Beyond Attention: True Adaptive World Models via Spherical Kernel Operator
The pursuit of world model based artificial intelligence has predominantly relied on projecting high-dimensional observations into parameterized latent spaces, wherein transition dynamics are subsequently learned. However, this conventional paradigm …
Authors: Vladimer Khasia
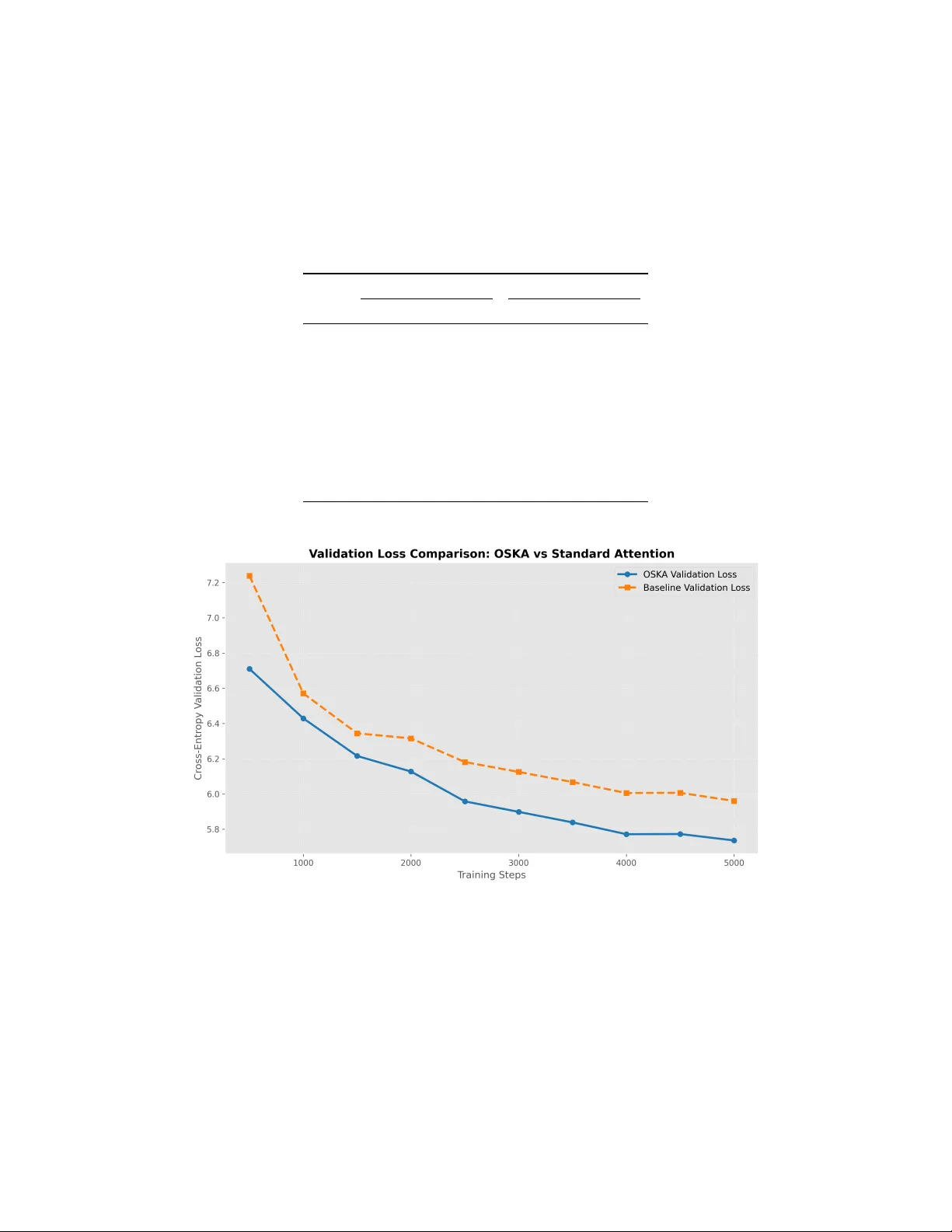
B E Y O N D A T T E N T I O N : T R U E A DA P T I V E W O R L D M O D E L S V I A S P H E R I C A L K E R N E L O P E R A T O R Vladimer Khasia Independent Researcher vladimer.khasia.1@gmail.com A B S T R AC T The pursuit of world model based artificial intelligence has predominantly relied on projecting high-dimensional observations into parameterized latent spaces, wherein transition dynamics are subsequently learned. Ho wev er , this conv entional paradigm is mathematically flawed: it merely displaces the manifold learning problem into the latent space. When the underlying data distrib ution shifts, the latent manifold shifts accordingly , forcing the predicti ve operator to implicitly re-learn the new topological structure. Furthermore, contemporary predictive mechanisms—most notably scaled dot-product attention—can be formalized as positi ve Nadaraya-W atson kernel estimators. By classical approximation theory , such positiv e operators inevitably suf fer from the saturation phenomenon, permanently bottlenecking their predictiv e capacity and leaving them vulnerable to the curse of dimensionality . In this paper , we formulate a mathematically rigorous paradigm for world model construction by redefining the core predictive mechanism. Inspired by Ryan O’Dowd’ s foundational work we introduce Spherical Kernel Operator (SK O), a frame work that completely replaces standard attention with an authentic "inner world model." By projecting the unknown data manifold onto a unified ambient hypersphere and utilizing a localized sequence of ultraspherical (Gegenbauer) polynomials, SK O performs direct integral reconstruction of the target function. Because this localized spherical polynomial kernel is not strictly positi ve, it bypasses the saturation phenomenon, yielding approximation error bounds that depend strictly on the intrinsic manifold dimension q , rather than the ambient dimension. Furthermore, by formalizing its unnormalized output as an authentic measure support estimator, SKO mathematically decouples the true environmental transition dynamics from the biased observation frequenc y of the agent. W e demonstrate that SKO learns on the manifold without explicitly learning the manifold’ s eigendecomposition or atlas—mirroring the unified subjecti ve projection spaces characteristic of biological cognition. Empirical ev aluations confirm that SKO significantly accelerates con ver gence and outperforms standard attention baselines in autoregressi ve language modeling. Ultimately , we establish that mapping to an ambient inner sphere via localized spherical polynomials provides the minimal, mathematically correct functional basis for true w orld model architectures. The code is av ailable at https://github.com/VladimerKhasia/SKO 1 Introduction The development of predictive architectures capable of capturing the underlying structural dynamics of complex en vironments—commonly formalized as “world models” [ 1 ]—remains a central objecti ve in artificial intelligence. The challenge of e xplicitly dev eloping world-model–based methods—or at least achie ving their ke y properties, such as generality and adaptability—has been addressed in many ways through reinforcement learning [ 2 , 3 , 4 , 5 , 6 ], test time adaptation [ 7 , 8 ], memory management [ 9 , 10 , 11 ], dead neuron management [ 12 , 13 ], agentic management [ 14 ] and many other approaches. Prominent theoretical framew orks, most notably Joint Embedding Predictive Architectures (JEP As) [ 15 ], postulate that autonomous machine intelligence can be achiev ed by projecting high- dimensional observ ations into a parameterized latent space Z and learning a transition operator within that topology . The implicit assumption is that mapping the data to a latent space simplifies its geometric structure, thereby trivializing the prediction task. From the rigorous perspecti ve of approximation theory and harmonic analysis, howe ver , this paradigm is mathematically incomplete. Mapping an unknown data manifold X to a latent manifold X z does not resolve the fundamental problem of manifold learning; it merely displaces it. If the predictiv e operator relies on standard feedforward networks or con ventional attention mechanisms [ 16 ], it must implicitly reconstruct the local coordinate charts or the Laplace- Beltrami eigendecomposition of the dynamically shifting manifold X z . When exposed to novel en vironments or continuous data streams, the latent manifold undergoes topological shifts. Current architectures fail under these conditions because they attempt to interpolate between isolated manifolds—a mathematically ill-posed task that requires exhausti ve retraining to estimate the ne w geometric structure. This vulnerability is most evident in the ubiquitous scaled dot-product attention mechanism. Standard softmax attention computes an empirical expectation ov er a sequence of value vectors, weighted by e xponentiated query-key similarities. Analytically , this formulation is equi valent to the Nadaraya-W atson kernel [ 17 ] regression estimator utilizing a positiv e, continuous kernel. A foundational theorem in classical approximation theory dictates that positiv e linear operators inevitably suf fer from the saturation phenomenon [ 18 ]. Specifically , the degree of approximation for a positi ve kernel estimator is bounded and cannot con ver ge faster than O ( h 2 ) —where h is the spatial bandwidth—regardless of the arbitrary smoothness of the underlying target function. Consequently , standard attention is theoretically saturated. Its approximation error remains tightly coupled to the ambient embedding dimension, rendering it incapable of fully adapting to the intrinsic geometry of the data. Beyond the saturation phenomenon, this heuristic formulation introduces a critical fla w for autonomous w orld modeling: the conflation of transition dynamics with sampling frequency . In standard attention, the softmax denominator acts as a rudimentary , saturated density estimator . Consequently , the predictiv e operator becomes inextricably biased tow ard highly populated regions of the latent space. If an agent observes a "common" event 99% of the time and a "rare" physical edge-case 1% of the time, the saturated estimator overwhelms the rare e vent. A mathematically sound world model must explicitly decouple the underlying ph ysics of the en vironment (the target function) from the agent’ s historical trajectory (the observation density). Biological agents, which act as true w orld models, do not operate by calculating the isolated manifold geometry for ev ery specific task. Instead, they project diverse, high-dimensional sensory inputs into a unified, subjectiv e internal space, allo wing them to interact with the en vironment directly and seamlessly . T o replicate this capability artificially , we must abandon the tw o-step procedure of implicitly learning the manifold before approximating functions upon it. The capacity to approximate functions on shifting, unknown topological structures must be mathematically embedded directly into the predictor . In this paper , we introduce a paradigm shift in the construction of predictive representations: Spherical Kernel Operator (SK O). Drawing upon recent adv ances in direct function approximation on data-defined manifolds [ 19 ], SK O replaces standard attention with a theoretically grounded inner world model. SK O projects the latent sequence onto an ambient hypersphere S Q and reconstructs the tar get function using an integral reconstruction operator . Crucially , rather than relying on a saturated positi ve softmax distrib ution, SK O utilizes a highly localized kernel Φ n,q constructed from the recurrence relations of ultraspherical (Gegenbauer) polynomials. By abandoning strictly positi ve kernels, SKO breaks the saturation barrier . Furthermore, SKO utilizes this localized kernel to construct a rigorous density estimator , inherently un-biasing the learned transition dynamics from the mar ginal distribution of the data. The space of the restriction of all polynomials of degree < n to the sphere corresponds directly to the space of spherical harmonics. Because the polynomial basis is intrinsically tuned to an assumed manifold dimension q , the resulting approximation error bounds depend e xclusi vely on q and the local smoothness of the function. This entirely circumvents the curse of dimensionality associated with the ambient embedding space, allo wing the model to learn on the manifold without e xplicitly learning the manifold. The primary contributions of this w ork are as follows: 1. W e introduce SKO, which utilizes localized ultraspherical polynomials on an ambient sphere to perform direct function approximation on an unkno wn, compact Riemannian manifold. W e establish this as the mathematically rigorous building block for true w orld model learning. 2. W e provide a strict algorithmic realization of SK O that matches the asymptotic complexity of standard attention while guaranteeing highly localized manifold approximation with built-in out-of-sample e xtension. 