2-Audio-7B-Instruct SpeechLLM, based on insights from related liter - ature. Among the evaluat ed strategies, MRR.GC achiev ed the strongest overall alignment with hu- man raters, with aggregated per formance across Accuracy , Fluency , and Prosody of PCC ≈ 0 . 81 , RMSE ≈ 0 . 83 , and QWK ≈ 0 . 50 . These results demonstrate that incorporating multi-rater super - vision, Gaussian uncer tainty modeling, and con- formal calibration yields reliable and interpretable scoring for multi-aspect L2 reading speech assess- ment. Howe ver , the model behaves conser vativel y at score extremes, highlighting the need to address mid-range bias and extend the framework to diag- nostic feedback and error localization to im pro ve assessment validity . F uture work will e xtend be- yond scoring to diagnostic feedback and error lo- calization for actionable learner guidance. 6. Acknowledgements This publication is par t of the project Responsible AI for V oice Diagnostics (RAIVD) with file number NGF .1607.22.013 of the research programme NGF AiNed Fello wship Grants which is financed by the Dutch Research Council (NWO). 7. Bibliographical References Anastasios N Angelopoulos and Stephen Bates. 2021. A gentle introduction to conformal predic- tion and distribution-free uncer tainty q uantifica- tion. arXiv preprint arXiv :2107.07511 . Alex ei Baev ski, Y uhao Zhou, Abdelrahman Mo- hamed, and Michael Auli. 2020. wav2v ec 2.0: A framew ork for self-super vised learning of speech representations. Adv ances in neural information processing syst ems , 33:12449–12460. Sacha Braun, Eugène Ber ta, Michael I. Jordan, and Fr ancis Bach. 2025. Multivariat e Conformal Prediction via Conformalized Gaussian Scoring . arXiv preprint arXiv:2507.20941 . Xinwei Cao, Zijian Fan, T orbjørn Svendsen, and Gi- ampiero Salvi. 2024. A Fr amework for Phoneme- Lev el Pronunciation Assessment Using CT C . In Interspeec h 2024 , pages 302–306. Y a-Ning Chang, JSH T ay lor , Kathleen Rastle, and P adraic Monaghan. 2020. The relationships be- tween oral language and reading instruction: Ev- idence from a computational model of reading. Cognitiv e Psychology , 123:101336. Lei Chen, Klaus Zechner , Su- Y oun Y oon, Keelan Evanini, Xinhao Wang, Anastassia Loukina, Ji- dong T ao, Lawrence Davis, Chong Min Lee, Min Ma, et al. 2018. Automat ed scoring of nonnative speech using the speechrater sm v . 5.0 engine. ET S Research Repor t Series , 2018(1):1–31. Y unfei Chu, Jin X u, Qian Y ang, Haojie W ei, Xipin W ei, Zhifang Guo, Yichong Leng, Y uan- jun Lv , Jinzheng He, Juny ang Lin, et al. 2024. Qwen2-audio technical report. arXiv preprint arXiv :2407.10759 . Y unfei Chu, Jin Xu, Xiaohuan Zhou, Qian Y ang, Shiliang Zhang, Zhijie Y an, Chang Zhou, and Jingren Zhou. 2023. Qwen-audio: Adv ancing universal audio understanding via unified large- scale audio-language models. arXiv preprint arXiv :2311.07919 . Catia Cucchiarini, Helmer Strik, and Lou Boves. 2000a. Different aspects of expert pronunciation quality ratings and their relation to scores pro- duced by speech recognition algorithms. Speech Communication , 30(2-3):109–119. Catia Cucchiarini, Helmer Strik, and Lou Boves. 2000b. Quantitative assessment of second lan- guage learners’ fluency by means of automatic speech recognition technology . The Journal of the Acoustical Society of America , 107(2):989– 999. Catia Cucchiarini, Helmer Strik, and Lou Boves. 2002. Quantitative assessment of second lan- guage learners’ fluency: Com parisons between read and spontaneous speech. the Journal of the Acoustical Society of America , 111(6):2862– 2873. Jacob Devlin, Ming-W ei Chang, Kent on Lee, and Kristina T outanova. 2019. Ber t : Pre-training of deep bidirectional transformers for language un- derstanding. In Proceedings of the 2019 con- fer ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 , pages 4171– 4186. Heejin Do, Y unsu Kim, and Gary Geunbae Lee. 2023. Score-balanced loss for multi-aspect pro- nunciation assessment . In Interspeech 2023 , pages 4998–5002. K eelan Evanini, Matthew Mulholland, Rutuja Ubale, Y ao Qian, Robert A Pugh, Vikram Rama- nara yanan, and Aoif e Cahill. 2018. Improv e- ments to an Automat ed Content Scoring System for Spoken CALL Responses: the ETS Submis- sion to the Second Spoken CALL Shared T ask. In Interspeech 2018 , pages 2379–2383. Sre yan Ghosh, Zhifeng Kong, Sonal Kumar , S Sak - shi, Jaeh yeon Kim, W ei Ping, Rafael V alle, Di- nesh Manocha, and Br yan Catanzaro. 2025. Au- dio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities . In Proceedings of the 42nd International Confer ence on Machine Learning , volume 267 of Proceedings of Machine Learning Research , pages 19358–19405. PMLR. Sre yan Ghosh, Sonal Kumar , Ashish Seth, Chan- dra Kiran Reddy Evuru, Utkarsh T yagi, S Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha. 2024. GAMA: A large audio-language model with advanced audio understanding and complex reasoning abilities . In Proceedings of the 2024 Conference on Empirical Methods in Natur al Language Processing , pages 6288– 6313, Miami, Florida, USA. Association for Com- putational Linguistics. Karianne Megard Grønli, Bente Rigmor W algermo, Erin M McTigue, and Per Henning Uppstad. 2024. T eachers’ feedback on oral reading: A critical revie w of its effects and the use of the- ory in research. Educational Psyc hology Re view , 36(4):121. Edward J Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean Wang, Lu W ang, W eizhu Chen, et al. 2022. Lora: Low-rank adap- tation of large language models. ICLR , 1(2):3. Shin’ichiro Ishikaw a. 2023. Effects of raters ’ l1, assessment experience, and teaching experi- ence on their assessment of l2 english speech: A study based on the icnale global rating archives. LEARN Journal: Language Education and Ac- quisition Research Netw ork , 16(2):411–428. Alex Kendall and Y arin Gal. 2017. What uncer tain- ties do we need in bay esian deep learning for computer vision? Advances in neural infor mation processing syst ems , 30. Y oon Kim, Horacio F ranco, and Leonardo Neumey er . 1997. Automatic pronunciation scor - ing of specific phone segments for language in- struction. In Eurospeech , pages 645–648. Melanie R Kuhn and St ev en A Stahl. 2003. Flu- ency: A review of developmental and remedial practices. Jour nal of educational psychology , 95(1):3. Yinhan Liu, Myle Ott, Naman Go yal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy , Mike Lewis, Luke Zettlemoy er , and V eselin Sto yano v . 2019. Roberta: A robustly optimized ber t pre- training approach . Rao Ma, Mengjie Qian, Siyuan T ang, Stefano Bannò, Kate M. Knill, and Mark J.F . Gales. 2025. Assessment of L2 Oral Proficiency using Speech Large Language Models . In Interspeech 2025 , pages 5078–5082. Reeta Neittaanmäki and Iasonas Lamprianou. 2024. Communal factors in rat er severity and consistency over time in high-stakes oral assess- ment. Language T esting , 41(3):584–605. Kirsten W Newell, Robin S Codding, and T ara W Fortune. 2020. Oral reading fluency as a screen- ing tool with english learners: A sys tematic re- view . Psy chology in the Schools , 57(8):1208– 1239. Adity a Kamlesh Parikh, Cristian T ejedor -Garcia, Ca- tia Cucchiarini, and Helmer Strik. 2025a. En- hancing GOP in CT C-Based Mispronunciation Detection with Phonological Knowledge . In Inter - speech 2025 , pages 5068–5072. Adity a Kamlesh Parikh, Cristian T ejedor -Garcia, Ca- tia Cucchiarini, and Helmer Strik. 2025b. Eval- uating Logit-Based GOP Scores for Mispronun- ciation Det ection . In Int erspeech 2025 , pages 2405–2409. Adity a Kamlesh Parikh, Cristian T ejedor -Garcia, Ca- tia Cucchiarini, and Helmer Strik. 2025c. Zero- Shot Speech LLMs for Multi-Aspect Evaluation of L2 Speech: Challenges and Oppor tunities. Proc. SLaTE 2025 , pages 11–15. Nhan Phan, Mikko Kuronen, Maria Kautonen, Ri- ikka Ullakonoja, Anna von Zansen, Y arosla v Get- man, Ekaterina V oskoboinik, T amás Grósz, and Mikko K urimo. 2025. Mispronunciation Detec- tion Without L2 Pronunciation Dataset in Low- Resource Se tting: A Case Study in Finland Swedish . In Int erspeech 2025 , pages 2435– 2439. P aula J Schwanenflugel, Anne Marie Hamilton, Melanie R Kuhn, Joseph M Wisenbaker , and Ste ven A Stahl. 2004. Becoming a fluent reader: reading skill and prosodic featur es in the oral reading of young readers. Journal of educational psy chology , 96(1):119. Mike Sleeman, John Everatt, Alison Arrow , and Amanda Denston. 2022. The identification and classification of struggling readers based on the simple view of reading. Dysle xia , 28(3):256–275. Grant S Smith and David D Paige. 2019. A study of reliability across multiple raters when using the naep and mdfs rubrics to measure oral reading fluency . Reading Psychology , 40(1):34–69. Changli T ang, Wen yi Y u, Guangzhi Sun, Xianzhao Chen, Tian T an, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2023. Salmonn: T owards generic hearing abilities for large language models. arXiv preprint arXiv:2310.13289 . Max van der V elde, Bo Molenaar , Bernard P V eld- kamp, Remco Fesk ens, and Jos Keuning. 2024. What do they say? assessment of oral reading fluency in early primar y school children: A scop- ing revie w . International Journal of Educational Researc h , 128:102444. Kuo W ang, Xin Qiao, George Sammit, Eric C Lar- son, Joseph Nese, and Akihito Kamata. 2024. Improving automated scoring of prosody in oral reading fluency using deep learning algorithm. In F rontiers in Education , volume 9, page 1440760. F rontiers Media SA. Tianrui W ang, Long Zhou, Ziqiang Zhang, Y u W u, Shujie Liu, Y ashesh Gaur , Zhuo Chen, Jinyu Li, and Furu Wei. 2023. Viola: Unified codec lan- guage models for speech recognition, synthesis, and translation. arXiv preprint . Silke Maren Witt. 2000. Use of speech recognition in computer -assist ed language learning . Ph.D. thesis, University of Cambridge. Silke Maren Witt and Stev e J Y oung. 2000. Phone- lev el pronunciation scoring and assessment for interactiv e language learning. Speech communi- cation , 30(2-3):95–108. Thomas Wolf, L ysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan F untowicz, Joe Davison, Sam Shleifer , P atrick von Platen, Clara Ma, Y acine Jernite, Julien Plu, Canwen Xu, T even Le Scao, Sylvain Gugger , Mariama Drame, Quentin Lhoest, and Ale xan- der Rush. 2020. T ransformers: State-of-the-art natural language processing . In Proceedings of the 2020 Conference on Empirical Met hods in Natur al Language Processing: Sy st em Demon- str ations , pages 38–45, Online. Association for Computational Linguistics. Jian Wu, Y ashesh Gaur , Zhuo Chen, Long Zhou, Yimeng Zhu, Tianrui W ang, Jinyu Li, Shujie Liu, Bo Ren, Linquan Liu, et al. 2023. On decoder - only architectur e for speech-to-te xt and large lan- guage model integration. In 2023 IEEE Aut o- matic Speech Recognition and Underst anding W orkshop (ASRU) , pages 1–8. IEEE. Xiaoming Xi, Derrick Higgins, Klaus Zechner , and David Williamson. 2012. A comparison of two scoring methods for an automated speech scor - ing system. Language T esting , 29(3):371–394. Klaus Zechner , Lei Chen, Larr y Davis, K eelan Evanini, Chong Min Lee, Chee Wee Leong, Xin- hao W ang, and Su- Y oun Y oon. 2015. Automat ed scoring of speaking tasks in the test of english-for - teaching (tef t ™ ). ETS Research Report Series , 2015(2):1–17. Junbo Zhang, Zhiwen Zhang, Y ongqing W ang, Zhiyong Y an, Qiong Song, Y ukai Huang, Ke Li, Daniel Po ve y , and Y ujun Wang. 2021. spee- chocean762: An Open-Source Non-Native En- glish Speech Cor pus for Pronunciation Assess- ment . In Interspeech 2021 , pages 3710–3714.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment