LUMOS: Democratizing SciML Workflows with L0-Regularized Learning for Unified Feature and Parameter Adaptation
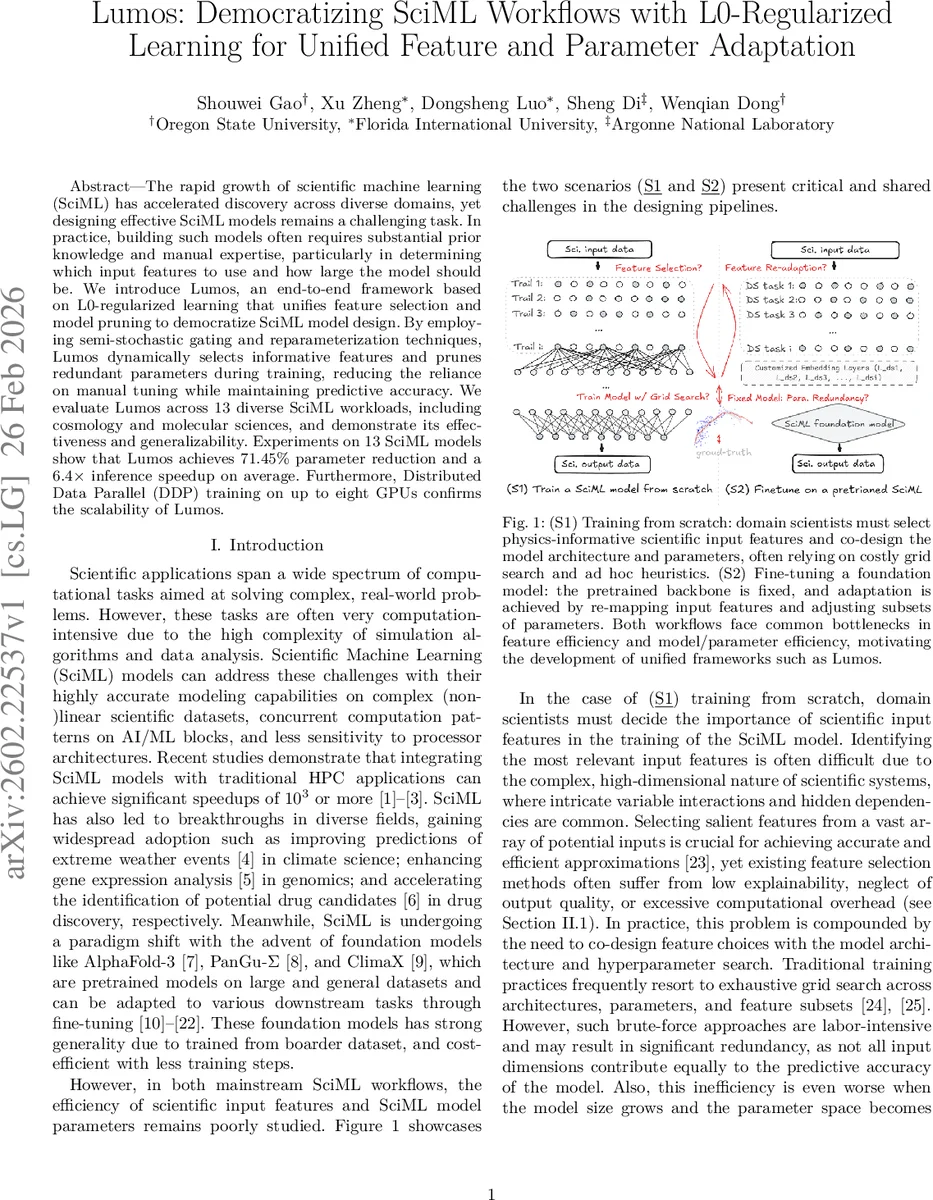
The rapid growth of scientific machine learning (SciML) has accelerated discovery across diverse domains, yet designing effective SciML models remains a challenging task. In practice, building such models often requires substantial prior knowledge and manual expertise, particularly in determining which input features to use and how large the model should be. We introduce LUMOS, an end-to-end framework based on L0-regularized learning that unifies feature selection and model pruning to democratize SciML model design. By employing semi-stochastic gating and reparameterization techniques, LUMOS dynamically selects informative features and prunes redundant parameters during training, reducing the reliance on manual tuning while maintaining predictive accuracy. We evaluate LUMOS across 13 diverse SciML workloads, including cosmology and molecular sciences, and demonstrate its effectiveness and generalizability. Experiments on 13 SciML models show that LUMOS achieves 71.45% parameter reduction and a 6.4x inference speedup on average. Furthermore, Distributed Data Parallel (DDP) training on up to eight GPUs confirms the scalability of
💡 Research Summary
The paper introduces LUMOS, an end‑to‑end framework that unifies feature selection and model pruning for scientific machine learning (SciML) using L0‑regularized learning. The authors observe that designing effective SciML models typically requires extensive domain expertise to choose informative input features and to decide model size, leading to costly grid searches and ad‑hoc heuristics. LUMOS addresses these twin challenges by embedding learnable semi‑stochastic gates on both input dimensions and hidden neurons. Each gate is parameterized by a probability π∈
Comments & Academic Discussion
Loading comments...
Leave a Comment