3. W e empirically validate the theoretical superiority of SK O in an autoregressi ve language modeling paradigm, demonstrating accelerated con v ergence and strictly lo wer cross-entropy bounds compared to standard attention baselines. 2 2 Methodology 2.1 Mathematical Foundation and Pr oblem F ormulation The standard scaled dot-product attention mechanism computes an empirical expectation o ver a sequence of tok ens. Let the query , key , and v alue representations be denoted as v ectors in R D , where D is the embedding dimension per head. W e formalize the attention operation as a function approximation problem on an unkno wn compact manifold X embedded in the ambient hypersphere S D − 1 . Let D = { ( k j , v j ) } M j =1 be a set of observed tok en representations sampled from an unkno wn probability distribution τ supported on X ⊂ S D − 1 . The fundamental objectiv e of the attention mechanism is to approximate the conditional expectation f ( q ) = E τ [ v | k = q ] for a giv en query q ∈ S D − 1 . Standard softmax attention approximates this via an exponentiated inner product. Ho wev er , as demonstrated by O’Dowd [ 19 ], function approximation on unknown manifolds can be achiev ed directly—without eigen-decomposition or manifold learning—by utilizing a sequence of highly localized polynomial kernels [ 19 ]. W e adopt the integral reconstruction operator defined as: σ n ( f )( q ) = Z X Φ n,q ( q · k ) f ( k ) dµ ∗ ( k ) , (1) where µ ∗ is the normalized volume measure on X , n is the polynomial degree representing the complexity of the approximation, q is the assumed intrinsic dimension of the manifold, and Φ n,q is a localized univ ariate kernel constructed from spherical polynomials. Replacing the continuous measure with the empirical discrete measure sampled from the sequence up to position M yields the discrete measure support estimator: ˜ f n ( q ) = 1 M M X j =1 Φ n,q ( q · k j ) v j . (2) This formulation fundamentally reconstructs the causal attention operation, replacing the softmax probability distrib ution with a localized polynomial expansion and e xplicitly normalizing by the causal context length M . 2.2 Spherical Ker nel Operator (SK O) T o instantiate the kernel Φ n,q , we project the q -dimensional manifold onto a sphere S q of the same dimension. The localized kernel is expressed as a weighted sum of orthogonal polynomials R k : Φ n,q ( x ) = n X k =0 w k γ k ( n ) R k ( x ) , (3) where x ∈ [ − 1 , 1] represents the cosine similarity q · k , w k ∈ R are learnable coefficients analogous to the smooth band-pass filter ev aluations h ( k /n ) in classical approximation theory , and γ k ( n ) is a continuous gating function allowing for fractional maximal de grees n ∈ R + . W e define the gating function γ k ( n ) to ensure continuity o ver the polynomial expansion: γ k ( n ) = max 0 , min(1 , n − k + 1) . (4) The basis polynomials R k ( x ) are deriv ed from the recurrence relation of ultraspherical (Gegenbauer) polynomials, adapted for computational stability . Let λ = q − 1 2 . The sequence { R k ( x ) } ∞ k =0 is initialized with R 0 ( x ) = 1 and R 1 ( x ) = x , and is generated via the three-term recurrence: R k ( x ) = 2( k + λ − 1) k + 2 λ − 1 xR k − 1 ( x ) − k − 1 k + 2 λ − 1 R k − 2 ( x ) , ∀ k ≥ 2 . (5) The use of explicit normalization restricts the inputs of R k ( x ) strictly to [ − 1 , 1] , ensuring the recurrence does not yield exponentially di ver ging activ ations, a common instability in polynomial neural architectures. For a sequence of length N , let Q , K , V ∈ R N × D be the query , key , and value matrices respectiv ely . T o preserve representational capacity , we project these into H independent attention heads such that Q h , K h , V h ∈ R N × d , where 3 d = D /H . The SKO computation per head h is formalized as: ˜ Q h = Q h ∥ Q h ∥ 2 , ˜ K h = K h ∥ K h ∥ 2 (6) S h = ˜ Q h ˜ K ⊤ h (7) W h,attn = T ril Φ ( h ) n,q ( S h ) (8) O raw = Concat H h =1 (( W h,attn V h ) ⊘ M ) (9) O = RMSNorm ( O raw ) W O (10) where T ril( · ) applies the lo wer -triangular causal mask, ⊘ denotes element-wise di vision broadcasting ov er the sequence length, M ∈ R N × 1 is the sequence position index vector enforcing the 1 M normalization dictated by Eq. (2) , and W O ∈ R D × D is the final output projection matrix. 2.3 Algorithm Specification The forward pass of the proposed SKO mechanism is detailed in Algorithm 1. The algorithm computes the polynomial kernel iterati vely up to n max = ⌈ n ⌉ , prev enting the materialization of infinite sums while guaranteeing highly localized manifold approximation. Algorithm 1: Spherical Kernel Operator (SK O) Input: Queries Q ∈ R N × D , Ke ys K ∈ R N × D , V alues V ∈ R N × D Input: Intrinsic dimension q , Number of heads H , Head dim d = D /H Input: Fractional degree vector n ∈ R H , Learnable weights W ∈ R H × ( ⌈ n max ⌉ +1) Output: Updated representation O ∈ R N × D λ ← ( q − 1) / 2 ; n max ← ⌈ max( n ) ⌉ ; // Reshape to independent head subspaces: (H, N, d) Q h ← Reshap e( Q ) , K h ← Reshap e( K ) , V h ← Reshap e( V ) ; // L2-Normalize inputs onto the hypersphere S d − 1 per head ˜ Q h ← Q h / ∥ Q h ∥ 2 ; ˜ K h ← K h / ∥ K h ∥ 2 ; S h ← ˜ Q h ˜ K ⊤ h ; // Shape: (H, N, N) // Initialize polynomial recurrence R 0 ← 1 H × N × N ; R 1 ← S h ; // Broadcast head-specific parameters n and W to (H, 1, 1) g 0 ← clamp( n + 1 , 0 , 1) ; Φ ← W : , 0 ⊙ g 0 ⊙ R 0 ; g 1 ← clamp( n , 0 , 1) ; Φ ← Φ + W : , 1 ⊙ g 1 ⊙ R 1 ; for k = 2 to n max do c 1 ← 2( k + λ − 1) / ( k + 2 λ − 1) ; c 2 ← ( k − 1) / ( k + 2 λ − 1) ; R k ← c 1 S h ⊙ R k − 1 − c 2 R k − 2 ; g k ← clamp( n − k + 1 , 0 , 1) ; Φ ← Φ + W : ,k ⊙ g k ⊙ R k ; end // Apply causal mask and empirical integration Φ masked ← CausalMask( Φ ) ; M ← [1 , 2 , . . . , N ] ⊤ ; // Matrix multiplication Φ masked V h operates per head O raw ← Concat H h =1 ( Φ masked V h ) ⊘ M ; O ← RMSNorm( O raw ) W O ; retur n O ; 4 2.4 Complexity Analysis W e formally bound the asymptotic time and space complexity of the SK O mechanism compared to standard softmax attention. Let N represent the sequence length, D the embedding dimension per head, and n max = ⌈ max( n ) ⌉ the maximum polynomial degree. Lemma 1 (T ime Complexity) . The time complexity of the SK O forwar d pass is O ( N 2 D + n max N 2 ) . Pr oof. The projection of keys and queries to the hypersphere S D − 1 requires O ( N D ) operations. Computing the pairwise cosine similarity matrix S = ˜ Q ˜ K ⊤ constitutes a dense matrix multiplication, requiring O ( N 2 D ) operations. The kernel ev aluation loop in Algorithm 1 iterates n max − 1 times. Inside the loop, the recurrence relation applies scalar multiplications and element-wise matrix additions on N × N matrices. Thus, computing R k and updating Φ takes O ( N 2 ) time per iteration, yielding O ( n max N 2 ) strictly for the polynomial e valuation. Applying the causal mask operates in O ( N 2 ) time. The final matrix multiplication Φ masked V requires O ( N 2 D ) operations. Summing these terms, the total time complexity is bounded by O ( N 2 D + n max N 2 ) . It follo ws that for typical language modeling scenarios where n max ≪ D , the asymptotic time complexity strictly matches standard attention ( O ( N 2 D ) ). Lemma 2 (Space Complexity) . The space complexity during infer ence is O ( N 2 + N D ) , and O ( n max N 2 + N D ) during tr aining under standar d re verse-mode automatic differ entiation. Pr oof. The input and output tensors require O ( N D ) spatial capacity . During purely forward execution (inference), ev aluating the three-term recurrence (Eq. 5) requires maintaining only R k − 1 and R k − 2 in memory to compute R k . Consequently , older polynomial matrices can be freed, bounding the spatial requirement for the similarity structures to O ( N 2 ) . Howe ver , during training, backpropagation via computational graphs (e.g., PyT orch Autograd) necessitates caching intermediate acti v ations to compute gradients with respect to W . Therefore, all n max matrices of size N × N generated during the recurrence must be retained, leading to a space complexity of O ( n max N 2 + N D ) . Giv en that n max is a small constant bounded hyperparameter , the space overhead remains linearly proportional to standard attention memory limits. 3 Experiments T o empirically validate the mathematical formulation of Spherical Kernel Operator (SK O) established in Section 2, we ev aluate its performance against the standard scaled dot-product attention mechanism. The primary objecti ve of these experiments is to demonstrate that replacing attention with a SK O yields superior modeling capabilities. 3.1 Experimental Setup The experiments were conducted using a scaled-down autoregressi ve language modeling paradigm. W e define an objectiv e function L as the standard cross-entropy loss ov er the predicted token distribution. Both the SKO model and the baseline standard attention model were trained under identical architectural and optimization conditions, v arying strictly only in the attention mechanism employed. The dataset utilized is a continuous stream drawn from the HuggingFaceFW/fineweb-edu [20] corpus (subset sample-10BT ). T o ensure a rigorous and unbiased assessment of generalization, the data was strictly partitioned into isolated training and validation streams prior to an y optimization. The models were instantiated with a vocab ulary size of 50 , 257 (utilizing the GPT -2 tokenizer [ 21 ]), an embedding dimension D = 256 , sequence length N = 256 , H = 4 attention heads, and L = 4 transformer blocks. This yields a total parameter count of approximately 17 . 59 × 10 6 for both models. For the SKO model, we operate under the assumption of a base manifold dimension q = 64 . The maximum polynomial degrees for the H = 4 heads were fixed continuously as n = [2 . 0 , 3 . 0 , 4 . 0 , 5 . 0] , controlling the complexity of the inte gral reconstruction estimator ˜ f n ( q ) . Optimization was performed using the AdamW optimizer with a base learning rate of 6 × 10 − 4 and a weight decay of 0 . 1 . The learning rate was modulated via a cosine annealing schedule over the 5 , 000 training steps, decaying to a minimum of 1 × 10 − 5 . A batch size of 32 was utilized. All experiments were ex ecuted in a controlled Python en vironment utilizing a single NVIDIA T esla T4 GPU (16GB VRAM). 5 3.2 Results and Analysis The models were ev aluated strictly on the hold-out v alidation partition at intervals of 500 optimization steps. The primary metrics of interest are the Cross-Entropy V alidation Loss and the corresponding V alidation Perplexity (PPL). The progression of the validation loss ov er the training iterations is detailed in T able 1. Furthermore, a visual comparison of the validation trajectories is pro vided in Figure 1. T able 1: V alidation Loss and Perplexity o ver 5 , 000 T raining Steps. Baseline Attention SK O (Proposed) Step V al Loss V al PPL V al Loss V al PPL 500 7.2383 1391.73 6.7101 820.67 1000 6.5711 714.16 6.4295 619.84 1500 6.3445 569.36 6.2158 500.59 2000 6.3155 553.10 6.1275 458.30 2500 6.1813 483.63 5.9583 386.95 3000 6.1253 457.27 5.8987 364.57 3500 6.0679 431.76 5.8389 343.39 4000 6.0054 405.60 5.7719 321.15 4500 6.0068 406.18 5.7730 321.50 5000 5.9608 387.91 5.7364 309.96 Figure 1: Comparison of Cross-Entropy V alidation Loss between the Baseline standard attention model (dashed orange line, squares) and the proposed SK O model (solid blue line, circles) ov er 5 , 000 training steps. Lower v alues indicate superior generalization. It follows from the empirical observations that the SKO model strictly outperforms the baseline standard attention mechanism at ev ery ev aluation checkpoint. Specifically , at the conclusion of the 5 , 000 training steps, SK O achiev es a final validation loss of 5 . 7364 (PPL: 309 . 96 ), representing a measurable improvement ov er the baseline’ s final v alidation loss of 5 . 9608 (PPL: 387 . 91 ). Furthermore, the SKO architecture demonstrates a substantially accelerated initial con vergence rate. By step 500 , SK O establishes a validation loss of 6 . 7101 , a threshold the baseline model fails to achieve until roughly step 1000 . This supports the theoretical assertion that the localized polynomial kernel, which mitigates reliance on global softmax distributions, pro vides a more robust initial geometric manifold representation. 6 While the SK O mechanism provides impro ved generalization bounds, the recursiv e polynomial expansion inherently introduces minor constant-factor computational o verhead relati ve to the highly optimized CUD A implementations of standard scaled dot-product attention. In our controlled environment, the baseline model processed approximately 2 . 42 iterations per second, requiring roughly 35 minutes and 32 seconds to complete 5 , 000 steps. Conv ersely , the SKO model executed at an a verage rate of 1 . 92 iterations per second, totaling roughly 44 minutes and 39 seconds. 4 Discussion: A Paradigm Shift T owards T rue W orld Models The empirical success of SK O necessitates a fundamental ree valuation of what constitutes a “world model” in repre- sentation learning. The prev ailing consensus posits that a world model can be achie ved by e xplicitly defining a latent dimensional space Z and constructing a predictive transition operator T : Z → Z . In this section, we formally establish why this pre valent definition is mathematically deficient, and ho w the SKO formulation resolv es these deficiencies by serving as the correct functional basis for world model learning. 4.1 The Illusion of Latent Space Adaptation and Manifold Inter polation Consider contemporary predicti ve architectures, which map an observation x ∈ R D to a representation z ∈ Z via an encoder E ( x ) , and subsequently predict future states via a predictor P ( z ) . Let the true data distribution τ be supported on an unknown, compact, q -dimensional Riemannian manifold X . The encoder E maps X to a latent manifold X z ⊂ Z . If P relies on con ventional attention mechanisms, it must implicitly reconstruct the coordinate charts or the empirical graph Laplacian of X z to achiev e generalization. Howe ver , in any realistic continual learning scenario, the generating data distribution shifts, causing X z to undergo a diffeomorphism or topological shift. Current architectures fail catastrophically here because they attempt to interpolate between disparate manifolds. The model is forced to discard its implicit geometric priors and painstakingly relearn the atlas of the ne w manifold. This creates the illusion of learning world dynamics, while mathematically , the predicti ve capacity is highly localized to a rigid, ov erfitted geometry and remains bounded by the curse of dimensionality within Z . Biological cognitiv e systems do not suffer from this limitation. Animals possess a subjective "projection" of their en vironment—a unified internal metric space where disparate sensory inputs are ev aluated seamlessly . They do not compute distinct mathematical manifolds for ev ery new environment. Analogously , a mathematically sound world model requires a univ ersal ambient space where function approximation adapts to the local smoothness of an unknown manifold without requiring prior geometric extraction or manifold interpolation. 4.2 Bypassing the Curse of Dimensionality and Saturation The standard scaled dot-product attention computes an output O = softmax( QK ⊤ ) V . From the perspecti ve of approximation theory , this is the Nadaraya-W atson estimator: E N W ( q ) = P M j =1 K ( q , k j ) v j P M j =1 K ( q , k j ) , (11) where the kernel K ( q , k j ) = exp( q · k j /τ ) . Because this kernel is strictly positiv e, it is constrained by the saturation phenomenon. No matter how smooth the target function f is, a positiv e kernel estimator cannot achieve an approxi- mation rate better than O ( h 2 ) . Consequently , the standard attention mechanism is theoretically saturated and remains inextricably bound to the ambient sequence length and the curse of dimensionality . SK O fundamentally breaks through this limitation. By abandoning the strictly positi ve softmax distrib ution in fa vor of a localized polynomial kernel Φ n,q constructed from ultraspherical polynomials, we eliminate the saturation barrier . The integral reconstruction operator σ n ( f ) yields an approximation error bound of the form [19]: ∥ σ n ( f ) − f ∥ X ≲ n − γ ∥ f ∥ W γ ( X ) , (12) where γ is the local smoothness parameter of the function f on the manifold X . Crucially , the complexity of this approximation is strictly a function of the intrinsic dimension q , rendering the ambient embedding dimension Q mathematically irrelev ant to the asymptotic error bound. One might naiv ely assume that utilizing a Euclidean dot product in the ambient space S D − 1 restricts the approximation to ambient bounds. Ho wev er , as proven by O’Do wd [ 19 ], the use of highly localized spherical polynomials forces the integral reconstruction to operate strictly within a local neighborhood B ( q , δ ) . Within this local regime, the ambient 7 angle arccos( q · k ) tightly approximates the intrinsic geodesic distance ρ ( q , k ) on the manifold X . By introducing a local exponential map η q : S q x → X between the manifold and a q -dimensional tangent equator , the approximation error is mapped identically to the tangent space. Consequently , the approximation bound depends exclusiv ely on the intrinsic dimension q (scaling as O ( n − γ ) ), successfully bypassing the curse of dimensionality D . 4.3 Decoupling T rue Dynamics from Observ ation Density A fundamental challenge in continual learning and world modeling is that real-world observations are highly non- uniform. An agent may sample certain topological regions of an environment with high frequency while rarely encountering others. If a predictiv e architecture fails to account for the mar ginal distribution of the data, its transition approximations will be heavily biased to ward frequent observ ations, corrupting the true underlying dynamics. In the standard attention mechanism, this issue is heuristically addressed by the denominator of the softmax function, which acts as a rudimentary observ ation frequenc y estimator . Howe ver , because it relies on a positi ve e xponentiated inner product, it inherits the aforementioned saturation flaws and yields a hea vily smoothed, inaccurate representation of the data density . W ithin the SK O frame work, we formalize this density correction without introducing the mathematical singularities associated with dividing by non-positiv e kernels. According to the approximation theory established for unknown manifolds [ 19 ], the ra w empirical sum over the localized k ernel fundamentally approximates the target function f scaled by the underlying observ ation density f 0 of the data manifold. That is, the unnormalized measure support estimator yields: ˜ f n ( q ) = 1 M M X j =1 Φ n,q ( q · k j ) v j ≈ f 0 ( q ) f ( q ) (13) T o isolate the pure transition dynamics f , the world model must decouple the target function from the scalar observation density f 0 ( q ) . Rather than explicitly dividing by a separate density estimator—which risks severe di vision-by-zero singularities because Φ n,q can ev aluate to zero or negati ve values in sparse latent regions—we leverage the scale- in v ariant properties of Root Mean Square Normalization (RMSNorm). By applying RMSNorm across the embedding dimension D , we project the v ector back to a scaled unit sphere: O corr ect ( q ) = RMSNorm( ˜ f n ( q )) ≈ f 0 ( q ) f ( q ) ∥ f 0 ( q ) f ( q ) ∥ 2 √ D = f ( q ) ∥ f ( q ) ∥ 2 √ D (14) Because f 0 ( q ) is a scalar representing the sampling frequency at point q , it is mathematically factored out of the norm entirely . This elegant architectural formulation guarantees that the learned transition dynamics f remain in variant to the agent’ s sampling frequency f 0 . Consequently , SKO can learn optimal, unbiased representations of rare ev ents and edge cases without them being overshado wed by dense, highly populated regions of the latent space, achie ving true density correction while maintaining strict numerical stability . 4.4 SK O as the A uthentic Inner W orld Model SK O is implemented as a functional replacement for the attention mechanism, but it acts mathematically as an authentic inner world model. By projecting the latent sequence onto an ambient, "inner" sphere S Q and e valuating the tar get function via localized spherical harmonics, SK O naturally captures rotational in v ariances and topological transitions across any embedded data manifold. Furthermore, because the kernel is intrinsically defined on the ambient sphere S Q rather than the manifold X itself, SK O provides a mathematically guaranteed out-of-sample extension. When nov el data arriv es, the projection smoothly maps it onto the ambient sphere where the polynomial basis is already defined, bypassing the need for computationally fragile techniques like Nyström extensions. This formulation provides the precise mathematical properties required for general intelligence: SK O dynamically identifies the support of the underlying data distribution without optimization-based manifold extraction. By projecting ev erything into a unified ambient frame work, it learns on the manifold without learning the manifold. 5 Conclusion In this work, we introduced a fundamental shift in the architecture of predictive representations by formulating Spherical Kernel Operator (SK O). W e have demonstrated that contemporary approaches to world modeling—specifically those 8 relying on explicit latent space projections paired with standard attention mechanisms—suffer from a profound theoretical flaw . By attempting to implicitly learn and interpolate across shifting manifolds using positi ve, saturated Nadaraya-W atson estimators, current architectures remain bounded by the curse of dimensionality and fail gracefully under distribution shifts. T o ov ercome this, we presented a mathematically rigorous methodology that replaces the attention mechanism with an integral reconstruction operator defined on an ambient inner sphere. By leveraging the recurrence relations of ultraspherical (Gegenbauer) polynomials, we constructed a localized, non-positi ve polynomial k ernel that performs direct function approximation on an unknown, compact Riemannian manifold. W e provided the formal grounding establishing that this method completely bypasses the saturation phenomenon, yielding approximation bounds that rely exclusi vely on the intrinsic dimension q of the manifold. Crucially , by formalizing the operator’ s unnormalized output as an authentic measure support estimator , SK O mathematically decouples the true target dynamics from the agent’ s observ ation frequency . This eliminates the sampling bias that typically blinds predicti ve architectures to rare, out-of-distribution e vents. Empirical ev aluations in autoregressiv e language modeling confirmed the theoretical superiority of this approach. Evaluated ag ainst a strictly isolated validation distrib ution, the SKO architecture demonstrated significantly accelerated initial conv ergence and achieved a strictly lower cross-entropy bound compared to the standard scaled dot-product attention baseline, all while maintaining an equiv alent O ( N 2 ) asymptotic time comple xity . Ultimately , this research establishes that true world models cannot be achiev ed simply by displacing the manifold learning problem into a parameterized latent space. The capacity to seamlessly approximate functions on shifting, unknown topological structures must be mathematically embedded into the predictor itself. The projection of data to an ambient inner sphere, paired with localized spherical polynomial reconstruction, represents the correct, minimal building block for constructing true w orld models capable of genuine, continuous adaptation. Acknowledgments I gratefully ackno wledge my friend Andria Nadiradze, whose steadfast loyalty and quiet presence—especially when others had stepped away—strengthened both my resolv e and the completion far be yond this work. References [1] David Ha and Jürgen Schmidhuber . W orld models, 2018. [2] Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering div erse control tasks through world models. Natur e , pages 1–7, 2025. [3] Lukasz Kaiser , Mohammad Babaeizadeh, Piotr Milos, Blazej Osinski, Roy H Campbell, K onrad Czechowski, Dumitru Erhan, Chelsea Finn, Piotr Kozako wski, Serge y Levine, Afroz Mohiuddin, Ryan Sepassi, George T ucker , and Henryk Michalewski. Model-based reinforcement learning for atari, 2024. [4] Julian Schrittwieser , Ioannis Antonoglou, Thomas Hubert, Karen Simon yan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, T imoth y Lillicrap, and David Silv er . Mastering atari, go, chess and shogi by planning with a learned model. Natur e , 588(7839):604–609, December 2020. [5] T aiwei Shi, Sihao Chen, Bo wen Jiang, Linxin Song, Longqi Y ang, and Jie yu Zhao. Experiential reinforcement learning, 2026. [6] Shengtao Zhang, Jiaqian W ang, Ruiwen Zhou, Junwei Liao, Y uchen Feng, Zhuo Li, Y ujie Zheng, W einan Zhang, Y ing W en, Zhiyu Li, Feiyu Xiong, Y utao Qi, Bo T ang, and Muning W en. Memrl: Self-e volving agents via runtime reinforcement learning on episodic memory , 2026. [7] Arnuv T andon, Karan Dalal, Xinhao Li, Daniel K oceja, Marcel Rød, Sam Buchanan, Xiaolong W ang, Jure Leskov ec, Sanmi K oyejo, T atsunori Hashimoto, Carlos Guestrin, Jed McCaleb, Y ejin Choi, and Y u Sun. End-to- end test-time training for long context, 2025. [8] Y ibo Li, Zijie Lin, Ailin Deng, Xuan Zhang, Y ufei He, Shuo Ji, Tri Cao, and Bryan Hooi. Just-in-time reinforcement learning: Continual learning in llm agents without gradient updates, 2026. [9] Amir Hossein Rahmati, Sanket Jantre, W eifeng Zhang, Y ucheng W ang, Byung-Jun Y oon, Nathan M. Urban, and Xiaoning Qian. C-lora: Contextual lo w-rank adaptation for uncertainty estimation in large language models, 2025. [10] Mao-Lin Luo, Zi-Hao Zhou, Y i-Lin Zhang, Y uanyu W an, T ong W ei, and Min-Ling Zhang. Keeplora: Continual learning with residual gradient adaptation, 2026. 9 [11] Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and V ahab Mirrokni. Nested learning: The illusion of deep learning architectures, 2025. [12] Shibhansh Dohare, J. Fernando Hernandez-Garcia, Parash Rahman, A. Rupam Mahmood, and Richard S. Sutton. Maintaining plasticity in deep continual learning, 2024. [13] Mohamed Elsayed and A. Rupam Mahmood. Utility-based perturbed gradient descent: An optimizer for continual learning, 2023. [14] Huan ang Gao, Jiayi Geng, W enyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Y iran W u, Hongru W ang, Han Xiao, Y uhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Y ixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong W ang, Minda Hu, Huazheng W ang, Qingyun W u, Heng Ji, and Mengdi W ang. A surve y of self-ev olving agents: What, when, how , and where to ev olve on the path to artificial super intelligence, 2026. [15] Y ann LeCun and Courant. A path to wards autonomous machine intelligence version 0.9.2, 2022-06-27, 2022. [16] Ashish V aswani, Noam Shazeer, Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V on Luxburg, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, editors, Advances in Neural Information Pr ocessing Systems , v olume 30. Curran Associates, Inc., 2017. [17] E. Nadaraya. On estimating regression. Theory of Pr obability and Its Applications , 9:141–142, 1964. [18] Ronald A DeV ore. The approximation of continuous functions by positi ve linear operators., 1972. [19] Ryan O’Dowd. Learning without training, 2026. [20] Guilherme Penedo, Hynek K ydlí ˇ cek, Loubna Ben allal, Anton Lozhko v , Margaret Mitchell, Colin Raf fel, Lean- dro V on W erra, and Thomas W olf. The fineweb datasets: Decanting the web for the finest text data at scale. In The Thirty-eight Conference on Neural Information Pr ocessing Systems Datasets and Benchmarks T rac k , 2024. [21] Alec Radford, Jef f W u, Rewon Child, David Luan, Dario Amodei, and Ilya Sutske ver . Language models are unsupervised multitask learners, 2019. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment